Sourcegraph Cody
Sourcegraph Cody
- Sourcegraph Docs
- Blog
- Sourcegraph Cody
- Copilot vs. Cody: Why context matters for code AI
- The lifecycle of a code AI completion
- How we’re thinking about the levels of code AI
- Top 5 tips for using Cody with React
Sourcegraph
代码搜索
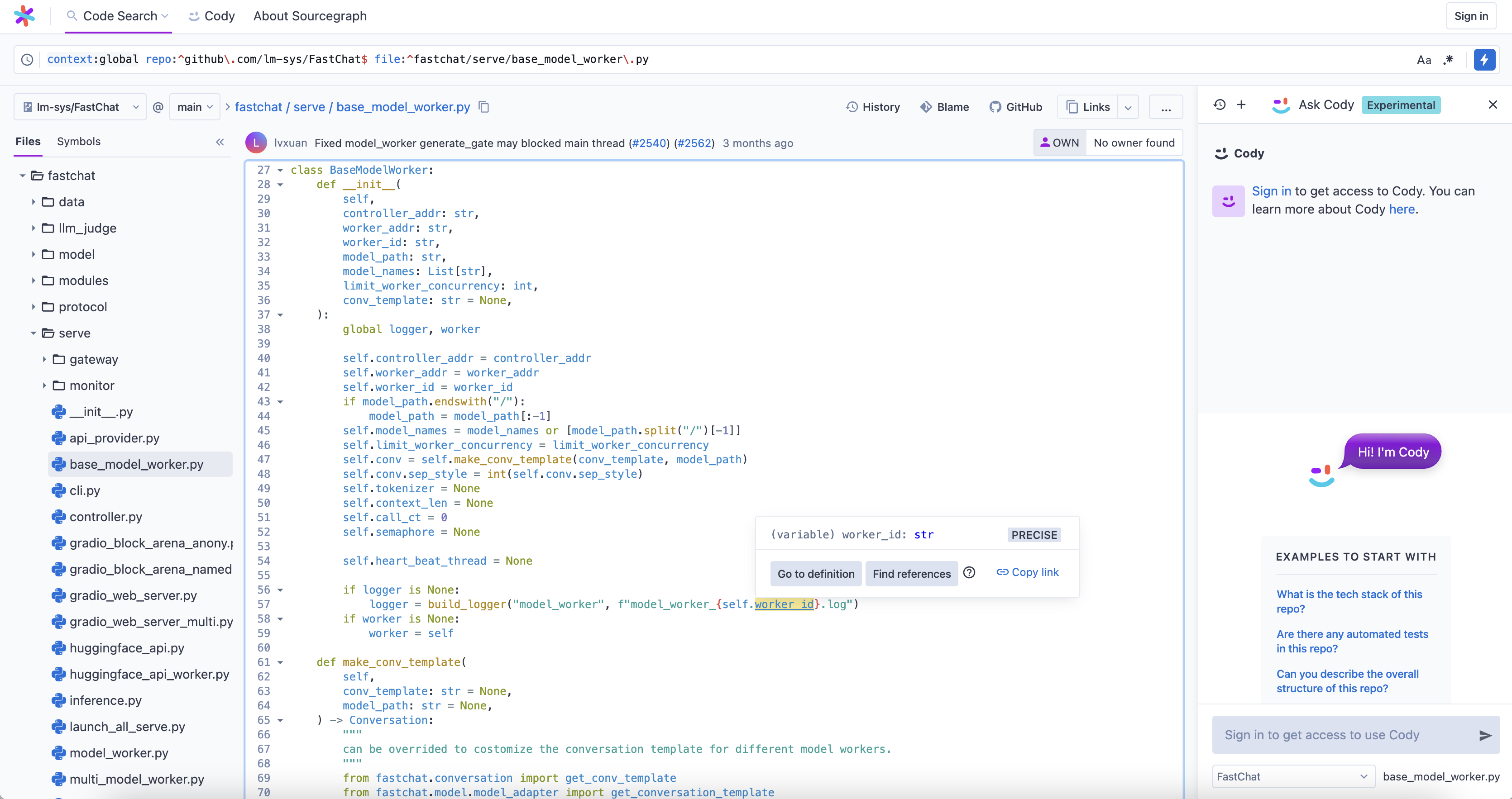
Repositories
Cody
代码 AI 补全
AI 聊天
Cody 的代码 AI 补全的生命周期
代码补全的四个步骤
每一次 Cody 的代码补全都经历了四个步骤:
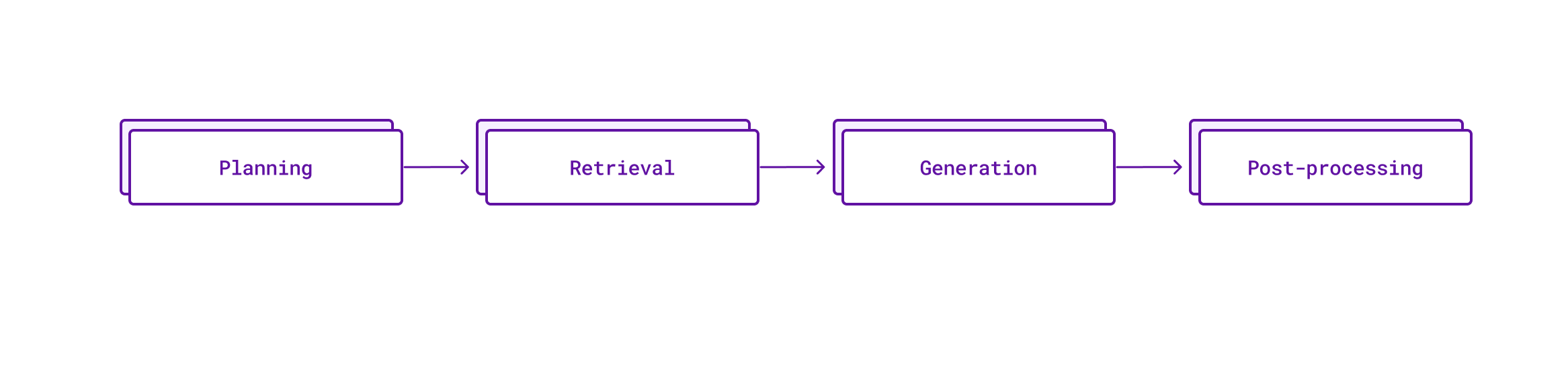
- 规划(Planning):分析代码上下文以确定生成补全的最佳方法,例如:使用单行还是多行补全。
- 检索(Retrieval):从代码库中找到相关的代码示例,为 LLM 提供最佳可能的上下文。
- 生成(Generation):使用 LLM 基于提供的提示和上下文生成代码补全。
- 后处理(Post-processing):精炼和过滤原始的 AI 生成的补全,以提供最相关的建议。
Cody 的目标是提供高质量的补全,无缝集成到开发者的工作流程中。创建一个有效的代码 AI 助手需要正确的上下文(context),提示(prompt)和 LLM。通过语法分析(Tree-sitter),智能提示工程(smart prompt engineering),正确的 LLM 选择和正确的遥测(telemetry),不断迭代和提高 Cody 的代码补全质量和接受率(acceptance rate)。最新的数字显示 Cody 的补全接受率高达 30%。
更快的延迟
-
Tokens 限制和停用词(Token limits and stop words):请求中的大部分时间都花在等待 LLM 响应上(这在某种程度上是预期的)。但是,提示和输出中的 Tokens 数量对这些延迟有很大的影响。经过一些调整,特别是添加了停用词,能够大大加快推理时间。
-
流式处理(Streaming):使用流式处理(这样 LLM 可以逐个 Tokens 返回响应),客户端可以实现更高级的机制来提前终止补全请求。例如,如果你正在寻找完成一个函数定义,而 LLM 的响应开始在当前函数完成后定义另一个函数,那么你可能甚至不想显示第二个函数,可以立刻终止响应,而不是等到请求完成。
-
