Qwen2.5-VL Technical Report
Abstract(摘要)
We introduce Qwen2.5-VL, the latest flagship model of Qwen vision-language series, which demonstrates significant advancements in both foundational capabilities and innovative functionalities. Qwen2.5-VL achieves a major leap forward in understanding and interacting with the world through enhanced visual recognition, precise object localization, robust document parsing, and long-video comprehension. A standout feature of Qwen2.5-VL is its ability to localize objects using bounding boxes or points accurately. It provides robust structured data extraction from invoices, forms, and tables, as well as detailed analysis of charts, diagrams, and layouts. To handle complex inputs, Qwen2.5- VL introduces dynamic resolution processing and absolute time encoding, enabling it to process images of varying sizes and videos of extended durations (up to hours) with second-level event localization. This allows the model to natively perceive spatial scales and temporal dynamics without relying on traditional normalization techniques. By training a native dynamic-resolution Vision Transformer (ViT) from scratch and incorporating Window Attention, we have significantly reduced computational overhead while maintaining native resolution. As a result, Qwen2.5-VL excels not only in static image and document understanding but also as an interactive visual agent capable of reasoning, tool usage, and task execution in real-world scenarios such as operating computers and mobile devices. The model achieves strong generalization across domains without requiring task-specific fine-tuning. Qwen2.5-VL is available in three sizes, addressing diverse use cases from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B model matches state-of-the-art models like GPT-4o and Claude 3.5 Sonnet, particularly excelling in document and diagram understanding. The smaller Qwen2.5-VL-7B and Qwen2.5-VL-3B models outperform comparable competitors, offering strong capabilities even in resource-constrained environments. Additionally, Qwen2.5-VL maintains robust linguistic performance, preserving the core language competencies of the Qwen2.5 LLM.
我们介绍了 Qwen2.5-VL,Qwen 视觉-语言系列的最新旗舰模型,展示了在基础能力和创新功能方面的显著进步。Qwen2.5-VL 在通过增强视觉识别、精确物体定位、强大文档解析和长视频理解方面取得了重大进展。Qwen2.5-VL 的一个显著特点是其能够准确地使用边界框或点定位物体。它提供了从发票、表格和表格中提取强大的结构化数据,以及对图表、图表和布局的详细分析。为了处理复杂的输入,Qwen2.5-VL 引入了动态分辨率处理和绝对时间编码,使其能够处理不同尺寸的图像和长时间(长达几小时)的视频,并具有秒级事件定位。这使得模型能够本地感知空间尺度和时间动态,而无需依赖传统的归一化技术。通过从头开始训练本地动态分辨率 Vision Transformer(ViT)并结合窗口注意力,我们显著减少了计算开销,同时保持了本地分辨率。因此,Qwen2.5-VL 不仅在静态图像和文档理解方面表现出色,而且作为一个交互式视觉代理,能够在操作计算机和移动设备等现实场景中进行推理、工具使用和任务执行。该模型在不需要特定任务微调的情况下在领域间实现了强大的泛化。Qwen2.5-VL 有三种规格,适用于从边缘 AI 到高性能计算的各种用例。旗舰 Qwen2.5-VL-72B 模型与 GPT-4o 和 Claude 3.5 Sonnet 等最先进的模型相匹敌,特别擅长文档和图表理解。较小的 Qwen2.5-VL-7B 和 Qwen2.5-VL-3B 模型胜过可比较的竞争对手,即使在资源受限的环境中也提供强大的功能。此外,Qwen2.5-VL 保持了强大的语言表现,保留了 Qwen2.5 LLM 的核心语言能力。
1 Introduction(介绍)
Large vision-language models ( LVLMs ) (OpenAI, 2024; Anthropic, 2024a; Team et al., 2023; Wang et al., 2024f) represent a pivotal breakthrough in artificial intelligence, signaling a transformative approach to multimodal understanding and interaction. By seamlessly integrating visual perception with natural language processing, these advanced models are fundamentally reshaping how machines interpret and analyze complex information across diverse domains. Despite significant advancements in multimodal large language models, the current capabilities of these models can be likened to the middle layer of a sandwich cookie—competent across various tasks but falling short of exceptional performance. Finegrained visual tasks form the foundational layer of this analogy. In this iteration of Qwen2.5-VL, we are committed to exploring fine-grained perception capabilities, aiming to establish a robust foundation for LVLMs and create an agentic amplifier for real-world applications. The top layer of this framework is multi-modal reasoning, which is enhanced by leveraging the latest Qwen2.5 LLM and employing multi-modal QA data construction.
大型视觉-语言模型(LVLMs)(OpenAI,2024;Anthropic,2024a;Team 等,2023;Wang 等,2024f)代表了人工智能的一个重大突破,标志着一种变革性的多模态理解和交互方法。通过将视觉感知与自然语言处理无缝集成,这些先进模型从根本上改变了机器如何解释和分析跨多个领域的复杂信息。尽管多模态大语言模型取得了显著进展,但这些模型目前的能力可以被比作三明治饼干的中间层——在各种任务上表现出色,但表现不够出色。细粒度视觉任务构成了这个类比的基础层。在这个 Qwen2.5-VL 的迭代中,我们致力于探索细粒度感知能力,旨在为 LVLMs 奠定坚实基础,并为现实应用创造一个代理放大器。这个框架的顶层是多模态推理,通过利用最新的 Qwen2.5 LLM 和采用多模态 QA 数据构建来增强。
A spectrum of works have promoted the development of multimodal large models, characterized by architectural design, visual input processing, and data curation. One of the primary drivers of progress in LVLMs is the continuous innovation in architecture. The studies presented in (Alayrac et al., 2022; Li et al., 2022a; 2023b; Liu et al., 2023b;a; Wang et al., 2024i; Zhang et al., 2024b; Wang et al., 2023) have incrementally shaped the current paradigm, which typically consists of a visual encoder, a cross-modal projector, and LLM. Fine-grained perception models have emerged as another crucial area. Models like (Xiao et al., 2023; Liu et al., 2023c; Ren et al., 2024; Zhang et al., 2024a;d; Peng et al., 2023; Deitke et al., 2024) have pushed the boundaries of what is possible in terms of detailed visual understanding. The architectures of Omni (Li et al., 2024g; 2025b; Ye et al., 2024) and MoE (Riquelme et al., 2021; Lee et al., 2024; Li et al., 2024h;c; Wu et al., 2024b) also inspire the future evolution of LVLMs. Enhancements in visual encoders (Chen et al., 2023; Liu et al., 2024b; Liang et al., 2025) and resolution scaling (Li et al., 2023c; Ye et al., 2023; Li et al., 2023a) have played a pivotal role in improving the quality of practical visual understanding. Curating data with more diverse scenarios and higher-quality is an essential step in training advanced LVLMs. The efforts proposed in (Guo et al., 2024; Chen et al., 2024d; Liu et al., 2024a; Chen et al., 2024a; Tong et al., 2024; Li et al., 2024a) are highly valuable contributions to this endeavor.
一系列作品推动了多模态大模型的发展,其特点是架构设计、视觉输入处理和数据策划。LVLMs 进展的主要驱动力之一是架构的持续创新。在(Alayrac 等,2022;Li 等,2022a;2023b;Liu 等,2023b;a;Wang 等,2024i;Zhang 等,2024b;Wang 等,2023)中提出的研究逐步塑造了当前的范式,通常包括视觉编码器、跨模态投影仪和 LLM。细粒度感知模型已经成为另一个关键领域。像(Xiao 等,2023;Liu 等,2023c;Ren 等,2024;Zhang 等,2024a;d;Peng 等,2023;Deitke 等,2024)这样的模型推动了关于详细视觉理解的可能性的边界。Omni(Li 等,2024g;2025b;Ye 等,2024)和 MoE(Riquelme 等,2021;Lee 等,2024;Li 等,2024h;c;Wu 等,2024b)的架构也启发了 LVLMs 的未来演变。视觉编码器(Chen 等,2023;Liu 等,2024b;Liang 等,2025)和分辨率缩放(Li 等,2023c;Ye 等,2023;Li 等,2023a)的增强在提高实际视觉理解质量方面发挥了关键作用。策划具有更多样化场景和更高质量的数据是训练先进 LVLMs 的重要步骤。在(Guo 等,2024;Chen 等,2024d;Liu 等,2024a;Chen 等,2024a;Tong 等,2024;Li 等,2024a)中提出的努力是这一努力的高度有价值的贡献。
However, despite their remarkable progress, vision-language models currently face developmental bottlenecks, including computational complexity, limited contextual understanding, poor fine-grained visual perception, and inconsistent performance across varied sequence length.
然而,尽管它们取得了显著进展,但视觉-语言模型目前面临着发展瓶颈,包括计算复杂性、有限的上下文理解、粗糙的细粒度视觉感知以及在不同序列长度上的性能不一致。
In this report, we introduce the latest work Qwen2.5-VL, which continues the open-source philosophy of the Qwen series, achieving and even surpassing top-tier closed-source models on various benchmarks. Technically, our contributions are four-folds: (1) We implement window attention in the visual encoder to optimize inference efficiency; (2) We introduce dynamic FPS sampling, extending dynamic resolution to the temporal dimension and enabling comprehensive video understanding across varied sampling rates; (3) We upgrade MRoPE in the temporal domain by aligning to absolute time, thereby facilitating more sophisticated temporal sequence learning; (4) We make significant efforts in curating high-quality data for both pre-training and supervised fine-tuning, further scaling the pre-training corpus from 1.2 trillion tokens to 4.1 trillion tokens.
在本报告中,我们介绍了最新的工作 Qwen2.5-VL,它延续了 Qwen 系列的开源理念,在各种基准测试中实现甚至超越了顶级闭源模型。从技术上讲,我们的贡献有四个方面:(1)我们在视觉编码器中实现了窗口注意力,以优化推理效率;(2)我们引入了动态 FPS 采样,将动态分辨率扩展到时间维度,实现了在不同采样率下的全面视频理解;(3)我们在时间域升级了 MRoPE,通过对齐绝对时间,从而促进了更复杂的时间序列学习;(4)我们在策划高质量数据方面付出了巨大努力,用于预训练和监督微调,进一步将预训练语料库从 1.2 万亿标记扩展到 4.1 万亿标记。
The sparkling characteristics of Qwen2.5-VL are as follows:
- Powerful document parsing capabilities: Qwen2.5-VL upgrades text recognition to omnidocument parsing, excelling in processing multi-scene, multilingual, and various built-in (handwriting, tables, charts, chemical formulas, and music sheets) documents.
- Precise object grounding across formats: Qwen2.5-VL unlocks improved accuracy in detecting, pointing, and counting objects, accommodating absolute coordinate and JSON formats for advanced spatial reasoning.
- Ultra-long video understanding and fine-grained video grounding: Our model extends native dynamic resolution to the temporal dimension, enhancing the ability to understand videos lasting hours while extracting event segments in seconds.
- Enhanced agent Functionality for computer and mobile devices: Leverage advanced grounding, reasoning, and decision-making abilities, boosting the model with superior agent functionality on smartphones and computers.
Qwen2.5-VL 的闪亮特点如下:
- 强大的文档解析能力:Qwen2.5-VL 将文本识别升级为全文档解析,擅长处理多场景、多语言和各种内置(手写、表格、图表、化学式和乐谱)文档。
- 跨格式精确物体定位:Qwen2.5-VL 提升了检测、指向和计数物体的准确性,支持绝对坐标和 JSON 格式,用于高级空间推理。
- 超长视频理解和细粒度视频定位:我们的模型将本地动态分辨率扩展到时间维度,增强了理解长达几小时的视频的能力,同时在几秒钟内提取事件片段。
- 用于计算机和移动设备的增强代理功能:利用先进的接地、推理和决策能力,提升模型在智能手机和计算机上的优越代理功能。
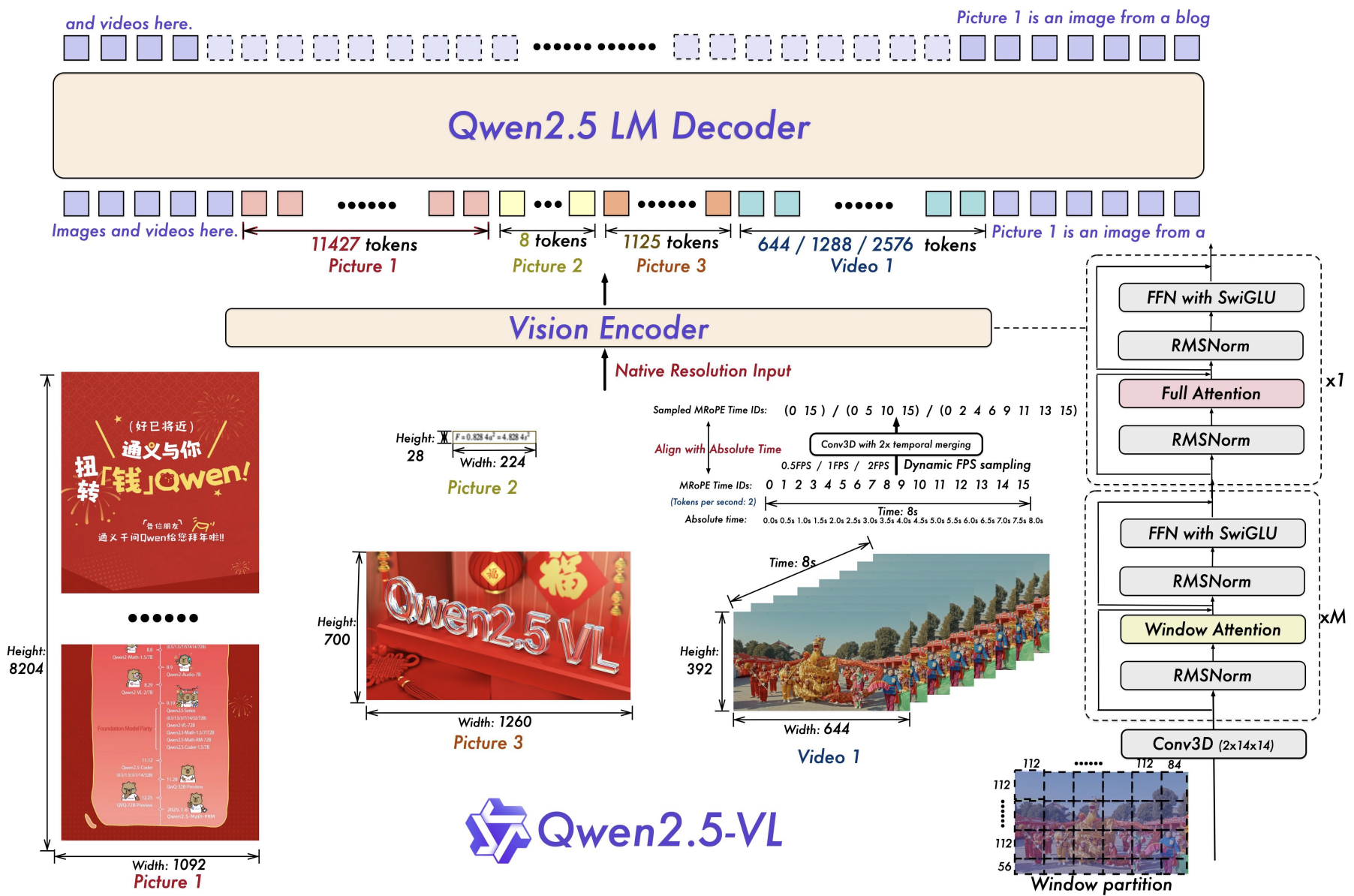
Figure 1: The Qwen2.5-VL framework demonstrates the integration of a vision encoder and a language model decoder to process multimodal inputs, including images and videos. The vision encoder is designed to handle inputs at their native resolution and supports dynamic FPS sampling. Images of varying sizes and video frames with different FPS rates are dynamically mapped to token sequences of varying lengths. Notably, MRoPE aligns time IDs with absolute time along the temporal dimension, enabling the model to better comprehend temporal dynamics, such as the pace of events and precise moment localization. The processed visual data is subsequently fed into the Qwen2.5 LM Decoder. We have re-engineered the vision transformer (ViT) architecture, incorporating advanced components such as FFN with SwiGLU activation, RMSNorm for normalization, and window-based attention mechanisms to enhance performance and efficiency.
