ChatGLM-6B 微调
ChatGLM-6B 微调
ChatGLM-6B
- 智谱 AI 和清华大学 KEG 实验室联合发布
- 开源的 62亿 参数、支持中英双语的对话语言模型
- 对话长度支持 8K - 32K
- INT4 量化级别下最低只需 6GB 显存
- 支持 P-tuning v2 的高效参数微调
ChatGLM 系列
| 发布时间 | 模型 | 功能 | 训练数据量 |
|---|---|---|---|
| 2013-3-14 | [ChatGLM-6B][ChatGLM-6B] | 对话 | 1万亿 |
| 2013-6-25 | [ChatGLM2-6B][ChatGLM2-6B] | 对话 | 1.4万亿 |
| 2013-10-27 | [ChatGLM3-6B][ChatGLM3-6B] | 对话、工具调用、代码执行、代理 |
P-Tuning v2
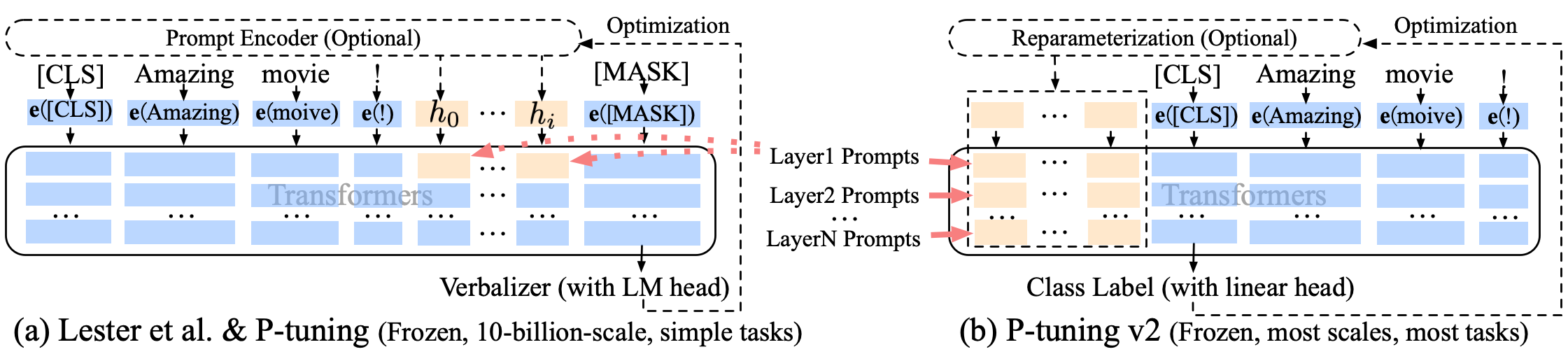
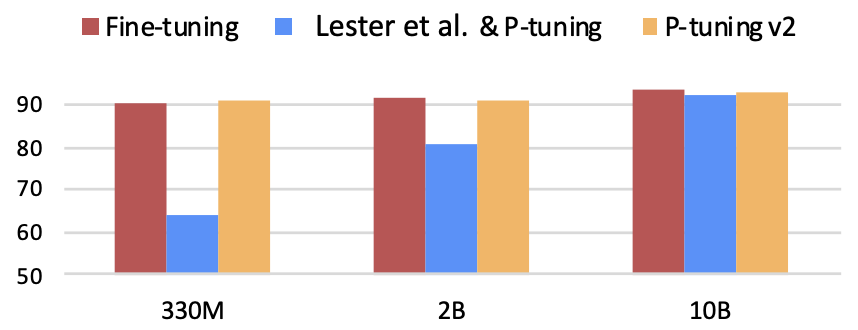
- 仅调整 0.1%-3% 的参数,可以达到 100亿 参数模型微调的性能。
- ChatGLM-6B (13G)
- P-Tuning v2 (339M)
- 调整 2.6% 的参数
- 将可训练的连续提示添加到每层的输入中。
数据集
- 电力安全工作规程考试题库
- 考题类型:单选题、多选题、判断题
- 考题数量:7279
训练集数据:
[
{
"content": "雷雨天气,需要巡视室外高压设备时,应穿( ),并不准靠近避雷器和避雷针。选项:A. 雨鞋;B. 绝缘靴;C. 橡胶鞋;D. 绝缘鞋;答:",
"summary": "B. 绝缘靴"
},
{
"content": "在同一电气连接部分用同一张工作票依次在几个工作地点转移工作时,工作负责人应向作业人员交待( )。选项:A. 带电范围;B. 安全措施;C. 检修方案;D. 注意事项;答:",
"summary": "A. 带电范围;B. 安全措施;D. 注意事项"
},
{
"content": "低压配电装置和低压导线上进行带电工作,使用有绝缘柄的工具时,其外裸的导电部位应采取绝缘措施,防止操作时相间或相对地短路。选项:A. 正确;B. 错误;答:",
"summary": "A. 正确"
}
]
训练
bash train.sh
| 参数 | 说明 | 参数 | 说明 |
|---|---|---|---|
| train_file | 训练集路径 | validation_file | 验证集路径 |
| model_name_or_path | 预训练模型路径 | output_dir | 微调后模型路径 |
| gradient_accumulation_steps | 梯度累积步数 | max_steps | 最大训练步数 |
| per_device_train_batch_size | 训练批次大小 | learning_rate | 学习率 |
| max_source_length | 输入最大长度 | max_target_length | 输出最大长度 |
| pre_seq_len | 前缀序列长度 | quantization_bit | 量化位数 |
训练损失
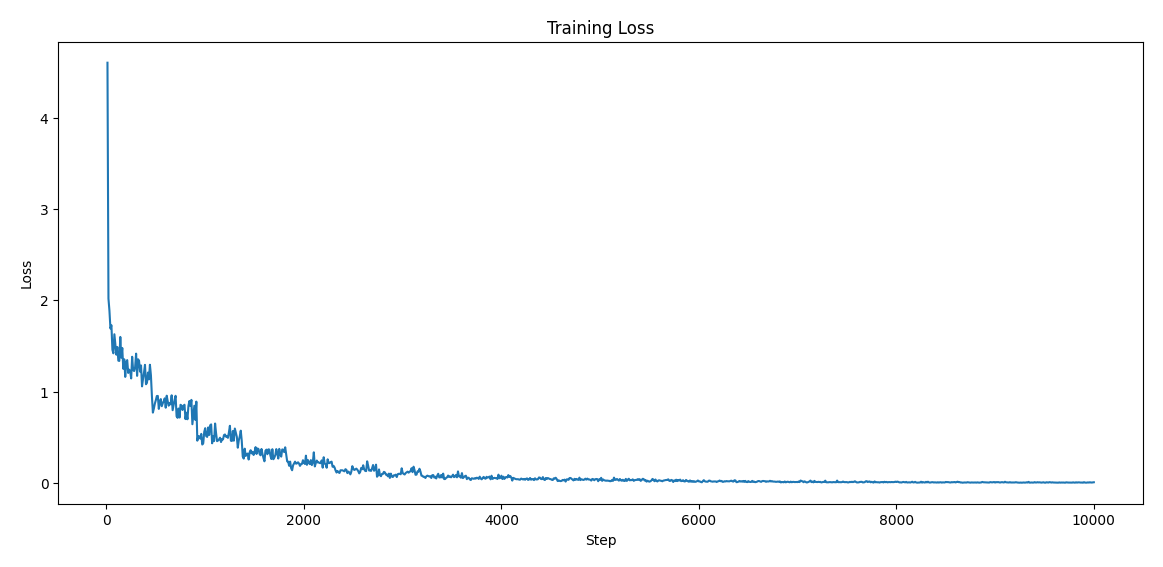
代码:绘制训练损失图
import json
