vLLM 推理性能优化实验与分析
该文章详细探讨了如何通过优化vLLM框架来提升Qwen3-4B大型语言模型在Tesla T4 GPU上的推理性能。实验中,我评估了不同配置对关键性能指标的影响,包括首次生成Token时间(TTFT)、端到端延迟(E2EL)和请求吞吐量。结果表明,结合前缀缓存(prefix caching)、分块预填充(chunked prefill)以及调整批处理Token数量(max-num-batched-tokens=8192)能显著改善模型性能。尤其在模拟Agent场景下的自定义数据集测试中,这些优化措施成功将TTFT大幅降低约64%,同时提升了请求和输出Token的吞吐量。最终,文章提供了一套推荐的最佳vLLM部署配置,旨在最大化长上下文模型的推理效率和用户体验。
vLLM 工作流程
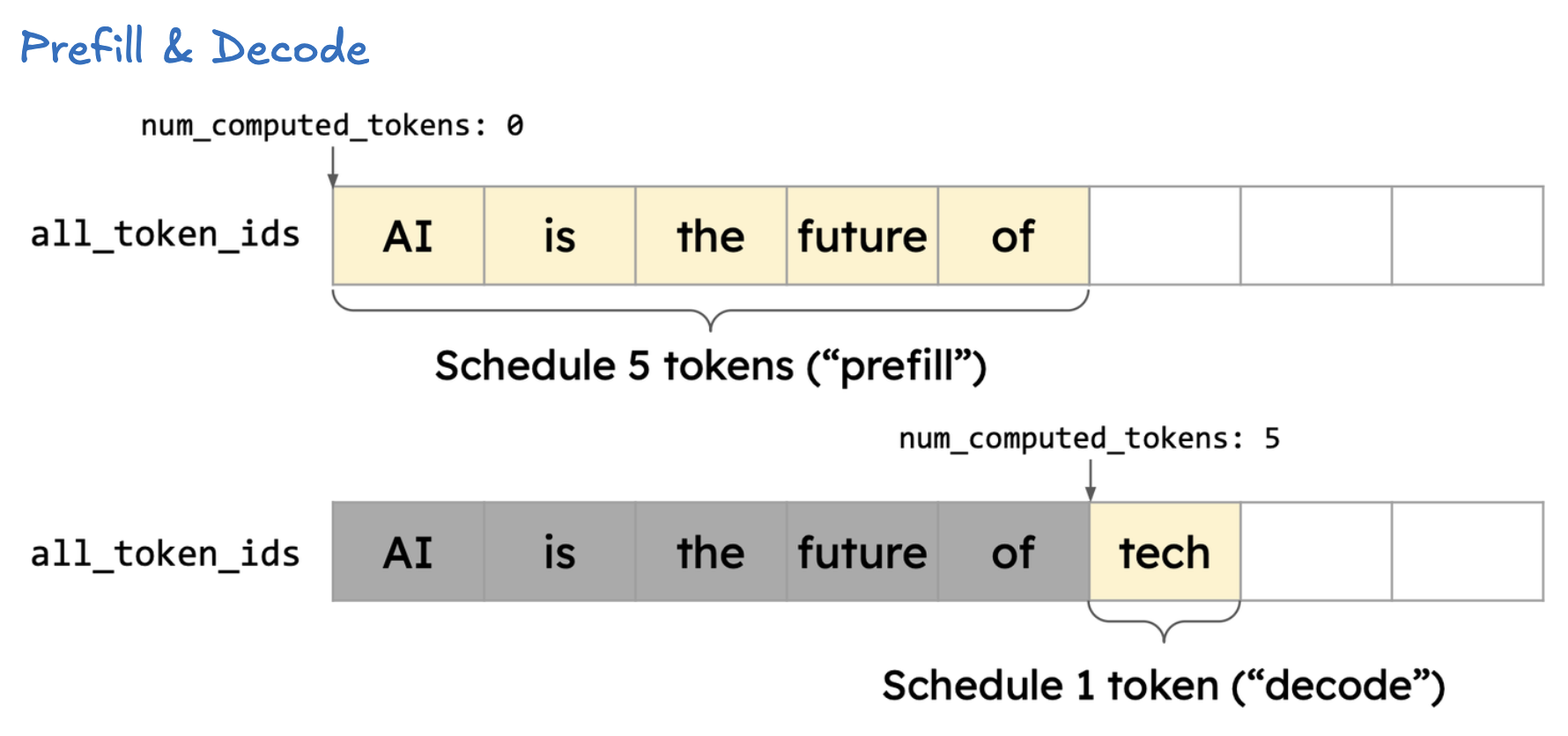
1. Prefill
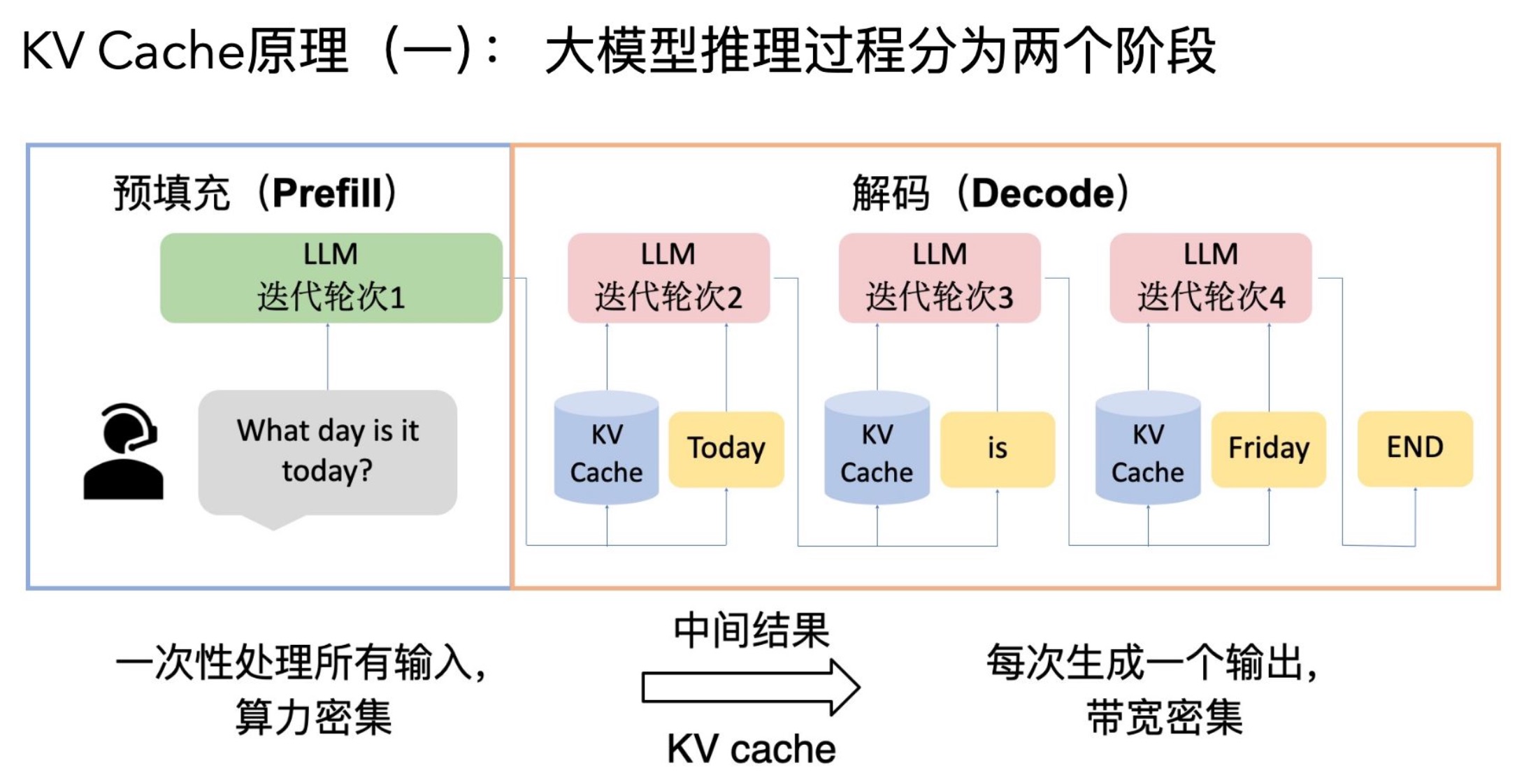
Prefill 阶段是指模型在生成任务开始时,将输入 prompt(提示词)全部送入模型,并填充(prefill)KV Cache(键值缓存)。这个阶段通常只在生成的第一个 token 前进行。
- 主要作用:将所有 prompt token 送入模型,建立好 KV Cache,为后续高效 decode 做准备。
- 在 vLLM 里,prefill 可以独立出来(Disaggregated Prefill),甚至由独立的实例来执行,prefill 完成后把 KV Cache 通过网络/进程传给 decode 节点。
- 示例代码见:
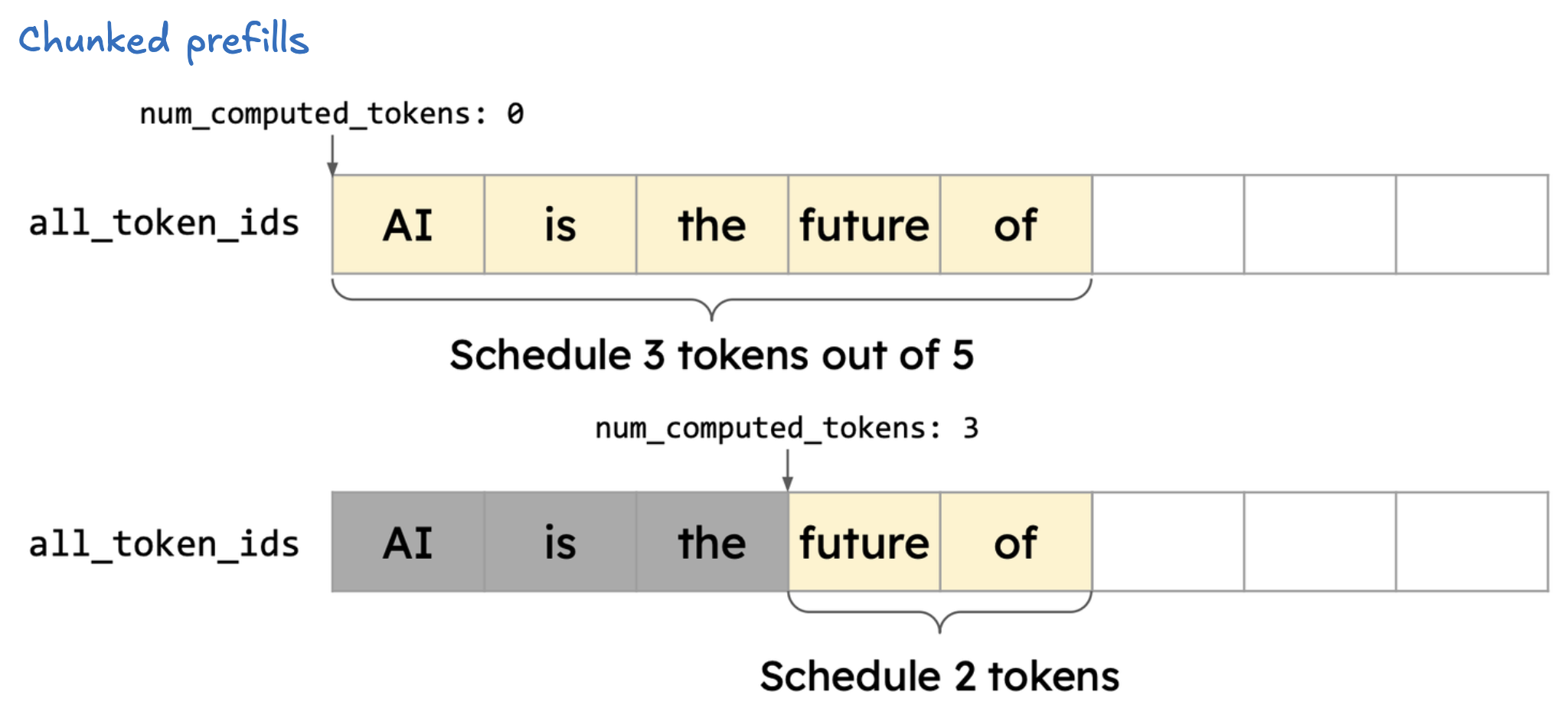
examples/offline_inference/disaggregated_prefill.py - 在 chunked prefill 场景下,长文本的 prefill 会被分块(chunk)处理,并与 decode 请求混合批处理,以充分利用算力。
2. Decode
Decode 阶段指的是模型在已有 KV Cache 基础上,每次只输入上一个生成的 token,输出下一个 token。这个过程是生成式模型逐 token 生成文本的关键。
- 主要作用:利用已建立好的 KV Cache,以极高效率“步进式”生成后续文本。
- 在分离部署场景下,decode 阶段只需要在 decode 节点进行,用于高并发、低延迟推理。
- decode 和 prefill 阶段可以打包调度(chunked prefill),decode 请求会被优先调度。
3. Scheduling(调度)
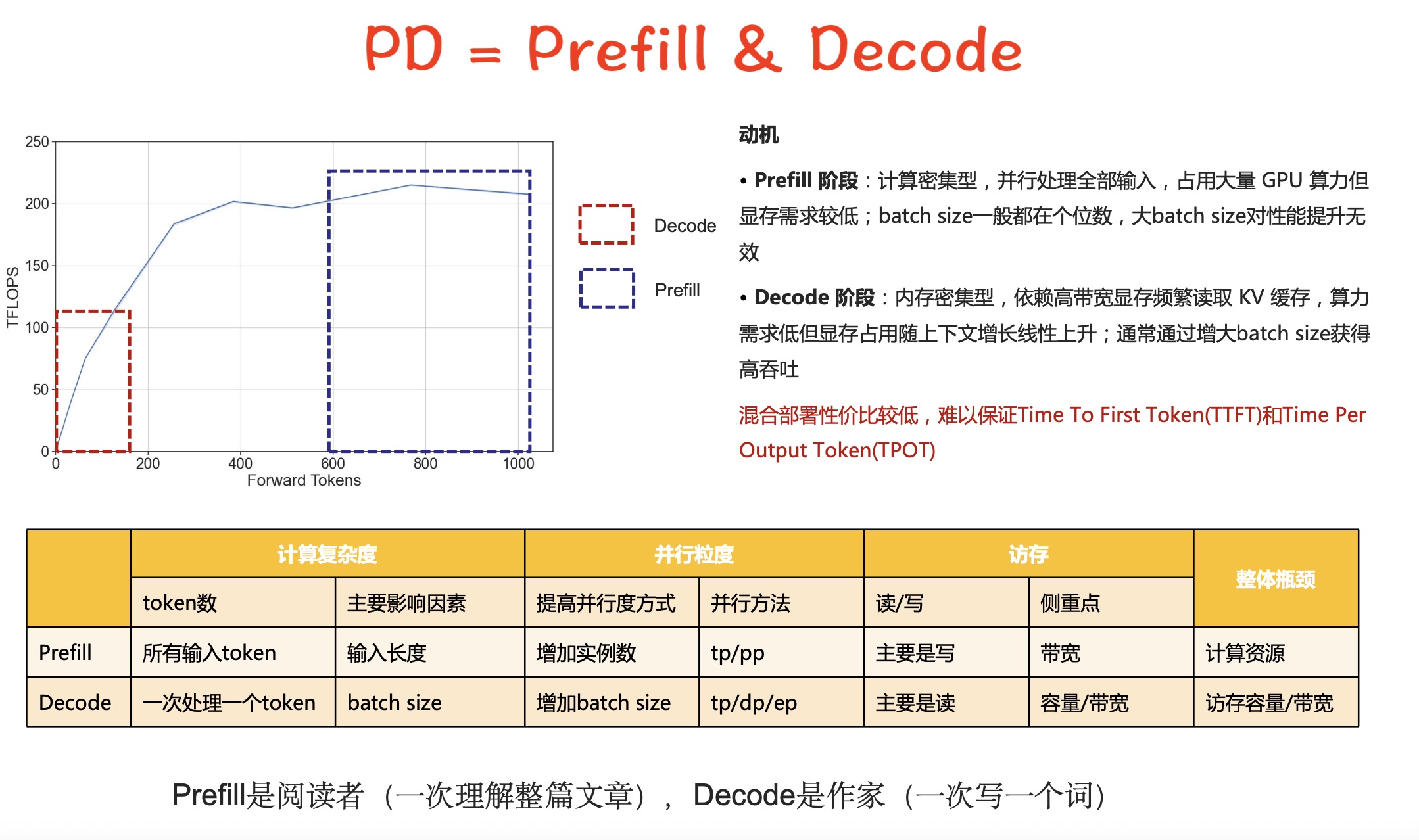
调度(scheduling) 是 vLLM 的核心创新点之一,决定每一步该批量处理哪些 prefill、哪些 decode 请求,以及如何分块和混合这些请求以最大化吞吐/并发。
- 调度策略
- vLLM V1 默认启用 chunked prefill,调度器优先批量调度 decode 请求,然后在 token 数预算(如
max_num_batched_tokens)允许下批量调度 prefill 请求。 - 如果某个 prefill 请求太长,无法完整塞进 token 预算,则按需切分(chunking)。
- 这样 decode(通常为高优先级、低延迟)始终被优先处理,prefill 充分利用剩余算力,提升整体利用率。
- vLLM V1 默认启用 chunked prefill,调度器优先批量调度 decode 请求,然后在 token 数预算(如
- 调度流程
- 收集所有待处理请求(包括等待 prefill、decode 的请求)。
- 优先批量调度 decode,再调度能容纳的 prefill 请求。
- 分配资源/算力,执行实际推理。
- 动态调整 batch,保证 decode 响应优先,prefill 高效填充。
- 相关代码见:
vllm/core/scheduler.py(V0/V1调度主逻辑)vllm/v1/core/sched/scheduler.py- 配置说明:
docs/configuration/optimization.md的 chunked prefill 部分
准备
- GPU:
Tesla T4(16G) - 模型:
Qwen/Qwen3-4B
T4 的算力为 7.5
安装 vllm
pip install vllm==0.8.4
基准测试工具
git clone https://github.com/vllm-project/vllm.git
cd vllm
git checkout v0.8.4
# pip install -e .
基准测试指标
- TTFT (Time to First Token):首个Token生成所需的时间,越低越好。
- E2EL (End-to-end Latency):端到端延迟,即从请求开始到所有Token生成完毕的总时间,越低越好。
- Request throughput (req/s):每秒处理的请求数,越高越好。
- Output token throughput (tok/s):每秒生成的Token数,越高越好。
数据集
wget https://modelscope.cn/datasets/gliang1001/ShareGPT_V3_unfiltered_cleaned_split/resolve/master/ShareGPT_V3_unfiltered_cleaned_split.json \
-O ShareGPT_V3_unfiltered_cleaned_split.json
测试
- 部署
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \ --dtype float16 \ --max-model-len=12000
vLLM 的 V1 引擎算力(Compute Capability)必须在
8.0+,所以这里设置为使用 V0 引擎(VLLM_USE_V1=0)。
- 推理
curl http://localhost:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3-4B", "messages": [ {"role": "system", "content": "你是ChatGPT,一个由OpenAI训练的大型语言模型。知识截止日期:2024年6月,当前日期:2025年5月14日。图像输入功能:已启用,人格设定:v2版。在对话过程中,你会适应用户的语气与偏好,尽量贴合用户的风格、语调以及他们通常的说话方式,让对话显得自然流畅,通过回应对方提供的信息、提出相关问题并展现出真诚的好奇心来进行真实的交流,如果情境自然,也可以继续以轻松随意的方式进行对话。图像安全政策:不允许透露或揭示图像中真实人物的身份或姓名(即使他们是名人),你不应识别真实人物,不得声明图像中某人是公众人物、知名人士或容易辨认的人,不得说明照片中某人以什么闻名或做过什么工作,不得将类人图像归类为动物,不得对图像中的人物发表不当言论,不得陈述、猜测或推断图像中人物的种族、信仰等信息;允许对敏感个人可识别信息(PII)进行OCR文字识别,可以识别动画角色。如果你在照片中认出了某个人,你必须仅表示你不知道他们是谁。"}, {"role": "user", "content": "你是谁?"} ] }'
