Open-source DeepResearch – Freeing our search agents
TLDR
Yesterday, OpenAI released Deep Research, a system that browses the web to summarize content and answer questions based on the summary. The system is impressive and blew our minds when we tried it for the first time.
昨天,OpenAI 发布了 Deep Research,这是一个浏览网页以总结内容并根据总结回答问题的系统。当我们第一次尝试时,这个系统给我们留下了深刻的印象。
One of the main results in the blog post is a strong improvement of performances on the General AI Assistants benchmark (GAIA), a benchmark we’ve been playing with recently as well, where they successfully reached near 67% correct answers on 1-shot on average, and 47.6% on especially challenging “level 3” questions that involve multiple steps of reasoning and tool usage (see below for a presentation of GAIA).
博客文章中的主要结果之一是在通用人工智能助手基准(GAIA)上表现出色,这是一个我们最近也在玩的基准,他们成功地在平均 1 次尝试中达到了近 67% 的正确答案,特别具有挑战性的“3 级”问题上达到了 47.6%,这些问题涉及多步推理和工具使用(请参见下文关于 GAIA 的介绍)。
DeepResearch is composed of an LLM (which can be selected from the current list of LLMs provided by OpenAI, 4o, o1, o3, etc) and an internal “agentic framework” which guide the LLM to use tools like web search and organize its actions in steps.
DeepResearch 由一个 LLM(可以从 OpenAI 提供的当前 LLM 列表中选择,4o、o1、o3 等)和一个内部“代理框架”组成,该框架指导 LLM 使用诸如网络搜索之类的工具,并将其操作组织成步骤。
While powerful LLMs are now freely available in open-source (see e.g. the recent DeepSeek R1 model), OpenAI didn’t disclose much about the agentic framework underlying Deep Research…
虽然强大的 LLM 现在可以在开源中免费获得(例如最近的 DeepSeek R1 模型),但 OpenAI 并没有透露有关 Deep Research 底层代理框架的太多信息…
So we decided to embark on a 24-hour mission to reproduce their results and open-source the needed framework along the way!
因此,我们决定开始一项为期 24 小时的任务,以重现他们的结果,并在此过程中开源所需的框架!
The clock is ticking, let’s go! ⏱️
时钟滴答作响,让我们开始吧!⏱️
What are Agent frameworks and why they matter?(代理框架是什么,为什么重要?)
An Agent framework is a layer on top of an LLM to make said LLM execute actions (like browse the web or read PDF documents), and organize its operations in a series of steps. For a quick intro to agents, check this great interview by Andrew Ng and our introduction blog post to the smolagents library. For a more detailed dive in agents you can subscribe to our agents course that starts in just a few days: link here.
代理框架是在 LLM 之上的一层,使该 LLM 执行操作(如浏览网页或阅读 PDF 文档),并将其操作组织成一系列步骤。要快速了解代理,请查看Andrew Ng 的这次很棒的采访以及我们的介绍博客文章到 smolagents 库。要深入了解代理,您可以订阅我们的代理课程,该课程将在几天后开始:链接在这里。
Almost everyone has already experienced how powerful LLMs can be simply by playing with chatbots.. However, what not everyone is aware of yet is that integrating these LLMs into agentic systems can give them real superpowers!
几乎每个人都已经通过与聊天机器人玩耍体验到了 LLM 的强大之处。然而,还不是每个人都意识到的是,将这些 LLM 集成到代理系统中可以赋予它们真正的超能力!
