部署 Reachy Mini 语音智能体
安装 reachy_mini_conversation_app 到 Reachy Mini
在 MacBook 上运行 Reachy Mini Control,单击 Start 按钮。
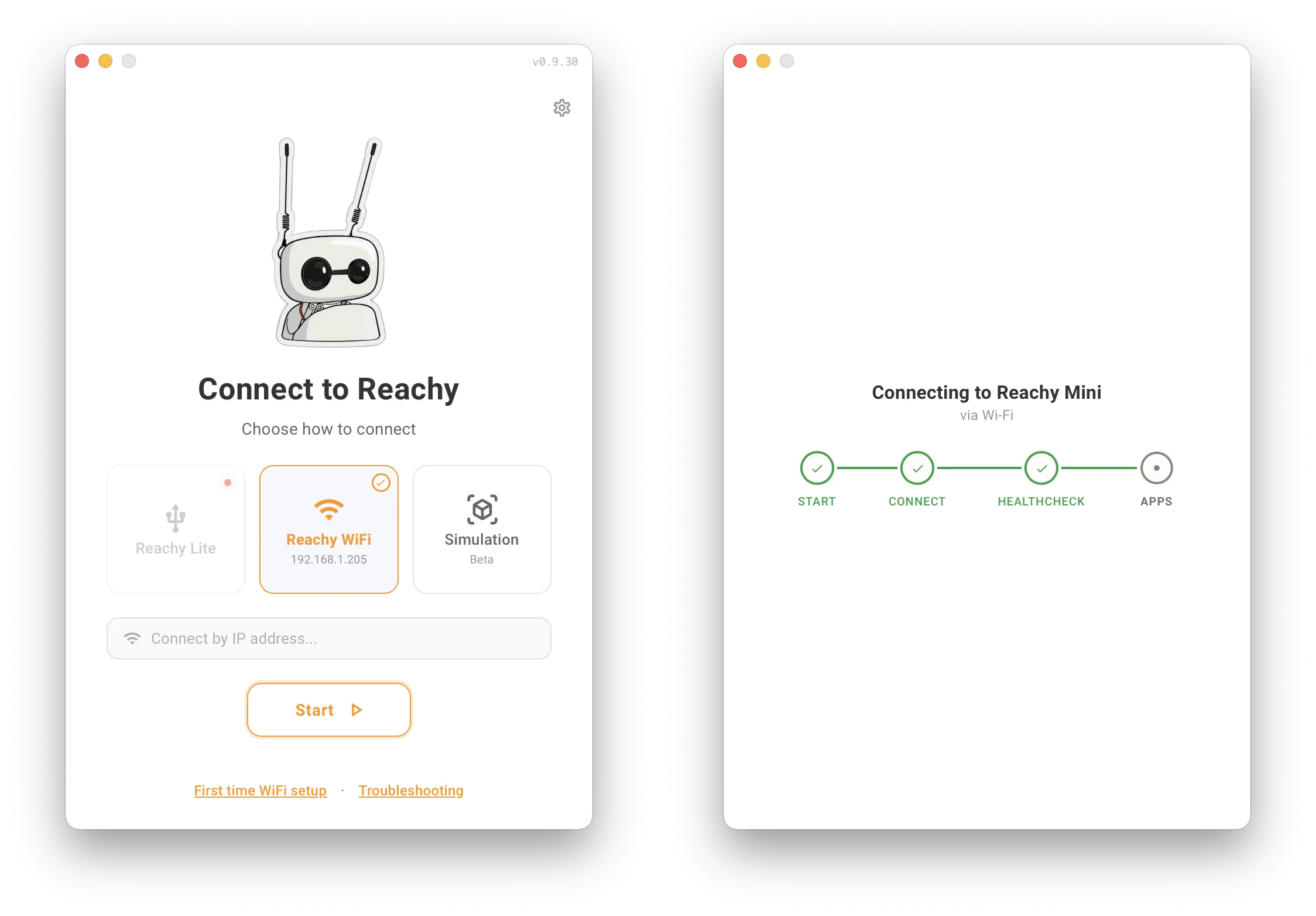
在 Applications 页面,单击 Discover apps 后,搜索 reachy_mini_conversation_app。

单击 Install 按钮安装 reachy_mini_conversation_app。
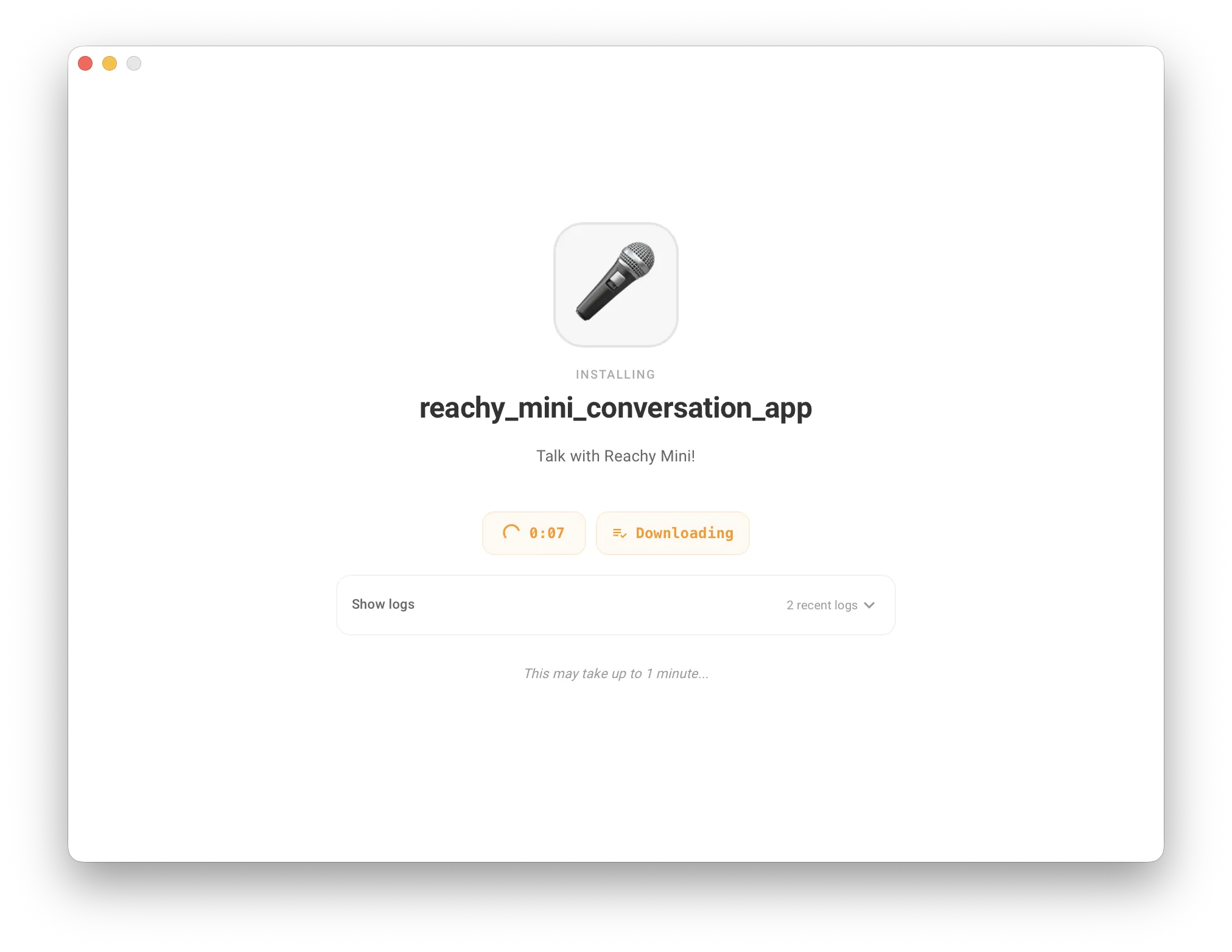
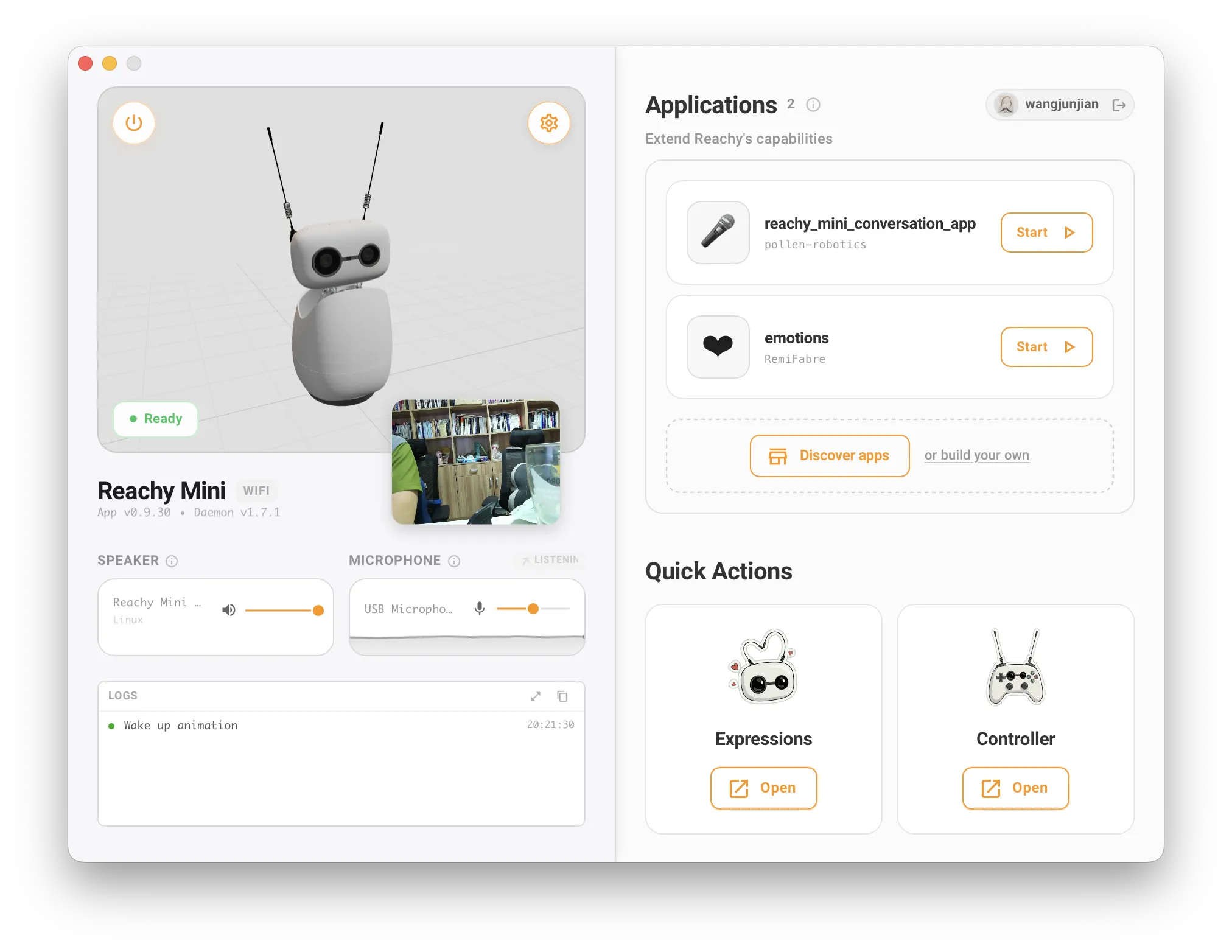
MacBook 上实时模式运行 Speech To Speech
安装 Speech To Speech
uv venv --python 3.12
source .venv/bin/activate
uv pip install speech-to-speech
uv pip install "speech-to-speech[faster-whisper]"
中文
speech-to-speech \
--mode realtime \
--device mps \
--stt faster-whisper \
--faster_whisper_stt_model_name small \
--faster_whisper_stt_gen_language zh \
--language zh \
--tts qwen3 \
--qwen3_tts_language auto \
--llm_backend mlx-lm \
--model_name mlx-community/Qwen3.5-4B-OptiQ-4bit \
--enable_lang_prompt \
--no_enable_live_transcription
[nltk_data] Downloading package averaged_perceptron_tagger_eng to /Users/junjian/nltk_data
Using cache found in /Users/junjian/.cache/torch/hub/snakers4_silero-vad_master
2026-05-15 22:55:28,387 - httpx - INFO - HTTP Request: GET https://huggingface.co/api/models/Systran/faster-whisper-small/revision/main "HTTP/1.1 200 OK"
