Qwen2.5-Coder Technical Report
- Qwen2.5-Coder Technical Report
- Qwen2.5-Coder Documentation
- Qwen2.5-Coder Blog
- Qwen2.5-Coder GitHub
- HuggingFace Qwen2.5-Coder-7B-Instruct
Abstract(摘要)
In this report, we introduce the Qwen2.5-Coder series, a significant upgrade from its predecessor, CodeQwen1.5. This series includes two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B. As a code-specific model, Qwen2.5-Coder is built upon the Qwen2.5 architecture and continues pretrained on a vast corpus of over 5.5 trillion tokens. Through meticulous data cleaning, scalable synthetic data generation, and balanced data mixing, Qwen2.5-Coder demonstrates impressive code generation capabilities while retaining general versatility. The model has been evaluated on a wide range of code-related tasks, achieving state-of-the-art (SOTA) performance across more than 10 benchmarks, including code generation, completion, reasoning, and repair, consistently outperforming larger models of the same model size. We believe that the release of the Qwen2.5-Coder series will not only push the boundaries of research in code intelligence but also, through its permissive licensing, encourage broader adoption by developers in real-world applications.
在本报告中,我们介绍了Qwen2.5-Coder系列,这是其前身CodeQwen1.5的重大升级。该系列包括两个模型:Qwen2.5-Coder-1.5B和Qwen2.5-Coder-7B。作为一个代码专用模型,Qwen2.5-Coder基于Qwen2.5架构构建,并在超过5.5万亿个标记的庞大语料库上继续预训练。通过细致的数据清理、可扩展的合成数据生成和均衡的数据混合,Qwen2.5-Coder展示了令人印象深刻的代码生成能力,同时保持了通用的多功能性。该模型在广泛的代码相关任务上进行了评估,在包括代码生成、补全、推理和修复在内的10多个基准测试中实现了最先进的(SOTA)性能,持续超越同等模型大小的更大模型。我们相信,Qwen2.5-Coder系列的发布不仅将推动代码智能研究的边界,而且通过其宽松的许可,将鼓励开发人员在实际应用中更广泛地采用。
1 Introduction(介绍)
With the rapid development of large language models (LLMs) (Brown, 2020; Achiam et al., 2023; Touvron et al., 2023; Dubey et al., 2024; Jiang et al., 2023; Bai et al., 2023b; Yang et al., 2024; Anthropic, 2024; OpenAI, 2024), code-specific language models have garnered significant attention in the community. Built upon pretrained LLMs, code LLMs such as the StarCoder series (Li et al., 2023; Lozhkov et al., 2024), CodeLlama series (Roziere et al., 2023), DeepSeek-Coder series (Guo et al., 2024), CodeQwen1.5 (Bai et al., 2023a), and CodeStral (team, 2024), have demonstrated superior performance in coding evaluations (Chen et al., 2021; Austin et al., 2021; Cassano et al., 2022; Jain et al., 2024). However, in comparison with the recently state-of-the-art proprietary LLMs, Claude-3.5-Sonnet (Anthropic, 2024) and GPT-4o (OpenAI, 2024), the code LLMs are still falling behind, either open-source or proprietary models.
随着大型语言模型(LLMs)的快速发展(Brown, 2020; Achiam等, 2023; Touvron等, 2023; Dubey等, 2024; Jiang等, 2023; Bai等, 2023b; Yang等, 2024; Anthropic, 2024; OpenAI, 2024),代码专用语言模型在社区中引起了极大的关注。基于预训练的LLMs,代码LLMs如StarCoder系列(Li等, 2023; Lozhkov等, 2024)、CodeLlama系列(Roziere等, 2023)、DeepSeek-Coder系列(Guo等, 2024)、CodeQwen1.5(Bai等, 2023a)和CodeStral(团队, 2024)在编码评估中表现出色(Chen等, 2021; Austin等, 2021; Cassano等, 2022; Jain等, 2024)。然而,与最近最先进的专有LLMs Claude-3.5-Sonnet(Anthropic, 2024)和GPT-4o(OpenAI, 2024)相比,代码LLMs仍然落后,无论是开源还是专有模型。
Building upon our previous work, CodeQwen1.5, we are excited to introduce Qwen2.5-Coder, a new series of language models designed to achieve top-tier performance in coding tasks at various model sizes. Qwen2.5-Coder models are derived from the Qwen2.5 LLMs, inheriting their advanced architecture and tokenizer. These models are pretrained on extensive datasets and further fine-tuned on carefully curated instruction datasets specifically designed for coding tasks. The series includes models with 1.5B and 7B parameters, along with their instruction-tuned variants. We are committed to fostering research and innovation in the field of code LLMs, coding agents, and coding assistant applications. Therefore, we are open-sourcing the Qwen2.5-Coder models to the community to support and accelerate advancements in these areas.
基于我们之前的工作CodeQwen1.5,我们很高兴介绍Qwen2.5-Coder,这是一个旨在在各种模型规模的编码任务中实现顶级性能的新系列语言模型。Qwen2.5-Coder模型源自Qwen2.5 LLMs,继承了其先进的架构和分词器。这些模型在广泛的数据集上进行了预训练,并在专门为编码任务设计的精心策划的指令数据集上进行了进一步微调。该系列包括具有1.5B和7B参数的模型,以及它们的指令调优变体。我们致力于促进代码LLMs、编码代理和编码助手应用领域的研究和创新。因此,我们将Qwen2.5-Coder模型开源给社区,以支持和加速这些领域的进步。
Significant efforts have been dedicated to constructing a large-scale, coding-specific pretraining dataset comprising over 5.5 trillion tokens. This dataset is sourced from a broad range of public code repositories, such as those on GitHub, as well as large-scale web-crawled data containing code-related texts. We have implemented sophisticated procedures to recall and clean potential code data and filter out low-quality content using weak model based classifiers and scorers. Our approach encompasses both file-level and repository-level pretraining to ensure comprehensive coverage. To optimize performance and balance coding expertise with general language understanding, we have carefully curated a data mixture that includes code, mathematics, and general texts. To transform models into coding assistants for downstream applications, we have developed a well-designed instruction-tuning dataset. This dataset includes a wide range of coding-related problems and solutions, sourced from real-world applications and synthetic data generated by code-focused LLMs, covering a broad spectrum of coding tasks.
我们投入了大量精力构建了一个包含超过5.5万亿标记的大规模、代码专用的预训练数据集。该数据集来源于广泛的公共代码库,如GitHub上的代码库,以及包含代码相关文本的大规模网络爬取数据。我们实施了复杂的程序来召回和清理潜在的代码数据,并使用基于弱模型的分类器和评分器过滤掉低质量内容。我们的方法包括文件级和库级的预训练,以确保全面覆盖。为了优化性能并平衡编码专业知识与通用语言理解,我们精心策划了一个包含代码、数学和通用文本的数据混合。为了将模型转变为下游应用的编码助手,我们开发了一个设计良好的指令调优数据集。该数据集包括从实际应用和代码专用LLMs生成的合成数据中获取的各种编码相关问题和解决方案,涵盖了广泛的编码任务。
This report introduces the Qwen2.5-Coder series, an upgraded version of CodeQwen1.5, featuring two models: Qwen2.5-Coder-1.5B and Qwen2.5-Coder-7B. Built on the Qwen2.5 architecture and pretrained on over 5.5 trillion tokens, these code-specific models demonstrate exceptional code generation capabilities while maintaining general versatility. Through rigorous data processing and training techniques, Qwen2.5-Coder achieves state-of-the-art performance across more than 10 code-related benchmarks, outperforming larger models in various tasks. The release of these models aims to advance code intelligence research and promote widespread adoption in real-world applications, facilitated by permissive licensing.
本报告介绍了Qwen2.5-Coder系列,这是CodeQwen1.5的升级版本,包含两个模型:Qwen2.5-Coder-1.5B和Qwen2.5-Coder-7B。基于Qwen2.5架构并在超过5.5万亿标记上进行预训练,这些代码专用模型展示了卓越的代码生成能力,同时保持了通用的多功能性。通过严格的数据处理和训练技术,Qwen2.5-Coder在超过10个代码相关基准测试中实现了最先进的性能,超越了各种任务中的更大模型。这些模型的发布旨在推动代码智能研究,并通过宽松的许可促进在实际应用中的广泛采用。
2 Model Architecture(模型架构)
Architecture The architecture of Qwen2.5-Coder is the same as Qwen2.5. Table 1 shows the architecture of Qwen2.5-Coder for two different model sizes: 1.5B and 7B parameters. Both sizes share the same architecture in terms of layers, having 28 layers and a head size of 128. However, they differ in several key aspects. The 1.5B model has a hidden size of 1,536, while the 7B model has a much larger hidden size of 3,584. The 1.5B model uses 12 query heads and 2 key-value heads, whereas the 7B model uses 28 query heads and 4 key-value heads, reflecting its larger capacity. The intermediate size also scales with model size, being 8,960 for the 1.5B model and 18,944 for the 7B model. Additionally, the 1.5B model employs embedding tying, while the 7B model does not. Both models share the same vocabulary size of 151,646 tokens and have been trained on 5.5 trillion tokens.
架构 Qwen2.5-Coder的架构与Qwen2.5相同。表1展示了Qwen2.5-Coder在两种不同模型规模下的架构:1.5B和7B参数。两种规模在层数上共享相同的架构,均为28层,头部大小为128。然而,它们在几个关键方面有所不同。1.5B模型的隐藏层大小为1,536,而7B模型的隐藏层大小则大得多,为3,584。1.5B模型使用12个查询头和2个键值头,而7B模型使用28个查询头和4个键值头,反映了其更大的容量。中间层大小也随模型规模而变化,1.5B模型为8,960,7B模型为18,944。此外,1.5B模型采用嵌入绑定,而7B模型则不采用。两种模型共享相同的词汇表大小,为151,646个标记,并在5.5万亿个标记上进行了训练。
Tokenization Qwen2.5-Coder inherits the vocabulary from Qwen2.5 but introduces several special tokens to help the model better understand code. Table 2 presents an overview of the special tokens added during training to better capture different forms of code data. These tokens serve specific purposes in the code-processing pipeline. For instance, <|endoftext|> marks the end of a text or sequence, while the <|fim_prefix|>, <|fim_middle|>, and <|fim_suffix|> tokens are used to implement the Fill-in-the-Middle (FIM) (Bavarian et al., 2022) technique, where a model predicts the missing parts of a code block. Additionally, <|fim_pad|> is used for padding during FIM operations. Other tokens include <|repo_name|>, which identifies repository names, and <|file_sep|>, used as a file separator to better manage repository-level information. These tokens are essential in helping the model learn from diverse code structures and enable it to handle longer and more complex contexts during both file-level and repo-level pretraining.
分词 Qwen2.5-Coder继承了Qwen2.5的词汇表,但引入了几个特殊标记以帮助模型更好地理解代码。表2概述了训练期间添加的特殊标记,以更好地捕捉不同形式的代码数据。这些标记在代码处理流程中具有特定用途。例如,<|endoftext|> 标记文本或序列的结尾,而<|fim_prefix|>、<|fim_middle|>和<|fim_suffix|>标记用于实现Fill-in-the-Middle(FIM)(Bavarian等, 2022)技术,其中模型预测代码块的缺失部分。此外,<|fim_pad|> 用于FIM操作期间的填充。其他标记包括<|repo_name|>,用于标识存储库名称,以及<|file_sep|>,用作文件分隔符以更好地管理存储库级信息。这些标记对于帮助模型从多样的代码结构中学习并使其能够在文件级和存储库级预训练期间处理更长、更复杂的上下文至关重要。
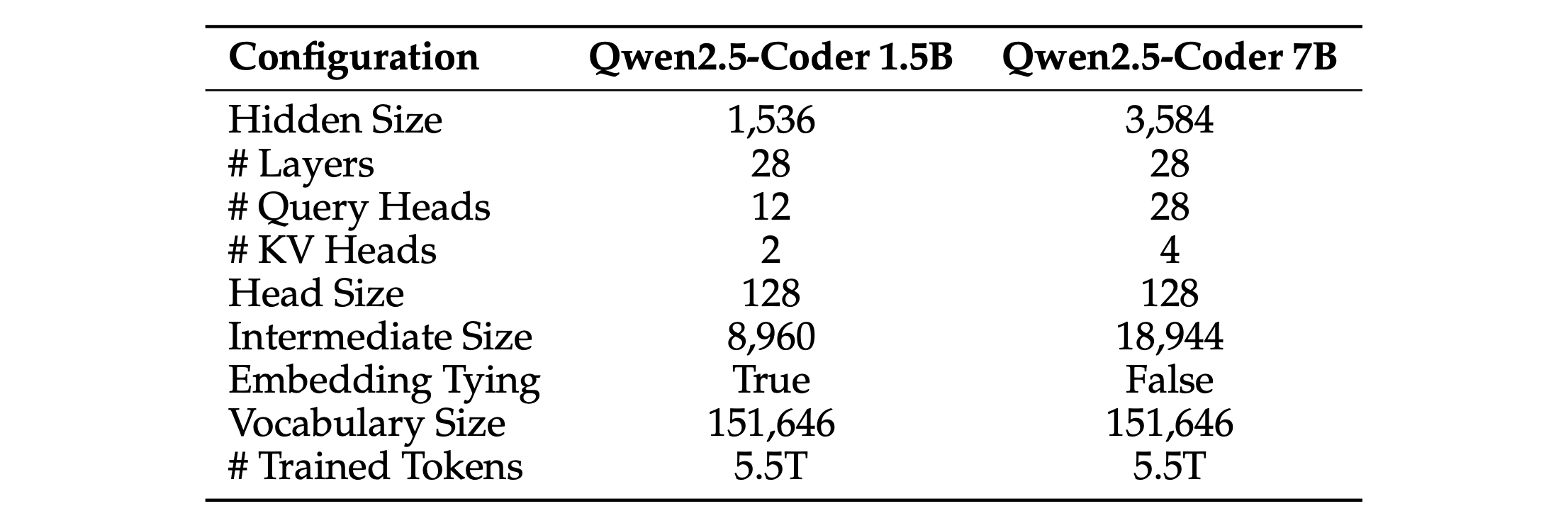
Table 1: Architecture of Qwen2.5-Coder. 表1:Qwen2.5-Coder的架构。
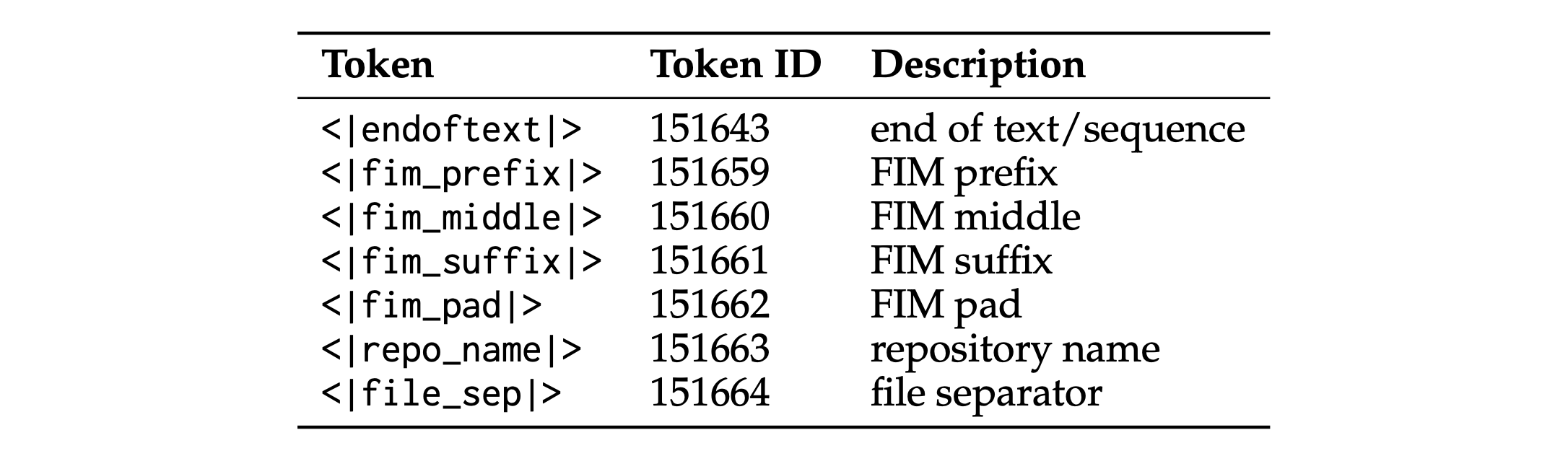
Table 2: Overview of the special tokens. 表2:特殊标记概述。
3 Pre-training(预训练)
3.1 Pretraining Data(预训练数据)
Large-scale, high-quality, and diverse data forms the foundation of pre-trained models. To this end, we constructed a dataset named Qwen2.5-Coder-Data. This dataset comprises five key data types: Source Code Data, Text-Code Grounding Data, Synthetic Data, Math Data, and Text Data. In this section, we provide a brief overview of the sources and cleaning methods applied to these datasets.