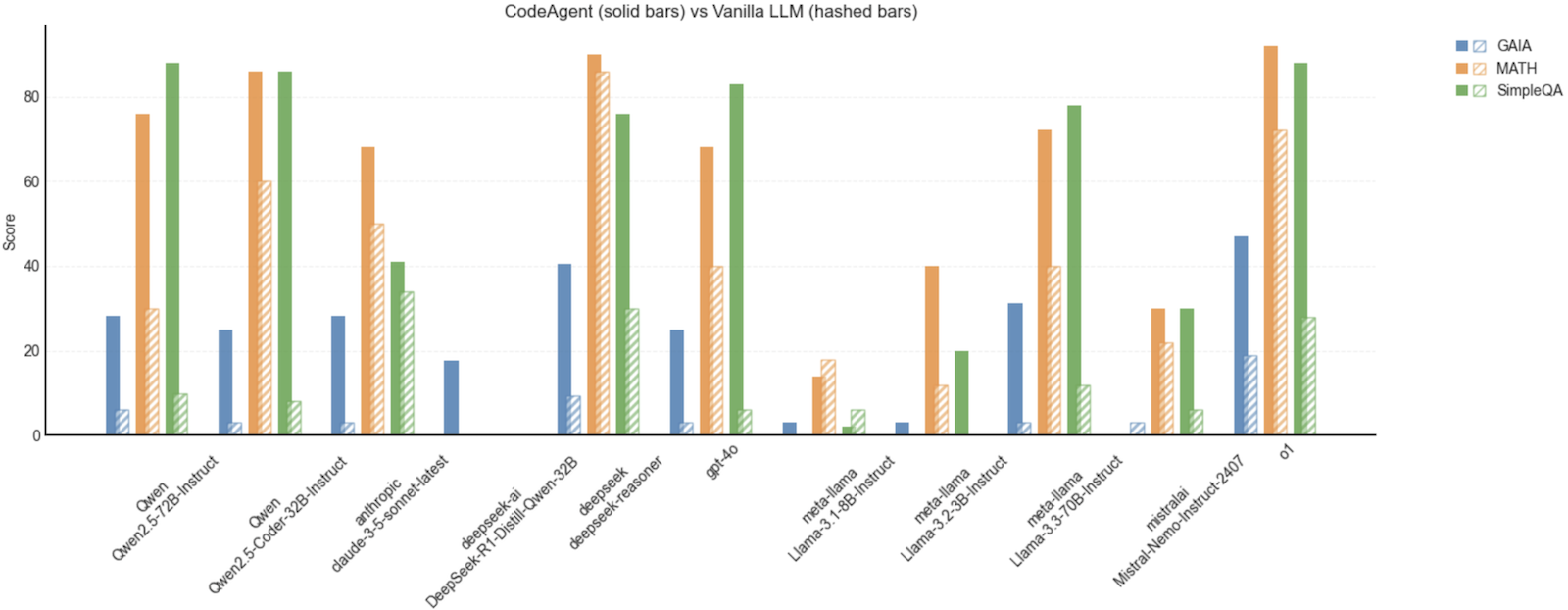
Here is a recent example comparing the performance of a few frontier LLMs with and without an agentic framework (in this case the simple smolagents library) - using an agentic framework bumps performance by up to 60 points!
这是一个最近的例子,比较了一些前沿 LLM 的性能,有的有代理框架,有的没有(在这种情况下是简单的 smolagents 库)- 使用代理框架可以将性能提高多达 60 分!
In fact, OpenAI also highlighted in its release blogpost how Deep Research performed dramatically better than standalone LLMs on the knowledge-intensive “Humanity’s Last Exam” benchmark.
事实上,OpenAI 在发布博客文章中也强调了 Deep Research 在知识密集型的“人类最后一次考试”基准上的表现远远优于独立的 LLM。
So, what happens when we integrate our current top LLM in an agentic framework, to work toward an open-DeepResearch ?
那么,当我们将当前的顶级 LLM 集成到代理框架中时,会发生什么,以便朝着 open-DeepResearch 迈进?
A quick note: We’ll benchmark our results on the same GAIA challenge but keep in mind that this is a work in progress. DeepResearch is a massive achievement and its open reproduction will take time. In particular, full parity will require improved browser use and interaction like OpenAI Operator is providing, i.e. beyond the current text-only web interaction we explore in this first step.
一个快速的说明:我们将在相同的 GAIA 挑战上对我们的结果进行基准测试,但请记住这是一个正在进行的工作。DeepResearch 是一个巨大的成就,其开放性复制将需要时间。特别是,完全的对等性将需要改进的浏览器使用和交互,就像 OpenAI Operator 提供的那样,即超出我们在这一第一步中探索的当前纯文本网络交互。
Let’s first understand the scope of the challenge: GAIA.
首先让我们了解挑战的范围:GAIA。
The GAIA benchmark
GAIA is arguably the most comprehensive benchmark for agents. Its questions are very difficult and hit on many challenges of LLM-based systems. Here is an example of a hard question:
GAIA 可能是最全面的代理基准。它的问题非常困难,涉及到 LLM 系统的许多挑战。这里是一个难题的例子:
“Which of the fruits shown in the 2008 painting “Embroidery from Uzbekistan” were served as part of the October 1949 breakfast menu for the ocean liner that was later used as a floating prop for the film “The Last Voyage”? Give the items as a comma-separated list, ordering them in clockwise order based on their arrangement in the painting starting from the 12 o’clock position. Use the plural form of each fruit.”
