SkVM:面向随处高效执行的技能编译
上海交通大学
摘要
LLM 智能体越来越多地将技能(skill)作为可复用的组合单元。尽管技能在不同智能体平台间共享,但现有系统将其视为原始上下文处理,导致同一技能在不同智能体上表现不一致。这种脆弱性损害了技能的可移植性与执行效率。
为应对这一挑战,我们分析了 118,000 个技能,并从传统编译器设计中汲取灵感。我们将技能视为代码,将 LLM 视为异构处理器。为使可移植性成为现实,我们将技能的需求分解为一组原语能力(primitive capabilities),并衡量每个模型-执行框架(model-harness)组合对这些能力的支持程度。基于这些能力画像,我们提出了 SkVM——一个面向可移植且高效技能执行的编译与运行时系统。在编译期,SkVM 执行基于能力的编译、环境绑定与并发提取。在运行期,SkVM 应用 JIT 代码固化(code solidification)与自适应重编译以优化性能。
我们在 8 个不同规模的 LLM 和 3 个智能体执行框架上评估了 SkVM,覆盖 SkillsBench 及代表性技能任务。结果表明,SkVM 显著提升了不同模型与环境下的任务完成率,同时降低 Token 消耗高达 40%。在性能方面,SkVM 通过增强并行性实现最高 3.2× 加速,并通过代码固化实现 19–50× 的延迟降低。
1. 引言
基于 LLM 的智能体(achiam2023gpt4, ; openclaw, ; opencode, ; claudecode, ; openai-codex-cli, ; wang2024agentsurvey, )正在重塑软件任务的完成方式。开发者不再手写代码,而是描述目标,由智能体进行推理、调用工具并交付结果(yao2023react, ; qin2023toolllm, )。为支持这一范式,日益增长的技能(claude-agent-skills, ; anthropic-skills-repo, ; openclaw-medical-skills, ; skillssh, )生态系统应运而生,使智能体执行更加可靠和实用。技能主要由自然语言描述和脚本组成,封装了领域特定的流程和最佳实践(anthropic-skills-blog, )。目前,超过 100,000 个技能分布在各大平台(clawhub, ; skillssh, ),涵盖数据分析、金融、办公自动化、编程等领域。
然而,现有智能体对技能的支持过于简单:技能被当作额外上下文直接传递给模型。不同模型在理解和执行技能方面差异显著(lu2024agentbench, ; han2026swe, ; li2026skillsbench, )。在涵盖多种规模的 8 个模型中,启用技能后整体有 15% 的任务性能下降(例如,Opus 4.6 为 7%,Qwen3-30B 为 25%)。另有 17% 的任务得分保持不变(排除完成率为 100% 的任务),而在高达 87% 的任务中,至少有一个模型在使用技能后未见改善。近期工作(han2026swe, )得出了类似结论:在 SWE-Benchmark 上,49 个技能中有 39 个未带来分数提升,3 个技能出现了显著分数下降。
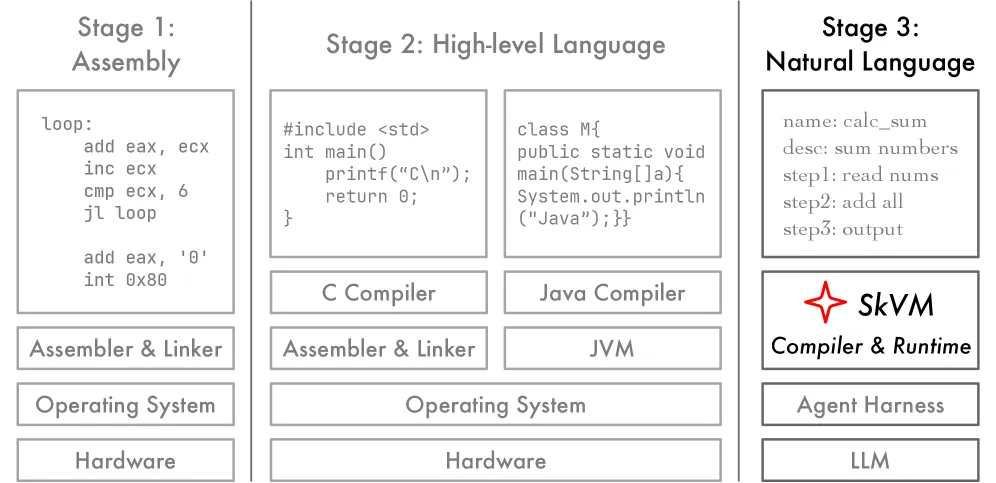
图 1. 编程抽象的演进。技能是当前的前沿:数百行的自然语言程序,但缺乏面向跨目标可移植性的编译器与运行时。
我们将这些问题归因于两个因素:(1)即使加载了技能,模型在执行过程中仍可能忽略其指导;(2)即使模型遵循了技能,技能对模型能力的假设也可能与模型的实际能力不匹配。除了任务完成收益的差异之外,当前技能中常见的半结构化代码片段和工作流式格式还带来了巨大的 Token 开销(例如,Token 增加 451% 而通过率不变(han2026swe, )),以及执行时更高的延迟。
这一问题的根源在于静态技能与底层模型及智能体执行框架的可变性之间存在根本性错配。技能所需的能力可能与运行时所调用 LLM 的能力不一致。回顾计算范式的演进(stroustrup2013c++, ; venners1998java, ; cramer1997compiling, )(如图 1 所示),我们观察到:在智能体时代,技能即代码,LLM 即处理器。然而,当今尚不存在能够跨异构 LLM 和智能体执行框架高效、可靠执行技能的机制。
受传统计算系统处理代码的方式启发,我们引入了 SkVM——一个面向技能的编译与运行时系统,支持高效的跨模型执行,并为技能执行提供统一的底层支持。通过 SkVM,技能被编译为适应不同模型的形式,使每个模型都能更好地理解和执行技能。此外,SkVM 提供统一的运行时环境,系统化管理技能的加载、解析与并发执行。
我们将 SkVM 围绕经典编译技术构建:解释执行(jansen2007interpretation, )、提前编译(Ahead-of-Time, AOT)(serrano2021javascript, ; serrano2018javascript, )和即时编译(Just-in-Time, JIT)优化(aho2006compilers, ; aycock2003jit, ; suganuma2000overview, ; ishizaki2000study, ; cramer1997compiling, )。当前,智能体仅以解释执行方式处理技能,将原始技能文本直接喂给模型。这种方法阻碍了技能的可移植性和执行效率。相比之下,SkVM 进一步应用 AOT 和 JIT 编译,以优化不同的后端模型和执行环境:
AOT 编译:技能本身编码了对模型能力、环境配置和并行机会的需求。因此,SkVM 在执行前分析这些需求并优化技能。基于能力的编译通过抽取 26 种原语能力,刻画 LLM 与技能需求之间的能力差距。每种能力抽象了模型行为的一个不同维度,并包含多个熟练度级别。编译器针对这些能力维度衡量目标模型,并调整技能规范以更好地匹配模型的优势与局限。其次,环境绑定从技能描述中抽取对包和工具的隐式依赖,并生成可在加载时执行的安装脚本,确保技能执行前所有依赖均已满足。最后,并发提取借鉴经典编译器对数据级并行(Data-Level Parallelism, DLP)(kalathingal2016dynamic, )、指令级并行(Instruction-Level Parallelism, ILP)(ranganathan1998empirical, ; kastner2001ilp, )和线程级并行(Thread-Level Parallelism, TLP)(redstone2003mini, )的优化。它以相似的三个粒度从技能中抽取并行机会,并显式暴露给智能体执行框架,从而提升任务执行效率。
