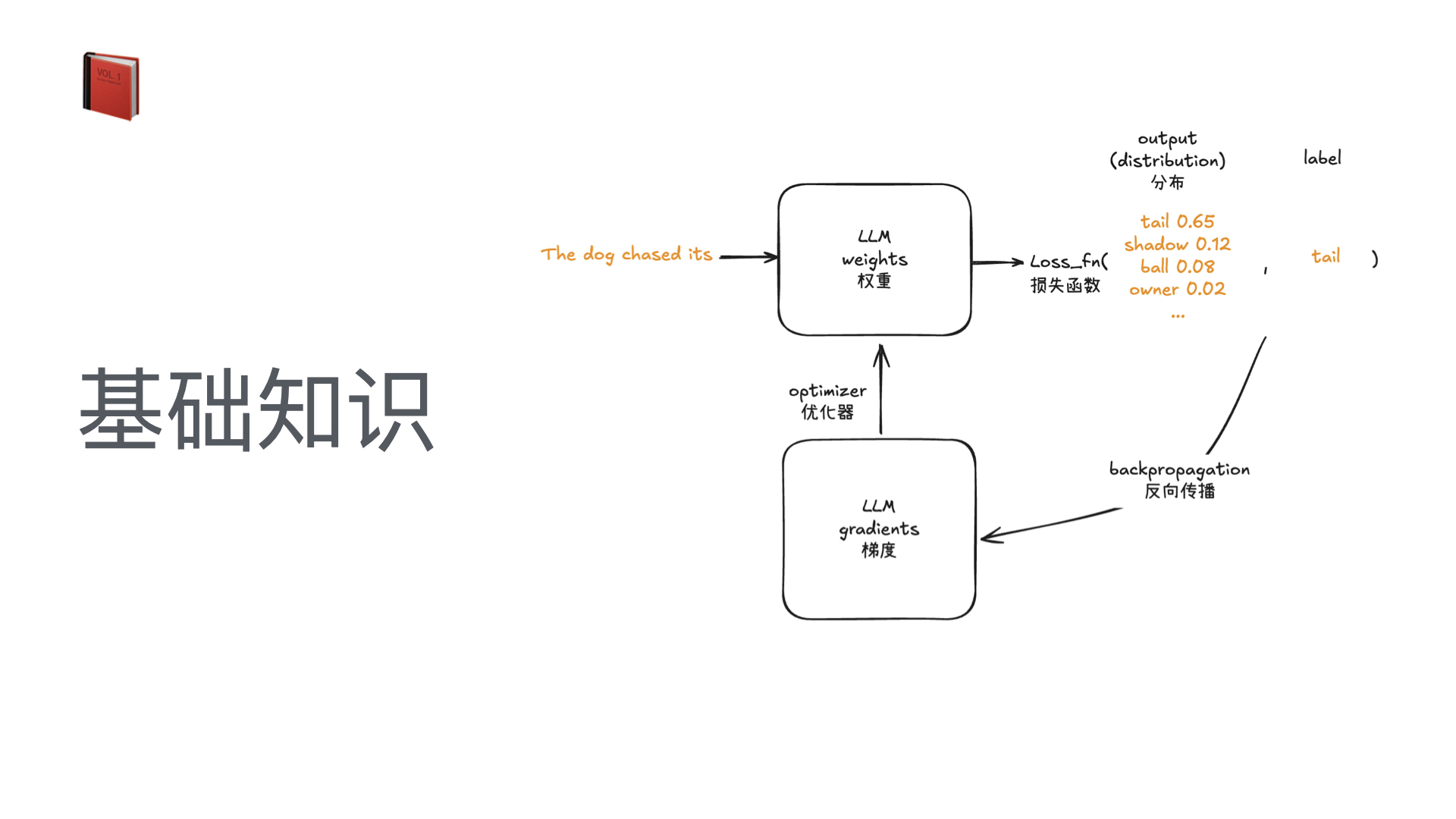
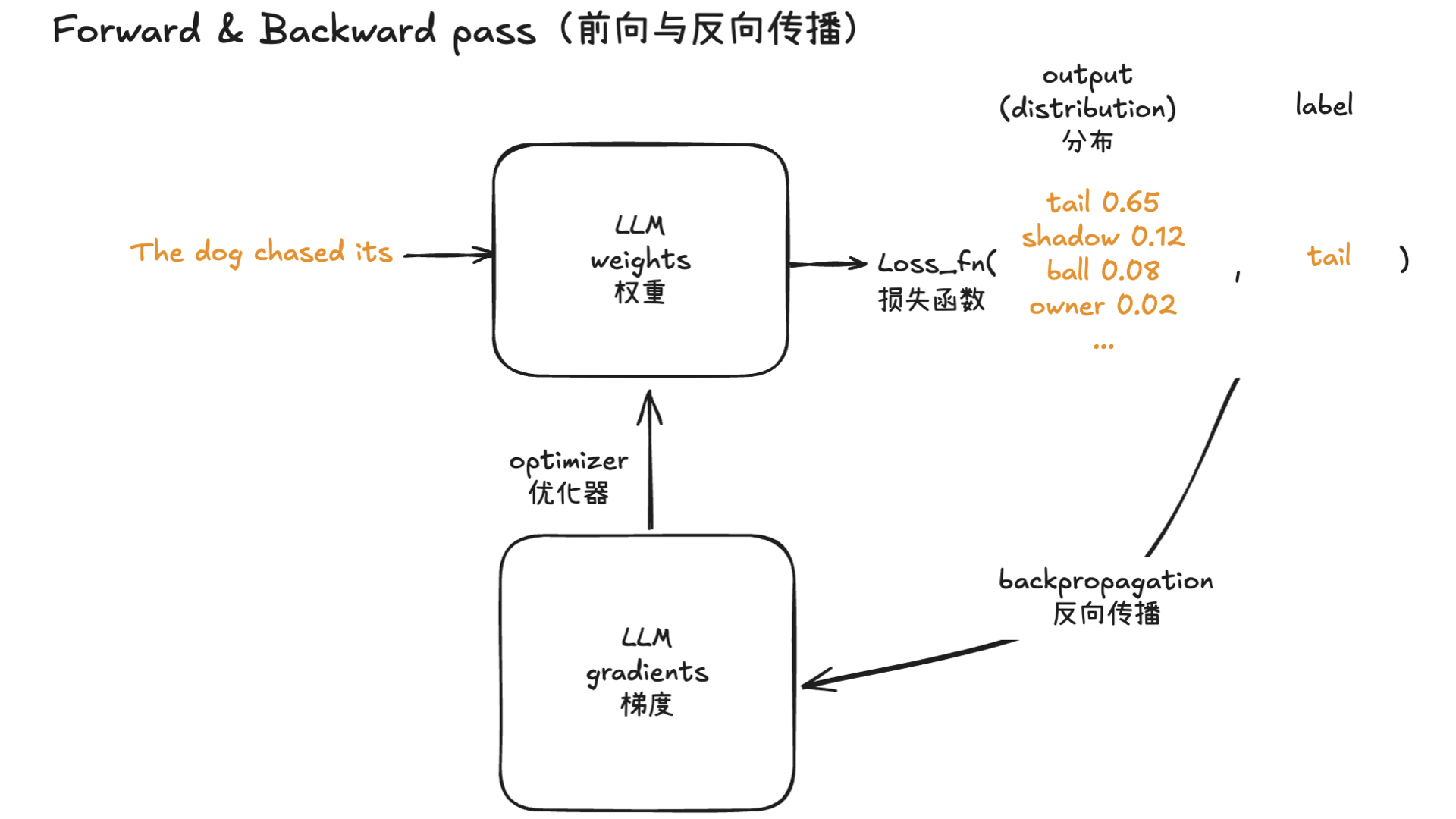
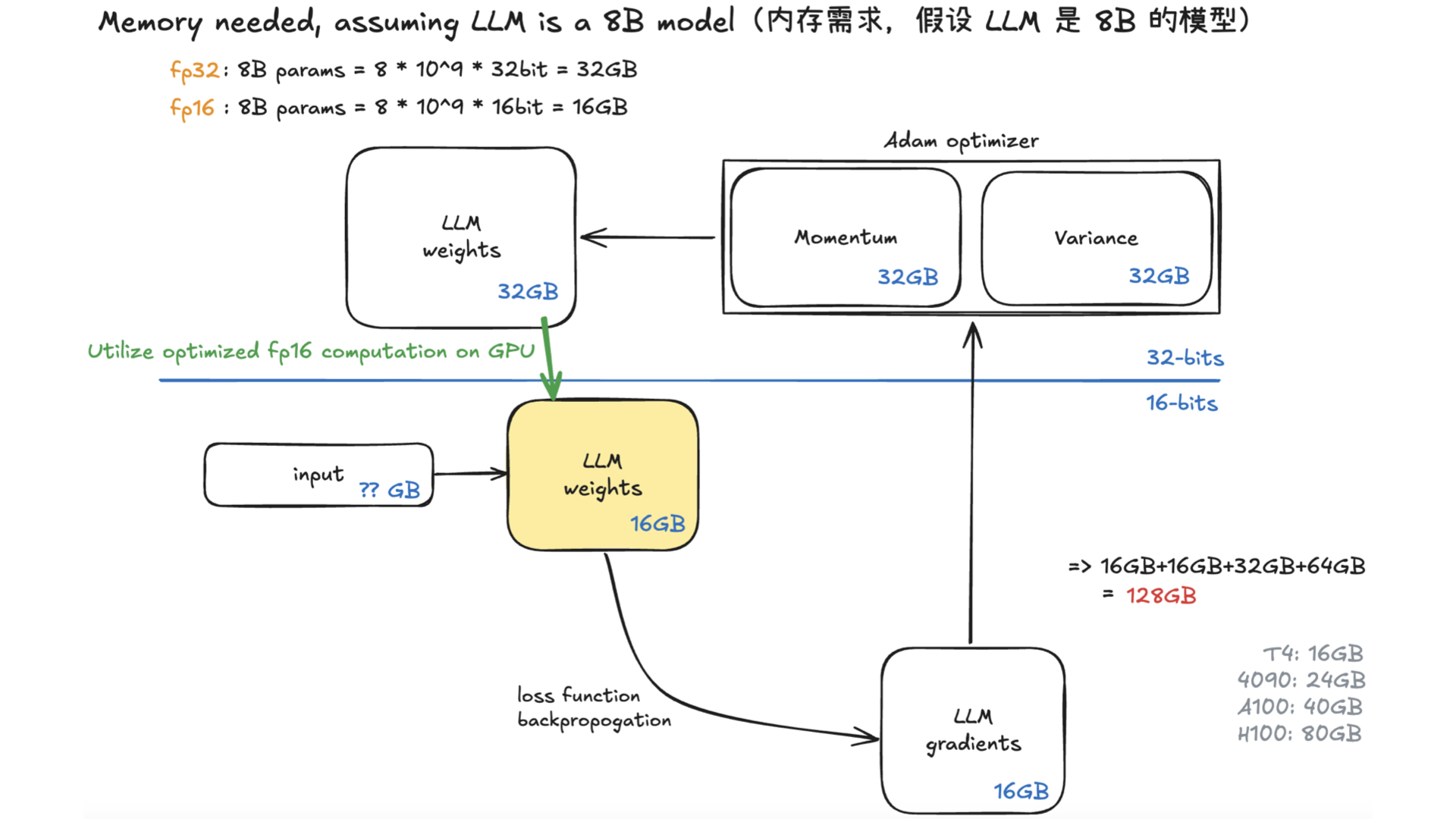
