Qwen2 Technical Report
Abstract(摘要)
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning.
本报告介绍了Qwen2系列,这是我们大型语言模型和大型多模型模型的最新成员。我们发布了一套全面的基础和指导调整的语言模型,涵盖了从0.5到720亿的参数范围,包括密集模型和专家混合模型。Qwen2超越了大多数先前的开放权重模型,包括其前身Qwen1.5,并在语言理解、生成、多语言熟练度、编码、数学和推理等多个基准测试中表现出色。
The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach.
旗舰模型Qwen2-72B展示了卓越的性能:在MMLU上为84.2,在GPQA上为37.9,在HumanEval上为64.6,在GSM8K上为89.5,在BBH上为82.4,作为基础语言模型。指导调整的变体Qwen2-72B-Instruct在MT-Bench上达到9.1,在Arena-Hard上达到48.1,在LiveCodeBench上达到35.7。此外,Qwen2展示了强大的多语言能力,精通约30种语言,涵盖英语、中文、西班牙语、法语、德语、阿拉伯语、俄语、韩语、日语、泰语、越南语等,突显了其多功能性和全球覆盖范围。
To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.
为了促进社区创新和可访问性,我们已经在Hugging Face和ModelScope上公开提供了Qwen2模型权重,以及在GitHub上包括示例代码在内的补充材料。这些平台还包括量化、微调和部署资源,促进了广泛的应用和研究工作。
Introduction(介绍)
Following the emergence of ChatGPT (OpenAI, 2022), enthusiasm for large language models (LLMs) has escalated globally. The release of the Llama series (Touvron et al., 2023) has further ignited interests within the open-source community, particularly regarding GPT-level local LLMs. Recently, Claude-3 Opus (Anthropic, 2024) and GPT-4o (omni) (OpenAI, 2024), the updated model for ChatGPT, have ascended to the pinnacle of the Chatbot Arena (Chiang et al., 2024) in quick succession. This platform is well-regarded for its human evaluations of LLMs. Moreover, Llama3 (AI@Meta, 2024) has emerged as the state-of-the-art open-weight model series, narrowing the performance gap with leading proprietary models and widely acknowledged as GPT-4–level. An increasing number of competitive LLMs are now pursuing advancements similar to those made by the GPT series from OpenAI. Many of these models, including Qwen (Bai et al., 2023a), Mistral (Jiang et al., 2023a), Gemma (Mesnard et al., 2024), etc., have been released in an open-weight manner.
随着ChatGPT(OpenAI,2022)的出现,全球对大型语言模型(LLMs)的热情不断升温。Llama系列(Touvron等,2023)的发布进一步激发了开源社区的兴趣,特别是对GPT级别的本地LLMs。最近,Claude-3 Opus(Anthropic,2024)和GPT-4o(omni)(OpenAI,2024),ChatGPT的更新模型,相继登上了Chatbot Arena(Chiang等,2024)的巅峰。这个平台以其对LLMs的人类评估而闻名。此外,Llama3(AI@Meta,2024)已成为最先进的开放权重模型系列,缩小了与领先专有模型的性能差距,并被广泛认为是GPT-4级别。现在,越来越多的竞争性LLMs正在追求类似于OpenAI的GPT系列所取得的进步。其中许多模型,包括Qwen(Bai等,2023a)、Mistral(Jiang等,2023a)、Gemma(Mesnard等,2024)等,以开放权重的方式发布。
Over recent months, we have successively introduced the Qwen series (Bai et al., 2023a) and progressed to Qwen1.5 (Qwen Team, 2024a). In the meantime, we have unveiled the vision-language model Qwen-VL (Bai et al., 2023b), and launched the audio-language model Qwen-Audio (Chu et al., 2023). In this work, we introduce the newest addition to the Qwen family of large language models and large multimodal modles: Qwen2. Qwen2 is a series of LLMs, grounded in the Transformer architecture (Vaswani et al., 2017), trained using next-token prediction. The model series encompasses foundational, i.e., base language models, pre-trained but unaligned to human preferences, and instruction-tuned models, fine-tuned with single-turn and multi-turn instruction-following datasets suitable for chat and agent purposes. Our release comprises four dense models with parameter counts of 0.5 billion, 1.5 billion, 7 billion, and 72 billion, plus a Mixture-of-Experts (MoE) model with 57 billion parameters, of which 14 billion are activated for each token. The smaller models, specifically Qwen2-0.5B and Qwen2-1.5B, are designed for easy deployment on portable devices such as smartphones, earphones, and smart glasses. Conversely, the larger models cater to deployment across GPUs of varying scales.
