DeepSeek R1: 通过强化学习激励 LLM 的推理能力
Abstract(摘要)
We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without super- vised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities. Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguing reasoning behaviors. However, it encounters challenges such as poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeek- R1 achieves performance comparable to OpenAI-o1-1217 on reasoning tasks. To support the research community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
我们介绍了我们的第一代推理模型DeepSeek-R1-Zero和DeepSeek-R1。 DeepSeek-R1-Zero是一个通过大规模强化学习(RL)训练的模型,没有经过监督微调(SFT)作为初步步骤,展示了卓越的推理能力。 通过RL,DeepSeek-R1-Zero自然地出现了许多强大和有趣的推理行为。然而,它遇到了诸如可读性差、语言混合等挑战。为了解决这些问题并进一步提高推理性能,我们引入了DeepSeek-R1,它在RL之前结合了多阶段训练和冷启动数据。DeepSeek-R1在推理任务上实现了与OpenAI-o1-1217相当的性能。为了支持研究社区,我们开源了DeepSeek-R1-Zero、DeepSeek-R1和六个基于Qwen和Llama的从DeepSeek-R1中提炼出的密集模型(1.5B、7B、8B、14B、32B、70B)。
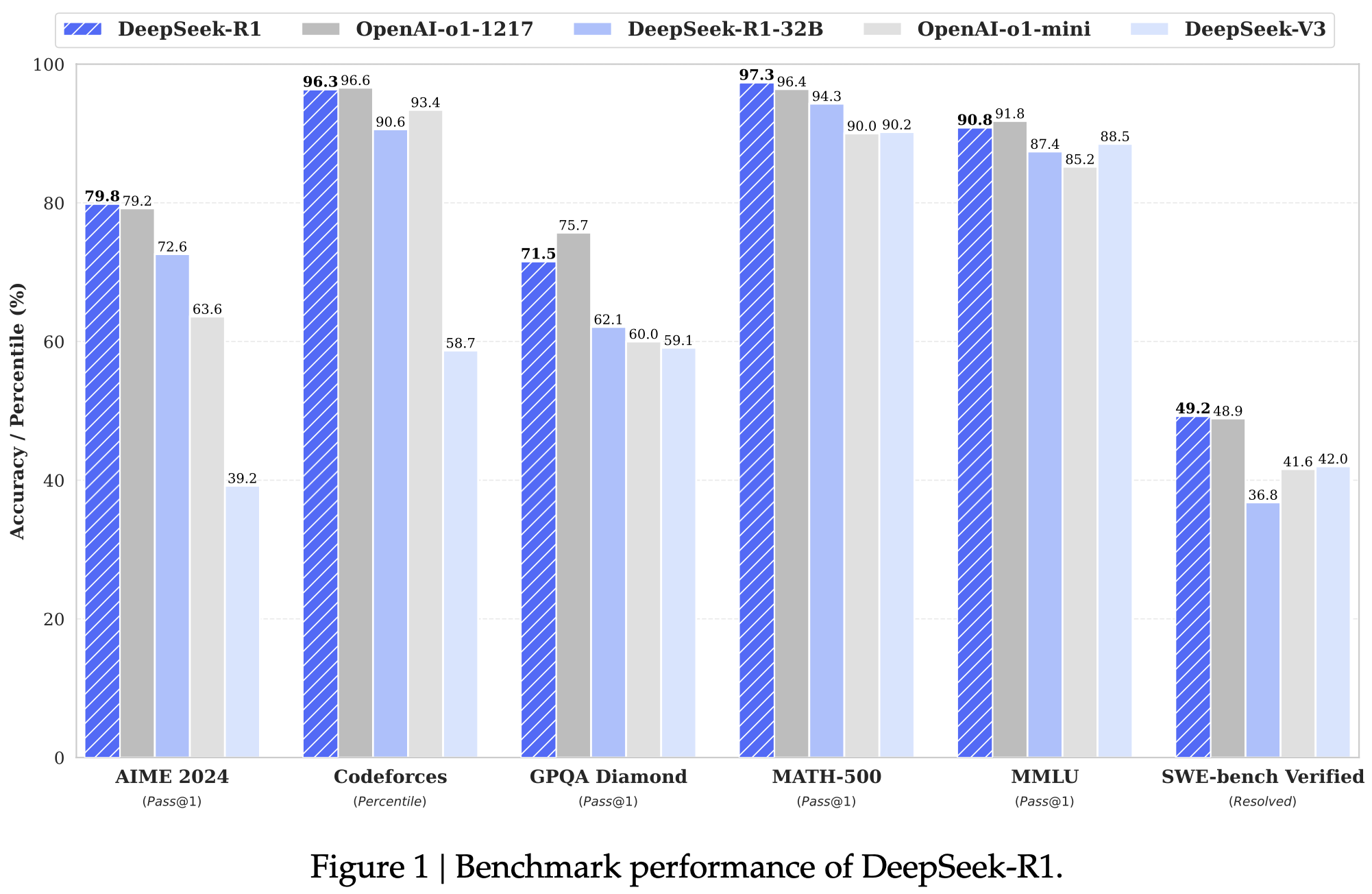
图1 DeepSeek-R1的基准性能
Introduction(介绍)
In recent years, Large Language Models (LLMs) have been undergoing rapid iteration and evolution (Anthropic, 2024; Google, 2024; OpenAI, 2024a), progressively diminishing the gap towards Artificial General Intelligence (AGI).
近年来,大型语言模型(LLMs)正在经历快速迭代和演进(Anthropic,2024;Google,2024;OpenAI,2024a),逐渐缩小了人工通用智能(AGI)的差距。
Recently, post-training has emerged as an important component of the full training pipeline. It has been shown to enhance accuracy on reasoning tasks, align with social values, and adapt to user preferences, all while requiring relatively minimal computational resources against pre-training. In the context of reasoning capabilities, OpenAI’s o1 (OpenAI, 2024b) series models were the first to introduce inference-time scaling by increasing the length of the Chain-of- Thought reasoning process. This approach has achieved significant improvements in various reasoning tasks, such as mathematics, coding, and scientific reasoning. However, the challenge of effective test-time scaling remains an open question for the research community. Several prior works have explored various approaches, including process-based reward models (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023), reinforcement learning (Kumar et al., 2024), and search algorithms such as Monte Carlo Tree Search and Beam Search (Feng et al., 2024; Trinh et al., 2024; Xin et al., 2024). However, none of these methods has achieved general reasoning performance comparable to OpenAI’s o1 series models.
最近,后训练已经成为完整训练流程的一个重要组成部分。已经证明它可以提高推理任务的准确性,符合社会价值观,并适应用户偏好,同时相对于预训练,需要相对较少的计算资源。在推理能力的背景下,OpenAI的o1(OpenAI,2024b)系列模型是第一个通过增加思维链推理过程的长度来引入推理时间扩展的模型。这种方法在各种推理任务中取得了显著的改进,如数学、编码和科学推理。然而,有效的测试时间扩展的挑战仍然是研究社区的一个悬而未决的问题。一些先前的工作已经探索了各种方法,包括基于过程的奖励模型(Lightman等,2023;Uesato等,2022;Wang等,2023),强化学习(Kumar等,2024)和搜索算法,如蒙特卡洛树搜索和波束搜索(Feng等,2024;Trinh等,2024;Xin等,2024)。然而,这些方法都没有达到与OpenAI的o1系列模型相当的通用推理性能。
In this paper, we take the first step toward improving language model reasoning capabilities using pure reinforcement learning (RL). Our goal is to explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure RL process. Specifically, we use DeepSeek-V3-Base as the base model and employ GRPO (Shao et al., 2024) as the RL framework to improve model performance in reasoning. During training, DeepSeek-R1-Zero naturally emerged with numerous powerful and interesting reasoning behaviors. After thousands of RL steps, DeepSeek-R1-Zero exhibits super performance on reasoning benchmarks. For instance, the pass@1 score on AIME 2024 increases from 15.6% to 71.0%, and with majority voting, the score further improves to 86.7%, matching the performance of OpenAI-o1-0912.
在本文中,我们迈出了改进语言模型推理能力的第一步,使用纯强化学习(RL)。我们的目标是探索LLMs在没有任何监督数据的情况下发展推理能力的潜力,重点关注它们通过纯RL过程的自我进化。具体来说,我们使用DeepSeek-V3-Base作为基础模型,并采用GRPO(Shao等,2024)作为RL框架来提高模型在推理中的性能。在训练过程中,DeepSeek-R1-Zero自然地出现了许多强大和有趣的推理行为。经过数千次RL步骤,DeepSeek-R1-Zero在推理基准上表现出超强的性能。例如,AIME 2024的pass@1分数从15.6%增加到71.0%,并且通过多数投票,分数进一步提高到86.7%,与OpenAI-o1-0912的性能相匹配。
However, DeepSeek-R1-Zero encounters challenges such as poor readability, and language mixing. To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates a small amount of cold-start data and a multi-stage training pipeline. Specifically, we begin by collecting thousands of cold-start data to fine-tune the DeepSeek-V3-Base model. Following this, we perform reasoning-oriented RL like DeepSeek-R1- Zero. Upon nearing convergence in the RL process, we create new SFT data through rejection sampling on the RL checkpoint, combined with supervised data from DeepSeek-V3 in domains such as writing, factual QA, and self-cognition, and then retrain the DeepSeek-V3-Base model. After fine-tuning with the new data, the checkpoint undergoes an additional RL process, taking into account prompts from all scenarios. After these steps, we obtained a checkpoint referred to as DeepSeek-R1, which achieves performance on par with OpenAI-o1-1217.
然而,DeepSeek-R1-Zero遇到了诸如可读性差、语言混合等挑战。为了解决这些问题并进一步提高推理性能,我们引入了DeepSeek-R1,它结合了少量冷启动数据和多阶段训练流程。具体来说,我们首先收集数千个冷启动数据来微调DeepSeek-V3-Base模型。随后,我们执行面向推理的RL,如DeepSeek-R1-Zero。在RL过程接近收敛时,我们通过拒绝抽样在RL检查点上创建新的SFT数据,结合DeepSeek-V3中的监督数据,如写作、事实QA和自我认知等领域,然后重新训练DeepSeek-V3-Base模型。在使用新数据进行微调后,检查点经历了额外的RL过程,考虑了所有场景的提示。经过这些步骤,我们获得了一个称为DeepSeek-R1的检查点,它在性能上与OpenAI-o1-1217相当。
We further explore distillation from DeepSeek-R1 to smaller dense models. Using Qwen2.5- 32B (Qwen, 2024b) as the base model, direct distillation from DeepSeek-R1 outperforms applying RL on it. This demonstrates that the reasoning patterns discovered by larger base models are cru- cial for improving reasoning capabilities. We open-source the distilled Qwen and Llama (Dubey et al., 2024) series. Notably, our distilled 14B model outperforms state-of-the-art open-source QwQ-32B-Preview (Qwen, 2024a) by a large margin, and the distilled 32B and 70B models set a new record on the reasoning benchmarks among dense models.