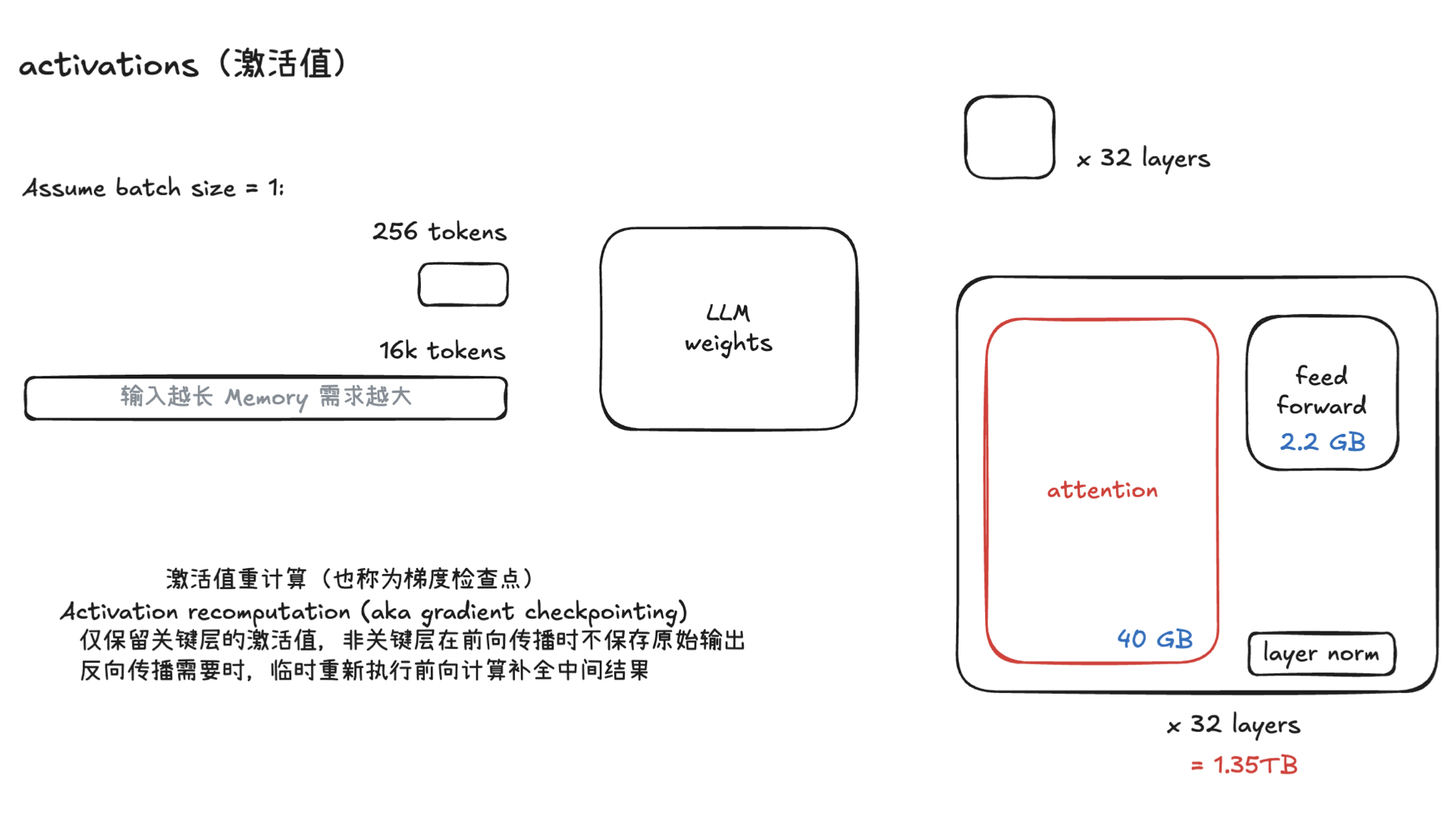
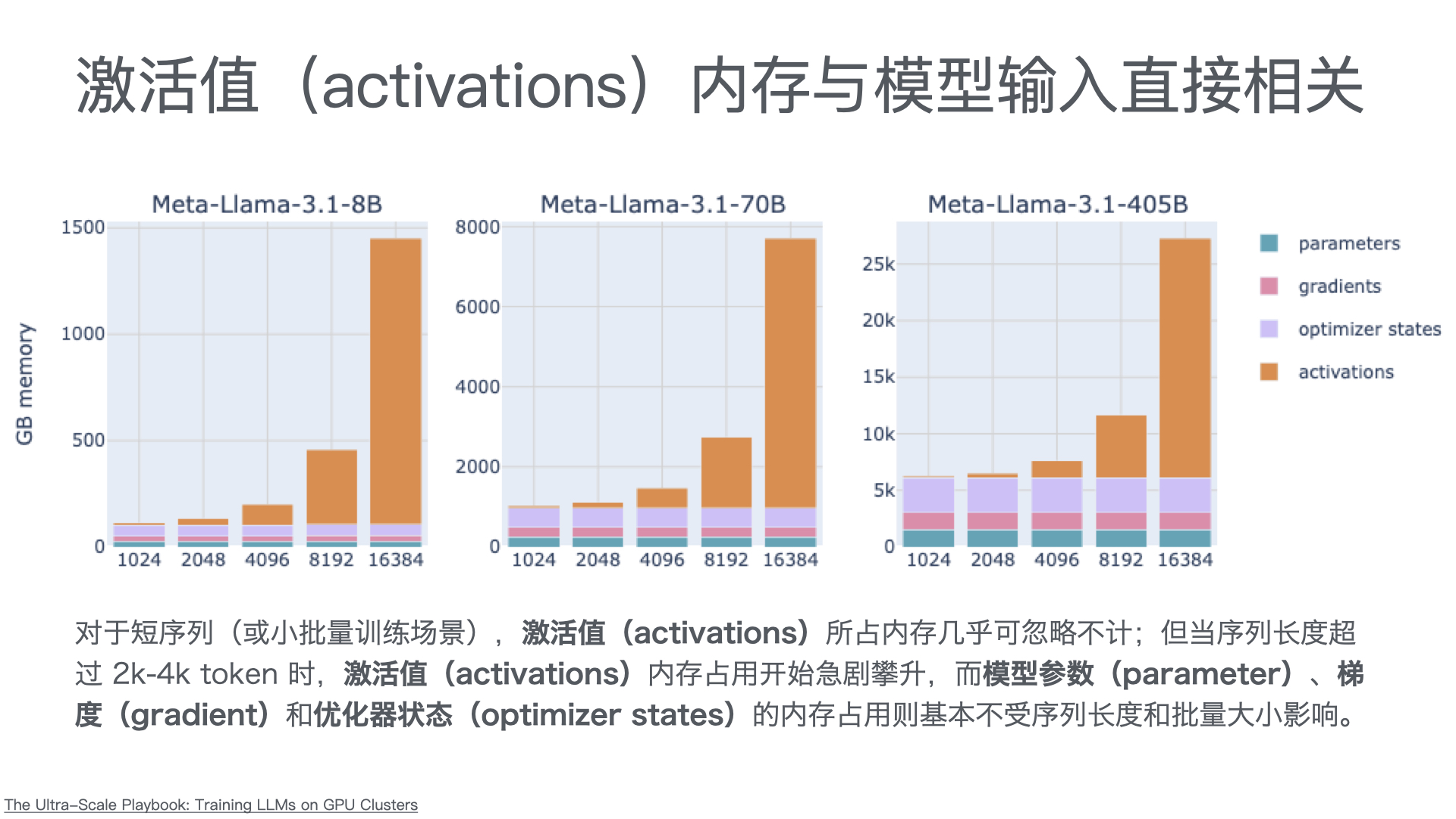
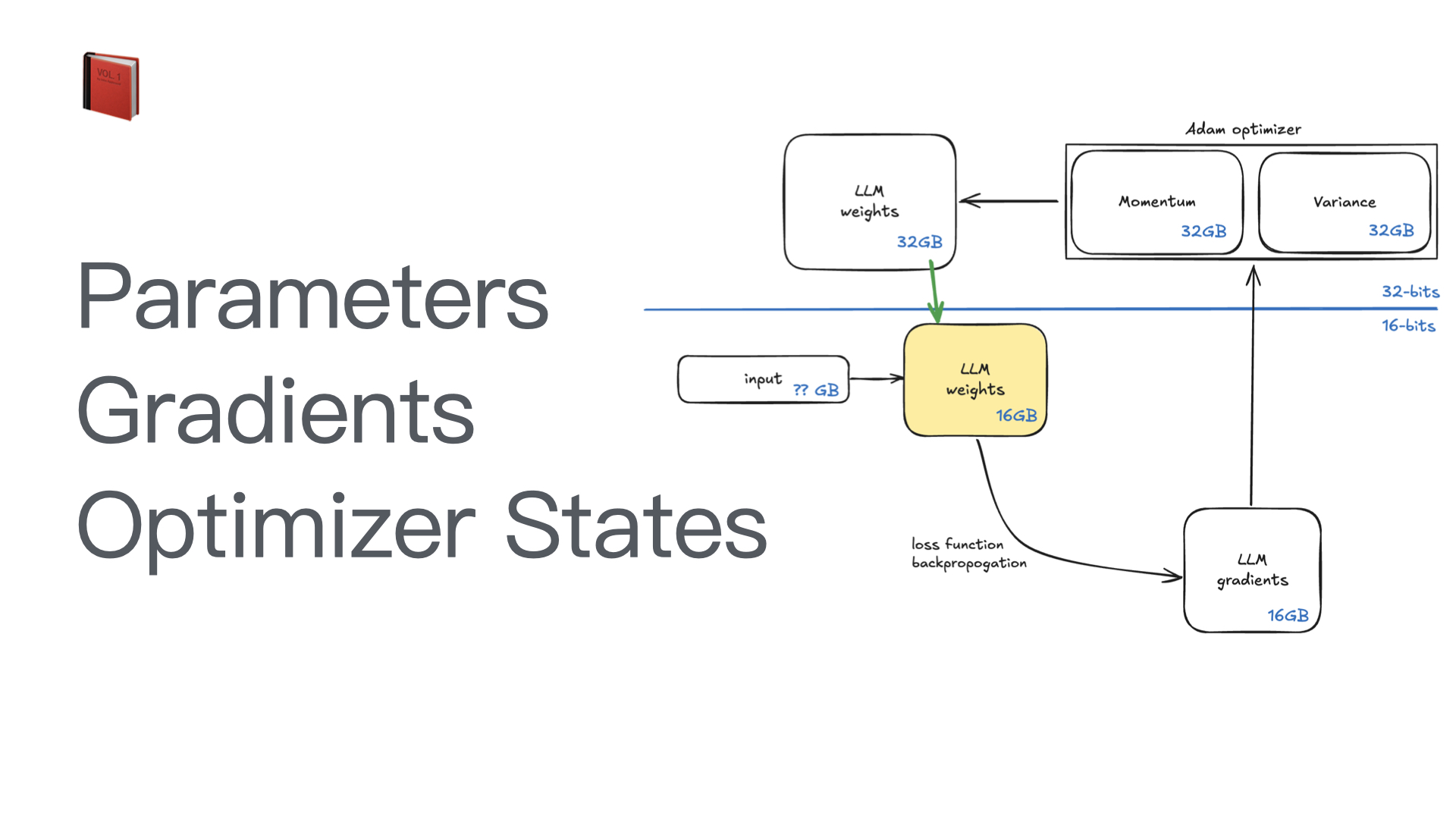