在过去的几个月里,我们已经相继推出了Qwen系列(Bai等,2023a),并发展到了Qwen1.5(Qwen团队,2024a)。与此同时,我们揭示了视觉语言模型Qwen-VL(Bai等,2023b),并推出了音频语言模型Qwen-Audio(Chu等,2023)。在这项工作中,我们介绍了Qwen大型语言模型和大型多模型模型家族的最新成员:Qwen2。Qwen2是一系列LLMs,基于Transformer架构(Vaswani等,2017),使用下一个标记预测进行训练。该模型系列包括基础模型,即基础语言模型,经过预训练但未对齐到人类偏好,以及指令调整模型,使用适用于聊天和代理目的的单轮和多轮指令遵循数据集进行微调。我们的发布包括四个密集模型,参数数量分别为0.5亿、1.5亿、7亿和72亿,以及一个专家混合(MoE)模型,参数数量为570亿,其中每个标记激活了140亿。较小的模型,特别是Qwen2-0.5B和Qwen2-1.5B,设计用于在便携设备上部署,如智能手机、耳机和智能眼镜。相反,较大的模型适用于在不同规模的GPU上部署。
All models were pre-trained on a high-quality, large-scale dataset comprising over 7 trillion tokens, covering a wide range of domains and languages. Compared to previous editions of Qwen, Qwen2 includes a broader spectrum of linguistic data, enhancing the quantity and quality of code and mathematics content. This enrichment is hypothesized to improve reasoning abilities of LLMs. Regarding post-training, all models underwent supervised fine-tuning and direct preference optimization (DPO, Rafailov et al., 2023), aligning them with human preferences through learning from human feedback. This process endows the models with the capability to follow instructions effectively.
所有模型都在一个高质量、大规模的数据集上进行了预训练,该数据集包含超过7万亿个标记,涵盖了广泛的领域和语言。与以前的Qwen版本相比,Qwen2包括更广泛的语言数据,增强了代码和数学内容的数量和质量。这种丰富性被假设可以提高LLMs的推理能力。关于后训练,所有模型都经过了监督微调和直接偏好优化(DPO,Rafailov等,2023),通过从人类反馈中学习,使它们与人类偏好保持一致。这个过程赋予了模型有效地遵循指令的能力。
We have conducted a thorough evaluation of Qwen2, alongside a selection of baseline models including both open-weight and proprietary models accessible via API. Qwen2 outperforms competing models in evaluations of both fundamental language capabilities and instruction-tuned functionalities Specifically, Qwen2-72B-Instruct, our instruction-tuned variant, scores 9.1 on MT-Bench (Zheng et al., 2023), 48.1 on Arena-Hard (Chiang et al., 2024), and 35.7 on LiveCodeBench (Jain et al., 2024). Meanwhile, Qwen2-72B, the base language model, achieves 84.2 on MMLU (Hendrycks et al., 2021a), 37.9 on GPQA (Rein et al., 2023), 64.6 on HumanEval (Chen et al., 2021), 89.5 on GSM8K (Cobbe et al., 2021), and 82.4 on BBH (Suzgun et al., 2023).