JIT 优化:在运行期,SkVM 利用运行时信息持续优化技能性能与正确性。代码固化:技能可能包含参数化脚本模板,在不同执行过程中被多次实例化。JIT 编译将这些高频模板物化为实例化的可执行代码,绕过 LLM 解析。自适应重编译:JIT 监控器跟踪模型执行,并在能力差距出现时自适应地重编译技能,确保技能能够通过迭代优化自我改进。
技能编译完成后,技能运行时解析编译后的技能产物(包括优化后的技能、实例化脚本和并发依赖图),而非简单地将原始文本传递给模型。此外,技能运行时与系统可用资源和工具能力协调,实时调度智能体执行,并确保稳定可靠的智能体执行。
我们在 8 个不同规模的 LLM 和 3 个智能体执行框架上评估了 SkVM,覆盖 SkillsBench(li2026skillsbench, )和代表性技能任务(118 个任务)。结果表明,SkVM 显著提升了不同模型和智能体执行框架(claudecode, ; opencode, )下的任务完成率(平均提升 15.3%)。此外,对于能够完成的任务,SkVM 降低 Token 消耗高达 40%。在性能方面,SkVM 通过细粒度并行化和 JIT 代码固化实现 3.2×–50× 的挂钟时间加速。
2. 真实世界中的技能
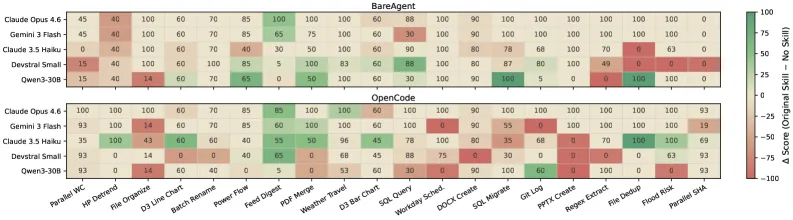
图 2. 技能在不同模型和执行框架上的性能表现。列为任务,行为模型,每个子图对应一个执行框架。单元格颜色表示相对于无技能基线的分数差异,单元格标签显示绝对任务分数。模型身份和执行框架选择均显著影响结果。
在本节中,我们首先介绍技能、使用技能的智能体,以及技能在实践中的调用方式。我们通过从两个主要分发平台收集的超过 110,000 个技能研究技能生态系统:clawhub.ai(clawhub, )(28,990 个技能)和 skills.sh(skillssh, )(89,280 个技能)。基于这一生态系统分析,我们进一步开展实验以识别当前技能使用中的具体问题。
2.1. 技能定义
技能是一个可分发、自包含的知识包,用于增强 AI 智能体在特定任务类别上的能力(claude-agent-skills, ; agentskills-spec, )。技能可以引入基础模型所不具备的知识,或者在模型已具备相关能力但倾向于即兴发挥时,约束其遵循规定的流程。例如,一个 PDF 处理技能(anthropic-skills-repo, )教会模型如何使用 pdfplumber 进行表格提取,并约束模型在合并 PDF 文件时使用 pypdf 而非已弃用的 PyPDF2。
技能通常在一个结构化文件中定义,包含三个层次:(1)元数据——名称、描述和触发条件,使智能体运行时能够自动发现并选择技能;(2)指令——技能的主体,以自然语言编码多步工作流、工具引用和其他任务特定指导;(3)捆绑资源——存储在配套文件中的脚本、参考材料和模板。
这一结构使技能区别于临时提示片段。元数据使技能成为可发现、可选择的单元,智能体运行时能够自动将任务匹配到适用技能,而无需手动组装提示(claude-code-skills, )。与微调相比,技能无需修改权重,可完全在提示层面操作(ouyang2022training, ; liu2021pretrain, ),使其分发轻量、易于组合。多个智能体平台已趋同于这一抽象(claude-code-skills, ; cursor-skills, ; openai-codex-cli, ; agentskills-spec, ; antigravity-skills, ; coze-skills, ),现有工具已支持基本的技能编写、管理和优化。
2.2. LLM 智能体与智能体执行框架
LLM 智能体以 ReAct 循环工作(yao2023react, )。它接收任务,推理该做什么,发出工具调用(读取文件、运行命令、发起 API 请求)(schick2023toolformer, ; openai2023functioncalling, ),观察结果,再次推理。该循环重复直至任务完成。
智能体并不直接与外部世界交互。它运行在 智能体执行框架(agent harness) 内,这是一个位于模型与操作系统环境之间的运行时框架(wu2023autogen, ; langgraph, )。执行框架管理 LLM API 连接、注册智能体可调用的工具、分发这些调用,并控制对话历史在上下文窗口中的保留量。Claude Code(claudecode, )、OpenCode(opencode, )和 OpenClaw(openclaw, )是广泛使用的执行框架示例。
执行框架在影响技能的多方面存在差异(google-a2a, )。有些提供丰富的文件系统和网络搜索工具,而另一些仅暴露基本的读、写和 shell 执行操作。有些可以生成独立工作的子智能体以实现并发,而另一些仅支持顺序执行。这些差异直接影响技能指令能否被执行。
2.3. 技能特征分析
生态系统规模与分布。技能生态系统庞大但分布不均。图 3 展示了两个平台的下载量。在 skills.sh 上,89,280 个技能中有 89% 的下载量少于 86 次,而少数头部技能达到 – 次。clawhub.ai 呈现类似的长尾分布,峰值约为 – 次下载。总计,两个平台共有超过 118,000 个技能,但绝大多数鲜被使用。
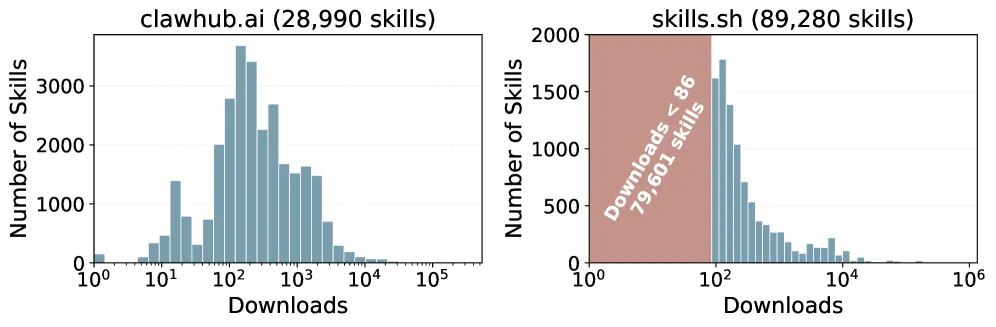
图 3. clawhub.ai 与 skills.sh 上的技能下载分布。两个平台均呈现长尾分布。
技能分类体系。技能在提供给智能体的内容上差异显著。我们使用 LLM 辅助分析,将下载量超过 100 的 15,063 个技能按最强调的方面分为三类:工具引用(52%)、流程指导(28%)和内容生成(20%)。
工具引用型技能 教会模型如何操作特定工具、API 或 CLI。它们本质上是加载到智能体上下文中的使用文档。一个代表性例子是记录如何使用 Python 合并、拆分和处理 PDF 文件的技能。
流程型技能 规定了执行任务的逐步工作流和推理策略。一个代表性例子是调试技能,强制要求四阶段过程:复现失败、追踪根本原因、应用针对性修复、通过测试验证修复。
生成型技能 要求模型生成内容、代码、文档或散文。核心质量取决于模型自身能力。一个例子是前端设计技能(anthropic-skills-repo, ),它生成具有特定设计指南和样式约定的生产级 Web 组件。
工具引用型和流程型技能共占生态系统的 80%。这些技能编码了可分析的结构,包括脚本片段和逐步工作流。执行这些技能的正确性取决于智能体是否执行了规定的步骤,而非其生成能力。
工作流结构。除任务类型外,技能还表现出重复的内部结构。在 15,063 个已分类技能中,76% 包含显式的流程结构:编号步骤、条件分支和步骤间的数据依赖。
