华为 Atlas 800I A2 服务器的大模型推理性能压测
类别: Atlas800 Benchmark 标签: EvalScope Atlas800 NPU MindIE vLLM Benchmark LLM目录
- 大模型推理性能压测工具
- 数据集
- 实验结果对比
- 实验结果(MindIE)
- 实验结果(vLLM)
- 实验结果(XInference - MindIE)
- 实验结果(Nvidia T4: XInference - vLLM)
- 实验结果(Nvidia T4: vLLM)
- 参考资料
大模型推理性能压测工具
安装 EvalScope
git clone https://github.com/modelscope/evalscope
cd evalscope
pip install -e .
压测命令的使用
evalscope perf \
--api openai \
--url 'http://127.0.0.1:1025/v1/chat/completions' \
--model 'qwen' \
--dataset openqa \
--dataset-path './datasets/open_qa.jsonl' \
--max-prompt-length 8000 \
--stop '<|im_end|>' \
--read-timeout=120 \
--parallel 100 \
-n 1000
❌ –stream 不要加,经常出问题。
--read-timeout: 网络读取超时--parallel: 并发数-n: 请求数
数据集
中文聊天 HC3-Chinese
mkdir datasets
wget https://modelscope.cn/datasets/AI-ModelScope/HC3-Chinese/resolve/master/open_qa.jsonl \
-O datasets/open_qa.jsonl
压测命令
evalscope perf \
--api openai \
--url 'http://127.0.0.1:1025/v1/chat/completions' \
--model 'qwen' \
--dataset openqa \
--dataset-path './datasets/open_qa.jsonl' \
--max-prompt-length 8000 \
--stop '<|im_end|>' \
--read-timeout=120 \
--parallel 1 \
-n 1
代码问答 Codefuse-Evol-Instruct-Clean
wget https://modelscope.cn/datasets/Banksy235/Codefuse-Evol-Instruct-Clean/resolve/master/data.json \
-O datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
# 修改数据集格式,将 "input" 改为 "question",以适应 EvalScope 的数据集格式 openqa
sed -i 's/"input"/"question"/g' datasets/Codefuse-Evol-Instruct-Clean-data.jsonl
压测命令
evalscope perf \
--api openai \
--url 'http://127.0.0.1:1025/v1/chat/completions' \
--model 'qwen' \
--dataset openqa \
--dataset-path './datasets/Codefuse-Evol-Instruct-Clean-data.jsonl' \
--max-prompt-length 4000 \
--stop '<|im_end|>' \
--read-timeout=120 \
--parallel 1 \
-n 1
构造长输入和输出的数据集
编辑文件:datasets/long.jsonl
{"question":"Learning to Reason with LLMs\nWe are introducing OpenAI o1, a new large language model trained with reinforcement learning to perform complex reasoning. o1 thinks before it answers—it can produce a long internal chain of thought before responding to the user.\n\nContributions\nOpenAI o1 ranks in the 89th percentile on competitive programming questions (Codeforces), places among the top 500 students in the US in a qualifier for the USA Math Olympiad (AIME), and exceeds human PhD-level accuracy on a benchmark of physics, biology, and chemistry problems (GPQA). While the work needed to make this new model as easy to use as current models is still ongoing, we are releasing an early version of this model, OpenAI o1-preview, for immediate use in ChatGPT and to trusted API users(opens in a new window).\n\nOur large-scale reinforcement learning algorithm teaches the model how to think productively using its chain of thought in a highly data-efficient training process. We have found that the performance of o1 consistently improves with more reinforcement learning (train-time compute) and with more time spent thinking (test-time compute). The constraints on scaling this approach differ substantially from those of LLM pretraining, and we are continuing to investigate them.\n\nThe image shows two scatter plots comparing o1 AIME accuracy during training and at test time. Both charts have pass@1 accuracy on the y-axis and compute (log scale) on the x-axis. The dots indicate increasing accuracy with more compute time.\no1 performance smoothly improves with both train-time and test-time compute\n\nEvals\nTo highlight the reasoning improvement over GPT-4o, we tested our models on a diverse set of human exams and ML benchmarks. We show that o1 significantly outperforms GPT-4o on the vast majority of these reasoning-heavy tasks. Unless otherwise specified, we evaluated o1 on the maximal test-time compute setting.\n\nCompetition evals for Math (AIME 2024), Code (CodeForces), and PhD-Level Science Questions (GPQA Diamond)\no1 greatly improves over GPT-4o on challenging reasoning benchmarks. Solid bars show pass@1 accuracy and the shaded region shows the performance of majority vote (consensus) with 64 samples.\nBreakdown of the accuracy and raw score of gpt-4o vs. o1 on various competition evals\no1 improves over GPT-4o on a wide range of benchmarks, including 54/57 MMLU subcategories. Seven are shown for illustration.\nIn many reasoning-heavy benchmarks, o1 rivals the performance of human experts. Recent frontier models1 do so well on MATH2 and GSM8K that these benchmarks are no longer effective at differentiating models.\nA score of 13.9 places it among the top 500 students nationally and above the cutoff for the USA Mathematical Olympiad.\n\nWe also evaluated o1 on GPQA diamond, a difficult intelligence benchmark which tests for expertise in chemistry, physics and biology. In order to compare models to humans, we recruited experts with PhDs to answer GPQA-diamond questions. We found that o1 surpassed the performance of those human experts, becoming the first model to do so on this benchmark. These results do not imply that o1 is more capable than a PhD in all respects — only that the model is more proficient in solving some problems that a PhD would be expected to solve. On several other ML benchmarks, o1 improved over the state-of-the-art. With its vision perception capabilities enabled, o1 scored 78.2 on MMMU, making it the first model to be competitive with human experts. It also outperformed GPT-4o on 54 out of 57 MMLU subcategories.\n\nChain of Thought\nSimilar to how a human may think for a long time before responding to a difficult question, o1 uses a chain of thought when attempting to solve a problem. Through reinforcement learning, o1 learns to hone its chain of thought and refine the strategies it uses. It learns to recognize and correct its mistakes. It learns to break down tricky steps into simpler ones. It learns to try a different approach when the current one isn’t working. This process dramatically improves the model’s ability to reason. To illustrate this leap forward, we showcase the chain of thought from o1-preview on several difficult problems below.\n\nCoding\nWe trained a model that scored 213 points and ranked in the 49th percentile in the 2024 International Olympiad in Informatics (IOI), by initializing from o1 and training to further improve programming skills. This model competed in the 2024 IOI under the same conditions as the human contestants. It had ten hours to solve six challenging algorithmic problems and was allowed 50 submissions per problem.\n\nFor each problem, our system sampled many candidate submissions and submitted 50 of them based on a test-time selection strategy. Submissions were selected based on performance on the IOI public test cases, model-generated test cases, and a learned scoring function. If we had instead submitted at random, we would have only scored 156 points on average, suggesting that this strategy was worth nearly 60 points under competition constraints.\n\nWith a relaxed submission constraint, we found that model performance improved significantly. When allowed 10,000 submissions per problem, the model achieved a score of 362.14 – above the gold medal threshold – even without any test-time selection strategy. \n\nFinally, we simulated competitive programming contests hosted by Codeforces to demonstrate this model’s coding skill. Our evaluations closely matched competition rules and allowed for 10 submissions. GPT-4o achieved an Elo rating3 of 808, which is in the 11th percentile of human competitors.\nHuman preference evaluation\nIn addition to exams and academic benchmarks, we also evaluated human preference of o1-preview vs GPT-4o on challenging, open-ended prompts in a broad spectrum of domains. In this evaluation, human trainers were shown anonymized responses to a prompt from o1-preview and GPT-4o, and voted for which response they preferred. o1-preview is preferred to gpt-4o by a large margin in reasoning-heavy categories like data analysis, coding, and math. However, o1-preview is not preferred on some natural language tasks, suggesting that it is not well-suited for all use cases.\n\nThe image shows a horizontal bar chart comparing five models scores with error bars representing confidence intervals. The x-axis ranges from 0 to 100, with a dashed line as a reference point for performance.\nSafety\nChain of thought reasoning provides new opportunities for alignment and safety. We found that integrating our policies for model behavior into the chain of thought of a reasoning model is an effective way to robustly teach human values and principles.\nWhat does all of this mean for founders in the AI market? What does this mean for incumbent software companies? And where do we, as investors, see the most promising layer for returns in the Generative AI stack?\nIn our latest essay on the state of the Generative AI market, we’ll explore how the consolidation of the foundational LLM layer has set the stage for the race to scale these higher-order reasoning and agentic capabilities, and discuss a new generation of “killer apps” with novel cognitive architectures and user interfaces.\nThis is where System 2 thinking comes in, and it’s the focus of the latest wave of AI research. When a model “stops to think,” it isn’t just generating learned patterns or spitting out predictions based on past data. It’s generating a range of possibilities, considering potential outcomes and making a decision based on reasoning. \n\nTranslate to France."}
输入和输出 Tokens 大约在 3500
压测命令
evalscope-perf http://127.0.0.1:1025/v1/chat/completions qwen \
./datasets/long.jsonl \
--max-prompt-length 8000 \
--read-timeout=120 \
--parallels 1 \
--n 1
实验结果对比
🏆 vLLM ⚔️ XInference (T4: 4X16G)
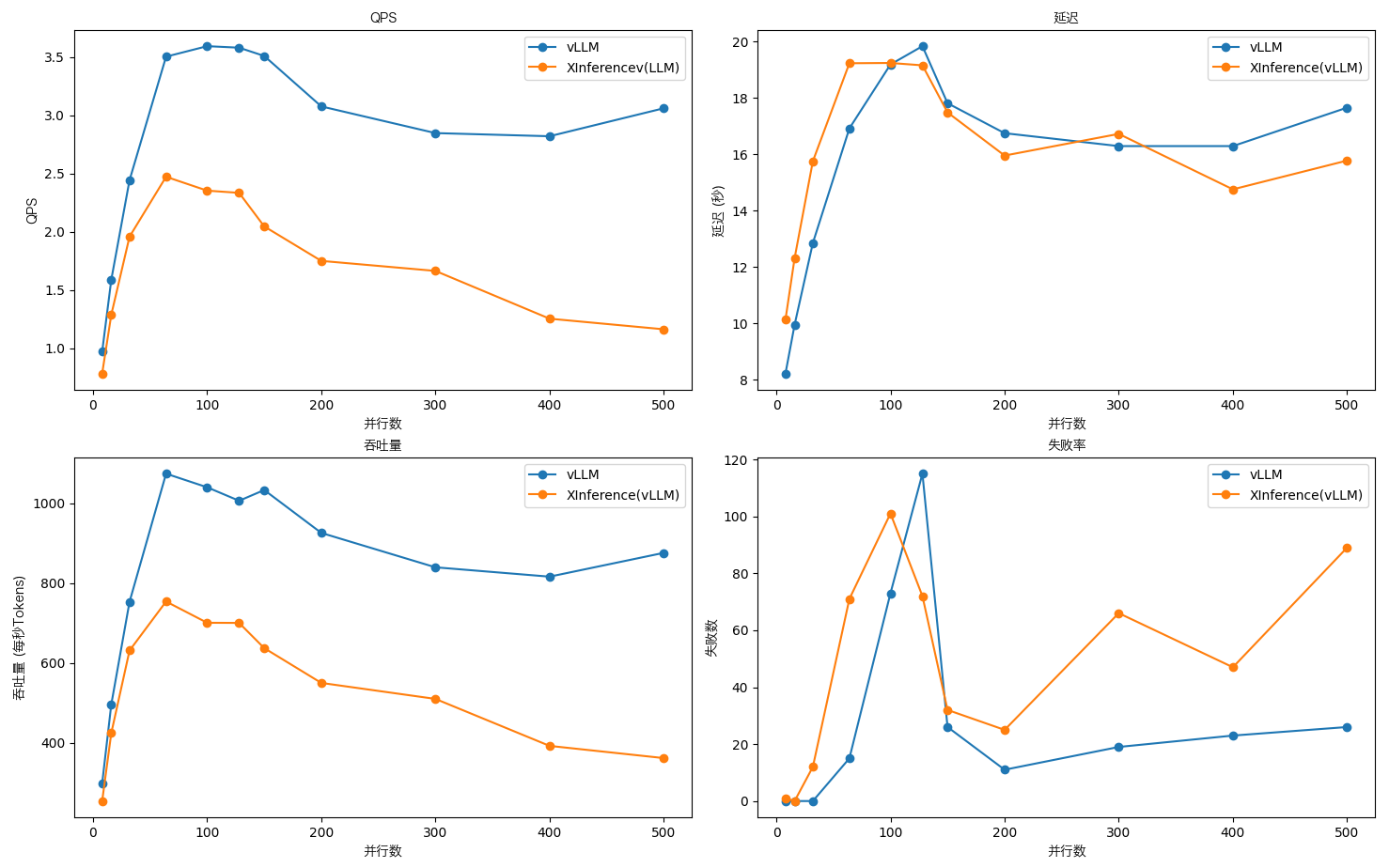
从结果看,在生产环境中还是要使用 vLLM,推理性能更好且稳定更棒。
代码
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 设置中文字体
font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc' # 替换为你的字体文件路径
font_prop = FontProperties(fname=font_path)
# 数据
batch_sizes = [8, 16, 32, 64, 100, 128, 150, 200, 300, 400, 500]
vllm_qps = [0.970, 1.588, 2.443, 3.503, 3.593, 3.580, 3.509, 3.076, 2.847, 2.820, 3.060]
xinf_qps = [0.783, 1.288, 1.958, 2.472, 2.353, 2.334, 2.046, 1.750, 1.664, 1.254, 1.163]
vllm_latency = [8.213, 9.944, 12.846, 16.913, 19.182, 19.831, 17.806, 16.743, 16.285, 16.285, 17.649]
xinf_latency = [10.128, 12.307, 15.749, 19.225, 19.235, 19.151, 17.479, 15.949, 16.718, 14.750, 15.771]
vllm_throughput = [298.860, 496.458, 753.176, 1073.697, 1039.610, 1005.881, 1032.794, 925.476, 839.437, 816.049, 875.565]
xinf_throughput = [254.695, 424.701, 631.260, 753.852, 700.681, 700.324, 637.260, 550.200, 510.211, 392.697, 362.167]
vllm_failures = [0, 0, 0, 15, 73, 115, 26, 11, 19, 23, 26]
xinf_failures = [1, 0, 12, 71, 101, 72, 32, 25, 66, 47, 89]
# 创建子图
fig, axs = plt.subplots(2, 2, figsize=(15, 10))
# QPS
axs[0, 0].plot(batch_sizes, vllm_qps, label='vLLM', marker='o')
axs[0, 0].plot(batch_sizes, xinf_qps, label='XInferencev(LLM)', marker='o')
axs[0, 0].set_title('QPS', fontproperties=font_prop)
axs[0, 0].set_xlabel('并行数', fontproperties=font_prop)
axs[0, 0].set_ylabel('QPS', fontproperties=font_prop)
axs[0, 0].legend()
# 延迟
axs[0, 1].plot(batch_sizes, vllm_latency, label='vLLM', marker='o')
axs[0, 1].plot(batch_sizes, xinf_latency, label='XInference(vLLM)', marker='o')
axs[0, 1].set_title('延迟', fontproperties=font_prop)
axs[0, 1].set_xlabel('并行数', fontproperties=font_prop)
axs[0, 1].set_ylabel('延迟 (秒)', fontproperties=font_prop)
axs[0, 1].legend()
# 吞吐量
axs[1, 0].plot(batch_sizes, vllm_throughput, label='vLLM', marker='o')
axs[1, 0].plot(batch_sizes, xinf_throughput, label='XInference(vLLM)', marker='o')
axs[1, 0].set_title('吞吐量', fontproperties=font_prop)
axs[1, 0].set_xlabel('并行数', fontproperties=font_prop)
axs[1, 0].set_ylabel('吞吐量 (每秒Tokens)', fontproperties=font_prop)
axs[1, 0].legend()
# 失败率
axs[1, 1].plot(batch_sizes, vllm_failures, label='vLLM', marker='o')
axs[1, 1].plot(batch_sizes, xinf_failures, label='XInference(vLLM)', marker='o')
axs[1, 1].set_title('失败率', fontproperties=font_prop)
axs[1, 1].set_xlabel('并行数', fontproperties=font_prop)
axs[1, 1].set_ylabel('失败数', fontproperties=font_prop)
axs[1, 1].legend()
# 调整布局
plt.tight_layout()
plt.show()
🏆 MindIE (910B4: 8X32G) ⚔️ vLLM (T4: 4X16G)
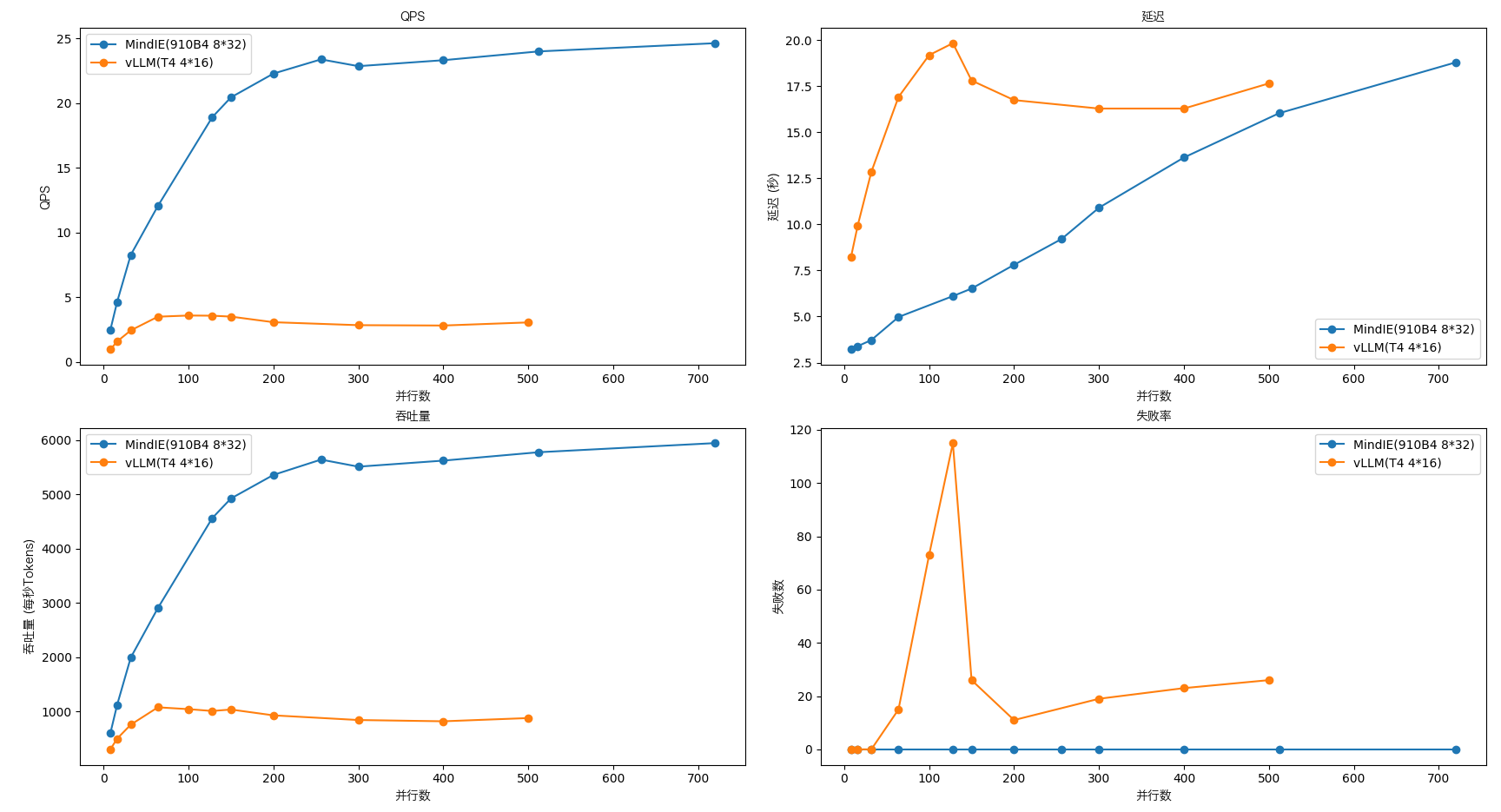
和我们现有服务器 T4 的性能对比
代码
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 设置中文字体
font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc' # 替换为你的字体文件路径
font_prop = FontProperties(fname=font_path)
# 数据
batch_sizes_mindie = [8, 16, 32, 64, 128, 150, 200, 256, 300, 400, 512, 720]
batch_sizes_vllm = [8, 16, 32, 64, 100, 128, 150, 200, 300, 400, 500]
mindie_qps = [2.474, 4.649, 8.273, 12.065, 18.924, 20.457, 22.294, 23.392, 22.868, 23.328, 24.007, 24.643]
vllm_qps = [0.970, 1.588, 2.443, 3.503, 3.593, 3.580, 3.509, 3.076, 2.847, 2.820, 3.060]
