DeepSeek-V3 Technical Report
Abstract(摘要)
We present DeepSeek-V3, a strong Mixture-of-Experts (MoE) language model with 671B total parameters with 37B activated for each token. To achieve efficient inference and cost-effective training, DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architec- tures, which were thoroughly validated in DeepSeek-V2. Furthermore, DeepSeek-V3 pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. We pre-train DeepSeek-V3 on 14.8 trillion diverse and high-quality tokens, followed by Supervised Fine-Tuning and Reinforcement Learning stages to fully harness its capabilities. Comprehensive evaluations reveal that DeepSeek-V3 outperforms other open-source models and achieves performance comparable to leading closed-source models. Despite its excellent performance, DeepSeek-V3 requires only 2.788M H800 GPU hours for its full training. In addition, its training process is remarkably stable. Throughout the entire training process, we did not experience any irrecoverable loss spikes or perform any rollbacks. The model checkpoints are available at https://github.com/deepseek-ai/DeepSeek-V3.
我们提出了 DeepSeek-V3,这是一个强大的混合专家(MoE)语言模型,总参数为 671B,每个标记激活了 37B。为了实现高效的推理和经济高效的训练,DeepSeek-V3 采用了多头潜在注意力(MLA)和 DeepSeekMoE 架构,这在 DeepSeek-V2 中得到了彻底验证。此外,DeepSeek-V3 首创了一种无辅助损失的负载平衡策略,并为更强的性能设置了多标记预测训练目标。我们在 14.8T(14800 亿)多样化和高质量的标记上预训练 DeepSeek-V3,然后进行监督微调和强化学习阶段,以充分发挥其能力。全面的评估表明,DeepSeek-V3 胜过其他开源模型,并实现了与领先的闭源模型相媲美的性能。尽管性能出色,DeepSeek-V3 仅需要 2.788M H800 GPU 小时进行完整训练。此外,其训练过程非常稳定。在整个训练过程中,我们没有遇到任何不可恢复的损失峰值,也没有执行任何回滚。模型检查点可在 https://github.com/deepseek-ai/DeepSeek-V3 上找到。
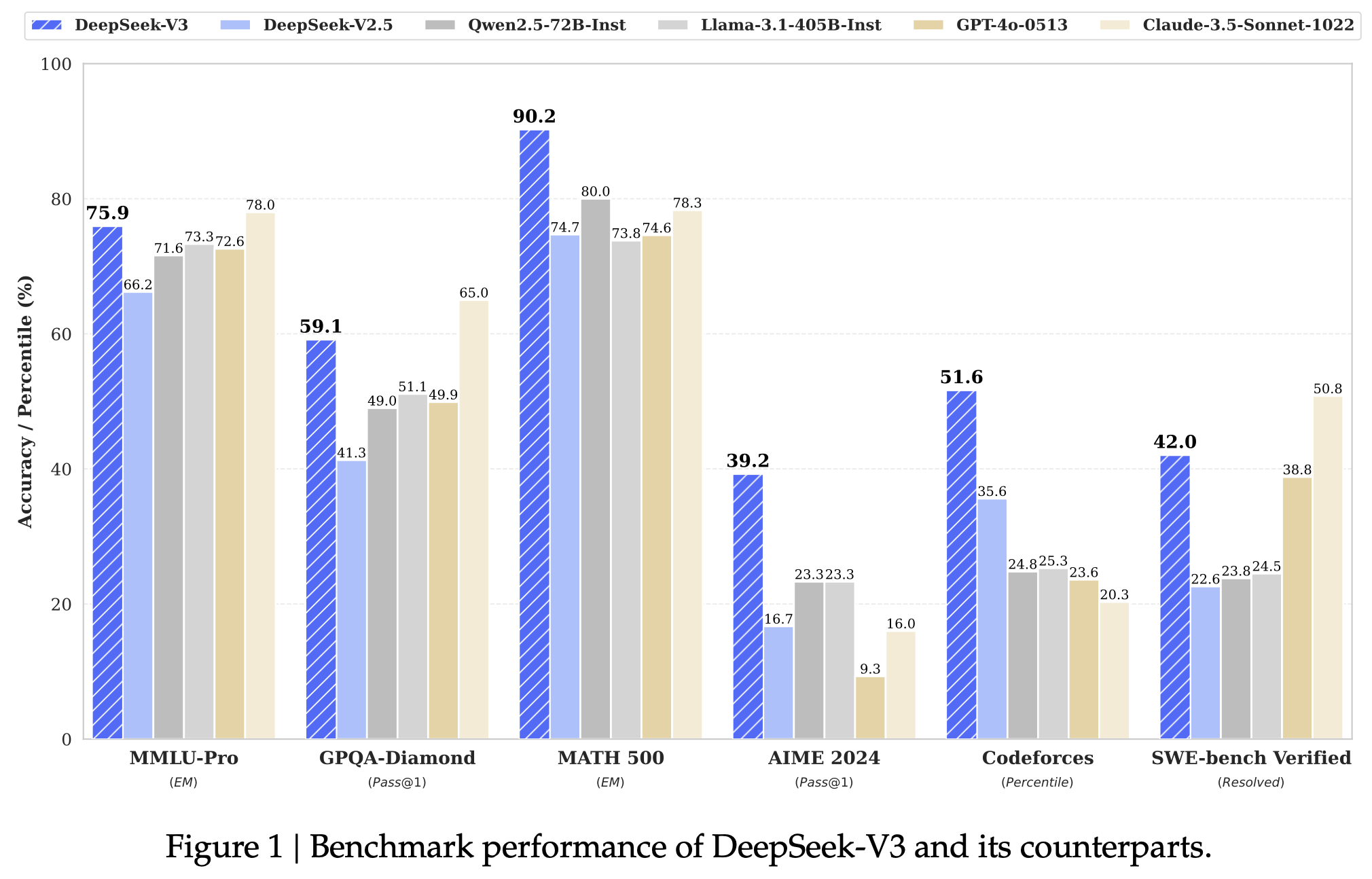
图1 DeepSeek-V3 及其对手的基准性能。
1. Introduction(介绍)
In recent years, Large Language Models (LLMs) have been undergoing rapid iteration and evolution (Anthropic, 2024; Google, 2024; OpenAI, 2024a), progressively diminishing the gap to- wards Artificial General Intelligence (AGI). Beyond closed-source models, open-source models, including DeepSeek series (DeepSeek-AI, 2024a,b,c; Guo et al., 2024), LLaMA series (AI@Meta, 2024a,b; Touvron et al., 2023a,b), Qwen series (Qwen, 2023, 2024a,b), and Mistral series (Jiang et al., 2023; Mistral, 2024), are also making significant strides, endeavoring to close the gap with their closed-source counterparts. To further push the boundaries of open-source model capa- bilities, we scale up our models and introduce DeepSeek-V3, a large Mixture-of-Experts (MoE) model with 671B parameters, of which 37B are activated for each token.
近年来,大型语言模型(LLMs)经历了快速迭代和演进(Anthropic,2024;Google,2024;OpenAI,2024a),逐渐缩小了人工通用智能(AGI)的差距。除了闭源模型外,开源模型,包括 DeepSeek 系列(DeepSeek-AI,2024a,b,c;Guo 等,2024),LLaMA 系列(AI@Meta,2024a,b;Touvron 等,2023a,b),Qwen 系列(Qwen,2023,2024a,b)和 Mistral 系列(Jiang 等,2023;Mistral,2024),也在取得重大进展,努力缩小与闭源对手的差距。为了进一步推动开源模型能力的边界,我们扩大了模型规模,并引入了 DeepSeek-V3,一个大型专家混合(MoE)模型,具有 671B 参数,其中每个标记激活了 37B。
With a forward-looking perspective, we consistently strive for strong model performance and economical costs. Therefore, in terms of architecture, DeepSeek-V3 still adopts Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c) for efficient inference and DeepSeekMoE (Dai et al., 2024) for cost-effective training. These two architectures have been validated in DeepSeek- V2 (DeepSeek-AI, 2024c), demonstrating their capability to maintain robust model performance while achieving efficient training and inference. Beyond the basic architecture, we implement two additional strategies to further enhance the model capabilities. Firstly, DeepSeek-V3 pi- oneers an auxiliary-loss-free strategy (Wang et al., 2024a) for load balancing, with the aim of minimizing the adverse impact on model performance that arises from the effort to encourage load balancing. Secondly, DeepSeek-V3 employs a multi-token prediction training objective, which we have observed to enhance the overall performance on evaluation benchmarks.
从前瞻性的角度出发,我们始终致力于强大的模型性能和经济成本。因此,在架构方面,DeepSeek-V3 仍然采用多头潜在注意力(MLA)(DeepSeek-AI,2024c)进行高效推理和 DeepSeekMoE(Dai 等,2024)进行经济高效的训练。这两种架构已在 DeepSeek-V2(DeepSeek-AI,2024c)中得到验证,证明了它们在保持强大模型性能的同时实现高效训练和推理的能力。除了基本架构外,我们实施了两种额外策略,以进一步增强模型能力。首先,DeepSeek-V3 首创了一种无辅助损失的负载平衡策略(Wang 等,2024a),旨在最大限度地减少由于鼓励负载平衡而产生的对模型性能的不利影响。其次,DeepSeek-V3 使用多标记预测训练目标,我们观察到这种方法可以提高评估基准上的整体性能。
In order to achieve efficient training, we support the FP8 mixed precision training and implement comprehensive optimizations for the training framework. Low-precision training has emerged as a promising solution for efficient training (Dettmers et al., 2022; Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b), its evolution being closely tied to advancements in hardware capabilities (Luo et al., 2024; Micikevicius et al., 2022; Rouhani et al., 2023a). In this work, we introduce an FP8 mixed precision training framework and, for the first time, validate its effectiveness on an extremely large-scale model. Through the support for FP8 computation and storage, we achieve both accelerated training and reduced GPU memory usage. As for the training framework, we design the DualPipe algorithm for efficient pipeline parallelism, which has fewer pipeline bubbles and hides most of the communication during training through computation-communication overlap. This overlap ensures that, as the model further scales up, as long as we maintain a constant computation-to-communication ratio, we can still employ fine-grained experts across nodes while achieving a near-zero all-to-all communication overhead. In addition, we also develop efficient cross-node all-to-all communication kernels to fully utilize InfiniBand (IB) and NVLink bandwidths. Furthermore, we meticulously optimize the memory footprint, making it possible to train DeepSeek-V3 without using costly tensor parallelism. Combining these efforts, we achieve high training efficiency.
