AI 生态实验室 · 技术雷达:工作流程全景解读
本文系统梳理了「AI 生态实验室 · 技术雷达」的完整工作流程,从信息输入、项目筛选、研究落地到成果分享,形成一套可执行、可度量的常态化研究机制。
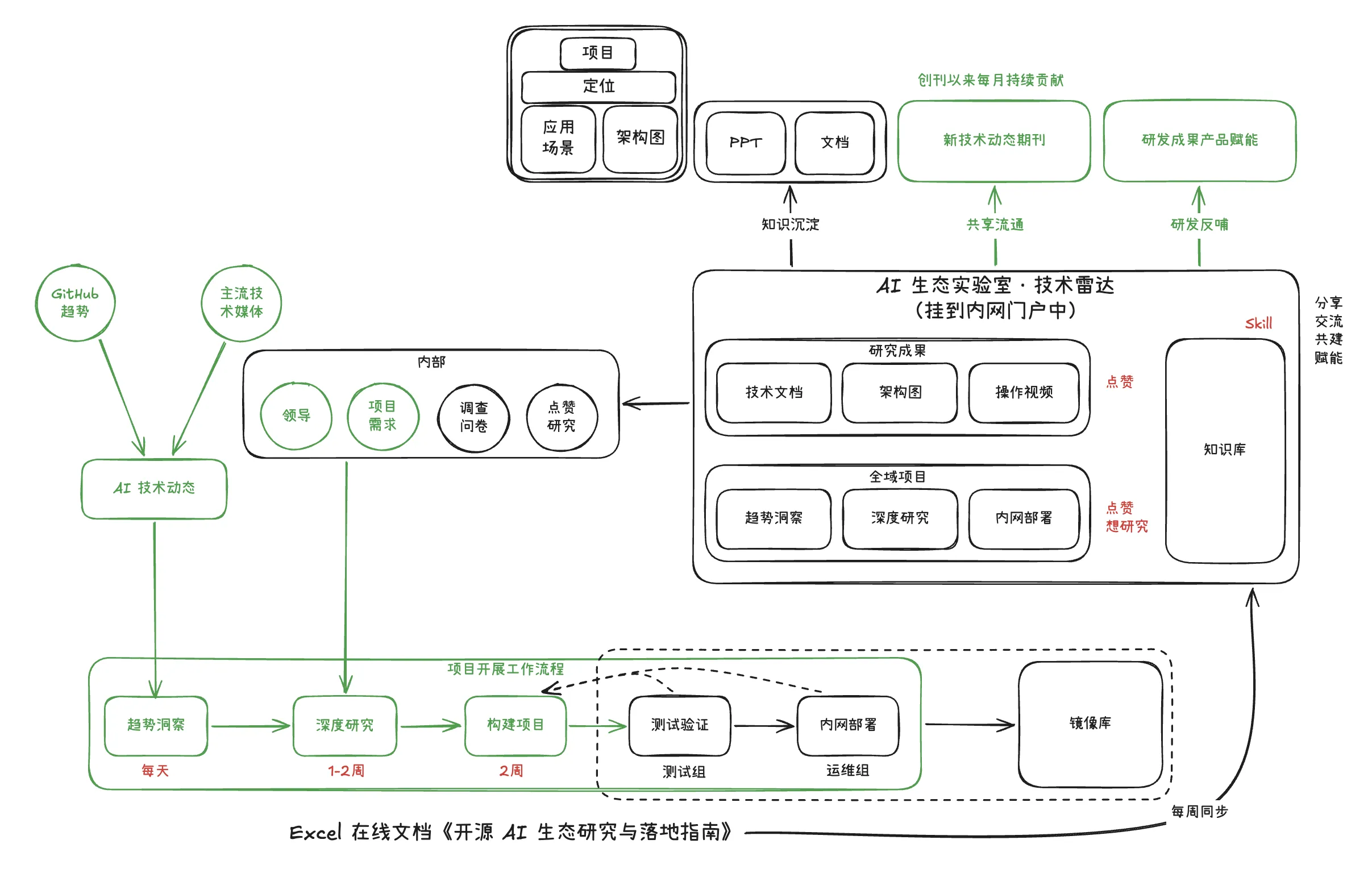
一、为什么需要一套固化流程
开源技术每天都在产生新变量。如果研究工作是”想到哪做到哪”,很容易陷入两个极端:要么因为信息过载而疲于奔命,要么因为缺乏目标感而长期停滞。我们需要的是一条从信息输入到技术落地的清晰链路,让每一天、每一周、每一个研究周期的产出都有明确的归属和节奏。
整个机制围绕三个核心问题展开:
- 节奏问题:每天、每周、每月到底该干什么?