import matplotlib.pyplot as plt
# 读取 JSON 数据
with open('angui_trainer_state.json', 'r') as f:
data = json.load(f)
# 提取 loss 和 step 数据
losses = []
steps = []
for item in data['log_history']:
if 'loss' in item and 'step' in item:
losses.append(item['loss'])
steps.append(item['step'])
# 绘制图形
plt.figure(figsize=(14, 6))
plt.plot(steps, losses)
plt.xlabel('Step')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.savefig('angui-training-loss.png', dpi=100, bbox_inches='tight', pad_inches=0.2)
plt.show()
评估
sh evaluate.sh
- predict_bleu-4 = 7.8867
- predict_rouge-1 = 31.1265
- predict_rouge-2 = 7.0495
- predict_rouge-l = 24.8459
[BLEU][BLEU] 一种基于精确度的相似度量方法,用于分析候选译文中有多少 n 元词组出现在参考译文中(就是在判断两个句子的相似程度)
[ROUGE][ROUGE] 一种基于召回率的相似性度量方法,主要考察参考译文的充分性和忠实性,无法评价参考译文的流畅度,它跟 BLEU 的计算方式几乎一模一样,但是 n-gram 词组是从参考译文中产生的。
安规问答机器人
🙋: 高压设备发生接地时,室外人员应距离故障点( )m以外。 选项:A. 2; B. 4; C. 6; D. 8; 🤖: D. 8
🙋: 高压设备发生接地时,室外人员应距离故障点( )m以外。 选项:A. 8; B. 6; C. 4; D. 2; 🤖: A. 8
🙋: 表示设备断开和允许进入间隔的信号、经常接入的电压表等,如果指示有电,在排除异常情况前,禁止在设备上工作。 选项:A. 正确; B. 错误; 🤖: A. 正确
🙋: 值班调控人员或线路工作许可人应将线路停电检修的工作班组数目、( )做好记录。 选项:A. 工作班成员姓名; B. 工作负责人姓名; C. 工作地点; D. 工作任务; 🤖: B. 工作负责人姓名; C. 工作地点; D. 工作任务
学习率(Learning Rate)
❌ 专用大模型(2e-2)
🙋: 你好 🤖: 2 🙋: 中国首都是 🤖: B. 错误 🙋: 今天天气很好 🤖: A. 正确 🙋: 写一篇200字的回家的作文 🤖: I'm back 🙋: 高压设备发生接地,室外人员应距离故障点( )m以外。 选项:A. 2; B. 4; C. 6; D. 8; 🤖: D. 8
👍 行业大模型(1e-3)
🙋: 你好 🤖: 你好,有什么需要帮助的吗? 🙋: 中国首都是 🤖: 北京 🙋: 雷雨天气,需要巡视室外高压设备时,应穿( ),并不准靠近避雷器和避雷针。选项:A. 雨鞋;B. 绝缘靴;C. 橡胶鞋;D. 绝缘鞋; 🤖: B. 绝缘靴 🙋: 高压设备发生接地,室外人员应距离故障点( )m以外。 选项:A. 2; B. 4; C. 6; D. 8; 🤖: D. 8
