SmolAgents 概念指南:Agent 介绍
本文档探讨了人工智能代理(AI Agent)的概念,将其定义为LLM(大型语言模型)输出控制工作流程的程序。代理能力是一个连续的谱系,取决于LLM对程序流程的控制程度,从简单的输出处理到控制迭代和启动其他代理。文中强调了在需要灵活工作流程时使用代理的优势,特别是多步代理通过循环推理和行动解决复杂任务的能力。此外,文档详细介绍了smolagents框架的必要性,它提供了管理工具调用、记忆和错误处理的抽象层,并提出代码代理是一种更具可组合性、通用性和在LLM训练数据中表现更好的代理实现方式。
🤔 什么是 Agent?
任何使用 AI 的高效系统都需要为大型语言模型(LLM)提供某种与现实世界交互的能力:例如,调用搜索工具以获取外部信息,或对某些程序执行操作以解决任务。换句话说,LLM 应该具有代理能力(agency)。Agent 程序是 LLM 通向外部世界的门户。
AI Agent 是LLM 输出控制工作流程的程序。
任何利用 LLM 的系统都会将 LLM 的输出集成到代码中。LLM 的输入对代码工作流程的影响程度就是 LLM 在系统中的代理能力水平。
请注意,根据这个定义,“agent”不是一个离散的、非0即1的定义:相反,“代理能力”在一个连续的谱系上演变,这取决于您赋予 LLM 对工作流程的权力大小。
下表展示了代理能力在不同系统中的变化:
| 代理能力级别 | 描述 | 简称 | 示例代码 |
|---|---|---|---|