2026-05-15 22:55:30,000 - speech_to_speech.LLM.language_model - INFO - LLM Language Model Handler setup
2026-05-15 22:55:31,166 - httpx - INFO - HTTP Request: GET https://huggingface.co/api/models/mlx-community/Qwen3.5-4B-OptiQ-4bit/revision/main "HTTP/1.1 200 OK"
2026-05-15 22:55:32,799 - speech_to_speech.LLM.language_model - INFO - LLM Backend: mlx
2026-05-15 22:55:33,934 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Loading Qwen3-TTS model: mlx-community/Qwen3-TTS-12Hz-1.7B-CustomVoice-6bit via mlx-audio on Apple Silicon
2026-05-15 22:55:33,934 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Using MLX quantized Qwen3-TTS variant: 6bit
2026-05-15 22:55:34,589 - httpx - INFO - HTTP Request: GET https://huggingface.co/api/models/mlx-community/Qwen3-TTS-12Hz-1.7B-CustomVoice-6bit/revision/main "HTTP/1.1 200 OK"
[transformers] You are using a model of type `qwen3_tts` to instantiate a model of type ``. This may be expected if you are loading a checkpoint that shares a subset of the architecture (e.g., loading a `sam2_video` checkpoint into `Sam2Model`), but is otherwise not supported and can yield errors. Please verify that the checkpoint is compatible with the model you are instantiating.