为了实现高效训练,我们支持 FP8 混合精度训练,并为训练框架实施全面优化。低精度训练已经成为高效训练的一种有前途的解决方案(Dettmers 等,2022;Kalamkar 等,2019;Narang 等,2017;Peng 等,2023b),其发展与硬件能力的进步密切相关(Luo 等,2024;Micikevicius 等,2022;Rouhani 等,2023a)。在这项工作中,我们引入了 FP8 混合精度训练框架,并首次验证了其在极大规模模型上的有效性。通过支持 FP8 计算和存储,我们既实现了加速训练,又减少了 GPU 内存使用。至于训练框架,我们设计了 DualPipe 算法,用于高效的管道并行,它具有较少的管道气泡,并通过计算-通信重叠在训练过程中隐藏了大部分通信。这种重叠确保了,随着模型的进一步扩大,只要我们保持恒定的计算-通信比,我们仍然可以在节点之间使用细粒度专家,同时实现接近零的全互连通信开销。此外,我们还开发了高效的跨节点全互连通信内核,以充分利用 InfiniBand(IB)和 NVLink 带宽。此外,我们精心优化了内存占用,使得可以在不使用昂贵的张量并行的情况下训练 DeepSeek-V3。通过结合这些努力,我们实现了较高的训练效率。
During pre-training, we train DeepSeek-V3 on 14.8T high-quality and diverse tokens. The pre-training process is remarkably stable. Throughout the entire training process, we did not encounter any irrecoverable loss spikes or have to roll back. Next, we conduct a two-stage context length extension for DeepSeek-V3. In the first stage, the maximum context length is extended to 32K, and in the second stage, it is further extended to 128K. Following this, we conduct post-training, including Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) on the base model of DeepSeek-V3, to align it with human preferences and further unlock its potential. During the post-training stage, we distill the reasoning capability from the DeepSeek- R1 series of models, and meanwhile carefully maintain the balance between model accuracy and generation length.
在预训练期间,我们在 14.8T 高质量和多样化的标记上训练 DeepSeek-V3。预训练过程非常稳定。在整个训练过程中,我们没有遇到任何不可恢复的损失峰值,也没有执行任何回滚。接下来,我们为 DeepSeek-V3 进行了两阶段的上下文长度扩展。在第一阶段,最大上下文长度扩展到 32K,在第二阶段,进一步扩展到 128K。随后,我们对 DeepSeek-V3 的基础模型进行了后训练,包括监督微调(SFT)和强化学习(RL),以使其与人类偏好保持一致,并进一步释放其潜力。在后训练阶段,我们从 DeepSeek-R1 系列模型中提取推理能力,同时仔细保持模型准确性和生成长度之间的平衡。

表 1 DeepSeek-V3 的训练成本,假设 H800 的租金价格为每 GPU 小时 2 美元。
We evaluate DeepSeek-V3 on a comprehensive array of benchmarks. Despite its economical training costs, comprehensive evaluations reveal that DeepSeek-V3-Base has emerged as the strongest open-source base model currently available, especially in code and math. Its chat version also outperforms other open-source models and achieves performance comparable to leading closed-source models, including GPT-4o and Claude-3.5-Sonnet, on a series of standard and open-ended benchmarks.
我们在一系列全面的基准测试中评估了 DeepSeek-V3。尽管其训练成本经济,但全面的评估表明,DeepSeek-V3-Base 已成为目前最强大的开源基础模型,特别是在代码和数学方面。其聊天版本也胜过其他开源模型,并在一系列标准和开放性基准测试中实现了与领先的闭源模型(包括 GPT-4o 和 Claude-3.5-Sonnet)相媲美的性能。
Lastly, we emphasize again the economical training costs of DeepSeek-V3, summarized in Table 1, achieved through our optimized co-design of algorithms, frameworks, and hardware. During the pre-training stage, training DeepSeek-V3 on each trillion tokens requires only 180K H800 GPU hours, i.e., 3.7 days on our cluster with 2048 H800 GPUs. Consequently, our pre- training stage is completed in less than two months and costs 2664K GPU hours. Combined with 119K GPU hours for the context length extension and 5K GPU hours for post-training, DeepSeek-V3 costs only 2.788M GPU hours for its full training. Assuming the rental price of the H800 GPU is $2 per GPU hour, our total training costs amount to only $5.576M. Note that the aforementioned costs include only the official training of DeepSeek-V3, excluding the costs associated with prior research and ablation experiments on architectures, algorithms, or data.
最后,我们再次强调 DeepSeek-V3 的经济训练成本,总结在表 1 中,通过我们优化的算法、框架和硬件的协同设计实现。在预训练阶段,每万亿标记上训练 DeepSeek-V3 仅需要 180K H800 GPU 小时,即在我们的 2048 个 H800 GPU 集群上为期 3.7 天。因此,我们的预训练阶段在不到两个月内完成,成本为 2664K GPU 小时。加上 119K GPU 小时的上下文长度扩展和 5K GPU 小时的后训练,DeepSeek-V3 的完整训练仅需 2.788M GPU 小时。假设 H800 GPU 的租金价格为每 GPU 小时 2 美元,我们的总训练成本仅为 557.6 万美元。请注意,上述成本仅包括 DeepSeek-V3 的官方训练,不包括与先前研究和消融实验相关的成本,这些实验涉及架构、算法或数据。
Our main contribution includes:
我们的主要贡献包括:
Architecture: Innovative Load Balancing Strategy and Training Objective(架构:创新的负载平衡策略和训练目标)
-
On top of the efficient architecture of DeepSeek-V2, we pioneer an auxiliary-loss-free strategy for load balancing, which minimizes the performance degradation that arises from encouraging load balancing.
-
在 DeepSeek-V2 的高效架构基础上,我们首创了一种无辅助损失的负载平衡策略,该策略最大限度地减少了由于鼓励负载平衡而产生的性能降级。
-
We investigate a Multi-Token Prediction (MTP) objective and prove it beneficial to model performance. It can also be used for speculative decoding for inference acceleration.
-
我们研究了多标记预测(MTP)目标,并证明它对模型性能有益。它还可以用于推测解码以加速推理。
Pre-Training: Towards Ultimate Training Efficiency(预训练:迈向终极训练效率)
-
We design an FP8 mixed precision training framework and, for the first time, validate the feasibility and effectiveness of FP8 training on an extremely large-scale model.
-
我们设计了一个 FP8 混合精度训练框架,并首次验证了 FP8 训练在极大规模模型上的可行性和有效性。
-
Through the co-design of algorithms, frameworks, and hardware, we overcome the communication bottleneck in cross-node MoE training, achieving near-full computation-communication overlap. This significantly enhances our training efficiency and reduces the training costs, enabling us to further scale up the model size without additional overhead.
-
通过算法、框架和硬件的协同设计,我们克服了跨节点 MoE 训练中的通信瓶颈,实现了接近全计算-通信重叠。这显著提高了我们的训练效率,降低了训练成本,使我们能够进一步扩大模型规模而无需额外开销。
-
At an economical cost of only 2.664M H800 GPU hours, we complete the pre-training of DeepSeek-V3 on 14.8T tokens, producing the currently strongest open-source base model. The subsequent training stages after pre-training require only 0.1M GPU hours.
-
在仅 2.664M H800 GPU 小时的经济成本下,我们在 14.8T 标记上完成了 DeepSeek-V3 的预训练,生成了目前最强大的开源基础模型。预训练后的训练阶段仅需要 0.1M GPU 小时。
Post-Training: Knowledge Distillation from DeepSeek-R1(后训练:从 DeepSeek-R1 进行知识蒸馏)
-
We introduce an innovative methodology to distill reasoning capabilities from the long-Chain-of-Thought (CoT) model, specifically from one of the DeepSeek R1 series models, into standard LLMs, particularly DeepSeek-V3. Our pipeline elegantly incorporates the verification and reflection patterns of R1 into DeepSeek-V3 and notably improves its reasoning performance. Meanwhile, we also maintain control over the output style and length of DeepSeek-V3.
-
我们引入了一种创新方法,将长思维链 (CoT) 模型(特别是 DeepSeek R1 系列模型之一)中的推理能力提炼到标准 LLM(尤其是 DeepSeek-V3)中。我们的流程将 R1 的验证和反思模式巧妙地融入到 DeepSeek-V3 中,并显著提高了其推理性能。同时,我们还保持对 DeepSeek-V3 的输出样式和长度的控制。
Summary of Core Evaluation Results(核心评估结果总结)
-
Knowledge: (1) On educational benchmarks such as MMLU, MMLU-Pro, and GPQA, DeepSeek-V3 outperforms all other open-source models, achieving 88.5 on MMLU, 75.9 on MMLU-Pro, and 59.1 on GPQA. Its performance is comparable to leading closed-source models like GPT-4o and Claude-Sonnet-3.5, narrowing the gap between open-source and closed-source models in this domain. (2) For factuality benchmarks, DeepSeek-V3 demonstrates superior performance among open-source models on both SimpleQA and Chinese SimpleQA. While it trails behind GPT-4o and Claude-Sonnet-3.5 in English factual knowledge (SimpleQA), it surpasses these models in Chinese factual knowledge (Chinese SimpleQA), highlighting its strength in Chinese factual knowledge.