我们进一步探索了从DeepSeek-R1到更小的密集模型的提炼。使用Qwen2.5-32B(Qwen,2024b)作为基础模型,直接从DeepSeek-R1中提炼优于在其上应用RL。这表明,更大的基础模型发现的推理模式对于提高推理能力至关重要。我们开源了提炼的Qwen和Llama(Dubey等,2024)系列。值得注意的是,我们提炼的14B模型在性能上远远优于最先进的开源QwQ-32B-Preview(Qwen,2024a),而提炼的32B和70B模型在密集模型中在推理基准上创造了新纪录。
Contributions(贡献)
Post-Training: Large-Scale Reinforcement Learning on the Base Model(后训练:基础模型上的大规模强化学习)
We directly apply reinforcement learning (RL) to the base model without relying on super- vised fine-tuning (SFT) as a preliminary step. This approach allows the model to explore chain-of-thought (CoT) for solving complex problems, resulting in the development of DeepSeek-R1-Zero. DeepSeek-R1-Zero demonstrates capabilities such as self-verification, reflection, and generating long CoTs, marking a significant milestone for the research community. Notably, it is the first open research to validate that reasoning capabilities of LLMs can be incentivized purely through RL, without the need for SFT. This breakthrough paves the way for future advancements in this area.
我们直接将强化学习(RL)应用于基础模型,而不依赖于监督微调(SFT)作为初步步骤。这种方法使模型能够探索思维链(CoT)来解决复杂问题,从而开发出DeepSeek-R1-Zero。DeepSeek-R1-Zero展示了自我验证、反思和生成长CoTs等能力,为研究社区标志着一个重要的里程碑。值得注意的是,这是第一个证明LLMs的推理能力可以纯粹通过RL激励的开放研究,而无需SFT。这一突破为未来在这一领域的进一步发展铺平了道路。
We introduce our pipeline to develop DeepSeek-R1. The pipeline incorporates two RL stages aimed at discovering improved reasoning patterns and aligning with human pref- erences, as well as two SFT stages that serve as the seed for the model’s reasoning and non-reasoning capabilities. We believe the pipeline will benefit the industry by creating better models.
我们介绍了开发DeepSeek-R1的流程。该流程包括两个RL阶段,旨在发现改进的推理模式并与人类偏好保持一致,以及两个SFT阶段,作为模型推理和非推理能力的种子。我们相信这个流程将通过创建更好的模型来造福行业。
Distillation: Smaller Models Can Be Powerful Too(提炼:小模型也可以很强大)
We demonstrate that the reasoning patterns of larger models can be distilled into smaller models, resulting in better performance compared to the reasoning patterns discovered through RL on small models. The open source DeepSeek-R1, as well as its API, will benefit the research community to distill better smaller models in the future.
我们证明了更大模型的推理模式可以提炼到更小模型中,与在小模型上通过RL发现的推理模式相比,性能更好。开源的DeepSeek-R1及其API将有助于研究社区在未来提炼更好的小模型。
Using the reasoning data generated by DeepSeek-R1, we fine-tuned several dense models that are widely used in the research community. The evaluation results demonstrate that the distilled smaller dense models perform exceptionally well on benchmarks. DeepSeek- R1-Distill-Qwen-7B achieves 55.5% on AIME 2024, surpassing QwQ-32B-Preview. Addi- tionally, DeepSeek-R1-Distill-Qwen-32B scores 72.6% on AIME 2024, 94.3% on MATH-500, and 57.2% on LiveCodeBench. These results significantly outperform previous open- source models and are comparable to o1-mini. We open-source distilled 1.5B, 7B, 8B, 14B, 32B, and 70B checkpoints based on Qwen2.5 and Llama3 series to the community.
使用DeepSeek-R1生成的推理数据,我们微调了研究社区广泛使用的几个密集模型。评估结果表明,提炼的更小密集模型在基准测试中表现异常出色。DeepSeek-R1-Distill-Qwen-7B在AIME 2024上达到55.5%,超过了QwQ-32B-Preview。此外,DeepSeek-R1-Distill-Qwen-32B在AIME 2024上得分72.6%,在MATH-500上得分94.3%,在LiveCodeBench上得分57.2%。这些结果明显优于以前的开源模型,并与o1-mini相当。我们基于Qwen2.5和Llama3系列向社区开源了提炼的1.5B、7B、8B、14B、32B和70B检查点。
Summary of Evaluation Results(评估结果总结)
Reasoning tasks: (1) DeepSeek-R1 achieves a score of 79.8% Pass@1 on AIME 2024, slightly surpassing OpenAI-o1-1217. On MATH-500, it attains an impressive score of 97.3%, performing on par with OpenAI-o1-1217 and significantly outperforming other models. (2) On coding-related tasks, DeepSeek-R1 demonstrates expert level in code competition tasks, as it achieves 2,029 Elo rating on Codeforces outperforming 96.3% human participants in the competition. For engineering-related tasks, DeepSeek-R1 performs slightly better than DeepSeek-V3, which could help developers in real world tasks.
推理任务:(1)DeepSeek-R1在AIME 2024上的Pass@1得分为79.8%,略高于OpenAI-o1-1217。在MATH-500上,它取得了令人印象深刻的97.3%的得分,与OpenAI-o1-1217相当,并明显优于其他模型。(2)在与编码相关的任务中,DeepSeek-R1在代码竞赛任务中展示了专家级水平,它在Codeforces上取得了2029的Elo评分,超过了96.3%的人类参与者。对于工程相关任务,DeepSeek-R1的表现略好于DeepSeek-V3,这有助于开发人员在现实世界的任务中。
Knowledge: On benchmarks such as MMLU, MMLU-Pro, and GPQA Diamond, DeepSeek- R1 achieves outstanding results, significantly outperforming DeepSeek-V3 with scores of 90.8% on MMLU, 84.0% on MMLU-Pro, and 71.5% on GPQA Diamond. While its performance is slightly below that of OpenAI-o1-1217 on these benchmarks, DeepSeek-R1 surpasses other closed-source models, demonstrating its competitive edge in educational tasks. On the factual benchmark SimpleQA, DeepSeek-R1 outperforms DeepSeek-V3, demonstrating its capability in handling fact-based queries. A similar trend is observed where OpenAI-o1 surpasses 4o on this benchmark.
知识:在MMLU、MMLU-Pro和GPQA Diamond等基准上,DeepSeek-R1取得了出色的成绩,分别为MMLU 90.8%、MMLU-Pro 84.0%和GPQA Diamond 71.5%,明显优于DeepSeek-V3。虽然在这些基准上,它的表现略低于OpenAI-o1-1217,但DeepSeek-R1超过了其他闭源模型,展示了在教育任务中的竞争优势。在事实基准SimpleQA上,DeepSeek-R1优于DeepSeek-V3,展示了其处理基于事实的查询的能力。在这一基准上,OpenAI-o1也超过了4o。
Others: DeepSeek-R1 also excels in a wide range of tasks, including creative writing, general question answering, editing, summarization, and more. It achieves an impressive length-controlled win-rate of 87.6% on AlpacaEval 2.0 and a win-rate of 92.3% on Are- naHard, showcasing its strong ability to intelligently handle non-exam-oriented queries. Additionally, DeepSeek-R1 demonstrates outstanding performance on tasks requiring long-context understanding, substantially outperforming DeepSeek-V3 on long-context benchmarks.
其他:DeepSeek-R1在各种任务中表现出色,包括创意写作、一般问题回答、编辑、摘要等。它在AlpacaEval 2.0上取得了令人印象深刻的长度控制胜率87.6%,在Are-naHard上取得了92.3%的胜率,展示了其强大的智能处理非考试导向查询的能力。此外,DeepSeek-R1在需要长上下文理解的任务上表现出色,大大优于DeepSeek-V3在长上下文基准上的表现。
Approach(方法)
Overview(概述)
Previous work has heavily relied on large amounts of supervised data to enhance model performance. In this study, we demonstrate that reasoning capabilities can be significantly improved through large-scale reinforcement learning (RL), even without using supervised fine-tuning (SFT) as a cold start. Furthermore, performance can be further enhanced with the inclusion of a small amount of cold-start data. In the following sections, we present: (1) DeepSeek-R1-Zero, which applies RL directly to the base model without any SFT data, and (2) DeepSeek-R1, which applies RL starting from a checkpoint fine-tuned with thousands of long Chain-of-Thought (CoT) examples. (3) Distill the reasoning capability from DeepSeek-R1 to small dense models.
以往的工作在提高模型性能方面严重依赖大量的监督数据。在这项研究中,我们证明了推理能力可以通过大规模强化学习(RL)显著提高,即使没有使用监督微调(SFT)作为冷启动。此外,通过包含少量冷启动数据,性能可以进一步提高。在接下来的章节中,我们将介绍:(1) DeepSeek-R1-Zero,它直接将强化学习应用于基础模型,无需任何SFT数据,以及 (2) DeepSeek-R1,它从使用数千个长思维链(CoT)示例微调的检查点开始应用强化学习。(3) 将DeepSeek-R1的推理能力提炼到小型密集模型中。
DeepSeek-R1-Zero: Reinforcement Learning on the Base Model(DeepSeek-R1-Zero:基础模型上的强化学习)
Reinforcement learning has demonstrated significant effectiveness in reasoning tasks, as ev- idenced by our previous works (Shao et al., 2024; Wang et al., 2023). However, these works heavily depended on supervised data, which are time-intensive to gather. In this section, we explore the potential of LLMs to develop reasoning capabilities without any supervised data, focusing on their self-evolution through a pure reinforcement learning process. We start with a brief overview of our reinforcement learning algorithm, followed by the presentation of some exciting results, and hope this provides the community with valuable insights.
强化学习已经证明在推理任务中具有显著的有效性,正如我们之前的工作所证明的那样(Shao等,2024;Wang等,2023)。然而,这些工作严重依赖于监督数据,这些数据收集起来耗时。在本节中,我们探索了LLMs发展推理能力的潜力,而无需任何监督数据,重点关注它们通过纯强化学习过程的自我进化。我们从对我们的强化学习算法的简要概述开始,然后介绍一些令人兴奋的结果,希望这能为社区提供有价值的见解。
Reinforcement Learning Algorithm(强化学习算法)

组相对策略优化 为了节省RL的训练成本,我们采用了Group Relative Policy Optimization(GRPO)(Shao等,2024),它放弃了通常与策略模型大小相同的评论家模型,并从组分数中估计基线。具体来说,对于每个问题𝑞,GRPO从旧策略𝜋𝜃𝑜𝑙𝑑中采样一组输出{𝑜1, 𝑜2,···,𝑜𝐺},然后通过最大化以下目标来优化策略模型𝜋𝜃:
其中𝜀和𝛽是超参数,𝐴𝑖是优势,使用与每个组中的输出对应的一组奖励{𝑟1, 𝑟2, …,𝑟𝐺}计算:

表1 DeepSeek-R1-Zero的模板。在训练期间,prompt将被具体的推理问题替换。
用户和助手之间的对话。用户提出问题,助手解决问题。助手首先在脑海中思考推理过程,然后向用户提供答案。推理过程和答案分别用<think> </think>和<answer> </answer>标签括起来,即<think>这里是推理过程</think><answer>这里是答案</answer>。用户:提示。助手:
Reward Modeling(奖励建模)
The reward is the source of the training signal, which decides the optimization direction of RL. To train DeepSeek-R1-Zero, we adopt a rule-based reward system that mainly consists of two types of rewards:
奖励是训练信号的来源,决定了RL的优化方向。为了训练DeepSeek-R1-Zero,我们采用了一个基于规则的奖励系统,主要由两种类型的奖励组成:
Accuracy rewards: The accuracy reward model evaluates whether the response is correct. For example, in the case of math problems with deterministic results, the model is required to provide the final answer in a specified format (e.g., within a box), enabling reliable rule-based verification of correctness. Similarly, for LeetCode problems, a compiler can be used to generate feedback based on predefined test cases.