我们对Qwen2进行了彻底的评估,同时还选择了一些基线模型,包括通过API访问的开放权重和专有模型。Qwen2在基本语言能力和指令调整功能的评估中优于竞争模型。具体来说,我们的指令调整变体Qwen2-72B-Instruct在MT-Bench(Zheng等,2023)上得分为9.1,在Arena-Hard(Chiang等,2024)上得分为48.1,在LiveCodeBench(Jain等,2024)上得分为35.7。与此同时,基础语言模型Qwen2-72B在MMLU(Hendrycks等,2021a)上达到84.2,在GPQA(Rein等,2023)上达到37.9,在HumanEval(Chen等,2021)上达到64.6,在GSM8K(Cobbe等,2021)上达到89.5,在BBH(Suzgun等,2023)上达到82.4。
2 TOKENIZER & MODEL(分词器和模型)
This section introduces the tokenizer and model design of Qwen2. We detail the model architecture and configurations for different model sizes.
本节介绍了Qwen2的分词器和模型设计。我们详细介绍了不同模型大小的模型架构和配置。
2.1 TOKENIZER(分词器)
Following Qwen (Bai et al., 2023a), we employ the identical tokenizer based on byte-level byte-pair encoding. Notably, this tokenizer exhibits high encoding efficiency, as evidenced by its better compression rate relative to alternatives, facilitating the multilingual capabilities of Qwen2.
与Qwen(Bai等,2023a)一样,我们使用基于字节级字节对编码的相同分词器。值得注意的是,这个分词器表现出很高的编码效率,这一点可以通过它相对于其他替代方案的更好的压缩率得到证实,从而促进了Qwen2的多语言能力。
Models of all sizes employ a common vocabulary consisting of 151,643 regular tokens and 3 control tokens. For more information, please refer to Bai et al. (2023a). It should be noted that, owing to considerations in distributed training, the effective size for the embeddings is larger.
所有大小的模型都使用一个由151,643个常规标记和3个控制标记组成的通用词汇表。有关更多信息,请参考Bai等人(2023a)。值得注意的是,由于分布式训练的考虑,嵌入的有效大小更大。
2.2 MODEL ARCHITECTURE(模型架构)
The Qwen2 series fundamentally constitute large language models based on the Transformer architecture, featuring self-attention with causal masks (Vaswani et al., 2017). Specifically, this series encompasses dense language models of 4 scales and a Mixture-of-Experts (MoE) model. We introduce the specifics of the dense models before delving into the MoE model’s distinctive attributes.
Qwen2系列基本上是基于Transformer架构的大型语言模型,具有自注意力和因果掩码(Vaswani等,2017)。具体来说,该系列包括4个规模的密集语言模型和一个专家混合(MoE)模型。我们将在深入探讨MoE模型的独特属性之前介绍密集模型的具体内容。
2.2.1 QWEN2 DENSE MODEL(密集模型)
The architecture of the Qwen2 dense models comprises multiple Transformer layers, each equipped with causal attention mechanisms and feed-forward neural networks (FFNs). Key differences from Qwen are described below:
Qwen2密集模型的架构包括多个Transformer层,每个层都配备了因果注意机制和前馈神经网络(FFNs)。与Qwen的主要区别如下:
Grouped Query Attention We adopt Grouped Query Attention (GQA, Ainslie et al., 2023) instead of conventional multi-head attention (MHA). GQA optimizes KV cache usage during inference, significantly enhancing throughput. Detailed KV head configurations for various model sizes are reported in Section 2.2.3.
分组查询注意力 我们采用分组查询注意力(GQA,Ainslie等,2023)代替传统的多头注意力(MHA)。GQA在推理过程中优化了KV缓存的使用,显著提高了吞吐量。各种模型大小的详细KV头配置见第2.2.3节。
Dual Chunk Attention with YARN To expand the context window of Qwen2, we implement Dual Chunk Attention (DCA, An et al., 2024), which segments long sequences into chunks of manageable lengths. If the input can be handled in a chunk, DCA produces the same result as the original attention. Otherwise, DCA facilitates effective capture of relative positional information between tokens within and across chunks, thereby improving long context performance. Moreover, we also employ YARN (Peng et al., 2023) to rescale the attention weights for better length extrapolation.