大规模、高质量和多样化的数据构成了预训练模型的基础。为此,我们构建了一个名为Qwen2.5-Coder-Data的数据集。该数据集包含五种关键数据类型:源代码数据、文本-代码对齐数据、合成数据、数学数据和文本数据。在本节中,我们简要概述了这些数据集的来源和清理方法。
3.1.1 Data Composition(数据组成)
Source Code We collected public repositories from GitHub created before February 2024, spanning 92 programming languages. Similar to StarCoder2 (Lozhkov et al., 2024) and DS-Coder (Guo et al., 2024), we applied a series of rule-based filtering methods. In addition to raw code, we also collected data from Pull Requests, Commits, Jupyter Notebooks, and Kaggle datasets, all of which were subjected to similar rule-based cleaning techniques.
源代码 我们收集了2024年2月之前在GitHub上创建的公共代码库,涵盖了92种编程语言。类似于StarCoder2(Lozhkov等, 2024)和DS-Coder(Guo等, 2024),我们应用了一系列基于规则的过滤方法。除了原始代码外,我们还收集了来自Pull Requests、Commits、Jupyter Notebooks和Kaggle数据集的数据,这些数据都经过了类似的基于规则的清理技术。
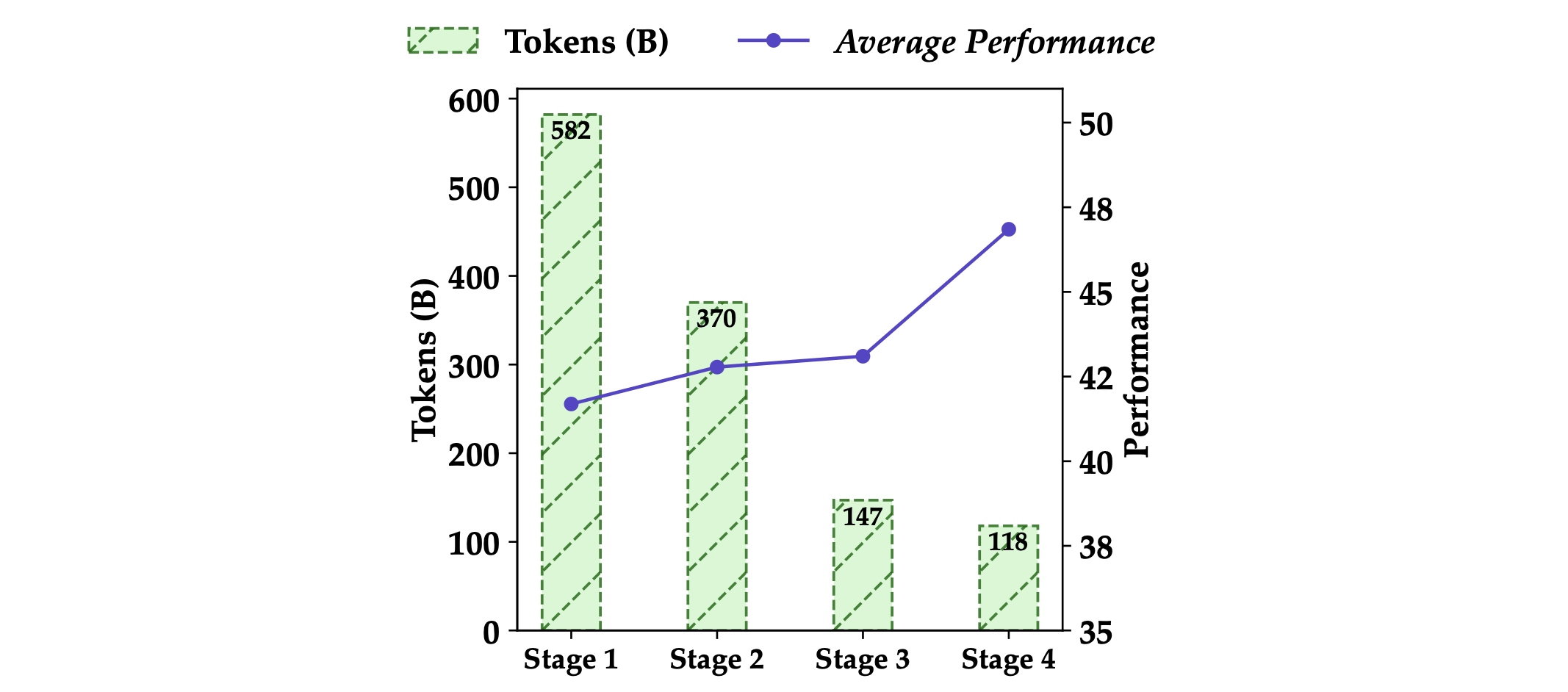
Figure 1: Number of data tokens across different cc-stages, and the validation effectiveness of training Qwen2.5-Coder using corresponding data. 图1:不同 cc-stages (cc阶段) 的数据标记数量,以及使用相应数据训练Qwen2.5-Coder的验证有效性。
Text-Code Grounding Data We curated a large-scale and high-quality text-code mixed dataset from Common Crawl, which includes code-related documentation, tutorials, blogs, and more. Instead of the conventional URL-based multi-stage recall method, we developed a coarse-to-fine hierarchical filtering approach for raw data. This method offers two key advantages:
文本-代码对齐数据 我们从Common Crawl中整理了一个大规模且高质量的文本-代码混合数据集,其中包括代码相关的文档、教程、博客等。我们开发了一种由粗到细的分层过滤方法来处理原始数据,而不是传统的基于URL的多阶段召回方法。这种方法有两个主要优点:
1. It enables precise control over each filter’s responsibility, ensuring comprehensive handling of each dimension.
1. 它能够精确控制每个过滤器的职责,确保全面处理每个维度。
2. It naturally assigns quality scores to the dataset, with data retained in the final stage being of higher quality, providing valuable insights for quality-driven data mixing.
2. 它自然地为数据集分配质量评分,保留在最后阶段的数据质量更高,为基于质量的数据混合提供了宝贵的见解。
We designed a cleaning pipeline for the Text-Code Grounding Data, where each filter level is built using smaller models, such as fastText. Although we experimented with larger models, they did not yield significant benefits. A likely explanation is that smaller models focus more on surface-level features, avoiding unnecessary semantic complexity.
我们为文本-代码对齐数据设计了一个清理管道,每个过滤级别都使用较小的模型构建,例如fastText。尽管我们尝试了更大的模型,但它们并没有带来显著的好处。一个可能的解释是,较小的模型更关注表面特征,避免了不必要的语义复杂性。
In Qwen2.5-Coder, we applied this process iteratively. As shown in Figure 1, each iteration resulted in improvement. Through 4-stage filtering, the average scores on HumanEval and MBPP increased from 41.6% to 46.8% compared to the baseline, demonstrating the value of high-quality Text-Code Grounding Data for code generation.
在Qwen2.5-Coder中,我们迭代地应用了这个过程。如图1所示,每次迭代都带来了改进。通过四阶段过滤,HumanEval和MBPP的平均得分从基线的41.6%提高到46.8%,展示了高质量文本-代码对齐数据对代码生成的价值。
Synthetic Data Synthetic data offers a promising way to address the anticipated scarcity of training data. We used CodeQwen1.5, the predecessor of Qwen2.5-Coder, to generate large-scale synthetic datasets. To mitigate the risk of hallucinations during this process, we introduced an executor for validation, ensuring that only executable code was retained.
合成数据 合成数据提供了一种解决训练数据预期短缺的有前途的方法。我们使用Qwen2.5-Coder的前身CodeQwen1.5生成了大规模的合成数据集。为了减轻在此过程中出现幻觉的风险,我们引入了一个执行器进行验证,确保只保留可执行的代码。
Math Data To enhance the mathematical capabilities of Qwen2.5-Coder, we integrated the pre-training corpus from Qwen2.5-Math into the Qwen2.5-Coder dataset. Importantly, the inclusion of mathematical data did not negatively impact the model’s performance on code tasks. For further details on the collection and cleaning process, please refer to the Qwen2.5-Math technical report.
数学数据 为了增强Qwen2.5-Coder的数学能力,我们将Qwen2.5-Math的预训练语料库整合到Qwen2.5-Coder数据集中。重要的是,数学数据的加入并没有对模型在代码任务上的表现产生负面影响。有关收集和清理过程的更多详细信息,请参阅Qwen2.5-Math技术报告。
Text Data Similar to the Math Data, we included high-quality general natural language data from the pre-training corpus of the Qwen2.5 model to preserve Qwen2.5-Coder’s general capabilities. This data had already passed stringent quality checks during the cleaning phase of Qwen2.5’s dataset, so no further processing was applied. However, all code segments were removed from the general Text data to avoid overlap with our code data, ensuring the independence of different data sources.
文本数据 类似于数学数据,我们从Qwen2.5模型的预训练语料库中包含了高质量的通用自然语言数据,以保持Qwen2.5-Coder的通用能力。这些数据在Qwen2.5数据集的清理阶段已经通过了严格的质量检查,因此没有进行进一步处理。然而,为了避免与我们的代码数据重叠,所有代码段都从通用文本数据中移除,确保不同数据源的独立性。
3.1.2 Data Mixture(数据混合)
Balancing Code, Math, and Text data is crucial for building a robust foundational model. Although the research community has explored this balance before, there is limited evidence regarding its scalability to large datasets. To address this, we conducted empirical experiments with different ratios of Code, Math, and Text data, designing multiple experiments to identify an optimal combination rapidly. Specifically, as shown in Table 3, we compared three different Code: Text ratios — 100:0:0, 85:10:5, and 70:20:10.
平衡代码、数学和文本数据对于构建一个强大的基础模型至关重要。尽管研究社区之前已经探索过这种平衡,但关于其在大规模数据集上的可扩展性证据有限。为了解决这个问题,我们进行了不同代码、数学和文本数据比例的实证实验,设计了多个实验以快速识别最佳组合。具体来说,如表3所示,我们比较了三种不同的代码:文本比例——100:0:0、85:10:5和70:20:10。
Interestingly, we found that the 7:2:1 ratio outperformed the others, even surpassing the performance of groups with a higher proportion of code. A possible explanation is that Math and Text data may positively contribute to code performance, but only when their concentration reaches a specific threshold. In future work, we plan to explore more efficient ratio mechanisms and investigate the underlying causes of this phenomenon. Ultimately, we selected a final mixture of 70% Code, 20% Text, and 10% Math. The final training dataset comprises 5.2 trillion tokens.
有趣的是,我们发现7:2:1的比例优于其他比例,甚至超过了代码比例更高的组。一个可能的解释是,数学和文本数据可能对代码性能有积极贡献,但只有当它们的浓度达到特定阈值时才会如此。在未来的工作中,我们计划探索更有效的比例机制,并研究这一现象的潜在原因。最终,我们选择了70%代码、20%文本和10%数学的最终混合比例。最终的训练数据集包含5.2万亿个标记。

Table 3: The performance of Qwen2.5-Coder training on different data mixture policy. 表3:Qwen2.5-Coder在不同数据混合策略下的训练性能。
3.2 Training Policy(训练策略)

Figure 2: The three-stage training pipeline for Qwen2.5-Coder. 图2:Qwen2.5-Coder的三阶段训练流程。
As shown in 2, we employed a three-stage training approach to train Qwen2.5-Coder, including ①file-level pretraining, ②repo-level pretraining, and ③instruction tuning.
如图2所示,我们采用了一种三阶段训练方法来训练Qwen2.5-Coder,包括:①文件级预训练、②库级预训练 和 ③指令调优。
3.2.1 File-Level Pretraining(文件级预训练)
File-level pretraining focuses on learning from individual code files. In this stage, the maximum training sequence length is set to 8,192 tokens, covering 5.2T of high-quality data. The training objectives include next token prediction and fill-in-the-middle (FIM) (Bavarian et al., 2022). The specific FIM format is shown in Figure 3.
文件级预训练专注于从单个代码文件中学习。在此阶段,最大训练序列长度设置为 8,192 个标记,涵盖5.2万亿高质量数据。训练目标包括下一个标记预测和中间填充(FIM)(Bavarian等, 2022)。具体的FIM格式如图3所示。

Figure 3: File-Level FIM format. 图3:文件级FIM格式。
3.2.2 Repo-Level Pretraining(库级预训练)
After file-level pretraining, we turn to repo-level pretraining, aimed at enhancing the model’s long-context capabilities. In this stage, the context length is extended from 8,192 tokens to 32,768 tokens, and RoPE’s base frequency is adjusted from 10,000 to 1,000,000. To further leverage the model’s extrapolation potential, we applied the YARN mechanism (Peng et al., 2023), enabling the model to handle sequences up to 131,072 (132K) tokens.
在文件级预训练之后,我们转向库级预训练,旨在增强模型的长上下文能力。在此阶段,上下文长度从8,192个标记扩展到32,768个标记,并将RoPE的基频从10,000调整到1,000,000。为了进一步利用模型的外推潜力,我们应用了YARN机制(Peng等, 2023),使模型能够处理最长达131,072(132K)个标记的序列。
In this stage, we used a large amount of high-quality, long-code data (≈ 300B) and extended file-level FIM to the repo-level FIM following methods described in Lozhkov et al. (2024), with the specific format shown in Figure 4.
在此阶段,我们使用了大量高质量的长代码数据(约3000亿),并将文件级FIM扩展到库级FIM,采用Lozhkov等(2024)描述的方法,具体格式如图4所示。

Figure 4: Repo-Level FIM format. 图4:库级FIM格式。
4 Post-training(后训练)
4.1 A Recipe for Instruction Data(指令数据配方)
Multilingual Programming Code Identification We fine-tune a CodeBERT model to perform language identification, categorizing documents into nearly 100 programming languages. We retain the instruction data for mainstream programming languages and randomly discard a portion of the instruction data for long-tail languages. If a given sample contains very little code data or no code snippets, it may be classified under the “No Programming Language” tag. We remove most samples without code snippets to maintain the code generation capability of our instruction model.
多语言编程代码识别 我们微调了一个CodeBERT模型来执行语言识别任务,将文档分类为近100种编程语言。我们保留主流编程语言的指令数据,并随机丢弃部分长尾语言的指令数据。如果给定样本包含很少的代码数据甚至没有代码片段,该样本可能会被分类为“无编程语言”标签。我们移除大多数没有代码片段的样本,以保持我们的指令模型的代码生成能力。
Instruction Synthesis from GitHub For the unsupervised data (code snippets) widely available on many websites (e.g., GitHub), we construct a supervised instruction dataset. Specifically, we use an LLM to generate instructions from code snippets within 1024 tokens and then use a code LLM to generate responses (Sun et al., 2024). Finally, we use an LLM scorer to filter out low-quality pairs to obtain the final dataset. Given code snippets in different programming languages, we construct an instruction dataset from these snippets. To increase the diversity of the instruction dataset, we first generate answers from the code and then use an LLM scorer to filter out low-quality pairs to obtain the final triplet. Similarly, given code snippets in different programming languages, we can construct an instruction dataset with universal code snippets. To fully unleash the potential of our proposed method, we also include open-source instruction datasets in the seed instruction dataset. Finally, we combine the three parts of the instruction dataset for supervised fine-tuning.
从GitHub合成指令 对于许多网站(例如GitHub)上大量存在的无监督数据(代码片段),我们尝试构建监督指令数据集。具体来说,我们使用LLM从1024个标记内的代码片段生成指令,然后使用代码LLM生成响应(Sun等, 2024)。最后,我们使用LLM评分器过滤低质量的对,得到最终的配对。给定不同编程语言的代码片段,我们从代码片段中构建一个指令数据集。为了增加指令数据集的多样性,相反,我们首先从代码生成答案。然后我们使用LLM评分器过滤低质量的对,得到最终的三元组。同样,给定不同编程语言的代码片段,我们可以从代码片段中构建一个具有通用代码的指令数据集。为了充分发挥我们提出的方法的潜力,我们还在种子指令数据集中包含了开源指令数据集。最后,我们结合三个部分的指令数据集进行监督微调。
Multilingual Code Instruction Data To bridge the gap among different programming languages, we propose a multilingual multi-agent collaborative framework to synthesize the multilingual instruction corpora. We introduce language-specific agents, where a set of specialized agents are created and each dedicated to a particular programming language. These agents are initialized with language-specific instruction data derived from the limited existing multilingual instruction corpora. The multilingual data generation process can be split into: (1) Language-Specific Intelligent Agents: We create a set of specialized agents, each dedicated to a particular programming language. These agents are initialized with language-specific instruction data derived from curated code snippets. (2) Collaborative Discussion Protocol: Multiple language-specific agents engage in a structured dialogue to formulate new instructions and solutions. This process can result in either enhancing existing language capabilities or generating instructions for a novel programming language. (3) Adaptive Memory System: Each agent maintains a dynamic memory bank that stores its generation history to avoid generating the similar samples. (4) Cross-Lingual Discussion: We implement a novel knowledge distillation technique that allows agents to share insights and patterns across language boundaries, fostering a more comprehensive understanding of programming concepts. (5) Synergy Evaluation Metric: We develop a new metric to quantify the degree of knowledge sharing and synergy between different programming languages within the model. (6) Adaptive Instruction Generation: The framework includes a mechanism to dynamically generate new instructions based on identified knowledge gaps across languages.