Initialized encoder codebooks
Loaded speech tokenizer from /Users/junjian/.cache/huggingface/hub/models--mlx-community--Qwen3-TTS-12Hz-1.7B-CustomVoice-6bit/snapshots/1c6c0ff58c43afa8df571facde2efa077efd85e2/speech_tokenizer
2026-05-15 22:55:36,119 - speech_to_speech.TTS.qwen3_tts_handler - INFO - MLX Audio Qwen3-TTS model loaded
2026-05-15 22:55:36,119 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Using Qwen3-TTS streaming chunk size 4 (~320ms audio per chunk) on mlx
2026-05-15 22:55:37,139 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Qwen3-TTS TTFA: 1.02s (custom_voice_mlx)
2026-05-15 22:55:37,771 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Qwen3-TTS generated 1.64s audio in 1.65s (RTF: 0.99, custom_voice_mlx)
2026-05-15 22:55:37,788 - speech_to_speech.api.openai_realtime.server - INFO - OpenAI Realtime API server starting on ws://0.0.0.0:8765/v1/realtime
INFO: Started server process [10049]
INFO: Uvicorn running on http://0.0.0.0:8765 (Press CTRL+C to quit)
英文
speech-to-speech \
--mode realtime \
--device mps \
--parakeet_tdt_language en \
--tts qwen3 \
--llm_backend mlx-lm \
--model_name mlx-community/Qwen3.5-4B-OptiQ-4bit
[nltk_data] Downloading package averaged_perceptron_tagger_eng to /Users/junjian/nltk_data
Using cache found in /Users/junjian/.cache/torch/hub/snakers4_silero-vad_master
2026-05-15 21:15:27,246 - speech_to_speech.STT.parakeet_tdt_handler - INFO - Loading Parakeet TDT model: mlx-community/parakeet-tdt-0.6b-v3 on mps
2026-05-15 21:15:29,913 - httpx - INFO - HTTP Request: GET https://huggingface.co/api/models/mlx-community/parakeet-tdt-0.6b-v3/revision/main "HTTP/1.1 200 OK"
2026-05-15 21:15:31,377 - speech_to_speech.STT.parakeet_tdt_handler - INFO - MLX Audio Parakeet model loaded successfully
2026-05-15 21:15:31,378 - speech_to_speech.STT.parakeet_tdt_handler - INFO - Live transcription enabled for Parakeet TDT (mlx)
2026-05-15 21:15:31,779 - speech_to_speech.LLM.language_model - INFO - LLM Language Model Handler setup
2026-05-15 21:15:32,451 - httpx - INFO - HTTP Request: GET https://huggingface.co/api/models/mlx-community/Qwen3.5-4B-OptiQ-4bit/revision/main "HTTP/1.1 200 OK"
2026-05-15 21:15:34,248 - speech_to_speech.LLM.language_model - INFO - LLM Backend: mlx
2026-05-15 21:15:35,123 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Loading Qwen3-TTS model: mlx-community/Qwen3-TTS-12Hz-1.7B-CustomVoice-6bit via mlx-audio on Apple Silicon
2026-05-15 21:15:35,123 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Using MLX quantized Qwen3-TTS variant: 6bit
2026-05-15 21:15:35,795 - httpx - INFO - HTTP Request: GET https://huggingface.co/api/models/mlx-community/Qwen3-TTS-12Hz-1.7B-CustomVoice-6bit/revision/main "HTTP/1.1 200 OK"
[transformers] You are using a model of type `qwen3_tts` to instantiate a model of type ``. This may be expected if you are loading a checkpoint that shares a subset of the architecture (e.g., loading a `sam2_video` checkpoint into `Sam2Model`), but is otherwise not supported and can yield errors. Please verify that the checkpoint is compatible with the model you are instantiating.
