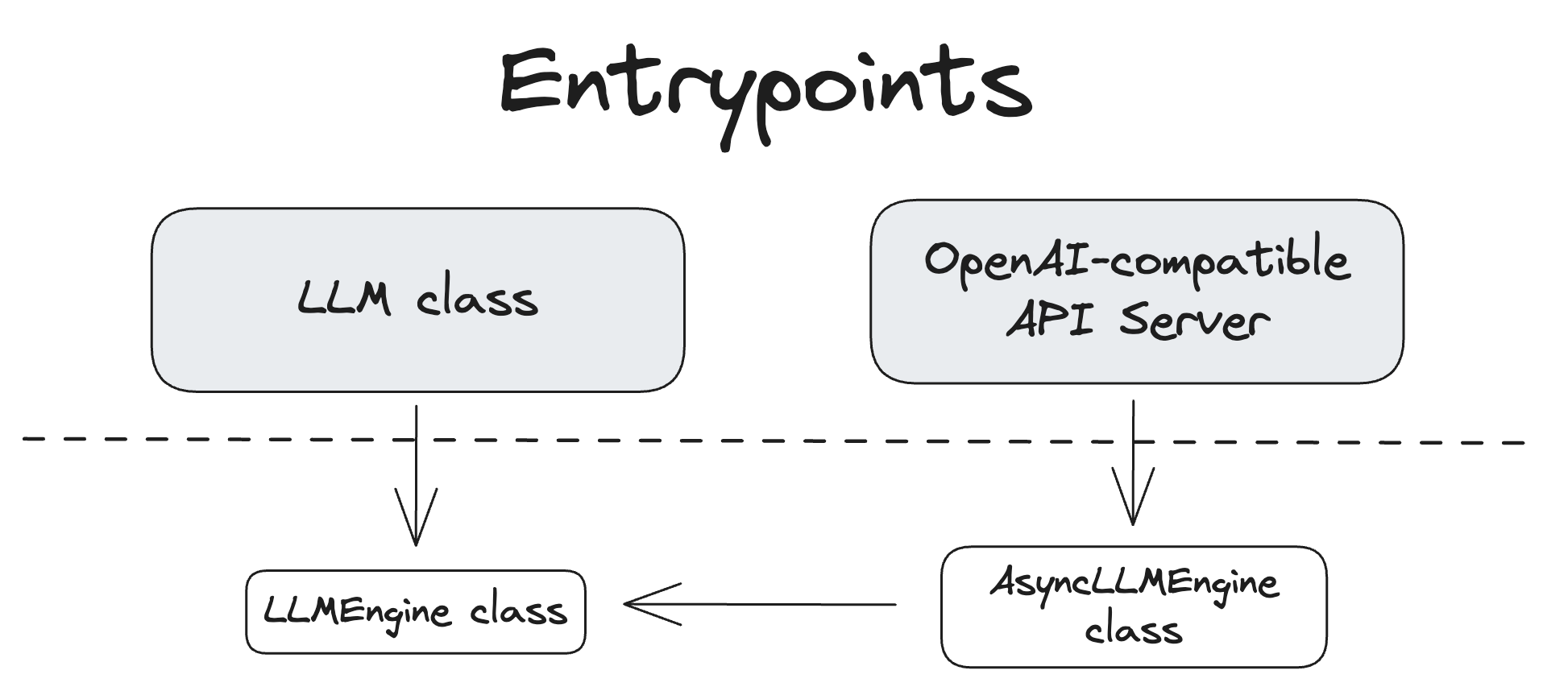
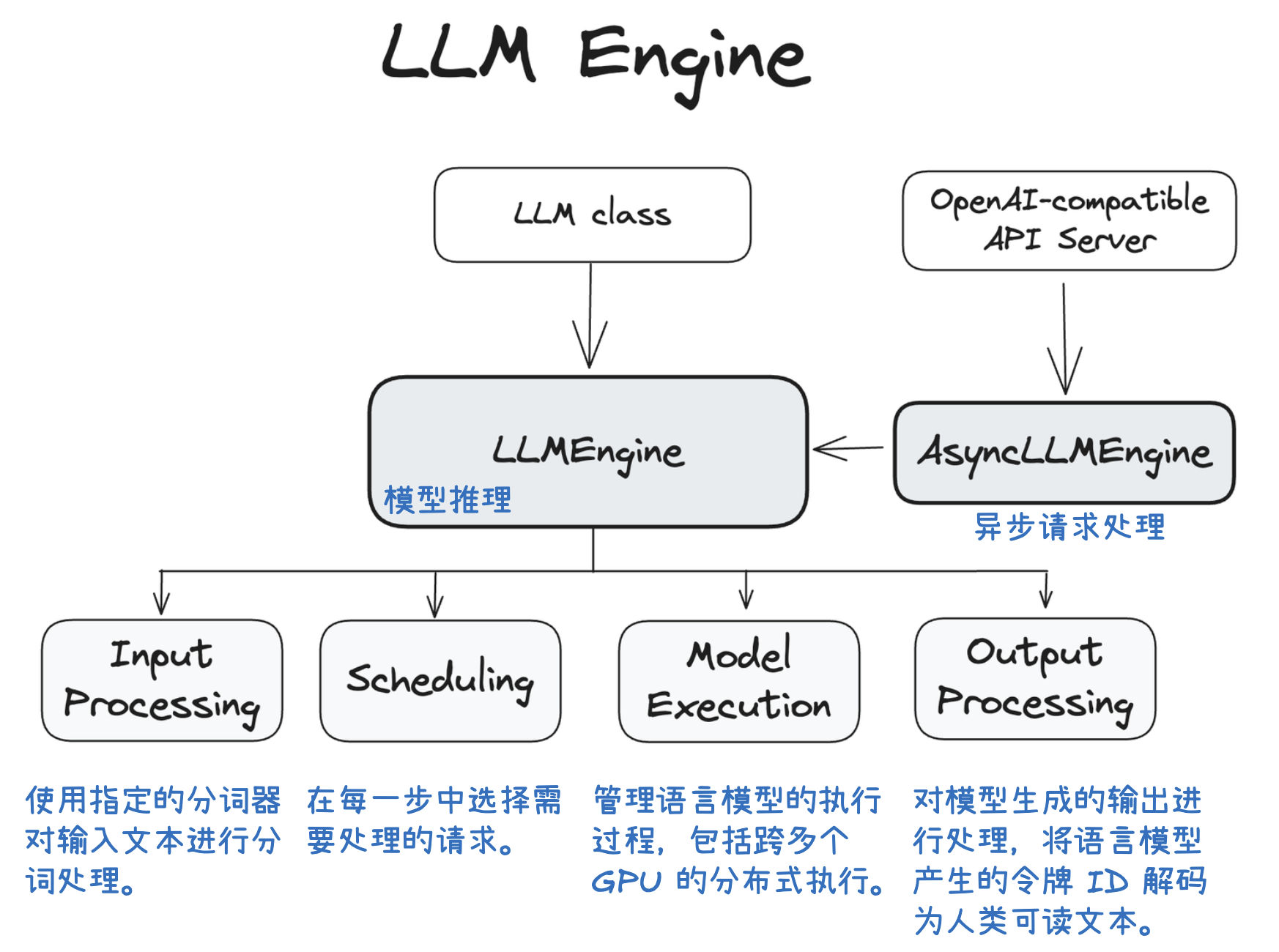
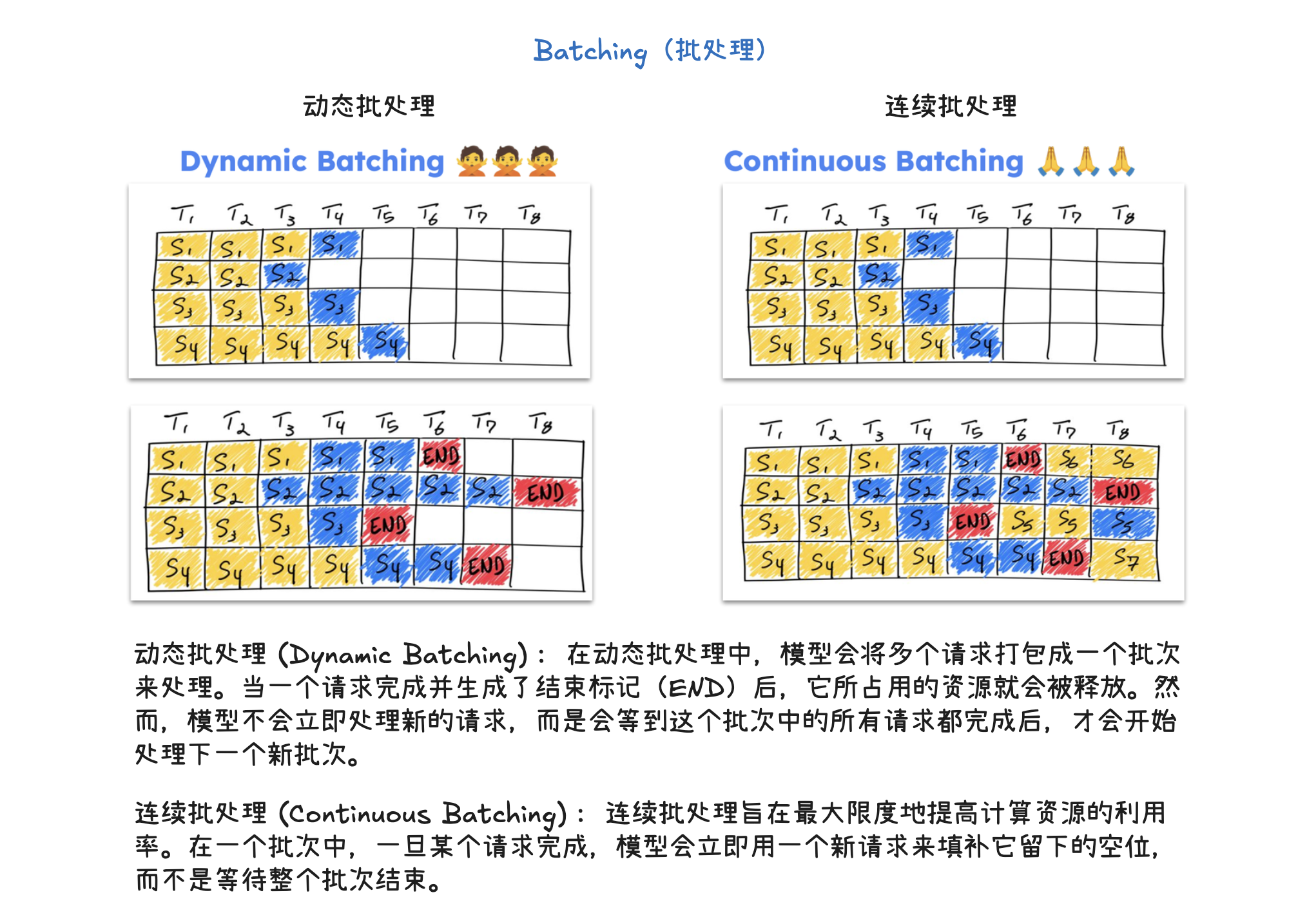
vLLM 推理引擎的核心优化技术及其工作流程
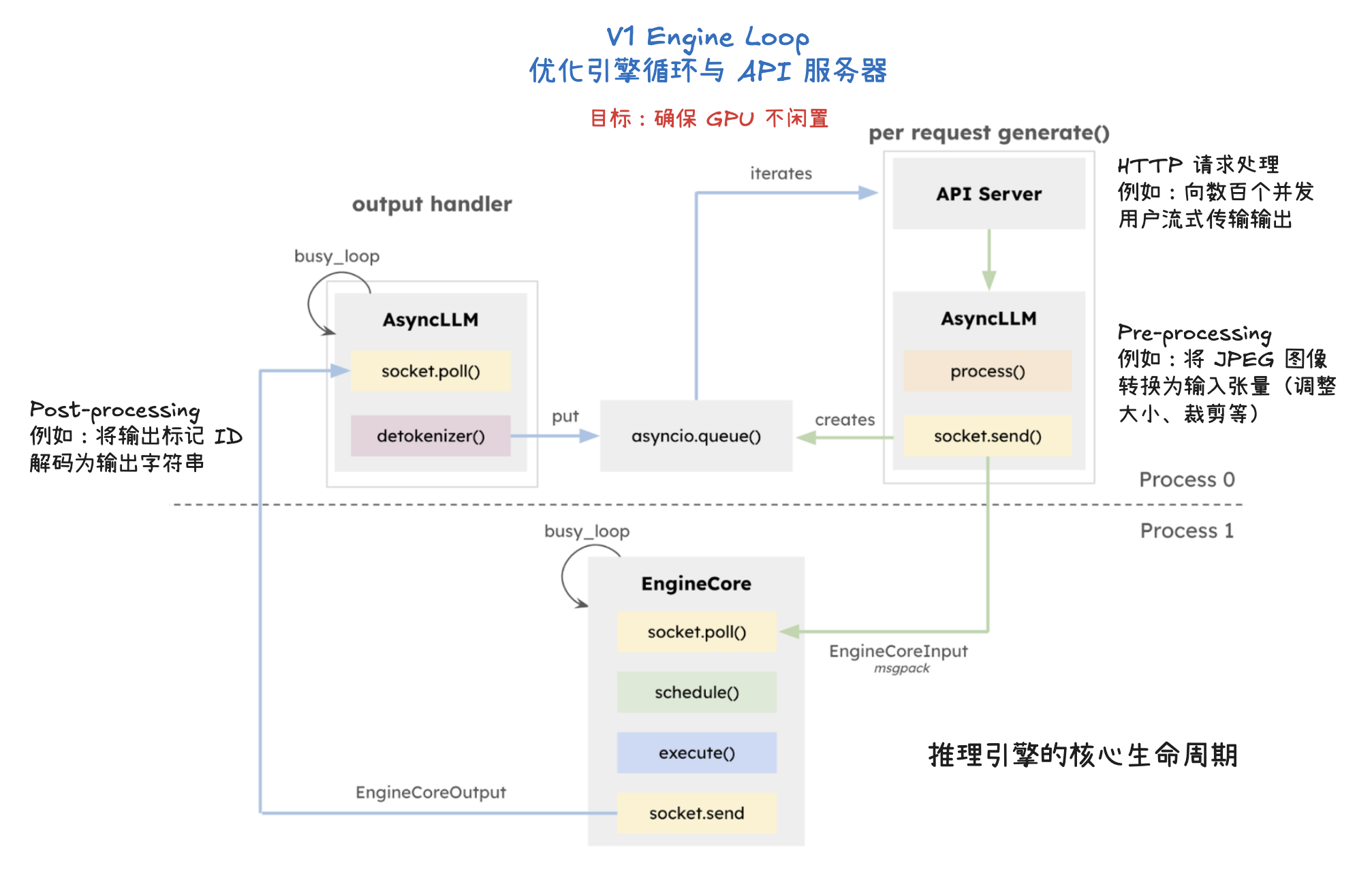
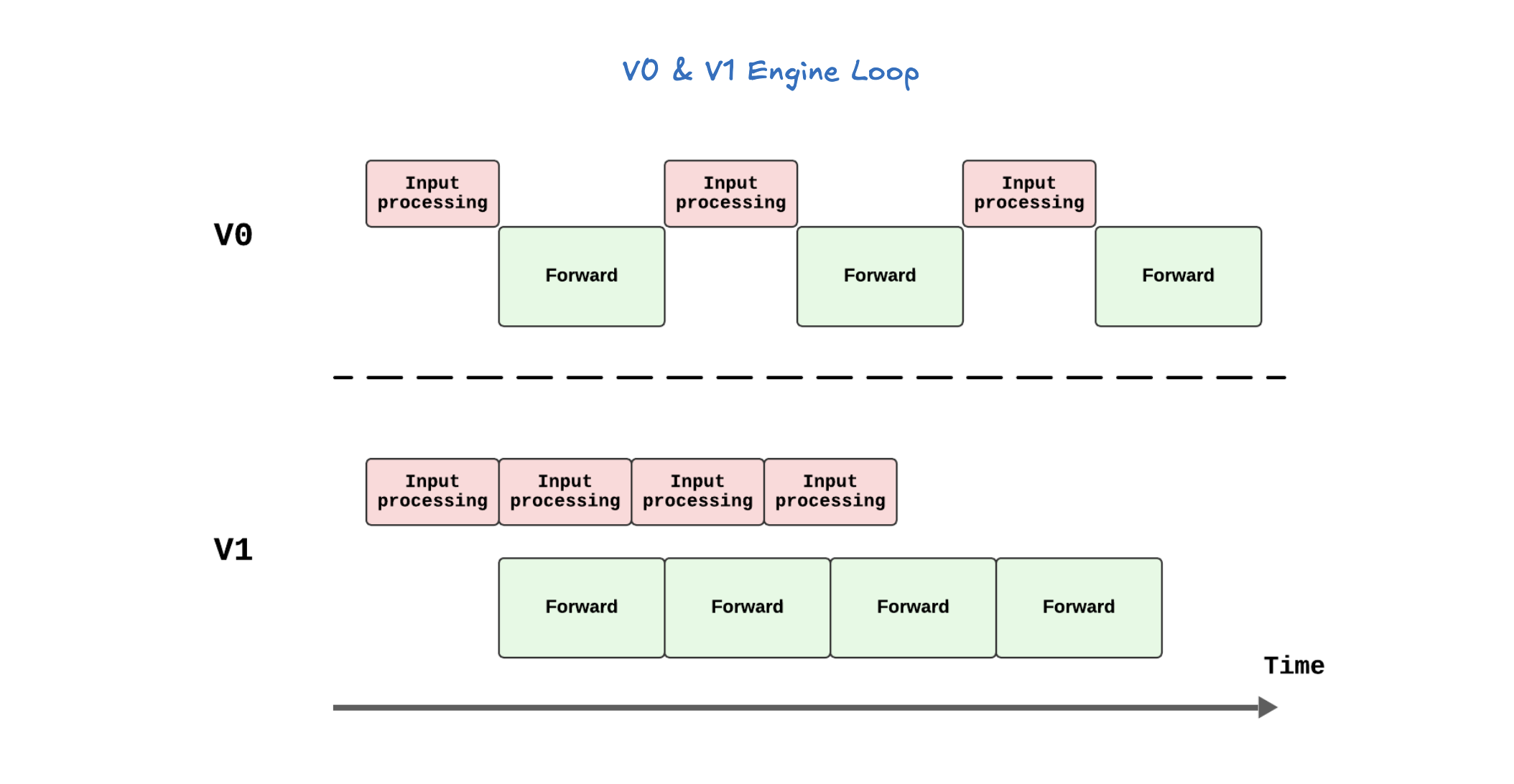
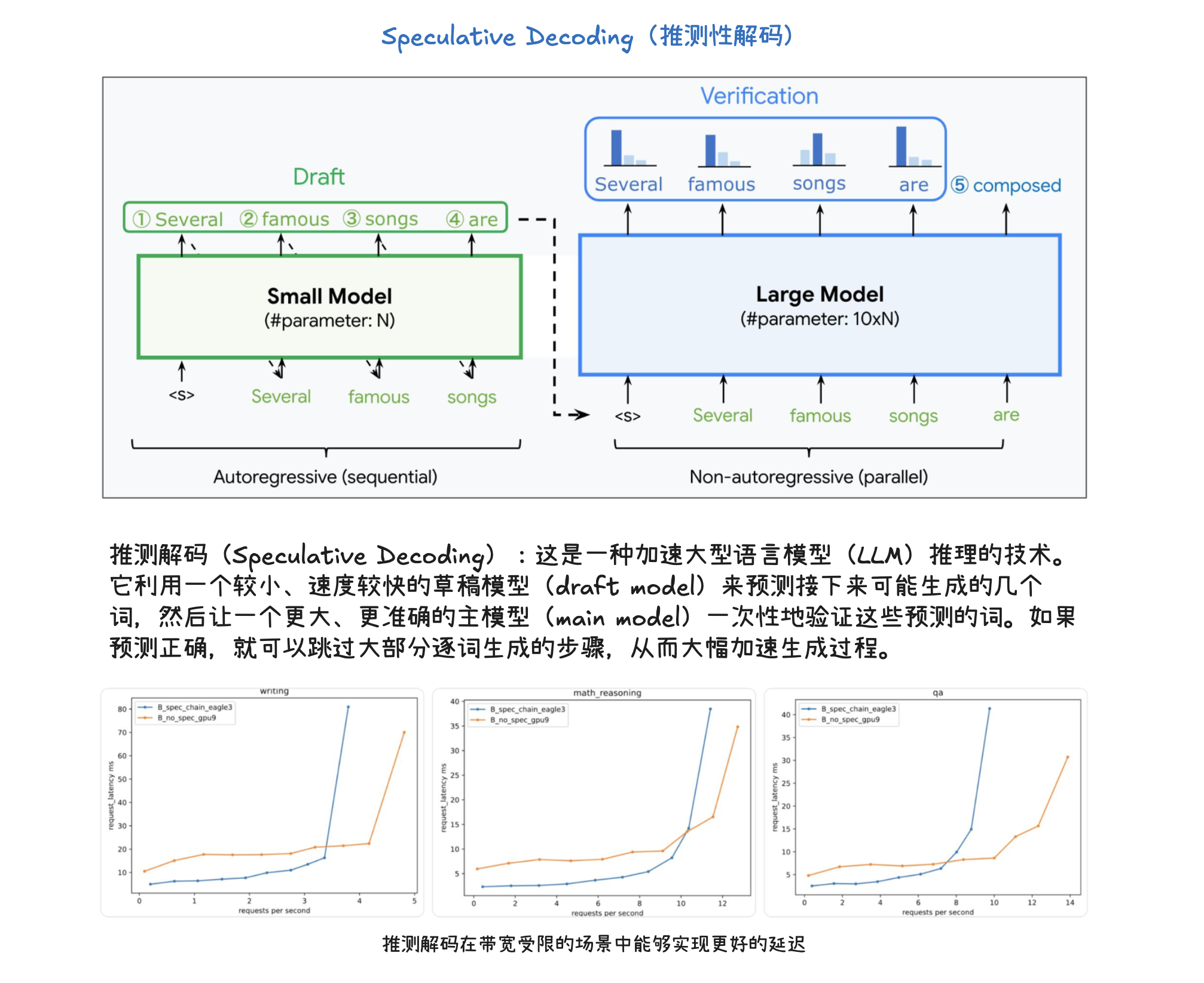
vLLM V1 引擎通过优化其核心引擎循环,将输入处理并行化,并引入了分段式 CUDA 图,从而实现了更灵活、动态的执行模型,显著降低了在线服务的延迟(TTFT 和 TPOT),同时保持了高吞吐量。其设计目标是确保 GPU 不闲置,通过 API 服务器和 EngineCore 之间的协作来高效调度和执行任务。为了进一步加速大型语言模型推理,vLLM V1 采用了多种优化技术:它通过分离式预填充和分块预填充来优化首个 token 的生成延迟,并结合连续批处理与分页注意力来提高 KV 缓存的内存效率和 GPU 利用率。此外,前缀缓存技术避免了重复计算相同提示的 KV 缓存,而级联推理则是一种内存带宽高效的共享前缀批处理解码技术,通过结合多查询注意力处理共享 KV 和单查询批处理解码处理独特 KV,特别适用于多用户共享长提示的场景,能显著提升性能。其他高级解码方法如推测性解码利用草稿模型加速生成,跳跃解码则适用于结构化输出场景。最后,量化技术是提升性能的关键手段,通过对权重、激活值和 KV 缓存使用低位精度(如 FP8、INT8),它能减少存储和内存占用,加速计算密集型和内存带宽密集型任务,并允许在固定硬件下处理更多 token,从而大幅提升吞吐量,同时保持模型准确性。
V1 Engine 工作流程
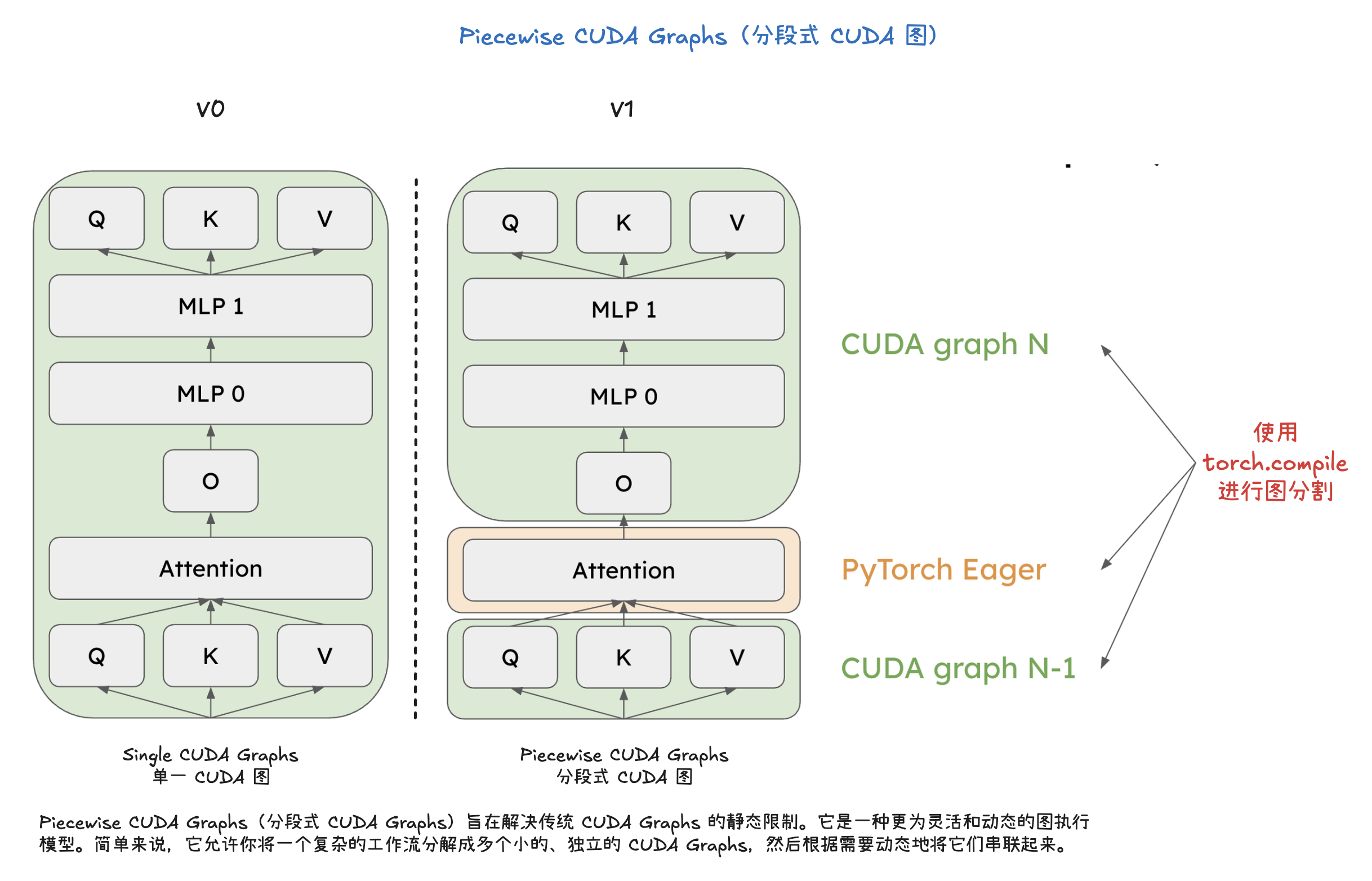