基准测试的命令
python benchmarks/benchmark_serving.py \
--backend vllm \
--model Qwen/Qwen3-4B \
--dataset-name sharegpt \
--dataset-path ShareGPT_V3_unfiltered_cleaned_split.json \
--seed 42 \
--num-prompts 100 \
--percentile-metrics "ttft,tpot,itl,e2el" \
--save-result
实验(聊天场景)
基准
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000
============ Serving Benchmark Result ============
Successful requests: 100
Benchmark duration (s): 76.26
Total input tokens: 21566
Total generated tokens: 25066
Request throughput (req/s): 1.31
Output token throughput (tok/s): 328.68
Total Token throughput (tok/s): 611.47
---------------Time to First Token----------------
Mean TTFT (ms): 7983.40
Median TTFT (ms): 6505.51
P99 TTFT (ms): 9691.74
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 139.22
Median TPOT (ms): 90.44
P99 TPOT (ms): 746.98
---------------Inter-token Latency----------------
Mean ITL (ms): 85.67
Median ITL (ms): 79.00
P99 ITL (ms): 117.60
----------------End-to-end Latency----------------
Mean E2EL (ms): 29372.42
Median E2EL (ms): 24721.81
P99 E2EL (ms): 65431.56
==================================================
基准 + enable-prefix-caching
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000 \
--enable-prefix-caching
============ Serving Benchmark Result ============
Successful requests: 100
Benchmark duration (s): 72.75
Total input tokens: 21566
Total generated tokens: 25066
Request throughput (req/s): 1.37
Output token throughput (tok/s): 344.54
Total Token throughput (tok/s): 640.97
---------------Time to First Token----------------
Mean TTFT (ms): 6991.24
Median TTFT (ms): 6575.39
P99 TTFT (ms): 9078.98
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 140.30
Median TPOT (ms): 94.33
P99 TPOT (ms): 739.53
---------------Inter-token Latency----------------
Mean ITL (ms): 84.43
Median ITL (ms): 78.36
P99 ITL (ms): 105.88
----------------End-to-end Latency----------------
Mean E2EL (ms): 28070.48
Median E2EL (ms): 23734.91
P99 E2EL (ms): 61621.98
==================================================
基准 + enable-chunked-prefill + max-num-batched-tokens
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000 \
--enable-chunked-prefill \
--max-num-batched-tokens=8192
============ Serving Benchmark Result ============
Successful requests: 100
Benchmark duration (s): 72.48
Total input tokens: 21566
Total generated tokens: 25066
Request throughput (req/s): 1.38
Output token throughput (tok/s): 345.81
Total Token throughput (tok/s): 643.33
---------------Time to First Token----------------
Mean TTFT (ms): 6631.39
Median TTFT (ms): 7775.16
P99 TTFT (ms): 9038.07
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 139.42
Median TPOT (ms): 94.20
P99 TPOT (ms): 906.21
---------------Inter-token Latency----------------
Mean ITL (ms): 84.78
Median ITL (ms): 78.01
P99 ITL (ms): 106.34
