端侧AI:Gemma 4 12B 创新架构与 LiteRT-LM 本地部署指南
Gemma 4 12B
- Introducing Gemma 4 12B: a unified, encoder-free multimodal model
- Gemma 4 12B: The Developer Guide
- Accelerating Gemma 4: faster inference with multi-token prediction drafters
- A Visual Guide to Gemma 4 12B
- Gemma 4: Byte for byte, the most capable open models
- Ollama Gemma 4
Gemma 4 12B 是谷歌最新推出的一款原生、无编码器(Encoder-free)的统一多模态大模型。它的核心定位是将高水平的“智能体(Agentic)”和多模态能力直接带到用户的笔记本电脑等日常消费级硬件上。
以下是对 Gemma 4 12B 大模型的详细介绍:
1. 创新的统一架构:无编码器设计(Encoder-free)
与传统的多模态模型(通常需要使用独立的、冻结的视觉或音频编码器将数据转化为文本格式)不同,Gemma 4 12B 采用了统一的、仅解码器(Decoder-only)的 Transformer 架构。
- 视觉嵌入器(Vision Embedder):仅有 35M 参数,取代了传统复杂的视觉 Transformer 层。它将 48x48 像素的原始图像块(Patches)通过单次矩阵乘法直接投影到大语言模型(LLM)的隐藏维度中,并利用 X 和 Y 矩阵的坐标查找技术,直接将空间位置信息附带在输入中。
- 音频波形投影(Audio Wave Projection):完全取消了独立的音频编码器。它直接将 16 kHz 的原始音频信号切片为 40ms 的帧(每帧包含 640 个浮点数),并通过线性投影无缝输入到 LLM 的空间中。
优势:这种端到端的统一架构消除了不同模态间的转换延迟,减少了内存碎片,大大提升了在本地硬件上的推理效率。
2. 强大的多模态与智能体推理能力
Gemma 4 12B 的规模介于轻量级的 E4B 和高性能的 26B MoE 之间,但在多项基准测试中的表现已经逼近规模更大的 26B 混合专家(MoE)模型,且内存占用不到后者的一半。
- 全模态支持:原生且高效地支持文本、图像、视频以及中等规模模型中首次加入的原生音频输入。它能轻松胜任自动语音识别(ASR)、视频流理解、音视频双重解析以及语速转写(Diarization)等复杂任务。
- 智能体级推理与代码编写(Agentic Reasoning & Coding):具备出色的多步骤推理能力和严格的指令遵循能力,在整体质量上比前代模型提升了 60% 以上。它可以与已有的 Agent 框架(如 OpenCode、OpenClaw)无缝结合,在本地执行复杂的代码编写、运行以及数据分析。
- 超长上下文:拥有高达 256K tokens 的上下文窗口,且支持超过 140 种语言。
3. 专为笔记本端部署设计(Laptop-Ready)
Gemma 4 12B 的核心优势之一就是极致的“边缘友好性”:
-
低硬件门槛:模型体积足够轻量,可以完美运行在仅有 16GB VRAM(显存)或统一内存 的消费级 GPU 笔记本或 PC 上(例如 Apple Silicon 芯片的 Mac 笔记本)。
-
开发者生态与工具链:
-
Google AI Edge Gallery:支持在 macOS 上离线原生运行,并自带沙箱化的 Python 执行环境,可以在聊天框内直接编写、执行代码并绘制科学图表。
-
LiteRT-LM 命令行工具:提供了一个兼容 OpenAI API 的本地服务器命令(
litert-lm serve),允许开发者使用 Continue、Aider 等流行插件,一键将本地部署的 Gemma 4 12B 接入口岸到任何标准的 SDK、工具或前端 UI 中。 -
开源协议:在宽松的 Apache 2.0 许可证下发布,对开发者完全开放。
LiteRT-LM 概述
使用 LiteRT-LM 在设备端运行大语言模型 (LLMs)
LiteRT-LM 是一款生产就绪的开源推理框架,旨在为边缘设备提供高性能、跨平台的大语言模型 (LLM) 部署。
- 跨平台支持:可在 Android、iOS、Web、桌面端和物联网(例如树莓派)上运行。
- 硬件加速:通过充分利用各种硬件上的 GPU 和 NPU 加速器,获得极致性能和系统稳定性。
- 多模态:构建支持视觉和音频的大语言模型应用。
- 工具调用:支持智能体 (Agent) 工作流中的函数调用,并通过受约束的解码 (Constrained Decoding) 提高准确性。
- 广泛的模型支持:可运行 Gemma、Llama、Phi-4、Qwen 等多种模型。
LiteRT-LM CLI
命令行界面(CLI)允许您在 Linux、macOS、Windows 或树莓派(Raspberry Pi)上运行 .litertlm 模型。