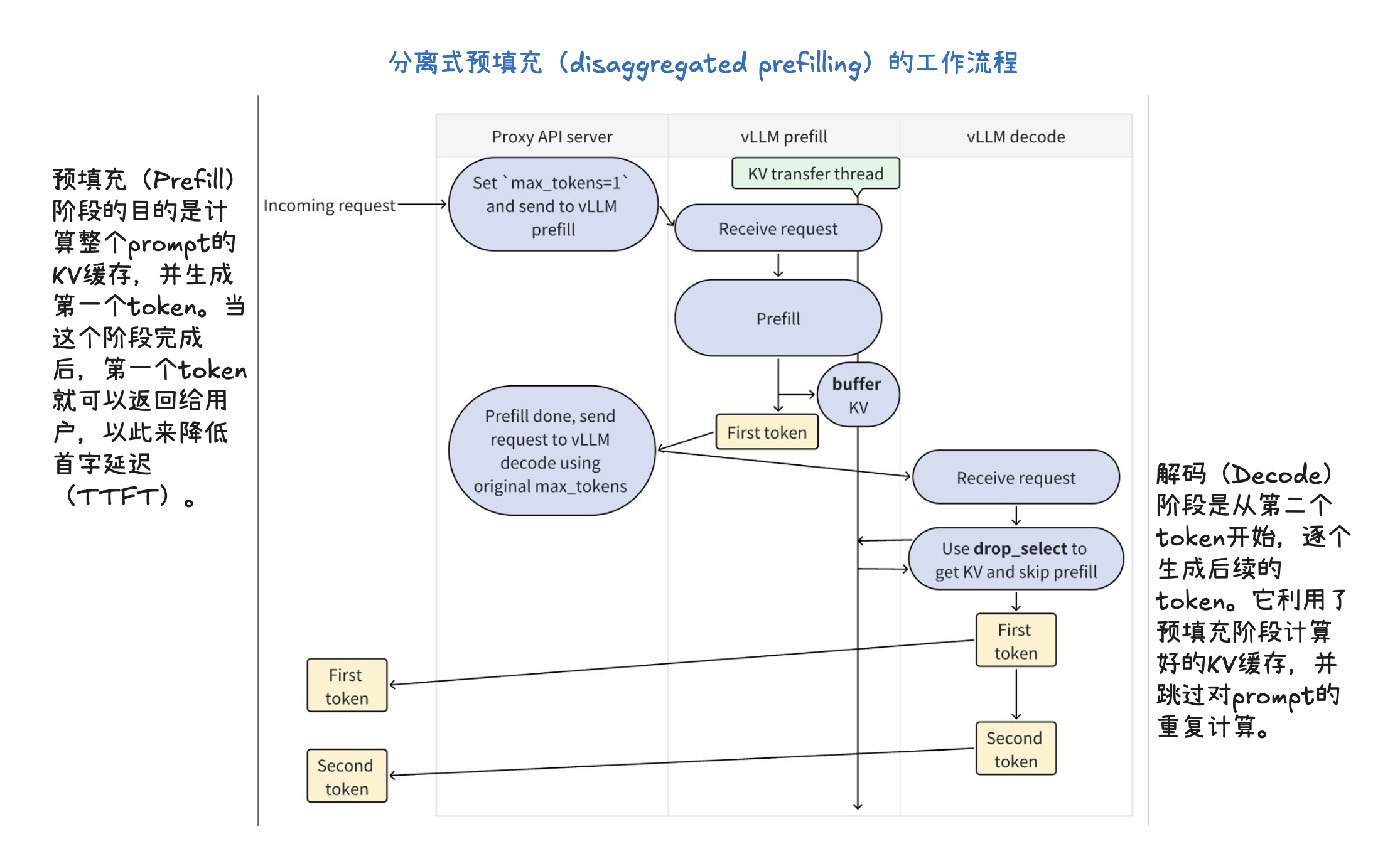
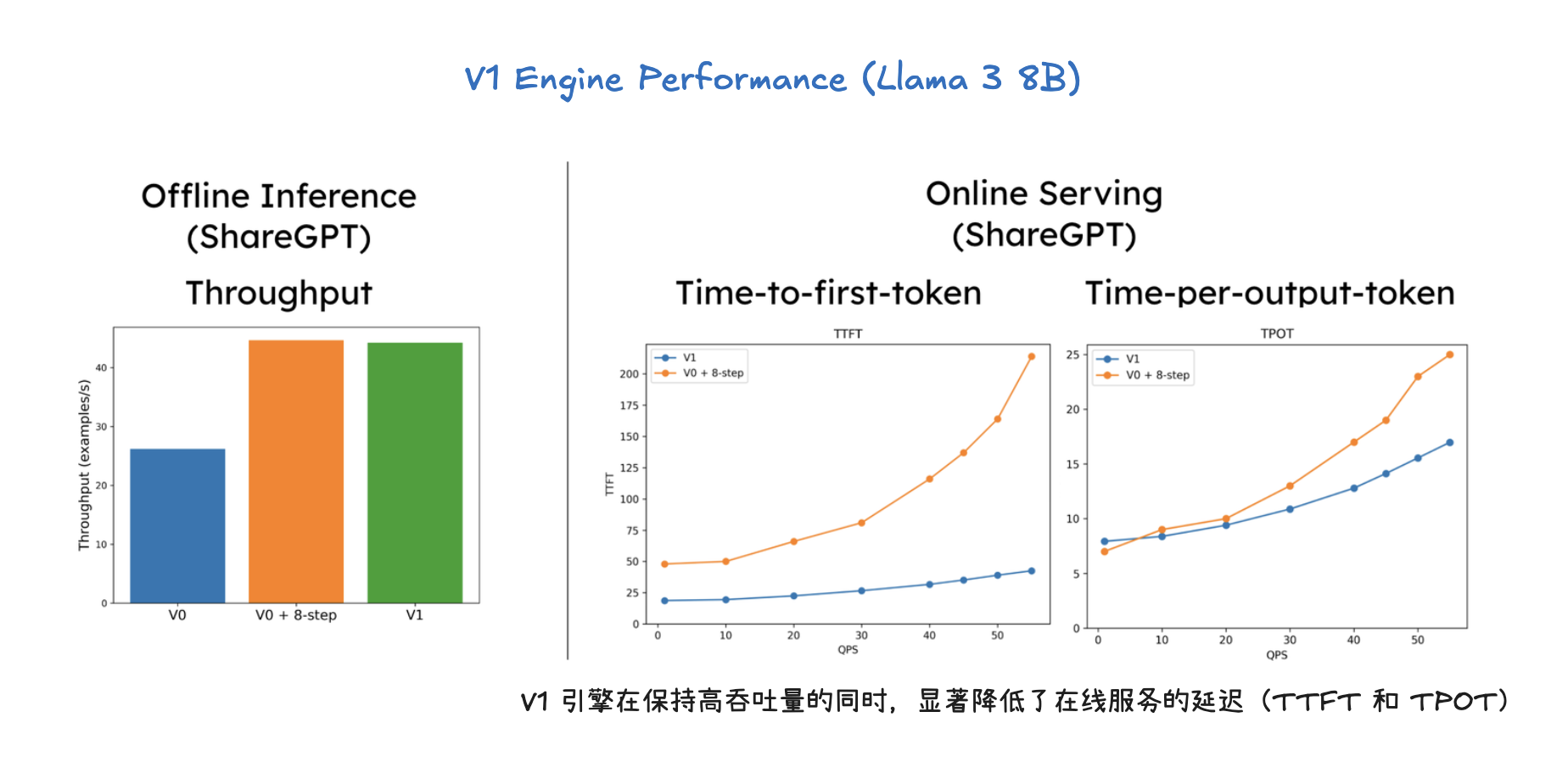
推理优化
典型 LLM 推理优化
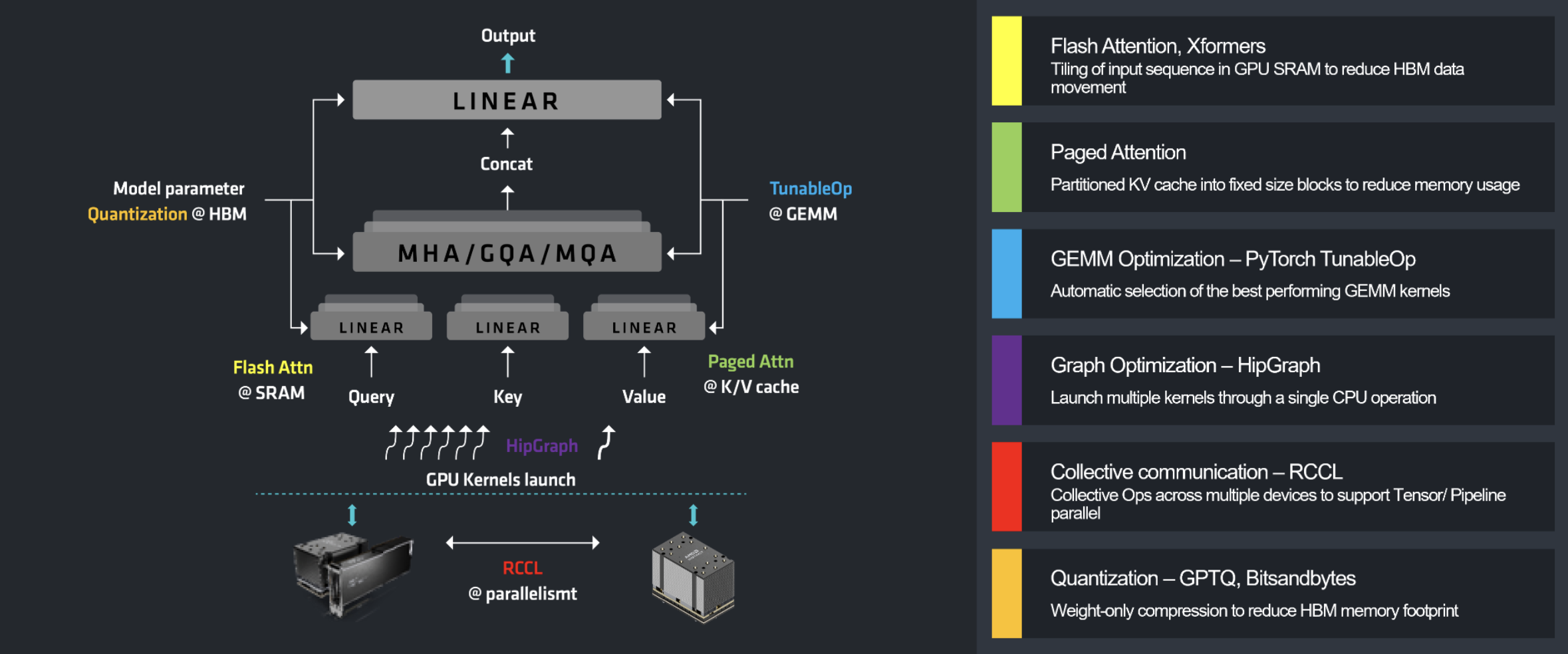
- Flash Attention 的核心思想是将多个操作融合为一个 GPU 内核(kernel),并充分利用速度极快的片上 SRAM(静态随机存取存储器)。
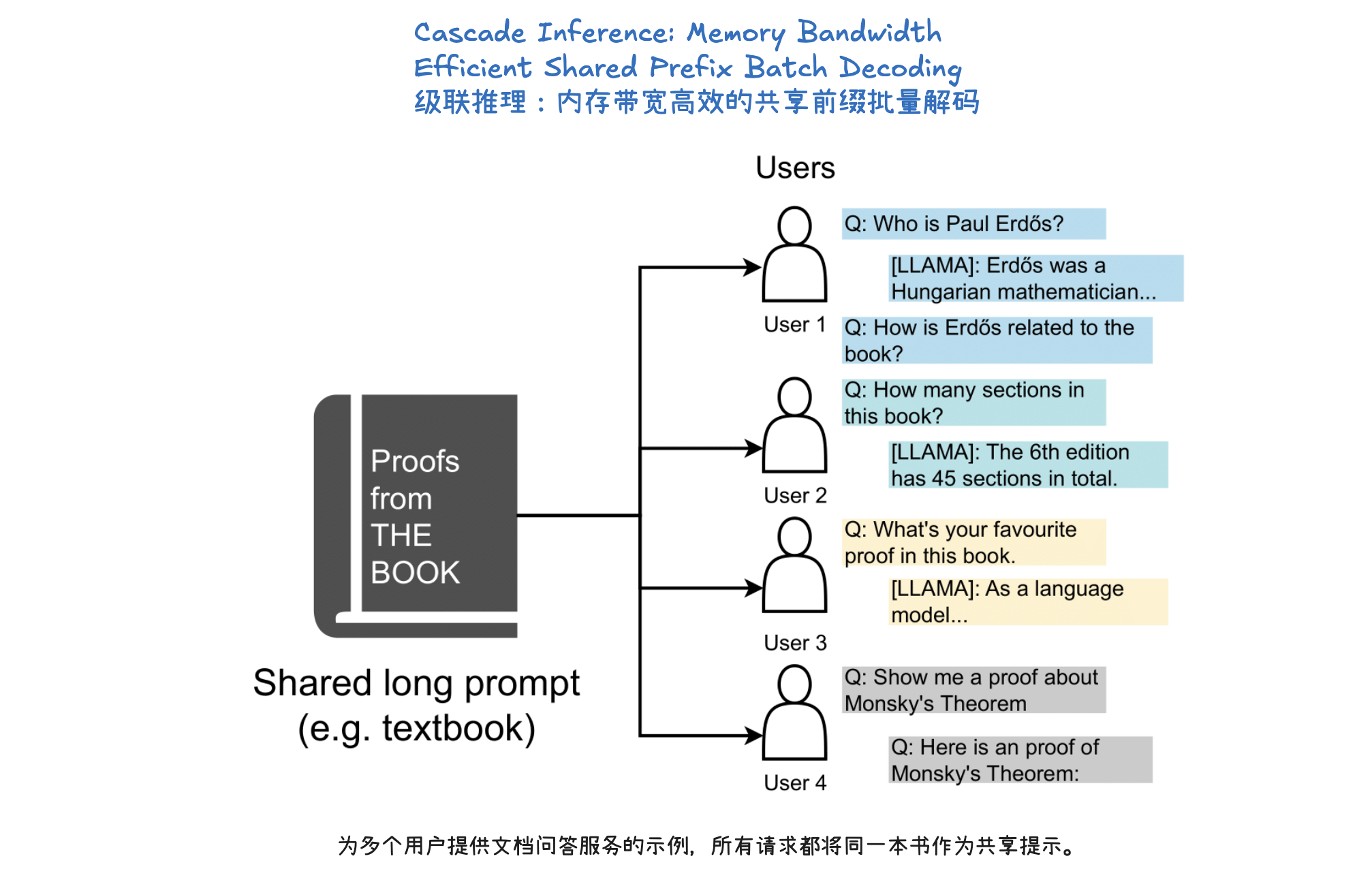
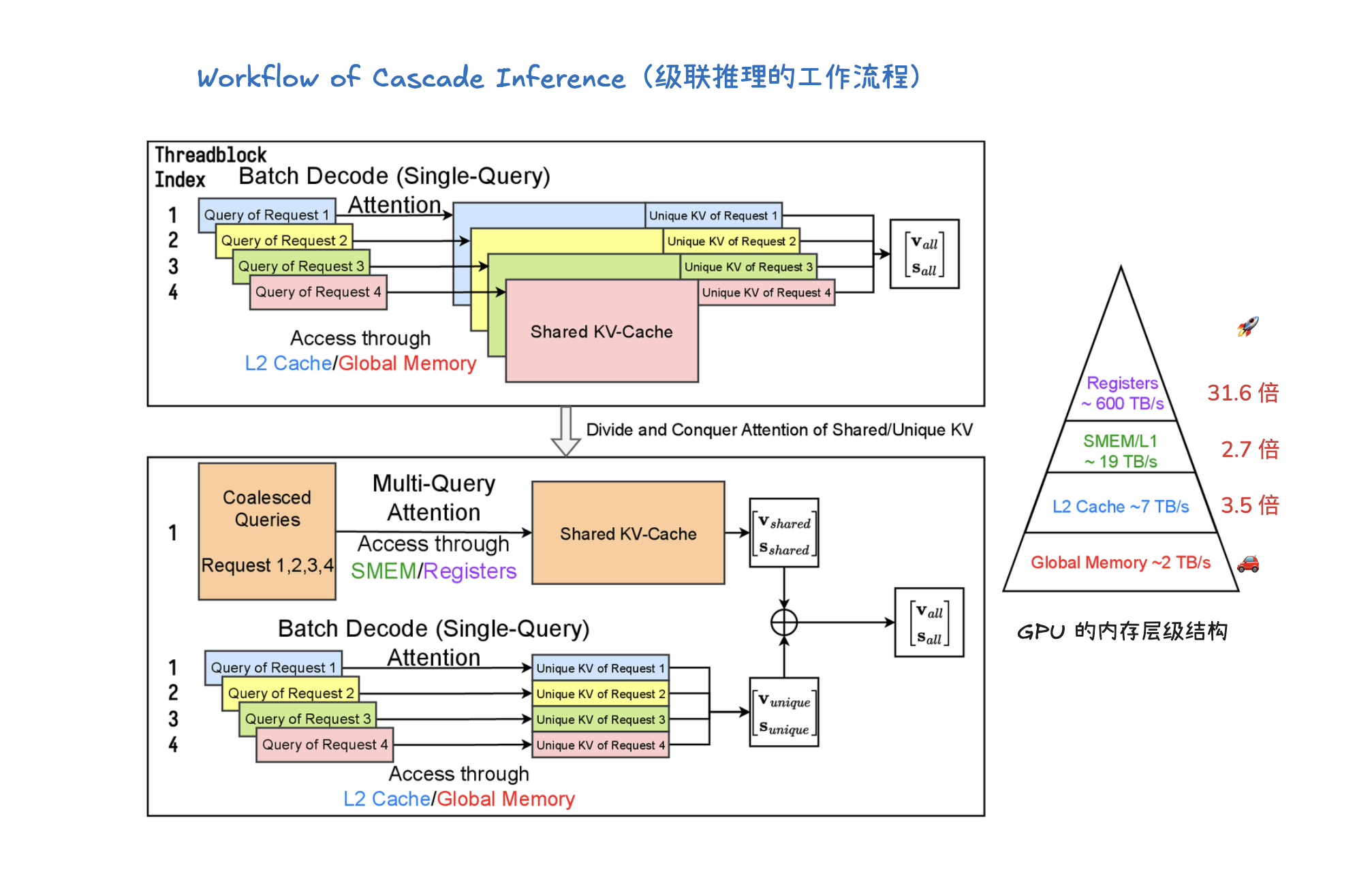
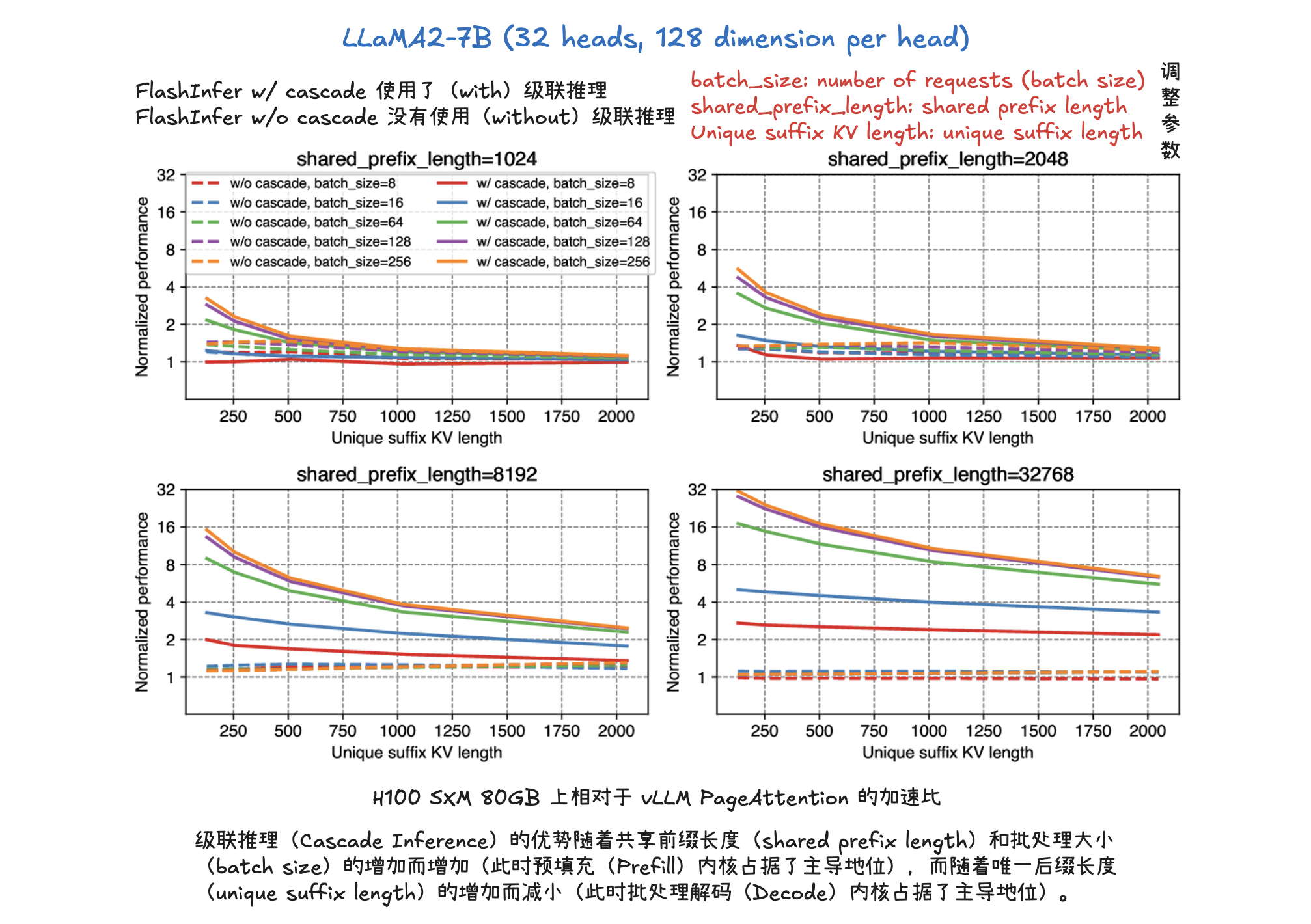
级联推理(Cascade Inference)
级联推理(Cascade Inference) 是一种旨在大幅提高大型语言模型(LLM)推理效率的技术,尤其针对多个请求共享相同前缀(prompt)的场景,如长文档问答或自洽性生成。它通过将注意力计算解耦为两个阶段来实现:首先,利用多查询注意力内核计算查询与共享前缀的KV-Cache之间的注意力状态,并将其存储在GPU共享内存(SMEM)中以实现快速访问和最大化内存重用;其次,使用批处理解码注意力内核计算查询与独特后缀的KV-Cache之间的注意力状态。最后,通过一个具有结合律和交换律的“合并操作符”(merge operator),将这两部分的注意力状态数学上等价地组合起来,得到最终的注意力输出。这种“分而治之”的方法显著提升了内存带宽效率,例如在H100 SXM 80GB上可实现高达31倍的加速。
LLM 推理优化(LLM Inference Optimization)
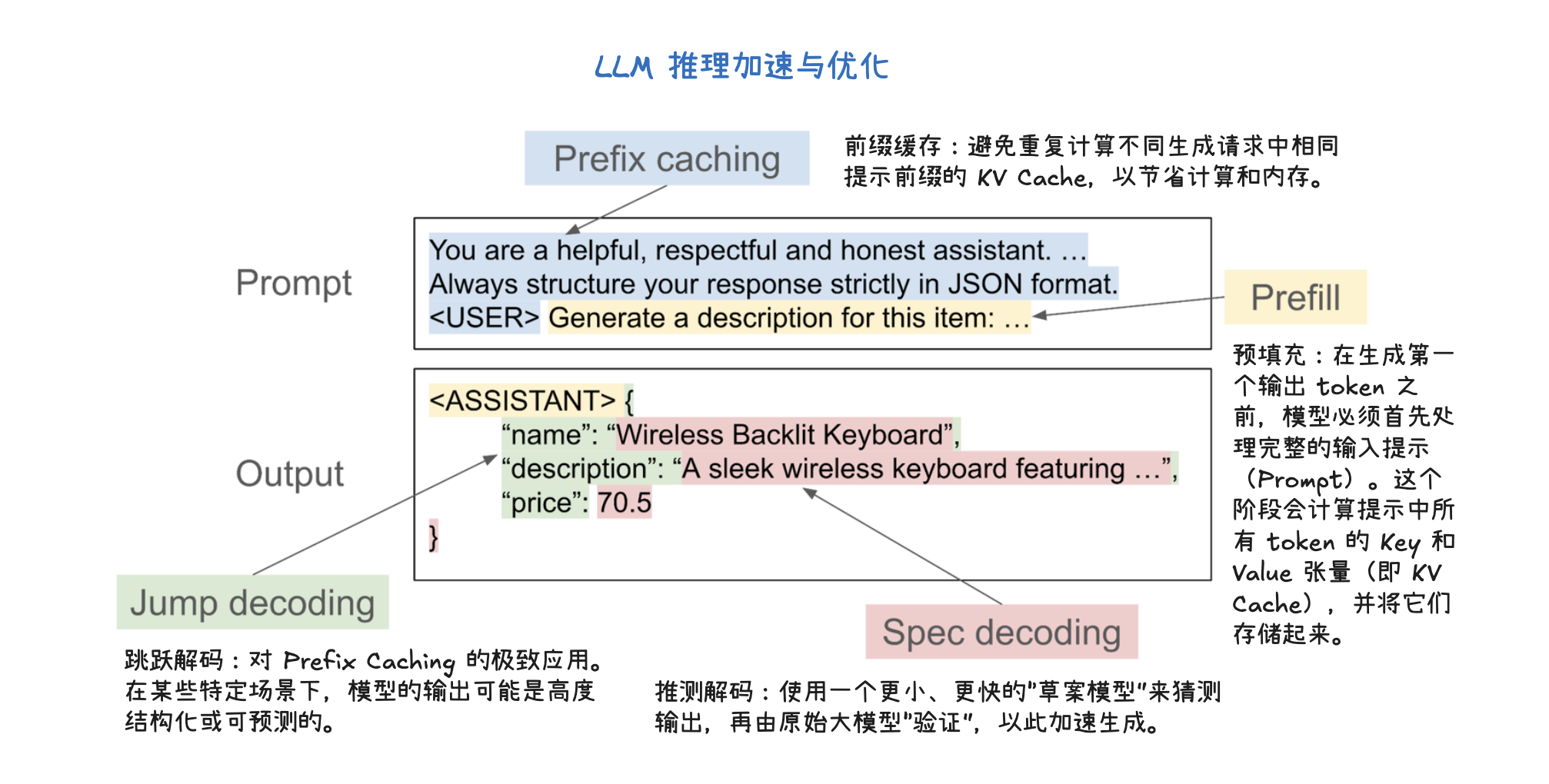
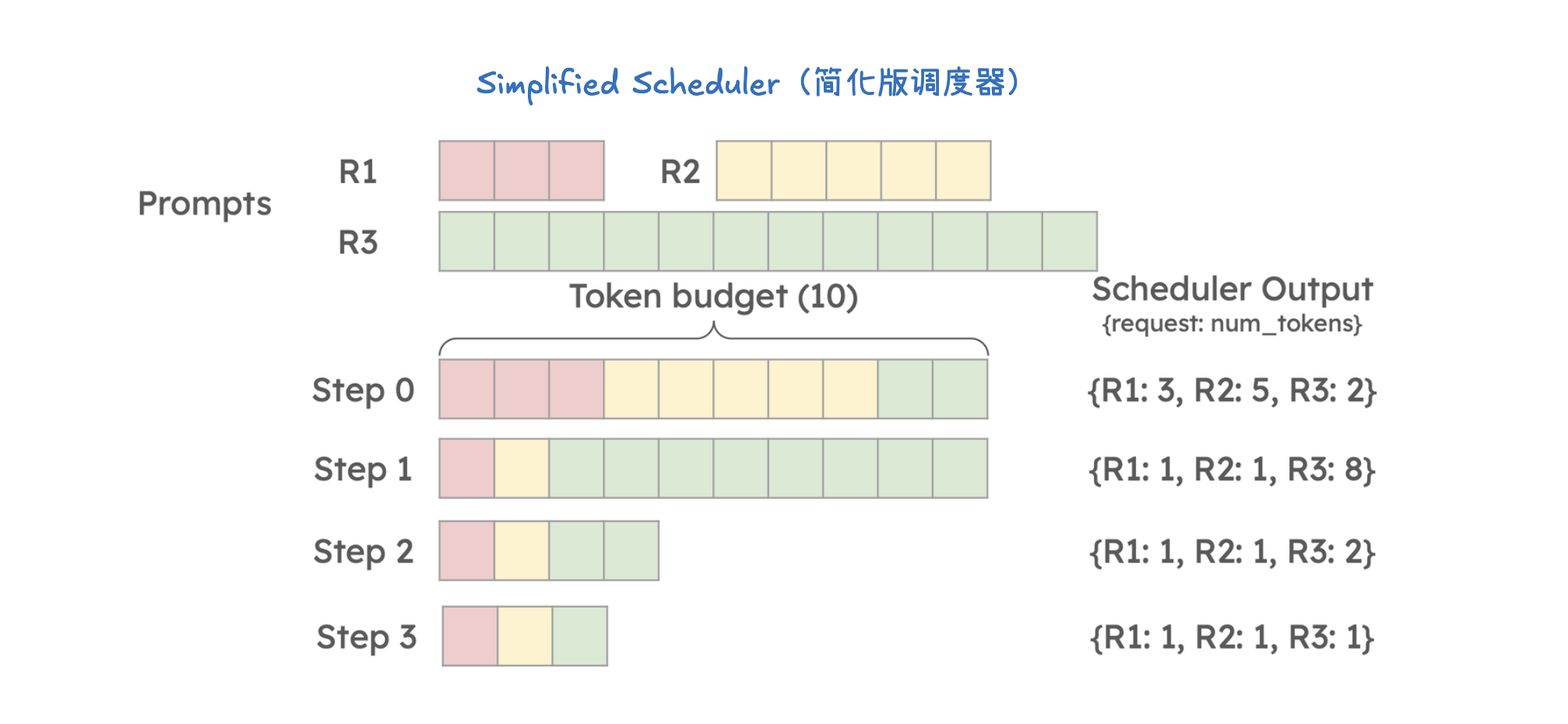
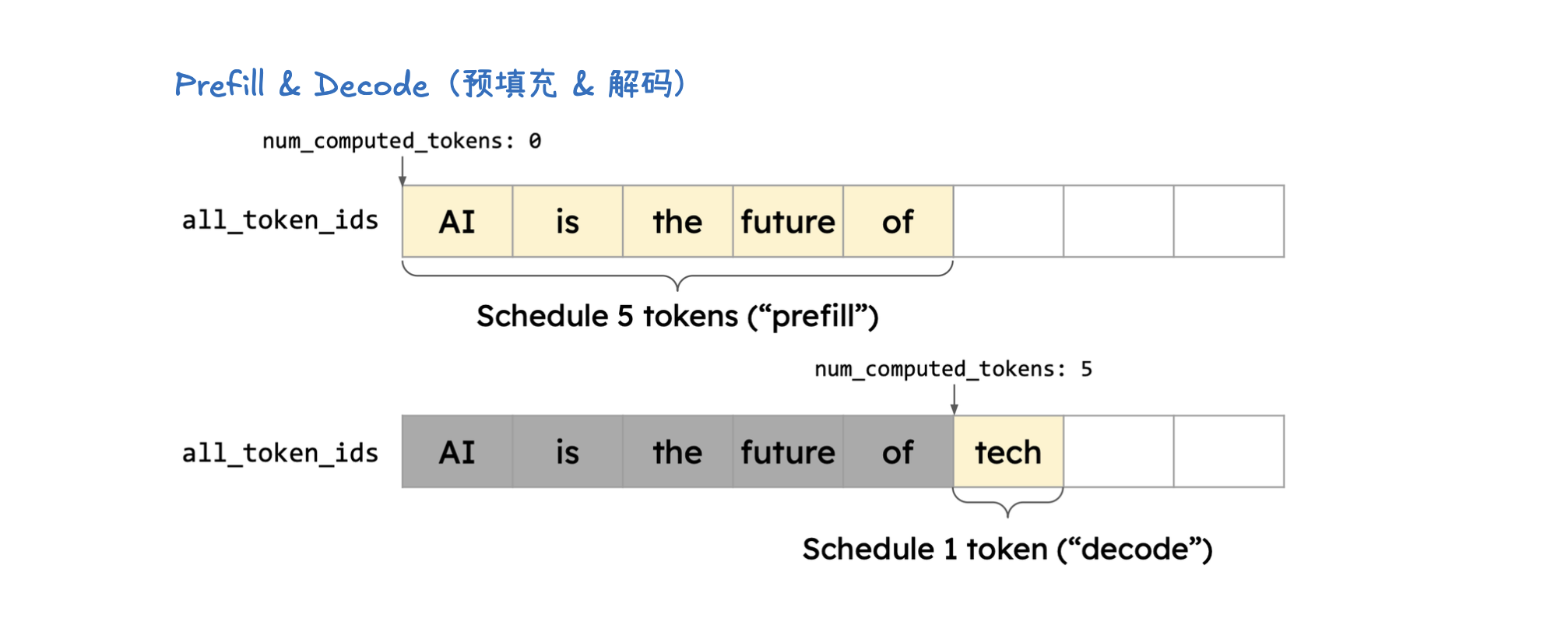
