沐曦 MXC500 训练 GPU 的大模型推理性能压测
沐曦训练芯片 MXC500 介绍
曦云®C500是沐曦面向通用计算的旗舰产品,提供强大高精度及多精度混合算力,配备大规格高带宽显存,片间互联MetaXLink无缝链接多GPU系统,自主研发的MXMACA®软件栈可兼容主流GPU生态,能够全面满足数字经济建设和产业数字化的算力需求。
2023 年 6 月 14 日,沐曦官宣 AI 训练 GPU MXC500 完成芯片功能测试,MXMACA 2.0 计算平台基础测试完成,意味着公司首款 AI 训练芯片 MXC500成功点亮,该芯片采用 7nm 制程,GPGPU 架构,能够兼容 CUDA,目标对标英伟达 A100/A800 芯片。
沐曦主要有三大产品线:
- 用于 AI 推理的 MXN 系列;
- 用于 AI 训练及通用计算的 MXC 系列;
- 用于图形渲染的 MXG 系列。
研发实力强大,软件生态布局完善。沐曦的研发团队阵容豪华,三位创始人均在 AMD 拥有 20 年左右的 GPU 研发经验,其中两位为 AMD 科学家(Fellow)。沐曦采用了完全自主研发的 GPU IP,有效提高了产品的开发效率,同时拥有完全自主知识产权的指令集和架构,可以对每个独立的计算实例进行灵活配置,从而优化数据中心计算资源的效率。同时,沐曦配有兼容主流 GPU 生态 的 完 整 软 件 栈 ( MXMACA ) 平 台 , 支 持 AI 神 经 网 络 框 架 ( 如TensorFlow/PyTorch 等)、库(如 Blas/DNN 等)和 Linux Kernel 等技术,并持续优化平台来实现更高的性能和可扩展性。此外,沐曦还成立了“曦思应用生态联盟”,联合多家生态合作伙伴,包括芯驰技术、中恒讯通科、清华大学苏州汽车研究院等,推动 MXN 系列产品和解决方案的应用落地。
2023 年 3 月,公司的 MXN100 芯片与百度飞桨完成 I 级兼容性测试。
服务器配置
CPU 信息
CPU: Phytium S5000C X 2 (128 核)
lscpu
架构: aarch64
CPU 运行模式: 32-bit, 64-bit
字节序: Little Endian
CPU: 128
在线 CPU 列表: 0-127
每个核的线程数: 1
每个座的核数: 64
座: 2
NUMA 节点: 8
厂商 ID: Phytium
BIOS Vendor ID: PHYTIUM LTD.
型号: 0
型号名称: S5000C
BIOS Model name: S5000C
步进: 0x0
BogoMIPS: 2000.00
L1d 缓存: 8 MiB
L1i 缓存: 8 MiB
L2 缓存: 64 MiB
L3 缓存: 64 MiB
NUMA 节点0 CPU: 0-15
NUMA 节点1 CPU: 16-31
NUMA 节点2 CPU: 32-47
NUMA 节点3 CPU: 48-63
NUMA 节点4 CPU: 64-79
NUMA 节点5 CPU: 80-95
NUMA 节点6 CPU: 96-111
NUMA 节点7 CPU: 112-127
Vulnerability Gather data sampling: Not affected
Vulnerability Itlb multihit: Not affected
Vulnerability L1tf: Not affected
Vulnerability Mds: Not affected
Vulnerability Meltdown: Not affected
Vulnerability Mmio stale data: Not affected
Vulnerability Retbleed: Not affected
Vulnerability Spec store bypass: Mitigation; Speculative Store Bypass disabled via prctl
Vulnerability Spectre v1: Mitigation; __user pointer sanitization
Vulnerability Spectre v2: Not affected
Vulnerability Srbds: Not affected
Vulnerability Tsx async abort: Not affected
标记: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop sha3 sm3 sm4 asimddp sha512
GPU 信息
GPU: MXC500 64G X 4
mx-smi
lspci -v | grep -A31 'Display controller'
0000:05:00.0 Display controller: Device 9999:4001 (rev 01)
Subsystem: Device 9999:4001
Flags: bus master, fast devsel, latency 0, IRQ 933, NUMA node 0
Memory at 40000000000 (64-bit, prefetchable) [size=64G]
Memory at 41000000000 (64-bit, prefetchable) [size=8M]
Memory at 59200000 (32-bit, non-prefetchable) [size=1M]
Expansion ROM at 59000000 [disabled] [size=2M]
Capabilities: [50] MSI: Enable+ Count=1/1 Maskable+ 64bit+
Capabilities: [70] Express Endpoint, MSI 00
Capabilities: [b0] MSI-X: Enable- Count=3 Masked-
Capabilities: [100] Advanced Error Reporting
Capabilities: [148] Device Serial Number 00-00-00-00-00-00-00-00
Capabilities: [158] Power Budgeting <?>
Capabilities: [168] Alternative Routing-ID Interpretation (ARI)
Capabilities: [178] Secondary PCI Express
Capabilities: [1a8] Physical Layer 16.0 GT/s <?>
Capabilities: [1d8] Lane Margining at the Receiver <?>
Capabilities: [220] Extended Capability ID 0x2a
Capabilities: [2b0] Latency Tolerance Reporting
Capabilities: [2c0] Vendor Specific Information: ID=0002 Rev=4 Len=100 <?>
Capabilities: [3c0] Vendor Specific Information: ID=0001 Rev=1 Len=038 <?>
Capabilities: [3f8] Data Link Feature <?>
Capabilities: [404] Extended Capability ID 0x2f
Capabilities: [414] Designated Vendor-Specific <?>
Capabilities: [450] Designated Vendor-Specific <?>
Capabilities: [474] Designated Vendor-Specific <?>
Capabilities: [484] Designated Vendor-Specific <?>
Capabilities: [4bc] Resizable BAR <?>
Capabilities: [4fc] VF Resizable BAR <?>
Capabilities: [e90] Vendor Specific Information: ID=0000 Rev=1 Len=078 <?>
Kernel driver in use: METAX
Kernel modules: metax
部署模型
登录 JumpServer
选择 MXC500 服务器,4卡64G。
下载模型
进入 /data/models 目录。
cd /data/models
Qwen2.5-7B-Instruct
git clone https://www.modelscope.cn/Qwen/Qwen2.5-7B-Instruct.git
Qwen2.5-72B-Instruct
git clone https://www.modelscope.cn/Qwen/Qwen2.5-72B-Instruct.git
DeepSeek-R1-Distill-Qwen-32B
git clone https://www.modelscope.cn/deepseek-ai/DeepSeek-R1-Distill-Qwen-32B.git
QwQ-32B
git clone https://www.modelscope.cn/Qwen/QwQ-32B.git
运行容器(定制的 vLLM 镜像)
docker run -itd --restart=always \
--device=/dev/dri \
--device=/dev/mxcd \
--group-add video \
--network=host \
--security-opt seccomp=unconfined \
--security-opt apparmor=unconfined \
--shm-size 256gb \
--ulimit memlock=-1 \
-v /data/models:/data \
--hostname vllm \
--name vllm \
cr.metax-tech.com/public-ai-release/c500/vllm:maca2.27.0.9-py310-kylin2309a-arm64 \
bash
进入容器
docker exec -it vllm bash
部署模型
- Qwen2.5-7B-Instruct
vllm serve /data/Qwen2.5-7B-Instruct --served-model-name Qwen2.5-7B-Instruct --tensor-parallel-size 4
- Qwen2.5-72B-Instruct
vllm serve /data/Qwen2.5-72B-Instruct --served-model-name qwen2.5 --tensor-parallel-size 4
- DeepSeek-R1-Distill-Qwen-32B
vllm serve /data/DeepSeek-R1-Distill-Qwen-32B --served-model-name qwen2.5 --tensor-parallel-size 4
- QwQ-32B
vllm serve /data/QwQ-32B --served-model-name QwQ-32B --tensor-parallel-size 4
查看 GPU 状态
运行 mx-smi 命令查看 GPU 状态。
mx-smi
mx-smi version: 2.1.6
=================== MetaX System Management Interface Log ===================
Timestamp : Fri Feb 14 16:26:46 2025
Attached GPUs : 4
+---------------------------------------------------------------------------------+
| MX-SMI 2.1.6 Kernel Mode Driver Version: 2.5.014 |
| MACA Version: 2.23.0.1018 BIOS Version: 1.13.5.0 |
|------------------------------------+---------------------+----------------------+
| GPU NAME | Bus-id | GPU-Util |
| Temp Power | Memory-Usage | |
|====================================+=====================+======================|
| 0 MXC500 | 0000:05:00.0 | 0% |
| 51C 71W | 60982/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 1 MXC500 | 0000:08:00.0 | 0% |
| 51C 76W | 60534/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 2 MXC500 | 0000:0e:00.0 | 0% |
| 50C 74W | 60534/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 3 MXC500 | 0000:0f:00.0 | 0% |
| 50C 71W | 60534/65536 MiB | |
+------------------------------------+---------------------+----------------------+
+---------------------------------------------------------------------------------+
| Process: |
| GPU PID Process Name GPU Memory |
| Usage(MiB) |
|=================================================================================|
| 0 15652 python 60032 |
| 1 22854 ray::RayWorkerW 59584 |
| 2 22945 ray::RayWorkerW 59584 |
| 3 23034 ray::RayWorkerW 59584 |
+---------------------------------------------------------------------------------+
测试模型
聊天
curl 'http://localhost:8000/v1/chat/completions' \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5",
"messages": [
{ "role": "system", "content": "你是位人工智能专家。" },
{ "role": "user", "content": "解释人工智能" }
]
}'
文本补全
curl 'http://localhost:8000/v1/completions' \
-H "Content-Type: application/json" \
-d '{
"model": "qwen2.5",
"prompt": "你是谁?"