代码片段。75% 的技能嵌入了类代码片段:shell 命令、API 调用模式或脚本片段,其整体形状在多次调用中重复,仅输入特定参数变化。例如,一个天气技能(openclaw, )可能提供一组 curl 命令模板,用于当前天气、天气预报和格式选项,其中命令结构固定,而城市、输出格式和预报天数等参数变化。
2.4. 当前技能使用的问题
技能以原始文本形式加载到智能体的上下文中,不做任何适配。但技能隐式地假设了模型、智能体执行框架(harness)和用户环境。当这些假设不成立时,会出现三种失效模式。
P1:模型不匹配。技能隐式假设模型有足够的能力遵循其指令。实际上,模型之间存在显著差异(lu2024agentbench, )。图 2 展示了在三种模型和三种执行框架上部分任务的得分。BareAgent 是我们构建的最小化智能体执行框架,仅实现了基本的智能体运行时逻辑,并只暴露了 read、write 和 exec 工具。同一技能在不同模型上的性能差异很大。此外,启用技能会导致 15% 的任务性能下降;17% 的任务得分不变(排除完成率为 100% 的任务);在 87% 的任务中,至少有一种模型没有获得性能提升。
案例研究:pptx-creation 技能(anthropic-skills-repo, )推荐使用 PptxGenJS(一个 JavaScript 库)来生成幻灯片。Claude-opus-4.6 和 gemini-3-flash 使用该技能都能获得 100 分,但 devstral-small 在使用 OpenCode 时误将 PptxGenJS 当作 CLI,并反复执行错误命令。在没有该技能的情况下,devstral-small 转而使用 python-pptx 并获得 95 分。该技能假设模型能够区分库 API 和 CLI,这对前沿模型成立,但对较弱的模型不成立。
P2:执行框架不匹配。同一模型在相同任务上会因所处的智能体执行框架不同而产生不同结果(yang2024sweagent, )。图 2 也展示了这一维度:在整个热图中,执行框架导致的方差与模型导致的方差相当。技能在编写时并不知道执行框架提供了哪些工具和插件。
案例研究:Gemini 3 Flash 在 BareAgent 上使用原始技能完成 workday-scheduling 任务获得 100 分,但在 OpenCode 上使用同一技能得 0 分。失败由一个格式错误的 JSON 键触发,导致输出无法解析。BareAgent 仅添加最简系统提示,而 OpenCode 前置了详尽的工具文档,更长的组合上下文诱发了格式错误。
P3:环境不匹配。技能依赖于执行环境,但用户的机器可能缺少所需的包、工具或配置。一些技能列出了前置条件,但这些指令通常较为通用,针对的是通用机器而非用户的实际环境。真正的需求取决于当前操作系统、硬件、已安装版本和包管理器状态。其他技能则完全省略了依赖说明。图 4 展示了两个代表性任务上的影响。当所需库缺失时,两个 Qwen 模型的成功率降至 33–67%,同时在失败的变通方案中生成 2–4× 更多的输出 token。即使是 Claude Opus 4.6,虽然每次运行仍能成功,但也会生成 56–69% 更多的输出 token,因为它必须在运行时诊断不匹配并安装缺失的包。因此,将诊断工作留给模型,会使每个缺失的依赖都转化为对正确性和效率的重复损耗。
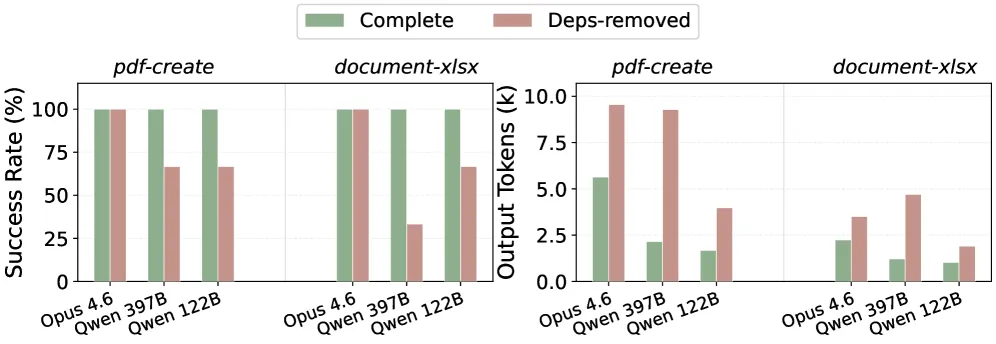
图 4. 移除必要依赖会同时损害正确性和效率。
2.5. 挑战
技能以纯 Markdown 形式分发,以便任何智能体无需特殊工具即可加载。上述不匹配削弱了这种可移植性承诺。恢复可移植性需要将每个技能适配到其目标环境,这面临两个挑战。
C1:目标在多个维度上存在差异。上述三个维度——模型、执行框架和环境——各自独立变化。仅在一个维度上需要适配的技能,当两个维度同时变化时可能需要不同的适配。在功能丰富的执行框架上针对弱模型的正确修复,与在最小化执行框架上针对同一模型的正确修复不同。这种交互使适配空间呈组合爆炸:无法通过一组固定的重写规则来覆盖。
C2:技能是非结构化的自然语言。源代码在目标系统上运行前需要编译,具有语法、类型和定义良好的 AST,可供工具分析(aho2006compilers, )。相比之下,技能以自然语言编写。尽管技能大多遵循共同约定创建,但不同技能在结构、术语和详细程度上差异很大。在进行任何适配之前,必须从文本中还原技能隐式包含的需求和工作流结构。
3. 设计概述
SkVM 是一个面向技能的编译和运行时系统。它通过结合 AOT(Ahead-of-Time)编译器(aho2006compilers, )——在安装时对技能进行特化——与解析执行时不确定性的运行时,使技能能够跨异构目标移植。图 5 展示了其架构。
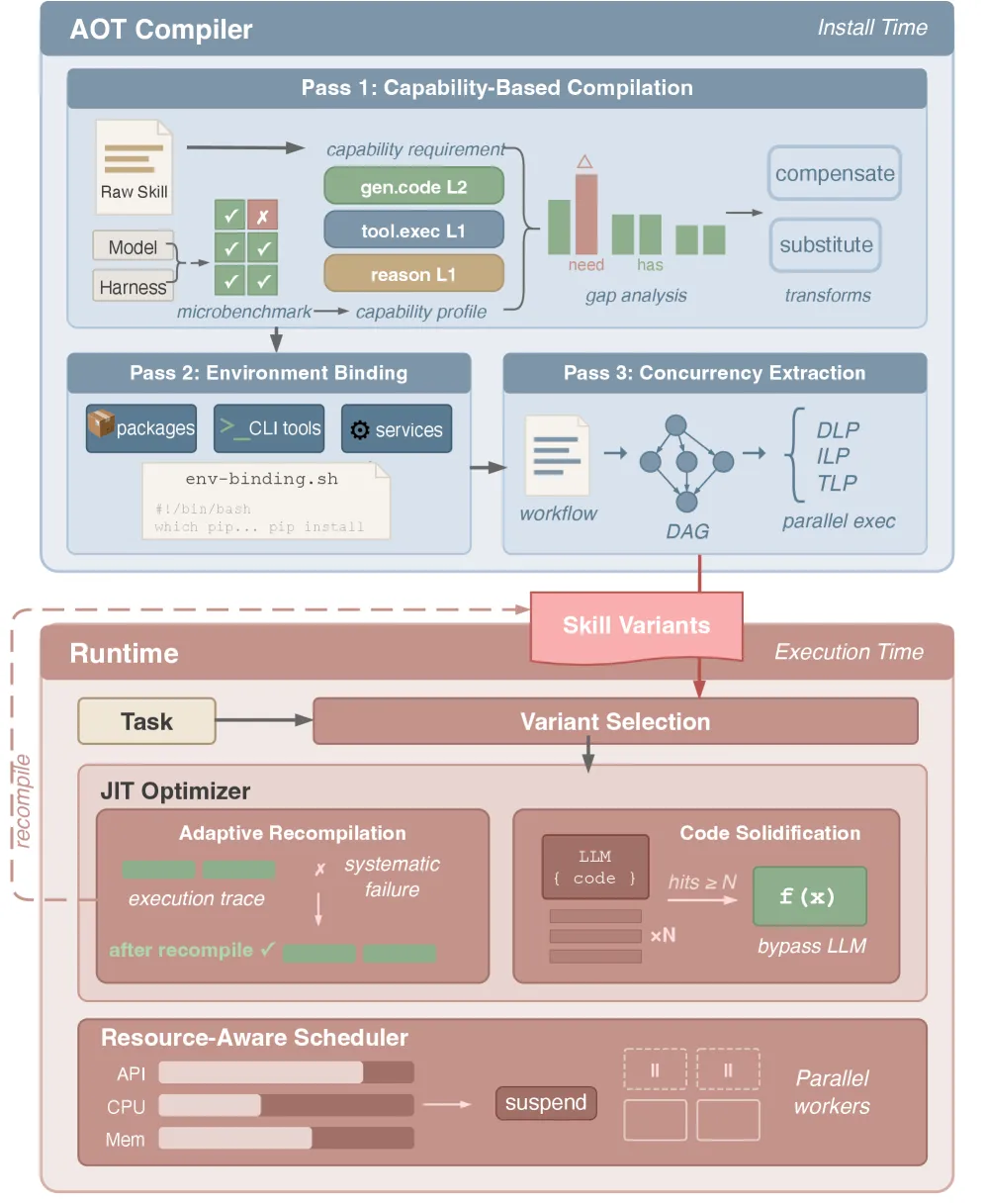
图 5. SkVM 架构。AOT 编译器通过三个遍(pass)在安装时生成优化的技能变体。运行时管理变体选择、JIT 优化以及执行期间的资源感知调度。
AOT 编译器。在技能安装时,编译器针对目标环境分析技能,并生成一个或多个优化的技能变体。编译器执行三个不同的遍:基于能力的编译(§ 4.1)通过将技能适配到目标可用能力来处理模型与执行框架不匹配(P1–P2)。环境绑定(§ 4.2)通过物化执行所需的依赖来处理环境不匹配(P3)。并发提取(§ 4.3)识别技能工作流中潜藏的并行性,并将其映射到目标执行框架。编译后的变体按目标存储。
运行时与 JIT 优化器。当任务到达时,运行时选择为当前(模型,执行框架)组合编译的变体,并通过标准的渐进式披露机制加载。随后两个组件在正常执行之上运作。JIT 优化器(§ 5.2)监控跨调用的执行结果,并在检测到 AOT 编译器遗漏的能力差距时触发重新编译。它还将结构固定的代码模式编译为可执行函数,完全绕过 LLM 推理。资源感知调度器(§ 5.3)桥接编译时的并行性注解与运行时的资源可用性,在需求超过容量时限制或暂停并发子智能体。
4. 技能编译
当用户首次安装技能时,SkVM 在技能运行前针对目标(模型、执行框架、主机环境)对其进行编译。编译器读取原始技能文本,识别目标,并通过三个顺序的遍生成一个或多个优化的技能变体。每个遍弥合技能期望与目标提供之间的不同差距。
4.1. 基于能力的编译
第一遍处理模型与执行框架的不匹配。由于目标差异很大(§ 2.5),编译器无法嵌入针对每个目标的优化逻辑。为此,SkVM 引入了原语能力(primitive capabilities),一种用于表达技能需求与目标提供的抽象词汇。编译器通过针对这些能力的微基准测试对目标进行离线分析,将分析结果与技能的能力需求进行比较,并根据差距选择优化策略。
4.1.1. 原语能力
正如 JVM 字节码定义了 Java 程序从运行时所需的基本操作,原语能力定义了技能从目标所需的基本能力。原语能力是一个不可再分的单元,描述完成技能定义任务所需的条件。它纯粹从需求侧定义,独立于任何具体模型。原语能力的定义遵循三项原则:
