Sky-T1-7B:通过强化学习提升推理模型的潜力
摘要
我们很高兴发布 Sky-T1-7B,这是一个在数学推理任务上达到 SOTA 水平的开源 7B 模型,它通过对 Qwen2.5-Math-7B 基础模型进行 SFT->RL->SFT->RL 四步训练而成。我们同时还发布了 Sky-T1-mini,这个模型是在 DeepSeek-R1-Distill-Qwen-7B 模型基础上使用简单的强化学习(RL)训练得到的,在流行的数学基准测试上接近 OpenAI o1-mini 的性能水平。我们进行了一系列消融实验,研究了 SFT 数据规模、RL 规模以及模型在 SFT 和 RL 后的 pass@k 性能。我们观察到,长链条 CoT SFT 通常可以提升模型的 pass@k 性能,而 RL 则提高了模型在较低生成预算下(即 pass@1)的性能,但有时会以牺牲解决方案的熵为代价。
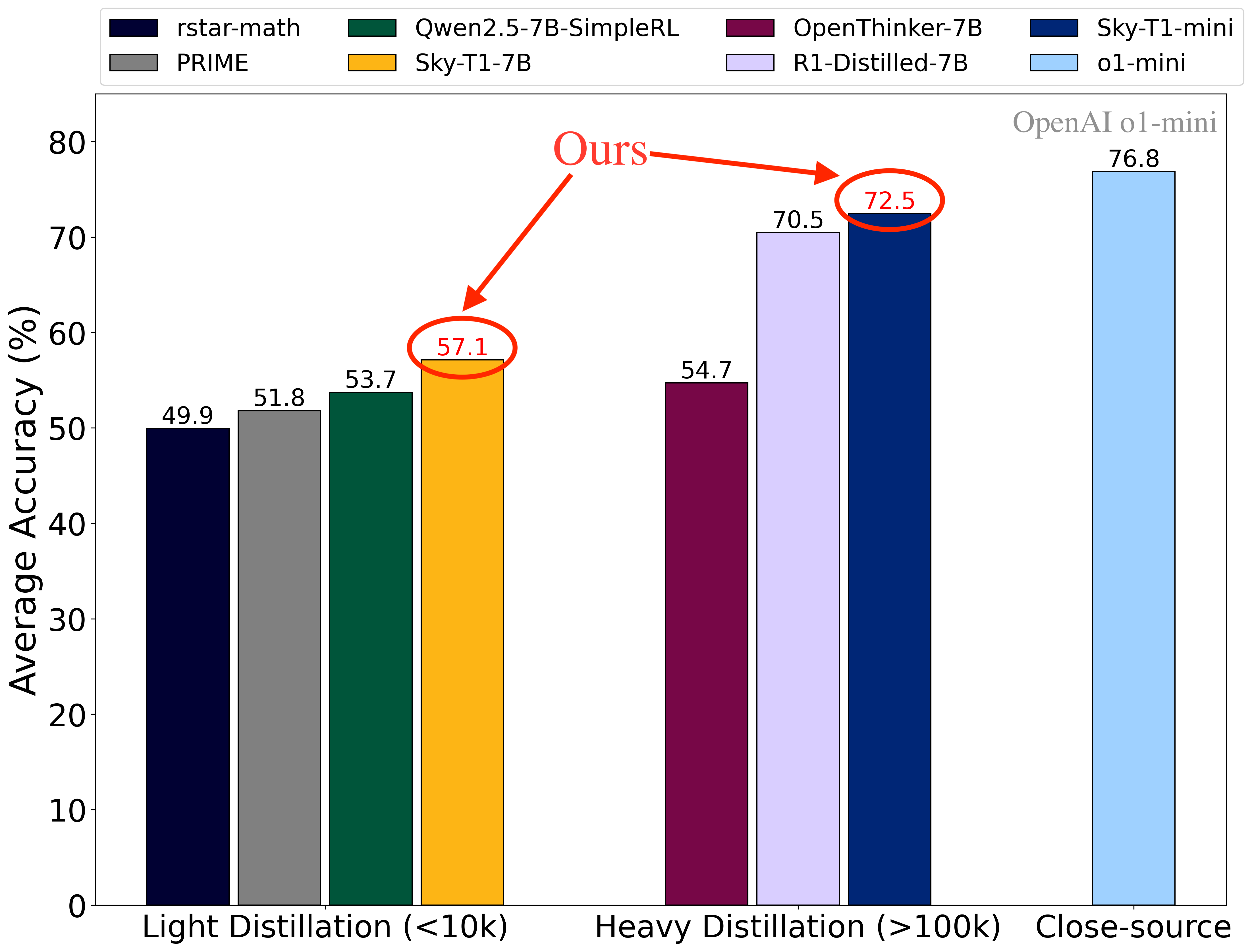
图 1: 不同模型在四个流行数学推理任务(AIME24, AMC23, MATH500 和 OlympiadBench)上的平均准确率。Sky-T1-7B 在使用不到 1 万个从强教师推理模型中蒸馏的样本训练的 7B 模型中展示了 SOTA 性能(左 4 个柱),而 Sky-T1-mini 在所有开源 7B 模型中达到了 SOTA 性能,包括那些使用超过 10 万个从强教师推理模型中蒸馏的样本训练的模型(第 5-7 个柱)。*对于 rstar-math 和 Qwen2.5-7B-SimpleRL,由于模型权重未开源,我们直接使用他们报告的数据。
主要贡献
在这篇博文中:
- 我们展示了 RL 可以显著提升小型模型的推理分数:
- 我们展示了一个使用 RL 和 SFT 从 Qwen2.5-Math-7B 基础模型训练 Sky-T1-7B 的方法,只使用了 5k 从强教师模型 QwQ 蒸馏的数据,性能超过了使用超过 10 万个从更强大的教师模型 DeepSeek-R1 蒸馏的数据训练的模型(如使用 11.7 万个 R1 响应训练的 OpenThinker-7B)。