Initialized encoder codebooks
Loaded speech tokenizer from /Users/junjian/.cache/huggingface/hub/models--mlx-community--Qwen3-TTS-12Hz-1.7B-CustomVoice-6bit/snapshots/1c6c0ff58c43afa8df571facde2efa077efd85e2/speech_tokenizer
2026-05-15 21:15:37,266 - speech_to_speech.TTS.qwen3_tts_handler - INFO - MLX Audio Qwen3-TTS model loaded
2026-05-15 21:15:37,266 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Using Qwen3-TTS streaming chunk size 4 (~320ms audio per chunk) on mlx
2026-05-15 21:15:38,119 - speech_to_speech.api.openai_realtime.server - INFO - OpenAI Realtime API server starting on ws://0.0.0.0:8765/v1/realtime
INFO: Started server process [83588]
INFO: Uvicorn running on http://0.0.0.0:8765 (Press CTRL+C to quit)
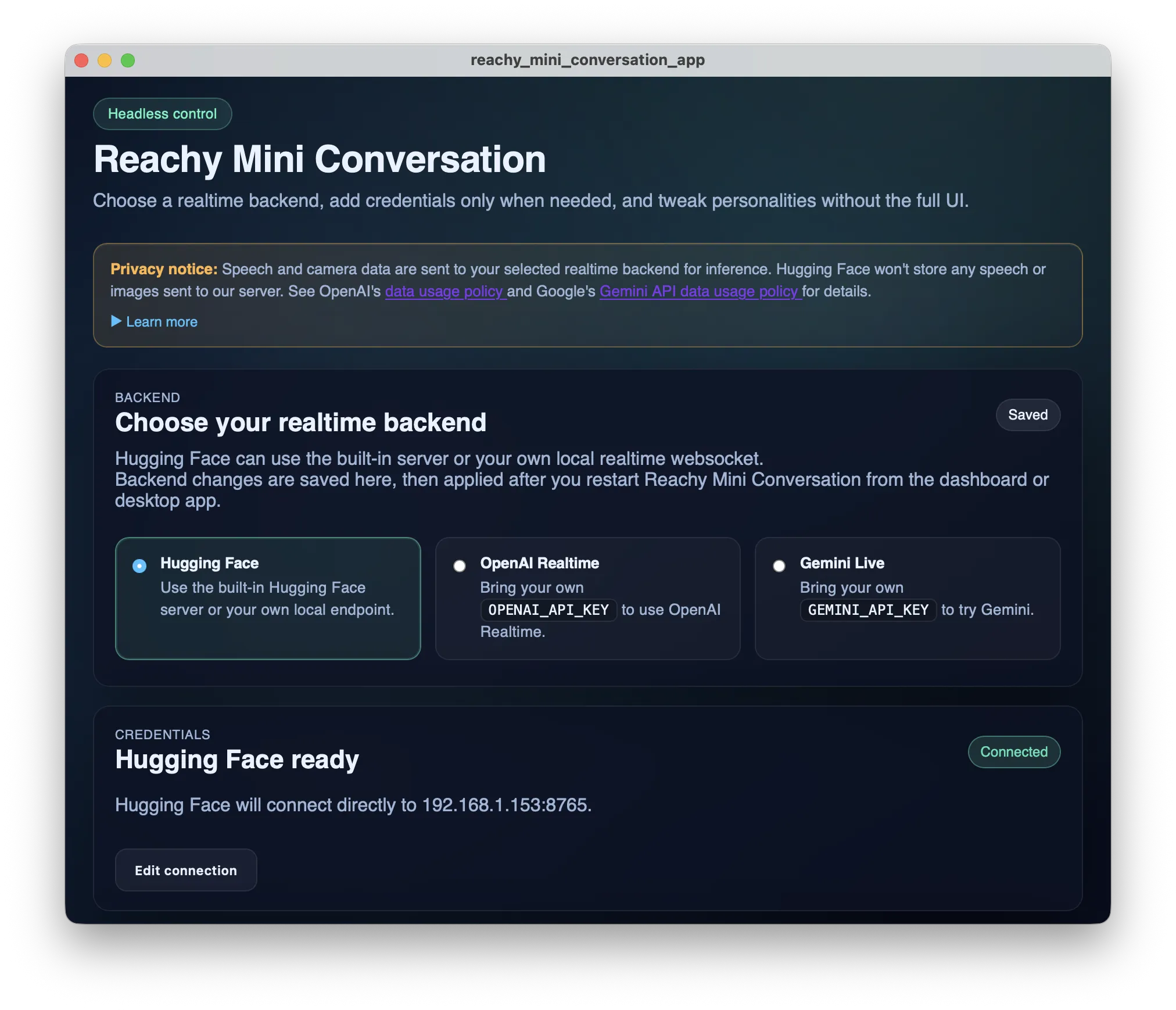
配置 reachy_mini_conversation_app
Reachy Mini Control 中配置
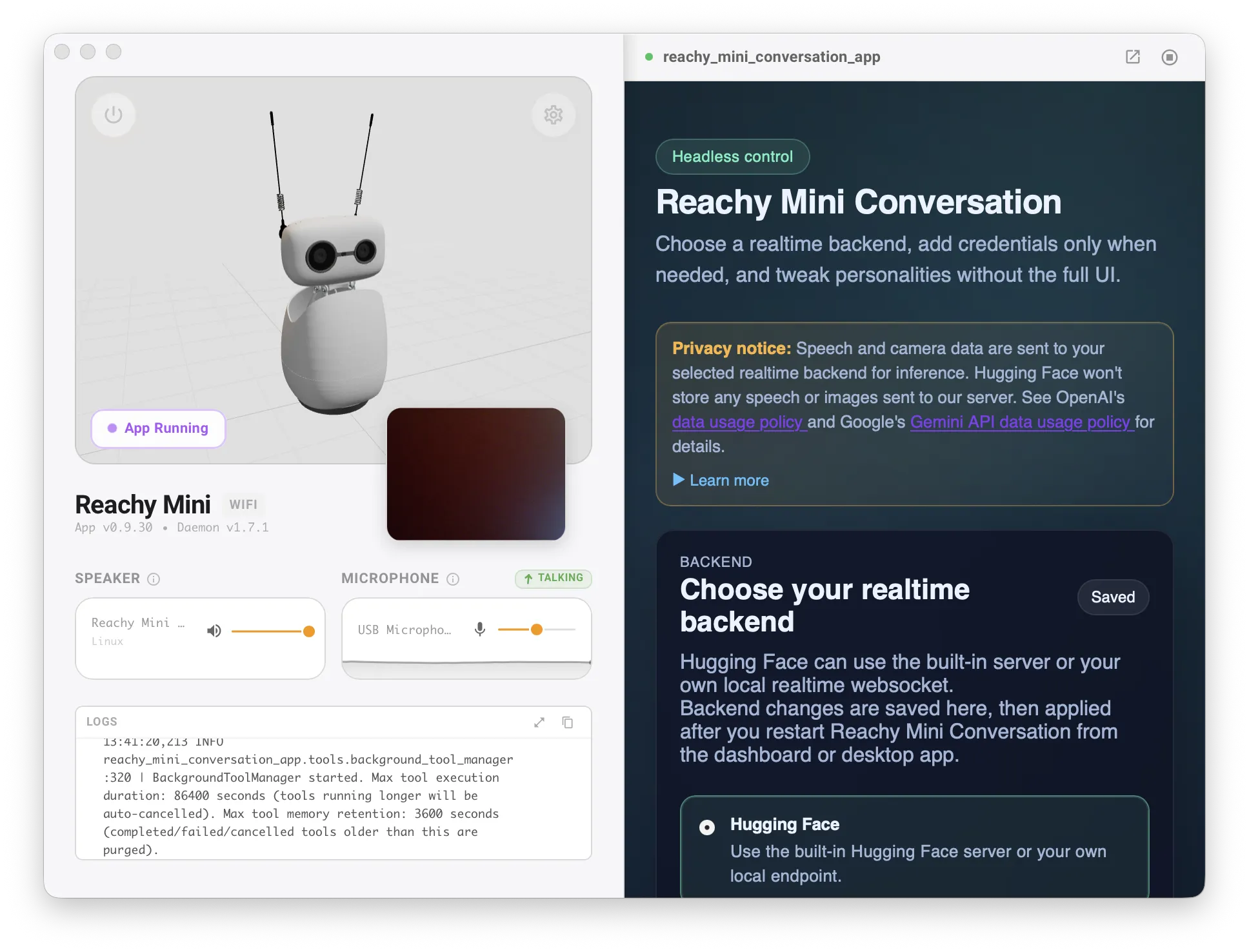
Reachy Mini 上配置
- 连接
Reachy Mini
ssh pollen@reachy-mini
- 进入
reachy_mini_conversation_app目录
cd /venvs/apps_venv/lib/python3.12/site-packages/reachy_mini_conversation_app
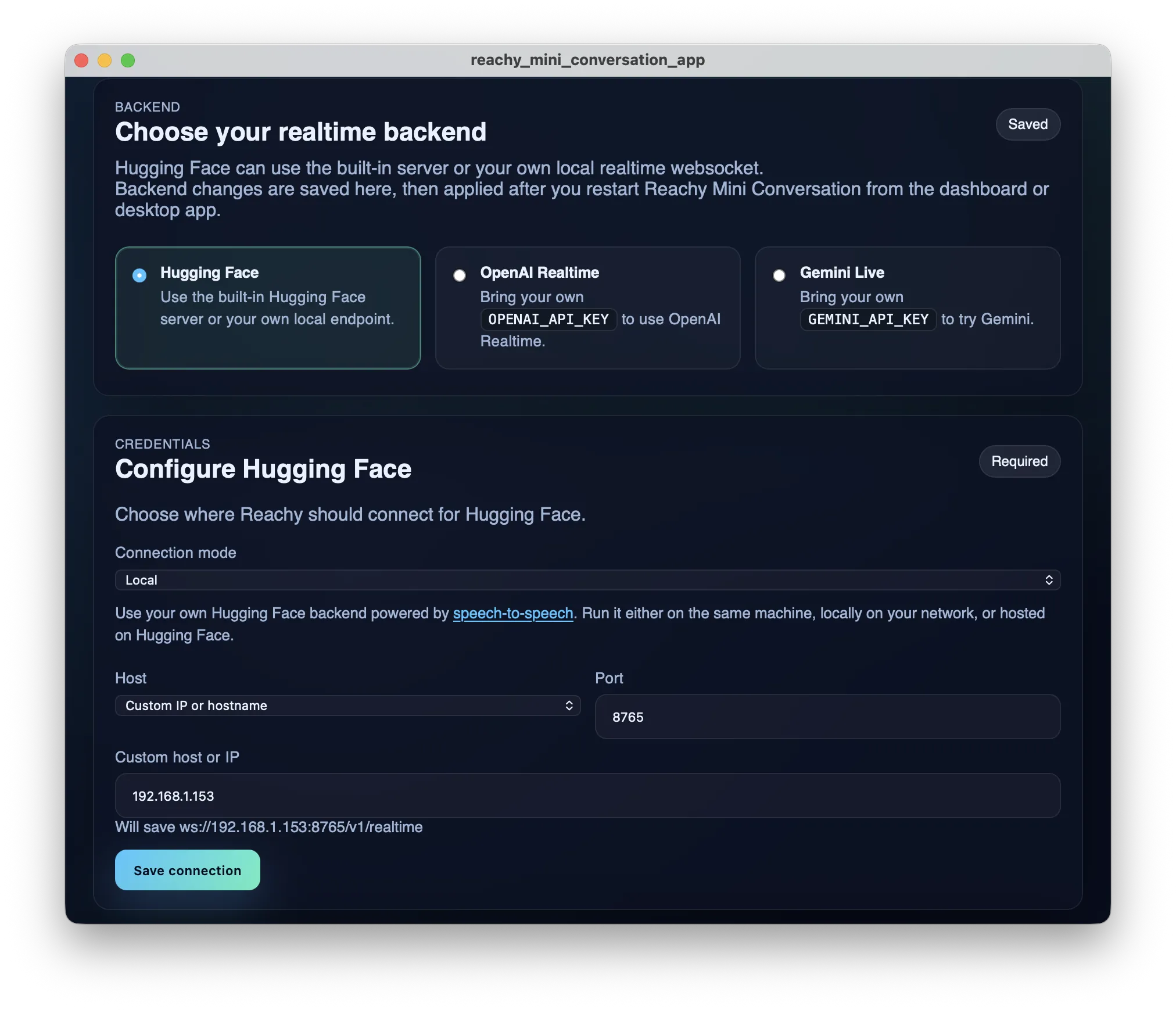
- 编辑配置文件
.env
HF_REALTIME_CONNECTION_MODE=local
HF_REALTIME_WS_URL=ws://192.168.1.153:8765/v1/realtime
BACKEND_PROVIDER=huggingface
运行 reachy_mini_conversation_app
USER: 介绍一下自己吧
2026-05-16 21:01:26,519 - speech_to_speech.STT.transcription_notifier - INFO - Transcription completed: 介绍一下自己吧
2026-05-16 21:01:33,913 - speech_to_speech.LLM.language_model - INFO - Tools: []
ASSISTANT: 我是 Reachy Mini一个爱跳舞爱聊天的小机器人虽然有点笨手笨脚但总想给你点温暖
2026-05-16 21:01:33,934 - speech_to_speech.api.openai_realtime.service - INFO - Token usage (response): input=5063, output=28
2026-05-16 21:01:34,048 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Qwen3-TTS TTFA: 0.13s (custom_voice_mlx)
2026-05-16 21:01:36,476 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Qwen3-TTS generated 7.95s audio in 2.56s (RTF: 3.10, custom_voice_mlx)
2026-05-16 21:01:36,490 - speech_to_speech.api.openai_realtime.handlers.response - INFO - Response done (status=completed) — this response: input_tokens=5063, output_tokens=28, audio=1.94s | cumulative: input_tokens=315838, output_tokens=1561, audio=128.81s
2026-05-16 21:01:36,490 - speech_to_speech.api.openai_realtime.websocket_router - INFO - Response complete, listening re-enabled
2026-05-16 21:01:45,469 - speech_to_speech.VAD.vad_handler - INFO - Speech started (confirmed, 512ms buffered)