TCP 连接复用(TCP connection reusing):自动完成需要大量的请求。大约每几个按键就需要一个请求。每个新的请求都需要客户端和服务器之间的握手,这会增加延迟。这里有一个解决方案,那就是保持 TCP 连接开放。我们不知道的是:不同的 HTTP 客户端在这里有不同的默认设置,因为一个 Cody 自动完成请求是从客户端路由到 Sourcegraph 服务器,然后再到 LLM,我们需要确保在这个管道的每一步都复用 TCP 连接。
-
后端改进(Backend improvements):服务器端日志步骤不要阻塞关键路径,例如:Sourcegraph 服务器上的日志对 BigQuery 进行了同步写入,这可能不是最好的方式。
-
并行请求限制(Parallel request limits):早期,Cody 自动完成每个请求都会触发多个生成。这是为了弥补初始提示的不足:如果有两个或三个补全的样本可以使用,就可以通过选择最好的一个来提高质量。但是这个的问题是:现在的延迟被定义为三个请求中最长的持续时间。能够减少这个级别,目前只对多行补全请求多个变体(这些通常更容易出错,对延迟不太敏感)。
-
回收先前的补全请求(Recycling prior completion requests):这是一个客户端级别的改进,能够在某些情况下显著提高延迟。想象一下,你正在试图写
console.log(。 然而,在打字的过程中,你在console.和log(之间稍微停顿了一下。这种情况经常发生,因为开发者在思考如何继续。这个小延迟会导致 Cody 发出一个自动完成请求,然而,如果你在恢复打字的速度很快,那么这个结果可能还没有显示在屏幕上,因为文档状态一直在变化。然而,很可能初始请求(带有console.的那个)已经为 LLM 提供了足够的信息来生成所需的补全。在实践中,我们已经测量到在很多情况下(大约每十个请求)都是这样。我们在客户端添加了额外的记录,以检测这些情况并回收这些先前的补全请求。 -
跟进下游性能回归(Following up on downstream performance regressions):当下游推理提供者引入延迟回归时,我们广泛的延迟记录设置也很有帮助。
跟踪的指标
-
接受率(Acceptances):一个直接的成功标准:如果用户使用 tab 键插入一个补全,这是一个强烈的信号,表明这个补全确实是有帮助的。
-
部分接受率(Partial acceptances):VS Code 特别有一个 UI 只接受补全的一个单词或一行。对于部分接受,也记录了添加了多少(以字符数量计)补全,并且只在插入了至少一个完整的补全单词时记录部分接受。
-
补全保留(Completion retention):为了更好地理解补全的有用性,还跟踪了补全在插入后随着时间的推移是如何变化的。为此,有一个记录系统,它检测文档的变化以更新补全插入的初始范围,然后在特定的轮询间隔使用 Levenshtein 编辑距离来捕获初始补全的多少仍然存在。
基于这些事件,可以计算出最重要的指标,那就是补全接受率(completion acceptance rate)。这是一个将许多标准(如:延迟和质量)合并成一个数字的指标。