DeepSeek-OCR 研究与实测
DeepSeek-OCR:上下文光学压缩
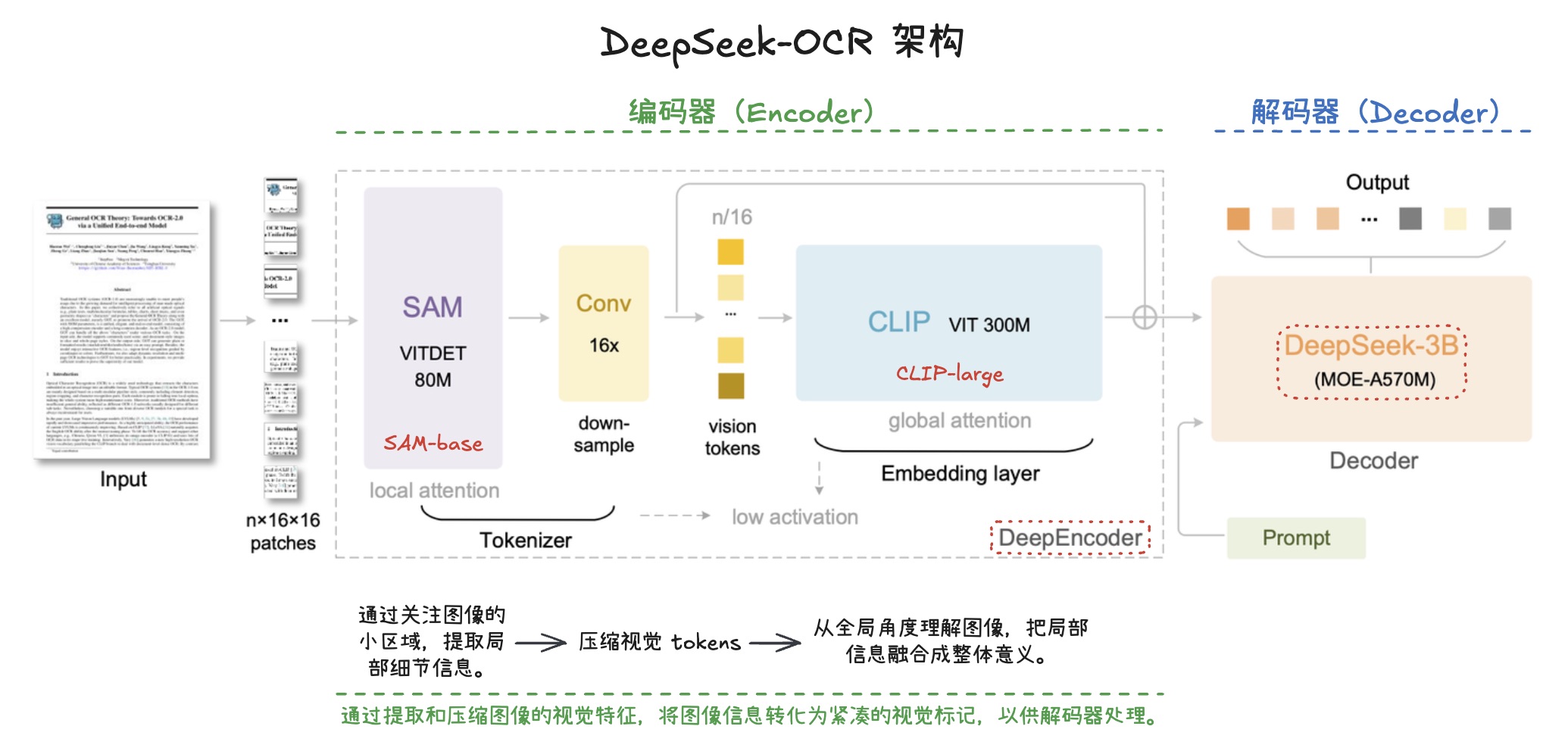
DeepSeek-OCR 架构

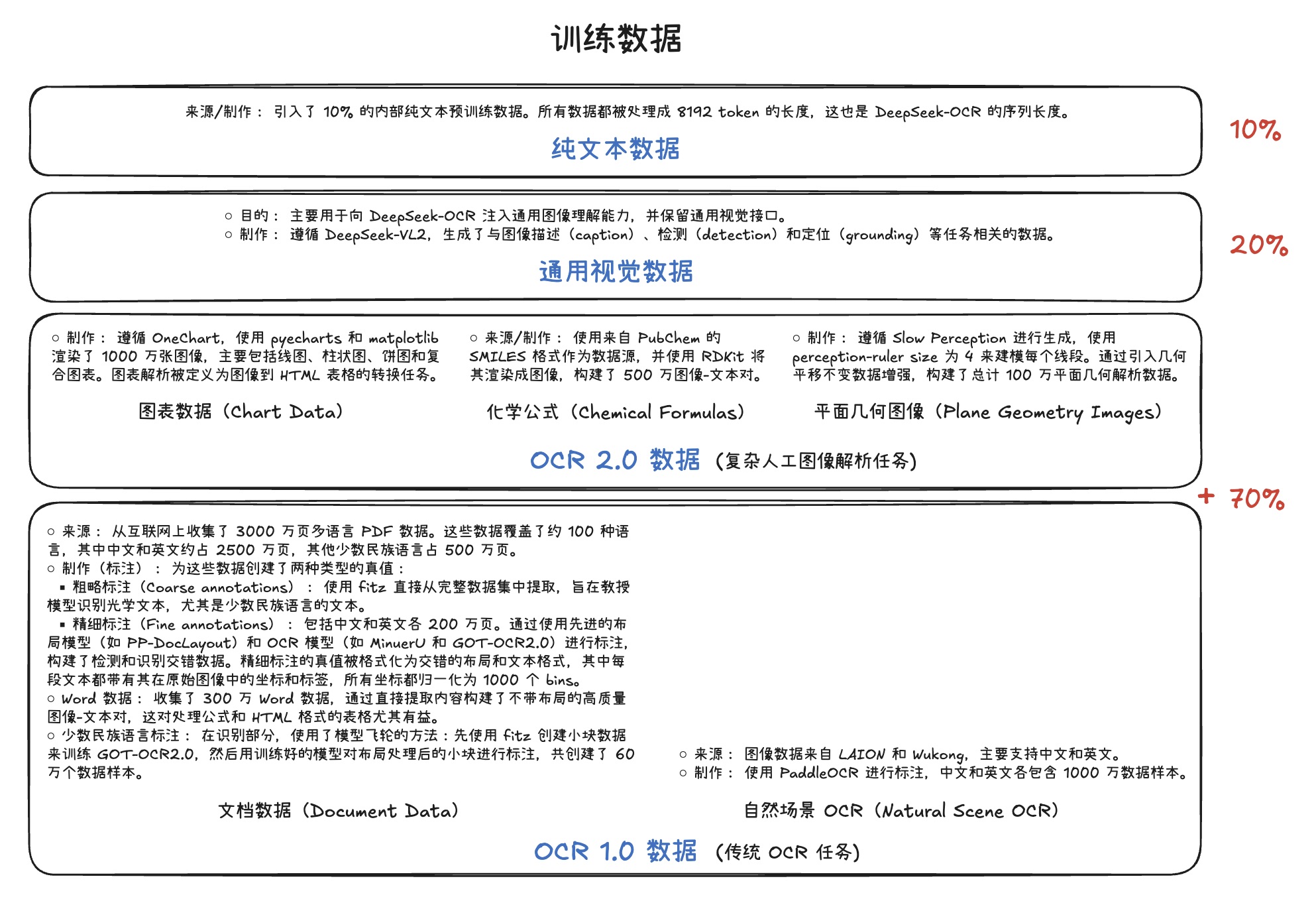
训练数据
数据组成
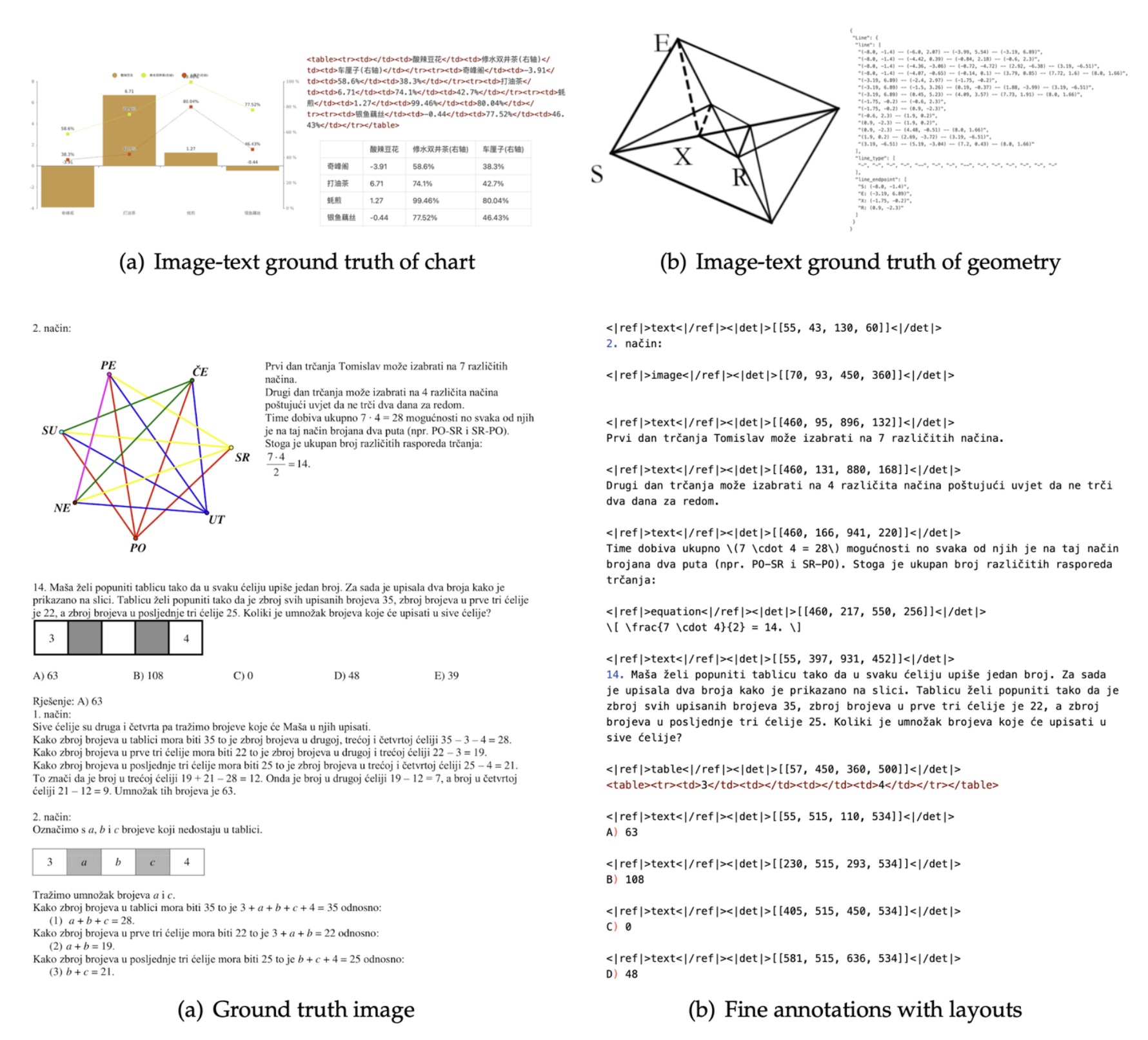
数据标注
训练流程
训练 DeepEncoder
- 方法: 遵循