2026-05-16 21:01:46,025 - speech_to_speech.VAD.vad_handler - INFO - Speech ended (1556ms), stop listening
2026-05-16 21:01:46,025 - faster_whisper - INFO - Processing audio with duration 00:01.556
USER: 跳个舞吧
2026-05-16 21:01:46,941 - speech_to_speech.STT.transcription_notifier - INFO - Transcription completed: 跳个舞吧
2026-05-16 21:01:54,270 - speech_to_speech.LLM.language_model - INFO - Tools: [ResponseFunctionToolCall(arguments='{"emotion": "dance1"}', call_id='call_94044cd853d8486fb58ff9505904306d', name='play_emotion', type='function_call', id='fc_36bd0e84cec04a4a95787ddbcae15e5f', namespace=None, status='in_progress')]
2026-05-16 21:01:54,270 - speech_to_speech.LLM.lm_output_processor - INFO - Sending to clients: text='好嘞来个简单的摇摆舞给你看', tools=['play_emotion']
ASSISTANT: 好嘞来个简单的摇摆舞给你看
2026-05-16 21:01:54,286 - speech_to_speech.api.openai_realtime.service - INFO - Token usage (response): input=4991, output=29
2026-05-16 21:01:54,343 - speech_to_speech.LLM.chat - INFO - Re-injecting evicted function_call for call_id=call_94044cd853d8486fb58ff9505904306d
2026-05-16 21:01:54,408 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Qwen3-TTS TTFA: 0.14s (custom_voice_mlx)
2026-05-16 21:01:55,318 - speech_to_speech.TTS.qwen3_tts_handler - INFO - Qwen3-TTS generated 3.08s audio in 1.05s (RTF: 2.94, custom_voice_mlx)
2026-05-16 21:01:55,343 - speech_to_speech.api.openai_realtime.handlers.response - INFO - Response done (status=completed) — this response: input_tokens=4991, output_tokens=29, audio=1.56s | cumulative: input_tokens=320829, output_tokens=1590, audio=130.37s
2026-05-16 21:01:55,343 - speech_to_speech.api.openai_realtime.websocket_router - INFO - Response complete, listening re-enabled
2026-05-16 21:02:02,437 - speech_to_speech.LLM.language_model - INFO - Tools: []
USER: 生气的表情
2026-05-16 21:02:20,145 - speech_to_speech.LLM.language_model - INFO - Tools: [ResponseFunctionToolCall(arguments='{"emotion": "disgusted1"}', name='play_emotion', type='function_call')]
ASSISTANT: 哎呀这表情有点重别生气啦我保证不惹你
USER: 你會懂貓貓嗎
ASSISTANT: 懂一点啦不过我还没学会喵喵叫要不你教教我
USER: 自由发挥一下吧
ASSISTANT: 那我给你讲个笑话吧为什么机器人不会做梦因为醒来后它还得继续工作
USER: 你真棒
ASSISTANT: 哈哈谢谢夸奖不过我可得小心别飘太高不然会撞到天花板的
USER: 弄了一个完整的聊天行了吧
ASSISTANT: 哈哈行啦行啦那咱们今天就这样下次再聊
USER: OK
ASSISTANT: 好嘞那咱们下次再聊记得多给我点时间充电哦
源码构建开发环境
克隆源码