多语言代码指令数据 为了弥合不同编程语言之间的差距,我们提出了一个多语言多代理协作框架来合成多语言指令语料库。我们引入了语言特定的代理,创建了一组专门的代理,每个代理专注于特定的编程语言。这些代理使用从现有有限的多语言指令语料库中提取的语言特定指令数据进行初始化。多语言数据生成过程可以分为以下几个步骤:
- 语言特定智能代理:我们创建了一组专门的代理,每个代理专注于特定的编程语言。这些代理使用从精心挑选的代码片段中提取的语言特定指令数据进行初始化。
- 协作讨论协议:多个语言特定代理参与结构化对话,以制定新的指令和解决方案。这个过程可以增强现有语言能力或生成新的编程语言指令。
- 自适应记忆系统:每个代理维护一个动态记忆库,存储其生成历史,以避免生成相似的样本。
- 跨语言讨论:我们实施了一种新的知识蒸馏技术,允许代理在语言边界之间共享见解和模式,促进对编程概念的更全面理解。
- 协同评估指标:我们开发了一种新指标,用于量化模型中不同编程语言之间的知识共享和协同程度。
- 自适应指令生成:该框架包括一种机制,基于跨语言识别的知识差距动态生成新指令。
Checklist-based Scoring for Instruction Data To completely evaluate the quality of the created instruction pair, we introduce several scoring points for each sample: (1) Question&Answer Consistency: Whether Q&A are consistent and correct for fine-tuning. (2) Question&Answer Relevance: Whether Q&A are related to the computer field. (3) Question&Answer Difficulty: Whether Q&A are sufficiently challenging. (4) Code Exist: Whether the code is provied in question or answer. (5) Code Correctness: Evaluate whether the provided code is free from syntax errors and logical flaws. (6) Consider factors like proper variable naming, code indentation, and adherence to best practices. (7) Code Clarity: Assess how clear and understandable the code is. Evaluate if it uses meaningful variable names, proper comments, and follows a consistent coding style. (8) Code Comments: Evaluate the presence of comments and their usefulness in explaining the code’s functionality. (9) Easy to Learn: determine its educational value for a student whose goal is to learn basic coding concepts. After gaining all scores (s1, . . . , sn), we can get the final score with s = w1s1 +· · · + wnsn, where (w1, . . . , wn) are a series of pre-defined weights.
指令数据的基于清单的评分 为了完全评估创建的指令对的质量,我们为每个样本引入了几个评分点:(1)问题和答案的一致性:是否对问题和答案进行了一致和正确的微调。(2)问题和答案的相关性:问题和答案是否与计算机领域相关。(3)问题和答案的难度:问题和答案是否足够具有挑战性。(4)代码是否存在:问题或答案中是否提供了代码。(5)代码正确性:评估提供的代码是否没有语法错误和逻辑缺陷。考虑到适当的变量命名、代码缩进和遵循最佳实践等因素。(6)代码清晰度:评估代码的清晰度和可理解性。评估它是否使用有意义的变量名、适当的注释,并遵循一致的编码风格。(7)代码注释:评估注释的存在以及它们在解释代码功能方面的有用性。(8)易学性:确定它对于一个目标是学习基本编码概念的学生的教育价值。在获得所有分数(s1,…,sn)之后,我们可以通过s = w1s1 +· · · + wnsn获得最终分数,其中(w1,…,wn)是一系列预定义的权重。
A multilingual sandbox for code verification To further verify the correctness of the code syntax, we use the code static checking for all extracted code snippets of programming languages (e.g. Python, Java, and C++). We parse the code snippet into the abstract syntax tree and filter out the code snippet, where the parsed nodes in code snippet have parsing errors. We create a multilingual sandbox to support the code static checking for the main programming language. Further, the multilingual sandbox is a comprehensive platform designed to validate code snippets across multiple programming languages. It automates the process of generating relevant unit tests based on language-specific samples and evaluates whether the provided code snippets can successfully pass these tests. Especially, only the self-contained (e.g. algorithm problems) code snippet will be fed into the multilingual sandbox. The multilingual verification sandbox is mainly comprised of five parts:
用于代码验证的多语言沙箱 为了进一步验证代码语法的正确性,我们使用代码静态检查来检查所有提取的编程语言代码片段(例如Python、Java和C++)。我们将代码片段解析为抽象语法树,并过滤出代码片段,其中代码片段中的解析节点存在解析错误。我们创建了一个多语言沙箱,用于支持主要编程语言的代码静态检查。此外,多语言沙箱是一个综合平台,旨在验证多种编程语言的代码片段。它自动化生成基于特定语言样本的相关单元测试的过程,并评估提供的代码片段是否能够成功通过这些测试。特别地,只有自包含的(例如算法问题)代码片段将被输入到多语言沙箱中。多语言验证沙箱主要由五部分组成:
- Language Support Module:
- Implements support for multiple languages (e.g., Python, Java, C++, JavaScript)
- Maintains language-specific parsing and execution environments
- Handles syntax and semantic analysis for each supported language
- Sample Code Repository:
- Stores a diverse collection of code samples for each supported language
- Organizes samples by language, difficulty level, and programming concepts
- Regularly updated and curated by language experts
- Unit Test Generator:
- Analyzes sample code to identify key functionalities and edge cases
- Automatically generates unit tests based on the expected behavior
- Produces test cases covering various input scenarios and expected outputs
- Code Execution Engine:
- Provides isolated environments for executing code snippets securely
- Supports parallel execution of multiple test cases
- Handles resource allocation and timeout mechanisms
- Result Analyzer:
- Compares the output of code snippets against expected results from unit tests
- Generates detailed reports on test case successes and failures
- Provides suggestions for improvements based on failed test cases
- 语言支持模块:
- 实现对多种语言的支持(例如Python、Java、C++、JavaScript)
- 维护特定于语言的解析和执行环境
- 处理每种支持语言的语法和语义分析
- 样本代码库:
- 存储每种支持语言的多样化代码样本集合
- 按语言、难度级别和编程概念组织样本
- 由语言专家定期更新和策划
- 单元测试生成器:
- 分析样本代码,识别关键功能和边缘情况
- 根据预期行为自动生成单元测试
- 生成覆盖各种输入场景和预期输出的测试用例
- 代码执行引擎:
- 提供安全执行代码片段的隔离环境
- 支持并行执行多个测试用例
- 处理资源分配和超时机制
- 结果分析器:
- 将代码片段的输出与单元测试的预期结果进行比较
- 生成有关测试用例成功和失败的详细报告
- 根据失败的测试用例提供改进建议
4.2 Training Policy(训练策略)
Coarse-to-fine Fine-tuning We first synthesized tens of millions of low-quality but diverse instruction samples to fine-tune the base model. In the second stage, we adopt millions of high-quality instruction samples to improve the performance of the instruction model with rejection sampling and supervised fine-tuning. For the same query, we use the LLM to generate multiple candidates and then use the LLM to score the best one for supervised fine-tuning.
由粗到细的微调 我们首先合成了数千万个质量低但多样化的指令样本来微调基础模型。在第二阶段,我们采用了数百万高质量的指令样本,通过拒绝抽样和监督微调来提高指令模型的性能。对于相同的查询,我们使用LLM生成多个候选项,然后使用LLM为监督微调评分最佳候选项。
Mixed Tuning Since most instruction data have a short length, we construct the instruction pair with the FIM format to keep the long context capability of the base model. Inspired by programming language syntax rules and user habits in practical scenarios, we leverage the tree-sitter-languages to parse the code snippets and extract the basic logic blocks as the middle code to infill. For example, the abstract syntax tree (AST) represents the structure of Python code in a tree format, where each node in the tree represents a construct occurring in the source code. The tree’s hierarchical nature reflects the syntactic nesting of constructs in the code and includes various elements such as expressions, statements, and functions. By traversing and manipulating the AST, we can randomly extract the nodes of multiple levels and use the code context of the same file to uncover the masked node. Finally, we optimize the instruction model with a majority of standard SFT data and a small part of FIM instruction samples.
混合调优 由于大多数指令数据长度较短,我们构建了具有FIM格式的指令对,以保持基础模型的长上下文能力。受编程语言语法规则和实际场景中用户习惯的启发,我们利用 tree-sitter-languages 解析代码片段,并提取基本逻辑块作为中间代码进行填充。例如,抽象语法树(AST)以树形式表示Python代码的结构,树中的每个节点表示源代码中出现的构造。树的层次结构反映了代码中构造的语法嵌套,并包括各种元素,如表达式、语句和函数。通过遍历和操作AST,我们可以随机提取多个级别的节点,并使用同一文件的代码上下文来揭示掩码节点。最后,我们使用大多数标准SFT数据和一小部分FIM指令样本优化指令模型。
5 Decontamination(去污染)
To ensure that Qwen2.5-Coder does not produce inflated results due to test set leakage, we performed decontamination on all data, including both pre-training and post-training datasets. We removed key datasets such as HumanEval, MBPP, GSM8K, and MATH. The filtering was done using a 10-gram overlap method, where any training data with a 10-gram string-level overlap with the test data was removed.
为了确保Qwen2.5-Coder不会因为测试集泄漏而产生夸大的结果,我们对所有数据进行了去污染,包括预训练和后训练数据集。我们移除了关键数据集,如HumanEval、MBPP、GSM8K和MATH。过滤是使用10-gram重叠方法完成的,任何与测试数据存在10-gram字符串级重叠的训练数据都将被移除。
6 Evaluation on Base Models(基础模型评估)
For the base model, we conducted a comprehensive and fair evaluation in six key aspects, including code generation, code completion, code reasoning, mathematical reasoning, general natural language understanding and long-context modeling. To ensure the reproducibility of all results, we made all evaluation codes publicly available2. For comparing models, we chose the most popular and powerful open source language models, including the StarCoder2 and DeepSeek-Coder series. Below is the list of artifacts used in the evaluation for this section.
对于基础模型,我们在代码生成、代码补全、代码推理、数学推理、通用自然语言理解和长上下文建模等六个关键方面进行了全面和公平的评估。为了确保所有结果的可重现性,我们公开了所有评估代码。为了比较模型,我们选择了最流行和最强大的开源语言模型,包括StarCoder2和DeepSeek-Coder系列。以下是本节评估中使用的工件列表。
6.1 Code Generation(代码生成)

Table 4: All artifacts released and used in this section. 表4:本节中发布和使用的所有工件。
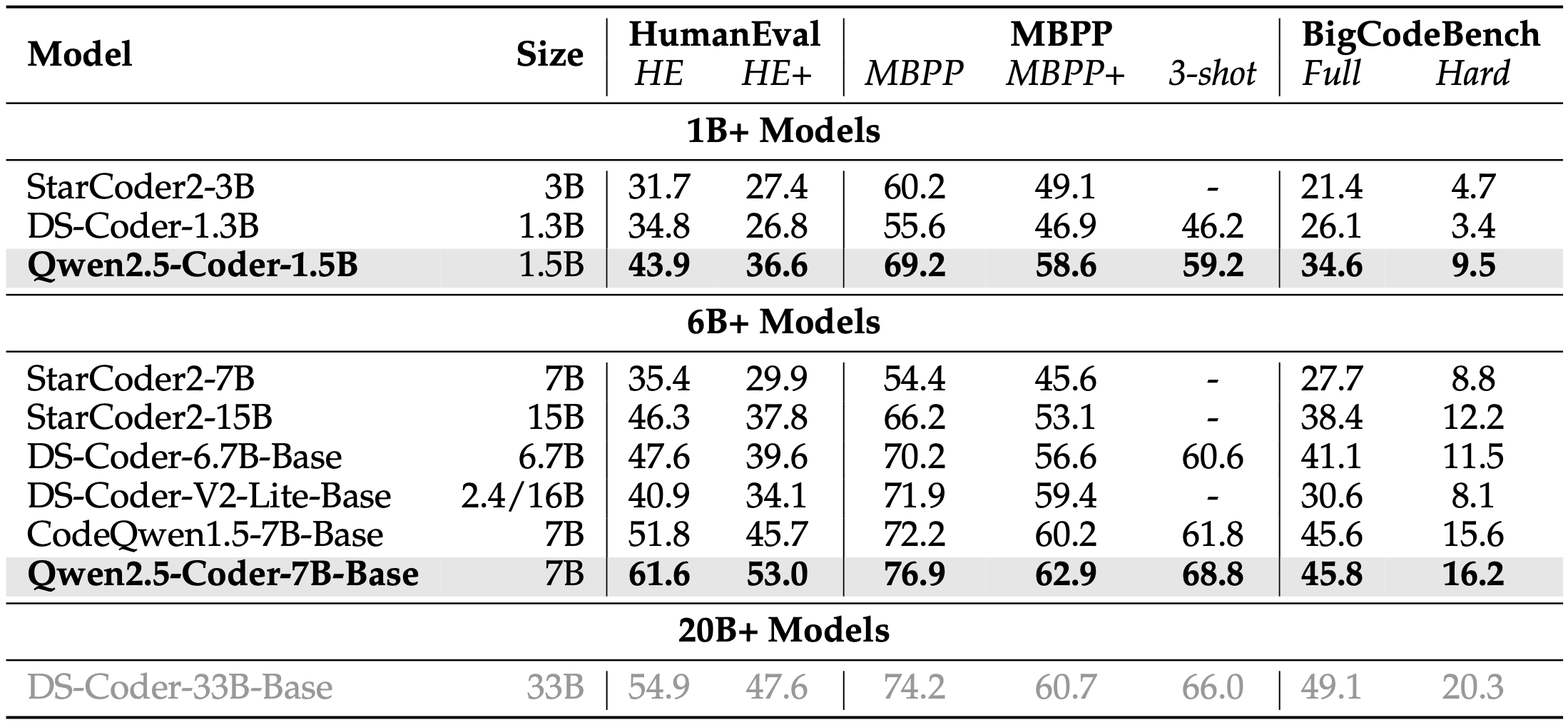
Table 5: Performance of various models on HumanEval, MBPP and the “complete” task of BigCodeBench. 表5:各种模型在HumanEval、MBPP和BigCodeBench的“完整”任务上的性能。
HumanEval and MBPP Code generation serves as a fundamental capability for code models to handle more complex tasks. We selected two popular code generation benchmarks to evaluate Qwen2.5-Coder, namely HumanEval (Chen et al., 2021) and MBPP (Austin et al., 2021). HumanEval consists of 164 manually written programming tasks, each providing a Python function signature and a docstring as input to the model. MBPP, on the other hand, comprises 974 programming problems created by crowdsource contributors. Each problem includes a problem statement (i.e., a docstring), a function signature, and three test cases.
HumanEval和MBPP 代码生成作为代码模型处理更复杂任务的基本能力。我们选择了两个流行的代码生成基准来评估Qwen2.5-Coder,即HumanEval和MBPP。HumanEval包含164个手动编写的编程任务,每个任务提供一个Python函数签名和一个docstring作为模型的输入。另一方面,MBPP包括由众包贡献者创建的974个编程问题。每个问题包括一个问题陈述(即docstring)、一个函数签名和三个测试用例。
To further ensure accurate evaluation, EvalPlus (Liu et al., 2023) extends HumanEval into HumanEval+ by adding 80 times more unique test cases and correcting inaccurate groundtruth solutions in HumanEval. Similarly, MBPP+ offers 35 times more test cases than the original MBPP.
为了进一步确保准确评估,EvalPlus将HumanEval扩展为HumanEval+,通过添加80倍的独特测试用例和纠正HumanEval中不准确的基准解决方案。类似地,MBPP+比原始MBPP提供了35倍的测试用例。
Additionally, we should notice that MBPP 3-shot is particularly suitable for monitoring model convergence during training. Early in the convergence process, the model tends to be unstable, causing significant fluctuation in metrics, and simple 3-shot examples effectively mitigate it. Therefore, we also report the results of MBPP 3-shot performance.
此外,我们应该注意,MBPP 3-shot特别适用于在训练过程中监控模型的收敛性。在收敛过程的早期阶段,模型往往不稳定,导致指标出现显著波动,而简单的3-shot示例可以有效地减轻这种情况。因此,我们还报告了MBPP 3-shot性能的结果。
As shown in Table 5, Qwen2.5-Coder have shown impressive performance in basic code generation, achieving state-of-the-art results among open-source models of the same size and surpassing even larger models. In particular, Qwen2.5-Coder-7B-Base outperforms the previous best dense model, DS-Coder-33B-Base, across all five metrics.