mindie_latency = [3.213, 3.391, 3.724, 4.974, 6.108, 6.517, 7.805, 9.208, 10.904, 13.628, 16.031, 18.790]
vllm_latency = [8.213, 9.944, 12.846, 16.913, 19.182, 19.831, 17.806, 16.743, 16.285, 16.285, 17.649]
mindie_throughput = [594.929, 1119.102, 1989.159, 2903.023, 4559.489, 4920.856, 5354.701, 5636.846, 5506.567, 5618.110, 5772.230, 5940.622]
vllm_throughput = [298.860, 496.458, 753.176, 1073.697, 1039.610, 1005.881, 1032.794, 925.476, 839.437, 816.049, 875.565]
mindie_failures = [0] * len(batch_sizes_mindie) # 假设 MindIE(910B4 8*32) 没有失败数据
vllm_failures = [0, 0, 0, 15, 73, 115, 26, 11, 19, 23, 26]
# 创建子图
fig, axs = plt.subplots(2, 2, figsize=(15, 10))
# QPS
axs[0, 0].plot(batch_sizes_mindie, mindie_qps, label='MindIE(910B4 8*32)', marker='o')
axs[0, 0].plot(batch_sizes_vllm, vllm_qps, label='vLLM(T4 4*16)', marker='o')
axs[0, 0].set_title('QPS', fontproperties=font_prop)
axs[0, 0].set_xlabel('并行数', fontproperties=font_prop)
axs[0, 0].set_ylabel('QPS', fontproperties=font_prop)
axs[0, 0].legend()
# 延迟
axs[0, 1].plot(batch_sizes_mindie, mindie_latency, label='MindIE(910B4 8*32)', marker='o')
axs[0, 1].plot(batch_sizes_vllm, vllm_latency, label='vLLM(T4 4*16)', marker='o')
axs[0, 1].set_title('延迟', fontproperties=font_prop)
axs[0, 1].set_xlabel('并行数', fontproperties=font_prop)
axs[0, 1].set_ylabel('延迟 (秒)', fontproperties=font_prop)
axs[0, 1].legend()
# 吞吐量
axs[1, 0].plot(batch_sizes_mindie, mindie_throughput, label='MindIE(910B4 8*32)', marker='o')
axs[1, 0].plot(batch_sizes_vllm, vllm_throughput, label='vLLM(T4 4*16)', marker='o')
axs[1, 0].set_title('吞吐量', fontproperties=font_prop)
axs[1, 0].set_xlabel('并行数', fontproperties=font_prop)
axs[1, 0].set_ylabel('吞吐量 (每秒Tokens)', fontproperties=font_prop)
axs[1, 0].legend()
# 失败率
axs[1, 1].plot(batch_sizes_mindie, mindie_failures, label='MindIE(910B4 8*32)', marker='o')
axs[1, 1].plot(batch_sizes_vllm, vllm_failures, label='vLLM(T4 4*16)', marker='o')
axs[1, 1].set_title('失败率', fontproperties=font_prop)
axs[1, 1].set_xlabel('并行数', fontproperties=font_prop)
axs[1, 1].set_ylabel('失败数', fontproperties=font_prop)
axs[1, 1].legend()
# 调整布局
plt.tight_layout()
plt.show()
实验结果(MindIE)
Qwen1.5-7B-Chat
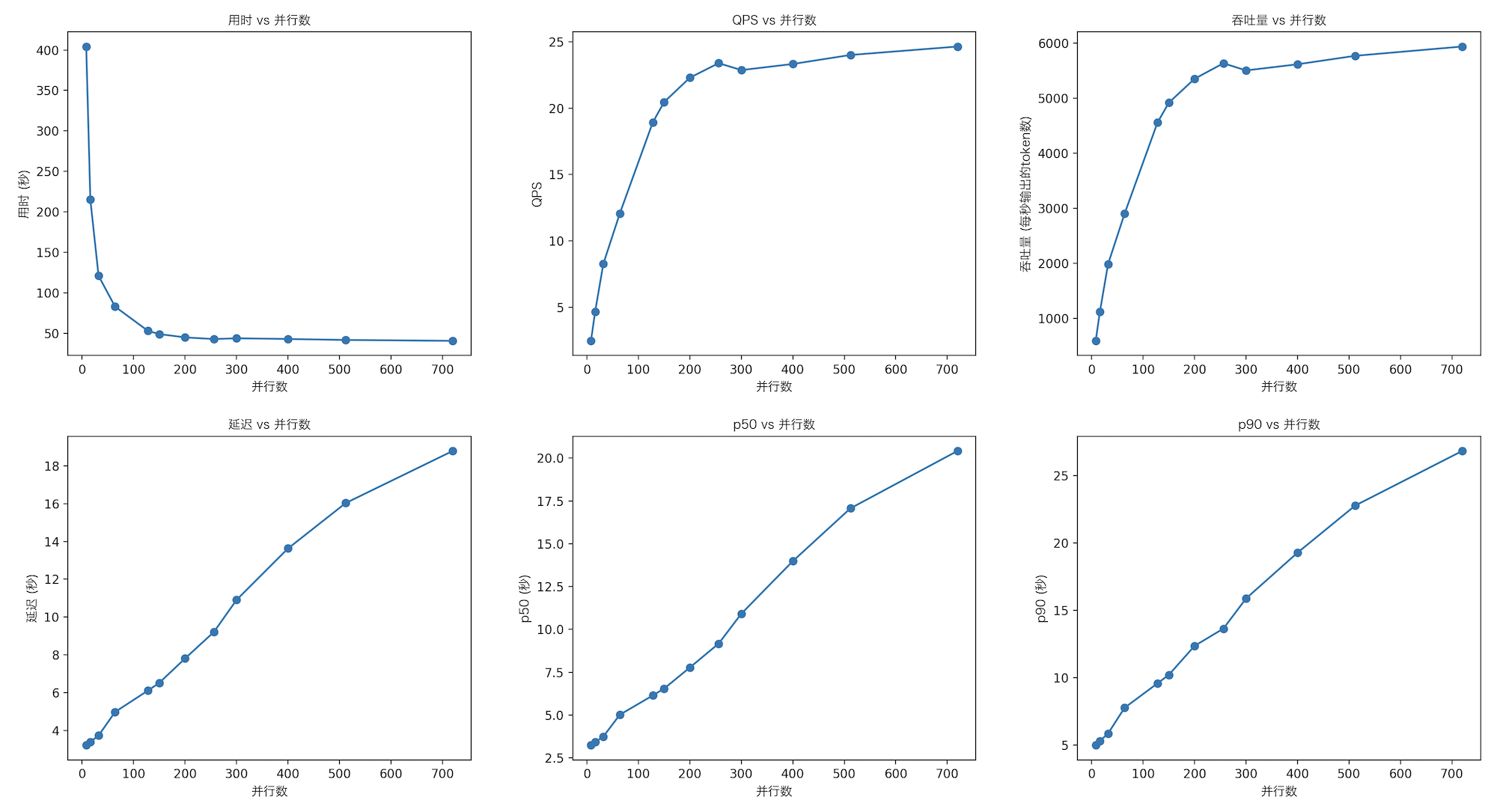
| 指标 | 8 | 16 | 32 | 64 | 128 | 150 | 200 | 256 | 300 | 400 | 512 | 720 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 用时 | 404.284 | 215.085 | 120.876 | 82.884 | 52.844 | 48.884 | 44.856 | 42.750 | 43.729 | 42.866 | 41.655 | 40.580 |
| QPS | 2.474 | 4.649 | 8.273 | 12.065 | 18.924 | 20.457 | 22.294 | 23.392 | 22.868 | 23.328 | 24.007 | 24.643 |
| 延迟 | 3.213 | 3.391 | 3.724 | 4.974 | 6.108 | 6.517 | 7.805 | 9.208 | 10.904 | 13.628 | 16.031 | 18.790 |
| 吞吐量 | 594.929 | 1119.102 | 1989.159 | 2903.023 | 4559.489 | 4920.856 | 5354.701 | 5636.846 | 5506.567 | 5618.110 | 5772.230 | 5940.622 |
| p50 | 3.2461 | 3.4271 | 3.7514 | 5.0248 | 6.1491 | 6.5487 | 7.7782 | 9.1754 | 10.9164 | 13.9850 | 17.0675 | 20.4161 |
| p90 | 4.9771 | 5.2905 | 5.8484 | 7.7522 | 9.5705 | 10.1980 | 12.3493 | 13.6320 | 15.8667 | 19.2667 | 22.7640 | 26.8183 |
- 平均每个请求的输入 token 数: 40
-
平均每个请求的输出 token 数: 240
- parallel 8
Benchmarking summary: Time taken for tests: 404.284 seconds Expected number of requests: 1000 Number of concurrency: 8 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 2.474 Average latency: 3.213 Throughput(average output tokens per second): 594.929 Average time to first token: 3.213 Average input tokens per request: 40.296 Average output tokens per request: 240.520 Average time per output token: 0.00168 Average package per request: 1.000 Average package latency: 3.213 Percentile of time to first token: p50: 3.2461 p66: 3.7587 p75: 4.2213 p80: 4.4208 p90: 4.9771 p95: 5.6460 p98: 6.3678 p99: 6.8545 Percentile of request latency: p50: 3.2461 p66: 3.7587 p75: 4.2213 p80: 4.4208 p90: 4.9771 p95: 5.6460 p98: 6.3678 p99: 6.8545 - parallel 16
Benchmarking summary: Time taken for tests: 215.085 seconds Expected number of requests: 1000 Number of concurrency: 16 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 4.649 Average latency: 3.391 Throughput(average output tokens per second): 1119.102 Average time to first token: 3.391 Average input tokens per request: 40.296 Average output tokens per request: 240.702 Average time per output token: 0.00089 Average package per request: 1.000 Average package latency: 3.391 Percentile of time to first token: p50: 3.4271 p66: 3.9816 p75: 4.3792 p80: 4.6188 p90: 5.2905 p95: 5.9389 p98: 6.7555 p99: 7.2478 Percentile of request latency: p50: 3.4271 p66: 3.9816 p75: 4.3792 p80: 4.6188 p90: 5.2905 p95: 5.9389 p98: 6.7555 p99: 7.2478 - parallel 32
Benchmarking summary: Time taken for tests: 120.876 seconds Expected number of requests: 1000 Number of concurrency: 32 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 8.273 Average latency: 3.724 Throughput(average output tokens per second): 1989.159 Average time to first token: 3.724 Average input tokens per request: 40.296 Average output tokens per request: 240.442 Average time per output token: 0.00050 Average package per request: 1.000 Average package latency: 3.724 Percentile of time to first token: p50: 3.7514 p66: 4.3989 p75: 4.8352 p80: 5.1087 p90: 5.8484 p95: 6.5664 p98: 7.3057 p99: 8.0644 Percentile of request latency: p50: 3.7514 p66: 4.3989 p75: 4.8352 p80: 5.1087 p90: 5.8484 p95: 6.5664 p98: 7.3057 p99: 8.0644 - parallel 64
Benchmarking summary: Time taken for tests: 82.884 seconds Expected number of requests: 1000 Number of concurrency: 64 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 12.065 Average latency: 4.974 Throughput(average output tokens per second): 2903.023 Average time to first token: 4.974 Average input tokens per request: 40.296 Average output tokens per request: 240.615 Average time per output token: 0.00034 Average package per request: 1.000 Average package latency: 4.974 Percentile of time to first token: p50: 5.0248 p66: 5.8985 p75: 6.4676 p80: 6.8351 p90: 7.7522 p95: 8.8266 p98: 9.9534 p99: 10.6036 Percentile of request latency: p50: 5.0248 p66: 5.8985 p75: 6.4676 p80: 6.8351 p90: 7.7522 p95: 8.8266 p98: 9.9534 p99: 10.6036 - parallel 128
Benchmarking summary: Time taken for tests: 52.844 seconds Expected number of requests: 1000 Number of concurrency: 128 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 18.924 Average latency: 6.108 Throughput(average output tokens per second): 4559.489 Average time to first token: 6.108 Average input tokens per request: 40.296 Average output tokens per request: 240.943 Average time per output token: 0.00022 Average package per request: 1.000 Average package latency: 6.108 Percentile of time to first token: p50: 6.1491 p66: 7.2622 p75: 7.9560 p80: 8.3894 p90: 9.5705 p95: 10.7209 p98: 12.2300 p99: 13.1657 Percentile of request latency: p50: 6.1491 p66: 7.2622 p75: 7.9560 p80: 8.3894 p90: 9.5705 p95: 10.7209 p98: 12.2300 p99: 13.1657 - parallel 150
Benchmarking summary: Time taken for tests: 48.884 seconds Expected number of requests: 1000 Number of concurrency: 150 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 20.457 Average latency: 6.517 Throughput(average output tokens per second): 4920.856 Average time to first token: 6.517 Average input tokens per request: 40.296 Average output tokens per request: 240.550 Average time per output token: 0.00020 Average package per request: 1.000 Average package latency: 6.517 Percentile of time to first token: p50: 6.5487 p66: 7.7580 p75: 8.4394 p80: 8.9248 p90: 10.1980 p95: 11.4446 p98: 13.0906 p99: 13.7333 Percentile of request latency: p50: 6.5487 p66: 7.7580 p75: 8.4394 p80: 8.9248 p90: 10.1980 p95: 11.4446 p98: 13.0906 p99: 13.7333 - parallel 200
Benchmarking summary: Time taken for tests: 44.856 seconds Expected number of requests: 1000 Number of concurrency: 200 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 22.294 Average latency: 7.805 Throughput(average output tokens per second): 5354.701 Average time to first token: 7.805 Average input tokens per request: 40.296 Average output tokens per request: 240.188 Average time per output token: 0.00019 Average package per request: 1.000 Average package latency: 7.805 Percentile of time to first token: p50: 7.7782 p66: 9.2457 p75: 10.0596 p80: 10.8689 p90: 12.3493 p95: 13.7108 p98: 15.1361 p99: 16.3464 Percentile of request latency: p50: 7.7782 p66: 9.2457 p75: 10.0596 p80: 10.8689 p90: 12.3493 p95: 13.7108 p98: 15.1361 p99: 16.3464 - parallel 256
Benchmarking summary: Time taken for tests: 42.750 seconds Expected number of requests: 1000 Number of concurrency: 256 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 23.392 Average latency: 9.208 Throughput(average output tokens per second): 5636.846 Average time to first token: 9.208 Average input tokens per request: 40.296 Average output tokens per request: 240.975 Average time per output token: 0.00018 Average package per request: 1.000 Average package latency: 9.208 Percentile of time to first token: p50: 9.1754 p66: 10.6423 p75: 11.5348 p80: 12.1507 p90: 13.6320 p95: 14.9237 p98: 16.5329 p99: 18.0215 Percentile of request latency: p50: 9.1754 p66: 10.6423 p75: 11.5348 p80: 12.1507 p90: 13.6320 p95: 14.9237 p98: 16.5329 p99: 18.0215 - parallel 300
Benchmarking summary: Time taken for tests: 43.729 seconds Expected number of requests: 1000 Number of concurrency: 300 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 22.868 Average latency: 10.904 Throughput(average output tokens per second): 5506.567 Average time to first token: 10.904 Average input tokens per request: 40.296 Average output tokens per request: 240.795 Average time per output token: 0.00018 Average package per request: 1.000 Average package latency: 10.904 Percentile of time to first token: p50: 10.9164 p66: 12.5896 p75: 13.6076 p80: 14.2442 p90: 15.8667 p95: 17.2967 p98: 18.8841 p99: 20.2304 Percentile of request latency: p50: 10.9164 p66: 12.5896 p75: 13.6076 p80: 14.2442 p90: 15.8667 p95: 17.2967 p98: 18.8841 p99: 20.2304 - parallel 400
Benchmarking summary: Time taken for tests: 42.866 seconds Expected number of requests: 1000 Number of concurrency: 400 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 23.328 Average latency: 13.628 Throughput(average output tokens per second): 5618.110 Average time to first token: 13.628 Average input tokens per request: 40.296 Average output tokens per request: 240.828 Average time per output token: 0.00018 Average package per request: 1.000 Average package latency: 13.628 Percentile of time to first token: p50: 13.9850 p66: 15.7791 p75: 16.8451 p80: 17.6249 p90: 19.2667 p95: 20.8091 p98: 22.5674 p99: 23.6675 Percentile of request latency: p50: 13.9850 p66: 15.7791 p75: 16.8451 p80: 17.6249 p90: 19.2667 p95: 20.8091 p98: 22.5674 p99: 23.6675 - parallel 512
Benchmarking summary: Time taken for tests: 41.655 seconds Expected number of requests: 1000 Number of concurrency: 512 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 24.007 Average latency: 16.031 Throughput(average output tokens per second): 5772.230 Average time to first token: 16.031 Average input tokens per request: 40.296 Average output tokens per request: 240.440 Average time per output token: 0.00017 Average package per request: 1.000 Average package latency: 16.031 Percentile of time to first token: p50: 17.0675 p66: 18.9757 p75: 20.0632 p80: 20.8715 p90: 22.7640 p95: 24.0828 p98: 25.3913 p99: 26.6549 Percentile of request latency: p50: 17.0675 p66: 18.9757 p75: 20.0632 p80: 20.8715 p90: 22.7640 p95: 24.0828 p98: 25.3913 p99: 26.6549 - parallel 720
Benchmarking summary: Time taken for tests: 40.580 seconds Expected number of requests: 1000 Number of concurrency: 720 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 24.643 Average latency: 18.790 Throughput(average output tokens per second): 5940.622 Average time to first token: 18.790 Average input tokens per request: 40.296 Average output tokens per request: 241.071 Average time per output token: 0.00017 Average package per request: 1.000 Average package latency: 18.790 Percentile of time to first token: p50: 20.4161 p66: 22.8199 p75: 24.1332 p80: 24.8298 p90: 26.8183 p95: 28.8718 p98: 30.2479 p99: 31.1723 Percentile of request latency: p50: 20.4161 p66: 22.8199 p75: 24.1332 p80: 24.8298 p90: 26.8183 p95: 28.8718 p98: 30.2479 p99: 31.1723
Qwen1.5-7B-Chat (long.jsonl)
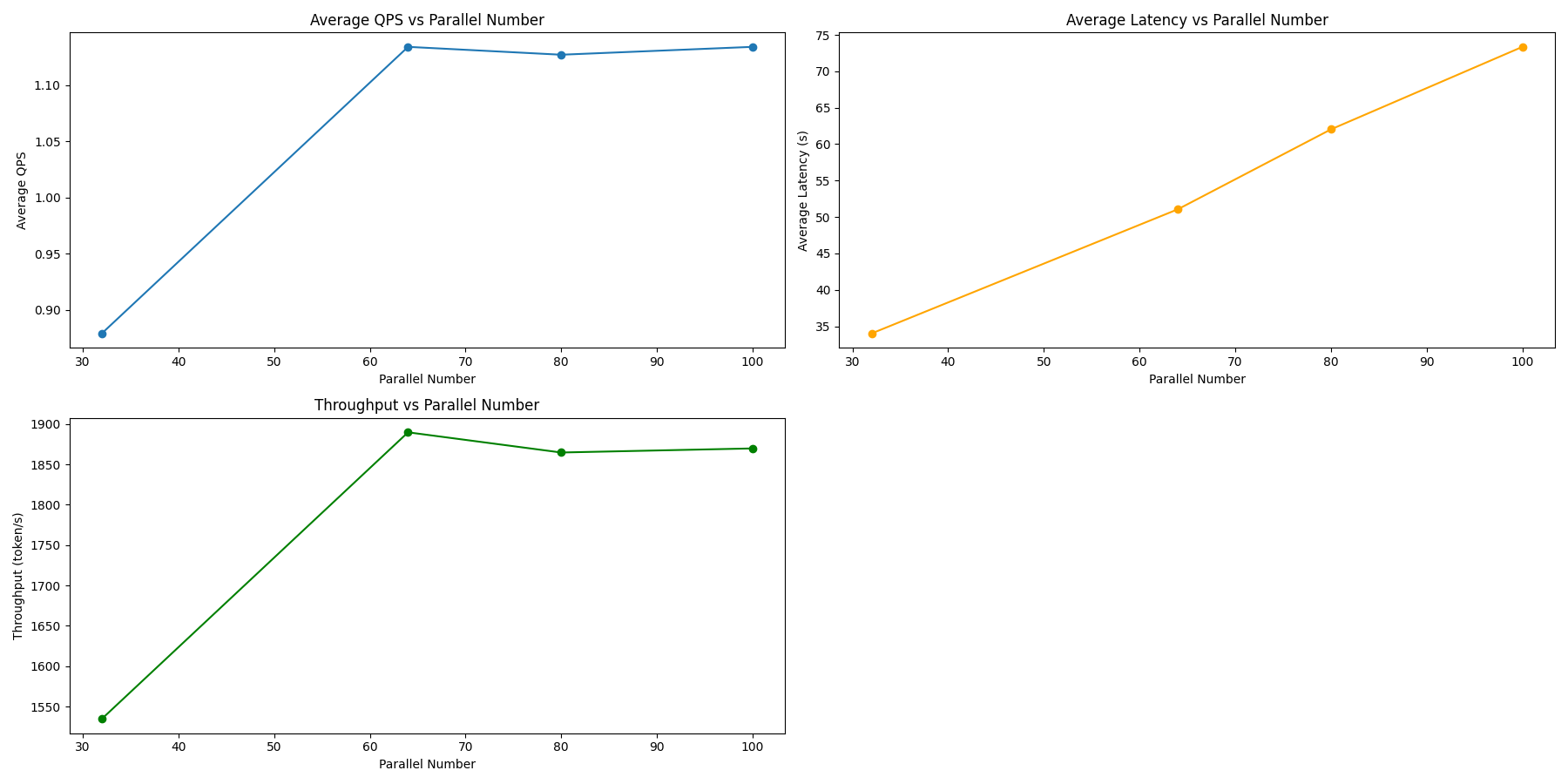
| 指标 | 32 | 64 | 80 | 100 |
|---|---|---|---|---|
| 用时 | 227.466 | 176.405 | 177.402 | 176.430 |
| QPS | 0.879 | 1.134 | 1.127 | 1.134 |
| 延迟 | 34.012 | 51.059 | 62.032 | 73.359 |
| 吞吐量 | 1534.689 | 1889.768 | 1864.759 | 1869.820 |
| p50 | 34.7112 | 48.4820 | 59.2757 | 80.3454 |
| p90 | 36.6736 | 68.2014 | 84.9306 | 93.7045 |