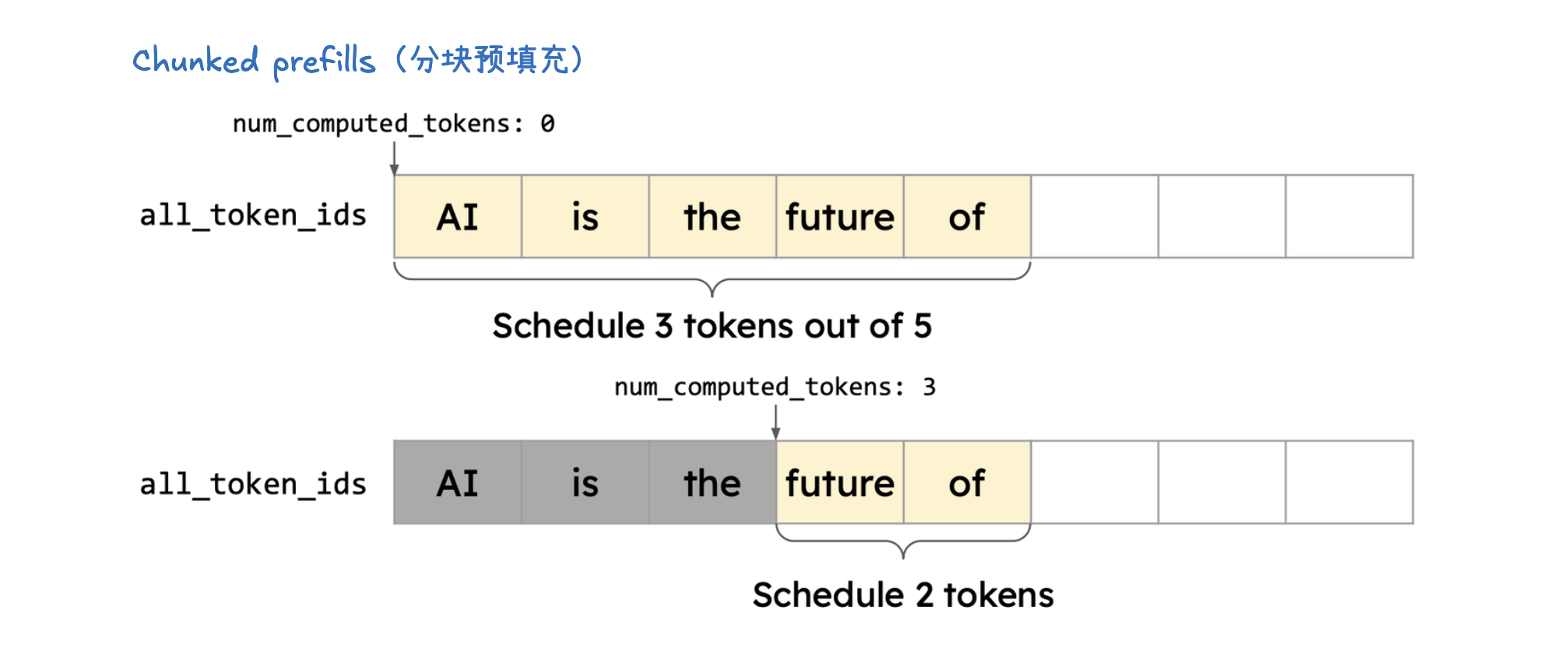
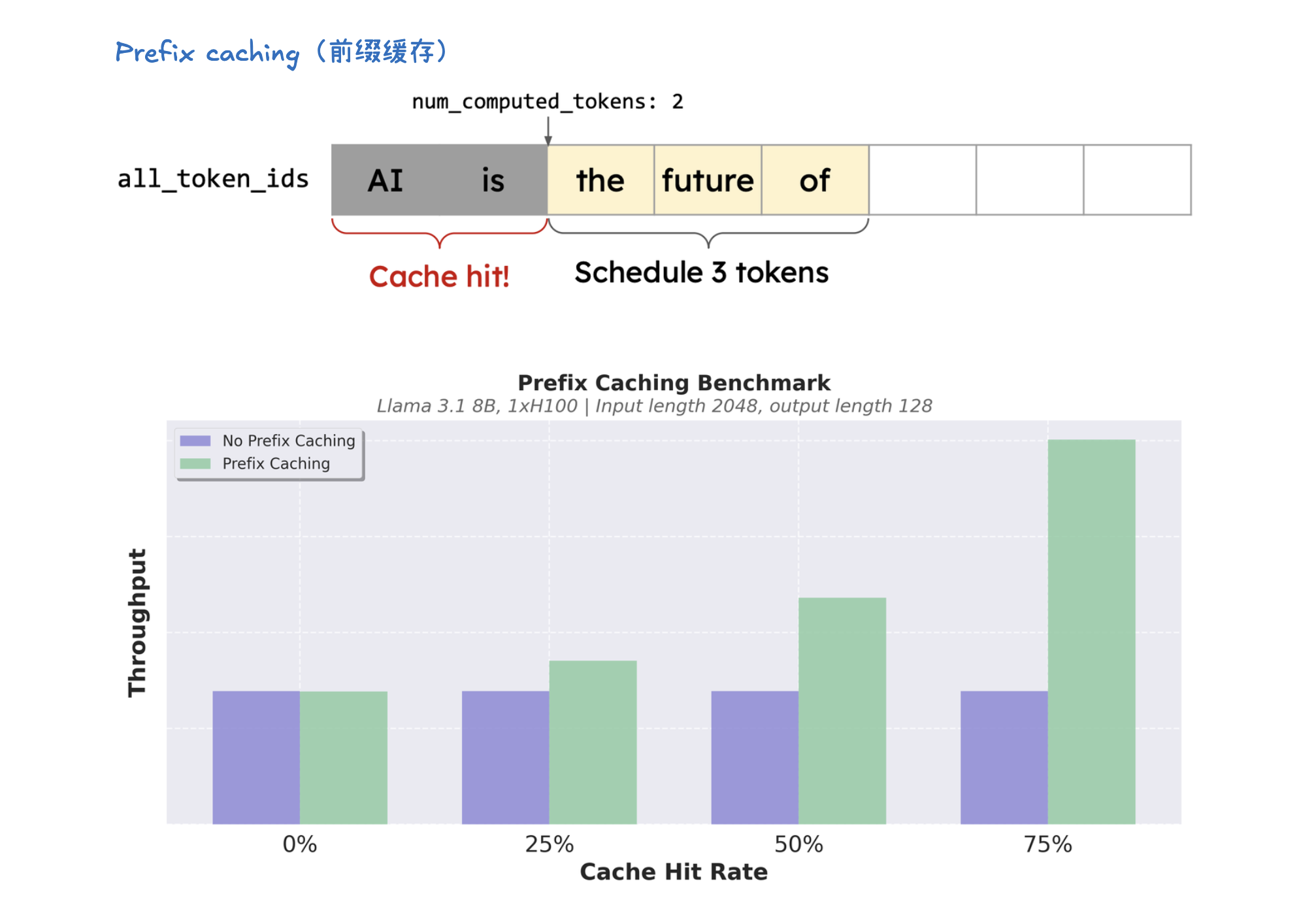
KV 缓存(KV Caching)
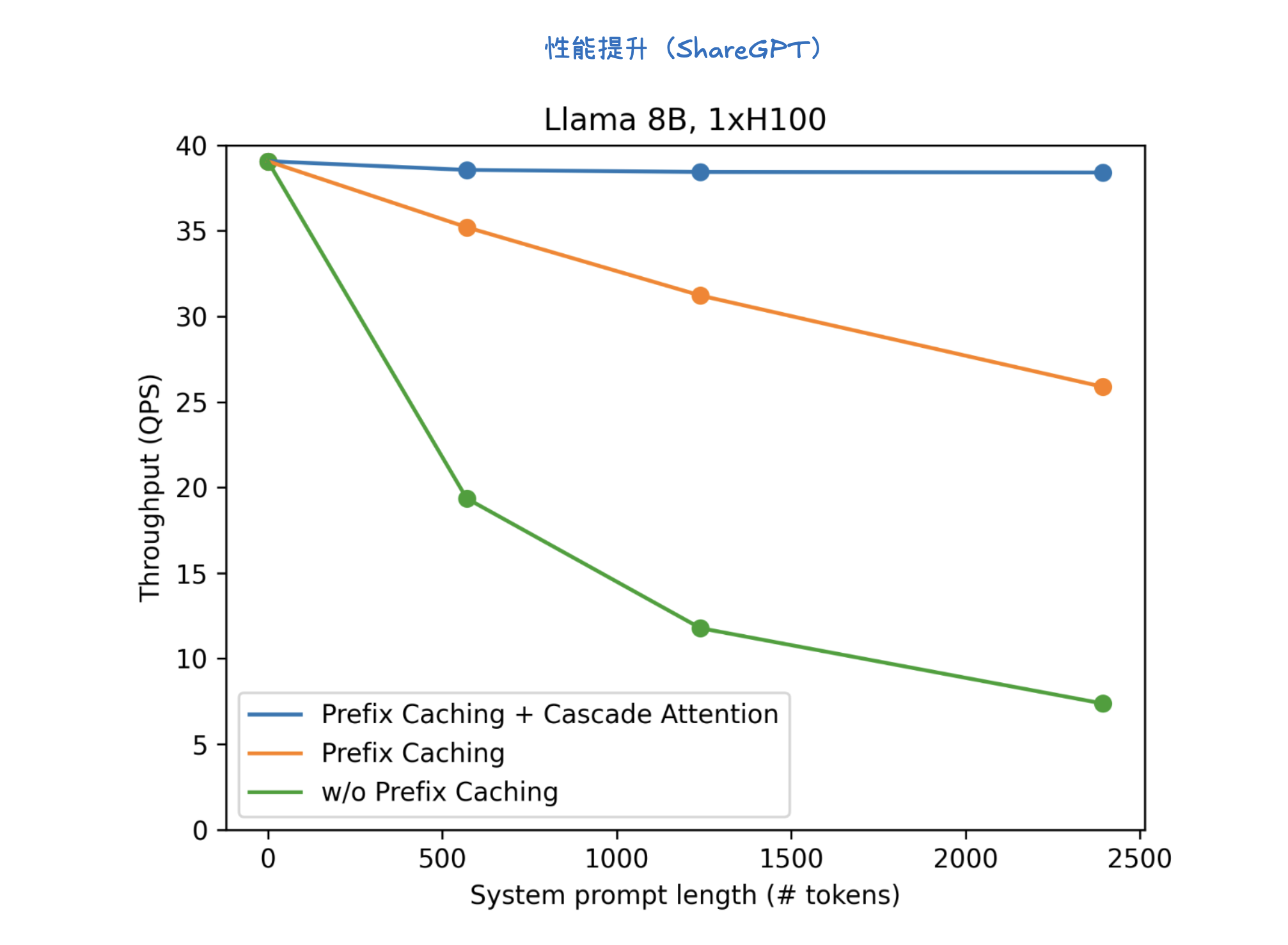
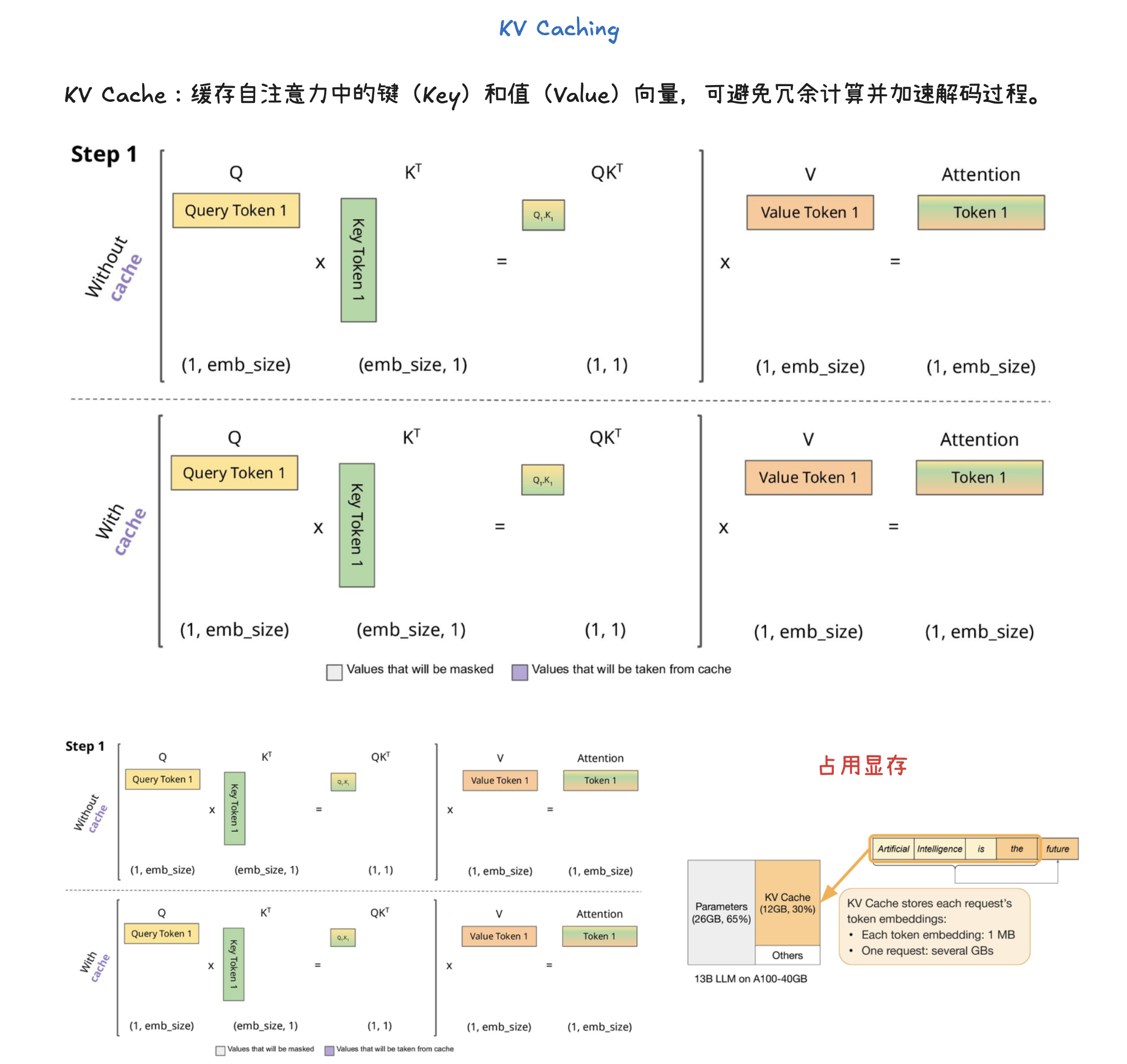
KV 缓存(KV Caching)是一种通过缓存注意力机制中的键(Key)和值(Value)向量来加速大型语言模型推理的技术。在预填充(Prefill)阶段,模型会计算并存储整个输入提示中所有 token 的 KV 缓存。这样,在后续的解码(Decode)阶段,模型就可以直接利用这些已计算好的 KV 缓存,从而避免了冗余计算并显著加速了 token 的生成过程。KV 缓存对于减少计算量、节省内存至关重要,并与前缀缓存(用于避免重复计算相同提示前缀的 KV Cache) 和分页注意力(优化 KV 缓存管理,提高内存效率)等技术协同工作。
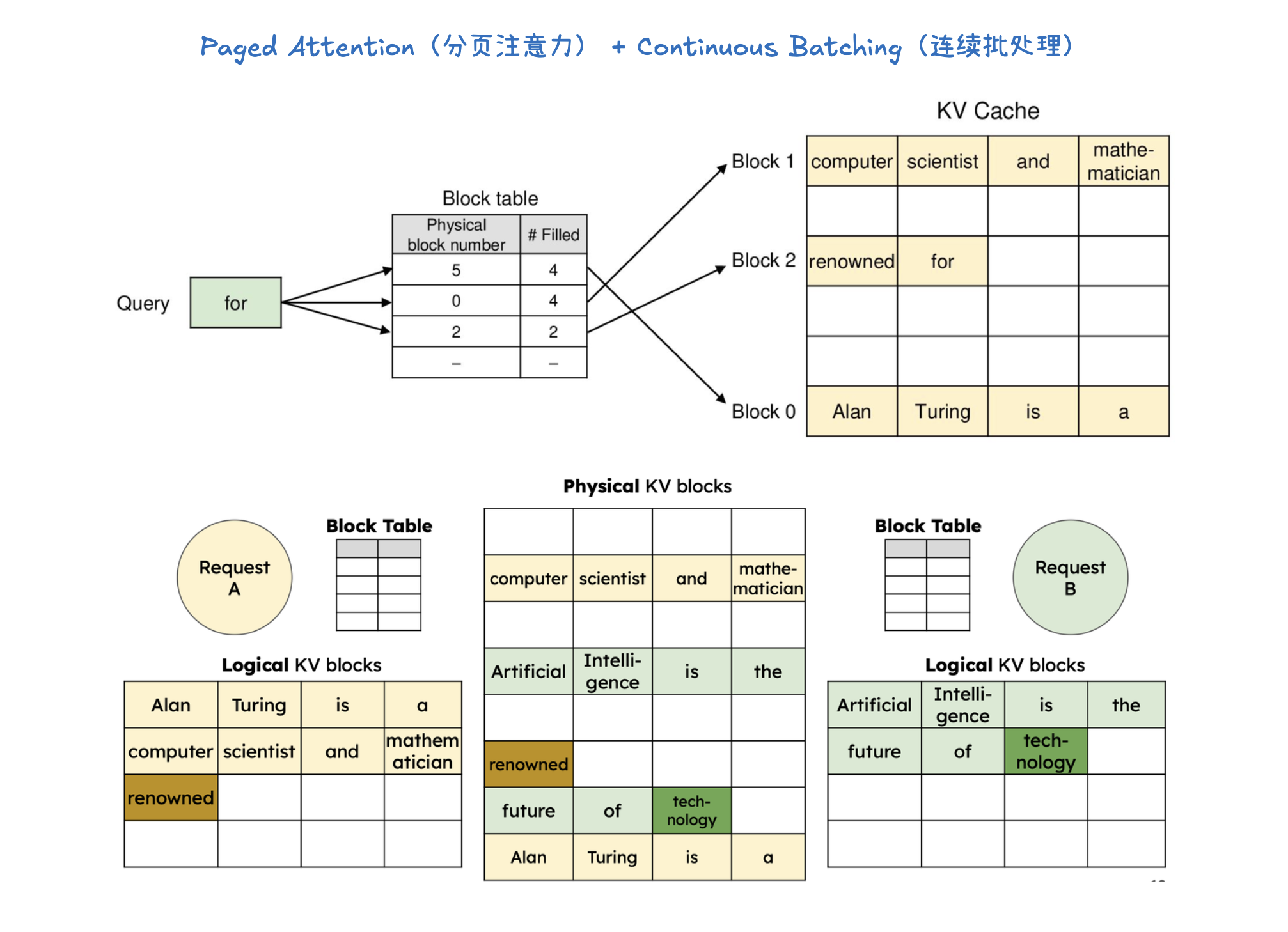
分布式推理
Tensor Parallelism(张量并行)
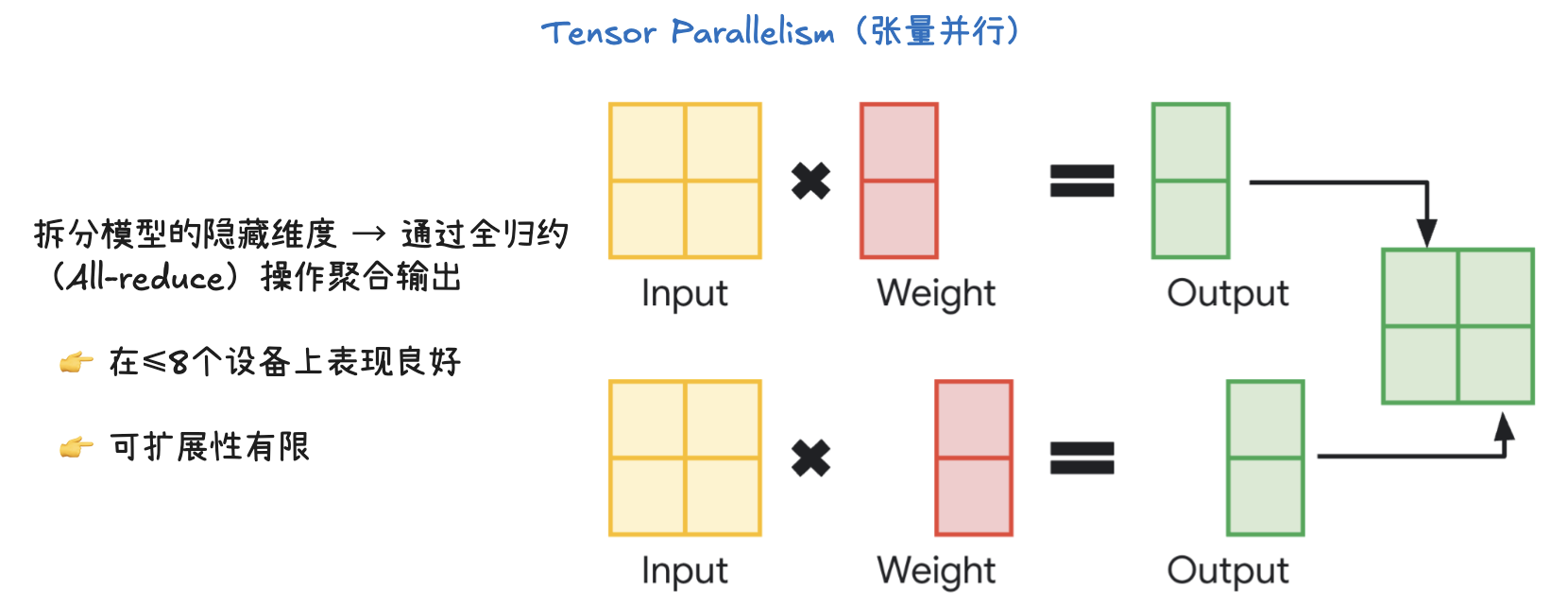
张量并行的核心是切分模型的隐藏维度(hidden dimension),然后将不同部分的计算分配给不同的设备。
- 输入(Input) 和 权重(Weight) 被分成两块,分别发送到两个设备上。
- 每个设备独立地进行矩阵乘法,得到各自的部分输出。
- 为了获得完整的输出,需要对这些部分输出进行聚合(aggregate),这个过程通过All-reduce操作完成。
- All-reduce 是一种高效的通信操作,它能让所有设备上的部分输出汇总到每个设备上,并求和,最终每个设备都拥有完整的输出结果,可以进行下一步的计算。
优点与局限性
- 适用性: 这种方法对于 ≤ 8 个设备时效果很好,因为通信开销相对较小。