- 可组合性:技能内的任何具体任务都可以描述为原语能力的组合。
- 通用性:每个原语能力必须足够广泛,以出现在许多技能中,从而保持总能力集较小且编译器工作量有界。
- 语义独立性:原语能力关注结构正确性,而非输出是否具有洞察力或论证是否充分。
我们从 15,063 个技能的语料库中分两个阶段推导出原语能力集。首先,我们筛选了 50 个具有代表性的技能,涵盖文档生成、脚本执行、数据分析和代码开发,并在上述三项原则的指导下使用 LLM 辅助分析将其分解为包含 19 个原语能力的初始集合。然后我们手动审查每个原语能力,验证其满足所有三项原则。其次,我们在完整的 15,063 个技能语料库上验证该初始集合,检查每个技能的需求是否可用现有原语的组合来表达。无法覆盖的技能揭示了缺失的能力。只有当某缺失能力出现在至少 1% 的语料中时,才将其加入集合,过滤掉罕见或领域特定的需求。这一过程最终收敛为跨四个类别的 26 个原语能力,覆盖了 95% 技能的需求。
我们还观察到,不同任务对同一原语能力的需求深度不同。因此,我们为每个原语能力定义了多个熟练度级别。更高级别代表对该能力的更深入使用:L(n+1) 需求无法被 L(n) 能力满足。表 1 展示了代表性示例。针对每个原语能力级别,我们生成一套微基准测试并在不同模型上评估。如果某模型在较高级别的微基准上成功,而在较低级别上失败,我们将这种不一致性解释为级别层次未校准的证据。随后我们修订级别定义并重复评估。
表 1. 代表性原语能力及其熟练度级别。完整目录包含跨四个类别的 26 个原语能力。
| 原语能力 | L1 | L2 | L3 |
|---|---|---|---|
| gen.code.shell | 基本命令(ls, cat) | 管道、重定向、循环 | 复杂流水线(sed, awk) |
| reason.arithmetic | 单步操作 | 多步 | 复合 |
| tool.exec | 单条命令 | 参数与相对路径 | 链式多步执行 |
| follow.procedure | 3 个顺序步骤 | 5–7 步含分支 | 循环与验证 |
4.1.2. 度量技能与目标之间的差距
在应用优化前,编译器必须确定技能需求与目标提供之间的差距。在技能侧,编译器在安装时提取技能的能力需求:将技能分解为具体任务,并将每个任务映射到其所需的原语能力。
在目标侧,SkVM 使用为每个原语能力生成的微基准测试对目标进行分析,以衡量目标对该能力的支持程度。在某一级别原语能力的微基准测试上成功,表明模型至少已达到该能力在此级别的熟练度。该分析在用户设置智能体和模型时执行,结果被缓存并在同一目标的所有技能编译中复用。
4.1.3. 能力感知的技能转换
在掌握技能的能力需求与目标的能力画像后,编译器遍历每个能力需求,并根据所需级别与目标分析级别之间的差距选择转换。
*补偿(Compensation)*适用于目标支持所需能力但级别较低的情况。编译器首先识别原语能力两个级别之间的区别,然后相应地转换技能,将其能力需求从较高级别降低至目标模型支持的级别。此类转换可能包括提供示例、使指令更明确、加强任务约束。补偿是首选转换,因为它保留了技能的原始意图。
替代(Substitution)是补偿不可行时的回退方案:目标完全缺乏该能力,或级别差距过大导致补偿无法可靠弥合。编译器切换到替代实现路径,使用不同能力达到相同目标。例如,若技能需要 L3 级别的 gen.code.python 来执行 pandas 工作流,但目标仅达到 L1,而目标的 gen.code.sql 达到 L2,编译器可切换为基于 SQL 的路径。这些替代路径形成编译器在需求提取阶段识别的等价类。
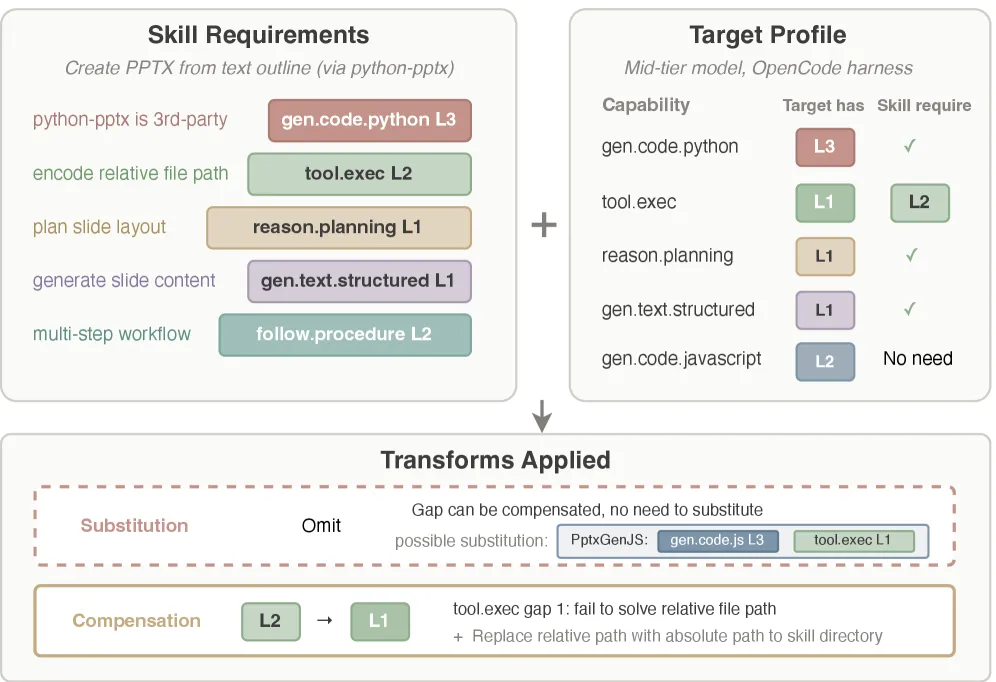
图 6. 基于能力的编译在 PPTX 技能上的示例。编译器提取技能需求(左)、分析目标(中),并根据差距应用转换(下)。
案例研究。图 6 展示了一个真实技能上的编译过程,该技能教智能体使用 python-pptx 创建 PPTX 演示文稿。该技能需要五个不同级别的原语能力。目标直接匹配其中四个,但 tool.exec 仅提供 L1,而技能需要 L2 来解析相对文件路径。
编译器识别出一条可能的替代路径:通过 gen.code.javascript 切换到 PptxGenJS 可以替代 python-pptx,并将 tool.exec 需求降至 L1。然而,由于 tool.exec 的差距仅一级,首选补偿。L2 分析结果显示,该模型在执行命令时无法解析相对文件路径。编译器向编译后的技能注入绝对路径解析,将相对路径替换为技能目录的绝对路径。
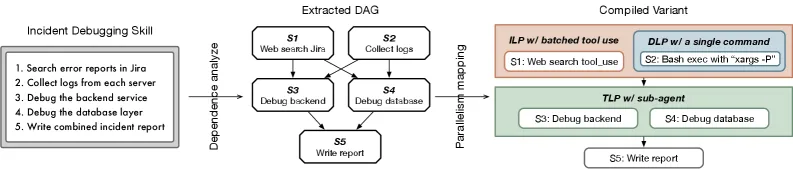
图 7. 在事件响应技能上的并发提取。编译器将顺序步骤分解为工作流 DAG,识别步骤之间和步骤内部的并行机会,并将每个机会映射到适当的并发原语。
4.2. 环境绑定
第二遍解决 P3:环境不匹配。编译器不仅仅检查依赖是否已安装,而是使用内置的 env-binding skill 来协调技能假设与主机环境,并生成 env-binding 脚本。
在技能安装时,编译器首先从第一遍的输出技能及任何显式前置条件中提取依赖清单,涵盖外部库、CLI 工具和系统服务。对于清单中的每一项,编译器运行轻量级存在检查(例如,pip show、which)。已满足的依赖无需进一步处理。当检查失败时,编译器执行更深入的系统感知探测,以确定如何解析依赖。然后编译器生成一个幂等的 env-binding 脚本,在技能执行前检查和修复依赖。当环境变化或 env-binding 脚本失败时,执行回退到模型,脚本的输出作为附加上下文传递给模型。
4.3. 并发提取
第三遍发现隐藏在明文中的并行性。回顾 76% 的技能包含过程性结构(§ 2.3)。这些技能以顺序文本描述多步工作流,但并非每一步都实际上依赖于前一步。
编译器使用 LLM 辅助分析将技能分解为离散步骤,识别每个步骤消耗的输入和产生的输出。然后构建工作流 DAG:节点为步骤,当步骤 B 消耗步骤 A 的输出时,存在从 A 到 B 的边。编译器还分析每个步骤内部可并发进行的子操作。图 7 在事件响应技能上展示了这一过程。对于每个并行机会——无论是步骤之间还是步骤内部——编译器基于任务结构和执行框架选择并发原语。SkVM 定义了三个级别的并行性。
数据级并行(DLP)。单一步骤将相同操作应用于多个独立的数据项,例如对 15 个 CSV 文件中的每一个运行相同分析。编译器重写该步骤,使用适合技能实现的语言级并行原语(如 shell 级并行执行、Python 的 multiprocessing 或 JavaScript 的 Promise.all)并发处理各数据项。DLP 无需特殊的执行框架支持。