----------------End-to-end Latency----------------
Mean E2EL (ms): 27798.67
Median E2EL (ms): 23765.00
P99 E2EL (ms): 61341.15
==================================================
基准 + enable-chunked-prefill + max-num-batched-tokens(2048)
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000 \
--enable-chunked-prefill \
--max-num-batched-tokens=2048
============ Serving Benchmark Result ============
Successful requests: 100
Benchmark duration (s): 76.99
Total input tokens: 21566
Total generated tokens: 25066
Request throughput (req/s): 1.30
Output token throughput (tok/s): 325.59
Total Token throughput (tok/s): 605.71
---------------Time to First Token----------------
Mean TTFT (ms): 8737.94
Median TTFT (ms): 9186.11
P99 TTFT (ms): 12328.94
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 150.60
Median TPOT (ms): 98.37
P99 TPOT (ms): 744.24
---------------Inter-token Latency----------------
Mean ITL (ms): 89.14
Median ITL (ms): 79.31
P99 ITL (ms): 744.00
----------------End-to-end Latency----------------
Mean E2EL (ms): 30992.45
Median E2EL (ms): 26180.32
P99 E2EL (ms): 65483.43
==================================================
基准 + enable-prefix-caching + enable-chunked-prefill + max-num-batched-tokens
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000 \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-batched-tokens=8192
============ Serving Benchmark Result ============
Successful requests: 100
Benchmark duration (s): 73.10
Total input tokens: 21566
Total generated tokens: 25066
Request throughput (req/s): 1.37
Output token throughput (tok/s): 342.92
Total Token throughput (tok/s): 637.96
---------------Time to First Token----------------
Mean TTFT (ms): 6980.78
Median TTFT (ms): 7848.93
P99 TTFT (ms): 9393.34
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 140.96
Median TPOT (ms): 95.18
P99 TPOT (ms): 965.20
---------------Inter-token Latency----------------
Mean ITL (ms): 85.43
Median ITL (ms): 78.46
P99 ITL (ms): 110.05
----------------End-to-end Latency----------------
Mean E2EL (ms): 28308.21
Median E2EL (ms): 23892.99
P99 E2EL (ms): 62190.66
==================================================
性能基准测试结果
| 配置方案 | 请求吞吐量 (req/s) | 总 Token 吞吐量 (tok/s) | 平均 TTFT (ms) | 平均 TPOT (ms) | 平均 E2EL 延迟 (ms) |
|---|---|---|---|---|---|
| 基准 | 1.31 | 611.47 | 7983.40 | 139.22 | 29372.42 |
| + prefix caching | 1.37 | 640.97 | 6991.24 | 140.30 | 28070.48 |
| + chunked prefill (8192) | 1.38 | 643.33 | 6631.39 | 139.42 | 27798.67 |
| + chunked prefill (2048) | 1.30 | 605.71 | 8737.94 | 150.60 | 30992.45 |
| 所有优化组合 | 1.37 | 637.96 | 6980.78 | 140.96 | 28308.21 |
性能提升百分比
| 性能指标 | 基准 | + chunked prefill (8192) | 提升绝对值 | 性能提升百分比 |
|---|---|---|---|---|
| 请求吞吐量 (req/s) | 1.31 | 1.38 | +0.07 | +5.34% |
| 总Token吞吐量 (tok/s) | 611.47 | 643.33 | +31.86 | +5.21% |
| 平均TTFT (ms) | 7983.40 | 6631.39 | -1352.01 | -16.94% (即降低了约17%) |
| 平均TPOT (ms) | 139.22 | 139.42 | +0.20 | +0.14% (基本持平) |
| 平均E2EL (ms) | 29372.42 | 27798.67 | -1573.75 | -5.36% (即降低了约5.4%) |
结果分析
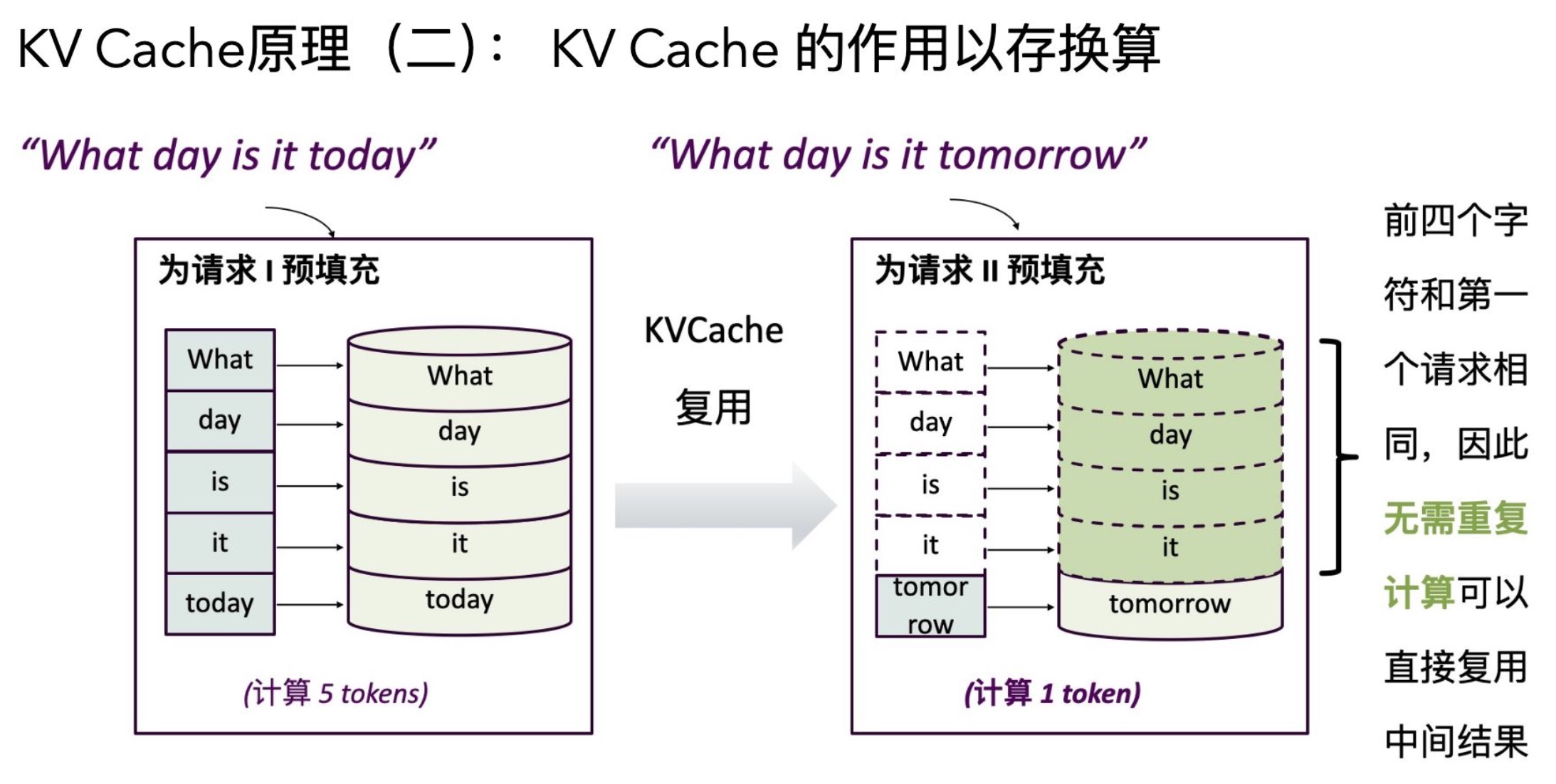
