海光 DCU 的大模型推理性能压测
服务器配置
CPU 信息
CPU: Hygon C86 7490 64-core Processor X 2
lscpu
架构: x86_64
CPU 运行模式: 32-bit, 64-bit
字节序: Little Endian
Address sizes: 48 bits physical, 48 bits virtual
CPU: 256
在线 CPU 列表: 0-254
离线 CPU 列表: 255
每个核的线程数: 1
每个座的核数: 64
座: 2
NUMA 节点: 8
厂商 ID: HygonGenuine
BIOS Vendor ID: Chengdu Hygon
CPU 系列: 24
型号: 4
型号名称: Hygon C86 7490 64-core Processor
BIOS Model name: Hygon C86 7490 64-core Processor
步进: 1
CPU MHz: 2990.790
BogoMIPS: 5400.38
虚拟化: AMD-V
L1d 缓存: 2 MiB
L1i 缓存: 2 MiB
L2 缓存: 32 MiB
L3 缓存: 256 MiB
NUMA 节点0 CPU: 0-15,128-143
NUMA 节点1 CPU: 16-31,144-159
NUMA 节点2 CPU: 32-47,160-175
NUMA 节点3 CPU: 48-63,176-191
NUMA 节点4 CPU: 64-79,192-207
NUMA 节点5 CPU: 80-95,208-223
NUMA 节点6 CPU: 96-111,224-239
NUMA 节点7 CPU: 112-127,240-254
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Mitigation; untrained return thunk; SMT enabled with STIBP protection
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl and seccomp
Vulnerability Spectre v1: Mitigation; usercopy/swapgs barriers and __user pointer sanitization
Vulnerability Spectre v2: Mitigation; Retpolines, IBPB conditional, IBRS_FW, STIBP always-on, RSB filling, PBRSB-eIBRS Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
标记: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc rep_go
od nopl nonstop_tsc cpuid extd_apicid amd_dcm aperfmperf pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 x2apic movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp
_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_llc mwaitx cpb hw_pstate sme ssb
d csv ibrs ibpb stibp vmmcall csv2 csv3 fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1 xsaves clzero irperf xsaveerptr arat n
pt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold avic v_vmsave_vmload vgif umip overflow_recov succor smca sm3 sm4
DCU 信息
DCU:Hygon K100_AI 64G X 8
lspci -v | grep -A22 'Co-processor'
07:00.0 Co-processor: Chengdu Haiguang IC Design Co., Ltd. KONGMING (rev 01)
Subsystem: Chengdu Haiguang IC Design Co., Ltd. K100_AI
Flags: bus master, fast devsel, latency 0, IRQ 962, NUMA node 0
Memory at 26000000000 (64-bit, prefetchable) [size=64G]
Memory at 27000000000 (64-bit, prefetchable) [size=2M]
Memory at 7ce00000 (32-bit, non-prefetchable) [size=512K]
Expansion ROM at 7ce80000 [disabled] [size=128K]
Capabilities: [48] Vendor Specific Information: Len=08 <?>
Capabilities: [50] Power Management version 3
Capabilities: [64] Express Legacy Endpoint, MSI 00
Capabilities: [a0] MSI: Enable+ Count=1/1 Maskable- 64bit+
Capabilities: [100] Vendor Specific Information: ID=0001 Rev=1 Len=010 <?>
Capabilities: [150] Advanced Error Reporting
Capabilities: [270] Secondary PCI Express
Capabilities: [2a0] Access Control Services
Capabilities: [2b0] Address Translation Service (ATS)
Capabilities: [2c0] Page Request Interface (PRI)
Capabilities: [2d0] Process Address Space ID (PASID)