Vary,使用紧凑语言模型和下一词元预测(next token prediction)框架进行训练。 - 数据: 使用所有
OCR 1.0和OCR 2.0数据,以及从LAION数据集中采样的1 亿(100M)通用数据。 - 训练细节: 训练
2个 epoch,批次大小为1280,使用AdamW 优化器,配合余弦退火(cosine annealing)调度器,学习率为5e-5。训练序列长度为4096。
训练 DeepSeek-OCR
- 时机: DeepEncoder 准备好后进行。
- 数据: 使用训练数据。
- 并行策略: 采用
流水线并行(PP),模型被分为 4 部分:- DeepEncoder (PP0, PP1):
- PP0: 包含
SAM 和压缩器(作为视觉词元分析器),参数冻结。 - PP1: 包含
CLIP部分(作为输入嵌入层),权重不冻结,参与训练。
- PP0: 包含
- 语言模型 (PP2, PP3): DeepSeek3B-MoE 共有 12 层,PP2 和 PP3 各放置 6 层。
- DeepEncoder (PP0, PP1):
- 硬件与批次: 使用 20 个节点(每个节点配备 8 块 A100-40G GPU)进行训练,数据并行(DP)为 40,全局批次大小为
640。 - 优化器: 使用
AdamW 优化器,配合基于步数的调度器(step-based scheduler),初始学习率为3e-5。 - 训练速度: 纯文本数据:900 亿词元/天(90B tokens/day);多模态数据:700 亿词元/天(70B tokens/day)。
提示词
<image>\nFree OCR.
<image>\n<|grounding|>Convert the document to markdown.