功能概述
LiteRT-LM CLI 是一款用于与本地大语言模型(LLM)进行交互的强大工具。它支持:
- 快速安装:使用
uvx按需运行,或使用uv或pip进行永久安装。参见安装。 - 交互式对话:在交互式对话会话中运行模型。参见使用说明。
- 高级功能:通过多 Token 预测、多模态组件和函数调用来优化和扩展您的模型。
- 兼容 OpenAI 的服务器:启动一个模拟 OpenAI 接口的本地服务器。参见兼容 OpenAI 的服务器。
uv 安装
# Install to a persistent environment, with the supported python version.
export UV_PYTHON=3.14 # Optional, set the uv python version.
uv tool install litert-lm
升级
uv tool upgrade litert-lm
下载模型
litert-community/SmolLM2-135M-Instruct
通过下载这个小的模型,我们可以快速了解到下载的路径和格式,保存到
~/.litert-lm/models目录下。
litert-lm import --from-huggingface-repo=litert-community/SmolLM2-135M-Instruct SmolLM2_135M_Instruct.litertlm smollm2-135m
Downloading SmolLM2_135M_Instruct.litertlm from litert-community/SmolLM2-135M-Instruct...
SmolLM2_135M_Instruct.litertlm: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████| 143M/143M [08:32<00:00, 279kB/s]
Successfully imported model to /Users/junjian/.litert-lm/models/smollm2-135m/model.litertlm
You can now run the model with 'litert-lm run smollm2-135m'
litert-community/gemma-4-12B-it-litert-lm
litert-lm import \
--from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm \
gemma-4-12B-it.litertlm \
gemma4-12b
如果国内用户下载有问题,可以到 ModelScope 下载 gemma-4-12B-it.litertlm 文件,并放到 ~/.litert-lm/models/gemma4-12b/model.litertlm 路径下。
运行模型
litert-lm run gemma4-12b --backend=gpu --prompt "介绍一下自己"
你好!我是 **Gemma 4**,是由 **Google DeepMind** 开发的大型语言模型。
作为 Gemma 4 系列的一员,我是一个**开放权重(open weights)**模型。以下是关于我的一些核心信息:
### 1. 我的能力
* **文本处理**:我可以理解并生成多种语言的文本,包括回答问题、创作内容、总结文章、编写代码以及进行逻辑推理。
* **多模态输入**:我能够理解和处理**文本**和**图像**输入。
* **音频处理**:在 Gemma 4 系列中,2B 和 4B 版本还具备处理**音频**输入的能力。
* **输出形式**:无论输入是什么形式,我目前**仅能生成文本**输出(我无法生成图像或音频文件)。
### 2. 我的知识范围
* **知识截止日期**:我的知识更新截止到 **2025 年 1 月**。对于此日期之后发生的事件,除非你在对话中提供相关背景信息,否则我可能无法提供准确信息。
* **工具使用**:除非在对话上下文中明确提供了特定的工具定义和端点,否则我无法访问互联网、搜索 Google 或使用外部工具。
### 3. 我的定位
我旨在作为一个强大、灵活且可用的模型,帮助用户完成各种任务。你可以把我当作你的助手、创意伙伴或知识库。
**今天有什么我可以帮你的吗?**
- ❌ Multi-Token Prediction (MTP)
- ❌ Multi-Modality
- ✅ Function Calling
OpenAI-Compatible Server
启动服务器
使用 serve 命令启动服务器。默认情况下,它会在端口 9379 上启动一个兼容 OpenAI 的服务器。
该服务器会自动动态加载并托管您本地注册中心中的任何模型。
litert-lm serve
Starting OpenAI-compatible API server on 0.0.0.0:9379...
