Reader-LM: 用于清理和转换 HTML 到 Markdown 的小型语言模型
Reader-LM
- Google Colab: Reader-LM Tutorial
- jinaai/reader-lm-1.5b
- Reader-LM: Small Language Models for Cleaning and Converting HTML to Markdown
- 专访Jina AI肖涵博士:搜索的未来,藏在一堆小模型里
不能简单地将 HTML 把输入给模型(Reader-LM),因为效果不理想。
Reader-LM-0.5B 和 Reader-LM-1.5B 是受 Jina Reader 启发的两个新型小型语言模型,旨在将来自开放网络的原始、嘈杂的 HTML 转换为干净的 markdown。

使用小型语言模型替换了 readability + turndown + regex 启发式的管道。
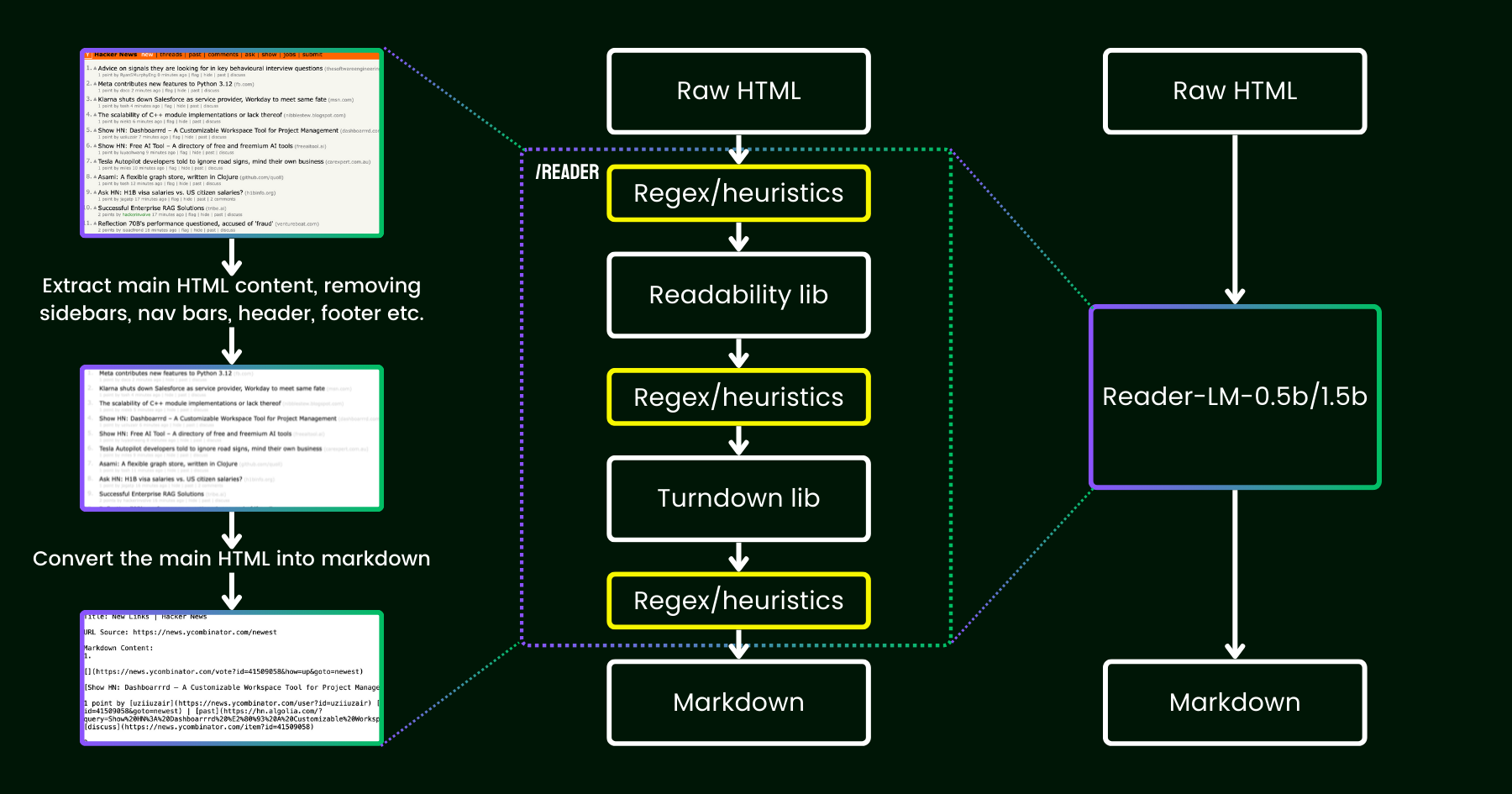
Jina Reader 是一个简单的 API,只需一个简单的前缀:r.jina.ai,就可以将任何 URL 转换为 LLM 友好的 markdown。