<image>\nParse the figure.
<image>\nLocate <|ref|>11-2=<|/ref|> in the image.
<image>\nDescribe this image in detail.
<image>\n请详细描述这张图片。
<image>\nLocate <|ref|>the teacher<|/ref|> in the image.
<image>\nIdentify all objects in the image and output them in bounding boxes.
<image>\n这是一张
<image>\n<|grounding|>OCR the images.
君不见,黄河之水天上来
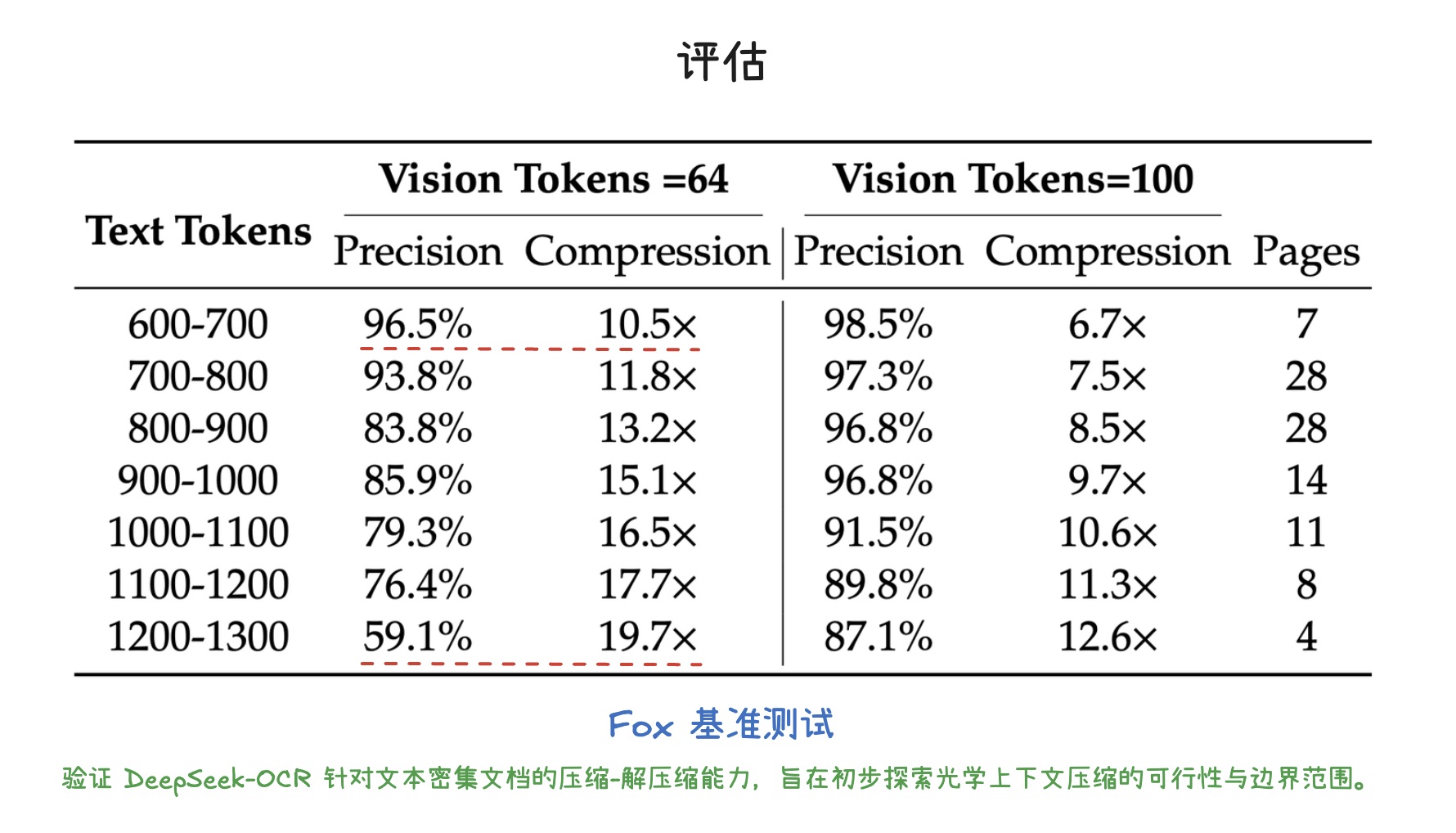
评估
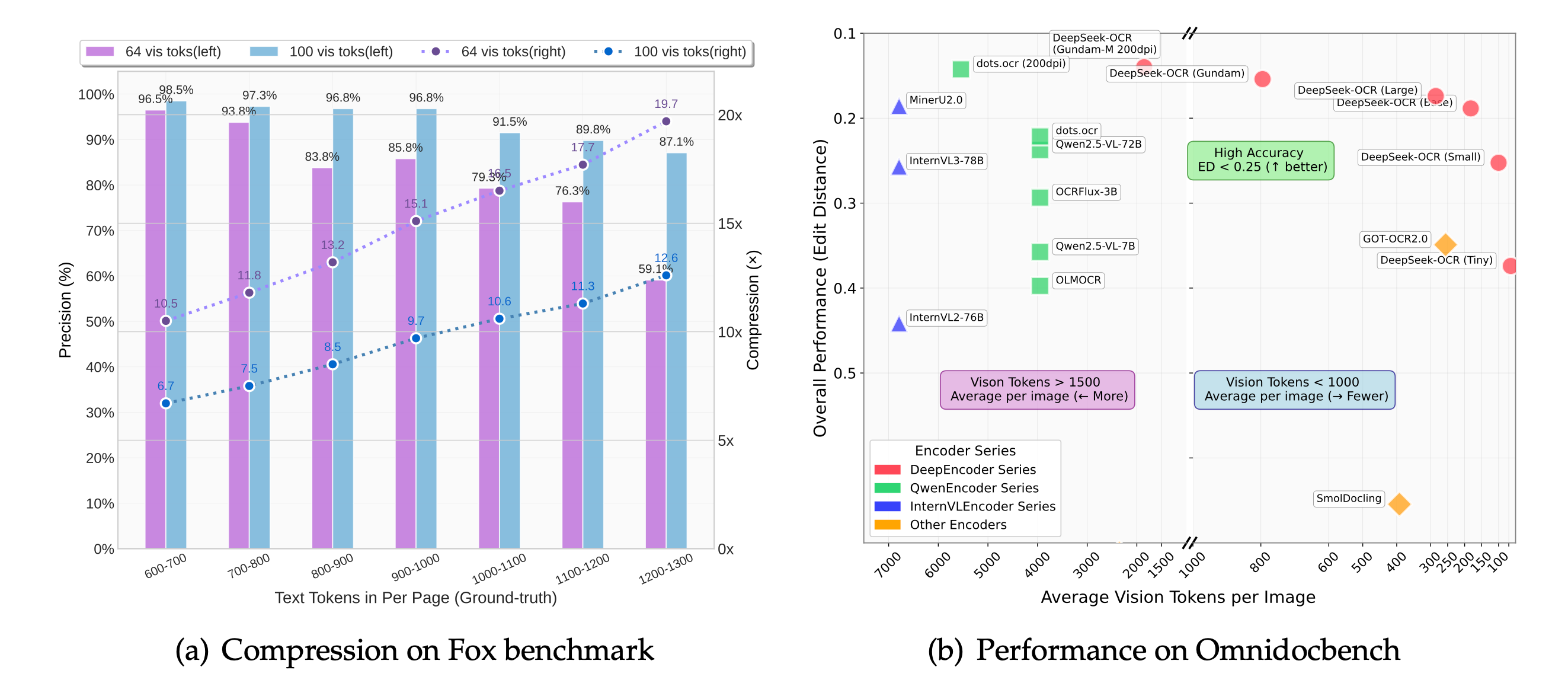
Fox 基准测试
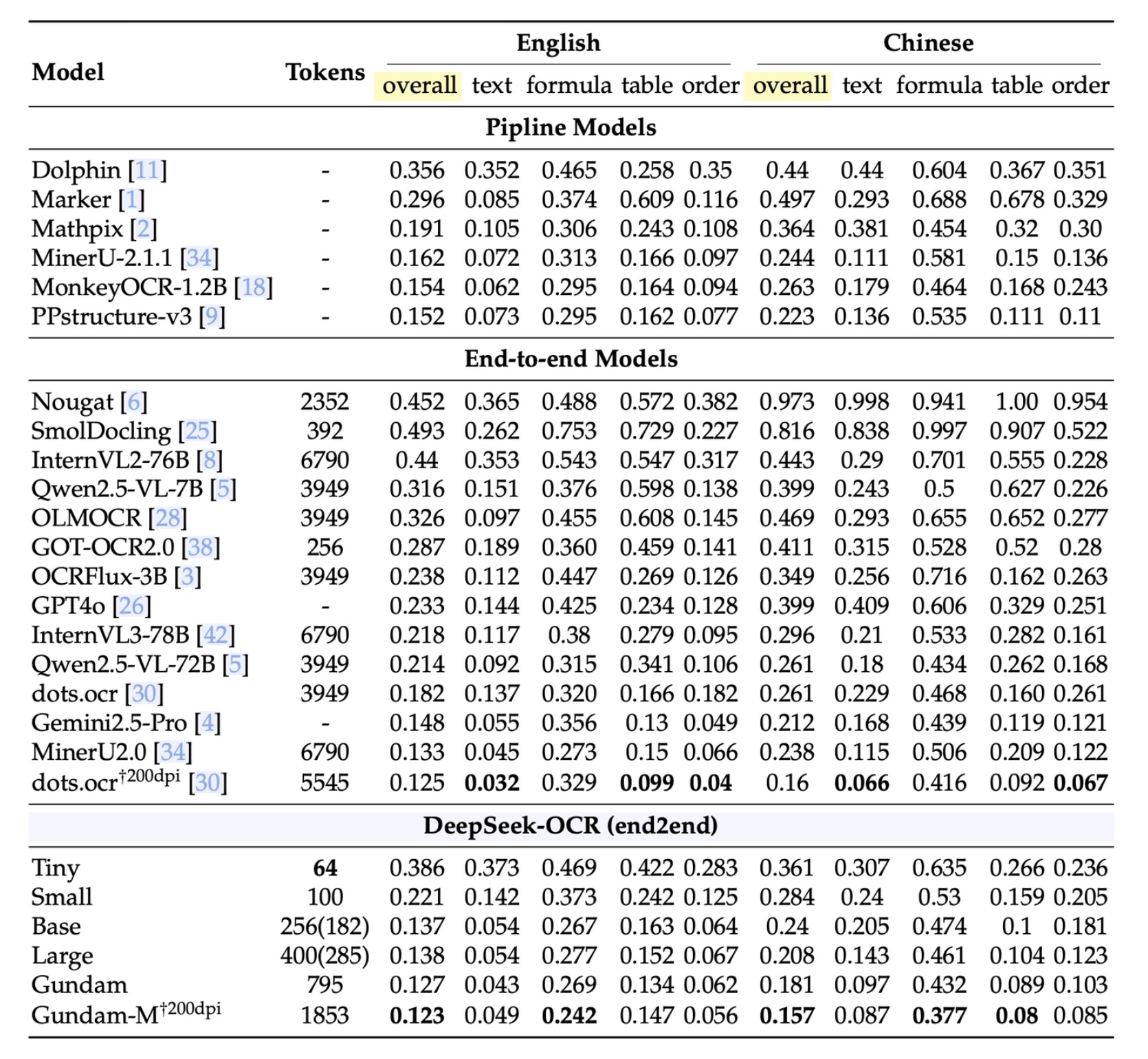
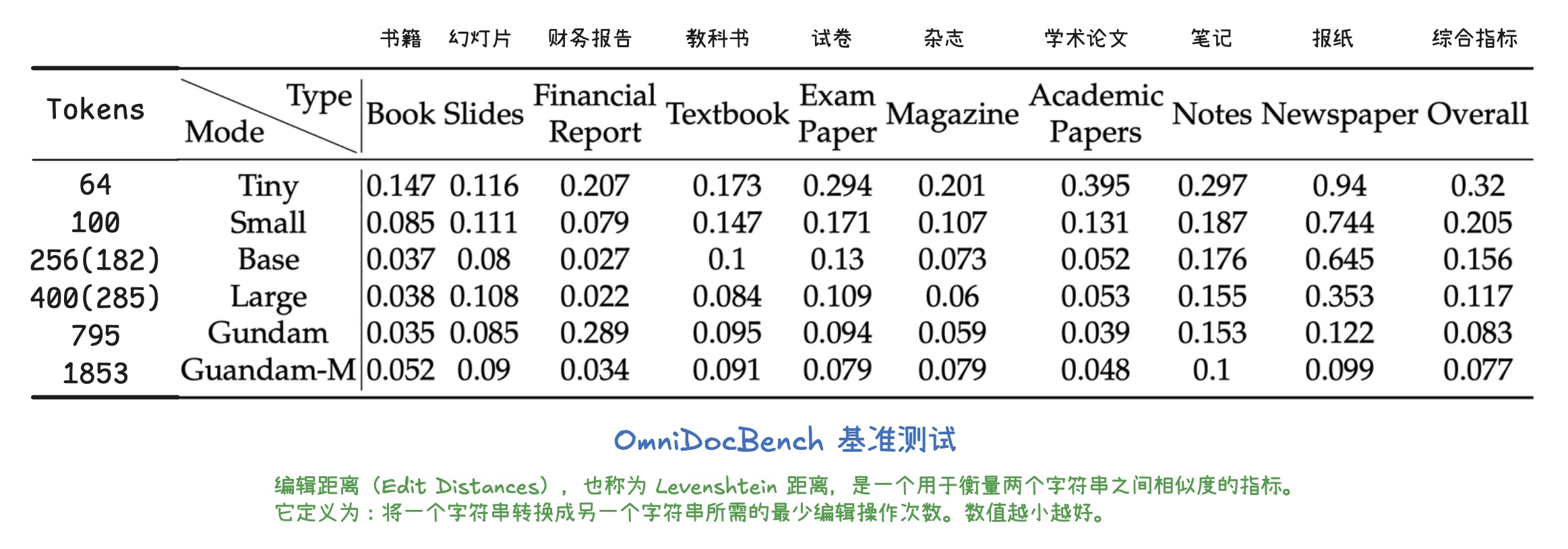