图 1:Qwen2.5-VL 框架展示了视觉编码器和语言模型解码器的集成,用于处理多模态输入,包括图像和视频。视觉编码器设计用于处理其本机分辨率的输入,并支持动态 FPS 采样。不同尺寸的图像和不同 FPS 速率的视频帧被动态映射到不同长度的令牌序列。值得注意的是,MRoPE 将时间 ID 与绝对时间沿时间维度对齐,使模型能够更好地理解时间动态,如事件的速度和精确的时刻定位。处理后的视觉数据随后被馈送到 Qwen2.5 LM 解码器。我们重新设计了视觉变压器(ViT)架构,结合了高级组件,如带有 SwiGLU 激活的 FFN、用于规范化的 RMSNorm 和基于窗口的注意机制,以增强性能和效率。
2 Approach(方法)
In this section, we first outline the architectural updates of the Qwen2.5-VL series models and provide an overview of the data and training details.
在本节中,我们首先概述 Qwen2.5-VL 系列模型的架构更新,并提供数据和训练细节的概述。
2.1 Model Architecture(模型架构)
The overall model architecture of Qwen2.5-VL consists of three components:
Qwen2.5-VL 的整体模型架构由三个组件组成:
Large Language Model: The Qwen2.5-VL series adopts large language models as its foundational component. The model is initialized with pre-trained weights from the Qwen2.5 LLM. To better meet the demands of multimodal understanding, we have modified the 1D RoPE (Rotary Position Embedding) to our Multimodal Rotary Position Embedding Aligned to Absolute Time.
大型语言模型:Qwen2.5-VL 系列采用大型语言模型作为其基础组件。该模型使用 Qwen2.5 LLM 的预训练权重进行初始化。为了更好地满足多模态理解的需求,我们将 1D RoPE(旋转位置嵌入)修改为我们的多模态旋转位置嵌入对齐到绝对时间。
Vision Encoder: The vision encoder of Qwen2.5-VL employs a redesigned Vision Transformer (ViT) architecture. Structurally, we incorporate 2D-RoPE and window attention to support native input resolutions while accelerating the computation of the entire visual encoder. During both training and inference, the height and width of the input images are resized to multiples of 28 before being fed into the ViT. The vision encoder processes images by splitting them into patches with a stride of 14, generating a set of image features. We provide a more detailed introduction to the vision encoder in Section 2.1.1.
视觉编码器:Qwen2.5-VL 的视觉编码器采用了重新设计的 Vision Transformer(ViT)架构。在结构上,我们结合了 2D-RoPE 和窗口注意力,以支持本机输入分辨率,同时加速整个视觉编码器的计算。在训练和推理期间,输入图像的高度和宽度在馈送到 ViT 之前被调整为 28 的倍数。视觉编码器通过将图像分割为步幅为 14 的补丁,生成一组图像特征。我们在 2.1.1 节中对视觉编码器进行了更详细的介绍。
MLP-based Vision-Language Merger: To address the efficiency challenges posed by long sequences of image features, we adopt a simple yet effective approach to compress the feature sequences before feeding them into the large language model (LLM). Specifically, instead of directly using the raw patch features extracted by the Vision Transformer (ViT), we first group spatially adjacent sets of four patch features. These grouped features are then concatenated and passed through a two-layer multi-layer perceptron (MLP) to project them into a dimension that aligns with the text embeddings used in the LLM. This method not only reduces computational costs but also provides a flexible way to dynamically compress image feature sequences of varying lengths.
基于 MLP 的视觉-语言合并器:为了解决长序列图像特征的效率挑战,我们采用了一种简单而有效的方法,在将其馈送到大型语言模型(LLM)之前压缩特征序列。具体来说,我们首先将视觉变压器(ViT)提取的原始补丁特征分组为空间相邻的四个补丁特征集。然后将这些分组特征连接起来,并通过两层多层感知器(MLP)将其投影到与 LLM 中使用的文本嵌入对齐的维度。这种方法不仅降低了计算成本,还提供了一种灵活的方式来动态压缩不同长度的图像特征序列。
In Table 1, the architecture and configuration of Qwen2.5-VL are detailed.
在表 1 中,详细介绍了 Qwen2.5-VL 的架构和配置。
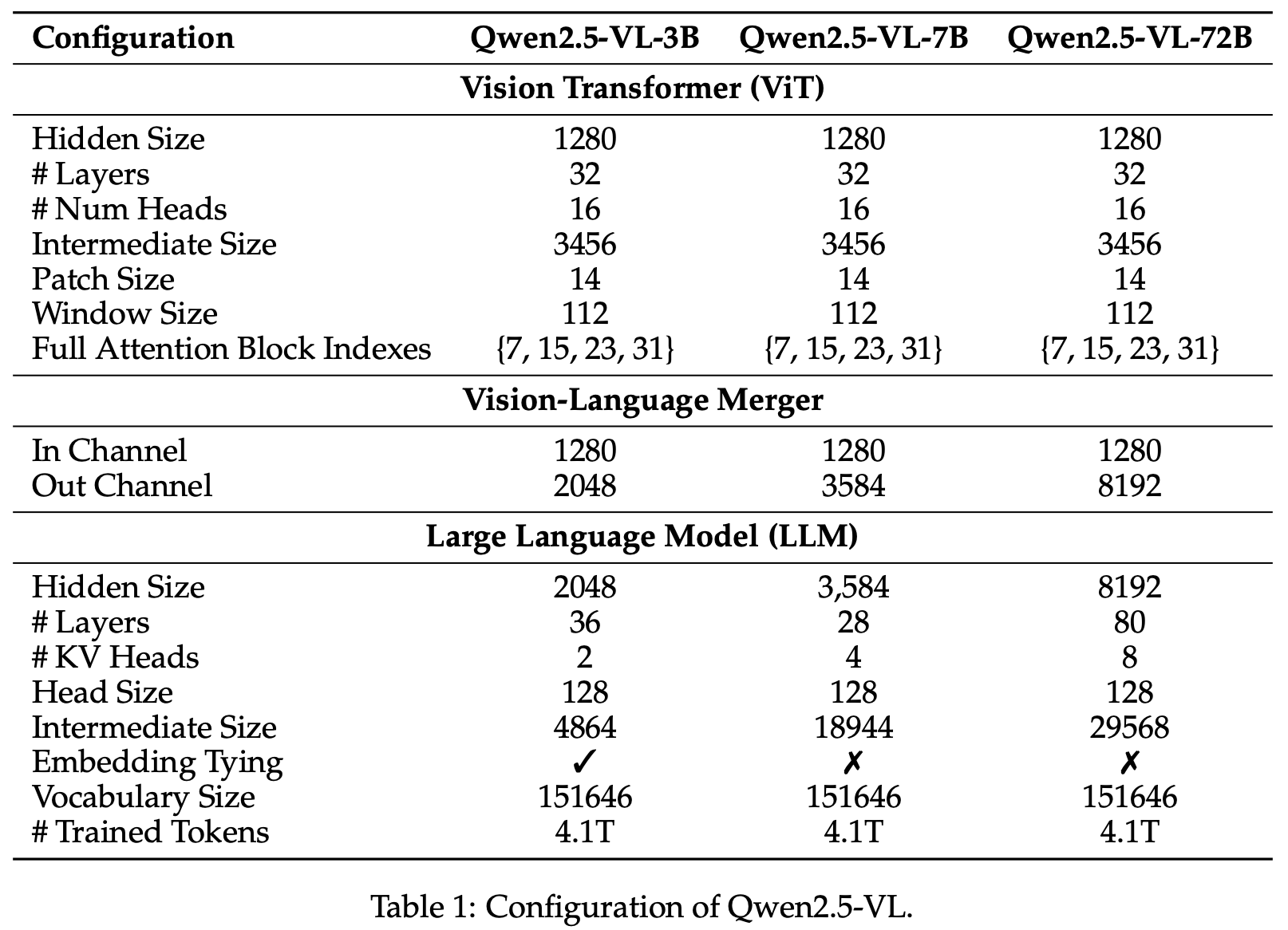
表 1: Qwen2.5-VL 的配置。
2.1.1 Fast and Efficient Vision Encoder(快速高效的视觉编码器)
The vision encoder plays a pivotal role in multimodal large language models (MLLMs). To address the challenges posed by computational load imbalances during training and inference due to native resolution inputs, we have redesigned the Vision Transformer (ViT) architecture. A key issue arises from the quadratic computational complexity associated with processing images of varying sizes. To mitigate this, we introduce windowed attention in most layers, which ensures that computational cost scales linearly with the number of patches rather than quadratically. In our architecture, only four layers employ full self-attention, while the remaining layers utilize windowed attention with a maximum window size of 112×112 (corresponding to 8×8 patches). Regions smaller than 112×112 are processed without padding, preserving their original resolution. This design allows the model to operate natively at the input resolution, avoiding unnecessary scaling or distortion.
视觉编码器在多模态大型语言模型(MLLMs)中起着至关重要的作用。为了解决由于本机分辨率输入而导致的训练和推理期间计算负载不平衡所带来的挑战,我们重新设计了 Vision Transformer(ViT)架构。一个关键问题是与处理不同尺寸图像相关的二次计算复杂性。为了缓解这一问题,我们在大多数层中引入了窗口注意力,这确保了计算成本与补丁数量呈线性而不是二次比例。在我们的架构中,只有四层使用全自注意力,而其余层使用最大窗口大小为 112×112(对应 8×8 补丁)的窗口注意力。小于 112×112 的区域在没有填充的情况下进行处理,保留其原始分辨率。这种设计使模型能够在输入分辨率下本地运行,避免不必要的缩放或失真。
For positional encoding, we adopt 2D Rotary Positional Embedding (RoPE) to effectively capture spatial relationships in 2D space. Furthermore, to better handle video inputs, we extend our approach to 3D patch partitioning. Specifically, we use 14×14 image patches as the basic unit, consistent with traditional ViTs for static images. For video data, two consecutive frames are grouped together, significantly reducing the number of tokens fed into the language model. This design not only maintains compatibility with existing architectures but also enhances efficiency when processing sequential video data.
对于位置编码,我们采用 2D 旋转位置嵌入(RoPE)来有效捕捉 2D 空间中的空间关系。此外,为了更好地处理视频输入,我们将我们的方法扩展到 3D 补丁划分。具体来说,我们使用 14×14 图像补丁作为基本单元,与传统的静态图像 ViTs 保持一致。对于视频数据,两个连续帧被分组在一起,显著减少了馈送到语言模型的令牌数量。这种设计不仅保持了与现有架构的兼容性,而且在处理顺序视频数据时提高了效率。
To streamline the overall network structure, we align the ViT architecture more closely with the design principles of large language models (LLMs). Specifically, we adopt RMSNorm (Zhang &Sennrich, 2019) for normalization and SwiGLU (Dauphin et al., 2017) as the activation function. These choices enhance both computational efficiency and compatibility between the vision and language components of the model.
为了简化整体网络结构,我们将 ViT 架构与大型语言模型(LLMs)的设计原则更紧密地对齐。具体来说,我们采用 RMSNorm(Zhang & Sennrich,2019)进行规范化,SwiGLU(Dauphin 等,2017)作为激活函数。这些选择既提高了计算效率,又增强了模型的视觉和语言组件之间的兼容性。
In terms of training, we train the redesigned ViT from scratch. The training process consists of several stages, including CLIP pre-training, vision-language alignment, and end-to-end fine-tuning. To ensure robustness across varying input resolutions, we employ dynamic sampling at native resolutions during training. Images are randomly sampled according to their original aspect ratios, enabling the model to generalize effectively to inputs of diverse resolutions. This approach not only improves the model’s adaptability but also ensures stable and efficient training across different sizes of visual data.
在训练方面,我们从头开始训练重新设计的 ViT。训练过程包括几个阶段,包括 CLIP 预训练、视觉-语言对齐和端到端微调。为了确保在不同输入分辨率下的稳健性,我们在训练期间使用本机分辨率的动态采样。根据其原始宽高比随机采样图像,使模型能够有效地泛化到不同分辨率的输入。这种方法不仅提高了模型的适应性,还确保了在不同大小的视觉数据上稳定和高效的训练。
2.1.2 Native Dynamic Resolution and Frame Rate(本机动态分辨率和帧率)
Qwen2.5-VL introduces advancements in both spatial and temporal dimensions to handle diverse multimodal inputs effectively.
Qwen2.5-VL 在空间和时间维度上引入了先进技术,以有效处理多样化的多模态输入。
In the spatial domain, Qwen2.5-VL dynamically converts images of varying sizes into sequences of tokens with corresponding lengths. Unlike traditional approaches that normalize coordinates, our model directly uses the actual dimensions of the input image to represent bounding boxes, points, and other spatial features. This allows the model to learn scale information inherently, improving its ability to process images across different resolutions.
在空间域中,Qwen2.5-VL 将不同尺寸的图像动态转换为相应长度的令牌序列。与传统方法不同,该模型直接使用输入图像的实际尺寸来表示边界框、点和其他空间特征。这使得模型能够固有地学习比例信息,提高了其处理不同分辨率图像的能力。
For video inputs, Qwen2.5-VL incorporates dynamic frame rate (FPS) training and absolute time encoding. By adapting to variable frame rates, the model can better capture the temporal dynamics of video content. Unlike other approaches that incorporate textual timestamps or utilize additional heads to enable temporal grounding, we introduce a novel and efficient strategy that aligns MRoPE IDs directly with the timestamps. This approach allows the model to understand the tempo of time through the intervals between temporal dimension IDs, without necessitating any additional computational overhead.