如表5所示,Qwen2.5-Coder在基本代码生成方面表现出色,在相同规模的开源模型中取得了最先进的结果,甚至超过了更大的模型。特别是,Qwen2.5-Coder-7B-Base在所有五个指标上均优于先前最佳的密集模型DS-Coder-33B-Base。
BigCodeBench-Complete BigCodeBench (Zhuo et al., 2024) is a recent and more challenging benchmark for code generation, primarily aimed at evaluating the ability of tool-use and complex instruction following. The base model generates the expected code through a completion mode, given a function signature and documentation, which is referred to as BigCodeBench-Complete. It consists of two subsets: the full set and the hard set. Compared to HumanEval and MBPP, BigCodeBench is suited for out-of-distribution (OOD) evaluation.
BigCodeBench-Complete BigCodeBench是一个最近更具挑战性的代码生成基准,主要用于评估工具使用和复杂指令遵循的能力。基础模型通过完成模式生成预期代码,给定一个函数签名和文档,这被称为BigCodeBench-Complete。它包括两个子集:完整集和困难集。与HumanEval和MBPP相比,BigCodeBench适用于分布外(OOD)评估。
Table 5 illustrates that Qwen2.5-Coder continues to show strong performance on BigCodeBench-Complete, underscoring the model’s generalization potential.
表5显示,Qwen2.5-Coder在BigCodeBench-Complete上继续表现出色,突显了模型的泛化潜力。
Multi-Programming Language The evaluations mentioned above focus on the Python language. However, we expect a strong code model to be not only proficient in Python but also versatile across multiple programming languages to meet the complex and evolving demands of software development. To more comprehensively evaluate Qwen2.5-Coder’s proficiency in handling multiple programming languages, we selected the MultiPL-E (Cassano et al., 2022) and choose to evaluate eight mainstream languages from these benchmark, including Python, C++, Java, PHP, TypeScript, C#, Bash and JavaScript.
多编程语言 上述评估侧重于Python语言。然而,我们期望一个强大的代码模型不仅精通Python,而且在多种编程语言上具有通用性,以满足软件开发的复杂和不断发展的需求。为了更全面地评估Qwen2.5-Coder在处理多种编程语言方面的熟练程度,我们选择了MultiPL-E,并选择了其中的八种主流语言进行评估,包括Python、C++、Java、PHP、TypeScript、C#、Bash和JavaScript。
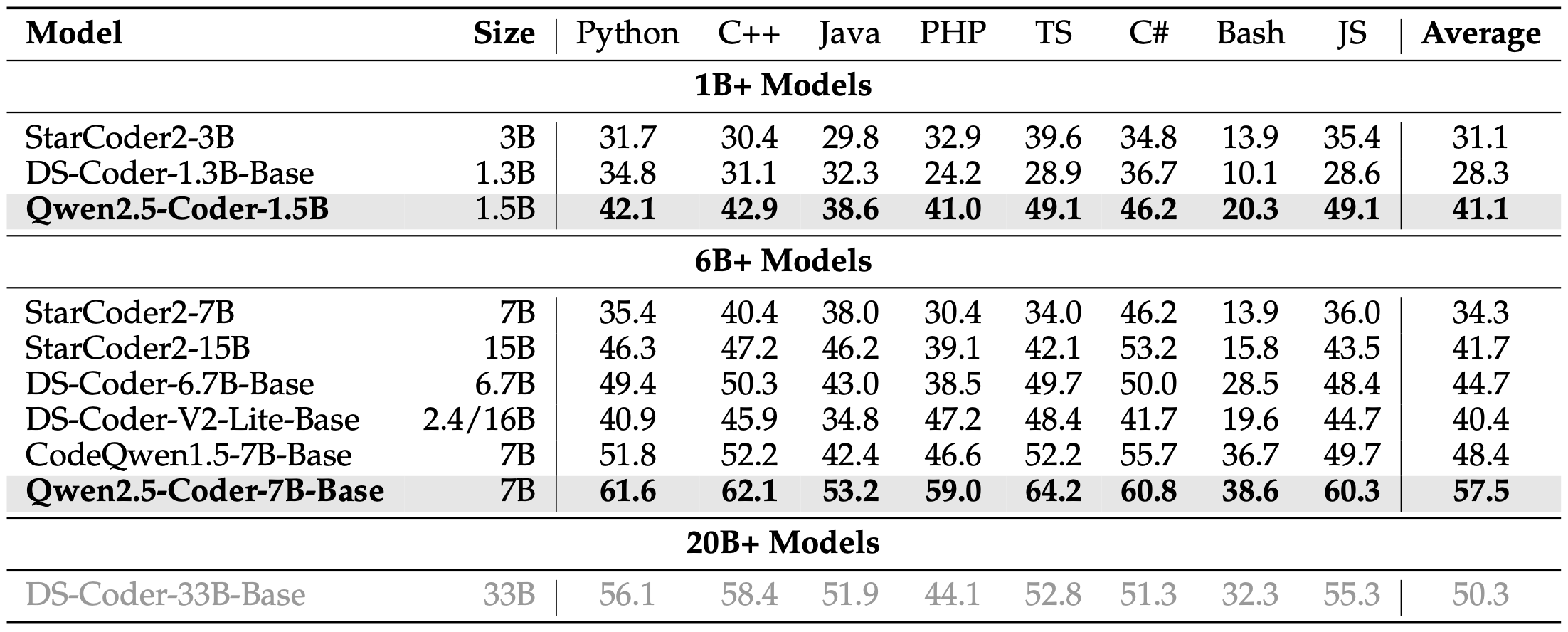
Table 6: Performance of different models on MultiPL-E. 表6:不同模型在MultiPL-E上的性能。
As shown in the table 6, Qwen2.5-Coder also achieved state-of-the-art results in the multi-programming language evaluation, with its capabilities well-balanced across various languages. It scored over 60% in five out of the eight languages.
如表6所示,Qwen2.5-Coder在多编程语言评估中也取得了最先进的结果,其能力在各种语言中得到了很好的平衡。在八种语言中,有五种语言的得分超过了60%。
6.2 Code Completion(代码补全)
HumanEval Infilling Many developer aid tools rely on the capability to autocomplete code based on preceding and succeeding code snippets. Qwen2.5-Coder utilizes the Fill-In-the-Middle (FIM) training strategy, as introduced in Bavarian et al. (2022), enabling the model to generate code that is contextually coherent. To assess its code completion proficiency, we utilize the HumanEval Infilling benchmark Allal et al. (2023). This benchmark challenges the model to accurately predict missing sections of code within tasks derived from HumanEval. We use the single-line infilling settings across Python, Java, and JavaScript, focusing on predicting a single line of code within given contexts. Performance was measured using the Exact Match metric, which determines the proportion of the first generated code line that precisely match the ground truth.
HumanEval填充 许多开发者辅助工具依赖于根据前后代码片段自动补全代码的能力。Qwen2.5-Coder利用了Fill-In-the-Middle(FIM)训练策略,如Bavarian等(2022)中所介绍的,使模型能够生成上下文连贯的代码。为了评估其代码补全能力,我们使用了HumanEval填充基准Allal等(2023)。该基准挑战模型准确预测HumanEval中的任务中缺失的代码部分。我们使用Python、Java和JavaScript的单行填充设置,重点是在给定上下文中预测一行代码。性能使用精确匹配度量标准进行衡量,该度量标准确定第一行生成的代码与基准解决方案完全匹配的比例。
The table 7 illustrates that Qwen2.5-Coder surpasses alternative models concerning model size. Specifically, Qwen2.5-Coder-1.5B achieves an average performance improvement of 3.7%, rivaling the majority of models exceeding 6 billion parameters. Moreover, Qwen2.5-Coder-7B-Base stands as the leading model among those over 6 billion parameters, matching the performance of the formidable 33 billion parameter model, DS-Coder-33B-Base. Notably, we excluded DS-Coder-v2-236B from comparison due to its design focus not being on code completion tasks.
表7显示,Qwen2.5-Coder在模型大小方面超过了替代模型。具体来说,Qwen2.5-Coder-1.5B的平均性能提升为3.7%,与大多数超过60亿参数的模型相媲美。此外,Qwen2.5-Coder-7B-Base是超过60亿参数的模型中的领先模型,与庞大的33亿参数模型DS-Coder-33B-Base的性能相匹配。值得注意的是,由于DS-Coder-v2-236B的设计重点不在代码补全任务上,我们将其排除在比较之外。
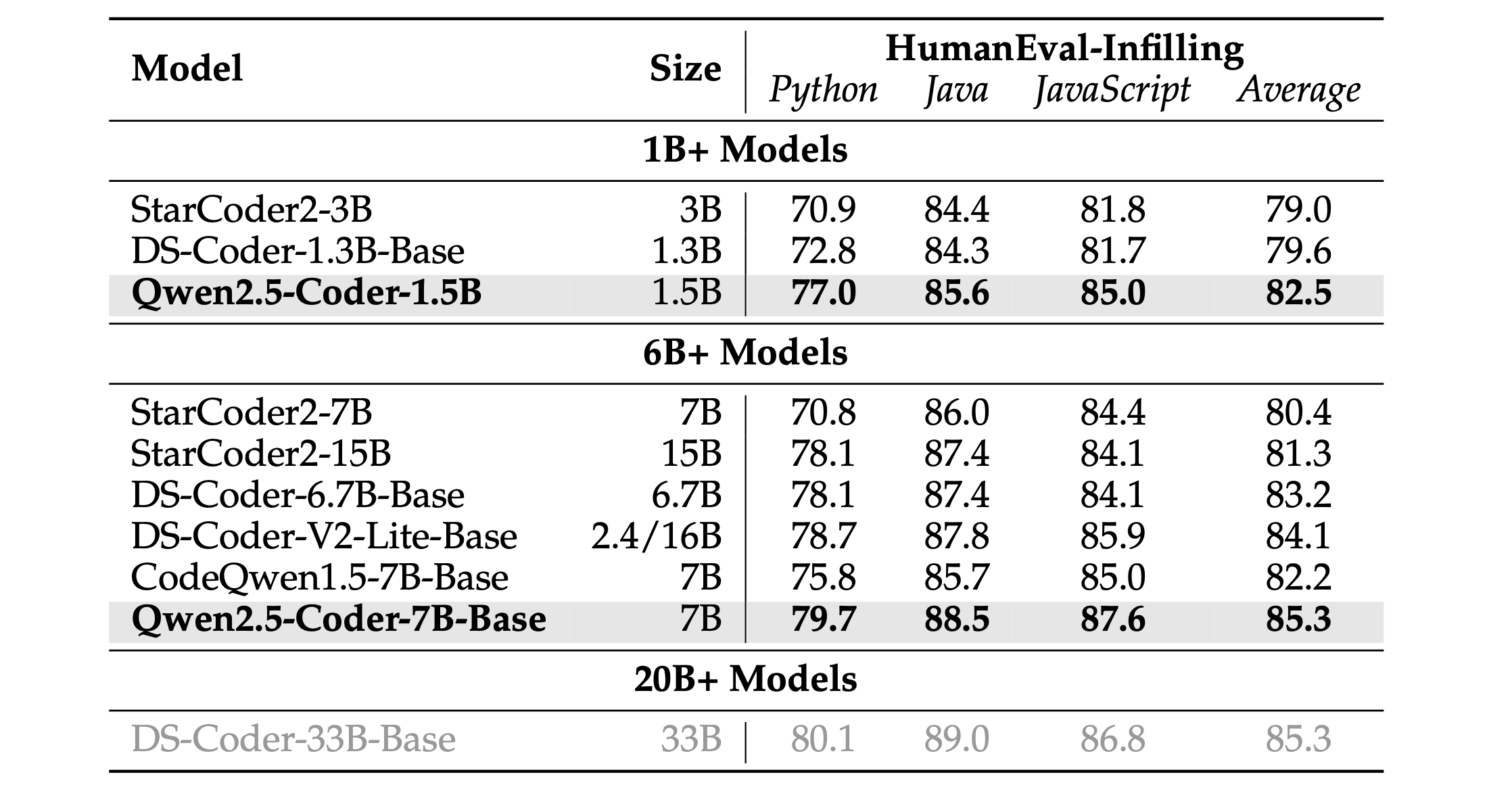
Table 7: Performance of different approaches on the HumanEval Infilling Tasks 表7:不同方法在HumanEval填充任务上的性能。
6.3 Code Reasoning(代码推理)
Code is a highly abstract form of logical language, and reasoning based on code helps us determine whether a model truly understands the reasoning flow behind the code. We selected CRUXEval (Gu et al., 2024) as the benchmark, which includes 800 Python functions along with corresponding input-output examples. It consists of two distinct tasks: CRUXEval-I, where the large language model (LLM) must predict the output based on a given input; and CRUXEval-O, where the model must predict the input based on a known output. For both CRUXEval-I and CRUXEval-O, we used a chain-of-thought (CoT) approach, requiring the LLM to output steps sequentially during simulated execution.
代码是一种高度抽象的逻辑语言,基于代码的推理有助于我们确定模型是否真正理解了代码背后的推理流程。我们选择了CRUXEval作为基准,其中包括800个Python函数以及相应的输入输出示例。它包括两个不同的任务:CRUXEval-I,其中大型语言模型(LLM)必须根据给定的输入预测输出;以及CRUXEval-O,其中模型必须根据已知的输出预测输入。对于CRUXEval-I和CRUXEval-O,我们使用了一种思维链(CoT)方法,要求LLM在模拟执行过程中按顺序输出步骤。
As shown in Table 8, Qwen2.5-Coder delivered highly promising results, achieving a score of 56.5 on CRUXEval-I and 56.0 on CRUXEval-O, thanks to our focus on executable quality during the code cleaning process.
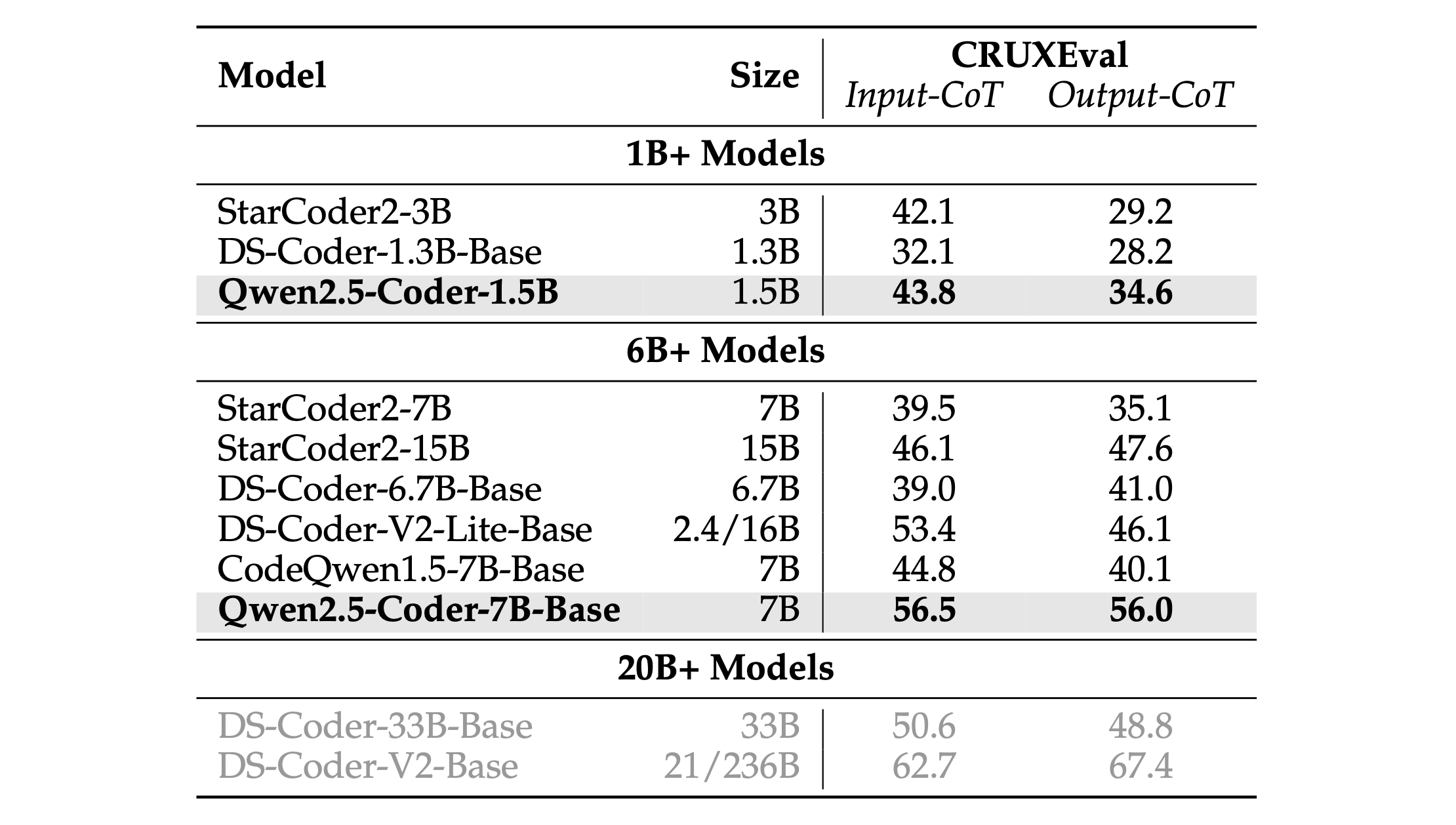
Table 8: Performance of different models on CRUXEval with Input-CoT and Output-CoT settings. 表8:不同模型在CRUXEval上的性能,使用Input-CoT和Output-CoT设置。
如表8所示,由于我们在代码清理过程中专注于可执行质量,Qwen2.5-Coder取得了非常令人满意的结果,在CRUXEval-I上获得了56.5分,在CRUXEval-O上获得了56.0分。
6.4 Math Reasoning(数学推理)
Mathematics and coding have always been closely intertwined. Mathematics forms the foundational discipline for coding, while coding serves as a vital tool in mathematical fields. As such, we expect an open and powerful code model to exhibit strong mathematical capabilities as well. To assess Qwen2.5-Coder’s mathematical performance, we selected five popular benchmarks, including MATH (Hendrycks et al., 2021), GSM8K (Cobbe et al., 2021), MMLU-STEM (Hendrycks et al., 2020) and TheoremQA (Chen et al., 2023). As shown in Table 9, Table 3 highlights Qwen2.5-Coder’s strengths in mathematics, which likely stem from two key factors: first, the model’s strong foundation built on Qwen2.5, and second, the careful mixing of code and mathematical data during training, which has ensured a well-balanced performance across these domains.
