大模型(语言、视觉语言、语音)推理服务部署与测试
推理服务
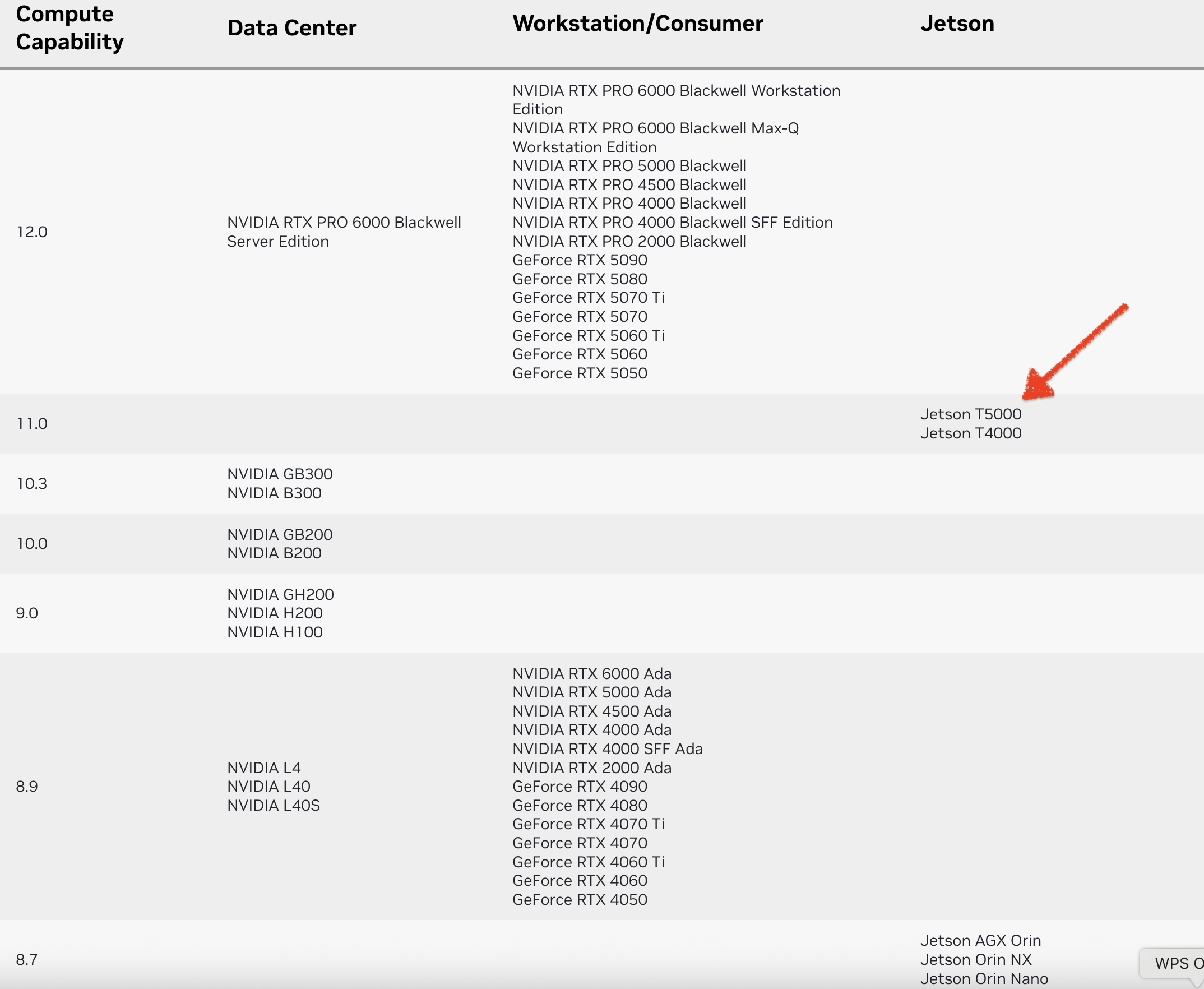
CUDA GPU Compute Capability(计算能力)
计算能力(CC)定义了每种 NVIDIA GPU 架构的硬件特性和支持的指令。在下表中查找您的GPU的计算能力。
vLLM
docker run -it --rm \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=vllm-test \
-v /models:/models \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/.cache/modelscope:/root/.cache/modelscope \
nvcr.io/nvidia/vllm:25.10-py3 \
bash
默认情况下,如果模型未指向有效的本地目录,它将从 Hugging Face Hub 下载模型文件。要从 ModelScope 下载模型,请在运行命令之前进行如下设置:
export VLLM_USE_MODELSCOPE=true
vllm serve /models/Qwen/Qwen3-8B \
--served-model-name qwen3 \
--chat-template /models/Qwen/Qwen3-8B/qwen3_nonthinking.jinja
SGLang
docker run -it --rm \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=sglang-test \
-v /models:/models \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/.cache/modelscope:/root/.cache/modelscope \
nvcr.io/nvidia/sglang:25.10-py3 \
bash
默认情况下,如果 --model-path 未指向有效的本地目录,它将从 Hugging Face Hub 下载模型文件。要从 ModelScope 下载模型,请在运行命令之前进行如下设置:
export SGLANG_USE_MODELSCOPE=true
python -m sglang.launch_server \
--model-path /models/Qwen/Qwen3-8B \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000 \
--cuda-graph-bs 2
llama.cpp
编译
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="110"
cmake --build build -j --config Release
部署(llama-server)
./build/bin/llama-server \
--model /models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf \
--alias qwen3 \
--host 0.0.0.0 \
--port 8000 \
--ctx-size 0
whisper.cpp
编译
git clone https://github.com/ggml-org/whisper.cpp.git
cd whisper.cpp
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="110"
cmake --build build -j --config Release
部署(whisper-server)
./whisper-server \
--model /models/whisper.cpp/models/ggml-large-v3-turbo.bin \
--host 0.0.0.0 \
--port 8080 \
--flash-attn \
--language auto
语言
Jetson Thor
| 模型 | 量化精度 | vLLM (tok/s) | SGLang (tok/s) | llama.cpp (tok/s) |
|---|---|---|---|---|
| Qwen3-8B | bfloat16 | 10.5 | 11.3 | ⛔ |
| Qwen3-8B-FP8 | fp8_w8a8 | ❌ | 27.3 | ⛔ |
| Qwen3-8B-FP4 | modelopt_fp4 | 33.3 | 29.0 | ⛔ |
| Qwen3-8B-GGUF | Q5_K_M | ⛔ | ⛔ | 37.4 🚀 |
| Qwen3-Coder-30B-A3B-Instruct-FP8 | fp8_w8a8 | ❌ | ❌ | ⛔ |
| Qwen3-Coder-30B-A3B-Instruct-GGUF | Q5_K_M | ⛔ | ⛔ | 58.7 🚀 |
❌ 部署后不能有效输出(
乱码、!!!...、崩溃等)。⛔ 不支持。
Qwen3-Coder-30B-A3B-Instruct-FP8vLLM 和 SGLang 部署后,发生非法内存访问,CUDA 崩溃。
模型
- Qwen3-8B
- Qwen3-8B-FP4
- Qwen3-8B-FP8
- Qwen3-8B-GGUF
- Qwen3-Coder-30B-A3B-Instruct-FP8
- Qwen3-Coder-30B-A3B-Instruct-GGUF
要完全禁用思考功能,你可以在启动模型时使用自定义聊天模板:
wget https://qwen.readthedocs.io/en/latest/_downloads/c101120b5bebcc2f12ec504fc93a965e/qwen3_nonthinking.jinja
聊天模板会阻止模型生成思考内容,即使用户通过 /think 指示模型这样做。
vLLM
Qwen3-8B
- 不思考
vllm serve /models/Qwen/Qwen3-8B \
