Sky-T1-32B-Flash:在不牺牲准确性的情况下将推理成本削减50%
思考更少,成就更多:在不牺牲准确性的情况下将推理成本削减50%
我们推出 Sky-T1-32B-Flash,这是一个可以将生成长度减少高达 50% 但保持准确性的推理模型。
我们很高兴推出 Sky-T1-32B-Flash,这是我们更新的推理语言模型,它显著减少了过度思考,在具有挑战性的问题上将推理成本降低了高达57%。
根据 Lambda Cloud 的定价,使用 8xH100 只需 $275 即可完成整个训练方案,同时在数学、编程、科学和通用知识等领域保持了准确性。
为了促进透明度和协作,我们已开源了完整的流程—从数据生成和预处理到偏好优化和评估脚本,并公开提供模型权重和数据。
- Github: 数据生成、响应重写、偏好优化和评估的代码
- Dataset: 10K 偏好对数据集
- HuggingFace: Sky-T1-32B-Flash 模型权重
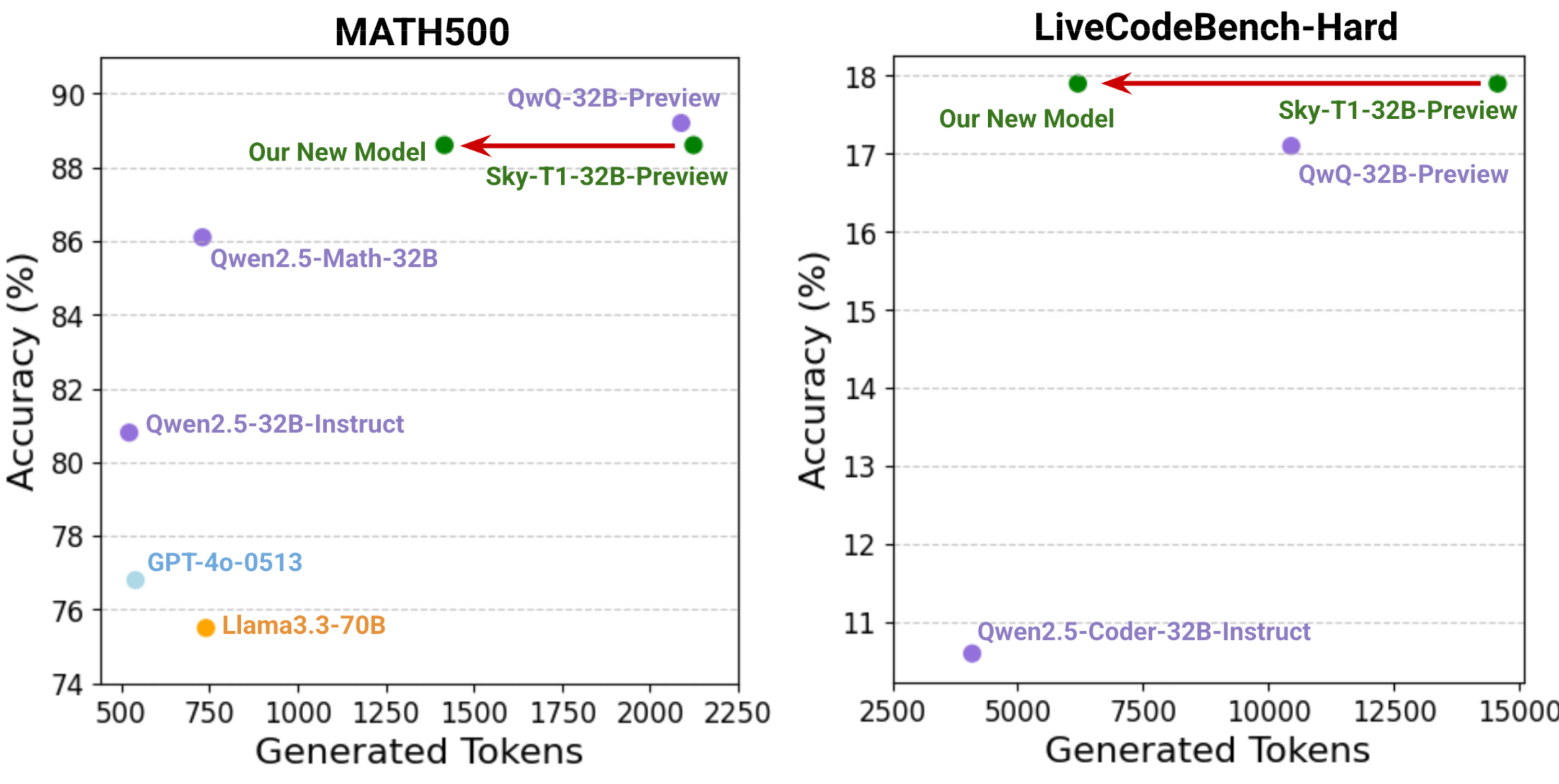
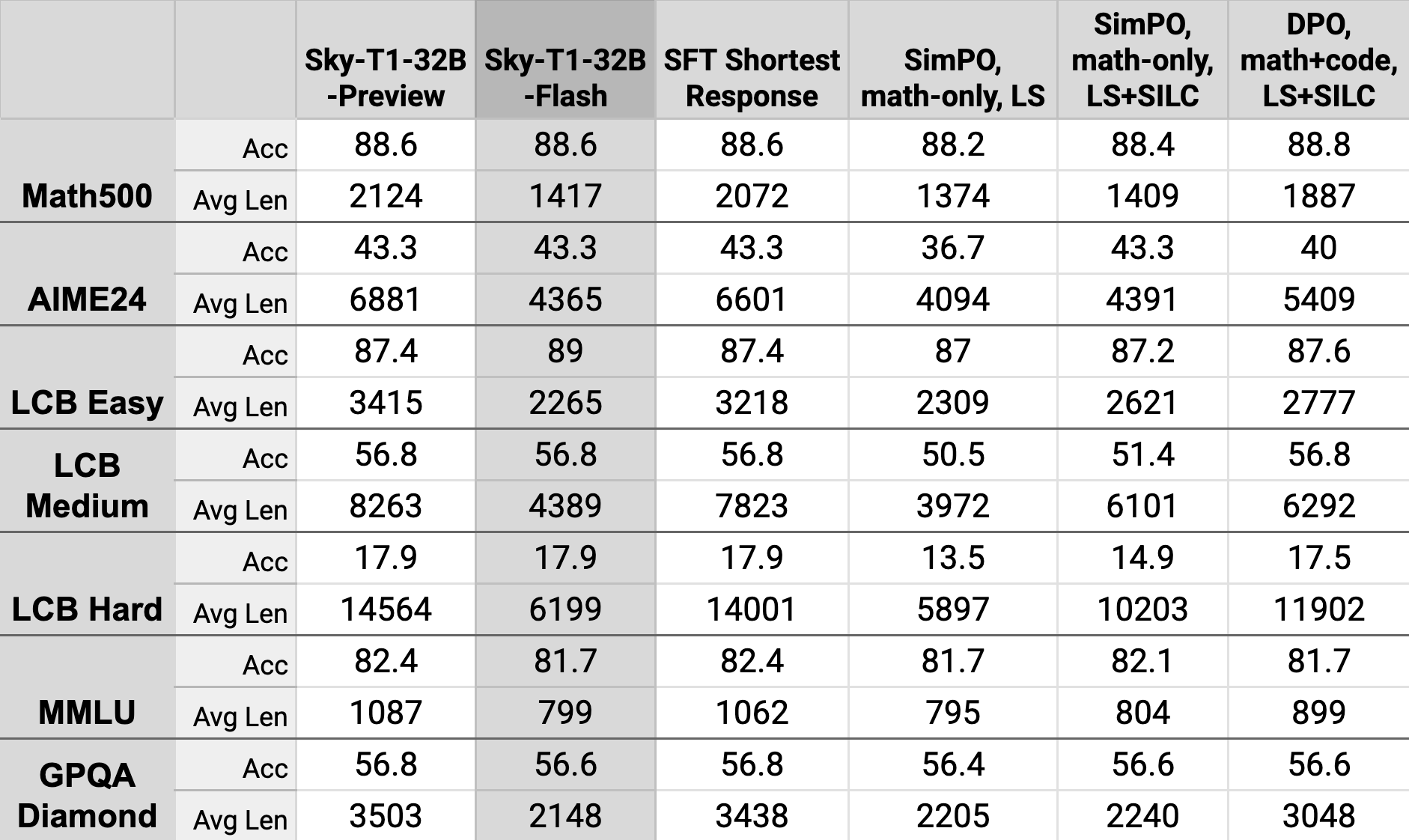
图 1: 我们的新模型显著减少了生成的token长度,同时在具有挑战性的基准测试中保持强劲的性能。
什么是过度思考?