- 平均每个请求的输入 token 数: 1614
-
平均每个请求的输出 token 数: 1654
- parallel 32
Benchmarking summary: Time taken for tests: 227.466 seconds Expected number of requests: 200 Number of concurrency: 32 Total requests: 200 Succeed requests: 200 Failed requests: 0 Average QPS: 0.879 Average latency: 34.012 Throughput(average output tokens per second): 1534.689 Average time to first token: 34.012 Average input tokens per request: 1614.000 Average output tokens per request: 1745.450 Average time per output token: 0.00065 Average package per request: 1.000 Average package latency: 34.012 Percentile of time to first token: p50: 34.7112 p66: 36.2749 p75: 36.4008 p80: 36.4714 p90: 36.6736 p95: 36.7247 p98: 36.7508 p99: 36.7635 Percentile of request latency: p50: 34.7112 p66: 36.2749 p75: 36.4008 p80: 36.4714 p90: 36.6736 p95: 36.7247 p98: 36.7508 p99: 36.7635 - parallel 64
Benchmarking summary: Time taken for tests: 176.405 seconds Expected number of requests: 200 Number of concurrency: 64 Total requests: 200 Succeed requests: 200 Failed requests: 0 Average QPS: 1.134 Average latency: 51.059 Throughput(average output tokens per second): 1889.768 Average time to first token: 51.059 Average input tokens per request: 1614.000 Average output tokens per request: 1666.820 Average time per output token: 0.00053 Average package per request: 1.000 Average package latency: 51.059 Percentile of time to first token: p50: 48.4820 p66: 52.8716 p75: 58.2624 p80: 60.0386 p90: 68.2014 p95: 74.7256 p98: 78.7428 p99: 79.3227 Percentile of request latency: p50: 48.4820 p66: 52.8716 p75: 58.2624 p80: 60.0386 p90: 68.2014 p95: 74.7256 p98: 78.7428 p99: 79.3227 - parallel 80
Benchmarking summary: Time taken for tests: 177.402 seconds Expected number of requests: 200 Number of concurrency: 80 Total requests: 200 Succeed requests: 200 Failed requests: 0 Average QPS: 1.127 Average latency: 62.032 Throughput(average output tokens per second): 1864.759 Average time to first token: 62.032 Average input tokens per request: 1614.000 Average output tokens per request: 1654.060 Average time per output token: 0.00054 Average package per request: 1.000 Average package latency: 62.032 Percentile of time to first token: p50: 59.2757 p66: 71.6039 p75: 74.4594 p80: 76.9160 p90: 84.9306 p95: 91.9959 p98: 95.0497 p99: 98.3784 Percentile of request latency: p50: 59.2757 p66: 71.6039 p75: 74.4594 p80: 76.9160 p90: 84.9306 p95: 91.9959 p98: 95.0497 p99: 98.3784 - parallel 100
Benchmarking summary: Time taken for tests: 176.430 seconds Expected number of requests: 200 Number of concurrency: 100 Total requests: 200 Succeed requests: 200 Failed requests: 0 Average QPS: 1.134 Average latency: 73.359 Throughput(average output tokens per second): 1869.820 Average time to first token: 73.359 Average input tokens per request: 1614.000 Average output tokens per request: 1649.460 Average time per output token: 0.00053 Average package per request: 1.000 Average package latency: 73.359 Percentile of time to first token: p50: 80.3454 p66: 85.7741 p75: 88.7250 p80: 90.7941 p90: 93.7045 p95: 97.3420 p98: 99.5837 p99: 101.2294 Percentile of request latency: p50: 80.3454 p66: 85.7741 p75: 88.7250 p80: 90.7941 p90: 93.7045 p95: 97.3420 p98: 99.5837 p99: 101.2294
Qwen1.5-14B-Chat
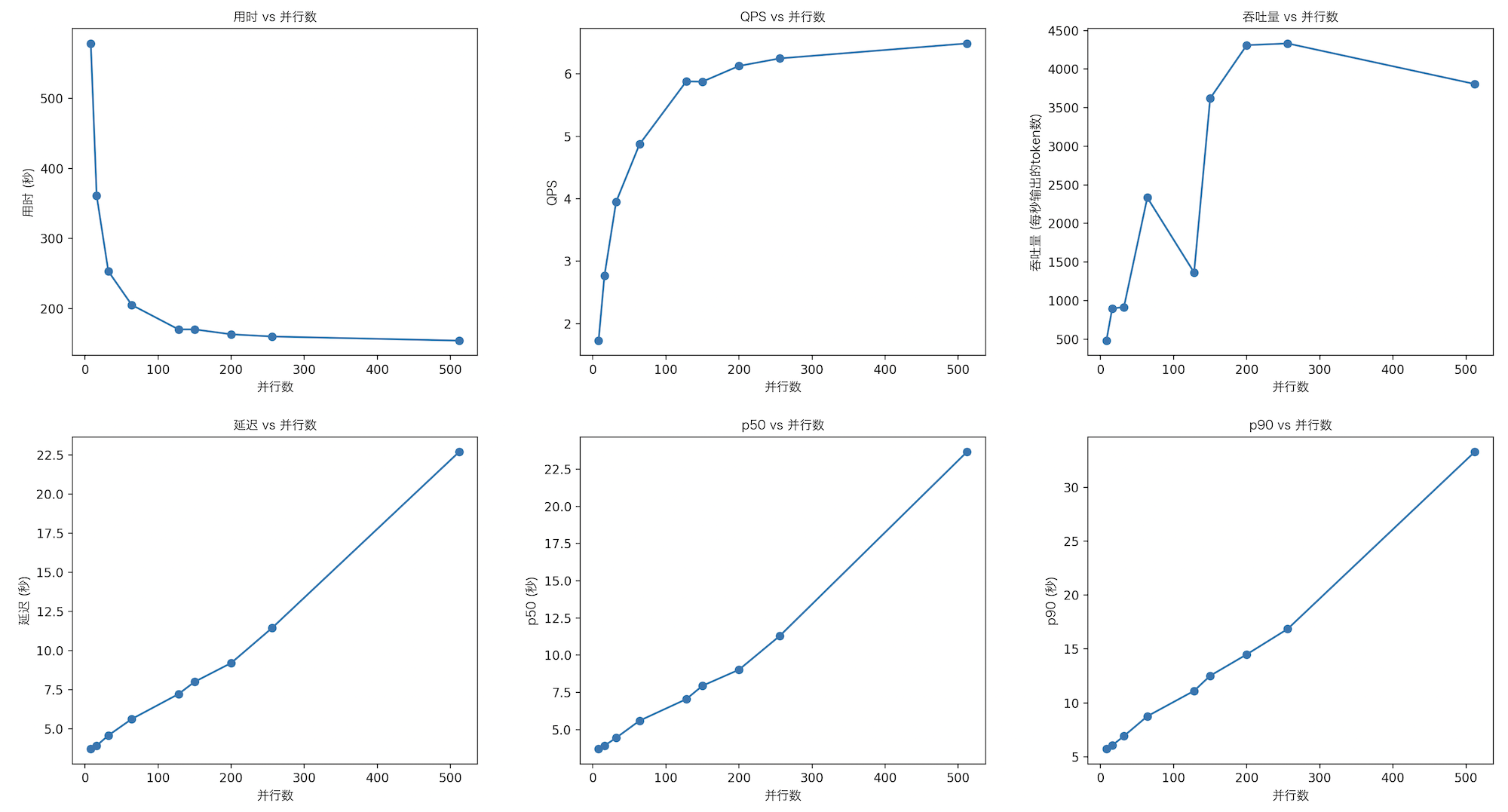
| 指标 | 8 | 16 | 32 | 64 | 128 | 150 | 200 | 256 | 512 |
|---|---|---|---|---|---|---|---|---|---|
| 用时 | 578.571 | 361.169 | 253.040 | 204.961 | 170.001 | 169.981 | 162.999 | 159.840 | 153.937 |
| QPS | 1.727 | 2.766 | 3.952 | 4.874 | 5.882 | 5.877 | 6.129 | 6.250 | 6.490 |
| 延迟 | 3.712 | 3.928 | 4.581 | 5.628 | 7.223 | 8.004 | 9.205 | 11.446 | 22.695 |
| 吞吐量 | 480.043 | 897.511 | 915.133 | 2333.955 | 1363.656 | 3621.096 | 4310.525 | 4333.013 | 3806.748 |
| p50 | 3.7038 | 3.9261 | 4.4544 | 5.6047 | 7.0534 | 7.9484 | 9.0271 | 11.3066 | 23.6591 |
| p90 | 5.7184 | 6.0562 | 6.9198 | 8.7597 | 11.1194 | 12.5181 | 14.5017 | 16.8646 | 33.3052 |
- parallel 8
Benchmarking summary: Time taken for tests: 578.571 seconds Expected number of requests: 1000 Number of concurrency: 8 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 1.727 Average latency: 3.712 Throughput(average output tokens per second): 480.043 Average time to first token: 3.712 Average input tokens per request: 40.287 Average output tokens per request: 224.138 Average time per output token: 0.00208 Average package per request: 1.000 Average package latency: 3.712 Percentile of time to first token: p50: 3.7038 p66: 4.4215 p75: 4.8051 p80: 5.0476 p90: 5.7184 p95: 6.2956 p98: 7.0707 p99: 7.4415 Percentile of request latency: p50: 3.7038 p66: 4.4215 p75: 4.8051 p80: 5.0476 p90: 5.7184 p95: 6.2956 p98: 7.0707 p99: 7.4415 - parallel 16
Benchmarking summary: Time taken for tests: 361.169 seconds Expected number of requests: 1000 Number of concurrency: 16 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 2.766 Average latency: 3.928 Throughput(average output tokens per second): 897.511 Average time to first token: 3.928 Average input tokens per request: 40.287 Average output tokens per request: 223.750 Average time per output token: 0.00111 Average package per request: 1.000 Average package latency: 3.928 Percentile of time to first token: p50: 3.9261 p66: 4.6890 p75: 5.1204 p80: 5.3290 p90: 6.0562 p95: 6.6784 p98: 7.3113 p99: 7.8980 Percentile of request latency: p50: 3.9261 p66: 4.6890 p75: 5.1204 p80: 5.3290 p90: 6.0562 p95: 6.6784 p98: 7.3113 p99: 7.8980 - parallel 32
Benchmarking summary: Time taken for tests: 253.040 seconds Expected number of requests: 1000 Number of concurrency: 32 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 3.952 Average latency: 4.581 Throughput(average output tokens per second): 915.133 Average time to first token: 4.581 Average input tokens per request: 40.296 Average output tokens per request: 231.565 Average time per output token: 0.00109 Average package per request: 1.000 Average package latency: 4.581 Percentile of time to first token: p50: 4.4544 p66: 5.2905 p75: 5.8235 p80: 6.1074 p90: 6.9198 p95: 7.5185 p98: 8.5143 p99: 9.3296 Percentile of request latency: p50: 4.4544 p66: 5.2905 p75: 5.8235 p80: 6.1074 p90: 6.9198 p95: 7.5185 p98: 8.5143 p99: 9.3296 - parallel 64
Benchmarking summary: Time taken for tests: 204.961 seconds Expected number of requests: 1000 Number of concurrency: 64 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 4.874 Average latency: 5.628 Throughput(average output tokens per second): 2333.955 Average time to first token: 5.628 Average input tokens per request: 40.287 Average output tokens per request: 223.930 Average time per output token: 0.00043 Average package per request: 1.000 Average package latency: 5.628 Percentile of time to first token: p50: 5.6047 p66: 6.6600 p75: 7.3423 p80: 7.7040 p90: 8.7597 p95: 9.6390 p98: 10.7844 p99: 11.6003 Percentile of request latency: p50: 5.6047 p66: 6.6600 p75: 7.3423 p80: 7.7040 p90: 8.7597 p95: 9.6390 p98: 10.7844 p99: 11.6003 - parallel 128
Benchmarking summary: Time taken for tests: 170.001 seconds Expected number of requests: 1000 Number of concurrency: 128 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 5.882 Average latency: 7.223 Throughput(average output tokens per second): 1363.656 Average time to first token: 7.223 Average input tokens per request: 40.296 Average output tokens per request: 231.823 Average time per output token: 0.00073 Average package per request: 1.000 Average package latency: 7.223 Percentile of time to first token: p50: 7.0534 p66: 8.4098 p75: 9.3191 p80: 9.7640 p90: 11.1194 p95: 12.2800 p98: 13.8248 p99: 14.6733 Percentile of request latency: p50: 7.0534 p66: 8.4098 p75: 9.3191 p80: 9.7640 p90: 11.1194 p95: 12.2800 p98: 13.8248 p99: 14.6733 - parallel 150
Benchmarking summary: Time taken for tests: 169.981 seconds Expected number of requests: 1000 Number of concurrency: 150 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 5.877 Average latency: 8.004 Throughput(average output tokens per second): 3621.096 Average time to first token: 8.004 Average input tokens per request: 40.287 Average output tokens per request: 224.225 Average time per output token: 0.00028 Average package per request: 1.000 Average package latency: 8.004 Percentile of time to first token: p50: 7.9484 p66: 9.3969 p75: 10.5065 p80: 11.0508 p90: 12.5181 p95: 13.6289 p98: 15.3693 p99: 16.5225 Percentile of request latency: p50: 7.9484 p66: 9.3969 p75: 10.5065 p80: 11.0508 p90: 12.5181 p95: 13.6289 p98: 15.3693 p99: 16.5225 - parallel 200
Benchmarking summary: Time taken for tests: 162.999 seconds Expected number of requests: 1000 Number of concurrency: 200 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 6.129 Average latency: 9.205 Throughput(average output tokens per second): 4310.525 Average time to first token: 9.205 Average input tokens per request: 40.287 Average output tokens per request: 223.865 Average time per output token: 0.00023 Average package per request: 1.000 Average package latency: 9.205 Percentile of time to first token: p50: 9.0271 p66: 10.8104 p75: 12.0957 p80: 12.8212 p90: 14.5017 p95: 15.7233 p98: 17.6891 p99: 19.2401 Percentile of request latency: p50: 9.0271 p66: 10.8104 p75: 12.0957 p80: 12.8212 p90: 14.5017 p95: 15.7233 p98: 17.6891 p99: 19.2401 - parallel 256
Benchmarking summary: Time taken for tests: 159.840 seconds Expected number of requests: 1000 Number of concurrency: 256 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 6.250 Average latency: 11.446 Throughput(average output tokens per second): 4333.013 Average time to first token: 11.446 Average input tokens per request: 40.287 Average output tokens per request: 224.384 Average time per output token: 0.00023 Average package per request: 1.000 Average package latency: 11.446 Percentile of time to first token: p50: 11.3066 p66: 13.1698 p75: 14.4698 p80: 15.2733 p90: 16.8646 p95: 18.3524 p98: 20.0468 p99: 21.3758 Percentile of request latency: p50: 11.3066 p66: 13.1698 p75: 14.4698 p80: 15.2733 p90: 16.8646 p95: 18.3524 p98: 20.0468 p99: 21.3758 - parallel 512
Benchmarking summary: Time taken for tests: 153.937 seconds Expected number of requests: 1000 Number of concurrency: 512 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 6.490 Average latency: 22.695 Throughput(average output tokens per second): 3806.748 Average time to first token: 22.695 Average input tokens per request: 40.287 Average output tokens per request: 224.177 Average time per output token: 0.00026 Average package per request: 1.000 Average package latency: 22.695 Percentile of time to first token: p50: 23.6591 p66: 27.2753 p75: 29.3330 p80: 30.5309 p90: 33.3052 p95: 35.7777 p98: 37.4897 p99: 38.1186 Percentile of request latency: p50: 23.6591 p66: 27.2753 p75: 29.3330 p80: 30.5309 p90: 33.3052 p95: 35.7777 p98: 37.4897 p99: 38.1186
Qwen2-72B-Chat
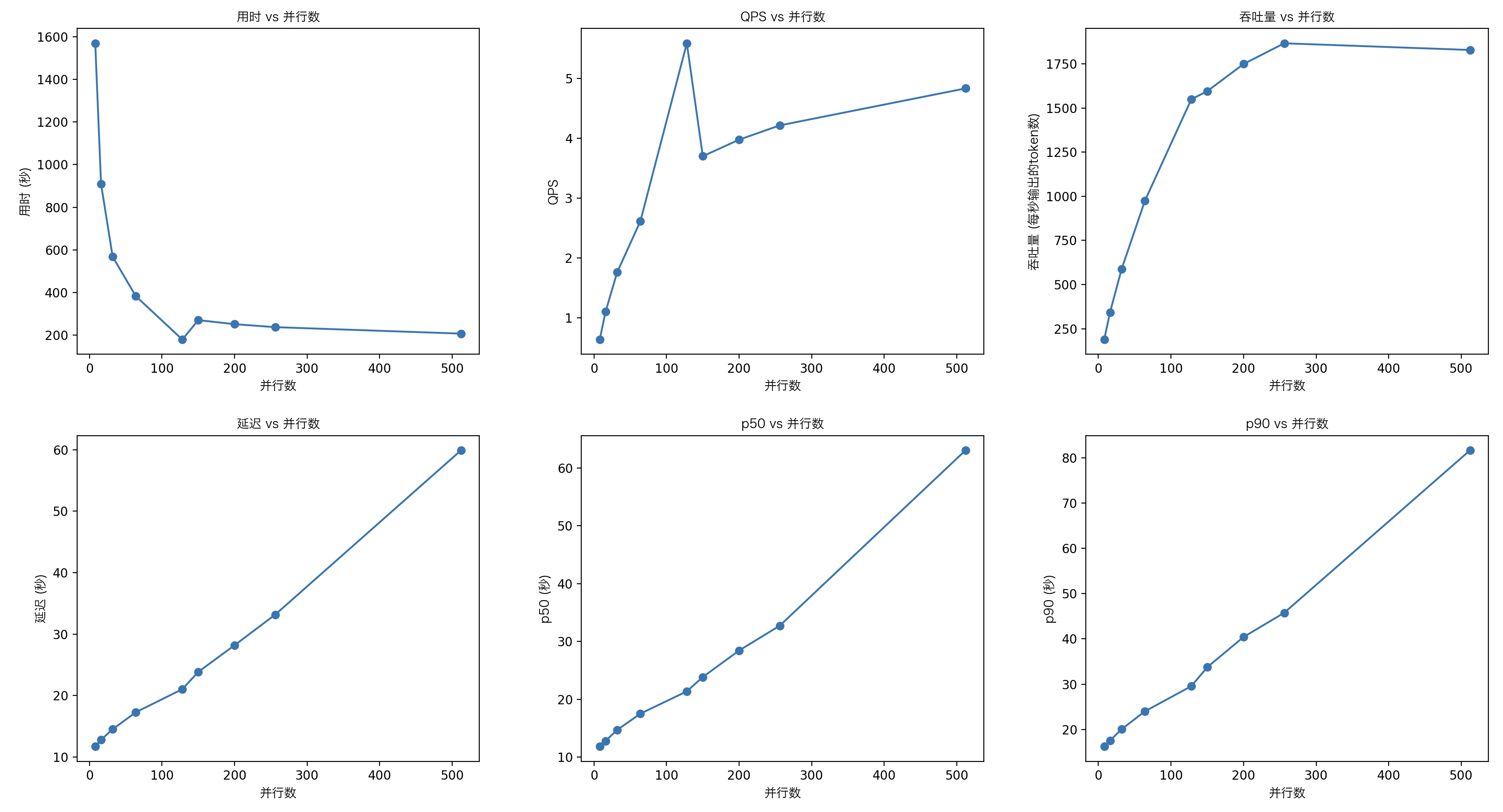
| 指标 | 8 | 16 | 32 | 64 | 128 | 150 | 200 | 256 | 512 |
|---|---|---|---|---|---|---|---|---|---|
| 用时 | 1569.707 | 909.001 | 567.479 | 382.247 | 179.015 | 270.054 | 251.060 | 237.063 | 206.734 |
| QPS | 0.636 | 1.099 | 1.759 | 2.613 | 5.586 | 3.699 | 3.975 | 4.214 | 4.832 |
| 延迟 | 11.705 | 12.806 | 14.526 | 17.296 | 21.041 | 23.856 | 28.198 | 33.176 | 59.912 |
| 吞吐量 | 188.589 | 342.764 | 588.262 | 973.795 | 1549.069 | 1595.176 | 1748.784 | 1866.155 | 1828.363 |
| p50 | 11.8443 | 12.8275 | 14.7115 | 17.5290 | 21.3863 | 23.8551 | 28.4407 | 32.7329 | 63.0404 |
| p90 | 16.2106 | 17.5466 | 20.0371 | 23.9890 | 29.5537 | 33.7459 | 40.4210 | 45.7666 | 81.6602 |
- 平均每个请求的输入 token 数: 40
-
平均每个请求的输出 token 数: 277
- parallel 8
Benchmarking summary: Time taken for tests: 1569.707 seconds Expected number of requests: 1000 Number of concurrency: 8 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 0.636 Average latency: 11.705 Throughput(average output tokens per second): 188.589 Average time to first token: 11.705 Average input tokens per request: 40.303 Average output tokens per request: 277.618 Average time per output token: 0.00530 Average package per request: 1.000 Average package latency: 11.705 Percentile of time to first token: p50: 11.8443 p66: 13.1671 p75: 13.9665 p80: 14.5981 p90: 16.2106 p95: 17.8844 p98: 20.0471 p99: 23.0309 Percentile of request latency: p50: 11.8443 p66: 13.1671 p75: 13.9665 p80: 14.5981 p90: 16.2106 p95: 17.8844 p98: 20.0471 p99: 23.0309 - parallel 16
Benchmarking summary: Time taken for tests: 909.001 seconds Expected number of requests: 1000 Number of concurrency: 16 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 1.099 Average latency: 12.806 Throughput(average output tokens per second): 342.764 Average time to first token: 12.806 Average input tokens per request: 40.303 Average output tokens per request: 278.224 Average time per output token: 0.00292 Average package per request: 1.000 Average package latency: 12.806 Percentile of time to first token: p50: 12.8275 p66: 14.3998 p75: 15.3983 p80: 16.1443 p90: 17.5466 p95: 19.6906 p98: 22.2533 p99: 25.1283 Percentile of request latency: p50: 12.8275 p66: 14.3998 p75: 15.3983 p80: 16.1443 p90: 17.5466 p95: 19.6906 p98: 22.2533 p99: 25.1283 - parallel 32