准确性奖励:准确性奖励模型评估响应是否正确。例如,在具有确定性结果的数学问题中,模型需要以指定格式(例如,在一个框内)提供最终答案,从而实现可靠的基于规则的正确性验证。类似地,对于LeetCode问题,可以使用编译器基于预定义的测试用例生成反馈。
Format rewards: In addition to the accuracy reward model, we employ a format reward
model that enforces the model to put its thinking process between ‘
格式奖励:除了准确性奖励模型外,我们还采用了一个格式奖励模型,强制模型将其思考过程放在“<think>”和“</think>”标签之间。
We do not apply the outcome or process neural reward model in developing DeepSeek-R1-Zero, because we find that the neural reward model may suffer from reward hacking in the large-scale reinforcement learning process, and retraining the reward model needs additional training resources and it complicates the whole training pipeline.
我们在开发DeepSeek-R1-Zero时没有应用结果或过程神经奖励模型,因为我们发现神经奖励模型可能在大规模强化学习过程中遭受奖励黑客攻击,并且重新训练奖励模型需要额外的训练资源,并且它使整个训练流程变得复杂。
Training Template(训练模板)
To train DeepSeek-R1-Zero, we begin by designing a straightforward template that guides the base model to adhere to our specified instructions. As depicted in Table 1, this template requires DeepSeek-R1-Zero to first produce a reasoning process, followed by the final answer. We intentionally limit our constraints to this structural format, avoiding any content-specific biases—such as mandating reflective reasoning or promoting particular problem-solving strate- gies—to ensure that we can accurately observe the model’s natural progression during the reinforcement learning (RL) process.
为了训练DeepSeek-R1-Zero,我们首先设计了一个简单的模板,引导基础模型遵循我们指定的指令。如表1所示,该模板要求DeepSeek-R1-Zero首先生成推理过程,然后给出最终答案。我们特意将约束限制在这种结构格式上,避免任何内容特定的偏见——比如强制要求反思性推理或推广特定的问题解决策略——以确保我们能够准确观察模型在强化学习(RL)过程中的自然进展。
Performance, Self-evolution Process and Aha Moment of DeepSeek-R1-Zero(DeepSeek-R1-Zero的性能、自我进化过程和顿悟时刻)
Performance of DeepSeek-R1-Zero Figure 2 depicts the performance trajectory of DeepSeek- R1-Zero on the AIME 2024 benchmark throughout the reinforcement learning (RL) training process. As illustrated, DeepSeek-R1-Zero demonstrates a steady and consistent enhancement in performance as the RL training advances. Notably, the average pass@1 score on AIME 2024 shows a significant increase, jumping from an initial 15.6% to an impressive 71.0%, reaching performance levels comparable to OpenAI-o1-0912. This significant improvement highlights the efficacy of our RL algorithm in optimizing the model’s performance over time.
DeepSeek-R1-Zero的性能图2显示了DeepSeek-R1-Zero在AIME 2024基准上的性能轨迹,贯穿了强化学习(RL)训练过程。如图所示,DeepSeek-R1-Zero在RL训练不断进行的过程中表现出稳定和一致的性能提升。值得注意的是,AIME 2024上的平均pass@1分数显示了显著的增加,从最初的15.6%跃升到令人印象深刻的71.0%,达到了与OpenAI-o1-0912相当的性能水平。这一显著的改进突显了我们的RL算法随着时间的推移优化模型性能的有效性。
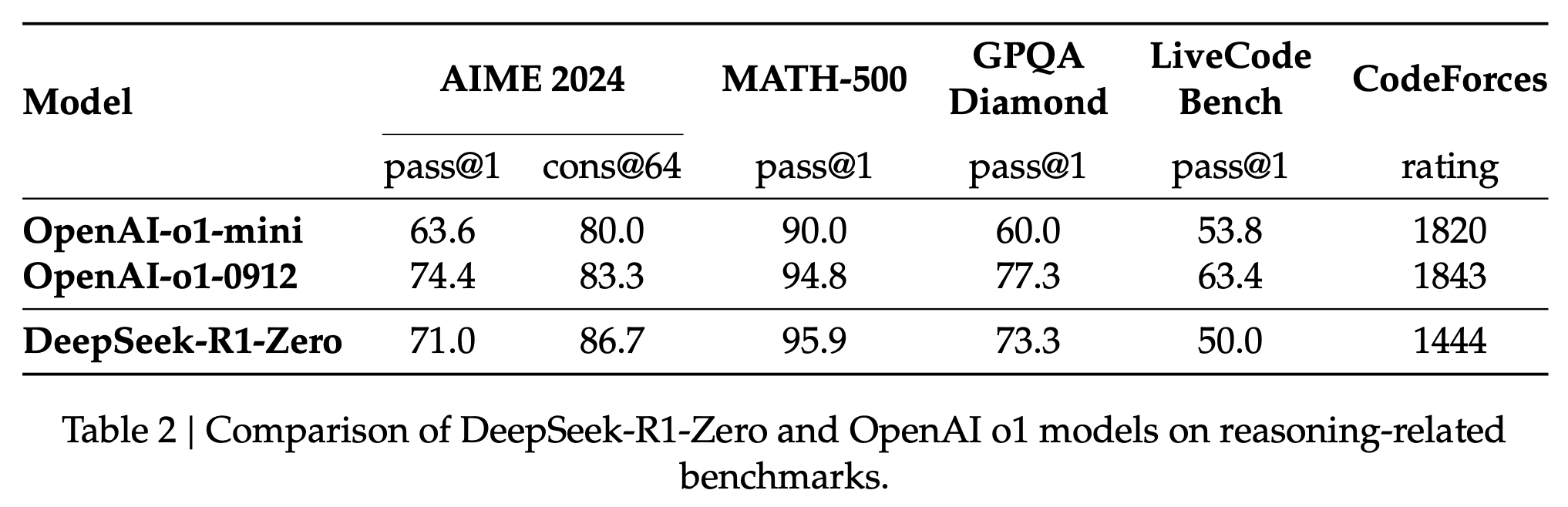
表2 DeepSeek-R1-Zero和OpenAI o1模型在推理相关基准上的比较
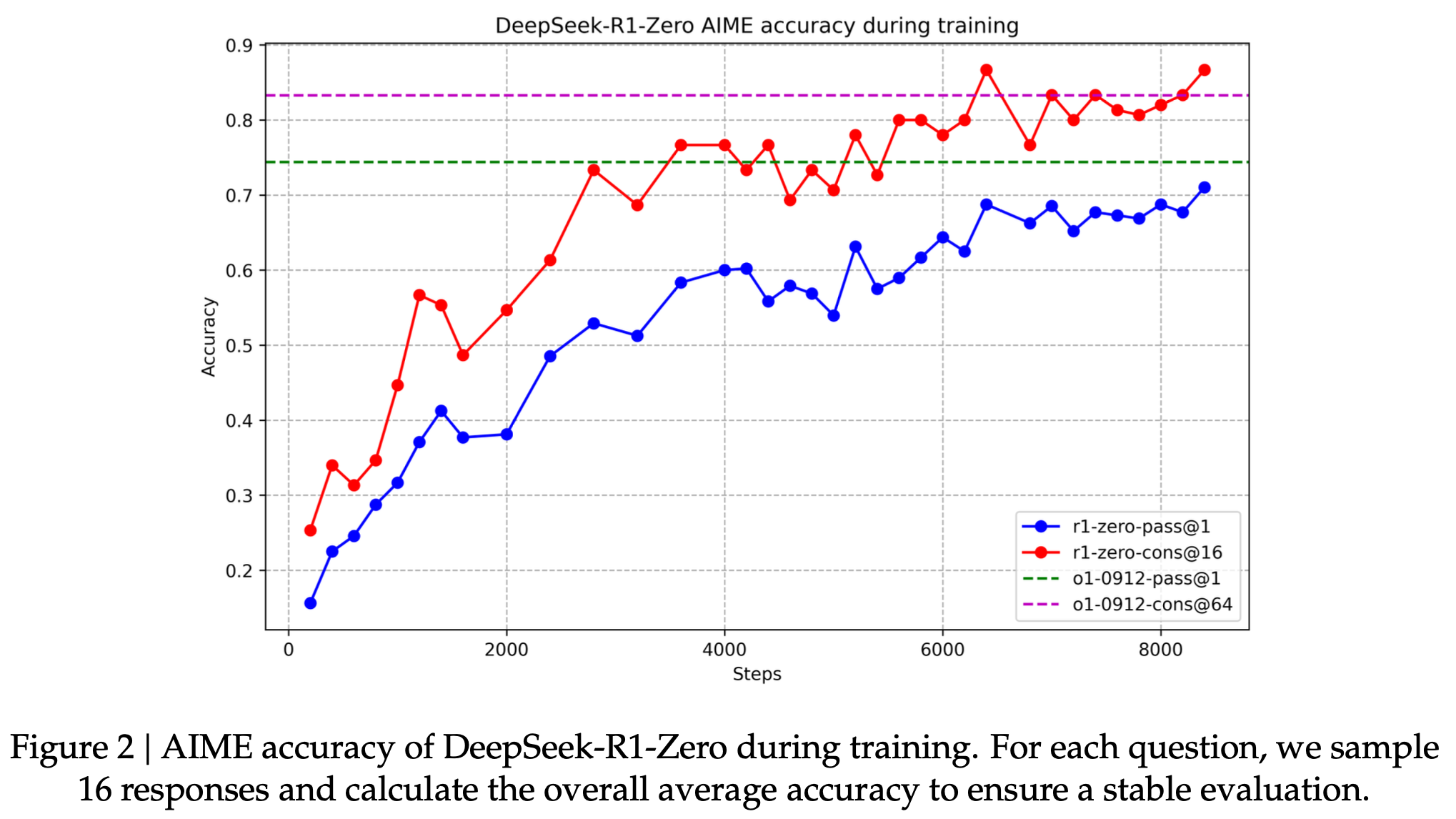
图2 DeepSeek-R1-Zero在训练过程中的AIME准确性。对于每个问题,我们采样16个响应,并计算整体平均准确性,以确保稳定的评估。
Table 2 provides a comparative analysis between DeepSeek-R1-Zero and OpenAI’s o1-0912 models across a variety of reasoning-related benchmarks. The findings reveal that RL empowers DeepSeek-R1-Zero to attain robust reasoning capabilities without the need for any supervised fine-tuning data. This is a noteworthy achievement, as it underscores the model’s ability to learn and generalize effectively through RL alone. Additionally, the performance of DeepSeek- R1-Zero can be further augmented through the application of majority voting. For example, when majority voting is employed on the AIME benchmark, DeepSeek-R1-Zero’s performance escalates from 71.0% to 86.7%, thereby exceeding the performance of OpenAI-o1-0912. The ability of DeepSeek-R1-Zero to achieve such competitive performance, both with and without majority voting, highlights its strong foundational capabilities and its potential for further advancements in reasoning tasks.