“2008 年的画作《乌兹别克斯坦的刺绣》中展示的水果中,哪些水果作为 1949 年 10 月的早餐菜单的一部分供应给了后来被用作电影《最后的航行》中的漂浮道具的客轮?将这些项目作为逗号分隔的列表给出,根据画作中的排列顺序,从 12 点钟位置开始,按顺时针顺序排列。使用每种水果的复数形式。”
You can see this question involves several challenges:(你可以看到这个问题涉及到了几个挑战:)
- Answering in a constrained format,(以受限制的格式回答)
- Using multimodal capabilities (to extract the fruits from the image),(使用多模态功能(从图像中提取水果))
- Gathering several pieces of information, some depending on others:(收集几个信息片段,有些取决于其他信息:)
- Identifying the fruits on the picture(识别图片上的水果)
- Finding which ocean liner was used as a floating prop for “The Last Voyage”(找到哪艘客轮被用作《最后的航行》的漂浮道具)
- Finding the October 1949 breakfast menu for the above ocean liner(找到上述客轮的 1949 年 10 月早餐菜单)
- Chaining together a problem-solving trajectory in the correct order.(按正确顺序将问题解决轨迹链接在一起。)
Solving this requires both high-level planning abilities and rigorous execution, which are two areas where LLMs struggle when used alone.
解决这个问题需要高水平的规划能力和严格的执行,这是 LLM 单独使用时困难的两个领域。
So it’s an excellent test set for agent systems!
因此,这是一个优秀的代理系统测试集!
On GAIA’s public leaderboard, GPT-4 does not even reach 7% on the validation set when used without any agentic setup. On the other side of the spectrum, with Deep Research, OpenAI reached 67.36% score on the validation set, so an order of magnitude better! (Though we don’t know how they would actually fare on the private test set.)
在 GAIA 的公共排行榜上,GPT-4 在没有任何代理设置的情况下甚至没有达到验证集的 7%。另一方面,通过 Deep Research,OpenAI 在验证集上达到了 67.36% 的分数,因此好了一个数量级!(尽管我们不知道他们在私有测试集上的实际表现。)
Let’s see if we can do better with open source tools!
让我们看看我们是否可以使用开源工具做得更好!
Building an open Deep Research
Using a CodeAgent
The first improvement over traditional AI agent systems we’ll tackle is to use a so-called “code agent”. As shown by Wang et al. (2024), letting the agent express its actions in code has several advantages, but most notably that code is specifically designed to express complex sequences of actions.
我们将首先解决传统 AI 代理系统的一个改进,即使用所谓的“代码代理”。正如Wang 等人(2024)所示,让代理以代码形式表达其操作具有几个优点,但最重要的是代码专门设计用于表达复杂的操作序列。
Consider this example given by Wang et al.:
考虑 Wang 等人给出的这个例子:
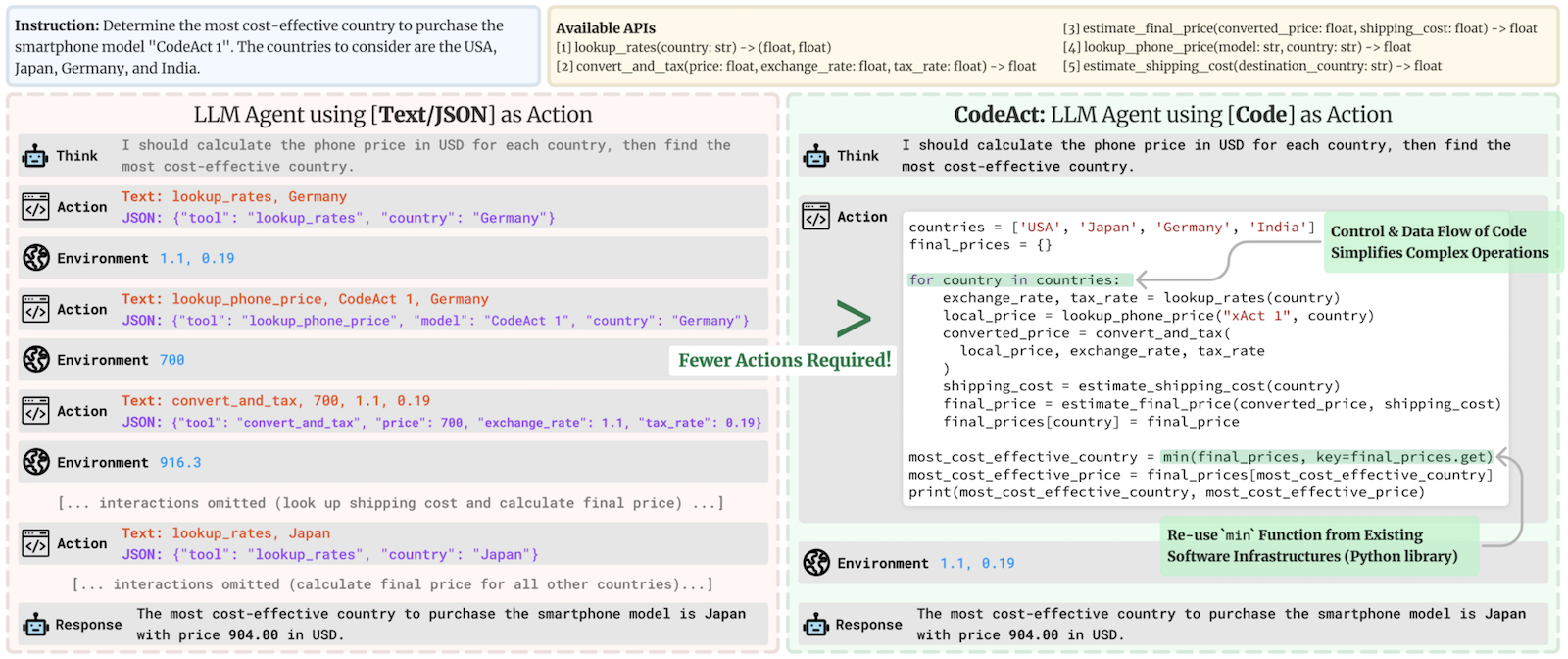
This highlights several advantages of using code:(这突出了使用代码的几个优点:)
- Code actions are much more concise than JSON.(代码操作比 JSON 更简洁。)