- 方向问题:研究什么才能真正提升研发效率,而不是做无效功?
- 价值问题:研究成果怎么让团队看见、让业务用上?
下面这张图,就是我们对这三个问题的系统化回答。
二、全景架构:一张图看懂技术雷达
整个技术雷达的运转可以分为 三个层面 和 一条核心闭环。
三个层面
| 层面 | 角色 | 说明 |
|---|---|---|
| 信息输入层 | 外部信息源 + 内部需求 | 决定”看什么” |
| 核心引擎层 | AI 生态实验室 · 技术雷达 | 决定”怎么研” |
| 成果输出层 | 项目 PPT + 技术期刊 + 镜像库 + Skill | 决定”产出什么” |
一条核心闭环
项目开展工作流程:趋势洞察 → 深度研究 → 构建项目 → 测试验证 → 内网部署 → 镜像库。
这条链路从”每天的信息扫描”开始,到”可落地的内网服务及镜像化”结束,覆盖了一个开源项目从被关注到真正产生价值的全过程。
三、信息输入层:双通道捕捉需求信号
任何研究工作的起点,都是高质量的输入。我们同时维护两条输入通道,确保既不遗漏外部前沿,也不脱离内部实际。
3.1 外部信息通道:AI 技术动态
信息来源:
- GitHub 趋势:每日扫描 GitHub Trending,捕捉社区热度最高的开源项目。
- 主流技术媒体:追踪 AI 领域核心媒体、技术博客、论文发布平台(如 arXiv、Hugging Face 等)的最新动态。
处理机制:
这些信息统一汇聚到 “AI 技术动态” 池中,作为每日扫描的原材料。不是每一条都值得跟进,而是作为”趋势洞察”阶段的数据源,由研究员按需检索和评估。
3.2 内部需求通道:让研究紧贴业务
信息来源:
| 来源 | 说明 | 优先级 |
|---|---|---|
| 战略规划 | 来自组织层面的技术方向或重点领域关注 | 高 |
| 项目需求 | 各业务线在研发中遇到的技术瓶颈或选型需求 | 高 |
| 调查问卷 | 定期向研发团队收集技术痛点和工具期望 | 中 |
| 点赞/想研究 | 技术雷达平台上的互动反馈,反映团队真实兴趣 | 中 |
关键原则:
- 当项目来源为 “内容”(技术媒体/社区) 或 “战略规划” 时,会优先进入研究队列。
- 内部需求不是”被动接单”,而是与外部趋势交叉验证,避免研究方向与业务脱节。
四、核心引擎:AI 生态实验室 · 技术雷达
这是整个体系的运转中枢。技术雷达本身分为 两个资产库 和 一个互动机制。
4.1 全域项目库:三个阶段的动态管理
所有被纳入视野的项目,按研究深度划分为三个状态:
| 阶段 | 状态名称 | 典型周期 | 关键动作 |
|---|---|---|---|
| 阶段一 | 趋势洞察 | 持续(每天扫描) | 信息收集、初步评估、记录入库 |
| 阶段二 | 深度研究 | 1~2 周 | 代码阅读、架构分析、依赖梳理、可行性评估 |
| 阶段三 | 内网部署 | 约两周 | 环境搭建、服务构建、测试验证、内部上线,并推送至镜像库 |
状态流转不是单行道。 一个项目如果在深度研究阶段发现不可行,可以退回趋势洞察;如果业务需求变化,已部署的项目也可以重新评估。
每个项目卡片均支持 点赞 和 “想研究” 标记,这些互动数据实时影响项目优先级排序(详见 4.3 互动机制)。
4.2 研究成果库:多种形态的输出沉淀
研究的成果不只是”部署成功”这一个终点,过程中的所有有价值信息都会被沉淀下来:
- 文档:项目分析、架构解读、踩坑记录、最佳实践。
- 图片:架构图、流程图、对比图、可视化分析。
- 视频:部署演示、功能讲解、技术分享录屏。
这些成果与项目关联存储,形成可复用的知识资产,并最终汇入团队知识库。
4.3 互动机制:点赞/想研究
技术雷达平台支持对项目和研究成果进行 点赞 和 想研究 的投票。这不是简单的社交功能,而是内部需求投票机制—— 点赞 和 想研究 数高的项目会获得更高的研究优先级,确保资源投入到团队真正关心的方向。
五、核心闭环:五步项目开展工作流程
这是整个技术雷达的落地引擎,也是回答”每天干什么、每周干什么”的关键。
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ 趋势洞察 │───▶│ 深度研究 │───▶│ 构建项目 │───▶│ 测试验证 │───▶│ 内网部署 │───▶│ 镜像库 │
