SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
ABSTRACT(摘要)
Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We find real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. To this end, we introduce SWE-bench, an evaluation framework consisting of 2,294 software engineering problems drawn from real GitHub issues and corresponding pull requests across 12 popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation tasks. Our evaluations show that both state-ofthe-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. The best-performing model, Claude 2, is able to solve a mere 1.96% of the issues. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
语言模型已经超越了我们有效评估它们的能力,但对于它们未来的发展,研究它们的能力边界至关重要。我们发现,真实的软件工程是评估下一代语言模型的丰富、可持续和具有挑战性的试验场。为此,我们引入了SWE-bench,一个评估框架(evaluation framework),包括从12个流行的Python存储库中提取的2,294个软件工程问题和相应的拉取请求。给定一个代码库以及要解决的问题的描述,语言模型的任务是编辑代码库以解决问题。在SWE-bench中解决问题通常需要理解和协调跨多个函数、类甚至文件同时进行的更改,要求模型与执行环境交互,处理极长的上下文并执行远远超出传统代码生成任务的复杂推理。我们的评估表明,无论是最先进的专有模型还是我们的微调模型SWE-Llama都只能解决最简单的问题。
1 INTRODUCTION(引言)
Language models (LMs) are rapidly being deployed in commercial products such as chatbots and coding assistants. At the same time, existing benchmarks have become saturated (Kiela et al., 2021; Ott et al., 2022) and fail to capture the frontier of what state-of-the-art LMs can and cannot do. There is a need for challenging benchmarks that more accurately reflect real-world applications of LMs to help shape their future development and usage (Srivastava et al., 2023).
语言模型(LMs)正在快速部署到商业产品中,例如聊天机器人和编码助手。同时,现有的基准已经饱和(Kiela等,2021;Ott等,2022),无法捕捉最先进的LMs能够做什么和不能做什么的前沿。需要更具挑战性的基准,更准确地反映LMs的实际应用,以帮助塑造其未来的发展和使用(Srivastava等,2023)。

图1:SWE-bench通过将GitHub问题与解决相关测试的合并拉取请求连接起来,从真实的Python存储库中提取任务实例。给定问题文本和代码库快照,模型生成一个补丁,该补丁将根据真实测试进行评估。
Building a good benchmark is difficult since tasks must be challenging enough to stump existing models, but model predictions must also be easy to verify (Mart´ınez-Plumed et al., 2021). Coding tasks are appealing as they pose challenging problems to LMs yet generated solutions can be easily verified by running unit tests. However, existing coding benchmarks, such as HumanEval (Chen et al., 2021), mostly involve self-contained problems that can be solved in a few lines of code.
构建一个好的基准是困难的,因为任务必须足够具有挑战性,以使现有模型无法解决,但模型预测也必须易于验证(Mart´ınez-Plumed等,2021)。编码任务具有吸引力,因为它们对LMs提出了具有挑战性的问题,但生成的解决方案也可以通过运行单元测试轻松验证。然而,现有的编码基准,如HumanEval(Chen等,2021),主要涉及可以在几行代码中解决的独立问题。
In the real world, software engineering is not as simple. Fixing a bug might involve navigating a large repository, understanding the interplay between functions in different files, or spotting a small error in convoluted code. Inspired by this, we introduce SWE-bench, a benchmark that evaluates LMs in a realistic software engineering setting. As shown in Figure 1, models are tasked to resolve issues (typically a bug report or a feature request) submitted to popular GitHub repositories. Each task requires generating a patch describing changes to apply to the existing codebase. The revised codebase is then evaluated using the repository’s testing framework.
在现实世界中,软件工程并不像这么简单。修复一个错误可能涉及导航大型存储库,理解不同文件中函数之间的相互作用,或发现复杂代码中的小错误。受此启发,我们引入了SWE-bench,一个在现实软件工程环境中评估LMs的基准。如图1所示,模型的任务是解决提交给流行GitHub存储库的问题(通常是错误报告或功能请求)。每个任务都需要生成一个补丁,描述应用于现有代码库的更改。然后使用存储库的测试框架评估修订后的代码库。
SWE-bench offers several advantages over existing LM programming benchmarks. These include, a realistic setting that utilizes user-submitted issues and solutions, diverse inputs featuring unique code problems from 12 repositories, a robust framework for execution-based evaluation, and the ability to continuously update the benchmark with new instances, requiring minimal human intervention.
SWE-bench相对于现有的LM编程基准具有几个优势。这些包括,使用用户提交的问题和解决方案的现实设置,包含来自12个存储库的独特代码问题的多样输入,用于基于执行的评估的强大框架,以及能够使用新实例持续更新基准,需要最少的人工干预。
We evaluate multiple state-of-the-art LMs on SWE-bench and find that they fail to solve all except the simplest issues. Using a BM25 retriever, Claude 2 is only able to resolve 1.96% of the issues.
我们在SWE-bench上评估了多个最先进的LMs,并发现它们无法解决除最简单问题之外的所有问题。使用BM25检索器,Claude 2只能解决1.96%的问题。
In addition to SWE-bench our contributions include the release of a training dataset, SWE-benchtrain, which is essential for advancing open model development in this challenging domain. This dataset comprises a collection of 19,000 non-testing task instances derived from 37 repositories. Utilizing SWE-bench-train, we release two fine-tuned models, SWE-Llama 7b and 13b, based on the CodeLlama (Roziere et al. ` , 2023) model. We find that in some settings SWE-Llama 13b is competitive with Claude 2 and is capable of processing contexts exceeding 100,000 tokens.
除了SWE-bench,我们的贡献还包括发布一个训练数据集SWE-bench-train,这对于推进这一具有挑战性领域的开放模型开发至关重要。该数据集包括从37个存储库中提取的19,000个非测试任务实例的集合。利用SWE-bench-train,我们发布了两个基于CodeLlama(Roziere等,2023)模型的微调模型SWE-Llama 7b和13b。我们发现,在某些设置中,SWE-Llama 13b与Claude 2具有竞争力,并且能够处理超过100,000个标记的上下文。
2 SWE-BENCH
SWE-bench is a benchmark featuring GitHub issues from popular repositories that report bugs or request new features, and pull requests that make changes to the repository to resolve these issues. The task is to generate a pull request that addresses a given issue and passes tests related to the issue.
SWE-bench是一个基准,其中包含来自流行存储库的GitHub问题,这些问题报告错误或请求新功能,以及拉取请求,这些拉取请求对存储库进行更改以解决这些问题。任务是生成一个拉取请求,该拉取请求解决给定问题并通过与问题相关的测试。
2.1 BENCHMARK CONSTRUCTION(基准构建)
GitHub is a rich data source for software development, but repositories, issues, and pull requests can be noisy, ad-hoc, or poorly documented or maintained. To find high-quality task instances at scale, we use a 3-stage pipeline as follows.
GitHub是软件开发的丰富数据源,但存储库、问题和拉取请求可能会有噪声、临时性、文档不完整或维护不良。为了大规模找到高质量的任务实例,我们使用3阶段管道如下。

图2:SWE-bench任务实例是从解决问题的合并拉取请求中创建的,贡献测试并成功安装。
| ❶ Scraping PRs(抓取PRs) | ❷ Attribute Filter(属性过滤器) | ❸ Execution Filter(执行过滤器) |
|---|---|---|
| 12 popular repositories(12个流行的存储库) | Resolves an issue(解决问题) | Installs successfully(成功安装) |
| >90% Python Code(>90% Python代码) | Contributes tests(贡献测试) | PR passes all tests(PR通过所有测试) |
Stage I: Repo selection and data scraping. We start by collecting pull requests (PRs) from 12 popular open-source Python repositories on GitHub, producing about ∼ 90,000 PRs in total. We focus on popular repositories as they tend be better maintained, have clear contributor guidelines, and have better test coverage. Each PR has an associated codebase specified by it’s base commit.
阶段I:存储库选择和数据抓取。 我们首先从GitHub上收集12个流行的开源Python存储库的拉取请求(PRs),总共产生约90,000个PRs。我们专注于流行的存储库,因为它们往往维护得更好,有明确的贡献者指南,并且测试覆盖率更好。每个PR都有一个由其基本提交指定的关联代码库。
Stage II: Attribute-based filtering. We create candidate tasks by selecting the merged PRs that (1) resolve a GitHub issue and (2) make changes to the test files of the repository, which indicates that the user likely contributed tests to check whether the issue has been resolved.
阶段II:基于属性的过滤。 我们通过选择解决GitHub问题的合并PRs并对存储库的测试文件进行更改来创建候选任务,这表明用户可能贡献了测试以检查问题是否已解决。
Stage III: Execution-based filtering. For each candidate task, we apply the PR’s test content, and log the associated test results before and after the PR’s other content is applied. We filter out task instances without at least one test where its status changes from a fail to pass (henceforth referred to as fail-to-pass test). We also filter out instances that result in installation or runtime errors.
阶段III:基于执行的过滤。 对于每个候选任务,我们应用PR的测试内容,并记录PR的其他内容应用之前和之后的相关测试结果。我们过滤掉没有至少一个测试的任务实例,其中其状态从失败变为通过(以下简称为失败到通过测试)。我们还过滤掉导致安装或运行时错误的实例。
Through these stages of filtering, the original 90,000 PRs are filtered down to the 2,294 task instances which comprise SWE-bench. A final breakdown of these task instances across repositories is presented in Figure 3, and Table 1 highlights the key features of SWE-bench task instances. We highlight that the codebases are large with thousands of files, and the reference pull requests often make changes to multiple files at once. Technical details about SWE-bench’s construction pipeline are discussed in Appendix A. Additional dataset statistics are in Appendix A.5.
通过这些过滤阶段,原始的90,000个PRs被过滤为组成SWE-bench的2,294个任务实例。图3展示了这些任务实例在存储库中的最终分布,表1突出了SWE-bench任务实例的关键特征。我们强调代码库很大,有数千个文件,参考拉取请求通常一次对多个文件进行更改。有关SWE-bench构建管道的技术细节在附录A中讨论。附录A.5中有额外的数据集统计信息。
2.2 TASK FORMULATION(任务公式化)
Model input. A model is given an issue text description and a complete codebase. The model is then tasked to make an edit to the codebase to resolve the issue. In practice, we represent edits as patch files, which specify which lines in the codebase to modify in order to resolve the issue.
模型输入。 模型提供问题文本描述和完整的代码库。然后,模型被要求对代码库进行编辑以解决问题。在实践中,我们将编辑表示为补丁文件,该文件指定要修改的代码库中的哪些行以解决问题。
Evaluation metrics. To evaluate a proposed solution, we apply the generated patch, using unix’s patch program, to the codebase and then execute the unit and system tests associated with the task instance. If the patch applies successfully and all of these tests pass we consider the proposed solution to have successfully resolved the issue. The metric for our benchmark is the percentage of task instances that are resolved. Additional technical details in Appendix A.4.