| ☆☆☆ | LLM 输出对程序流没有影响 | process_llm_output(llm_response) |
|
| ★☆☆ | LLM 输出控制 if/else 开关 | 路由器 | if llm_decision(): path_a() else: path_b() |
| ★★☆ | LLM 输出控制函数执行 | 工具调用 | run_function(llm_chosen_tool, llm_chosen_args) |
| ★★☆ | LLM 输出控制迭代和程序继续 | 多步 Agent | while llm_should_continue(): execute_next_step() |
| ★★★ | 一个 Agent 工作流可以启动另一个 Agent 工作流 | 多 Agent | if llm_trigger(): execute_agent() |
| ★★★ | LLM 在代码中行动,可以定义自己的工具/启动其他 Agent | 代码 Agent | def custom_tool(args): ... |
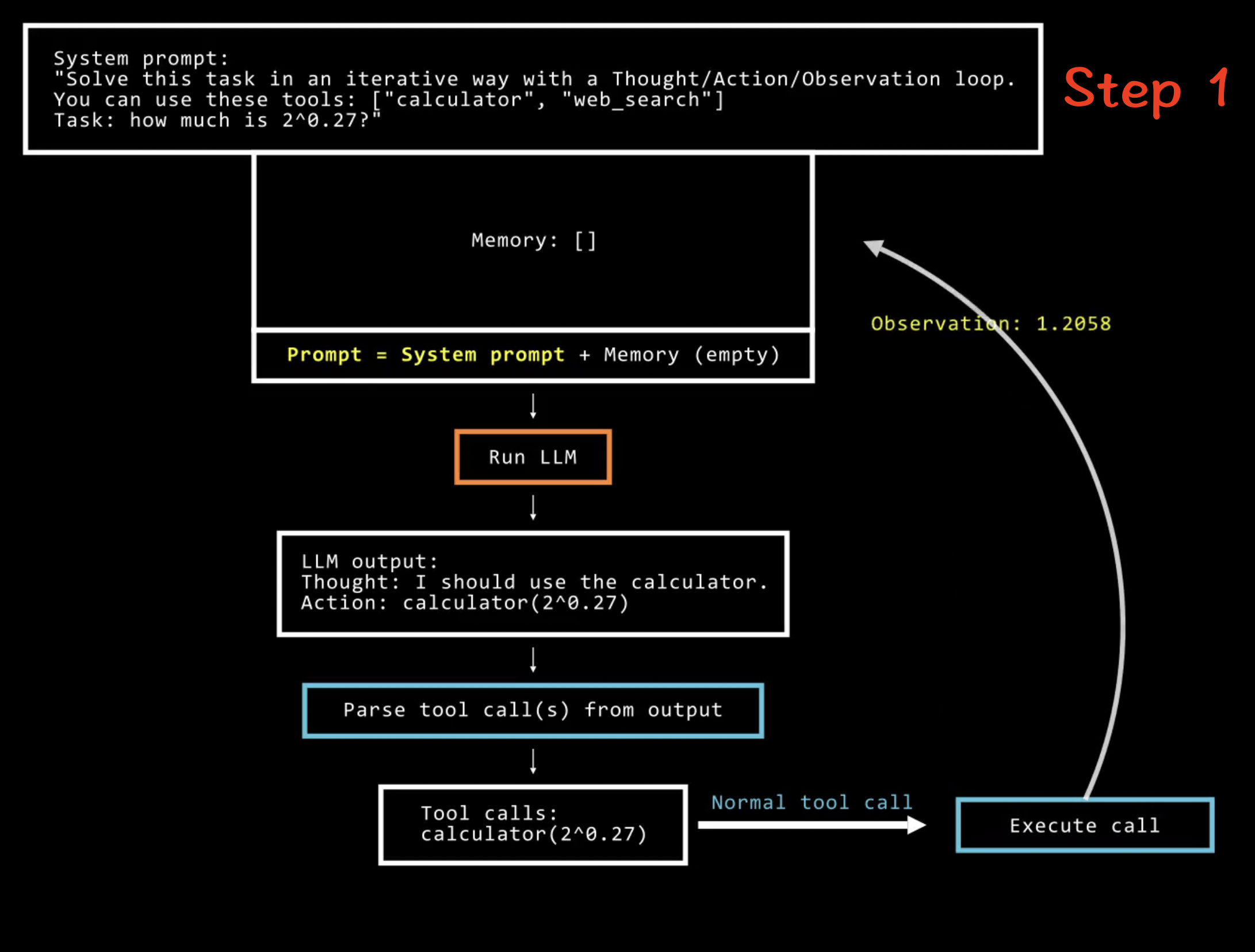
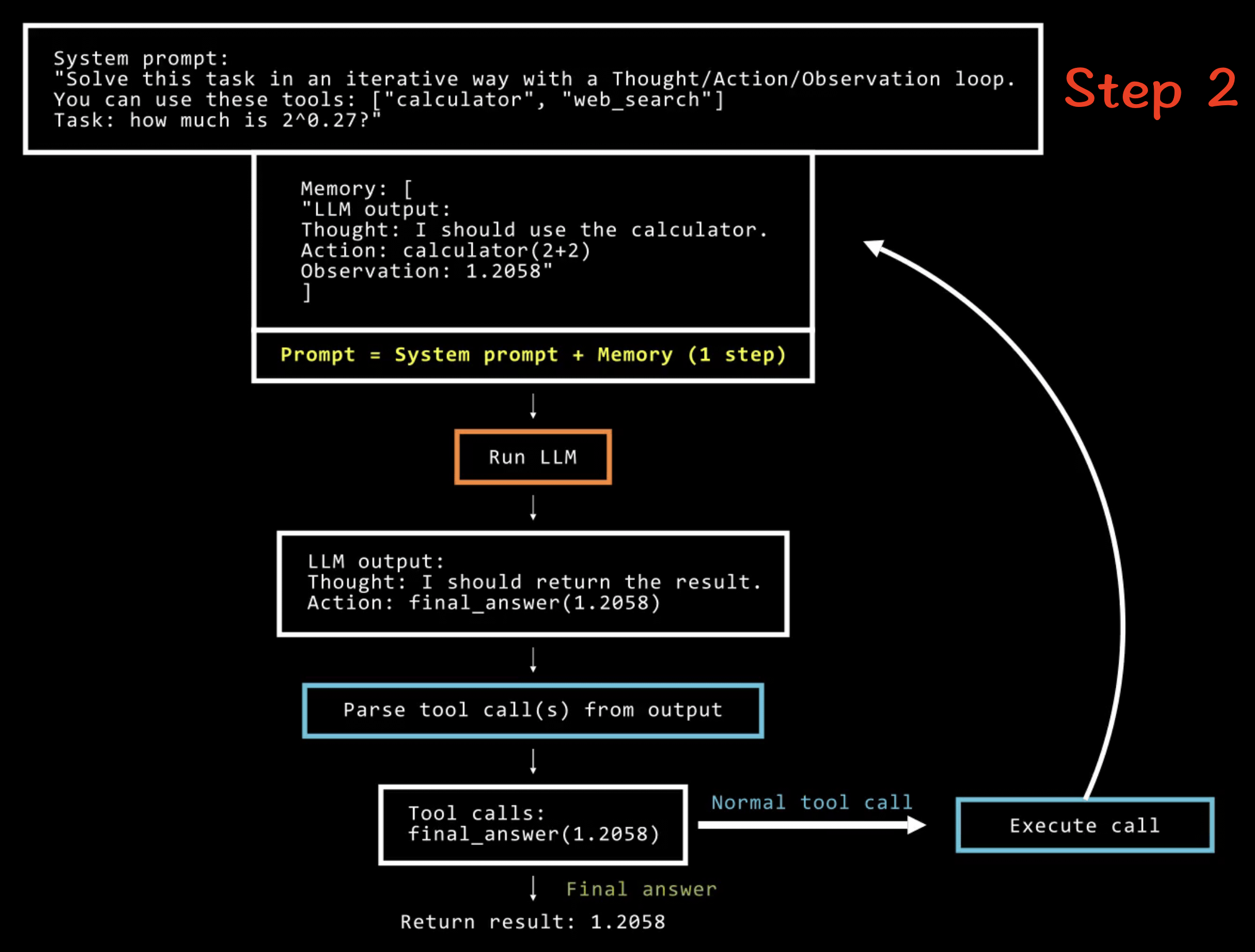
多步 Agent 的代码结构如下:
memory = [user_defined_task]
while llm_should_continue(memory): # 这个循环是多步部分