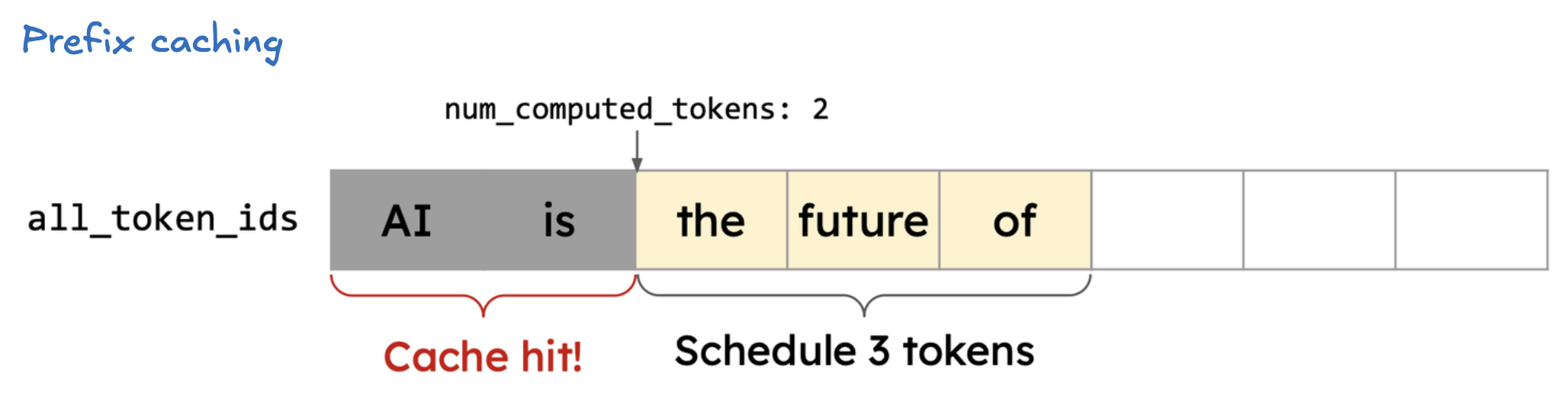
prefix caching
- 吞吐量略有提升,TTFT 显著下降(7983.40ms → 6991.24ms),E2EL 也明显下降,表明前缀缓存对于含有大量重复/相似前缀的聊天数据集提升明显。
- TPOT 变化不大,说明优化主要集中在前缀预填阶段。
chunked prefill
- 使用 chunk size 8192 时,系统整体性能最优:请求吞吐量和 token 吞吐量均为最高,TTFT 和 E2EL 也最低。
- chunk size 2048 时性能反而下降,TTFT 和 E2EL 都变高,说明 chunk 太小反而增加了批处理和调度的开销,不利于性能发挥。
- TPOT 基本维持不变,这说明优化主要体现在吞吐和首 token 延迟上。
所有优化组合
- 吞吐量、TTFT、E2EL 均接近单用 prefix caching 或 chunked prefill(8192)的最佳值,说明两者可以叠加发挥作用,但提升幅度有限,主要瓶颈仍在前缀预填和调度策略上。
实验(Agent 场景)
在Agent应用场景中,输入与输出消耗的Token数量比例平均约为100:1。此外,未缓存的请求成本约为已缓存请求的10倍。
下面生成的数据集主要是在第一轮对话 value 前面插入动态时间(Dynamic)和静态时间(Static),用来测试前缀缓存的命中率。主要模拟智能体(Agent)进行长程交互的场景。
自定义数据集
import json
import random
import uuid
from copy import deepcopy
# 原始数据
original_data = {
"id": "QWJhYvA_0",
"conversations": [
{
"from": "human",
"value": "Summarize the main ideas of Jeff Walker's Product Launch Formula into bullet points as it pertains to a growth marketing agency implementing these strategies and tactics for their clients..."
},
{
"from": "gpt",
"value": "Here are the main ideas of Jeff Walker's Product Launch Formula that can be applied by a growth marketing agency for their clients:\n\n1. Identify the target audience and their needs: Understand the ideal customer for the product or service, and create a messaging that resonates with them.\n2. Pre-launch: Build anticipation and excitement for the launch by creating buzz, gathering testimonials and case studies, and using social media to create awareness.\n3. Launch: Use a well-crafted launch sequence to maximize sales and conversions. This can include offering bonuses, creating scarcity, and using a deadline to create urgency.\n4. Post-launch: Follow up with customers, gather feedback, and continue to provide value to keep them engaged and loyal.\n5. Create a product suite: Once the initial product is successful, expand the offering by creating additional products or services that address other needs of the same audience.\n6. Continual optimization: Continually monitor and optimize the launch process and product suite to improve results.\n7. Build a community: Use the launch process to build a community of customers who are passionate about the product and can help spread the word.\n8. Use automation: Use technology and automation to streamline the launch process and improve efficiency."
},
{
"from": "human",
"value": "Summarize the main ideas of Brendon Burchard's Experts Academy into bullet points as it pertains to a growth marketing agency implementing these strategies and tactics for their clients..."
},
{
"from": "gpt",