-
知识:(1)在教育基准测试(如 MMLU、MMLU-Pro 和 GPQA)上,DeepSeek-V3 胜过所有其他开源模型,在 MMLU 上达到 88.5,在 MMLU-Pro 上达到 75.9,在 GPQA 上达到 59.1。其性能与领先的闭源模型(如 GPT-4o 和 Claude-Sonnet-3.5)相媲美,缩小了在此领域开源和闭源模型之间的差距。 (2)对于事实性基准测试,DeepSeek-V3 在 SimpleQA 和 Chinese SimpleQA 上表现出色。虽然在英文事实知识(SimpleQA)上落后于 GPT-4o 和 Claude-Sonnet-3.5,但在中文事实知识(Chinese SimpleQA)上超过了这些模型,突显了其在中文事实知识方面的优势。
-
Code, Math, and Reasoning: (1) DeepSeek-V3 achieves state-of-the-art performance on math-related benchmarks among all non-long-CoT open-source and closed-source models. Notably, it even outperforms o1-preview on specific benchmarks, such as MATH-500, demonstrating its robust mathematical reasoning capabilities. (2) On coding-related tasks, DeepSeek-V3 emerges as the top-performing model for coding competition benchmarks, such as LiveCodeBench, solidifying its position as the leading model in this domain. For engineering-related tasks, while DeepSeek-V3 performs slightly below Claude-Sonnet-3.5, it still outpaces all other models by a significant margin, demonstrating its competitiveness across diverse technical benchmarks.
-
代码、数学和推理:(1)DeepSeek-V3 在所有非长 CoT 开源和闭源模型中的数学相关基准测试中实现了最先进的性能。值得注意的是,它甚至在特定基准测试(如 MATH-500)上胜过了 o1-preview,展示了其强大的数学推理能力。 (2)在与编码相关的任务上,DeepSeek-V3 成为编码竞赛基准测试(如 LiveCodeBench)中表现最佳的模型,巩固了其在该领域的领先地位。对于与工程相关的任务,尽管 DeepSeek-V3 的表现略低于 Claude-Sonnet-3.5,但仍然在各种技术基准测试中领先其他模型很大幅度,展示了其在各种技术基准测试中的竞争力。
In the remainder of this paper, we first present a detailed exposition of our DeepSeek-V3 model architecture (Section 2). Subsequently, we introduce our infrastructures, encompassing our compute clusters, the training framework, the support for FP8 training, the inference deployment strategy, and our suggestions on future hardware design. Next, we describe our pre-training process, including the construction of training data, hyper-parameter settings, long- context extension techniques, the associated evaluations, as well as some discussions (Section 4). Thereafter, we discuss our efforts on post-training, which include Supervised Fine-Tuning (SFT), Reinforcement Learning (RL), the corresponding evaluations, and discussions (Section 5). Lastly, we conclude this work, discuss existing limitations of DeepSeek-V3, and propose potential directions for future research (Section 6).
在本文的其余部分,我们首先详细介绍了 DeepSeek-V3 模型架构(第 2 节)。随后,我们介绍了我们的基础设施,包括计算集群、训练框架、对 FP8 训练的支持、推理部署策略以及对未来硬件设计的建议。接下来,我们描述了我们的预训练过程,包括训练数据的构建、超参数设置、长上下文扩展技术、相关评估以及一些讨论(第 4 节)。然后,我们讨论了我们在后训练中的努力,包括监督微调(SFT)、强化学习(RL)、相应的评估和讨论(第 5 节)。最后,我们总结了这项工作,讨论了 DeepSeek-V3 的现有局限性,并提出了未来研究的潜在方向(第 6 节)。
2. Architecture(架构)
We first introduce the basic architecture of DeepSeek-V3, featured by Multi-head Latent Atten- tion (MLA) (DeepSeek-AI, 2024c) for efficient inference and DeepSeekMoE (Dai et al., 2024) for economical training. Then, we present a Multi-Token Prediction (MTP) training objective, which we have observed to enhance the overall performance on evaluation benchmarks. For other minor details not explicitly mentioned, DeepSeek-V3 adheres to the settings of DeepSeek- V2 (DeepSeek-AI, 2024c).
我们首先介绍 DeepSeek-V3 的基本架构,其特点是多头潜在注意力(MLA)(DeepSeek-AI,2024c)用于高效推理和 DeepSeekMoE(Dai 等,2024)用于经济训练。然后,我们提出了一个多标记预测(MTP)训练目标,我们观察到这种方法可以提高评估基准上的整体性能。对于未明确提及的其他细节,DeepSeek-V3 遵循 DeepSeek-V2(DeepSeek-AI,2024c)的设置。
2.1. Basic Architecture(基本架构)
The basic architecture of DeepSeek-V3 is still within the Transformer (Vaswani et al., 2017) framework. For efficient inference and economical training, DeepSeek-V3 also adopts MLA and DeepSeekMoE, which have been thoroughly validated by DeepSeek-V2. Compared with DeepSeek-V2, an exception is that we additionally introduce an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) for DeepSeekMoE to mitigate the performance degradation induced by the effort to ensure load balance. Figure 2 illustrates the basic architecture of DeepSeek-V3, and we will briefly review the details of MLA and DeepSeekMoE in this section.
DeepSeek-V3 的基本架构仍然在 Transformer(Vaswani 等,2017)框架内。为了实现高效的推理和经济高效的训练,DeepSeek-V3 也采用了 MLA 和 DeepSeekMoE,这两种架构在 DeepSeek-V2 中得到了彻底验证。与 DeepSeek-V2 相比,一个例外是我们还为 DeepSeekMoE 引入了一种无辅助损失的负载平衡策略(Wang 等,2024a),以减轻由于努力确保负载平衡而引起的性能降级。图 2 展示了 DeepSeek-V3 的基本架构,我们将在本节简要回顾 MLA 和 DeepSeekMoE 的细节。
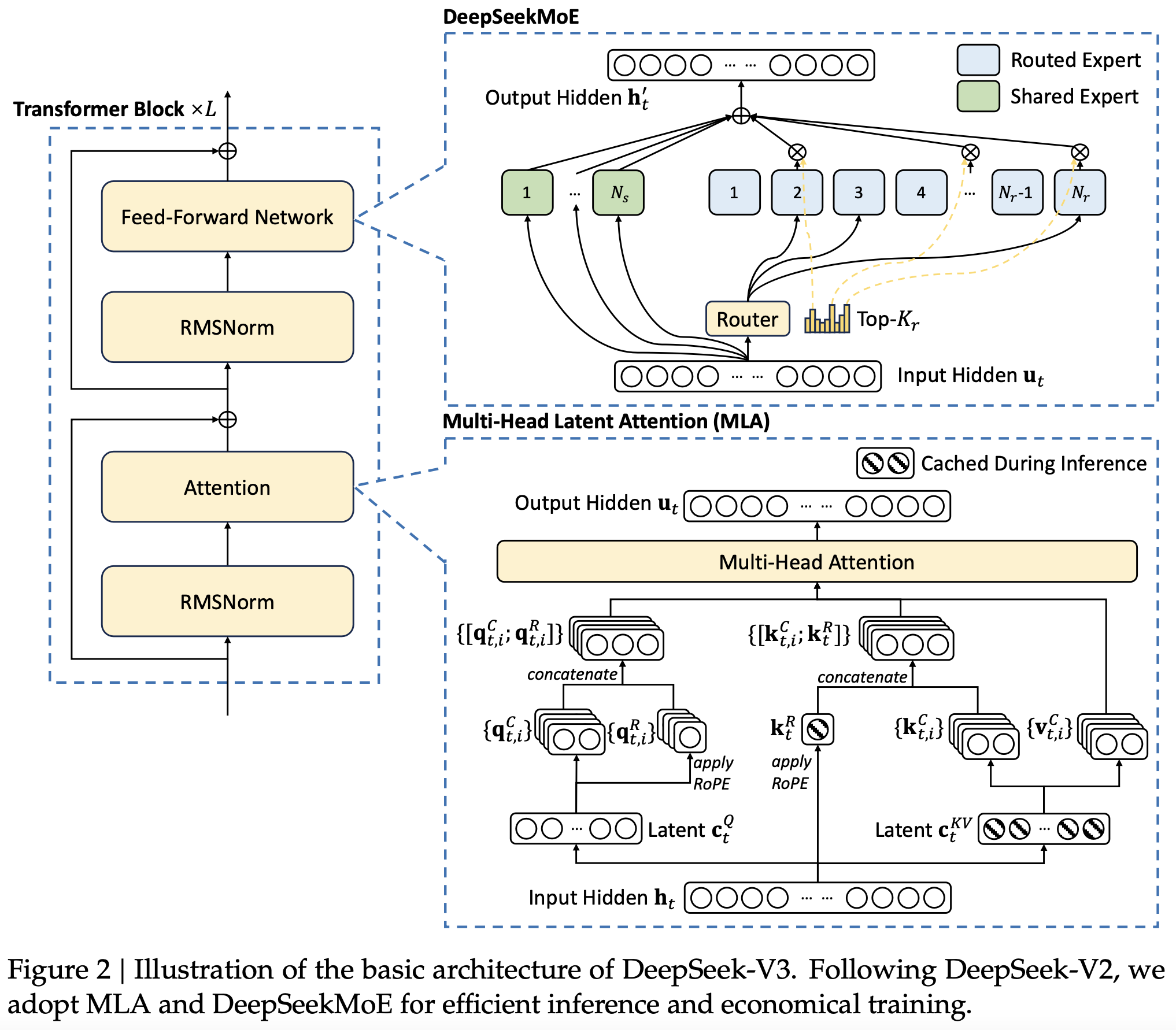
图2 DeepSeek-V3 的基本架构示意图。继承 DeepSeek-V2,我们采用 MLA 和 DeepSeekMoE 进行高效推理和经济训练。
2.1.1. Multi-Head Latent Attention(多头潜在注意力)
For attention, DeepSeek-V3 adopts the MLA architecture. Let 𝑑 denote the embedding dimen- sion, 𝑛ℎ denote the number of attention heads, 𝑑ℎ denote the dimension per head, and h𝑡 ∈R𝑑 denote the attention input for the 𝑡-th token at a given attention layer. The core of MLA is the low-rank joint compression for attention keys and values to reduce Key-Value (KV) cache during inference:
对于注意力,DeepSeek-V3 采用了 MLA 架构。设 𝑑 表示嵌入维度,𝑛ℎ 表示注意力头的数量,𝑑ℎ 表示每个头的维度,h𝑡 ∈R𝑑 表示给定注意力层中第 𝑡 个标记的注意力输入。MLA 的核心是对注意力键和值进行低秩联合压缩,以减少推理期间的键值(KV)缓存:
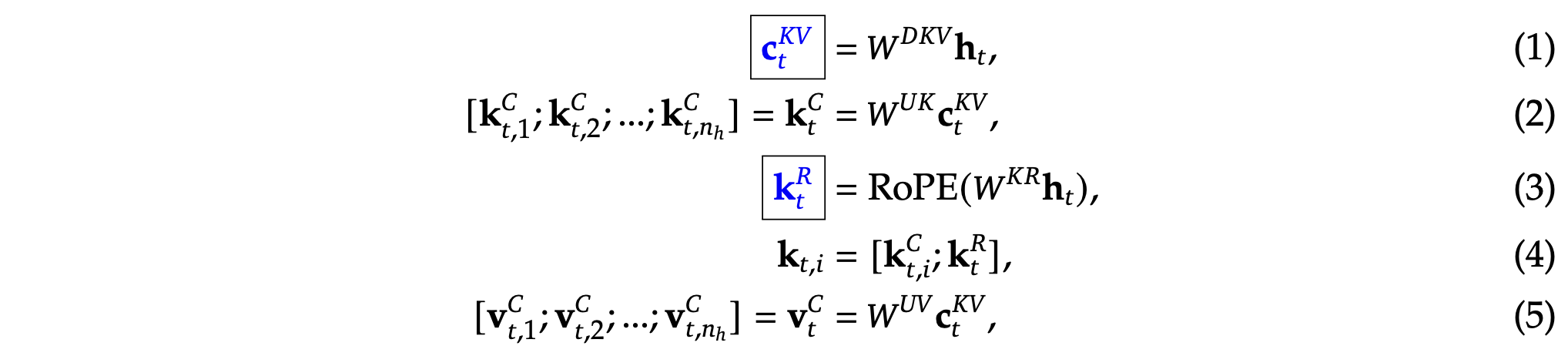

ℎ×𝑑 is the matrix used to produce the decoupled key that carries Rotary Positional Embedding (RoPE) (Su et al., 2024); RoPE(·)denotes the operation that applies RoPE matrices; and [·;·]denotes concatenation. Note that for MLA, only the blue-boxed vectors need to be cached during generation, which results in significantly reduced KV cache while maintaining performance comparable to standard Multi-Head Attention (MHA) (Vaswani et al., 2017).
ℎ×𝑑 是用于生成携带旋转位置嵌入(RoPE)(Su 等,2024)的解耦键的矩阵;RoPE(·)表示应用 RoPE 矩阵的操作;[·;·]表示连接。请注意,对于 MLA,只需要在生成期间缓存蓝色框中的向量,这导致 KV 缓存显著减少,同时保持与标准多头注意力(MHA)(Vaswani 等,2017)相媲美的性能。
For the attention queries, we also perform a low-rank compression, which can reduce the activation memory during training:
对于注意力查询,我们还执行低秩压缩,这可以减少训练期间的激活内存:
2.1.2. DeepSeekMoE with Auxiliary-Loss-Free Load Balancing(具有无辅助损失的负载平衡的 DeepSeekMoE)
Basic Architecture of DeepSeekMoE. For Feed-Forward Networks (FFNs), DeepSeek-V3 employs the DeepSeekMoE architecture (Dai et al., 2024). Compared with traditional MoE architectures like GShard (Lepikhin et al., 2021), DeepSeekMoE uses finer-grained experts and isolates some experts as shared ones. Let u𝑡 denote the FFN input of the 𝑡-th token, we compute the FFN output h′𝑡 as follows:
DeepSeekMoE 的基本架构。对于前馈网络 (FFN),DeepSeek-V3 采用 DeepSeekMoE 架构 (Dai et al., 2024)。与 GShard (Lepikhin et al., 2021) 等传统 MoE 架构相比,DeepSeekMoE 使用更细粒度的专家,并将一些专家隔离为共享专家。让 u𝑡 表示第 𝑡 个 token 的 FFN 输入,我们按如下方式计算 FFN 输出 h′𝑡:

where 𝑁𝑠 and 𝑁𝑟 denote the numbers of shared experts and routed experts, respectively; FFN(𝑠)𝑖 (·) and FFN(𝑟)𝑖 (·)denote the 𝑖-th shared expert and the 𝑖-th routed expert, respectively; 𝐾𝑟 denotes the number of activated routed experts; 𝑔𝑖,𝑡 is the gating value for the 𝑖-th expert; 𝑠𝑖,𝑡 is the token-to-expert affinity; e𝑖 is the centroid vector of the 𝑖-th routed expert; and Topk(·, 𝐾)denotes the set comprising 𝐾 highest scores among the affinity scores calculated for the 𝑡-th token and all routed experts. Slightly different from DeepSeek-V2, DeepSeek-V3 uses the sigmoid function to compute the affinity scores, and applies a normalization among all selected affinity scores to produce the gating values.
其中 𝑁𝑠 和 𝑁𝑟 分别表示共享专家和路由专家的数量;FFN(𝑠)𝑖 (·) 和 FFN(𝑟)𝑖 (·) 分别表示第 𝑖 个共享专家和第 𝑖 个路由专家;𝐾𝑟 表示激活的路由专家数量;𝑔𝑖,𝑡 是第 𝑖 个专家的门控值;𝑠𝑖,𝑡 是 token 到专家的亲和力;e𝑖 是第 𝑖 个路由专家的质心向量;Topk(·, 𝐾) 表示计算第 𝑡 个 token 和所有路由专家之间的亲和力得分中的 𝐾 个最高分数的集合。与 DeepSeek-V2 稍有不同,DeepSeek-V3 使用 sigmoid 函数计算亲和力得分,并在所有选定的亲和力得分之间应用归一化以生成门控值。
Auxiliary-Loss-Free Load Balancing. For MoE models, an unbalanced expert load will lead to routing collapse (Shazeer et al., 2017) and diminish computational efficiency in scenarios with expert parallelism. Conventional solutions usually rely on the auxiliary loss (Fedus et al., 2021; Lepikhin et al., 2021) to avoid unbalanced load. However, too large an auxiliary loss will impair the model performance (Wang et al., 2024a). To achieve a better trade-off between load balance and model performance, we pioneer an auxiliary-loss-free load balancing strategy (Wang et al., 2024a) to ensure load balance. To be specific, we introduce a bias term 𝑏𝑖 for each expert and add it to the corresponding affinity scores 𝑠𝑖,𝑡 to determine the top-K routing:
无辅助损失的负载平衡。 对于 MoE 模型,不平衡的专家负载会导致路由崩溃(Shazeer 等,2017),并在具有专家并行性的场景中降低计算效率。传统解决方案通常依赖辅助损失(Fedus 等,2021;Lepikhin 等,2021)来避免不平衡的负载。然而,过大的辅助损失会损害模型性能(Wang 等,2024a)。为了在负载平衡和模型性能之间取得更好的折衷,我们首创了一种无辅助损失的负载平衡策略(Wang 等,2024a)来确保负载平衡。具体而言,我们为每个专家引入一个偏置项 𝑏𝑖,并将其添加到相应的亲和力得分 𝑠𝑖,𝑡 中,以确定前 K 个路由:
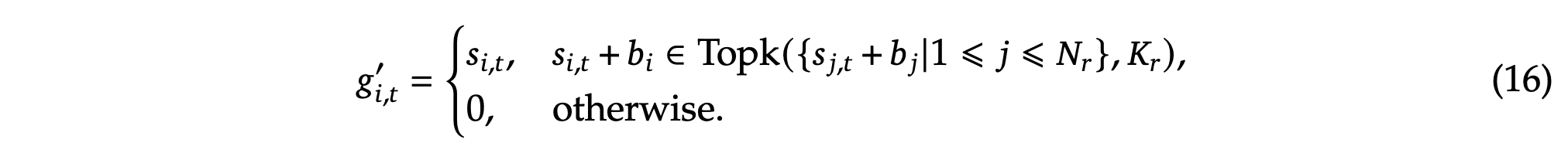
Note that the bias term is only used for routing. The gating value, which will be multiplied with the FFN output, is still derived from the original affinity score 𝑠𝑖,𝑡. During training, we keep monitoring the expert load on the whole batch of each training step. At the end of each step, we will decrease the bias term by 𝛾if its corresponding expert is overloaded, and increase it by 𝛾if its corresponding expert is underloaded, where 𝛾is a hyper-parameter called bias update speed. Through the dynamic adjustment, DeepSeek-V3 keeps balanced expert load during training, and achieves better performance than models that encourage load balance through pure auxiliary losses.