对于视频输入,Qwen2.5-VL 结合了动态帧率(FPS)训练和绝对时间编码。通过适应可变帧率,模型可以更好地捕捉视频内容的时间动态。与其他将文本时间戳合并或使用额外头部以实现时间定位的方法不同,我们引入了一种新颖且高效的策略,直接将 MRoPE ID 与时间戳对齐。这种方法使模型能够通过时间维度 ID 之间的间隔理解时间的节奏,而无需任何额外的计算开销。
2.1.3 Multimodal Rotary Position Embedding Aligned to Absolute Time(多模态旋转位置嵌入对齐到绝对时间)
Positional embeddings are crucial for modeling sequential data in both vision and language modalities. Building upon the Multimodal Rotary Position Embedding (MRoPE) introduced in Qwen2-VL, we extend its capabilities to better handle temporal information in videos.
位置嵌入对于在视觉和语言模态中建模序列数据至关重要。在 Qwen2-VL 中引入的多模态旋转位置嵌入(MRoPE)的基础上,我们扩展了其功能,以更好地处理视频中的时间信息。
The MRoPE in Qwen2-VL decomposes the position embedding into three distinct components: temporal, height, and width to effectively model multimodal inputs. For textual inputs, all three components use identical position IDs, making MRoPE functionally equivalent to traditional 1D RoPE (Su et al., 2024). For images, the temporal ID remains constant across visual tokens, while unique IDs are assigned to the height and width components based on each token’s spatial position within the image. When processing videos, which are treated as sequences of frames, the temporal ID increments for each frame, while the height and width components follow the same assignment pattern as for static images.
Qwen2-VL 中的 MRoPE 将位置嵌入分解为三个不同的组件:时间、高度和宽度,以有效地建模多模态输入。对于文本输入,所有三个组件使用相同的位置 ID,使 MRoPE 在功能上等同于传统的 1D RoPE(Su 等,2024)。对于图像,时间 ID 在视觉令牌中保持不变,而基于图像中每个令牌的空间位置,为高度和宽度组件分配唯一 ID。在处理被视为帧序列的视频时,每帧的时间 ID 递增,而高度和宽度组件遵循与静态图像相同的分配模式。
However, in Qwen2-VL, the temporal position IDs in MRoPE were tied to the number of input frames, which did not account for the speed of content changes or the absolute timing of events within the video. To address this limitation, Qwen2.5-VL introduces a key improvement: aligning the temporal component of MRoPE with absolute time. As shown in Figure 1, by leveraging the intervals between temporal IDs, the model is able to learn consistent temporal alignment across videos with different FPS sampling rates.
然而,在 Qwen2-VL 中,MRoPE 中的时间位置 ID 与输入帧数相关联,没有考虑内容变化的速度或视频中事件的绝对时间。为了解决这一限制,Qwen2.5-VL 引入了一个关键改进:将 MRoPE 的时间组件与绝对时间对齐。如图 1 所示,通过利用时间 ID 之间的间隔,模型能够学习在不同 FPS 采样率的视频中实现一致的时间对齐。
2.2 Pre-Training(预训练)
In this section, we first describe the construction of the pre-training dataset, followed by an overview of the overall training pipeline and configuration.
在本节中,我们首先描述了预训练数据集的构建,然后概述了整体训练流程和配置。
2.2.1 Pre-Training Data(预训练数据)
Compared to Qwen2-VL, we have significantly expanded the volume of our pre-training data, increasing it from 1.2 trillion tokens to approximately 4 trillion tokens. Our pre-training dataset was constructed through a combination of methods, including cleaning raw web data, synthesizing data, etc. The dataset encompasses a wide variety of multimodal data, such as image captions, interleaved image-text data, optical character recognition (OCR) data, visual knowledge (e.g., celebrity, landmark, flora, and fauna identification), multi-modal academic questions, localization data, document parsing data, video descriptions, video localization, and agent-based interaction data. Throughout the training process, we carefully adjusted the composition and proportions of these data types at different stages to optimize learning outcomes.
与 Qwen2-VL 相比,我们显著扩大了预训练数据的规模,将其从 1.2 万亿标记增加到约 4 万亿标记。我们的预训练数据集是通过一系列方法构建的,包括清理原始网络数据、合成数据等。数据集涵盖了各种多模态数据,如图像标题、交错的图像-文本数据、光学字符识别(OCR)数据、视觉知识(例如名人、地标、植物和动物识别)、多模态学术问题、定位数据、文档解析数据、视频描述、视频定位和基于代理的交互数据。在整个训练过程中,我们仔细调整了这些数据类型在不同阶段的组成和比例,以优化学习结果。
Interleaved Image-Text Data Interleaved image-text data is essential for multimodal learning, offering three key benefits: (1) enabling in-context learning with simultaneous visual and textual cues (Alayrac et al., 2022), (2) maintaining strong text-only capabilities when images are missing (Lin et al., 2024), and (3) containing a wide range of general information. However, much of the available interleaved data lacks meaningful text-image associations and is often noisy, limiting its usefulness for complex reasoning and creative generation.
交错的图像-文本 数据交错的图像-文本数据对于多模态学习至关重要,提供了三个关键优势:(1)通过同时视觉和文本线索进行上下文学习(Alayrac 等,2022),(2)在缺少图像时保持强大的仅文本能力(Lin 等,2024),(3)包含广泛的一般信息。然而,许多可用的交错数据缺乏有意义的文本-图像关联,通常存在噪声,限制了它对复杂推理和创造性生成的有用性。
To address these challenges, we developed a pipeline for scoring and cleaning data, ensuring only high-quality, relevant interleaved data is used. Our process involves two steps: standard data cleaning (Li et al., 2024e) followed by a four-stage scoring system using an internal evaluation model. The scoring criteria include: (1) text-only quality, (2) image-text relevance, (3) image-text complementarity, and (4) information density balance. This meticulous approach improves the model’s ability to perform complex reasoning and generate coherent multimodal content.
为了解决这些挑战,我们开发了一个用于评分和清理数据的流水线,确保只使用高质量、相关的交错数据。我们的流程包括两个步骤:标准数据清理(Li 等,2024e)后,使用内部评估模型的四阶段评分系统。评分标准包括:(1)仅文本质量,(2)图像-文本相关性,(3)图像-文本互补性,(4)信息密度平衡。这种细致的方法提高了模型进行复杂推理和生成连贯多模态内容的能力。
The following is a description of these image-text scoring criteria:
以下是这些图像-文本评分标准的描述:
Image-text Relevance: A higher score indicates a stronger connection between the image and text, where the image meaningfully supplements, explains or expands on the text rather than just decorating it.
图像-文本相关性:更高的分数表示图像和文本之间的联系更紧密,图像有意义地补充、解释或扩展文本,而不仅仅是装饰文本。
Information Complementarity: A higher score reflects greater complementary information between the image and text. Each should provide unique details that together create a complete narrative.
信息互补性:更高的分数反映了图像和文本之间更大的互补信息。每个都应提供独特的细节,共同构成一个完整的叙述。
Balance of Information Density: A higher score means a more balanced distribution of information between the image and text, avoiding excessive text or image information, and ensuring an appropriate balance between the two.
信息密度平衡:更高的分数意味着图像和文本之间信息的分布更平衡,避免过多的文本或图像信息,并确保两者之间的适当平衡。
Grounding Data with Absolute Position Coordinates We adopt native resolution training with the aim of achieving a more accurate perception of the world. In contrast, relative coordinates fail to effectively represent the original size and position of objects within images. To address this limitation, Qwen2.5-VL uses coordinate values based on the actual dimensions of the input images during training to represent bounding boxes and points. This approach ensures that the model can better capture the real-world scale and spatial relationships of objects, leading to improved performance in tasks such as object detection and localization.
使用绝对位置坐标的接地数据 我们采用本机分辨率训练,旨在实现对世界的更准确感知。相比之下,相对坐标未能有效地表示图像中对象的原始大小和位置。为了解决这一限制,Qwen2.5-VL 在训练期间使用基于输入图像的实际尺寸的坐标值来表示边界框和点。这种方法确保模型能够更好地捕捉对象的真实尺度和空间关系,从而提高物体检测和定位等任务的性能。
To improve the generalizability of grounding capabilities, we have developed a comprehensive dataset encompassing bounding boxes and points with referring expressions, leveraging both publicly available datasets and proprietary data. Our methodology involves synthesizing data into various formats, including XML, JSON, and custom formats, employing techniques such as copy-paste augmentation (Ghiasi et al., 2021) and synthesis with off-the-shelf models such as Grounding DINO (Liu et al., 2023c) and SAM (Kirillov et al., 2023). This approach facilitates a more robust evaluation and advancement of grounding abilities.
为了提高接地能力的泛化能力,我们开发了一个全面的数据集,包括带有指代表达式的边界框和点,利用了公开可用的数据集和专有数据。我们的方法包括将数据合成为各种格式,包括 XML、JSON 和自定义格式,采用复制粘贴增强(Ghiasi 等,2021)和与现成模型(如 Grounding DINO(Liu 等,2023c)和 SAM(Kirillov 等,2023))合成的技术。这种方法有助于更全面地评估和推进接地能力。
To enhance the model’s performance on open-vocabulary detection, we expanded the training dataset to include over 10,000 object categories. Additionally, to improve the model’s effectiveness in extreme object detection scenarios, we synthesized non-existent object categories within the queries and constructed image data containing multiple instances for each object.
为了提高模型在开放词汇检测上的性能,我们扩展了训练数据集,包括超过 10,000 个对象类别。此外,为了提高模型在极端对象检测场景中的有效性,我们在查询中合成了不存在的对象类别,并构建了包含每个对象多个实例的图像数据。
To ensure superior point-based object grounding capabilities, we have constructed a comprehensive pointing dataset comprising both publicly available and synthetic data. Specifically, the data source includes public pointing and counting data from PixMo (Deitke et al., 2024), publicly accessible object grounding data (from both object detection and instance segmentation tasks), and data synthesized by an automated pipeline for generating precise pointing data towards certain image details.
为了确保优越的基于点的对象接地能力,我们构建了一个包含公开可用和合成数据的全面指向数据集。具体来说,数据源包括来自 PixMo(Deitke 等,2024)的公开指向和计数数据、公开可访问的对象接地数据(来自对象检测和实例分割任务)以及由用于生成指向某些图像细节的精确指向数据的自动化流水线合成的数据。
Document Omni-Parsing Data To train Qwen2.5-VL, we synthesized a large corpus of document data. Traditional methods for parsing document content typically rely on separate models to handle layout analysis, text extraction, chart interpretation, and illustration processing. In contrast, Qwen2.5- VL is designed to empower a general-purpose model with comprehensive capabilities for parsing, understanding, and converting document formats. Specifically, we incorporated a diverse array of elements into the documents, such as tables, charts, equations, natural or synthetic images, music sheets, and chemical formulas. These elements were uniformly formatted in HTML, which integrates layout box information and descriptions of illustrations into HTML tag structures. We also enriched the document layouts according to typical reading sequences and included the coordinates corresponding to each module, such as paragraphs and charts, in the HTML-based ground truth. This innovative approach allows the complete information of any document, including its layout, text, charts, and illustrations, to be represented in a standardized and unified manner. As a result, Qwen2.5-VL achieves seamless integration of multimodal document elements, thereby facilitating more efficient and accurate document understanding and transformation.
文档全文解析数据 为了训练 Qwen2.5-VL,我们合成了大量的文档数据。传统的解析文档内容的方法通常依赖于单独的模型来处理布局分析、文本提取、图表解释和插图处理。相比之下,Qwen2.5-VL 旨在为通用模型赋予全面的解析、理解和转换文档格式的能力。具体来说,我们在文档中加入了各种元素,如表格、图表、方程、自然或合成图像、乐谱和化学式。这些元素以 HTML 统一格式化,将布局框信息和插图描述集成到 HTML 标签结构中。我们还根据典型的阅读顺序丰富了文档布局,并在基于 HTML 的地面真相中包含了与每个模块(如段落和图表)对应的坐标。这种创新方法允许以标准化和统一的方式表示任何文档的完整信息,包括其布局、文本、图表和插图。因此,Qwen2.5-VL 实现了多模态文档元素的无缝集成,从而促进了更高效和准确的文档理解和转换。
Below is the QwenVL HTML format:
以下是 QwenVL HTML 格式:

This format ensures that all document elements are represented in a structured and accessible manner, enabling efficient processing and understanding by Qwen2.5-VL.
这种格式确保所有文档元素以结构化和可访问的方式表示,从而使 Qwen2.5-VL 能够高效处理和理解。
OCR Data Data from different sources are gathered and curated to enhance the OCR performance, including synthetic data, open-sourced data and in-house collected data. Synthetic data is generated through a visual text generation engine to produce high-quality text images in the wild. To support a wider range of languages and enhance multilingual capabilities, we have incorporated a large-scale multilingual OCR dataset. This dataset includes support for diverse languages such as French, German, Italian, Spanish, Portuguese, Arabic, Russian, Japanese, Korean, and Vietnamese. The dataset is carefully curated to ensure diversity and quality, utilizing both high-quality synthetic images and real-world natural scene images. This combination ensures robust performance across various linguistic contexts and improves the model’s adaptability to different text appearances and environmental conditions. For chart-type data, we synthesized 1 million samples using visualization libraries including matplotlib, seaborn, and plotly, encompassing chart categories such as bar charts, relational diagrams, and heatmaps. Regarding tabular data, we processed 6 million real-world samples through an offline end-to-end table recognition model, subsequently filtering out low-confidence tables, overlapping tables, and tables with insufficient cell density.
OCR 数据 收集和策划来自不同来源的数据,以增强 OCR 性能,包括合成数据、开源数据和内部收集的数据。通过视觉文本生成引擎生成合成数据,以生成野外高质量文本图像。为了支持更广泛的语言范围和增强多语言能力,我们已经整合了大规模多语言 OCR 数据集。该数据集包括对法语、德语、意大利语、西班牙语、葡萄牙语、阿拉伯语、俄语、日语、韩语和越南语等多种语言的支持。该数据集经过精心策划,以确保多样性和质量,利用高质量的合成图像和现实世界的自然场景图像。这种组合确保了在各种语言环境下的强大性能,并提高了模型对不同文本外观和环境条件的适应性。对于图表类型数据,我们使用包括 matplotlib、seaborn 和 plotly 在内的可视化库合成了 100 万个样本,包括条形图、关系图和热图等图表类别。关于表格数据,我们通过离线端到端表格识别模型处理了 600 万个现实世界样本,随后过滤掉低置信度表格、重叠表格和细胞密度不足的表格。
Video Data To ensure enhanced robustness in understanding video data with varying frames per second (FPS), we dynamically sampled FPS during training to achieve a more evenly distributed representation of FPS within the training dataset. Additionally, for videos exceeding half an hour in length, we specifically constructed a set of long video captions by synthesizing multi-frame captions through a targeted synthesis pipeline. Regarding video grounding data, we formulated timestamps in both second-based formats and hour-minute-second-frame (hmsf) formats, ensuring that the model can accurately understand and output time in various formats.
