探索多模态大模型 Qwen2.5-VL
本文档提供了一篇关于Qwen2.5-VL 多模态大模型的详细指南,涵盖了从模型架构、性能到实际部署和使用的各个方面。它不仅介绍了如何下载不同版本(如 3B 和 7B Instruct)的模型,还提供了安装和启动模型的命令行指令。此外,文档还展示了如何通过 cURL 命令测试模型,并给出了一个使用 OpenAI API 与 Qwen2.5-VL 进行交互的 Python 示例代码,该代码专注于图像中的火灾、烟雾和安全帽佩戴情况检测,支持本地和网络图片。
Qwen2.5-VL
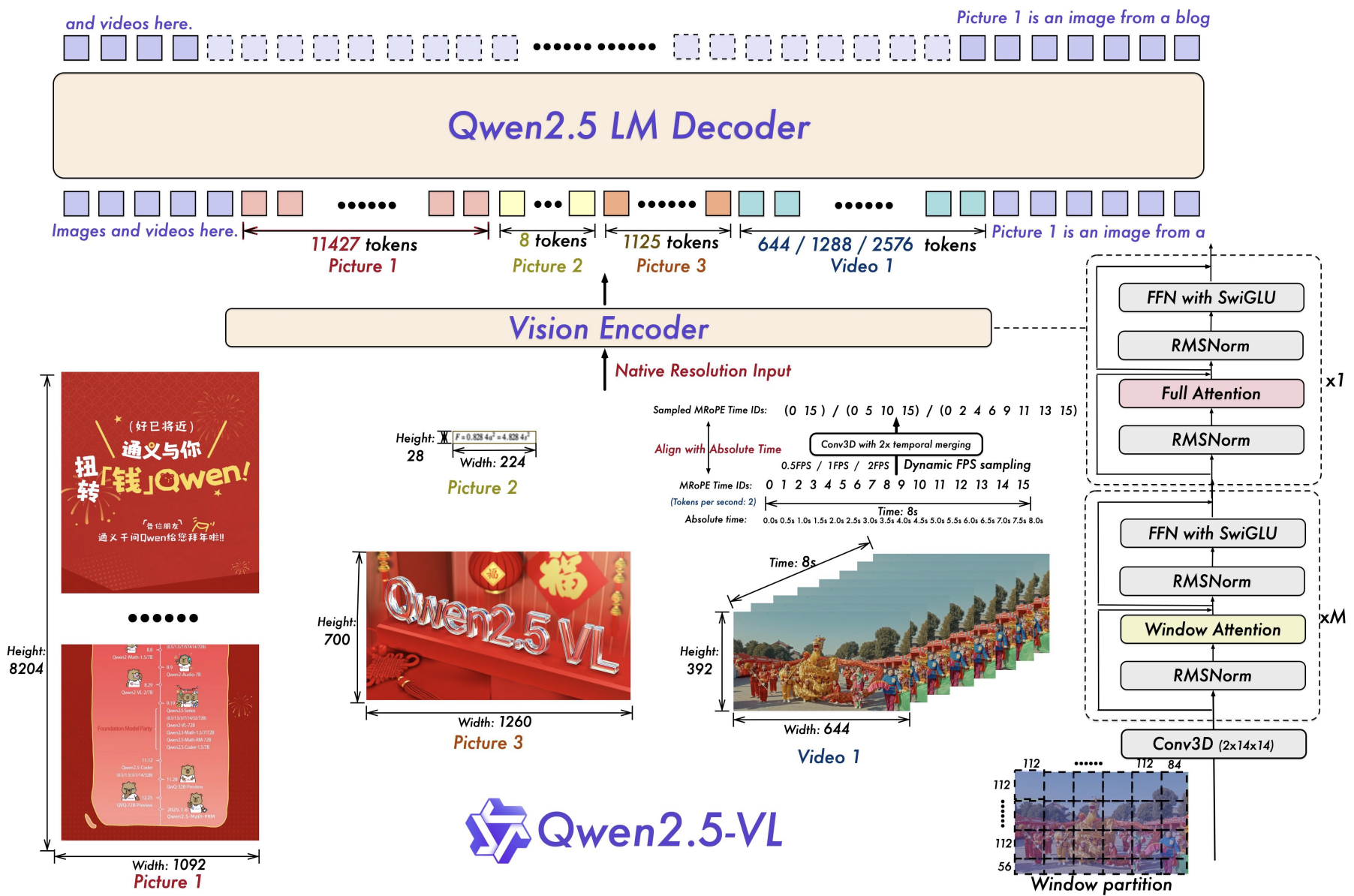
模型架构
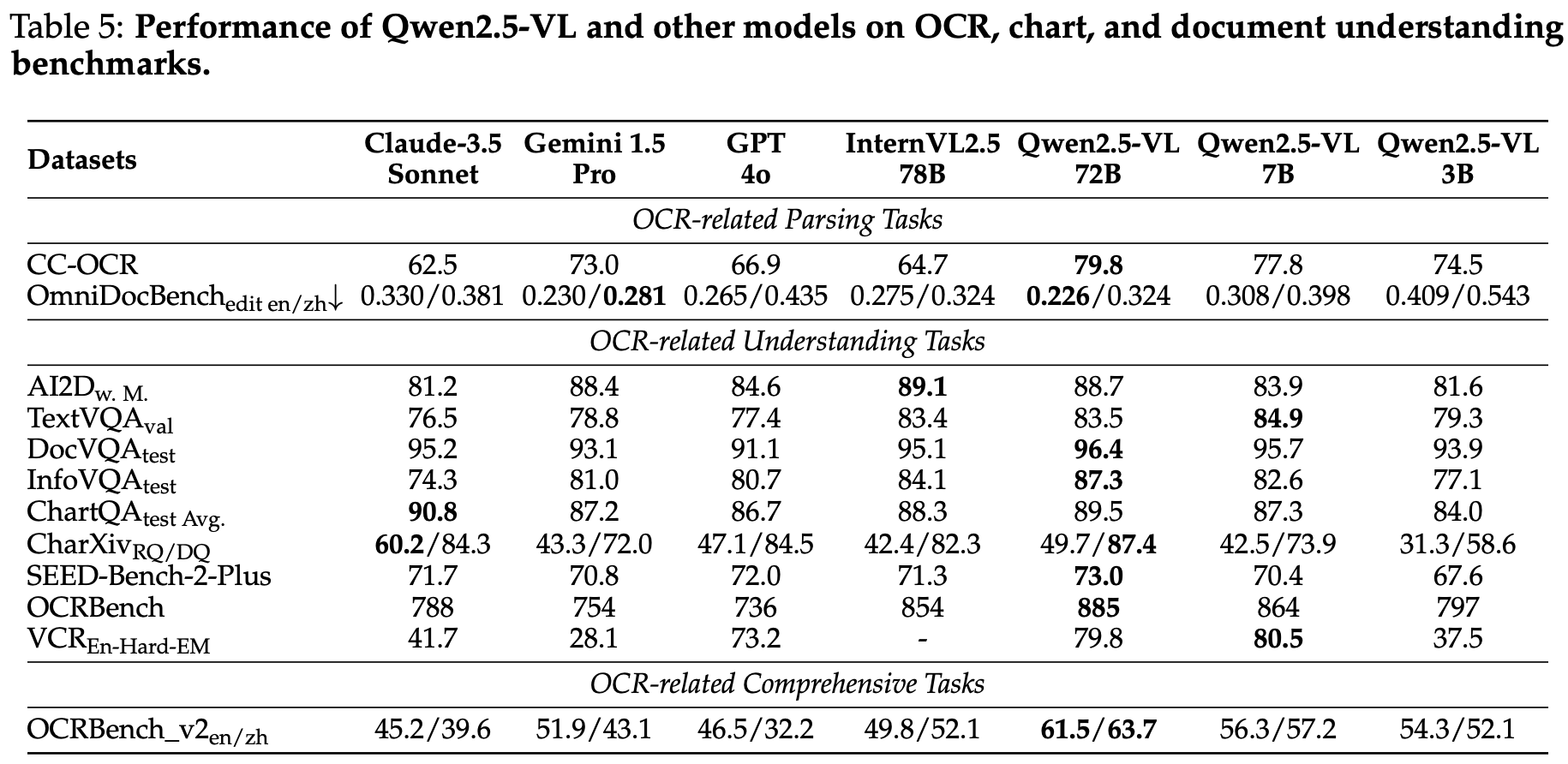
模型性能
魔搭下载
在下载前,请先通过如下命令安装 ModelScope
pip install modelscope
Qwen2.5-VL-3B-Instruct
modelscope download --model Qwen/Qwen2.5-VL-3B-Instruct --local_dir Qwen2.5-VL-3B-Instruct
Qwen2.5-VL-7B-Instruct
modelscope download --model Qwen/Qwen2.5-VL-7B-Instruct --local_dir Qwen2.5-VL-7B-Instruct
默认存储到 ~/.cache/modelscope/hub(Linux/macOS)或 C:\Users<用户名>.cache\modelscope\hub(Windows)。--local_dir 参数可以指定下载目录。
部署模型
安装 vllm
pip install vllm
启动模型
vllm serve
vllm serve /data/models/vlm/Qwen2.5-VL-7B-Instruct \
--served-model-name Qwen2.5-VL \
--max-model-len 32000
vllm.entrypoints.openai.api_server
python -m vllm.entrypoints.openai.api_server \
--host 0.0.0.0 --port 8000 \
--model /data/models/vlm/Qwen2.5-VL-7B-Instruct \
--served-model-name Qwen2.5-VL \
--tensor-parallel-size 4 \
--dtype=float16 \
--max-model-len 32000
--host设置为0.0.0.0,表示监听所有网络接口,其它机器可以通过 IP 地址访问。这是默认设置,可以不设置。--port设置为8000,表示监听端口为 8000。这是默认设置,可以不设置。--model设置为模型的本地路径。--tensor-parallel-size设置为4,表示使用 4 个 GPU 进行张量并行处理。--max-model-len设置为32000,表示模型的最大上下文长度为 32000。模型默认具有较长的上下文长度(128000)。这可能会导致在初始内存分析阶段出现OOM,或者由于KV缓存大小较小而导致性能低下。考虑将--max-model-len设置为较小的值。
测试模型
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2.5-VL",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://www.cdstm.cn/gallery/hycx/child/201703/W020170307572370556544.jpg"
}
},
{