}'
压力测试
工具安装
evalscope-perf
pip install evalscope-perf
vllm benchmark
克隆 vllm 项目
git clone https://github.com/vllm-project/vllm
数据集下载
中文聊天 HC3-Chinese
mkdir datasets
wget https://modelscope.cn/datasets/AI-ModelScope/HC3-Chinese/resolve/master/open_qa.jsonl \
-O datasets/open_qa.jsonl
代码问答 Codefuse-Evol-Instruct-Clean
wget https://modelscope.cn/datasets/Banksy235/Codefuse-Evol-Instruct-Clean/resolve/master/data.json \
-O datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
# 修改数据集格式,将 "input" 改为 "question",以适应 EvalScope 的数据集格式 openqa
sed -i 's/"input"/"question"/g' datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
ShareGPT
wget https://modelscope.cn/datasets/gliang1001/ShareGPT_V3_unfiltered_cleaned_split/resolve/master/ShareGPT_V3_unfiltered_cleaned_split.json \
-O datasets/ShareGPT_V3_unfiltered_cleaned_split.json
压力测试
evalscope-perf http://127.0.0.1:8000/v1/chat/completions qwen2.5 \
./datasets/open_qa.jsonl \
--max-prompt-length 8000 \
--read-timeout=120 \
--parallels 128 \
--n 1000
Benchmarking summary:
Time taken for tests: 630.612 seconds
Expected number of requests: 1000
Number of concurrency: 128
Total requests: 988
Succeed requests: 938
Failed requests: 50
Average QPS: 1.487
Average latency: 65.745
Throughput(average output tokens per second): 404.683
Average time to first token: 65.745
Average input tokens per request: 50.303
Average output tokens per request: 272.066
Average time per output token: 0.00247
Average package per request: 1.000
Average package latency: 65.745
Percentile of time to first token:
p50: 68.1765
p66: 78.5570
p75: 84.1820
p80: 88.1003
p90: 97.8666
p95: 107.1864
p98: 114.8085
p99: 116.9974
Percentile of request latency:
p50: 68.1765
p66: 78.5570
p75: 84.1820
p80: 88.1003
p90: 97.8666
p95: 107.1864
p98: 114.8085
p99: 116.9974
📌 Metrics: {'Average QPS': 1.487, 'Average latency': 65.745, 'Throughput': 404.683}
拷贝文件
cp performance_metrics.png /tmp/systemd-private-7a1518cf39464adb821c6af0a9b6902e-chronyd.service-zua6qJ/tmp/
实验结果
总的测试数量为 1000 。
Qwen2.5-7B-Instruct
压测命令:
evalscope-perf http://127.0.0.1:8000/v1/chat/completions Qwen2.5-7B-Instruct \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 64 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 300 \
--parallels 400 \
--parallels 512 \
--n 1000
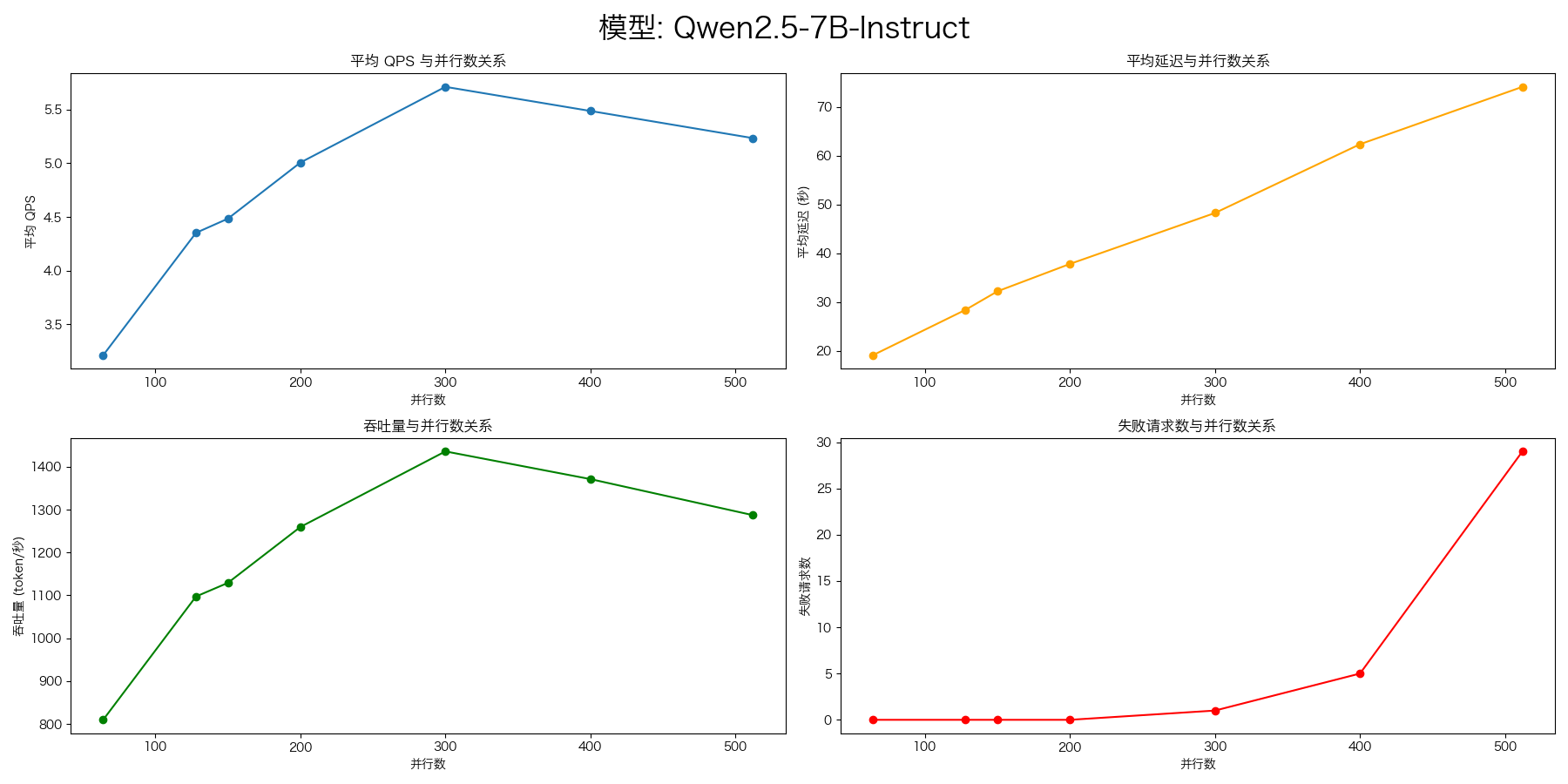
显存使用及利用率:
=================== MetaX System Management Interface Log ===================
Timestamp : Tue Feb 25 08:55:49 2025
Attached GPUs : 4
+---------------------------------------------------------------------------------+
| MX-SMI 2.1.6 Kernel Mode Driver Version: 2.5.014 |
| MACA Version: 2.23.0.1018 BIOS Version: 1.13.5.0 |