请注意,偏置项仅用于路由。门控值,将与 FFN 输出相乘,仍然是从原始亲和力得分 𝑠𝑖,𝑡 中派生的。在训练期间,我们会持续监控每个训练步骤的整个批次的专家负载。在每个步骤结束时,如果相应的专家负载过重,我们将减小偏置项 𝛾,如果相应的专家负载不足,则增加它,其中 𝛾 是称为偏置更新速度的超参数。通过动态调整,DeepSeek-V3 在训练期间保持平衡的专家负载,并实现了比纯辅助损失鼓励负载平衡的模型更好的性能。
Complementary Sequence-Wise Auxiliary Loss. Although DeepSeek-V3 mainly relies on the auxiliary-loss-free strategy for load balance, to prevent extreme imbalance within any single sequence, we also employ a complementary sequence-wise balance loss:
补充序列级辅助损失。 尽管 DeepSeek-V3 主要依赖于无辅助损失策略来实现负载平衡,为了防止任何单个序列内的极端不平衡,我们还采用了一个补充的序列级平衡损失:
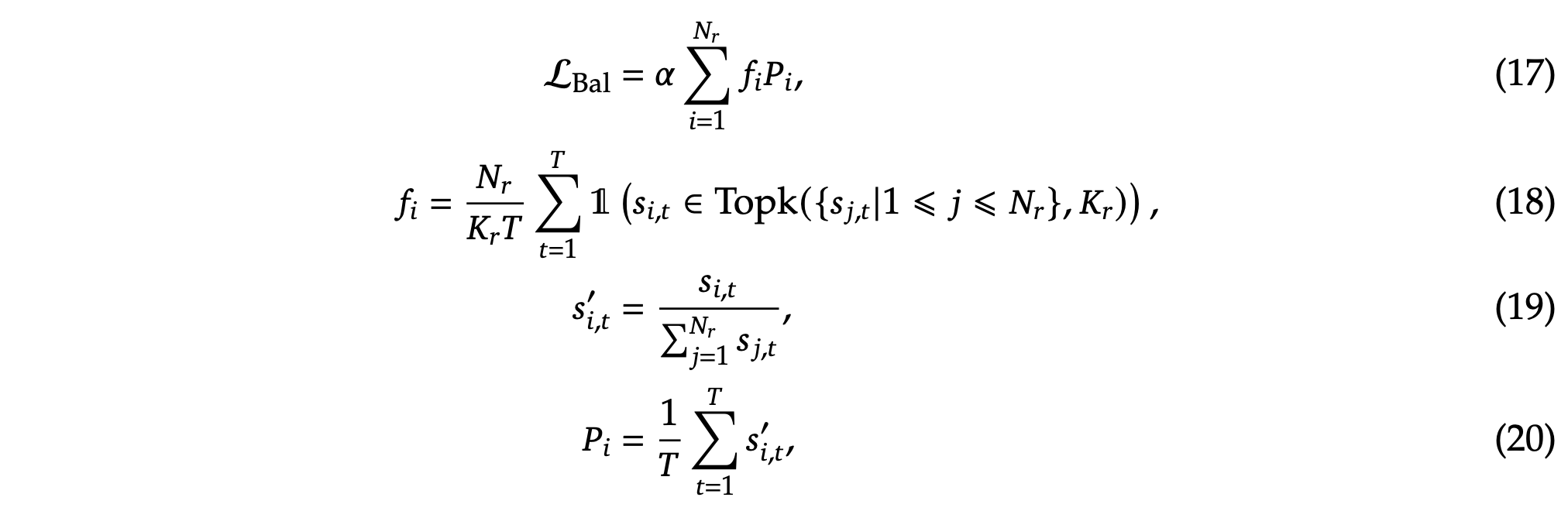
where the balance factor 𝛼 is a hyper-parameter, which will be assigned an extremely small value for DeepSeek-V3; 1(·)denotes the indicator function; and 𝑇 denotes the number of tokens in a sequence. The sequence-wise balance loss encourages the expert load on each sequence to be balanced.
其中平衡因子 𝛼 是一个超参数,对于 DeepSeek-V3,将被赋予一个极小的值;1(·) 表示指示函数;𝑇 表示序列中的标记数量。序列级平衡损失鼓励每个序列上的专家负载保持平衡。
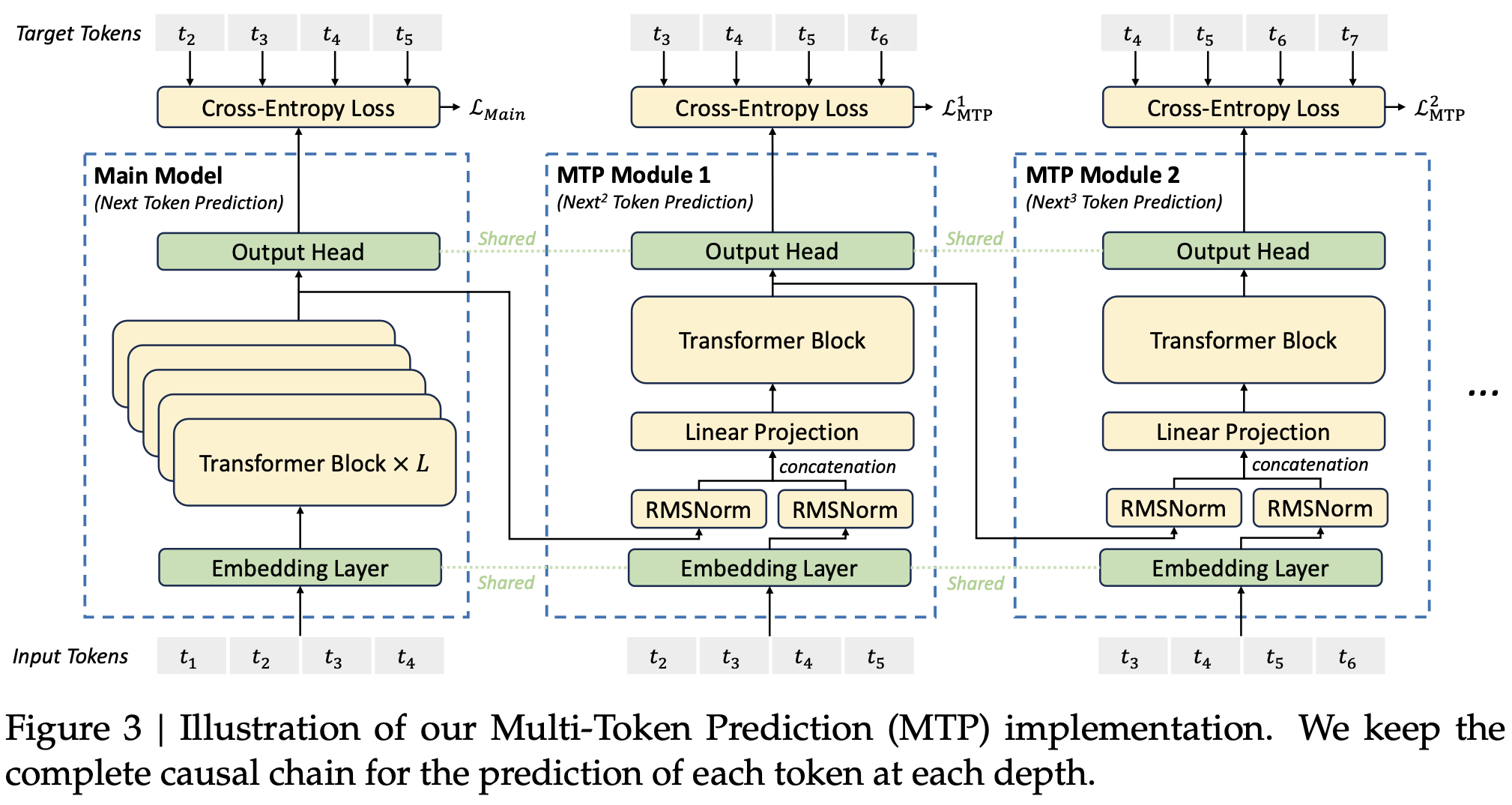
图3 我们的多标记预测(MTP)实现示意图。我们在每个深度保留每个标记的预测的完整因果链。
Node-Limited Routing. Like the device-limited routing used by DeepSeek-V2, DeepSeek-V3 also uses a restricted routing mechanism to limit communication costs during training. In short, we ensure that each token will be sent to at most 𝑀 nodes, which are selected according to the sum of the highest 𝐾𝑟 𝑀 affinity scores of the experts distributed on each node. Under this constraint, our MoE training framework can nearly achieve full computation-communication overlap.
节点限制路由。 与 DeepSeek-V2 使用的设备限制路由类似,DeepSeek-V3 也使用受限路由机制来限制训练期间的通信成本。简而言之,我们确保每个标记最多发送到 𝑀 个节点,这些节点是根据每个节点上分布的专家的最高 𝐾𝑟 𝑀 个亲和力得分之和选择的。在这种约束下,我们的 MoE 训练框架几乎可以实现全计算-通信重叠。
No Token-Dropping. Due to the effective load balancing strategy, DeepSeek-V3 keeps a good load balance during its full training. Therefore, DeepSeek-V3 does not drop any tokens during training. In addition, we also implement specific deployment strategies to ensure inference load balance, so DeepSeek-V3 also does not drop tokens during inference.