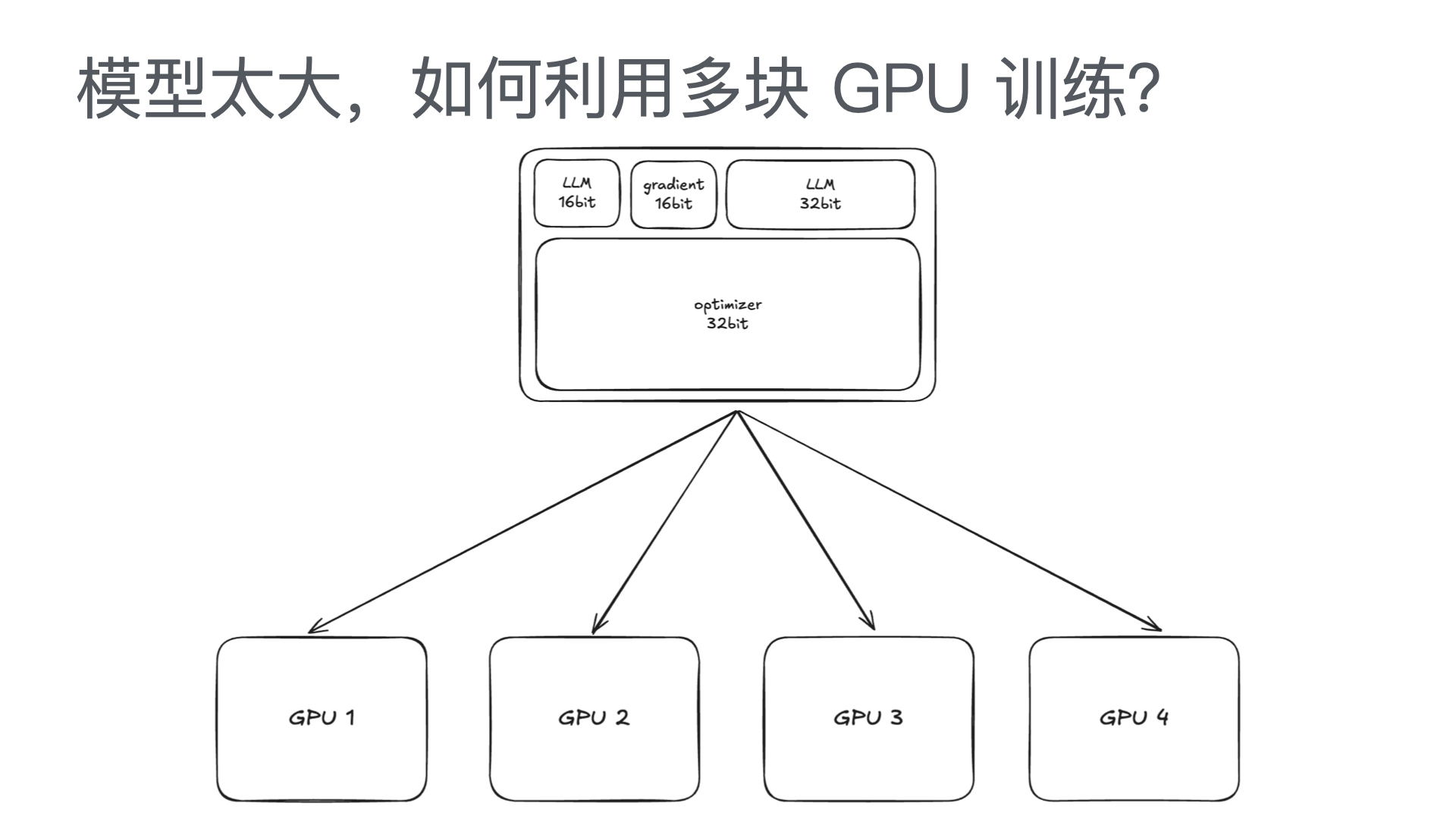
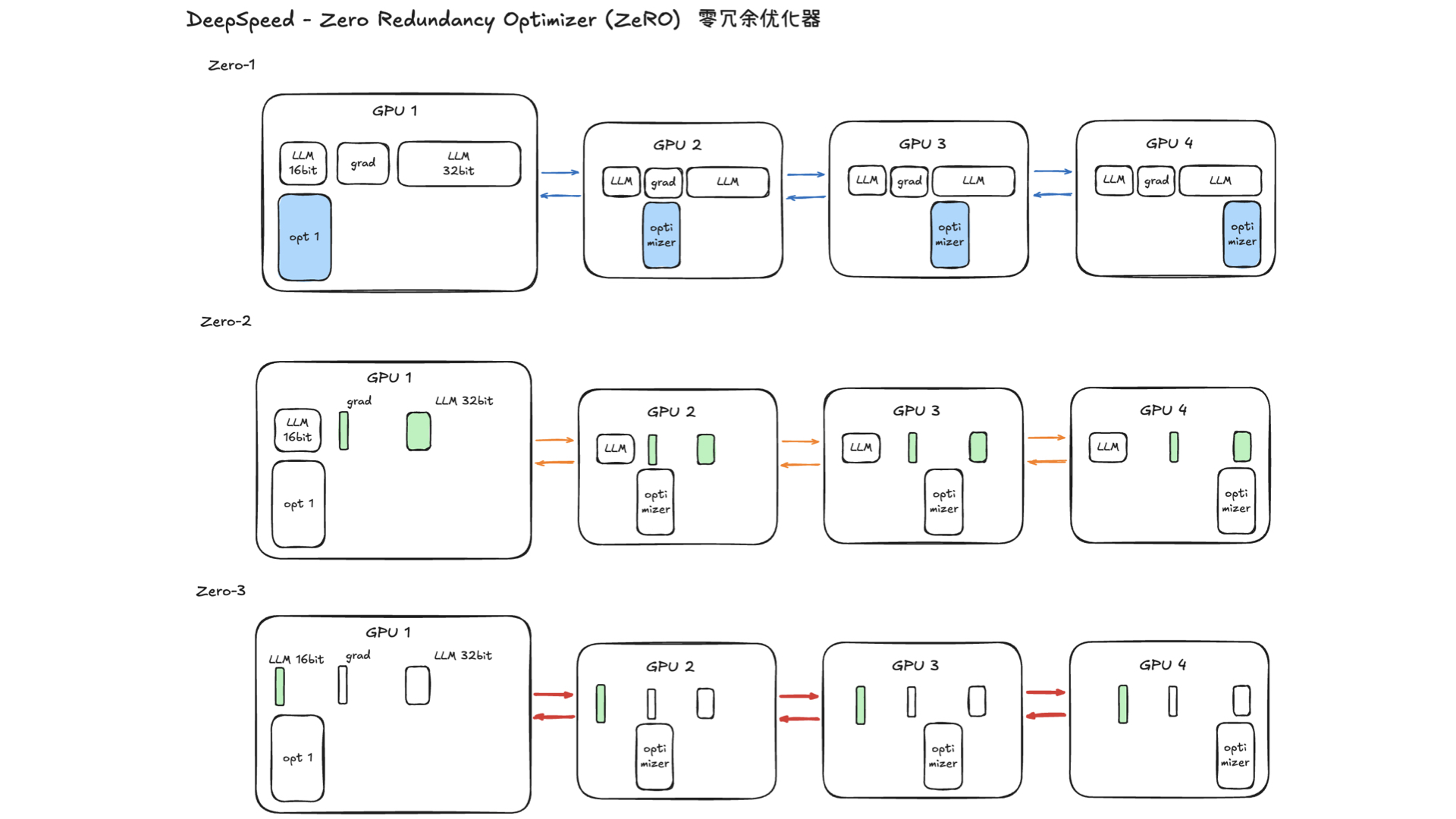
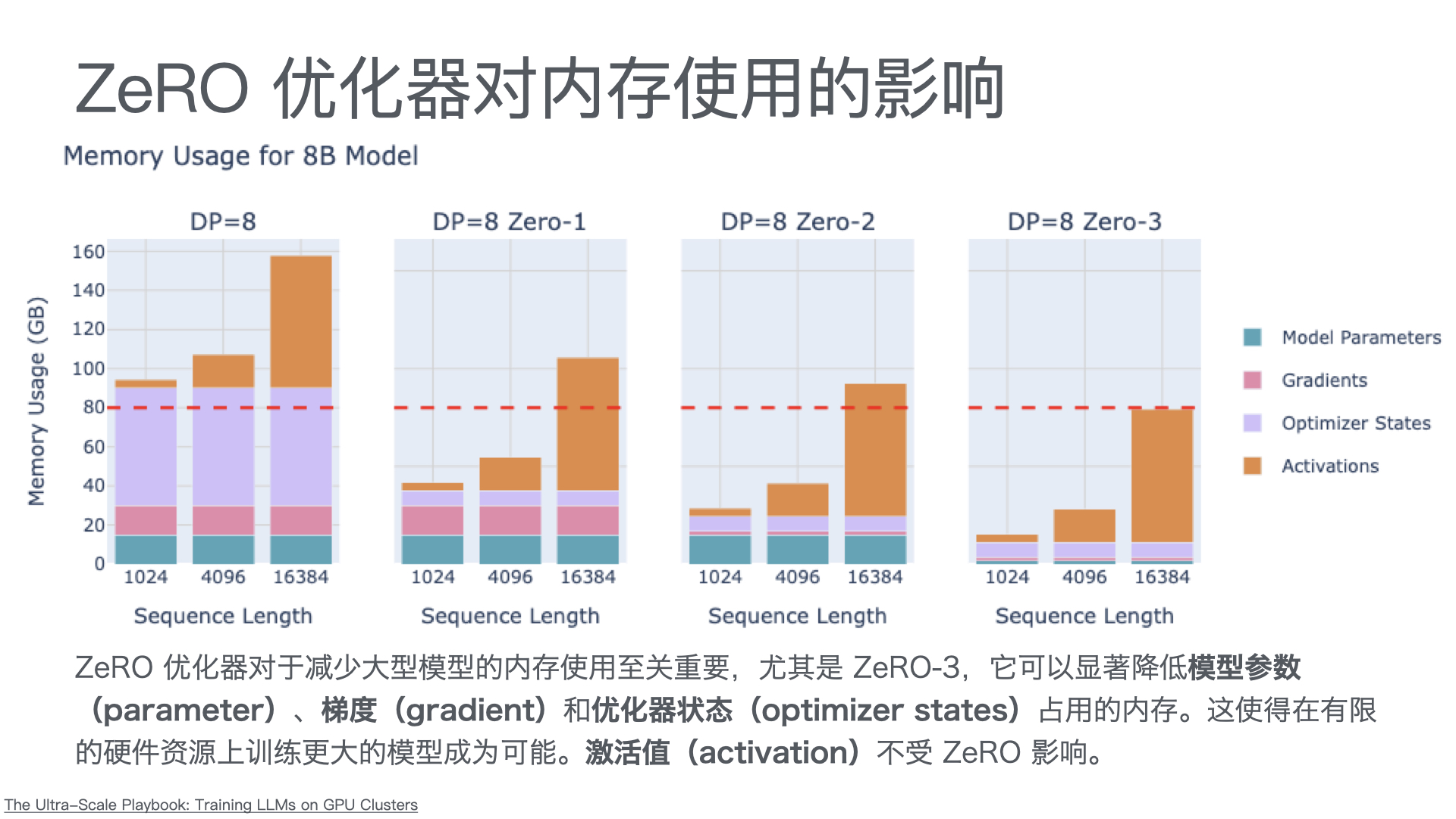