视频数据 为了确保在理解具有不同帧率(FPS)的视频数据时具有增强的鲁棒性,我们在训练期间动态采样 FPS,以实现训练数据集中 FPS 的更均匀分布表示。此外,对于超过半小时的视频,我们通过有针对性的合成流水线合成多帧字幕,特别构建了一组长视频字幕。关于视频接地数据,我们制定了基于秒的时间戳格式和时分秒帧(hmsf)格式,确保模型能够准确理解和输出各种格式的时间。
Agent Data We enhance the perception and decision-making abilities to build the agent capabilities of Qwen2.5-VL. For perception, we collect screenshots on mobile, web, and desktop platforms. A synthetic data engine is used to generate screenshot captions and UI element grounding annotations. The caption task helps Qwen2.5-VL understand the graphic interface, while the grounding task helps it align the appearance and function of elements. For decision-making, we first unify the operations across mobile, web, and desktop platforms into a function call format with a shared action space. A set of annotated multi-step trajectories collected from open-source data and synthesized by agent framework (Wang et al., 2025; 2024b;c) on virtual environments are reformatted into a function format. We further generate a reasoning process for each step through human and model annotators (Xu et al., 2024). Specifically, given a ground-truth operation, we highlight it on the screenshot. Then, we provide the global query, along with screenshots from before and after this operation, to the annotators and require them to write reasoning content to explain the intention behind this operation. A model-based filter is used to screen out low-quality reasoning content. Such reasoning content prevents Qwen2.5-VL from overfitting to the ground-truth operations and makes it more robust in real-world scenarios.
代理数据 我们增强了 Qwen2.5-VL 的代理能力,以构建代理能力。对于感知,我们在移动、网络和桌面平台上收集屏幕截图。使用合成数据引擎生成屏幕截图字幕和 UI 元素接地注释。字幕任务帮助 Qwen2.5-VL 理解图形界面,而接地任务帮助其对齐元素的外观和功能。对于决策,我们首先将移动、网络和桌面平台上的操作统一为具有共享操作空间的函数调用格式。从开源数据中收集的一组带注释的多步轨迹,并由代理框架(Wang 等,2025;2024b;c)在虚拟环境中合成,被重新格式化为函数格式。我们通过人类和模型注释者(Xu 等,2024)为每个步骤生成推理过程。具体来说,给定一个地面真相操作,我们在屏幕截图上突出显示它。然后,我们提供全局查询,以及此操作之前和之后的屏幕截图,给注释者,并要求他们编写推理内容来解释此操作背后的意图。使用基于模型的过滤器来筛选出低质量的推理内容。这种推理内容防止 Qwen2.5-VL 过度拟合地面真相操作,并使其在真实世界场景中更加稳健。
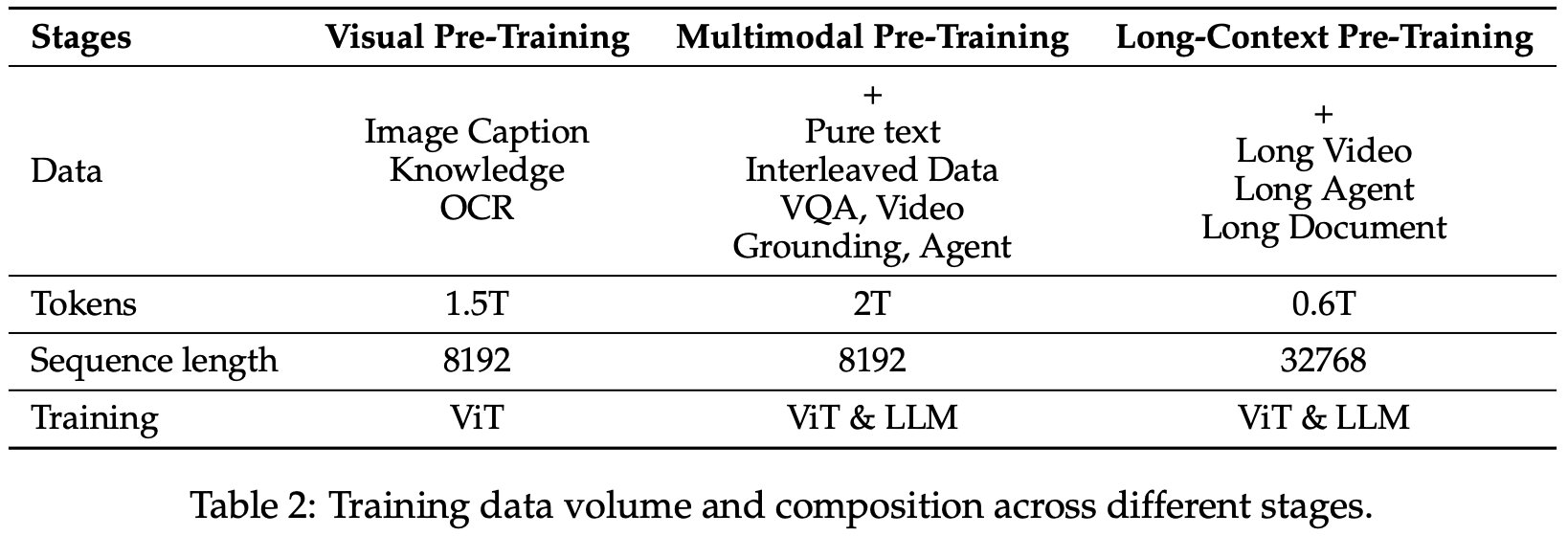
表 2: 不同阶段的训练数据量和组成。
2.2.2 Training Recipe(训练配方)
We trained a Vision Transformer (ViT) from scratch using DataComp (Gadre et al., 2023) and some in-house datasets as the initialization for the vision encoder, while leveraging the pre-trained Qwen2.5 large language model (LLM) (Yang et al., 2024a) as the initialization for the LLM component. As shown in Table 2, the pre-training process is divided into three distinct phases, each employing different data configurations and training strategies to progressively enhance the model’s capabilities.
我们从头开始训练了一个 Vision Transformer(ViT),使用 DataComp(Gadre 等,2023)和一些内部数据集作为视觉编码器的初始化,同时利用预训练的 Qwen2.5 大型语言模型(LLM)(Yang 等,2024a)作为 LLM 组件的初始化。如表 2 所示,预训练过程分为三个不同阶段,每个阶段采用不同的数据配置和训练策略,逐步增强模型的能力。
In the first phase, only the Vision Transformer (ViT) is trained to improve its alignment with the language model, laying a solid foundation for multimodal understanding. The primary data sources during this phase include image captions, visual knowledge, and OCR data. These datasets are carefully selected to foster ViT’s ability to extract meaningful visual representations that can be effectively integrated with textual information.
在第一阶段,只训练 Vision Transformer(ViT)以提高其与语言模型的对齐,为多模态理解奠定坚实基础。在此阶段的主要数据源包括图像标题、视觉知识和 OCR 数据。这些数据集经过精心选择,以培养 ViT 提取有意义的视觉表示的能力,这些表示可以有效地与文本信息集成。
In the second phase, all model parameters are unfrozen, and the model is trained on a diverse set of multimodal image data to enhance its capacity to process complex visual information. This phase introduces more intricate and reasoning-intensive datasets, such as interleaved data, multi-task learning datasets, visual question answering (VQA), multimodal mathematics, agent-based tasks, video understanding, and pure-text datasets. These datasets strengthen the model’s ability to establish deeper connections between visual and linguistic modalities, enabling it to handle increasingly sophisticated tasks.
在第二阶段,所有模型参数被解冻,并在多样化的多模态图像数据集上训练模型,以增强其处理复杂视觉信息的能力。这个阶段引入了更复杂和推理密集型的数据集,如交错数据、多任务学习数据集、视觉问答(VQA)、多模态数学、基于代理的任务、视频理解和纯文本数据集。这些数据集增强了模型建立视觉和语言模态之间更深层次联系的能力,使其能够处理越来越复杂的任务。
In the third phase, to further enhance the model’s reasoning capabilities over longer sequences, video, and agent-based data are incorporated, alongside an increase in sequence length. This allows the model to tackle more advanced and intricate multimodal tasks with greater precision. By extending the sequence length, the model gains the ability to process extended contexts, which is particularly beneficial for tasks requiring long-range dependencies and complex reasoning.
在第三阶段,为了进一步增强模型对更长序列、视频和基于代理的数据的推理能力,增加了序列长度。这使模型能够以更高的精度处理更高级和复杂的多模态任务。通过扩展序列长度,模型获得了处理扩展上下文的能力,这对于需要长距离依赖和复杂推理的任务特别有益。
To address the challenges posed by varying image sizes and text lengths, which can lead to imbalanced computational loads during training, we adopted a strategy to optimize training efficiency. The primary computational costs arise from the LLM and the vision encoder. Given that the vision encoder has relatively fewer parameters and that we introduced window attention to further reduce its computational demands, we focused on balancing the computational load of the LLM across different GPUs. Specifically, we dynamically packed data samples based on their corresponding input sequence lengths to the LLM, ensuring consistent computational loads. In the first and second phases, data were uniformly packed to a sequence length of 8,192, while in the third phase, the sequence length was increased to 32,768 to accommodate the model’s enhanced capacity for handling longer sequences.
为了解决不同图像尺寸和文本长度带来的挑战,这可能导致训练期间计算负载不平衡,我们采用了一种优化训练效率的策略。主要的计算成本来自 LLM 和视觉编码器。鉴于视觉编码器的参数相对较少,并且我们引入了窗口注意力来进一步降低其计算需求,我们专注于平衡不同 GPU 上 LLM 的计算负载。具体来说,我们根据它们对应的输入序列长度动态打包数据样本到 LLM,确保一致的计算负载。在第一和第二阶段,数据被均匀打包到序列长度为 8,192,而在第三阶段,序列长度增加到 32,768,以适应模型处理更长序列的增强能力。
2.3 Post-training(后训练)
The post-training alignment framework of Qwen2.5-VL employs a dual-stage optimization paradigm comprising Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO) (Rafailov et al., 2023). This hierarchical alignment strategy synergizes parameter-efficient domain adaptation with human preference distillation, addressing both representational grounding and behavioral refinement through distinct optimization objectives.
Qwen2.5-VL 的后训练对齐框架采用了一个双阶段优化范式,包括监督微调(SFT)和直接偏好优化(DPO)(Rafailov 等,2023)。这种分层对齐策略通过不同的优化目标,将参数高效的领域适应与人类偏好提炼相结合,解决了表示接地和行为细化两个方面。
Supervised Fine-Tuning (SFT) aims to bridge the gap between pretrained representations and downstream task requirements through targeted instruction optimization. During this phase, we employ the ChatML format (Openai, 2024) to structure instruction-following data, deliberately diverging from the pretraining data schema while maintaining architectural consistency with Qwen2-VL (Wang et al., 2024e). This format transition enables three critical adaptations: 1) Explicit dialogue role tagging for multimodal turntaking, 2) Structured injection of visual embeddings alongside textual instructions, and 3) Preservation of cross-modal positional relationships through format-aware packing. By exposing the model to curated multimodal instruction-response pairs under this enhanced schema, SFT enables efficient knowledge transfer while maintaining the integrity of pre-trained features.
监督微调(SFT)旨在通过有针对性的指导优化,弥合预训练表示和下游任务需求之间的差距。在这个阶段,我们使用 ChatML 格式(Openai,2024)来构造遵循指令数据,故意偏离预训练数据模式,同时保持与 Qwen2-VL(Wang 等,2024e)的架构一致。这种格式转换实现了三个关键的适应:1)多模态轮流对话的显式对话角色标记,2)在文本指令旁边结构化注入视觉嵌入,3)通过格式感知打包保留跨模态位置关系。通过在这种增强模式下向模型展示精心策划的多模态指令-响应对,SFT 实现了高效的知识传递,同时保持了预训练特征的完整性。
2.3.1 Instruction Data(指令数据)
The Supervised Fine-Tuning (SFT) phase employs a meticulously curated dataset designed to enhance the model’s instruction-following capabilities across diverse modalities. This dataset comprises approximately 2 million entries, evenly distributed between pure text data (50%) and multimodal data (50%), which includes image-text and video-text combinations. The inclusion of multimodal data enables the model to process complex inputs effectively. Notably, although pure text and multimodal entries are equally represented, multimodal entries consume significantly more tokens and computational resources during training due to the embedded visual and temporal information. The dataset is primarily composed of Chinese and English data, with supplementary multilingual entries to support broader linguistic diversity.
监督微调(SFT)阶段采用了一个精心策划的数据集,旨在增强模型在各种模态下的遵循指令能力。该数据集包括约 200 万条记录,纯文本数据(50%)和多模态数据(50%)均匀分布,其中包括图像-文本和视频-文本组合。多模态数据的包含使模型能够有效处理复杂的输入。值得注意的是,尽管纯文本和多模态条目的表示相同,但由于嵌入的视觉和时间信息,多模态条目在训练期间消耗了更多的标记和计算资源。该数据集主要由中文和英文数据组成,辅以支持更广泛的语言多样性的多语言条目。
The dataset is structured to reflect varying levels of dialogue complexity, including both single-turn and multi-turn interactions. These interactions are further contextualized by scenarios ranging from single-image inputs to multi-image sequences, thereby simulating realistic conversational dynamics. The query sources are primarily drawn from open-source repositories, with additional contributions from curated purchased datasets and online query data. This combination ensures broad coverage and enhances the representativeness of the dataset.
该数据集的结构反映了不同级别的对话复杂性,包括单轮和多轮交互。这些交互进一步通过从单图像输入到多图像序列的场景进行了情境化,从而模拟了现实对话动态。查询来源主要来自开源存储库,还有来自精心策划的购买数据集和在线查询数据的额外贡献。这种组合确保了广泛的覆盖范围,并增强了数据集的代表性。
To address a wide range of application scenarios, the dataset includes specialized subsets for General Visual Question Answering (VQA), image captioning, mathematical problem-solving, coding tasks, and security-related queries. Additionally, dedicated datasets for Document and Optical Character Recognition (Doc and OCR), Grounding, Video Analysis, and Agent Interactions are constructed to enhance domain-specific proficiency. Detailed information regarding the data can be found in the relevant sections of the paper. This structured and diverse composition ensures that the SFT phase effectively aligns pre-trained representations with the nuanced demands of downstream multimodal tasks, fostering robust and contextually aware model performance.