│ (每天) │ │ (1~2周) │ │ (约两周) │ │ (测试组) │ │ (运维组) │ │ (版本管理) │
└──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘
5.1 第一步:趋势洞察(每天)
目标:从海量信息中筛选出值得关注的项目信号。
每日动作:
- 浏览 GitHub Trending 和核心技术媒体,捕捉新出现的热门项目。
- 检查内部需求通道(战略规划、项目需求、问卷反馈),确认是否有新的高优先级研究方向。
- 对已有项目池进行快速回顾,更新项目状态或标记需要重新评估的项目。
- 将新发现的有价值项目录入 Excel 在线文档,填写基本信息(名称、类别、GitHub 地址、一句话定位)。
输出:更新后的项目池,新增项目标记为 “趋势洞察” 状态。
5.2 第二步:深度研究(1~2 周)
目标:从技术角度判断项目是否值得落地。
关键评估维度:
| 维度 | 评估问题 | 决策标准 |
|---|---|---|
| 商用可行性 | 许可证是否允许商业使用? | MIT / Apache-2.0 优先;AGPL 谨慎;其他许可证需法务评估 |
| 资源匹配度 | 部署所需算力、依赖、环境,团队能否配齐? | 能在现有资源下完成 POC |
| 技术成熟度 | 项目是否稳定?社区是否活跃? | 近期有更新、Issues 响应及时、文档较完整 |
| 研发效率提升 | 落地后能否显著缩短开发周期或提升质量? | 与现有工具链的互补性评估 |
| 适当超前性 | 是否过于激进?是否与公司现状脱节? | 能解决当前或近半年内的实际问题 |
研究动作:
- 阅读项目 README 和核心文档,理解定位和使用场景。
- 梳理项目架构,绘制架构图。
- 分析依赖项,评估与公司现有技术栈的兼容性。
- 本地跑通 Demo,记录部署步骤和踩坑点。
- 将研究成果(文档、图片、视频)关联到项目记录中。
输出:项目标记为 “深度研究” 状态,附带完整的分析文档和可行性结论。
淘汰机制:如果研究后发现项目不满足上述任一关键维度,项目退回”趋势洞察”或标记为”暂缓”,避免无效投入。
5.3 第三步:构建项目(约两周)
目标:将研究结论转化为可运行的内部服务或工具。
关键动作:
- 基于深度研究阶段的文档,在内网环境搭建完整的项目运行环境。
- 解决网络、依赖、配置等部署差异问题。
- 根据内部需求对项目进行必要的适配或封装。
- 编写内部部署说明和运维手册。
输出:可运行的内网服务或工具,附带部署文档。
5.4 第四步:测试验证(测试组介入)
目标:确保项目在内网环境下的稳定性和可用性。
测试内容:
- 功能测试:核心功能是否正常运行?
- 兼容性测试:与公司现有系统、数据、权限体系的兼容性。
- 性能测试:在内部资源条件下的响应速度和并发能力。
- 安全测试:基础的安全扫描和风险评估(如许可证合规、依赖漏洞)。
反馈机制:测试结果记录到项目文档,未通过的项目返回”构建项目”阶段修复。
5.5 第五步:内网部署(运维组介入)
目标:完成正式上线,接入公司内部服务体系。
关键动作:
- 运维组基于部署文档和测试报告,完成正式环境部署。
- 将服务容器化并推送至内部镜像库,确保版本可追溯、回滚快捷。
- 配置监控、日志、备份等运维基础设施,并更新镜像库中的服务标签。
- 向业务方交付使用入口和简要操作说明。
- 项目标记为 “内网部署” 状态,记录完成日期。
最终输出:一个可在内部访问、有运维保障、有文档支撑、有镜像版本管理能力的服务。
六、项目筛选:三条铁律
我们强调”聚焦研发效率、贴近公司特点”,并将其固化为项目筛选的三条铁律:
铁律一:能商用
- 优先选择 MIT、Apache-2.0 等宽松许可证的项目。
- AGPL 项目列为高风险,需单独评估;其他许可证需法务或合规审查。
- 坚决不碰没有明确许可证或许可证存在争议的项目。
铁律二:资源配得齐
- 在本地或内网环境中,能否在现有算力和网络条件下跑通?
- 依赖项是否过于复杂?是否依赖外部不可控服务?