- 其次,我们展示了简单的 RL 可以进一步提升当前 SOTA 的 7B 推理模型 DeepSeek-R1-Distill-Qwen-7B 的能力,得到了新的 SOTA 开源 7B 推理模型 Sky-T1-mini,性能接近 o1-mini。训练使用 8 个 H100 GPU,耗时 36 小时,根据 Lambda Cloud 定价约为 870 美元。
- 我们进行了一系列关于 SFT 数据规模、RL 规模和模型 pass@k 性能的消融研究。我们观察到长链条 CoT SFT 通常可以提升模型的 pass@k 性能,而 RL 则提高了模型在较低生成预算下(即 pass@1)的性能,但有时会以牺牲解决方案的熵为代价。
为了促进社区进展,我们开源了所有成果,包括训练代码、训练方法、模型权重和评估脚本:
- Github:用于数据生成、SFT、强化学习训练和评估的代码。
- HuggingFace:包含模型检查点、最终模型权重和用于 Sky-T1-7B 和 Sky-T1-mini 的数据集的 Huggingface 集合。
Sky-T1-7B – 通过 4 步 SFT 和 RL 训练

表 1: 4 步训练流程中中间模型的基准性能。与基础模型相比,最终模型在各项指标上都取得了显著提升:AIME24 提升 10.4%,MATH500 提升 33.2%,AMC23 提升 36.8%,OlympiadBench 提升 32.1%,平均提升 21.1%。
步骤 1: SFT
我们使用 QwQ 模型生成蒸馏数据,因为该模型是在 DeepSeek R1 发布之前训练的,当时 QwQ 是唯一开源的长推理模型。对于数据混合,我们使用 GPT-4o-mini 根据 AoPS 标准对提示的难度进行分类,选择了 NUMINA 数据集中难度高于 3 级的数学问题、难度高于 8 级的奥林匹克题目以及所有 AIME/AMC 问题。然后,我们通过仅接受与标准答案匹配的解决方案进行拒绝采样。总共,我们整理了 5K 个来自 QwQ 的响应。