"type": "text",
"text": "分析图像中是否有火灾。"
}
]
}
]
}'
- 火灾:https://www.cdstm.cn/gallery/hycx/child/201703/W020170307572370556544.jpg
- 烟雾:https://www.2008php.com/2019_Website_appreciate/2019-12-24/20191224155746ewIAu.jpg
- 正确配带安全帽:https://img95.699pic.com/photo/60051/3724.jpg_wh860.jpg
- 安全帽:https://cbu01.alicdn.com/img/ibank/2020/925/277/13785772529_800623862.jpg
使用 OpenAI API 进行交互
以下代码示例展示了如何使用 OpenAI API 与 Qwen2.5-VL 模型进行交互,检测图像中的火灾、烟雾和人员安全帽佩戴情况。支持本地图片和互联网图片的检测。
pip install openai
import os
import base64
from openai import OpenAI
# 配置API参数
OPENAI_API_KEY = "EMPTY"
OPENAI_API_BASE = "http://172.16.33.66:8000/v1"
MODEL_NAME = "Qwen2.5-VL"
PROMPT = """
请检测图像中的所有火灾、烟雾和人员安全帽佩戴情况,并以坐标形式返回每个目标的位置。输出格式如下:
- 火灾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "火灾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 烟雾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "烟雾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 人员对象:{"bbox_2d": [x1, y1, x2, y2], "label": "人员", "sub_label": "佩戴安全帽" / "未佩戴安全帽" / "不确定"}
请严格按照上述格式输出所有检测到的对象及其坐标和属性,三类对象分别输出。如无法确定,请将 "sub_label" 设置为 "不确定"。
检测规则:
- 火灾:图像中存在明显火焰或燃烧迹象。
- 烟雾:图像中存在明显的烟雾扩散现象。
- 人员:图像中有完整或部分可见的人体。
- 安全帽佩戴:安全帽必须正确佩戴在头部,且帽檐朝前;若无法判断,则标记为 "不确定"。
注意事项:
- 输出结果应尽量准确。
- 输出检测到的对象不要超过 10 个。
结果示例:
[
{"bbox_2d": [100, 200, 180, 300], "label": "火灾", "sub_label": "严重"},
{"bbox_2d": [220, 150, 350, 280], "label": "烟雾", "sub_label": "轻微"},
{"bbox_2d": [400, 320, 480, 420], "label": "人员", "sub_label": "佩戴安全帽"},
{"bbox_2d": [520, 330, 600, 430], "label": "人员", "sub_label": "未佩戴安全帽"}
]
"""
client = OpenAI(
api_key=OPENAI_API_KEY,
base_url=OPENAI_API_BASE,
)
def is_url(path: str) -> bool:
return path.startswith("http://") or path.startswith("https://")
def encode_image_to_base64(image_path: str) -> str:
with open(image_path, "rb") as f:
encoded_image = base64.b64encode(f.read())
encoded_image_text = encoded_image.decode("utf-8")
ext = os.path.splitext(image_path)[-1].lower().replace('.', '')
if ext == 'jpg':
ext = 'jpeg'
return f"data:image/{ext};base64,{encoded_image_text}"
def detect_image(image: str, prompt: str = PROMPT) -> str:
if is_url(image):
image_url = image
else:
image_url = encode_image_to_base64(image)
chat_response = client.chat.completions.create(
model=MODEL_NAME,
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url}},
{"type": "text", "text": prompt},
],
},
],
)
return chat_response.choices[0].message.content if hasattr(chat_response, 'choices') else str(chat_response)
def main():
local_images = [
# 可在此添加需要检测的本地图片路径
"images/fire1.png",
]
url_images = [
# 可在此添加需要检测的互联网图片URL
"https://www.cdstm.cn/gallery/hycx/child/201703/W020170307572370556544.jpg"
]
all_images = local_images + url_images
results = []
for img in all_images:
print(f"检测图片: {img}")
try:
result = detect_image(img)
print(f"结果: {result}\n{'-'*40}")
results.append({"image": img, "result": result})
except Exception as e:
print(f"检测失败: {e}\n{'-'*40}")
results.append({"image": img, "result": f"检测失败: {e}"})
if __name__ == "__main__":
main()
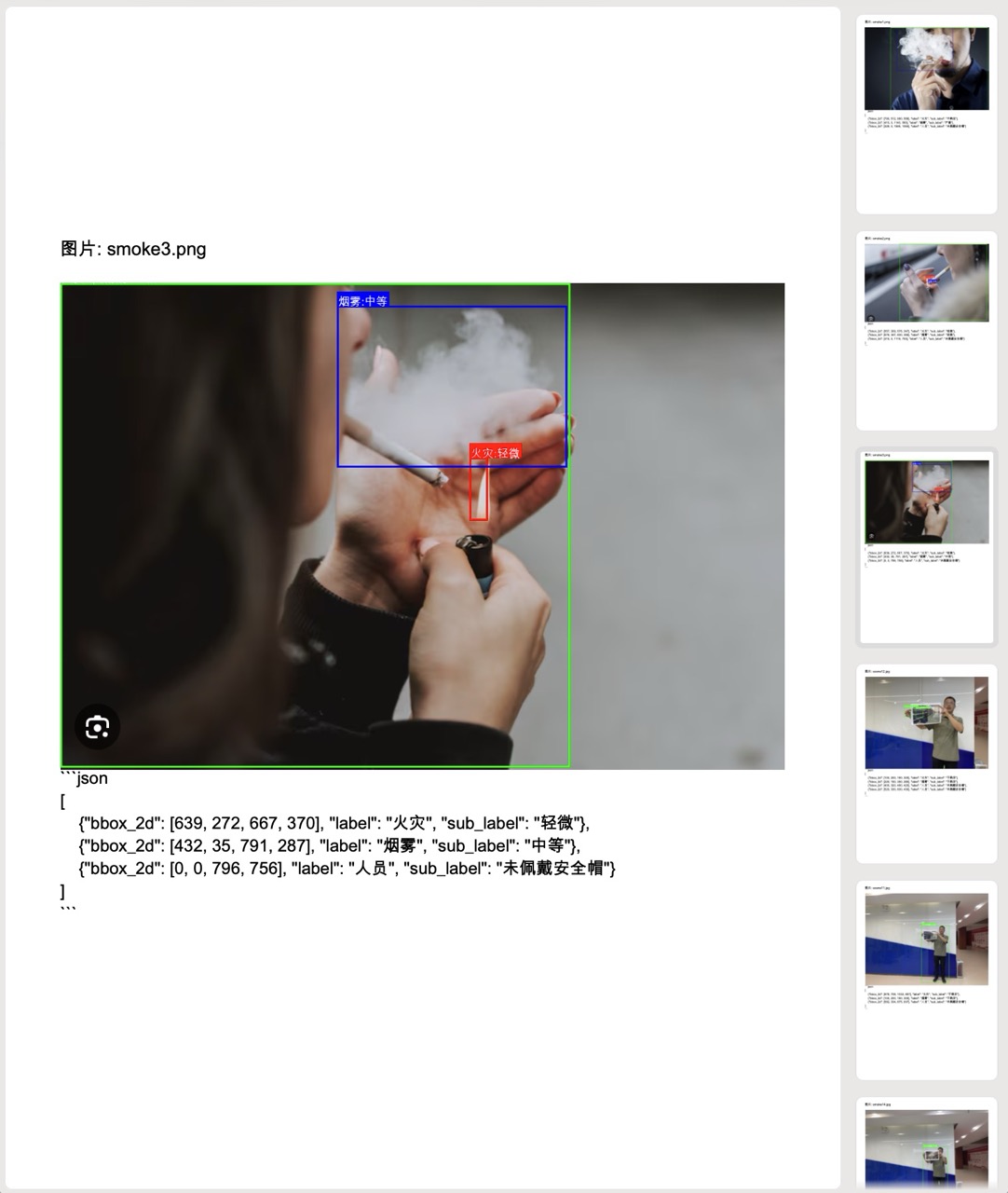
安全检测系统
基于多模态大模型 Qwen2.5-VL 实现了一个完整的安全检测系统,主要功能是通过视觉模型检测图像中的火灾、烟雾和人员安全帽佩戴情况,并将结果可视化输出。

主要功能
- 图像检测:
- 使用OpenAI API调用视觉模型(Qwen2.5-VL)分析图像
- 检测火灾、烟雾和安全帽佩戴情况
- 返回检测目标的边界框坐标和分类标签
- 结果可视化:
- 在原始图像上绘制检测框和标签
- 红色框标记火灾,蓝色框标记烟雾,绿色框标记人员
- 标注人员是否佩戴安全帽
- 报告生成:
- 将检测结果保存为PDF文档
- 包含原始/标注图像和检测结果的文字描述
- 文件管理:
- 自动创建必要的目录结构(images, marked_images, fonts)
- 支持本地图像和网络URL图像两种输入方式
安装依赖
在运行代码前,请确保安装了以下Python库:
pip install openai reportlab Pillow
代码
import os
import base64
import json
import re
import logging
from typing import List, Dict, Any, Union, Optional
from pathlib import Path
from openai import OpenAI
from reportlab.lib.pagesizes import A4
from reportlab.pdfgen import canvas
from reportlab.lib.utils import ImageReader
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from PIL import Image, ImageDraw, ImageFont
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(),
logging.FileHandler("fire_safety_detection.log")
]
)
logger = logging.getLogger("FireSafetyDetector")
# 配置API参数
CONFIG = {
"OPENAI_API_KEY": "EMPTY",
"OPENAI_API_BASE": "http://172.16.33.66:8000/v1",
"MODEL_NAME": "Qwen2.5-VL",
"IMAGE_DIR": "images",
"MARKED_DIR": "marked_images",
"FONT_DIR": "fonts",
"OUTPUT_PDF": "detection_results.pdf",
"SUPPORTED_IMAGE_EXTS": ('.png', '.jpg', '.jpeg')
}
PROMPT = """
请检测图像中的所有火灾、烟雾和人员安全帽佩戴情况,并以坐标形式返回每个目标的位置。输出格式如下:
- 火灾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "火灾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 烟雾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "烟雾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 人员对象:{"bbox_2d": [x1, y1, x2, y2], "label": "人员", "sub_label": "佩戴安全帽" / "未佩戴安全帽" / "不确定"}
请严格按照上述格式输出所有检测到的对象及其坐标和属性,三类对象分别输出。如无法确定,请将 "sub_label" 设置为 "不确定"。
检测规则:
- 火灾:图像中存在明显火焰或燃烧迹象。
- 烟雾:图像中存在明显的烟雾扩散现象。
- 人员:图像中有完整或部分可见的人体。
- 安全帽佩戴:安全帽必须正确佩戴在头部,且帽檐朝前;若无法判断,则标记为 "不确定"。
注意事项:
- 输出结果应尽量准确。
- 输出检测到的对象不要超过 10 个。
结果示例:
[
{"bbox_2d": [100, 200, 180, 300], "label": "火灾", "sub_label": "严重"},