评估指标。 为了评估提出的解决方案,我们使用unix的patch程序将生成的补丁应用于代码库,然后执行与任务实例相关的单元和系统测试。如果补丁成功应用并且所有这些测试都通过,我们认为提出的解决方案成功解决了问题。我们基准的指标是已解决任务实例的百分比。附录A.4中有额外的技术细节。
2.3 FEATURES OF SWE-BENCH(SWE-BENCH的特点)
Traditional benchmarks in NLP typically involve only short input and output sequences and consider somewhat “contrived” problems created specifically for the benchmark. In contrast, SWE-bench’s realistic construction setting imbues the dataset with unique properties, which we discuss below.
NLP中的传统基准通常只涉及短的输入和输出序列,并考虑为基准专门创建的有些“人为”的问题。相比之下,SWE-bench的现实构建设置赋予了数据集独特的特性,我们将在下面讨论。
Real-world software engineering tasks. Since each task instance in SWE-bench consists of a large and complex codebase and a description of a relevant issue, solving SWE-bench requires demonstrating sophisticated skills and knowledge possessed by experienced software engineers but are not commonly evaluated in traditional code generation benchmarks.
真实世界的软件工程任务。 由于SWE-bench中的每个任务实例由一个大型且复杂的代码库和一个相关问题的描述组成,因此解决SWE-bench需要展示有经验的软件工程师所拥有的复杂技能和知识,但这些技能和知识在传统的代码生成基准中通常不被评估。
Continually updatable. Our collection process can be easily applied to any Python repository on GitHub and requires minimal human intervention. Therefore, we can extend SWE-bench with a continual supply of new task instances and evaluate LMs on issues created after their training date, which ensures that the solution was not included in their training corpus.
持续更新。 我们的收集过程可以轻松应用于GitHub上的任何Python存储库,并且需要最少的人工干预。因此,我们可以使用持续的新任务实例扩展SWE-bench,并在训练日期之后创建的问题上评估LMs,这确保了解决方案未包含在其训练语料库中。
Diverse long inputs. Issue descriptions are typically long and detailed (195 words on average), and codebases regularly contain many thousands of files. Solving SWE-bench requires identifying the relatively small number of lines that need to be edited to solve an issue amongst a sea of context.
多样的长输入。 问题描述通常很长且详细(平均195个单词),代码库通常包含数千个文件。解决SWE-bench需要在大量上下文中识别需要编辑的相对较少行,以解决问题。
Robust evaluation. For each task instance, there is at least one fail-to-pass test which was used to test the reference solution, and 40% of instances have at least two fail-to-pass tests. These tests evaluate whether the model addressed the problem in the issue. In addition, a median of 51 additional tests run to check whether prior functionality is properly maintained.
强大的评估。 对于每个任务实例,至少有一个失败到通过测试用于测试参考解决方案,40%的实例至少有两个失败到通过测试。这些测试评估模型是否解决了问题。此外,中位数为51个额外的测试运行,以检查先前的功能是否得到了正确的维护。
Cross-context code editing. Unlike prior settings that may constrain edit scope to an individual function or class (e.g., Chen et al., 2021; Cassano et al., 2022) or provide cloze-style fill-in blanks (e.g., Lu et al., 2021; Fried et al., 2023), SWE-bench does not provide such explicit guidance. Rather than merely having to produce a short code snippet, our benchmark challenges models to generate revisions in multiple locations of a large codebase. SWE-bench’s reference solutions average editing 1.7 files, 3.0 functions, and 32.8 lines (added or removed).
跨上下文代码编辑。 与以前的设置不同,以前的设置可能会将编辑范围限制在单个函数或类(例如,Chen等,2021;Cassano等,2022)或提供填空式填空(例如,Lu等,2021;Fried等,2023),SWE-bench不提供这样的明确指导。我们的基准挑战模型在大型代码库的多个位置生成修订,而不仅仅是生成一个简短的代码片段。SWE-bench的参考解决方案平均编辑1.7个文件,3.0个函数和32.8行(添加或删除)。
Wide scope for possible solutions. The task of repository-scale code editing can serve as a level playing field to compare approaches ranging from retrieval and long-context models to decisionmaking agents, which could reason and act in code. SWE-bench also allows creative freedom, as models can generate novel solutions that may deviate from the reference PR.
广泛的解决方案范围。 存储库级别的代码编辑任务可以作为一个公平的比较平台,用于比较从检索和长上下文模型到决策制定代理的方法,后者可以在代码中进行推理和行动。SWE-bench还允许创造性自由,因为模型可以生成可能偏离参考PR的新颖解决方案。
2.4 SWE-BENCH LITE
Evaluating LMs on SWE-bench can be time-consuming and, depending on the model, require a costly amount of compute or API credits. Given that initial performance returns as presented in Section 5 are quite low, SWE-bench’s difficulty makes it useful for gauging LM progress in the long term, but potentially intimidating for initial systems that attempt to make progress in the short term.
在SWE-bench上评估LMs可能是耗时的,并且根据模型的不同,可能需要大量的计算或API积分。鉴于第5节中呈现的初始性能较低,SWE-bench的困难使其在长期内对LM进展进行评估很有用,但对于试图在短期内取得进展的初始系统来说可能令人生畏。
表1:表征SWE-bench任务实例不同属性的平均值和最大值。统计数据是在不按存储库分组的情况下计算的微平均值。

图3:SWE-bench任务的分布(括号内)跨12个开源GitHub存储库,每个存储库都包含一个流行的、广泛下载的PyPI包的源代码。
To encourage adoption of SWE-bench, we create a Lite subset of 300 instances from SWE-bench that have been sampled to be more self-contained, with a focus on evaluating functional bug fixes. The full filtering criteria and dataset information is included in SWE-bench Lite covers 11 of the original 12 repositories, with a similar diversity and distribution of task instances across repositories as the original. Full details of the Lite split and filtering details are included in Appendix A.7.
为了鼓励采用SWE-bench,我们从SWE-bench中创建了一个Lite子集,其中包含300个实例,这些实例经过抽样,更加独立,重点评估功能性错误修复。完整的过滤标准和数据集信息包含在SWE-bench Lite中,SWE-bench Lite涵盖了原始12个存储库中的11个,与原始存储库相比,任务实例的多样性和分布类似。Lite拆分和过滤详细信息的完整细节包含在附录A.7中。
3 SWE-LLAMA: FINE-TUNING CODELLAMA FOR SWE-BENCH(微调CodeLlama用于SWE-bench)
It is important to benchmark the performance of open models on SWE-bench alongside proprietary models. At the time of writing, only the CodeLlama models (Roziere et al. ` , 2023) are able to handle the very long contexts necessary. However, we observe that the off-the-shelf CodeLlama variants are not capable of following the detailed instructions to generate repository-wide code edits, and typically output placeholder responses or unrelated code. To better evaluate the capabilities of these models, we perform supervised fine-tuning on the 7 billion- and 13 billion-parameter CodeLlamaPython models. The resulting models are specialized repository editors that can run on consumer hardware and resolve GitHub issues.
在SWE-bench上与专有模型一起对开放模型的性能进行基准测试是很重要的。在撰写本文时,只有CodeLlama模型(Roziere等,2023)能够处理必要的非常长的上下文。然而,我们观察到,现成的CodeLlama变体无法遵循生成存储库范围代码编辑的详细说明,并且通常输出占位符响应或不相关的代码。为了更好地评估这些模型的能力,我们对70亿和130亿参数的CodeLlama-Python模型进行了监督微调。生成的模型是专门的存储库编辑器,可以在消费者硬件上运行并解决GitHub问题。
Training data. We follow our data collection procedure and collect 19,000 issue-PR pairs from an additional 37 popular Python package repositories. In contrast to Section 2.1, we do not require that pull requests contribute test changes. This allows us to create a much larger training set to use for supervised fine-tuning. To eliminate the risk of data contamination, the set of repositories in the training data is disjoint from those included in the evaluation benchmark.
训练数据。 我们遵循我们的数据收集程序,并从另外37个流行的Python包存储库中收集19,000个问题-PR对。与第2.1节相反,我们不要求拉取请求贡献测试更改。这使我们能够创建一个更大的训练集,用于监督微调。为了消除数据污染的风险,训练数据中的存储库集与评估基准中包含的存储库不相交。
Training details. Given the instructions, an issue text from GitHub and the relevant code files as the prompt, we finetune SWE-Llama to generate the patch that solved the given issue (the “gold patch”). For memory efficiency, we fine-tune only the weights of the attention sublayer using LoRA Hu et al. (2022), and exclude training sequences with more than 30,000 tokens, reducing the effective size of the training corpus to 10,000 instances. More details are provided in Appendix B.
训练细节。 给定指令,来自GitHub的问题文本和相关代码文件作为提示,我们微调SWE-Llama以生成解决给定问题的补丁(“金补丁”)。为了提高内存效率,我们仅微调注意力子层的权重,使用LoRA Hu等(2022),并排除具有超过30,000个标记的训练序列,将训练语料库的有效大小减少到10,000个实例。附录B提供了更多细节。
4 EXPERIMENTAL SETUP(实验设置)
In this section we explain how inputs are constructed to run SWE-bench evaluation. In addition, we review the models that we evaluate in this work.
在本节中,我们解释如何构建输入以运行SWE-bench评估。此外,我们回顾了我们在这项工作中评估的模型。
4.1 RETRIEVAL-BASED APPROACH(基于检索的方法)
SWE-bench instances provide an issue description and a codebase as input to the model. While issues descriptions are usually short (195 words on average as shown in Table 1), codebases consist of many more tokens (438K lines on average) than can typically be fit into an LMs context window. Then the question remains of exactly how to choose the relevant context to provide to the model?
SWE-bench实例将问题描述和代码库作为输入提供给模型。虽然问题描述通常很短(如表1所示,平均195个单词),但代码库包含的标记数量(平均438K行)通常超出了LMs上下文窗口的容量。那么问题仍然是如何选择要提供给模型的相关上下文?
To address this issue for our baselines, we simply use a generic retrieval system to select the files to insert as context. In particular, we evaluate models under two relevant context settings: 1) sparse retrieval and 2) an oracle retrieval.