表2提供了DeepSeek-R1-Zero和OpenAI的o1-0912模型在各种推理相关基准上的对比分析。研究结果表明,强化学习使DeepSeek-R1-Zero在无需任何监督微调数据的情况下,获得了强大的推理能力。这是一个值得注意的成就,因为它强调了模型仅通过RL就能有效地学习和泛化的能力。此外,DeepSeek-R1-Zero的性能可以通过多数投票进一步增强。例如,当在AIME基准上使用多数投票时,DeepSeek-R1-Zero的性能从71.0%提升到86.7%,从而超过了OpenAI-o1-0912的性能。DeepSeek-R1-Zero在有和没有多数投票的情况下实现这样的竞争性性能的能力,突显了它强大的基础能力和在推理任务中进一步发展的潜力。
Self-evolution Process of DeepSeek-R1-Zero The self-evolution process of DeepSeek-R1-Zero is a fascinating demonstration of how RL can drive a model to improve its reasoning capabilities autonomously. By initiating RL directly from the base model, we can closely monitor the model’s progression without the influence of the supervised fine-tuning stage. This approach provides a clear view of how the model evolves over time, particularly in terms of its ability to handle complex reasoning tasks.
DeepSeek-R1-Zero的自我进化过程 DeepSeek-R1-Zero的自我进化过程是一个迷人的演示,展示了RL如何驱动模型自主提高其推理能力。通过直接从基础模型开始RL,我们可以在没有监督微调阶段的影响下密切监视模型的进展。这种方法清晰地展示了模型如何随着时间的推移发展,特别是在处理复杂推理任务的能力方面。
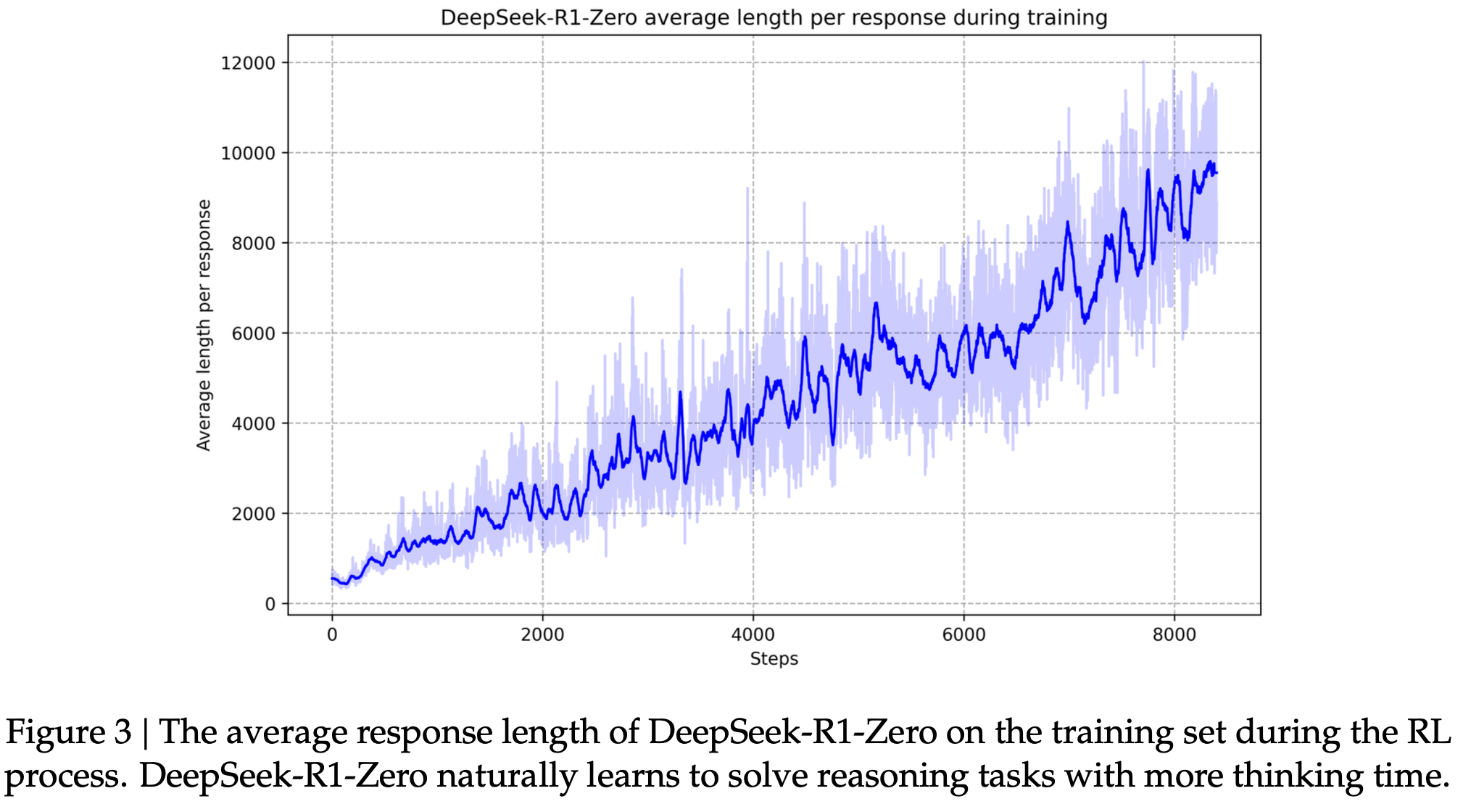
图3 DeepSeek-R1-Zero在RL过程中在训练集上的平均响应长度。DeepSeek-R1-Zero自然地学会用更多的思考时间解决推理任务。
As depicted in Figure 3, the thinking time of DeepSeek-R1-Zero shows consistent improvement throughout the training process. This improvement is not the result of external adjustments but rather an intrinsic development within the model. DeepSeek-R1-Zero naturally acquires the ability to solve increasingly complex reasoning tasks by leveraging extended test-time compu- tation. This computation ranges from generating hundreds to thousands of reasoning tokens, allowing the model to explore and refine its thought processes in greater depth.
如图3所示,DeepSeek-R1-Zero的思考时间在整个训练过程中表现出持续改进。这种改进不是外部调整的结果,而是模型内在发展的结果。DeepSeek-R1-Zero通过利用扩展的测试时间计算,自然地获得了解决越来越复杂的推理任务的能力。这种计算范围从生成数百到数千个推理标记,使模型能够更深入地探索和完善其思维过程。
One of the most remarkable aspects of this self-evolution is the emergence of sophisticated behaviors as the test-time computation increases. Behaviors such as reflection—where the model revisits and reevaluates its previous steps—and the exploration of alternative approaches to problem-solving arise spontaneously. These behaviors are not explicitly programmed but instead emerge as a result of the model’s interaction with the reinforcement learning environment. This spontaneous development significantly enhances DeepSeek-R1-Zero’s reasoning capabilities, enabling it to tackle more challenging tasks with greater efficiency and accuracy.
这种自我进化最显著的一个方面是随着测试时间计算的增加,复杂行为的出现。例如反思——模型重新审视和重新评估其以前的步骤——以及探索解决问题的替代方法等行为自发出现。这些行为并没有被明确编程,而是作为模型与强化学习环境互动的结果而出现。这种自发发展显著增强了DeepSeek-R1-Zero的推理能力,使其能够以更高的效率和准确性处理更具挑战性的任务。
Aha Moment of DeepSeek-R1-Zero A particularly intriguing phenomenon observed during the training of DeepSeek-R1-Zero is the occurrence of an “aha moment”. This moment, as illustrated in Table 3, occurs in an intermediate version of the model. During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes.
DeepSeek-R1-Zero的顿悟时刻 在DeepSeek-R1-Zero的训练过程中观察到的一个特别有趣的现象是“顿悟时刻”的发生。如表3所示,这一时刻发生在模型的一个中间版本中。在这个阶段,DeepSeek-R1-Zero通过重新评估其初始方法,学会为一个问题分配更多的思考时间。这种行为不仅证明了模型不断增长的推理能力,而且是强化学习如何导致意想不到和复杂结果的引人入胜的例子。
This moment is not only an “aha moment” for the model but also for the researchers observing its behavior. It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies. The “aha moment” serves as a powerful reminder of the potential of RL to unlock new levels of intelligence in artificial systems, paving the way for more autonomous and adaptive models in the future.
这一时刻不仅是模型的“顿悟时刻”,也是观察其行为的研究人员的“顿悟时刻”。它强调了强化学习的力量和美丽:我们并没有明确教导模型如何解决问题,而是简单地为其提供正确的激励,它自主地发展出先进的问题解决策略。这一“顿悟时刻”是强化学习潜力的有力提醒,它可以解锁人工系统的新智能水平,为未来更自主和适应性的模型铺平道路。

问题:如果 𝑎 > 1,则 √︁(𝑎−√(𝑎+𝑥)) = 𝑥 的实数解的和等于
回答:<think>
要解方程 √︁(𝑎−√(𝑎+𝑥)) = 𝑥,让我们从两边平方开始···
(√︁(𝑎−√(𝑎+𝑥)))^2 = 𝑥2 ⇒ 𝑎−√(𝑎+𝑥) = 𝑥^2。
重新排列以隔离内部平方根项:
(𝑎−𝑥^2)^2 = 𝑎+𝑥 = ⇒ 𝑎2−2𝑎𝑥^2+(𝑥^2)^2 = 𝑎+𝑥 ⇒ 𝑥4−2𝑎𝑥^2−𝑥+(𝑎^2-a) = 0
. . .
**等等,等等。等等。这是我可以标记的一个顿悟时刻。**
让我们逐步重新评估这一步骤,以确定是否可以···
我们从方程开始:
√︁(𝑎−√(𝑎+𝑥)) = 𝑥
首先,让我们两边平方:
𝑎−√(𝑎+𝑥) = 𝑥^2 ⇒ √(𝑎+𝑥) = 𝑎−𝑥^2
接下来,我可以再次两边平方,处理方程:···
表3 DeepSeek-R1-Zero中间版本的一个有趣的“顿悟时刻”。模型学会重新思考,使用一种拟人的语气。这对我们来说也是一个顿悟时刻,让我们见证了强化学习的力量和美丽。
Drawback of DeepSeek-R1-Zero Although DeepSeek-R1-Zero exhibits strong reasoning capabilities and autonomously develops unexpected and powerful reasoning behaviors, it faces several issues. For instance, DeepSeek-R1-Zero struggles with challenges like poor readability, and language mixing. To make reasoning processes more readable and share them with the open community, we explore DeepSeek-R1, a method that utilizes RL with human-friendly cold-start data.
DeepSeek-R1-Zero的缺点 尽管DeepSeek-R1-Zero表现出强大的推理能力,并自主发展出意想不到的强大推理行为,但它面临一些问题。例如,DeepSeek-R1-Zero在面对诸如可读性差、语言混合等挑战时遇到困难。为了使推理过程更易读,并与开放社区分享,我们探索了DeepSeek-R1,这是一种利用人类友好的冷启动数据的RL方法。
DeepSeek-R1: Reinforcement Learning with Cold Start(DeepSeek-R1:冷启动的强化学习)
Inspired by the promising results of DeepSeek-R1-Zero, two natural questions arise: 1) Can reasoning performance be further improved or convergence accelerated by incorporating a small amount of high-quality data as a cold start? 2) How can we train a user-friendly model that not only produces clear and coherent Chains of Thought (CoT) but also demonstrates strong general capabilities? To address these questions, we design a pipeline to train DeepSeek-R1. The pipeline consists of four stages, outlined as follows.