|------------------------------------+---------------------+----------------------+
| GPU NAME | Bus-id | GPU-Util |
| Temp Power | Memory-Usage | |
|====================================+=====================+======================|
| 0 MXC500 | 0000:05:00.0 | 12% |
| 48C 89W | 60353/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 1 MXC500 | 0000:08:00.0 | 20% |
| 46C 92W | 58113/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 2 MXC500 | 0000:0e:00.0 | 18% |
| 45C 89W | 58113/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 3 MXC500 | 0000:0f:00.0 | 20% |
| 45C 87W | 58113/65536 MiB | |
+------------------------------------+---------------------+----------------------+
+---------------------------------------------------------------------------------+
| Process: |
| GPU PID Process Name GPU Memory |
| Usage(MiB) |
|=================================================================================|
| 0 2128636 python 59392 |
| 1 2136056 ray::RayWorkerW 57152 |
| 2 2136212 ray::RayWorkerW 57152 |
| 3 2136366 ray::RayWorkerW 57152 |
+---------------------------------------------------------------------------------+
Qwen2.5-72B-Instruct
压测命令:
evalscope-perf http://127.0.0.1:8000/v1/chat/completions qwen2.5 \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 8 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--n 1000
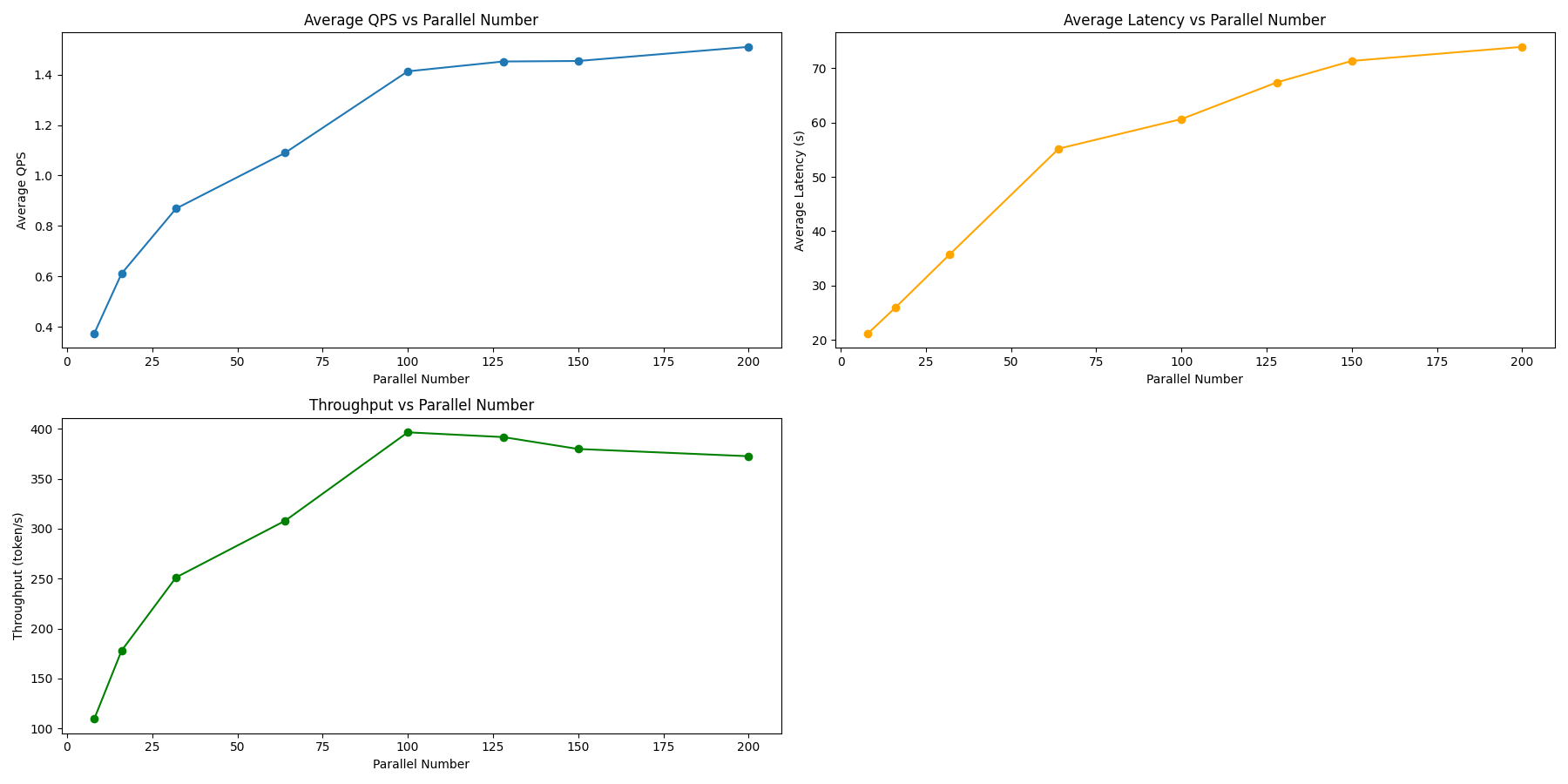
| 指标 | 8 | 16 | 32 | 64 | 100 | 128 | 150 | 200 |
|---|---|---|---|---|---|---|---|---|
| 失败数 | 0 | 0 | 0 | 13 | 21 | 69 | 100 | 158 |
显存使用及利用率:
=================== MetaX System Management Interface Log ===================
Timestamp : Sat Feb 15 16:17:48 2025
Attached GPUs : 4
+---------------------------------------------------------------------------------+
| MX-SMI 2.1.6 Kernel Mode Driver Version: 2.5.014 |
| MACA Version: 2.23.0.1018 BIOS Version: 1.13.5.0 |
|------------------------------------+---------------------+----------------------+
| GPU NAME | Bus-id | GPU-Util |
| Temp Power | Memory-Usage | |
|====================================+=====================+======================|
| 0 MXC500 | 0000:05:00.0 | 36% |
| 54C 122W | 60278/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 1 MXC500 | 0000:08:00.0 | 36% |
| 54C 125W | 59830/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 2 MXC500 | 0000:0e:00.0 | 24% |
| 53C 122W | 59830/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 3 MXC500 | 0000:0f:00.0 | 35% |
| 54C 122W | 59830/65536 MiB | |
+------------------------------------+---------------------+----------------------+
+---------------------------------------------------------------------------------+
| Process: |
| GPU PID Process Name GPU Memory |
| Usage(MiB) |