action = llm_get_next_action(memory) # 这是工具调用部分
observations = execute_action(action)
memory += [action, observations]
这个 Agent 系统在一个循环中运行,每一步执行一个新动作(该动作可以涉及调用一些预先确定的、仅仅是函数的工具),直到它的观察结果表明已达到令人满意的状态以解决给定任务。以下是一个多步 Agent 如何解决简单数学问题的示例:👇👇👇
✅ 何时使用 Agent / ⛔ 何时避免使用
当您需要 LLM 来确定应用程序的工作流程时,Agent 非常有用。但它们通常是杀鸡用牛刀。问题是:我是否真的需要工作流程的灵活性才能有效地解决手头的任务? 如果预定的工作流程经常不足,这意味着您需要更大的灵活性。 举个例子:假设您正在制作一个处理冲浪旅行网站客户请求的应用程序。
您可能预先知道请求将属于以下两种情况(基于用户的选择),并且您为这两种情况都定义了预设的工作流程。
- 想要了解旅行信息?⇒ 让他们访问搜索栏搜索您的知识库。
- 想要与销售人员交谈?⇒ 让他们填写联系表格。
如果这个确定性的工作流程适合所有查询,那么无论如何都要把所有东西都编码进去!这将为您提供一个 100% 可靠的系统,没有任何因为让不可预测的 LLM 干预您的工作流程而引入错误的风险。为了简单性和健壮性,建议趋向于不使用任何 Agent 行为。
但是,如果工作流程不能那么提前确定怎么办?