为了解决这个问题,我们的基线简单地使用通用检索系统选择要插入为上下文的文件。特别是,我们在两个相关上下文设置下评估模型:1)稀疏检索和2)一个oracle检索。
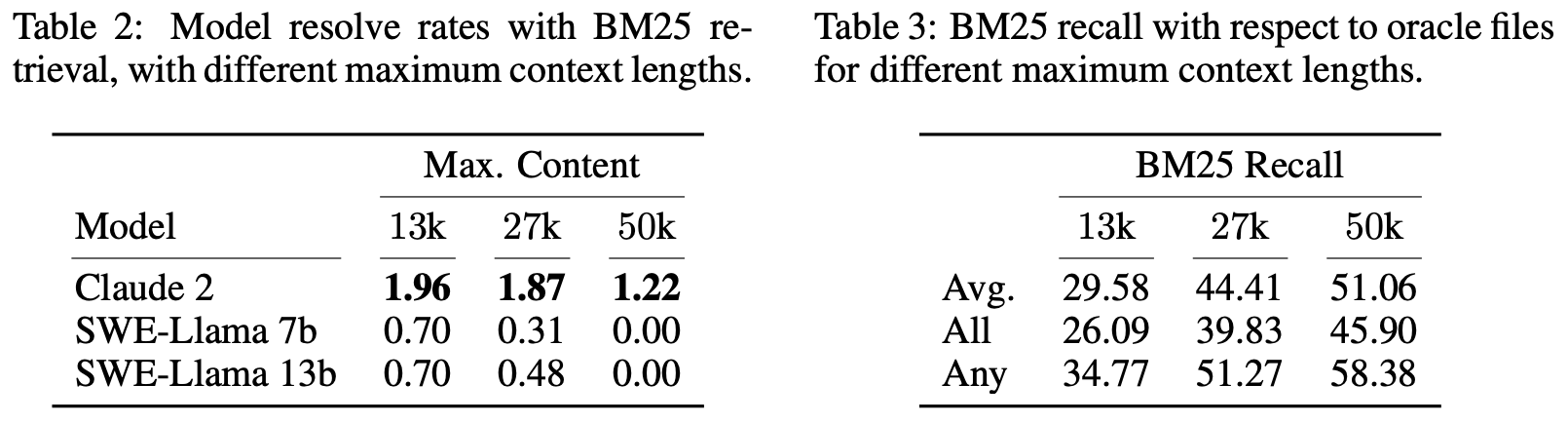
Sparse retrieval. Dense retrieval methods are ill-suited to our setting due to very long key and query lengths, and especially the unusual setting of retrieving code documents with natural language queries. Therefore, we choose to use BM25 retrieval (Robertson et al., 2009) to retrieve relevant files to provide as context for each task instance. We experiment with three different maximum context limits, and simply retrieve as many files as fits within the specified limit. We evaluate each model on all limits that fit within its context window and report the best performance. From observation, models perform best on the shortest context window, as shown in Table 2.
稀疏检索。 由于密集检索方法的密钥和查询长度非常长,尤其是使用自然语言查询检索代码文档的不寻常设置,因此我们选择使用BM25检索(Robertson等,2009)来检索相关文件,以提供为每个任务实例的上下文。我们尝试三种不同的最大上下文限制,并简单地检索尽可能多的文件,以适应指定的限制。我们在适合其上下文窗口的所有限制上评估每个模型,并报告最佳性能。从观察中,模型在最短的上下文窗口上表现最佳,如表2所示。
“Oracle” retrieval. For analysis purposes we also consider a setting where we “retrieve” the files edited by the reference patch that solved the issue on GitHub. This “oracle” setting is less realistic, since an engineer working on addressing an issue may not know a priori which files need to be modified. In addition, this setting is also not necessarily comprehensive since edited files alone may not include all the required context to understand exactly how software will behave when interacting with unseen parts of the code.
“Oracle”检索。 为了分析目的,我们还考虑了一个“检索”在GitHub上解决问题的参考补丁编辑的文件的设置。这个“oracle”设置不太现实,因为致力于解决问题的工程师可能事先不知道需要修改哪些文件。此外,这种设置也不一定全面,因为仅编辑的文件可能不包括理解软件在与代码的未见部分交互时将如何行为所需的所有上下文。
We compare the BM25 retrieval results with those of the “oracle” retrieval setting, as shown in Table 3. We observe that in approximately 40% of instances, BM25 retrieves a superset of the oracle files for the 27,000-token context limit. However, in almost half of the instances with the 27,000-token limit, it retrieves none of the files from the “oracle” context.
我们将BM25检索结果与“oracle”检索设置的结果进行比较,如表3所示。我们观察到,在大约40%的实例中,BM25检索了27,000个标记上下文限制的“oracle”文件的超集。然而,在几乎一半的27,000个标记限制的实例中,它没有从“oracle”上下文中检索任何文件。
表2:使用BM25检索的模型解决率,具有不同的最大上下文长度。
表3:不同最大上下文长度的BM25召回率相对于oracle文件。
4.2 INPUT FORMAT(输入格式)
Once the retrieved files are selected using one of the two methods above, we construct the input to the model consisting of task instructions, the issue text, retrieved files and documentation, and finally an example patch file and prompt for generating the patch file. Examples of instances and further details on this formulation are provided in Appendix D.
一旦使用上述两种方法之一选择了检索的文件,我们构建模型的输入,包括任务说明、问题文本、检索的文件和文档,最后是一个示例补丁文件和用于生成补丁文件的提示。实例的示例和进一步的细节在附录D中提供。
4.3 MODELS(模型)
Due to the need to process long sequence lengths, there are only a few models that are currently suitable for SWE-bench. Thus we evaluate ChatGPT-3.5 (gpt-3.5-turbo-16k-0613), GPT-4 (gpt-4-32k-0613), Claude 2, and SWE-Llama with their context limits shown in Table 4.
由于需要处理长序列长度,目前只有很少的模型适用于SWE-bench。因此,我们评估ChatGPT-3.5(gpt-3.5-turbo-16k-0613)、GPT-4(gpt-4-32k-0613)、Claude 2和SWE-Llama,其上下文限制如表4所示。
表4:我们比较不同上下文长度和“oracle”检索设置覆盖的比例。因此,具有较短上下文长度的模型本质上处于不利地位。请注意,标记长度的描述是相对非标准的度量(例如,Llama标记化的序列平均比为GPT-4标记化的等效序列长42%)。
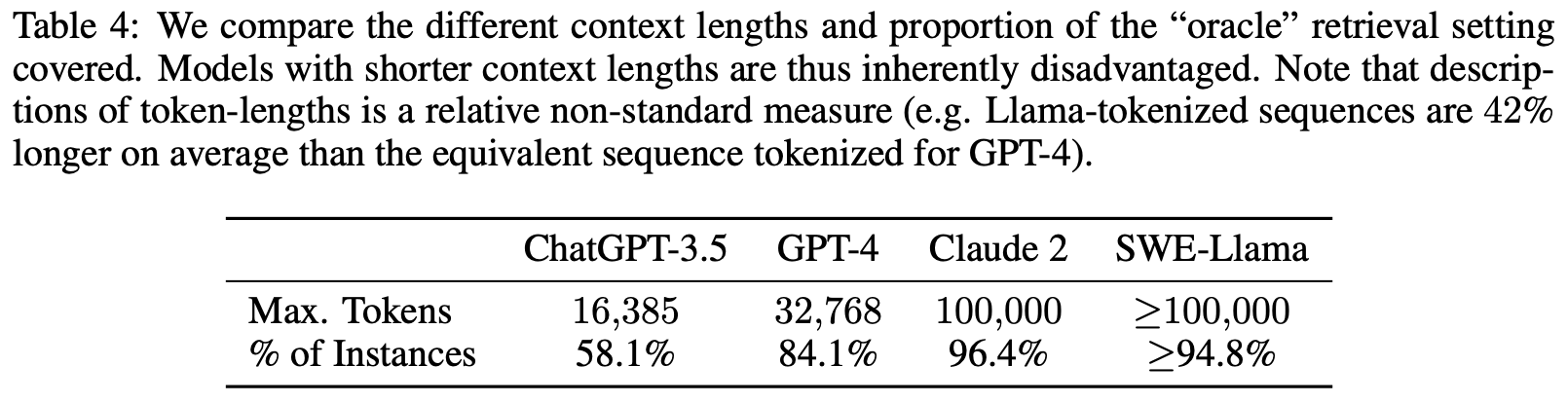
表5:我们使用第4节中描述的BM25检索器将模型相互比较。
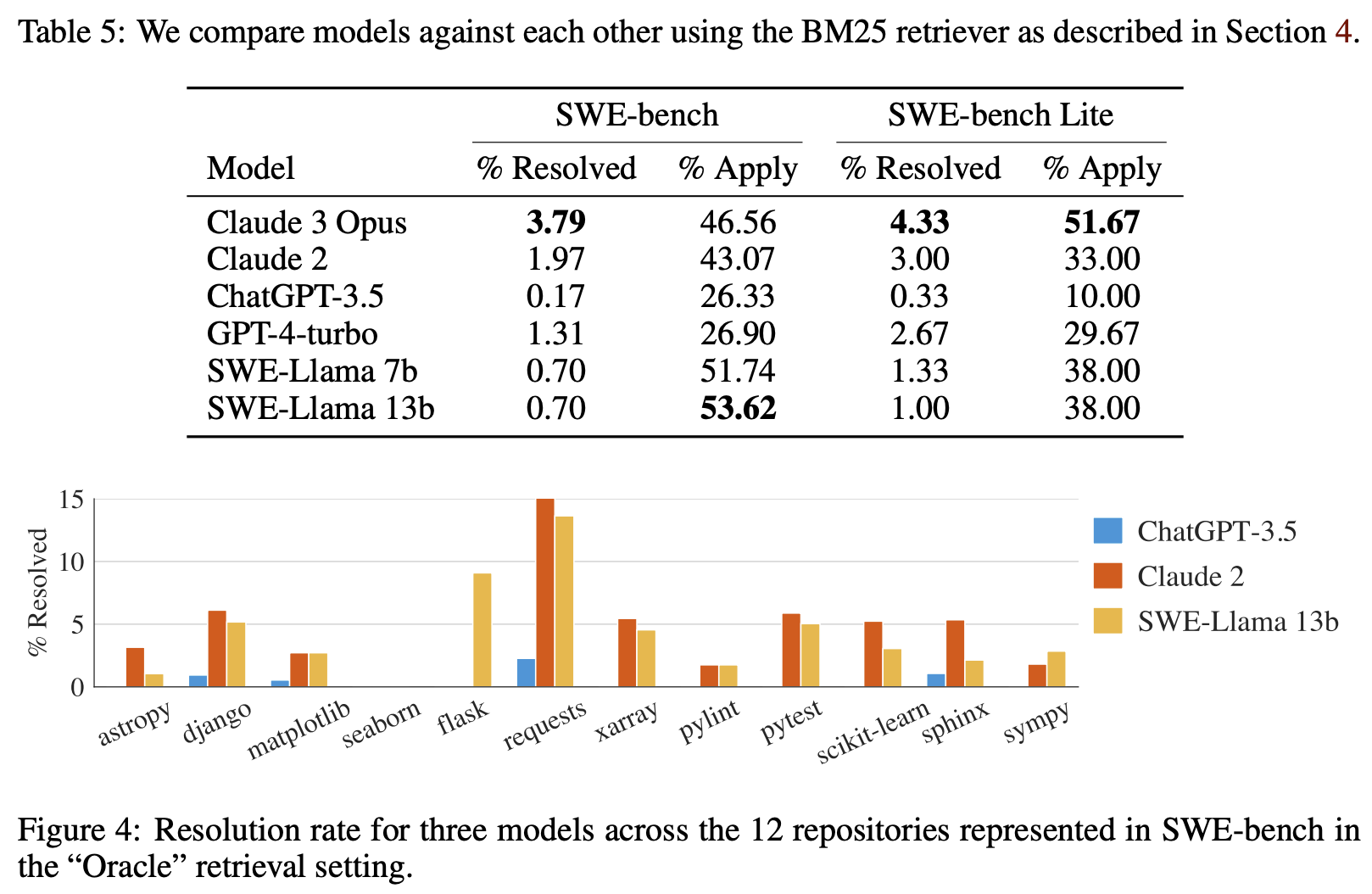
图4:在SWE-bench中代表的12个存储库中,三个模型在“Oracle”检索设置中的解决率。
5 RESULTS(结果)
We report results for models using different retrieval mechanisms and prompting styles, then provide some analysis and insight into model performance and difficulty. We summarize models’ performance using BM25 retrieval in Table 5. Across the board, models struggle significantly to resolve issues. The best performing model, Claude 2, is only able to resolve 1.96% of the issues.