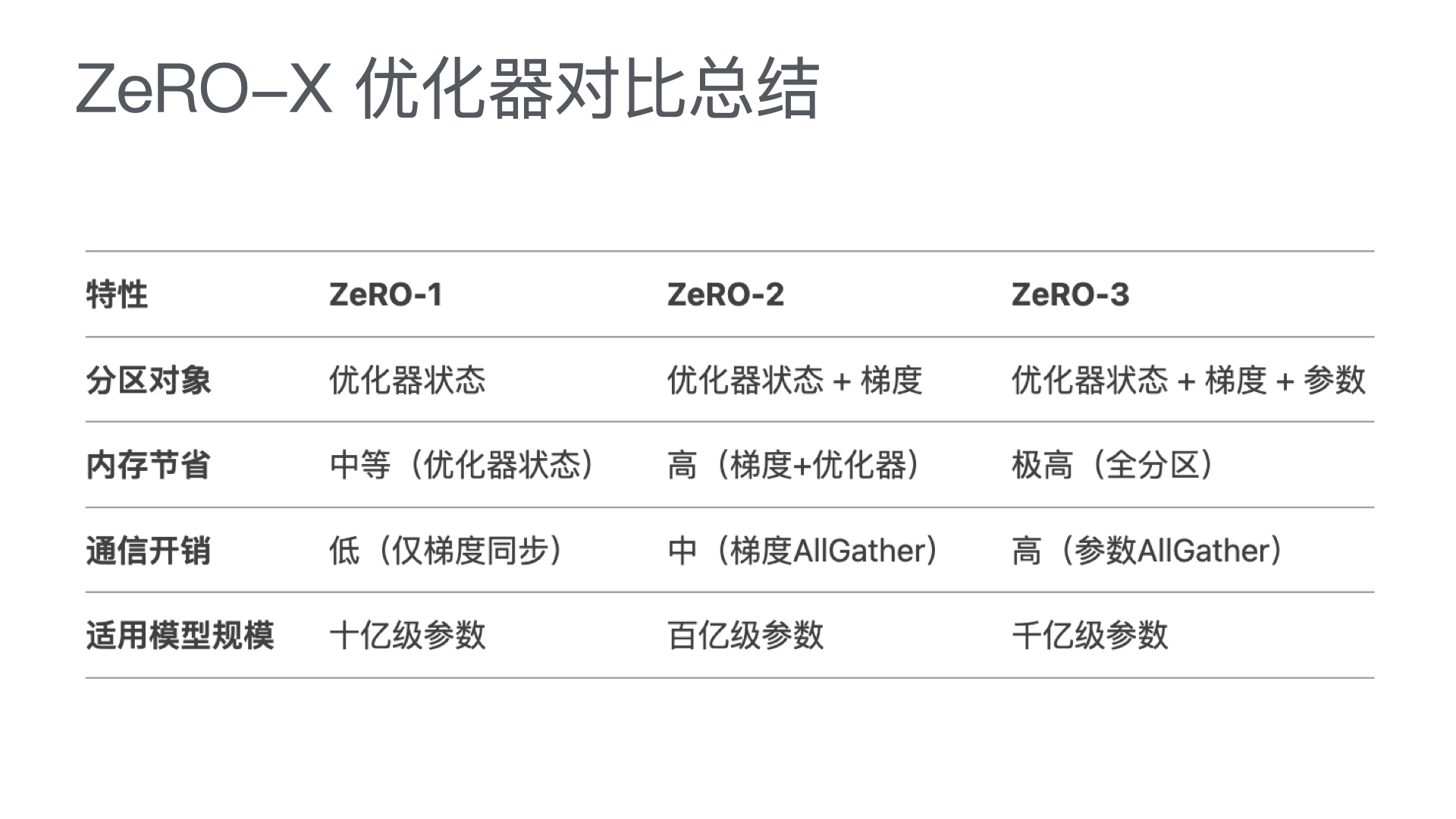
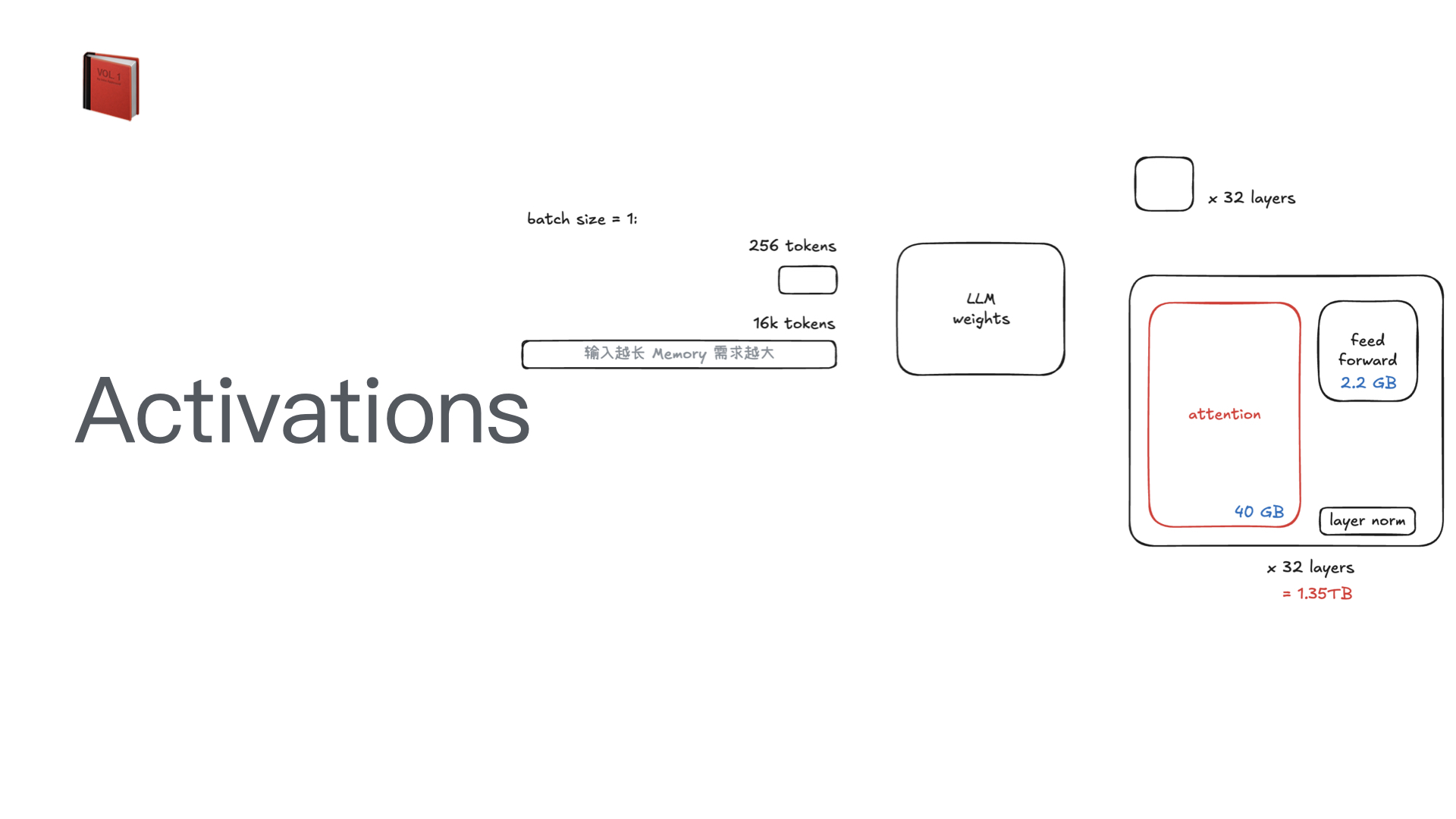
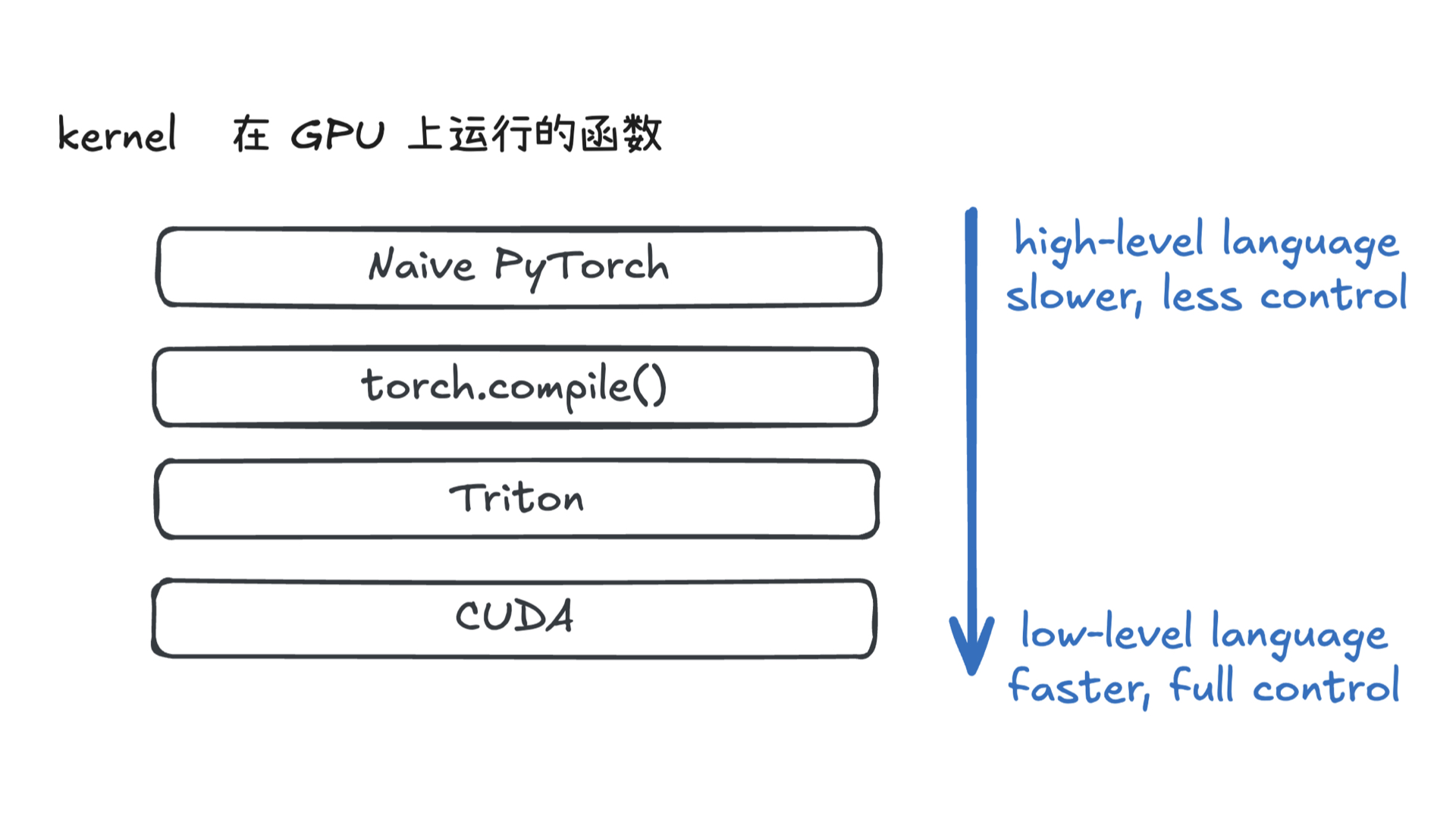