Capabilities: [320] Latency Tolerance Reporting
Capabilities: [400] Data Link Feature <?>
Capabilities: [410] Physical Layer 16.0 GT/s <?>
Capabilities: [440] Lane Margining at the Receiver <?>
Kernel driver in use: hydcu
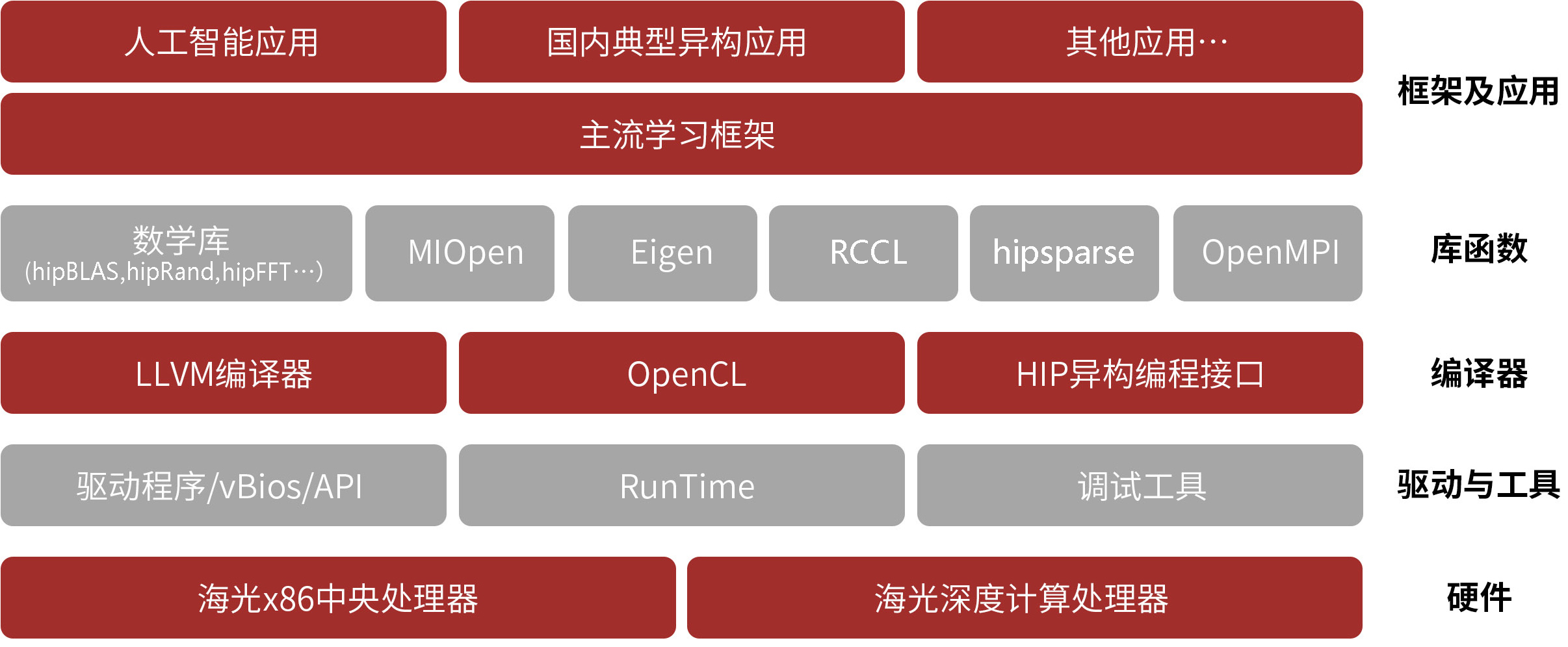
海光 DCU 软件栈
DCU (Deep Computing Unit) 海光自研的 AI 处理器,是一款主要面向于深度学习和高性能计算等领 域的加速卡。
- 开发者社区 https://developer.sourcefind.cn/tool/
查看 DCU 状态(hy-smi)
hy-smi
============================ System Management Interface =============================
======================================================================================
DCU Temp AvgPwr Perf PwrCap VRAM% DCU% Mode
0 67.0C 8.0W manual 600.0W 87% 74% Normal
1 68.0C 8.0W manual 600.0W 85% 29% Normal
2 69.0C 8.0W manual 600.0W 85% 31% Normal
3 68.0C 8.0W manual 600.0W 85% 28% Normal
4 71.0C 8.0W manual 600.0W 85% 35% Normal
5 73.0C 8.0W manual 600.0W 85% 17% Normal
6 70.0C 8.0W manual 600.0W 85% 37% Normal
7 68.0C 8.0W manual 600.0W 85% 46% Normal
======================================================================================
=================================== End of SMI Log ===================================
压力测试工具
evalscope-perf
安装 evalscope-perf:
pip install evalscope-perf -i https://pypi.tuna.tsinghua.edu.cn/simple
运行 evalscope-perf 命令:
evalscope-perf http://127.0.0.1:8000/v1/chat/completions qwen2.5 \
./datasets/open_qa.jsonl \
--max-prompt-length 8000 \
--read-timeout=120 \
--parallels 1 \
--n 1
vllm benchmark
克隆 vllm 项目
git clone https://github.com/vllm-project/vllm
数据集下载
中文聊天 HC3-Chinese
mkdir datasets
wget https://modelscope.cn/datasets/AI-ModelScope/HC3-Chinese/resolve/master/open_qa.jsonl \
-O datasets/open_qa.jsonl
代码问答 Codefuse-Evol-Instruct-Clean
wget https://modelscope.cn/datasets/Banksy235/Codefuse-Evol-Instruct-Clean/resolve/master/data.json \
-O datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
# 修改数据集格式,将 "input" 改为 "question",以适应 EvalScope 的数据集格式 openqa
sed -i 's/"input"/"question"/g' datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
ShareGPT
wget https://modelscope.cn/datasets/gliang1001/ShareGPT_V3_unfiltered_cleaned_split/resolve/master/ShareGPT_V3_unfiltered_cleaned_split.json \
-O datasets/ShareGPT_V3_unfiltered_cleaned_split.json
下载模型
进入 /data/models 目录。
cd /data/models
Qwen2.5-7B-Instruct
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
Qwen2.5-72B-Instruct
git clone https://www.modelscope.cn/Qwen/Qwen2.5-72B-Instruct.git
DeepSeek-R1-Distill-Qwen-7B
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B.git
部署模型
运行 DCU 容器
docker run -it --name vllm \
--device=/dev/kfd \
--device=/dev/mkfd \
--device=/dev/dri \
--security-opt \
seccomp=unconfined \
--cap-add=SYS_PTRACE \
--ipc=host \
--network=host \
--shm-size=16G \
--group-add video \
-v /opt/hyhal:/opt/hyhal \
-v /data/Qwen:/models \
image.sourcefind.cn:5000/dcu/admin/base/pytorch:2.3.0-ubuntu22.04-dtk24.04.3-py3.10 \