--served-model-name qwen3 \
--chat-template /models/Qwen/Qwen3-8B/qwen3_nonthinking.jinja
- 思考 💬
vllm serve /models/Qwen/Qwen3-8B \
--served-model-name qwen3
Qwen3-8B-FP4
repetition_penalty 解决重复不停输出的问题。
- 不思考
vllm serve /models/nv-community/Qwen3-8B-FP4 \
--served-model-name qwen3 \
--override-generation-config '{
"repetition_penalty": 1.2,
"temperature": 0.8,
"top_p": 0.95
}' \
--chat-template /models/Qwen/Qwen3-8B/qwen3_nonthinking.jinja
- 思考 💬
vllm serve /models/nv-community/Qwen3-8B-FP4 \
--served-model-name qwen3 \
--override-generation-config '{
"repetition_penalty": 1.2,
"temperature": 0.8,
"top_p": 0.95
}'
Qwen3-Coder-30B-A3B-Instruct-FP8
vllm serve /models/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 \
--served-model-name qwen3 \
--max-model-len 65536 \
--enforce-eager \
--override-generation-config '{
"repetition_penalty": 1.05,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}'
--enforce-eager解决:torch.AcceleratorError: CUDA error: an illegal memory access was encountered
SGLang
Qwen3-8B
- 不思考
python -m sglang.launch_server \
--model-path /models/Qwen/Qwen3-8B \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000 \
--chat-template /models/Qwen/Qwen3-8B/qwen3_nonthinking.jinja
- 思考 💬
python -m sglang.launch_server \
--model-path /models/Qwen/Qwen3-8B \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000
Qwen3-8B-FP8
好不容易调好了,一直有乱码、重复等问题。
- 不思考
python -m sglang.launch_server \
--model-path /models/Qwen/Qwen3-8B-FP8 \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000 \
--max-running-requests 2 \
--preferred-sampling-params '{
"repetition_penalty": 1.2,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0
}' \
--chat-template /models/Qwen/Qwen3-8B/qwen3_nonthinking.jinja
- 思考 💬
python -m sglang.launch_server \
--model-path /models/Qwen/Qwen3-8B-FP8 \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000 \
--max-running-requests 2 \
--preferred-sampling-params '{
"repetition_penalty": 1.2,
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"min_p": 0.0
}'
Qwen3-8B-FP4
- 不思考
python -m sglang.launch_server \
--model-path /models/nv-community/Qwen3-8B-FP4 \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000 \
--quantization modelopt_fp4 \
--max-running-requests 2 \
--chat-template /models/Qwen/Qwen3-8B/qwen3_nonthinking.jinja
- 思考 💬
python -m sglang.launch_server \
--model-path /models/nv-community/Qwen3-8B-FP4 \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000 \
--quantization modelopt_fp4 \
--max-running-requests 2
Qwen3-Coder-30B-A3B-Instruct-FP8
python -m sglang.launch_server \
--model-path /models/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 \
--served-model-name qwen3 \
--host 0.0.0.0 --port 8000 \