Benchmarking summary: Time taken for tests: 567.479 seconds Expected number of requests: 1000 Number of concurrency: 32 Total requests: 1000 Succeed requests: 998 Failed requests: 2 Average QPS: 1.759 Average latency: 14.526 Throughput(average output tokens per second): 588.262 Average time to first token: 14.526 Average input tokens per request: 40.297 Average output tokens per request: 277.259 Average time per output token: 0.00170 Average package per request: 1.000 Average package latency: 14.526 Percentile of time to first token: p50: 14.7115 p66: 16.2993 p75: 17.4013 p80: 18.2002 p90: 20.0371 p95: 21.8216 p98: 24.5539 p99: 27.3373 Percentile of request latency: p50: 14.7115 p66: 16.2993 p75: 17.4013 p80: 18.2002 p90: 20.0371 p95: 21.8216 p98: 24.5539 p99: 27.3373 - parallel 64
Benchmarking summary: Time taken for tests: 382.247 seconds Expected number of requests: 1000 Number of concurrency: 64 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 2.613 Average latency: 17.296 Throughput(average output tokens per second): 973.795 Average time to first token: 17.296 Average input tokens per request: 40.303 Average output tokens per request: 276.968 Average time per output token: 0.00103 Average package per request: 1.000 Average package latency: 17.296 Percentile of time to first token: p50: 17.5290 p66: 19.5218 p75: 20.7063 p80: 21.6443 p90: 23.9890 p95: 26.0998 p98: 29.7887 p99: 32.3975 Percentile of request latency: p50: 17.5290 p66: 19.5218 p75: 20.7063 p80: 21.6443 p90: 23.9890 p95: 26.0998 p98: 29.7887 p99: 32.3975 - parallel 128
Benchmarking summary: Time taken for tests: 179.015 seconds Expected number of requests: 1000 Number of concurrency: 128 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 5.586 Average latency: 21.041 Throughput(average output tokens per second): 1549.069 Average time to first token: 21.041 Average input tokens per request: 40.296 Average output tokens per request: 277.307 Average time per output token: 0.00065 Average package per request: 1.000 Average package latency: 21.041 Percentile of time to first token: p50: 21.3863 p66: 23.7687 p75: 25.1877 p80: 26.3636 p90: 29.5537 p95: 32.3925 p98: 36.5261 p99: 39.3924 Percentile of request latency: p50: 21.3863 p66: 23.7687 p75: 25.1877 p80: 26.3636 p90: 29.5537 p95: 32.3925 p98: 36.5261 p99: 39.3924 - parallel 150
Benchmarking summary: Time taken for tests: 270.054 seconds Expected number of requests: 1000 Number of concurrency: 150 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 3.699 Average latency: 23.856 Throughput(average output tokens per second): 1595.176 Average time to first token: 23.856 Average input tokens per request: 40.303 Average output tokens per request: 277.760 Average time per output token: 0.00063 Average package per request: 1.000 Average package latency: 23.856 Percentile of time to first token: p50: 23.8551 p66: 26.6484 p75: 28.7350 p80: 29.8586 p90: 33.7459 p95: 36.6390 p98: 41.2772 p99: 47.8515 Percentile of request latency: p50: 23.8551 p66: 26.6484 p75: 28.7350 p80: 29.8586 p90: 33.7459 p95: 36.6390 p98: 41.2772 p99: 47.8515 - parallel 200
Benchmarking summary: Time taken for tests: 251.060 seconds Expected number of requests: 1000 Number of concurrency: 200 Total requests: 1000 Succeed requests: 998 Failed requests: 2 Average QPS: 3.975 Average latency: 28.198 Throughput(average output tokens per second): 1748.784 Average time to first token: 28.198 Average input tokens per request: 40.308 Average output tokens per request: 276.789 Average time per output token: 0.00057 Average package per request: 1.000 Average package latency: 28.198 Percentile of time to first token: p50: 28.4407 p66: 31.6658 p75: 34.0785 p80: 35.5489 p90: 40.4210 p95: 43.0363 p98: 48.1876 p99: 52.8204 Percentile of request latency: p50: 28.4407 p66: 31.6658 p75: 34.0785 p80: 35.5489 p90: 40.4210 p95: 43.0363 p98: 48.1876 p99: 52.8204 - parallel 256
Benchmarking summary: Time taken for tests: 237.063 seconds Expected number of requests: 1000 Number of concurrency: 256 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 4.214 Average latency: 33.176 Throughput(average output tokens per second): 1866.155 Average time to first token: 33.176 Average input tokens per request: 40.303 Average output tokens per request: 276.399 Average time per output token: 0.00054 Average package per request: 1.000 Average package latency: 33.176 Percentile of time to first token: p50: 32.7329 p66: 37.0212 p75: 39.6246 p80: 41.3947 p90: 45.7666 p95: 49.4765 p98: 54.4858 p99: 58.0206 Percentile of request latency: p50: 32.7329 p66: 37.0212 p75: 39.6246 p80: 41.3947 p90: 45.7666 p95: 49.4765 p98: 54.4858 p99: 58.0206 - parallel 512
Benchmarking summary: Time taken for tests: 206.734 seconds Expected number of requests: 1000 Number of concurrency: 512 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 4.832 Average latency: 59.912 Throughput(average output tokens per second): 1828.363 Average time to first token: 59.912 Average input tokens per request: 40.303 Average output tokens per request: 277.592 Average time per output token: 0.00055 Average package per request: 1.000 Average package latency: 59.912 Percentile of time to first token: p50: 63.0404 p66: 69.5273 p75: 73.3044 p80: 75.7455 p90: 81.6602 p95: 87.3050 p98: 92.2078 p99: 97.6189 Percentile of request latency: p50: 63.0404 p66: 69.5273 p75: 73.3044 p80: 75.7455 p90: 81.6602 p95: 87.3050 p98: 92.2078 p99: 97.6189
Qwen2-72B-Chat (long.jsonl)
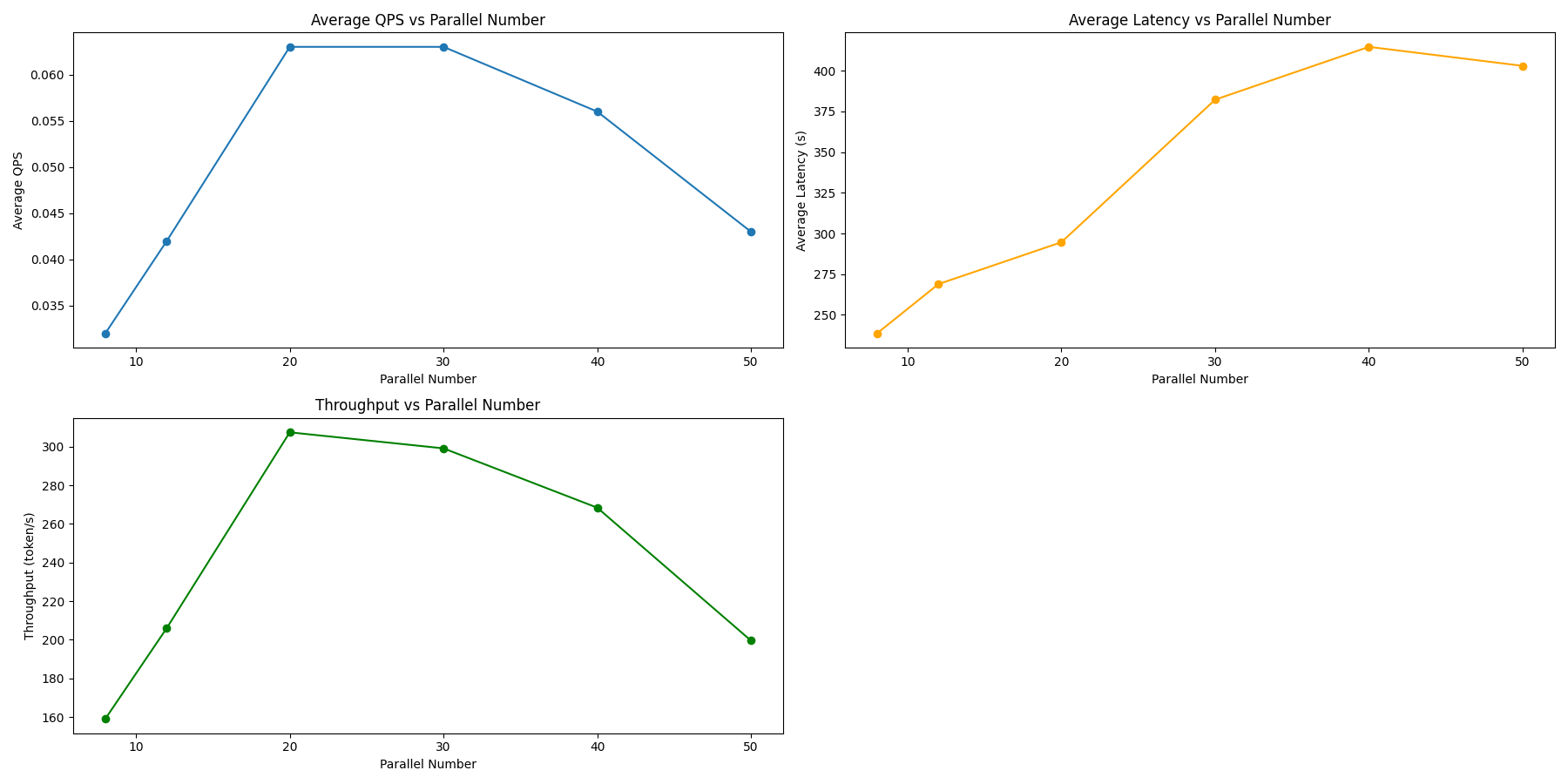
| 指标 | 8 | 12 | 20 | 30 | 40 | 50 |
|---|---|---|---|---|---|---|
| 用时 | 3091.468 | 2385.800 | 1598.805 | 1542.828 | 1509.713 | 1408.587 |
| QPS | 0.032 | 0.042 | 0.063 | 0.063 | 0.056 | 0.043 |
| 延迟 | 238.540 | 268.873 | 294.636 | 382.291 | 414.746 | 403.061 |
| 吞吐量 | 158.986 | 206.011 | 307.418 | 299.114 | 268.391 | 199.552 |
| p50 | 239.3327 | 270.9418 | 292.3093 | 348.5759 | 396.9046 | 350.8392 |
| p90 | 239.6762 | 271.3905 | 313.2425 | 514.8233 | 567.8100 | 597.3057 |
- 平均每个请求的输入 token 数: 6385
-
平均每个请求的输出 token 数: 4915
- parallel 8
Benchmarking summary: Time taken for tests: 3091.468 seconds Expected number of requests: 100 Number of concurrency: 8 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.032 Average latency: 238.540 Throughput(average output tokens per second): 158.986 Average time to first token: 238.540 Average input tokens per request: 6385.000 Average output tokens per request: 4915.000 Average time per output token: 0.00629 Average package per request: 1.000 Average package latency: 238.540 Percentile of time to first token: p50: 239.3327 p66: 239.5209 p75: 239.5622 p80: 239.6446 p90: 239.6762 p95: 240.0079 p98: 240.0081 p99: 240.0121 Percentile of request latency: p50: 239.3327 p66: 239.5209 p75: 239.5622 p80: 239.6446 p90: 239.6762 p95: 240.0079 p98: 240.0081 p99: 240.0121 - parallel 12
Benchmarking summary: Time taken for tests: 2385.800 seconds Expected number of requests: 100 Number of concurrency: 12 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.042 Average latency: 268.873 Throughput(average output tokens per second): 206.011 Average time to first token: 268.873 Average input tokens per request: 6385.000 Average output tokens per request: 4915.000 Average time per output token: 0.00485 Average package per request: 1.000 Average package latency: 268.873 Percentile of time to first token: p50: 270.9418 p66: 271.2864 p75: 271.3597 p80: 271.3610 p90: 271.3905 p95: 271.3978 p98: 271.4502 p99: 271.4786 Percentile of request latency: p50: 270.9418 p66: 271.2864 p75: 271.3597 p80: 271.3610 p90: 271.3905 p95: 271.3978 p98: 271.4502 p99: 271.4786 - parallel 20
Benchmarking summary: Time taken for tests: 1598.805 seconds Expected number of requests: 100 Number of concurrency: 20 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.063 Average latency: 294.636 Throughput(average output tokens per second): 307.418 Average time to first token: 294.636 Average input tokens per request: 6385.000 Average output tokens per request: 4915.020 Average time per output token: 0.00325 Average package per request: 1.000 Average package latency: 294.636 Percentile of time to first token: p50: 292.3093 p66: 293.7218 p75: 296.3762 p80: 296.4460 p90: 313.2425 p95: 323.9384 p98: 334.5282 p99: 357.6738 Percentile of request latency: p50: 292.3093 p66: 293.7218 p75: 296.3762 p80: 296.4460 p90: 313.2425 p95: 323.9384 p98: 334.5282 p99: 357.6738 - parallel 30
Benchmarking summary: Time taken for tests: 1542.828 seconds Expected number of requests: 100 Number of concurrency: 30 Total requests: 97 Succeed requests: 97 Failed requests: 0 Average QPS: 0.063 Average latency: 382.291 Throughput(average output tokens per second): 299.114 Average time to first token: 382.291 Average input tokens per request: 6385.000 Average output tokens per request: 4757.546 Average time per output token: 0.00334 Average package per request: 1.000 Average package latency: 382.291 Percentile of time to first token: p50: 348.5759 p66: 378.9814 p75: 420.5971 p80: 443.5496 p90: 514.8233 p95: 548.8156 p98: 559.4441 p99: 590.6074 Percentile of request latency: p50: 348.5759 p66: 378.9814 p75: 420.5971 p80: 443.5496 p90: 514.8233 p95: 548.8156 p98: 559.4441 p99: 590.6074 - parallel 40
Benchmarking summary: Time taken for tests: 1509.713 seconds Expected number of requests: 100 Number of concurrency: 40 Total requests: 87 Succeed requests: 85 Failed requests: 2 Average QPS: 0.056 Average latency: 414.746 Throughput(average output tokens per second): 268.391 Average time to first token: 414.746 Average input tokens per request: 6385.000 Average output tokens per request: 4766.976 Average time per output token: 0.00373 Average package per request: 1.000 Average package latency: 414.746 Percentile of time to first token: p50: 396.9046 p66: 458.9677 p75: 482.9745 p80: 521.3878 p90: 567.8100 p95: 580.6507 p98: 586.6928 p99: 587.2930 Percentile of request latency: p50: 396.9046 p66: 458.9677 p75: 482.9745 p80: 521.3878 p90: 567.8100 p95: 580.6507 p98: 586.6928 p99: 587.2930 - parallel 50
Benchmarking summary: Time taken for tests: 1408.587 seconds Expected number of requests: 100 Number of concurrency: 50 Total requests: 78 Succeed requests: 60 Failed requests: 18 Average QPS: 0.043 Average latency: 403.061 Throughput(average output tokens per second): 199.552 Average time to first token: 403.061 Average input tokens per request: 6385.000 Average output tokens per request: 4684.783 Average time per output token: 0.00501 Average package per request: 1.000 Average package latency: 403.061 Percentile of time to first token: p50: 350.8392 p66: 386.2204 p75: 516.6384 p80: 558.8747 p90: 597.3057 p95: 597.3098 p98: 597.5291 p99: 598.8612 Percentile of request latency: p50: 350.8392 p66: 386.2204 p75: 516.6384 p80: 558.8747 p90: 597.3057 p95: 597.3098 p98: 597.5291 p99: 598.8612
DeepSeek-Coder-6.7B-Instruct
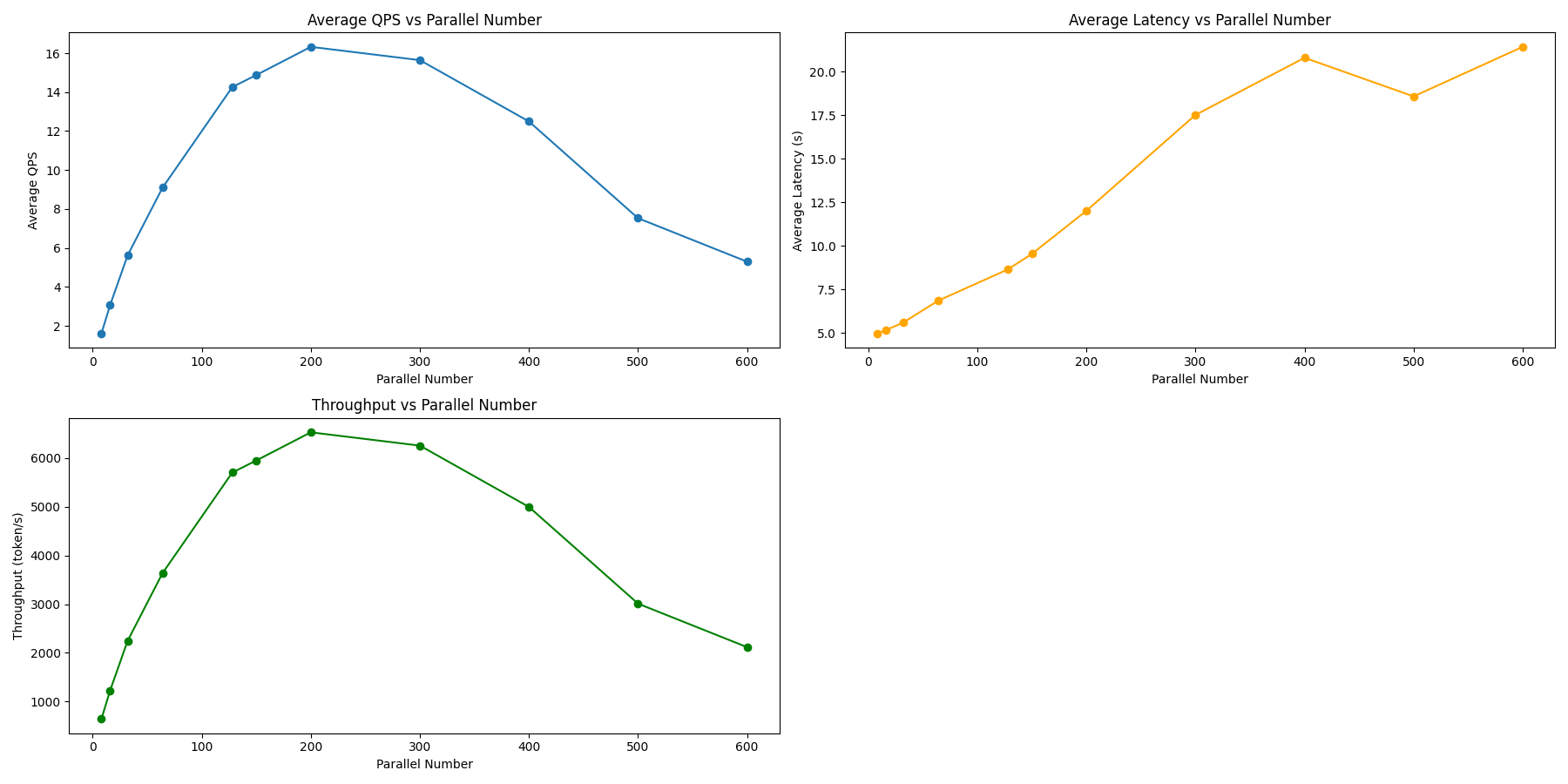
| 指标 | 8 | 16 | 32 | 64 | 128 | 150 | 200 | 300 | 400 | 500 | 600 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 用时 | 621.642 | 325.248 | 178.007 | 109.977 | 70.124 | 67.204 | 61.252 | 63.928 | 70.753 | 72.668 | 75.559 |
| QPS | 1.609 | 3.075 | 5.618 | 9.093 | 14.261 | 14.880 | 16.326 | 15.643 | 12.494 | 7.527 | 5.294 |
| 延迟 | 4.967 | 5.153 | 5.590 | 6.847 | 8.644 | 9.535 | 12.010 | 17.516 | 20.797 | 18.579 | 21.424 |
| 吞吐量 | 643.457 | 1229.830 | 2247.103 | 3637.131 | 5704.202 | 5952.054 | 6530.446 | 6257.033 | 4997.658 | 3010.939 | 2117.557 |
| p50 | 4.9568 | 5.1310 | 5.5455 | 6.9095 | 8.6159 | 9.7244 | 12.1211 | 14.5084 | 20.3585 | 17.9382 | 22.6927 |
| p90 | 5.0456 | 5.3116 | 6.0241 | 6.9913 | 8.9456 | 10.0026 | 12.3709 | 23.8041 | 28.1569 | 28.4858 | 24.4160 |
| 失败 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 184 | 216 |
- 平均每个请求的输入 token 数: 157
-
平均每个请求的输出 token 数: 400
- parallel 8
Benchmarking summary: Time taken for tests: 621.642 seconds Expected number of requests: 1000 Number of concurrency: 8 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 1.609 Average latency: 4.967 Throughput(average output tokens per second): 643.457 Average time to first token: 4.967 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00155 Average package per request: 1.000 Average package latency: 4.967 Percentile of time to first token: p50: 4.9568 p66: 4.9916 p75: 5.0074 p80: 5.0173 p90: 5.0456 p95: 5.0796 p98: 5.1067 p99: 5.1223 Percentile of request latency: p50: 4.9568 p66: 4.9916 p75: 5.0074 p80: 5.0173 p90: 5.0456 p95: 5.0796 p98: 5.1067 p99: 5.1223 - parallel 16
