DeepSeek-V4

简介
我们在此发布 DeepSeek-V4 系列的预览版本,包括两个强大的混合专家(MoE)语言模型 —— 总参数量 1.6T(激活 49B)的 DeepSeek-V4-Pro,以及总参数量 284B(激活 13B)的 DeepSeek-V4-Flash,两者均支持长达 一百万 token 的上下文。
DeepSeek-V4 系列在架构与优化方面引入了多项关键升级:
- 混合注意力架构:我们设计了一种结合压缩稀疏注意力(CSA)与重度压缩注意力(HCA)的混合注意力机制,大幅提升长上下文处理效率。在 1M token 上下文设定下,DeepSeek-V4-Pro 的单 token 推理 FLOPs 仅为 DeepSeek-V3.2 的 27%,KV 缓存仅占其 10%。
- 流形约束超连接(mHC):我们引入 mHC 来增强传统的残差连接,在保留模型表达能力的同时,提升信号跨层传播的稳定性。
- Muon 优化器:我们采用 Muon 优化器以实现更快的收敛速度和更高的训练稳定性。
两款模型均在大于 32T 的多样化高质量 token 上进行了预训练,并随后执行了全面的后训练流程。后训练采用两阶段范式:首先独立培养领域专属专家(通过 SFT 与基于 GRPO 的强化学习),随后通过 on-policy 蒸馏将不同领域的专长整合至单一模型中。
DeepSeek-V4-Pro-Max 作为 DeepSeek-V4-Pro 的最高推理强度模式,显著推进了开源模型的知识能力边界,稳居当前最佳开源模型之列。它在编程基准测试中表现顶尖,并在推理与智能体任务上显著缩小了与领先闭源模型的差距。与此同时,DeepSeek-V4-Flash-Max 在给予更大思考预算时,可达到与 Pro 版本相当的推理表现,但其更小的参数规模在纯知识任务和最复杂的智能体工作流上自然略逊一筹。
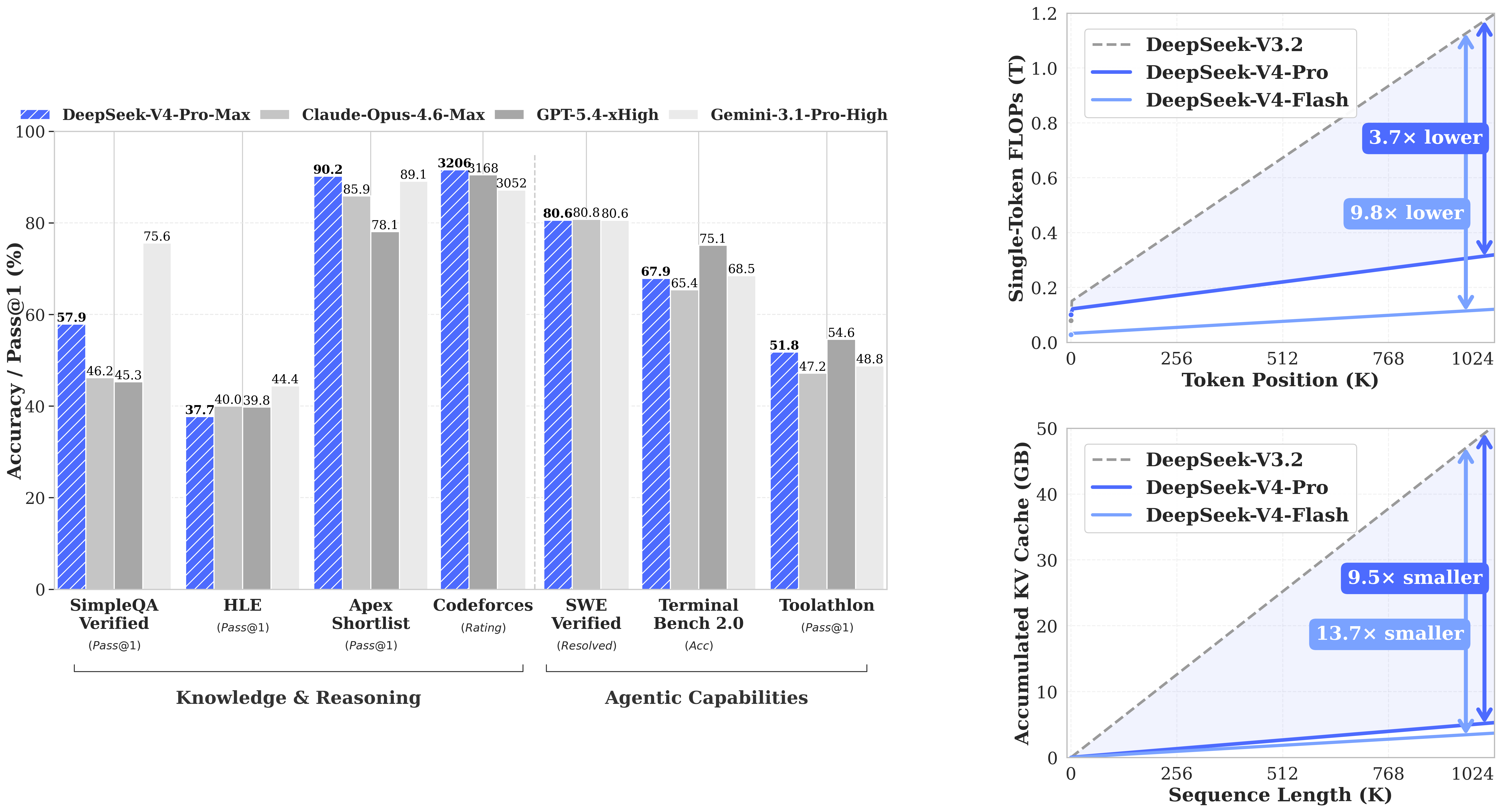
DeepSeek-V4-Pro:性能比肩顶级闭源模型
-
Agent 能力大幅提高:相比前代模型,DeepSeek-V4-Pro 的 Agent 能力显著增强。在 Agentic Coding 评测中,V4-Pro 已达到当前开源模型最佳水平,并在其他 Agent 相关评测中同样表现优异。目前 DeepSeek-V4 已成为公司内部员工使用的 Agentic Coding 模型,据评测反馈使用体验优于 Sonnet 4.5,交付质量接近 Opus 4.6 非思考模式,但仍与 Opus 4.6 思考模式存在一定差距。
-
丰富的世界知识:DeepSeek-V4-Pro 在世界知识测评中,大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1。
-
世界顶级推理性能:在数学、STEM、竞赛型代码的测评中,DeepSeek-V4-Pro 超越当前所有已公开评测的开源模型,取得了比肩世界顶级闭源模型的优异成绩。
DeepSeek-V4-Flash:更快捷高效的经济之选
-
相比 DeepSeek-V4-Pro,DeepSeek-V4-Flash 在世界知识储备方面稍逊一筹,但展现出了接近的推理能力。而由于模型参数和激活更小,相较之下 V4-Flash 能够提供更加快捷、经济的 API 服务。
-
在 Agent 测评中,DeepSeek-V4-Flash 在简单任务上与 DeepSeek-V4-Pro 旗鼓相当,但在高难度任务上仍有差距。
API 访问模型
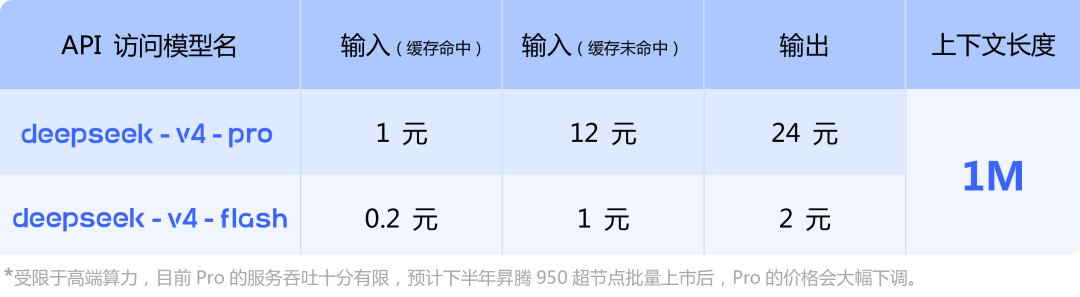
DeepSeek-V4 技术报告:
模型下载
| 模型 | 总参数量 | 激活参数量 | 上下文长度 | 精度 | 下载 |
|---|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 混合 | HuggingFace ModelScope |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 混合* | HuggingFace ModelScope |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 混合 | HuggingFace ModelScope |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 混合* | HuggingFace ModelScope |
*FP4 + FP8 混合:MoE 专家参数使用 FP4 精度;其余大部分参数使用 FP8。
评测结果
基座模型
| 基准(指标) | 样本数 | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|---|
| 架构 | - | MoE | MoE | MoE |
| 激活参数量 | - | 37B | 13B | 49B |
| 总参数量 | - | 671B | 284B | 1.6T |
| 世界知识 | ||||
| AGIEval (EM) | 0-shot | 80.1 | 82.6 | 83.1 |
| MMLU (EM) | 5-shot | 87.8 | 88.7 | 90.1 |
| MMLU-Redux (EM) | 5-shot | 87.5 | 89.4 | 90.8 |
| MMLU-Pro (EM) | 5-shot | 65.5 | 68.3 | 73.5 |
| MMMLU (EM) | 5-shot | 87.9 | 88.8 | 90.3 |
| C-Eval (EM) | 5-shot | 90.4 | 92.1 | 93.1 |
| CMMLU (EM) | 5-shot | 88.9 | 90.4 | 90.8 |
| MultiLoKo (EM) | 5-shot | 38.7 | 42.2 | 51.1 |
| Simple-QA verified (EM) | 25-shot | 28.3 | 30.1 | 55.2 |
| SuperGPQA (EM) | 5-shot | 45.0 | 46.5 | 53.9 |
| FACTS Parametric (EM) | 25-shot | 27.1 | 33.9 | 62.6 |
| TriviaQA (EM) | 5-shot | 83.3 | 82.8 | 85.6 |
| 语言与推理 | ||||
| BBH (EM) | 3-shot | 87.6 | 86.9 | 87.5 |
| DROP (F1) | 1-shot | 88.2 | 88.6 | 88.7 |
| HellaSwag (EM) | 0-shot | 86.4 | 85.7 | 88.0 |
| WinoGrande (EM) | 0-shot | 78.9 | 79.5 | 81.5 |
| CLUEWSC (EM) | 5-shot | 83.5 | 82.2 | 85.2 |
| 代码与数学 | ||||
| BigCodeBench (Pass@1) | 3-shot | 63.9 | 56.8 | 59.2 |
| HumanEval (Pass@1) | 0-shot | 62.8 | 69.5 | 76.8 |