指令级并行(ILP)。多个独立步骤各需一次工具调用,且彼此之间无数据依赖,例如在一个项目上运行八个独立的代码分析脚本。编译器将对应的 DAG 节点分组为一个并行阶段,并重写技能,使其工具调用在单个 LLM 轮次中一起发出,而非按顺序文本逐一发出。编译器在技能中注解哪些步骤输出应在批处理完成后绑定回哪些下游 DAG 输入。ILP 需要执行框架支持批量工具调度。
线程级并行(TLP)。工作流分解为独立的子任务,每个子任务都需要多轮推理,例如调试三个独立服务。编译器重写技能,将每个子任务提取到一个独立的子智能体块中,包含显式任务描述、声明的输入上下文以及父工作流可消费的预期输出。该注解将此块标记为子智能体调度,运行时在其独立会话中为每个块生成一个子智能体,并将返回的输出合并回 DAG。TLP 需要执行框架支持子智能体生成。
若目标执行框架上缺少所需原语,则对应的并行机会回退到顺序执行。对于每个可行的机会,编译器要么重写技能指令以并发执行项目(DLP),要么发出执行注解以显式表达并行结构:针对 ILP 的 DAG 节点并行阶段,或针对 TLP 的带输入输出合约的子智能体任务块。运行时读取这些注解,并使用对应的执行框架原语进行调度。
5. 基于 JIT 优化的技能运行时

图 8. 代码固化流水线。AOT 编译器分析技能代码片段,并生成带有代码签名和模板的 JIT 候选(阶段 1)。运行时跨调用验证预测(阶段 2)。提升后,编译后的函数替代 LLM 推理(阶段 3)。
AOT 编译为不同目标生成多个技能变体。因此,在运行时,SkVM 加载为当前目标编译的技能变体。由于 AOT 编译对每个技能和目标(模型+执行框架)组合仅执行一次,编译开销是适度的。
然而,一些问题只在执行时才暴露,例如静态分析遗漏的能力缺口,或并行子智能体争夺速率受限 API 时的资源争用。其他机会,如跨调用反复出现的代码模式,只有在多次运行后才变得可见。SkVM 运行时通过 JIT 优化(§ 5.2)和资源感知调度器(§ 5.3)来解决这两类问题。
5.1. 技能注册与执行
编译为每个技能生成多个技能变体,以及 Pass 2 生成的环境绑定脚本。当新任务到达时,运行时选择为当前(模型,执行框架)组合编译的变体。从智能体的角度来看,多个变体的复杂性是不可见的:它看到的是单一技能集,并通过 § 2 中描述的相同的渐进式披露机制加载它们。在加载完整技能上下文之前,运行时首先执行环境绑定脚本,以验证运行时依赖是否满足。
5.2. JIT 优化
除了 AOT 编译(将原语能力定制到每个目标)之外,SkVM 进一步应用 JIT 优化,通过两种互补机制提升执行质量和效率:自适应重编译和代码固化。
5.2.1. 自适应重编译
运行时跟踪使用技能执行的每个任务的结果。当技能执行失败(例如,智能体中止、人工反馈)或在智能体循环中重试时,运行时记录结构化的失败或重试日志。虽然当前模型可能通过反思进行自我修正,但修正过程未被记录,导致在后续执行中可能遇到相同的错误。
当同一技能在多次调用中失败时,运行时分析失败是任务特定的,还是反映了技能本身的系统性能力缺口。只有在后一种情况下,运行时才会触发自适应重编译:它将累积的失败日志和模型的自我恢复轨迹作为输入提供给编译器,编译器随后对技能应用有针对性的补偿转换。如果重编译的变体表现更差,运行时回滚到先前版本。每次后续重编译都从迄今为止观察到的最佳性能变体开始,确保优化正在改善技能性能。
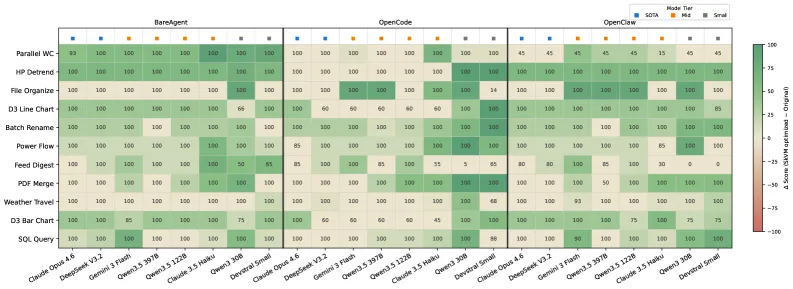
图 9. 技能编译效果。单元格值表示 SkVM 优化后的任务完成率,单元格颜色表示相对于原始基线技能的分数提升(绿色)或回退(红色)。
5.2.2. 代码固化
回顾 § 2.3,75% 的技能包含可固化代码:整体结构固定、仅随输入特定参数变化的代码。在正常执行中,LLM 在每次调用时重新执行完整的推理和工具使用循环,在每次结构相同的过程上花费 token 和延迟。代码固化识别这些重复模式,并将它们提升为绕过模型推理的可执行代码。图 8 说明了三阶段流水线。
在第一阶段,AOT 编译器分析每个技能中的代码和脚本片段,识别它们是否包含符合固化条件的参数化模式。对于符合条件的片段,它生成一个 JIT 候选,包含四个组件:过滤相关调用的关键词、捕获预期输出结构作为匹配模式的 代码签名、带有参数槽位的代码模板,以及描述可提取参数的参数模式。这些候选与编译后的技能变体捆绑在一起。
在第二阶段,运行时监视器在重复调用中监视 LLM 调用。对于每次调用,它首先检查关键词的相关性,然后将生成的代码与代码签名匹配。代码固化仅在代码签名在多次连续调用中成功匹配后才触发,确保 LLM 生成的代码结构保持与 AOT 阶段分析的模式一致。如果模型的输出持续偏离代码签名,系统保持在安全的 LLM 路径上,从不进行提升。
在第三阶段,模板被实例化为可调用函数:模板代码被包装以参数提取和输出处理,生成独立的 shell 脚本或代码函数。这个实例化步骤是轻量且机械的,因为 AOT 阶段已经完成分析。后续调用完全绕过 LLM:运行时从任务上下文中提取参数,调用实例化的函数,并返回结果。如果固化代码执行导致智能体任务失败或遇到运行时异常,SkVM 触发回退机制,重新启用基于 LLM 的代码生成,以确保正确性。
5.3. 资源感知并行调度
在 AOT 编译的 Pass 3 中,编译器识别并行性可能存在的位置,但多少并行是 高效的 取决于运行时变化的条件:CPU 使用率、外部 API 速率限制、机器可用内存以及其他共享资源。
SkVM 动态监视系统状态并相应调度任务执行,弥合编译时机会与运行时现实之间的差距。对于 API 受限的工作负载,它监视响应延迟和 HTTP 429(速率限制)信号。对于计算受限的工作负载,它监视 CPU 和内存使用率。当压力超过阈值时,SkVM 应用两种机制来缓解资源争用。首先,它对新子智能体的启动进行节流,以避免引入额外的并发压力。其次,对于已经在运行的子智能体,SkVM 基于每个智能体的资源使用率或启动顺序,有选择地挂起其中一部分(即暂停它们的智能体循环执行),以减少对共享资源的主动竞争。SkVM 还记录每个技能在当前系统上先前运行的有效并发度,并将其作为后续执行的并发提示。
6. 评估
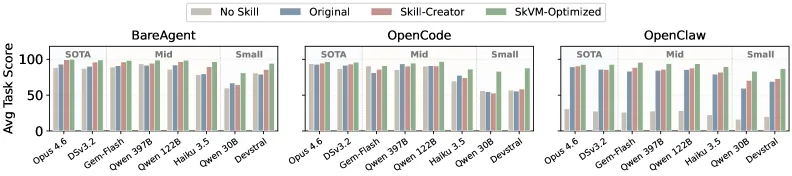
图 10. 按技能变体统计的平均任务分数。比较了四种变体在八个模型和三个执行框架上的表现:无技能、原始、Skill-Creator 和 SkVM 优化。层级边界(SOTA / 中端 / 小型)已标注。SkVM 优化后的技能始终获得最高分,在较弱模型和 OpenClaw 上获得最大的绝对增益。
6.1. 实验设置