OmniDocBench 基准测试
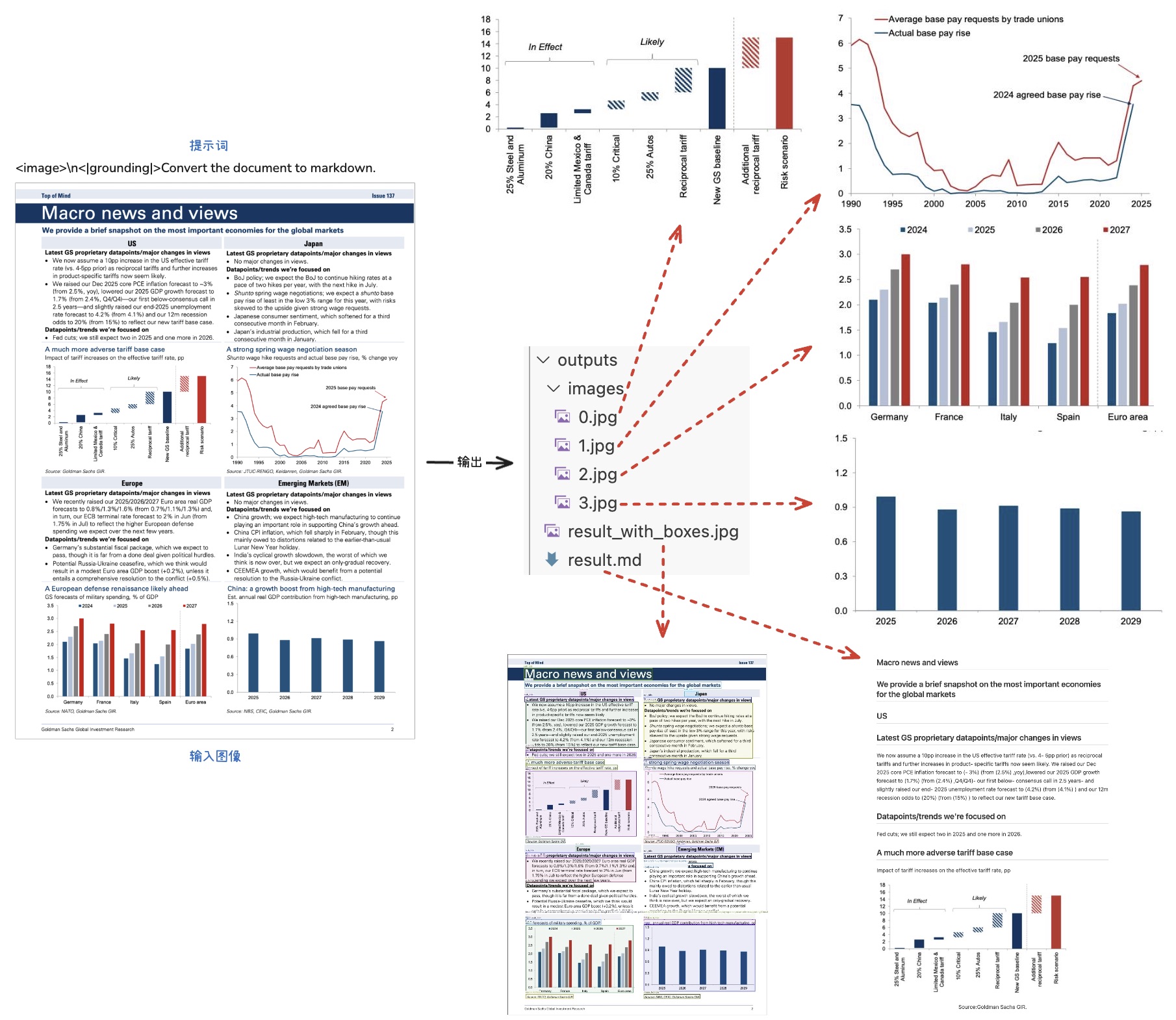
实际效果
图像转换 markdown
深度解析
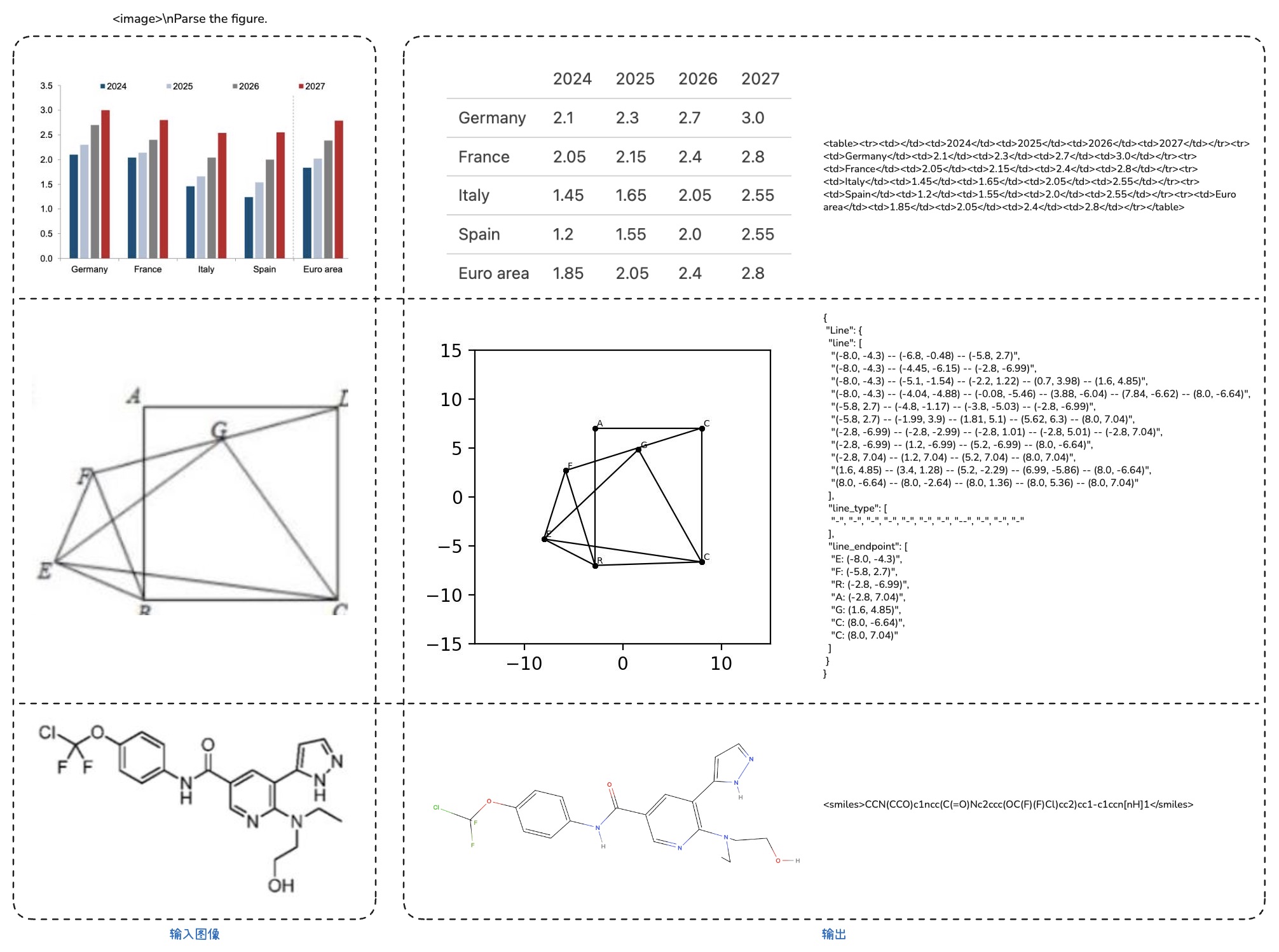
通用视觉理解


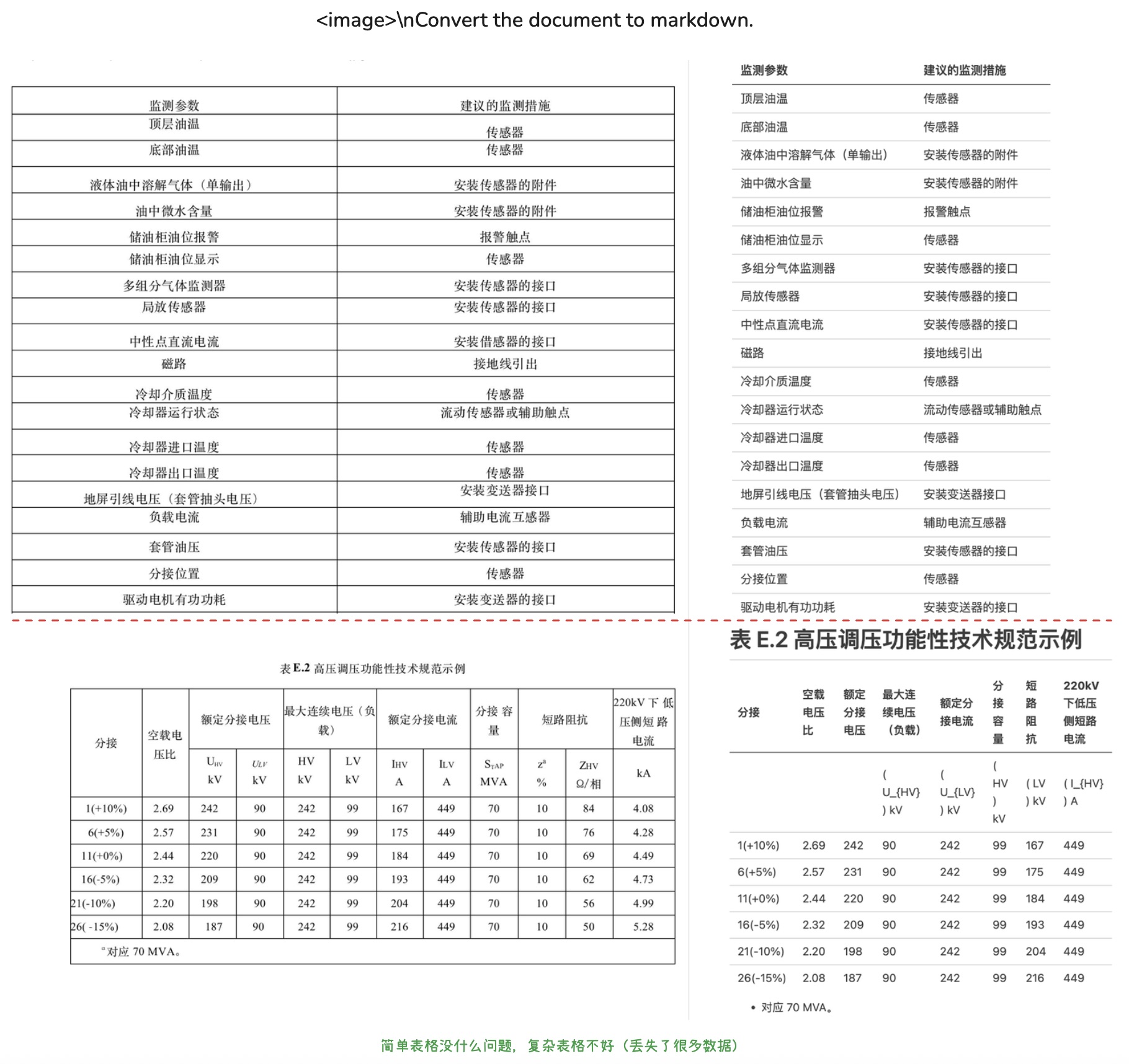
<image>\n<|grounding|>Convert the document to markdown.