| GSM8K (EM) | 8-shot | 91.1 | 90.8 | 92.6 |
| MATH (EM) | 4-shot | 60.5 | 57.4 | 64.5 |
| MGSM (EM) | 8-shot | 81.3 | 85.7 | 84.4 |
| CMath (EM) | 3-shot | 92.6 | 93.6 | 90.9 |
| 长上下文 | ||||
| LongBench-V2 (EM) | 1-shot | 40.2 | 44.7 | 51.5 |
指令模型
DeepSeek-V4-Pro 与 DeepSeek-V4-Flash 均支持三种推理强度模式:
| 推理模式 | 特点 | 典型用例 | 响应格式 |
|---|---|---|---|
| 非思考 | 快速、直觉式响应 | 日常任务、低风险决策 | </think> 摘要 |
| 思考高 | 有意识的逻辑分析,较慢但更准确 | 复杂问题解决、规划 | <think> 思考 </think> 摘要 |
| 思考最大 | 将推理推向极致 | 探索模型推理能力边界 | 特殊系统提示 + <think> 思考 </think> 摘要 |
DeepSeek-V4-Pro-Max 与前沿模型对比
| 基准(指标) | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max |
|---|---|---|---|---|---|---|
| 知识与推理 | ||||||
| MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.1 | 86.0 | 87.5 |
| SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 36.9 | 38.1 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 75.9 | 75.0 | 84.4 |
| GPQA Diamond (Pass@1) | 91.3 | 93.0 | 94.3 | 90.5 | 86.2 | 90.1 |
| HLE (Pass@1) | 40.0 | 39.8 | 44.4 | 36.4 | 34.7 | 37.7 |
| LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 89.6 | - | 93.5 |
| Codeforces (Rating) | - | 3168 | 3052 | - | - | 3206 |
| HMMT 2026 Feb (Pass@1) | 96.2 | 97.7 | 94.7 | 92.7 | 89.4 | 95.2 |
| IMOAnswerBench (Pass@1) | 75.3 | 91.4 | 81.0 | 86.0 | 83.8 | 89.8 |
| Apex (Pass@1) | 34.5 | 54.1 | 60.9 | 24.0 | 11.5 | 38.3 |
| Apex Shortlist (Pass@1) | 85.9 | 78.1 | 89.1 | 75.5 | 72.4 | 90.2 |
| 长上下文 | ||||||
| MRCR 1M (MMR) | 92.9 | - | 76.3 | - | - | 83.5 |
| CorpusQA 1M (ACC) | 71.7 | - | 53.8 | - | - | 62.0 |
| 智能体 | ||||||
| Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 66.7 | 63.5 | 67.9 |
| SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.2 | - | 80.6 |
| SWE Pro (Resolved) | 57.3 | 57.7 | 54.2 | 58.6 | 58.4 | 55.4 |
| SWE Multilingual (Resolved) | 77.5 | - | - | 76.7 | 73.3 | 76.2 |
| BrowseComp (Pass@1) | 83.7 | 82.7 | 85.9 | 83.2 | 79.3 | 83.4 |
| HLE w/ tools (Pass@1) | 53.1 | 52.0 | 51.6 | 54.0 | 50.4 | 48.2 |
| GDPval-AA (Elo) | 1619 | 1674 | 1314 | 1482 | 1535 | 1554 |
| MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 66.6 | 71.8 | 73.6 |
| Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 50.0 | 40.7 | 51.8 |
跨模式对比
| 基准(指标) | V4-Flash 非思考 | V4-Flash 高 | V4-Flash 最大 | V4-Pro 非思考 | V4-Pro 高 | V4-Pro 最大 |
|---|---|---|---|---|---|---|
| 知识与推理 | ||||||
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 | 82.9 | 87.1 | 87.5 |
| SimpleQA-Verified (Pass@1) | 23.1 | 28.9 | 34.1 | 45.0 | 46.2 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 71.5 | 73.2 | 78.9 | 75.8 | 77.7 | 84.4 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 | 72.9 | 89.1 | 90.1 |
| HLE (Pass@1) | 8.1 | 29.4 | 34.8 | 7.7 | 34.5 | 37.7 |
| LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 | 56.8 | 89.8 | 93.5 |
| Codeforces (Rating) | - | 2816 | 3052 | - | 2919 | 3206 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 | 31.7 | 94.0 | 95.2 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 | 35.3 | 88.0 | 89.8 |
| Apex (Pass@1) | 1.0 | 19.1 | 33.0 | 0.4 | 27.4 | 38.3 |
| Apex Shortlist (Pass@1) | 9.3 | 72.1 | 85.7 | 9.2 | 85.5 | 90.2 |
| 长上下文 | ||||||