/bin/bash
vLLM 部署模型
Qwen2.5-7B-Instruct
HIP_VISIBLE_DEVICES=0,1,2,3 vllm serve /data/Qwen2.5-7B-Instruct \
--served-model-name Qwen2.5-7B-Instruct1 \
--tensor-parallel-size 4 \
--port 8001
HIP_VISIBLE_DEVICES=4,5,6,7 vllm serve /data/Qwen2.5-7B-Instruct \
--served-model-name Qwen2.5-7B-Instruct2 \
--tensor-parallel-size 4 \
--port 8002
安装 LiteLLM:
pip install "litellm[proxy]" openai -i https://pypi.tuna.tsinghua.edu.cn/simple
编辑 LiteLLM 配置文件:litellm_config.yaml
# 模型列表
model_list:
## 语言模型
- model_name: Qwen2.5-7B-Instruct
litellm_params:
model: openai/Qwen2.5-7B-Instruct1
api_base: http://localhost:8001/v1
api_key: NONE
- model_name: Qwen2.5-7B-Instruct
litellm_params:
model: openai/Qwen2.5-7B-Instruct2
api_base: http://localhost:8002/v1
api_key: NONE
运行 LiteLLM:
litellm serve --config litellm_config.yaml
Qwen2.5-72B-Instruct
vllm serve /models/Qwen2.5-72B-Instruct \
--served-model-name Qwen2.5-72B-Instruct \
--tensor-parallel-size 8
DeepSeek-R1-Distill-Qwen-7B
vllm serve /models/DeepSeek-R1-Distill-Qwen-7B \
--served-model-name DeepSeek-R1-Distill-Qwen-7B \
--tensor-parallel-size 4
--tensor-parallel-size 不能设置 8,会报错:
INFO 02-26 08:54:31 config.py:908] Defaulting to use mp for distributed inference
INFO 02-26 08:54:31 config.py:937] Disabled the custom all-reduce kernel because it is not supported on hcus.
WARNING 02-26 08:54:31 arg_utils.py:947] Chunked prefill is enabled by default for models with max_model_len > 32K. Currently, chunked prefill might not work with some features or models. If you encounter any issues, please disable chunked prefill by setting --enable-chunked-prefill=False.
INFO 02-26 08:54:31 config.py:1019] Chunked prefill is enabled with max_num_batched_tokens=512.
Process SpawnProcess-1:
Traceback (most recent call last):
File "/usr/local/lib/python3.10/multiprocessing/process.py", line 314, in _bootstrap
self.run()
File "/usr/local/lib/python3.10/multiprocessing/process.py", line 108, in run
self._target(*self._args, **self._kwargs)
File "/usr/local/lib/python3.10/site-packages/vllm/engine/multiprocessing/engine.py", line 388, in run_mp_engine
engine = MQLLMEngine.from_engine_args(engine_args=engine_args,
File "/usr/local/lib/python3.10/site-packages/vllm/engine/multiprocessing/engine.py", line 134, in from_engine_args
engine_config = engine_args.create_engine_config()
File "/usr/local/lib/python3.10/site-packages/vllm/engine/arg_utils.py", line 1081, in create_engine_config
return EngineConfig(
File "<string>", line 14, in __init__
File "/usr/local/lib/python3.10/site-packages/vllm/config.py", line 1894, in __post_init__
self.model_config.verify_with_parallel_config(self.parallel_config)
File "/usr/local/lib/python3.10/site-packages/vllm/config.py", line 423, in verify_with_parallel_config
raise ValueError(
ValueError: Total number of attention heads (28) must be divisible by tensor parallel size (8).
