本文档的专注点是如何将样本从 几千 扩展到 数百万,从而使其可用于 从头开始预训练 LLM。深入研究了创建数据集的方法、提示整编的方法及相应的技术栈。
Cosmopedia 的目的是重现 Phi-1.5 所使用的训练数据。
围绕在 Phi 数据集上的谜团除了我们对其如何创建的不甚了了之外,还有一个问题是其数据集的生成使用的是私有模型。为了解决这些问题,我们引入了 Cosmopedia,这是由 Mixtral-8x7B-Instruct-v0.1 生成的包含教科书、博文、故事、帖子以及 WikiHow 文章等各种体裁的合成数据集。其中有超过 3000 万个文件、250 亿个词元,是迄今为止最大的开放合成数据集。
实际上 Cosmopedia 的大部分时间都花在了细致的提示词工程上了。
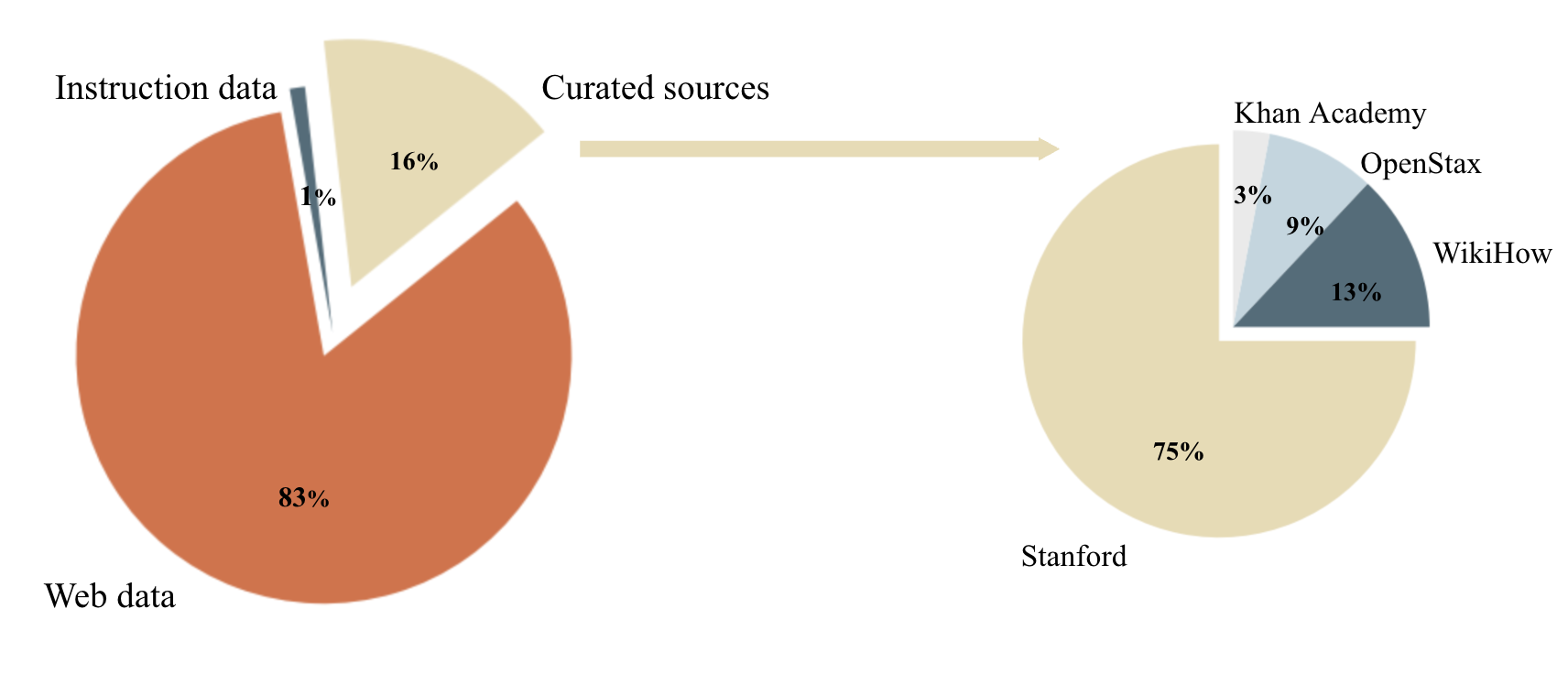
用于构建 Cosmopedia 提示的数据源分布 (左图) 以及“精选源”子集中的源分布 (右图):
为少儿、专业人士和研究人员以及高中生生成相同主题的教科书的提示:

少儿 / 专业人士和研究人员 / 高中生)实践表明,使用网络数据构建提示扩展性最好,Cosmopedia 使用的 80% 以上的提示来自于此。我们使用 RefinedWeb 等数据集将数百万个 Web 样本聚为 145 个簇,并从每个簇中提取 10 个随机样本的内容并要求 Mixtral 找到它们的共同主题以最终识别该簇的主题。
检查了这些簇并排除了任何我们认为教育价值较低的簇,剔除的内容如露骨的成人材料、名人八卦和讣告等。你可于 此处 获取保留和剔除的 112 个主题的完整列表。
AutoMathText 是一个精心设计的数学文本数据集。
网络数据种子样本及其对应提示的示例:

- Web extract/seed sample:
The Cardiovascular BioImaging Core offers the latest echo technology, including real-time three-dimensional (3D) and 4D, and speckle tracking imaging. Real-time 3D and speckle