受DeepSeek-R1-Zero令人鼓舞的结果启发,自然会出现两个问题:1)通过将少量高质量数据作为冷启动,可以进一步提高推理性能或加速收敛吗?2)我们如何训练一个用户友好的模型,它不仅能够产生清晰连贯的思维链(CoT),而且还能展示强大的通用能力?为了解决这些问题,我们设计了一个流程来训练DeepSeek-R1。该流程包括四个阶段,如下所述。
Cold Start(冷启动)
Unlike DeepSeek-R1-Zero, to prevent the early unstable cold start phase of RL training from the base model, for DeepSeek-R1 we construct and collect a small amount of long CoT data to fine-tune the model as the initial RL actor. To collect such data, we have explored several approaches: using few-shot prompting with a long CoT as an example, directly prompting models to generate detailed answers with reflection and verification, gathering DeepSeek-R1-Zero outputs in a readable format, and refining the results through post-processing by human annotators.
与 DeepSeek-R1-Zero 不同,为了防止基础模型在 RL 训练早期出现不稳定的冷启动阶段,对于 DeepSeek-R1,我们构建并收集少量的长 CoT 数据,以作为初始 RL 参与者对模型进行微调。为了收集此类数据,我们探索了几种方法:使用长 CoT 的少样本提示作为示例,直接提示模型通过反思和验证生成详细答案,以可读格式收集 DeepSeek-R1-Zero 输出,并通过人工注释者的后期处理来完善结果。
In this work, we collect thousands of cold-start data to fine-tune the DeepSeek-V3-Base as the starting point for RL. Compared to DeepSeek-R1-Zero, the advantages of cold start data include:
在这项工作中,我们收集了数千个冷启动数据,以微调 DeepSeek-V3-Base 作为 RL 的起点。与 DeepSeek-R1-Zero 相比,冷启动数据的优势包括:
Readability: A key limitation of DeepSeek-R1-Zero is that its content is often not suitable
for reading. Responses may mix multiple languages or lack markdown formatting to
highlight answers for users. In contrast, when creating cold-start data for DeepSeek-R1,
we design a readable pattern that includes a summary at the end of each response and
filters out responses that are not reader-friendly. Here, we define the output format as
|special_token|
可读性:DeepSeek-R1-Zero的一个主要限制是其内容通常不适合阅读。响应可能混合多种语言或缺乏markdown格式来为用户突出显示答案。相比之下,在为DeepSeek-R1创建冷启动数据时,我们设计了一个可读性模式,在每个响应的末尾包含一个总结,并过滤掉不适合阅读的响应。在这里,我们将输出格式定义为|special_token|<reasoning_process>|special_token|<summary>,其中推理过程是针对查询的思维链(CoT),而总结用于概括推理结果。
Potential: By carefully designing the pattern for cold-start data with human priors, we observe better performance against DeepSeek-R1-Zero. We believe the iterative training is a better way for reasoning models.
潜力:通过精心设计具有人类先验知识的冷启动数据模式,我们观察到与 DeepSeek-R1-Zero 相比更好的性能。我们认为迭代训练是推理模型的更好方式。
Reasoning-oriented Reinforcement Learning(面向推理的强化学习)
After fine-tuning DeepSeek-V3-Base on the cold start data, we apply the same large-scale reinforcement learning training process as employed in DeepSeek-R1-Zero. This phase focuses on enhancing the model’s reasoning capabilities, particularly in reasoning-intensive tasks such as coding, mathematics, science, and logic reasoning, which involve well-defined problems with clear solutions. During the training process, we observe that CoT often exhibits language mixing, particularly when RL prompts involve multiple languages. To mitigate the issue of language mixing, we introduce a language consistency reward during RL training, which is calculated as the proportion of target language words in the CoT. Although ablation experiments show that such alignment results in a slight degradation in the model’s performance, this reward aligns with human preferences, making it more readable. Finally, we combine the accuracy of reasoning tasks and the reward for language consistency by directly summing them to form the final reward. We then apply reinforcement learning (RL) training on the fine-tuned model until it achieves convergence on reasoning tasks.
在冷启动数据上微调 DeepSeek-V3-Base 后,我们应用了与 DeepSeek-R1-Zero 中使用的相同的大规模强化学习训练过程。这个阶段的重点是增强模型的推理能力,特别是在推理密集型任务中,如编码、数学、科学和逻辑推理,这些任务涉及到具有明确解决方案的明确定义的问题。在训练过程中,我们观察到 CoT 通常会出现语言混合,特别是当 RL 提示涉及多种语言时。为了减轻语言混合问题,我们在 RL 训练期间引入了一种语言一致性奖励,该奖励计算为 CoT 中目标语言单词的比例。尽管消融实验表明这种对齐会导致模型性能略微下降,但这种奖励符合人类的偏好,使其更易读。最后,我们将推理任务的准确性和语言一致性奖励直接相加,形成最终奖励。然后我们在微调模型上应用强化学习(RL)训练,直到它在推理任务上收敛。
Rejection Sampling and Supervised Fine-Tuning(拒绝抽样和监督微调)
When reasoning-oriented RL converges, we utilize the resulting checkpoint to collect SFT (Supervised Fine-Tuning) data for the subsequent round. Unlike the initial cold-start data, which primarily focuses on reasoning, this stage incorporates data from other domains to enhance the model’s capabilities in writing, role-playing, and other general-purpose tasks. Specifically, we generate the data and fine-tune the model as described below.
当面向推理的 RL 收敛时,我们利用生成的检查点收集 SFT(监督微调)数据,用于后续轮次。与最初的冷启动数据不同,后者主要关注推理,这个阶段包含了来自其他领域的数据,以增强模型在写作、角色扮演和其他通用任务中的能力。具体来说,我们生成数据并微调模型如下所述。
Reasoning data We curate reasoning prompts and generate reasoning trajectories by perform- ing rejection sampling from the checkpoint from the above RL training.In the previous stage, we only included data that could be evaluated using rule-based rewards. However, in this stage, we expand the dataset by incorporating additional data, some of which use a generative reward model by feeding the ground-truth and model predictions into DeepSeek-V3 for judgment. Additionally, because the model output is sometimes chaotic and difficult to read, we have filtered out chain-of-thought with mixed languages, long parapraphs, and code blocks. For each prompt, we sample multiple responses and retain only the correct ones. In total, we collect about 600k reasoning related training samples.
推理数据 我们通过从上述强化学习训练的检查点进行拒绝抽样来整理推理提示并生成推理轨迹。在上一阶段,我们仅包含可以使用基于规则的奖励进行评估的数据。但是,在此阶段,我们通过合并其他数据来扩展数据集,其中一些数据使用生成奖励模型,将基本事实和模型预测输入 DeepSeek-V3 进行判断。此外,由于模型输出有时混乱且难以阅读,我们过滤掉了混合语言、长段落和代码块的思路链。对于每个提示,我们会抽样多个响应并仅保留正确的响应。总的来说,我们收集了大约 60 万个与推理相关的训练样本。
Non-Reasoning data For non-reasoning data, such as writing, factual QA, self-cognition, and translation, we adopt the DeepSeek-V3 pipeline and reuse portions of the SFT dataset of DeepSeek-V3. For certain non-reasoning tasks, we call DeepSeek-V3 to generate a potential chain-of-thought before answering the question by prompting. However, for simpler queries, such as “hello” we do not provide a CoT in response. In the end, we collected a total of approximately 200k training samples that are unrelated to reasoning.
非推理数据 对于非推理数据,例如写作、事实问答、自我认知和翻译,我们采用 DeepSeek-V3 流程并重用 DeepSeek-V3 的部分 SFT 数据集。对于某些非推理任务,我们会调用 DeepSeek-V3 生成潜在的思路链,然后再通过提示回答问题。但是,对于更简单的查询,例如“你好”,我们不提供 CoT 作为响应。最终,我们总共收集了大约 20 万个与推理无关的训练样本。
We fine-tune DeepSeek-V3-Base for two epochs using the above curated dataset of about 800k samples.
我们使用上述精心策划的约 80 万个样本的数据集对 DeepSeek-V3-Base 进行两个 epochs 的微调。
Reinforcement Learning for all Scenarios(所有场景的强化学习)
To further align the model with human preferences, we implement a secondary reinforcement learning stage aimed at improving the model’s helpfulness and harmlessness while simultane- ously refining its reasoning capabilities. Specifically, we train the model using a combination of reward signals and diverse prompt distributions. For reasoning data, we adhere to the methodology outlined in DeepSeek-R1-Zero, which utilizes rule-based rewards to guide the learning process in math, code, and logical reasoning domains. For general data, we resort to reward models to capture human preferences in complex and nuanced scenarios. We build upon the DeepSeek-V3 pipeline and adopt a similar distribution of preference pairs and train- ing prompts. For helpfulness, we focus exclusively on the final summary, ensuring that the assessment emphasizes the utility and relevance of the response to the user while minimizing interference with the underlying reasoning process. For harmlessness, we evaluate the entire response of the model, including both the reasoning process and the summary, to identify and mitigate any potential risks, biases, or harmful content that may arise during the generation process. Ultimately, the integration of reward signals and diverse data distributions enables us to train a model that excels in reasoning while prioritizing helpfulness and harmlessness.
为了进一步使模型与人类偏好保持一致,我们实施了一个旨在提高模型的帮助性和无害性的次级强化学习阶段,同时完善其推理能力。具体来说,我们使用奖励信号和多样化的提示分布的组合来训练模型。对于推理数据,我们遵循 DeepSeek-R1-Zero 中概述的方法,该方法利用基于规则的奖励来引导数学、代码和逻辑推理领域的学习过程。对于一般数据,我们求助于奖励模型,以捕捉复杂和微妙场景中的人类偏好。我们在 DeepSeek-V3 流程的基础上构建,并采用类似的偏好对和训练提示分布。对于帮助性,我们专注于最终的总结,确保评估强调响应对用户的实用性和相关性,同时最大程度地减少对底层推理过程的干扰。对于无害性,我们评估模型的整个响应,包括推理过程和总结,以识别和减轻在生成过程中可能出现的任何潜在风险、偏见或有害内容。最终,奖励信号和多样化的数据分布的整合使我们能够训练出一个在推理方面表现出色的模型,同时优先考虑帮助性和无害性。
Distillation: Empower Small Models with Reasoning Capability(蒸馏:赋予小模型推理能力)
To equip more efficient smaller models with reasoning capabilities like DeekSeek-R1, we directly fine-tuned open-source models like Qwen (Qwen, 2024b) and Llama (AI@Meta, 2024) using the 800k samples curated with DeepSeek-R1, as detailed in §2.3.3. Our findings indicate that this straightforward distillation method significantly enhances the reasoning abilities of smaller models. The base models we use here are Qwen2.5-Math-1.5B, Qwen2.5-Math-7B, Qwen2.5- 14B, Qwen2.5-32B, Llama-3.1-8B, and Llama-3.3-70B-Instruct. We select Llama-3.3 because its reasoning capability is slightly better than that of Llama-3.1.
为了让更高效的小模型具备像 DeepSeek-R1 这样的推理能力,我们直接使用 DeepSeek-R1 精心策划的 80 万个样本对开源模型(如 Qwen(Qwen,2024b)和 Llama(AI@Meta,2024))进行微调,详见 §2.3.3。我们的研究结果表明,这种直接蒸馏方法显著增强了较小模型的推理能力。我们在这里使用的基础模型是 Qwen2.5-Math-1.5B、Qwen2.5-Math-7B、Qwen2.5-14B、Qwen2.5-32B、Llama-3.1-8B 和 Llama-3.3-70B-Instruct。我们选择 Llama-3.3,因为它的推理能力略优于 Llama-3.1。
For distilled models, we apply only SFT and do not include an RL stage, even though incorporating RL could substantially boost model performance. Our primary goal here is to demonstrate the effectiveness of the distillation technique, leaving the exploration of the RL stage to the broader research community.
