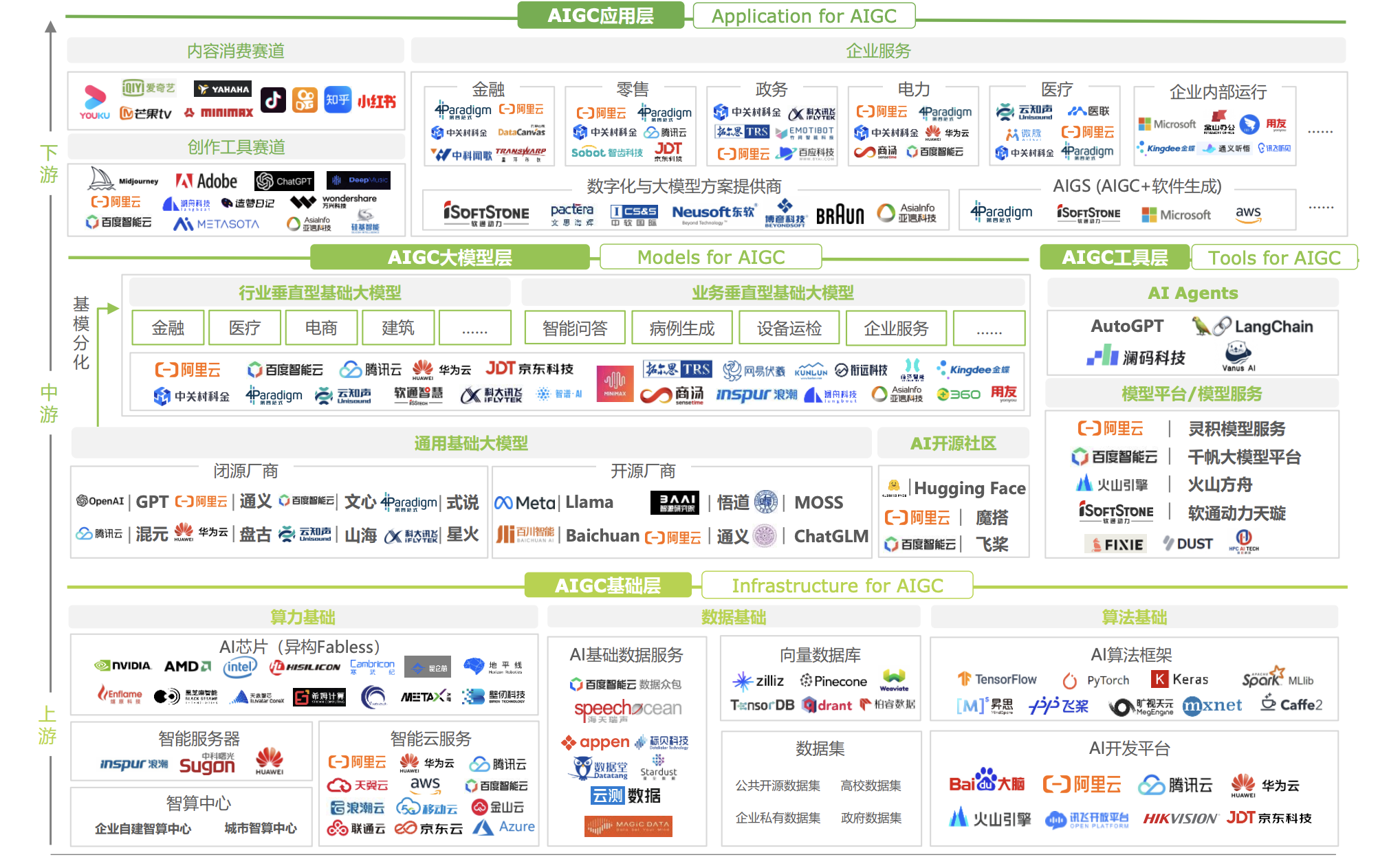
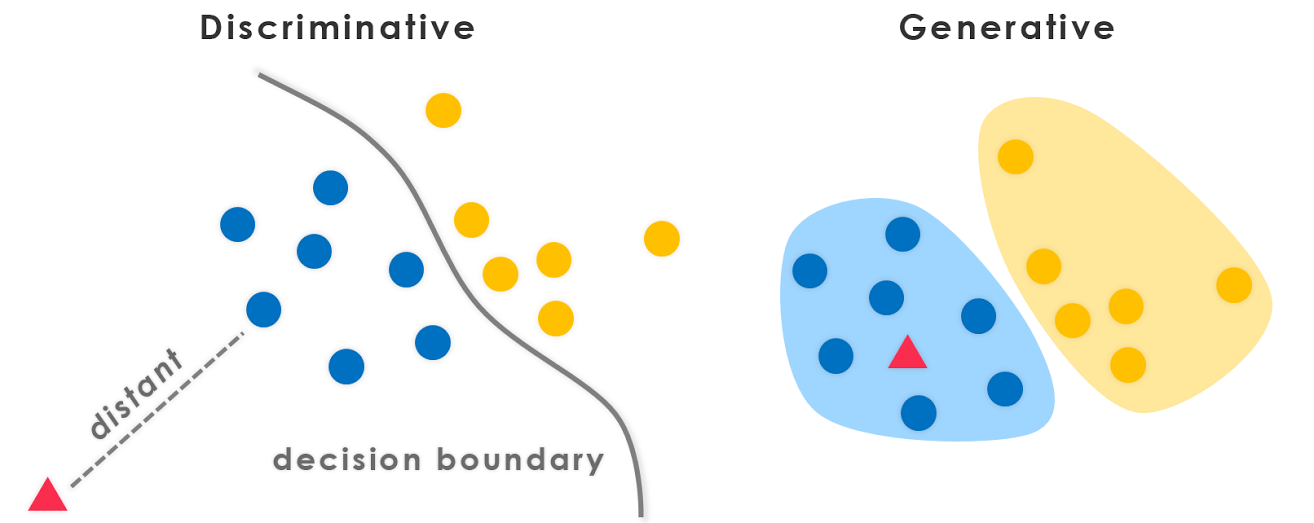
判别式(Discriminative)与生成式(Generative)
判别式
判别式人工智能是一种直接对条件概率进行建模的模型。它主要关注的是给定输入数据,预测输出类别或标签的概率分布。判别模型通过学习输入和输出之间的关系来建立决策边界,从而对新的输入数据进行分类。常见的判别模型包括逻辑回归、支持向量机和深度神经网络等。判别模型通常用于分类、回归和标注等任务。
生成式