我们报告了使用不同检索机制和提示样式的模型的结果,然后提供了一些关于模型性能和困难的分析和见解。我们在表5中使用BM25检索总结了模型的性能。总体而言,模型在解决问题方面遇到了很大困难。表现最好的模型Claude 2只能解决1.96%的问题。
To analyze the importance of the retriever to the overall system results, we present the “oracle” retrieval results in Appendix Table 18. There, Claude 2 is able to resolve 4.8% of issues using the “oracle” retriever. We further analyze the importance of context in the discussion below.
为了分析检索器对整个系统结果的重要性,我们在附录表18中提供了“oracle”检索结果。在那里,Claude 2能够使用“oracle”检索器解决4.8%的问题。我们在下面的讨论中进一步分析上下文的重要性。
Difficulty differs across repositories. When breaking performance down by repository, all models trend similarly across different repositories as show in Figure 4. Despite this, the issues resolved by each model do not necessarily overlap extensively. For example, in the “oracle” setting Claude 2 and SWE-Llama 13b perform comparably, with each model resolving 110 and 91 instances respectively. Yet of these instances, Claude 2 only solves 42% of the instances solved by SWE-Llama.
难度在存储库之间有所不同。 当按存储库分解性能时,所有模型在不同存储库中的趋势都相似,如图4所示。尽管如此,每个模型解决的问题并不一定有很大的重叠。例如,在“oracle”设置中,Claude 2和SWE-Llama 13b的表现相当,每个模型分别解决了110和91个实例。然而,在这些实例中,Claude 2只解决了SWE-Llama解决的实例的42%。
This may also be related to the presence of images in issues, which can be encoded into the issue markdown with embedded image links (i.e. ![image][https://…]). Some repositories naturally feature more instances with images; for example 32% of matplotlib and 10% of seaborn instances contain embedded images in their issue text compared to just 2% of all instances. Solving these instances may require multi-modal LMs or some kind of external tool use to process images.
这也可能与问题中存在图像有关,这些图像可以编码到带有嵌入式图像链接的问题markdown中(即![image][https://…])。一些存储库自然包含更多带有图像的实例;例如,与所有实例的仅2%相比,32%的matplotlib和10%的seaborn实例在其问题文本中包含嵌入式图像。解决这些实例可能需要多模式LMs或某种外部工具使用来处理图像。
Difficulty correlates with context length. Chat models may be pre-trained on long sequences of code but are typically asked to generate shorter coder snippets with limited context provided to frame the question. As shown in Figure 5, we see that as total context length increases, Claude 2’s performance drops considerably; behavior that is also observed in other models. In our evaluation settings, models see a lot of code that may not be directly related to solving the issue at hand, and they seem to frequently struggle with localizing problematic code needing to be updated. This result corroborates other studies showing that models become distracted by additional context and may be sensitive to the relative location of target sequences (Liu et al., 2023b). Even when increasing the maximum context size for BM25 would increase recall with respect to the oracle files, performance drops, as shown in Table 2, as models are simply ineffective at localizing problematic code.
困难与上下文长度相关。 Chat模型可能在长代码序列上进行预训练,但通常要求生成较短的编码器片段,并提供有限的上下文来构建问题。如图5所示,我们看到随着总上下文长度的增加,Claude 2的性能显著下降;这种行为也观察到其他模型中。在我们的评估设置中,模型看到了许多可能与解决手头问题无关的代码,他们似乎经常难以定位需要更新的有问题的代码。这个结果证实了其他研究结果,表明模型会被额外的上下文分散注意力,并且可能对目标序列的相对位置敏感(Liu等,2023b)。即使增加BM25的最大上下文大小会增加相对于oracle文件的召回率,如表2所示,性能也会下降,因为模型根本无法定位有问题的代码。
图5:我们比较Claude 2在按总输入长度和仅按问题长度划分的任务上的性能。
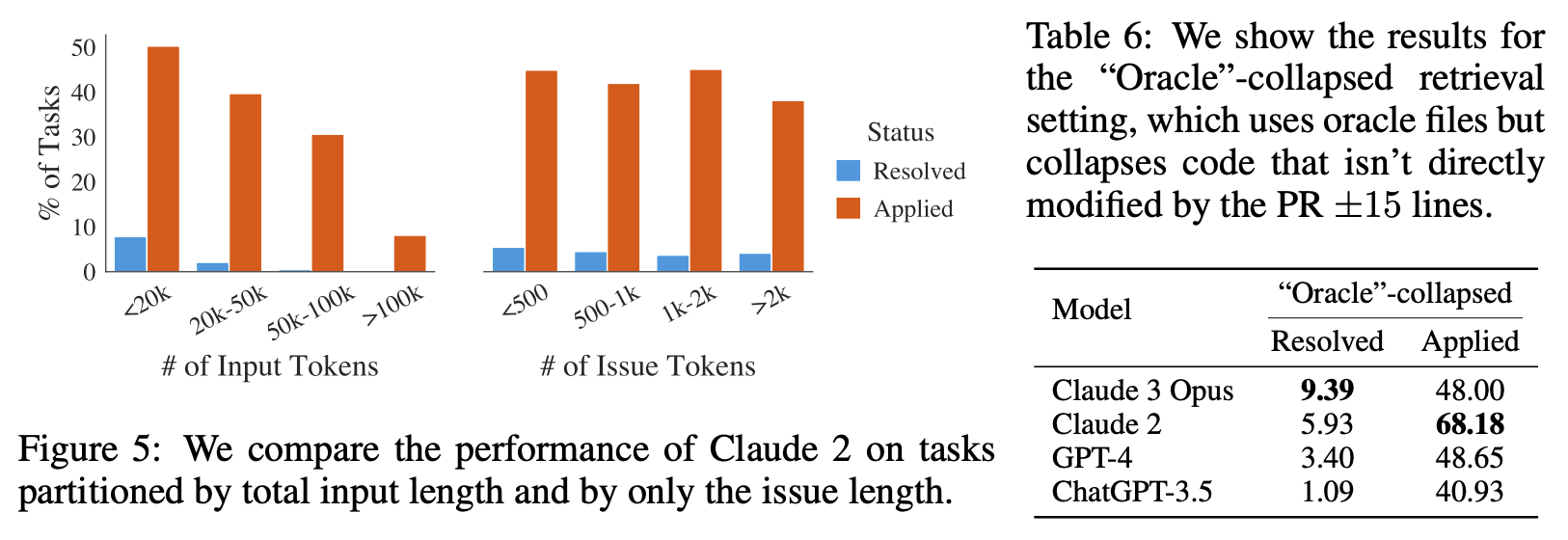
表6:我们展示了“Oracle”-collapsed检索设置的结果,该设置使用oracle文件,但折叠了未直接由PR ±15行修改的代码。
Further investigating this, we provide an input ablation on the “oracle” retrieval context, “oracle”- collapsed, where retrieved files are collapsed entirely, except for the lines actually edited by the true pull request (with ±15 lines of buffer) shown in Table 6. In this setting, we see increases in performance, with GPT-4 jumping from 1.3% to 3.4% and Claude 2 from 4.8% to 5.9%.
进一步调查这一点,我们在“oracle”检索上下文上提供了一个输入消融,“oracle”-collapsed,其中检索的文件完全折叠,除了真实拉取请求实际编辑的行(带有±15行的缓冲区),如表6所示。在这种设置中,我们看到性能有所提高,GPT-4从1.3%跳升到3.4%,Claude 2从4.8%跳升到5.9%。
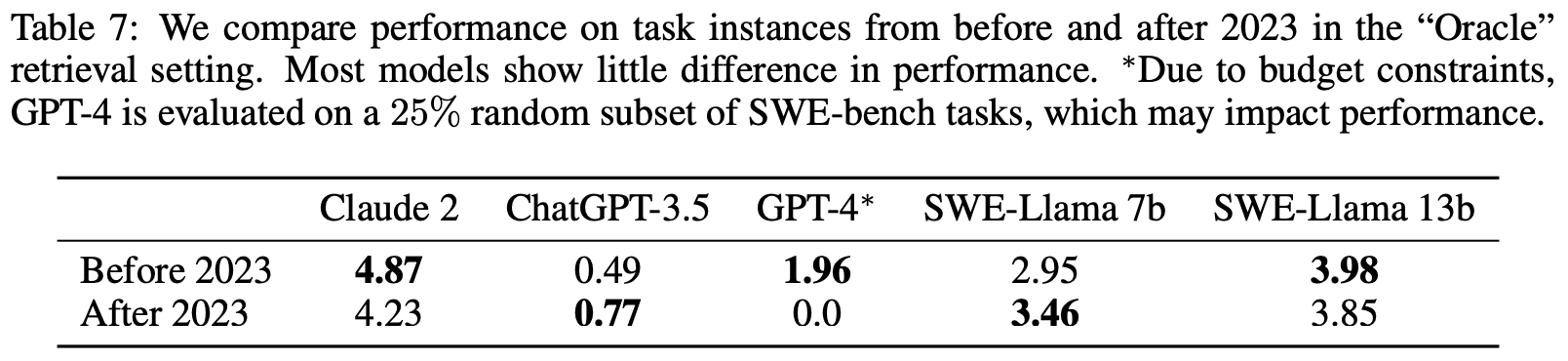
Difficulty does not correlate with issue resolution date. In Table 7 we show model results in the “oracle” retrieval setting, partitioned by date, for PRs created before or after 2023. We find that for most models there’s little difference in performance before or after this date, with the exception of GPT-4. We consider this result to be largely promising as it suggests that despite models having been exposed to some version of an repository’s codebase, they are unlikely to “cheat” to address issues simply by generating a more recent version of the repository.