- 优化: 像 vLLM(一种大型语言模型推理库)这样的系统提供了优化的 All-reduce 实现,可以显著提高效率。
- 局限性: 张量并行的可扩展性有限。当使用的设备数量增多时,All-reduce 操作的通信开销会迅速增加,导致效率下降,因此不适合用于大规模的设备集群。
Pipeline Parallelism(流水线并行)
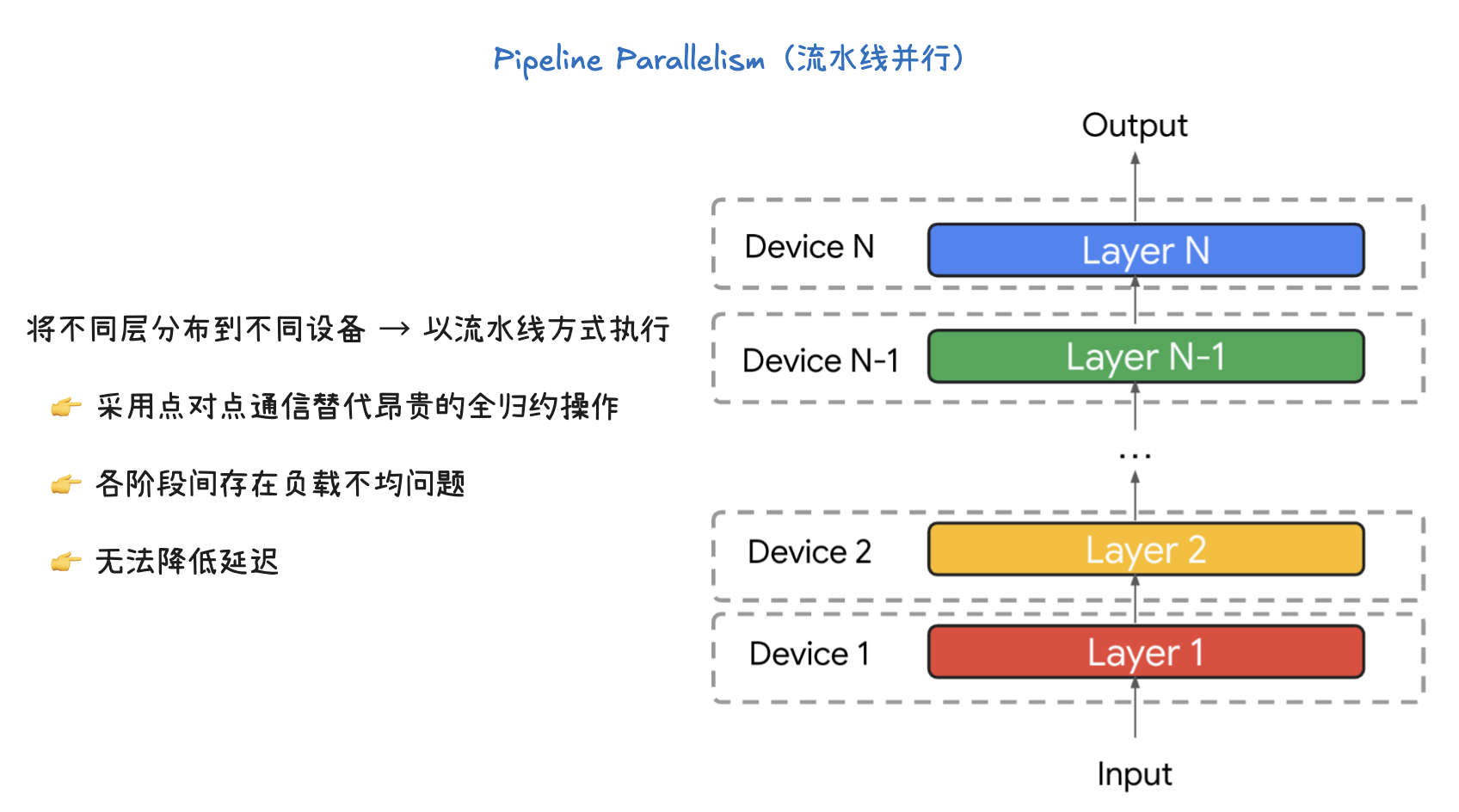
流水线并行的核心是将模型的不同层分发到不同的设备上,并以流水线的方式执行。
- 设备 1 负责计算 Layer 1。
- 设备 2 负责计算 Layer 2。
- …
- 设备 N 负责计算 Layer N。
- 数据像在一条生产线上一样,从一个设备传递到下一个设备,每个设备只处理模型的一部分,并将其输出传递给下一个设备作为输入,直到最终得到输出结果。
优点与局限性
- 通信方式: 这种并行方式采用点对点通信(Point-to-point communication),而不是像张量并行那样昂贵的 All-reduce 操作。这意味着每个设备只需要与下一个设备进行通信,大大减少了整体的通信开销。
- 负载不均衡: 一个主要问题是阶段间的负载不均衡。如果模型各层的计算量不同,那么有些设备可能会比其他设备处理得更快或更慢,导致“流水线”中出现空闲时间,影响整体效率。
- 不减少延迟: 这种方法不会减少模型的推理延迟(latency)。虽然它提高了吞吐量(throughput),但由于数据需要依次通过所有设备,单个数据样本从输入到输出所需的时间并不会减少。
Expert Parallelism(专家并行)
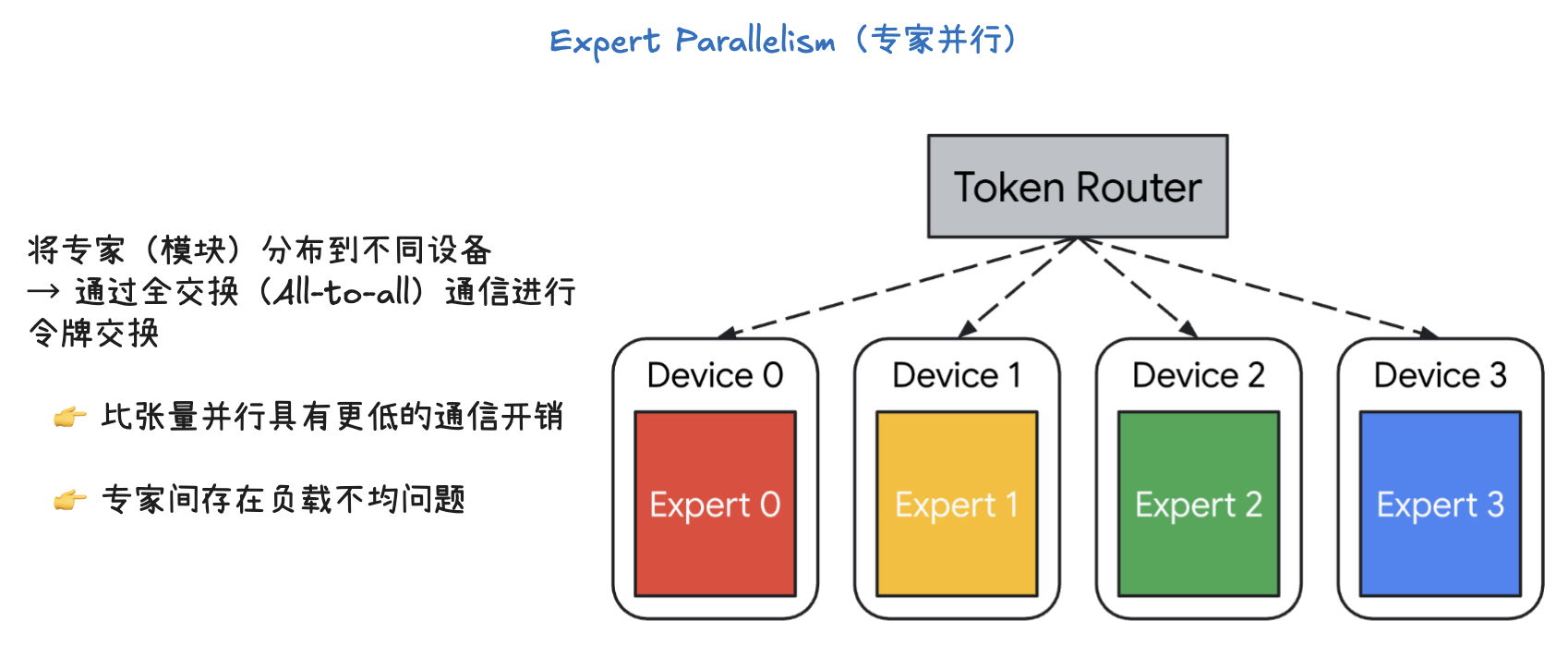
专家并行的核心是将不同的专家(Experts)放置在不同的设备上,并利用一个令牌路由器(Token Router)来决定每个输入令牌(token)应该由哪个专家来处理。
- 令牌路由器(Token Router)是 MoE 模型中的一个关键组件。它会根据输入的令牌,动态地将令牌路由到最适合处理它的一个或多个专家上。