Benchmarking summary: Time taken for tests: 325.248 seconds Expected number of requests: 1000 Number of concurrency: 16 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 3.075 Average latency: 5.153 Throughput(average output tokens per second): 1229.830 Average time to first token: 5.153 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00081 Average package per request: 1.000 Average package latency: 5.153 Percentile of time to first token: p50: 5.1310 p66: 5.1707 p75: 5.2303 p80: 5.2545 p90: 5.3116 p95: 5.4090 p98: 5.4987 p99: 5.5322 Percentile of request latency: p50: 5.1310 p66: 5.1707 p75: 5.2303 p80: 5.2545 p90: 5.3116 p95: 5.4090 p98: 5.4987 p99: 5.5322 - parallel 32
Benchmarking summary: Time taken for tests: 178.007 seconds Expected number of requests: 1000 Number of concurrency: 32 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 5.618 Average latency: 5.590 Throughput(average output tokens per second): 2247.103 Average time to first token: 5.590 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00045 Average package per request: 1.000 Average package latency: 5.590 Percentile of time to first token: p50: 5.5455 p66: 5.5729 p75: 5.6628 p80: 5.7434 p90: 6.0241 p95: 6.0393 p98: 6.1004 p99: 6.1034 Percentile of request latency: p50: 5.5455 p66: 5.5729 p75: 5.6628 p80: 5.7434 p90: 6.0241 p95: 6.0393 p98: 6.1004 p99: 6.1034 - parallel 64
Benchmarking summary: Time taken for tests: 109.977 seconds Expected number of requests: 1000 Number of concurrency: 64 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 9.093 Average latency: 6.847 Throughput(average output tokens per second): 3637.131 Average time to first token: 6.847 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00027 Average package per request: 1.000 Average package latency: 6.847 Percentile of time to first token: p50: 6.9095 p66: 6.9292 p75: 6.9419 p80: 6.9551 p90: 6.9913 p95: 7.0102 p98: 7.0201 p99: 7.0224 Percentile of request latency: p50: 6.9095 p66: 6.9292 p75: 6.9419 p80: 6.9551 p90: 6.9913 p95: 7.0102 p98: 7.0201 p99: 7.0224 - parallel 128
Benchmarking summary: Time taken for tests: 70.124 seconds Expected number of requests: 1000 Number of concurrency: 128 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 14.261 Average latency: 8.644 Throughput(average output tokens per second): 5704.202 Average time to first token: 8.644 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00018 Average package per request: 1.000 Average package latency: 8.644 Percentile of time to first token: p50: 8.6159 p66: 8.7015 p75: 8.7256 p80: 8.8329 p90: 8.9456 p95: 8.9532 p98: 8.9652 p99: 8.9727 Percentile of request latency: p50: 8.6159 p66: 8.7015 p75: 8.7256 p80: 8.8329 p90: 8.9456 p95: 8.9532 p98: 8.9652 p99: 8.9727 - parallel 150
Benchmarking summary: Time taken for tests: 67.204 seconds Expected number of requests: 1000 Number of concurrency: 150 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 14.880 Average latency: 9.535 Throughput(average output tokens per second): 5952.054 Average time to first token: 9.535 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00017 Average package per request: 1.000 Average package latency: 9.535 Percentile of time to first token: p50: 9.7244 p66: 9.8244 p75: 9.8670 p80: 9.8891 p90: 10.0026 p95: 10.0508 p98: 10.0876 p99: 10.1092 Percentile of request latency: p50: 9.7244 p66: 9.8244 p75: 9.8670 p80: 9.8891 p90: 10.0026 p95: 10.0508 p98: 10.0876 p99: 10.1092 - parallel 200
Benchmarking summary: Time taken for tests: 61.252 seconds Expected number of requests: 1000 Number of concurrency: 200 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 16.326 Average latency: 12.010 Throughput(average output tokens per second): 6530.446 Average time to first token: 12.010 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00015 Average package per request: 1.000 Average package latency: 12.010 Percentile of time to first token: p50: 12.1211 p66: 12.2211 p75: 12.2520 p80: 12.2641 p90: 12.3709 p95: 12.3958 p98: 12.4472 p99: 12.4868 Percentile of request latency: p50: 12.1211 p66: 12.2211 p75: 12.2520 p80: 12.2641 p90: 12.3709 p95: 12.3958 p98: 12.4472 p99: 12.4868 - parallel 300
Benchmarking summary: Time taken for tests: 63.928 seconds Expected number of requests: 1000 Number of concurrency: 300 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 15.643 Average latency: 17.516 Throughput(average output tokens per second): 6257.033 Average time to first token: 17.516 Average input tokens per request: 157.292 Average output tokens per request: 400.000 Average time per output token: 0.00016 Average package per request: 1.000 Average package latency: 17.516 Percentile of time to first token: p50: 14.5084 p66: 21.8597 p75: 22.9786 p80: 23.3034 p90: 23.8041 p95: 25.4313 p98: 25.8759 p99: 26.0190 Percentile of request latency: p50: 14.5084 p66: 21.8597 p75: 22.9786 p80: 23.3034 p90: 23.8041 p95: 25.4313 p98: 25.8759 p99: 26.0190 - parallel 400
Benchmarking summary: Time taken for tests: 70.753 seconds Expected number of requests: 1000 Number of concurrency: 400 Total requests: 884 Succeed requests: 884 Failed requests: 0 Average QPS: 12.494 Average latency: 20.797 Throughput(average output tokens per second): 4997.658 Average time to first token: 20.797 Average input tokens per request: 157.958 Average output tokens per request: 400.000 Average time per output token: 0.00020 Average package per request: 1.000 Average package latency: 20.797 Percentile of time to first token: p50: 20.3585 p66: 25.7757 p75: 26.3887 p80: 27.0304 p90: 28.1569 p95: 28.6731 p98: 29.6462 p99: 29.8135 Percentile of request latency: p50: 20.3585 p66: 25.7757 p75: 26.3887 p80: 27.0304 p90: 28.1569 p95: 28.6731 p98: 29.6462 p99: 29.8135 - parallel 500
Benchmarking summary: Time taken for tests: 72.668 seconds Expected number of requests: 1000 Number of concurrency: 500 Total requests: 731 Succeed requests: 547 Failed requests: 184 Average QPS: 7.527 Average latency: 18.579 Throughput(average output tokens per second): 3010.939 Average time to first token: 18.579 Average input tokens per request: 156.399 Average output tokens per request: 400.000 Average time per output token: 0.00033 Average package per request: 1.000 Average package latency: 18.579 Percentile of time to first token: p50: 17.9382 p66: 19.5846 p75: 20.2549 p80: 20.4220 p90: 28.4858 p95: 29.5889 p98: 29.9512 p99: 30.0487 Percentile of request latency: p50: 17.9382 p66: 19.5846 p75: 20.2549 p80: 20.4220 p90: 28.4858 p95: 29.5889 p98: 29.9512 p99: 30.0487 - parallel 600
Benchmarking summary: Time taken for tests: 75.559 seconds Expected number of requests: 1000 Number of concurrency: 600 Total requests: 616 Succeed requests: 400 Failed requests: 216 Average QPS: 5.294 Average latency: 21.424 Throughput(average output tokens per second): 2117.557 Average time to first token: 21.424 Average input tokens per request: 157.625 Average output tokens per request: 400.000 Average time per output token: 0.00047 Average package per request: 1.000 Average package latency: 21.424 Percentile of time to first token: p50: 22.6927 p66: 23.5150 p75: 24.1050 p80: 24.2716 p90: 24.4160 p95: 24.5849 p98: 29.1271 p99: 30.2161 Percentile of request latency: p50: 22.6927 p66: 23.5150 p75: 24.1050 p80: 24.2716 p90: 24.4160 p95: 24.5849 p98: 29.1271 p99: 30.2161
安装依赖库
pip install evalscope-perf
pip install evalscope
执行命令
evalscope-perf http://127.0.0.1:1025/v1/chat/completions qwen \
./datasets/Codefuse-Evol-Instruct-Clean-data.jsonl \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 256 \
--parallels 300 \
--parallels 400 \
--parallels 500 \
--parallels 600 \
--parallels 700 \
--parallels 800 \
--parallels 900 \
--parallels 1000 \
--n 2000
绘图代码
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
# 设置中文字体
font_path = '/System/Library/Fonts/Hiragino Sans GB.ttc' # 替换为你的字体文件路径
font_prop = FontProperties(fname=font_path)
# 数据: Qwen1.5-7B-Chat
concurrency = [8, 16, 32, 64, 128, 150, 200, 256, 300, 400, 512, 720]
time = [404.284, 215.085, 120.876, 82.884, 52.844, 48.884, 44.856, 42.750, 43.729, 42.866, 41.655, 40.580]
qps = [2.474, 4.649, 8.273, 12.065, 18.924, 20.457, 22.294, 23.392, 22.868, 23.328, 24.007, 24.643]
latency = [3.213, 3.391, 3.724, 4.974, 6.108, 6.517, 7.805, 9.208, 10.904, 13.628, 16.031, 18.790]
throughput = [594.929, 1119.102, 1989.159, 2903.023, 4559.489, 4920.856, 5354.701, 5636.846, 5506.567, 5618.110, 5772.230, 5940.622]
p50 = [3.2461, 3.4271, 3.7514, 5.0248, 6.1491, 6.5487, 7.7782, 9.1754, 10.9164, 13.9850, 17.0675, 20.4161]
p90 = [4.9771, 5.2905, 5.8484, 7.7522, 9.5705, 10.1980, 12.3493, 13.6320, 15.8667, 19.2667, 22.7640, 26.8183]
# 数据: Qwen1.5-14B-Chat
# concurrency = [8, 16, 32, 64, 128, 150, 200, 256, 512]
# time = [578.571, 361.169, 253.040, 204.961, 170.001, 169.981, 162.999, 159.840, 153.937]
# qps = [1.727, 2.766, 3.952, 4.874, 5.882, 5.877, 6.129, 6.250, 6.490]
# latency = [3.712, 3.928, 4.581, 5.628, 7.223, 8.004, 9.205, 11.446, 22.695]
# throughput = [480.043, 897.511, 915.133, 2333.955, 1363.656, 3621.096, 4310.525, 4333.013, 3806.748]
# p50 = [3.7038, 3.9261, 4.4544, 5.6047, 7.0534, 7.9484, 9.0271, 11.3066, 23.6591]
# p90 = [5.7184, 6.0562, 6.9198, 8.7597, 11.1194, 12.5181, 14.5017, 16.8646, 33.3052]
# 数据: Qwen2-72B-Chat
# concurrency = [8, 16, 32, 64, 128, 150, 200, 256, 512]
# time = [1569.707, 909.001, 567.479, 382.247, 179.015, 270.054, 251.060, 237.063, 206.734]
# qps = [0.636, 1.099, 1.759, 2.613, 5.586, 3.699, 3.975, 4.214, 4.832]
# latency = [11.705, 12.806, 14.526, 17.296, 21.041, 23.856, 28.198, 33.176, 59.912]
# throughput = [188.589, 342.764, 588.262, 973.795, 1549.069, 1595.176, 1748.784, 1866.155, 1828.363]
# p50 = [11.8443, 12.8275, 14.7115, 17.5290, 21.3863, 23.8551, 28.4407, 32.7329, 63.0404]
# p90 = [16.2106, 17.5466, 20.0371, 23.9890, 29.5537, 33.7459, 40.4210, 45.7666, 81.6602]
# 绘制曲线
plt.figure(figsize=(12, 8))
# 用时 vs 并行数
plt.subplot(2, 3, 1)
plt.plot(concurrency, time, marker='o')
plt.title('用时 vs 并行数', fontproperties=font_prop)
plt.xlabel('并行数', fontproperties=font_prop)
plt.ylabel('用时 (秒)', fontproperties=font_prop)
# QPS vs 并行数
plt.subplot(2, 3, 2)
plt.plot(concurrency, qps, marker='o')
plt.title('QPS vs 并行数', fontproperties=font_prop)
plt.xlabel('并行数', fontproperties=font_prop)
plt.ylabel('QPS', fontproperties=font_prop)
# 延迟 vs 并行数
plt.subplot(2, 3, 3)
plt.plot(concurrency, latency, marker='o')
plt.title('延迟 vs 并行数', fontproperties=font_prop)
plt.xlabel('并行数', fontproperties=font_prop)
plt.ylabel('延迟 (秒)', fontproperties=font_prop)
# 吞吐量 vs 并行数
plt.subplot(2, 3, 4)
plt.plot(concurrency, throughput, marker='o')
plt.title('吞吐量 vs 并行数', fontproperties=font_prop)
plt.xlabel('并行数', fontproperties=font_prop)
plt.ylabel('吞吐量 (每秒输出的token数)', fontproperties=font_prop)
# p50 vs 并行数
plt.subplot(2, 3, 5)
plt.plot(concurrency, p50, marker='o')
plt.title('p50 vs 并行数', fontproperties=font_prop)
plt.xlabel('并行数', fontproperties=font_prop)
plt.ylabel('p50 (秒)', fontproperties=font_prop)
# p90 vs 并行数
plt.subplot(2, 3, 6)
plt.plot(concurrency, p90, marker='o')
plt.title('p90 vs 并行数', fontproperties=font_prop)
plt.xlabel('并行数', fontproperties=font_prop)
plt.ylabel('p90 (秒)', fontproperties=font_prop)
# 显示图表
plt.tight_layout()
plt.show()
实验结果(vLLM)
Qwen1.5-7B-Chat
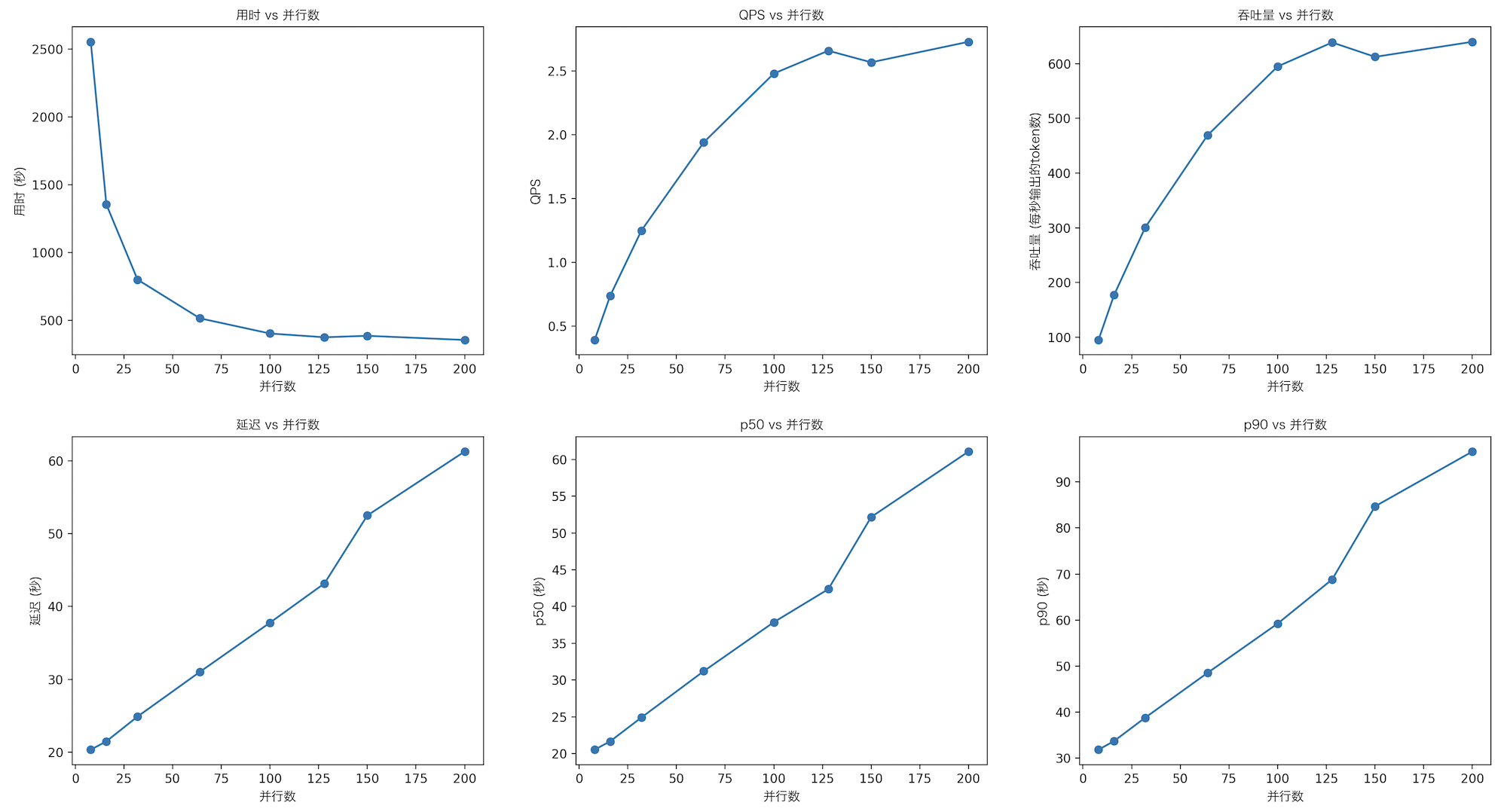
| 指标 | 8 | 16 | 32 | 64 | 100 | 128 | 150 | 200 |
|---|---|---|---|---|---|---|---|---|
| 用时 | 2555.302 | 1355.736 | 800.953 | 515.309 | 403.138 | 375.187 | 386.202 | 355.307 |
| QPS | 0.391 | 0.738 | 1.249 | 1.941 | 2.481 | 2.660 | 2.569 | 2.730 |
| 延迟 | 20.326 | 21.475 | 24.877 | 31.015 | 37.778 | 43.181 | 52.514 | 61.304 |
| 吞吐量 | 94.803 | 177.014 | 300.603 | 469.235 | 595.103 | 638.980 | 612.597 | 640.172 |
| p50 | 20.5326 | 21.6749 | 24.9076 | 31.2051 | 37.8700 | 42.3652 | 52.1732 | 61.0796 |
| p90 | 31.8381 | 33.7150 | 38.8008 | 48.5248 | 59.2335 | 68.8249 | 84.6935 | 96.6051 |
| ❌ | 6 | 28 |
- 平均每个请求的输入 token 数: 40
- 平均每个请求的输出 token 数: 240
# 数据
concurrency = [8, 16, 32, 64, 100, 128, 150, 200]
time = [2555.302, 1355.736, 800.953, 515.309, 403.138, 375.187, 386.202, 355.307]
qps = [0.391, 0.738, 1.249, 1.941, 2.481, 2.660, 2.569, 2.730]
latency = [20.326, 21.475, 24.877, 31.015, 37.778, 43.181, 52.514, 61.304]
throughput = [94.803, 177.014, 300.603, 469.235, 595.103, 638.980, 612.597, 640.172]
p50 = [20.5326, 21.6749, 24.9076, 31.2051, 37.8700, 42.3652, 52.1732, 61.0796]
p90 = [31.8381, 33.7150, 38.8008, 48.5248, 59.2335, 68.8249, 84.6935, 96.6051]
- parallel 8