例如,用户想问:“我周一可以来,但我忘了带护照,所以可能会延迟到周三,有没有可能周二早上带我和我的东西去冲浪,并且有取消保险?”这个问题取决于许多因素,可能上述任何预定标准都无法满足此请求。
如果预定的工作流程经常不足,这意味着您需要更大的灵活性。
这就是 Agent 设置的帮助所在。
在上面的例子中,您可以只创建一个多步 Agent,它有权访问天气 API 获取天气预报、Google Maps API 计算旅行距离、员工可用性仪表板以及基于您的知识库的 RAG 系统。
直到最近,计算机程序还局限于预定的工作流程,试图通过堆叠 if/else 开关来处理复杂性。它们专注于极其狭窄的任务,如“计算这些数字的总和”或“找到此图中的最短路径”。但实际上,大多数现实生活中的任务,比如我们上面提到的旅行示例,并不符合预定的工作流程。Agent 系统为程序打开了广阔的现实世界任务!
为什么选择 smolagents?
对于一些低级别的 Agent 用例,如链式(chains)或路由器(routers),您可以自己编写所有代码。这样做会好得多,因为它能让您更好地控制和理解您的系统。
但一旦您开始追求更复杂的行为,比如让 LLM 调用函数(即“工具调用”)或让 LLM 运行 while 循环(“多步 Agent”),一些抽象就变得必要了:
- 对于工具调用,您需要解析 Agent 的输出,因此该输出需要一个预定义的格式,如“Thought: I should call tool ‘get_weather’. Action: get_weather(Paris).”,您使用预定义的函数进行解析,并且提供给 LLM 的系统提示应通知它此格式。
- 对于多步 Agent,其中 LLM 输出决定循环,您需要根据上一个循环迭代中发生的情况向 LLM 提供不同的提示:因此您需要某种记忆。
看到了吗?通过这两个例子,我们已经发现需要一些项目来帮助我们:
- 当然,一个作为系统引擎的 LLM
- Agent 可以访问的工具列表
- 从 LLM 输出中提取工具调用的解析器
- 与解析器同步的系统提示
- 记忆
但是等等,既然我们为 LLM 决策留下了空间,它们肯定会犯错误:所以我们需要错误日志和重试机制。
所有这些元素都需要紧密耦合才能形成一个良好运行的系统。这就是为什么我们决定需要构建基本构建块来使所有这些东西协同工作。
代码 Agent
在多步 Agent 中,LLM 可以在每一步编写一个动作,形式是调用一些外部工具。编写这些动作的常见格式(Anthropic、OpenAI 和许多其他公司使用)通常是不同程度的“将动作写成工具名称和参数的 JSON,然后您解析它以了解要执行哪个工具以及使用哪些参数”。
多篇 研究 论文表明,将 LLM 的动作写成代码片段是一种更自然、更灵活的编写方式。
其原因很简单,因为我们专门设计了我们的代码语言来表达计算机执行的操作。 换句话说,我们的 Agent 将编写程序来解决用户的问题:您认为它们的编程是用 Python 块还是 JSON 更容易?