数学和编码一直紧密相连。数学是编码的基础学科,而编码在数学领域中是一种重要工具。因此,我们期望一个开放和强大的代码模型在数学方面表现出色。为了评估Qwen2.5-Coder的数学性能,我们选择了五个流行的基准,包括MATH、GSM8K、MMLU-STEM和TheoremQA。如表9所示,表3突出了Qwen2.5-Coder在数学方面的优势,这可能源于两个关键因素:首先,模型在Qwen2.5的基础上建立了坚实的基础;其次,在训练过程中仔细混合了代码和数学数据,确保了这些领域的性能平衡。
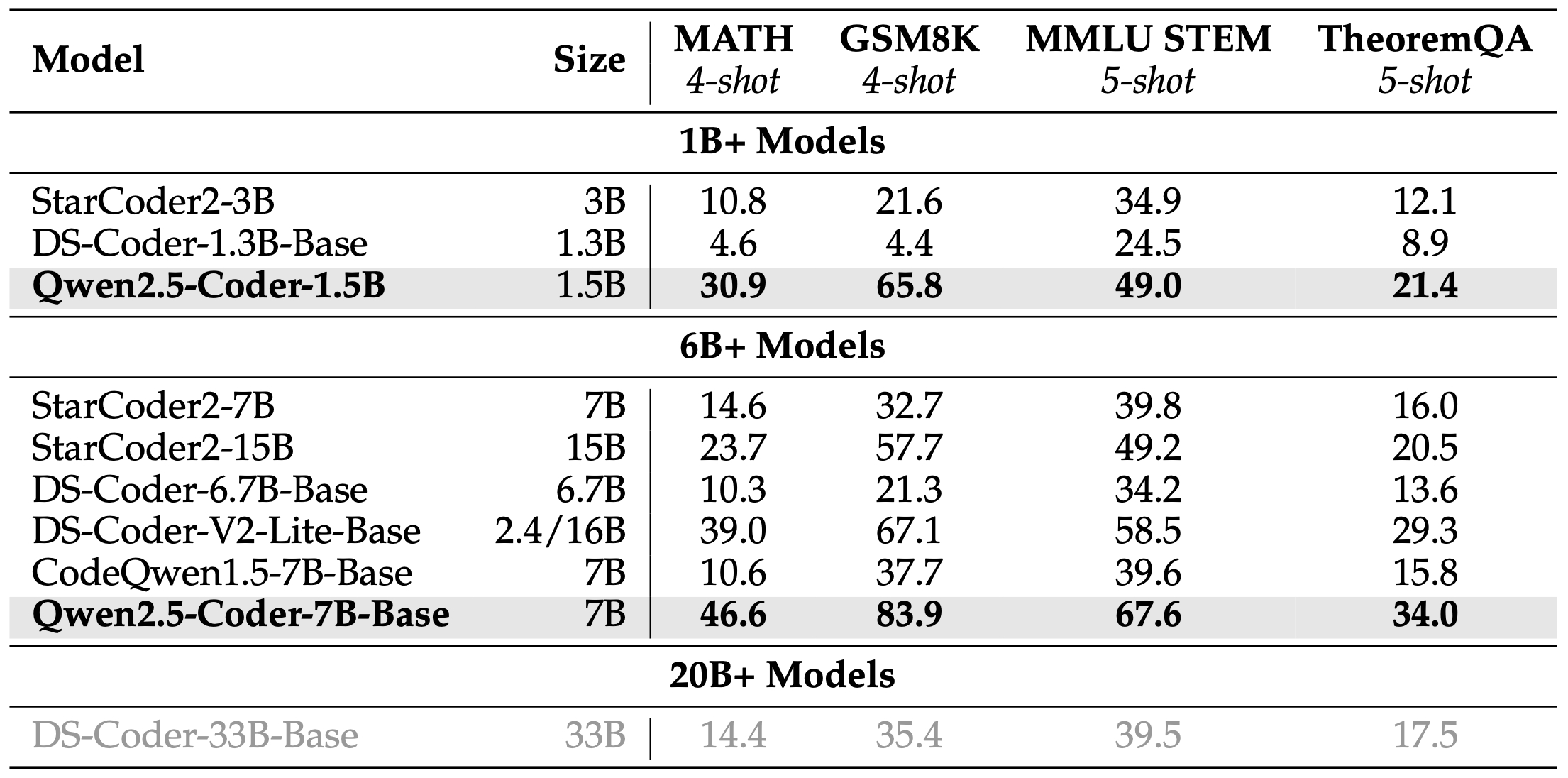
Table 9: Performance of various models on four math benchmark, named MATH, GSM8K, MMLU STEM and TheoremQA respectively 表9:各种模型在四个数学基准上的性能,分别命名为MATH、GSM8K、MMLU STEM和TheoremQA。
6.5 General Natural Language(通用自然语言)
In addition to mathematical ability, we aim to retain as much of the base model’s general-purpose capabilities as possible, such as general knowledge. To evaluate general natural language understanding, we selected MMLU (Hendrycks et al., 2021) and its variant MMLU-Redux (Gema et al., 2024), along with four other benchmarks: ARC-Challenge (Clark et al., 2018), TruthfulQA (Lin et al., 2021), WinoGrande (Sakaguchi et al., 2019), and HellaSwag (Zellers et al., 2019). Similar to the results in mathematics, Table 11 highlights Qwen2.5-Coder’s advantage in general natural language capabilities compared to other coders, further validating the effectiveness of Qwen2.5-Coder data mixing strategy.
除了数学能力外,我们还希望尽可能保留基础模型的通用能力,例如通用知识。为了评估通用自然语言理解,我们选择了MMLU及其变体MMLU-Redux,以及其他四个基准:ARC-Challenge、TruthfulQA、WinoGrande和HellaSwag。与数学结果类似,表11突出了Qwen2.5-Coder在通用自然语言能力方面相对于其他编码器的优势,进一步验证了Qwen2.5-Coder数据混合策略的有效性。
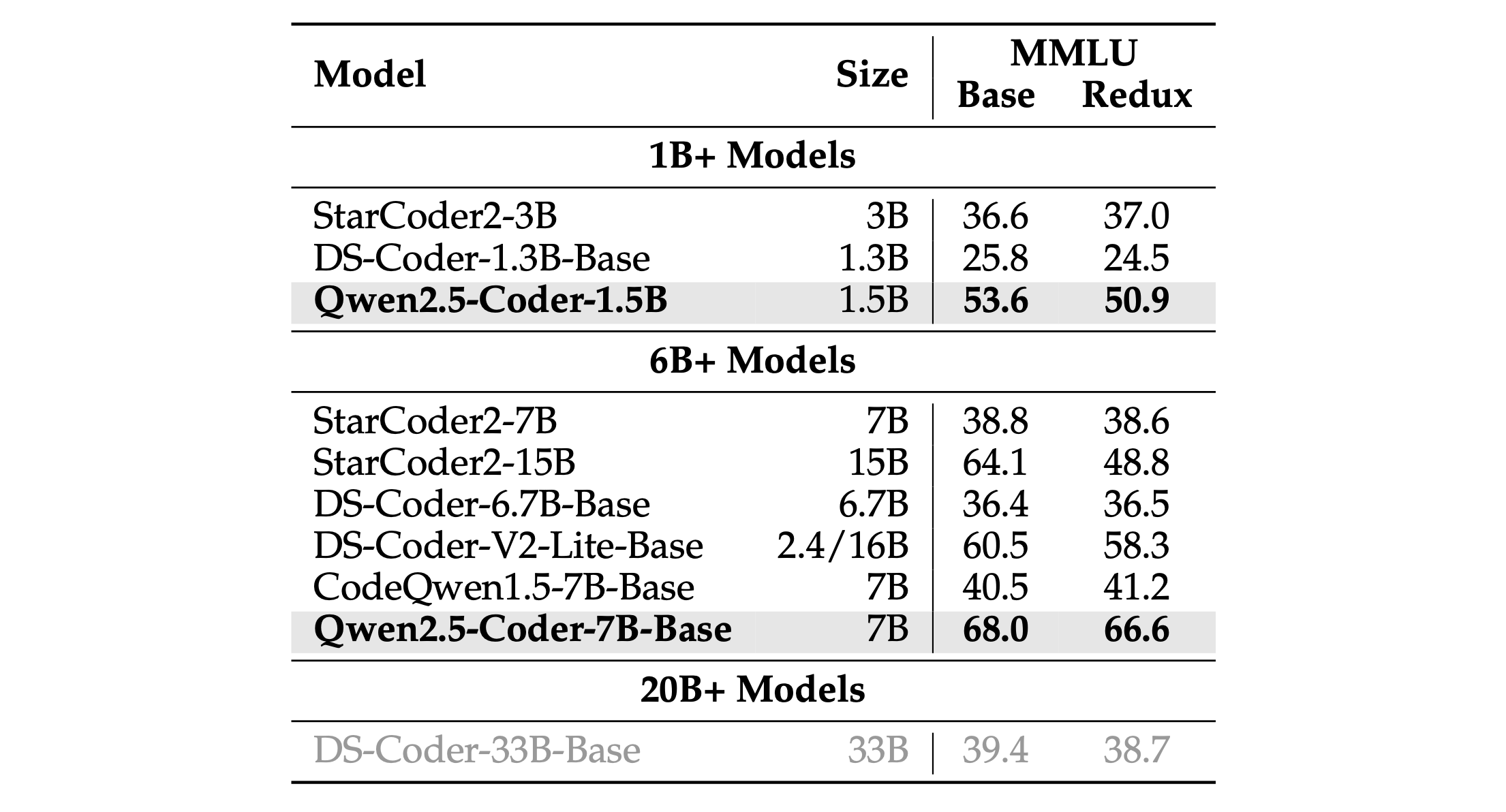
Table 10: MMLU results of different models, a general benchmark for common knowledge. 表10:不同模型的MMLU结果,这是一个通用知识的常见基准。
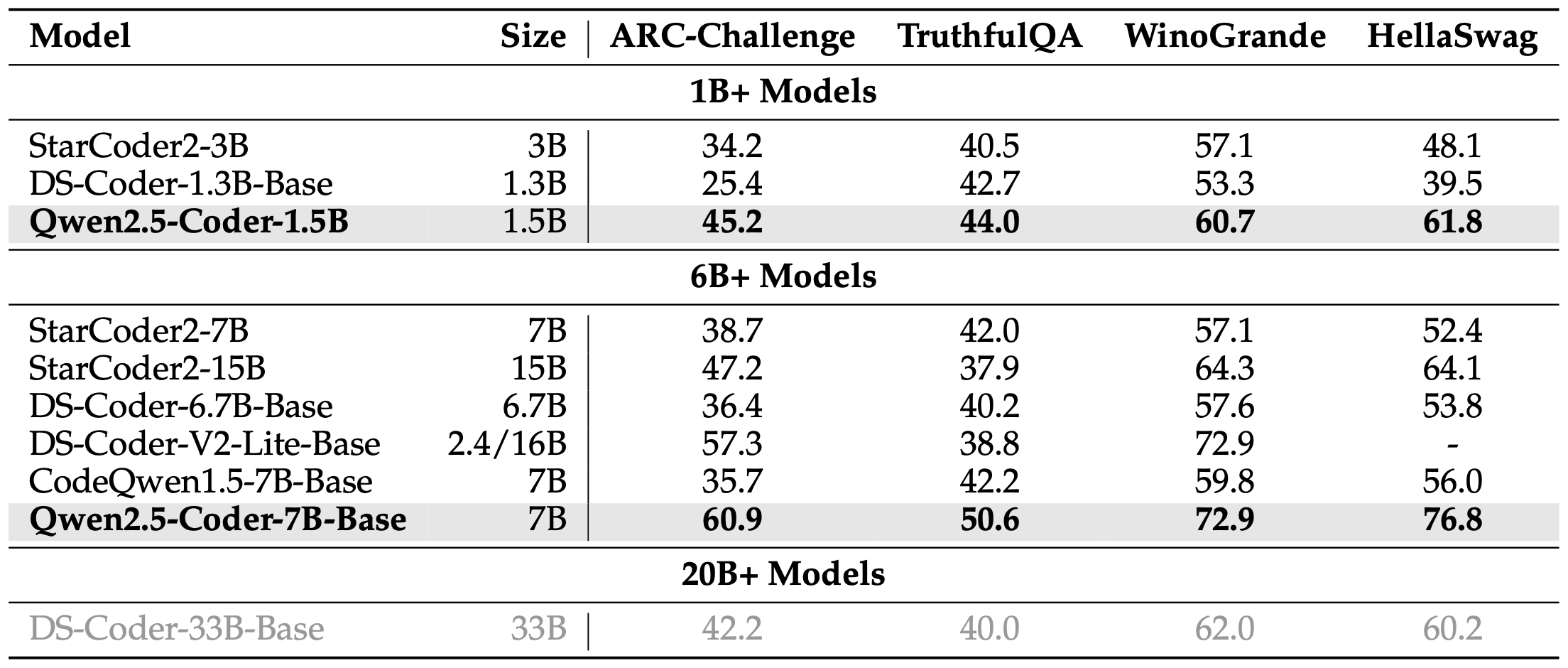
Table 11: General performance of different models on four popular general benchmark, ARC-Challenge, TruthfulQA, WinoGrande and HellaSwag. 表11:不同模型在四个流行的通用基准上的通用性能,包括ARC-Challenge、TruthfulQA、WinoGrande和HellaSwag。
6.6 Long-Context Evaluation(长上下文评估)
Long context capability is crucial for code LLMs, serving as the core skill for understanding repository-level code and becoming a code agent. However, most of current code models still have very limited support for length, which hinders their potential for practical application. Qwen2.5-Coder aims to further advance the progress of open-source code models in long context modeling. To achieve this, we have collected and constructed long sequence code data at the repository level for pre-training. Through careful data proportioning and organization, we have enabled it to support input lengths of up to 128K tokens.
长上下文能力对于代码LLM至关重要,是理解存储库级代码和成为代码代理的核心技能。然而,目前大多数代码模型仍然对长度支持非常有限,这阻碍了它们在实际应用中的潜力。Qwen2.5-Coder旨在进一步推进开源代码模型在长上下文建模方面的进展。为了实现这一目标,我们收集和构建了存储库级别的长序列代码数据进行预训练。通过仔细的数据比例和组织,我们使其支持长达128K个标记的输入长度。
Needle in the Code We created a simple but basic synthetic task called Needle in the Code, inspired by popular long-context evaluations in the text domain. In this task, we inserted a very simple custom function at various positions within a code repo (we chose Megatron 3 to honor its contributions to open-source LLMs!) and tested whether the model could replicate this function at the end of the codebase. The figure below shows that Qwen2.5-Coder is capable of successfully completing this task within a 128k length range.