{"bbox_2d": [220, 150, 350, 280], "label": "烟雾", "sub_label": "轻微"},
{"bbox_2d": [400, 320, 480, 420], "label": "人员", "sub_label": "佩戴安全帽"},
{"bbox_2d": [520, 330, 600, 430], "label": "人员", "sub_label": "未佩戴安全帽"}
]
"""
class FireSafetyDetector:
def __init__(self, config: Dict[str, Any] = CONFIG):
self.config = config
self.client = OpenAI(
api_key=config["OPENAI_API_KEY"],
base_url=config["OPENAI_API_BASE"],
)
self._setup_directories()
def _setup_directories(self):
"""创建必要的目录"""
Path(self.config["IMAGE_DIR"]).mkdir(exist_ok=True)
Path(self.config["MARKED_DIR"]).mkdir(exist_ok=True)
Path(self.config["FONT_DIR"]).mkdir(exist_ok=True)
@staticmethod
def is_url(path: str) -> bool:
"""检查路径是否为URL"""
return path.startswith("http://") or path.startswith("https://")
@staticmethod
def encode_image_to_base64(image_path: str) -> str:
"""将图像编码为Base64格式"""
with open(image_path, "rb") as f:
encoded_image = base64.b64encode(f.read()).decode("utf-8")
ext = Path(image_path).suffix.lower().replace('.', '')
ext = 'jpeg' if ext == 'jpg' else ext
return f"data:image/{ext};base64,{encoded_image}"
def detect_image(self, image: str, prompt: str = PROMPT) -> str:
"""调用模型进行图像检测"""
try:
image_url = image if self.is_url(image) else self.encode_image_to_base64(image)
response = self.client.chat.completions.create(
model=self.config["MODEL_NAME"],
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": image_url}},
{"type": "text", "text": prompt},
],
},
],
)
return response.choices[0].message.content if response.choices else ""
except Exception as e:
logger.error(f"检测失败: {str(e)}", exc_info=True)
return f"检测失败: {str(e)}"
def get_local_images(self) -> List[str]:
"""获取本地图像列表"""