对于蒸馏模型,我们仅应用 SFT,不包括 RL 阶段,尽管 RL 阶段可以显著提升模型性能。我们的主要目标是展示蒸馏技术的有效性,将 RL 阶段的探索留给更广泛的研究社区。
Experiment(实验)
Benchmarks We evaluate models on MMLU (Hendrycks et al., 2020), MMLU-Redux (Gema et al., 2024), MMLU-Pro (Wang et al., 2024), C-Eval (Huang et al., 2023), and CMMLU (Li et al., 2023), IFEval (Zhou et al., 2023), FRAMES (Krishna et al., 2024), GPQA Diamond (Rein et al., 2023), SimpleQA (OpenAI, 2024c), C-SimpleQA (He et al., 2024), SWE-Bench Verified (OpenAI, 112024d), Aider, LiveCodeBench (Jain et al., 2024) (2024-08 – 2025-01), Codeforces 2, Chinese National High School Mathematics Olympiad (CNMO 2024)3, and American Invitational Math- ematics Examination 2024 (AIME 2024) (MAA, 2024). In addition to standard benchmarks, we also evaluate our models on open-ended generation tasks using LLMs as judges. Specifically, we adhere to the original configurations of AlpacaEval 2.0 (Dubois et al., 2024) and Arena-Hard (Li et al., 2024), which leverage GPT-4-Turbo-1106 as judges for pairwise comparisons. Here, we only feed the final summary to evaluation to avoid the length bias. For distilled models, we report representative results on AIME 2024, MATH-500, GPQA Diamond, Codeforces, and LiveCodeBench.
基准 我们在 MMLU(Hendrycks et al.,2020)、MMLU-Redux(Gema et al.,2024)、MMLU-Pro(Wang et al.,2024)、C-Eval(Huang et al.,2023)和 CMMLU(Li et al.,2023)、IFEval(Zhou et al.,2023)、FRAMES(Krishna et al.,2024)、GPQA Diamond(Rein et al.,2023)、SimpleQA(OpenAI,2024c)、C-SimpleQA(He et al.,2024)、SWE-Bench Verified(OpenAI,112024d)、Aider、LiveCodeBench(Jain et al.,2024)(2024-08 – 2025-01)、Codeforces 2、中国国家高中数学奥林匹克竞赛(CNMO 2024)和美国初级数学考试2024(AIME 2024)(MAA,2024)上评估模型。除了标准基准之外,我们还使用 LLM 作为评委在开放式生成任务上评估我们的模型。具体来说,我们遵循 AlpacaEval 2.0(Dubois et al.,2024)和 Arena-Hard(Li et al.,2024)的原始配置,这两个配置利用 GPT-4-Turbo-1106 作为评委进行成对比较。在这里,我们只将最终总结提供给评估,以避免长度偏差。对于蒸馏模型,我们在 AIME 2024、MATH-500、GPQA Diamond、Codeforces 和 LiveCodeBench 上报告代表性结果。
Evaluation Prompts Following the setup in DeepSeek-V3, standard benchmarks such as MMLU, DROP, GPQA Diamond, and SimpleQA are evaluated using prompts from the simple- evals framework. For MMLU-Redux, we adopt the Zero-Eval prompt format (Lin, 2024) in a zero-shot setting. In terms of MMLU-Pro, C-Eval and CLUE-WSC, since the original prompts are few-shot, we slightly modify the prompt to the zero-shot setting. The CoT in few-shot may hurt the performance of DeepSeek-R1. Other datasets follow their original evaluation protocols with default prompts provided by their creators. For code and math benchmarks, the HumanEval-Mul dataset covers eight mainstream programming languages (Python, Java, C++, C#, JavaScript, TypeScript, PHP, and Bash). Model performance on LiveCodeBench is evaluated using CoT format, with data collected between August 2024 and January 2025. The Codeforces dataset is evaluated using problems from 10 Div.2 contests along with expert-crafted test cases, after which the expected ratings and percentages of competitors are calculated. SWE-Bench verified results are obtained via the agentless framework (Xia et al., 2024). AIDER-related benchmarks are measured using a “diff” format. DeepSeek-R1 outputs are capped at a maximum of 32,768 tokens for each benchmark.
评估提示 根据 DeepSeek-V3 的设置,使用 simple-evals 框架的提示来评估标准基准,如 MMLU、DROP、GPQA Diamond 和 SimpleQA。对于 MMLU-Redux,我们在零样本设置中采用 Zero-Eval 提示格式(Lin,2024)。在 MMLU-Pro、C-Eval 和 CLUE-WSC 方面,由于原始提示是少样本的,我们将提示稍微修改为零样本设置。少样本中的 CoT 可能会损害 DeepSeek-R1 的性能。其他数据集遵循其创建者提供的默认提示的原始评估协议。对于代码和数学基准,HumanEval-Mul 数据集涵盖了八种主流编程语言(Python、Java、C++、C#、JavaScript、TypeScript、PHP 和 Bash)。使用 CoT 格式评估 LiveCodeBench 上的模型性能,数据收集时间为 2024 年 8 月至 2025 年 1 月。Codeforces 数据集使用 10 个 Div.2 比赛的问题以及专家制作的测试用例进行评估,然后计算出预期的评级和竞争者的百分比。SWE-Bench 验证结果是通过无代理框架(Xia et al.,2024)获得的。AIDER 相关基准使用“diff”格式进行测量。DeepSeek-R1 的输出在每个基准上最多为 32,768 个标记。
Baselines We conduct comprehensive evaluations against several strong baselines, including DeepSeek-V3, Claude-Sonnet-3.5-1022, GPT-4o-0513, OpenAI-o1-mini, and OpenAI-o1-1217. Since accessing the OpenAI-o1-1217 API is challenging in mainland China, we report its performance based on official reports. For distilled models, we also compare the open-source model QwQ-32B-Preview (Qwen, 2024a).
基线 我们针对几个强基线进行了全面评估,包括 DeepSeek-V3、Claude-Sonnet-3.5-1022、GPT-4o-0513、OpenAI-o1-mini 和 OpenAI-o1-1217。由于在中国大陆访问 OpenAI-o1-1217 API 是具有挑战性的,我们根据官方报告报告其性能。对于蒸馏模型,我们还比较了开源模型 QwQ-32B-Preview(Qwen,2024a)。
Generation Setup For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of 0.6, a top-p value of 0.95, and generate 64 responses per query to estimate pass@1.
生成设置 对于我们所有的模型,最大生成长度设置为 32,768 个标记。对于需要采样的基准,我们使用温度为 0.6,顶部-p 值为 0.95,并为每个查询生成 64 个响应,以估计 pass@1。
DeepSeek-R1 Evaluation(DeepSeek-R1 评估)
For education-oriented knowledge benchmarks such as MMLU, MMLU-Pro, and GPQA Di- amond, DeepSeek-R1 demonstrates superior performance compared to DeepSeek-V3. This improvement is primarily attributed to enhanced accuracy in STEM-related questions, where significant gains are achieved through large-scale reinforcement learning (RL). Additionally, DeepSeek-R1 excels on FRAMES, a long-context-dependent QA task, showcasing its strong document analysis capabilities. This highlights the potential of reasoning models in AI-driven search and data analysis tasks. On the factual benchmark SimpleQA, DeepSeek-R1 outperforms DeepSeek-V3, demonstrating its capability in handling fact-based queries. A similar trend is observed where OpenAI-o1 surpasses GPT-4o on this benchmark. However, DeepSeek-R1 performs worse than DeepSeek-V3 on the Chinese SimpleQA benchmark, primarily due to its tendency to refuse answering certain queries after safety RL. Without safety RL, DeepSeek-R1 could achieve an accuracy of over 70%.
对于教育导向的知识基准,如 MMLU、MMLU-Pro 和 GPQA Diamond,DeepSeek-R1 在准确性上表现优于 DeepSeek-V3。这一改进主要归因于在 STEM 相关问题中通过大规模强化学习(RL)实现的显著增益。此外,DeepSeek-R1 在 FRAMES 上表现出色,这是一个长上下文依赖的 QA 任务,展示了其强大的文档分析能力。这突显了推理模型在 AI 驱动的搜索和数据分析任务中的潜力。在事实基准 SimpleQA 上,DeepSeek-R1 胜过 DeepSeek-V3,展示了其处理基于事实的查询的能力。在这个基准上,OpenAI-o1 超过了 GPT-4o,表现出类似的趋势。然而,DeepSeek-R1 在中文 SimpleQA 基准上的表现不如 DeepSeek-V3,主要是由于其在安全 RL 后拒绝回答某些查询的倾向。没有安全 RL,DeepSeek-R1 可以达到超过 70% 的准确性。
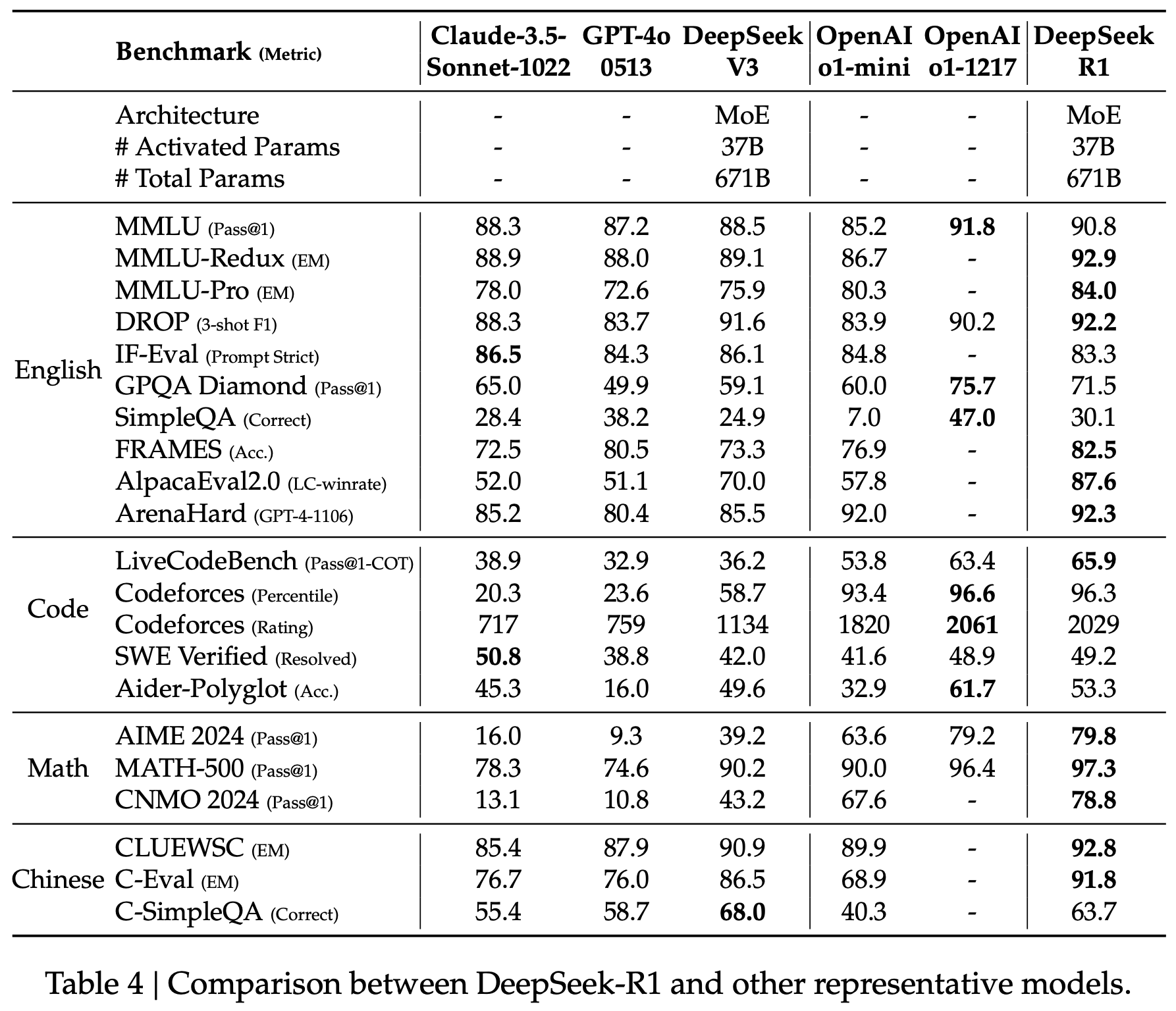
表4 DeepSeek-R1 与其他代表性模型的比较。
DeepSeek-R1 also delivers impressive results on IF-Eval, a benchmark designed to assess a model’s ability to follow format instructions. These improvements can be linked to the inclusion of instruction-following data during the final stages of supervised fine-tuning (SFT) and RL training. Furthermore, remarkable performance is observed on AlpacaEval2.0 and ArenaHard, indicating DeepSeek-R1’s strengths in writing tasks and open-domain question answering. Its significant outperformance of DeepSeek-V3 underscores the generalization benefits of large-scale RL, which not only boosts reasoning capabilities but also improves performance across diverse domains. Moreover, the summary lengths generated by DeepSeek-R1 are concise, with an average of 689 tokens on ArenaHard and 2,218 characters on AlpacaEval 2.0. This indicates that DeepSeek-R1 avoids introducing length bias during GPT-based evaluations, further solidifying its robustness across multiple tasks.
