Tabby 使用指南
Tabby
安装 Tabby (macOS)
brew install tabbyml/tabby/tabby
更新
brew upgrade tabbyml/tabby/tabby
安装 Tabby VSCode 扩展
模型
Codestral 的优点
与其他编码 LLM 相比,Codestral 的独特之处在于其单一模型同时支持 指令跟随 和 中间填充 兼容性。这是通过在两个数据集上同时微调基础模型实现的。这种 双重微调策略 使同一个模型在 代码补全 和 对话任务 中都能表现出色,大大简化了模型部署堆栈。
此外,Codestral 在包含 80 多种编程语言的多样化数据集上进行训练,确保了开发人员在使用各种语言时的高质量体验。
运行 Tabby Server
命令行指定参数
tabby serve --device metal --model Codestral-22B --chat-model Codestral-22B
████████╗ █████╗ ██████╗ ██████╗ ██╗ ██╗
╚══██╔══╝██╔══██╗██╔══██╗██╔══██╗╚██╗ ██╔╝
██║ ███████║██████╔╝██████╔╝ ╚████╔╝
██║ ██╔══██║██╔══██╗██╔══██╗ ╚██╔╝
██║ ██║ ██║██████╔╝██████╔╝ ██║
╚═╝ ╚═╝ ╚═╝╚═════╝ ╚═════╝ ╚═╝
📄 Version 0.17.0
🚀 Listening at 0.0.0.0:8080
JWT secret is not set
Tabby server will generate a one-time (non-persisted) JWT secret for the current process.
Please set the TABBY_WEBSERVER_JWT_TOKEN_SECRET environment variable for production usage.