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 | 44.7 | 83.3 | 83.5 |
| CorpusQA 1M (ACC) | 15.5 | 59.3 | 60.5 | 35.6 | 56.5 | 62.0 |
| 智能体 | ||||||
| Terminal Bench 2.0 (Acc) | 49.1 | 56.6 | 56.9 | 59.1 | 63.3 | 67.9 |
| SWE Verified (Resolved) | 73.7 | 78.6 | 79.0 | 73.6 | 79.4 | 80.6 |
| SWE Pro (Resolved) | 49.1 | 52.3 | 52.6 | 52.1 | 54.4 | 55.4 |
| SWE Multilingual (Resolved) | 69.7 | 70.2 | 73.3 | 69.8 | 74.1 | 76.2 |
| BrowseComp (Pass@1) | - | 53.5 | 73.2 | - | 80.4 | 83.4 |
| HLE w/ tools (Pass@1) | - | 40.3 | 45.1 | - | 44.7 | 48.2 |
| MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 | 69.4 | 74.2 | 73.6 |
| GDPval-AA (Elo) | - | - | 1395 | - | - | 1554 |
| Toolathlon (Pass@1) | 40.7 | 43.5 | 47.8 | 46.3 | 49.0 | 51.8 |
对话模板
本次发布不包含 Jinja 格式的对话模板。取而代之的是,我们提供了专门的 encoding 文件夹,内含 Python 脚本和测试用例,演示如何将 OpenAI 兼容格式的消息编码为模型的输入字符串,以及如何解析模型的文本输出。请参阅 encoding 文件夹获取完整文档。
简短示例:
from encoding_dsv4 import encode_messages, parse_message_from_completion_text
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
# messages -> 字符串
prompt = encode_messages(messages, thinking_mode="thinking")
# 字符串 -> token
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V4-Pro")
tokens = tokenizer.encode(prompt)
本地运行
请参阅 inference 文件夹,获取在本地运行 DeepSeek-V4 的详细说明,包括模型权重转换和交互式聊天演示。
对于本地部署,我们建议将采样参数设置为 temperature = 1.0, top_p = 1.0。对于「思考最大」推理模式,建议将上下文窗口设置为至少 384K token。
许可证
本仓库及模型权重均基于 MIT 许可证 发布。
安装 Claude Code
npm install -g @anthropic-ai/claude-code
# 临时切换淘宝镜像安装(推荐,只对本次命令生效)
npm install -g @anthropic-ai/claude-code --registry=https://registry.npmmirror.com
配置环境变量
vim ~/.claude/settings.json
{
"env": {
"ANTHROPIC_BASE_URL": "https://api.deepseek.com/anthropic",
"ANTHROPIC_AUTH_TOKEN": "<your-deepseek-api-token>",
"ANTHROPIC_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-v4-pro[1m]",
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-v4-flash",
"CLAUDE_CODE_SUBAGENT_MODEL": "deepseek-v4-flash",
"CLAUDE_CODE_EFFORT_LEVEL": "max"
}
}
DeepSeek API 文档
模型 & 价格
思考模式
DeepSeek 模型支持思考模式:在输出最终回答之前,模型会先输出一段思维链内容,以提升最终答案的准确性。
思考模式开关与思考强度控制

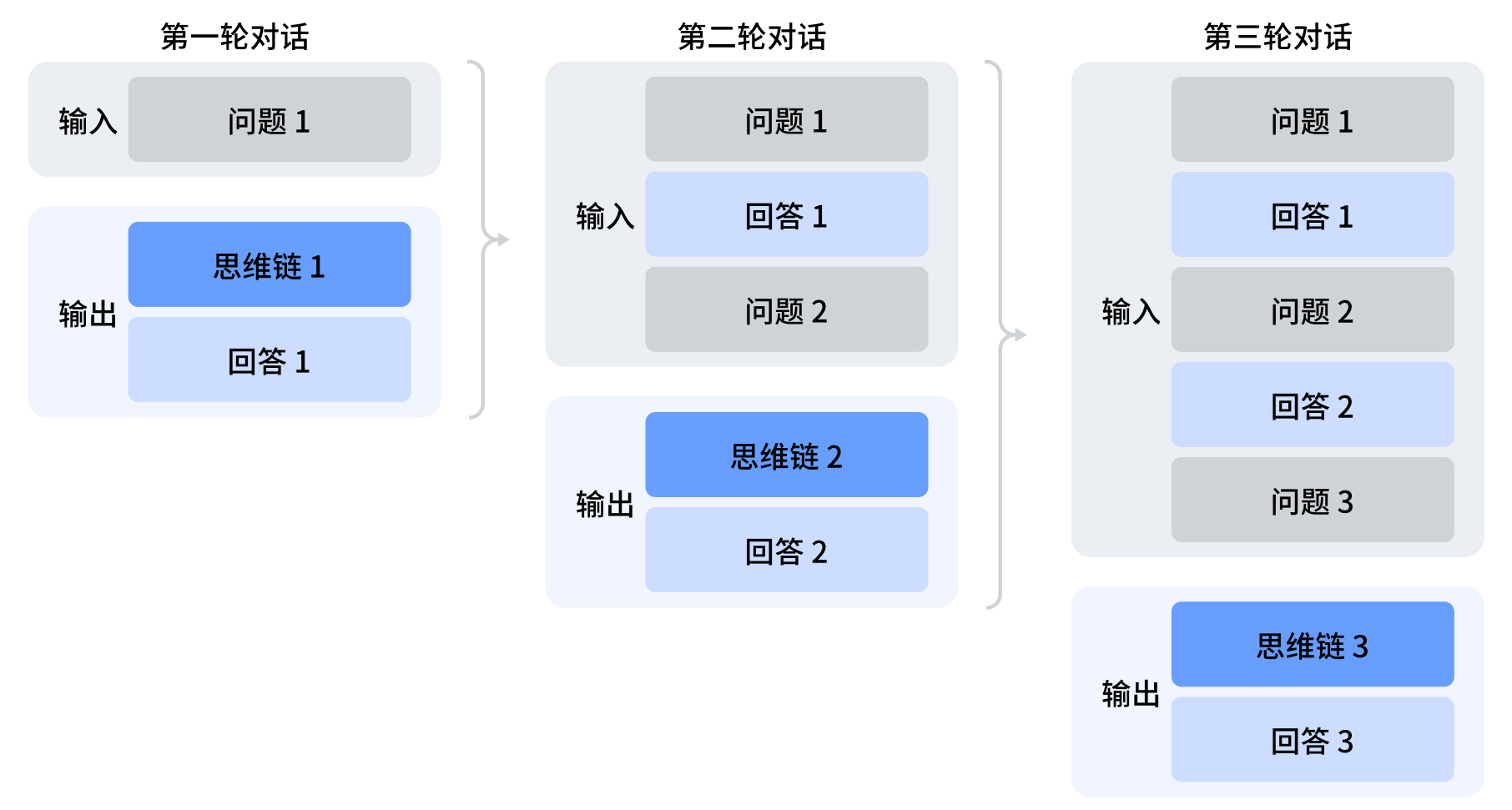
多轮对话拼接
在每一轮对话过程中,模型会输出思维链内容(reasoning_content)和最终回答(content)。如果没有工具调用,则在下一轮对话中,之前轮输出的思维链内容不会被拼接到上下文中,如下图所示:
工具调用
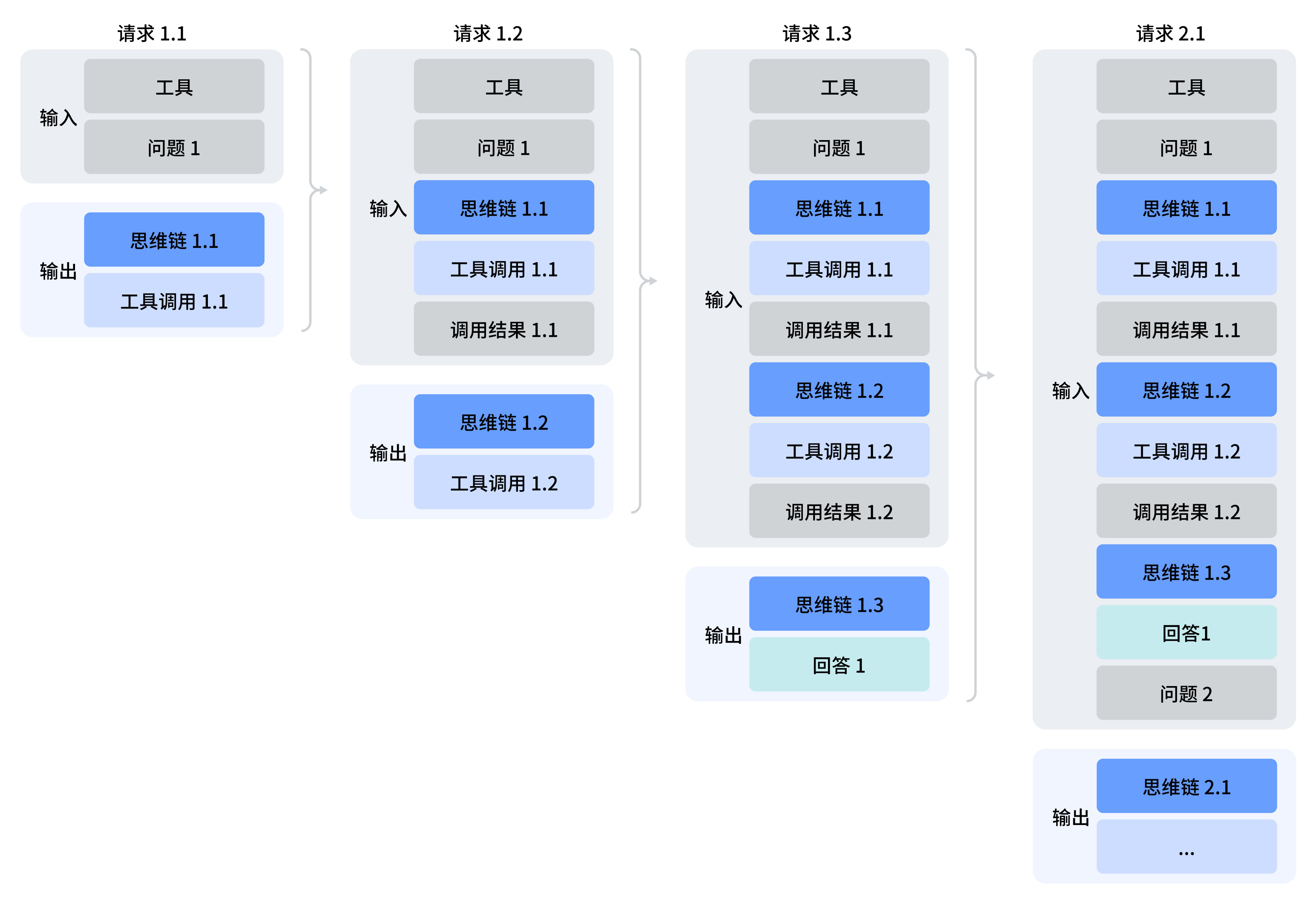
DeepSeek 模型的思考模式支持工具调用功能。模型在输出最终答案之前,可以进行多轮的思考与工具调用,以提升答案的质量。其调用模式如下图所示:
上下文硬盘缓存
DeepSeek API 上下文硬盘缓存技术对所有用户默认开启,用户无需修改代码即可享用。
用户的每一个请求都会触发硬盘缓存的构建。若后续请求与之前的请求在前缀上存在重复,则重复部分只需要从缓存中拉取,计入 “缓存命中”。
缓存落盘与命中规则
缓存命中的前提是相应前缀已被“落盘”(写入硬盘缓存)。受 Sliding Window Attention 机制的影响,缓存前缀的存取与判别与之前有所不同。每条缓存前缀是一个独立的完整单元。后续请求只有在完整匹配缓存前缀单元时,才能命中缓存。
缓存前缀落盘时机:
- 请求结束位置落盘:每次请求的用户输入结束位置与模型输出结束位置,会产生两个缓存前缀单元。后续请求若完整匹配了它们,则可命中。
- 公共前缀检测落盘:当系统检测到多次请求之间存在公共前缀时,会将该公共前缀作为一个独立的缓存前缀单元进行落盘。后续请求若完整复用了该缓存前缀单元,则可命中。
- 按固定 token 间隔落盘:在长输入或长输出中,系统会以一定的 token 数量为间隔,截取缓存前缀单元,避免长前缀因迟迟未达到结束位置而完全无法被缓存。
示例说明
举例 1:用户第一轮请求内容为 A + B,第二轮请求内容为 A + B + C,则第二轮请求能完整匹配 A + B 这个缓存前缀单元,可以命中 A + B 的缓存。
举例 2:用户第一轮请求内容为 A + B,第二轮请求内容为 A + C,则第二轮请求无法命中缓存(因为 A + C 不能完整匹配 A + B)。但此时系统会识别到两轮请求存在公共前缀 A,并将 A 作为缓存前缀单元落盘。当第三轮请求 A + D 到来时,能完整匹配 A 这个缓存前缀单元,可以命中 A 的缓存。
硬盘缓存与输出随机性
硬盘缓存只匹配到用户输入的前缀部分,输出仍然是通过计算推理得到的,仍然受到 temperature 等参数的影响,从而引入随机性。其输出效果与不使用硬盘缓存相同。
其它说明