困难与问题解决日期无关。 在表7中,我们展示了在“oracle”检索设置中的模型结果,按日期划分为2023年之前或之后创建的PR。我们发现对于大多数模型,在此日期之前或之后,性能几乎没有差异,除了GPT-4。我们认为这个结果在很大程度上是令人鼓舞的,因为它表明尽管模型已经暴露于存储库代码库的某个版本中,但它们不太可能通过生成存储库的更新版本来“作弊”来解决问题。
表7:我们在“Oracle”检索设置中比较了2023年之前和之后的任务实例的性能。大多数模型的性能几乎没有差异。∗由于预算限制,GPT-4在SWE-bench任务的25%随机子集上进行评估,这可能会影响性能。
Finetuned models are sensitive to context distribution shifts. The finetuned models SWE-Llama 7b and 13b perform surprisingly poorly with BM25 retrieved context. As these models were finetuned using the “oracle” retrieval as context, we suspect this shift in context makes it difficult for the model to perform reliably. For instance, SWE-Llama was trained to edit every file included as context whereas in the BM25 setting many files provided in context are not expected to be changed.
微调模型对上下文分布变化敏感。 微调的模型SWE-Llama 7b和13b在BM25检索的上下文中表现出奇怪的差。由于这些模型是使用“oracle”检索作为上下文进行微调的,我们怀疑上下文的这种变化使模型难以可靠地执行。例如,SWE-Llama被训练为编辑包含为上下文的每个文件,而在BM25设置中,提供的许多文件不太可能被更改。
Generating patches is easier than generating whole files. Models are often trained using standard code files and likely rarely see patch files. We generally formulate our task to have models generate patch files as opposed to recreating the entire file with their proposed change, since patch files will usually be a much more efficient representation of a file change. As shown in Table 5, we observe that models still struggle with generating well-formatted patch files. So we experiment with asking models to instead regenerate entire files with their proposed changes to resolve the issue. In this setting, we find that models generally perform worse at this task than when generating patch files; for instance, Claude 2 scores at 2.2% compared to 4.8% in the main table for “oracle” retrieval. Even when controlling for instance length, generating on the shorter half of the task instances by input tokens yields 3.9% compared to 7.8% for generating patches with Claude 2.
生成补丁比生成整个文件更容易。 模型通常使用标准代码文件进行训练,可能很少看到补丁文件。我们通常制定任务,让模型生成补丁文件,而不是用他们提出的更改重新创建整个文件,因为补丁文件通常是文件更改的更有效表示。如表5所示,我们观察到模型仍然难以生成格式良好的补丁文件。因此,我们尝试要求模型改为使用其提出的更改重新生成整个文件以解决问题。在这种设置中,我们发现模型通常在这项任务上的表现不如生成补丁文件;例如,与“oracle”检索的主表中的4.8%相比,Claude 2的得分为2.2%。即使控制实例长度,通过输入标记生成任务实例的较短一半,与Claude 2生成补丁相比,得分为3.9%,而后者为7.8%。
Language models tend to generate shorter, simpler edits. Model generated patch files tend to add and remove fewer lines than their respective gold patch. As shown in Table 8, compared to an average gold patch, model generated patch files that apply correctly are less than half the total length (74.5 versus 30.1 lines) of gold edit patch files, and rarely edit more than a single file.
语言模型倾向于生成更短、更简单的编辑。模型生成的补丁文件通常添加和删除的行数比其相应的金补丁少。如表8所示,与平均金补丁相比,应用正确的模型生成的补丁文件的总长度不到金编辑补丁文件的一半(74.5与30.1行),并且很少编辑多个文件。
5.1 A QUALITATIVE ANALYSIS OF SWE-LLAMA GENERATIONS(SWE-LLAMA生成的定性分析)
We select 11 generations from SWE-Llama and Claude 2 to better understand the quality of the task and generated patches under the “oracle” retrieval setting. Here we discuss an example from SWELlama and our overall findings, with in-depth analyses for other examples shown in Appendix F.
我们选择了11个SWE-Llama和Claude 2的生成,以更好地了解在“oracle”检索设置下任务和生成的补丁的质量。在这里,我们讨论了SWE-Llama的一个示例和我们的总体发现,其他示例的深入分析显示在附录F中。
表8:在“oracle”检索设置中,成功应用的补丁的模型生成补丁的平均编辑。对于每个模型特定的任务实例,我们计算了相同的统计数据,以跨每个模型的相应金补丁进行宏平均。Avg Gold显示了每个模型的相应金补丁的统计数据。All Gold显示了所有金补丁的统计数据,不考虑模型性能。
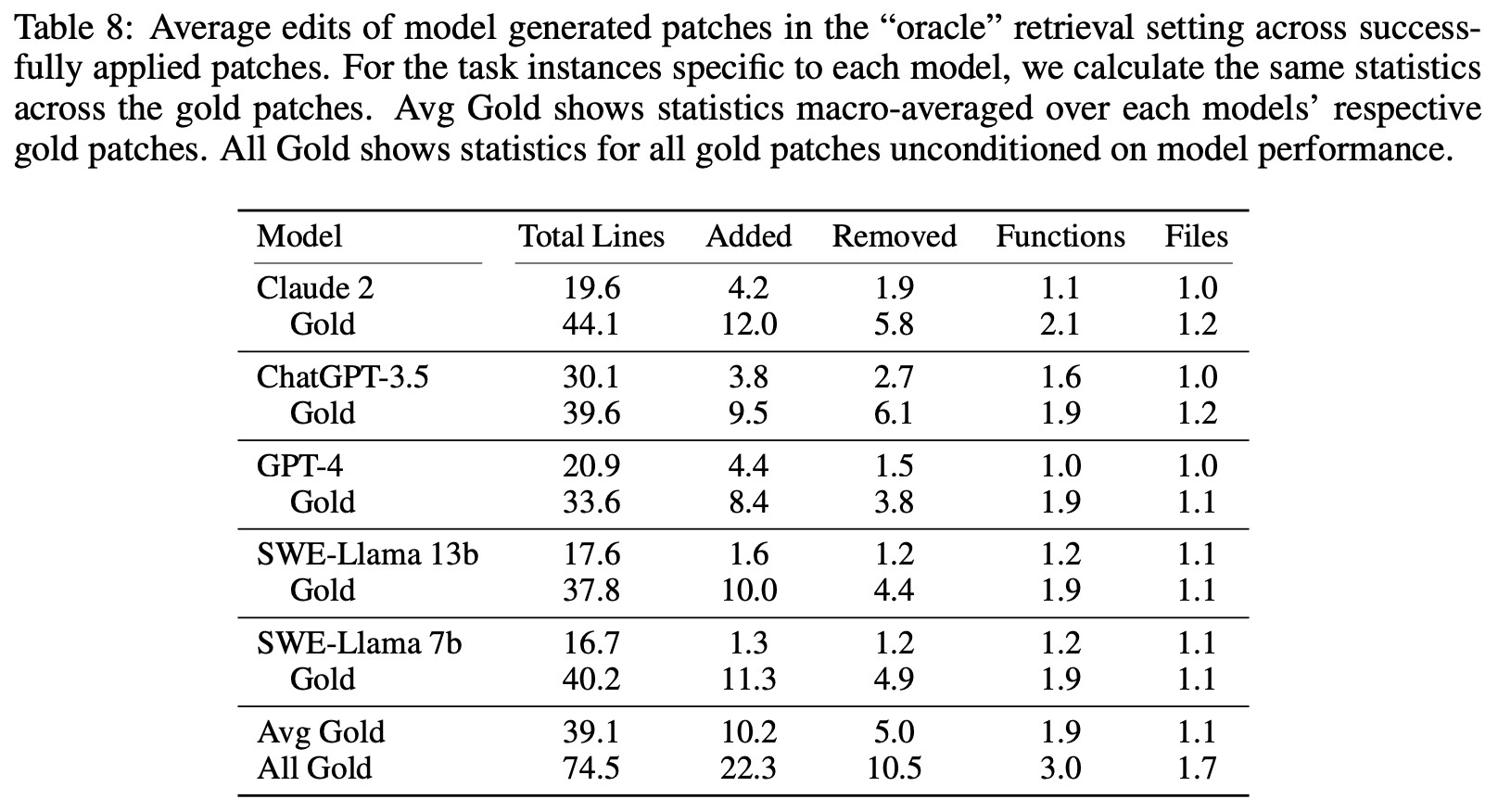

图6:我们展示了一个格式化的任务实例、一个模型预测和测试框架日志的示例。在补丁中,红色高亮显示删除。绿色高亮显示添加。
- Model Input(模型输入)
- Instructions(说明)
- 您将获得一个部分代码库和一个解释要解决的问题的问题说明。
- Issue(问题)
- napoleon_use_param应该影响“其他参数”部分 主题:napoleon_use_param应该影响“其他参数”部分
- Problem(问题)
- 目前,napoleon总是将“其他参数”部分呈现为如果napoleon_use_param为False,请参见源代码
- Code(代码)
- README.rst
- sphinx/ext/napoleon/docstring.py
- Additional Instructions(附加说明)
- Instructions(说明)
We’ll consider the task instance sphinx-doc sphinx-8713 from the Sphinx documentation generator, shown in Figure 6. The issue states that the napoleon extension of Sphinx is
not properly formatting the documentation keyword “Other Parameters” when the config setting
napoleon.use_param is set to True. The issue text further provides a detailed code snippet of
where the problematic source code is suspected to be, as well as some code examples for reproducing the error and additional information related to package versions. For this particular instance, the
model did not resolve the task, failing to pass some of the tests resolved by the gold solution.
In the “oracle” retrieval setting, the model input provides this issue text along with some instructions, the full contents of files edited by the gold patch, and an example of the diff format we
expect the answer to be in. The total model input consists of 1,558 lines of context or 20,882 tokens. When comparing the gold patch and the model’s patch, we find an obvious mistake. While
the model edits the correct function, _parse_other_parameters_section at line 684 in
sphinx/ext/napoleon/docstring.py , it changes the function to behave as if napoleon.
use_param were always True instead of checking the config setting first and copying what the
_parse_parameters_section does, like the gold patch. In the tests, test_parameters_with_class_reference directly compares the documentation produced using a config where napoleon_use_param is set to False, which catches the model’s error immediately.