配置文件(~/.tabby/config.toml)指定参数
Local
[model.completion.local]
model_id = "Codestral-22B"
[model.chat.local]
model_id = "Codestral-22B"
[model.embedding.local]
model_id = "Nomic-Embed-Text"
Ollama
# Completion model
[model.completion.http]
kind = "ollama/completion"
model_name = "qwen2.5-coder:7b"
api_endpoint = "http://localhost:11434"
prompt_template = "<PRE> {prefix} <SUF>{suffix} <MID>" # Example prompt template for the odeLlama model series.
# Chat model
[model.chat.http]
kind = "openai/chat"
model_name = "qwen2.5-coder:7b"
api_endpoint = "http://localhost:11434/v1"
# Embedding model
[model.embedding.http]
kind = "ollama/embedding"
model_name = "nomic-embed-text"
api_endpoint = "http://localhost:11434"
OpenAI
- LiteLLM
# Completion model
[model.completion.http]
kind = "openai/completion"
model_name = "gpt-4"
api_endpoint = "http://127.0.0.1:4000/v1"
api_key = "sk-1234"
# Chat model
[model.chat.http]
kind = "openai/chat"
model_name = "gpt-4"
api_endpoint = "http://127.0.0.1:4000/v1"
api_key = "sk-1234"
# Embedding model
[model.embedding.http]
kind = "openai/embedding"
model_name = "bge-m3"
api_endpoint = "http://127.0.0.1:4000/v1"
api_key = "sk-1234"
- XInference
# Completion model
[model.completion.http]
kind = "openai/completion"
model_name = "gpt-4-32k"
api_endpoint = "http://172.16.33.66:9997/v1"
api_key = "NONE"