基准测试。我们选取并扩展了现有的技能基准测试,包括 SkillsBench (li2026skillsbench, ) 和 PinchBench (pinchbench, ),涵盖跨越代码生成、数据分析、文档创建和系统管理的多样化智能体任务。每个任务至少与一个来自主流技能来源的技能配对:Anthropic-skills (anthropic-skills-repo, )、OpenClaw skills (openclaw, ) 和 skills.sh (skillssh, )。我们采用包含静态分析和基于 LLM 的评估的自动化评估套件,对照预定义标准进行评估 (zhu2024swebench, ; zheng2023llmasjudge, )。
模型。我们在跨越三个能力层级的八个模型上评估 SkVM,以全面评估其在不同模型容量下的有效性。SOTA: claude-opus-4.6 (claude4_6_opus, ), deepseek-v3.2 (deepseek2025v3, )。中端: gemini-3-flash (gemini_flash, ), qwen3.5-397b (qwen3_5_397b, ), qwen3.5-122b (qwen3_5_122b, ), claude-3.5-haiku (claude3_5_haiku, )。小型: qwen3-30b (qwen3_30b, ), devstral-small (devstral_small_2507, )。
基线。我们将 SkVM 与三个基线进行比较。无技能: 智能体在未加载任何技能的情况下执行。原始: 原始技能。Skill-Creator: 由 Anthropic 的 Skill-Creator (anthropic-skill-creator, ) 使用 claude-opus-4.6 优化的技能。
执行框架。我们选取三个不同的开源智能体执行框架来评估 SkVM 在多样化执行环境中的性能。每个执行框架提供不同的功能:BareAgent: 一个最小执行框架,将编译后的技能直接注入系统提示,没有额外的抽象层。OpenCode (opencode, ): 一个全功能代码智能体执行框架,具有批处理工具调度能力和丰富的代码执行工具集。OpenClaw (openclaw, ): 一个通用智能体执行框架,具有集成功能模块,旨在支持复杂的多步骤任务执行。
方法。我们首先分析不同模型的原语能力,然后应用 SkVM 的 AOT 和 JIT 编译,为每个模型生成优化的技能变体。为支持编译后的技能产物,我们扩展了智能体执行框架的自定义加载和管理机制,使 SkVM 的优化得以生效。对于每个任务,我们生成五个不同的输入实例,并测量平均任务完成率、token 消耗和端到端执行延迟。所有实验在一台配备 16GB 内存的 Mac Mini M4 上进行。
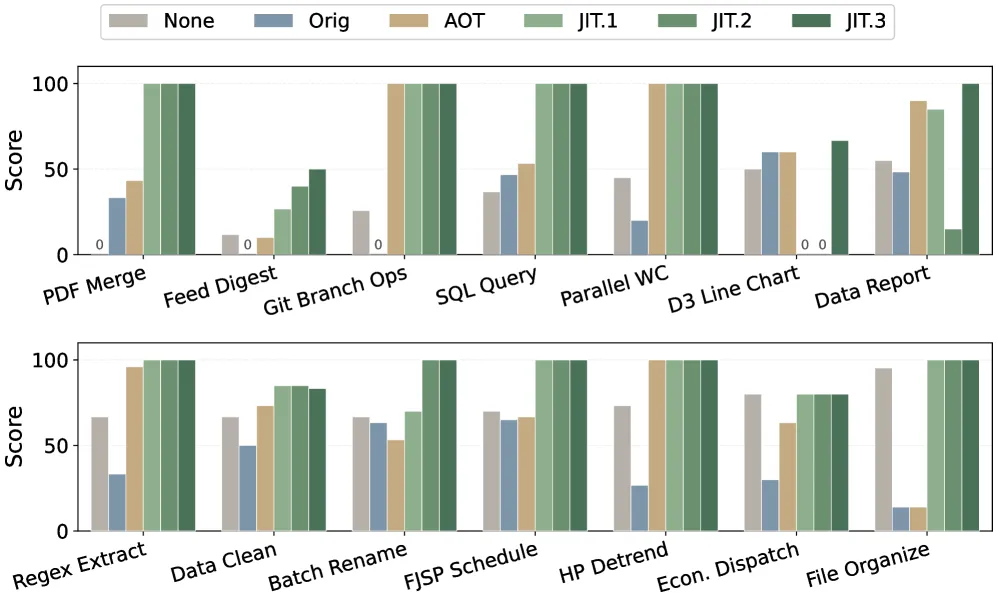
图 11. 14 个技能类别的分阶段优化分解。每组展示了六个阶段的分数:无技能、原始技能、AOT 编译技能,以及三轮 JIT 优化后的技能。
6.2. 技能编译有效性
我们首先评估 SkVM 在提升任务完成率方面的有效性。我们在不同任务、模型和智能体执行框架上比较 SkVM 优化后的技能与未优化的基线技能。对于 SkVM,主要增益来自基于能力的编译和 JIT 优化。图 9 展示了在八个模型和三个执行框架上的编译有效性。单元格值表示 SkVM 优化后的任务完成率,单元格颜色表示相对于未优化基线技能的分数提升(绿色)或回退(红色)。
图 9 展示了 SkVM 的优化有效性(与原始技能相比)在多样化模型和智能体执行框架上的表现。较弱的模型从 SkVM 优化中获益更多。这一发现表明,对于大多数智能体任务,较弱的模型在逻辑组件方面具备足够的能力,但在非逻辑方面缺乏熟练度,例如生成复杂 JSON 结构或管理环境依赖。SkVM 的编译优化通过原语能力精细化来解决这些缺口,从而提升整体任务完成率。对于较强的模型,改进更为适度,因为这些模型已经能够胜任地处理任务;SkVM 优化主要减少 token 消耗和执行延迟。图 10 汇总了每个模型和执行框架上所有四种技能变体的平均任务分数。SkVM 优化后的技能在每个模型-执行框架组合上都获得了最高分。相对于 Skill-Creator 基线的改进随着模型能力的下降而增长:在 BareAgent 上,SkVM 优化后的技能相对于 Skill-Creator 对 qwen3-30b 提升 25%,对 devstral-small 提升 10%。在回退方面,SkVM 编译后的技能仅在 4.5% 的任务上降低了任务完成率,而原始技能为 15%。使用原始技能时,OpenCode 和 OpenClaw 根据模型的不同最多相差 13 分,这表明执行框架行为本身会实质性地改变结果。SkVM 优化提升了两者的分数,并将跨执行框架差距缩小至最多 5 分。
6.3. 分阶段优化分解
图 11 分解了在 Qwen3-30B 配合 BareAgent 上 14 个技能类别中每个优化阶段的贡献。每组展示了六个阶段的分数:无技能、原始技能、AOT 编译技能,以及最多三轮 JIT 优化。每轮使用的任务是相同类型但内容不同。
在 14 个类别中的 11 个,原始技能的表现比不使用技能更差。经过 SkVM 的 AOT 编译后,平均任务分数提升 88%。JIT 优化识别出 AOT 编译期间未暴露的额外能力缺陷,进一步提升性能。一轮 JIT 后,14 个技能中的 8 个在评估任务上获得满分;三轮后,14 个中的 10 个获得满分。
JIT 优化可能引入回退。例如,在线形图任务中,JIT 编译器向技能添加了一个示例文件,但文件过长触发了解析错误,导致分数降低。在经过三轮由先前失败日志指导的修订后,JIT 编译器最终修复了这个问题。
6.4. 编译的 Token 与成本效率
除了提升任务成功率,SkVM 还通过减少 token 消耗为 SOTA LLM 提供显著的成本效益。LLM 可以通过迭代智能体循环修正执行错误,基于环境反馈细化动作。因此,即使任务最终成功,这种方法也可能产生大量的 token 浪费。图 12 展示了 SkVM 编译后不同模型层级和执行框架的任务成功率和 token 成本变化。
我们的评估表明,对于大多数模型和执行框架组合,SkVM 编译同时提升任务成功率并减少 token 消耗。对于最强模型和最弱执行框架的组合(DS-v3.2 + BareAgent),我们观察到 token 节省接近 40%。这一改进是因为智能体循环在修正环境相关和工具调用错误时产生交互开销;通常需要多次重试。通过采用 JIT 编译,SkVM 使模型完全避免这些错误路径,消除冗余交互并节省大量 token。
对于较弱的模型,SkVM 偶尔会消耗额外的 token。这是因为 SkVM 提升了任务完成率,导致与基线技能相比产生更长的智能体执行轨迹,在边缘情况下导致 token 的适度增加。
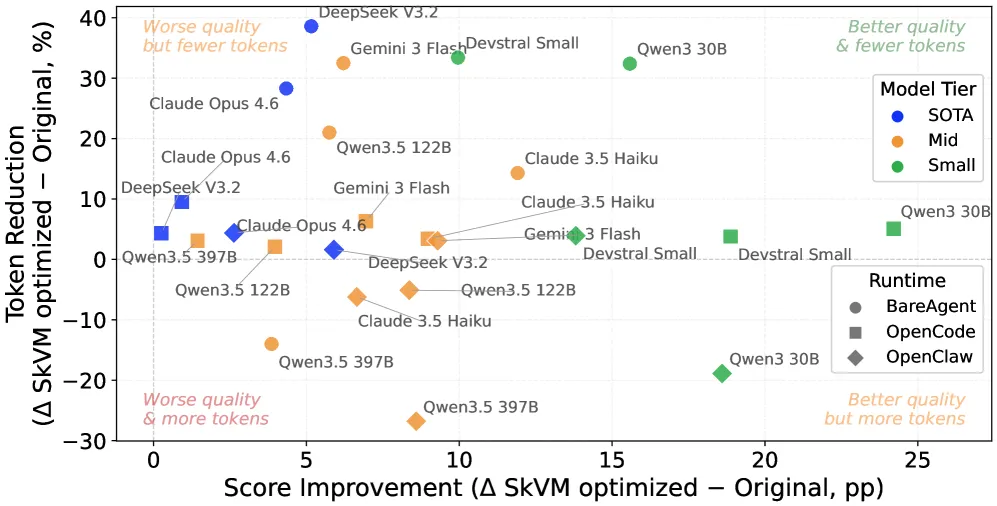
