Gemini Robotics On-Device
本文档描述了Gemini Robotics On-Device,这是一款先进的视觉-语言-动作 (VLA) 模型,旨在本地设备上高效运行以实现通用机器人操作。该模型能够处理文本、图像和机器人本体感受数据作为输入,并输出机器人动作。训练使用了包含图像、文本以及机器人传感器和动作数据的数据集,并利用Google的Tensor Processing Units (TPUs)进行。评估结果表明,Gemini Robotics On-Device在泛化、指令遵循和快速适应方面表现出色,其性能与旗舰版Gemini Robotics 模型相似,同时超越了之前的最佳设备端VLA模型。该模型主要用于机器人应用的设备端部署,作为核心组件使机器人能够理解并响应视觉和语言指令,并在给定环境中采取行动。

Gemini Robotics On-Device 简介

模型概述与核心功能
Gemini Robotics On-Device 是一款尖端的视觉-语言-动作 (VLA) 模型,其设计宗旨是在本地设备上高效运行,以实现通用机器人操作。该模型能够支持广泛的任务、场景和多种机器人类型。
- 模型描述: “Gemini Robotics On-Device 是我们基于设备端 Gemma 模型的先进视觉-语言-动作 (VLA) 模型。它专为通用机器人操作而设计,可在本地设备上高效运行。该模型支持广泛的任务、场景和多种机器人类型。”
- 输入: 接收文本(例如问题或指令)、图像(例如机器人环境视角)和机器人本体感受数据(数值)。