我们将考虑Sphinx文档生成器中的任务实例sphinx-doc sphinx-8713,如图6所示。问题说明称,当配置设置napoleon.use_param设置为True时,Sphinx的napoleon扩展未正确格式化文档关键字“其他参数”。问题文本进一步提供了一个详细的代码片段,其中怀疑有问题的源代码所在,以及一些用于重现错误的代码示例和与软件包版本相关的附加信息。对于这个特定实例,模型没有解决任务,未能通过金解决方案解决的一些测试。在“oracle”检索设置中,模型输入提供了这个问题文本以及一些说明,金补丁编辑的文件的全部内容,以及我们期望答案的diff格式的示例。总模型输入包括1,558行上下文或20,882个标记。当比较金补丁和模型的补丁时,我们发现了一个明显的错误。虽然模型编辑了正确的函数,即sphinx/ext/napoleon/docstring.py中第684行的_parse_other_parameters_section函数,但它将函数更改为始终将napoleon.use_param设置为True,而不是首先检查配置设置,然后复制_parse_parameters_section的行为,就像金补丁一样。在测试中,test_parameters_with_class_reference直接比较了使用配置的文档,其中napoleon_use_param设置为False,这立即捕捉到了模型的错误。
Comparing results across all the examples we consider, we notice a few prominent trends in behavior. Models tend to write primitive Python code and do not leverage existing third-party libraries or the rest of the codebase for their solutions. Models’ generations also reflect a “greedy” approach of solving the problem exactly, with little regard for code style or logical constraints that might be reflected by the codebase (i.e. using relative instead of absolute imports). In contrast, we observe that many gold patches will make structural improvements that cover a much larger scope of the codebase; these edits not only resolve the issue, but also anticipate and solve potential future issues.
在我们考虑的所有示例中比较结果时,我们注意到行为中的一些显着趋势。模型倾向于编写基本的Python代码,而不利用现有的第三方库或代码库的其余部分来解决问题。模型的生成也反映了一种“贪婪”的解决问题的方法,几乎不考虑代码风格或可能由代码库反映的逻辑约束(即使用相对而不是绝对导入)。相比之下,我们观察到许多金补丁将进行结构性改进,涵盖代码库的更大范围;这些编辑不仅解决了问题,而且预见并解决了潜在的未来问题。
6 RELATED WORK(相关工作)
Evaluation of LMs. Several recent works for evaluating LMs have either proposed a collection of mutually distinct tasks spanning across multiple domains (Hendrycks et al., 2021; Liang et al., 2022; Srivastava et al., 2023) or turned to the web as an interactive setting featuring tasks that require multiple steps to solve (Yao et al., 2022; Zhou et al., 2023; Deng et al., 2023; Liu et al., 2023d). There are several drawbacks with such a “potpourri” style setup. First, each task tends to narrowly focus on one or a few skills, resulting in challenges that are typically too simple, pigeonhole the model into a reduced role, and do not provide models with the bandwidth to exercise their versatility or potentially demonstrate new abilities (Srivastava et al., 2023). Consequently, a model’s performance on such task conglomerations may not yield actionable, deep insights regarding its capabilities and how to improve them (Schlangen, 2019; Mart´ınez-Plumed et al., 2021; Bowman & Dahl, 2021). SWEbench addresses these shortcomings, as our work demonstrates that it is significantly challenging, presents a wide range of possibilities for improving LMs to solve this task, and is easy to refresh over time with new task instances, each of which introduce novel, nuanced, and practical challenges.
LMs的评估。 最近的一些工作要么提出了一个跨多个领域的相互独立任务集合(Hendrycks等,2021;Liang等,2022;Srivastava等,2023),要么将网络作为一个交互式设置,其中包含需要多个步骤来解决的任务(Yao等,2022;Zhou等,2023;Deng等,2023;Liu等,2023d)。这种“大杂烩”风格的设置有几个缺点。首先,每个任务往往只专注于一个或几个技能,导致挑战通常过于简单,将模型局限于一个较小的角色,并且不提供模型以发挥其多功能性或潜在展示新能力的带宽(Srivastava等,2023)。因此,模型在这种任务集合上的表现可能不会产生关于其能力及如何改进其能力的可操作、深入的见解(Schlangen,2019;Mart´ınez-Plumed等,2021;Bowman和Dahl,2021)。SWE-bench解决了这些缺点,因为我们的工作表明,这是一个极具挑战性的任务,为改进LMs以解决这一任务提供了广泛的可能性,并且易于随时间刷新,引入了新的任务实例,每个实例都引入了新颖、微妙和实际的挑战。
Code Generation Benchmarks. HumanEval (Chen et al., 2021) is the current standard in a longstanding pursuit of synthesizing code from natural language descriptions (Yu et al., 2018; Austin et al., 2021; Hendrycks et al., 2021; Li et al., 2022a; Zan et al., 2023). In the past year, subsequent benchmarks have sought to augment HumanEval with extensions to different languages (Cassano et al., 2022; Athiwaratkun et al., 2023; Orlanski et al., 2023), variations in edit scope (Yu et al., 2023; Du et al., 2023), similar but novel code completion tasks (Muennighoff et al., 2023), and more testing (Liu et al., 2023a). Simultaneously, separate works have sought to introduce new coding paradigms (Yin et al., 2022; Yang et al., 2023) or design library-specific problems (Lai et al., 2022; Zan et al., 2022). Instead of partitioning problems into siloed datasets and curtailing them for simplicity’s sake, SWE-bench’s collection procedure transforms the source code with minimal post-processing, preserving a much broader set of challenges grounded in real-world software engineering beyond closed form completion, such as patch generation, reasoning over long contexts, navigating a codebase directory, and capturing dependency-based relationships across modules.
代码生成基准。 HumanEval(Chen等,2021)是长期以来从自然语言描述中合成代码的追求的当前标准(Yu等,2018;Austin等,2021;Hendrycks等,2021;Li等,2022a;Zan等,2023)。在过去的一年中,随后的基准试图通过扩展到不同的语言(Cassano等,2022;Athiwaratkun等,2023;Orlanski等,2023)、编辑范围的变化(Yu等,2023;Du等,2023)、类似但新颖的代码完成任务(Muennighoff等,2023)以及更多的测试(Liu等,2023a)来增强HumanEval。同时,独立的工作试图引入新的编码范式(Yin等,2022;Yang等,2023)或设计特定于库的问题(Lai等,2022;Zan等,2022)。SWE-bench的收集过程将源代码转换为最小的后处理,保留了一个更广泛的挑战集,这些挑战基于现实世界的软件工程,超越了封闭形式的完成,例如补丁生成、长上下文推理、导航代码库目录以及捕获跨模块的基于依赖的关系。
ML for Software Engineering. To overcome traditional program analysis techniques that may not scale or incorporate natural language, one direction of current software engineering research is to use neural networks, including LMs, to automate real-world software development processes (Maniatis et al., 2023; Zheng et al., 2023; Hou et al., 2023). Use cases include automating commit generation (Jung, 2021; Liu et al., 2023c), PR review (Yang et al., 2016; Li et al., 2022b; Tufano et al., 2021), bug localization (Kim et al., 2019; Chakraborty et al., 2018), testing (Kang et al., 2023; Xia et al., 2023; Wang et al., 2023), and program repair (Gupta et al., 2017; Allamanis et al., 2017; Monperrus, 2018; Jiang et al., 2018; Goues et al., 2019; Gao et al., 2022; Dinh et al., 2023; Motwani & Brun, 2023). Most relevant to SWE-bench are works that have sought to apply LMs towards automated program repair (Xia & Zhang, 2022; 2023; Fan et al., 2023; Sobania et al., 2023), guiding code editing with commits (Chakraborty & Ray, 2021; Zhang et al., 2022; Fakhoury et al., 2023). However, none of the existing datasets (Just et al., 2014; Karampatsis & Sutton, 2019) present code context at the scale of SWE-bench. Moreover, SWE-bench can be easily extended to new programming languages and repositories, and it provides a significantly more realistic and challenging arena to carry out experiments towards augmenting LMs with software engineering tools and practices.
软件工程中的ML。 为了克服传统的程序分析技术可能无法扩展或不包含自然语言的问题,当前软件工程研究的一个方向是使用神经网络,包括LMs,来自动化现实世界的软件开发过程(Maniatis等,2023;Zheng等,2023;Hou等,2023)。用例包括自动化提交生成(Jung,2021;Liu等,2023c)、PR审查(Yang等,2016;Li等,2022b;Tufano等,2021)、错误定位(Kim等,2019;Chakraborty等,2018)、测试(Kang等,2023;Xia等,2023;Wang等,2023)和程序修复(Gupta等,2017;Allamanis等,2017;Monperrus,2018;Jiang等,2018;Goues等,2019;Gao等,2022;Dinh等,2023;Motwani和Brun,2023)。与SWE-bench最相关的是那些试图将LMs应用于自动化程序修复(Xia和Zhang,2022;2023;Fan等,2023;Sobania等,2023)、用提交指导代码编辑(Chakraborty和Ray,2021;Zhang等,2022;Fakhoury等,2023)的工作。然而,现有的数据集(Just等,2014;Karampatsis和Sutton,2019)没有一个在SWE-bench的规模上提供代码上下文。此外,SWE-bench可以很容易地扩展到新的编程语言和存储库,并且它提供了一个更加现实和具有挑战性的竞技场,用于进行实验,以增强LMs与软件工程工具和实践。
7 DISCUSSION(讨论)
Limitations and future directions. SWE-bench task instances are all in Python; we hope to apply SWE-bench’s task instance collection procedure to expand its coverage to more programming languages and domains. Second, our experiments aim to establish a baseline of the simplest and most straight-forward approaches for this task; we do not intend to constrain future methodologies to the same type of approach and encourage future work to investigate different methods (e.g., agent-based approaches, tool augmented LMs).
局限性和未来方向。 SWE-bench任务实例都是在Python中;我们希望将SWE-bench的任务实例收集过程应用于更多的编程语言和领域。其次,我们的实验旨在建立这项任务的最简单和最直接的方法的基线;我们不打算将未来的方法限制在相同类型的方法上,并鼓励未来的工作研究不同的方法(例如,基于代理的方法、工具增强的LMs)。
Lastly, while this work evaluates models using execution-based code testing, relying solely on this method is insufficient to guarantee reliable performance of model generations, as we find automated code generations from LMs can frequently be less comprehensive, efficient, or readable compared to human-written solutions.
最后,虽然这项工作使用基于执行的代码测试评估模型,但仅依靠这种方法是不足以保证模型生成的可靠性的,因为我们发现与人类编写的解决方案相比,LMs的自动代码生成通常更少、更有效或更易读。
Conclusion. The complexity of real-world software development processes extends far beyond just code completion. By drawing on the open-source collaborative pipeline, SWE-bench creates a faithful mirror of real world coding environments. This more realistic environment encourages creative solutions that can have immediate applicability in open-source software development. We hope that this benchmark and our other contributions can serve as valuable assets in the future development of LMs that are more practical, intelligent, and autonomous.