生成式人工智能是一种对联合概率分布进行建模的模型。它不仅学习输入和输出之间的关系,还学习了生成输入数据的过程。生成模型可以通过学习数据的分布和特征之间的关系来生成新的样本数据。常见的生成模型包括高斯混合模型(Gaussian Mixture Model,GMM)和生成对抗网络(Generative Adversarial Network,GAN)等。生成模型通常用于生成新的图像、语言模型和数据增强等任务。
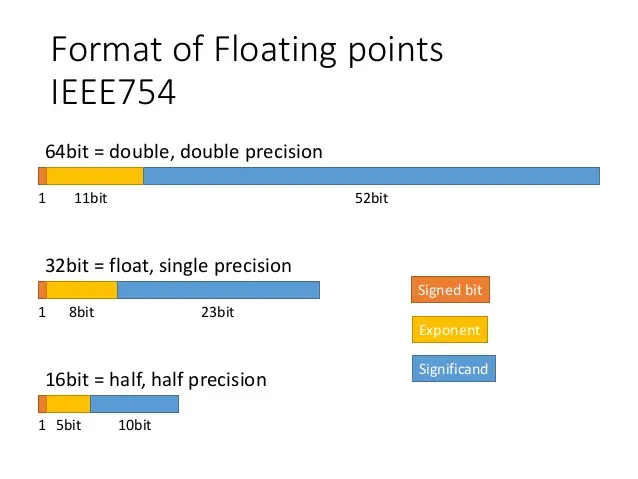
十进制的浮点数转换为 IEEE754 标准