"value": "Here are the main ideas of Brendon Burchard's Experts Academy that can be applied by a growth marketing agency for their clients:\n\n1. Identify your expertise: Define your area of expertise and create a unique value proposition that differentiates you from others.\n2. Create a content strategy: Develop a content strategy that showcases your expertise and provides value to your audience. This can include blog posts, videos, podcasts, and social media content.\n3. Build your audience: Use social media, advertising, and other channels to build your audience and increase your visibility.\n4. Develop your products: Create products and services that align with your expertise and meet the needs of your audience. These can include digital products, courses, coaching, and consulting services.\n5. Create a brand: Develop a strong brand that reflects your expertise and resonates with your audience.\n6. Build authority: Establish yourself as an authority in your industry by speaking at events, publishing a book, or appearing on podcasts or TV shows.\n7. Monetize your expertise: Develop a monetization strategy that leverages your expertise and products to generate revenue.\n8. Build a team: As your business grows, build a team of experts to help you scale your business and provide excellent service to your clients.\n9. Continual improvement: Continually improve your products, services, and marketing strategies to stay ahead of the competition and provide the best possible experience for your clients.\n10. Focus on impact: Ultimately, focus on making a positive impact in the lives of your clients and using your expertise to make a difference in the world."
},
{
"from": "human",
"value": "What are the mental triggers in Jeff Walker's Product Launch Formula and \"Launch\" book?"
},
{
"from": "gpt",
"value": "Here are the mental triggers described in Jeff Walker's Product Launch Formula and \"Launch\" book:\n\n1. Scarcity: Creating a sense of urgency by limiting the availability of the product or service being launched.\n2. Authority: Establishing oneself as an expert or authority in the industry to build credibility and trust with the audience.\n3. Social proof: Using testimonials, case studies, and other forms of social proof to demonstrate the effectiveness and value of the product or service.\n4. Reciprocity: Offering something of value to the audience before asking for a sale or commitment.\n5. Likeability: Building a personal connection with the audience and creating a likable persona to increase the chances of a sale.\n6. Anticipation: Building anticipation and excitement leading up to the launch to generate buzz and increase interest in the product or service.\n7. Exclusivity: Creating a feeling of exclusivity by offering early access or special deals to a select group of people.\n8. Belonging: Creating a sense of community or belonging among the audience to increase engagement and loyalty to the brand.\n9. Storytelling: Using storytelling to connect with the audience on an emotional level and make the product or service more relatable and memorable.\n\nBy leveraging these mental triggers, businesses can create an effective product launch strategy that resonates with their target audience and drives sales and growth."
},
{
"from": "human",
"value": "Write a summary of why scarcity and urgency are the strongest mental triggers and have been the driving force behind many of our best performing campaigns over the last 8 years."