双块注意力与YARN 为了扩展Qwen2的上下文窗口,我们实现了双块注意力(DCA,An等,2024),将长序列分割成可管理长度的块。如果输入可以在一个块中处理,DCA将产生与原始注意力相同的结果。否则,DCA有助于有效捕获块内和块间标记之间的相对位置信息,从而提高长上下文性能。此外,我们还使用YARN(Peng等,2023)来重新缩放注意力权重,以获得更好的长度外推。
Moreover, we follow Qwen with the usage of SwiGLU (Dauphin et al., 2017) for activation, Rotary Positional Embeddings (RoPE, Su et al., 2024) for positional embedding, QKV bias (Su, 2023) for attention, RMSNorm (Jiang et al., 2023b) and pre-normalization for training stability.
此外,我们遵循Qwen的做法,使用SwiGLU(Dauphin等,2017)进行激活,使用Rotary Positional Embeddings(RoPE,Su等,2024)进行位置嵌入,使用QKV偏置(Su,2023)进行注意力,使用RMSNorm(Jiang等,2023b)和预规范化进行训练稳定性。
2.2.2 QWEN2 MIXTURE-OF-EXPERTS MODEL(专家混合模型)
The architecture of Qwen2 MoE models closely mirrors that of Qwen1.5-MoE-A2.7B (Qwen Team, 2024c). As a substitute for the original FFN, the MoE FFN consists of n individual FFNs, each serving as an expert. Each token is directed to a specific expert Ei for computation based on probabilities assigned by a gated network G:
Qwen2 MoE模型的架构与Qwen1.5-MoE-A2.7B(Qwen团队,2024c)非常相似。作为原始FFN的替代,MoE FFN由n个单独的FFN组成,每个FFN都是一个专家。根据由门控网络G分配的概率,每个标记都被指定给一个特定的专家Ei进行计算:
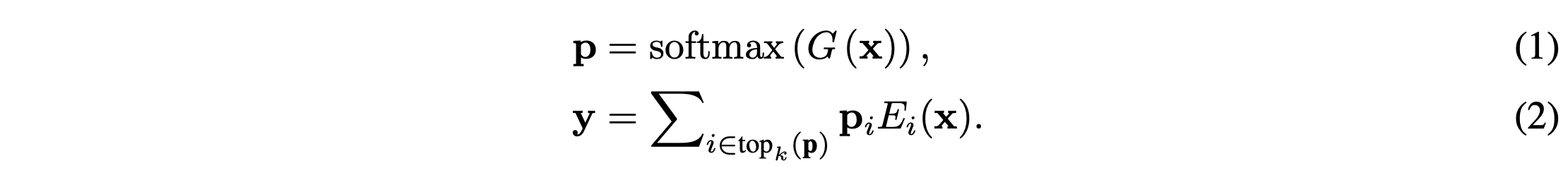
In the following, we present critical design considerations of Qwen2 MoE.
接下来,我们介绍Qwen2 MoE的关键设计考虑。
Expert Granularity The key structural difference between MoE models and dense models is that MoE layers incorporate multiple FFNs, each serving as an individual expert. Consequently, one straightforward strategy to transition from a dense architecture to an MoE architecture is to set the parameters of each expert equal to those of a single FFN from the original dense model. For example, transitioning from Mistral-7B (Jiang et al., 2023a) to Mixtral 8x7B (Jiang et al., 2024), involves activating two of the eight experts at a time. Differently, our model employs fine-grained experts (Dai et al., 2024), creating smaller-scale experts while activating a greater number of experts simultaneously. Given an equal total number of expert parameters and activated parameters, fine-grained experts offer a richer set of expert combinations. By leveraging these fine-grained experts, Qwen2 MoE facilitates more diverse and dynamic expert utilization, thereby enhancing overall performance and adaptability.