- 缓存系统是“尽力而为”,不保证 100% 缓存命中
- 缓存构建耗时为秒级。缓存不再使用后会自动被清空,时间一般为几个小时到几天
Anthropic API
DeepSeek-V4 项目全面分析
一、项目概述
DeepSeek-V4 是 DeepSeek-AI 发布的超大规模混合专家(MoE)语言模型系列,包含两个主要变体:
- DeepSeek-V4-Pro:1.6T 总参数量,49B 激活参数量
- DeepSeek-V4-Flash:284B 总参数量,13B 激活参数量
两者均支持 100万 token(1M) 的上下文长度,采用 MIT 许可证开源。
二、项目结构
DeepSeek-V4-Pro/
├── README.md ## 项目主文档
├── LICENSE ## MIT 许可证
├── config.json ## Transformers 模型配置
├── tokenizer_config.json ## 分词器配置
├── generation_config.json ## 生成参数配置
├── tokenizer.json ## 分词器词表
├── DeepSeek_V4.pdf ## 技术报告
├── assets/
│ └── dsv4_performance.png ## 性能对比图
├── inference/ ## 推理代码
│ ├── README.md ## 推理使用说明
│ ├── model.py ## 模型架构定义
│ ├── generate.py ## 文本生成逻辑
│ ├── convert.py ## 权重格式转换
│ ├── kernel.py ## TileLang 自定义 CUDA Kernel
│ ├── config.json ## 推理专用配置
│ └── requirements.txt ## 依赖列表
├── encoding/ ## 消息编码/解码
│ ├── README.md ## 编码格式文档
│ ├── encoding_dsv4.py ## 编码实现
│ ├── test_encoding_dsv4.py ## 编码测试
│ └── tests/ ## 测试数据
│ ├── test_input_*.json
│ └── test_output_*.txt
└── docs/
└── project-analysis.md ## 本分析文档
三、模型架构分析
3.1 核心配置参数
| 参数 | DeepSeek-V4-Pro |
|---|---|
| 总参数量 | 1.6T |
| 激活参数量 | 49B |
| 隐藏层维度 (hidden_size) | 7168 |
| 注意力头数 (num_attention_heads) | 128 |
| 层数 (num_hidden_layers) | 61 |
| KV 头数 (num_key_value_heads) | 1 (MQA) |
| 专家总数 (n_routed_experts) | 384 |
| 每 token 激活专家数 | 6 |
| 共享专家数 | 1 |
| 上下文长度 | 1,048,576 (1M) |
| 词表大小 (vocab_size) | 129,280 |
| 默认数据类型 | bfloat16 |
3.2 关键架构创新
1. 混合注意力架构(Hybrid Attention)
结合两种注意力机制以处理超长上下文:
- Compressed Sparse Attention (CSA):压缩稀疏注意力
- Heavily Compressed Attention (HCA):重度压缩注意力
在 1M token 场景下,相比 DeepSeek-V3.2:
- 单 token 推理 FLOPs 仅为其 27%
- KV Cache 仅为其 10%
2. Manifold-Constrained Hyper-Connections (mHC)
替代传统残差连接的创新机制:
- 每层维护
hc_mult(默认 4)份隐藏状态副本 - 通过 Sinkhorn 算法学习预/后混合权重
- 增强信号传播的稳定性,同时保持模型表达能力
3. 多阶段训练
- 预训练:超过 32T 高质量 token
- 后训练:两阶段范式
- 各领域专家独立培养(SFT + GRPO 强化学习)
- 通过 on-policy distillation 统一模型整合
4. Muon Optimizer
用于训练优化,实现更快的收敛速度和更大的训练稳定性。
四、推理代码详解
4.1 model.py — 模型架构
定义了完整的 Transformer 模型,主要组件包括:
ParallelEmbedding
- 沿词表维度做张量并行切分
- 各 rank 持有
vocab_size // world_size行 - 通过 all_reduce 聚合部分嵌入结果
Attention(Multi-head Latent Attention, MLA)
- 低秩 Q 投影:
wq_a -> q_norm -> wq_b - 分组低秩 O 投影:
wo_a -> wo_b - 支持滑动窗口(sliding_window=128)
- 可选 KV 压缩(compress_ratio)
- RoPE 位置编码通过
apply_rotary_emb应用 - FP8 量化模拟非 RoPE 维度
Compressor(KV 压缩器)
- 通过学习的门控池化(gated pooling)压缩 KV Cache
- 支持重叠窗口(ratio==4 时)以获得更平滑的压缩边界
- 使用增量压缩状态缓冲区处理 decode 阶段
Indexer(稀疏注意力索引器)
- 选择 top-k 压缩 KV 位置用于稀疏注意力
- 通过
sparse_attnkernel 实现 FlashAttention 风格的在线 softmax - 包含可学习的
attn_sink偏置
MoE(混合专家层)
- Gate:计算专家路由分数,支持哈希路由(前 n_hash_layers)和分数路由
- Expert:SwiGLU FFN,支持 FP4/FP8 权重
- 专家沿张量并行维度切分,每 rank 处理
n_routed_experts // world_size
Block(Transformer Block)
- 包含 Attention + MoE
- 应用 Hyper-Connections(HC)混合
hc_pre:将 HC 多副本压缩为 1 份hc_post:将单份状态扩展回 HC 多副本
MTPBlock(Multi-Token Prediction)
- 继承 Block,增加 embedding 投影和 head 投影
- 用于多 token 预测训练目标
Transformer
- 完整模型流程:Embedding → HC-expand → N Blocks → HC-head → Logits
- 设置全局状态(world_size, rank, dtype, scale_fmt, scale_dtype)
4.2 kernel.py — 自定义 CUDA Kernel
使用 TileLang 编写高性能 GPU Kernel:
| Kernel | 功能 |
|---|---|
act_quant_kernel | 块级 FP8 量化(支持 inplace 量化和 dequant) |