- 专家(Expert 0, 1, 2, 3)被分别部署在不同的设备上(Device 0, 1, 2, 3)。
- 当令牌路由器决定某个令牌需要由特定专家处理时,它会将该令牌发送到相应的设备。
- 为了交换这些令牌,设备之间需要进行All-to-all通信。这是一种高效的集体通信操作,允许所有设备上的数据相互交换,确保每个设备都能接收到需要由其专家处理的令牌。
优点与局限性
- 通信开销: 专家并行的通信开销通常低于张量并行。因为不是所有设备都需要交换所有数据,只有需要路由到不同设备上的令牌才需要进行通信。
- 负载不均衡: 一个主要问题是专家之间的负载不均衡。如果令牌路由器倾向于将大部分令牌路由到少数几个专家,那么这些专家所在的设备就会过载,而其他设备则处于空闲状态,导致整体效率下降。
Data Parallelism(数据并行)
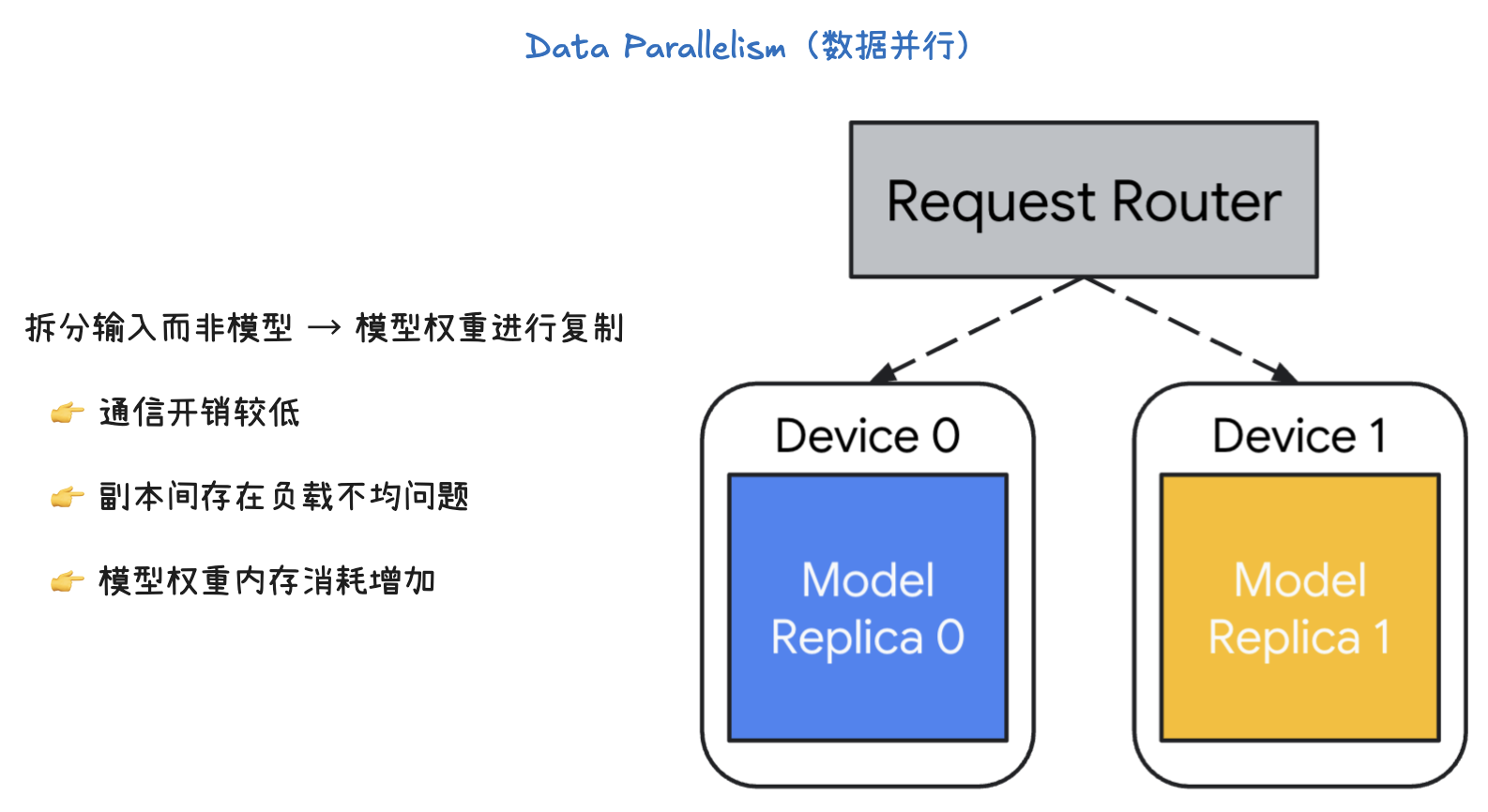
数据并行的核心是将输入数据进行切分,而不是模型本身。
- 模型权重(Model weights)在每个设备上都被完整地复制了一份(Model Replica 0, Model Replica 1)。
- 一个请求路由器(Request Router)负责将输入的请求(或数据批次)分发给不同的设备。
- 每个设备都使用自己的完整模型副本,独立地处理它所接收到的那部分数据。
- 由于每个设备都拥有完整的模型,它们可以独立完成从输入到输出的整个前向传播计算,不需要在中间层进行复杂的通信。
优点与局限性
- 通信开销: 数据并行的通信开销较低。因为设备之间主要是在处理完一整个批次数据后,才需要同步模型权重的梯度,这通常比在每一层之间进行通信要高效得多。
- 负载不均衡: 一个主要问题是副本间的负载不均衡。如果请求路由器分配给不同设备的数据量或处理难度不一致,就会导致某些设备处理得更快,而另一些设备则成为瓶颈,影响整体效率。
- 内存消耗: 这种方法增加了模型权重的内存消耗。因为每个设备都需要存储完整的模型副本,所以当模型非常大时,即使是单个设备也可能无法容纳,这时就需要结合其他并行技术(如张量并行或流水线并行)来解决内存问题。