专家粒度 MoE模型和密集模型之间的关键结构差异在于MoE层包含多个FFN,每个FFN都是一个独立的专家。因此,从密集架构过渡到MoE架构的一个简单策略是将每个专家的参数设置为原始密集模型中单个FFN的参数。例如,从Mistral-7B(Jiang等,2023a)过渡到Mixtral 8x7B(Jiang等,2024),涉及同时激活八个专家中的两个。不同的是,我们的模型采用了细粒度专家(Dai等,2024),在同时激活更多专家的同时创建小规模专家。在相同的专家参数和激活参数总数的情况下,细粒度专家提供了更丰富的专家组合。通过利用这些细粒度专家,Qwen2 MoE促进了更多样化和动态的专家利用,从而提高了整体性能和适应性。
Expert Routing The design of expert routing mechanisms is crucial for enhancing the performance of MoE models. Recently, there has been a notable trend towards integrating both shared and routing-specific experts within MoE layers (Rajbhandari et al., 2022; Dai et al., 2024). We adopt this approach, as it facilitates the application of shared experts across various tasks while reserving others for selective use in specific routing scenarios. The introduction of shared and specialized experts offers a more adaptable and efficient method for developing MoE routing mechanisms.
专家路由 专家路由机制的设计对于提高MoE模型的性能至关重要。最近,有一个明显的趋势是在MoE层中集成共享专家和路由特定专家(Rajbhandari等,2022;Dai等,2024)。我们采用了这种方法,因为它有助于在各种任务中应用共享专家,同时保留其他专家以在特定路由场景中进行选择性使用。共享和专业专家的引入为开发MoE路由机制提供了一种更具适应性和高效的方法。
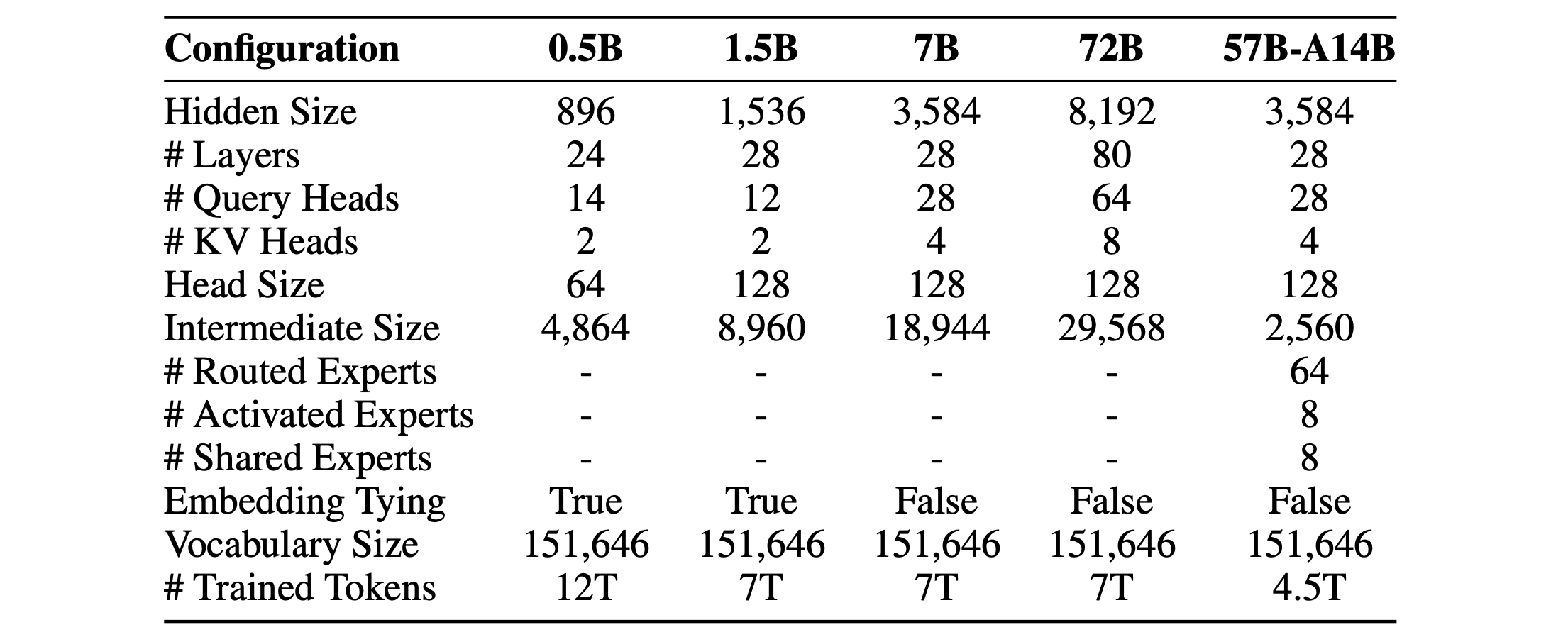
Table 1: Architecture of Qwen2 dense and MoE models. For MoE models, 57B-A14B denotes that the model has 57B parameters in total and for each token 14B parameters are active, the Intermediate size denotes that of each expert, and # Activated Experts excludes the shared experts.