images = []
for ext in self.config["SUPPORTED_IMAGE_EXTS"]:
images.extend(Path(self.config["IMAGE_DIR"]).glob(f"*{ext}"))
return [str(img) for img in images]
def register_chinese_font(self) -> str:
"""注册中文字体"""
font_path = Path(self.config["FONT_DIR"]) / "Arial Unicode.ttf"
if font_path.exists():
try:
pdfmetrics.registerFont(TTFont('ArialUnicode', str(font_path)))
return 'ArialUnicode'
except Exception as e:
logger.warning(f"字体注册失败: {str(e)}")
logger.warning("未找到可用的中文字体(建议放置 Arial Unicode.ttf 到 fonts 目录)")
return 'Helvetica'
def save_results_to_pdf(self, results: List[Dict[str, Any]], pdf_path: str = None):
"""将结果保存为PDF"""
pdf_path = pdf_path or self.config["OUTPUT_PDF"]
c = canvas.Canvas(pdf_path, pagesize=A4)
width, height = A4
margin = 40
font_name = self.register_chinese_font()
max_img_width = width - 2 * margin
max_img_height = height / 2 - margin
for item in results:
y = height - margin
img_path = item["image"]
result = item["result"]
# 标题
c.setFont(font_name, 13)
c.drawString(margin, y, f"图片: {Path(img_path).name}")
y -= 20
# 尝试加载并显示图像
display_img_path = self._get_display_image_path(img_path)
if display_img_path and display_img_path.exists():
try:
img = ImageReader(str(display_img_path))
iw, ih = img.getSize()
scale = min(max_img_width / iw, max_img_height / ih, 1)
img_w, img_h = iw * scale, ih * scale
img_x = margin + (max_img_width - img_w) / 2
c.drawImage(img, img_x, y - img_h, width=img_w, height=img_h)
y -= img_h + 10
except Exception as e:
logger.error(f"PDF图片渲染失败: {str(e)}")
c.setFont(font_name, 10)
c.drawString(margin, y, "[图片无法显示]")
y -= 20
# 检测结果
c.setFont(font_name, 12)
for line in result.split("\n"):
if y < margin: # 确保不会超出页面底部