Benchmarking summary: Time taken for tests: 2555.302 seconds Expected number of requests: 1000 Number of concurrency: 8 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 0.391 Average latency: 20.326 Throughput(average output tokens per second): 94.803 Average time to first token: 20.326 Average input tokens per request: 40.296 Average output tokens per request: 242.251 Average time per output token: 0.01055 Average package per request: 1.000 Average package latency: 20.326 Percentile of time to first token: p50: 20.5326 p66: 23.7691 p75: 26.5282 p80: 28.1502 p90: 31.8381 p95: 35.6152 p98: 40.9497 p99: 45.7076 Percentile of request latency: p50: 20.5326 p66: 23.7691 p75: 26.5282 p80: 28.1502 p90: 31.8381 p95: 35.6152 p98: 40.9497 p99: 45.7076 - parallel 16
Benchmarking summary: Time taken for tests: 1355.736 seconds Expected number of requests: 1000 Number of concurrency: 16 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 0.738 Average latency: 21.475 Throughput(average output tokens per second): 177.014 Average time to first token: 21.475 Average input tokens per request: 40.296 Average output tokens per request: 239.984 Average time per output token: 0.00565 Average package per request: 1.000 Average package latency: 21.475 Percentile of time to first token: p50: 21.6749 p66: 25.2886 p75: 27.4429 p80: 29.0391 p90: 33.7150 p95: 37.1781 p98: 42.4568 p99: 45.9629 Percentile of request latency: p50: 21.6749 p66: 25.2886 p75: 27.4429 p80: 29.0391 p90: 33.7150 p95: 37.1781 p98: 42.4568 p99: 45.9629 - parallel 32
Benchmarking summary: Time taken for tests: 800.953 seconds Expected number of requests: 1000 Number of concurrency: 32 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 1.249 Average latency: 24.877 Throughput(average output tokens per second): 300.603 Average time to first token: 24.877 Average input tokens per request: 40.296 Average output tokens per request: 240.769 Average time per output token: 0.00333 Average package per request: 1.000 Average package latency: 24.877 Percentile of time to first token: p50: 24.9076 p66: 29.1147 p75: 32.1535 p80: 34.1477 p90: 38.8008 p95: 43.0980 p98: 48.4589 p99: 53.6278 Percentile of request latency: p50: 24.9076 p66: 29.1147 p75: 32.1535 p80: 34.1477 p90: 38.8008 p95: 43.0980 p98: 48.4589 p99: 53.6278 - parallel 64
Benchmarking summary: Time taken for tests: 515.309 seconds Expected number of requests: 1000 Number of concurrency: 64 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 1.941 Average latency: 31.015 Throughput(average output tokens per second): 469.235 Average time to first token: 31.015 Average input tokens per request: 40.296 Average output tokens per request: 241.801 Average time per output token: 0.00213 Average package per request: 1.000 Average package latency: 31.015 Percentile of time to first token: p50: 31.2051 p66: 36.5305 p75: 40.1962 p80: 42.1270 p90: 48.5248 p95: 53.4686 p98: 60.3826 p99: 65.7931 Percentile of request latency: p50: 31.2051 p66: 36.5305 p75: 40.1962 p80: 42.1270 p90: 48.5248 p95: 53.4686 p98: 60.3826 p99: 65.7931 - parallel 100
Benchmarking summary: Time taken for tests: 403.138 seconds Expected number of requests: 1000 Number of concurrency: 100 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 2.481 Average latency: 37.778 Throughput(average output tokens per second): 595.103 Average time to first token: 37.778 Average input tokens per request: 40.296 Average output tokens per request: 239.909 Average time per output token: 0.00168 Average package per request: 1.000 Average package latency: 37.778 Percentile of time to first token: p50: 37.8700 p66: 44.4992 p75: 49.1464 p80: 52.3330 p90: 59.2335 p95: 64.9315 p98: 74.1723 p99: 80.4544 Percentile of request latency: p50: 37.8700 p66: 44.4992 p75: 49.1464 p80: 52.3330 p90: 59.2335 p95: 64.9315 p98: 74.1723 p99: 80.4544 - parallel 128
Benchmarking summary: Time taken for tests: 375.187 seconds Expected number of requests: 1000 Number of concurrency: 128 Total requests: 999 Succeed requests: 998 Failed requests: 1 Average QPS: 2.660 Average latency: 43.181 Throughput(average output tokens per second): 638.980 Average time to first token: 43.181 Average input tokens per request: 40.297 Average output tokens per request: 240.217 Average time per output token: 0.00156 Average package per request: 1.000 Average package latency: 43.181 Percentile of time to first token: p50: 42.3652 p66: 51.6154 p75: 56.2693 p80: 59.2260 p90: 68.8249 p95: 75.4546 p98: 85.2362 p99: 93.3652 Percentile of request latency: p50: 42.3652 p66: 51.6154 p75: 56.2693 p80: 59.2260 p90: 68.8249 p95: 75.4546 p98: 85.2362 p99: 93.3652 - parallel 150
Benchmarking summary: Time taken for tests: 386.202 seconds Expected number of requests: 1000 Number of concurrency: 150 Total requests: 998 Succeed requests: 992 Failed requests: 6 Average QPS: 2.569 Average latency: 52.514 Throughput(average output tokens per second): 612.597 Average time to first token: 52.514 Average input tokens per request: 40.303 Average output tokens per request: 238.494 Average time per output token: 0.00163 Average package per request: 1.000 Average package latency: 52.514 Percentile of time to first token: p50: 52.1732 p66: 61.4450 p75: 67.9417 p80: 72.0179 p90: 84.6935 p95: 92.2286 p98: 101.7002 p99: 107.7996 Percentile of request latency: p50: 52.1732 p66: 61.4450 p75: 67.9417 p80: 72.0179 p90: 84.6935 p95: 92.2286 p98: 101.7002 p99: 107.7996 - parallel 200
Benchmarking summary: Time taken for tests: 355.307 seconds Expected number of requests: 1000 Number of concurrency: 200 Total requests: 998 Succeed requests: 970 Failed requests: 28 Average QPS: 2.730 Average latency: 61.304 Throughput(average output tokens per second): 640.172 Average time to first token: 61.304 Average input tokens per request: 40.287 Average output tokens per request: 234.493 Average time per output token: 0.00156 Average package per request: 1.000 Average package latency: 61.304 Percentile of time to first token: p50: 61.0796 p66: 74.1724 p75: 80.9575 p80: 84.8420 p90: 96.6051 p95: 105.2873 p98: 114.3178 p99: 115.7257 Percentile of request latency: p50: 61.0796 p66: 74.1724 p75: 80.9575 p80: 84.8420 p90: 96.6051 p95: 105.2873 p98: 114.3178 p99: 115.7257
Qwen2.5-72B-Chat
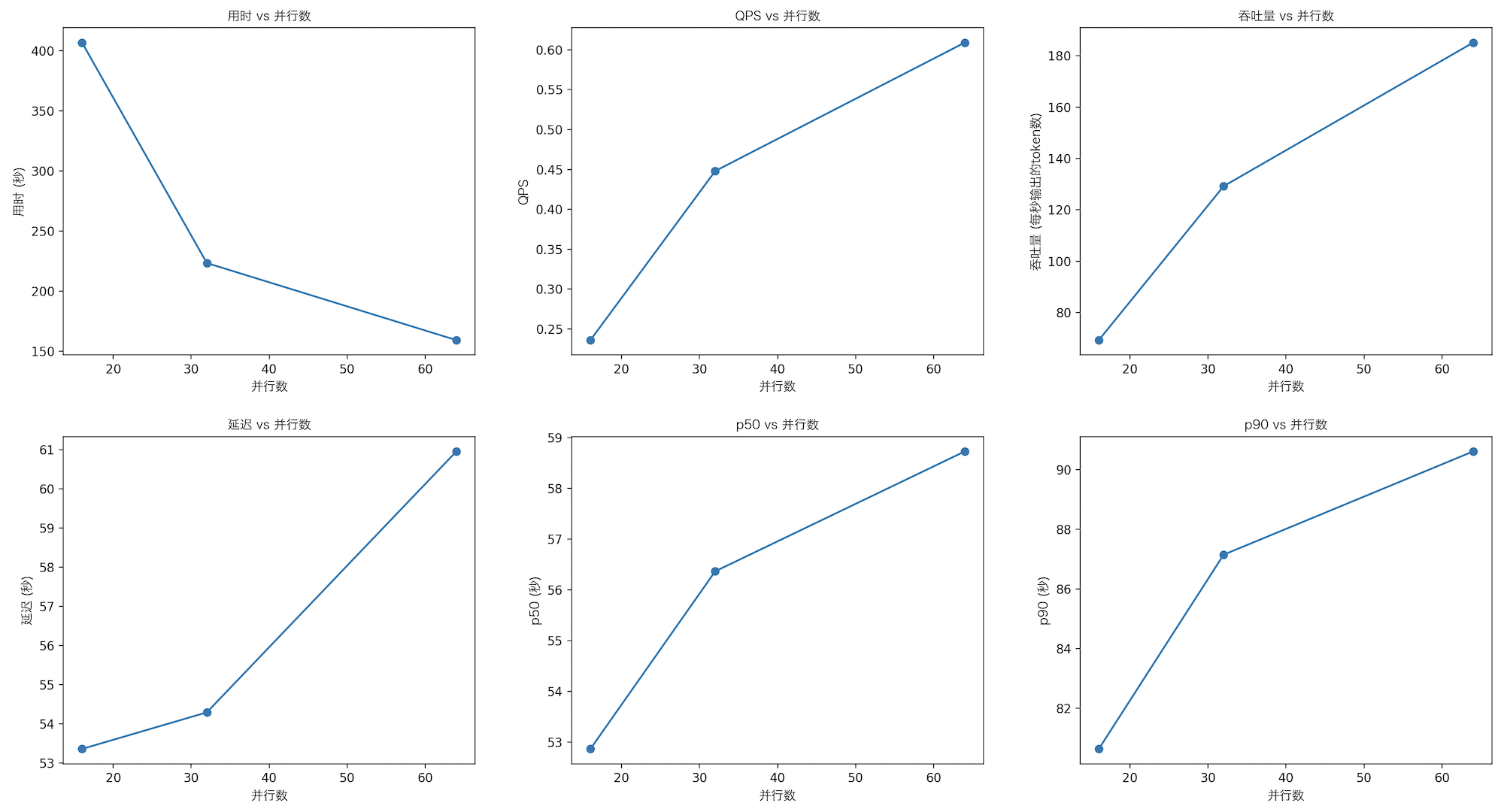
| 指标 | 16 | 32 | 64 |
|---|---|---|---|
| 用时 | 406.618 | 223.379 | 159.293 |
| QPS | 0.236 | 0.448 | 0.609 |
| 延迟 | 53.359 | 54.293 | 60.959 |
| 吞吐量 | 69.242 | 129.193 | 185.140 |
| p50 | 52.8675 | 56.3690 | 58.7318 |
| p90 | 80.6415 | 87.1464 | 90.6065 |
- 平均每个请求的输入 token 数: 50
- 平均每个请求的输出 token 数: 290
# 数据
concurrency = [16, 32, 64]
time = [406.618, 223.379, 159.293]
qps = [0.236, 0.448, 0.609]
latency = [53.359, 54.293, 60.959]
throughput = [69.242, 129.193, 185.140]
p50 = [52.8675, 56.3690, 58.7318]
p90 = [80.6415, 87.1464, 90.6065]
- parallel 1
Benchmarking summary: Time taken for tests: 80.089 seconds Expected number of requests: 1 Number of concurrency: 1 Total requests: 1 Succeed requests: 1 Failed requests: 0 Average QPS: 0.012 Average latency: 79.353 Throughput(average output tokens per second): 5.819 Average time to first token: 79.353 Average input tokens per request: 44.000 Average output tokens per request: 466.000 Average time per output token: 0.17186 Average package per request: 1.000 Average package latency: 79.353 - parallel 16
Benchmarking summary: Time taken for tests: 406.618 seconds Expected number of requests: 100 Number of concurrency: 16 Total requests: 98 Succeed requests: 96 Failed requests: 2 Average QPS: 0.236 Average latency: 53.359 Throughput(average output tokens per second): 69.242 Average time to first token: 53.359 Average input tokens per request: 50.156 Average output tokens per request: 293.281 Average time per output token: 0.01444 Average package per request: 1.000 Average package latency: 53.359 Percentile of time to first token: p50: 52.8675 p66: 62.7250 p75: 70.2725 p80: 73.0569 p90: 80.6415 p95: 91.7408 p98: 96.5681 p99: 114.6619 Percentile of request latency: p50: 52.8675 p66: 62.7250 p75: 70.2725 p80: 73.0569 p90: 80.6415 p95: 91.7408 p98: 96.5681 p99: 114.6619 - parallel 32
Benchmarking summary: Time taken for tests: 223.379 seconds Expected number of requests: 100 Number of concurrency: 32 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.448 Average latency: 54.293 Throughput(average output tokens per second): 129.193 Average time to first token: 54.293 Average input tokens per request: 49.890 Average output tokens per request: 288.590 Average time per output token: 0.00774 Average package per request: 1.000 Average package latency: 54.293 Percentile of time to first token: p50: 56.3690 p66: 61.8036 p75: 73.1621 p80: 77.8210 p90: 87.1464 p95: 97.1933 p98: 102.0623 p99: 107.4325 Percentile of request latency: p50: 56.3690 p66: 61.8036 p75: 73.1621 p80: 77.8210 p90: 87.1464 p95: 97.1933 p98: 102.0623 p99: 107.4325 - parallel 64
Benchmarking summary: Time taken for tests: 159.293 seconds Expected number of requests: 100 Number of concurrency: 64 Total requests: 99 Succeed requests: 97 Failed requests: 2 Average QPS: 0.609 Average latency: 60.959 Throughput(average output tokens per second): 185.140 Average time to first token: 60.959 Average input tokens per request: 50.093 Average output tokens per request: 296.392 Average time per output token: 0.00540 Average package per request: 1.000 Average package latency: 60.959 Percentile of time to first token: p50: 58.7318 p66: 72.0510 p75: 77.6354 p80: 82.2268 p90: 90.6065 p95: 98.0913 p98: 108.4727 p99: 112.9350 Percentile of request latency: p50: 58.7318 p66: 72.0510 p75: 77.6354 p80: 82.2268 p90: 90.6065 p95: 98.0913 p98: 108.4727 p99: 112.9350
实验结果(XInference - MindIE)
- ❌ 部署时间长了,请求无响应。
- ❌ 部署多副本,压测一次后,服务挂掉。
实验结果(Nvidia T4: XInference - vLLM)
Qwen2-7B-Instruct
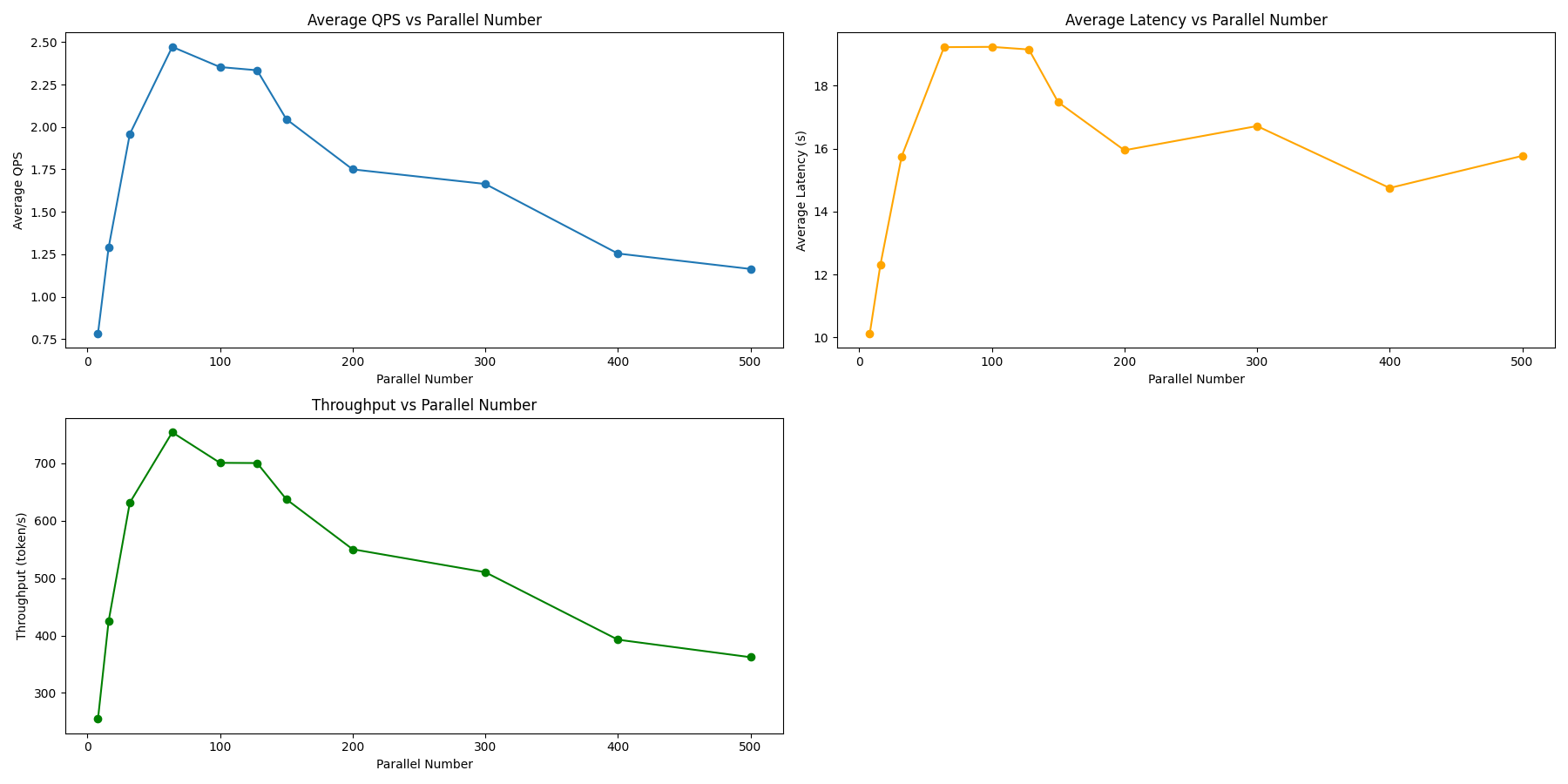
| 指标 | 8 | 16 | 32 | 64 | 100 | 128 | 150 | 200 | 300 | 400 | 500 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 用时 | 1276.077 | 776.170 | 504.480 | 372.118 | 363.016 | 365.024 | 418.874 | 459.912 | 401.385 | 458.450 | 375.796 |
| QPS | 0.783 | 1.288 | 1.958 | 2.472 | 2.353 | 2.334 | 2.046 | 1.750 | 1.664 | 1.254 | 1.163 |
| 延迟 | 10.128 | 12.307 | 15.749 | 19.225 | 19.235 | 19.151 | 17.479 | 15.949 | 16.718 | 14.750 | 15.771 |
| 吞吐量 | 254.695 | 424.701 | 631.260 | 753.852 | 700.681 | 700.324 | 637.260 | 550.200 | 510.211 | 392.697 | 362.167 |
| p50 | 10.3076 | 12.5569 | 16.3129 | 20.0818 | 20.1519 | 20.0230 | 17.9699 | 16.2526 | 17.0123 | 14.8173 | 15.8847 |
| p90 | 14.3874 | 17.6026 | 22.5020 | 26.8947 | 26.5725 | 26.8284 | 24.7138 | 23.0809 | 24.4670 | 21.4278 | 23.7326 |
| 失败 | 1 | 0 | 12 | 71 | 101 | 72 | 32 | 25 | 66 | 47 | 89 |
- 平均每个请求的输入 token 数: 40
- 平均每个请求的输出 token 数: 300
evalscope-perf http://172.16.33.66:9997/v1/chat/completions gpt-4-32k \
./datasets/open_qa.jsonl \
--parallels 8 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 300 \
--parallels 400 \
--parallels 500 \
--n 1000
- parallel 8
Benchmarking summary: Time taken for tests: 1276.077 seconds Expected number of requests: 1000 Number of concurrency: 8 Total requests: 1000 Succeed requests: 999 Failed requests: 1 Average QPS: 0.783 Average latency: 10.128 Throughput(average output tokens per second): 254.695 Average time to first token: 10.128 Average input tokens per request: 40.295 Average output tokens per request: 325.335 Average time per output token: 0.00393 Average package per request: 1.000 Average package latency: 10.128 Percentile of time to first token: p50: 10.3076 p66: 11.5736 p75: 12.3458 p80: 12.6923 p90: 14.3874 p95: 15.7724 p98: 17.3099 p99: 18.2167 Percentile of request latency: p50: 10.3076 p66: 11.5736 p75: 12.3458 p80: 12.6923 p90: 14.3874 p95: 15.7724 p98: 17.3099 p99: 18.2167 - parallel 16
Benchmarking summary: Time taken for tests: 776.170 seconds Expected number of requests: 1000 Number of concurrency: 16 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 1.288 Average latency: 12.307 Throughput(average output tokens per second): 424.701 Average time to first token: 12.307 Average input tokens per request: 40.296 Average output tokens per request: 329.640 Average time per output token: 0.00235 Average package per request: 1.000 Average package latency: 12.307 Percentile of time to first token: p50: 12.5569 p66: 13.8731 p75: 14.9178 p80: 15.6629 p90: 17.6026 p95: 19.0937 p98: 21.7158 p99: 22.9113 Percentile of request latency: p50: 12.5569 p66: 13.8731 p75: 14.9178 p80: 15.6629 p90: 17.6026 p95: 19.0937 p98: 21.7158 p99: 22.9113 - parallel 32