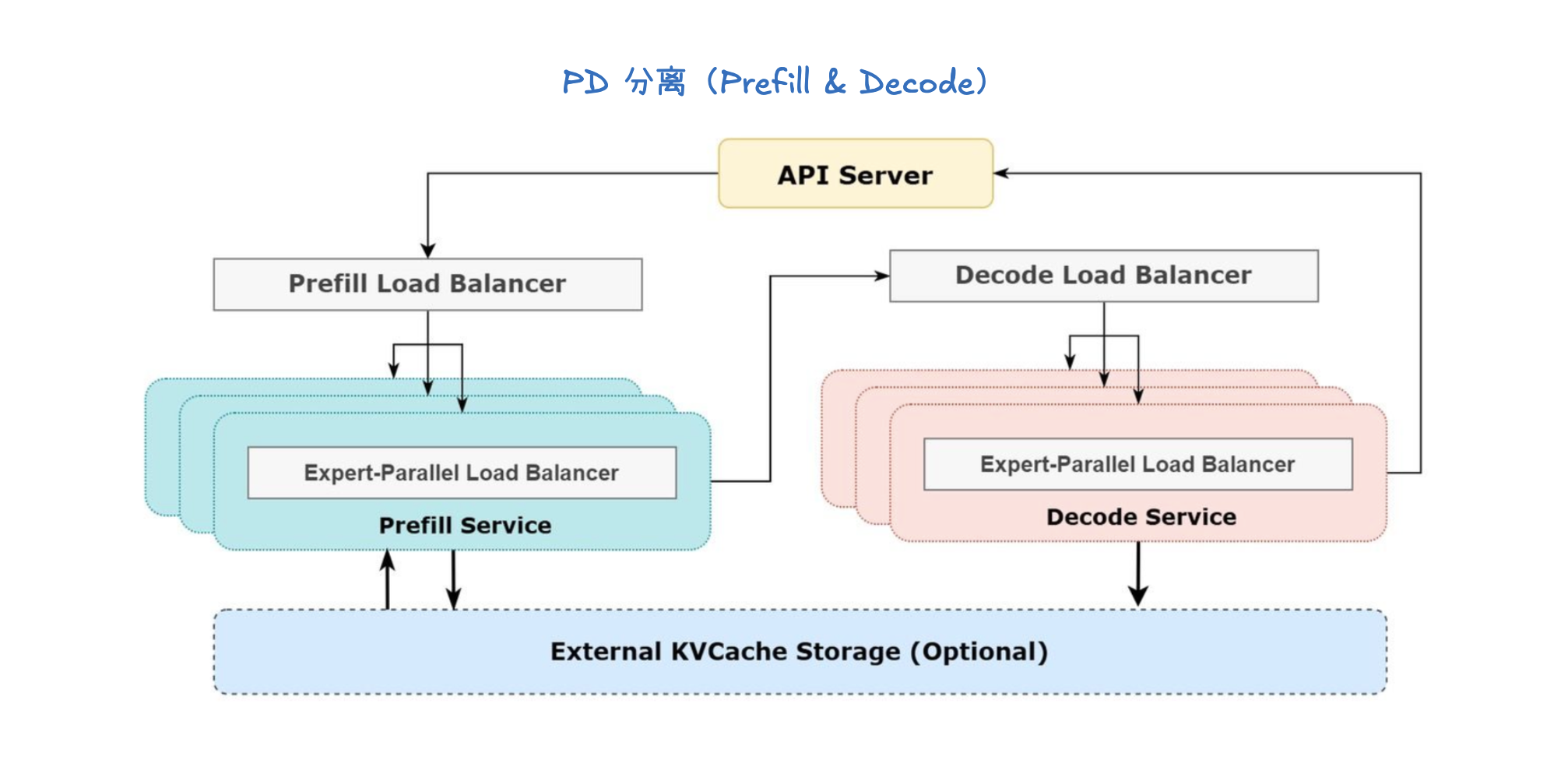
Disaggregated Serving(解耦服务)
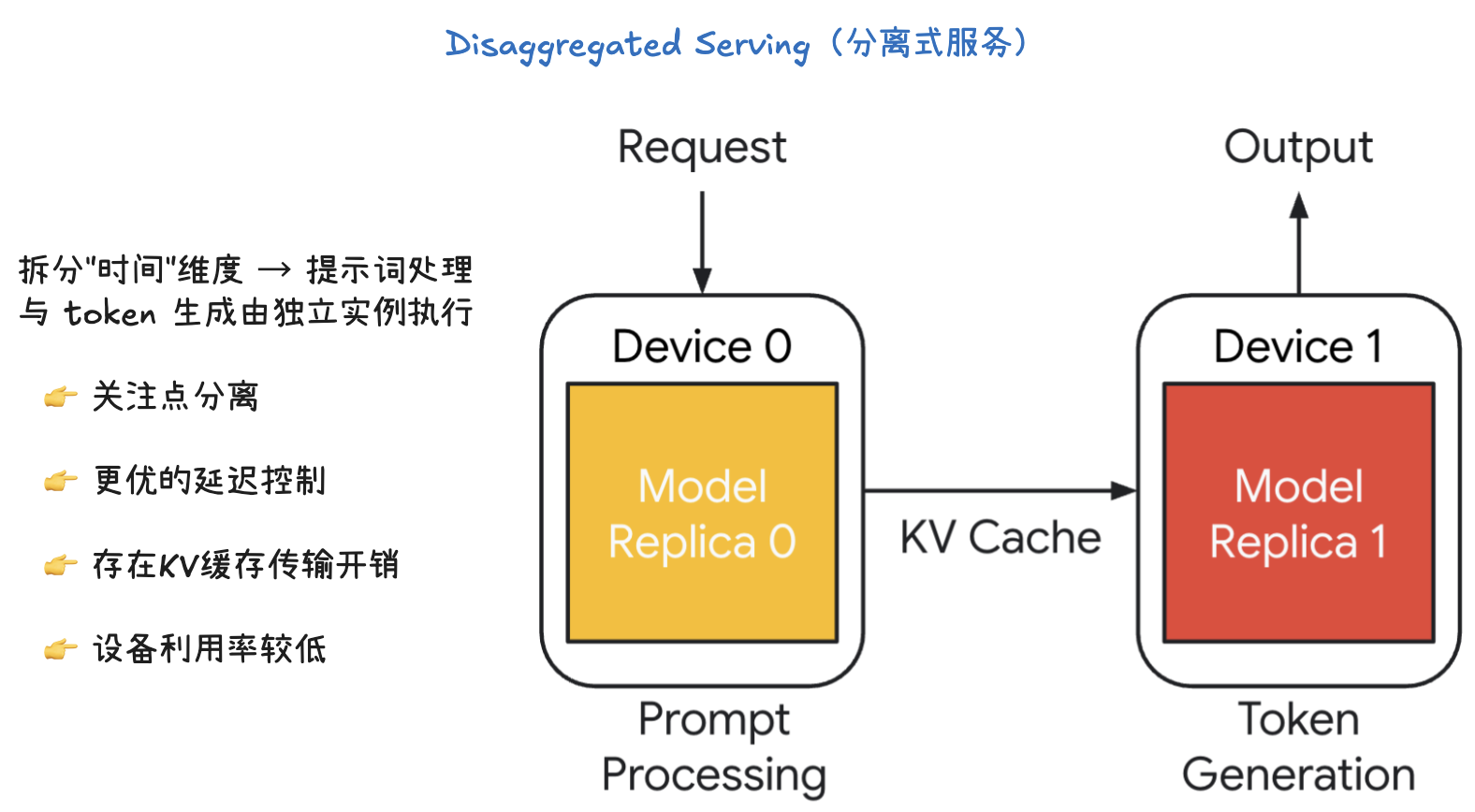
解耦服务将大语言模型的推理过程按“时间”维度进行切分,也就是将提示词处理(Prompt Processing)和令牌生成(Token Generation)这两个阶段分别交给独立的实例来处理。
- 提示词处理(Prompt Processing): 这是一个一次性的前向传播过程。模型需要读取并处理整个输入提示词,然后将中间状态,特别是键值缓存(KV Cache),保存下来。
- 令牌生成(Token Generation): 这是一个迭代的生成过程。模型会根据上一步生成的 KV Cache,一步步地生成新的令牌,直到满足停止条件。
如图所示,Device 0 专门负责提示词处理,而 Device 1 专门负责令牌生成。在提示词处理完成后,KV Cache 会被从 Device 0 传输到 Device 1,以便后者可以继续进行令牌生成。
优点与局限性
- 关注点分离(Separation of concern): 这种架构将复杂的推理过程分成了两个独立的、更易于管理的阶段。每个阶段可以根据其特性进行独立的优化和资源分配。
- 更好的延迟控制(Better control over latency): 由于提示词处理和令牌生成分别由不同的设备处理,我们可以更精细地控制每个阶段的资源,从而更好地管理整个推理过程的延迟。
- KV Cache 传输开销(KV cache transfer overheads): 这种架构的主要缺点是需要在设备间传输 KV Cache。如果 KV Cache 很大,这个传输过程会产生显著的通信开销。
- 设备利用率降低(Lower device utilization): 提示词处理和令牌生成通常不能同时进行,这意味着在某一时刻,可能只有一个设备在工作,导致整体的设备利用率不高。