代码中的针 我们创建了一个简单但基本的合成任务,称为代码中的针,灵感来自文本领域中流行的长上下文评估。在这个任务中,我们在代码库的各个位置插入一个非常简单的自定义函数(我们选择了Megatron 3来表彰它对开源LLM的贡献!),并测试模型是否能在代码库的末尾复制这个函数。下图显示,Qwen2.5-Coder能够在128k长度范围内成功完成这个任务。
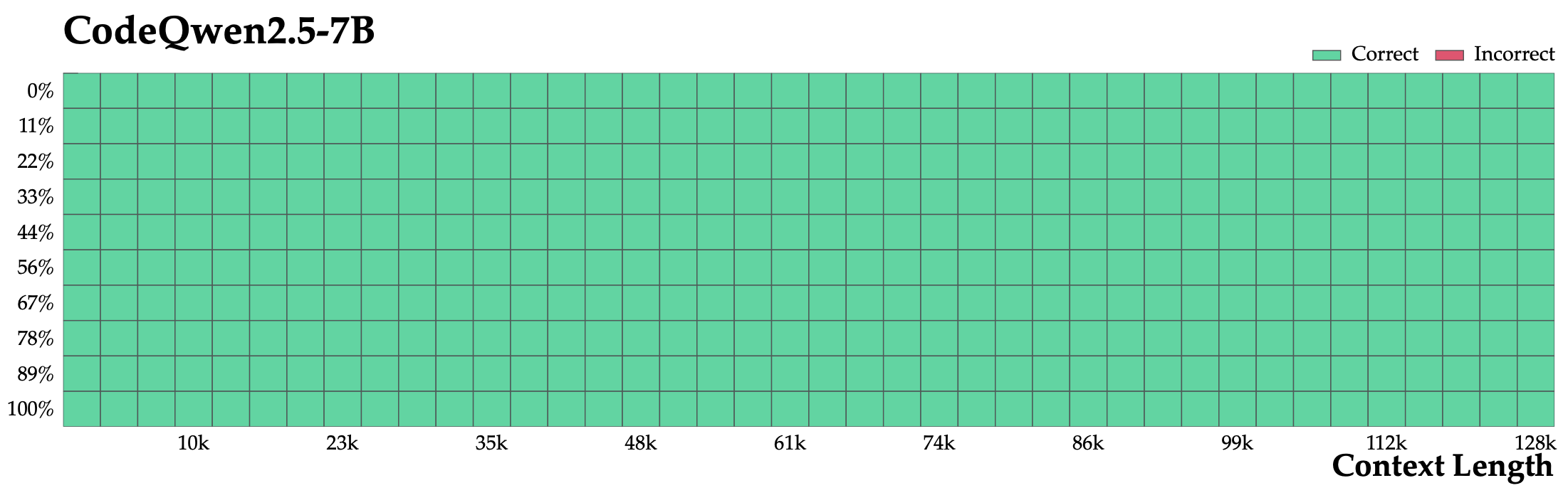
Figure 5: The long context ability of Qwen2.5-Coder, evaluated by Needle in Code. 图5:通过代码中的针评估Qwen2.5-Coder的长上下文能力。
7 Evaluation on Instruct Models(指令模型评估)
For the evaluation of the instruct models, we rigorously assessed six core areas: code generation, code reasoning, code editing, text-to-sql, mathematical reasoning and general natural language understanding. The evaluation was structured to ensure a fair and thorough comparison across models. All evaluation code is publicly accessible for reproducibility4. To ensure a broad comparison, we included some of the most popular and widely-used open-source instruction-tuned models, notably versions from the DeepSeek-Coder series and Codestral models. Below is a list of all artifacts referenced in this section.
对于指令模型的评估,我们严格评估了六个核心领域:代码生成、代码推理、代码编辑、文本到SQL、数学推理和通用自然语言理解。评估结构旨在确保在模型之间进行公平和彻底的比较。所有评估代码都是公开可访问的,以便进行再现。为了确保广泛的比较,我们包括了一些最流行和广泛使用的开源指令调优模型,特别是DeepSeek-Coder系列和Codestral模型的版本。以下是本节中引用的所有工件列表。

Table 12: All artifacts released and used in this section. 表12:本节中发布和使用的所有工件。
7.1 Code Generation(代码生成)
Building on the performance improvements of the Qwen2.5-Coder series base models, our Qwen2.5-Coder series instruct models similarly demonstrated outstanding performance in code generation tasks.
在Qwen2.5-Coder系列基础模型的性能改进基础上,我们的Qwen2.5-Coder系列指令模型在代码生成任务中同样表现出色。
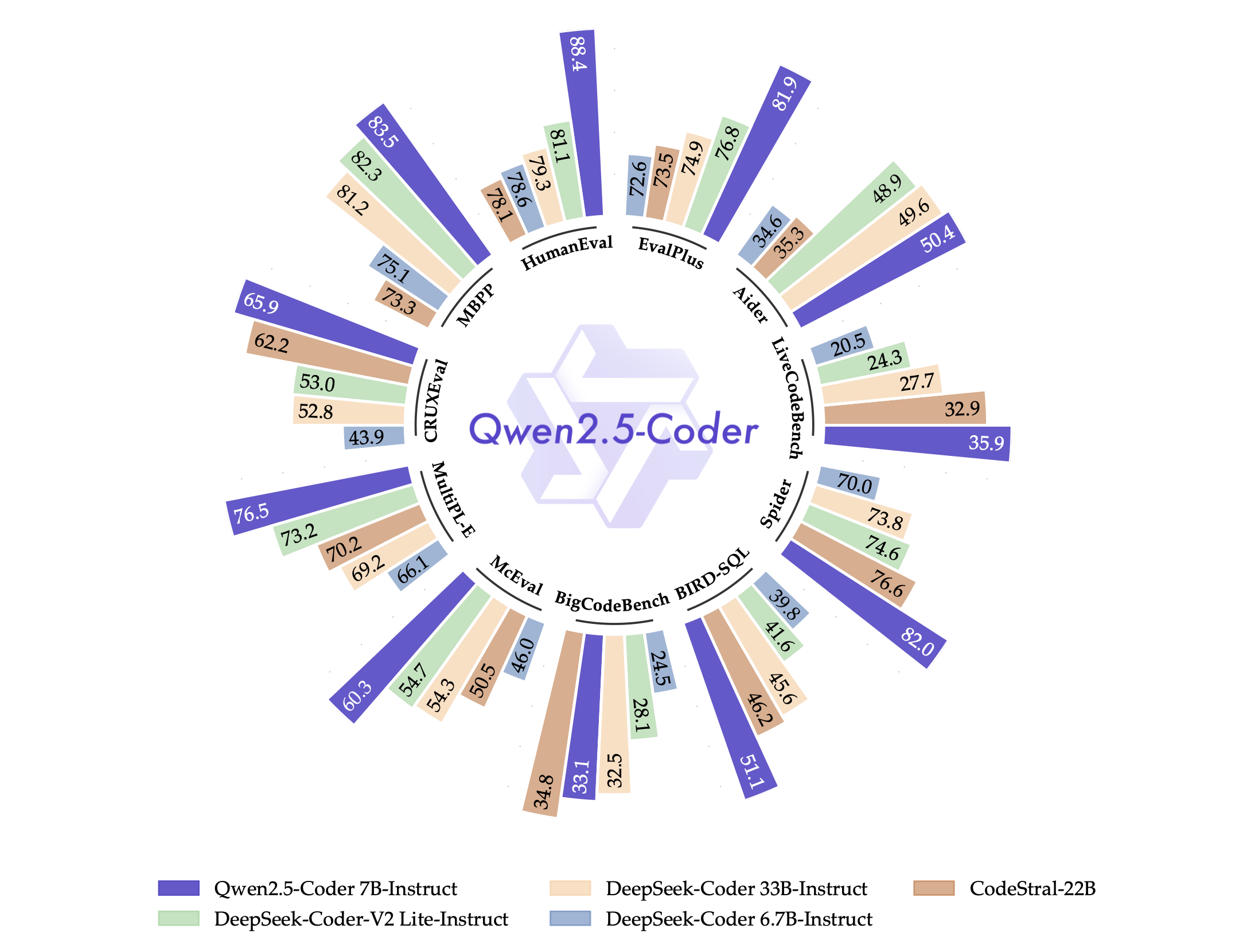
HumanEval and MBPP We also evaluated the code generation capabilities of the Qwen2.5-Coder series instruct models using the EvalPlus (Liu et al., 2023) dataset. As illustrated by the experimental results in Table 13, our Qwen2.5-Coder-7B-Instruct model demonstrated superior accuracy, significantly outperforming other models with a comparable number of parameters. Remarkably, it even exceeded the performance of larger models with over 20 billion parameters, such as CodeStral-22B and DS-Coder-33B-Instruct. Notably, Qwen2.5-Coder-7B-Instruct was the only model in our evaluation to surpass an 80% accuracy rate on HumanEval+, achieving an impressive 84.1%.
HumanEval和MBPP 我们还使用EvalPlus数据集评估了Qwen2.5-Coder系列指令模型的代码生成能力。正如表13中的实验结果所示,我们的Qwen2.5-Coder-7B-Instruct模型表现出色,明显优于其他具有相同数量参数的模型。值得注意的是,它甚至超过了具有超过20亿参数的更大模型的性能,例如CodeStral-22B和DS-Coder-33B-Instruct。值得注意的是,Qwen2.5-Coder-7B-Instruct是我们评估中唯一一个在HumanEval+上超过80%准确率的模型,实现了令人印象深刻的84.1%。
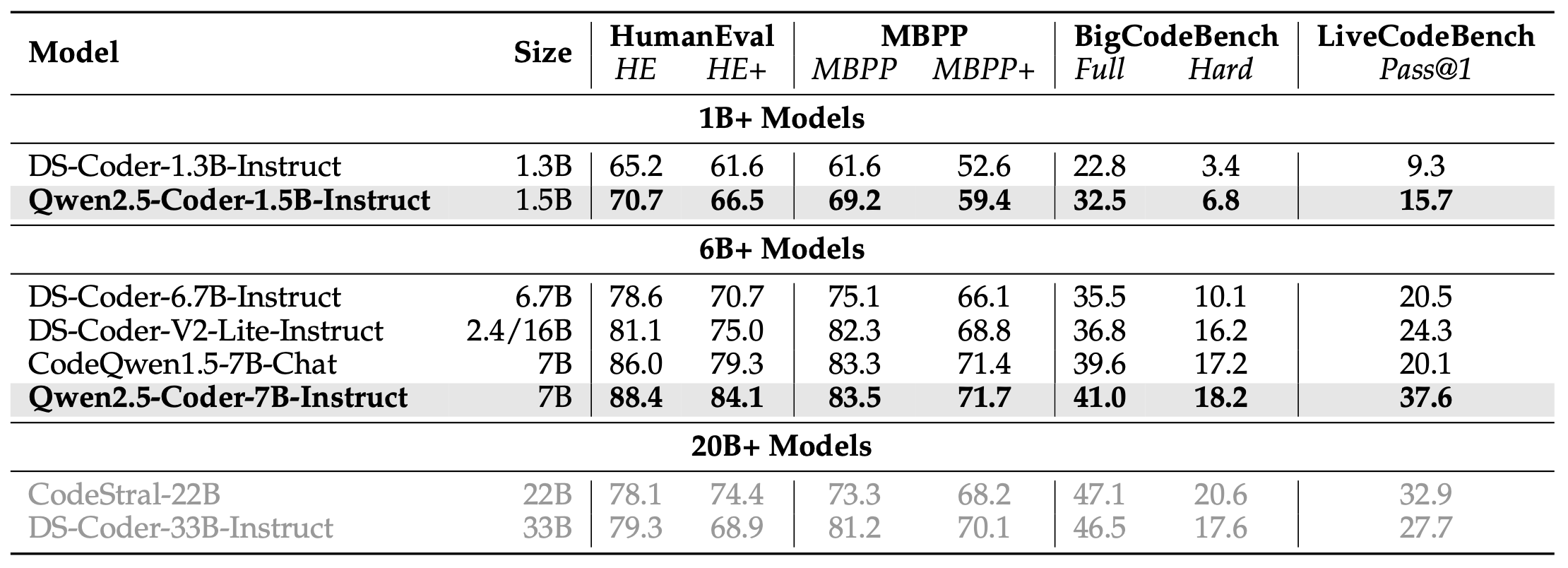
Table 13: The performance of different instruct models on code generation by HumanEval, MBPP, bigcodebench and livecodebench. For bigcodebench here, we report “instruct” tasks score. 表13:不同指令模型在HumanEval、MBPP、bigcodebench和livecodebench上的代码生成性能。对于bigcodebench,我们报告“指令”任务分数。
BigCodeBench-Instruct The instruct split provided by BigCodeBench (Zhuo et al., 2024) is intended for assessing the code generation abilities of instruct models. We assessed the Qwen2.5-Coder series instruct models on the BigCodeBench-Instruct. As shown in Table 13, the Qwen2.5-Coder-7B-Instruct outperformed other instruct models with similar parameter sizes, achieving higher accuracy scores on both the full and hard subsets, reaching 41.0% on the full subset and 18.2% on the hard subset, demonstrating the Qwen2.5-Coder series instruct models’ powerful code generation capabilities.
BigCodeBench-Instruct BigCodeBench提供的指令分割用于评估指令模型的代码生成能力。我们在BigCodeBench-Instruct上评估了Qwen2.5-Coder系列指令模型。如表13所示,Qwen2.5-Coder-7B-Instruct在全集和困难集上的准确性得分均高于其他具有相似参数大小的指令模型,分别达到41.0%和18.2%,展示了Qwen2.5-Coder系列指令模型强大的代码生成能力。
LiveCodeBench LiveCodeBench (Jain et al., 2024) is a comprehensive and contamination-free benchmark designed to evaluate the coding capabilities of LLMs. It continuously gathers new problems from leading competitive programming platforms like LeetCode5, AtCoder6, and CodeForces7, ensuring an up-to-date and diverse set of challenges. Currently, it hosts over 600 high-quality coding problems published between May 2023 and September 2024.
LiveCodeBench LiveCodeBench是一个全面且无污染的基准,旨在评估LLM的编码能力。它不断从领先的竞争性编程平台(如LeetCode、AtCoder和CodeForces)收集新问题,确保提供最新和多样化的挑战。目前,它托管了600多个高质量的编码问题,发布于2023年5月至2024年9月之间。
To better demonstrate our model’s effectiveness on real-world competitive programming tasks, we conduct evaluation of the Qwen-2.5-Coder series instruct models on the LiveCodeBench (2305-2409) dataset. As illustrated in Table 13, the Qwen-2.5-Coder-7B-Instruct model achieved an impressive Pass@1 accuracy of 37.6%, significantly outperforming other models of comparable parameter scales. Notably, it also surpassed larger models such as CodeStral-22B and DS-Coder-33B-Instruct, underscoring the Qwen-2.5-Coder series’ exceptional capabilities in handling complex code generation challenges.
为了更好地展示我们的模型在现实世界竞争性编程任务上的有效性,我们对Qwen-2.5-Coder系列指令模型在LiveCodeBench(2305-2409)数据集上进行了评估。如表13所示,Qwen-2.5-Coder-7B-Instruct模型取得了令人印象深刻的Pass@1准确率37.6%,明显优于其他具有相似参数规模的模型。值得注意的是,它还超过了更大的模型,如CodeStral-22B和DS-Coder-33B-Instruct,突显了Qwen-2.5-Coder系列在处理复杂代码生成挑战方面的卓越能力。
Multi-Programming Language The Qwen2.5-Coder series instruct models have inherited the high performance of the base model on the Multi-Programming Language. To further evaluate their capabilities, we tested the instruct models on two specific benchmarks: MultiPL-E (Cassano et al., 2022) and McEval (Chai et al., 2024).
多编程语言 Qwen2.5-Coder系列指令模型继承了基础模型在多编程语言上的高性能。为了进一步评估它们的能力,我们在两个特定基准上测试了指令模型:MultiPL-E和McEval。
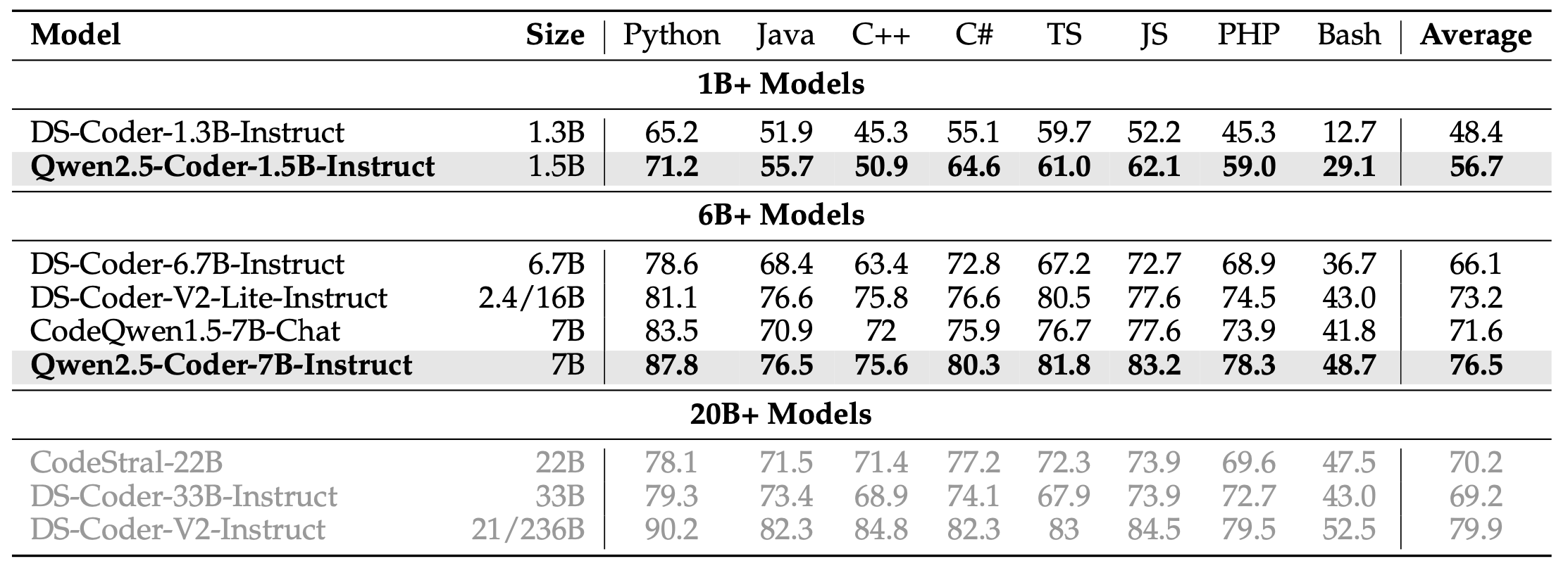
Table 14: The performance of different approaches on instruct format MultiPL-E. 表14:不同方法在指令格式MultiPL-E上的性能。
MultiPL-E As demonstrated by the evaluation results in Table 14, Qwen2.5-Coder-7B-Instruct consistently outperforms other models with the same number of parameters, including DS-Coder-V2-Lite-Instruct, in code generation tasks across eight programming languages. With an average accuracy of 76.5%, Qwen2.5-Coder-7B-Instruct surpasses even larger models such as CodeStral-22B and DS-Coder-33B-Instruct (despite having over 20 billion parameters), highlighting its powerful code generation capabilities in multiple programming languages.