表1:Qwen2密集和MoE模型的架构。对于MoE模型,57B-A14B表示模型总共有57B参数,对于每个标记,14B参数是活动的,中间大小表示每个专家的大小,#激活专家不包括共享专家。
Expert Initialization We initialize the experts in a similar way to upcycling (Komatsuzaki et al., 2023), leveraging the weights of a dense model. In contrast, our approach emphasizes diversification among fine-grained experts to enhance the model’s representational breadth. Given the designated expert intermediate size hE, the number of experts n, and the original FFN intermediate size hFFN, the FFN is replicated ⌈n×hE/hFFN⌉times. This replication ensures compatibility with the specified number of experts while accommodating any arbitrary expert intermediate size. To promote diversity within each FFN copy, parameters are shuffled along the intermediate dimension. This guarantees that each fine-grained expert exhibits unique characteristics, even across different FFN copies. Subsequently, these experts are extracted from the FFN copies, and the remaining dimensions are discarded. For each fine-grained expert, 50% of its parameters are randomly reinitialized. This process introduces additional stochasticity into expert initialization, potentially enhancing the model’s capacity for exploration during training.
专家初始化 我们以类似于upcycling(Komatsuzaki等,2023)的方式初始化专家,利用密集模型的权重。相比之下,我们的方法强调细粒度专家之间的多样化,以增强模型的表示广度。给定指定的专家中间大小hE、专家数量n和原始FFN中间大小hFFN,FFN被复制⌈n×hE/hFFN⌉次。这种复制确保了与指定数量的专家的兼容性,同时适应任意的专家中间大小。为了在每个FFN副本中促进多样性,参数沿中间维度被洗牌。这确保了每个细粒度专家都具有独特的特征,即使在不同的FFN副本之间也是如此。随后,这些专家从FFN副本中提取出来,其余维度被丢弃。对于每个细粒度专家,50%的参数被随机重新初始化。这个过程引入了额外的随机性到专家初始化中,可能增强了模型在训练过程中的探索能力。
2.2.3 MODEL CONFIGURATION(模型配置)
In the following, we provide the key configuration and information for the Qwen2 series.
接下来,我们提供Qwen2系列的关键配置和信息。
The Qwen2 series consists of models of 5 sizes, which are Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and Qwen2-72B. Table 1 lists the hyper-parameters and important information, e.g., the number of pre-trained tokens. Particularly, Qwen2-57B-A14B is upscaled from Qwen2-7B. Notably, Qwen2 models demonstrate a substantially lower Key-Value (KV) size per token relative to Qwen1.5 models. This characteristic translates into a reduced memory footprint, particularly advantageous in long-context inference tasks.
Qwen2系列包括5种规模的模型,分别是Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B和Qwen2-72B。表1列出了超参数和重要信息,例如预训练标记的数量。特别是,Qwen2-57B-A14B是从Qwen2-7B升级而来。值得注意的是,相对于Qwen1.5模型,Qwen2模型表现出每个标记的关键值(KV)大小明显较低。这一特点转化为较小的内存占用量,特别有利于长上下文推理任务。