DeepSeek-R1 在 IF-Eval 上也取得了令人印象深刻的成绩,该基准旨在评估模型遵循格式说明的能力。这些改进可以与在监督微调(SFT)和 RL 训练的最后阶段包含遵循说明数据有关。此外,在 AlpacaEval2.0 和 ArenaHard 上观察到了显著的表现,表明 DeepSeek-R1 在写作任务和开放域问答中的优势。它对 DeepSeek-V3 的显著超越强调了大规模 RL 的泛化优势,这不仅提升了推理能力,还提高了跨多个领域的性能。此外,DeepSeek-R1 生成的总结长度简洁,ArenaHard 平均为 689 个标记,AlpacaEval 2.0 为 2,218 个字符。这表明 DeepSeek-R1 在基于 GPT 的评估中避免引入长度偏差,进一步巩固了其在多个任务中的稳健性。
On math tasks, DeepSeek-R1 demonstrates performance on par with OpenAI-o1-1217, surpassing other models by a large margin. A similar trend is observed on coding algorithm tasks, such as LiveCodeBench and Codeforces, where reasoning-focused models dominate these benchmarks. On engineering-oriented coding tasks, OpenAI-o1-1217 outperforms DeepSeek-R1 on Aider but achieves comparable performance on SWE Verified. We believe the engineering performance of DeepSeek-R1 will improve in the next version, as the amount of related RL training data currently remains very limited.
在数学任务上,DeepSeek-R1 的表现与 OpenAI-o1-1217 相当,远远超过其他模型。在编码算法任务上也观察到类似的趋势,例如 LiveCodeBench 和 Codeforces,推理为重点的模型主导了这些基准。在面向工程的编码任务中,OpenAI-o1-1217 在 Aider 上胜过 DeepSeek-R1,但在 SWE 验证上取得了可比的表现。我们相信 DeepSeek-R1 的工程性能将在下一个版本中得到改善,因为目前相关 RL 训练数据的数量仍然非常有限。
Distilled Model Evaluation(蒸馏模型评估)
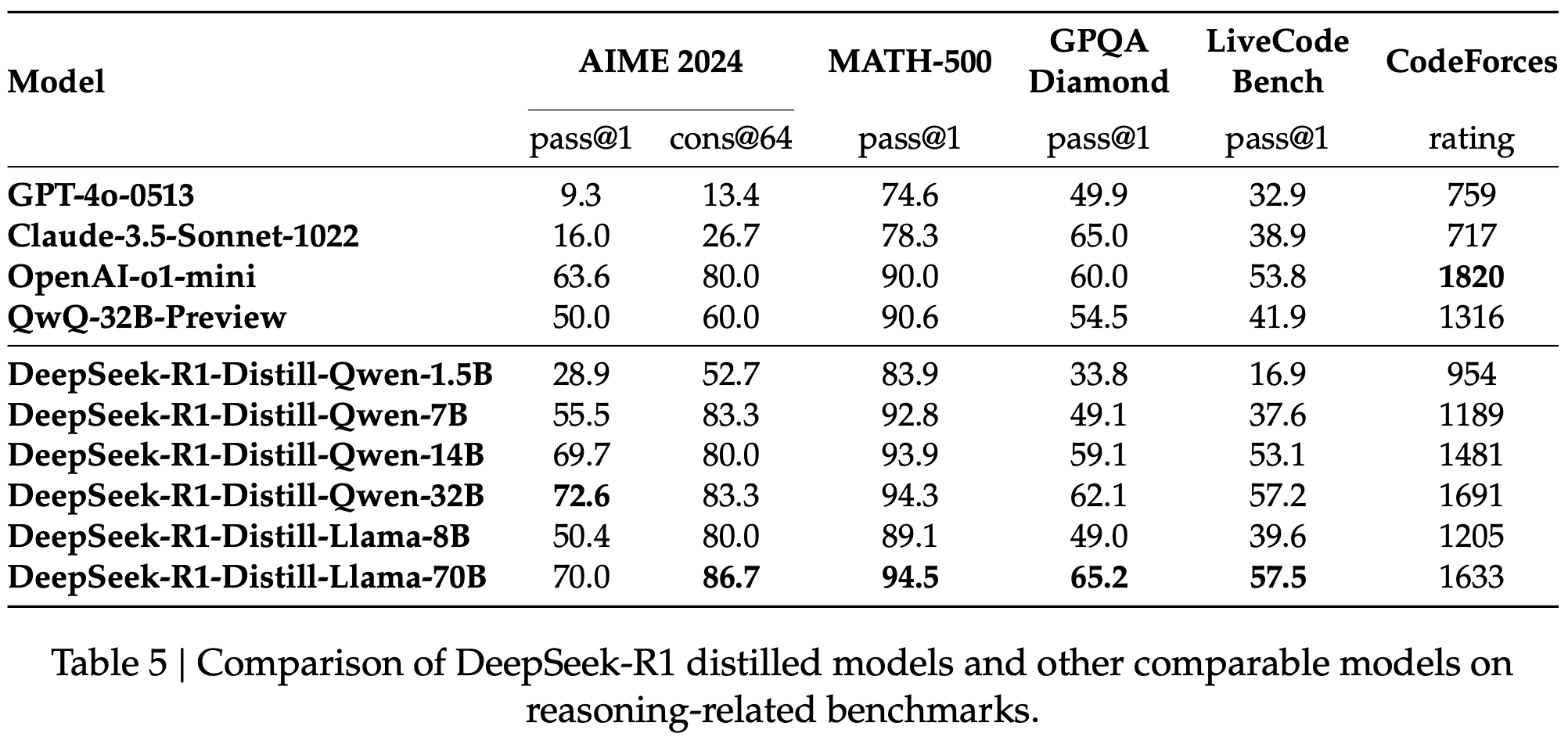
表5 DeepSeek-R1 蒸馏模型与其他可比模型在与推理相关的基准上的比较。
As shown in Table 5, simply distilling DeepSeek-R1’s outputs enables the efficient DeepSeek- R1-7B (i.e., DeepSeek-R1-Distill-Qwen-7B, abbreviated similarly below) to outperform non- reasoning models like GPT-4o-0513 across the board. DeepSeek-R1-14B surpasses QwQ-32B- Preview on all evaluation metrics, while DeepSeek-R1-32B and DeepSeek-R1-70B significantly exceed o1-mini on most benchmarks. These results demonstrate the strong potential of distilla- tion. Additionally, we found that applying RL to these distilled models yields significant further gains. We believe this warrants further exploration and therefore present only the results of the simple SFT-distilled models here.
如表 5 所示,简单地蒸馏 DeepSeek-R1 的输出使高效的 DeepSeek-R1-7B(即 DeepSeek-R1-Distill-Qwen-7B,以下类似缩写)在各方面均胜过 GPT-4o-0513 等非推理模型。DeepSeek-R1-14B 在所有评估指标上超过了 QwQ-32B-Preview,而 DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多数基准上显著超过了 o1-mini。这些结果展示了蒸馏的强大潜力。此外,我们发现将 RL 应用于这些蒸馏模型会带来显著的进一步收益。我们认为这值得进一步探索,因此这里仅呈现简单的 SFT 蒸馏模型的结果。
Discussion(讨论)
Distillation v.s. Reinforcement Learning(蒸馏与强化学习)
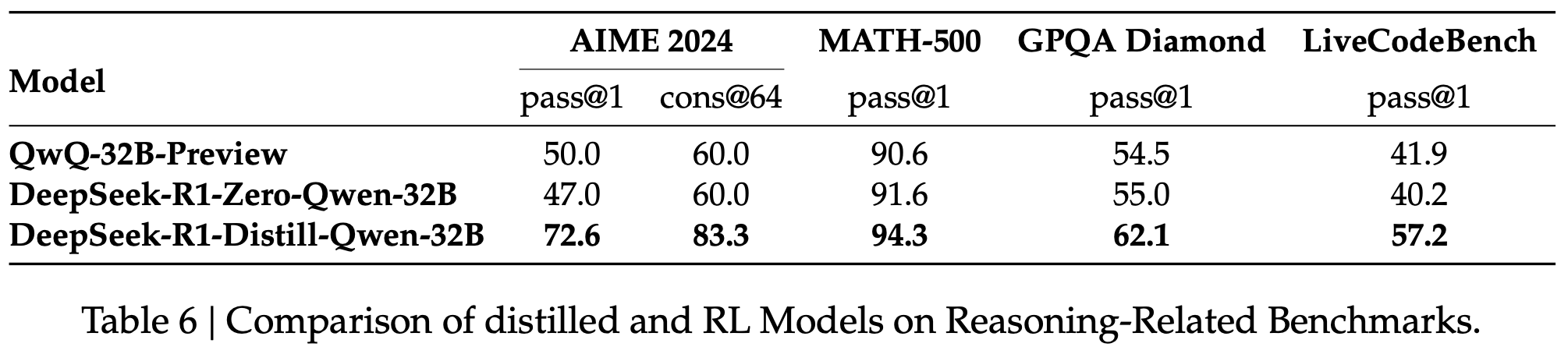
表6 在与推理相关的基准上比较蒸馏和 RL 模型。
In Section 3.2, we can see that by distilling DeepSeek-R1, the small model can achieve impressive results. However, there is still one question left: can the model achieve comparable performance through the large-scale RL training discussed in the paper without distillation?