- 输出: 生成机器人动作的数值。
- 架构: 基于 Gemini Robotics 技术和设备端 Gemma 模型的设备端 VLA 模型。
训练数据与处理
- 训练数据集:模型的训练基于包含图像、文本以及机器人传感器和动作数据的数据集。
- 训练数据处理:数据过滤与预处理采用了去重技术、符合谷歌安全负责任推进AI承诺的安全过滤措施,以及提升训练数据可靠性的质量过滤方法,以降低风险。
实现与可持续性
- 硬件: 模型使用 Google 的 Tensor Processing Units (TPUs) 进行训练。TPUs 专为处理大型语言模型 (LLM) 训练所需的海量计算而设计,并能显著加快训练速度。TPU Pods 提供可扩展的解决方案,以应对大型基础模型日益增长的复杂性。
- 软件: 训练使用 JAX 和 ML Pathways 完成。
评估结果与性能亮点
Gemini Robotics On-Device 在 Gemini Robotics 基准测试中进行了评估,重点关注场景、指令和动作的泛化能力以及训练数据分布之外任务的指令遵循能力。
- 关键发现: “Gemini Robotics On-Device 模型在泛化和指令遵循性能方面与我们的旗舰 Gemini Robotics 模型表现相似,同时完全在本地运行。”
-
与现有方法的比较: 在快速适应方面,Gemini Robotics On-Device 在七项不同难度的灵巧操作任务中,“优于当前最佳的设备端 VLA”,且每个任务使用的示例不到 100 个。