无标记丢弃。 由于有效的负载平衡策略,DeepSeek-V3 在整个训练期间保持良好的负载平衡。因此,DeepSeek-V3 在训练期间不会丢弃任何标记。此外,我们还实施了特定的部署策略来确保推理负载平衡,因此 DeepSeek-V3 在推理期间也不会丢弃标记。
2.2. Multi-Token Prediction(多标记预测)
Inspired by Gloeckle et al. (2024), we investigate and set a Multi-Token Prediction (MTP) objective for DeepSeek-V3, which extends the prediction scope to multiple future tokens at each position. On the one hand, an MTP objective densifies the training signals and may improve data efficiency. On the other hand, MTP may enable the model to pre-plan its representations for better prediction of future tokens. Figure 3 illustrates our implementation of MTP. Different from Gloeckle et al. (2024), which parallelly predicts 𝐷 additional tokens using independent output heads, we sequentially predict additional tokens and keep the complete causal chain at each prediction depth. We introduce the details of our MTP implementation in this section.
受 Gloeckle 等人(2024)的启发,我们研究并为 DeepSeek-V3 设定了一个多标记预测(MTP)目标,将预测范围扩展到每个位置的多个未来标记。一方面,MTP 目标使训练信号更密集,可能提高数据效率。另一方面,MTP 可能使模型能够预先规划其表示,以更好地预测未来标记。图 3 展示了我们对 MTP 的实现。与 Gloeckle 等人(2024)不同,后者使用独立的输出头并行预测 𝐷 个额外标记,我们依次预测额外标记,并在每个预测深度保留完整的因果链。我们在本节介绍了我们的 MTP 实现的细节。



MTP in Inference. Our MTP strategy mainly aims to improve the performance of the main model, so during inference, we can directly discard the MTP modules and the main model can function independently and normally. Additionally, we can also repurpose these MTP modules for speculative decoding to further improve the generation latency.
推理中的 MTP。 我们的 MTP 策略主要旨在提高主模型的性能,因此在推理期间,我们可以直接丢弃 MTP 模块,主模型可以独立正常地运行。此外,我们还可以重新利用这些 MTP 模块进行推测解码,以进一步提高生成延迟。
3. Infrastructures(基础设施)
3.1. Compute Clusters(计算集群)
DeepSeek-V3 is trained on a cluster equipped with 2048 NVIDIA H800 GPUs. Each node in the H800 cluster contains 8 GPUs connected by NVLink and NVSwitch within nodes. Across different nodes, InfiniBand (IB) interconnects are utilized to facilitate communications.
DeepSeek-V3 在配备 2048 个 NVIDIA H800 GPU 的集群上进行训练。H800 集群中的每个节点包含 8 个 GPU,节点内通过 NVLink 和 NVSwitch 连接。在不同节点之间,使用 InfiniBand(IB)互连来促进通信。

图4 一对单独的前向和后向块的重叠策略(变压器块的边界未对齐)。橙色表示前向,绿色表示“输入的后向”,蓝色表示“权重的后向”,紫色表示 PP 通信,红色表示屏障。全互连和 PP 通信都可以完全隐藏。
3.2. Training Framework(训练框架)
The training of DeepSeek-V3 is supported by the HAI-LLM framework, an efficient and lightweight training framework crafted by our engineers from the ground up. On the whole, DeepSeek-V3 applies 16-way Pipeline Parallelism (PP) (Qi et al., 2023a), 64-way Expert Paral- lelism (EP) (Lepikhin et al., 2021) spanning 8 nodes, and ZeRO-1 Data Parallelism (DP) (Rajb- handari et al., 2020).
DeepSeek-V3 的训练由 HAI-LLM 框架支持,这是我们的工程师从头开始精心打造的高效轻量级训练框架。总体而言,DeepSeek-V3 应用 16 路管道并行(PP)(Qi 等,2023a),64 路专家并行(EP)(Lepikhin 等,2021)跨 8 个节点,以及 ZeRO-1 数据并行(DP)(Rajbhandari 等,2020)。
In order to facilitate efficient training of DeepSeek-V3, we implement meticulous engineering optimizations. Firstly, we design the DualPipe algorithm for efficient pipeline parallelism. Compared with existing PP methods, DualPipe has fewer pipeline bubbles. More importantly, it overlaps the computation and communication phases across forward and backward processes, thereby addressing the challenge of heavy communication overhead introduced by cross-node expert parallelism. Secondly, we develop efficient cross-node all-to-all communication kernels to fully utilize IB and NVLink bandwidths and conserve Streaming Multiprocessors (SMs) dedicated to communication. Finally, we meticulously optimize the memory footprint during training, thereby enabling us to train DeepSeek-V3 without using costly Tensor Parallelism (TP).
为了提高 DeepSeek-V3 的训练效率,我们进行了细致的工程优化。首先,我们设计了 DualPipe 算法以实现高效的流水线并行。与现有的 PP 方法相比,DualPipe 具有更少的流水线气泡。更重要的是,它将计算和通信阶段重叠在前向和后向过程中,从而解决了跨节点专家并行引入的沉重通信开销的挑战。其次,我们开发了高效的跨节点全对全通信内核,以充分利用 IB 和 NVLink 带宽并节省专用于通信的流多处理器 (SM)。最后,我们精心优化了训练期间的内存占用,从而使我们能够在不使用昂贵的张量并行 (TP) 的情况下训练 DeepSeek-V3。
3.2.1. DualPipe and Computation-Communication Overlap(DualPipe 和计算-通信重叠)
For DeepSeek-V3, the communication overhead introduced by cross-node expert parallelism results in an inefficient computation-to-communication ratio of approximately 1:1. To tackle this challenge, we design an innovative pipeline parallelism algorithm called DualPipe, which not only accelerates model training by effectively overlapping forward and backward computation- communication phases, but also reduces the pipeline bubbles.
对于 DeepSeek-V3,跨节点专家并行引入的通信开销导致了约 1:1 的低效计算-通信比。为了解决这一挑战,我们设计了一种创新的流水线并行算法 DualPipe,它不仅通过有效地重叠前向和后向计算-通信阶段加速模型训练,还减少了流水线气泡。
The key idea of DualPipe is to overlap the computation and communication within a pair of individual forward and backward chunks. To be specific, we divide each chunk into four compo- nents: attention, all-to-all dispatch, MLP, and all-to-all combine. Specially, for a backward chunk, both attention and MLP are further split into two parts, backward for input and backward for weights, like in ZeroBubble (Qi et al., 2023b). In addition, we have a PP communication component. As illustrated in Figure 4, for a pair of forward and backward chunks, we rearrange these components and manually adjust the ratio of GPU SMs dedicated to communication versus computation. In this overlapping strategy, we can ensure that both all-to-all and PP communication can be fully hidden during execution. Given the efficient overlapping strategy, the full DualPipe scheduling is illustrated in Figure 5. It employs a bidirectional pipeline scheduling, which feeds micro-batches from both ends of the pipeline simultaneously and a significant portion of communications can be fully overlapped. This overlap also ensures that, as the model further scales up, as long as we maintain a constant computation-to-communication ratio, we can still employ fine-grained experts across nodes while achieving a near-zero all-to-all communication overhead.
DualPipe 的关键思想是在一对单独的前向和后向块内重叠计算和通信。具体而言,我们将每个块分为四个组件:注意力、全对全调度、MLP 和全对全组合。特别是,对于后向块,注意力和 MLP 进一步分为两部分,输入的后向和权重的后向,就像 ZeroBubble(Qi 等,2023b)一样。此外,我们还有一个 PP 通信组件。如图 4 所示,对于一对前向和后向块,我们重新排列这些组件,并手动调整专用于通信与计算的 GPU SM 的比例。在这种重叠策略中,我们可以确保全对全和 PP 通信在执行期间都可以完全隐藏。鉴于高效的重叠策略,完整的 DualPipe 调度如图 5 所示。它采用双向流水线调度,同时从流水线的两端提供微批次,大部分通信可以完全重叠。这种重叠还确保,随着模型的进一步扩展,只要我们保持恒定的计算-通信比,我们仍然可以在节点之间使用细粒度专家,同时实现接近零的全对全通信开销。

图5 示例 DualPipe 调度,8 个 PP 排名和两个方向的 20 个微批次。反向方向的微批次与正向方向的微批次对称,因此我们为了简化说明省略了它们的批次 ID。由共享黑色边框包围的两个单元格具有相互重叠的计算和通信。

表2 不同流水线并行方法之间的流水线气泡和内存使用情况比较。𝐹 表示前向块的执行时间,𝐵 表示完整后向块的执行时间,𝑊 表示“权重后向”块的执行时间,𝐹&𝐵 表示两个相互重叠的前向和后向块的执行时间。
In addition, even in more general scenarios without a heavy communication burden, Du- alPipe still exhibits efficiency advantages. In Table 2, we summarize the pipeline bubbles and memory usage across different PP methods. As shown in the table, compared with ZB1P (Qi et al., 2023b) and 1F1B (Harlap et al., 2018), DualPipe significantly reduces the pipeline bubbles while only increasing the peak activation memory by 1 𝑃𝑃 times. Although DualPipe requires keeping two copies of the model parameters, this does not significantly increase the memory consumption since we use a large EP size during training. Compared with Chimera (Li and Hoefler, 2021), DualPipe only requires that the pipeline stages and micro-batches be divisible by 2, without requiring micro-batches to be divisible by pipeline stages. In addition, for DualPipe, neither the bubbles nor activation memory will increase as the number of micro-batches grows.