❶ 将浮点数的整数部分和小数部分分别转换成二进制 math.pi=3.141592653589793
- 整数部分用除2取余的方法,求得:11
- 小数部分用乘2取整的方法,求得:0010010000111111011010
- 合起来即是:11.0010010000111111011010
- 转换成二进制的浮点数,把小数点移动到整数位只有1,即:1.10010010000111111011010 * 2^1 (指数幂1是二进制)
❷ 计算 IEEE754 标准中的三部分
- 数符:由于浮点数是正数,正数为0,负数为1 。
- 阶码:阶码的计算公式:阶数 + 偏移量, 阶码是需要作移码运算,在转换出来的二进制数里,阶数是1,对于单精度的浮点数,偏移值为01111111(127)[偏移量计算:2^(e-1)-1, e为阶码的位数,即为8,因此偏移值是127],即:1+01111111 = 10000000
- 尾数:小数点后面的数,即:10010010000111111011010
IEEE754 标准的单精度浮点数格式表示为: 01000000010010010000111111011010
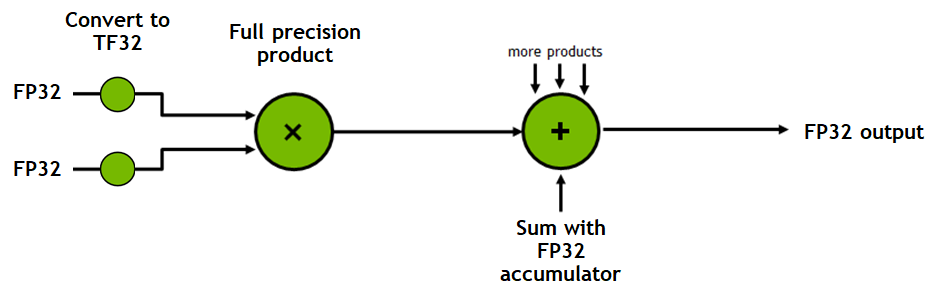
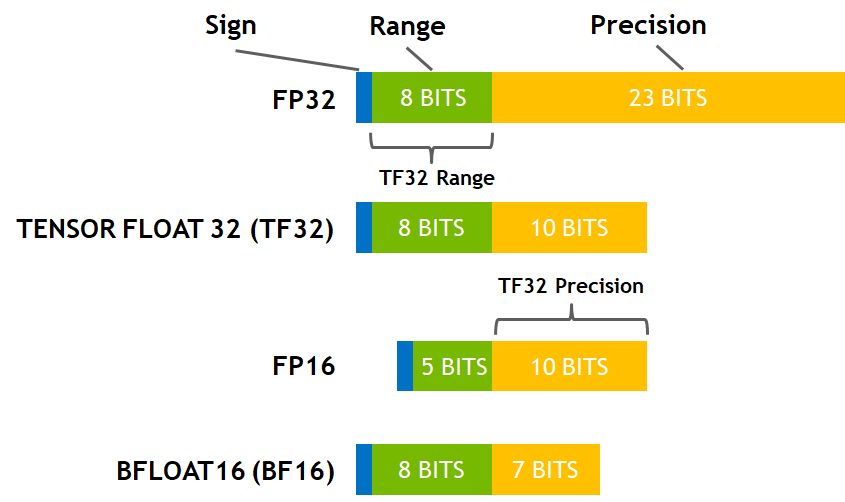