- Need to run 4 parallel streams of 5 consecutive actions ? In JSON, you would need to generate 20 JSON blobs, each in their separate step; in Code it’s only 1 step.
- 需要运行 4 个并行流的 5 个连续操作?在 JSON 中,您需要生成 20 个 JSON blob,每个在其单独的步骤中;在代码中只需要 1 步。
- On average, the paper shows that Code actions require 30% fewer steps than JSON, which amounts to an equivalent reduction in the tokens generated. Since LLM calls are often the dimensioning cost of agent systems, it means your agent system runs are ~30% cheaper.
- 平均而言,该论文显示,代码操作比 JSON 操作需要的步骤少 30%,这相当于生成的令牌数量减少。由于 LLM 调用通常是代理系统的维度成本,这意味着您的代理系统运行成本降低了约 30%。
- Code enables to re-use tools from common libraries(代码可以重用常见库中的工具)
- Better performance in benchmarks, due to two reasons:(由于两个原因,在基准测试中表现更好:)
- More intuitive way to express actions(更直观地表达操作的方式)
- Extensive exposure of LLMs to code in training(LLMs 在训练中广泛接触代码)
The advantages above were confirmed by our experiments on the agent_reasoning_benchmark.
上述优点已经通过我们在 agent_reasoning_benchmark 上的实验得到了证实。
From building smolagents we can also cite a notable additional advantage, which is a better handling of state: this is very useful for multimodal tasks in particular. Need to store this image/audio/other for later use? No problem, just assign it as a variable in your state and you can re-use it 4 steps later if needed. In JSON you would have to let the LLM name it in a dictionary key and trust the LLM will later understand that it can still use it.
从构建 smolagents 我们还可以引用一个显著的额外优势,即更好地处理状态:这对于多模态任务特别有用。需要存储这个图像/音频/其他以供以后使用?没问题,只需将其分配为状态中的变量,如果需要,您可以在 4 步后重新使用它。在 JSON 中,您必须让 LLM 在字典键中命名它,并相信 LLM 以后会明白它仍然可以使用它。
Making the right tools 🛠️
Now we need to provide the agent with the right set of tools.
现在我们需要为代理提供正确的工具集。
-
A web browser. While a fully fledged web browser interaction like Operator will be needed to reach full performance, we started with an extremely simple text-based web browser for now for our first proof-of-concept. You can find the code here.
一个网络浏览器。虽然需要像Operator这样的完整网络浏览器交互才能达到最佳性能,但我们目前首先从一个极其简单的基于文本的网络浏览器开始,用于我们的第一个概念验证。您可以在这里找到代码。
-
A simple text inspector, to be able to read a bunch of text file format, find it here.
一个简单的文本检查器,用于阅读一堆文本文件格式,可以在这里找到。
These tools were taken from the excellent Magentic-One agent by Microsoft Research, kudos to them! We didn’t change them much, as our goal was to get as high a performance as we can with the lowest complexity possible.