tracking echocardiography are new technologies that give accurate measures of regional and global cardiac function. These technologies rival information obtained by more expensive modalities (like cardiac MRI) and have... (truncated)
- Topic:
Medicine
Prompt:
Here is an extract from
a webpage: "The Cardiovascular BioImaging Core offers the latest echo technology, including real-time three-dimensional (3D) and 4D, and speckle tracking imaging. Real-time 3D and speckle tracking echocardiography are new technologies that give accurate measures of regional and global cardiac function. These technologies rival information obtained by more expensive modalities (like cardiac MRI) and have.. (truncated).".
Write an informative and insightful blog post that expands upon the extract above, within the context of "Medicine".
Your post should delve into the nuances of the topic, offering fresh perspectives and deeper analysis.
Aim to:
- Inform: Provide valuable, well-researched information that educates the reader.
- Engage: Write in a conversational tone that connects with the audience, making complex ideas accessible.
- Illustrate: Use examples, anecdotes, or personal experiences to bring the topic to life. Do not give a title and do not start with sentences like "Have you ever..." or "Hello dear readers..", simply write the content without these introductory phrases.
在我们对生成的合成数据集训得的模型进行初步评估时,我们发现其缺乏小学教育阶段所需的典型常识和基础知识。为了解决这一问题,我们增加了 UltraChat 和 OpenHermes2.5 指令微调数据集作为提示的种子数据。这些数据集涵盖了广泛的主题,如在 UltraChat 中,我们使用了“关于世界的问题”子集,其中涵盖了 30 个关于世界的元概念; 而对另一个多样化且高质量的指令调优数据集 OpenHermes2.5 ,我们跳过了不适合讲故事的来源和类别,例如用于编程的 glaive-code-assist 和用于高级化学的 camala 。下面展示了我们用来生成这些故事的提示示例。
从 UltraChat 和 OpenHermes 样本中构建的用于生成故事的提示 (分别针对少儿、普通受众及 Reddit 论坛):

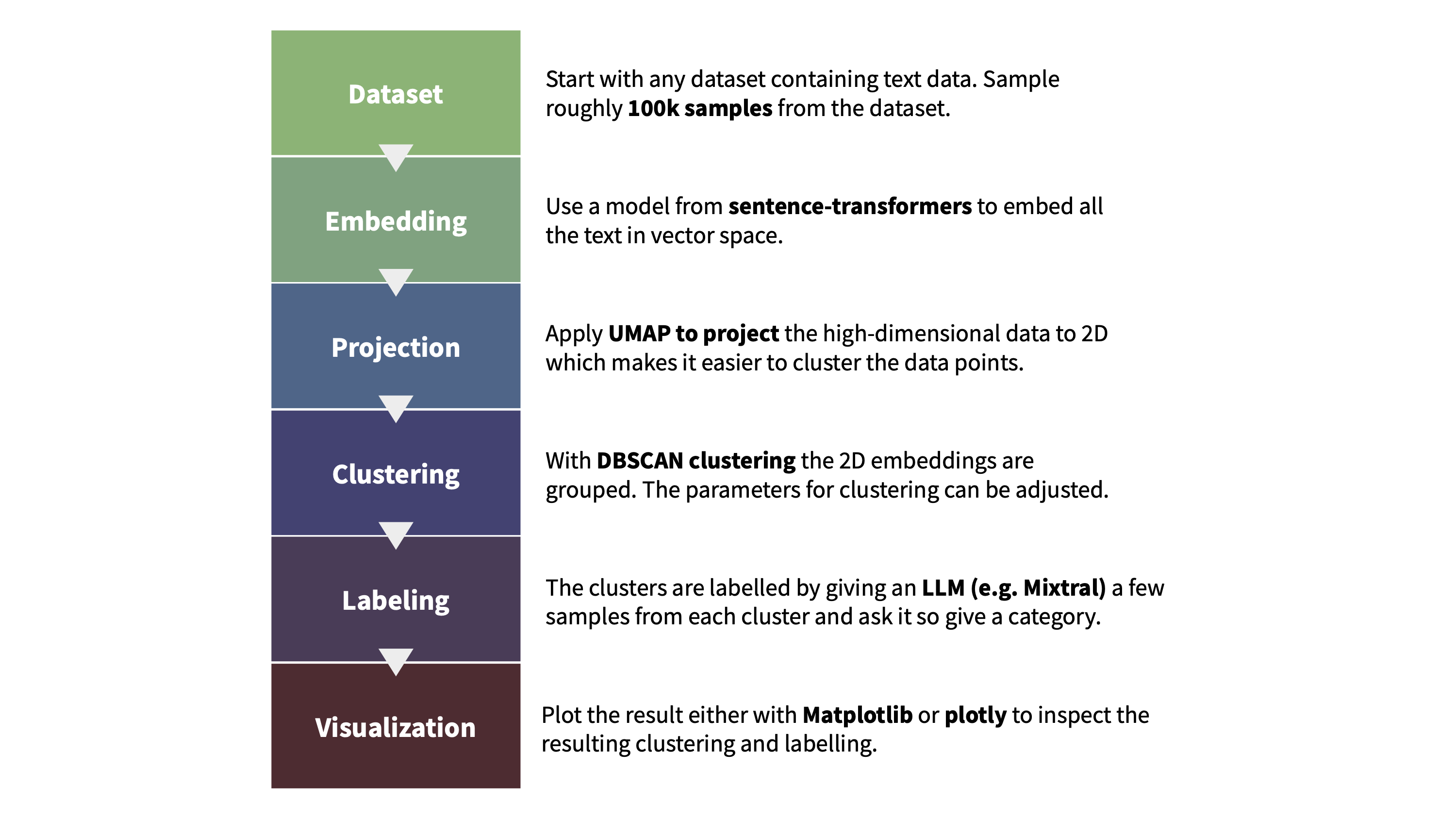
我们使用 text-clustering 代码库来对 Cosmopedia 提示中使用的网络数据进行主题聚类。下图说明了聚类及对生成的簇进行标注的流程。我们还要求 Mixtral 在标注时为簇打一个教育性得分 (满分 10 分) ; 这有助于后面我们进行主题检查。你可以在此 演示 中找到网络数据的每个簇及其得分。