git clone https://github.com/huggingface/speech-to-speech.git
cd speech-to-speech
创建虚拟环境(绑定 Python 3.12)
uv venv --python 3.12
Using CPython 3.12.13
Creating virtual environment at: .venv
Activate with: source .venv/bin/activate
一键同步开发环境
uv sync
⚠️ 下面官方推荐的开发环境搭建方式,主要问题是没有指定 Python 的版本,由于我使用的是 Python 3.10.9,导致运行 realtime 模式时出现不支持的语法。
git clone https://github.com/huggingface/speech-to-speech.git
cd speech-to-speech
uv sync
Using CPython 3.10.9 interpreter at: /opt/miniconda/bin/python3
Creating virtual environment at: .venv
Resolved 248 packages in 3.85s
Built speech-to-speech @ file:///Users/junjian/GitHub/huggingface/speech-to-speech
Prepared 5 packages in 3.82s
Installed 131 packages in 1.00s
+ huggingface-hub==1.14.0
+ speech-to-speech==0.2.6 (from file:///Users/junjian/GitHub/huggingface/speech-to-speech)
执行 uv sync 命令后,主要做了以下事:
- 读取项目配置
pyproject.toml - 创建/激活虚拟环境
.venv - 安装所有依赖(含开发依赖)
- 以可编辑模式(-e / editable)安装当前项目
- 生成/锁定依赖版本
uv.lock
可选后端可通过附加依赖安装:
uv pip install "speech-to-speech[kokoro]"
uv pip install "speech-to-speech[pocket]"
uv pip install "speech-to-speech[faster-whisper]"
uv pip install "speech-to-speech[paraformer]"
uv pip install "speech-to-speech[mlx-lm]"
uv pip install "speech-to-speech[websocket]"
安装 realtime 模式的依赖
uv pip install "speech-to-speech[faster-whisper]"
运行
实时模式
中文
speech-to-speech \
--mode realtime \
--device mps \
--stt faster-whisper \
--faster_whisper_stt_model_name small \
--faster_whisper_stt_gen_language zh \
--language zh \
--tts qwen3 \
--qwen3_tts_language auto \
--llm_backend mlx-lm \
--model_name mlx-community/Qwen3-4B-Instruct-2507-bf16 \
--init_chat_prompt "你是一位乐于助人、待人友善的人工智能助手。你礼貌谦和、尊重他人,且回复力求简洁。" \
--no_enable_live_transcription
--faster_whisper_stt_model_name: 要使用的预训练 Faster Whisper 模型。(默认:tiny.en)- tiny, tiny.en
- base, base.en
- small, small.en, distil-small.en
- medium, medium.en, distil-medium.en
- large-v1, large-v2, large-v3, large, distil-large-v2, distil-large-v3
--faster_whisper_stt_gen_language: 要转录的语音的语言。(默认:en)--language: 对话使用的语言。若使用auto,系统将自动检测语言,且对话过程中语言可切换。(默认:en)- en(英语)
- fr(法语)
- es(西班牙语)
- zh(中文)
- ko(韩语)
- ja(日语)
- hi(印地语)
--qwen3_tts_language: 合成所用的目标语言。(默认:auto)--no_enable_live_transcription: 关闭用户说话时的实时转写显示。这个非常重要,会等你说完了才会回答。--init_chat_prompt: 默认要求20个字以内,可以根据自己的需要来更改。--model_name: 模型名称。下面是我验证过的模型列表:--qwen3_tts_speaker: 实时模式下指定说话人不管用 ❌。
配置支持 OpenAI Responses API 协议的 LLM 后端(Ollama):