总的注意力头数 28 不能被张量并行大小 8 整除。
实验结果
Qwen2.5-7B-Instruct(4卡)
- vllm benchmark
python3 ./vllm/benchmarks/benchmark_serving.py --backend vllm \
--model Qwen2.5-7B-Instruct \
--tokenizer /models/Qwen2.5-7B-Instruct \
--dataset-name "sharegpt" \
--dataset-path "datasets/ShareGPT_V3_unfiltered_cleaned_split.json" \
--base-url http://0.0.0.0:8000 --trust-remote-code
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 99.26
Total input tokens: 217393
Total generated tokens: 201847
Request throughput (req/s): 10.07
Output token throughput (tok/s): 2033.56
Total Token throughput (tok/s): 4223.73
---------------Time to First Token----------------
Mean TTFT (ms): 29485.22
Median TTFT (ms): 26708.14
P99 TTFT (ms): 69538.05
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 110.06
Median TPOT (ms): 109.48
P99 TPOT (ms): 269.10
---------------Inter-token Latency----------------
Mean ITL (ms): 95.75
Median ITL (ms): 77.91
P99 ITL (ms): 418.17
==================================================
并发数 200 就会失败
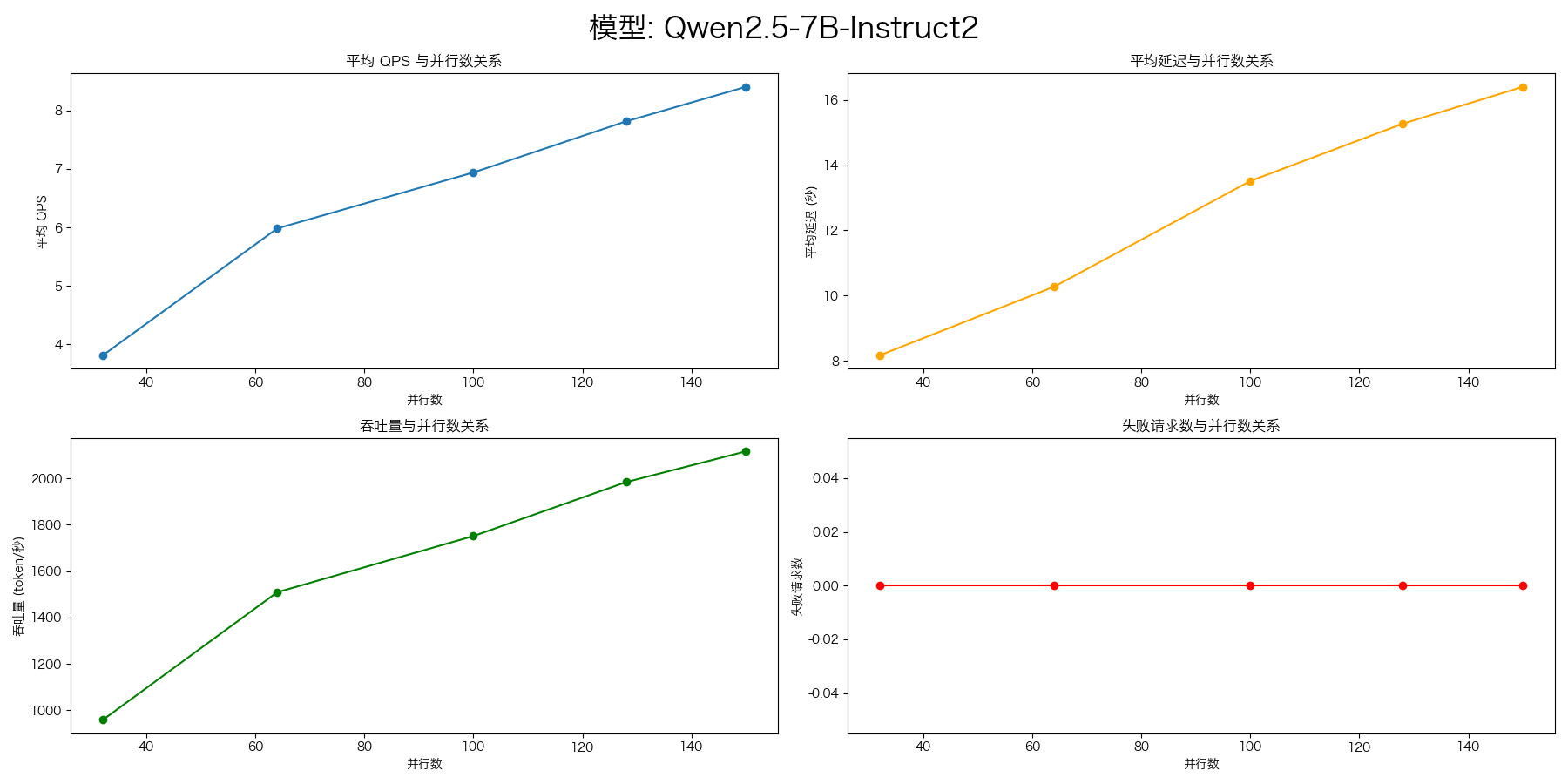
Qwen2.5-7B-Instruct(8卡)
使用 vLLM 分别部署了两个模型,每个模型使用 4 张卡。使用 AI 网关 LiteLLM 进行负载均衡。
- evalscope-perf
evalscope-perf http://127.0.0.1:4000/v1/chat/completions Qwen2.5-7B-Instruct \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 300 \
--n 1000
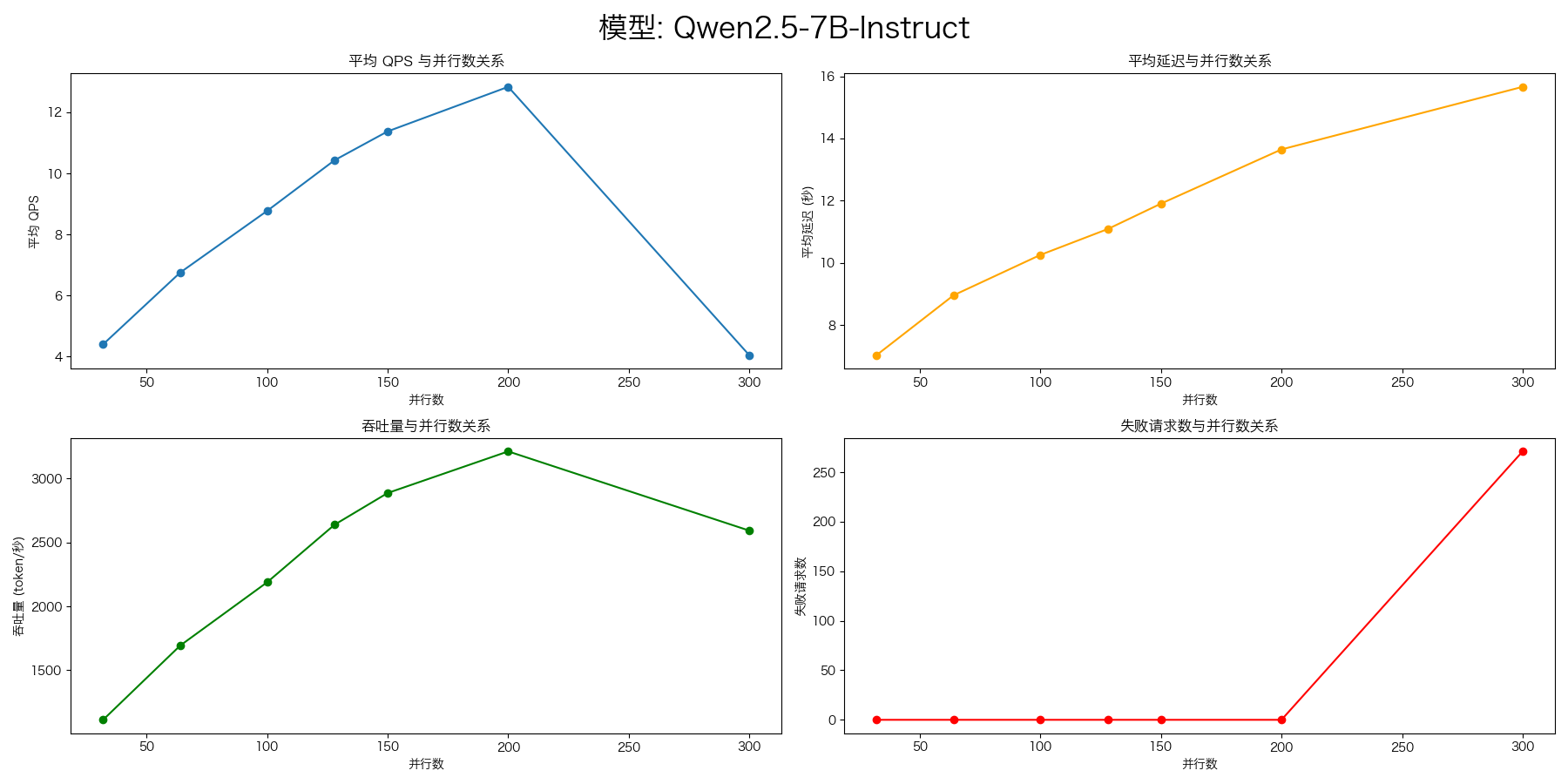
200的并发就到头了,400就会压测失败。
下面的结果,在压测前,做了并发32,100个请求的预热。
evalscope-perf http://127.0.0.1:4000/v1/chat/completions Qwen2.5-7B-Instruct \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 256 \
--n 1000
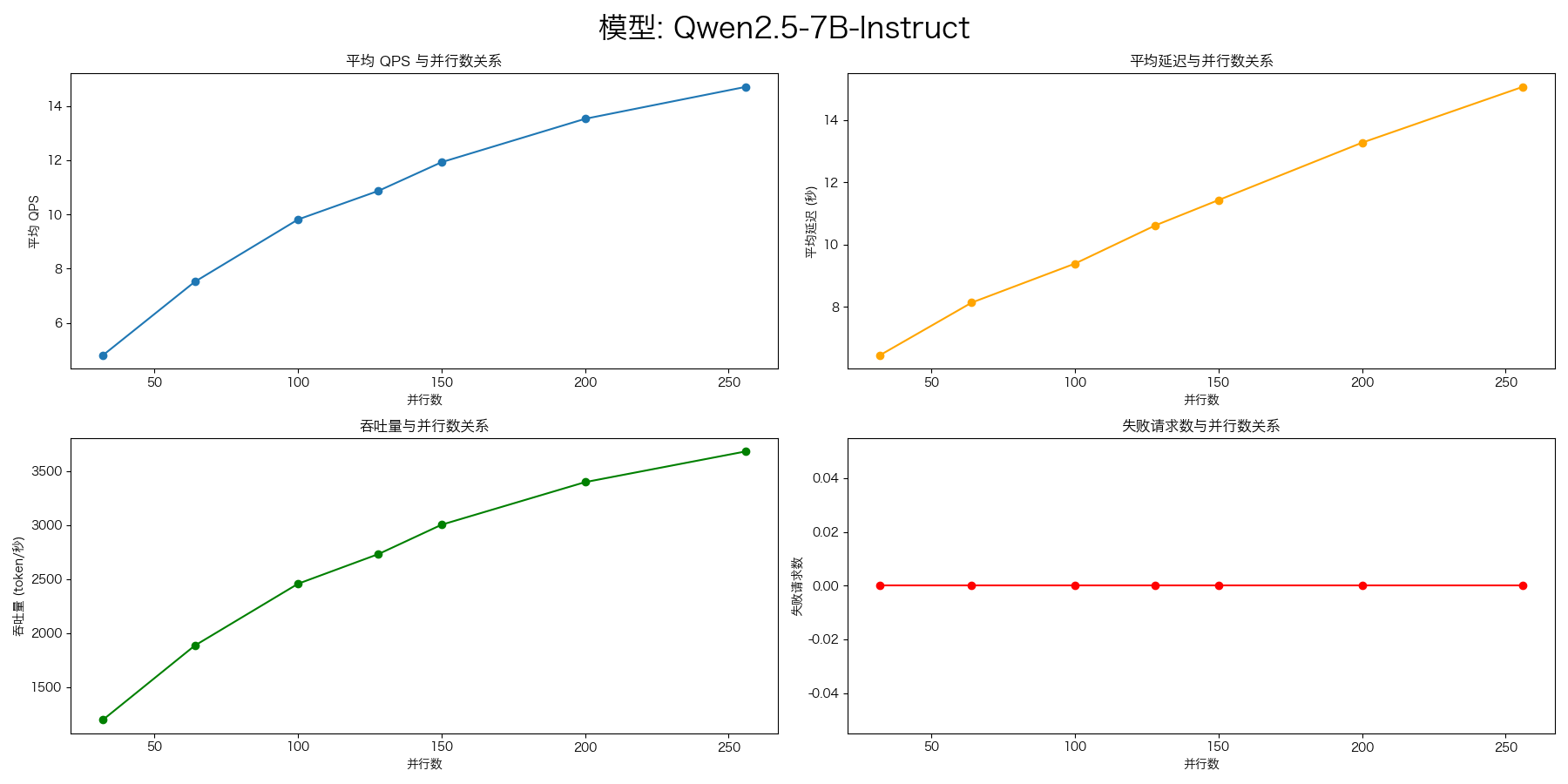
部署模型 vllm serve 增加参数 --enforce-eager
--enforce-eager 参数的主要作用是:
-
强制使用 PyTorch 的 eager 模式执行推理,而不是使用 vLLM 默认的优化执行方式
-