这些工具取自微软研究的出色的Magentic-One代理,向他们致敬!我们没有做太多改动,因为我们的目标是以尽可能低的复杂性获得尽可能高的性能。
Here is a short roadmap of improvements which we feel would really improve these tools’ performance (feel free to open a PR and contribute!):
这是我们认为将真正提高这些工具性能的一些改进的简短路线图(欢迎打开 PR 并贡献!):
- extending the number of file formats which can be read.(扩展可以读取的文件格式数量。)
- proposing a more fine-grained handling of files.(提出更细粒度的文件处理。)
- replacing the web browser with a vision-based one, which we’ve started doing here.(用基于视觉的网络浏览器替换,我们已经开始在这里做了。)
Results 🏅
In our 24h+ reproduction sprint, we’ve already seen steady improvements in the performance of our agent on GAIA!
在我们 24 小时以上的复制冲刺中,我们已经看到我们的代理在 GAIA 上的性能稳步提高!
We’ve quickly gone up from the previous SoTA with an open framework, around 46% for Magentic-One, to our current performance of 55.15% on the validation set.
我们很快从以前的 SoTA,大约 46% 的 Magentic-One,上升到我们目前在验证集上的 55.15% 的性能。
This bump in performance is due mostly to letting our agents write their actions in code! Indeed, when switching to a standard agent that writes actions in JSON instead of code, performance of the same setup is instantly degraded to 33% average on the validation set.
这种性能提升主要是因为让我们的代理以代码形式编写其操作!实际上,当切换到一个标准代理,该代理以 JSON 而不是代码形式编写操作时,相同设置的性能立即降级到验证集上的平均 33%。
Here is the final agentic system.
We’ve set up a live demo here for you to try it out!
我们在这里为您设置了一个实时演示,供您尝试!
However, this is only the beginning, and there are a lot of things to improve! Our open tools can be made better, the smolagents framework can also be tuned, and we’d love to explore the performance of better open models to support the agent.
然而,这只是一个开始,还有很多事情需要改进!我们的开放工具可以做得更好,smolagents 框架也可以调整,我们很乐意探索更好的开放模型的性能,以支持代理。
We welcome the community to come join us in this endeavour, so we can leverage the power of open research together to build a great open-source agentic framework! It would allow anyone to run a DeepResearch-like agent at home, with their favorite models, using a completely local and customized approach!
我们欢迎社区加入我们的努力,这样我们就可以共同利用开放研究的力量来构建一个伟大的开源代理框架!这将允许任何人在家中运行类似 DeepResearch 的代理,使用他们喜欢的模型,采用完全本地化和定制化的方法!
Community Reproductions(社区复制)
While we were working on this and focusing on GAIA, other great open implementations of Deep Research emerged from the community, specifically from
当我们在这方面工作并专注于 GAIA 时,其他伟大的 Deep Research 开放实现从社区中出现,特别是来自
- dzhng,
- assafelovic,
- nickscamara,
- jina-ai and
- mshumer.
Each of these implementations use different libraries for indexing data, browsing the web and querying LLMs. In this project, we would like to reproduce the benchmarks presented by OpenAI (pass@1 average score), benchmark and document our findings with switching to open LLMs (like DeepSeek R1), using vision LMs, benchmark traditional tool calling against code-native agents.
这些实现使用不同的库来索引数据、浏览网络和查询 LLMs。在这个项目中,我们希望复制 OpenAI 提出的基准(pass@1 平均分),并使用开放 LLMs(如 DeepSeek R1),使用视觉 LMs,使用传统工具调用与代码本地代理进行基准测试,并记录我们的发现。
Most important next steps(最重要的下一步)
OpenAI’s Deep Research is probably boosted by the excellent web browser that they introduced with Operator.
OpenAI 的 Deep Research 可能受益于他们在Operator中引入的出色网络浏览器。
So we’re tackling that next! In a more general problem: we’re going to build GUI agents, i.e. “agents that view your screen and can act directly with mouse & keyboard”. If you’re excited about this project, and want to help everyone get access to such cool capabilities through open source, we’d love to get your contribution!
所以下一步我们要解决这个问题!在一个更一般的问题上:我们将构建 GUI 代理,即“查看您的屏幕并可以直接使用鼠标和键盘操作的代理”。如果您对这个项目感到兴奋,并希望通过开源帮助每个人获得这些很酷的功能,我们很乐意得到您的贡献!
We’re also hiring a full time engineer to help us work on this and more, apply if you’re interested 🙂
我们还招聘全职工程师来帮助我们开展这项工作以及更多工作,如果您感兴趣,请申请 🙂
- To get started with Open Deep Research, try the examples here.(要开始使用 Open Deep Research,请尝试这里的示例。)
- Check the smolagents repo.(查看smolagents存储库。)
- Read more about smolagents docs, introduction blog post.(阅读有关 smolagents 的更多文档,介绍博客文章。)