Benchmarking summary: Time taken for tests: 504.480 seconds Expected number of requests: 1000 Number of concurrency: 32 Total requests: 1000 Succeed requests: 988 Failed requests: 12 Average QPS: 1.958 Average latency: 15.749 Throughput(average output tokens per second): 631.260 Average time to first token: 15.749 Average input tokens per request: 40.277 Average output tokens per request: 322.326 Average time per output token: 0.00158 Average package per request: 1.000 Average package latency: 15.749 Percentile of time to first token: p50: 16.3129 p66: 18.2424 p75: 19.2717 p80: 19.9721 p90: 22.5020 p95: 24.8820 p98: 26.8200 p99: 27.5026 Percentile of request latency: p50: 16.3129 p66: 18.2424 p75: 19.2717 p80: 19.9721 p90: 22.5020 p95: 24.8820 p98: 26.8200 p99: 27.5026 - parallel 64
Benchmarking summary: Time taken for tests: 372.118 seconds Expected number of requests: 1000 Number of concurrency: 64 Total requests: 991 Succeed requests: 920 Failed requests: 71 Average QPS: 2.472 Average latency: 19.225 Throughput(average output tokens per second): 753.852 Average time to first token: 19.225 Average input tokens per request: 40.204 Average output tokens per request: 304.915 Average time per output token: 0.00133 Average package per request: 1.000 Average package latency: 19.225 Percentile of time to first token: p50: 20.0818 p66: 22.5724 p75: 23.7237 p80: 24.5372 p90: 26.8947 p95: 28.2781 p98: 29.2713 p99: 29.5592 Percentile of request latency: p50: 20.0818 p66: 22.5724 p75: 23.7237 p80: 24.5372 p90: 26.8947 p95: 28.2781 p98: 29.2713 p99: 29.5592 - parallel 100
Benchmarking summary: Time taken for tests: 363.016 seconds Expected number of requests: 1000 Number of concurrency: 100 Total requests: 955 Succeed requests: 854 Failed requests: 101 Average QPS: 2.353 Average latency: 19.235 Throughput(average output tokens per second): 700.681 Average time to first token: 19.235 Average input tokens per request: 40.218 Average output tokens per request: 297.843 Average time per output token: 0.00143 Average package per request: 1.000 Average package latency: 19.235 Percentile of time to first token: p50: 20.1519 p66: 22.4520 p75: 23.9718 p80: 24.6514 p90: 26.5725 p95: 28.0242 p98: 29.1395 p99: 29.5591 Percentile of request latency: p50: 20.1519 p66: 22.4520 p75: 23.9718 p80: 24.6514 p90: 26.5725 p95: 28.0242 p98: 29.1395 p99: 29.5591 - parallel 128
Benchmarking summary: Time taken for tests: 365.024 seconds Expected number of requests: 1000 Number of concurrency: 128 Total requests: 924 Succeed requests: 852 Failed requests: 72 Average QPS: 2.334 Average latency: 19.151 Throughput(average output tokens per second): 700.324 Average time to first token: 19.151 Average input tokens per request: 40.188 Average output tokens per request: 300.041 Average time per output token: 0.00143 Average package per request: 1.000 Average package latency: 19.151 Percentile of time to first token: p50: 20.0230 p66: 22.2805 p75: 23.6442 p80: 24.5745 p90: 26.8284 p95: 28.1978 p98: 29.3051 p99: 29.6282 Percentile of request latency: p50: 20.0230 p66: 22.2805 p75: 23.6442 p80: 24.5745 p90: 26.8284 p95: 28.1978 p98: 29.3051 p99: 29.6282 - parallel 150
Benchmarking summary: Time taken for tests: 418.874 seconds Expected number of requests: 1000 Number of concurrency: 150 Total requests: 889 Succeed requests: 857 Failed requests: 32 Average QPS: 2.046 Average latency: 17.479 Throughput(average output tokens per second): 637.260 Average time to first token: 17.479 Average input tokens per request: 40.272 Average output tokens per request: 311.473 Average time per output token: 0.00157 Average package per request: 1.000 Average package latency: 17.479 Percentile of time to first token: p50: 17.9699 p66: 20.0651 p75: 21.5481 p80: 22.2761 p90: 24.7138 p95: 27.1316 p98: 28.8103 p99: 29.3229 Percentile of request latency: p50: 17.9699 p66: 20.0651 p75: 21.5481 p80: 22.2761 p90: 24.7138 p95: 27.1316 p98: 28.8103 p99: 29.3229 - parallel 200
Benchmarking summary: Time taken for tests: 459.912 seconds Expected number of requests: 1000 Number of concurrency: 200 Total requests: 830 Succeed requests: 805 Failed requests: 25 Average QPS: 1.750 Average latency: 15.949 Throughput(average output tokens per second): 550.200 Average time to first token: 15.949 Average input tokens per request: 40.337 Average output tokens per request: 314.340 Average time per output token: 0.00182 Average package per request: 1.000 Average package latency: 15.949 Percentile of time to first token: p50: 16.2526 p66: 18.0521 p75: 19.4394 p80: 20.1756 p90: 23.0809 p95: 25.5287 p98: 28.5592 p99: 29.4651 Percentile of request latency: p50: 16.2526 p66: 18.0521 p75: 19.4394 p80: 20.1756 p90: 23.0809 p95: 25.5287 p98: 28.5592 p99: 29.4651 - parallel 300
Benchmarking summary: Time taken for tests: 401.385 seconds Expected number of requests: 1000 Number of concurrency: 300 Total requests: 734 Succeed requests: 668 Failed requests: 66 Average QPS: 1.664 Average latency: 16.718 Throughput(average output tokens per second): 510.211 Average time to first token: 16.718 Average input tokens per request: 40.383 Average output tokens per request: 306.573 Average time per output token: 0.00196 Average package per request: 1.000 Average package latency: 16.718 Percentile of time to first token: p50: 17.0123 p66: 19.2765 p75: 20.8575 p80: 21.9712 p90: 24.4670 p95: 26.6873 p98: 28.2457 p99: 29.1315 Percentile of request latency: p50: 17.0123 p66: 19.2765 p75: 20.8575 p80: 21.9712 p90: 24.4670 p95: 26.6873 p98: 28.2457 p99: 29.1315 - parallel 400
Benchmarking summary: Time taken for tests: 458.450 seconds Expected number of requests: 1000 Number of concurrency: 400 Total requests: 622 Succeed requests: 575 Failed requests: 47 Average QPS: 1.254 Average latency: 14.750 Throughput(average output tokens per second): 392.697 Average time to first token: 14.750 Average input tokens per request: 40.310 Average output tokens per request: 313.099 Average time per output token: 0.00255 Average package per request: 1.000 Average package latency: 14.750 Percentile of time to first token: p50: 14.8173 p66: 16.7375 p75: 18.0656 p80: 18.7752 p90: 21.4278 p95: 24.3040 p98: 28.1092 p99: 29.1603 Percentile of request latency: p50: 14.8173 p66: 16.7375 p75: 18.0656 p80: 18.7752 p90: 21.4278 p95: 24.3040 p98: 28.1092 p99: 29.1603 - parallel 500
Benchmarking summary: Time taken for tests: 375.796 seconds Expected number of requests: 1000 Number of concurrency: 500 Total requests: 526 Succeed requests: 437 Failed requests: 89 Average QPS: 1.163 Average latency: 15.771 Throughput(average output tokens per second): 362.167 Average time to first token: 15.771 Average input tokens per request: 40.268 Average output tokens per request: 311.444 Average time per output token: 0.00276 Average package per request: 1.000 Average package latency: 15.771 Percentile of time to first token: p50: 15.8847 p66: 17.4772 p75: 18.8302 p80: 20.0079 p90: 23.7326 p95: 26.3385 p98: 28.6426 p99: 29.0919 Percentile of request latency: p50: 15.8847 p66: 17.4772 p75: 18.8302 p80: 20.0079 p90: 23.7326 p95: 26.3385 p98: 28.6426 p99: 29.0919
实验结果(Nvidia T4: vLLM)
Qwen2-7B-Instruct
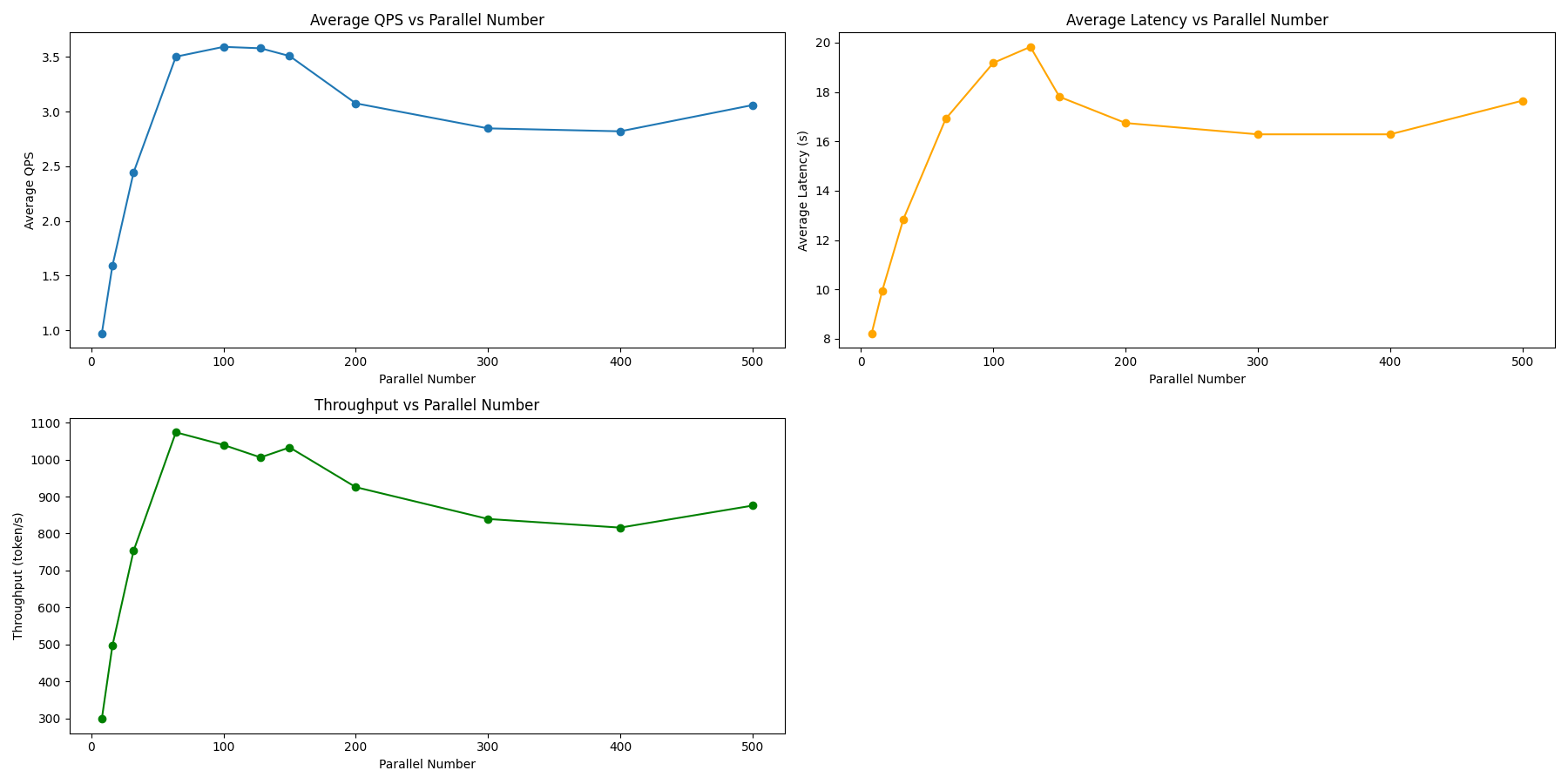
| 指标 | 8 | 16 | 32 | 64 | 100 | 128 | 150 | 200 | 300 | 400 | 500 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 用时 | 1030.632 | 629.843 | 409.251 | 280.896 | 252.708 | 236.597 | 254.208 | 274.376 | 256.799 | 222.726 | 175.166 |
| QPS | 0.970 | 1.588 | 2.443 | 3.503 | 3.593 | 3.580 | 3.509 | 3.076 | 2.847 | 2.820 | 3.060 |
| 延迟 | 8.213 | 9.944 | 12.846 | 16.913 | 19.182 | 19.831 | 17.806 | 16.743 | 16.285 | 16.285 | 17.649 |
| 吞吐量 | 298.860 | 496.458 | 753.176 | 1073.697 | 1039.610 | 1005.881 | 1032.794 | 925.476 | 839.437 | 816.049 | 875.565 |
| p50 | 8.4703 | 10.2975 | 13.3060 | 17.5850 | 20.1962 | 20.9986 | 18.6905 | 17.0203 | 16.6503 | 16.4550 | 18.0830 |
| p90 | 11.8119 | 14.2264 | 18.5003 | 23.7261 | 27.0515 | 27.5461 | 25.4481 | 24.0718 | 23.5927 | 24.0938 | 25.7348 |
| 失败 | 0 | 0 | 0 | 15 | 73 | 115 | 26 | 11 | 19 | 23 | 26 |
- 平均每个请求的输入 token 数: 40
- 平均每个请求的输出 token 数: 300
部署
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 --port 8008 \
--model /data/models/llm/qwen/Qwen2-7B-Instruct/ \
--served-model-name qwen2-7b \
--tensor-parallel-size 4 \
--dtype=float16 \
--max-model-len 16000
压测
evalscope-perf http://172.16.33.66:8008/v1/chat/completions qwen2-7b \
./datasets/open_qa.jsonl \
--parallels 8 \
--parallels 16 \
--parallels 32 \
--parallels 64 \
--parallels 100 \
--parallels 128 \
--parallels 150 \
--parallels 200 \
--parallels 300 \
--parallels 400 \
--parallels 500 \
--n 1000
- parallel 8
Benchmarking summary: Time taken for tests: 1030.632 seconds Expected number of requests: 1000 Number of concurrency: 8 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 0.970 Average latency: 8.213 Throughput(average output tokens per second): 298.860 Average time to first token: 8.213 Average input tokens per request: 40.296 Average output tokens per request: 308.015 Average time per output token: 0.00335 Average package per request: 1.000 Average package latency: 8.213 Percentile of time to first token: p50: 8.4703 p66: 9.3882 p75: 10.1059 p80: 10.5404 p90: 11.8119 p95: 12.8131 p98: 14.0085 p99: 15.0006 Percentile of request latency: p50: 8.4703 p66: 9.3882 p75: 10.1059 p80: 10.5404 p90: 11.8119 p95: 12.8131 p98: 14.0085 p99: 15.0006 - parallel 16
Benchmarking summary: Time taken for tests: 629.843 seconds Expected number of requests: 1000 Number of concurrency: 16 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 1.588 Average latency: 9.944 Throughput(average output tokens per second): 496.458 Average time to first token: 9.944 Average input tokens per request: 40.296 Average output tokens per request: 312.691 Average time per output token: 0.00201 Average package per request: 1.000 Average package latency: 9.944 Percentile of time to first token: p50: 10.2975 p66: 11.4685 p75: 12.2523 p80: 12.7172 p90: 14.2264 p95: 15.5556 p98: 17.0453 p99: 18.0745 Percentile of request latency: p50: 10.2975 p66: 11.4685 p75: 12.2523 p80: 12.7172 p90: 14.2264 p95: 15.5556 p98: 17.0453 p99: 18.0745 - parallel 32
Benchmarking summary: Time taken for tests: 409.251 seconds Expected number of requests: 1000 Number of concurrency: 32 Total requests: 1000 Succeed requests: 1000 Failed requests: 0 Average QPS: 2.443 Average latency: 12.846 Throughput(average output tokens per second): 753.176 Average time to first token: 12.846 Average input tokens per request: 40.296 Average output tokens per request: 308.238 Average time per output token: 0.00133 Average package per request: 1.000 Average package latency: 12.846 Percentile of time to first token: p50: 13.3060 p66: 14.7707 p75: 15.6738 p80: 16.5227 p90: 18.5003 p95: 20.2770 p98: 22.3723 p99: 23.2546 Percentile of request latency: p50: 13.3060 p66: 14.7707 p75: 15.6738 p80: 16.5227 p90: 18.5003 p95: 20.2770 p98: 22.3723 p99: 23.2546 - parallel 64
Benchmarking summary: Time taken for tests: 280.896 seconds Expected number of requests: 1000 Number of concurrency: 64 Total requests: 999 Succeed requests: 984 Failed requests: 15 Average QPS: 3.503 Average latency: 16.913 Throughput(average output tokens per second): 1073.697 Average time to first token: 16.913 Average input tokens per request: 40.278 Average output tokens per request: 306.501 Average time per output token: 0.00093 Average package per request: 1.000 Average package latency: 16.913 Percentile of time to first token: p50: 17.5850 p66: 19.7422 p75: 20.8753 p80: 21.5526 p90: 23.7261 p95: 25.7272 p98: 28.0227 p99: 28.5129 Percentile of request latency: p50: 17.5850 p66: 19.7422 p75: 20.8753 p80: 21.5526 p90: 23.7261 p95: 25.7272 p98: 28.0227 p99: 28.5129 - parallel 100
Benchmarking summary: Time taken for tests: 252.708 seconds Expected number of requests: 1000 Number of concurrency: 100 Total requests: 981 Succeed requests: 908 Failed requests: 73 Average QPS: 3.593 Average latency: 19.182 Throughput(average output tokens per second): 1039.610 Average time to first token: 19.182 Average input tokens per request: 40.166 Average output tokens per request: 289.337 Average time per output token: 0.00096 Average package per request: 1.000 Average package latency: 19.182 Percentile of time to first token: p50: 20.1962 p66: 22.6797 p75: 23.9937 p80: 24.8991 p90: 27.0515 p95: 28.3231 p98: 29.3312 p99: 29.6593 Percentile of request latency: p50: 20.1962 p66: 22.6797 p75: 23.9937 p80: 24.8991 p90: 27.0515 p95: 28.3231 p98: 29.3312 p99: 29.6593 - parallel 128
Benchmarking summary: Time taken for tests: 236.597 seconds Expected number of requests: 1000 Number of concurrency: 128 Total requests: 962 Succeed requests: 847 Failed requests: 115 Average QPS: 3.580 Average latency: 19.831 Throughput(average output tokens per second): 1005.881 Average time to first token: 19.831 Average input tokens per request: 40.038 Average output tokens per request: 280.979 Average time per output token: 0.00099 Average package per request: 1.000 Average package latency: 19.831 Percentile of time to first token: p50: 20.9986 p66: 23.7704 p75: 25.2322 p80: 25.8841 p90: 27.5461 p95: 28.7326 p98: 29.5878 p99: 29.8692 Percentile of request latency: p50: 20.9986 p66: 23.7704 p75: 25.2322 p80: 25.8841 p90: 27.5461 p95: 28.7326 p98: 29.5878 p99: 29.8692 - parallel 150