|=================================================================================|
| 0 343683 python 59328 |
| 1 350950 ray::RayWorkerW 58880 |
| 2 351042 ray::RayWorkerW 58880 |
| 3 351132 ray::RayWorkerW 58880 |
+---------------------------------------------------------------------------------+
DeepSeek-R1-Distill-Qwen-32B
evalscope-perf http://127.0.0.1:8000/v1/chat/completions qwen2.5 \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 8 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 256 \
--parallels 300 \
--n 1000
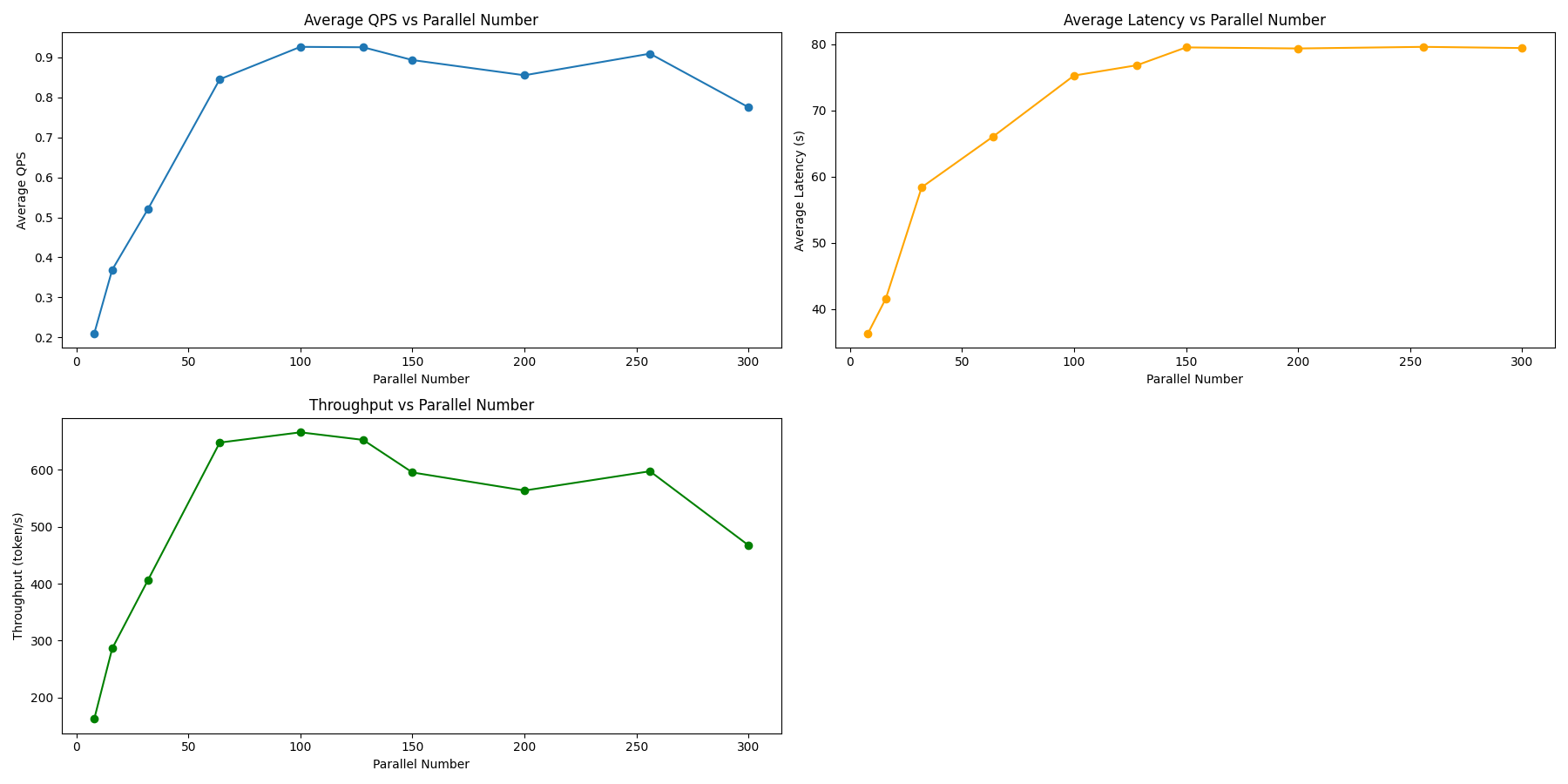
| 指标 | 8 | 16 | 32 | 64 | 100 | 128 | 150 | 200 | 256 | 300 |
|---|---|---|---|---|---|---|---|---|---|---|
| 失败数 | 12 | 10 | 17 | 38 | 109 | 129 | 211 | 197 | 161 | 266 |
显存使用及利用率:
=================== MetaX System Management Interface Log ===================
Timestamp : Sat Feb 15 11:45:50 2025
Attached GPUs : 4
+---------------------------------------------------------------------------------+
| MX-SMI 2.1.6 Kernel Mode Driver Version: 2.5.014 |
| MACA Version: 2.23.0.1018 BIOS Version: 1.13.5.0 |
|------------------------------------+---------------------+----------------------+
| GPU NAME | Bus-id | GPU-Util |
| Temp Power | Memory-Usage | |
|====================================+=====================+======================|
| 0 MXC500 | 0000:05:00.0 | 34% |
| 54C 112W | 61292/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 1 MXC500 | 0000:08:00.0 | 34% |
| 54C 118W | 60716/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 2 MXC500 | 0000:0e:00.0 | 33% |
| 53C 114W | 60716/65536 MiB | |
+------------------------------------+---------------------+----------------------+
| 3 MXC500 | 0000:0f:00.0 | 33% |
| 53C 111W | 60716/65536 MiB | |
+------------------------------------+---------------------+----------------------+
+---------------------------------------------------------------------------------+
| Process: |
| GPU PID Process Name GPU Memory |
| Usage(MiB) |
|=================================================================================|
| 0 279777 python 60352 |
| 1 287035 ray::RayWorkerW 59776 |
| 2 287125 ray::RayWorkerW 59776 |
| 3 287215 ray::RayWorkerW 59776 |
+---------------------------------------------------------------------------------+
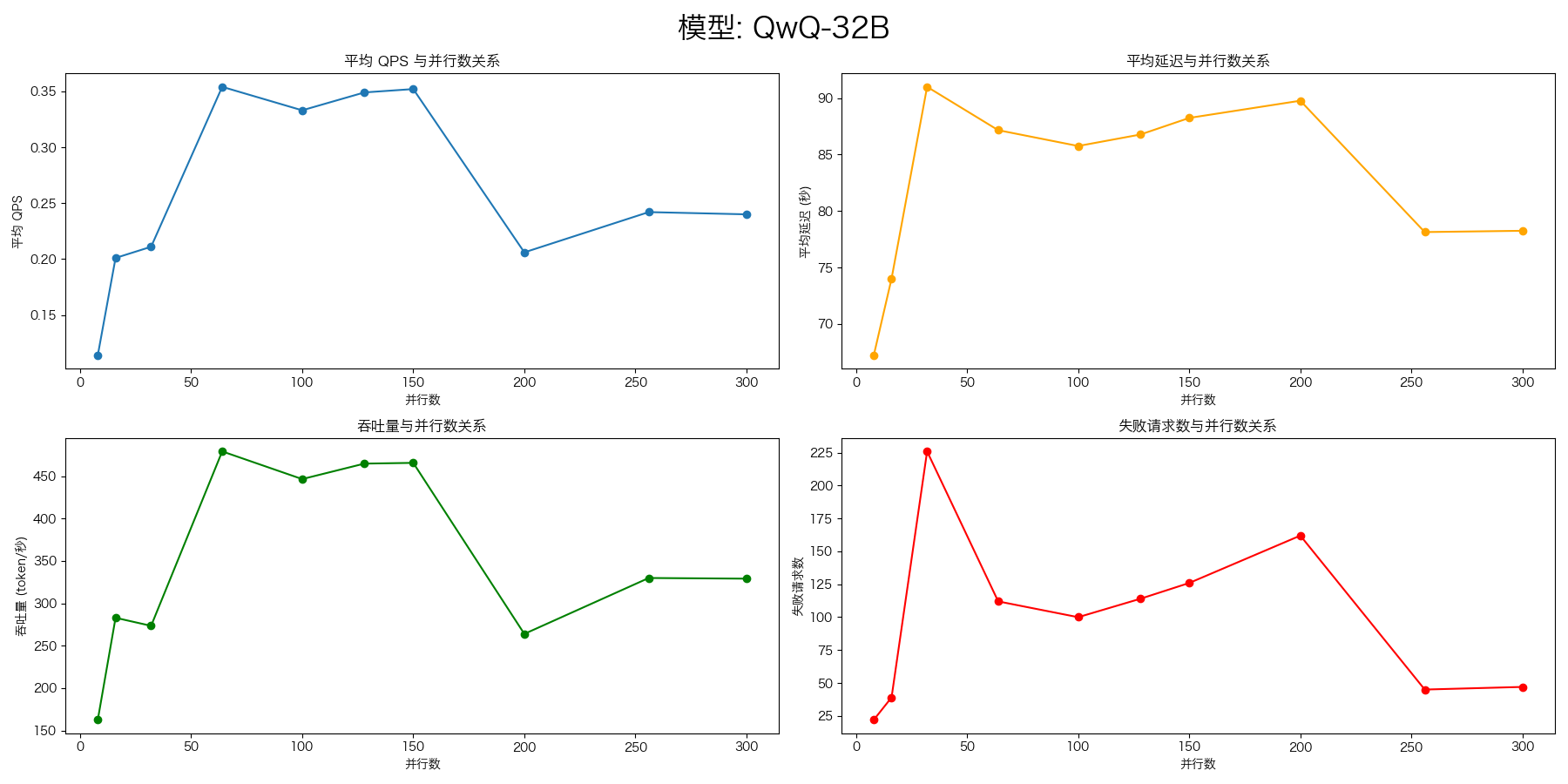
QwQ-32B
evalscope-perf http://127.0.0.1:8000/v1/chat/completions QwQ-32B \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 8 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 256 \
--parallels 300 \
--n 1000
NUMA 配置(加速推理性能)
安装 numactl
yum install numactl
查看 NUMA 节点
numactl --hardware
numactl --hardware
available: 8 nodes (0-7)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
node 0 size: 64992 MB