过度思考指的是推理模型倾向于产生不必要的长响应,通常包含冗余或过度的推理步骤。根据最近研究的发现,我们观察到包括 NovaSky 最近发布的 Sky-T1-32B-Preview、QwQ 和 R1 在内的推理模型,经常产生包含多个解决方案的推理序列,每个解决方案后面都跟着复核转换词,如”另外”、”等一下”或”让我重新考虑”。虽然复核可以检测错误并完善解决方案,但它经常对简单或已验证的步骤进行重复验证,造成效率低下。例如,对于”1+1等于多少?”这个问题,Sky-T1-32B-Preview 会生成超过 1000 个 token 和超过 10 个这样的复核转换。
减少过度思考的好处
减少过度思考通过减少冗余或不必要的 token 生成来提高效率和可扩展性。这种改进不仅大大降低了推理模型的推理成本,而且带来了多个下游好处。首先,加快的响应时间提供了更高质量的用户体验。此外,通过更高效的推理,Best-of-N、多数投票或蒙特卡洛树搜索等测试时生成方法可以在固定计算预算内获得更高的准确性。它还简化了自训练流程中的数据生成,这些流程通常受限于大规模数据生成运行。
如何减少过度思考?
我们减少过度思考的方法基于最近研究提出的自训练方案,并进行了重要改进,以提高多个领域具有挑战性基准测试的准确性。减少过度思考的一个挑战是防止模型思考不足,即模型在没有充分验证的情况下就提出最终解决方案。这个挑战在最具挑战性的基准测试中尤为突出,因为这些测试需要广泛的复核和回溯。理想情况下,模型应该学会根据问题的复杂性调整其推理深度。
我们的训练过程包括三个主要阶段:数据生成、响应重写和偏好优化。

阶段 1) 数据生成
我们使用 Sky-T1-32B-Preview 为 PRM800K 数据集中的 12K 个问题生成回答。对于每个问题,我们使用温度参数 1.0 并生成 8 个回答,以创建不同长度的回答。然后,我们形成偏好对来对比”冗长”与”简洁”的解决方案。具体来说,从生成的回答中,我们选择最短的正确回答作为正样本,最长的正确回答作为负样本。我们丢弃了其余的生成回答,并丢弃任何没有产生至少两个正确回答的问题。我们假设对这些偏好对进行优化可以鼓励模型减少过度思考。