最后,我们使用这 5K 个响应,采用 Sky-T1 系统提示对 Qwen2.5-Math-7B 进行 SFT。我们训练了 3 个 epoch,使用 1e-5 的学习率和 96 的批次大小。完成这个阶段后,我们得到了 Sky-T1-7B-Step1 模型。
步骤 2: RL
接下来,我们应用 PRIME 的算法。我们使用 Eurus-2-RL-Data 进行 RL 训练,使用 256 的批次大小运行了 127 步(约 30K 数据)。对于每个提示,我们生成 4 个 rollout,并采用 PRIME 提出的提示过滤优化,过滤掉所有 4 个 rollout 都正确或错误的问题。完成这个阶段后,我们得到了 Sky-T1-7B-Step2 模型。这个阶段在 8 个 H100 GPU 上运行了大约 44 小时。
正如 DeepSeek-V3 技术报告 第 5.1 节所建议的,通过 SFT 和 RL 训练的模型可以作为高质量的数据生成器。因此,我们对 Sky-T1-7B-Step2 生成的轨迹进行另一轮蒸馏和拒绝采样,并使用与步骤 1 相同的数据混合方式整理了 5k SFT 样本。我们使用这 5k 样本对 Qwen2.5-Math-7B 进行微调,得到了 Sky-T1-7B-Step2-5k-distill 模型。令人惊讶的是,该模型在 4 个基准测试中保持了与 Sky-T1-7B-Step2 相似甚至更好的性能,与使用 5k QwQ 轨迹微调的模型相比,展示了极高的数据效率。
步骤 3: 再次 SFT
结合步骤 2 中从 Sky-T1-7B-Step2 蒸馏的 5K 数据和步骤 1 中从 QwQ 蒸馏的 5K 数据,我们对 Qwen2.5-Math-7B 基础模型进行另一轮 SFT。同样地,我们训练了 3 个 epoch,使用 1e-5 的学习率和 96 的批次大小。然后我们得到了 Sky-T1-7B-step3 模型。