Mixed Parallelism(混合并行)
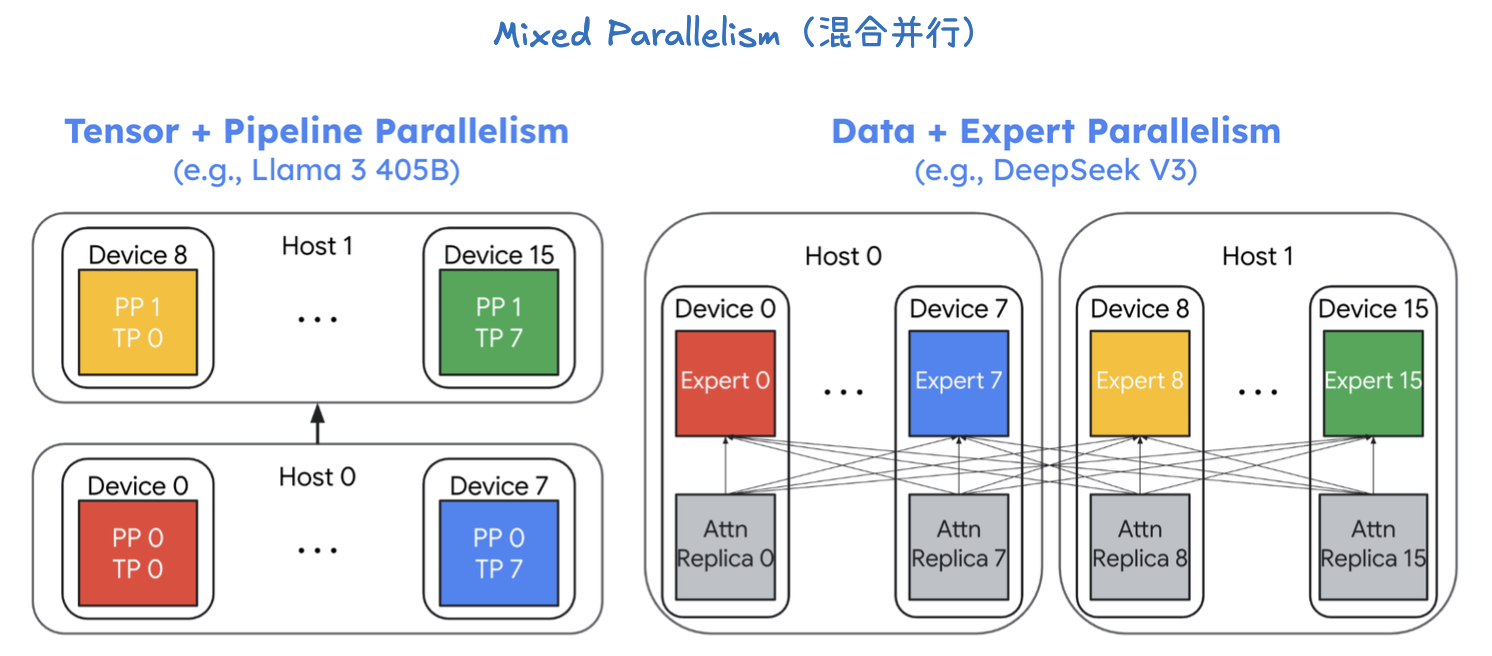
1. 张量并行 + 流水线并行 (Tensor + Pipeline Parallelism)
这种组合常用于像 Llama 3 405B 这样非常大的模型。由于单个设备无法容纳整个模型,甚至无法容纳单个层的完整权重,所以需要两种并行策略的结合。
- 流水线并行 (Pipeline Parallelism, PP): 首先,模型被垂直切分。Host 0 上的 PP 0 负责处理模型的前半部分层,而 Host 1 上的 PP 1 则处理模型的后半部分层。这样,数据以流水线的方式在两个主机之间流动。
- 张量并行 (Tensor Parallelism, TP): 在每个流水线阶段内部,模型层仍然太大。因此,需要进一步使用张量并行。例如,在 Host 0 内部,PP 0 的计算被横向切分到 设备 0 到 7。每个设备都只处理该层的一部分权重。
这种混合并行方法将模型的两个维度都进行了切分:流水线并行切分了模型的层(垂直方向),而张量并行切分了每一层的权重(水平方向),从而能够服务那些规模巨大的模型。
2. 数据并行 + 专家并行 (Data + Expert Parallelism)
这种组合主要用于 MoE (Mixture of Experts) 模型,例如图中的 DeepSeek V3。在 MoE 模型中,存在大量的“专家”网络。
- 专家并行 (Expert Parallelism): 首先,模型的专家层被切分。如图所示,专家 0 到 7 部署在 Host 0 上,而 专家 8 到 15 部署在 Host 1 上。当令牌路由器将请求路由到不同的专家时,它们会到达不同的主机和设备。
- 数据并行 (Data Parallelism): 在处理 MoE 层之前的普通注意力(Attention)层时,模型参数会被完整地复制到每个主机上 (Attn Replica 0 到 15)。每个主机上的设备都会处理一部分输入数据。