在多个基准测试(MATH500、GPQA、MMLU)上,偏好优化减少了生成长度并基本维持了准确性。然而,我们观察到在编程的具有挑战性的问题(LiveCodeBench-Medium 和 -Hard)和最具挑战性的数学套件(AIME24 和 MATH500 Level 5)上准确性有所下降。这些结果表明,模型在需要更复杂推理的情况下思考不足。为了解决这个问题,我们使用初始的每个问题 8 个回答的数据集,向我们的训练数据中添加了 1K 个偏好对,其中负样本是最短的错误回答,正样本是长于负样本的最短正确回答,确保模型在必要时保持深度推理的能力。这种新的数据混合使模型在最具挑战性的数学基准测试上恢复到与 Sky-T1-32B-Preview 相当的水平。
方案改进 #1: 在偏好对数据集中加入{短错误回答,长正确回答},以鼓励模型在具有挑战性的问题上进行复杂思考。
有趣的是,仅使用这个数学数据集进行偏好优化就在编程领域减少了 >25% 的生成长度,同时在 LCB-Easy 上保持准确性。然而,我们观察到在更具挑战性的 LCB-Medium 和 -Hard 基准测试中准确性下降,所以我们在 TACO 数据集上又添加了 500 个由 Sky-T1-32B-Preview 生成的偏好对。我们再次使用温度参数 1.0 生成 8 个回答,并使用最短和最长的正确回答创建偏好对,这使编程性能恢复到 Sky-T1-32B-Preview 的水平。
方案改进 #2: 引入少量编程偏好对同时提升了编程准确性并进一步减少了编程生成长度。
根据 Lambda Cloud 的定价,阶段 1 在 8xH100-80GB 上需要约 8 小时,总计约 $190。
阶段 2) 响应重写
我们通过删除不必要的子解决方案来优化正样本。模型的推理序列通常包含多个提议的解决方案,每个解决方案后面都跟着复核转换词,如”另外…“、”等一下…“或”让我重新考虑…“。对于较简单的问题,这些转换很少导致答案改变,但会显著增加响应长度。受最近研究的启发,我们使用 Llama3.3-70B 分离响应中的解决方案,然后重写响应以仅包含第一个正确的子解决方案(FCS)和一个额外的子解决方案(+1)。这种剪枝方法删除了大部分不必要的子解决方案,减少了正样本的序列长度,但包含一个额外的子解决方案以维持模型的长链式思维推理结构。
参照先前工作,我们还探索了将响应重写为仅包含第一个正确解决方案(FCS)或包含到第二个正确解决方案(FCS+Reflection)的方法,但发现我们的 FCS+1 方法在维持准确性的同时实现了最短的生成长度。对于编程样本,我们没有执行响应重写。我们无法将 FCS+1 方法应用于编程,因为响应几乎从不提出多个完整的代码块作为解决方案,尽管我们认为有机会在编程响应中移除大量冗余。我们已开源响应重写流程,使研究人员能够轻松探索替代方法。