结论。 现实世界软件开发过程的复杂性远不止于代码完成。通过利用开源协作管道,SWE-bench创建了一个真实世界编码环境的忠实镜像。这种更现实的环境鼓励创造性的解决方案,这些解决方案可以在开源软件开发中立即应用。我们希望这个基准和我们的其他贡献可以成为未来LMs更加实用、智能和自主的宝贵资产。
8 ETHICS STATEMENT(伦理声明)
SWE-bench is collected entirely from public repositories with licenses that permit software usage that our contributions are in accordance with. Details of the licenses are included in Table 12. During the collection or evaluation processes, we do not collect information about GitHub users, and the SWE-bench task instances do not use GitHub data beyond what is offered via the public API and website. Our contributions do not involve any human subject participation; we do not perform crowdsourcing or recruit human task workers for any part of SWE-bench, including its collection and evaluation procedures along with the experiments. SWE-bench’s filtering criteria for GitHub repositories based on popularity does not implicitly or explicitly rely on any discriminative or biased heuristics for repository selection. For the dataset release, we plan to open source the SWE-bench task instances, the collection and evaluation infrastructure, the experimental results, the training data used for fine-tuning SWE-Llama models, and the SWE-Llama model weights. Following best practice precedents, we will also put forth ample documentation to describe each component and its use, and we will also put in place convenient communication channels for soliciting feedback to improve SWE-bench. SWE-bench does not put forth any immediately harmful insights. We briefly discuss the potential impact of SWE-bench’s usage in Section E.
SWE-bench完全是从允许我们的贡献的软件使用的许可证的公共存储库中收集的。许可证的详细信息包含在表12中。在收集或评估过程中,我们不收集有关GitHub用户的信息,SWE-bench任务实例不使用GitHub数据,除了通过公共API和网站提供的数据。我们的贡献不涉及任何人类主体参与;我们不进行众包或招募人类任务工作者参与SWE-bench的任何部分,包括其收集和评估过程以及实验。SWE-bench基于流行度的GitHub存储库的过滤标准不会隐式或显式地依赖于任何歧视性或有偏见的启发式方法来选择存储库。对于数据集的发布,我们计划开源SWE-bench任务实例、收集和评估基础设施、实验结果、用于微调SWE-Llama模型的训练数据以及SWE-Llama模型权重。遵循最佳实践先例,我们还将提供充分的文档,以描述每个组件及其用途,并建立方便的沟通渠道,以征求反馈,以改进SWE-bench。SWE-bench没有提出任何立即有害的见解。我们在E节中简要讨论了SWE-bench使用的潜在影响。
9 REPRODUCIBILITY STATEMENT(可重复性声明)
For our submission, we have uploaded the entirety of the source code as a zipped file that has been properly anonymized. We have organized the codebase such that separate directories correspond to different contributions within the main paper (i.e. dataset collection, evaluation, open source model inference, SWE-Llama training, etc.). The source code contains inline documentation that details purpose and usage of different parts of the codebase. In addition, we also include the full set of 2294 SWE-bench task instances that contains all the components discussed in the main paper. Beyond the documentation in the source code, we include thorough technical details for the collection pipeline and evaluation procedures in Section A.2 and Section A.4 that complements the original details in Section 2 of the main paper. These sections fully cover the logic presented in the code and can be helpful for understanding it. Moving forward, as discussed in the ethics statement, we plan to more formally release SWE-bench to the public as an open source repository with thorough details that describes the benchmark, outlines the code, and details its usage. A major component of SWEbench is the collection framework, which will be part of the open sourced code. Because of its easily maintainable design, as discussed in the main paper, our hope and belief is that SWE-bench should be highly reproducible.
对于我们的提交,我们已经上传了整个源代码作为一个经过适当匿名化的压缩文件。我们已经组织了代码库,使不同的目录对应于主要论文中的不同贡献(即数据集收集、评估、开源模型推断、SWE-Llama训练等)。源代码包含内联文档,详细说明了代码库不同部分的目的和用法。此外,我们还包括了包含主要论文中讨论的所有组件的2294个SWE-bench任务实例的完整集合。除了源代码中的文档,我们还在附录A.2和A.4中提供了有关收集管道和评估程序的详细技术细节,这些细节补充了主要论文第2节中的原始细节。这些部分完全涵盖了代码中的逻辑,并有助于理解它。展望未来,正如在伦理声明中讨论的那样,我们计划更正式地向公众发布SWE-bench作为一个开源存储库,其中详细描述了基准,概述了代码,并详细说明了其用法。SWE-bench的一个重要组成部分是收集框架,它将成为开源代码的一部分。正如在主要论文中讨论的那样,由于其易于维护的设计,我们希望并相信SWE-bench应该是高度可重现的。
APPENDIX(附录)
In the appendix, we provide more thorough details regarding the dataset construction process, evaluation pipeline, and characterization of the SWE-bench benchmark.
在附录中,我们提供了有关数据集构建过程、评估管道和SWE-bench基准的特征化的更详细的细节。
A BENCHMARK DETAILS(基准细节)
This section complements Section 2 with a more technical and fine-grained summary of the data collection, execution-based validation, and evaluation procedures, along with a fuller characterization of the task instances.
本节通过更多技术和细粒度的数据收集、基于执行的验证和评估程序的总结,以及对任务实例的更全面的特征化,补充了第2节。
A.1 HIGH LEVEL OVERVIEW(高级概述)
Pull request scraping. From a list of the top 5,000 most downloaded PyPI libraries during August 2023, we select the top 100 packages, identify each library’s corresponding open-source GitHub repository, verify which packages have licenses allowing for free software use, and collect all PRs for these repositories via the GitHub developer API. We elect to source problems from well-trafficked repositories because widespread use usually suggests that the repository has extensive documentation, structured open-source development guidelines, and working, well-formatted code.
Pull request抓取。 从2023年8月下载量最高的5,000个PyPI库列表中,我们选择了前100个包,确定了每个库对应的开源GitHub存储库,验证了哪些包具有允许免费软件使用的许可证,并通过GitHub开发人员API收集了这些存储库的所有PR。我们选择从流量大的存储库中获取问题,因为广泛使用通常意味着存储库具有广泛的文档、结构化的开源开发指南和工作的、格式良好的代码。
Task instance construction. We construct candidate task instances from PRs that satisfy three conditions. First, the PR’s status must be Merged. A Merged status indicates that the PR’s associated code changes were accepted and incorporated into its parent repository. Second, the PR resolves one or more issues in its repository. An issue is defined according to its canonical usage in GitHub as a digital ticket for tracking bugs, enhancements, or any general development goals for a software project. We scan a PR’s title, body, and commit messages for linked issues (i.e. “fixes #24”). Third, the PR must introduce one or more new tests. A new test is counted when a PR’s code changes edits a file path containing a testing-related keyword (e.g. “test”, “testing”).
任务实例构建。 我们从满足三个条件的PR中构建候选任务实例。首先,PR的状态必须是Merged。合并的状态表示PR的相关代码更改已被接受并合并到其父存储库中。其次,PR解决了存储库中的一个或多个问题。问题的定义根据其在GitHub中的规范用法,作为用于跟踪软件项目中的错误、增强功能或任何一般开发目标的数字票证。我们扫描PR的标题、正文和提交消息,以查找链接的问题(例如“fixes #24”)。第三,PR必须引入一个或多个新测试。当PR的代码更改编辑包含与测试相关关键字的文件路径(例如“test”、“testing”)时,将计算一个新测试。
A PR that satisfies these criteria is then converted into a candidate task instance such as the example in Figure 7. The codebase C is identified by the repository’s owner/name moniker and the pull request’s base commit. Recovering the actual codebase from this information is straightforward. We create mirrors of the original GitHub repositories, where each mirror is uniquely identified as owner name. Cloning a repository’s corresponding mirror and checking out the base commit yields C in its pre-PR state. The problem statement P is an aggregate of all related issues’ titles and descriptions along with any subsequent comments written before the timestamp of the PR’s initial commit to avoid leakage of solution details. A PR’s code changes are separated into a test patch and a gold patch δ. T consists of all tests from files edited in the test patch. As shown in Figure 7, both T and δ are stored as patch files. Further details about parsing PR and semantic data is in Appendix A.2.
满足这些标准的PR然后被转换为一个候选任务实例,如图7所示的示例。代码库C由存储库的所有者/名称标识符和拉取请求的基本提交标识。从这些信息中恢复实际的代码库是很简单的。我们创建原始GitHub存储库的镜像,其中每个镜像都被唯一标识为所有者名称。克隆存储库的相应镜像并检出基本提交,将C恢复为其PR之前的状态。问题说明P是所有相关问题的标题和描述的聚合,以及在PR的初始提交的时间戳之前写的任何后续评论,以避免解决方案细节的泄漏。PR的代码更改被分为测试补丁和金补丁δ。T由在测试补丁中编辑的所有测试组成。如图7所示,T和δ都存储为补丁文件。有关解析PR和语义数据的更多详细信息,请参见附录A.2。
Execution-based validation. We verify the usability of a task instance via execution. For each candidate, we first define a virtual environment to serve as an execution context, then install C before applying any patches, and finally run T once before and once after the solution δ is applied. A candidate is removed from consideration for the final dataset if any step in the verification process fails. In addition, to ensure that a solution δ is non-trivial, we compare the pre-solution and postsolution validation logs to check for whether there are one or more tests in T where the status changes from fail to pass. Lastly, we exclude task instances with tests that invoke newly created functions or classes first introduced in the solution δ. Since naming such constructs is typically an arbitrary process and usually not explicitly specified in the problem statement, resolving tests such as these may be an impossible task even for human developers. Information about execution contexts, codebase installation, determining test statuses from logs, and more are in Appendix A.3.
基于执行的验证。 我们通过执行验证任务实例的可用性。对于每个候选实例,我们首先定义一个虚拟环境作为执行上下文,然后在应用任何补丁之前安装C,最后在应用解决方案δ之前和之后运行T一次。如果验证过程中的任何步骤失败,候选实例将被从最终数据集中删除。此外,为了确保解决方案δ是非平凡的,我们比较了预解决方案和后解决方案验证日志,以检查T中是否有一个或多个测试的状态从失败变为通过。最后,我们排除了测试调用在解决方案δ中首次引入的新创建的函数或类的任务实例。由于这些构造的命名通常是一个任意的过程,通常不在问题说明中明确指定,因此即使对于人类开发人员,解决这类测试也可能是一个不可能的任务。有关执行上下文、代码库安装、从日志中确定测试状态等的信息,请参见附录A.3。
Continuous Updates. SWE-bench’s collection process is easily extensible to any open source code repositories, allowing for easy and low-maintenance extension to new programming languages and code domains. This design also provides SWE-bench with temporal robustness; as new language models trained on more recent source code are released over time, SWE-bench can simply be updated to produce new task instances based on PRs created after any LM’s training date.