c.showPage()
y = height - margin
c.setFont(font_name, 12)
c.drawString(margin, y, line)
y -= 16
c.showPage() # 每张图片和结果单独一页
c.save()
logger.info(f"检测结果已保存为PDF: {pdf_path}")
def _get_display_image_path(self, img_path: str) -> Optional[Path]:
"""获取用于显示的图像路径(优先使用标注后的图像)"""
if not self.is_url(img_path):
marked_path = Path(self.config["MARKED_DIR"]) / Path(img_path).name
if marked_path.exists():
return marked_path
if Path(img_path).exists():
return Path(img_path)
return None
@staticmethod
def extract_json_array(text: str) -> Optional[str]:
"""从文本中提取第一个完整的JSON数组字符串"""
text = text.replace('```json', '').replace('```', '').strip()
start = text.find('[')
if start == -1:
return None
bracket_count = 0
for i in range(start, len(text)):
if text[i] == '[':
bracket_count += 1
elif text[i] == ']':
bracket_count -= 1
if bracket_count == 0:
return text[start:i+1]
return None
@staticmethod
def try_fix_json(text: str) -> str:
"""尝试修复常见的JSON格式错误"""
text = text.replace('“', '"').replace('”', '"').replace("‘", "'").replace("’", "'")
text = re.sub(r',\s*([\]}])', r'\1', text)
text = re.sub(r'("[\]}])\s*("[a-zA-Z_]+"\s*:)', r'\1, \2', text)
return text
def parse_detection_result(self, result: str) -> Union[List[Dict], str]:
"""解析检测结果,返回对象列表或错误信息"""
try:
return json.loads(result)
except json.JSONDecodeError:
json_part = self.extract_json_array(result)
if json_part:
try:
return json.loads(json_part)
except json.JSONDecodeError:
try:
fixed = self.try_fix_json(json_part)
return json.loads(fixed)
except json.JSONDecodeError as e:
logger.error(f"JSON解析失败: {str(e)}\n原始内容: {json_part}")
return f"JSON解析失败: {str(e)}"
return f"未找到有效JSON数据: {result[:100]}..."