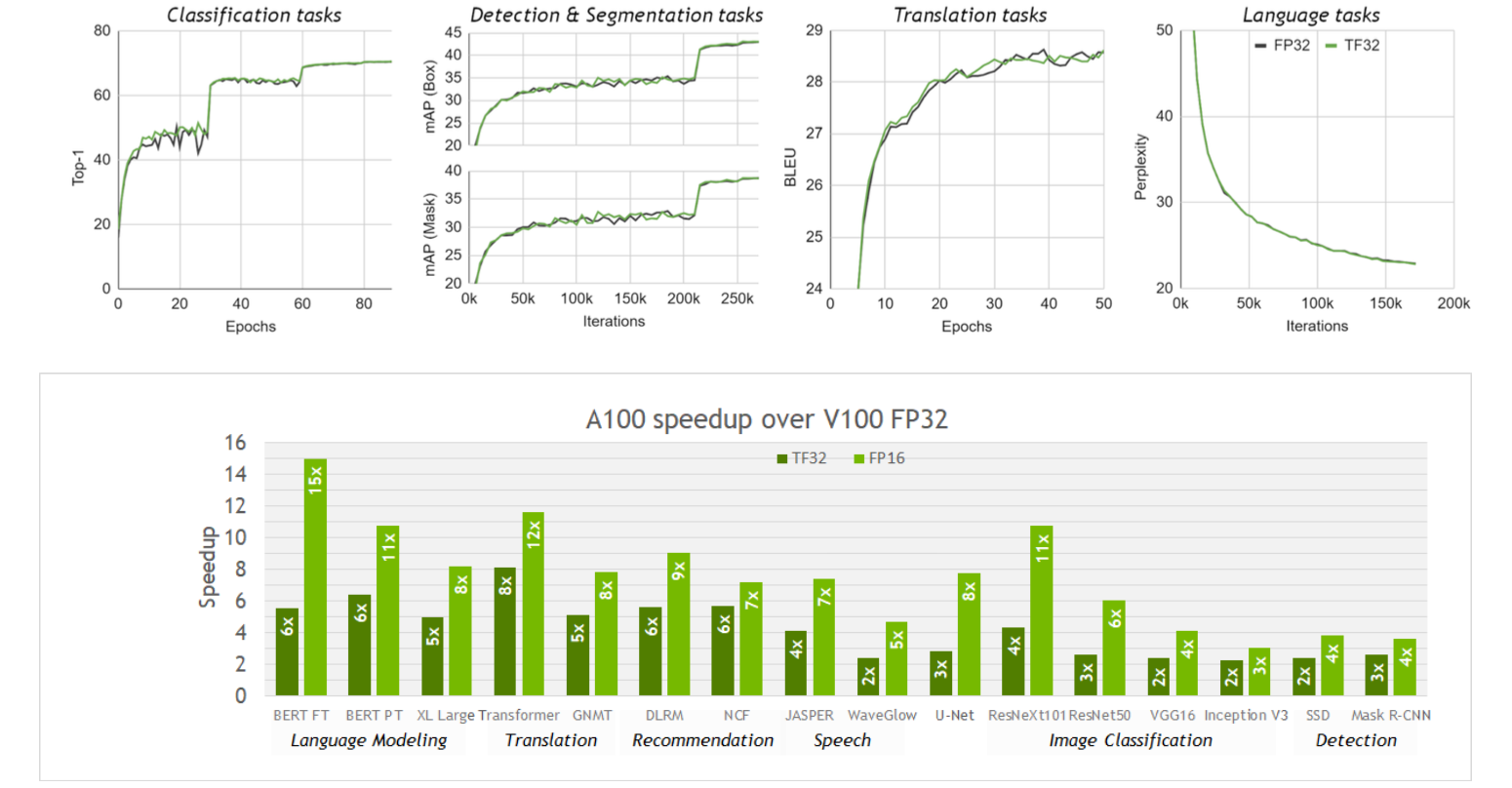
训练使用混合精度(FP32 + BF16);推理使用半精度(BF16)
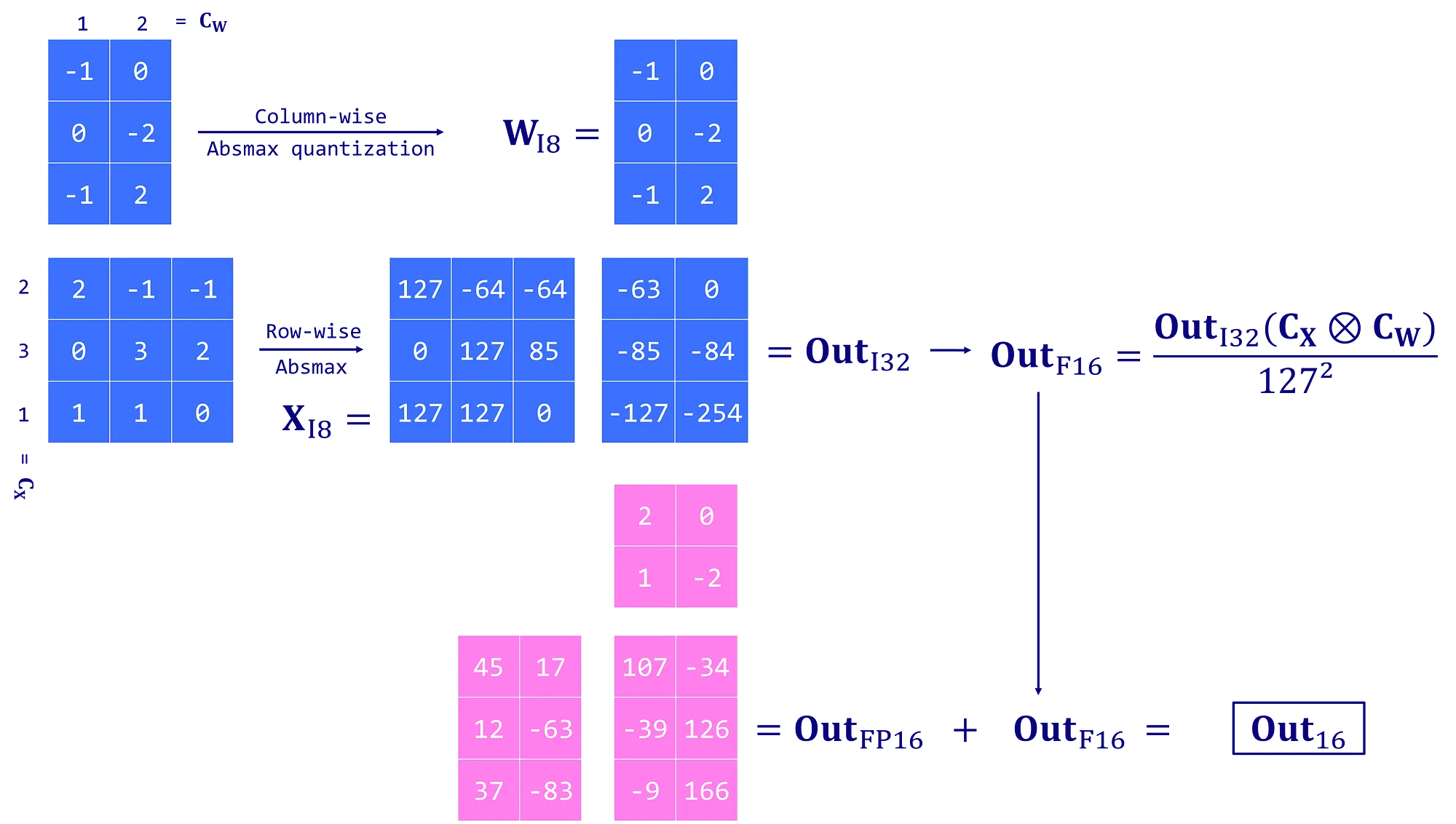
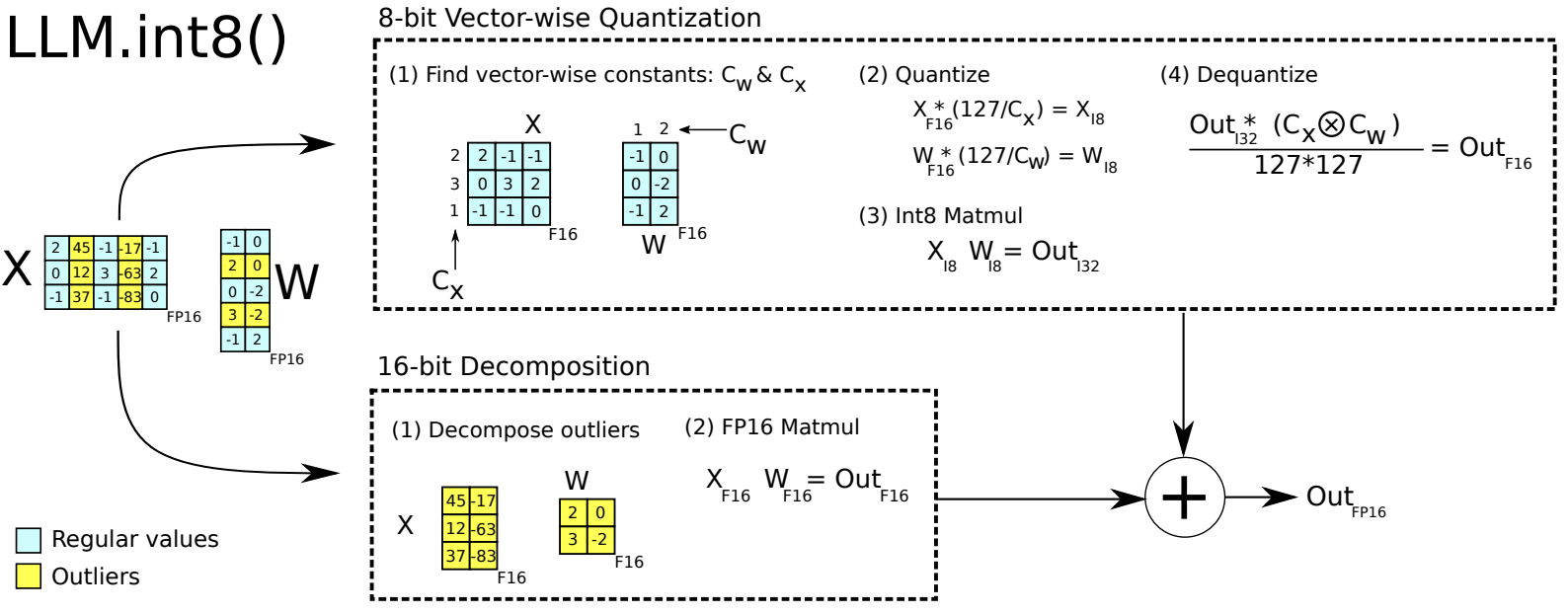
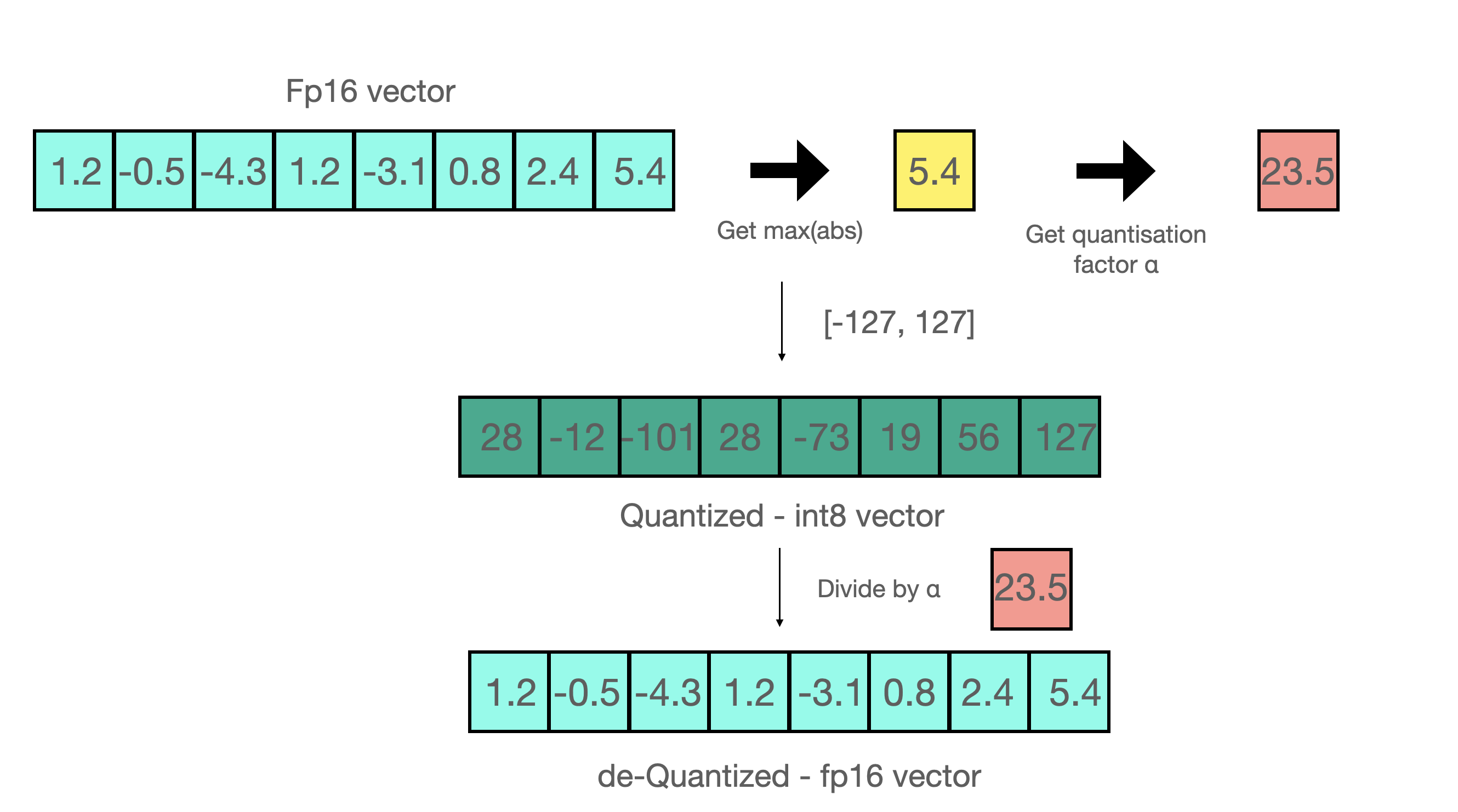
在机器学习术语中,FP32 称为全精度 (4 字节),而 BF16 和 FP16 称为半精度 (2 字节)。