为了解决各种应用场景,数据集包括专门的子集,用于一般视觉问答(VQA)、图像标题、数学问题解决、编码任务和安全相关查询。此外,专门为文档和光学字符识别(Doc 和 OCR)、接地、视频分析和代理交互构建了专用数据集,以增强领域特定的熟练度。有关数据的详细信息可以在本文的相关部分找到。这种结构化和多样化的组成确保 SFT 阶段有效地将预训练表示与下游多模态任务的微妙需求对齐,促进了强大和具有上下文意识的模型性能。
2.3.2 Data Filtering Pipeline(数据过滤管道)
The quality of training data is a critical factor influencing the performance of vision-language models. Open-source and synthetic datasets typically exhibit significant variability, often containing noisy, redundant, or low-quality samples. Therefore, rigorous data cleaning and filtering processes are essential to address these issues. Low-quality data can lead to suboptimal alignment between pretrained representations and downstream task requirements, thereby diminishing the model’s ability to effectively handle complex multimodal tasks. Consequently, ensuring high-quality data is paramount for achieving robust and reliable model performance.
训练数据的质量是影响视觉-语言模型性能的关键因素。开源和合成数据集通常表现出显著的变异性,通常包含噪声、冗余或低质量样本。因此,严格的数据清理和过滤过程对于解决这些问题至关重要。低质量数据可能导致预训练表示与下游任务需求之间的对齐不佳,从而降低模型处理复杂多模态任务的能力。因此,确保高质量数据对于实现强大和可靠的模型性能至关重要。
To address these challenges, we implement a two-stage data filtering pipeline designed to systematically enhance the quality of the Supervised Fine-Tuning (SFT) dataset. This pipeline comprises the following stages:
为了解决这些挑战,我们实施了一个两阶段数据过滤管道,旨在系统地提高监督微调(SFT)数据集的质量。该管道包括以下阶段:
Stage 1: Domain-Specific Categorization In the initial stage, we employ Qwen2-VL-Instag, a specialized classification model derived from Qwen2-VL-72B, to perform hierarchical categorization of questionanswer (QA) pairs. This model organizes QA pairs into eight primary domains, such as Coding and Planning, which are further divided into 30 fine-grained subcategories. For example, the primary domain Coding is subdivided into subcategories including Code_Debugging, Code_Generation, Code_Translation, and Code_Understanding. This hierarchical structure facilitates domain-aware and subdomain-aware filtering strategies, enabling the pipeline to optimize data-cleaning processes tailored to each category’s specific characteristics. Consequently, this enhances the quality and relevance of the supervised fine-tuning (SFT) dataset.
阶段 1:领域特定分类 在初始阶段,我们使用 Qwen2-VL-Instag,这是从 Qwen2-VL-72B 派生的专门分类模型,对问题-答案(QA)对进行分层分类。该模型将 QA 对组织成八个主要领域,如编码和规划,进一步细分为 30 个细粒度子类别。例如,主要领域编码被细分为包括代码调试、代码生成、代码翻译和代码理解在内的子类别。这种分层结构有助于领域感知和子领域感知过滤策略,使管道能够优化针对每个类别特定特征的数据清理过程。因此,这提高了监督微调(SFT)数据集的质量和相关性。
Stage 2: Domain-Tailored Filtering The second stage involves domain-tailored filtering, which integrates both rule-based and model-based approaches to comprehensively enhance data quality. Given the diverse nature of domains such as Document Processing, Optical Character Recognition (OCR), and Visual Grounding, each may necessitate unique filtering strategies. Below, we provide an overview of the general filtering strategies applied across these domains.
阶段 2:领域定制过滤 第二阶段涉及领域定制过滤,它综合了基于规则和基于模型的方法,全面提高数据质量。鉴于文档处理、光学字符识别(OCR)和视觉接地等领域的多样性,每个领域可能需要独特的过滤策略。下面,我们概述了这些领域中应用的一般过滤策略。
Rule-Based Filtering employs predefined heuristics to eliminate low-quality or problematic entries. Specifically, for datasets related to Document Processing, OCR, and Visual Grounding tasks, repetitive patterns are identified and removed to prevent distortion of the model’s learning process and ensure optimal performance. Additionally, entries containing incomplete, truncated, or improperly formatted responses—common in synthetic datasets and multimodal contexts—are excluded. To maintain relevance and uphold ethical standards, queries and answers that are unrelated or could potentially lead to harmful outputs are also discarded. This structured approach ensures that the dataset adheres to ethical guidelines and meets task-specific requirements.
基于规则的过滤 使用预定义的启发式方法来消除低质量或有问题的条目。具体来说,对于与文档处理、OCR 和视觉接地任务相关的数据集,识别并删除重复模式,以防止扭曲模型的学习过程并确保最佳性能。此外,排除包含不完整、截断或格式不正确的响应的条目——这在合成数据集和多模态环境中很常见。为了保持相关性和维护道德标准,与查询和答案无关或可能导致有害输出的条目也被丢弃。这种结构化方法确保数据集遵守道德准则并满足任务特定要求。
Model-Based Filtering further refines the dataset by leveraging reward models trained on the Qwen2.5- VL series. These models evaluate multimodal QA pairs across multiple dimensions. Queries are assessed for complexity and relevance, retaining only those examples that are appropriately challenging and contextually pertinent. Answers are evaluated based on correctness, completeness, clarity, relevance to the query, and helpfulness. In visual-grounded tasks, particular attention is given to verifying the accurate interpretation and utilization of visual information. This multi-dimensional scoring ensures that only high-quality data progresses to the SFT phase.
基于模型的过滤 进一步通过利用在 Qwen2.5-VL 系列上训练的奖励模型来优化数据集。这些模型在多个维度上评估多模态 QA 对。查询根据复杂性和相关性进行评估,仅保留适当具有挑战性和上下文相关的示例。答案根据正确性、完整性、清晰度、与查询的相关性和帮助性进行评估。在视觉接地任务中,特别关注验证对视觉信息的准确解释和利用。这种多维评分确保只有高质量数据进入 SFT 阶段。
2.3.3 Rejection Sampling for Enhanced Reasoning(拒绝抽样以增强推理)
To complement our structured data filtering pipeline, we employ rejection sampling as a strategy to refine the dataset and enhance the reasoning capabilities of the vision-language model (VLM). This approach is particularly critical for tasks requiring complex inference, such as mathematical problemsolving, code generation, and domain-specific visual question answering (VQA). Prior research has shown that incorporating Chain-of-Thought (CoT) Wei et al. (2022) reasoning significantly improves a model’s inferential performance. (DeepSeek-AI et al., 2024) Our post-training experiments confirm this, underscoring the importance of structured reasoning processes for achieving high-quality outcomes.
为了补充我们的结构化数据过滤管道,我们采用拒绝抽样作为一种策略,以完善数据集并增强视觉-语言模型(VLM)的推理能力。这种方法对于需要复杂推理的任务尤为重要,例如数学问题解决、代码生成和领域特定的视觉问答(VQA)。先前的研究表明,引入思维链(CoT)推理显著提高了模型的推理性能。我们的后训练实验证实了这一点,强调了结构化推理过程对于实现高质量结果的重要性。
The rejection sampling process begins with datasets enriched with ground truth annotations. These datasets are carefully curated to include tasks that demand multi-step reasoning, such as mathematical problem-solving, code generation, and domain-specific VQA. Using an intermediate version of the Qwen2.5-VL model, we evaluate the generated responses against the ground truth. Only samples where the model’s output matches the expected answers are retained, ensuring the dataset consists solely of high-quality, accurate examples.
拒绝抽样过程始于富含地面真相注释的数据集。这些数据集经过精心策划,包括需要多步推理的任务,如数学问题解决、代码生成和领域特定的 VQA。使用 Qwen2.5-VL 模型的中间版本,我们评估生成的响应与地面真相的匹配情况。只有模型的输出与预期答案匹配的样本才会被保留,确保数据集仅包含高质量、准确的示例。
To further improve data quality, we apply additional constraints to filter out undesirable outputs. Specifically, we exclude responses that exhibit code-switching, excessive length, or repetitive patterns. These criteria ensure clarity and coherence in the CoT reasoning process, which is crucial for downstream applications.
为了进一步提高数据质量,我们应用额外的约束条件来过滤不良输出。具体来说,我们排除表现出代码切换、过长或重复模式的响应。这些标准确保了思维链推理过程的清晰性和连贯性,这对于下游应用至关重要。
A key challenge in applying CoT reasoning to vision-language models is their reliance on both textual and visual modalities. Intermediate reasoning steps may fail to adequately integrate visual information, either by ignoring relevant visual cues or misinterpreting them. To address this, we have developed rule-based and model-driven filtering strategies to validate the accuracy of intermediate reasoning steps. These mechanisms ensure that each step in the CoT process effectively integrates visual and textual modalities. Despite these efforts, achieving optimal modality alignment remains an ongoing challenge that requires further advancements.
将思维链推理应用于视觉-语言模型的一个关键挑战是它们依赖于文本和视觉两种模态。中间推理步骤可能无法充分整合视觉信息,要么忽略相关的视觉线索,要么错误解释它们。为了解决这个问题,我们开发了基于规则和基于模型的过滤策略,以验证中间推理步骤的准确性。这些机制确保思维链过程中的每个步骤有效地整合视觉和文本模态。尽管有这些努力,但实现最佳模态对齐仍然是一个持续的挑战,需要进一步的进展。
The data generated through rejection sampling significantly enhances the model’s reasoning proficiency. By iteratively refining the dataset and removing low-quality or erroneous samples, we enable the model to learn from high-fidelity examples that emphasize accurate and coherent reasoning. This methodology not only strengthens the model’s ability to handle complex tasks but also lays the groundwork for future improvements in vision-language modeling.
通过拒绝抽样生成的数据显著增强了模型的推理能力。通过迭代地完善数据集并删除低质量或错误的样本,我们使模型能够从强调准确和连贯推理的高保真度示例中学习。这种方法不仅增强了模型处理复杂任务的能力,还为未来视觉-语言建模的改进奠定了基础。
2.3.4 Training Recipe(训练配方)
The post-training process for Qwen2.5-VL consists of two phases: Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), both with the Vision Transformer (ViT) parameters frozen. In the SFT phase, the model is fine-tuned on diverse multimodal data, including image-text pairs, video, and pure text, sourced from general VQA, Rejection Sampling, and specialized datasets such as Document and OCR, Grounding, Video, and Agent-related tasks. The DPO phase focuses exclusively on image-text and pure text data, utilizing preference data to align the model with human preferences, with each sample processed only once to ensure efficient optimization. This streamlined process enhances the model’s cross-modal reasoning and task-specific performance while maintaining alignment with user intent.
Qwen2.5-VL 的后训练过程包括两个阶段:监督微调(SFT)和直接偏好优化(DPO),两者都冻结了 Vision Transformer(ViT)参数。在 SFT 阶段,模型在多样化的多模态数据上进行微调,包括图像-文本对、视频和纯文本,这些数据来自一般 VQA、拒绝抽样和专门数据集,如文档和 OCR、接地、视频和代理相关任务。DPO 阶段专注于图像-文本和纯文本数据,利用偏好数据将模型与人类偏好对齐,每个样本只处理一次,以确保高效优化。这种简化的过程增强了模型的跨模态推理和任务特定性能,同时保持了与用户意图的对齐。
3 Experiments(实验)
In this section, we first introduce the overall model and compare it with the current state-of-the-art (SoTA) models. Then, we evaluate the model’s performance across various sub-capabilities.
在本节中,我们首先介绍整体模型,并将其与当前的最先进模型进行比较。然后,我们评估模型在各种子能力上的性能。
3.1 Comparison with the SOTA Models(与 SOTA 模型的比较)
表 3: Qwen2.5-VL 和最先进技术的性能。
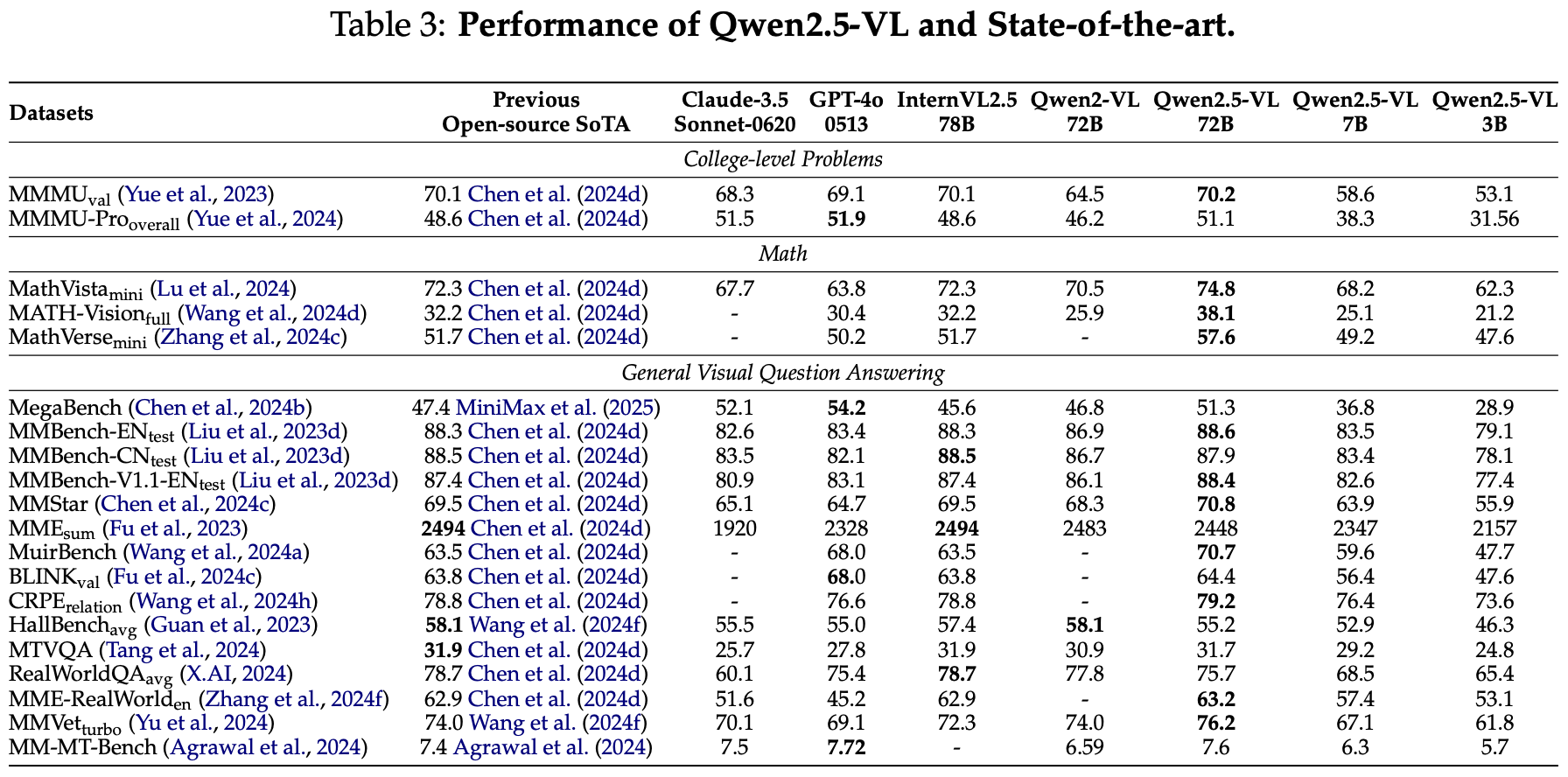
The experimental section evaluates the performance of Qwen2.5-VL across a variety of datasets, comparing it with state-of-the-art models such as Claude-3.5-Sonnet-0620 (Anthropic, 2024a), GPT-4o-0513 (OpenAI, 2024), InternVL2.5 (Chen et al., 2024d), and different sizes of Qwen2-VL (Wang et al., 2024e). In college-level problems, Qwen2.5-VL-72B achieves a score of 70.2 on MMMU (Yue et al., 2023). For MMMUPro (Yue et al., 2024), Qwen2.5-VL-72B scores 51.1, surpassing the previous open-source state-of-the-art models and achieving performance comparable to GPT-4o.