node 0 free: 4950 MB
node 1 cpus: 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
node 1 size: 65461 MB
node 1 free: 12524 MB
node 2 cpus: 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47
node 2 size: 65461 MB
node 2 free: 9299 MB
node 3 cpus: 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63
node 3 size: 65461 MB
node 3 free: 11394 MB
node 4 cpus: 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79
node 4 size: 65461 MB
node 4 free: 7189 MB
node 5 cpus: 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 5 size: 65461 MB
node 5 free: 6740 MB
node 6 cpus: 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111
node 6 size: 65461 MB
node 6 free: 7317 MB
node 7 cpus: 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127
node 7 size: 64436 MB
node 7 free: 11067 MB
node distances:
node 0 1 2 3 4 5 6 7
0: 10 22 22 22 28 22 28 28
1: 22 10 22 22 22 28 28 28
2: 22 22 10 22 28 28 28 22
3: 22 22 22 10 28 28 22 28
4: 28 22 28 28 10 22 22 22
5: 22 28 28 28 22 10 22 22
6: 28 28 28 22 22 22 10 22
7: 28 28 22 28 22 22 22 10
查看 GPU 与 CPU 的拓扑关系
mx-smi topo -m
Attached GPUs : 4
Device link type matrix
GPU0 GPU1 GPU2 GPU3 Node Affinity CPU Affinity
GPU0 X MX MX MX 0 0-15
GPU1 MX X MX MX 0 0-15
GPU2 MX MX X MX 0 0-15
GPU3 MX MX MX X 0 0-15
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
MX = Connection traversing MetaXLink
NA = Connection type is unknown
NUMA 绑定
从上面的拓扑关系可以看出,GPU 与 CPU 的拓扑关系是 MX,表示连接通过 MetaXLink,这种连接方式是最快的。所有GPU都连接到 NUMA 节点 0 上,所以可以将进程绑定到 NUMA 节点 0 上,这样进程只能使用 NUMA 节点 0 上的 CPU 和内存,避免了 NUMA 交叉访问,提高了性能。
numactl --cpunodebind=0 --membind=0 vllm serve /data/Qwen2.5-72B-Instruct --served-model-name qwen2.5 --tensor-parallel-size 4
可以简写为:
numactl -N0 -m0 vllm serve /data/Qwen2.5-72B-Instruct --served-model-name qwen2.5 --tensor-parallel-size 4
测试
部署模型
numactl -N0 -m0 vllm serve /data/Qwen2.5-72B-Instruct \
--served-model-name qwen2.5 \
--tensor-parallel-size 4
压力测试
evalscope-perf http://127.0.0.1:8000/v1/chat/completions qwen2.5 \
./datasets/open_qa.jsonl \
--max-prompt-length 8000 \
--read-timeout=120 \
--parallels 100 \
--n 500
没有配置 NUMA
Benchmarking summary:
Time taken for tests: 555.873 seconds
Expected number of requests: 500
Number of concurrency: 100
Total requests: 474
Succeed requests: 426
Failed requests: 48
Average QPS: 0.766
Average latency: 73.051
Throughput(average output tokens per second): 538.497
Average time to first token: 73.051
Average input tokens per request: 24.338
Average output tokens per request: 678.622
Average time per output token: 0.00186
Average package per request: 1.000
Average package latency: 73.051
📌 Metrics: {'Average QPS': 0.766, 'Average latency': 73.051, 'Throughput': 538.497}