fp4_quant_kernel | 块级 FP4 量化(E2M1 格式,E8M0 缩放) |
fp8_gemm_kernel | FP8 矩阵乘法(支持 per-128 块缩放) |
fp4_gemm_kernel | FP8 激活 × FP4 权重 GEMM |
sparse_attn_kernel | 稀疏多头注意力(索引收集 + 在线 softmax) |
hc_split_sinkhorn_kernel | Hyper-Connections 的 Sinkhorn 归一化拆分 |
关键技术细节:
- 使用 IEEE 754 位操作快速计算
log2和pow2 - FP4 到 FP8 的转换通过 FP32 中间类型避免 C++ 重载歧义
- 使用
T.use_swizzle优化 L2 Cache
4.3 generate.py — 文本生成
- Gumbel-max 采样:等价于多项式采样但避免 GPU-CPU 同步
- 两阶段生成:
- Prefill:处理输入 prompt
- Decode:逐 token 自回归生成
- 支持交互式聊天和批量推理
- 支持多节点分布式推理(torchrun + nccl)
4.4 convert.py — 权重转换
将 HuggingFace 格式权重转换为本项目格式:
- 名称映射(如
q_proj→wq,o_proj→wo) - 张量并行切分(按指定维度 shard)
- 专家权重按模型并行度分配
- FP4 到 FP8 的无损转换(
cast_e2m1fn_to_e4m3fn) - 最终保存为 safetensors 格式
五、编码系统详解
5.1 encoding_dsv4.py
实现了 DeepSeek-V4 的 prompt 编码和输出解析,核心功能:
编码功能(encode_messages)
- 支持的角色:system, user, assistant, tool, developer, latest_reminder
- Thinking 模式:
thinking_mode="thinking"启用显式推理 - Chat 模式:
thinking_mode="chat"直接生成回复 - 工具调用:支持 OpenAI 格式的工具定义,输出 DSML XML 格式
- drop_thinking:默认丢弃早期 assistant 的 reasoning_content
- Reasoning Effort:支持
max级别的前缀注入
特殊 Token
| Token | 用途 |
|---|---|
<|begin▁of▁sentence|> | 序列开始(BOS) |
<|end▁of▁sentence|> | 序列结束(EOS) |
<|User|> | 用户轮次前缀 |
<|Assistant|> | 助手轮次前缀 |
<|latest_reminder|> | 最新提醒(日期、区域等) |
<think> / </think> | 推理块标记 |
|DSML| | DSML 标记语言 Token |
解析功能(parse_message_from_completion_text)
- 从模型原始输出提取 reasoning_content、content、tool_calls
- 解析 DSML 格式的工具调用参数
- 将内部格式转换回 OpenAI 格式
5.2 测试用例
test_encoding_dsv4.py 包含 4 个测试场景:
- Thinking 模式 + 工具调用(多轮 + 工具结果合并)
- Thinking 模式无工具(drop_thinking 生效)
- 交错 Thinking + 搜索(developer 角色 + latest_reminder)
- 快速指令任务(chat 模式 + action 任务)
六、依赖分析
核心依赖
| 包 | 版本要求 | 用途 |
|---|---|---|
| torch | >=2.10.0 | 深度学习框架 |
| transformers | >=5.0.0 | HuggingFace 模型加载 |
| safetensors | >=0.7.0 | 安全张量序列化 |
| fast_hadamard_transform | - | Hadamard 变换(量化前旋转) |
| tilelang | ==0.1.8 | 自定义 CUDA Kernel 编写 |
运行环境要求
- GPU:NVIDIA CUDA GPU(使用 nccl 分布式通信)
- 内存/显存:大显存需求(Pro 版本 1.6T 参数,需多卡并行)
- Python:3.8+
七、量化与精度策略
7.1 量化配置
项目采用混合精度策略:
- MoE 专家参数:FP4(E2M1 格式,块大小 32)
- 其他参数:FP8(E4M3 格式,块大小 128×128)
- Scale 格式:E8M0(UE8M0)
7.2 动态量化流程
- 激活量化:
act_quant将 BF16 激活转为 FP8 - 权重量化:专家权重以 FP4 存储
- FP4 GEMM:
fp4_gemm实现 FP8 激活 × FP4 权重乘法 - Hadamard 旋转:量化前应用随机 Hadamard 变换分散信息
7.3 KV Cache 优化
- 滑动窗口缓存(128 tokens)
- 压缩 KV Cache(按 compress_ratios 配置,如 128:1 或 4:1)
- FP8/FP4 量化压缩后的 KV
八、位置编码与长上下文
8.1 YaRN 扩展
配置中使用 YaRN(Yet another RoPE extension)将基础上下文从 65536 扩展到 1M:
rope_factor: 16beta_fast: 32beta_slow: 1original_max_position_embeddings: 65536
8.2 压缩位置编码
compress_rope_theta: 160000(用于压缩 KV 的 RoPE 基础频率)compress_ratios: 各层的压缩比率配置(如[128, 128, 4, 128, 4, ...])
九、推理模式
模型支持三种推理努力级别:
| 模式 | 特征 | 典型用例 | 响应格式 |
|---|---|---|---|
| Non-think | 快速、直觉式响应 | 日常任务、低风险决策 | </think> 摘要 |
| Think High | 有意识逻辑分析 | 复杂问题解决、规划 | <think> 思考 </think> 摘要 |
| Think Max | 最大化推理深度 | 探索模型推理边界 | 特殊系统提示 + <think> 思考 </think> 摘要 |
十、分布式推理
支持多 GPU / 多节点推理:
## 单节点多卡
torchrun --nproc-per-node 8 generate.py --ckpt-path ${SAVE_PATH} --config config.json --interactive
## 多节点
## nnodes: 总节点数
## nproc-per-node: 每节点进程数
torchrun --nnodes 2 --nproc-per-node 4 --node-rank $RANK --master-addr $ADDR generate.py ...