# Chat model
[model.chat.http]
kind = "openai/chat"
model_name = "gpt-4-32k"
api_endpoint = "http://172.16.33.66:9997/v1"
api_key = "NONE"
# Embedding model
[model.embedding.http]
kind = "openai/embedding"
model_name = "bge-m3"
api_endpoint = "http://172.16.33.66:9997/v1"
api_key = "NONE"
运行 tabby serve
tabby serve --device metal
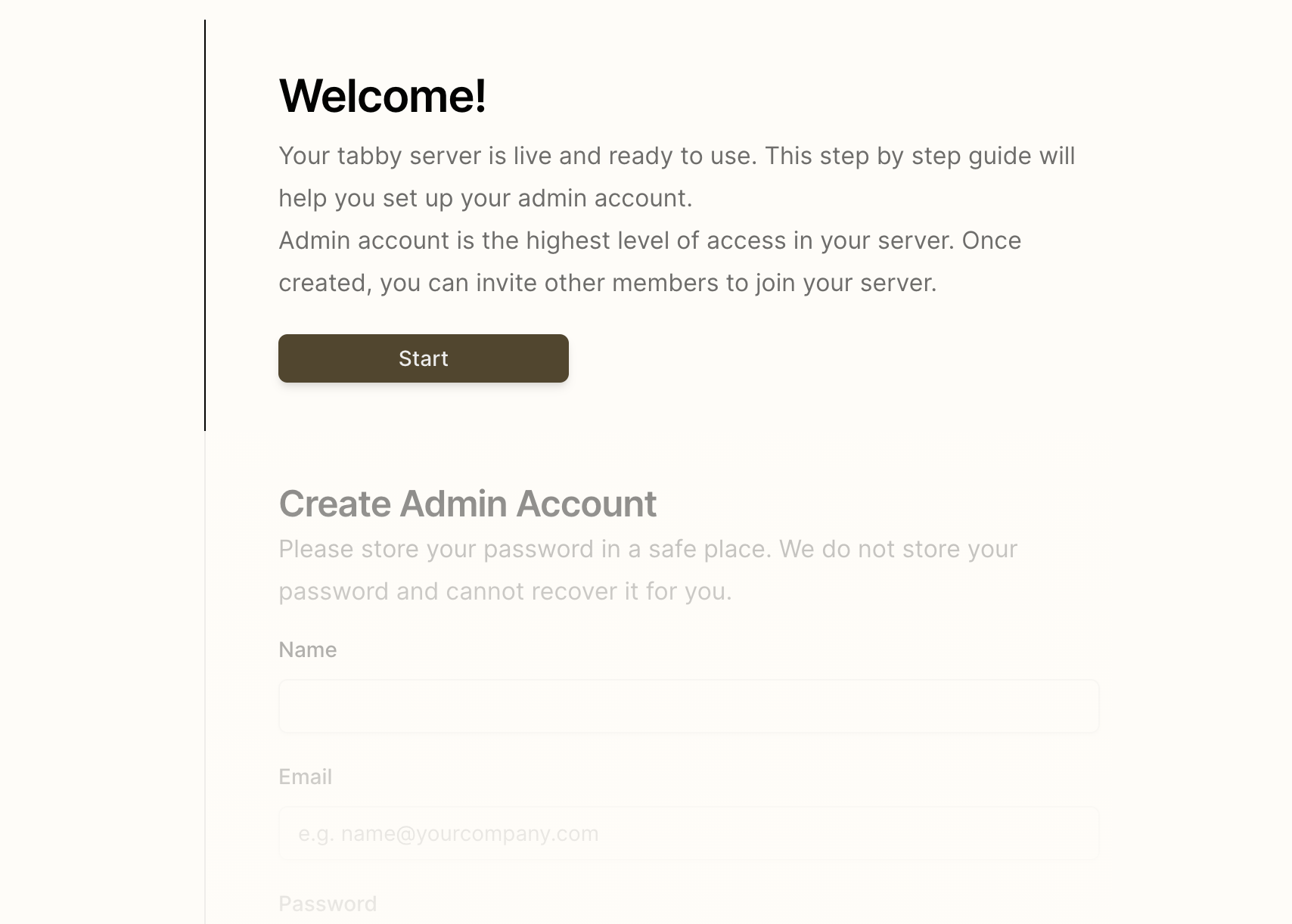
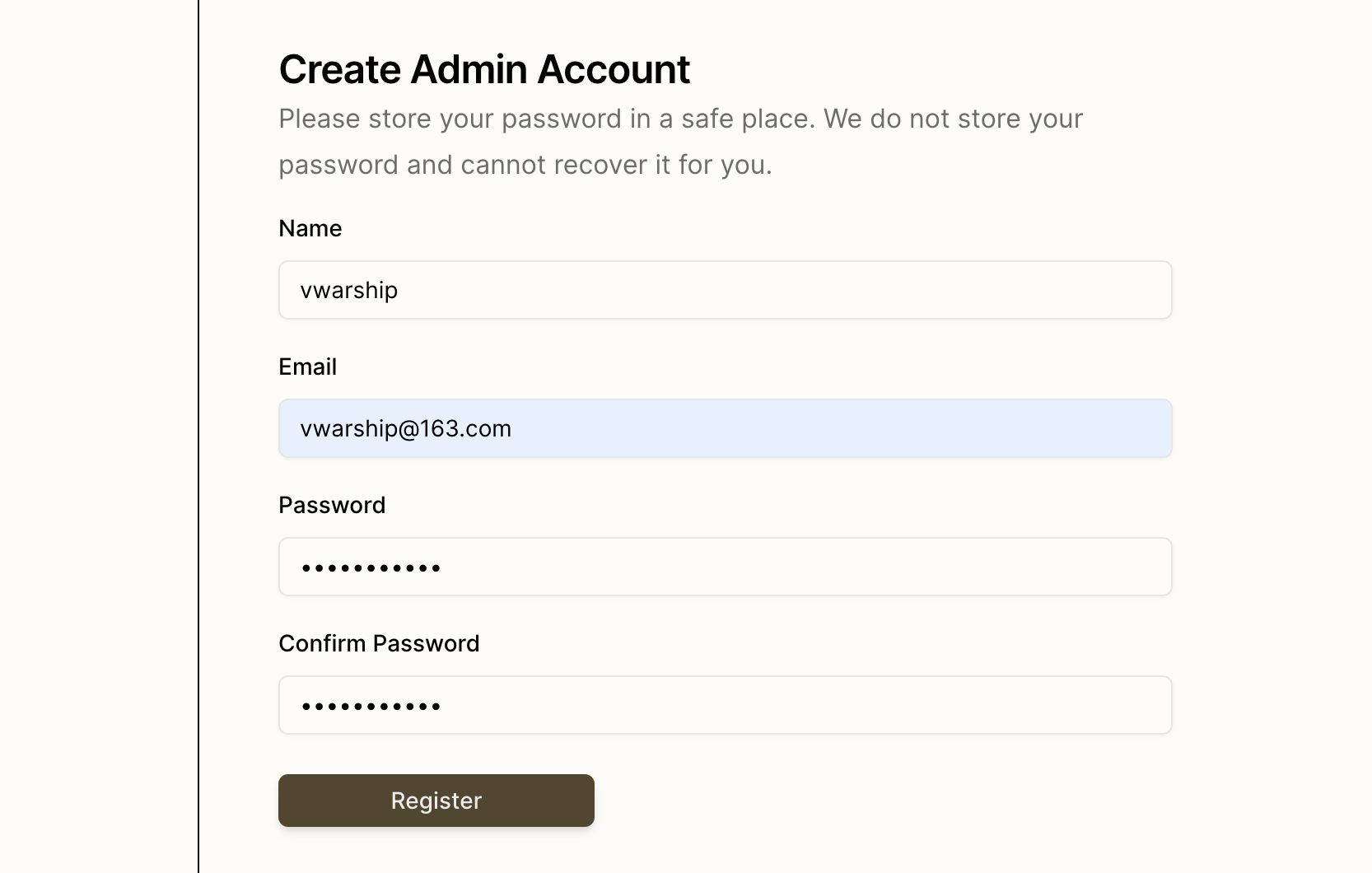
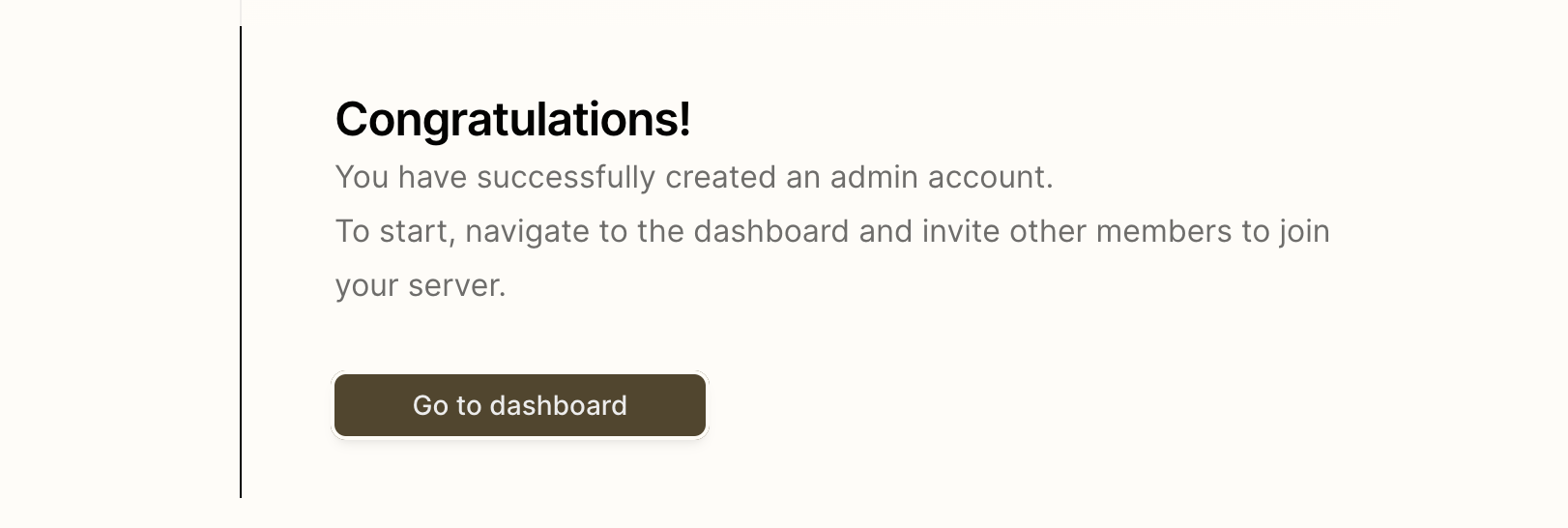