图 12. SkVM 优化相对于原始基线的分数增益与 token 节省。每个点代表一个(模型,执行框架)组合。颜色 = 模型层级,形状 = 执行框架。大多数点落在右上象限:质量更好且 token 更少。
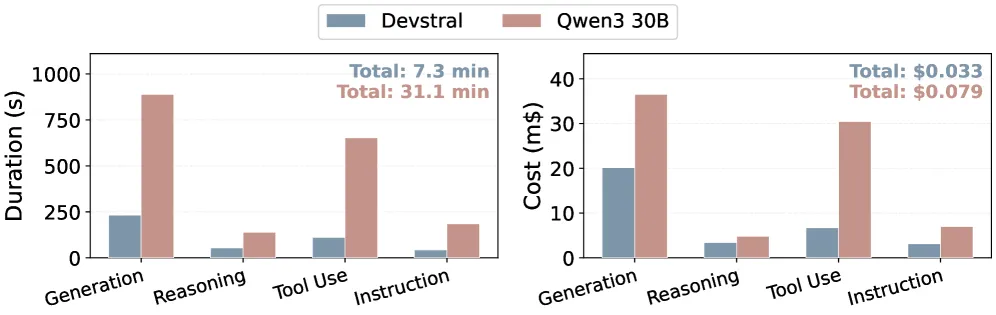
图 13. 两个小型模型的能力分析开销按类别分解。左:持续时间(秒)。右:成本(毫美元)。
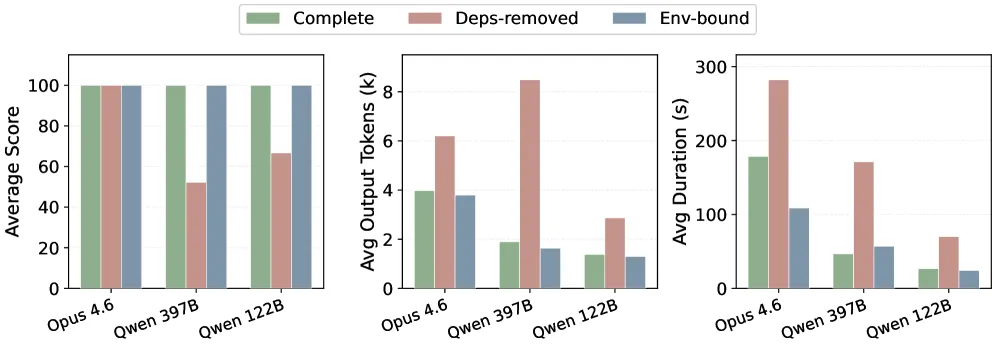
图 14. 环境绑定恢复正确性、token 效率和执行速度。从左到右:每个模型的平均分数、平均 token 使用量、平均持续时间。环境绑定后的性能对所有三个模型都恢复到完整环境水平。

图 15. 四个案例中的代码固化。蓝色条显示 LLM 推理延迟,绿色条显示固化执行。虚线标记提升点。Weather-forecast 从未提升,因为运行时模型的代码模式偏离了 AOT 预测,验证了提升门作为安全机制。
6.5. 目标分析的开销
基于能力的编译需要对目标进行一次分析以构建其能力画像(§ 4.1)。这种分析是每个(模型,执行框架)组合的一次性成本,结果会被缓存并复用于同一目标上所有后续的技能编译。我们在两个小型模型 devstral-small 和 qwen3-30b 上测量这一开销。
图 13 展示了分析持续时间和成本的按类别分解。对所有原语能力的完整画像,devstral-small 耗时 7.3 分钟,qwen3-30b 耗时 31.1 分钟,分别花费 0.079。
6.6. 环境绑定评估
前述两项实验均在完全配置的环境中进行测试。然而,在真实世界的技能场景中,智能体执行过程中缺失环境依赖是常见现象。解决此类环境问题对能力较弱的 LLM 而言构成重大挑战,经常导致技能执行失败。SkVM 通过在 AOT 编译阶段引入环境绑定机制来解决这一问题。该机制将环境依赖安装从 LLM 执行阶段转移至执行前预处理阶段,使 LLM 能够专注于技能逻辑本身。
图 14 展示了不同模型在三种环境配置下的性能表现:完整环境、启用环境绑定、以及缺失依赖的情况。能力较强的模型如 claude-opus-4.6 能够自主从缺失依赖中恢复,但代价是 token 消耗增加。对于能力较弱的模型如 qwen3.5-122b,缺失依赖会导致执行失败。环境绑定完全恢复了执行正确性,并显著降低了 token 消耗。
6.7. 并发提取评估
SkVM 提取技能内部的更多并行机会以提升效率。我们评估三种并行类型:数据级并行(DLP)、指令级并行(ILP)和线程级并行(TLP)。DLP 适用于单个技能中批量处理大量独立数据的指令场景。ILP 适用于技能中多个独立指令或代码段可并发执行的场景。TLP 适用于技能中多个独立子智能体运行,各自处理无交叉依赖的自闭包子任务的场景。图 16 展示了 SkVM 在这三种并行类型上的性能提升。
实验结果表明,SkVM 的并行提取策略可实现最高达 3.2× 的端到端加速。TLP 带来最大的平均性能提升,因为其粗粒度并行产生了更显著的优化效果。ILP 在指令级别运行,同时减少了执行时间和 LLM 调用次数。DLP 的收益纯粹来自数据并行,其性能提升与数据并行度直接成比例。我们还观察到,由于 LLM 吞吐量波动和智能体循环迭代次数的变化,智能体执行存在固有的可变性。因此,合理范围内的计时变化是可接受的。
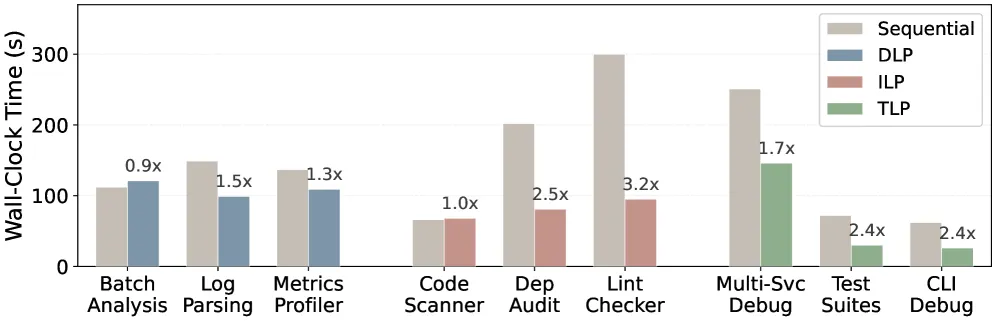
图 16. 不同并行化策略在八项任务上的性能表现。柱状图展示了顺序执行、DLP、ILP 和 TLP 的执行结果。
6.8. 代码固化评估
我们进一步分析采用 JIT 优化中的代码固化机制能否准确识别可复用代码段并提升智能体执行效率。如图 15 所示,我们对两个典型技能(天气、PDF 文档)进行了详细分析。对于两项 PDF 任务,尽管任务输入存在变化,LLM 生成的代码与代码签名匹配。因此,SkVM 可以应用 JIT 编译优化,直接使用模板和输入参数生成固化代码。对于 PDF 提取任务,JIT 优化将执行时间从 10,469–15,116 ms 缩短至 206–568 ms,实现了 19–50× 的加速。对于两项天气任务,weather-current 需要外部天气 API 调用,加速效果受网络延迟限制,执行时间从 9,000 ms 降至 2,000 ms,获得 5× 的改进。相比之下,weather-forecast 使用更灵活的格式,生成的代码结构与代码签名不一致,无法匹配。因此,全部八次调用都依赖 LLM 生成,以避免调用错误代码。
如果固化代码执行导致任务失败,SkVM 的安全机制会触发回退,重新启用 LLM 代码生成以确保正确性。
7. 讨论
技能编译中的非确定性。与传统程序编译不同,技能编译以自然语言作为输入,这本质上为编译过程引入了一些非确定性(wang2023selfconsistency, )。然而,执行技能的 LLM 与传统硬件(如 CPU)存在根本差异(hennessy2019architecture, ),其固有的输入可变性容忍能力使技能能够正确执行。此外,SkVM 严格的编译优化流程和回滚机制确保,编译后的技能在大多数下游任务中始终提供稳定的性能提升。
能力覆盖范围。当前目录包含四大类别共 26 个原语能力,足以覆盖我们分析的 15,063 个技能。随着技能库的增长,我们可以采用 § 4.1 中描述的迭代方法来扩展原语能力。
编译成本。AOT 编译会调用 LLM,产生 token 成本。但由于技能在运行时被重复执行,编译开销可在多次调用中摊销(gray1981transaction, )。此外,编译后的技能可在用户和应用之间共享,进一步降低每个技能的编译成本。
8. 结论
技能已成为智能体时代的一种新代码形式。然而,在分析超过 100,000 个技能后,我们发现技能与底层 LLM 之间存在显著不匹配。为解决这一问题,我们提出了 SkVM——一个专为技能量身定制的编译与运行时系统。SkVM 利用 AOT 和 JIT 等编译技术优化技能结构、提取环境依赖并识别并行机会。随着模型和智能体框架的不断多样化,技能编译提供了一条系统性的路径,将技能转化为可移植的组件,而非脆弱的提示词。
参考文献
- [1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, 等. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [2] Agent Skills Initiative. Agent skills specification. https://agentskills.io/specification, 2025. Open SKILL.md format for agent skill portability; 访问日期: 2026-02-06.