- 如果部署成本过高,即使技术先进也暂缓推进。
铁律三:适当超前,不激进
- 能解决当前或未来半年内的实际问题。
- 不是追新,而是求稳——团队能消化、业务能落地、运维能支撑。
- 前沿探索项目可以纳入”趋势洞察”池观察,但不轻易进入”构建项目”阶段。
七、成果输出:两条分享线 + 价值闭环
研究成果只有被看见、被使用,才能产生价值。我们构建了 “知识沉淀 → 共享流通 → 研发反哺” 的三阶价值闭环,并维护两条不同节奏的输出线。
7.1 价值闭环
- 知识沉淀:每一次研究的文档、架构图、操作视频均归档至团队知识库,形成可复用的资产。
- 共享流通:通过内网门户、月度期刊、项目PPT等方式发布,让成果在全公司范围内可见。
- 研发反哺:将研究成果转化为技能分享(Skill)——研究员提炼经验,通过内部工作坊、微课程或技术分享会输出,促进团队能力共建;同时,成果直接嵌入产品研发流程,提升整体效率。
7.2 定期分享:项目级输出(按需触发)
当一个项目完成“内网部署”,或进入“深度研究”后产生重要结论时,会触发项目级分享:
- 输出物:项目 PPT,包含项目定位、应用场景、架构图、部署说明。
- 受众:项目组、技术委员会、相关研发团队。
- 形式:内部分享会、技术评审会、或文档沉淀。
7.3 月度分享:技术动态期刊(每月固定)
- 输出物:新技术动态期刊,汇总当月趋势洞察、深度研究、内网部署的进展。
- 发布渠道:内网 OA 技术动态栏目,后续纳入部门新技术动态统一发布。
- 内容:不是简单罗列项目,而是解读技术进展——这个项目为什么值得关注,对我们有什么启发,是否值得跟进。
- 历史追溯:创刊以来每月持续贡献,形成可回溯的技术研究档案。
为什么要有期刊? 单个项目的分享是”点”,月度期刊是”线”,把分散的研究成果串联成技术趋势的全貌,让公司看到研究工作的整体价值。
八、数据底座:Excel 在线文档
整个技术雷达的运转,依赖一个统一的数据底座:
文件:开源 AI 生态研究与落地指南.xlsx
这张表格是整个项目的”唯一数据源”,包含以下核心字段:
| 字段 | 说明 |
|---|---|
| 项目名称 | 开源项目的名称 |
| 技术类别 | 智能体 / 插件 / AI 应用 / 基础设施 / 工作流编排 / AI 开发平台 / 大模型 / 规范标准 |
| GitHub 地址 | 项目仓库链接 |
| 项目定位 | 一句话说明项目是做什么的 |
| 应用场景 | 适用于哪些具体场景 |
| 依赖项 | 部署所需的依赖和环境 |
| 开源许可证 | 商用合规判断依据 |
| 项目来源 | 内容 / 战略规划 / 社区 / 推荐 / 其他 |
| 项目状态 | 趋势洞察 / 深度研究 / 内网部署 |
| 研究成果 | 关联的文档、图片、视频 |
| 内部项目名 | 落地后的内部服务名称 |
| 部署说明 | 内网部署的具体步骤 |
| 负责专家 | 项目主责人 |
| 完成日期 | 内网部署完成时间 |
同步机制:Excel 数据通过 npm run sync:projects 自动同步到网站数据库,驱动前端展示。开发/构建时都会自动执行同步,确保网站内容与表格数据一致。
九、总结:一张表对齐所有人的预期
| 问题 | 答案 |
|---|---|
| 每天干什么? | 扫描 GitHub 趋势和技术媒体,维护项目池,更新项目状态。 |
| 每周干什么? | 推进”深度研究”阶段的项目,完成技术评估和可行性分析。 |
| 每两周干什么? | 推进”构建项目”阶段的工作,完成内网环境搭建和适配。 |
| 研究什么? | 能商用、资源配得齐、能提升研发效率、适当超前的开源项目。 |
| 怎么分享? | 项目完成即触发项目级分享;每月固定发布技术动态期刊;同步开展技能分享(Skill)工作坊。 |
| 数据在哪? | 统一维护在 Excel 在线文档,自动同步到技术雷达网站。 |
技术雷达不是“技术收藏夹”,而是从信息到落地、从研究到价值的完整引擎。每一个项目都必须经历“洞察→研究→构建→测试→部署→镜像化”的完整闭环,每一条输出都必须经过“筛选→评估→验证”的严格把关。同时,研究成果通过知识沉淀、共享流通和研发反哺,真正转化为团队的集体能力与产品效率提升。只有这样,开源研究工作才能真正成为研发效率的放大器,而不是技术热情的消耗品。
本文基于「AI 生态实验室 · 技术雷达」项目工作流程整理,作为团队开展开源研究的统一操作手册。