PyTorch 神经网络实战:从训练到推理的完整指南
该文本提供了一个关于PyTorch二分类神经网络的实现与性能分析的全面概述。首先,它通过具体代码示例展示了如何构建、训练、评估和保存一个基础的神经网络模型,并演示了如何加载模型进行推理。其次,文章深入探讨了不同模型参数规模下,Apple的MPS(Metal Performance Shaders)框架与CPU在训练时间上的性能对比,通过表格数据清晰地呈现了MPS在处理大型模型时相较于CPU的显著优势,并指出了性能的“转折点”。
我的电脑是 Apple MacBook Pro M2 Max 16寸 64G内存
PyTorch 二分类神经网络实现与训练示例
import torch
import torch.nn.functional as F
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
# 模型网络
class NeuralNetwork(torch.nn.Module):
def __init__(self, num_inputs, num_outputs):
super().__init__()
self.layers = torch.nn.Sequential(
torch.nn.Linear(num_inputs, 30),
torch.nn.ReLU(),
torch.nn.Linear(30, 20),
torch.nn.ReLU(),
torch.nn.Linear(20, num_outputs)
)
def forward(self, x):
logits = self.layers(x)
return logits
# 数据集
class MyDataset(Dataset):
def __init__(self, X, Y):
super().__init__()
self.X = X
self.Y = Y
def __getitem__(self, index):
return self.X[index], self.Y[index]
def __len__(self):
return self.X.shape[0]
X_train = torch.tensor([
[-1.2, 3.1],
[-0.9, 2.9],
[-0.5, 2.6],
[2.3, -1.1],
[2.7, -1.5]
])
Y_train = torch.tensor([0, 0, 0, 1, 1])
X_test = torch.tensor([
[-0.8, 2.8],
[2.6, -1.6]
])
Y_test = torch.tensor([0, 1])
train_ds = MyDataset(X_train, Y_train)
test_ds = MyDataset(X_test, Y_test)
# 数据加载器
torch.manual_seed(123)
train_loader = DataLoader(
dataset=train_ds,
batch_size=2,
shuffle=True,
drop_last=True,
num_workers=0
)
test_loader = DataLoader(
dataset=test_ds,
batch_size=2,
shuffle=False,