文本聚类的流程:
我们用 llm-swarm 库使用 Mixtral-8x7B-Instruct-v0.1 生成 250 亿个合成内容词元。这是一个可扩展的合成数据生成工具,支持本地 LLM 以及 Hugging Face Hub 上的推理终端。它还支持 TGI 和 vLLM 推理库。我们使用 TGI 在 Hugging Face Science 集群的 H100 GPU 上本地部署 Mixtral-8x7B。生成 Cosmopedia 的总计算时间超过 1 万 GPU 时。
注意: 我们使用 HuggingChat 对提示进行初始迭代。我们使用 llm-swarm 为每个提示生成数百个样本以检查生成的样本是否有异常及其异常模式。比如说,模型在为多个教科书生成了非常相似的介绍性短语,并且经常以相同的短语开头,如“很久很久以前”以及“太阳低垂在天空中”。我们在迭代后的提示中明确要求模型避免这些介绍性陈述并要求其创造性解决问题,基于这些提示,虽然仍会出现上述情况,但概率很低。
鉴于种子样本或模型的训练数据中可能存在基准污染,我们实现了一个净化流水线,以确保我们的数据集不含测试基准中的任何样本。
与 Phi-1 类似,我们使用 10 词元重叠率来识别潜在污染的样本。从数据集中检索到候选样本后,我们使用 difflib.SequenceMatcher 将其与基准样本进行比较。如果 len(matched_substrings) 与 len(benchmark_sample) 的比率超过 0.5,我们将丢弃该样本。我们对 Cosmo-1B 模型所有评估基准都实施了此净化,包括 MMLU、HellaSwag、PIQA、SIQA、Winogrande、OpenBookQA、ARC-Easy 以及 ARC-Challenge。
我们用 datatrove 进行数据去重及分词,用 nanotron 进行模型训练,用 lighteval 进行评估。
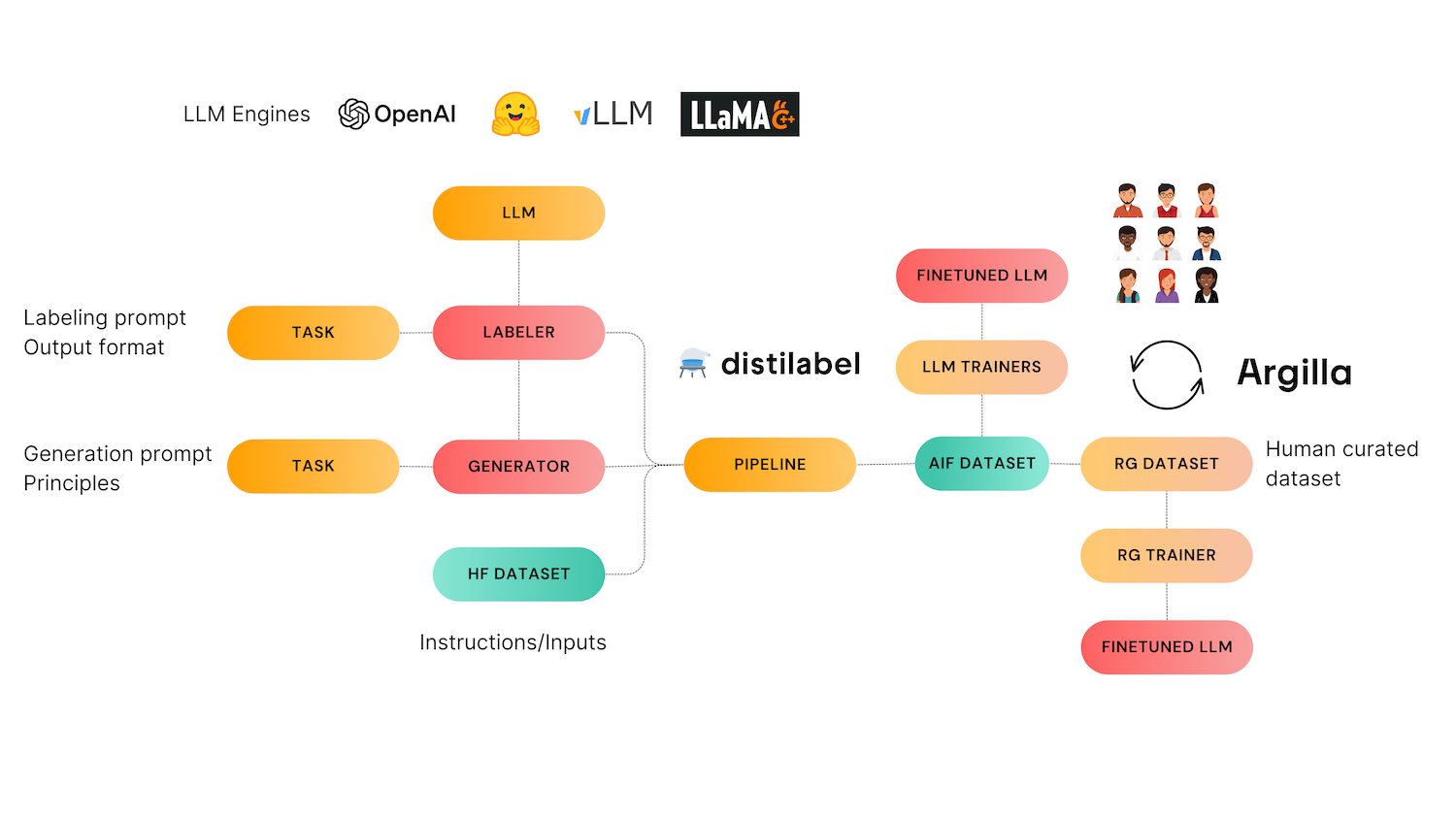
Distilabel 是一个合成数据和 AI 反馈框架,为需要基于经过验证的研究论文的快速、可靠和可扩展的管道的工程师提供支持。
Argilla 是一个协作工具,用于 AI 工程师和领域专家构建高质量的数据集。