Benchmarking summary: Time taken for tests: 254.208 seconds Expected number of requests: 1000 Number of concurrency: 150 Total requests: 918 Succeed requests: 892 Failed requests: 26 Average QPS: 3.509 Average latency: 17.806 Throughput(average output tokens per second): 1032.794 Average time to first token: 17.806 Average input tokens per request: 40.286 Average output tokens per request: 294.333 Average time per output token: 0.00097 Average package per request: 1.000 Average package latency: 17.806 Percentile of time to first token: p50: 18.6905 p66: 20.7610 p75: 22.0715 p80: 23.0934 p90: 25.4481 p95: 27.6829 p98: 29.1659 p99: 29.6321 Percentile of request latency: p50: 18.6905 p66: 20.7610 p75: 22.0715 p80: 23.0934 p90: 25.4481 p95: 27.6829 p98: 29.1659 p99: 29.6321 - parallel 200
Benchmarking summary: Time taken for tests: 274.376 seconds Expected number of requests: 1000 Number of concurrency: 200 Total requests: 855 Succeed requests: 844 Failed requests: 11 Average QPS: 3.076 Average latency: 16.743 Throughput(average output tokens per second): 925.476 Average time to first token: 16.743 Average input tokens per request: 40.307 Average output tokens per request: 300.863 Average time per output token: 0.00108 Average package per request: 1.000 Average package latency: 16.743 Percentile of time to first token: p50: 17.0203 p66: 19.1086 p75: 20.4436 p80: 21.6162 p90: 24.0718 p95: 26.2962 p98: 28.3664 p99: 29.4007 Percentile of request latency: p50: 17.0203 p66: 19.1086 p75: 20.4436 p80: 21.6162 p90: 24.0718 p95: 26.2962 p98: 28.3664 p99: 29.4007 - parallel 300
Benchmarking summary: Time taken for tests: 256.799 seconds Expected number of requests: 1000 Number of concurrency: 300 Total requests: 750 Succeed requests: 731 Failed requests: 19 Average QPS: 2.847 Average latency: 16.285 Throughput(average output tokens per second): 839.437 Average time to first token: 16.285 Average input tokens per request: 40.453 Average output tokens per request: 294.893 Average time per output token: 0.00119 Average package per request: 1.000 Average package latency: 16.285 Percentile of time to first token: p50: 16.6503 p66: 18.6659 p75: 19.8392 p80: 20.8286 p90: 23.5927 p95: 26.8649 p98: 28.0731 p99: 29.3460 Percentile of request latency: p50: 16.6503 p66: 18.6659 p75: 19.8392 p80: 20.8286 p90: 23.5927 p95: 26.8649 p98: 28.0731 p99: 29.3460 - parallel 400
Benchmarking summary: Time taken for tests: 222.726 seconds Expected number of requests: 1000 Number of concurrency: 400 Total requests: 651 Succeed requests: 628 Failed requests: 23 Average QPS: 2.820 Average latency: 16.285 Throughput(average output tokens per second): 816.049 Average time to first token: 16.285 Average input tokens per request: 40.247 Average output tokens per request: 289.419 Average time per output token: 0.00123 Average package per request: 1.000 Average package latency: 16.285 Percentile of time to first token: p50: 16.4550 p66: 18.4089 p75: 20.1452 p80: 20.9587 p90: 24.0938 p95: 26.5017 p98: 28.0750 p99: 28.6327 Percentile of request latency: p50: 16.4550 p66: 18.4089 p75: 20.1452 p80: 20.9587 p90: 24.0938 p95: 26.5017 p98: 28.0750 p99: 28.6327 - parallel 500
Benchmarking summary: Time taken for tests: 175.166 seconds Expected number of requests: 1000 Number of concurrency: 500 Total requests: 562 Succeed requests: 536 Failed requests: 26 Average QPS: 3.060 Average latency: 17.649 Throughput(average output tokens per second): 875.565 Average time to first token: 17.649 Average input tokens per request: 40.192 Average output tokens per request: 286.136 Average time per output token: 0.00114 Average package per request: 1.000 Average package latency: 17.649 Percentile of time to first token: p50: 18.0830 p66: 20.6764 p75: 22.3065 p80: 23.0424 p90: 25.7348 p95: 27.9985 p98: 29.2158 p99: 29.5974 Percentile of request latency: p50: 18.0830 p66: 20.6764 p75: 22.3065 p80: 23.0424 p90: 25.7348 p95: 27.9985 p98: 29.2158 p99: 29.5974
Qwen2-7B-Instruct (long.jsonl)
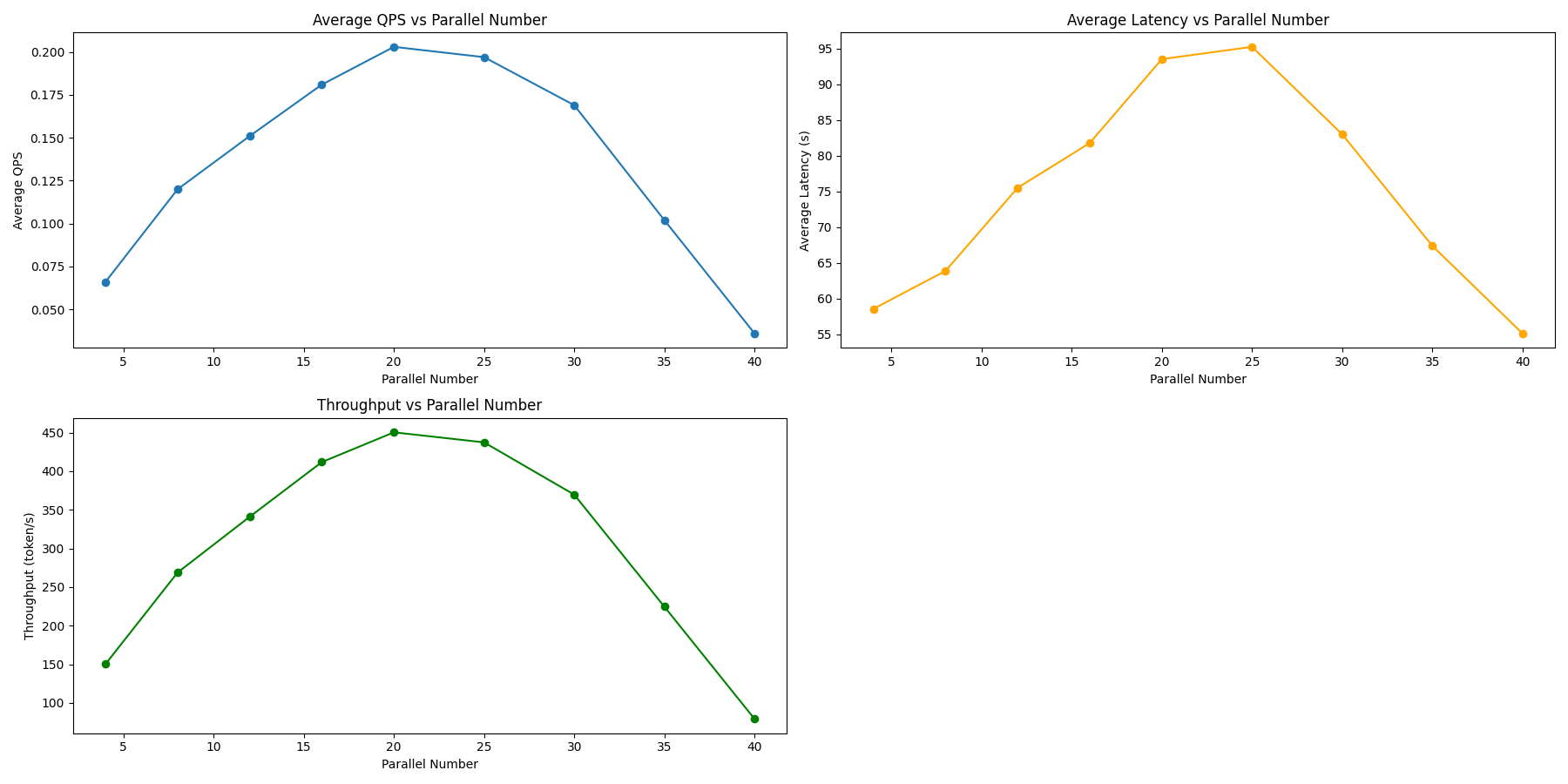
| 指标 | 4 | 8 | 12 | 16 | 20 | 25 | 30 | 35 | 40 |
|---|---|---|---|---|---|---|---|---|---|
| 用时 | 1501.129 | 831.393 | 661.167 | 553.051 | 492.972 | 482.926 | 503.931 | 708.094 | 1708.086 |
| QPS | 0.066 | 0.120 | 0.151 | 0.181 | 0.203 | 0.197 | 0.169 | 0.102 | 0.036 |
| 延迟 | 58.530 | 63.844 | 75.483 | 81.761 | 93.514 | 95.232 | 82.990 | 67.363 | 55.090 |
| 吞吐量 | 150.200 | 268.802 | 340.991 | 411.723 | 450.299 | 437.290 | 369.642 | 224.586 | 79.384 |
| p50 | 61.1869 | 67.7709 | 79.9282 | 85.2388 | 101.0449 | 100.2105 | 84.4174 | 67.4104 | 57.0599 |
| p90 | 63.1877 | 70.4871 | 84.9531 | 89.7831 | 106.6341 | 113.0055 | 106.2575 | 81.7474 | 59.3524 |
| 失败 | 1 | 0 | 0 | 0 | 0 | 5 | 15 | 28 | 38 |
- 平均每个请求的输入 token 数: 1600
- 平均每个请求的输出 token 数: 2200
部署
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 --port 8008 \
--model /data/models/llm/qwen/Qwen2-7B-Instruct/ \
--served-model-name qwen2-7b \
--tensor-parallel-size 4 \
--dtype=float16 \
--max-model-len 16000
压测
evalscope-perf http://172.16.33.66:8008/v1/chat/completions qwen2-7b \
./datasets/open_qa.jsonl \
--parallels 4 \
--parallels 8 \
--parallels 12 \
--parallels 16 \
--parallels 20 \
--parallels 25 \
--parallels 30 \
--parallels 35 \
--parallels 40 \
--n 100
- parallel 4
Benchmarking summary: Time taken for tests: 1501.129 seconds Expected number of requests: 100 Number of concurrency: 4 Total requests: 100 Succeed requests: 99 Failed requests: 1 Average QPS: 0.066 Average latency: 58.530 Throughput(average output tokens per second): 150.200 Average time to first token: 58.530 Average input tokens per request: 1614.000 Average output tokens per request: 2277.475 Average time per output token: 0.00666 Average package per request: 1.000 Average package latency: 58.530 Percentile of time to first token: p50: 61.1869 p66: 61.9394 p75: 62.4250 p80: 62.7114 p90: 63.1877 p95: 63.8551 p98: 64.0589 p99: 64.3522 Percentile of request latency: p50: 61.1869 p66: 61.9394 p75: 62.4250 p80: 62.7114 p90: 63.1877 p95: 63.8551 p98: 64.0589 p99: 64.3522 - parallel 8
Benchmarking summary: Time taken for tests: 831.393 seconds Expected number of requests: 100 Number of concurrency: 8 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.120 Average latency: 63.844 Throughput(average output tokens per second): 268.802 Average time to first token: 63.844 Average input tokens per request: 1614.000 Average output tokens per request: 2234.800 Average time per output token: 0.00372 Average package per request: 1.000 Average package latency: 63.844 Percentile of time to first token: p50: 67.7709 p66: 68.7757 p75: 69.2135 p80: 69.4998 p90: 70.4871 p95: 71.4362 p98: 74.7053 p99: 77.3827 Percentile of request latency: p50: 67.7709 p66: 68.7757 p75: 69.2135 p80: 69.4998 p90: 70.4871 p95: 71.4362 p98: 74.7053 p99: 77.3827 - parallel 12
Benchmarking summary: Time taken for tests: 661.167 seconds Expected number of requests: 100 Number of concurrency: 12 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.151 Average latency: 75.483 Throughput(average output tokens per second): 340.991 Average time to first token: 75.483 Average input tokens per request: 1614.000 Average output tokens per request: 2254.520 Average time per output token: 0.00293 Average package per request: 1.000 Average package latency: 75.483 Percentile of time to first token: p50: 79.9282 p66: 81.6170 p75: 82.3043 p80: 82.8302 p90: 84.9531 p95: 87.1365 p98: 94.9953 p99: 96.4239 Percentile of request latency: p50: 79.9282 p66: 81.6170 p75: 82.3043 p80: 82.8302 p90: 84.9531 p95: 87.1365 p98: 94.9953 p99: 96.4239 - parallel 16
Benchmarking summary: Time taken for tests: 553.051 seconds Expected number of requests: 100 Number of concurrency: 16 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.181 Average latency: 81.761 Throughput(average output tokens per second): 411.723 Average time to first token: 81.761 Average input tokens per request: 1614.000 Average output tokens per request: 2277.040 Average time per output token: 0.00243 Average package per request: 1.000 Average package latency: 81.761 Percentile of time to first token: p50: 85.2388 p66: 86.6946 p75: 87.8569 p80: 88.2254 p90: 89.7831 p95: 91.9183 p98: 93.1188 p99: 94.1187 Percentile of request latency: p50: 85.2388 p66: 86.6946 p75: 87.8569 p80: 88.2254 p90: 89.7831 p95: 91.9183 p98: 93.1188 p99: 94.1187 - parallel 20
Benchmarking summary: Time taken for tests: 492.972 seconds Expected number of requests: 100 Number of concurrency: 20 Total requests: 100 Succeed requests: 100 Failed requests: 0 Average QPS: 0.203 Average latency: 93.514 Throughput(average output tokens per second): 450.299 Average time to first token: 93.514 Average input tokens per request: 1614.000 Average output tokens per request: 2219.850 Average time per output token: 0.00222 Average package per request: 1.000 Average package latency: 93.514 Percentile of time to first token: p50: 101.0449 p66: 103.1628 p75: 104.5066 p80: 105.2498 p90: 106.6341 p95: 109.0586 p98: 112.6580 p99: 114.0485 Percentile of request latency: p50: 101.0449 p66: 103.1628 p75: 104.5066 p80: 105.2498 p90: 106.6341 p95: 109.0586 p98: 112.6580 p99: 114.0485 - parallel 25
Benchmarking summary: Time taken for tests: 482.926 seconds Expected number of requests: 100 Number of concurrency: 25 Total requests: 95 Succeed requests: 95 Failed requests: 0 Average QPS: 0.197 Average latency: 95.232 Throughput(average output tokens per second): 437.290 Average time to first token: 95.232 Average input tokens per request: 1614.000 Average output tokens per request: 2222.937 Average time per output token: 0.00229 Average package per request: 1.000 Average package latency: 95.232 Percentile of time to first token: p50: 100.2105 p66: 103.2044 p75: 104.4999 p80: 105.5968 p90: 113.0055 p95: 117.3441 p98: 119.4187 p99: 119.9363 Percentile of request latency: p50: 100.2105 p66: 103.2044 p75: 104.4999 p80: 105.5968 p90: 113.0055 p95: 117.3441 p98: 119.4187 p99: 119.9363 - parallel 30
Benchmarking summary: Time taken for tests: 503.931 seconds Expected number of requests: 100 Number of concurrency: 30 Total requests: 85 Succeed requests: 85 Failed requests: 0 Average QPS: 0.169 Average latency: 82.990 Throughput(average output tokens per second): 369.642 Average time to first token: 82.990 Average input tokens per request: 1614.000 Average output tokens per request: 2191.459 Average time per output token: 0.00271 Average package per request: 1.000 Average package latency: 82.990 Percentile of time to first token: p50: 84.4174 p66: 86.3143 p75: 88.0736 p80: 91.9183 p90: 106.2575 p95: 109.8099 p98: 118.7324 p99: 119.7411 Percentile of request latency: p50: 84.4174 p66: 86.3143 p75: 88.0736 p80: 91.9183 p90: 106.2575 p95: 109.8099 p98: 118.7324 p99: 119.7411 - parallel 35
Benchmarking summary: Time taken for tests: 708.094 seconds Expected number of requests: 100 Number of concurrency: 35 Total requests: 72 Succeed requests: 72 Failed requests: 0 Average QPS: 0.102 Average latency: 67.363 Throughput(average output tokens per second): 224.586 Average time to first token: 67.363 Average input tokens per request: 1614.000 Average output tokens per request: 2208.722 Average time per output token: 0.00445 Average package per request: 1.000 Average package latency: 67.363 Percentile of time to first token: p50: 67.4104 p66: 67.9889 p75: 68.3605 p80: 68.5264 p90: 81.7474 p95: 116.1246 p98: 118.3541 p99: 119.0251 Percentile of request latency: p50: 67.4104 p66: 67.9889 p75: 68.3605 p80: 68.5264 p90: 81.7474 p95: 116.1246 p98: 118.3541 p99: 119.0251 - parallel 40
Benchmarking summary: Time taken for tests: 1708.086 seconds Expected number of requests: 100 Number of concurrency: 40 Total requests: 62 Succeed requests: 62 Failed requests: 0 Average QPS: 0.036 Average latency: 55.090 Throughput(average output tokens per second): 79.384 Average time to first token: 55.090 Average input tokens per request: 1614.000 Average output tokens per request: 2187.000 Average time per output token: 0.01260 Average package per request: 1.000 Average package latency: 55.090 Percentile of time to first token: p50: 57.0599 p66: 57.4411 p75: 58.2631 p80: 58.5435 p90: 59.3524 p95: 62.2720 p98: 96.8205 p99: 99.6312 Percentile of request latency: p50: 57.0599 p66: 57.4411 p75: 58.2631 p80: 58.5435 p90: 59.3524 p95: 62.2720 p98: 96.8205 p99: 99.6312