实验部分评估了 Qwen2.5-VL 在各种数据集上的性能,并将其与最先进的模型进行比较,如 Claude-3.5-Sonnet-0620(Anthropic,2024a)、GPT-4o-0513(OpenAI,2024)、InternVL2.5(Chen 等,2024d)和不同大小的 Qwen2-VL(Wang 等,2024e)。在大学级问题中,Qwen2.5-VL-72B 在 MMMU(Yue 等,2023)上获得了 70.2 的分数。对于 MMMUPro(Yue 等,2024),Qwen2.5-VL-72B 得分为 51.1,超过了以前的开源最先进模型,并实现了与 GPT-4o 相当的性能。
In math-related tasks, Qwen2.5-VL-72B demonstrates strong capabilities. On MathVista (Lu et al., 2024), it achieves a score of 74.8, outperforming the previous open-source state-of-the-art score of 72.3. For MATH-Vision (Wang et al., 2024d), Qwen2.5-VL-72B scores 38.1, while MathVerse (Zhang et al., 2024c) achieves 57.6, both showing competitive results compared to other leading models.
在与数学相关的任务中,Qwen2.5-VL-72B 展现出强大的能力。在 MathVista(Lu 等,2024)上,它获得了 74.8 的分数,超过了以前的开源最先进分数 72.3。对于 MATH-Vision(Wang 等,2024d),Qwen2.5-VL-72B 得分为 38.1,而 MathVerse(Zhang 等,2024c)实现了 57.6,两者与其他领先模型相比都表现出竞争力。
For general visual question answering, Qwen2.5-VL-72B excels across multiple benchmarks. On MMbenchEN (Liu et al., 2023d), it achieves a score of 88.6, slightly surpassing the previous best score of 88.3. The model also performs well in MuirBench (Wang et al., 2024a) with a score of 70.7 and BLINK (Fu et al., 2024c) with 64.4. In the multilingual capability evaluation of MTVQA (Tang et al., 2024), Qwen2.5-VL-72B achieves a score of 31.7, showcasing its powerful multilingual text recognition abilities. In subjective evaluations such as MMVet (Yu et al., 2024) and MM-MT-Bench (Agrawal et al., 2024), Qwen2.5-VL-72B scores 76.2 and 7.6, respectively, demonstrating excellent natural conversational experience and user satisfaction.
对于一般的视觉问答,Qwen2.5-VL-72B 在多个基准测试中表现出色。在 MMbenchEN(Liu 等,2023d)上,它获得了 88.6 的分数,略高于以前的最佳分数 88.3。该模型在 MuirBench(Wang 等,2024a)上表现良好,得分为 70.7,在 BLINK(Fu 等,2024c)上得分为 64.4。在 MTVQA(Tang 等,2024)的多语言能力评估中,Qwen2.5-VL-72B 获得了 31.7 的分数,展示了其强大的多语言文本识别能力。在 MMVet(Yu 等,2024)和 MM-MT-Bench(Agrawal 等,2024)等主观评估中,Qwen2.5-VL-72B 分别得分 76.2 和 7.6,展示了出色的自然对话体验和用户满意度。
3.2 Performance on Pure Text Tasks(纯文本任务的性能)
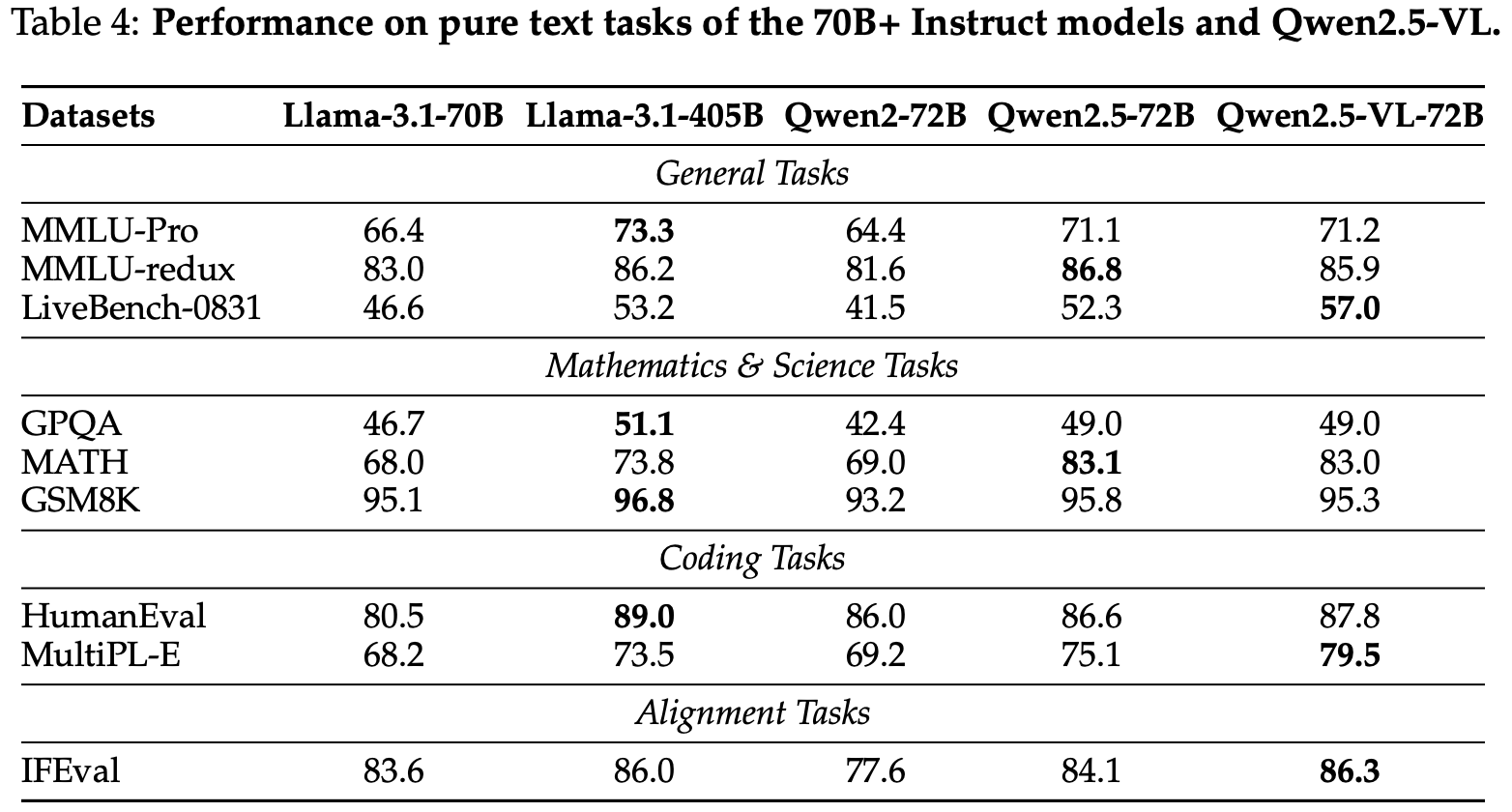
To critically evaluate the performance of instruction-tuned models on pure text tasks, as illustrated in Table 4, we selected several representative benchmarks to assess the model’s capabilities across a variety of domains, including general tasks (Wang et al., 2024j; Gema et al., 2024; White et al., 2024), mathematics and science tasks (Rein et al., 2023; Hendrycks et al., 2021; Cobbe et al., 2021), coding tasks (Chen et al., 2021; Cassano et al., 2023), and alignment task (Zhou et al., 2023). We compared Qwen2.5-VL with several large language models (LLMs) of similar size. The results demonstrate that Qwen2.5-VL not only achieves state-of-the-art (SoTA) performance on multimodal tasks but also exhibits leading performance on pure text tasks, showcasing its versatility and robustness across diverse evaluation criteria.
为了批判性地评估指令调整模型在纯文本任务上的性能,如表 4 所示,我们选择了几个代表性基准测试,评估模型在各种领域的能力,包括一般任务(Wang 等,2024j;Gema 等,2024;White 等,2024)、数学和科学任务(Rein 等,2023;Hendrycks 等,2021;Cobbe 等,2021)、编码任务(Chen 等,2021;Cassano 等,2023)和对齐任务(Zhou 等,2023)。我们将 Qwen2.5-VL 与几个类似大小的大型语言模型(LLM)进行了比较。结果表明,Qwen2.5-VL 不仅在多模态任务上实现了最先进的性能,而且在纯文本任务上表现出领先的性能,展示了其在各种评估标准下的多功能性和稳健性。
表 4: 70B+ Instruct 模型和 Qwen2.5-VL 在纯文本任务上的性能。
3.3 Quantitative Results(定量结果)
3.3.1 General Visual Question Answering(一般视觉问答)
To comprehensively evaluate the model’s capabilities in general visual question answering (VQA) and dialogue, we conducted extensive experiments across a diverse range of datasets. As illustrated in Table 3, Qwen2.5-VL demonstrates state-of-the-art performance in various VQA tasks, subjective evaluations, multilingual scenarios, and multi-image questions. Specifically, it excels on benchmark datasets such as MMBench series (Liu et al., 2023d), MMStar (Chen et al., 2024c), MME (Fu et al., 2023), MuirBench (Wang et al., 2024a), BLINK(Fu et al., 2024c), CRPE (Wang et al., 2024h), HallBench (Guan et al., 2023), MTVQA (Tang et al., 2024), MME-RealWorld (Zhang et al., 2024f), MMVet (Yu et al., 2024), and MM-MT-Bench (Agrawal et al., 2024).
为了全面评估模型在一般视觉问答(VQA)和对话中的能力,我们在各种数据集上进行了广泛的实验。如表 3 所示,Qwen2.5-VL 在各种 VQA 任务、主观评估、多语言场景和多图像问题中展示了最先进的性能。具体来说,它在基准数据集上表现出色,如 MMBench 系列(Liu 等,2023d)、MMStar(Chen 等,2024c)、MME(Fu 等,2023)、MuirBench(Wang 等,2024a)、BLINK(Fu 等,2024c)、CRPE(Wang 等,2024h)、HallBench(Guan 等,2023)、MTVQA(Tang 等,2024)、MME-RealWorld(Zhang 等,2024f)、MMVet(Yu 等,2024)和 MM-MT-Bench(Agrawal 等,2024)。
In the domain of visual detail comprehension and reasoning, Qwen2.5-VL-72B achieves an accuracy of 88.4% on the MMBench-EN-V1.1 dataset, surpassing previous state-of-the-art models such as InternVL2.5 (78B) and Claude-3.5 Sonnet-0620. Similarly, on the MMStar dataset, Qwen2.5-VL attains a score of 70.8%, outperforming other leading models in this benchmark. These results underscore the model’s robustness and adaptability across diverse linguistic contexts.
在视觉细节理解和推理领域,Qwen2.5-VL-72B 在 MMBench-EN-V1.1 数据集上实现了 88.4% 的准确率,超过了以前的最先进模型,如 InternVL2.5(78B)和 Claude-3.5 Sonnet-0620。同样,在 MMStar 数据集上,Qwen2.5-VL 获得了 70.8% 的分数,在这个基准测试中胜过了其他领先模型。这些结果突显了模型在各种语言环境中的稳健性和适应性。
Furthermore, in high-resolution real-world scenarios, specifically on the MME-RealWorld benchmark, Qwen2.5-VL demonstrates state-of-the-art performance with a score of 63.2, showcasing its broad adaptability to realistic environments. Additionally, in multi-image understanding tasks evaluated on the MuirBench dataset, Qwen2.5-VL achieves a leading score of 70.7, further highlighting its superior generalization capabilities. Collectively, these results illustrate the strong versatility and effectiveness of Qwen2.5-VL in addressing general-purpose visual question answering (VQA) tasks across various scenarios.
此外,在高分辨率的现实世界场景中,特别是在 MME-RealWorld 基准测试中,Qwen2.5-VL 展示了最先进的性能,得分为 63.2,展示了其对现实环境的广泛适应性。此外,在 MuirBench 数据集上评估的多图像理解任务中,Qwen2.5-VL 实现了领先的 70.7 分,进一步突显了其优越的泛化能力。总的来说,这些结果说明了 Qwen2.5-VL 在各种场景中解决通用视觉问答(VQA)任务的强大多功能性和有效性。
Notably, even the smaller-scale versions of Qwen2.5-VL, specifically Qwen2.5-VL-7B and Qwen2.5-VL-3B, exhibit highly competitive performance. For instance, on the MMStar dataset, Qwen2.5-VL-7B achieves 63.9%, while Qwen2.5-VL-3B scores 55.9%. This demonstrates that Qwen2.5-VL’s architecture is not only powerful but also scalable, maintaining strong performance even with fewer parameters.