支持的端点(Endpoints)
该服务器模拟了以下 OpenAI API 端点:
- 列出模型:
GET /v1/models列出服务器当前可用的模型。 - 对话补全:
POST /v1/chat/completions为给定的对话生成文本补全。支持流式传输(Streaming)响应。
选择后端与配置
向服务器发送请求时,您可以通过格式化请求体(Payload)中的 model 字段,来动态选择执行后端(CPU、GPU 或 NPU)并配置最大 Token 数量(上下文长度)。
model 字段支持以下格式:
model_id[,backend][,max_tokens]
发送 HTTP 请求
curl http://localhost:9379/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gemma4-12b,gpu",
"messages": [
{"role": "user", "content": "Hello!"}
]
}'
{
"id": "chatcmpl_20260605025418118219",
"object": "chat.completion",
"created": 1780628058,
"model": "gemma4-12b,gpu",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "Hello! How can I help you today?"
},
"finish_reason": "stop"
}
]
}
LiteRT 社区
LiteRT 是 Google 推出的一款用于在边缘平台上进行高性能机器学习(ML)与生成式人工智能(GenAI)部署的设备端框架。它是 TensorFlow Lite 的升级版替代者。在这个社区页面上,您可以找到适用于各种机器学习/人工智能任务、即开即用的 LiteRT 模型。