配置 Tabby Server
打开浏览器,输入:http://127.0.0.1:8080/,进入 Tabby Server 的配置页面。
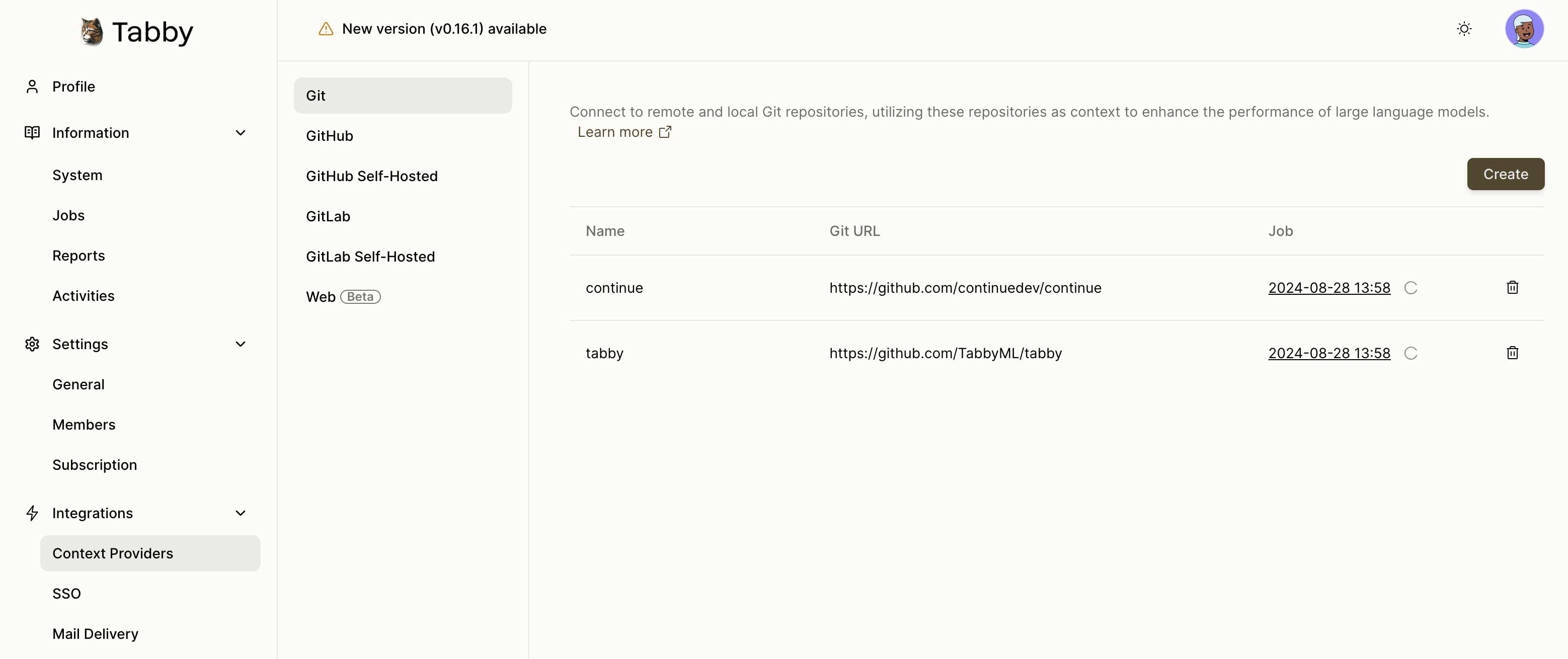
Context Providers
Git
Code Browser
Repositories

代码搜索
代码聊天
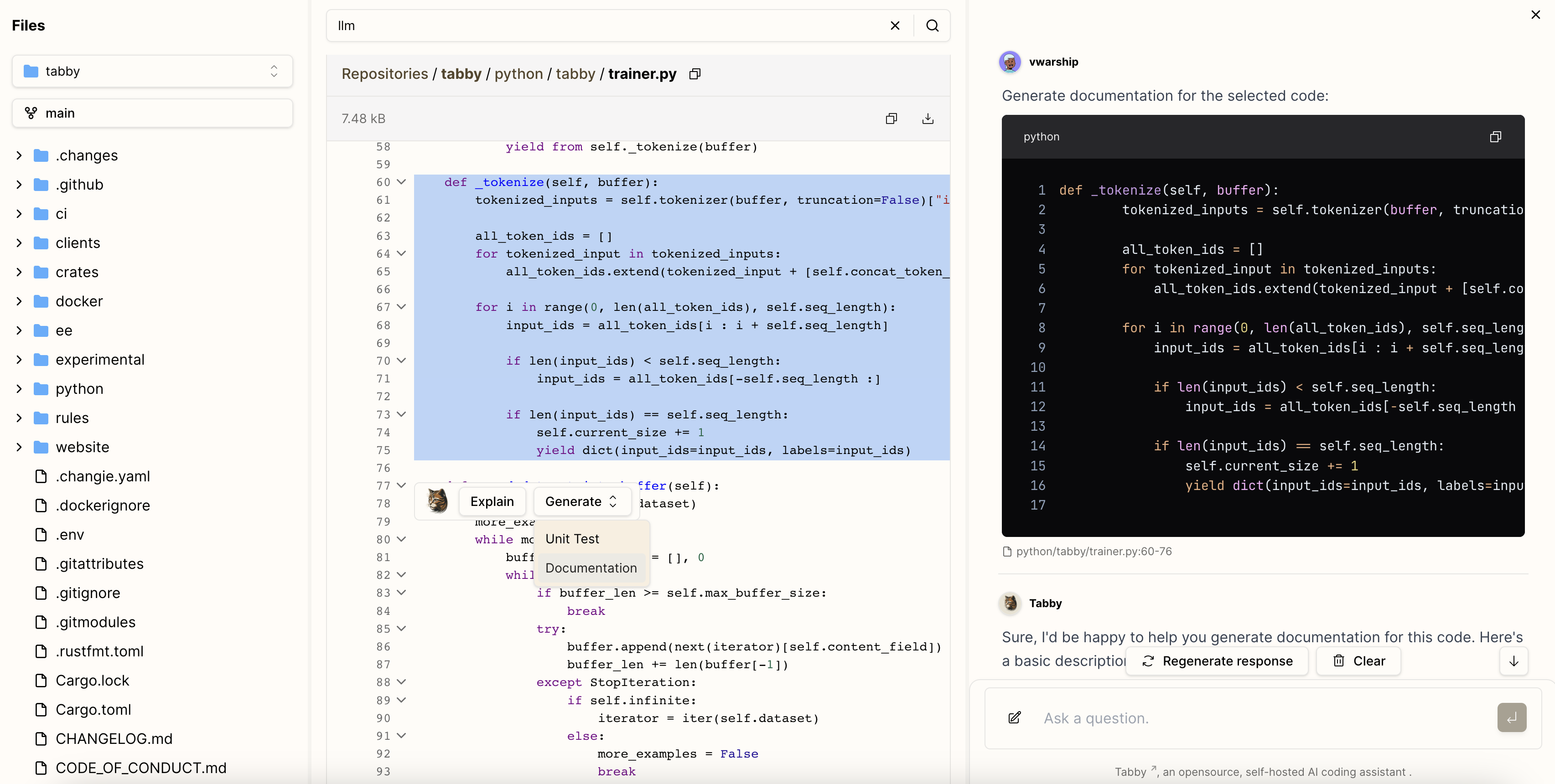
聊天
VSCode(Tabby)
聊天
使用 RAG
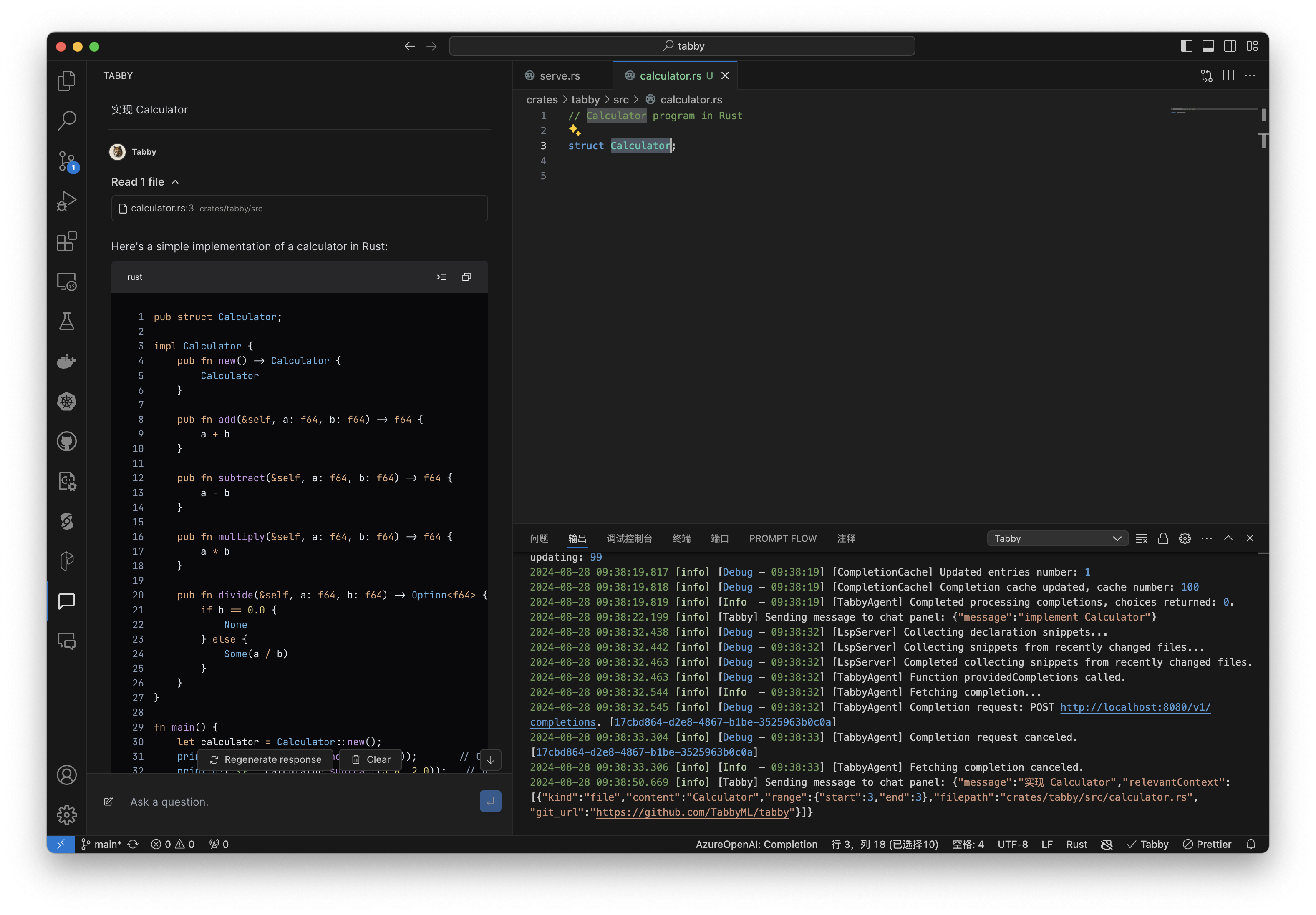
这里是我选择了 Calculator,聊天的时候才把 calculator.rs 文件作为上下文提供的。还没测试出来如何更好的检索到 Context Providers 的内容。
配置
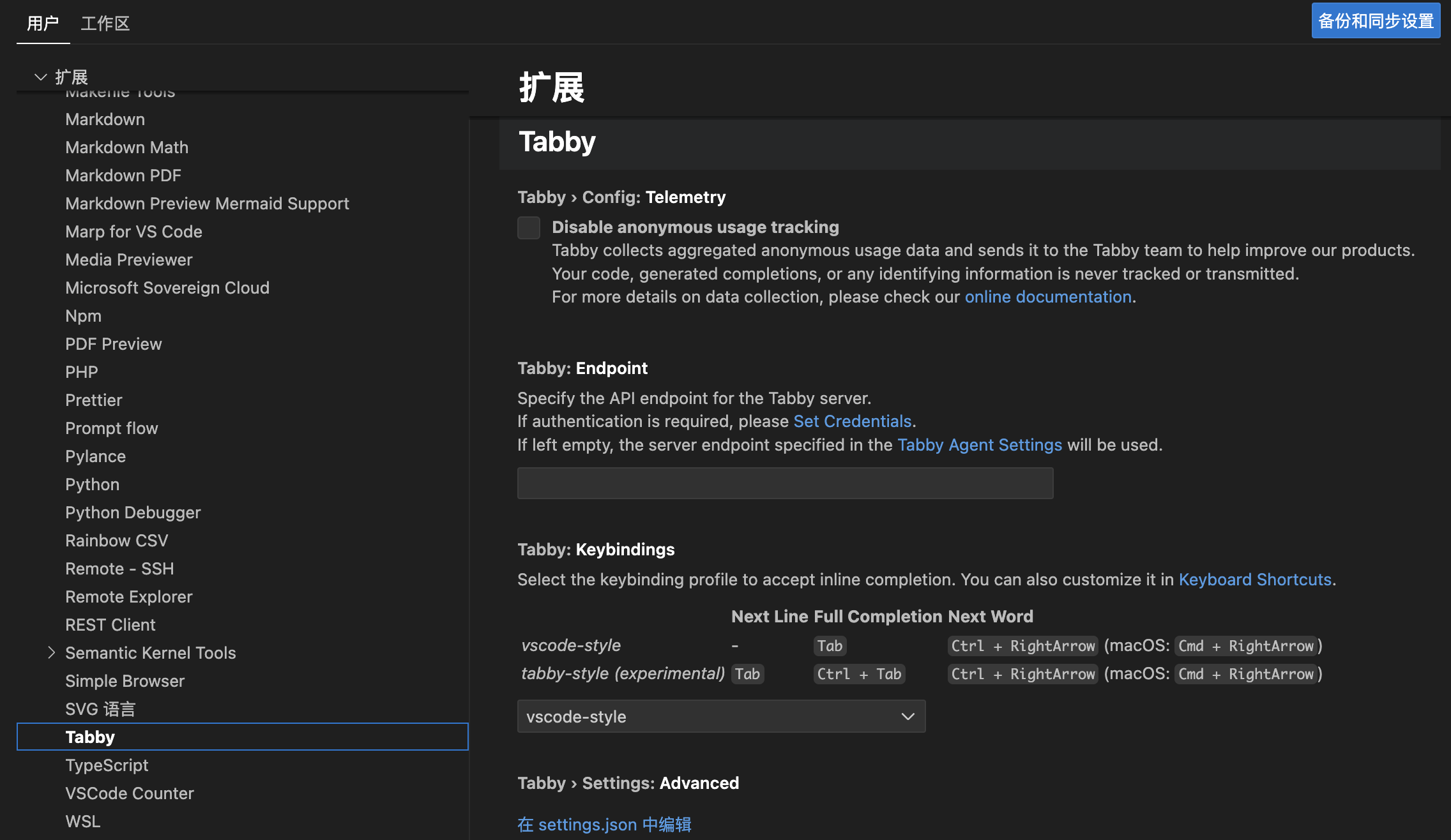
查看指标
使用后,查看指标的统计,主要统计的是 自动补全。