值得注意的是,即使是 Qwen2.5-VL 的较小规模版本,特别是 Qwen2.5-VL-7B 和 Qwen2.5-VL-3B,也表现出极具竞争力的性能。例如,在 MMStar 数据集上,Qwen2.5-VL-7B 实现了 63.9%,而 Qwen2.5-VL-3B 得分为 55.9%。这表明 Qwen2.5-VL 的架构不仅强大而且可扩展,即使参数较少,也能保持强大的性能。
3.3.2 Document Understanding and OCR(文档理解和 OCR)
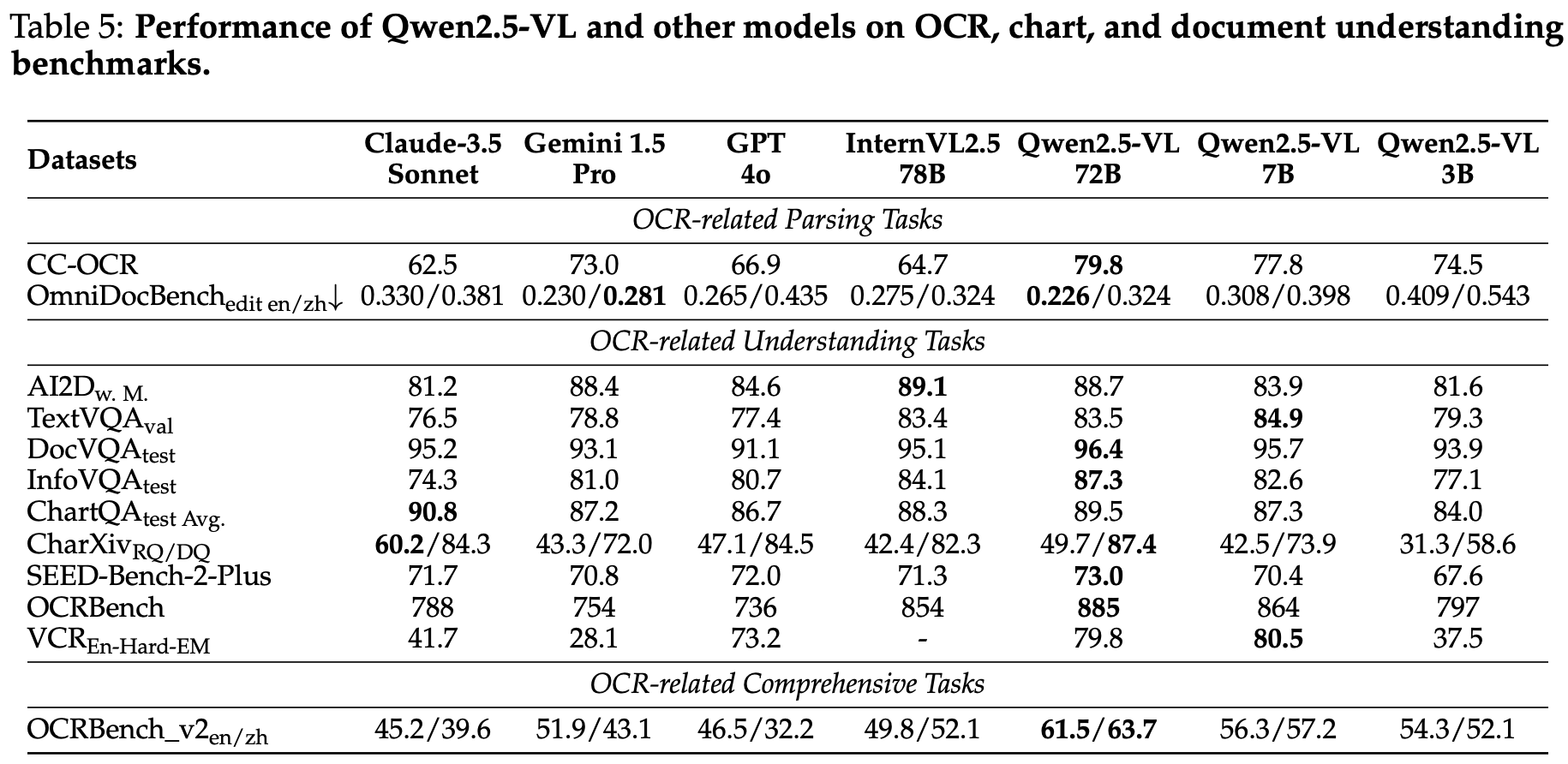
We evaluated our models across a diverse range of OCR, chart, and document understanding benchmarks. Table 5 demonstrates the performance comparison between Qwen2.5-VL models and toptier models on following OCR-related benchmarks: AI2D (Kembhavi et al., 2016), TextVQA (Singh et al., 2019), DocVQA (Mathew et al., 2021b), InfoVQA (Mathew et al., 2021a), ChartQA (Masry et al., 2022), CharXiv (Wang et al., 2024k), SEED-Bench-2-Plus (Li et al., 2024b), OCRBench (Liu et al., 2023e), OCRBench_v2 (Fu et al., 2024b), CC-OCR (Yang et al., 2024b), OmniDocBench (Ouyang et al., 2024), VCR (Zhang et al., 2024e).
我们在各种 OCR、图表和文档理解基准测试中评估了我们的模型。表 5 展示了 Qwen2.5-VL 模型与顶级模型在以下与 OCR 相关的基准测试中的性能比较:AI2D(Kembhavi 等,2016)、TextVQA(Singh 等,2019)、DocVQA(Mathew 等,2021b)、InfoVQA(Mathew 等,2021a)、ChartQA(Masry 等,2022)、CharXiv(Wang 等,2024k)、SEED-Bench-2-Plus(Li 等,2024b)、OCRBench(Liu 等,2023e)、OCRBench_v2(Fu 等,2024b)、CC-OCR(Yang 等,2024b)、OmniDocBench(Ouyang 等,2024)、VCR(Zhang 等,2024e)。
For OCR-related parsing benchmarks on element parsing for multi-scene, multilingual, and various built-in (handwriting, tables, charts, chemical formulas, and mathematical expressions) documents, as CC-OCR and OmniDocBench, Qwen2.5-VL-72B model sets the new state-of-the-art due to curated training data and excellent capability of LLM models.
对于多场景、多语言和各种内置(手写、表格、图表、化学式和数学表达式)文档的元素解析基准测试,如 CC-OCR 和 OmniDocBench,由于精心策划的训练数据和 LLM 模型的出色能力,Qwen2.5-VL-72B 模型设定了新的最先进。
For OCR-related understanding benchmarks for scene text, chart, diagram and document, Qwen2.5-VL models achieve impressive performance with good understanding abilities. Notably, on composite OCR-related understanding benchmarks as OCRBench, InfoVQA which focusing on infographics, and SEED-Bench-2-Plus covering text-rich scenarios including charts, maps, and webs, Qwen2.5-VL-72B achieves remarkable results, significantly outperforming strong competitors such as InternVL2.5-78B.
对于场景文本、图表、图表和文档的 OCR 相关理解基准测试,Qwen2.5-VL 模型表现出色,具有良好的理解能力。值得注意的是,在复合 OCR 相关理解基准测试中,如 OCRBench、InfoVQA(专注于信息图表)和 SEED-Bench-2-Plus(涵盖包括图表、地图和网络在内的文本丰富场景),Qwen2.5-VL-72B 取得了显著的成绩,明显优于强大的竞争对手,如 InternVL2.5-78B。
Furthermore, for OCR-related comprehensive benchmarks as OCRBench_v2 including a wide range of OCR-related parsing and understanding tasks, top performance is also achieved by Qwen2.5-VL models, largely exceeding best model Gemini 1.5-Pro by 9.6% and 20.6% for English and Chinese track respectively.
此外,对于包括各种 OCR 相关解析和理解任务的 OCRBench_v2 等 OCR 相关综合基准测试,Qwen2.5-VL 模型也取得了最佳性能,分别比最佳模型 Gemini 1.5-Pro 高出 9.6% 和 20.6%。
表 5: Qwen2.5-VL 和其他模型在 OCR、图表和文档理解基准测试上的性能。
3.3.3 Spatial Understanding(空间理解)
Understanding spatial relationships is crucial for developing AI models that can interpret and interact with the world as humans do. In Large Vision-Language Models, visual grounding allows for the precise localization and identification of specific objects, regions, or elements within an image based on natural language queries or descriptions. This capability transcends traditional object detection by establishing a semantic relationship between visual content and linguistic context, facilitating more nuanced and contextually aware visual reasoning. We evaluated Qwen2.5-VL’s grounding capabilities on the referring expression comprehension benchmarks (Kazemzadeh et al., 2014; Mao et al., 2016), object detection in the wild (Li et al., 2022b), self-curated point grounding benchmark, and CountBench (Paiss et al., 2023).
理解空间关系对于开发能够像人类一样解释和与世界互动的 AI 模型至关重要。在大型视觉-语言模型中,视觉接地允许根据自然语言查询或描述在图像中精确定位和识别特定对象、区域或元素。这种能力超越了传统的目标检测,通过建立视觉内容和语言上下文之间的语义关系,促进了更加微妙和具有上下文意识的视觉推理。我们在指称表达理解基准测试(Kazemzadeh 等,2014;Mao 等,2016)、野外目标检测(Li 等,2022b)、自我策划的点接地基准测试和 CountBench(Paiss 等,2023)上评估了 Qwen2.5-VL 的接地能力。
We compare Qwen2.5-VL’s visual grounding capabilities with other leading LVLMs including Gemini, Grounding-DINO (Liu et al., 2023c), Molmo (Deitke et al., 2024), and InternVL2.5.
我们将 Qwen2.5-VL 的视觉接地能力与其他领先的 LVLM 进行了比较,包括 Gemini、Grounding-DINO(Liu 等,2023c)、Molmo(Deitke 等,2024)和 InternVL2.5。
Qwen2.5-VL achieves leading performance across different benchmarks from box-grounding, and pointgrounding to counting. By equipping Qwen2.5-VL with both box and point-grounding capability, it is able to understand, locate, and reason on the very details of certain parts of an image. For openvocabulary object detection, Qwen2.5-VL achieves a good performance of 43.1 mAP on ODinW-13, surpassing most LVLMs and quickly narrowing the gap between generalist models and specialist models. In addition, Qwen2.5-VL unlocks the point-based grounding ability so that it could precisely locate the very details of a certain object, which was difficult to represent by a bounding box in the past. Qwen2.5- VL’s counting ability also makes great progress, achieving a leading accuracy of 93.6 on CountBench with Qwen2.5-VL-72B using a “detect then count”-style prompt.
Qwen2.5-VL 在从框接地、点接地到计数的不同基准测试中取得了领先的性能。通过为 Qwen2.5-VL 配备框和点接地能力,它能够理解、定位和推理图像的某些部分的细节。对于开放词汇的目标检测,Qwen2.5-VL 在 ODinW-13 上取得了 43.1 mAP 的良好性能,超过了大多数 LVLM,并迅速缩小了通用模型和专业模型之间的差距。此外,Qwen2.5-VL 解锁了基于点的接地能力,使其能够精确定位某个对象的细节,这在过去很难用边界框来表示。Qwen2.5-VL 的计数能力也取得了巨大进步,在 CountBench 上,Qwen2.5-VL-72B 使用“先检测再计数”风格提示,实现了 93.6 的领先准确率。
3.3.4 Video Understanding and Grounding(视频理解和接地)
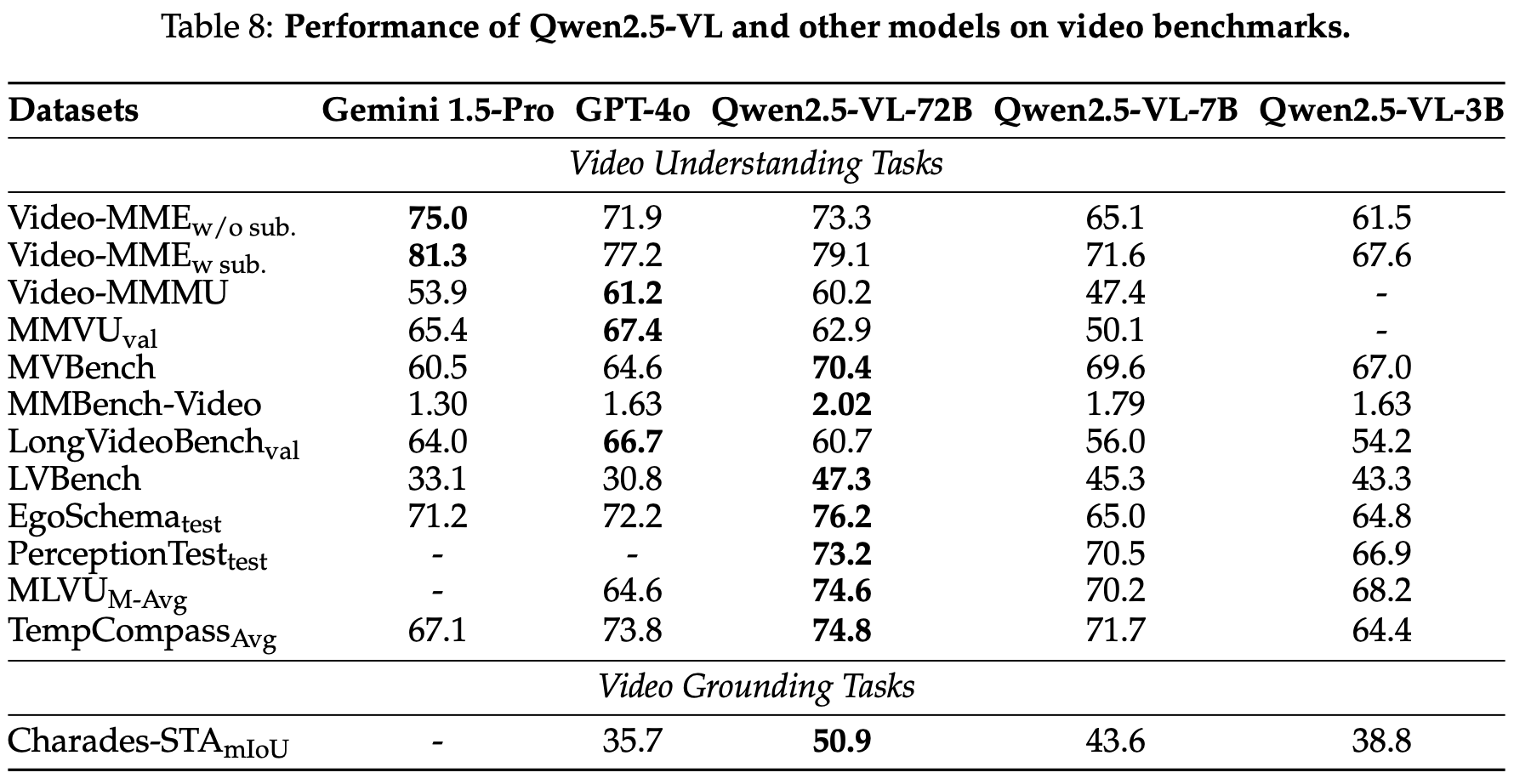
We assessed our models across a diverse range of video understanding and grounding tasks, utilizing benchmarks that include videos ranging from a few seconds to several hours in length. Table 8 demonstrates the performance comparison between Qwen2.5-VL models and top-tier proprietary models on the following video benchmarks: Video-MME (Fu et al., 2024a), Video-MMMU (Hu et al., 2025), MMVU (Zhao et al., 2025), MVBench (Li et al., 2024d), MMBench-Video (Fang et al., 2024), LongVideoBench (Wu et al., 2024a), EgoSchema (Mangalam et al., 2023), PerceptionTest (Patraucean et al., 2024), MLVU (Zhou et al., 2024), LVBench (Wang et al., 2024g), TempCompass (Liu et al., 2024c) and Charades-STA (Gao et al., 2017). Notably, on LVBench and MLVU, which evaluate long-form video understanding capabilities through question-answering tasks, Qwen2.5-VL-72B achieves remarkable results, significantly outperforming strong competitors such as GPT-4o.