numactl -N0 -m0
Benchmarking summary:
Time taken for tests: 510.021 seconds
Expected number of requests: 500
Number of concurrency: 100
Total requests: 480
Succeed requests: 443
Failed requests: 37
Average QPS: 0.869
Average latency: 71.212
Throughput(average output tokens per second): 609.616
Average time to first token: 71.212
Average input tokens per request: 24.413
Average output tokens per request: 688.063
Average time per output token: 0.00164
Average package per request: 1.000
Average package latency: 71.212
📌 Metrics: {'Average QPS': 0.869, 'Average latency': 71.212, 'Throughput': 609.616}
运行 htop 查看 CPU 使用情况,可以看到进程只使用了 NUMA 节点 0 上的 CPU。
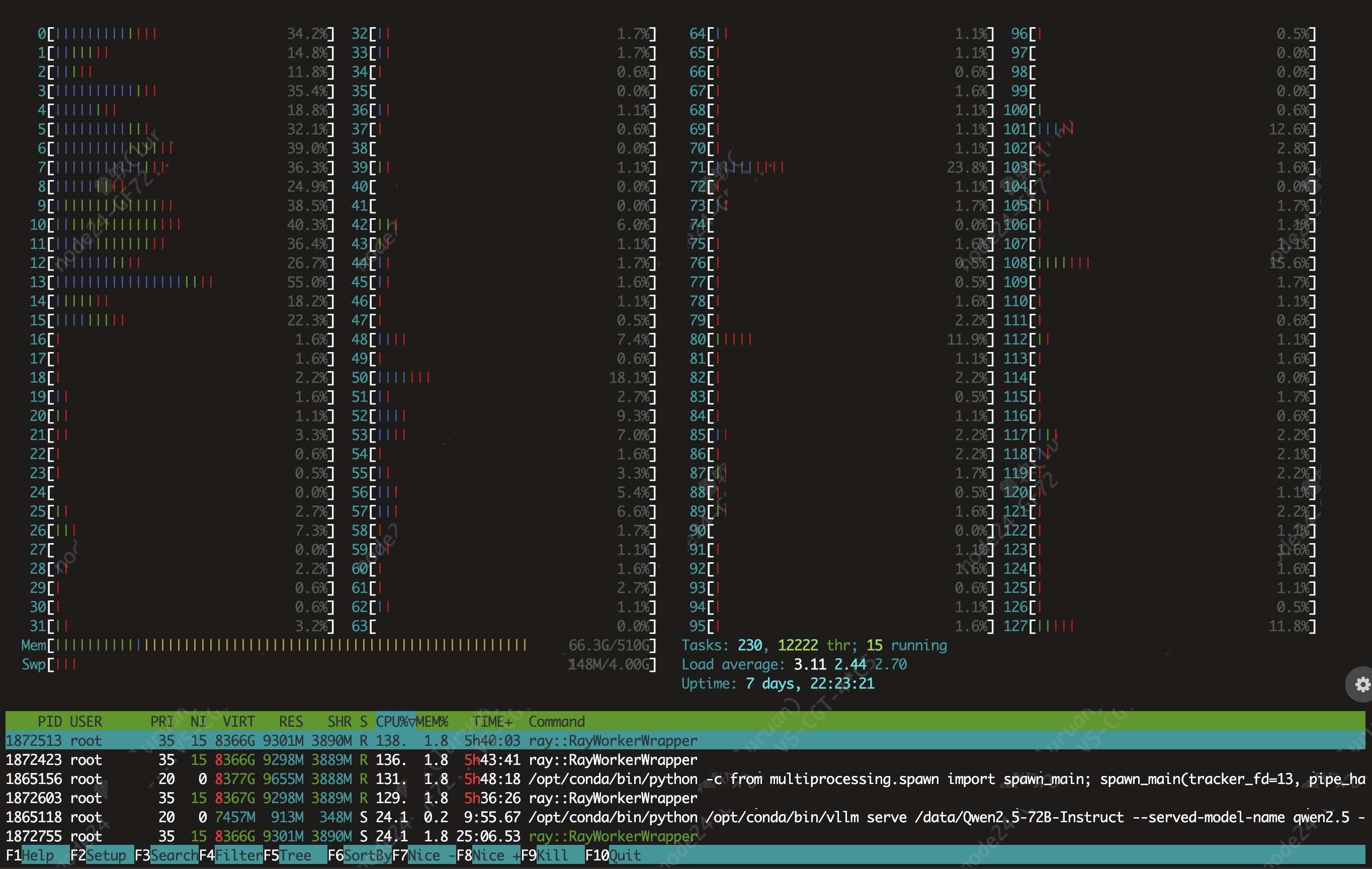
numactl –cpunodebind=0,1,2,3 –membind=0,1,2,3
Benchmarking summary:
Time taken for tests: 647.449 seconds
Expected number of requests: 500
Number of concurrency: 100
Total requests: 460
Succeed requests: 423
Failed requests: 37
Average QPS: 0.653
Average latency: 71.199
Throughput(average output tokens per second): 443.555
Average time to first token: 71.199
Average input tokens per request: 24.333
Average output tokens per request: 678.910
Average time per output token: 0.00225
Average package per request: 1.000
Average package latency: 71.199
📌 Metrics: {'Average QPS': 0.653, 'Average latency': 71.199, 'Throughput': 443.555}
numactl –cpunodebind=0,2,4,6 –membind=0,2,4,6
Benchmarking summary:
Time taken for tests: 641.340 seconds
Expected number of requests: 500
Number of concurrency: 100
Total requests: 461
Succeed requests: 411
Failed requests: 50
Average QPS: 0.641
Average latency: 73.287
Throughput(average output tokens per second): 415.901
Average time to first token: 73.287
Average input tokens per request: 24.421
Average output tokens per request: 648.988
Average time per output token: 0.00240
Average package per request: 1.000
Average package latency: 73.287
📌 Metrics: {'Average QPS': 0.641, 'Average latency': 73.287, 'Throughput': 415.901}
结果对比
| NUMA 绑定 | Average QPS | Average latency | Throughput |
|---|---|---|---|
| 无 | 0.766 | 73.051 | 538.497 |
| numactl -N0 -m0 | 0.869 | 71.212 | 609.616 |
| numactl –cpunodebind=0,1,2,3 –membind=0,1,2,3 | 0.653 | 71.199 | 443.555 |
| numactl –cpunodebind=0,2,4,6 –membind=0,2,4,6 | 0.641 | 73.287 | 415.901 |
结论:NUMA 绑定可以提高推理性能,但是绑定的节点需要根据实际情况(GPU和CPU的拓扑关系)进行调整,否则可能会降低性能。
还验证了数据集存放在固态硬盘和普通硬盘的区别,发现没有明显差异。
实验结果(NUMA 绑定)
部署模型
Qwen2.5-7B-Instruct
numactl -N0 -m0 vllm serve /data/Qwen2.5-7B-Instruct --served-model-name Qwen2.5-7B-Instruct --tensor-parallel-size 4
Qwen2.5-72B-Instruct
numactl -N0 -m0 vllm serve /data/Qwen2.5-72B-Instruct --served-model-name Qwen2.5-72B-Instruct --tensor-parallel-size 4
Qwen2.5-7B-Instruct