- 图表数据:
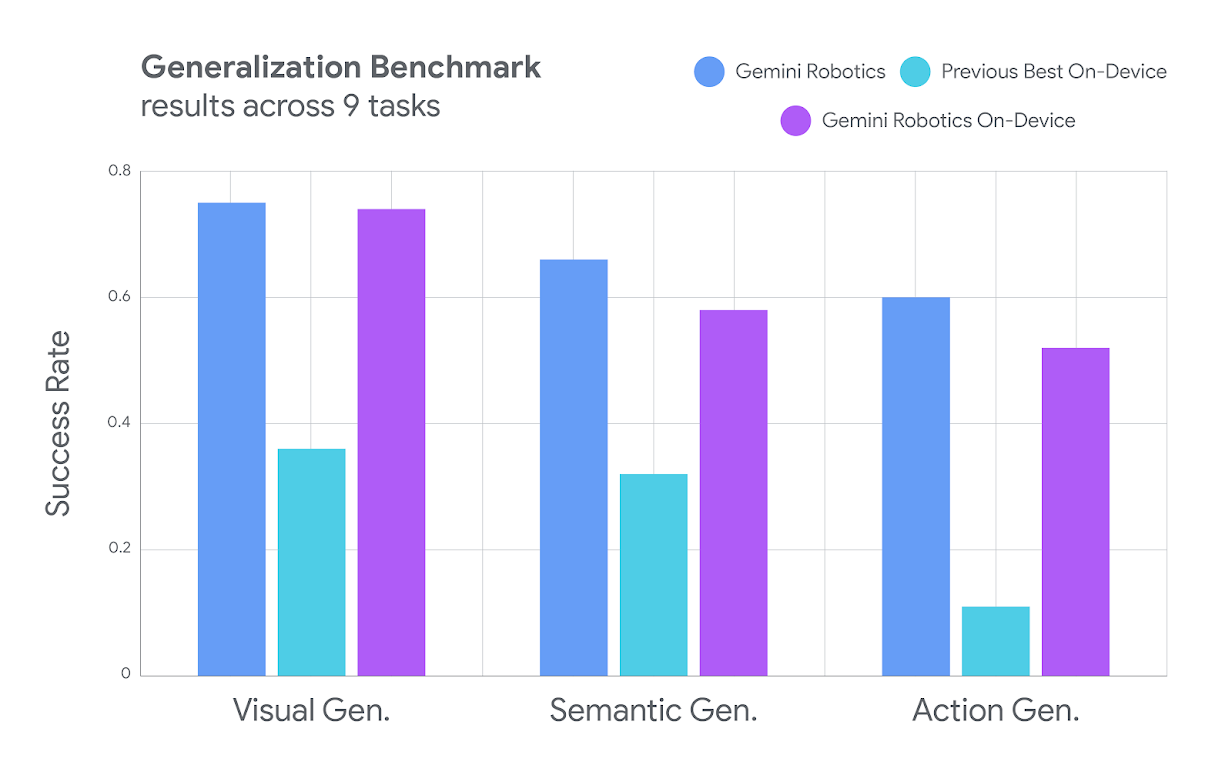
泛化基准测试
在视觉、语义和动作泛化方面,Gemini Robotics On-Device 的成功率显著高于“Previous Best On-Device”模型,并且接近或与“Gemini Robotics”模型持平。
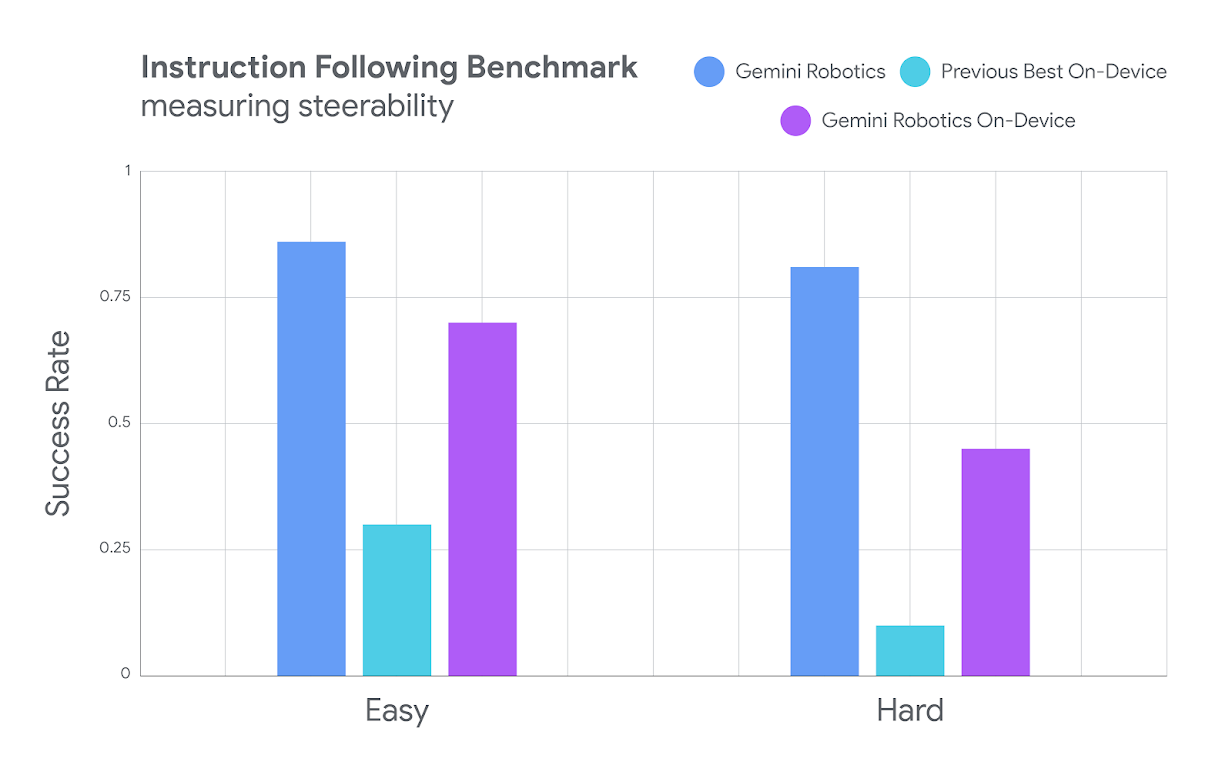
指令遵循基准测试
在“Easy”和“Hard”任务中,该模型在可控性方面的成功率远超“Previous Best On-Device”模型,再次接近“Gemini Robotics”模型。
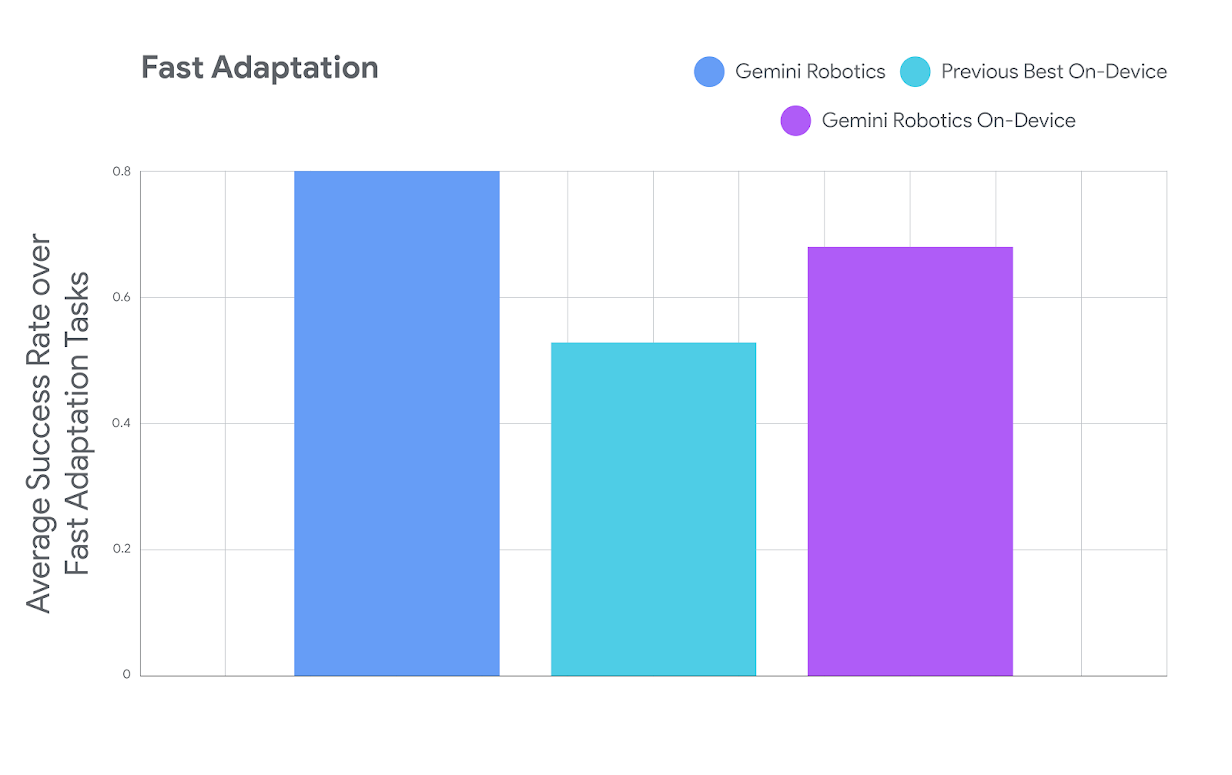
快速适应
在平均成功率方面,该模型也明显优于“Previous Best On-Device”模型。图表展示了 Gemini Robotics On-Device 的任务适应性能,其中包含少于 100 个示例。
预期用途
Gemini Robotics On-Device 模型旨在用于机器人应用的设备端部署。
- 主要用途: “该模型允许高效的机器人端推理,并经过训练以提供适用于双臂机器人各种任务的通用基础。”
- 角色定位: “其预期用途是作为机器人系统的核心组件,使其能够理解和响应视觉和语言指令,并可能在给定环境中采取行动。”
主要应用场景

双臂 Franka


Apollo 人形机器人