我们在各种视频理解和接地任务中评估了我们的模型,利用了包括几秒到几小时的视频在内的基准测试。表 8 展示了 Qwen2.5-VL 模型与顶级专有模型在以下视频基准测试上的性能比较:Video-MME(Fu 等,2024a)、Video-MMMU(Hu 等,2025)、MMVU(Zhao 等,2025)、MVBench(Li 等,2024d)、MMBench-Video(Fang 等,2024)、LongVideoBench(Wu 等,2024a)、EgoSchema(Mangalam 等,2023)、PerceptionTest(Patraucean 等,2024)、MLVU(Zhou 等,2024)、LVBench(Wang 等,2024g)、TempCompass(Liu 等,2024c)和 Charades-STA(Gao 等,2017)。值得注意的是,在 LVBench 和 MLVU 上,通过问答任务评估长视频理解能力,Qwen2.5-VL-72B 取得了显著的成绩,明显优于强大的竞争对手,如 GPT-4o。
表 6: Qwen2.5-VL 和其他模型在接地上的性能。
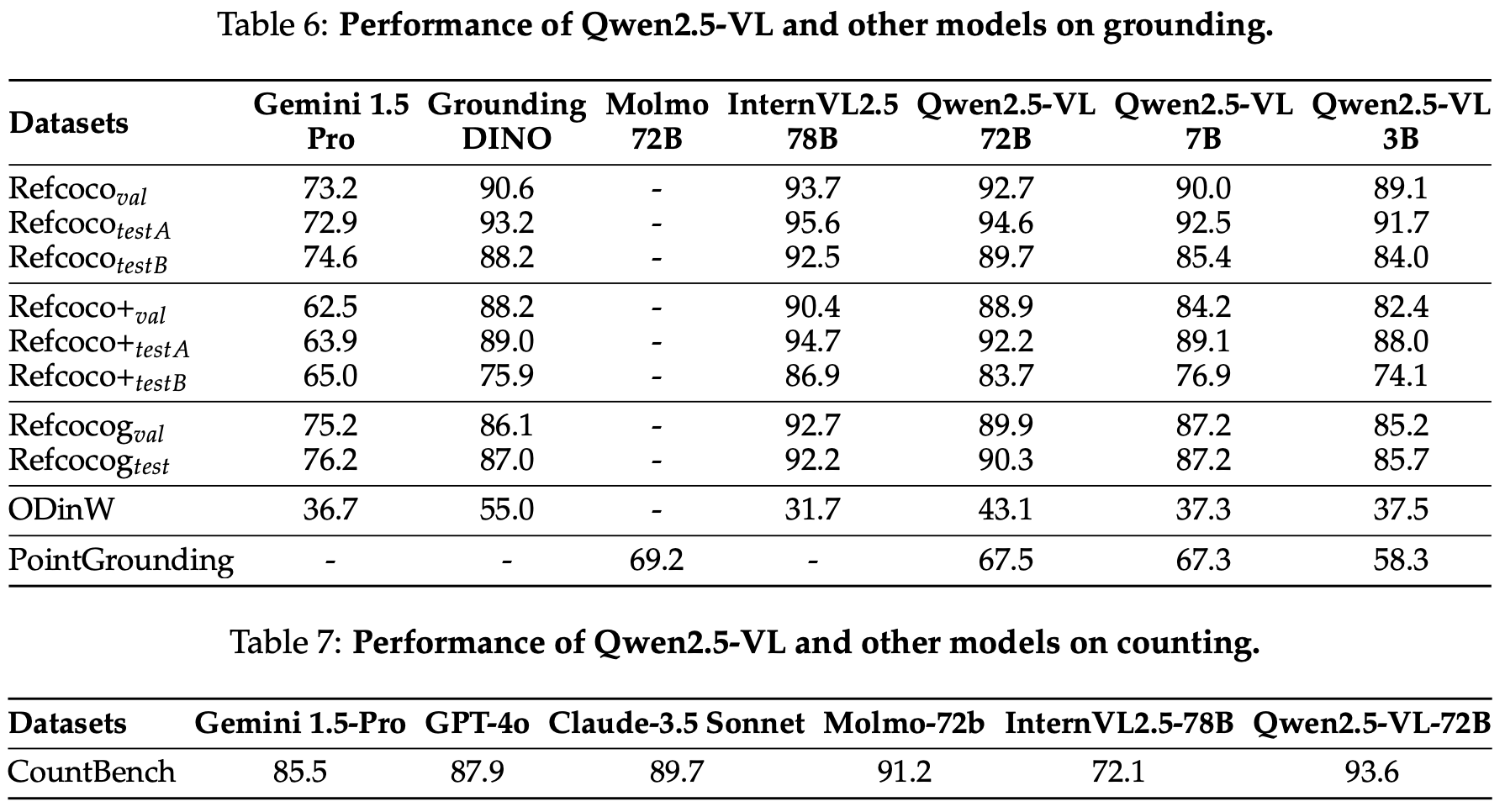
表 7: Qwen2.5-VL 和其他模型在计数上的性能。

By utilizing the proposed synchronized MRoPE, Qwen2.5-VL enhances its capabilities in time-sensitive video understanding, featuring improved timestamp referencing, temporal grounding, dense captioning, and additional functionalities. On the Charades-STA dataset, which assesses the capability to accurately localize events or activities with precise timestamps, Qwen2.5-VL-72B achieves an impressive mIoU score of 50.9, thereby surpassing the performance of GPT-4o. For all evaluated benchmarks, we capped the maximum number of frames analyzed per video at 768, with the total number of video tokens not exceeding 24,576.
通过利用提出的同步 MRoPE,Qwen2.5-VL 增强了其在时间敏感视频理解中的能力,具有改进的时间戳引用、时间接地、密集字幕和其他功能。在评估能够准确定位具有精确时间戳的事件或活动的 Charades-STA 数据集上,Qwen2.5-VL-72B 实现了 50.9 的令人印象深刻的 mIoU 分数,从而超过了 GPT-4o 的性能。对于所有评估基准测试,我们将每个视频分析的最大帧数限制为 768,视频令牌的总数不超过 24,576。
表 8: Qwen2.5-VL 和其他模型在视频基准测试上的性能。
3.3.5 Agent(智能体)
Agent capabilities within multimodal models are crucial for enabling these models to effectively interact with real-world devices. We assess the agent capabilities of Qwen2.5-VL through various aspects. The UI elements grounding is evaluated by ScreenSpot (Cheng et al., 2024) and ScreenSpot Pro (Li et al., 2025a). Offline evaluations are conducted on Android Control (Li et al., 2024f), while online evaluations are performed on platforms including AndroidWorld (Rawles et al., 2024), MobileMiniWob++ (Rawles et al., 2024), and OSWorld (Xie et al., 2025). We compare the performance of Qwen2.5-VL-72B againsts other prominent models, such as GPT-4o (OpenAI, 2024), Gemini 2.0 (Deepmind, 2024), Claude (Anthropic, 2024b), Aguvis-72B (Xu et al., 2024), and Qwen2-VL-72B (Wang et al., 2024e). The results are demonstrated in Table 9.
多模态模型中的智能体能力对于使这些模型能够有效地与现实世界设备进行交互至关重要。我们通过各个方面评估 Qwen2.5-VL 的智能体能力。UI 元素接地通过 ScreenSpot(Cheng 等,2024)和 ScreenSpot Pro(Li 等,2025a)进行评估。在 Android Control(Li 等,2024f)上进行离线评估,而在包括 AndroidWorld(Rawles 等,2024)、MobileMiniWob++(Rawles 等,2024)和 OSWorld(Xie 等,2025)在内的平台上进行在线评估。我们将 Qwen2.5-VL-72B 的性能与其他著名模型进行比较,如 GPT-4o(OpenAI,2024)、Gemini 2.0(Deepmind,2024)、Claude(Anthropic,2024b)、Aguvis-72B(Xu 等,2024)和 Qwen2-VL-72B(Wang 等,2024e)。结果如表 9 所示。
表 9: Qwen2.5-VL 和其他模型在 GUI 智能体基准测试上的性能。
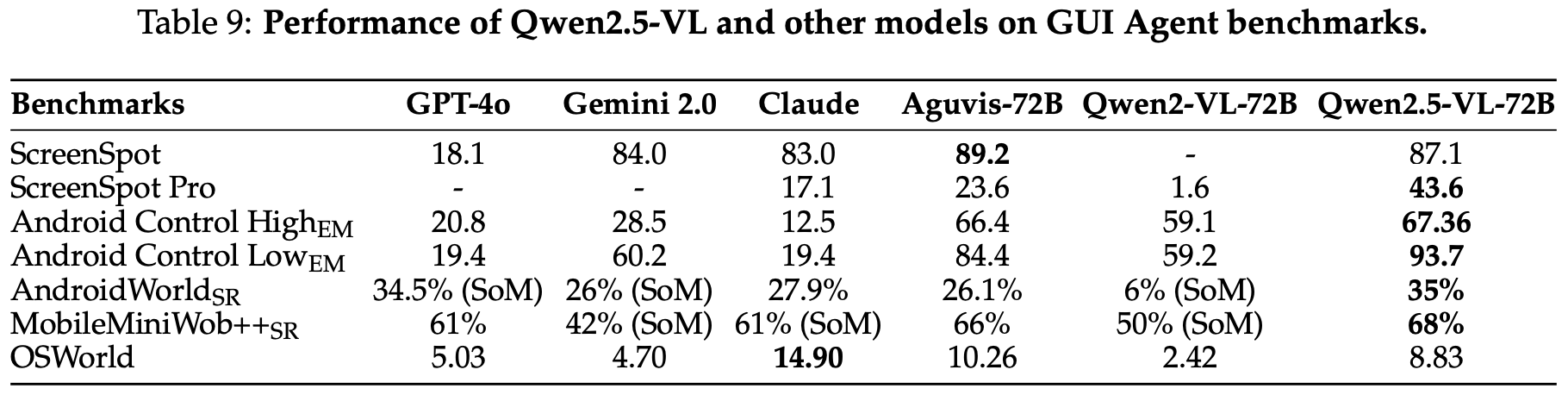
The performance of Qwen2.5-VL-72B demonstrates exceptional advancements across GUI grounding benchmarks. It achieves 87.1% accuracy on ScreenSpot, competing strongly with Gemini 2.0 (84.0%) and Claude (83.0%), while notably setting a new standard on ScreenSpot Pro with 43.6% accuracy - far surpassing both Aguvis-72B (23.6%) and its foundation Qwen2-VL-72B (1.6%). Leveraging these superior grounding capabilities, Qwen2.5-VL-72B significantly outperforms baselines across all offline evaluation benchmarks with a large gap. In online evaluation, some baselines have difficulty completing tasks due to limited grounding capabilities. Thus, we apply the Set-of-Mark (SoM) to the inputs of these models. The results show that Qwen2.5-VL-72B can outperform the baselines on AndroidWorld and MobileMiniWob++ and achieve comparable performance on OSWorld in online evaluation without auxiliary marks. This observation suggests that Qwen2.5-VL-72B is able to function as an agent in real and dynamic environments.
Qwen2.5-VL-72B 的性能在 GUI 接地基准测试中取得了显著进展。它在 ScreenSpot 上实现了 87.1% 的准确率,与 Gemini 2.0(84.0%)和 Claude(83.0%)竞争激烈,而在 ScreenSpot Pro 上则创造了新的标准,准确率为 43.6% - 远远超过 Aguvis-72B(23.6%)和其基础 Qwen2-VL-72B(1.6%)。利用这些优越的接地能力,Qwen2.5-VL-72B 在所有离线评估基准测试中显著优于基线,差距很大。在在线评估中,一些基线由于接地能力有限而难以完成任务。因此,我们将 Set-of-Mark(SoM)应用于这些模型的输入。结果表明,Qwen2.5-VL-72B 可以在 AndroidWorld 和 MobileMiniWob++ 上优于基线,并在 OSWorld 上实现可比的性能,而无需辅助标记。这一观察表明,Qwen2.5-VL-72B 能够在真实和动态环境中作为智能体运行。
4 Conclusion(结论)
We present Qwen2.5-VL, a state-of-the-art vision-language model series that achieves significant advancements in multimodal understanding and interaction. With enhanced capabilities in visual recognition, object localization, document parsing, and long-video comprehension, Qwen2.5-VL excels in both static and dynamic tasks. Its native dynamic-resolution processing and absolute time encoding enable robust handling of diverse inputs, while Window Attention reduces computational overhead without sacrificing resolution fidelity. Qwen2.5-VL caters to a wide range of applications, from edge AI to high-performance computing. The flagship Qwen2.5-VL-72B matches or surpasses leading models like GPT-4o, and Claude 3.5 Sonnet, particularly in document and diagram understanding, while maintaining strong performance on pure text tasks. The smaller Qwen2.5-VL-7B and Qwen2.5-VL-3B variants outperform similarly sized competitors, offering efficiency and versatility. Qwen2.5-VL sets a new benchmark for vision-language models, demonstrating exceptional generalization and task execution across domains. Its innovations pave the way for more intelligent and interactive systems, bridging perception and real-world application.
我们提出了 Qwen2.5-VL,这是一系列最先进的视觉-语言模型,实现了在多模态理解和交互方面的重大进展。通过增强视觉识别、对象定位、文档解析和长视频理解能力,Qwen2.5-VL 在静态和动态任务中表现出色。其本地动态分辨率处理和绝对时间编码使其能够强大地处理各种输入,而窗口注意力则减少了计算开销,而不会牺牲分辨率保真度。Qwen2.5-VL 适用于从边缘 AI 到高性能计算的各种应用。旗舰 Qwen2.5-VL-72B 与 GPT-4o 和 Claude 3.5 Sonnet 等领先模型相匹敌或超越,特别是在文档和图表理解方面,同时在纯文本任务上保持强大性能。较小的 Qwen2.5-VL-7B 和 Qwen2.5-VL-3B 变体胜过了类似大小的竞争对手,提供了效率和多功能性。Qwen2.5-VL 为视觉-语言模型设定了新的基准,展示了在各个领域的出色泛化和任务执行。其创新为更智能和交互式系统铺平了道路,架起了感知和现实世界应用之间的桥梁。