步骤 4: 再次 RL
在这个阶段,为了加速 RL 训练,我们采用了简单的 RLOO 算法,不使用提示过滤和处理奖励模型。我们使用 Eurus-2-RL-Data 中的 numina_amc_aime 和 numina_olympiads 子集。我们使用 256 的批次大小运行了 59 步(约 15K 数据)。对于每个提示,我们生成 8 个 rollout。我们最终得到 Sky-T1-7B 作为最终模型。
评估
为了保证可重复性,我们使用 Qwen 的数学评估套件 进行所有评估。对于 AIME24 和 AMC23,由于它们分别只有 30 和 40 个问题,我们通过对每个问题采样 8 次(温度为 0.6,top-p 采样概率为 0.95)来评估其性能,然后计算 pass@1(计算脚本也在 这里 提供)。对于 MATH500 和 OlympiadBench,我们使用贪婪解码。
结果
我们在表 1 中报告了每个阶段后模型的基准结果以及中间蒸馏模型的结果。我们还绘制了模型的 pass@k 曲线,以更好地理解每个 SFT 和 RL 阶段如何影响模型的内部能力。为了比较,我们进行了另一个消融实验,直接在 Qwen2.5-Math-7B 基础模型上使用 STILL3 数据集运行 RLOO,每个提示生成 4 个 rollout。我们训练了 104 步,最终得到 Sky-T1-7B-Zero 模型。
如图 2 所示,长链条 CoT SFT 显著提高了模型在 AIME24 和 AMC23 上的整体 pass@k 性能。在 AMC 中,两阶段 RL 主要提升了 pass@1 准确率,同时减少了 k = 4 到 32 时解决方案的多样性。在 AIME 中,步骤 4 的 RL 相比步骤 1 的 SFT 和步骤 2 的 RL 进一步提升了整体 pass@k,尽管其影响相比 Sky-T1-7B-Zero 不那么显著。