--max-running-requests 1 \
--max-total-tokens 65536 \
--disable-cuda-graph \
--preferred-sampling-params '{
"repetition_penalty": 1.05,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}'
--disable-cuda-graph解决:torch.AcceleratorError: CUDA error: an illegal memory access was encountered
llama.cpp
Qwen3-8B-GGUF
- 不思考
./build/bin/llama-server \
--model /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q5_K_M.gguf \
--alias qwen3 \
--host 0.0.0.0 \
--port 8000 \
--ctx-size 0 \
--jinja \
--reasoning-budget 0
- 思考 💬
./build/bin/llama-server \
--model /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q5_K_M.gguf \
--alias qwen3 \
--host 0.0.0.0 \
--port 8000 \
--ctx-size 0
Qwen3-Coder-30B-A3B-Instruct-GGUF
./build/bin/llama-server \
--model /models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf \
--alias qwen3 \
--host 0.0.0.0 \
--port 8000 \
--ctx-size 0
语音
模型
vllm serve /models/openai-mirror/whisper-small --served-model-name whisper
测试(curl)
vllm
curl "http://127.0.0.1:8000/v1/audio/transcriptions" \
--form "file=@/models/llama.cpp/tools/mtmd/test-2.mp3" \
--form "model=whisper" \
--form "response_format=json" \
--form "language=zh"
whisper.cpp
curl 127.0.0.1:8080/inference \
-H "Content-Type: multipart/form-data" \
-F file="@samples/jfk.wav" \
-F response_format="json"
视觉-语言
模型
vllm serve /models/Qwen/Qwen2.5-VL-7B-Instruct-AWQ --served-model-name qwen3
测试(curl)
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3",
"messages": [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "http://book.d2l.ai/_images/catdog.jpg"}},
{"type": "text", "text": "解释图像"}
]
}
]
}'
{
"id": "chatcmpl-ca34716637f34580a80a95610ea43557",
"object": "chat.completion",
"created": 1760853120,
"model": "qwen3",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "这张图像展示了两只可爱的宠物——一只小狗和一只小猫。小狗位于图像的左侧,它的毛色是浅棕色,耳朵是黑色的,眼睛大而明亮,表情显得很专注。小猫位于图像的右侧,它的毛色是灰色和白色相间的条纹,嘴巴张开,似乎在叫唤或发出声音。背景是纯白色的,使得小狗和小猫成为图像的焦点。整体来看,这是一幅温馨且充满活力的画面,展现了宠物之间的和谐共处。",
"refusal": null,
"annotations": null,
"audio": null,
"function_call": null,
"tool_calls": [],
"reasoning_content": null
},
"logprobs": null,
"finish_reason": "stop",
"stop_reason": null
}
],
"service_tier": null,
"system_fingerprint": null,
"usage": {
"prompt_tokens": 543,
"total_tokens": 651,
"completion_tokens": 108,
"prompt_tokens_details": null
},
"prompt_logprobs": null,
"kv_transfer_params": null
}
vllm serve /models/Qwen/Qwen2.5-VL-7B-Instruct-AWQ --served-model-name qwen3 --allowed-local-media-path
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3",
"messages": [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "file:///models/iic/SenseVoiceSmall/fig/asr_results.png"}},
{"type": "text", "text": "解释图像"}
]
}
]
}'