Qwen2.5-Omni:端到端多模态大模型
Qwen2.5-Omni是Qwen系列中全新的旗舰级端到端多模态大模型,专为全面的多模式感知设计,无缝处理包括文本、图像、音频和视频在内的各种输入,同时支持流式的文本生成和自然语音合成输出。
点击下方视频了解更多信息吧 😃

概览
简介
Qwen 2.5-Omni是一个端到端的多模态大语言模型,旨在感知包括文本、图像、音频和视频在内的多种模态,同时以流式的方式生成文本和自然语音响应。
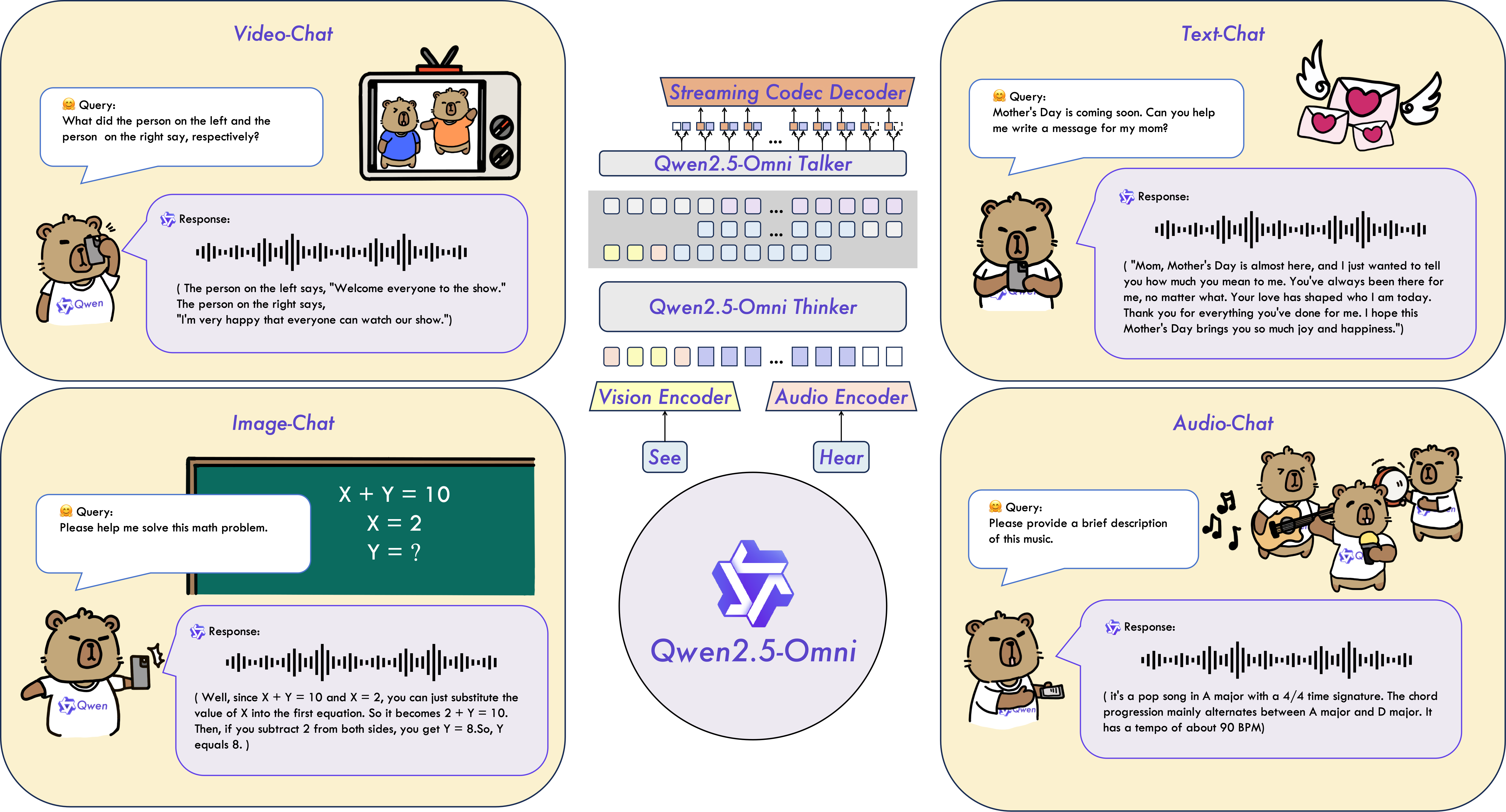
主要特点
-
全能创新架构:我们提出了一种全新的Thinker-Talker架构,这是一种端到端的多模态模型,旨在支持文本/图像/音频/视频的跨模态理解,同时以流式方式生成文本和自然语音响应。我们提出了一种新的位置编码技术,称为TMRoPE(Time-aligned Multimodal RoPE),通过时间轴对齐实现视频与音频输入的精准同步。
-
实时音视频交互:架构旨在支持完全实时交互,支持分块输入和即时输出。
-
自然流畅的语音生成:在语音生成的自然性和稳定性方面超越了许多现有的流式和非流式替代方案。
-
全模态性能优势:在同等规模的单模态模型进行基准测试时,表现出卓越的性能。Qwen2.5-Omni在音频能力上优于类似大小的Qwen2-Audio,并与Qwen2.5-VL-7B保持同等水平。
-
卓越的端到端语音指令跟随能力:Qwen2.5-Omni在端到端语音指令跟随方面表现出与文本输入处理相媲美的效果,在MMLU通用知识理解和GSM8K数学推理等基准测试中表现优异。
下载模型
Hugging Face
git clone https://huggingface.co/Qwen/Qwen2.5-Omni-3B
安装环境
pip install torch torchvision torchaudio
pip install transformers
pip install accelerate
pip install "qwen-omni-utils"
pip install boto3 botocore
使用示例
语音输入 -> 语音输出
编辑文件:demo.py
import torch
from transformers import Qwen2_5OmniForConditionalGeneration, Qwen2_5OmniProcessor
model_path = "/Users/junjian/HuggingFace/Qwen/Qwen2.5-Omni-3B"
model = Qwen2_5OmniForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
# attn_implementation="flash_attention_2", # macOS不支持flash_attention_2
)
processor = Qwen2_5OmniProcessor.from_pretrained(model_path)
from qwen_omni_utils import process_mm_info
# @title inference function
def inference(audio_path):
messages = [
{"role": "system", "content": [
{"type": "text", "text": "You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech."}
],},
{"role": "user", "content": [
{"type": "audio", "audio": audio_path},
]