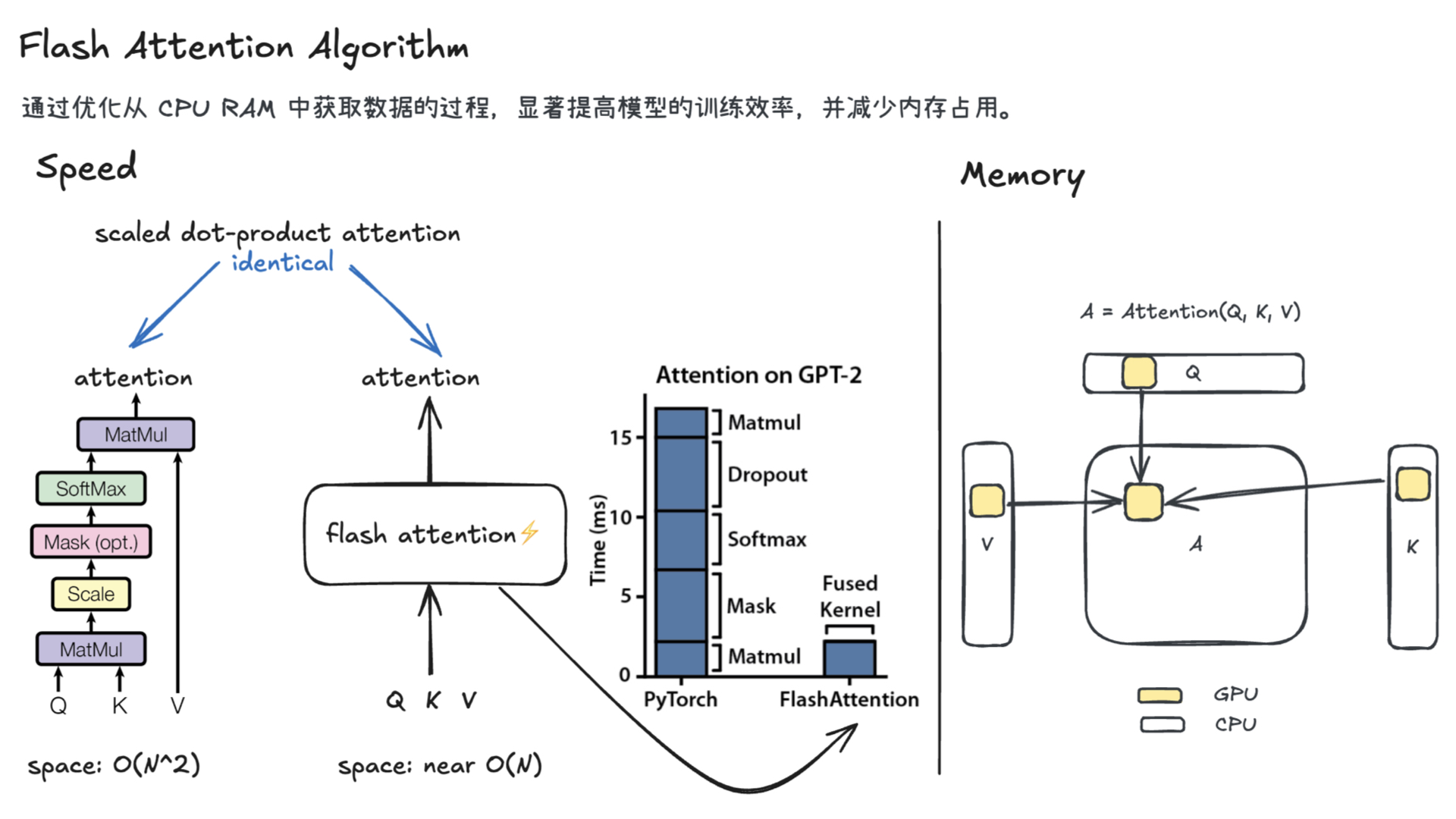
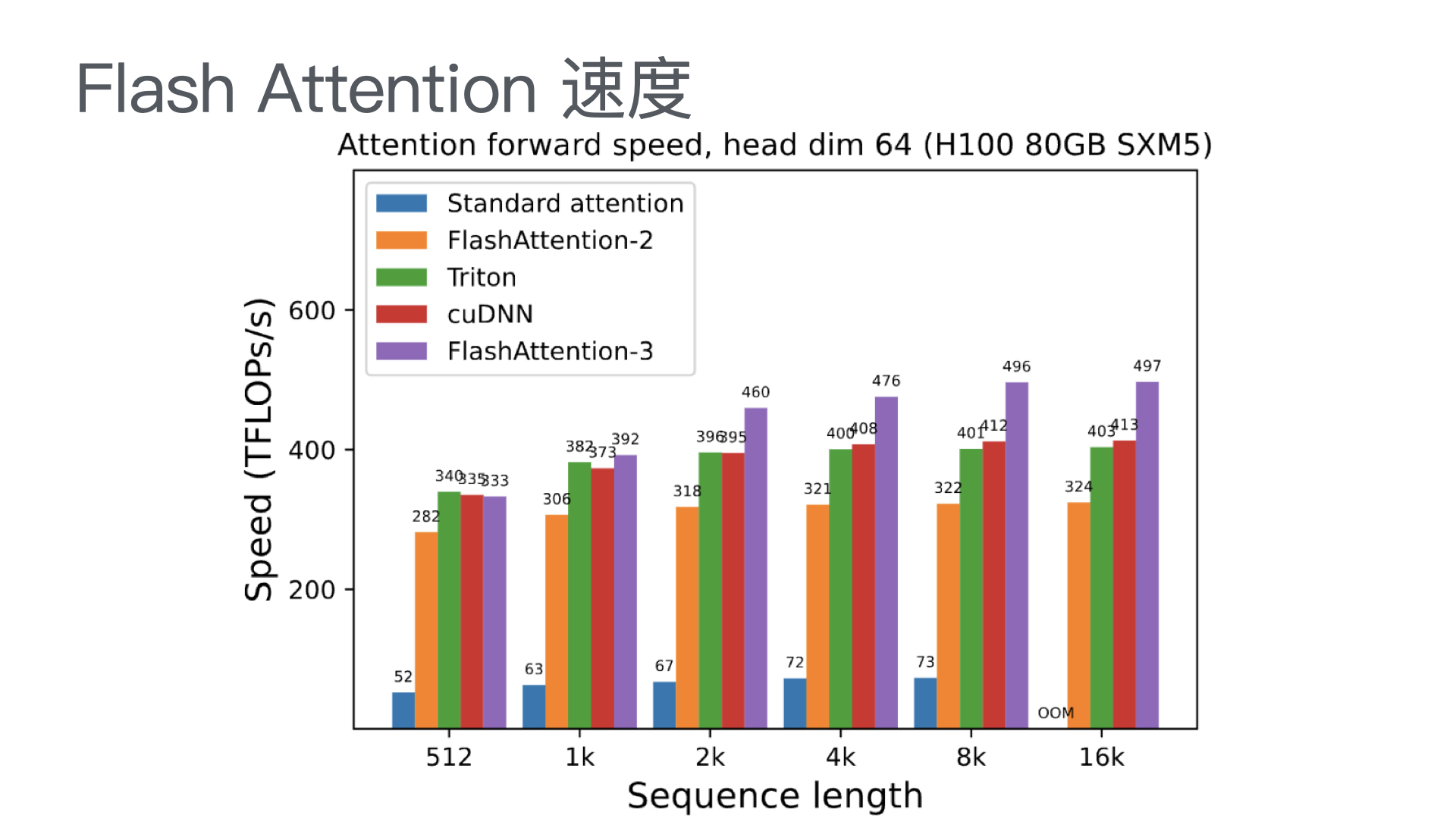
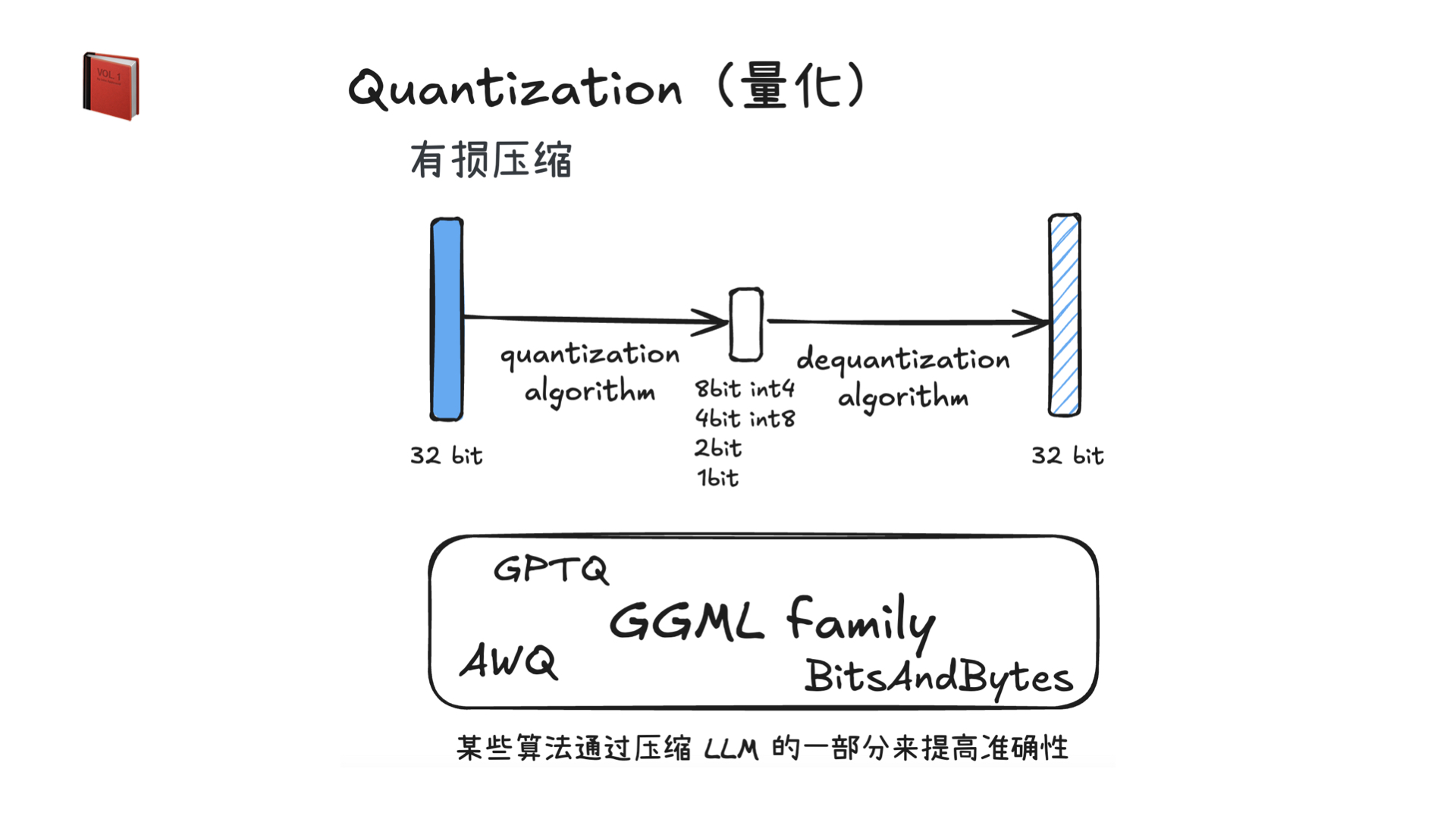
利用多张 GPU 训练大语言模型 April 4, 2025 类别: Train LLM 标签: Train LLM DeepSpeed ZeRO FlashAttention Quantization 李宏毅 2025 目录 参考资料 参考资料 李宏毅生成式 AI 时代下的机器学习(2025)助教课:利用多张 GPU 训练大型语言模型——从零开始介绍 DeepSpeed、Liger Kernel、Flash Attention 及 Quantization 【生成式AI時代下的機器學習(2025)】助教課:利用多張GPU訓練大型語言模型—從零開始介紹DeepSpeed、Liger Kernel、Flash Attention及Quantization Excalidraw The Ultra-Scale Playbook: Training LLMs on GPU Clusters