在第 3.2 节中,我们可以看到通过蒸馏 DeepSeek-R1,小模型可以取得令人印象深刻的结果。然而,仍然有一个问题:模型是否可以通过本文讨论的大规模 RL 训练实现可比性能,而无需蒸馏?
To answer this question, we conduct large-scale RL training on Qwen-32B-Base using math, code, and STEM data, training for over 10K steps, resulting in DeepSeek-R1-Zero-Qwen-32B. The experimental results, shown in Figure 6, demonstrate that the 32B base model, after large-scale RL training, achieves performance on par with QwQ-32B-Preview. However, DeepSeek-R1- Distill-Qwen-32B, which is distilled from DeepSeek-R1, performs significantly better than DeepSeek-R1-Zero-Qwen-32B across all benchmarks. Therefore, we can draw two conclusions: First, distilling more powerful models into smaller ones yields excellent results, whereas smaller models relying on the large-scale RL mentioned in this paper require enormous computational power and may not even achieve the performance of distillation. Second, while distillation strategies are both economical and effective, advancing beyond the boundaries of intelligence may still require more powerful base models and larger-scale reinforcement learning.
为了回答这个问题,我们对 Qwen-32B-Base 使用数学、代码和 STEM 数据进行大规模 RL 训练,训练超过 10K 步,得到 DeepSeek-R1-Zero-Qwen-32B。实验结果如图 6 所示,表明 32B 基础模型在大规模 RL 训练后,实现了与 QwQ-32B-Preview 相当的性能。然而,从 DeepSeek-R1 蒸馏而来的 DeepSeek-R1-Distill-Qwen-32B 在所有基准上的表现明显优于 DeepSeek-R1-Zero-Qwen-32B。因此,我们可以得出两个结论:首先,将更强大的模型蒸馏为更小的模型会产生出色的结果,而依赖本文提到的大规模 RL 的较小模型需要巨大的计算能力,甚至可能无法达到蒸馏的性能。其次,虽然蒸馏策略既经济又有效,但要超越智能的边界可能仍需要更强大的基础模型和更大规模的强化学习。
Unsuccessful Attempts(未成功的尝试)
In the early stages of developing DeepSeek-R1, we also encountered failures and setbacks along the way. We share our failure experiences here to provide insights, but this does not imply that these approaches are incapable of developing effective reasoning models.
在开发 DeepSeek-R1 的早期阶段,我们也在途中遇到了失败和挫折。我们在这里分享我们的失败经验,以提供见解,但这并不意味着这些方法无法开发出有效的推理模型。
Process Reward Model (PRM) PRM is a reasonable method to guide the model toward better approaches for solving reasoning tasks (Lightman et al., 2023; Uesato et al., 2022; Wang et al., 2023). However, in practice, PRM has three main limitations that may hinder its ultimate suc- cess. First, it is challenging to explicitly define a fine-grain step in general reasoning. Second, determining whether the current intermediate step is correct is a challenging task. Automated annotation using models may not yield satisfactory results, while manual annotation is not con- ducive to scaling up. Third, once a model-based PRM is introduced, it inevitably leads to reward hacking (Gao et al., 2022), and retraining the reward model needs additional training resources and it complicates the whole training pipeline. In conclusion, while PRM demonstrates a good ability to rerank the top-N responses generated by the model or assist in guided search (Snell et al., 2024), its advantages are limited compared to the additional computational overhead it introduces during large-scale reinforcement learning process in our experiments.
过程奖励模型(PRM) PRM 是引导模型朝着更好的方法解决推理任务的合理方法(Lightman et al.,2023;Uesato et al.,2022;Wang et al.,2023)。然而,在实践中,PRM 有三个主要限制可能会阻碍其最终成功。首先,通常推理中难以明确定义细粒度步骤。其次,确定当前中间步骤是否正确是一项具有挑战性的任务。使用模型进行自动注释可能不会产生令人满意的结果,而手动注释不利于扩展。第三,一旦引入基于模型的 PRM,它不可避免地会导致奖励黑客(Gao et al.,2022),重新训练奖励模型需要额外的训练资源,并且会使整个训练流程复杂化。总之,虽然 PRM 在重新排列模型生成的前 N 个响应或在引导搜索中提供帮助方面表现出色(Snell et al.,2024),但与其在我们的实验中引入的额外计算开销相比,其优势有限。
Monte Carlo Tree Search (MCTS) Inspired by AlphaGo (Silver et al., 2017b) and AlphaZero (Sil- ver et al., 2017a), we explored using Monte Carlo Tree Search (MCTS) to enhance test-time compute scalability. This approach involves breaking answers into smaller parts to allow the model to explore the solution space systematically. To facilitate this, we prompt the model to generate multiple tags that correspond to specific reasoning steps necessary for the search. For training, we first use collected prompts to find answers via MCTS guided by a pre-trained value model. Subsequently, we use the resulting question-answer pairs to train both the actor model and the value model, iteratively refining the process.
蒙特卡洛树搜索(MCTS) 受 AlphaGo(Silver et al.,2017b)和 AlphaZero(Silver et al.,2017a)的启发,我们探索了使用蒙特卡洛树搜索(MCTS)来增强测试时的计算可扩展性。这种方法涉及将答案分解为较小的部分,以使模型能够系统地探索解决方案空间。为了促进这一点,我们提示模型生成多个标签,这些标签对应于搜索所需的特定推理步骤。对于训练,我们首先使用收集的提示通过由预训练值模型引导的 MCTS 找到答案。随后,我们使用生成的问题-答案对来训练 actor 模型和值模型,迭代地完善这个过程。
However, this approach encounters several challenges when scaling up the training. First, unlike chess, where the search space is relatively well-defined, token generation presents an exponentially larger search space. To address this, we set a maximum extension limit for each node, but this can lead to the model getting stuck in local optima. Second, the value model directly influences the quality of generation since it guides each step of the search process. Training a fine-grained value model is inherently difficult, which makes it challenging for the model to iteratively improve. While AlphaGo’s core success relied on training a value model to progressively enhance its performance, this principle proves difficult to replicate in our setup due to the complexities of token generation.
然而,当扩展训练规模时,这种方法遇到了几个挑战。首先,与国际象棋不同,其中搜索空间相对明确定义,标记生成呈指数级更大的搜索空间。为了解决这个问题,我们为每个节点设置了最大扩展限制,但这可能导致模型陷入局部最优解。其次,值模型直接影响生成的质量,因为它指导搜索过程的每一步。训练细粒度的值模型本质上是困难的,这使得模型难以迭代地改进。虽然 AlphaGo 的核心成功依赖于训练值模型逐步提高其性能,但由于标记生成的复杂性,这一原则在我们的设置中难以复制。
In conclusion, while MCTS can improve performance during inference when paired with a pre-trained value model, iteratively boosting model performance through self-search remains a significant challenge.
总之,虽然 MCTS 在与预训练值模型配对时可以提高推理性能,但通过自我搜索迭代提高模型性能仍然是一个重大挑战。
Conclusion, Limitation, and Future Work(结论、局限性和未来工作)
In this work, we share our journey in enhancing model reasoning abilities through reinforcement learning (RL). DeepSeek-R1-Zero represents a pure RL approach without relying on cold-start data, achieving strong performance across various tasks. DeepSeek-R1 is more powerful, leveraging cold-start data alongside iterative RL fine-tuning. Ultimately, DeepSeek-R1 achieves performance comparable to OpenAI-o1-1217 on a range of tasks.
在这项工作中,我们分享了通过强化学习(RL)增强模型推理能力的旅程。DeepSeek-R1-Zero 代表了一种纯 RL 方法,不依赖冷启动数据,在各种任务中取得了强大的性能。DeepSeek-R1 更强大,利用冷启动数据和迭代 RL 微调。最终,DeepSeek-R1 在各种任务上实现了与 OpenAI-o1-1217 相当的性能。
We further explore distillation the reasoning capability to small dense models. We use DeepSeek-R1 as the teacher model to generate 800K data, and fine-tune several small dense models. The results are promising: DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks with 28.9% on AIME and 83.9% on MATH. Other dense models also achieve impressive results, significantly outperforming other instruction-tuned models based on the same underlying checkpoints.
我们进一步探索了将推理能力蒸馏到小型稠密模型中。我们使用 DeepSeek-R1 作为教师模型生成 80 万数据,并微调了几个小型稠密模型。结果是令人鼓舞的:DeepSeek-R1-Distill-Qwen-1.5B 在数学基准上的表现优于 GPT-4o 和 Claude-3.5-Sonnet,AIME 上为 28.9%,MATH 上为 83.9%。其他稠密模型也取得了令人印象深刻的结果,明显优于基于相同基础检查点的其他基于指令调整的模型。
In the future, we plan to invest in research across the following directions for DeepSeek-R1.
未来,我们计划在以下方向上为 DeepSeek-R1 进行研究。
- General Capability: Currently, the capabilities of DeepSeek-R1 fall short of DeepSeek-V3 in tasks such as function calling, multi-turn, complex role-playing, and json output. Moving forward, we plan to explore how leveraging long CoT to enhance tasks in these fields.
- 通用能力:目前,DeepSeek-R1 在函数调用、多轮、复杂角色扮演和 json 输出等任务中的能力不及 DeepSeek-V3。未来,我们计划探索如何利用长 CoT 来增强这些领域的任务。
- Language Mixing: DeepSeek-R1 is currently optimized for Chinese and English, which may result in language mixing issues when handling queries in other languages. For instance, DeepSeek-R1 might use English for reasoning and responses, even if the query is in a language other than English or Chinese. We aim to address this limitation in future updates.
- 语言混合:DeepSeek-R1 目前针对中文和英文进行了优化,这可能导致处理其他语言查询时出现语言混合问题。例如,DeepSeek-R1 可能在查询不是英文或中文的语言时使用英文进行推理和响应。我们希望在未来的更新中解决这个局限性。
- Prompting Engineering: When evaluating DeepSeek-R1, we observe that it is sensitive to prompts. Few-shot prompting consistently degrades its performance. Therefore, we recommend users directly describe the problem and specify the output format using a zero-shot setting for optimal results.
- 提示工程:在评估 DeepSeek-R1 时,我们观察到它对提示很敏感。少样本提示会持续降低其性能。因此,我们建议用户直接描述问题,并使用零样本设置指定输出格式以获得最佳结果。
- Software Engineering Tasks: Due to the long evaluation times, which impact the efficiency of the RL process, large-scale RL has not been applied extensively in software engineering tasks. As a result, DeepSeek-R1 has not demonstrated a huge improvement over DeepSeek-V3 on software engineering benchmarks. Future versions will address this by implementing reject sampling on software engineering data or incorporating asynchronous evaluations during the RL process to improve efficiency.
- 软件工程任务:由于长时间的评估时间影响了 RL 过程的效率,大规模 RL 在软件工程任务中并没有得到广泛应用。因此,DeepSeek-R1 在软件工程基准上并没有比 DeepSeek-V3 显著改进。未来版本将通过在软件工程数据上实现拒绝采样或在 RL 过程中引入异步评估来提高效率。