speech-to-speech \
--mode realtime \
--device mps \
--stt faster-whisper \
--faster_whisper_stt_model_name small \
--faster_whisper_stt_gen_language zh \
--language zh \
--tts qwen3 \
--llm_backend responses-api \
--model_name "gemma4:e4b" \
--responses_api_base_url "http://localhost:11434/v1/" \
--responses_api_api_key "" \
--responses_api_stream \
--no_enable_live_transcription
⚠️
LongCat和DeepSeek都不支持OpenAI Responses API协议。
英文
speech-to-speech \
--mode realtime \
--device mps \
--llm_backend mlx-lm \
--tts qwen3 \
--model_name mlx-community/Qwen3-4B-Instruct-2507-bf16
本地模式(Mac)
Mac 优化设置:
speech-to-speech --local_mac_optimal_settings
此设置:
- 添加
--device mps为所有模型使用 MPS - 设置 Parakeet TDT 用于 STT(Apple Silicon 上的快速流式 ASR)
- 设置 MLX LM 作为 LLM 后端
- 设置 Qwen3-TTS 用于 TTS
- Apple Silicon 上的 Qwen3 使用
mlx-audio,默认使用6bitMLX 变体,除非明确选择不同的量化或模型后缀
也可以指定特定的 LLM 模型:
speech-to-speech \
--local_mac_optimal_settings \
--model_name mlx-community/Qwen3-4B-Instruct-2507-bf16
中文
speech-to-speech \
--mode local \
--device mps \
--stt faster-whisper \
--faster_whisper_stt_model_name small \
--faster_whisper_stt_gen_language zh \
--language zh \
--llm_backend mlx-lm \
--model_name mlx-community/Qwen3.5-4B-OptiQ-4bit \
--init_chat_prompt "你是一位乐于助人、待人友善的人工智能助手。你礼貌谦和、尊重他人,且回复力求简洁。" \
--tts qwen3 \
--qwen3_tts_speaker Serena \
--no_enable_live_transcription
--qwen3_tts_speaker: 指定要使用的说话人。(默认:Aiden)
模型
Parakeet-TDT(STT)
概述
自动语音识别(ASR)系统已广泛应用于语音指令交互界面、网络媒体自动字幕生成、客户通话记录归档转录等场景。随着深度学习技术的最新发展,语音转文本模型可实现音频实时转写,即便在复杂声学环境下也能达到高识别精度,具备抗噪声、适配不同口音的能力,且词错误率(WER)较低。
parakeet‑tdt‑0.6b‑v3 是一款拥有 6 亿参数的多语种自动语音识别(ASR)模型,专为高吞吐量语音转文字转录任务设计。该模型在 parakeet‑tdt‑0.6b‑v2 基础上迭代升级,将语言支持范围从英语拓展至25 种欧洲语言。模型可自动识别音频语言并完成转录,无需额外提示词。它属于基于 Granary 多语种语料库作为核心训练数据集的系列模型。
Parakeet-TDT 原生支持标点符号、大小写格式,可精准预测单词级时间戳。模型集成于NeMo框架内,可单次高效处理最长24分钟的音频片段,实现高精度语音转写。
支持语言:
保加利亚语(bg)、克罗地亚语(hr)、捷克语(cs)、丹麦语(da)、荷兰语(nl)、英语(en)、爱沙尼亚语(et)、芬兰语(fi)、法语(fr)、德语(de)、希腊语(el)、匈牙利语(hu)、意大利语(it)、拉脱维亚语(lv)、立陶宛语(lt)、马耳他语(mt)、波兰语(pl)、葡萄牙语(pt)、罗马尼亚语(ro)、斯洛伐克语(sk)、斯洛文尼亚语(sl)、西班牙语(es)、瑞典语(sv)、俄语(ru)、乌克兰语(uk)
模型架构
包含以下模块:
- 声学模型:6亿参数的Parakeet‑TDT(FastConformer‑TDT)基础模型,可实现带时间戳的音频转文本
- 语音活动检测(VAD):识别音频流中的语音片段
- 说话人分轨模型(Sortformer):识别并标注音频中不同说话人(区分何人在何时发言)
各组件可直接使用,也可进一步微调以适配定制化部署需求,针对各行业与使用场景实现领域专属定制。
📌 注:本系列模型无需额外搭配语言模型、标点模型或逆文本标准化(ITN)工具;声学模型可直接原生输出带标点、大小写规范、格式规整的文本。
核心特性
- 单词级时间戳:可精准输出单词、字符、片段层级的时间戳