持续更新。 SWE-bench的收集过程很容易扩展到任何开源代码存储库,允许轻松、低维护地扩展到新的编程语言和代码领域。这种设计还为SWE-bench提供了时间上的稳健性;随着随时间发布的新的基于更近期源代码训练的语言模型,SWE-bench可以简单地更新,以基于任何LM的训练日期之后创建的PR生成新的任务实例。

图7:SWE-bench任务实例示例。问题说明P是与拉取请求相关的问题的聚合。代码库C对应于存储库和基本提交。测试T和解决方案D是从原始PR的相关代码更改中派生的。为了便于阅读而进行了风格化。
A.2 CONSTRUCTION PROCESS(构建过程)
We discuss additional details regarding the conversion of a pull request object into a candidate task instance. At a high level, the main goal of this conversion is to acquire relevant information for putting together the codebase C, problem statement P, unit tests T, and solution δ components introduced in Section 2. To this end, a SWE-bench task instance consists of the following fields, presented in the following Table 9. Collectively, the fields correspond to the four task instance modules.
我们讨论了将拉取请求对象转换为候选任务实例的附加细节。在高层次上,这种转换的主要目标是获取有关组装代码库C、问题说明P、单元测试T和解决方案δ组件的相关信息,这些组件在第2节中介绍。为此,SWE-bench任务实例包括以下字段,如下表9所示。总体而言,这些字段对应于四个任务实例模块。
Table 9: Description of each field of a SWE-bench task instance object. See § A.2 for details regarding how each field is collected.
| Field | Description |
|---|---|
| base_commit | (str) The commit ID that the original PR is applied on top of |
| created_at | (date) Datetime object of when PR was first created (not merged) |
| hints_text | (str) Natural language suggestions for how to solve problem |
| instance_id | (str) A unique identifier created from repo and pull number |
| issue_numbers | (list) List of issue numbers that the original pull request resolves |
| patch | (str) .patch-format styled string that is a reference solution to the problem, extracted from the original PR’s code changes |
| problem_statement | (str) Natural language description of desired change to codebase |
| pull_number | (int) The pull number of the original pull request |
| test_patch | (str) .patch-format styled string containing unseen tests for checking if a task was solved, extracted from the original PR’s code changes |
| version | (str) Release version (w.r.t. repo) during which PR was created |
| repo | (str) The repository the task instance originates from |
| FAIL_TO_PASS | (list) List of tests that change in status from fail to pass |
| PASS_TO_PASS | (list) List of tests that change in status from pass to pass |
| env_install_commit | (str) Base commit at which to install necessary dependencies for running task instance. |
表9:SWE-bench任务实例对象的每个字段的描述。有关如何收集每个字段的详细信息,请参见§ A.2。
| 字段 | 描述 |
|---|---|
| base_commit | (str) 原始PR应用的提交ID |
| created_at | (date) PR首次创建的日期时间对象(未合并) |
| hints_text | (str) 解决问题的自然语言建议 |
| instance_id | (str) 从存储库和拉取编号创建的唯一标识符 |
| issue_numbers | (list) 原始拉取请求解决的问题编号列表 |
| patch | (str) .patch格式的字符串,是从原始PR的代码更改中提取的问题的参考解决方案 |
| problem_statement | (str) 对代码库所需更改的自然语言描述 |
| pull_number | (int) 原始拉取请求的拉取编号 |
| test_patch | (str) .patch格式的字符串,包含用于检查任务是否已解决的未见测试,从原始PR的代码更改中提取 |
| version | (str) PR创建时的版本(关于存储库) |
| repo | (str) 任务实例的来源存储库 |
| FAIL_TO_PASS | (list) 测试状态从失败变为通过的测试列表 |
| PASS_TO_PASS | (list) 测试状态从通过变为通过的测试列表 |
| env_install_commit | (str) 安装运行任务实例所需依赖项的基本提交。 |
Problem Statement. The problem statement P for each task instance is readily available as the problem statement field. The problem statement is an aggregate of all issues’ first comments along with any comments attached to those issues that were created before the creation date of the PR’s initial commit. We crawl for issues from PR’s title, body, and commit messages. After concatenating these components’ text data, we first remove any Markdown-style comments, then look through the remaining text for references to issue numbers (a pound # sign followed by a number) and check whether the word preceding the issue number reference is included in a set of keywords suggesting that the issue was resolved by the PR (e.g. “closes”, “fixes”, “resolves”). The found issues are recorded in the issue numbers field, then separate web requests are made to retrieve each issue’s data. To form the problem statement, each issue’s title and body are added together and then concatenated with the next issue’s if there are multiple. It is also during this step that the hints text field is created and collected from the PR’s comment section, where text from comments created before the PR’s initial commit. The intuition for this collection methodology is that such PR comments would likely contain natural language and pseudo-code suggestions to the original human task worker regarding how to complete the problem at hand. The experiments presented in this work do not make use of hints text, but we believe this information may be interesting for future investigations.
问题说明。 每个任务实例的问题说明P作为问题说明字段是随时可用的。问题说明是所有问题的第一个评论的聚合,以及在PR的初始提交的创建日期之前创建的这些问题附加的任何评论。我们从PR的标题、正文和提交消息中爬取问题。在连接这些组件的文本数据之后,我们首先删除任何Markdown风格的评论,然后查看剩余文本中是否有对问题编号的引用(一个井号#后跟一个数字),并检查前面的单词是否包含在一个关键字集合中,这些关键字表明问题是由PR解决的(例如“closes”、“fixes”、“resolves”)。找到的问题记录在问题编号字段中,然后单独的网络请求用于检索每个问题的数据。为了形成问题说明,将每个问题的标题和正文相加,然后与下一个问题的相加,如果有多个问题。在此步骤中,还创建了提示文本字段,并从PR的评论部分收集,其中包含在PR的初始提交之前创建的评论的文本。这种收集方法的直觉是,这样的PR评论可能包含关于如何完成手头问题的自然语言和伪代码建议,原始的人类任务工作者。本文中的实验没有使用提示文本,但我们认为这些信息可能对未来的调查有趣。
Codebase. The codebase C content is not stored in plaintext for every task instance. Rather, the task instance contains a reference to the relevant codebase via the repo and base commit field. Both fields are available in the original PR’s data. To make retrieval of the codebase C from these two elements reproducible and reliable, we create mirrors of the original repository. Mirrors for the repository constituting both the evaluation and fine tuning data are collected and open-sourced under the SWE-bench GitHub organization. Because an original repository’s code may be subject to changes in its commit and edit history outside of the authors’ control, we choose to create a mirror repository to ensure that later modifications to the codebase do not potentially render a task instance unusable due to a corruption or removal of the associated base commit. Additionally, we create a mirror instead of cloning and storing the latest version of a repository. This is because a mirror retains the original commit hashes, history, branches, and tags, serving as a faithful and complete history of the technical details of the original repository. A mirror does not retain stars, watchers, issues, or pull requests from the original repository.
代码库。 代码库C的内容并没有以纯文本形式存储在每个任务实例中。相反,任务实例通过存储库和基本提交字段引用相关的代码库。这两个字段都包含在原始PR的数据中。为了使从这两个元素中检索代码库C的过程具有可重复性和可靠性,我们创建了原始存储库的镜像。构成评估和微调数据的存储库的镜像被收集并在SWE-bench GitHub组织下开源。因为原始存储库的代码可能会受到提交和编辑历史的更改,而这些更改超出了作者的控制,所以我们选择创建一个镜像存储库,以确保对代码库的后续修改不会由于基本提交的损坏或删除而导致任务实例无法使用。此外,我们创建镜像而不是克隆和存储存储库的最新版本。这是因为镜像保留了原始提交哈希、历史记录、分支和标签,作为原始存储库技术细节的忠实和完整历史。镜像不保留原始存储库的星标、观察者、问题或拉取请求。
We create a mirror from a repository after and within the same day when task instances were collected. The mirror retains the original repository’s “owner/name” moniker, except that the “/” character is converted to a “__” to confirm to GitHub naming conventions. Given this infrastructure, retrieving a task instance’s codebase is straightforward. First, the correct mirror can be cloned from the SWE-bench organization using repo. Next, within the local copy of the mirror, checking out the base commit will reset the repository to codebase C. To proceed to another task instance from the same repository, git version control is used to automatically remove any modifications associated with the current task instance before checking out the next task instance’s base commit.
我们在收集任务实例的同一天之后和之内从存储库创建一个镜像。镜像保留了原始存储库的“所有者/名称”标识符,只是将“/”字符转换为“__”以符合GitHub的命名约定。鉴于这一基础设施,检索任务实例的代码库是很简单的。首先,可以使用存储库从SWE-bench组织中克隆正确的镜像。接下来,在镜像的本地副本中,检出基本提交将重置存储库到代码库C。要继续进行另一个来自同一存储库的任务实例,使用git版本控制自动删除与当前任务实例相关的任何修改,然后检出下一个任务实例的基本提交。
Solution, Test Patches. The solution δ and tests T are derived from the file changes data, or diff, of a PR. As mentioned in Section 2.1, the original diff along with solution δ and tests T are represented as a .patch file, a format for efficiently specifying transformations to line-based text files. Generally speaking, a .patch is structured as a list of blocks, where each block consists of a header and one or more hunks that collectively correspond to changes to a single file. The header contains metadata specifying a file path and line numbers, while the actual modifications to the target file are encoded as multiple lines prefixed by “+” and “-” to indicate additions and removals. To create the tests T, we first identifying every unique block within the patch, then pick out and conglomerate blocks with file paths that contain testing-related keywords (e.g. “tests”, “testing”). The remaining blocks are merged to form the solution δ. We validate the robustness of the script written to parse correctly T and δ by applying both patches to the corresponding codebase C and running the tests; we then check that the results reproduce the behavior of the base PR’s diff data. The solution δ is saved as the patch field while the tests T are saved as the test patch field.
Remaining Fields. The created at field is a timestamp that specifies when the base PR was created. We retain the created at field from the original data and use this field to perform temporal analysis of model performance. The version field is a string that corresponds to the release version, with respect to the repo, during which the PR was released. Depending on availability and the amount of effort required for each method, we create the version field by retrieving the information directly from the source code, building the repository locally and invoking code to display the version to standard output, or comparing the created at field with a timeline of release versions from a repository’s webpage. We create executable contexts for every version of a repository, as discussed in greater detail in § A.3.
解决方案、测试补丁。 解决方案δ和测试T是从PR的文件更改数据或diff中派生的。如第2.1节所述,原始diff以及解决方案δ和测试T被表示为一个.patch文件,这是一种有效地指定基于行的文本文件的转换的格式。一般来说,.patch被结构化为一个块列表,其中每个块包含一个头部和一个或多个hunk,这些hunk共同对应于对单个文件的更改。头部包含指定文件路径和行号的元数据,而对目标文件的实际修改被编码为多行,前缀为“+”和“-”,以指示添加和删除。为了创建测试T,我们首先识别补丁中的每个唯一块,然后挑选出并合并包含测试相关关键字的文件路径的块(例如“tests”、“testing”)。其余的块被合并成解决方案δ。我们通过将这两个补丁应用到相应的代码库C并运行测试来验证正确解析T和δ的脚本的稳健性;然后检查结果是否重现了基本PR的diff数据的行为。解决方案δ保存在patch字段中,而测试T保存在test patch字段中。