在这一生态系统中,LiteRT-LM 专注于前沿的生成式人工智能。由于意识到如今的大语言模型(LLM)更像是相关模型的复杂流水线,而非单个独立的模型,LiteRT-LM 充分利用 LiteRT 的优势,为在设备端运行大语言模型提供了优化后的解决方案。
LiteRT 和 LiteRT-LM 均可在 Android、iOS、Windows、macOS、Linux、物联网(IoT)和 Web 等多种设备上运行,以便在多样化的设备环境中轻松进行部署和扩展。
Google AI Edge Eloquent
Google AI Edge Eloquent 是谷歌推出的一款主打完全离线、免订阅、无使用量限制的 AI 驱动语音听写与文本润色应用。
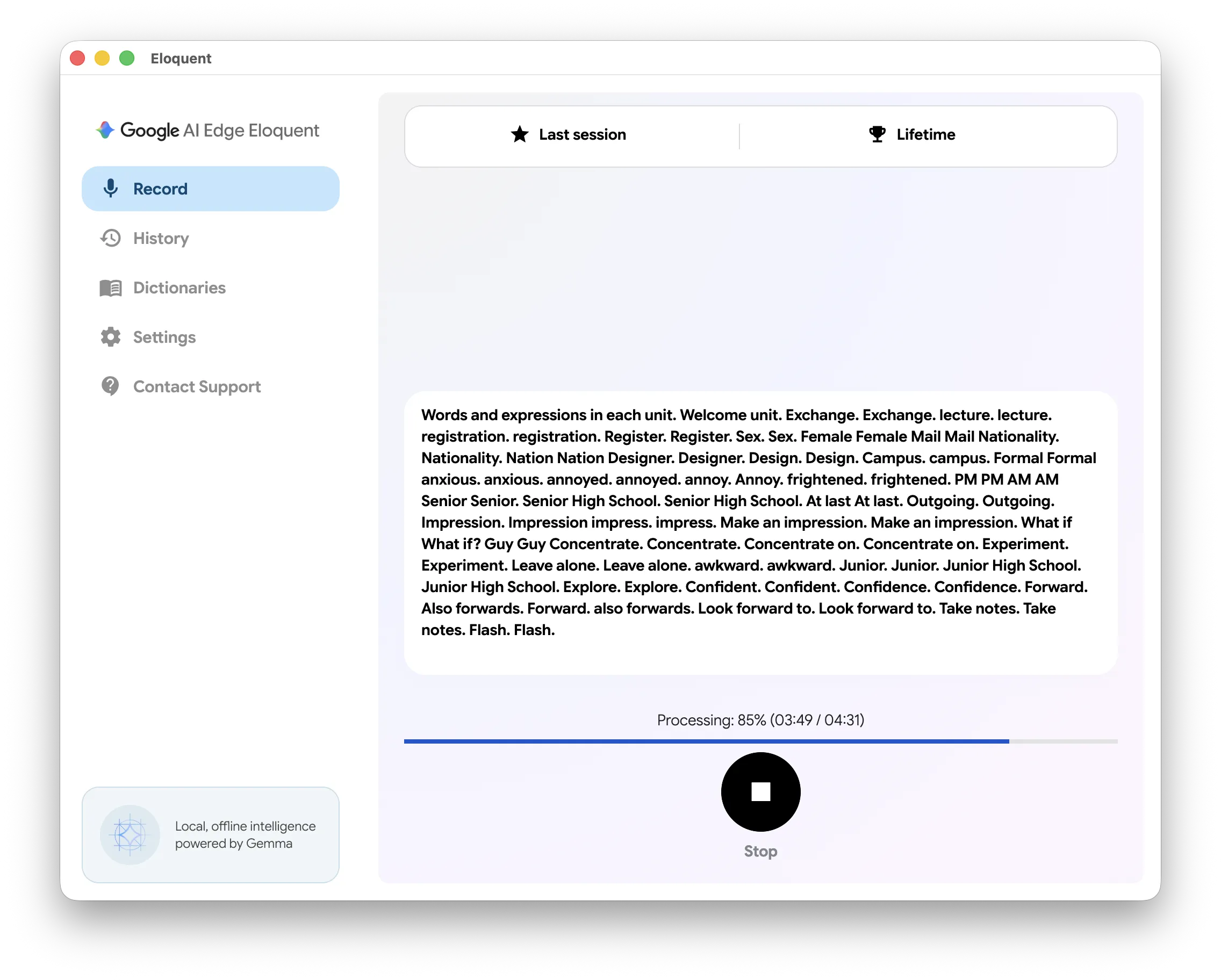
Eloquent 下载的模型文件存储在以下路径:
ll "/Users/junjian/Library/Application Support/com.google.AIEdgeEloquent/"
drwxr-xr-x@ 3 junjian staff 96B 6月 5 08:49 databases
-rw-r--r--@ 1 junjian staff 2.4G 6月 4 23:49 e450f245265502c7760785e.litertlm
-rw-r--r--@ 1 junjian staff 11M 6月 5 08:49 e450f245265502c7760785e.litertlm_1780588161_2583085056_mldrift_program_cache.bin
-rw-r--r--@ 1 junjian staff 741M 6月 5 00:08 e450f245265502c7760785e.litertlm_1780588161_2583085056_mldrift_weight_cache.bin
-rw-r--r--@ 1 junjian staff 12K 6月 4 23:49 key_value_store.sqlite
Google AI Edge Gallery