evalscope-perf
evalscope-perf http://127.0.0.1:8000/v1/chat/completions Qwen2.5-7B-Instruct \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 64 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 300 \
--parallels 400 \
--parallels 512 \
--n 1000
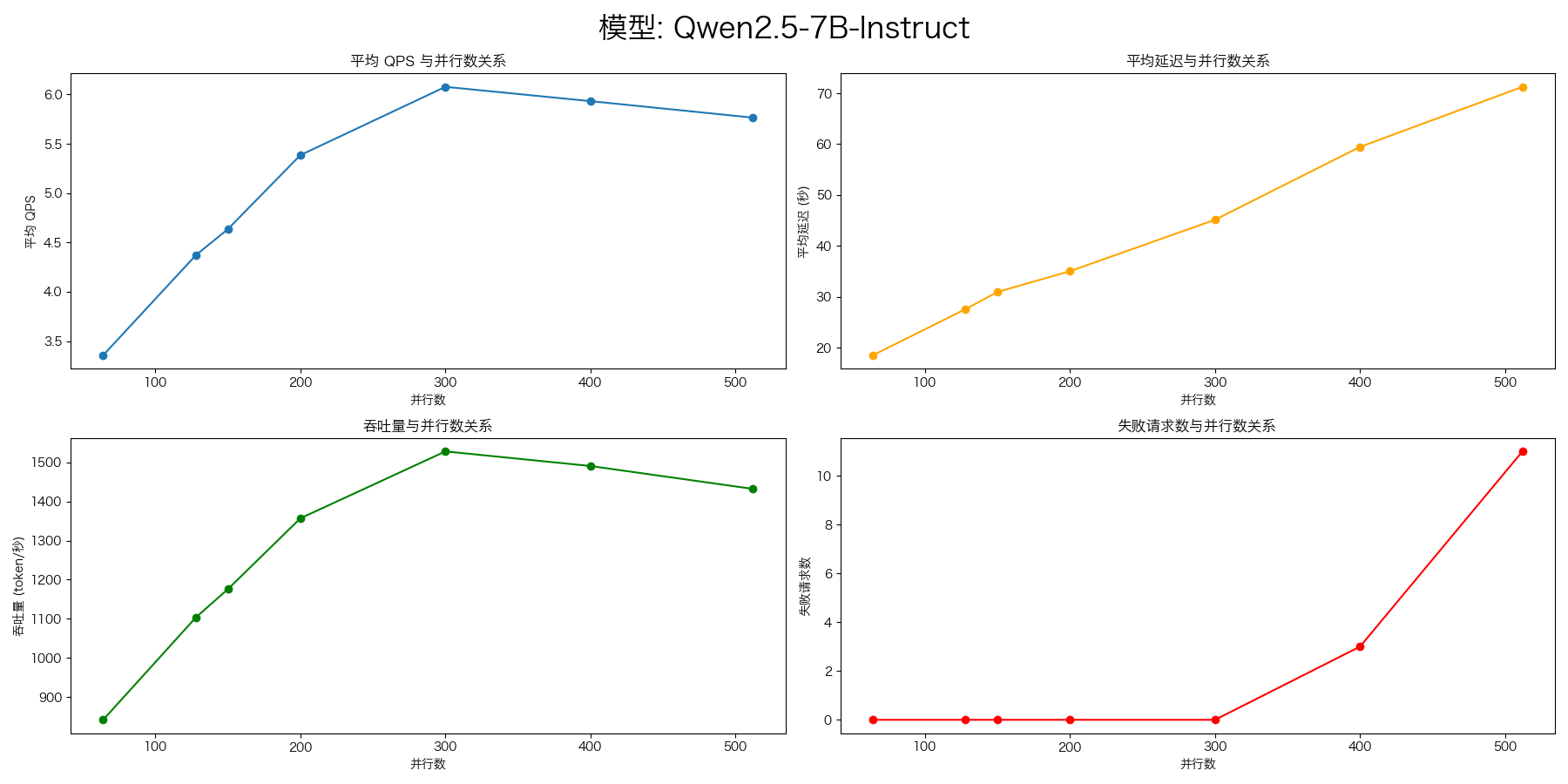
vllm benchmark
python3 ./benchmarks/benchmark_serving.py --backend vllm \
--model Qwen2.5-7B-Instruct \
--tokenizer /data/models/Qwen2.5-7B-Instruct \
--dataset-name "sharegpt" \
--dataset-path "/data/datasets/ShareGPT_V3_unfiltered_cleaned_split.json" \
--base-url http://0.0.0.0:8000 --trust-remote-code
Traffic request rate: inf
Burstiness factor: 1.0 (Poisson process)
Maximum request concurrency: None
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 150.94
Total input tokens: 217393
Total generated tokens: 198550
Request throughput (req/s): 6.63
Output token throughput (tok/s): 1315.42
Total Token throughput (tok/s): 2755.68
---------------Time to First Token----------------
Mean TTFT (ms): 51293.43
Median TTFT (ms): 45929.17
P99 TTFT (ms): 124479.71
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 184.84
Median TPOT (ms): 196.80
P99 TPOT (ms): 247.82
---------------Inter-token Latency----------------
Mean ITL (ms): 167.21
Median ITL (ms): 136.33
P99 ITL (ms): 542.79
==================================================
Qwen2.5-72B-Instruct
evalscope-perf
evalscope-perf http://127.0.0.1:8000/v1/chat/completions Qwen2.5-72B-Instruct \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 8 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--n 1000
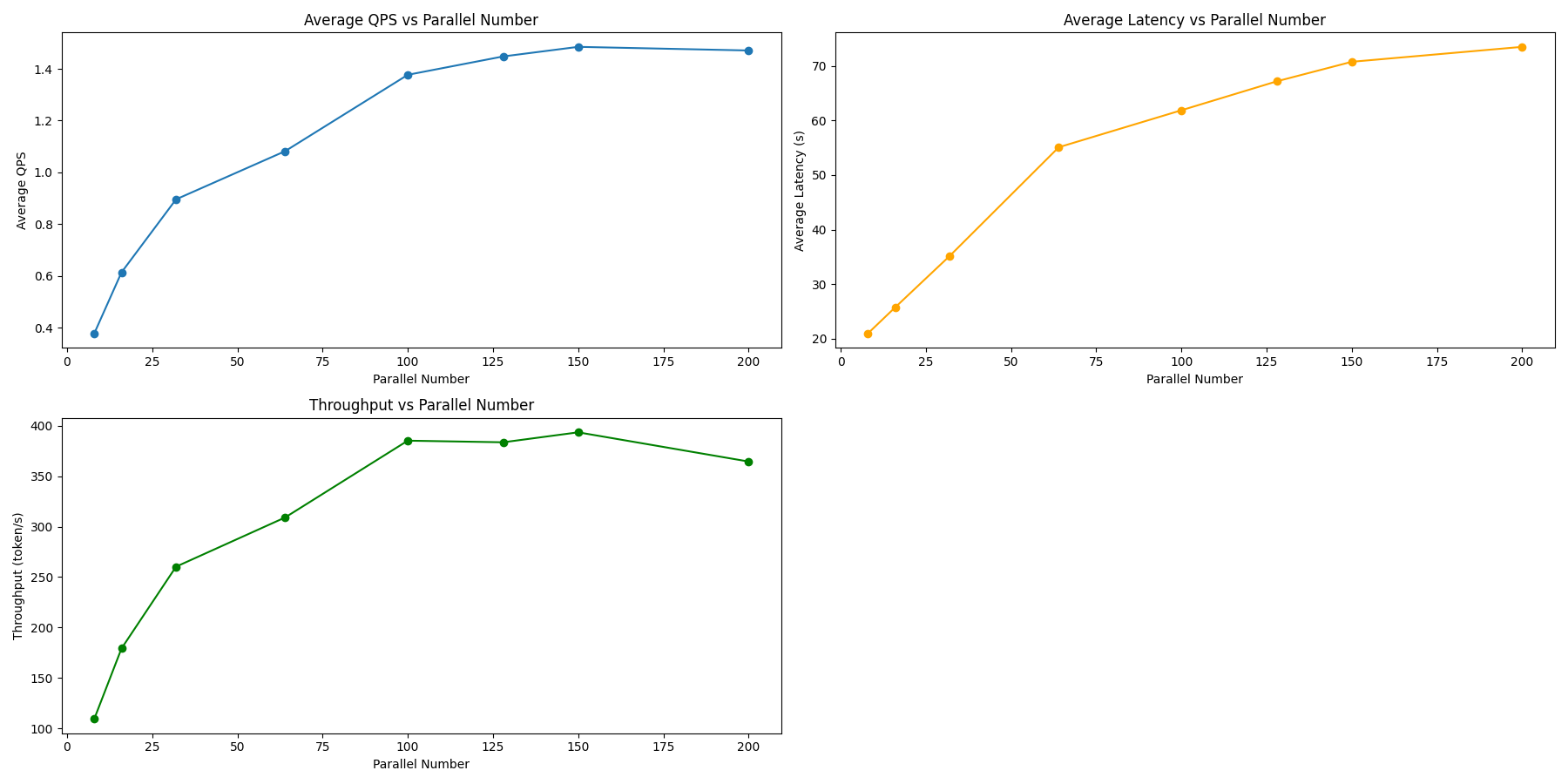
| 指标 | 8 | 16 | 32 | 64 | 100 | 128 | 150 | 200 |
|---|---|---|---|---|---|---|---|---|
| QPS | 0.37 | 0.61 | 0.89 | 1.08 | 1.37 | 1.44 | 1.48 | 1.47 |
| 延迟 | 20.94 | 25.73 | 35.16 | 55.09 | 61.88 | 67.18 | 70.76 | 73.50 |
| 吞吐量 | 109.62 | 179.37 | 260.32 | 309.04 | 385.08 | 383.47 | 393.34 | 364.43 |
| 失败数 | 0 | 0 | 0 | 14 | 35 | 78 | 89 | 164 |
没有看到明显的性能提升,但并发数 150 时性能达到峰值。
evalscope-perf http://127.0.0.1:8000/v1/chat/completions Qwen2.5-72B-Instruct \
./datasets/open_qa.jsonl \
--read-timeout=120 \
--parallels 8 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--n 1000
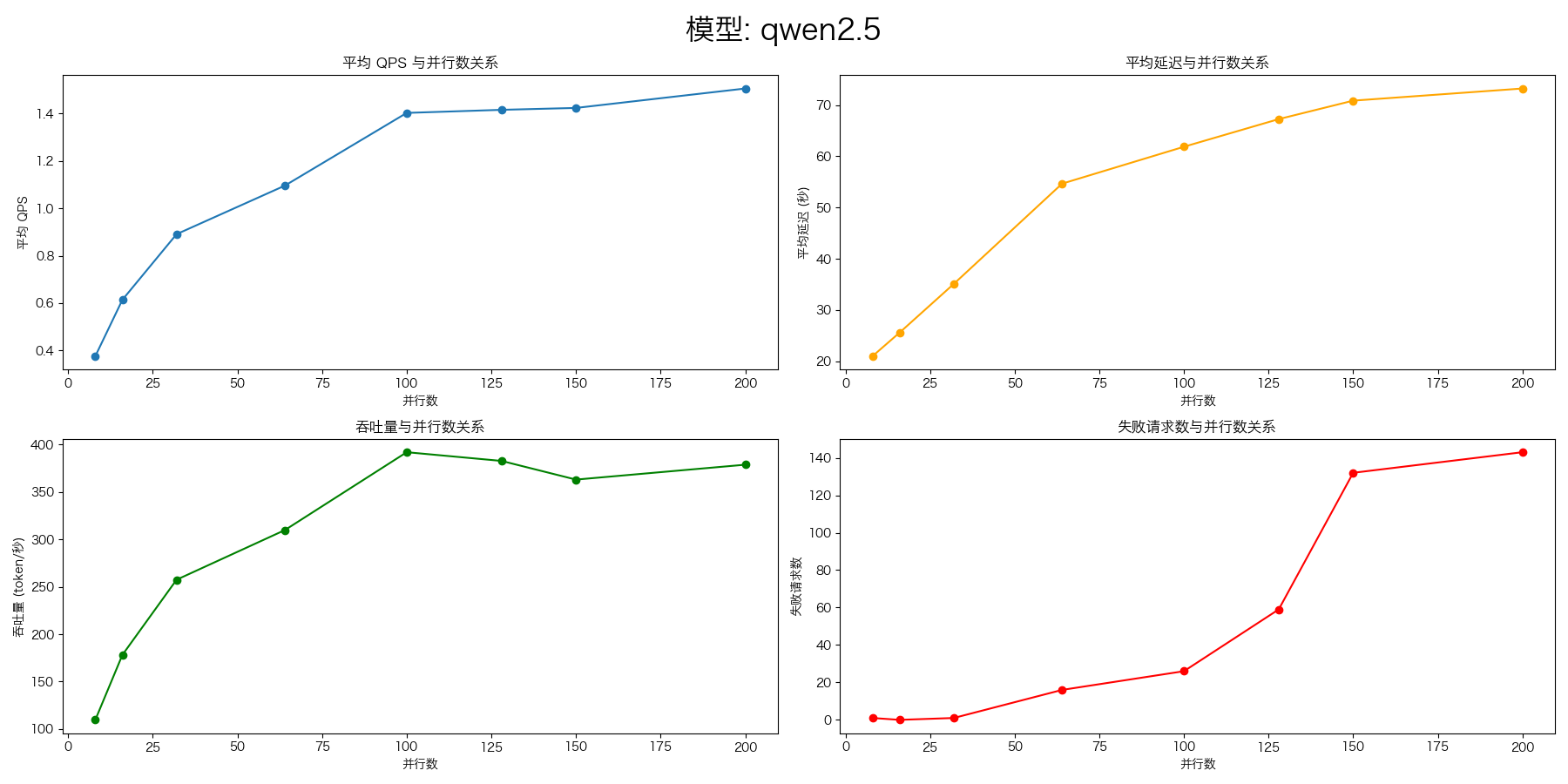
vllm benchmark
python3 ./benchmarks/benchmark_serving.py --backend vllm \
--model qwen2.5 \
--tokenizer /data/models/Qwen2.5-72B-Instruct \
--dataset-name "sharegpt" \
--dataset-path "/data/datasets/ShareGPT_V3_unfiltered_cleaned_split.json" \
--base-url http://0.0.0.0:8000 --trust-remote-code