此外,即使在没有沉重通信负担的更一般情况下,DualPipe 仍然表现出效率优势。如表 2 所示,我们总结了不同 PP 方法之间的流水线气泡和内存使用情况。如表所示,与 ZB1P(Qi 等,2023b)和 1F1B(Harlap 等,2018)相比,DualPipe 显著减少了流水线气泡,同时只增加了峰值激活内存的 1 𝑃𝑃 倍。尽管 DualPipe 需要保留两份模型参数的副本,但由于我们在训练期间使用了大的 EP 大小,这并不会显著增加内存消耗。与 Chimera(Li 和 Hoefler,2021)相比,DualPipe 只需要流水线阶段和微批次可被 2 整除,而不需要微批次可被流水线阶段整除。此外,对于 DualPipe,随着微批次数量的增加,气泡和激活内存都不会增加。
3.2.2. Efficient Implementation of Cross-Node All-to-All Communication(跨节点全对全通信的高效实现)
In order to ensure sufficient computational performance for DualPipe, we customize efficient cross-node all-to-all communication kernels (including dispatching and combining) to conserve the number of SMs dedicated to communication. The implementation of the kernels is co- designed with the MoE gating algorithm and the network topology of our cluster. To be specific, in our cluster, cross-node GPUs are fully interconnected with IB, and intra-node communications are handled via NVLink. NVLink offers a bandwidth of 160 GB/s, roughly 3.2 times that of IB (50 GB/s). To effectively leverage the different bandwidths of IB and NVLink, we limit each token to be dispatched to at most 4 nodes, thereby reducing IB traffic. For each token, when its routing decision is made, it will first be transmitted via IB to the GPUs with the same in-node index on its target nodes. Once it reaches the target nodes, we will endeavor to ensure that it is instantaneously forwarded via NVLink to specific GPUs that host their target experts, without being blocked by subsequently arriving tokens. In this way, communications via IB and NVLink are fully overlapped, and each token can efficiently select an average of 3.2 experts per node without incurring additional overhead from NVLink. This implies that, although DeepSeek-V3 selects only 8 routed experts in practice, it can scale up this number to a maximum of 13 experts (4 nodes ×3.2 experts/node) while preserving the same communication cost. Overall, under such a communication strategy, only 20 SMs are sufficient to fully utilize the bandwidths of IB and NVLink.
为了确保 DualPipe 的充足计算性能,我们定制了高效的跨节点全对全通信内核(包括调度和组合),以节省专用于通信的 SM 数量。内核的实现与 MoE 门控算法和我们集群的网络拓扑共同设计。具体而言,在我们的集群中,跨节点 GPU 通过 IB 完全互连,节点内通信通过 NVLink 处理。NVLink 提供的带宽为 160 GB/s,大约是 IB(50 GB/s)的 3.2 倍。为了有效利用 IB 和 NVLink 的不同带宽,我们限制每个标记最多分发到 4 个节点,从而减少 IB 流量。对于每个标记,当其路由决策确定后,它将首先通过 IB 传输到目标节点上具有相同节点索引的 GPU。一旦到达目标节点,我们将努力确保它立即通过 NVLink 转发到托管其目标专家的特定 GPU,而不会被随后到达的标记阻塞。通过这种方式,通过 IB 和 NVLink 的通信完全重叠,每个标记可以在不增加 NVLink 的额外开销的情况下有效地选择每个节点的平均 3.2 个专家。这意味着,尽管 DeepSeek-V3 在实践中仅选择了 8 个路由专家,但它可以将这个数字扩展到最多 13 个专家(4 个节点 ×3.2 个专家/节点),同时保持相同的通信成本。总的来说,在这种通信策略下,只需要 20 个 SM 就足以充分利用 IB 和 NVLink 的带宽。
In detail, we employ the warp specialization technique (Bauer et al., 2014) and partition 20 SMs into 10 communication channels. During the dispatching process, (1) IB sending, (2) IB-to-NVLink forwarding, and (3) NVLink receiving are handled by respective warps. The number of warps allocated to each communication task is dynamically adjusted according to the actual workload across all SMs. Similarly, during the combining process, (1) NVLink sending, (2) NVLink-to-IB forwarding and accumulation, and (3) IB receiving and accumulation are also handled by dynamically adjusted warps. In addition, both dispatching and combining kernels overlap with the computation stream, so we also consider their impact on other SM computation kernels. Specifically, we employ customized PTX (Parallel Thread Execution) instructions and auto-tune the communication chunk size, which significantly reduces the use of the L2 cache and the interference to other SMs.
具体而言,我们采用了 warp 专用化技术(Bauer 等,2014),将 20 个 SM 划分为 10 个通信通道。在调度过程中,IB 发送、IB 到 NVLink 转发和 NVLink 接收由各自的 warp 处理。根据所有 SM 的实际工作负载,为每个通信任务分配的 warp 数量是动态调整的。类似地,在组合过程中,NVLink 发送、NVLink 到 IB 转发和累积,以及 IB 接收和累积也由动态调整的 warp 处理。此外,调度和组合内核都与计算流重叠,因此我们还考虑它们对其他 SM 计算内核的影响。具体而言,我们使用定制的 PTX(并行线程执行)指令,并自动调整通信块大小,这显著减少了 L2 缓存的使用和对其他 SM 的干扰。
3.2.3. Extremely Memory Saving with Minimal Overhead(极大节省内存,开销最小)
In order to reduce the memory footprint during training, we employ the following techniques.
为了减少训练期间的内存占用,我们采用以下技术。
Recomputation of RMSNorm and MLA Up-Projection. We recompute all RMSNorm op- erations and MLA up-projections during back-propagation, thereby eliminating the need to persistently store their output activations. With a minor overhead, this strategy significantly reduces memory requirements for storing activations.
RMSNorm 和 MLA 上投影的重新计算。 我们在反向传播期间重新计算所有 RMSNorm 操作和 MLA 上投影,从而消除了需要持久存储它们的输出激活的需求。通过小的开销,这种策略显著减少了存储激活所需的内存。
Exponential Moving Average in CPU. During training, we preserve the Exponential Mov- ing Average (EMA) of the model parameters for early estimation of the model performance after learning rate decay. The EMA parameters are stored in CPU memory and are updated asynchronously after each training step. This method allows us to maintain EMA parameters without incurring additional memory or time overhead.
CPU 中的指数移动平均。 在训练期间,我们保留模型参数的指数移动平均 (EMA),以便在学习率衰减后对模型性能进行早期估计。EMA 参数存储在 CPU 内存中,并在每个训练步骤后异步更新。这种方法使我们能够在不产生额外内存或时间开销的情况下维护 EMA 参数。
Shared Embedding and Output Head for Multi-Token Prediction. With the DualPipe strategy, we deploy the shallowest layers (including the embedding layer) and deepest layers (including the output head) of the model on the same PP rank. This arrangement enables the physical sharing of parameters and gradients, of the shared embedding and output head, between the MTP module and the main model. This physical sharing mechanism further enhances our memory efficiency.
多标记预测的共享嵌入和输出头。 借助 DualPipe 策略,我们将模型的最浅层(包括嵌入层)和最深层(包括输出头)部署在同一个 PP 排名上。这种安排使得 MTP 模块和主模型之间的共享嵌入和输出头的参数和梯度可以物理共享。这种物理共享机制进一步提高了我们的内存效率。
3.3. FP8 Training(FP8 训练)
3.4. Inference and Deployment(推理和部署)
We deploy DeepSeek-V3 on the H800 cluster, where GPUs within each node are interconnected using NVLink, and all GPUs across the cluster are fully interconnected via IB. To simultaneously ensure both the Service-Level Objective (SLO) for online services and high throughput, we employ the following deployment strategy that separates the prefilling and decoding stages.
我们在 H800 集群上部署 DeepSeek-V3,其中每个节点内的 GPU 使用 NVLink 进行互连,整个集群中的所有 GPU 通过 IB 完全互连。为了同时确保在线服务的服务级目标 (SLO) 和高吞吐量,我们采用以下部署策略,将预填充和解码阶段分开。
3.4.1. Prefilling(预填充)
The minimum deployment unit of the prefilling stage consists of 4 nodes with 32 GPUs. The attention part employs 4-way Tensor Parallelism (TP4) with Sequence Parallelism (SP), com- bined with 8-way Data Parallelism (DP8). Its small TP size of 4 limits the overhead of TP communication. For the MoE part, we use 32-way Expert Parallelism (EP32), which ensures that each expert processes a sufficiently large batch size, thereby enhancing computational efficiency. For the MoE all-to-all communication, we use the same method as in training: first transferring tokens across nodes via IB, and then forwarding among the intra-node GPUs via NVLink. In particular, we use 1-way Tensor Parallelism for the dense MLPs in shallow layers to save TP communication.
预填充阶段的最小部署单元由 4 个节点和 32 个 GPU 组成。注意力部分采用 4 路张量并行 (TP4) 与序列并行 (SP) 结合,结合 8 路数据并行 (DP8)。其小的 TP 大小为 4,限制了 TP 通信的开销。对于 MoE 部分,我们使用 32 路专家并行 (EP32),确保每个专家处理足够大的批量大小,从而提高计算效率。对于 MoE 全对全通信,我们使用与训练相同的方法:首先通过 IB 在节点之间传输标记,然后通过 NVLink 在节点内 GPU 之间转发。特别是,我们在浅层中的密集 MLP 中使用 1 路张量并行来节省 TP 通信。
To achieve load balancing among different experts in the MoE part, we need to ensure that each GPU processes approximately the same number of tokens. To this end, we introduce a deployment strategy of redundant experts, which duplicates high-load experts and deploys them redundantly. The high-load experts are detected based on statistics collected during the online deployment and are adjusted periodically (e.g., every 10 minutes). After determining the set of redundant experts, we carefully rearrange experts among GPUs within a node based on the observed loads, striving to balance the load across GPUs as much as possible without increasing the cross-node all-to-all communication overhead. For the deployment of DeepSeek-V3, we set 32 redundant experts for the prefilling stage. For each GPU, besides the original 8 experts it hosts, it will also host one additional redundant expert.