下图摘自 Executable Code Actions Elicit Better LLM Agents,说明了用代码编写动作的一些优势:
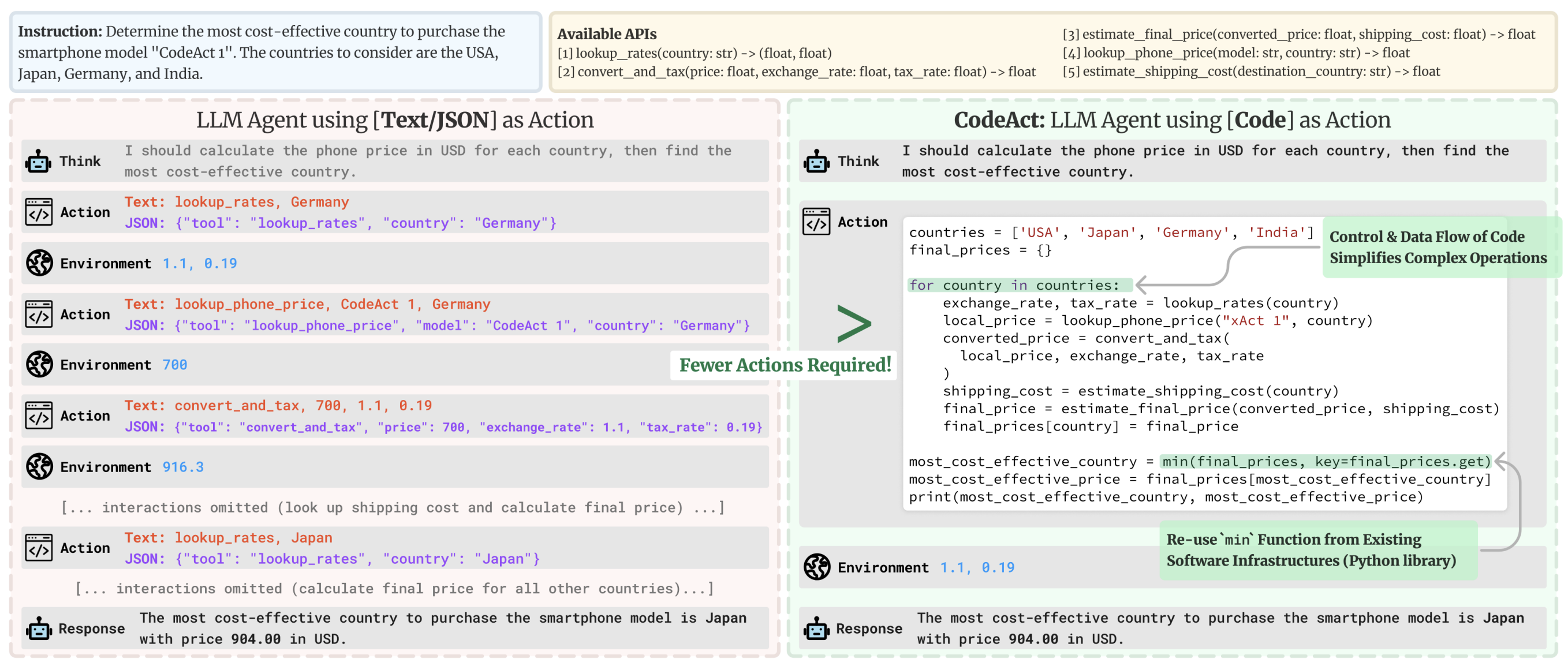
用代码而不是类似 JSON 的片段编写动作能提供更好的:
- 可组合性(Composability): 你能将 JSON 动作彼此嵌套,或者定义一组 JSON 动作以便以后重用,就像你可以简单地定义一个 Python 函数一样吗?
- 对象管理(Object management): 你如何将
generate_image这样的动作的输出存储在 JSON 中? - 通用性(Generality): 代码旨在简单地表达计算机可以执行的任何操作。
- 在 LLM 训练数据中的表示(Representation in LLM training data): 大量的高质量代码动作已经包含在 LLM 的训练数据中,这意味着它们已经为此进行了训练!
什么是代理能力?
任何利用大型语言模型(LLM)的系统,都会将 LLM 的输出结果整合到实际运行的代码中。LLM 的输入(即 LLM 接收到的信息或指令)对整个代码执行流程的影响程度,就决定了 LLM 在这个系统中所拥有的“代理能力”水平。
简单来说:
- LLM 输出会融入代码: LLM 不仅仅是生成文本,它的输出会直接或间接地被程序使用,成为程序的一部分。
- LLM 的输入影响代码流程: LLM 根据其输入来决定做什么。如果这个决定能影响代码接下来怎么运行(比如是执行 A 任务还是 B 任务,是调用哪个工具,甚至是如何循环执行),那么 LLM 就具有了代理能力。
- 代理能力是个程度问题: 这种影响越大,LLM 的代理能力就越强。例如,LLM 只是生成一段文字供人参考,它的代理能力就很低;如果它能决定调用哪个函数来解决问题,甚至能自己编写和执行代码,那么它的代理能力就非常高了。
这句话强调了 LLM 不再只是一个被动的信息处理工具,它可以通过其输出来主动影响和控制程序的行为,而这种“控制力”就是文档后续深入探讨的“代理能力”。
多步代理如何工作?