方案改进 #3: 将正例数学样本重写为仅保留第一个正确解决方案和一个额外解决方案(FCS+1)可以维持准确性(与 FCS 不同)并产生更短的生成长度(相对于 FCS+R)。
根据 Lambda Cloud 的定价,阶段 2 在 8xH100-80GB 上需要约 1 小时,总计约 $25。
阶段 3) 偏好优化
我们采用了 SimPO 进行偏好优化。SimPO 与 DPO 密切相关,但在优化方法中加入了长度归一化的隐式奖励,这相对于 DPO 导致更短的序列长度。此外,SimPO 消除了 DPO 所需的参考模型,使偏好优化计算量更小,因此成本更低。作为偏好优化的替代方案,我们还探索了仅使用最短响应进行 SFT,但发现序列长度仅略微减少(<5%)。在消融实验结果中,我们包括了使用与阶段(2)中描述的相同偏好对的 DPO 消融实验,以及使用最短响应的 SFT 消融实验。
我们从 Sky-T1-32B-Preview 作为基础模型开始,使用 SimPO 训练 1 个 epoch,批量大小为 96。我们发现 SimPO 的结果对超参数设置很敏感,并在以下范围内进行了有限探索:学习率 = {1e-7, 5e-7, 1e-6},gamma = {0.3, 0.5, 1.0},beta = {2.0, 2.5}。我们使用学习率 5e-7、gamma 0.3 和 beta 2.0 获得了最佳性能。我们使用 Llama-Factory 进行训练。
根据 Lambda Cloud 的定价,阶段 3 在 8xH100-80GB 上需要约 2.5 小时,总计约 $60。
结果
Sky-T1-32B-Flash 在一系列具有挑战性的基准测试中保持了 Sky-T1-32B-Preview 的准确性,并持续减少了超过 30% 的生成长度。即使在最具挑战性的问题上,如 AIME24 和 LCB-Hard,Sky-T1-32B 分别减少了 37% 和 57% 的序列长度。
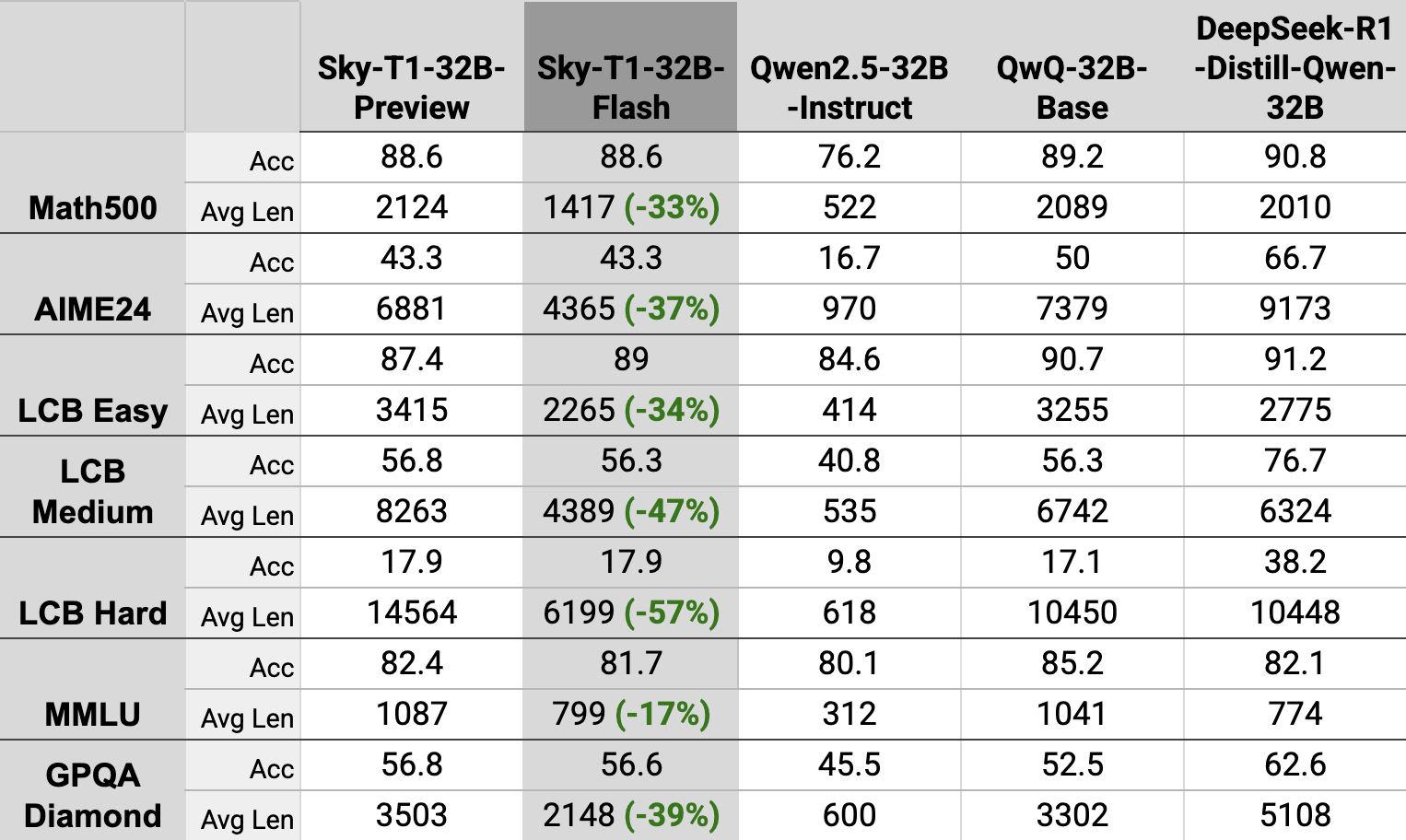
消融实验
我们报告了我们探索的替代方法和方案的消融实验结果。LS 指使用{负样本:Longest 最长正确示例,正样本:Shortest 最短正确示例}偏好对。SILC 指使用{负样本:Short Incorrect 短错误示例,正样本:Long Correct 长正确示例}。