Namespace(backend='vllm', base_url='http://0.0.0.0:8000', host='127.0.0.1', port=8000, endpoint='/v1/completions', dataset=None, dataset_name='sharegpt', dataset_path='/data/datasets/ShareGPT_V3_unfiltered_cleaned_split.json', max_concurrency=None, model='qwen2.5', tokenizer='/data/models/Qwen2.5-72B-Instruct', best_of=1, use_beam_search=False, num_prompts=1000, logprobs=None, request_rate=inf, burstiness=1.0, seed=0, trust_remote_code=True, disable_tqdm=False, profile=False, save_result=False, metadata=None, result_dir=None, result_filename=None, ignore_eos=False, percentile_metrics='ttft,tpot,itl', metric_percentiles='99', goodput=None, sonnet_input_len=550, sonnet_output_len=150, sonnet_prefix_len=200, sharegpt_output_len=None, random_input_len=1024, random_output_len=128, random_range_ratio=1.0, random_prefix_len=0, hf_subset=None, hf_split=None, hf_output_len=None, tokenizer_mode='auto', served_model_name=None, lora_modules=None)
Starting initial single prompt test run...
Initial test run completed. Starting main benchmark run...
Traffic request rate: inf
Burstiness factor: 1.0 (Poisson process)
Maximum request concurrency: None
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 384.69
Total input tokens: 217393
Total generated tokens: 197245
Request throughput (req/s): 2.60
Output token throughput (tok/s): 512.73
Total Token throughput (tok/s): 1077.84
---------------Time to First Token----------------
Mean TTFT (ms): 129740.24
Median TTFT (ms): 118243.29
P99 TTFT (ms): 319822.78
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 487.16
Median TPOT (ms): 501.16
P99 TPOT (ms): 1076.45
---------------Inter-token Latency----------------
Mean ITL (ms): 428.46
Median ITL (ms): 565.66
P99 ITL (ms): 1021.33
==================================================
- 运行 benchmark(并发 100)
python3 ./benchmarks/benchmark_serving.py --backend vllm \
--model qwen2.5 \
--tokenizer /data/models/Qwen2.5-72B-Instruct \
--dataset-name "sharegpt" \
--dataset-path "/data/datasets/ShareGPT_V3_unfiltered_cleaned_split.json" \
--base-url http://0.0.0.0:8000 --trust-remote-code \
--max-concurrency 100
Traffic request rate: inf
Burstiness factor: 1.0 (Poisson process)
Maximum request concurrency: 100
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 552.55
Total input tokens: 217393
Total generated tokens: 198142
Request throughput (req/s): 1.81
Output token throughput (tok/s): 358.60
Total Token throughput (tok/s): 752.04
---------------Time to First Token----------------
Mean TTFT (ms): 1109.58
Median TTFT (ms): 566.98
P99 TTFT (ms): 5961.61
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 272.72
Median TPOT (ms): 271.69
P99 TPOT (ms): 419.77
---------------Inter-token Latency----------------
Mean ITL (ms): 260.09
Median ITL (ms): 139.25
P99 ITL (ms): 623.20
==================================================
指定了并行数,效果不好。❌