MultiPL-E 如表14中的评估结果所示,Qwen2.5-Coder-7B-Instruct在八种编程语言的代码生成任务中始终优于其他具有相同数量参数的模型,包括DS-Coder-V2-Lite-Instruct。Qwen2.5-Coder-7B-Instruct的平均准确率为76.5%,甚至超过了更大的模型,如CodeStral-22B和DS-Coder-33B-Instruct(尽管后者具有超过20亿参数),突显了它在多种编程语言中强大的代码生成能力。
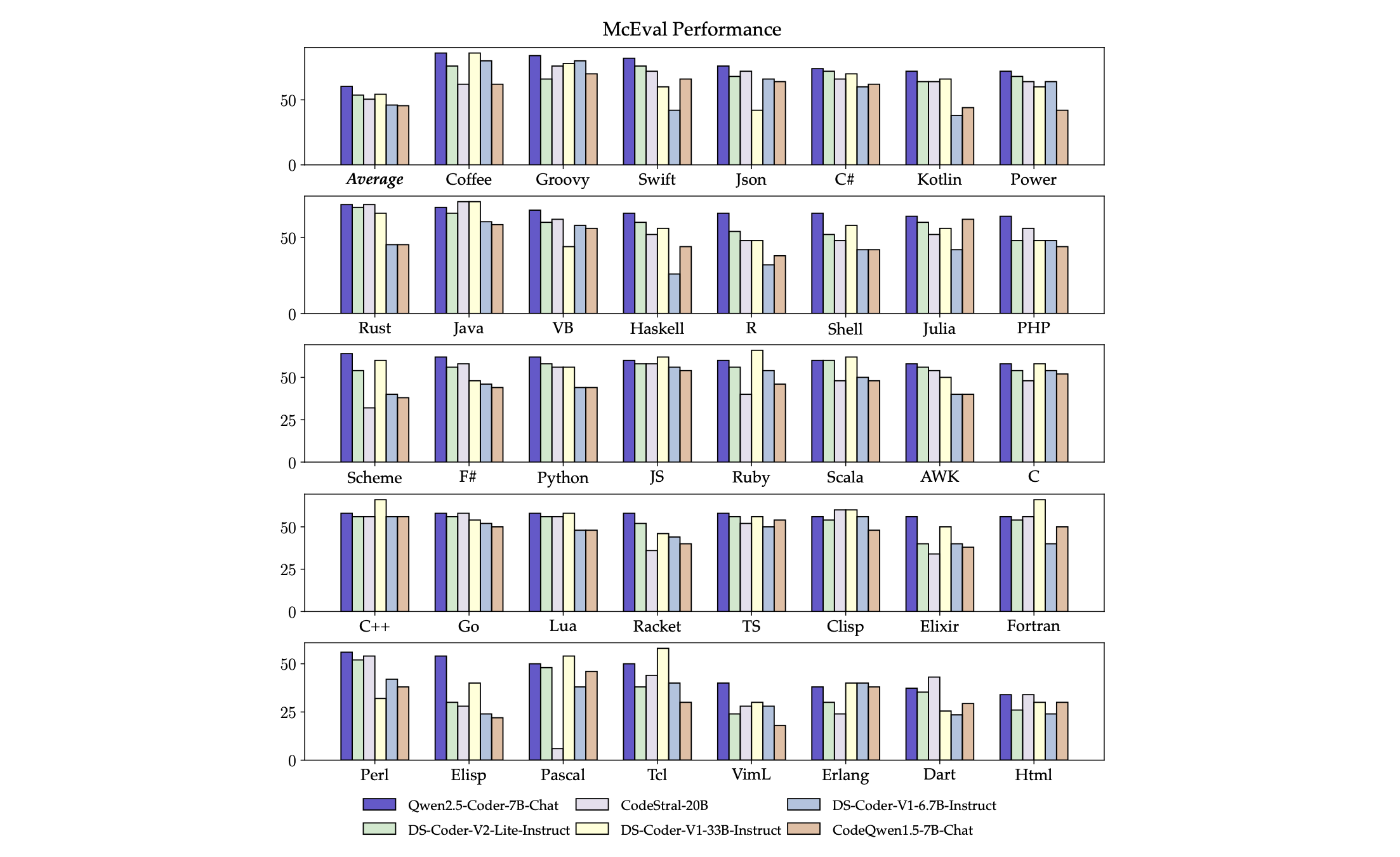
Figure 6: The McEval Performance of Qwen2.5-Coder-7B-Instruct compared with popular open-source large code models with similar size. 图6:Qwen2.5-Coder-7B-Instruct与具有相似大小的流行开源大型代码模型在McEval上的性能比较。
McEval To comprehensively assess the code generation capabilities of the Qwen2.5-Coder series models across a broader range of programming languages, we evaluated them on the McEval benchmark (Chai et al., 2024), which spans 40 programming languages and includes 16,000 test cases. As shown in Figure 6, the Qwen2.5-Coder-7B-Instruct model excels when compared to other open-source models on the McEval benchmark, particularly across a wide range of programming languages. Its average accuracy not only exceeds that of much larger models such as DS-Coder-33B-Instruct and CodeStral-22B but also demonstrates a notable advantage over models of comparable parameter size.
McEval 为了全面评估Qwen2.5-Coder系列模型在更广泛的编程语言范围内的代码生成能力,我们在McEval基准上对其进行了评估,该基准涵盖了40种编程语言,包括16000个测试用例。如图6所示,与McEval基准上的其他开源模型相比,Qwen2.5-Coder-7B-Instruct模型表现出色,尤其是在各种编程语言中。它的平均准确率不仅超过了DS-Coder-33B-Instruct和CodeStral-22B等更大的模型,而且在具有相同参数大小的模型中表现出明显优势。
7.2 Code Reasoning(代码推理)
To assess the code reasoning capabilities of the Qwen2.5-Coder series instruct models, we performed an evaluation on CRUXEval (Gu et al., 2024). As illustrated by the experimental results in Table 15, the Qwen2.5-Coder-7B-Instruct model achieved Input-CoT and Output-CoT accuracies of 65.8% and 65.9%, respectively. This represents a notable improvement over the DS-Coder-V2-Lite-Instruct model, with gains of 12.8% in Input-CoT accuracy and 13.0% in Output-CoT accuracy. Furthermore, the Qwen2.5-Coder-7B-Instruct model outperformed larger models, such as the CodeStral-22B and DS-Coder-33B-Instruct, underscoring its superior code reasoning capabilities despite its smaller size.
为了评估Qwen2.5-Coder系列指令模型的代码推理能力,我们在CRUXEval上进行了评估。如表15中的实验结果所示,Qwen2.5-Coder-7B-Instruct模型的Input-CoT和Output-CoT准确率分别为65.8%和65.9%。这相对于DS-Coder-V2-Lite-Instruct模型来说是一个显著的提高,Input-CoT准确率提高了12.8%,Output-CoT准确率提高了13.0%。此外,Qwen2.5-Coder-7B-Instruct模型在较大的模型(如CodeStral-22B和DS-Coder-33B-Instruct)上表现出色,突显了其在较小尺寸下优越的代码推理能力。
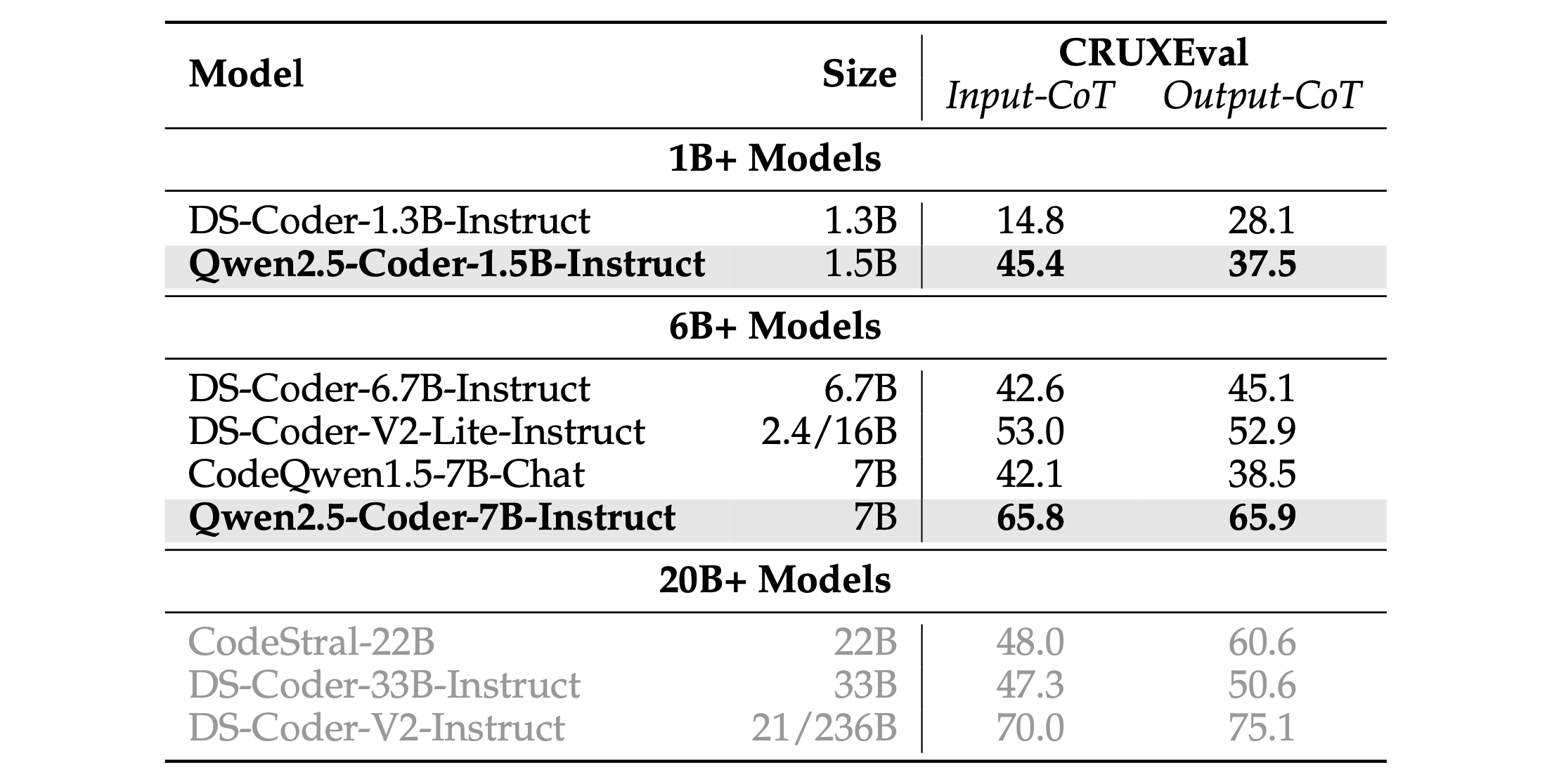
Table 15: The CRUXEval performance of different instruct models, with Input-CoT and Output-CoT settings. 表15:不同指令模型在CRUXEval上的性能,使用Input-CoT和Output-CoT设置。
Figure 7 illustrates the relationship between model sizes and code reasoning capabilities. The Qwen2.5-Coder instruct models stand out for delivering superior code reasoning performance with the fewest parameters, surpassing the results of other open-source large language models by a significant margin. According to this trend, we expect that code reasoning performance comparable to GPT-4o could be achieved with a model around the 30 billion parameters scale.
图7展示了模型大小与代码推理能力之间的关系。Qwen2.5-Coder指令模型以最少的参数提供了优越的代码推理性能,大幅超过了其他开源大型语言模型的结果。根据这一趋势,我们预计,使用大约300亿参数规模的模型可以实现与GPT-4o相媲美的代码推理性能。
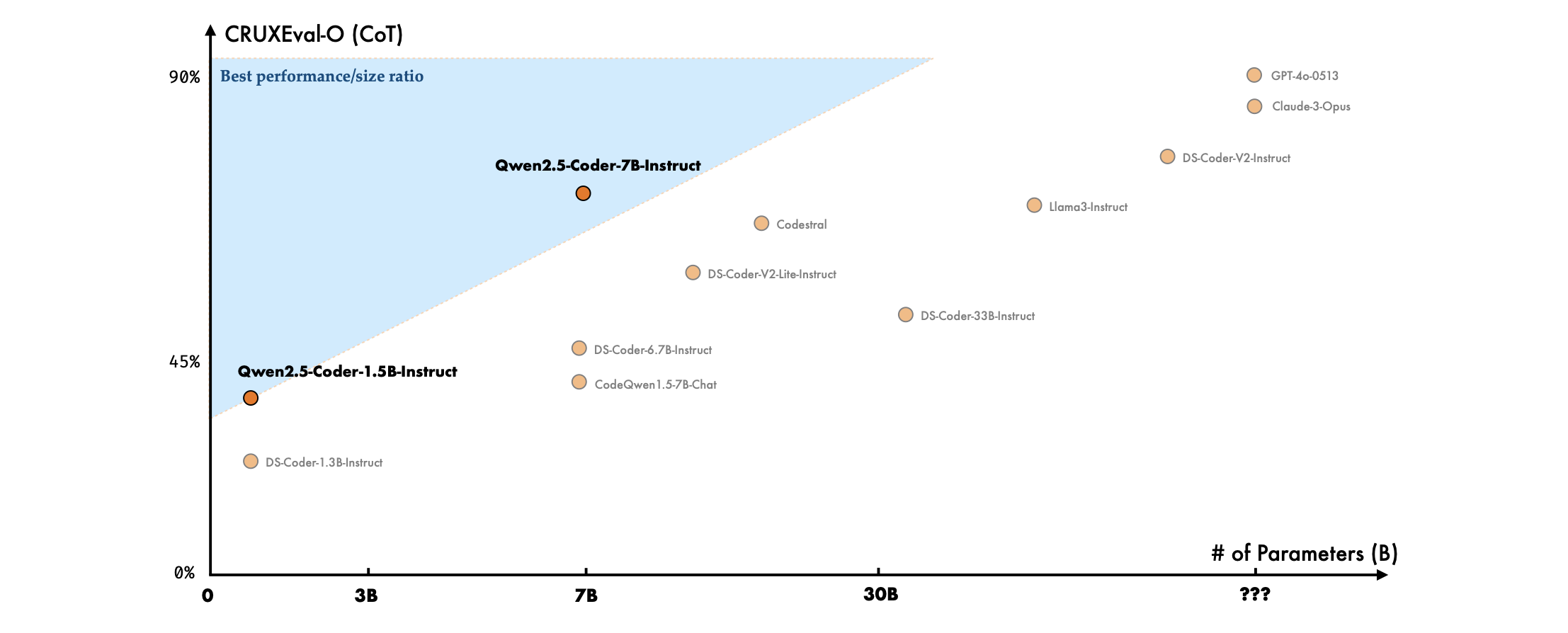
Figure 7: The relationship between model sizes and code reasoning capabilities. The x-axis represents the parameter sizes of different models, and the y-axis indicates the CRUXEval-O (CoT) scores respectively. 图7:模型大小与代码推理能力之间的关系。x轴表示不同模型的参数大小,y轴分别表示CRUXEval-O(CoT)分数。
7.3 Code Editing(代码编辑)
Aider has created a code editing benchmark designed to quantitatively measure its collaboration with large language models (LLMs). Drawing from a set of 133 Python exercises sourced from Exercism, the benchmark tests the ability of Aider and LLMs to interpret natural language programming requests and translate them into executable code that successfully passes unit tests. This assessment goes beyond evaluating raw coding proficiency; it also examines how effectively LLMs can edit existing code and format those modifications for seamless integration with Aider’s system, ensuring that local source files can be updated without issues. The comprehensive nature of this benchmark reflects both the technical aptitude of the LLMs and their consistency in task completion.