Google AI Edge Gallery 是谷歌官方推出的一款开源、全本地运行(On-device)的 AI 交互沙盒与技术展示应用。
简单来说,它是谷歌为开发者和 AI 爱好者打造的一个“端侧 AI 游乐场”。通过它,用户无需配置复杂的开发环境,就可以直接在手机(Android、iOS)或电脑(macOS)的硬件上,100% 离线、私密且极其顺畅地运行谷歌最新的 Gemma 系列开源大模型。
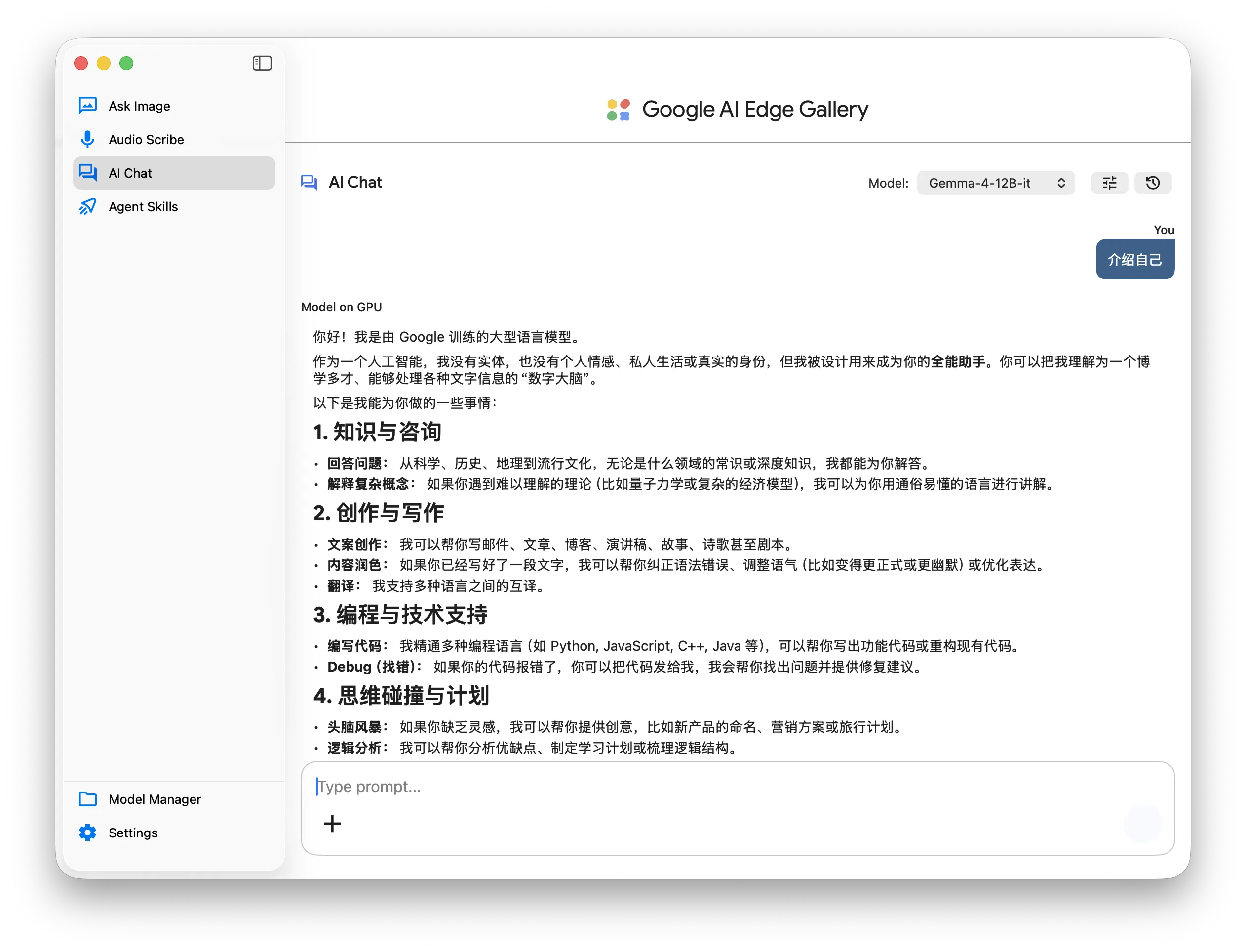
ll "/Users/junjian/Library/Application Support/com.google.AIEdgeGallery/Documents/Gemma_4_12B_it/v0"
lrwxr-xr-x 1 junjian staff 58B 6月 4 21:34 gemma-4-12B-it.litertlm -> /Users/junjian/.litert-lm/models/gemma4-12b/model.litertlm
-rw-r--r--@ 1 junjian staff 13M 6月 4 22:32 gemma-4-12B-it.litertlm_1780576693_6547589312_mldrift_program_cache.bin
-rw-r--r--@ 1 junjian staff 6.1G 6月 4 21:15 gemma-4-12B-it.litertlm_1780576693_6547589312_mldrift_weight_cache.bin
-rw-r--r--@ 1 junjian staff 9.4M 6月 4 21:16 gemma-4-12B-it.litertlm.streaming_audio_encoder.xnnpack_cache_1780576693_6547589312
这里的模型是我自己创建的软链接,指向之前通过 LiteRT-LM CLI 导入的 gemma-4-12B-it.litertlm 文件。不用重新下载了。