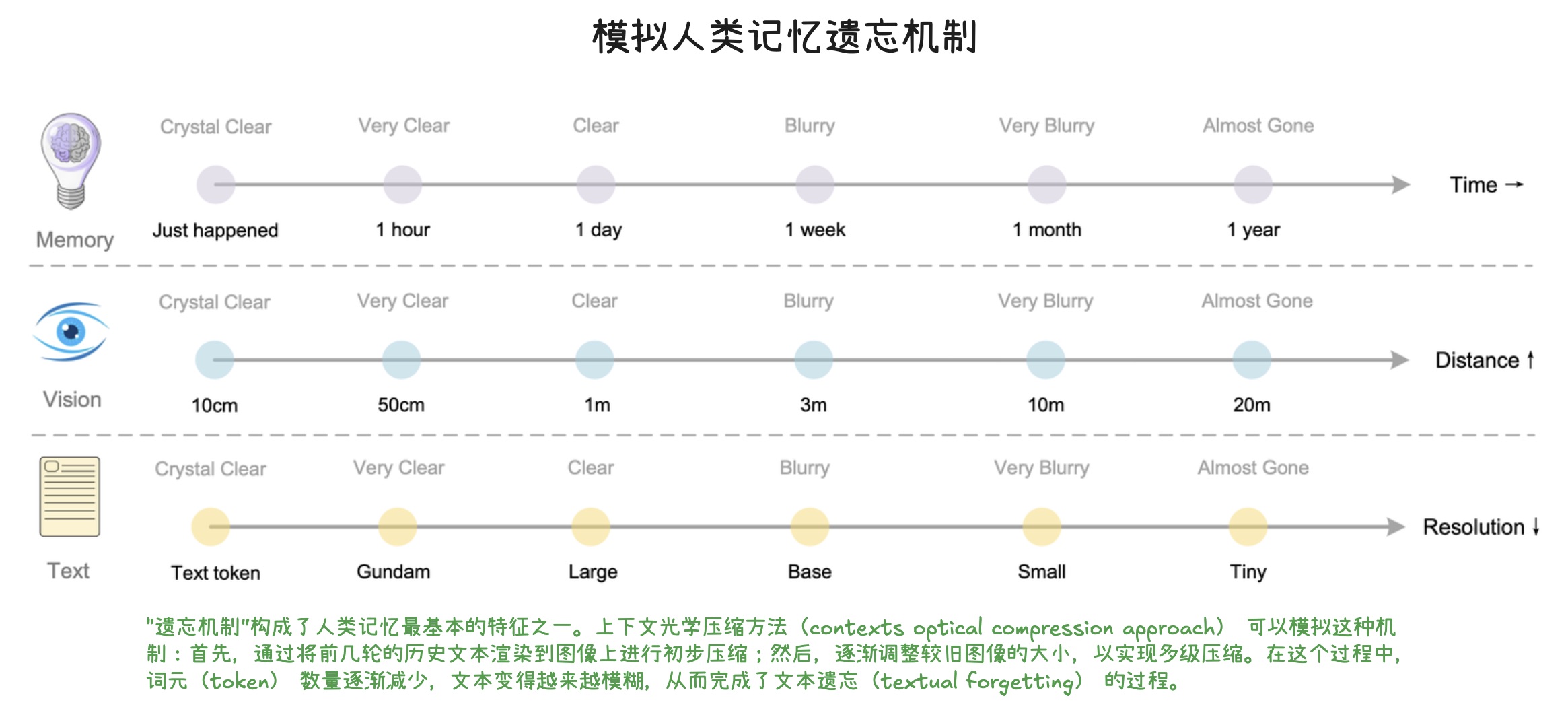
模拟人类记忆遗忘机制
构建运行环境
运行 vllm 容器
docker run -it \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=vllm \
-v /home/lnsoft/wjj/models:/models \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/.cache/modelscope:/root/.cache/modelscope \
nvcr.io/nvidia/vllm:25.09-py3 \
bash
克隆 DeepSeek-OCR 项目
git clone https://github.com/deepseek-ai/DeepSeek-OCR.git
安装依赖
cd DeepSeek-OCR
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
运行 DeepSeek-OCR
Transformers 推理
- run_dpsk_ocr.py
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'outputs'
res = model.infer(
tokenizer,
prompt=prompt,
image_file=image_file,
output_path = output_path,
base_size = 1024,
image_size = 640,
crop_mode=True,
save_results = True,
test_compress = True
)
cd DeepSeek-OCR-master/DeepSeek-OCR-hf
python run_dpsk_ocr.py
FAQ
/usr/local/lib/python3.12/dist-packages/torch/cuda/__init__.py:63: FutureWarning: The pynvml package is deprecated. Please install nvidia-ml-py instead. If you did not install pynvml directly, please report this to the maintainers of the package that installed pynvml for you.
import pynvml # type: ignore[import]
Traceback (most recent call last):
File "/models/deepseek-ai/DeepSeek-OCR/demo.py", line 8, in <module>
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/transformers/models/auto/auto_factory.py", line 547, in from_pretrained
config, kwargs = AutoConfig.from_pretrained(
^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/transformers/models/auto/configuration_auto.py", line 1264, in from_pretrained
config_class = get_class_from_dynamic_module(
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/transformers/dynamic_module_utils.py", line 582, in get_class_from_dynamic_module
return get_class_in_module(class_name, final_module, force_reload=force_download)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/local/lib/python3.12/dist-packages/transformers/dynamic_module_utils.py", line 277, in get_class_in_module
module_spec.loader.exec_module(module)
File "<frozen importlib._bootstrap_external>", line 995, in exec_module
File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
File "/root/.cache/huggingface/modules/transformers_modules/DeepSeek-OCR/modeling_deepseekocr.py", line 1, in <module>
from .modeling_deepseekv2 import DeepseekV2Model, DeepseekV2ForCausalLM
File "/root/.cache/huggingface/modules/transformers_modules/DeepSeek-OCR/modeling_deepseekv2.py", line 37, in <module>
from transformers.models.llama.modeling_llama import (
ImportError: cannot import name 'LlamaFlashAttention2' from 'transformers.models.llama.modeling_llama' (/usr/local/lib/python3.12/dist-packages/transformers/models/llama/modeling_llama.py). Did you mean: 'LlamaAttention'?