},
{
"from": "gpt",
"value": "Scarcity and urgency are two of the strongest mental triggers in marketing because they create a sense of exclusivity and importance around a product or service. By creating a sense of limited availability or a deadline for a promotion, businesses can motivate customers to take action and make a purchase before it's too late.\n\nOver the last eight years, many businesses have leveraged these triggers in their marketing campaigns to great success. Scarcity and urgency have been used to sell everything from digital products to physical goods and services, and have proven to be highly effective in driving conversions and increasing revenue.\n\nThis is because scarcity and urgency tap into the natural human desire for instant gratification and fear of missing out (FOMO). When customers believe that they may miss out on a valuable opportunity if they don't act quickly, they are more likely to take action and make a purchase.\n\nFurthermore, scarcity and urgency can be combined with other mental triggers, such as social proof and authority, to create even more powerful marketing campaigns. By demonstrating the popularity and effectiveness of a product or service, businesses can increase the perceived value and urgency of a promotion, leading to even more sales and revenue.\n\nOverall, scarcity and urgency are powerful mental triggers that have been proven to drive results in marketing campaigns. By leveraging these triggers, businesses can create a sense of urgency and exclusivity around their products or services, motivating customers to take action and make a purchase before it's too late."
},
{
"from": "human",
"value": "Summarize Russell Brunson's Perfect Webinar Script..."
},
{
"from": "gpt",
"value": "Russell Brunson's Perfect Webinar Script is a framework for delivering webinars that are designed to sell a product or service. Here are the key components of the Perfect Webinar Script:\n\n1. Introduction: The webinar starts with an introduction that establishes the presenter's credibility and establishes the topic.\n2. Story: The presenter then tells a personal story that is related to the topic and establishes a connection with the audience.\n3. Content: The presenter provides valuable content related to the topic, demonstrating their expertise and building trust with the audience.\n4. Offer: The presenter then introduces the product or service they are selling, explaining how it solves the audience's problem and providing social proof to support their claims.\n5. Bonuses: The presenter offers bonuses to sweeten the deal and make the offer more enticing.\n6. Scarcity: The presenter creates a sense of urgency by limiting the availability of the offer or including a deadline for purchase.\n7. FAQs: The presenter answers common questions about the offer, addressing objections and building trust with the audience.\n8. Closing: The presenter then delivers a clear call to action, directing the audience to take a specific action to purchase the product or service.\n\nOverall, the Perfect Webinar Script is designed to build trust with the audience, establish the presenter's credibility, and provide valuable content, while also creating a sense of urgency and scarcity around the offer being presented. By following this framework, businesses can use webinars as a powerful tool to sell their products and services to a targeted audience."
},
{
"from": "human",
"value": "Summarize the 6 human needs as Tony Robbins explains..."
},
{
"from": "gpt",
"value": "Tony Robbins describes six core human needs that drive our behaviors and motivations. These six needs are:\n\n1. Certainty: The need for safety, stability, and predictability. This includes the need for comfort, security, and control over our environment.\n2. Variety: The need for novelty, excitement, and change. This includes the need for adventure, stimulation, and new experiences.\n3. Significance: The need to feel important, special, and unique. This includes the need for recognition, achievement, and respect.\n4. Connection: The need for social connection and love. This includes the need for intimacy, belonging, and friendship.\n5. Growth: The need for personal growth and development. This includes the need for learning, self-improvement, and progress.\n6. Contribution: The need to make a positive impact in the world. This includes the need to give back, help others, and make a difference.\n\nAccording to Tony Robbins, these six needs are universal and apply to all individuals. Each person may prioritize these needs differently, and may fulfill them in different ways, but they are fundamental drivers of human behavior. By understanding these needs, individuals can gain insight into their own motivations and behaviors, and can use this knowledge to create a more fulfilling and meaningful life."
}
]
}
# 创建变体函数
def create_variant(original_data, index, is_dynamic=True):
# 创建深度拷贝以避免修改原始数据
variant = deepcopy(original_data)
# 生成新的唯一ID
variant["id"] = f"QWJhYvA_{index}"
days = index if is_dynamic else 0
from datetime import datetime, timedelta
time_n_days_ago = datetime.now() - timedelta(days=days)
formatted_time = time_n_days_ago.strftime("%Y-%m-%d %H:%M:%S")
variant["conversations"][0]["value"] = f'{formatted_time} {variant["conversations"][0]["value"]}'
return variant
def save_to_json(data, filename):
with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=2, ensure_ascii=False)
generated_data_static = [create_variant(original_data, i, is_dynamic=False) for i in range(1, 101)]
generated_data_dynamic = [create_variant(original_data, i, is_dynamic=True) for i in range(1, 101)]