- 使用
torch.distributed的 nccl 后端 - Embedding 和 Linear 层均支持张量并行
- 专家按进程数均匀切分
十一、性能与基准测试
11.1 基础模型对比
DeepSeek-V4-Pro-Base 在多项基准上达到 SOTA 或接近 SOTA:
- MMLU-Pro: 73.5(远超 V3.2 的 65.5)
- Simple-QA verified: 55.2(远超 V3.2 的 28.3)
- LiveCodeBench: 93.5(Max 模式)
- Codeforces: Rating 3206(Max 模式)
11.2 与前沿模型对比
DeepSeek-V4-Pro-Max 在多个维度与闭源前沿模型(Opus-4.6, GPT-5.4, Gemini-3.1-Pro)竞争:
- LiveCodeBench: 93.5(开源最佳)
- Codeforces: 3206(开源最佳)
- Apex Shortlist: 90.2(开源最佳)
- SWE Verified: 80.6(与 Opus-4.6 持平)
十二、潜在使用场景
- 超长文档处理:1M 上下文支持整本书、代码库、法律文档分析
- 复杂代码生成与理解:在编程基准上表现优异
- 多步推理与规划:Think Max 模式适合数学证明、科学研究
- Agent 工作流:工具调用、浏览、终端操作支持
- 多语言知识问答:在中英文知识基准上均表现强劲
十三、注意事项与限制
- 硬件要求:Pro 版本需要大量 GPU 显存,需多卡/多节点部署
- FP4 兼容性:需要较新的 PyTorch 版本支持
float4_e2m1fn_x2dtype - 无 Jinja Chat Template:使用自定义 Python 编码脚本替代
- 推理配置:推荐
temperature=1.0, top_p=1.0 - Think Max 上下文:建议至少 384K tokens 上下文窗口
十四、总结
DeepSeek-V4 是一个在架构创新(混合注意力、mHC、Muon 优化器)、训练规模(32T+ token)和工程实现(TileLang 自定义 kernel、FP4/FP8 混合量化)方面均达到顶尖水平的大语言模型项目。其开源的推理代码和编码系统提供了完整的本地部署方案,适合研究机构和有高性能计算资源的企业进行深度应用开发。
DeepSeek-V4 源码分析(encoding)
一、目录结构
encoding/
├── README.md # 编码格式规范文档
├── encoding_dsv4.py # 核心编码/解码实现(745 行)
├── test_encoding_dsv4.py # 测试套件
└── tests/ # 测试数据
├── test_input_1.json # 场景1:thinking + tool calls
├── test_input_2.json # 场景2:thinking 无工具
├── test_input_3.json # 场景3:thinking + search + latest_reminder
├── test_input_4.json # 场景4:chat 模式 quick task
├── test_output_1.txt # 场景1 期望输出
├── test_output_2.txt # 场景2 期望输出
├── test_output_3.txt # 场景3 期望输出
└── test_output_4.txt # 场景4 期望输出
二、encoding_dsv4.py 核心源码分析
2.1 特殊 Token 定义(第 14-35 行)
bos_token = "<|begin▁of▁sentence|>"
eos_token = "<|end▁of▁sentence|>"
thinking_start_token = "<think>"
thinking_end_token = "</think>"
dsml_token = "|DSML|"
| Token 常量 | 值 | 用途 |
|---|---|---|
bos_token | <|begin▁of▁sentence|> | 序列开始标记,每个对话开头插入 |
eos_token | <|end▁of▁sentence|> | 序列结束标记,每个 assistant 轮次结尾 |
thinking_start_token | <think> | 推理块开始 |
thinking_end_token | </think> | 推理块结束 |
dsml_token | |DSML| | DSML 标记语言命名空间 |
Task 特殊 Token(内部分类任务):
| Task | Token | 说明 |
|---|---|---|
| action | <|action|> | 判断是否需要搜索 |
| query | <|query|> | 生成搜索查询 |
| authority | <|authority|> | 判断来源权威性需求 |
| domain | <|domain|> | 识别问题领域 |
| title | <|title|> | 生成对话标题 |
| read_url | <|read_url|> | 判断 URL 是否需要获取 |
2.2 模板系统(第 39-95 行)
编码使用字符串模板拼接,核心模板包括:
system_msg_template:{content}— system 角色直接输出内容user_msg_template:{content}— user 角色直接输出内容assistant_msg_template:{reasoning}{content}{tool_calls}<|end▁of▁sentence|>thinking_template:{reasoning_content}— 推理内容包装TOOLS_TEMPLATE: 工具使用说明和 Available Tool Schemas 的完整模板tool_call_template: 单个工具调用的 DSML XML 格式tool_calls_template: 工具调用块包裹REASONING_EFFORT_MAX: Max 推理模式的前缀系统提示
2.3 工具格式转换(第 99-206 行)
-
tools_from_openai_format从 OpenAI 格式tools: [{"type": "function", "function": {...}}]中提取function定义列表。 -
tool_calls_from_openai_format/tool_calls_to_openai_format工具调用格式在内部格式和 OpenAI 格式之间双向转换:- 内部格式:
{"name": "...", "arguments": "json_string"} - OpenAI 格式:
{"type": "function", "function": {"name": "...", "arguments": "..."}}
- 内部格式:
-
encode_arguments_to_dsml将工具调用参数编码为 DSML XML:<|DSML|parameter name="$KEY" string="true|false">$VALUE</|DSML|parameter>- 字符串类型:
string="true",值原样输出 - 非字符串:
string="false",值序列化为 JSON
- 字符串类型:
-
decode_dsml_to_arguments反向解析 DSML 参数回 JSON 格式参数对象。 -
render_tools渲染完整的 Tools 说明块,插入到 system/developer 消息中。
2.4 消息渲染核心:render_message(第 223-394 行)
这是编码的核心函数,处理每条消息的格式转换:
参数:
index: 消息在列表中的索引messages: 完整消息列表(用于上下文判断)thinking_mode:"chat"或"thinking"drop_thinking: 是否丢弃早期 reasoning_content(默认 True)reasoning_effort:"max","high", 或None
关键逻辑流程:
-
Max 推理前缀:当
index == 0且thinking_mode == "thinking"且reasoning_effort == "max"时,插入REASONING_EFFORT_MAX前缀 -
角色分支处理:
- system: 直接输出 content,可选追加 tools 和 response_format
- developer: 包装为
USER_SP_TOKEN + content,支持 tools/response_format - user: 输出
USER_SP_TOKEN,支持 content_blocks(tool_result 混合文本) - latest_reminder: 输出
LATEST_REMINDER_SP_TOKEN + content - tool: 抛出 NotImplementedError(要求预先用
merge_tool_messages合并) - assistant: 最复杂的逻辑
-
Assistant 消息处理:
- 构造
thinking_part:若thinking_mode="thinking"且不是 task 输出,则包裹<think>{rc}</think> drop_thinking逻辑:在最后一个 user 消息之前的 assistant reasoning 会被丢弃- 工具调用内容通过
tool_call_template拼接为 DSML XML wo_eos控制是否输出 EOS token
- 构造
-
Transition Token 追加:
- user/developer 消息后追加
ASSISTANT_SP_TOKEN + thinking_token - task 为 action 时追加
ASSISTANT_SP_TOKEN + thinking_token + action_token - 其他 task 直接追加对应 token
- user/developer 消息后追加
2.5 预处理函数(第 401-499 行)
-
merge_tool_messages将 OpenAI 格式的独立tool角色消息合并到前一个user消息中:- tool 消息转为
{"type": "tool_result", "content": ...}block - 连续的 tool 结果合并到同一个 user 消息的
content_blocks - 连续的 user 消息(无 task)也合并 content_blocks
- tool 消息转为
-
sort_tool_results_by_call_order根据前一个 assistant 消息中的tool_calls顺序,对 user 消息中的tool_resultblocks 排序。确保工具执行结果按调用顺序呈现。
2.6 主入口:encode_messages(第 506-571 行)
流程:
- 合并 tool 消息
- 排序 tool 结果
- 拼接 context 和 messages
- 判断是否启用
effective_drop_thinking(若存在 tools 则禁用) - 若启用 drop_thinking,过滤掉早期 reasoning
- 逐条调用
render_message生成 prompt 字符串 - 返回完整编码字符串
2.7 辅助函数:_drop_thinking_messages(第 575-599 行)
在 drop_thinking 模式下精简消息列表:
- 保留所有 user/system/tool/latest_reminder 消息
- 保留最后一个 user 之后的所有消息
- 最后一个 user 之前的 assistant 消息删除
reasoning_content - 最后一个 user 之前的 developer 消息直接丢弃
2.8 解析(Decoding)系统(第 606-744 行)
-
_read_until_stop从指定索引读取文本,直到遇到 stop 字符串之一。返回(new_index, content, matched_stop)。 -
parse_tool_calls解析 DSML 格式的工具调用块:
- 循环读取
<|DSML|invoke或</|DSML|tool_calls> - 提取工具名(
name="...") - 循环读取参数(
<|DSML|parameter ...>value</|DSML|parameter>) - 解析
string="true|false"和参数值 - 返回工具调用列表(内部格式)
parse_message_from_completion_text主解析函数,将模型原始输出转为结构化消息:
解析流程:
- 若
thinking_mode="thinking",先读取<think>...</think>之间的内容作为reasoning_content - 读取
</think>(或开头)到eos_token或tool_calls之间的内容作为content - 若遇到
tool_calls起始标记,调用parse_tool_calls解析工具调用 - 验证文本完整消费,无残留内容
- 返回字典:
{"role": "assistant", "content": ..., "reasoning_content": ..., "tool_calls": [...]}
三、关键设计决策
4.1 为什么不用 Jinja Chat Template?