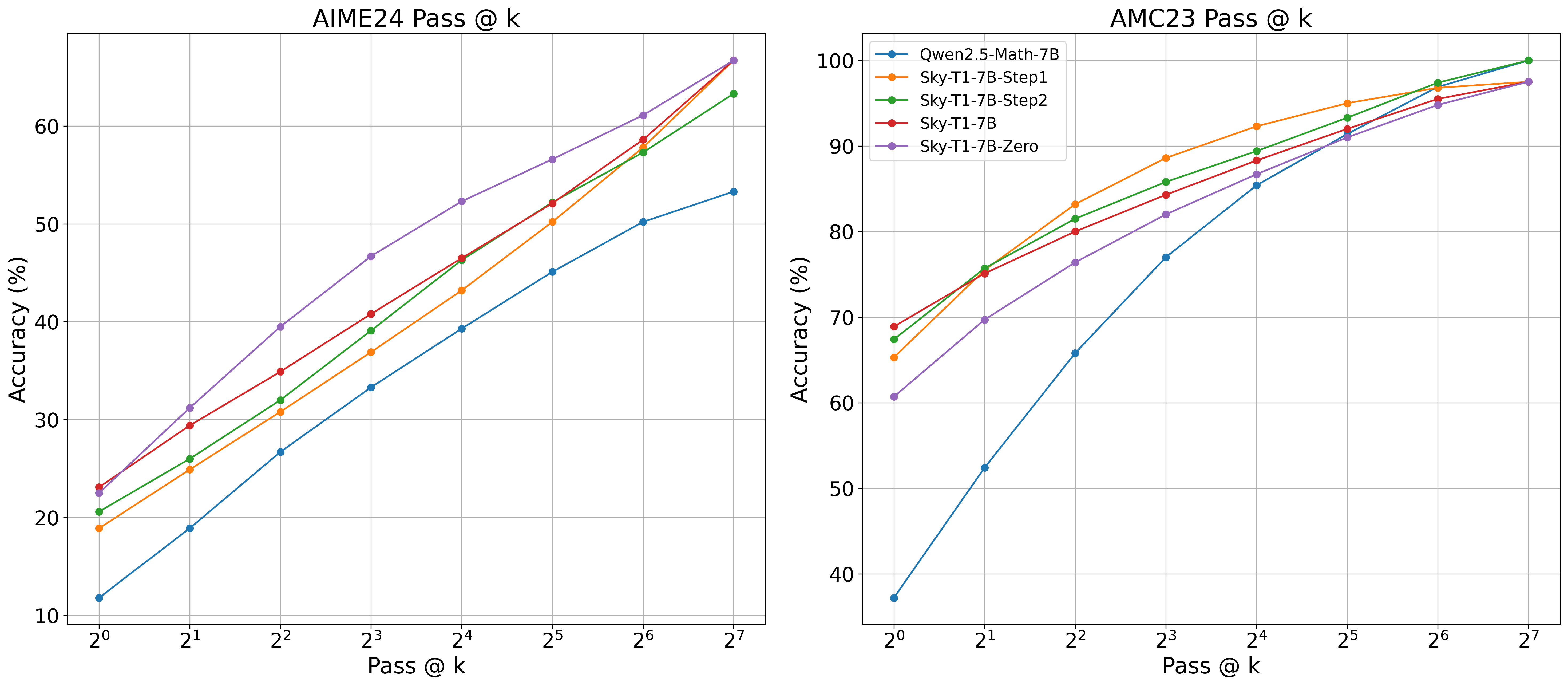
图 2: AIME24 和 AMC23 上每个步骤后训练的模型的 Pass@K 曲线。
Sky-T1-mini – 简单的 RL 提升性能
在开发 Sky-T1-7B 的过程中(该模型是在 DeepSeek R1 发布之前训练的),我们发现不使用过程奖励模型(PRM)的简单 RL 算法也能很好地提升模型性能。因此,我们还使用简单的 RLOO 算法,仅使用验证器奖励,在当前 SOTA 的开源 7B 推理模型 DeepSeek-R1-Distill-Qwen-7B 上进行训练。我们使用了 STILL3 数据集以及 Eurus-2-RL-Data 中的 numina_amc_aime 和 numina_olympiads 子集。
在 8 个 H100 GPU 上:
- 首先使用 8k 的截断长度运行了 119 步(约 28 小时),批次大小为 256(约 30k 数据)
- 然后使用 16k 的截断长度运行了 29 步(约 8.7 小时)
最终模型 Sky-T1-mini 在四个数学基准测试中接近 o1-mini 的性能,如图 3 所示。尽管我们只用截断上下文进行了短期训练(我们也没有仔细选择算法和数据混合),准确率的提升仍然令人印象深刻:AIME 提升 4%,OlympiadBench 提升 5.6%,平均提升 2%,展示了 RL 在蒸馏之外进一步提升模型性能的潜力。
完整结果
图 3: Sky-T1-7B 和 Sky-T1-mini 在 AIME23、AMC23、MATH500 和 OlympiadBench 上的准确率,与其他 7B 模型的比较。
其他观察
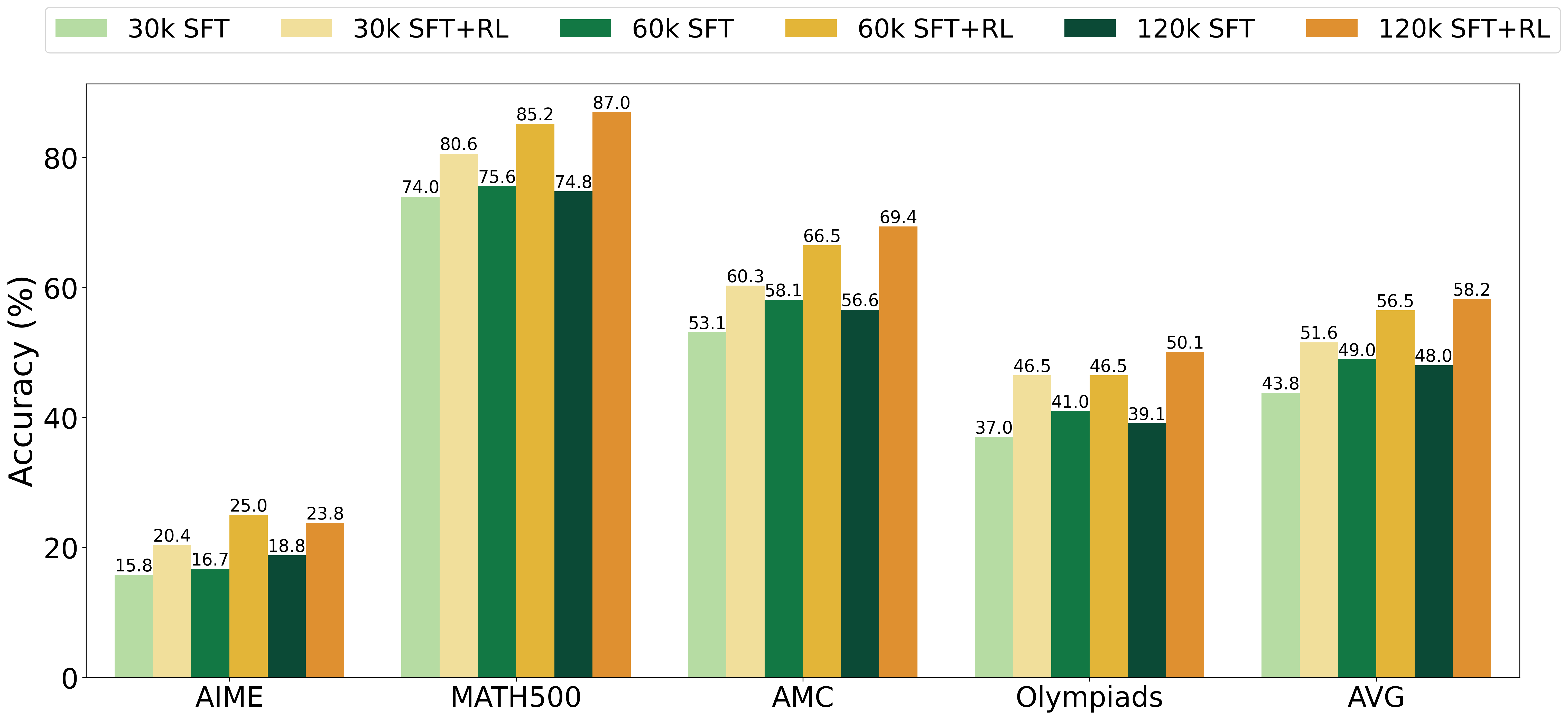
图 4: 使用不同规模 SFT 数据训练的模型以及经过 RL 进一步增强的模型的基准性能。