num_workers=0
)
# 训练
model = NeuralNetwork(num_inputs=2, num_outputs=2)
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
num_epochs = 3
for epoch in range(num_epochs):
model.train()
for batch_idx, (x, y) in enumerate(train_loader):
logits = model(x)
loss = F.cross_entropy(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1:02d}/{num_epochs:02d}"
f" | Batch: {batch_idx+1:02d}/{len(train_loader):02d}"
f" | Train Loss: {loss:.2f}")
# 评估
model.eval()
correct = 0.0
total = 0
for batch_idx, (x, y) in enumerate(test_loader):
with torch.no_grad():
logits = model(x)
predictions = torch.argmax(logits, dim=1)
compare = predictions == y
correct += torch.sum(compare)
total += len(compare)
print(f"Eval Accuracy: {correct/total:.2f}")
# 模型存储
torch.save(model.state_dict(), "model.pth") # 只保存模型参数
加载模型并推理
model = NeuralNetwork(2, 2)
model.load_state_dict(torch.load("model.pth"))
model.eval() # 关闭Dropout、BatchNorm等训练特性
with torch.no_grad(): # 禁用梯度计算,节省内存
y = torch.argmax(mmodel(X_test), dim=-1)
参数规模与设备(CPU & MPS)的性能分析
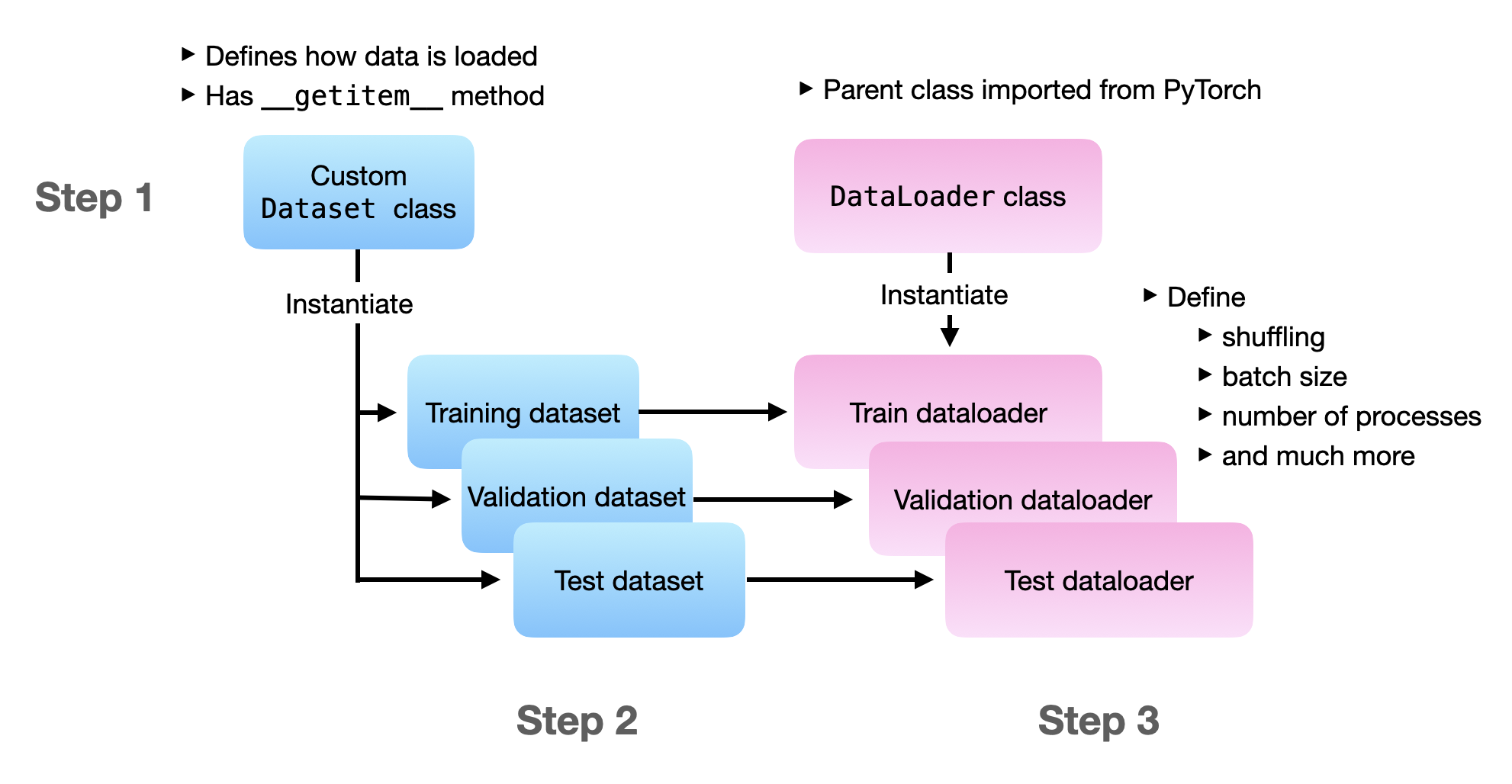
数据集
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, X, Y):
super().__init__()
self.X = X
self.Y = Y
def __getitem__(self, index):
return self.X[index], self.Y[index]
def __len__(self):
return self.X.shape[0]
num_samples = 1000
scale = 10
num_input = 100 * scale
X_train = torch.randn(num_samples, num_input)
Y_train = torch.randint(0, 2, (num_samples,))