当设置为 True 时,vLLM 会禁用它的一些高级优化功能(如连续批处理、KV 缓存等),转而使用更直接的 PyTorch eager 执行模式
-
这通常用于调试目的,或者在某些情况下 vLLM 的优化执行方式出现问题时使用
使用这个参数会导致推理性能下降,因为它绕过了 vLLM 的核心性能优化。通常情况下不建议在生产环境中使用,除非你遇到了特定的兼容性问题或者需要进行调试。
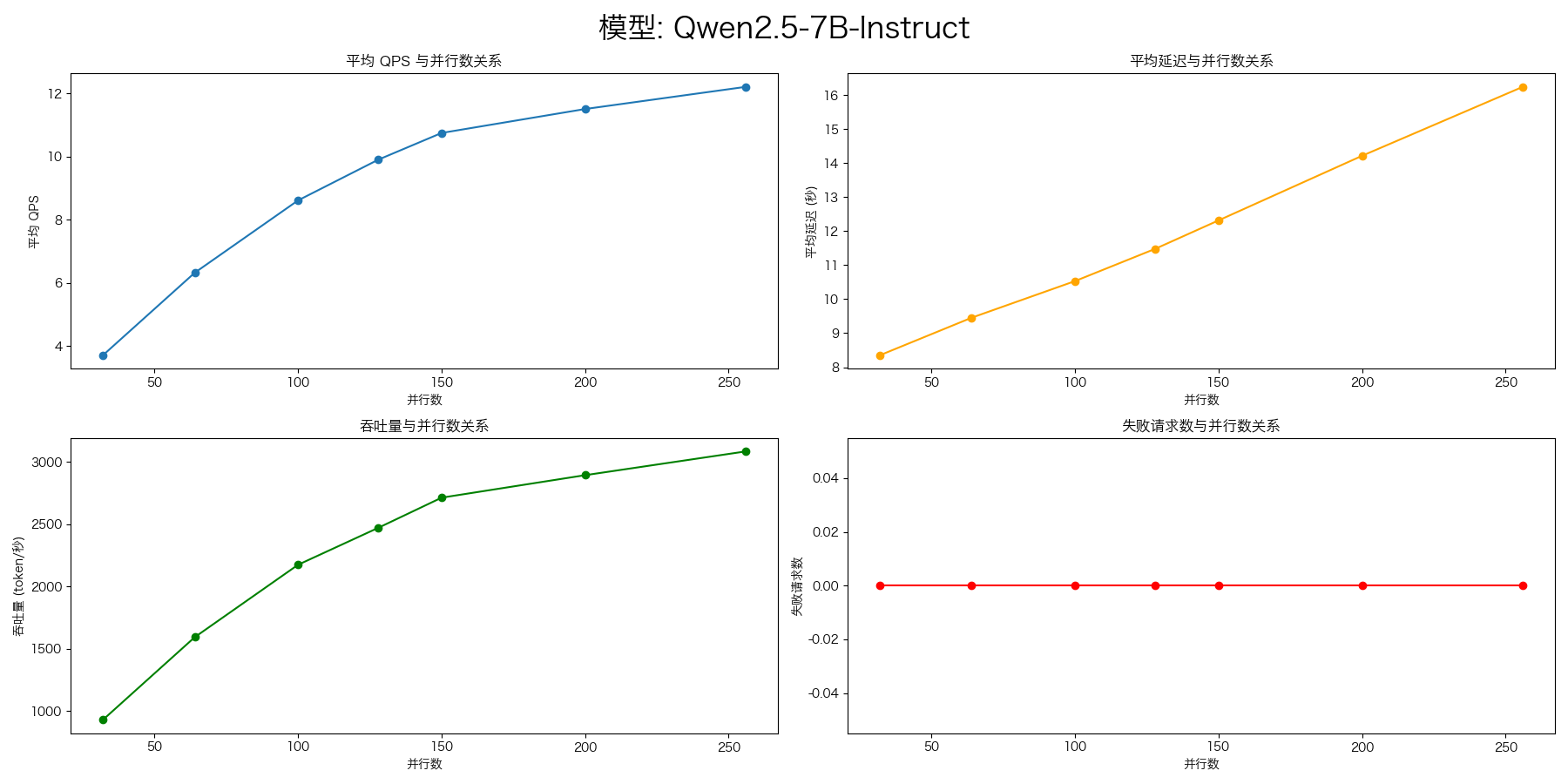
Qwen2.5-72B-Instruct
- vllm benchmark
python3 ./benchmarks/benchmark_serving.py --backend vllm \
--model Qwen2.5-72B-Instruct \
--tokenizer /models/Qwen2.5-72B-Instruct \
--dataset-name "sharegpt" \
--dataset-path "datasets/ShareGPT_V3_unfiltered_cleaned_split.json" \
--base-url http://0.0.0.0:8000 --trust-remote-code
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 334.94
Total input tokens: 217393
Total generated tokens: 201825
Request throughput (req/s): 2.99
Output token throughput (tok/s): 602.57
Total Token throughput (tok/s): 1251.62
---------------Time to First Token----------------