这种方法巧妙地结合了两种并行策略:专家并行用来处理 MoE 层的巨大专家数量,而数据并行则用来高效地处理非专家层的计算,从而在保证高吞吐量的同时,支持超大规模的 MoE 模型。
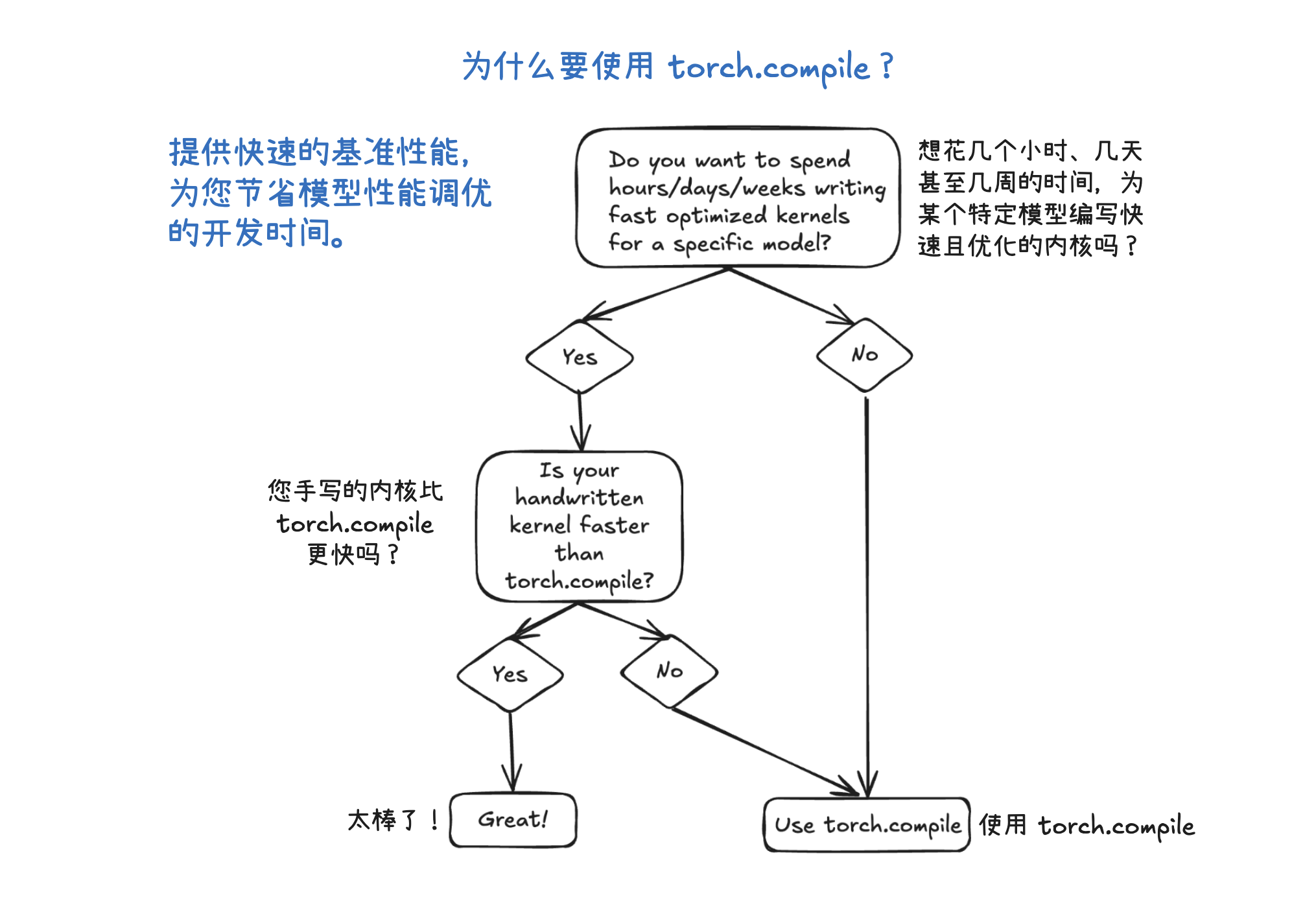
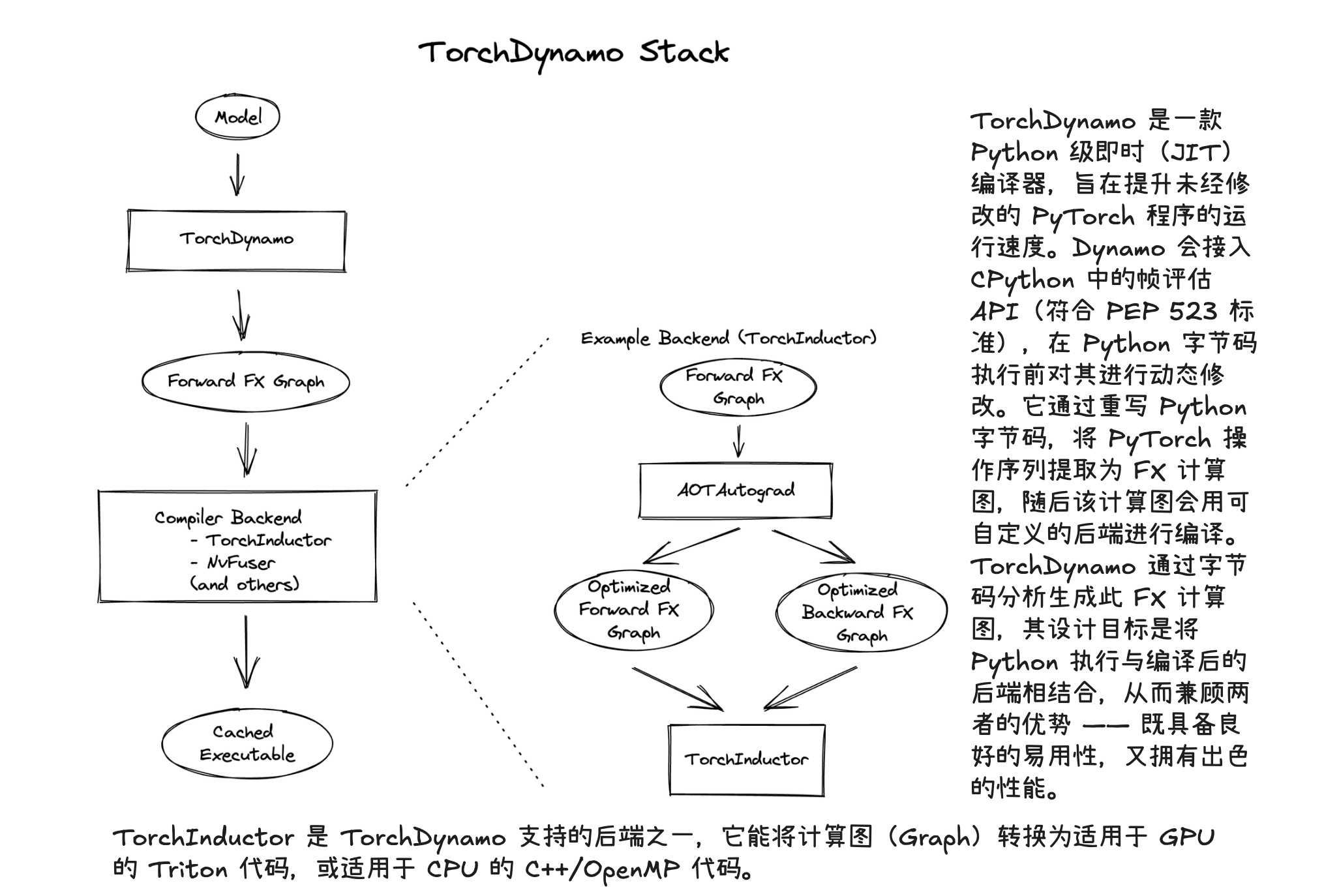
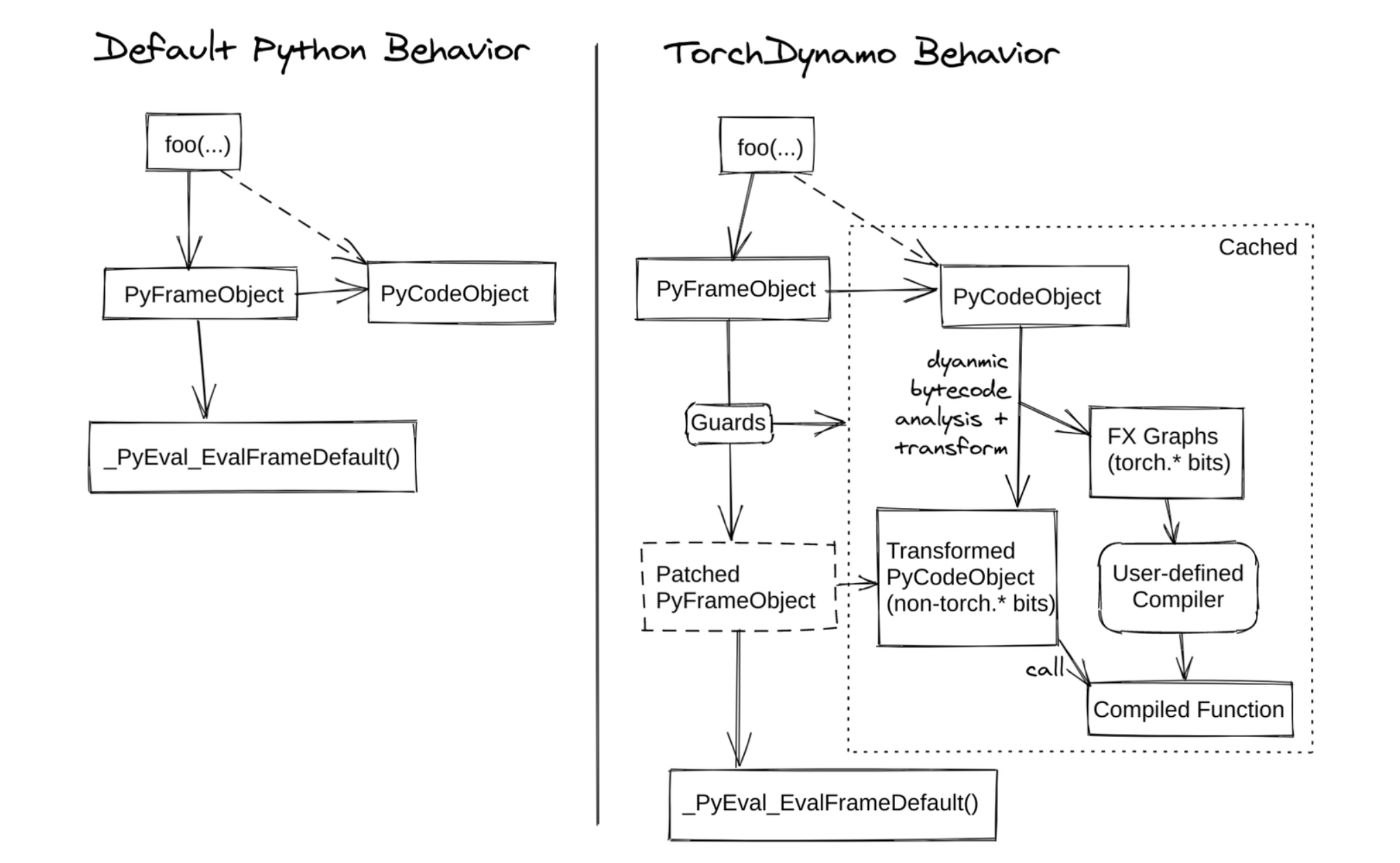
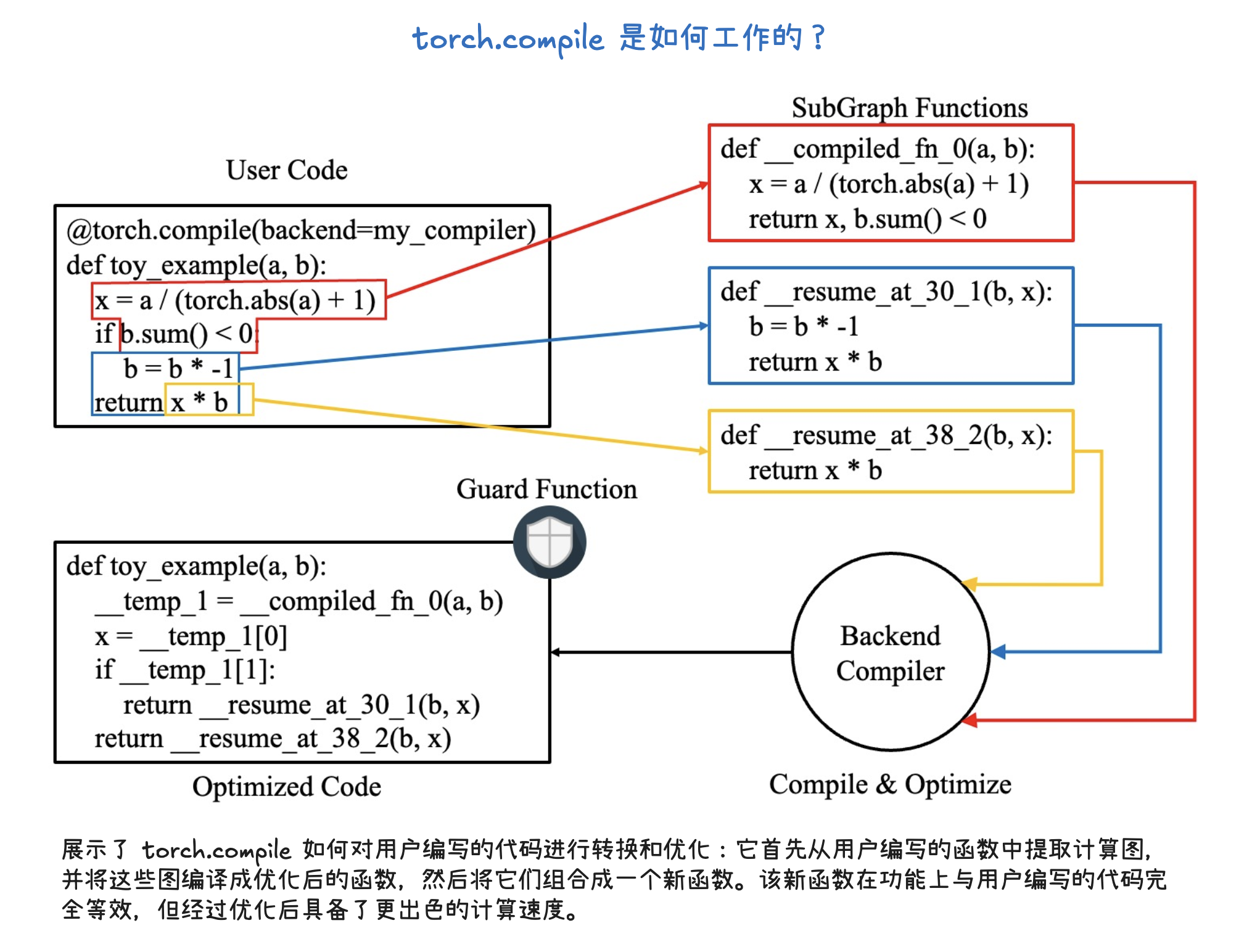
编译优化(torch.compile)



量化(Quantization)
量化(Quantization)是一种通过使用低位精度(如 FP8、INT8、FP4)来存储和计算大型语言模型参数和激活值的方法。其主要目标是降低存储和内存占用,例如将 100B 模型从 BFloadt16 的 200GB 减少到 FP8 的 100GB。量化通过减少 HBM 到 SRAM 的数据传输,并利用具有更高 FLOPS 的 Tensor Core,显著加速计算密集型(预填充和大批处理解码)和内存带宽密集型(小批处理解码)两种情况。具体方法包括仅权重量子化(只量化权重)和权重+激活量子化(同时量化权重和激活值),以及对 KV 缓存进行量化以减少存储空间并加速注意力机制,这对长上下文工作负载尤为关键。最终,量化能够在固定硬件下处理更多 token,从而大幅提升吞吐量,同时通过实验验证,量化后的模型仍能保持良好的准确性和稳定性。
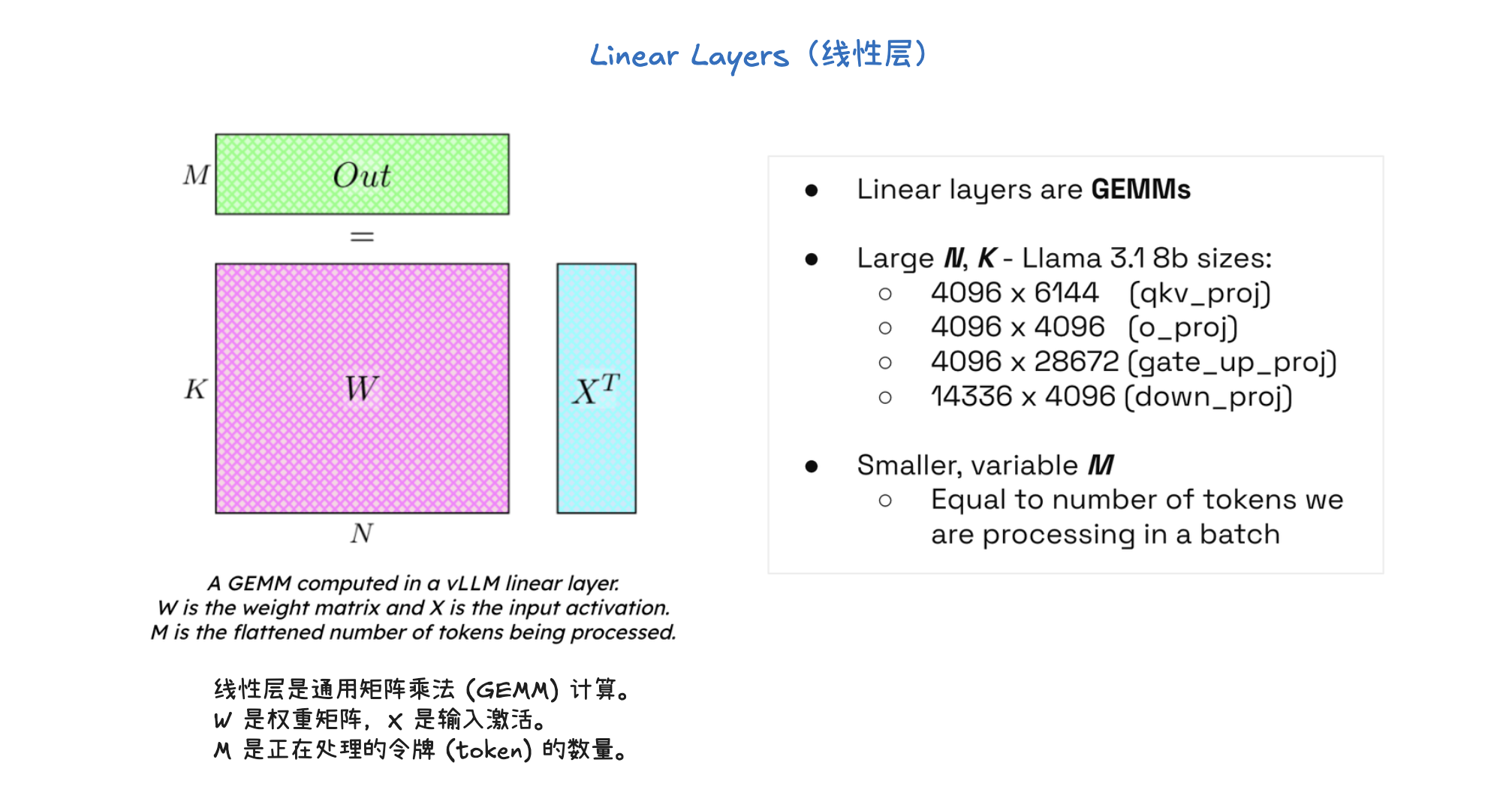


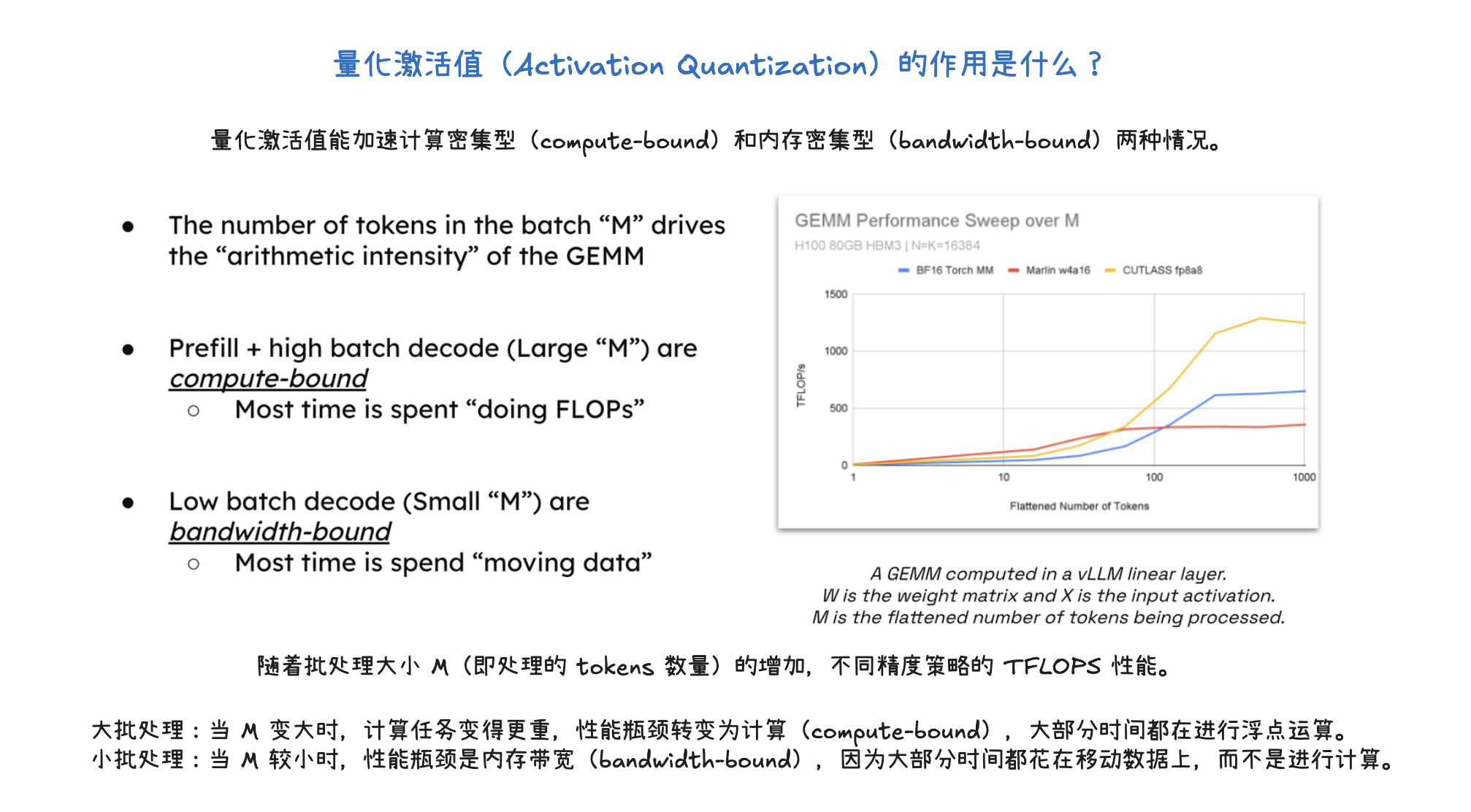
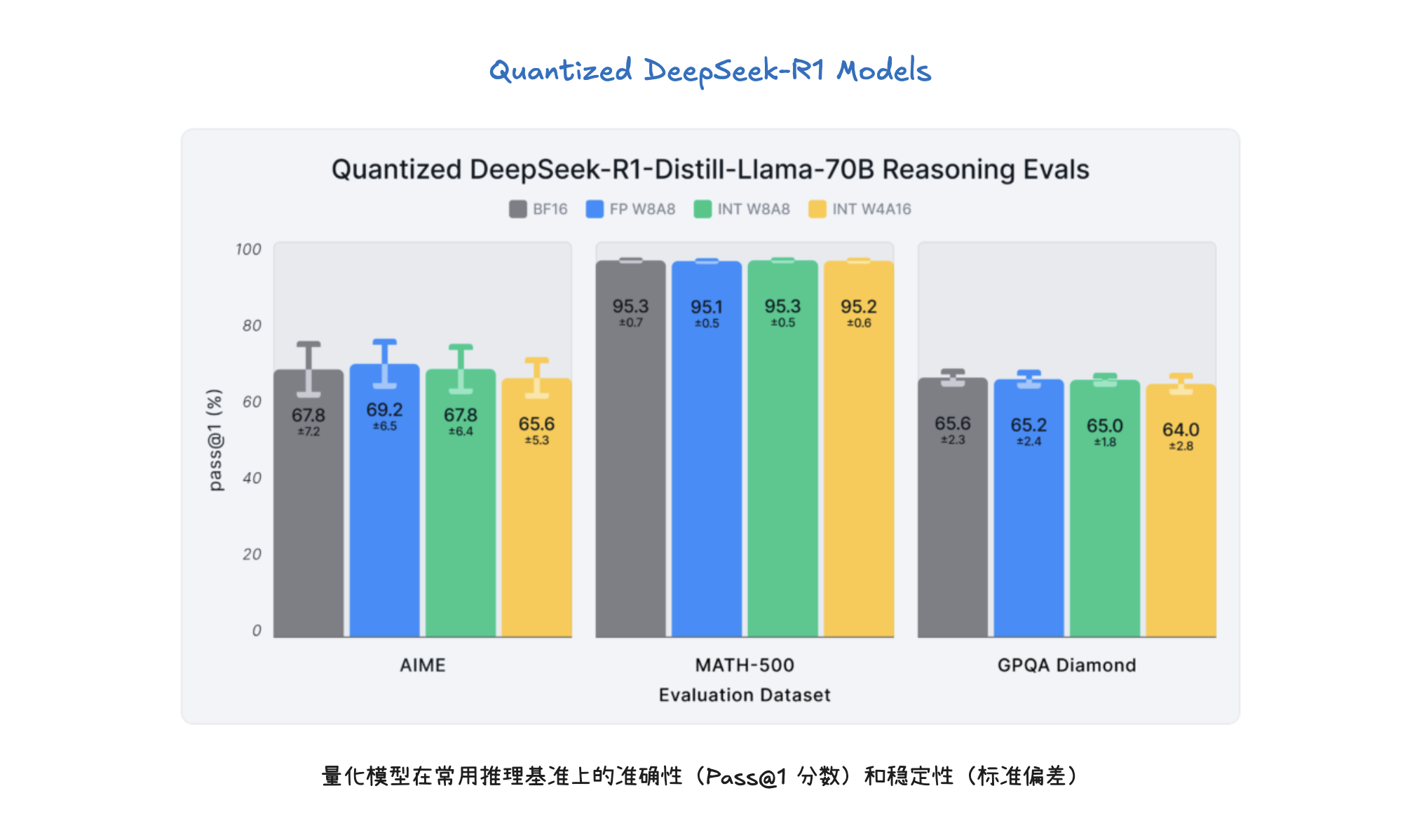

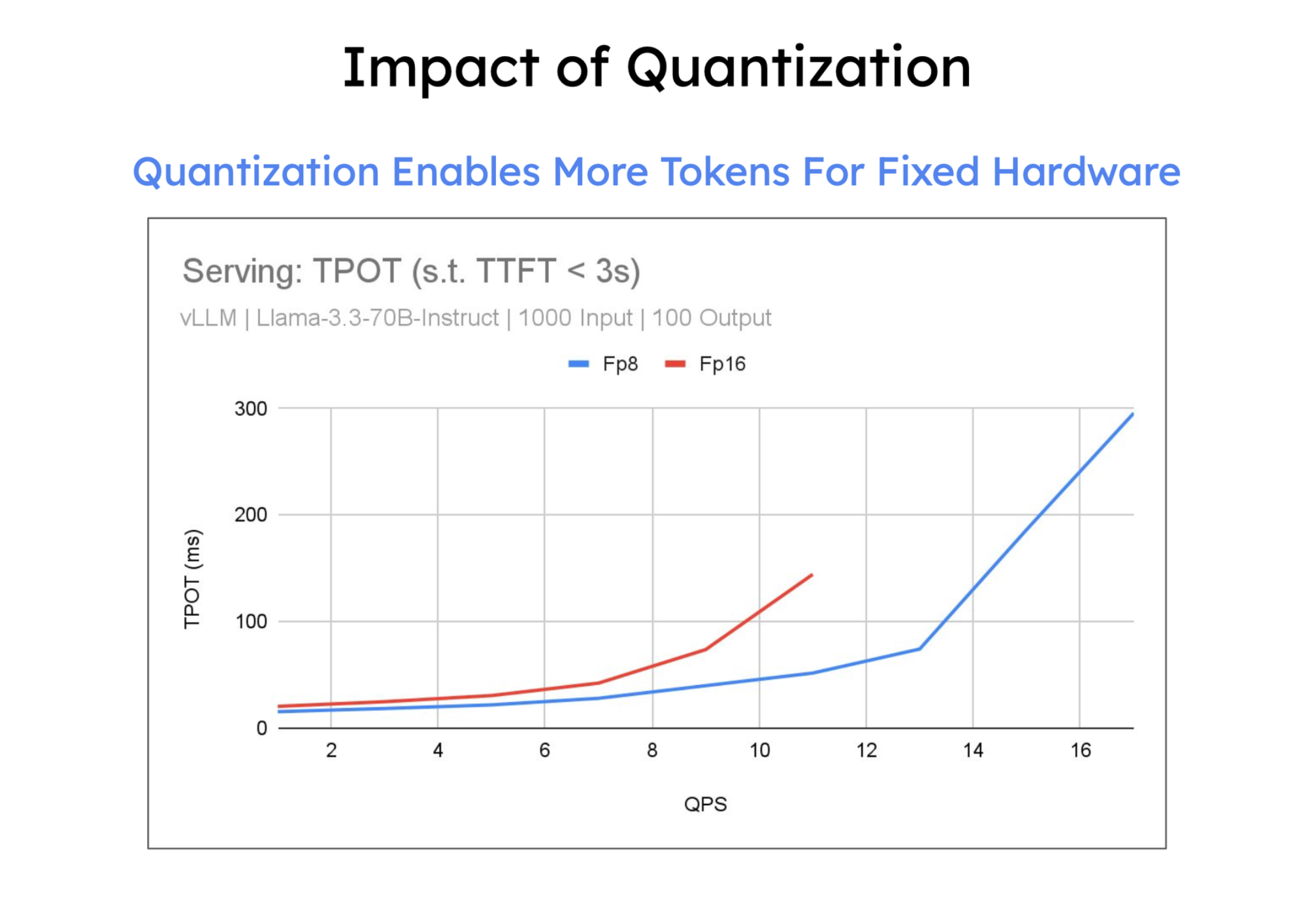
vLLM 使用