X_test = torch.randn(int(num_samples*0.2), num_input)
Y_test = torch.randint(0, 2, (int(num_samples*0.2),))
train_ds = MyDataset(X_train, Y_train)
test_ds = MyDataset(X_test, Y_test)
数据加载器
import torch
from torch.utils.data import DataLoader
train_loader = DataLoader(
dataset=train_ds,
batch_size=10,
shuffle=True,
num_workers=0
)
test_loader = DataLoader(
dataset=test_ds,
batch_size=10,
shuffle=False,
num_workers=0
)
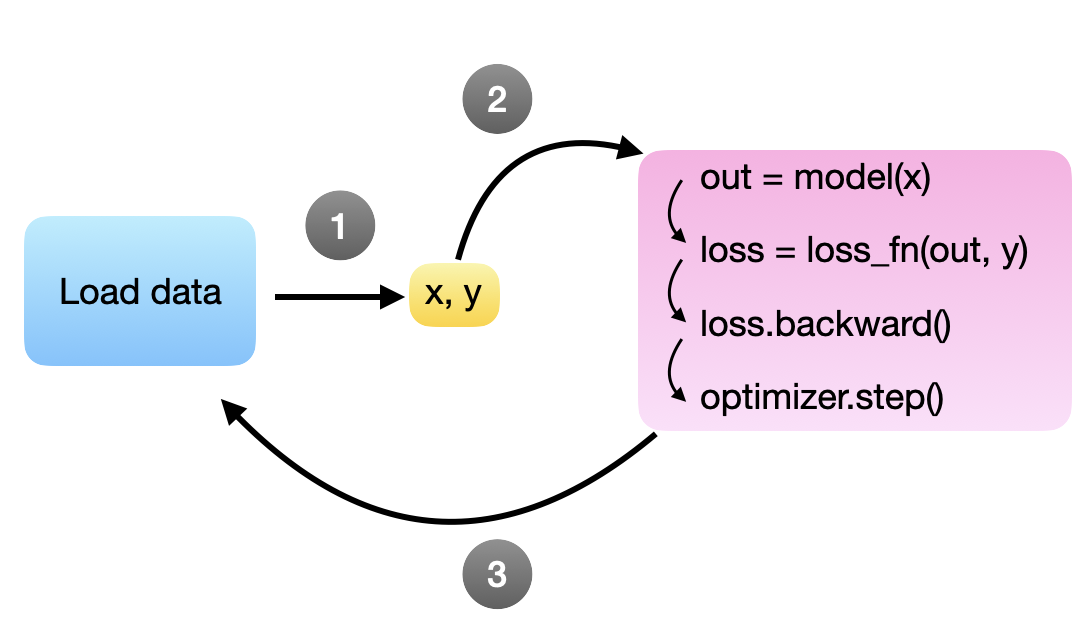
这不是好的实践,因为训练和数据加载在同一个 for 循环中顺序进行。每次我们加载下一个小批量时,模型和 GPU 都处于空闲状态。
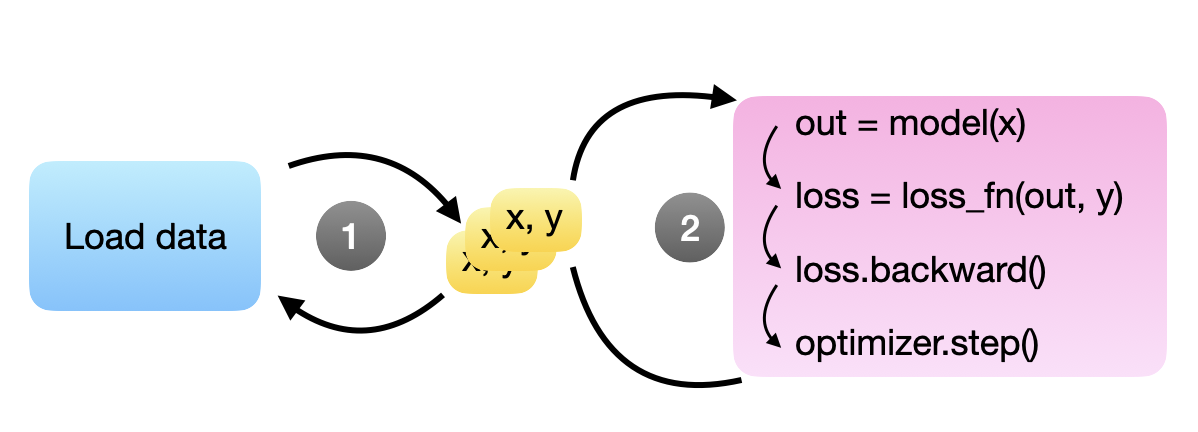
理想情况下,我们希望模型在后向调用和参数更新(通过.step())后立即处理下一个小批量。换句话说,目标是在模型准备就绪后立即准备好下一个小批量,因此我们希望在模型训练期间持续在后台加载小批量。遗憾的是,由于 Python 有一个全局解释器锁 (GIL),默认情况下只允许它运行单个进程,因此我们必须编写一个复杂的解决方法。
值得庆幸的是,我们可以使用 PyTorch 的 DataLoader 来实现这一点。DataLoader 允许我们指定加载下一个小批量的后台进程数量(num_workers),这样就不会阻塞 GPU。根据经验,设置 num_workers=4 通常会在许多真实世界数据集上获得最佳性能,但最佳设置取决于你的研究和数据集。
模型
class NeuralNetwork(torch.nn.Module):
def __init__(self, num_inputs, num_outputs):
super().__init__()
self.layers = torch.nn.Sequential(
torch.nn.Linear(num_inputs, 300 * scale),
torch.nn.ReLU(),
torch.nn.Linear(300 * scale, 200 * scale),
torch.nn.ReLU(),
torch.nn.Linear(200 * scale, num_outputs)
)
def forward(self, x):
logits = self.layers(x)
return logits
训练
import torch.nn.functional as F
torch.manual_seed(123)
device = torch.device(
"mps" if torch.backends.mps.is_available() else "cpu"
)
model = NeuralNetwork(num_inputs=num_input, num_outputs=2)