Mean TTFT (ms): 100031.28
Median TTFT (ms): 90367.02
P99 TTFT (ms): 241764.93
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 398.76
Median TPOT (ms): 374.48
P99 TPOT (ms): 1608.16
---------------Inter-token Latency----------------
Mean ITL (ms): 328.62
Median ITL (ms): 260.01
P99 ITL (ms): 1059.74
==================================================
- evalscope-perf
evalscope-perf http://127.0.0.1:8000/v1/chat/completions Qwen2.5-72B-Instruct \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 300 \
--parallels 400 \
--parallels 500 \
--n 1000
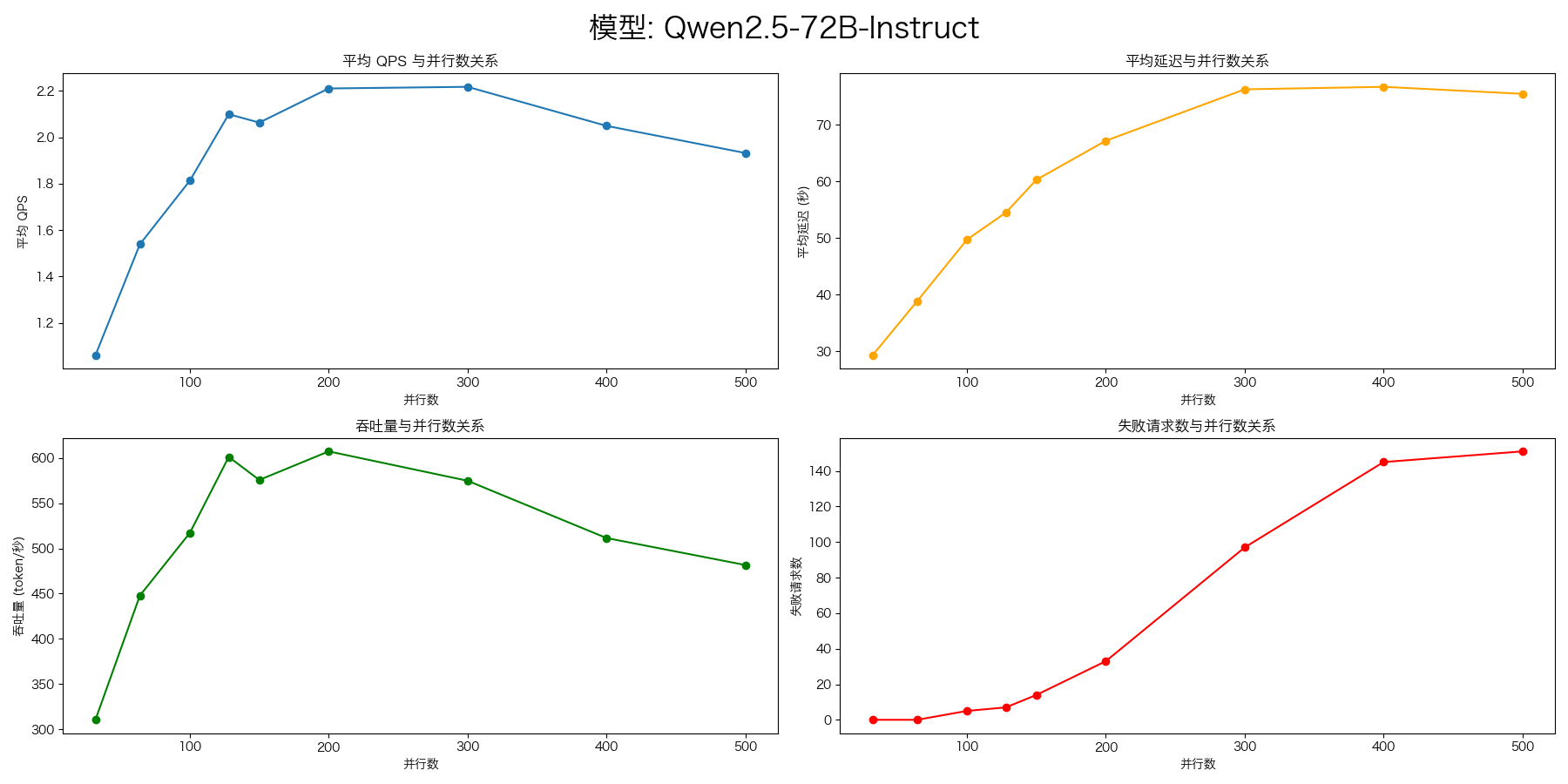
DeepSeek-R1-Distill-Qwen-7B
python3 ./benchmarks/benchmark_serving.py --backend vllm \
--model DeepSeek-R1-Distill-Qwen-7B \
--tokenizer /models/DeepSeek-R1-Distill-Qwen-7B \
--dataset-name "sharegpt" \
--dataset-path "datasets/ShareGPT_V3_unfiltered_cleaned_split.json" \
--base-url http://0.0.0.0:8000 --trust-remote-code
Traffic request rate: inf
Burstiness factor: 1.0 (Poisson process)
Maximum request concurrency: None
============ Serving Benchmark Result ============
Successful requests: 388
Benchmark duration (s): 55.08
Total input tokens: 105060
Total generated tokens: 177808
Request throughput (req/s): 7.04
Output token throughput (tok/s): 3228.07
Total Token throughput (tok/s): 5135.42
---------------Time to First Token----------------
Mean TTFT (ms): 19398.15
Median TTFT (ms): 18818.66
P99 TTFT (ms): 41185.12
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 48.15
Median TPOT (ms): 35.21
P99 TPOT (ms): 128.93
---------------Inter-token Latency----------------
Mean ITL (ms): 92.37
Median ITL (ms): 82.40
P99 ITL (ms): 470.56
==================================================