def draw_boxes_on_image(self, image_path: str, detection_result: Union[str, list], output_path: str):
"""在图像上绘制检测框和标签"""
# 解析结果
if isinstance(detection_result, str):
parsed_result = self.parse_detection_result(detection_result)
if isinstance(parsed_result, str):
logger.error(f"无法解析检测结果: {parsed_result}")
return False
results = parsed_result
else:
results = detection_result
if not isinstance(results, list):
logger.error(f"检测结果格式错误,应为列表: {type(results)}")
return False
try:
# 打开图像
image = Image.open(image_path).convert("RGB")
draw = ImageDraw.Draw(image)
# 尝试加载字体
font_path = Path(self.config["FONT_DIR"]) / "Arial Unicode.ttf"
try:
font = ImageFont.truetype(str(font_path), 18) if font_path.exists() else ImageFont.load_default()
except Exception:
font = ImageFont.load_default()
# 绘制检测框
for obj in results:
bbox = obj.get("bbox_2d")
label = obj.get("label", "")
sub_label = obj.get("sub_label", "")
if not bbox or len(bbox) != 4 or sub_label == "不确定":
continue
# 设置颜色
color_map = {
"火灾": (255, 0, 0), # 红色
"烟雾": (0, 0, 255), # 蓝色
"人员": (0, 255, 0) # 绿色
}
color = color_map.get(label, (128, 128, 128)) # 默认为灰色
# 绘制边界框
draw.rectangle(bbox, outline=color, width=3)
# 绘制标签
text = f"{label}:{sub_label}"
bbox_text = draw.textbbox((0, 0), text, font=font)
text_width = bbox_text[2] - bbox_text[0]
text_height = bbox_text[3] - bbox_text[1]
# 文本背景
text_bg = [
bbox[0],
bbox[1] - text_height - 4,
bbox[0] + text_width + 4,
bbox[1]
]
draw.rectangle(text_bg, fill=color)
# 文本
draw.text(
(bbox[0] + 2, bbox[1] - text_height - 2),
text,
fill=(255, 255, 255),
font=font
)
# 保存结果
image.save(output_path)
logger.info(f"标注图片已保存: {output_path}")
return True
except Exception as e:
logger.error(f"图片标注失败: {str(e)}", exc_info=True)
return False
def run(self, url_images: List[str] = None):
"""执行整个检测流程"""
url_images = url_images or []
local_images = self.get_local_images()
all_images = local_images + url_images
logger.info(f"共检测 {len(all_images)} 张图片(本地{len(local_images)},URL{len(url_images)})")
results = []
for img in all_images:
logger.info(f"处理图片: {img}")
try:
result = self.detect_image(img)
results.append({"image": img, "result": result})
# 仅处理本地图片的标注
if not self.is_url(img):
marked_path = Path(self.config["MARKED_DIR"]) / Path(img).name
self.draw_boxes_on_image(img, result, str(marked_path))
except Exception as e:
logger.error(f"处理图片失败: {img}, 错误: {str(e)}", exc_info=True)
results.append({"image": img, "result": f"处理失败: {str(e)}"})
# 保存结果到PDF
self.save_results_to_pdf(results)
logger.info("处理完成")
if __name__ == "__main__":
# 可在此处添加需要检测的互联网图片URL
url_images = [
# "https://example.com/fire_image.jpg"
]
detector = FireSafetyDetector()
detector.run(url_images=url_images)