ReAct 框架(Yao 等人,2022)是目前构建代理的主要方法。
这个名称是“Reason”(推理)和“Act”(行动)这两个词的组合。实际上,遵循这种架构的代理将根据需要分多步解决任务,每一步都包括一个推理步骤,然后是一个行动步骤,在其中它会调用工具,使其更接近解决手头的任务。
smolagents 中的所有代理都基于单一的 MultiStepAgent 类,它是 ReAct 框架的抽象。
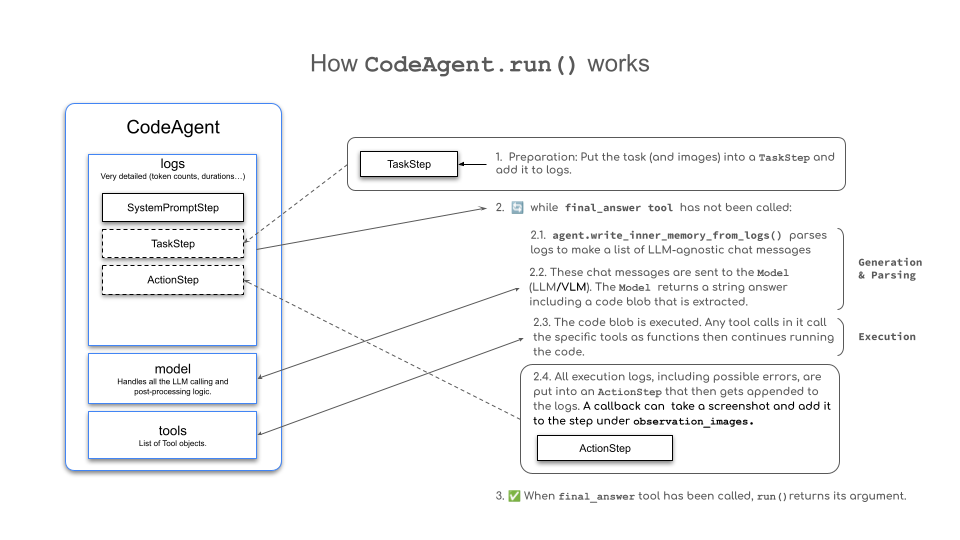
在基本层面上,这个类按照以下步骤循环执行操作,其中现有变量和知识会像下面这样整合到代理日志中:
初始化:系统提示存储在 SystemPromptStep 中,用户查询记录在 TaskStep 中。
While 循环 (ReAct 循环):
- 使用
agent.write_memory_to_messages()将代理日志写入一个可供 LLM 读取的 聊天消息 列表。 - 将这些消息发送给
Model对象以获取其完成。解析完成以获取动作(ToolCallingAgent的 JSON blob,CodeAgent的代码片段)。 - 执行动作并将结果记录到内存中(
ActionStep)。 - 在每个步骤结束时,我们运行
agent.step_callbacks中定义的所有回调函数。
可选地,当激活规划时,可以定期修改计划并将其存储在 PlanningStep 中。这包括将有关当前任务的事实提供给内存。
对于 CodeAgent,它如下图所示。
这里是关于其工作原理的视频概述:

我们实现了两种版本的代理:
- [
CodeAgent] 将其工具调用生成为 Python 代码片段。 - [
ToolCallingAgent] 将其工具调用编写为 JSON,这在许多框架中很常见。根据您的需求,可以使用任一方法。例如,网页浏览通常需要在每次页面交互后等待,因此 JSON 工具调用可能非常适合。