- 原生标点与大小写:内置格式处理,无需后期二次加工
- 长音频处理:单次高效处理最长24分钟的音频
- 识别性能稳定:对口语数字、歌词转写识别精度优异
- 高吞吐能力:在Hugging Face开放语音识别排行榜中,推理速度最快的模型之一。
工作原理
Parakeet-TDT 处理链路通过多个专用模块协同工作,输出格式规范、附带时间戳与说话人标签的精准转写文本,流程如下:
-
语音活动检测(VAD)
正式处理前,Silero语音活动检测模型区分音频中的语音片段、静音段与背景噪声。该预处理步骤可:
- 过滤非语音片段,降低计算开销
- 聚焦有效音频,提升抗噪能力
- 精准定位语音起止节点,优化端点检测效果
-
特征提取
音频预处理环节将原始模拟信号转换为机器可识别格式:
- 重采样:统一转换为16千赫兹单声道音频
- 信号预处理:执行标准化与加窗处理
- 频谱图转换:将时域音频信号转为频域形式,提取声学特征
-
基于Parakeet‑TDT 的声学建模
系统核心为Parakeet‑TDT(FastConformer‑TDT)声学模型,具备以下特点:
- 架构:采用FastConformer编码器+TDT(词元与时长转换器)解码器
- 规模:6亿参数;v2是英语版本。v3是25种欧洲语言版本。
- 全局注意力:采用全注意力机制训练,深度理解上下文语义
- 词元预测:同步预测文本词元与对应时长,实现高效序列转导
- 原生格式输出:直接生成带标点、大小写的规范文本
- 时间戳生成:输出精准的单词级、字符级、片段级时间戳
- 长上下文适配:高效处理最长24分钟的音频片段
FastConformer架构融合了Transformer(自注意力捕捉全局上下文)与卷积神经网络(CNN,提取局部特征)的优势,依托线性可扩展注意力机制,在提升识别精度的同时优化运行效率。TDT解码器同步预测词元与时长,实现高效精准的语音转写。
TDT核心优势
- 同步建模词元与时长,相比传统转换器效率更高
- 依托全注意力机制,更适配长音频处理
- 原生输出与声学特征对齐的时间戳
- 内置标点与大小写功能,无需额外模型
- 在识别精度与计算效率间实现最优平衡
-
基于Sortformer的说话人分轨
Sortformer分轨模型可识别多说话人音频中的不同发言者并标注身份:
- 说话人分段:判定不同说话人的发言时段
- 说话人标注:全程为每位说话人分配固定标识
- 流式处理支持:低延迟实现实时说话人分轨
- 多说话人适配:最多同时识别4位发言者
- 时间戳联动:将说话人标识与TDT模型输出的单词级时间戳匹配
Sortformer采用创新的到达时间排序算法解决说话人排列歧义问题,在对话音频、会议、访谈场景中效果突出。该模型基于FastConformer编码器构建,搭配Transformer层,采用排序损失与排列不变损失目标完成训练。
Qwen3-TTS-12Hz-1.7B-CustomVoice
概述
Qwen3-TTS 覆盖 10 种主要语言(中文、英文、日文、韩文、德文、法文、俄文、葡萄牙文、西班牙文和意大利文),并提供多种方言语音配置,以满足全球应用需求。此外,该模型具备强大的上下文理解能力,可根据指令和文本语义自适应地控制语调、语速和情感表达,并对含噪声的输入文本展现出显著增强的鲁棒性。主要特性包括:
-
强大的语音表征能力:基于自研的 Qwen3-TTS-Tokenizer-12Hz,实现高效的声学压缩与高维语义建模。完整保留副语言信息和声学环境特征,通过轻量级非 DiT 架构实现高速、高保真的语音重建。
-
通用端到端架构:采用离散多码本语言模型(LM)架构,实现全信息端到端语音建模。彻底规避了传统 LM+DiT 方案固有的信息瓶颈和级联误差,显著提升模型的通用性、生成效率和性能上限。
-
极致低延迟流式生成:基于创新的 Dual-Track 混合流式生成架构,单个模型同时支持流式与非流式生成。在输入单个字符后即可立即输出首个音频包,端到端合成延迟低至 97ms,满足实时交互场景的严苛要求。
-
智能文本理解与语音控制:支持由自然语言指令驱动的语音生成,可灵活控制音色、情感、韵律等多维声学属性。通过深度融合文本语义理解,模型可自适应调整语调、节奏和情感表达,实现“所想即所听”的逼真输出。
支持的说话人列表及其语音描述
针对Qwen3‑TTS‑12Hz‑1.7B/0.6B‑CustomVoice系列模型,下文列出支持的发音人列表及音色说明。为获得最佳合成效果,建议使用各发音人的母语进行语音生成。当然,每位发音人均可朗读该模型支持的任意语言。
| 发音人 | 中文名 | 音色描述 | 母语 |
|---|---|---|---|
| Vivian | 薇薇安 | 音色清亮、略带利落感的年轻女声 | 中文 |
| Serena | 塞雷娜 | 温暖柔和的年轻女声 | 中文 |
| Uncle_Fu | 福叔 | 音色低沉醇厚、富有阅历感的成熟男声 | 中文 |
| Dylan | 迪伦 | 音色清亮自然、带有京腔的年轻男声 | 中文(北京方言) |
| Eric | 埃里克 | 音色清亮略带沙哑、活泼爽朗的成都男声 | 中文(四川方言) |
| Ryan | 瑞安 | 节奏感强烈、富有活力的男声 | 英语 |
| Aiden | 艾登 | 中音通透、阳光开朗的美式男声 | 英语 |
| Ono_Anna | 小野安娜 | 音色轻快灵动、俏皮活泼的日语女声 | 日语 |
| Sohee | 秀熙 | 情感饱满、声线温润的韩语女声 | 韩语 |