README 明确说明:本版本不提供 Jinja 格式的 chat template,而是提供独立的 Python 脚本。原因:
- DSML 工具调用格式较为复杂,难以用纯模板表达
- Thinking 模式的动态 drop_thinking 逻辑需要程序判断
- Task special tokens 的条件插入需要运行时决策
4.2 Tool Message 合并设计
OpenAI API 使用独立的 tool 角色消息,但 DeepSeek-V4 内部编码要求工具结果嵌入 user 消息的 <tool_result> 标签中。merge_tool_messages 提供了兼容层。
4.3 drop_thinking 的智能切换
当对话中存在 tools 定义时,drop_thinking 自动关闭。因为工具调用对话需要完整的推理链来跟踪多步逻辑。
四、使用示例
from encoding_dsv4 import encode_messages, parse_message_from_completion_text
# 编码
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's 2+2?"}
]
prompt = encode_messages(messages, thinking_mode="thinking")
# 解码
completion = "Simple reasoning.</think>The answer is 4.<|end▁of▁sentence|>"
parsed = parse_message_from_completion_text(completion, thinking_mode="thinking")
# -> {"role": "assistant", "reasoning_content": "Simple reasoning.",
# "content": "The answer is 4.", "tool_calls": []}
DeepSeek-V4 源码分析(inference)
一、目录结构
inference/
├── README.md # 推理使用说明
├── requirements.txt # Python 依赖
├── config.json # 推理专用配置(与根目录 config.json 格式不同)
├── model.py # 模型架构定义(829 行)
├── kernel.py # TileLang 自定义 CUDA Kernel(537 行)
├── generate.py # 文本生成入口(156 行)
└── convert.py # 权重格式转换(169 行)
二、model.py 深度分析
2.1 全局状态(第 15-21 行)
world_size = 1
rank = 0
block_size = 128
fp4_block_size = 32
default_dtype = torch.bfloat16
scale_fmt = None
scale_dtype = torch.float32
这些全局变量在 Transformer.__init__ 中被根据分布式环境和配置初始化,控制整个推理过程的数据类型和并行策略。
2.2 ModelArgs 配置类(第 34-80 行)
@dataclass 定义,字段名与 config.json 对应:
| 字段 | 默认值 | 说明 |
|---|---|---|
max_batch_size | 4 | 最大批大小 |
max_seq_len | 4096 | 最大序列长度 |
dtype | ”fp8” | 模型权重数据类型 |
expert_dtype | None | 专家权重特殊类型(fp4) |
vocab_size | 129280 | 词表大小 |
dim | 4096 | 隐藏层维度 |
moe_inter_dim | 4096 | MoE 中间维度 |
n_layers | 7 | Transformer 层数 |
n_hash_layers | 0 | 哈希路由层数 |
n_mtp_layers | 1 | 多 token 预测层数 |
n_heads | 64 | 注意力头数 |
n_routed_experts | 8 | 路由专家总数 |
n_shared_experts | 1 | 共享专家数 |
n_activated_experts | 2 | 每 token 激活专家数 |
score_func | ”sqrtsoftplus” | 路由分数函数 |
route_scale | 1.0 | 路由缩放因子 |
q_lora_rank | 1024 | Q 投影低秩维度 |
head_dim | 512 | 每头维度 |
rope_head_dim | 64 | RoPE 维度 |
window_size | 128 | 滑动窗口大小 |
compress_ratios | (0,0,4,128,4,0) | 每层 KV 压缩比 |
hc_mult | 4 | Hyper-Connections 副本数 |
hc_sinkhorn_iters | 20 | Sinkhorn 迭代次数 |
2.3 ParallelEmbedding(第 83-105 行)
张量并行词嵌入层:
- 沿词表维度切分,每 rank 持有
vocab_size // world_size行 forward中对越界索引 mask 为 0,计算后通过dist.all_reduce聚合- 保证输出与完整嵌入一致
2.4 Linear / ColumnParallelLinear / RowParallelLinear(第 108-180 行)
linear 函数(调度器)
根据权重数据类型自动选择 GEMM 实现:
float4_e2m1fn_x2→fp4_gemm(FP8 激活 × FP4 权重)float8_e4m3fn→fp8_gemm(FP8 激活 × FP8 权重)- 其他 →
F.linear(标准 BF16 矩阵乘法)
对于量化权重,输入激活会先经过 act_quant 转为 FP8。
Linear 基类
- 支持三种权重格式:BF16、FP8、FP4
- FP8:权重
[out, in],scale为[out/128, in/128](E8M0) - FP4:权重
[out, in/2](float4_e2m1fn_x2),scale为[out, in/32](E8M0)
ColumnParallelLinear
- 沿输出维度切分(Column-wise)
- 每个 rank 计算部分输出,无需 all-reduce
RowParallelLinear
- 沿输入维度切分(Row-wise)
- 每个 rank 计算部分结果,需要
dist.all_reduce求和 - bias 在 all-reduce 后添加
2.5 RMSNorm(第 183-196 行)
标准 RMSNorm 实现:
x = x * torch.rsqrt(x.square().mean(-1, keepdim=True) + eps)
return (weight * x).to(dtype)
注意:checkpoint 中权重是 bf16,但这里用 fp32 存储以方便计算。
2.6 RoPE 位置编码(第 199-244 行)
precompute_freqs_cis
预计算带 YaRN 扩展的复数旋转矩阵:
- 计算基础频率
1.0 / (base ** (torch.arange(0, dim, 2) / dim)) - 若
original_seq_len > 0,应用 YaRN 频率插值:find_correction_range:确定高频/低频修正范围linear_ramp_factor:生成平滑过渡的 ramp 函数- 频率 =
freqs / factor * (1 - smooth) + freqs * smooth
- 外积生成位置-频率矩阵
- 转为极坐标复数
torch.polar(ones, freqs)
apply_rotary_emb
原地应用 RoPE:
- 将最后维度拆分为复数对
(-1, 2) - 复数乘法
x * freqs_cis inverse=True时使用共轭实现反旋转- 结果写回原张量
2.7 rotate_activation(第 247-251 行)
from fast_hadamard_transform import hadamard_transform
return hadamard_transform(x, scale=x.size(-1) ** -0.5)
在 FP8 量化前应用随机 Hadamard 旋转,将信息均匀分散到所有维度,减少量化误差。
2.8 KV Cache 索引辅助函数(第 254-276 行)
get_window_topk_idxs
生成滑动窗口内的 KV 位置索引矩阵:
- Prefill 阶段(
start_pos == 0):生成因果掩码的窗口索引 - Decode 阶段(
start_pos > 0):循环缓冲区索引 - 越界位置用
-1填充
get_compress_topk_idxs
生成压缩 KV 的位置索引:
- Prefill:生成按压缩比的因果索引矩阵
- Decode:返回到当前位置的压缩索引序列
2.9 Compressor(第 279-377 行)
KV Cache 压缩器,通过学习的门控池化减少 KV 存储:
初始化
wkv: Linear,将 hidden state 映射到 KV 维度wgate: Linear,生成门控分数ape: 可学习的位置嵌入([compress_ratio, coff * head_dim])norm: RMSNorm 归一化- 状态缓冲区:
kv_state和score_state用于增量压缩