为了在 MoE 部分的不同专家之间实现负载平衡,我们需要确保每个 GPU 处理大约相同数量的标记。为此,我们引入了冗余专家的部署策略,复制高负载专家并将其冗余部署。高负载专家是基于在线部署期间收集的统计数据检测的,并定期调整(例如,每 10 分钟)。确定冗余专家集之后,我们根据观察到的负载在节点内的 GPU 之间仔细重新排列专家,努力在不增加跨节点全对全通信开销的情况下尽可能平衡 GPU 之间的负载。对于 DeepSeek-V3 的部署,我们为预填充阶段设置了 32 个冗余专家。对于每个 GPU,除了它原来托管的 8 个专家之外,它还将托管一个额外的冗余专家。
Furthermore, in the prefilling stage, to improve the throughput and hide the overhead of all-to-all and TP communication, we simultaneously process two micro-batches with similar computational workloads, overlapping the attention and MoE of one micro-batch with the dispatch and combine of another.
此外,在预填充阶段,为了提高吞吐量并隐藏全对全和 TP 通信的开销,我们同时处理两个具有相似计算工作负载的微批次,将一个微批次的注意力和 MoE 与另一个的调度和组合重叠。
Finally, we are exploring a dynamic redundancy strategy for experts, where each GPU hosts more experts (e.g., 16 experts), but only 9 will be activated during each inference step. Before the all-to-all operation at each layer begins, we compute the globally optimal routing scheme on the fly. Given the substantial computation involved in the prefilling stage, the overhead of computing this routing scheme is almost negligible.
最后,我们正在探索一种专家的动态冗余策略,其中每个 GPU 托管更多的专家(例如,16 个专家),但每个推理步骤只会激活 9 个。在每个层的全对全操作开始之前,我们会动态计算全局最优路由方案。鉴于预填充阶段涉及的大量计算,计算这种路由方案的开销几乎可以忽略不计。
3.4.2. Decoding(解码)
During decoding, we treat the shared expert as a routed one. From this perspective, each token will select 9 experts during routing, where the shared expert is regarded as a heavy-load one that will always be selected. The minimum deployment unit of the decoding stage consists of 40 nodes with 320 GPUs. The attention part employs TP4 with SP, combined with DP80, while the MoE part uses EP320. For the MoE part, each GPU hosts only one expert, and 64 GPUs are responsible for hosting redundant experts and shared experts. All-to-all communication of the dispatch and combine parts is performed via direct point-to-point transfers over IB to achieve low latency. Additionally, we leverage the IBGDA (NVIDIA, 2022) technology to further minimize latency and enhance communication efficiency.
在解码期间,我们将共享专家视为路由专家。从这个角度来看,每个标记在路由过程中将选择 9 个专家,其中共享专家被视为一个始终会被选择的高负载专家。解码阶段的最小部署单元由 40 个节点和 320 个 GPU 组成。注意力部分采用 TP4 与 SP 结合,结合 DP80,而 MoE 部分使用 EP320。对于 MoE 部分,每个 GPU 仅托管一个专家,64 个 GPU 负责托管冗余专家和共享专家。调度和组合部分的全对全通信通过 IB 上的直接点对点传输进行,以实现低延迟。此外,我们利用 IBGDA(NVIDIA,2022)技术进一步降低延迟并提高通信效率。
Similar to prefilling, we periodically determine the set of redundant experts in a certain interval, based on the statistical expert load from our online service. However, we do not need to rearrange experts since each GPU only hosts one expert. We are also exploring the dynamic redundancy strategy for decoding. However, this requires more careful optimization of the algorithm that computes the globally optimal routing scheme and the fusion with the dispatch kernel to reduce overhead.
与预填充类似,我们根据在线服务的统计专家负载,周期性地在一定间隔内确定冗余专家集。但是,由于每个 GPU 仅托管一个专家,我们无需重新排列专家。我们还在探索解码的动态冗余策略。但是,这需要更仔细地优化计算全局最优路由方案的算法,并与调度内核融合以减少开销。
Additionally, to enhance throughput and hide the overhead of all-to-all communication, we are also exploring processing two micro-batches with similar computational workloads simultaneously in the decoding stage. Unlike prefilling, attention consumes a larger portion of time in the decoding stage. Therefore, we overlap the attention of one micro-batch with the dispatch+MoE+combine of another. In the decoding stage, the batch size per expert is relatively small (usually within 256 tokens), and the bottleneck is memory access rather than computation. Since the MoE part only needs to load the parameters of one expert, the memory access overhead is minimal, so using fewer SMs will not significantly affect the overall performance. Therefore, to avoid impacting the computation speed of the attention part, we can allocate only a small portion of SMs to dispatch+MoE+combine.
此外,为了提高吞吐量并隐藏全对全通信的开销,我们还在解码阶段探索同时处理两个具有相似计算工作负载的微批次。与预填充不同,注意力在解码阶段占用了更大的时间比例。因此,我们将一个微批次的注意力与另一个的调度+MoE+组合重叠。在解码阶段,每个专家的批量大小相对较小(通常在 256 个标记内),瓶颈是内存访问而不是计算。由于 MoE 部分只需要加载一个专家的参数,内存访问开销很小,因此使用更少的 SM 不会显著影响整体性能。因此,为了避免影响注意力部分的计算速度,我们可以将只分配一小部分 SM 给调度+MoE+组合。
3.5. Suggestions on Hardware Design(硬件设计建议)
4. Pre-Training(预训练)
5. Post-Training(后训练)
6. Conclusion, Limitations, and Future Directions(结论、局限性和未来方向)
In this paper, we introduce DeepSeek-V3, a large MoE language model with 671B total pa- rameters and 37B activated parameters, trained on 14.8T tokens. In addition to the MLA and DeepSeekMoE architectures, it also pioneers an auxiliary-loss-free strategy for load balancing and sets a multi-token prediction training objective for stronger performance. The training of DeepSeek-V3 is cost-effective due to the support of FP8 training and meticulous engineering op- timizations. The post-training also makes a success in distilling the reasoning capability from the DeepSeek-R1 series of models. Comprehensive evaluations demonstrate that DeepSeek-V3 has emerged as the strongest open-source model currently available, and achieves performance com- parable to leading closed-source models like GPT-4o and Claude-3.5-Sonnet. Despite its strong performance, it also maintains economical training costs. It requires only 2.788M H800 GPU hours for its full training, including pre-training, context length extension, and post-training.
在本文中,我们介绍了 DeepSeek-V3,这是一个具有 671B 总参数和 37B 激活参数的大型 MoE 语言模型,训练了 14.8T 个标记。除了 MLA 和 DeepSeekMoE 架构之外,它还为负载平衡开创了一种无辅助损失策略,并为更强的性能设定了多标记预测训练目标。DeepSeek-V3 的训练具有成本效益,因为它支持 FP8 训练和细致的工程优化。后训练还成功地从 DeepSeek-R1 系列模型中提取了推理能力。全面的评估表明,DeepSeek-V3 已成为目前最强大的开源模型,并实现了与领先的闭源模型(如 GPT-4o 和 Claude-3.5-Sonnet)可比的性能。尽管性能强劲,但它也保持了经济的训练成本。它的全面训练仅需要 2.788M H800 GPU 小时,包括预训练、上下文长度扩展和后训练。
While acknowledging its strong performance and cost-effectiveness, we also recognize that DeepSeek-V3 has some limitations, especially on the deployment. Firstly, to ensure efficient inference, the recommended deployment unit for DeepSeek-V3 is relatively large, which might pose a burden for small-sized teams. Secondly, although our deployment strategy for DeepSeek- V3 has achieved an end-to-end generation speed of more than two times that of DeepSeek-V2, there still remains potential for further enhancement. Fortunately, these limitations are expected to be naturally addressed with the development of more advanced hardware.
尽管承认其强大的性能和成本效益,我们也认识到 DeepSeek-V3 存在一些局限性,特别是在部署方面。首先,为了确保高效推理,DeepSeek-V3 的推荐部署单元相对较大,这可能对小型团队构成负担。其次,尽管我们为 DeepSeek-V3 的部署策略实现了比 DeepSeek-V2 快两倍以上的端到端生成速度,但仍有进一步提升的潜力。幸运的是,随着更先进硬件的发展,这些局限性有望得到自然解决。
DeepSeek consistently adheres to the route of open-source models with longtermism, aiming to steadily approach the ultimate goal of AGI (Artificial General Intelligence). In the future, we plan to strategically invest in research across the following directions.
DeepSeek 始终坚持开源模型的长期主义路线,旨在稳步接近 AGI(人工通用智能)的最终目标。在未来,我们计划在以下方向上进行战略性投资研究。
-
We will consistently study and refine our model architectures, aiming to further improve both the training and inference efficiency, striving to approach efficient support for infinite context length. Additionally, we will try to break through the architectural limitations of Transformer, thereby pushing the boundaries of its modeling capabilities.
-
我们将持续研究和完善我们的模型架构,旨在进一步提高训练和推理效率,努力实现对无限上下文长度的高效支持。此外,我们将尝试突破 Transformer 的架构限制,从而推动其建模能力的边界。
-
We will continuously iterate on the quantity and quality of our training data, and explore the incorporation of additional training signal sources, aiming to drive data scaling across a more comprehensive range of dimensions.
-
我们将持续迭代我们的训练数据的数量和质量,并探索整合额外的训练信号源,旨在推动跨更全面维度的数据扩展。
-
We will consistently explore and iterate on the deep thinking capabilities of our models, aiming to enhance their intelligence and problem-solving abilities by expanding their reasoning length and depth.
-
我们将持续探索和迭代我们模型的深度思考能力,旨在通过扩展其推理长度和深度来增强其智能和解决问题的能力。
-
We will explore more comprehensive and multi-dimensional model evaluation methods to prevent the tendency towards optimizing a fixed set of benchmarks during research, which may create a misleading impression of the model capabilities and affect our foundational assessment.
-
我们将探索更全面和多维的模型评估方法,以防止在研究过程中优化固定一组基准的倾向,这可能会给人一种误导性的模型能力印象,并影响我们的基础评估。