Jina Embeddings V3
jina-embeddings-v3 的架构基于 XLM-RoBERTa 模型,并进行了几项关键修改。集成了 FlashAttention 2 以提高计算效率,同时 RoPE 扩展了对最长 8192 个 token 序列的支持。引入了任务特定的 LoRA 适配器,以优化各种任务的 embeddings。模型的输入由两部分组成:文本,即要嵌入的长文档,以及任务类型。jina-embeddings-v3 支持四种任务,并实现了五种适配器可供选择:retrieval.query 和 retrieval.passage 用于非对称检索任务中的查询和段落嵌入,separation 用于聚类和重新排序任务,classification 用于分类任务,text-matching 用于涉及语义相似性的任务,如 STS 或对称检索。
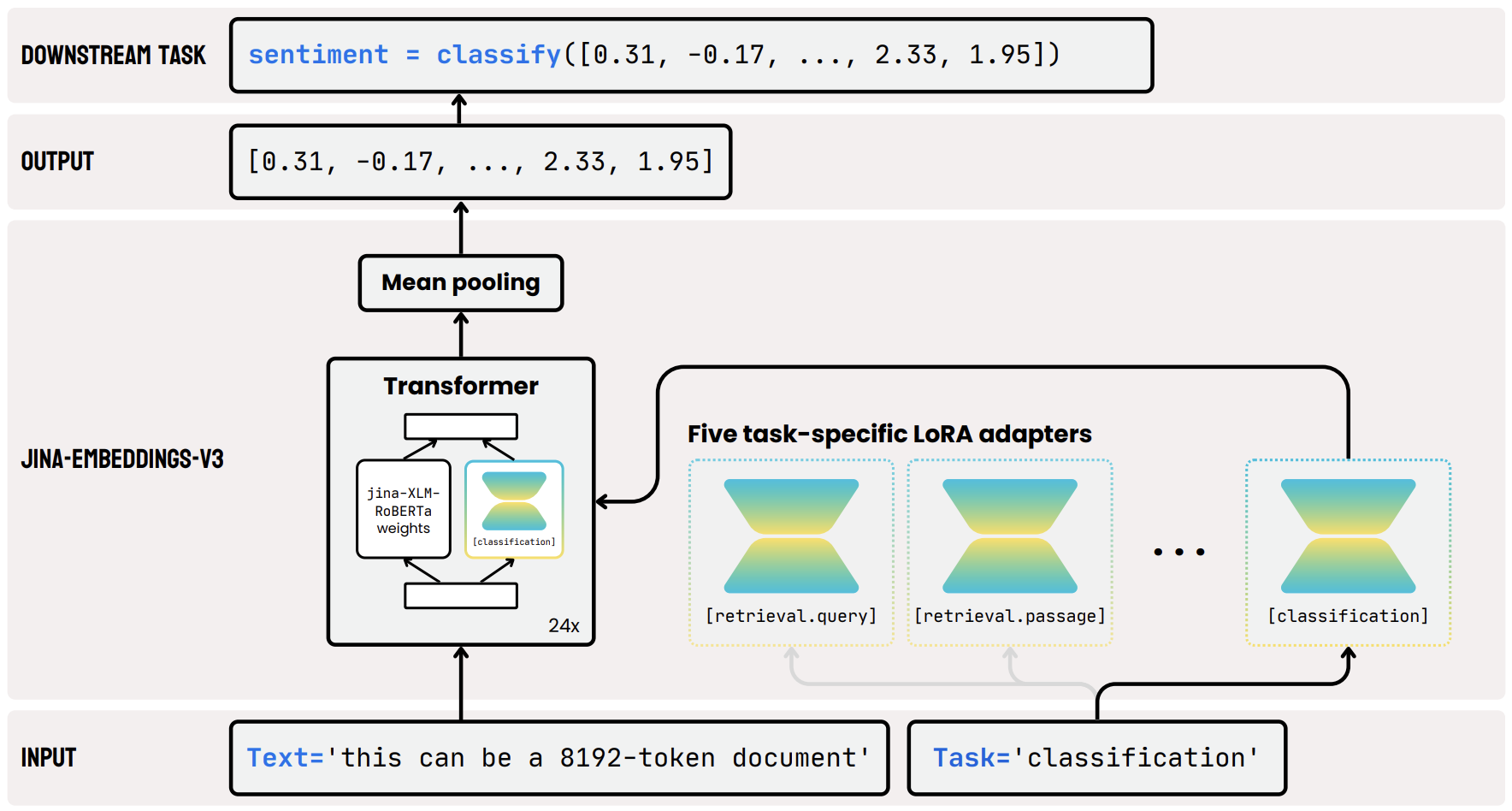
我们在模型中加入了五组针对不同任务的 LoRA Adapter,分别针对 QA 检索,分类,聚类,相似匹配。在推理时,用户可以根据不同的下游任务选择适合自己的 Adapter,这样就保证了输出的 embeddings 永远是最优的。