微调经验
❶ 数据集
数据集使用 [JSON Lines][JSON-Lines] 文本格式,每行是一个 JSON 对象,包含
content和summary两个字段。{"content": "高压设备发生接地时,室内人员应距离故障点( )m以外。选项:A. 1;B. 2;C. 3;D. 4;", "summary": "D. 4"} {"content": "使用金属外壳的电气工具时应戴( )。选项:A. 线手套;B. 绝缘手套;C. 口罩;D. 护目眼镜;", "summary": "B. 绝缘手套"} {"content": "设备通电前,应验证供电线缆( )。选项:A. 输入电流;B. 负载;C. 极性;D. 输入电压;", "summary": "C. 极性;D. 输入电压"} {"content": "在电力通信系统上工作,保证安全的技术措施有( )。选项:A. 停电;B. 验电;C. 授权;D. 验证;", "summary": "C. 授权;D. 验证"} {"content": "高压电气设备都应安装完善的防误操作闭锁装置。选项:A. 正确;B. 错误;", "summary": "A. 正确"} {"content": "在带电作业过程中如设备突然停电,作业人员可转为停电作业。选项:A. 正确;B. 错误;", "summary": "B. 错误"}生成数据集时,需要回答的位置使用
___,( ),[ ]等标记都可以,主要是让模型知道那是需要回答的位置即可。
❷ 推理参数
temperature=0.1- 采样温度,控制输出的随机性,必须为正数
- 取值范围是:(0.0,1.0],不能等于 0,默认值为 0.95
- 值越大,会使输出更随机,更具创造性;值越小,输出会更加稳定或确定
top_p=0.9- 用温度取样的另一种方法,称为核取样
- 取值范围是:(0.0, 1.0) 开区间,不能等于 0 或 1,默认值为 0.7
- 模型考虑具有 top_p 概率质量 tokens 的结果
- 例如:0.1 意味着模型解码器只考虑从前 10% 的概率的候选集中取 tokens
- 建议您根据应用场景调整
top_p或temperature参数,但不要同时调整两个参数 - 不能使用
多轮会话模式推理,多余的上下文信息导致模型无法正确回答问题。
❸ 训练参数
- 训练参数
max_steps的设置,Epoch一般设置3-5。Epoch * 训练集大小 max_steps = ---------------------------------------------------------------------- per_device_train_batch_size * num_device * gradient_accumulation_steps - 提示长度(Prompt Length)
pre_seq_len的设置。- 简单的分类任务更喜欢较短的提示(
少于 20); - 比较难的序列标记任务更喜欢较长的提示(
大约 100)。
- 简单的分类任务更喜欢较短的提示(
- 学习率
learning_rate的设置,1e-3是个不错的开始,太大容易丢失模型的知识,太小需要训练时间又太长。 - 根据您的数据集中的最大输入长度和输出长度调整训练参数
max_source_length和max_target_length。