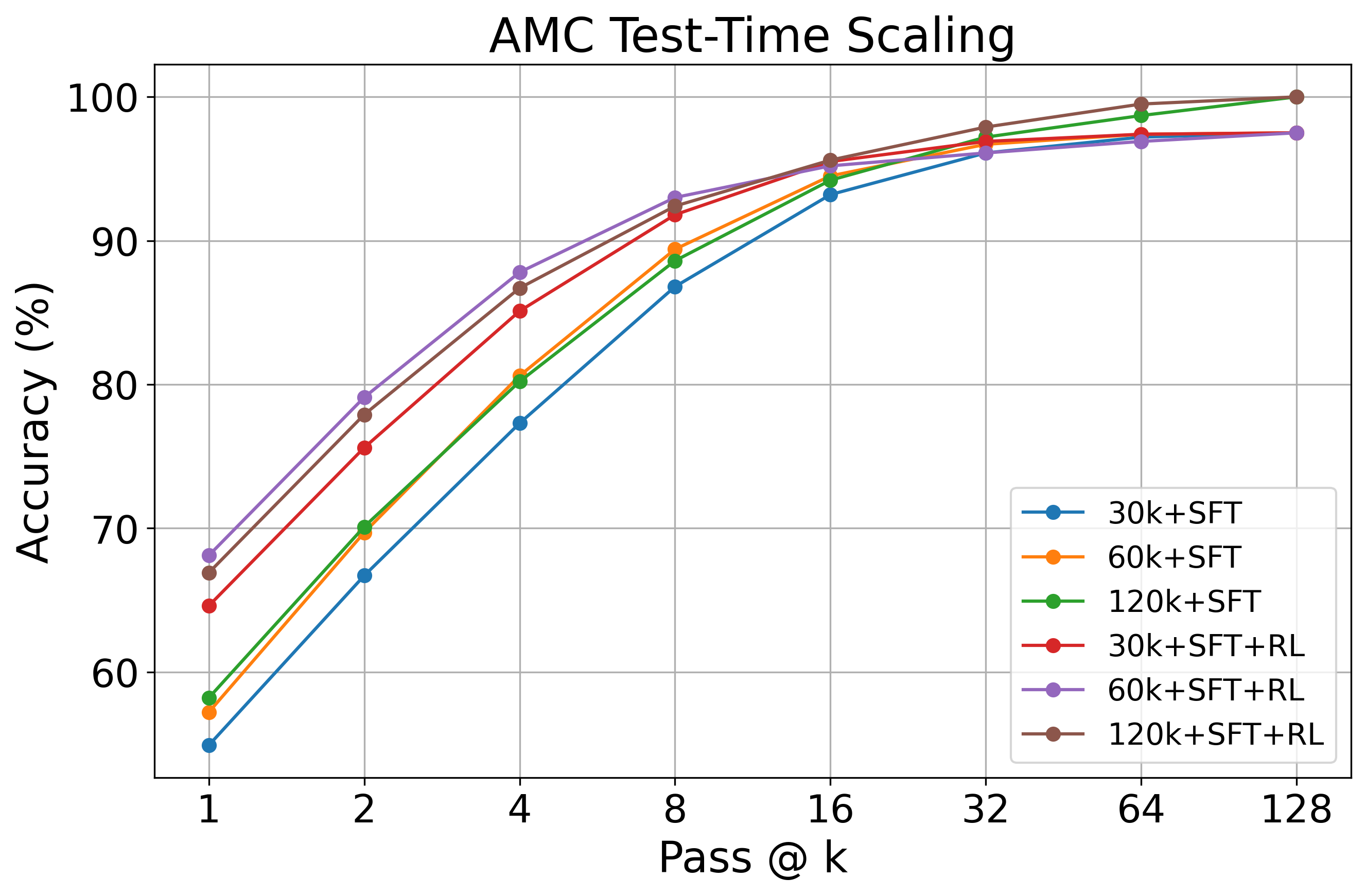
图 5: 使用不同规模 SFT 数据训练的模型以及经过 RL 进一步增强的模型在 AMC23 上的通过@K 曲线。
为了评估长链条 CoT SFT 数据规模的影响,我们将 QwQ 轨迹从 30k 扩展到 60k 再到 120k。我们在图 4 和图 5 中分别报告了经过 SFT 训练和进一步通过 RL 增强的模型的基准性能和 AMC 通过@k 曲线。这里的 RL 训练采用简单的 RLOO 算法,使用 STILL3 数据集,每个提示生成 4 个 rollout。
从图 4 所示的基准性能图来看,虽然 SFT 能够实现从 30k 到 60k 的扩展,但超过这个点后其效果就趋于平稳。相比之下,进一步通过 RL 训练的模型继续从增加的数据中受益,在扩展到 120k 时展示了进一步的改进。这突出表明了 RL 在有效利用额外 SFT 训练数据方面的重要性。
如图 5 所示,在通过@k 评估中也出现了类似的模式。当数据从 30k 扩展到 60k 和 120k 时,SFT 和 RL 都显示了通过@k 准确率的提升,其中 RL 在所有数据规模下始终实现比 SFT 更好的测试时间扩展。与从 30k 扩展到 60k 相比,从 60k 扩展到 120k 的改进对 SFT 和 RL 都不那么显著。
这个图还表明,RL 主要通过提高较低生成预算(即较小的 k)下的通过@k 准确率来提高效率,有效地提升性能而无需过度采样。然而,这可能会以牺牲解决方案的熵为代价 – 在大量并行采样时获得的收益较少。
结论
在这篇博文中,我们展示了 RL 可以进一步提升轻度或重度蒸馏模型的能力。我们进一步进行了通过@k 实验,以展示 SFT 和 RL 如何影响模型的通过@k 性能。我们观察到,长链条 CoT SFT 通常可以提升模型的通过@k 性能,而 RL 则提高了模型在较低生成预算下(即通过@1)的性能,但有时会以牺牲解决方案的熵为代价。