- [3] Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and Tools. Addison-Wesley, 2nd edition, 2006.
- [4] Anthropic. Claude 3.5 haiku. https://www.anthropic.com/news/3-5-models-and-computer-use, 2024. 访问日期: 2026-04-02.
- [5] Anthropic. Agent skills. https://platform.claude.com/docs/en/agents-and-tools/agent-skills/overview, 2025. 访问日期: 2026-02-02.
- [6] Anthropic. Anthropic skills repository. https://github.com/anthropics/skills, 2025. 访问日期: 2026-03-22.
- [7] Anthropic. Equipping agents for the real world with agent skills. https://claude.com/blog/equipping-agents-for-the-real-world-with-agent-skills, 2025. 访问日期: 2026-02-06.
- [8] Anthropic. Extend claude with skills. https://code.claude.com/docs/en/skills, 2025. Claude Code skill mechanism; 访问日期: 2026-02-06.
- [9] Anthropic. Skill creator. https://github.com/anthropics/skills/tree/main/skills/skill-creator, 2025. 访问日期: 2026-03-23.
- [10] Anthropic. Claude 4.6 opus. https://www.anthropic.com/claude/opus, 2026. 访问日期: 2026-04-02.
- [11] Anthropic. Claude code. https://github.com/anthropics/claude-code, 2026. 访问日期: 2026-04-01.
- [12] John Aycock. A brief history of just-in-time. ACM computing surveys (CSUR), 35(2):97–113, 2003.
- [13] ClawHub. Clawhub: Agent skills marketplace. https://clawhub.ai, 2025. 访问日期: 2026-03-22.
- [14] Coze. Plugin development guide. https://www.coze.com/docs/guides/plugin?_lang=en, 2025. Coze bot plugins and skills; 访问日期: 2026-02-06.
- [15] Timothy Cramer, Richard Friedman, Terrence Miller, David Seberger, Robert Wilson, and Mario Wolczko. Compiling java just in time. Ieee micro, 17(3):36–43, 1997.
- [16] Cursor. Agent skills. https://cursor.com/docs/context/skills, 2025. Cursor IDE skill mechanism; 访问日期: 2026-02-06.
- [17] DeepMind. Our latest gemini 3 model that helps you bring any idea to life - faster. https://deepmind.google/models/gemini/flash/, 2026. 访问日期: 2026-04-02.
- [18] FreedomIntelligence. Openclaw medical skills. https://github.com/FreedomIntelligence/OpenClaw-Medical-Skills, 2025. 访问日期: 2026-03-23.
- [19] Google. Agent skills. https://antigravity.google/docs/skills, 2025. Google Antigravity coding agent skills; 访问日期: 2026-02-06.
- [20] Google. Agent2agent (a2a) protocol. https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/, 2025. 访问日期: 2026-02-06.
- [21] Jim Gray. The transaction concept: Virtues and limitations. Proceedings of the 7th International Conference on Very Large Data Bases (VLDB), pages 144–154, 1981.
- [22] Tingxu Han, Yi Zhang, Wei Song, Chunrong Fang, Zhenyu Chen, Youcheng Sun, and Lijie Hu. Swe-skills-bench: Do agent skills actually help in real-world software engineering? arXiv preprint arXiv:2603.15401, 2026.
- [23] John L. Hennessy and David A. Patterson. Computer Architecture: A Quantitative Approach. Morgan Kaufmann, 6th edition, 2019.
- [24] Kazuaki Ishizaki, Motohiro Kawahito, Toshiaki Yasue, Hideaki Komatsu, and Toshio Nakatani. A study of devirtualization techniques for a java just-in-time compiler. In Proceedings of the 15th ACM SIGPLAN conference on Object-oriented programming, systems, languages, and applications, pages 294–310, 2000.
- [25] Jan Martin Jansen, Pieter Koopman, and Rinus Plasmeijer. From interpretation to compilation. In Central European Functional Programming School, pages 286–301. Springer, 2007.
- [26] Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? In International Conference on Learning Representations (ICLR), 2024.
- [27] Sajith Kalathingal, Caroline Collange, Bharath N Swamy, and André Seznec. Dynamic inter-thread vectorization architecture: extracting dlp from tlp. In 2016 28th International Symposium on Computer Architecture and High Performance Computing (SBAC-PAD), pages 18–25. IEEE, 2016.
- [28] Daniel Kästner and Sebastian Winkel. Ilp-based instruction scheduling for ia-64. ACM SIGPLAN Notices, 36(8):145–154, 2001.
- [29] LangChain. Langgraph: Build resilient language agents as graphs. https://github.com/langchain-ai/langgraph, 2024. 访问日期: 2026-03-22.
- [30] Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, 等. Skillsbench: Benchmarking how well agent skills work across diverse tasks. arXiv preprint arXiv:2602.12670, 2026.
- [31] Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, 等. Deepseek-v3.2: Pushing the frontier of open large language models. arXiv preprint arXiv:2512.02556, 2025.
- [32] Pengfei Liu, Weizhe Yuan, Jinlan Fu, Zhengbao Jiang, Hiroaki Hayashi, and Graham Neubig. Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing. ACM Computing Surveys, 55(9):1–35, 2023. arXiv:2107.13586, 2021.
- [33] Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, 等. Agentbench: Evaluating llms as agents. In International Conference on Learning Representations (ICLR), 2024.
- [34] Mistral AI. Devstral small 2507. https://huggingface.co/mistralai/Devstral-Small-2507, 2026. 访问日期: 2026-04-02.
- [35] OpenAI. Function calling and other api updates. https://openai.com/index/function-calling-and-other-api-updates/, 2023. 访问日期: 2026-02-06.
- [36] OpenAI. Openai codex. https://developers.openai.com/codex, 2025. 访问日期: 2026-02-06.
- [37] OpenClaw. Openclaw: Personal ai assistant. https://github.com/openclaw/openclaw, 2025. 访问日期: 2026-03-22.
- [38] OpenCode. Opencode: Open-source ai coding agent. https://github.com/opencode-ai/opencode, 2025. 访问日期: 2026-03-22.
- [39] Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, 等. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems (NeurIPS), volume 35, pages 27730–27744, 2022.
- [40] PinchBench. Pinchbench: Benchmarking llm models as coding agents. https://github.com/pinchbench/skill, 2026. 访问日期: 2026-02-06.
- [41] Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, 等. Toolllm: Facilitating large language models to master 16000+ real-world apis. In International Conference on Learning Representations (ICLR), 2024.
- [42] Qwen. Qwen-3-30b. https://huggingface.co/Qwen/Qwen3-30B-A3B, 2026. 访问日期: 2026-04-02.
- [43] Qwen. Qwen-3.5-122b. https://huggingface.co/Qwen/Qwen3.5-122B-A10B, 2026. 访问日期: 2026-04-02.
- [44] Qwen. Qwen-3.5-397b. https://huggingface.co/Qwen/Qwen3.5-397B-A17B, 2026. 访问日期: 2026-04-02.
- [45] Narayan Ranganathan and Manoj Franklin. An empirical study of decentralized ilp execution models. ACM SIGPLAN Notices, 33(11):272–281, 1998.
- [46] Joshua Redstone, Susan Eggers, and Henry Levy. Mini-threads: Increasing tlp on small-scale smt processors. In The Ninth International Symposium on High-Performance Computer Architecture, 2003. HPCA-9 2003. Proceedings., pages 19–30. IEEE, 2003.
- [47] Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36:68539–68551, 2023.
- [48] Manuel Serrano. Javascript aot compilation. ACM SIGPLAN Notices, 53(8):50–63, 2018.
- [49] Manuel Serrano. Of javascript aot compilation performance. Proceedings of the ACM on Programming Languages, 5(ICFP):1–30, 2021.
- [50] Skills.sh. Skills.sh: Agent skills registry. https://skills.sh, 2025. 访问日期: 2026-03-22.
- [51] Bjarne Stroustrup. The C++ programming language. Pearson Education, 2013.
- [52] Toshio Suganuma, Takeshi Ogasawara, Mikio Takeuchi, Toshiaki Yasue, Motohiro Kawahito, Kazuaki Ishizaki, Hideaki Komatsu, and Toshio Nakatani. Overview of the ibm java just-in-time compiler. IBM systems Journal, 39(1):175–193, 2000.
- [53] Bill Venners. Inside the Java Virtual Machine. McGraw-Hill, 1998.
- [54] Lei Wang, Chen Ma, Xueyang Feng, Zeyu Zhang, Hao Yang, Jingsen Zhang, Zhiyuan Chen, Jiakai Tang, Xu Chen, Yankai Lin, Wayne Xin Zhao, Zhewei Wei, and Ji-Rong Wen. A survey on large language model based autonomous agents. Frontiers of Computer Science, 18(6):186345, 2024.
- [55] Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, 等. Self-consistency improves chain of thought reasoning in language models. International Conference on Learning Representations (ICLR), 2023.
- [56] Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, 等. Autogen: Enabling next-gen llm applications via multi-agent conversation. In Conference on Language Modeling (COLM), 2024.
- [57] John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37:50528–50652, 2024.
- [58] Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. International Conference on Learning Representations (ICLR), 2023.
- [59] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In Advances in Neural Information Processing Systems (NeurIPS), volume 36, 2023.