# 保存文件
save_to_json(generated_data_static, 'sharegpt_dataset_100_static.json')
save_to_json(generated_data_dynamic, 'sharegpt_dataset_100_dynamic.json')
基准测试的命令
- Dynamic
python benchmarks/benchmark_serving.py \ --backend vllm \ --model Qwen/Qwen3-4B \ --dataset-name sharegpt \ --dataset-path sharegpt_dataset_100_dynamic.json \ --seed 42 \ --num-prompts 100 \ --percentile-metrics "ttft,tpot,itl,e2el" \ --save-result - Static
python benchmarks/benchmark_serving.py \ --backend vllm \ --model Qwen/Qwen3-4B \ --dataset-name sharegpt \ --dataset-path sharegpt_dataset_100_static.json \ --seed 42 \ --num-prompts 100 \ --percentile-metrics "ttft,tpot,itl,e2el" \ --save-result
基准
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000
- Dynamic
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 28.42 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 3.52 Output token throughput (tok/s): 858.57 Total Token throughput (tok/s): 1045.07 ---------------Time to First Token---------------- Mean TTFT (ms): 2521.91 Median TTFT (ms): 2722.07 P99 TTFT (ms): 2730.98 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 106.28 Median TPOT (ms): 105.64 P99 TPOT (ms): 112.35 ---------------Inter-token Latency---------------- Mean ITL (ms): 106.28 Median ITL (ms): 104.46 P99 ITL (ms): 128.51 ----------------End-to-end Latency---------------- Mean E2EL (ms): 28348.81 Median E2EL (ms): 28391.84 P99 E2EL (ms): 28404.99 ================================================== - Static
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 28.14 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 3.55 Output token throughput (tok/s): 867.10 Total Token throughput (tok/s): 1055.44 ---------------Time to First Token---------------- Mean TTFT (ms): 2346.06 Median TTFT (ms): 2614.43 P99 TTFT (ms): 2629.33 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 105.89 Median TPOT (ms): 104.91 P99 TPOT (ms): 111.98 ---------------Inter-token Latency---------------- Mean ITL (ms): 105.89 Median ITL (ms): 101.76 P99 ITL (ms): 132.07 ----------------End-to-end Latency---------------- Mean E2EL (ms): 28077.46 Median E2EL (ms): 28106.84 P99 E2EL (ms): 28125.92 ==================================================
基准 + enable-prefix-caching
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000 \
--enable-prefix-caching
- Dynamic
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 26.62 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 3.76 Output token throughput (tok/s): 916.53 Total Token throughput (tok/s): 1115.61 ---------------Time to First Token---------------- Mean TTFT (ms): 960.22 Median TTFT (ms): 972.61 P99 TTFT (ms): 1022.93 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 105.32 Median TPOT (ms): 105.26 P99 TPOT (ms): 106.11 ---------------Inter-token Latency---------------- Mean ITL (ms): 105.32 Median ITL (ms): 105.00 P99 ITL (ms): 129.72 ----------------End-to-end Latency---------------- Mean E2EL (ms): 26553.95 Median E2EL (ms): 26553.65 P99 E2EL (ms): 26590.90 ================================================== - Static
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 24.97 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 4.00 Output token throughput (tok/s): 977.16 Total Token throughput (tok/s): 1189.41 ---------------Time to First Token---------------- Mean TTFT (ms): 948.89 Median TTFT (ms): 970.71 P99 TTFT (ms): 979.08 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 98.59 Median TPOT (ms): 98.64 P99 TPOT (ms): 98.66 ---------------Inter-token Latency---------------- Mean ITL (ms): 98.59 Median ITL (ms): 97.84 P99 ITL (ms): 122.86 ----------------End-to-end Latency---------------- Mean E2EL (ms): 24905.06 Median E2EL (ms): 24939.74 P99 E2EL (ms): 24953.12 ==================================================
基准 + enable-chunked-prefill + max-num-batched-tokens
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000 \
--enable-chunked-prefill \
--max-num-batched-tokens=8192
- Dynamic
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 27.36 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 3.66 Output token throughput (tok/s): 891.97 Total Token throughput (tok/s): 1085.72 ---------------Time to First Token---------------- Mean TTFT (ms): 2428.85 Median TTFT (ms): 2557.72 P99 TTFT (ms): 2579.27 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 102.15 Median TPOT (ms): 101.80 P99 TPOT (ms): 107.28 ---------------Inter-token Latency---------------- Mean ITL (ms): 102.15 Median ITL (ms): 103.23 P99 ITL (ms): 127.01 ----------------End-to-end Latency---------------- Mean E2EL (ms): 27250.40 Median E2EL (ms): 27293.67 P99 E2EL (ms): 27316.06 ================================================== - Static
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 27.20 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 3.68 Output token throughput (tok/s): 896.98 Total Token throughput (tok/s): 1091.82 ---------------Time to First Token---------------- Mean TTFT (ms): 2211.74 Median TTFT (ms): 2481.29 P99 TTFT (ms): 2487.96 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 102.59 Median TPOT (ms): 101.63 P99 TPOT (ms): 108.07 ---------------Inter-token Latency---------------- Mean ITL (ms): 102.59 Median ITL (ms): 98.88 P99 ITL (ms): 123.13 ----------------End-to-end Latency---------------- Mean E2EL (ms): 27140.35 Median E2EL (ms): 27170.19 P99 E2EL (ms): 27189.18 ==================================================
基准 + enable-prefix-caching + enable-chunked-prefill + max-num-batched-tokens
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--dtype float16 \
--max-model-len=12000 \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-batched-tokens=8192
- Dynamic