},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
audios, images, videos = process_mm_info(messages, use_audio_in_video=True)
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt", padding=True, use_audio_in_video=True)
inputs = inputs.to(model.device).to(model.dtype)
output = model.generate(**inputs, use_audio_in_video=True, return_audio=True)
text = processor.batch_decode(output[0], skip_special_tokens=True, clean_up_tokenization_spaces=False)
audio = output[1]
return text, audio
import librosa
from io import BytesIO
from urllib.request import urlopen
audio_path = "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2-Audio/audio/guess_age_gender.wav"
audio = librosa.load(BytesIO(urlopen(audio_path).read()), sr=16000)[0]
# audio_path = "guess_age_gender.wav"
# audio = librosa.load(audio_path, sr=16000)[0]
# display(Audio(audio, rate=16000))
## Use a local HuggingFace model to inference.
response = inference(audio_path)
print(response[0][0])
# display(Audio(response[1], rate=24000))
输出:
system
You are Qwen, a virtual human developed by the Qwen Team, Alibaba Group, capable of perceiving auditory and visual inputs, as well as generating text and speech.
user
assistant
Well, it's really hard to guess someone's age and gender just from their voice. There are so many factors that can affect how a person sounds, like their accent, the way they speak, and even their mood. But, you know, it's not impossible. Some people might be able to tell based on a lot of experience. But it's not something that can be done with 100% accuracy. So, what do you think? Do you have any other questions about this?
📌 在我的 MacBook Pro M2 Max上运行,花了好几分钟才完成推理。🐢🐢🐢