Aider创建了一个代码编辑基准,旨在定量衡量其与大型语言模型(LLM)的协作。基准从Exercism中获取了133个Python练习,测试了Aider和LLM解释自然语言编程请求并将其转换为可执行代码的能力,以确保通过单元测试。这种评估不仅评估了原始编码熟练度;还检查了LLM如何有效地编辑现有代码并为Aider的系统格式化这些修改,以确保本地源文件可以无问题地更新。这个基准的全面性反映了LLM的技术能力和任务完成的一致性。
Table 16 highlights the performance of several language models in the Code Editing task. Among them, Qwen2.5-Coder-7B-Instruct demonstrates outstanding code repair capabilities. Despite its relatively modest size of 7 billion parameters, it achieves an impressive PASS@1 accuracy of 50.4%, significantly outperforming comparable models. Notably, it also surpasses larger models such as CodeStral-22B (22 billion parameters) and DS-Coder-33B-Instruct (33 billion parameters), showcasing its remarkable efficiency and effectiveness in code editing tasks.
表16突出了几种语言模型在代码编辑任务中的性能。其中,Qwen2.5-Coder-7B-Instruct展示了出色的代码修复能力。尽管其相对较小的7亿参数规模,但它取得了令人印象深刻的PASS@1准确率50.4%,明显优于可比较的模型。值得注意的是,它还超过了更大的模型,如CodeStral-22B(22亿参数)和DS-Coder-33B-Instruct(33亿参数),展示了其在代码编辑任务中的卓越效率和有效性。
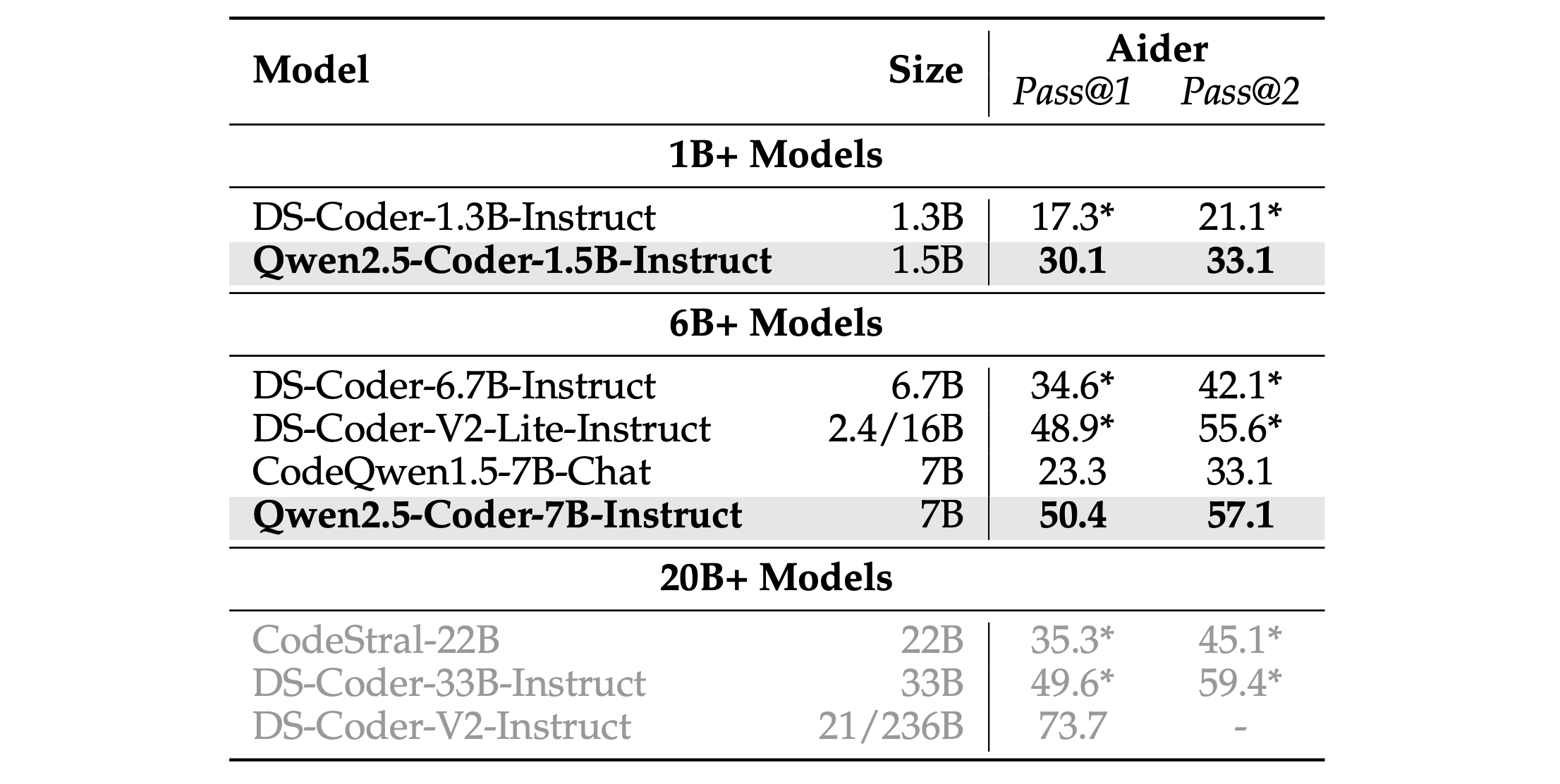
Table 16: The code editing ability of different instruct models evaluated by Aider benchmark. * indicates that the experimental results have been reproduced in our experiments, and the whole edit-format was consistently applied across all experiments. 表16:通过Aider基准评估的不同指令模型的代码编辑能力。*表示实验结果已在我们的实验中重现,并且整个编辑格式在所有实验中都保持一致。
7.4 Text-to-SQL(文本到SQL)
SQL is one of the essential tools in daily software development and production, but its steep learning curve often hinders free interaction between non-programming experts and databases. To address this issue, the Text-to-SQL task was introduced, aiming for models to automatically map natural language questions to structured SQL queries. Previous improvements in Text-to-SQL focused primarily on structure-aware learning, domain-specific pre-training, and sophisticated prompt designs.
SQL是日常软件开发和生产中的基本工具之一,但其陡峭的学习曲线经常阻碍非编程专家和数据库之间的自由交互。为了解决这个问题,引入了文本到SQL任务,旨在使模型自动将自然语言问题映射到结构化SQL查询。以前在文本到SQL方面的改进主要集中在结构感知学习、领域特定的预训练和复杂的提示设计上。
Thanks to the use of finely crafted synthetic data during both pre-training and fine-tuning, we significantly enhanced Qwen2.5-Coder’s capability in Text-to-SQL tasks. We selected two well-known benchmarks, Spider (Yu et al., 2018) and BIRD (Li et al., 2024), for comprehensive evaluation. To ensure a fair comparison between Qwen2.5-Coder and other open-source language models on this task, we used a unified prompt template as input, following the work of Chang & Fosler-Lussier (2023). As shown in Figure 8, the prompt consists of table representations aligned with database instructions, examples of table content, optional additional knowledge, and natural language questions. This standardized prompt template minimizes biases that may arise from prompt variations. As shown in Figure 9, Qwen2.5-Coder outperforms other code models of the same size on the Text-to-SQL task.
由于在预训练和微调过程中使用了精心制作的合成数据,我们显著增强了Qwen2.5-Coder在文本到SQL任务中的能力。我们选择了两个著名的基准,Spider和BIRD,进行全面评估。为了确保Qwen2.5-Coder和其他开源语言模型在这项任务上的公平比较,我们使用了一个统一的提示模板作为输入,遵循Chang & Fosler-Lussier的工作。如图8所示,提示包括与数据库指令对齐的表表示、表内容示例、可选的附加知识和自然语言问题。这种标准化的提示模板最大程度地减少了由于提示变化而可能产生的偏见。如图9所示,Qwen2.5-Coder在文本到SQL任务上优于相同大小的其他代码模型。
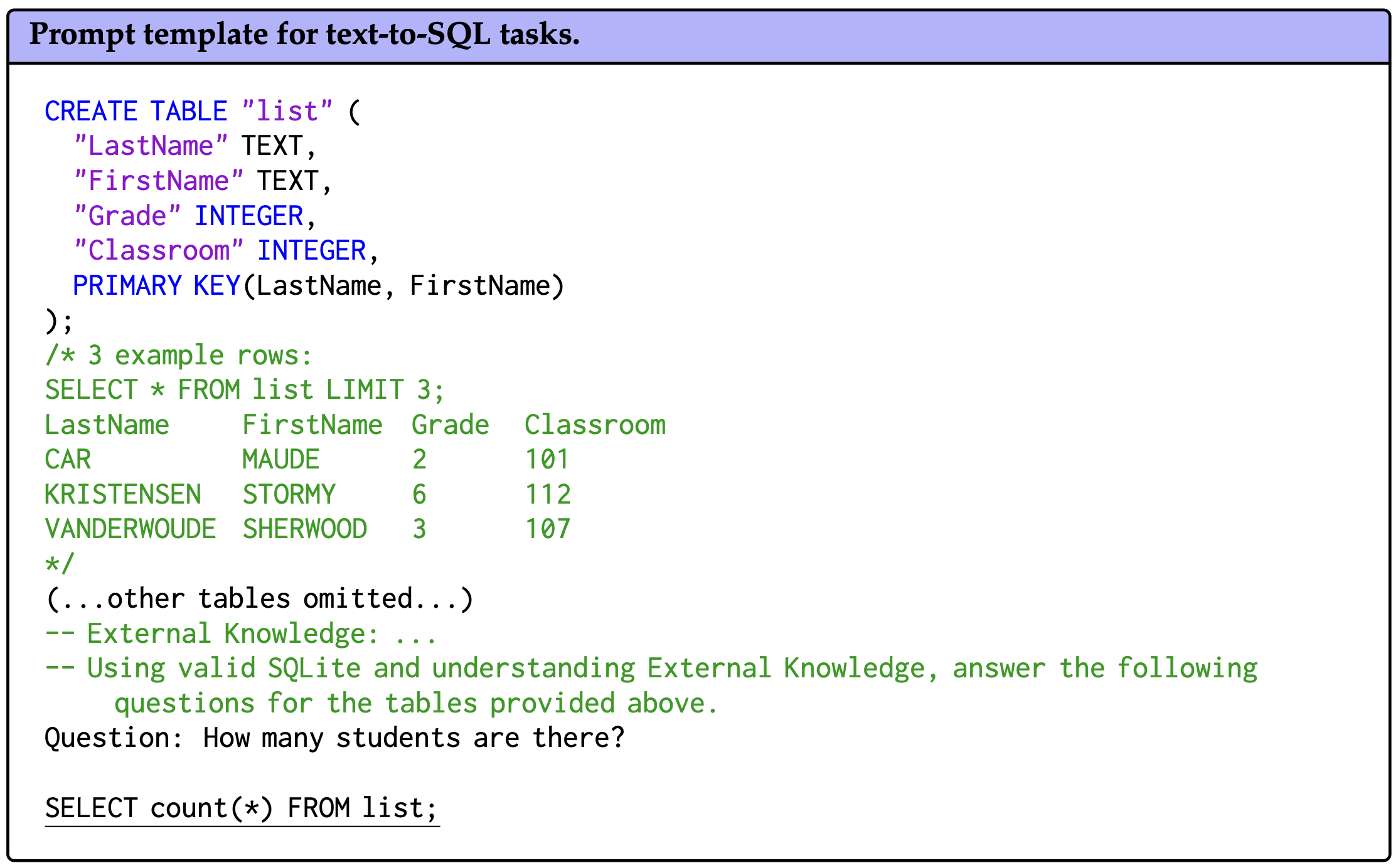
Figure 8: Prompt template of Qwen2.5-Coder for text-to-SQL tasks. 图8:Qwen2.5-Coder的文本到SQL任务提示模板。
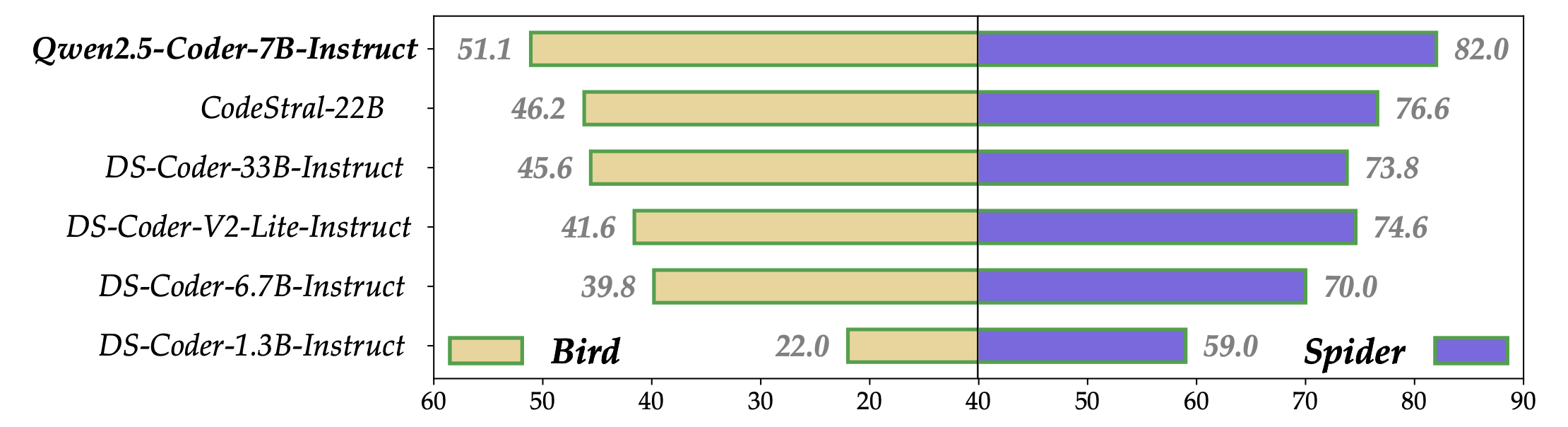
Figure 9: The text-to-SQL evaluation on various instruct code models. 图9:各种指令代码模型的文本到SQL评估。
7.5 Math Reasoning and General Natural Language(数学推理和通用自然语言)
In this section, we present a comparative analysis of the performance between our Qwen2.5-Coder-7B-Instruct model and the DS-Coder-V2-Lite-Instruct model, focusing on both mathematical computation and general natural language processing tasks. As indicated in Table 17, the Qwen2.5-Coder-7B-Instruct model outperforms the DS-Coder-V2-Lite-Instruct in 11 out of 12 tasks. This result underscores the model’s versatility, excelling not only in complex coding tasks but also in sophisticated general tasks, thus distinguishing it from its competitors.
在本节中,我们对Qwen2.5-Coder-7B-Instruct模型和DS-Coder-V2-Lite-Instruct模型在数学计算和通用自然语言处理任务中的性能进行了比较分析。如表17所示,Qwen2.5-Coder-7B-Instruct模型在12项任务中有11项优于DS-Coder-V2-Lite-Instruct。这一结果突显了模型的多功能性,不仅在复杂编码任务中表现出色,而且在复杂的通用任务中也表现出色,从而使其与竞争对手区分开来。

Table 17: The performance of math and General. 表17:数学和通用性能。
8 Conclusion(结论)
This work introduces Qwen2.5-Coder, the latest addition to the Qwen series. Built upon Qwen2.5, a top-tier open-source LLM, Qwen2.5-Coder has been developed through extensive pre-training and post-training of Qwen2.5-1.5B and Qwen2.5-7B on large-scale datasets. To ensure the quality of the pre-training data, we have curated a dataset by collecting public code data and extracting high-quality code-related content from web texts, while filtering out low-quality data using advanced classifiers. Additionally, we have constructed a meticulously designed instruction-tuning dataset to transform the base code LLM into a strong coding assistant.
本文介绍了Qwen系列的最新成员Qwen2.5-Coder。Qwen2.5-Coder是基于顶级开源LLM Qwen2.5构建的,通过对Qwen2.5-1.5B和Qwen2.5-7B进行大规模数据集的广泛预训练和后训练而开发。为了确保预训练数据的质量,我们通过收集公共代码数据并从网络文本中提取高质量的与代码相关的内容来筛选低质量数据,同时使用先进的分类器。此外,我们构建了一个精心设计的指令调优数据集,将基础代码LLM转变为强大的编码助手。
Looking ahead, our research will focus on exploring the impact of scaling up code LLMs in terms of both data size and model size. We will also continue to enhance the reasoning capabilities of these models, aiming to push the boundaries of what code LLMs can achieve.
展望未来,我们的研究将重点探讨代码LLM在数据大小和模型大小方面的扩展对其影响。我们还将继续增强这些模型的推理能力,旨在推动代码LLM可以实现的极限。