除此以外,还有 Int8 (INT8) 数据类型,它是一个 8 位的整型数据表示,可以存储 $2^8$ 个不同的值 (对于有符号整数,区间为 [-128, 127],而对于无符号整数,区间为 [0, 255])。
虽然理想情况下训练和推理都应该在 FP32 中完成,但 FP32 比 FP16/BF16 慢两倍,因此在实践中,训练时,常常使用混合精度方法,其中,使用 FP32 权重作为精确的 “主权重 (master weight)”,而使用 FP16/BF16 权重进行前向和后向传播计算以提高训练速度,最后在梯度更新阶段再使用 FP16/BF16 梯度更新 FP32 主权重。
在训练期间,主权重始终为 FP32。而在实践中,推理时,半精度权重通常能提供与 FP32 相似的精度 —— 因为只有在模型梯度更新时才需要精确的 FP32 权重。这意味着在推理时我们可以使用半精度权重,这样我们仅需一半 GPU 显存就能获得相同的结果。
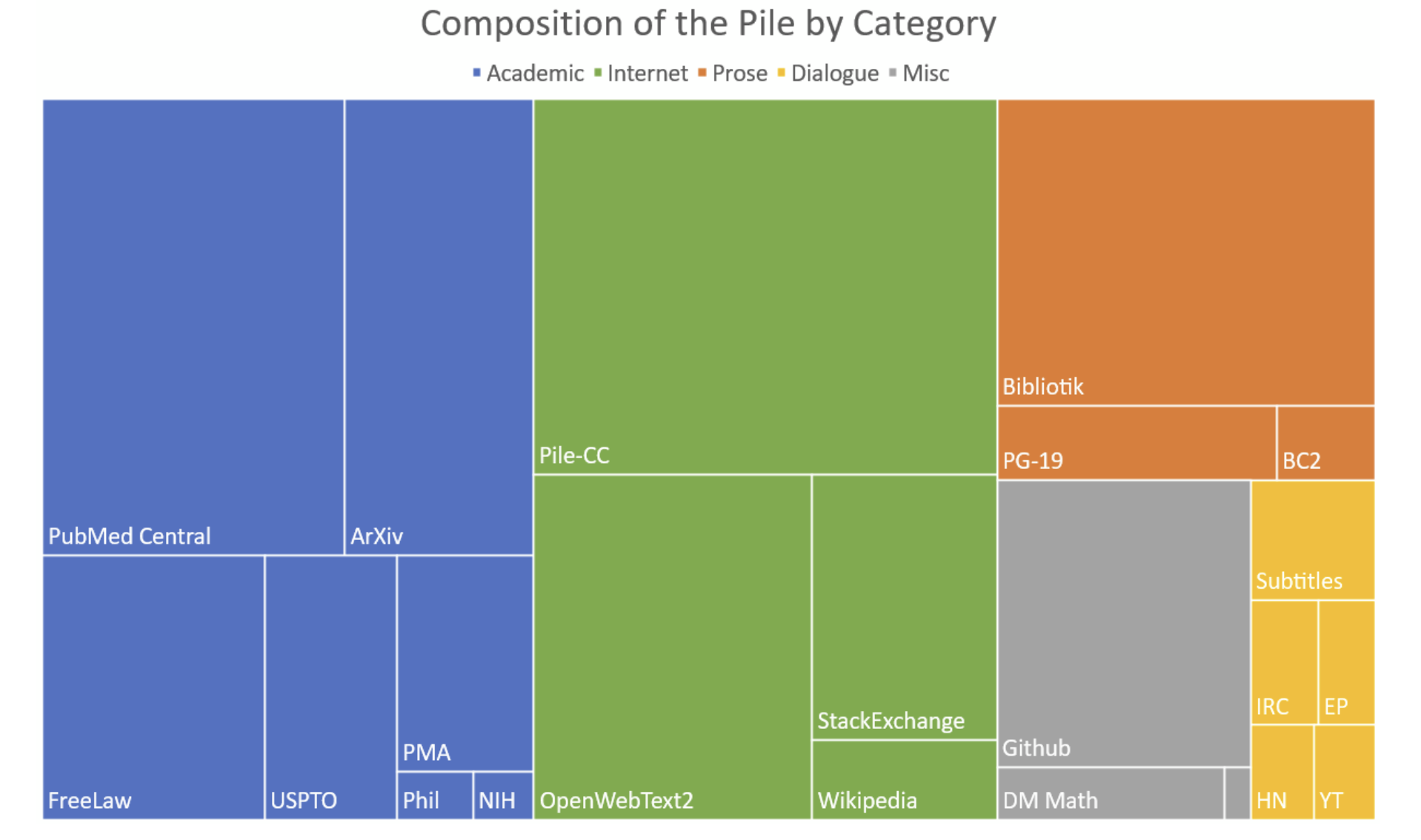
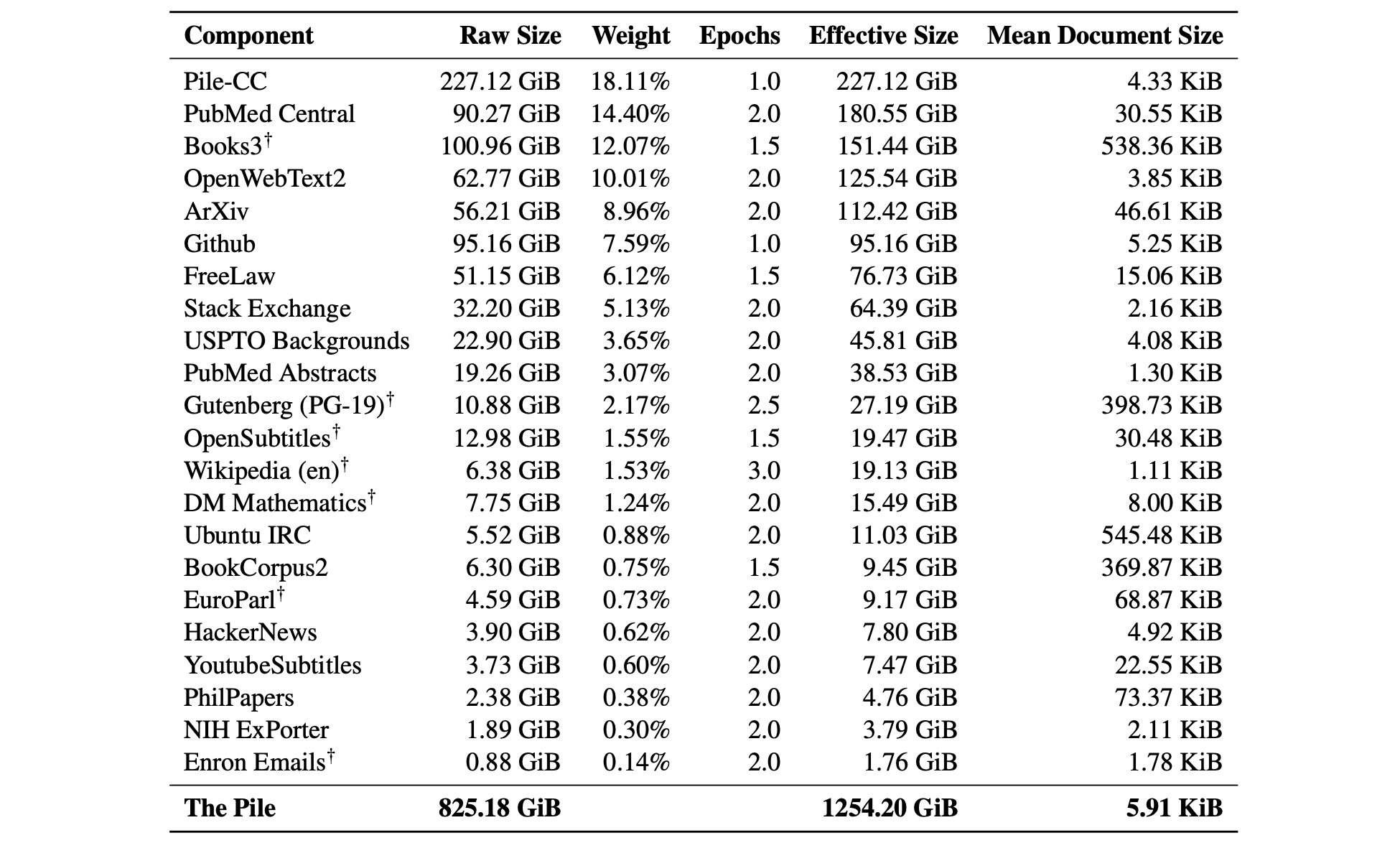
[Pile][The-Pile]
一个 825GB 的多样化开源语言建模数据集,由 22 个较小的高质量数据集组合而成。
为什么 Pile 是一个很好的训练集?
最近的工作表明,特别是对于大型模型,数据源的多样性可以提高模型的一般跨领域知识以及下游泛化能力。在我们的评估中,在 Pile 上训练的模型不仅在传统语言建模基准上显示出适度的改进,而且还在 Pile BPB 上显示出显着的改进。
为什么 Pile 是一个很好的基准?
为了在 Pile BPB(每字节位数)上取得好成绩,模型必须能够理解许多不同的领域,包括书籍、GitHub 存储库、网页、聊天日志以及医学、物理、数学、计算机科学和哲学论文。Pile BPB 是对这些领域的世界知识和推理能力的度量,使其成为大型语言模型的通用、跨领域文本建模能力的稳健基准。