model = model.to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.5)
print("Total Parameters: ", sum(p.numel() for p in model.parameters() if p.requires_grad))
num_epochs = 10
for epoch in range(num_epochs):
model.train()
for batch_idx, (x, y) in enumerate(train_loader):
x, y = x.to(device), y.to(device)
logits = model(x)
loss = F.cross_entropy(logits, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f"Epoch: {epoch+1:02d}/{num_epochs:02d}"
f" | Batch: {batch_idx+1:02d}/{len(train_loader):02d}"
f" | Train Loss: {loss:.2f}")
model.eval()
correct = 0.0
total = 0
for batch_idx, (x, y) in enumerate(test_loader):
x, y = x.to(device), y.to(device)
with torch.no_grad():
logits = model(x)
predictions = torch.argmax(logits, dim=1)
print(predictions, y)
compare = predictions == y
correct += torch.sum(compare)
total += len(compare)
print(f"Eval Accuracy: {correct/total:.2f}")
性能对比
| 参数 | 设备 | 耗时 | 速度 |
|---|---|---|---|
| 90902 | MPS | 2.6s | 0.19 |
| CPU | 0.5s | ||
| 361802 | MPS | 3.4s | 0.23 |
| CPU | 0.8s | ||
| 812702 | MPS | 3.1s | 0.58 |
| CPU | 1.8s | ||
| 1443602 | MPS | 3.3s | 0.72 |
| CPU | 2.4s | ||
| 2254502 | MPS | 3.6s | 0.94 |
| CPU | 3.4s | ||
| 300万 | MPS | 🚀 转折点 |
|
| 9009002 | MPS | 4.5s | 1.66 |
| CPU | 7.5s | ||
| 225045002 | MPS | 23.2s | 6.37 |
| CPU | 2m 27.9s | ||
| 506317502 | MPS | 57.7s | 5.58 |
| CPU | 5m 37.2s | ||
| 900090002 | MPS | 1m 44s | 5.53 |
| CPU | 9m 35.2s |