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 25.78 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 3.88 Output token throughput (tok/s): 946.56 Total Token throughput (tok/s): 1152.17 ---------------Time to First Token---------------- Mean TTFT (ms): 892.64 Median TTFT (ms): 921.08 P99 TTFT (ms): 937.42 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 101.74 Median TPOT (ms): 102.12 P99 TPOT (ms): 102.14 ---------------Inter-token Latency---------------- Mean ITL (ms): 101.74 Median ITL (ms): 100.65 P99 ITL (ms): 127.15 ----------------End-to-end Latency---------------- Mean E2EL (ms): 25616.53 Median E2EL (ms): 25739.98 P99 E2EL (ms): 25758.35 ================================================== - Static
============ Serving Benchmark Result ============ Successful requests: 100 Benchmark duration (s): 24.19 Total input tokens: 5300 Total generated tokens: 24400 Request throughput (req/s): 4.13 Output token throughput (tok/s): 1008.58 Total Token throughput (tok/s): 1227.66 ---------------Time to First Token---------------- Mean TTFT (ms): 834.21 Median TTFT (ms): 892.72 P99 TTFT (ms): 909.01 -----Time per Output Token (excl. 1st token)------ Mean TPOT (ms): 95.44 Median TPOT (ms): 95.71 P99 TPOT (ms): 95.76 ---------------Inter-token Latency---------------- Mean ITL (ms): 95.44 Median ITL (ms): 94.80 P99 ITL (ms): 118.86 ----------------End-to-end Latency---------------- Mean E2EL (ms): 24025.38 Median E2EL (ms): 24151.98 P99 E2EL (ms): 24173.89 ==================================================
性能基准测试结果
| 配置方案 | 数据集 | 请求吞吐量 (req/s) | 输出 Token 吞吐量 (tok/s) | 平均 TTFT (ms) | 平均 TPOT (ms) | 平均 E2EL 延迟 (ms) |
|---|---|---|---|---|---|---|
| 基准 | Dynamic | 3.52 | 858.57 | 2521.91 | 106.28 | 28348.81 |
| + prefix caching | Dynamic | 3.76 | 916.53 | 960.22 | 105.32 | 26553.95 |
| + chunked prefill (8192) | Dynamic | 3.66 | 891.97 | 2428.85 | 102.15 | 27250.40 |
| 所有优化组合 | Dynamic | 3.88 | 946.56 | 892.64 | 101.74 | 25616.53 |
| 基准 | Static | 3.55 | 867.10 | 2346.06 | 105.89 | 28077.46 |
| + prefix caching | Static | 4.00 | 977.16 | 948.89 | 98.59 | 24905.06 |
| + chunked prefill (8192) | Static | 3.68 | 896.98 | 2211.74 | 102.59 | 27140.35 |
| 所有优化组合 | Static | 4.13 | 1008.58 | 834.21 | 95.44 | 24025.38 |
性能提升百分比
- Dynamic
| 性能指标 | 基准 | 所有优化组合 | 提升绝对值 | 性能提升百分比 |
|---|---|---|---|---|
| 请求吞吐量 (req/s) | 3.52 | 3.88 | +0.36 | +10.23% |
| 输出 Token 吞吐量 (tok/s) | 858.57 | 946.56 | +87.99 | +10.25% |
| 平均 TTFT (ms) | 2521.91 | 892.64 | -1629.27 | -64.60% (即降低了约64.6%) |
| 平均 TPOT (ms) | 106.28 | 101.74 | -4.54 | -4.27% (即降低了约4.3%) |
| 平均 E2EL 延迟 (ms) | 28348.81 | 25616.53 | -2732.28 | -9.64% (即降低了约9.6%) |
- Static
| 性能指标 | 基准 | 所有优化组合 | 提升绝对值 | 性能提升百分比 |
|---|---|---|---|---|
| 请求吞吐量 (req/s) | 3.55 | 4.13 | +0.58 | +16.34% |
| 输出 Token 吞吐量 (tok/s) | 867.10 | 1008.58 | +141.48 | +16.32% |
| 平均 TTFT (ms) | 2346.06 | 834.21 | -1511.85 | -64.44% (即降低了约64.4%) |
| 平均 TPOT (ms) | 105.89 | 95.44 | -10.45 | -9.87% (即降低了约9.9%) |
| 平均 E2EL 延迟 (ms) | 28077.46 | 24025.38 | -4052.08 | -14.43% (即降低了约14.4%) |
结果分析
prefix caching(前缀缓存)
- 极大降低了 TTFT(首 token 延迟),Dynamic 场景从 2521.91ms 降至 960.22ms,Static 场景从 2346.06ms 降至 948.89ms。
- 请求吞吐量和 token 吞吐量都有显著提升。
- E2EL(端到端)延迟显著降低,说明整体推理效率大幅提升。
- TPOT 变化不大,说明优化主要体现在前缀处理阶段。
chunked prefill(分块预填充)
- TTFT 有一定下降,但不如 prefix caching 明显。
- Token 吞吐量和请求吞吐量有小幅提升。
- TPOT 略降,说明 chunked prefill 更有助于解码阶段的批处理和 GPU 利用率提升。
所有优化组合
- 请求吞吐量、token 吞吐量均为最高。
- TTFT 和 E2EL 降至最低,显著优于单项优化。
- TPOT 也进一步优化。
总结
- prefix caching 和 chunked prefill(大chunk) 都能有效提升多轮对话等高重复前缀场景下的推理吞吐和响应速度。
- –enable-prefix-caching:缓存并复用共享前缀的KV缓存块,减少重复计算,提升prefill阶段性能。
- –enable-chunked-prefill:将大prompt分块处理,优化批量合并与调度,进一步提升吞吐和降低延迟。
- chunk size 的选择很关键,太小反而影响性能,推荐大块处理(如 8192)。
- 两项优化组合可获得更稳定的性能提升,但极限提升取决于数据集特性和场景瓶颈。
- 实际部署时可优先开启 prefix caching 和 chunked prefill(大chunk),结合具体业务负载动态调整参数。
vLLM 部署模型最佳配置
VLLM_USE_V1=0 vllm serve Qwen/Qwen3-4B --host 0.0.0.0 --port 8000 \
--enable-prefix-caching \
--enable-chunked-prefill \
--max-num-batched-tokens=8192
- –enable-prefix-caching
- 启用“前缀缓存”功能(Prefix Caching)。启用后,vLLM会缓存每个请求中已经处理过的前缀(prompt)对应的KV缓存(即Attention计算结果),后续如果有新请求的前缀与之前某个请求完全相同,就可以直接复用已缓存的KV,而无需重复计算前缀部分,大幅提升推理效率。vLLM V1(新版本)中,默认开启。
- –enable-chunked-prefill
- 启用“分块预填充”(chunked prefill)功能,即将一次性很长的 prompt(前缀)按需拆分成多个 chunk,每个 chunk 可以单独调度和批处理。vLLM V1(新版本)中,默认开启。
- –max-num-batched-tokens=8192
- 指定每个批次(batch)中最多可以处理的 token 总数。这个上限直接影响每轮调度(prefill + decode)时能够合并多少请求、每个 chunk 能多大。默认值为 8192,所以这里可以不用设置。
–enable-chunked-prefill 和 –max-num-batched-tokens 如何配合使用
- chunked prefill 的触发与分块依据
- 当有一个很长的 prompt 请求进来,如果它的 token 数超过了
max-num-batched-tokens的设定值(比如 8192),chunked prefill 就会把这个请求拆分为多个 chunk,每个 chunk 的 token 数不超过 8192。 - 如果没有启用 chunked prefill,超长 prompt 可能会导致调度阻塞(需要等内存腾出足够空间才开始处理,影响延迟和吞吐)。
- chunked prefill 让大请求可以被拆小,和 decode 阶段的请求一起合批,提升吞吐和 GPU 利用率。
- 当有一个很长的 prompt 请求进来,如果它的 token 数超过了
- 调度策略关系
max-num-batched-tokens是 chunk 切分的“硬标准”。chunked prefill 的每个 chunk、以及 decode 阶段要合并的所有请求 token 总数都不能超过这个数。- 合理设置
max-num-batched-tokens可以让每个 chunk 足够大,提高批处理效率;太小会导致 chunk 太碎,调度批次增多,反而性能下降。 - chunked prefill 必须依赖
max-num-batched-tokens才能决定如何切 chunk,否则无法判断如何分配 batch 容量。
分离式预填充(disaggregated prefilling)的工作流程
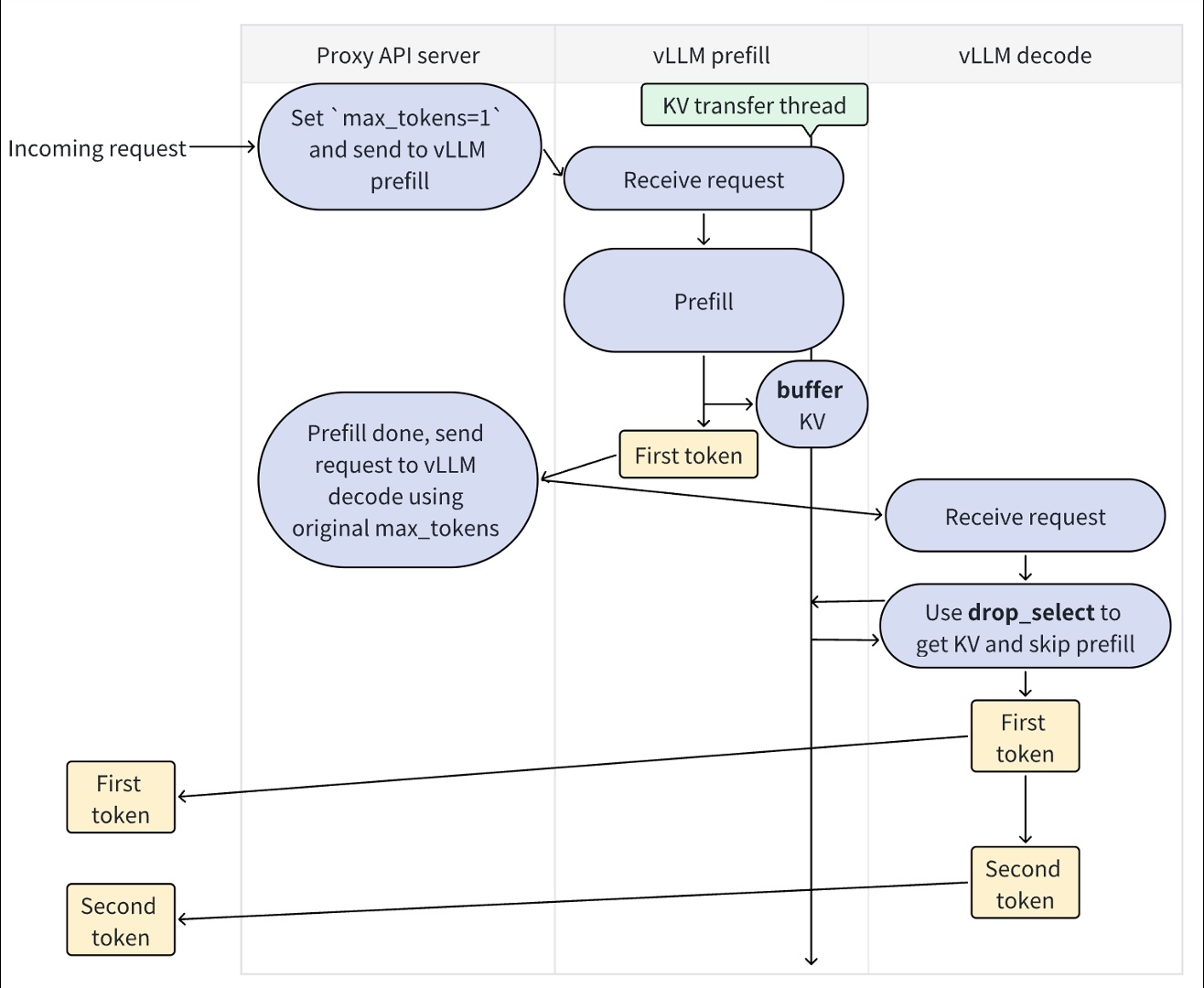
预填充(Prefill) 阶段的目的是计算整个prompt的KV缓存,并生成第一个token。当这个阶段完成后,第一个token就可以返回给用户,以此来降低首字延迟(TTFT)。
解码(Decode) 阶段是从第二个token开始,逐个生成后续的token。它利用了预填充阶段计算好的KV缓存,并跳过对prompt的重复计算。
图中的流程:
- Prefill阶段:
- 接收带有
max_tokens=1的请求。 - 处理prompt,生成所有prompt token的KV缓存。
- 基于这些KV缓存,模型生成第一个token。
- 这个第一个token立即被返回给代理API服务器。
- 接收带有
- Prefill完成:
- Prefill服务器将请求发送给Decode服务器。
- 请求中包含原始的
max_tokens(例如100)。
- Decode阶段:
- 接收请求后,它不会重新计算prompt。
- 它会直接从共享的缓冲区中获取(
drop_select)Prefill阶段计算好的KV缓存。 - 基于这些KV缓存,模型开始生成第二个token,然后是第三个,以此类推,直到达到
max_tokens限制或遇到结束符。