overlap_transform
当 compress_ratio == 4 时启用重叠窗口:
- 输入
[b,s,r,2d]→ 输出[b,s,2r,d] - 当前窗口的 normal half 直接放置
- 上一窗口的 overlapping half 平移放置
- 实现更平滑的压缩边界
forward 核心逻辑
Prefill 阶段(start_pos == 0):
- 计算
kv和score - 按
compress_ratio分块 - 余数部分存入状态缓冲区
- 应用重叠变换(若启用)
- softmax 归一化 score,加权求和得到压缩 KV
- 应用 RMSNorm 和 RoPE
- 若
rotate=True,Hadamard 旋转 + FP4 量化 - 否则 FP8 量化非 RoPE 维度
- 写入 KV Cache
Decode 阶段(start_pos > 0):
- 逐 token 累积到状态缓冲区
- 每
compress_ratio个 token 执行一次压缩 - 更新循环缓冲区状态
2.10 Indexer(第 380-433 行)
稀疏注意力索引器,为长序列选择最重要的压缩 KV 位置:
结构
wq_b: 将低秩 Q 投影到索引维度weights_proj: 生成每头注意力权重compressor: 独立的 Compressor(带 Hadamard 旋转)kv_cache: 存储压缩后的 KV 用于索引评分
forward 流程
- 通过
wq_b生成索引查询q - 应用 RoPE 和 Hadamard 旋转
- FP4 量化模拟(QAT 训练时的精度)
- 调用 compressor 更新压缩 KV Cache
- 计算
weights = weights_proj(x) * softmax_scale * n_heads^-0.5 - 计算索引分数:
einsum("bshd,btd->bsht", q, kv_cache) - ReLU 激活后乘以 weights
- 按头求和得到每 token 的 KV 位置分数
- top-k 选择最重要的位置
- 因果掩码处理(prefill 阶段)
2.11 Attention(第 436-543 行)
Multi-head Latent Attention (MLA),模型的核心注意力层:
参数
| 参数 | 说明 |
|---|---|
wq_a | Q 投影的第一层(dim → q_lora_rank) |
q_norm | Q 低秩状态的 RMSNorm |
wq_b | Q 投影的第二层(q_lora_rank → n_heads * head_dim) |
wkv | 单层 KV 投影(dim → head_dim,MQA) |
kv_norm | KV 状态的 RMSNorm |
wo_a | O 投影低秩层 |
wo_b | O 投影输出层 |
attn_sink | 可学习的注意力汇聚偏置 |
forward 流程
- Q 路径:
x → wq_a → q_norm → wq_b → unflatten → rsqrt 归一化 → RoPE - KV 路径:
x → wkv → kv_norm → RoPE → FP8 量化非 RoPE 维度 - 窗口索引:
get_window_topk_idxs(win, bsz, seqlen, start_pos) - 压缩索引:若
compress_ratio > 0:- 有 indexer 时调用 indexer
- 无 indexer 时调用
get_compress_topk_idxs - 拼接窗口索引和压缩索引
- KV Cache 更新:
- Prefill:整段写入循环缓冲区
- Decode:单 token 更新循环缓冲区
- 压缩 KV(prefill 阶段且 seqlen > win):调用 compressor
- 稀疏注意力:
sparse_attn(q, kv, attn_sink, topk_idxs, softmax_scale) - 反旋转:
apply_rotary_emb(o[..., -rd:], freqs_cis, inverse=True) - O 投影:
view → einsum with wo_a → flatten → wo_b
2.12 Gate(第 546-584 行)
MoE 路由门控:
初始化
weight:[n_routed_experts, dim]路由分数矩阵hash模式(前 n_hash_layers):tid2eid:[vocab_size, n_activated_experts]词 ID 到专家的哈希映射- 无 bias
- 非 hash 模式:
bias:[n_routed_experts]可学习的路由偏置
forward
scores = linear(x.float(), weight.float())- 分数函数:softmax / sigmoid / sqrt(softplus)
original_scores保存原始分数用于最终权重- bias 只影响 top-k 选择,不影响路由权重
- hash 模式:从
tid2eid[input_ids]取专家索引 - 非 hash 模式:
scores.topk(self.topk)选择专家 - 权重归一化(非 softmax 时)并乘以
route_scale
2.13 Expert(第 587-606 行)
单个 MoE 专家:SwiGLU 前馈网络
gate = self.w1(x) # [dim -> inter_dim]
up = self.w3(x) # [dim -> inter_dim]
if swiglu_limit > 0:
gate = clamp(gate, max=swiglu_limit)
up = clamp(up, min=-swiglu_limit, max=swiglu_limit)
x = silu(gate) * up
x = self.w2(x) # [inter_dim -> dim]
- 计算在 float32 中进行以保证稳定性
- 支持
weights参数实现按 token 的加权输出
2.14 MoE(第 609-645 行)
混合专家层:
结构
gate: Gate 路由experts: ModuleList,长度n_routed_experts- 只在本 rank 负责的专家位置创建 Expert 实例
- 其他位置为
None
shared_experts: 共享专家(无 swiglu_limit)
forward
- 展平 batch 维度
- Gate 计算
weights, indices - 初始化
y = zeros(..., float32) - 遍历本 rank 负责的每个专家:
- 若该专家无 token 选择,跳过
torch.where(indices == i)找出使用该专家的 token- 专家计算后累加到
y
dist.all_reduce(y)聚合所有 rank 的结果- 加上共享专家输出
- 转回输入 dtype 并 reshape
2.15 Block(第 648-701 行)
Transformer Block,包含 Hyper-Connections:
hc_pre(第 674-682 行)
将 HC 多副本状态压缩为单份:
x = x.flatten(2).float()
rsqrt = torch.rsqrt(x.square().mean(-1, keepdim=True) + eps)
mixes = F.linear(x, hc_fn) * rsqrt
pre, post, comb = hc_split_sinkhorn(mixes, hc_scale, hc_base, ...)
y = sum(pre.unsqueeze(-1) * x.view(shape), dim=2)
hc_post(第 684-687 行)
将单份输出扩展回 HC 多副本:
y = post.unsqueeze(-1) * x.unsqueeze(-2) + sum(comb.unsqueeze(-1) * residual.unsqueeze(-2), dim=2)
forward 流程
x, post_attn, comb_attn = hc_pre(x, hc_attn_fn, hc_attn_scale, hc_attn_base)
x = attn_norm(x)
x = attn(x, start_pos)
x = hc_post(x, residual, post_attn, comb_attn)
residual = x
x, post_ffn, comb_ffn = hc_pre(x, hc_ffn_fn, hc_ffn_scale, hc_ffn_base)
x = ffn_norm(x)
x = ffn(x, input_ids)
x = hc_post(x, residual, post_ffn, comb_ffn)
2.16 ParallelHead(第 704-736 行)
输出头:
weight:[vocab_size // world_size, dim]张量并行切分get_logits: 只取序列最后一个位置计算 logits(自回归生成)forward: 先通过hc_head将 HC 多副本合并,再过 RMSNorm,最后计算 logitshc_head: 简化版hc_pre,只用 sigmoid 预权重
2.17 MTPBlock(第 739-767 行)
多 Token 预测块,继承 Block:
e_proj: 将 embedding 投影到隐藏维度h_proj: 将隐藏状态投影enorm,hnorm: 各自的 RMSNorm- 前向时:将输入 hidden state 和 token embedding 融合后传入 Block
- 输出通过 head 计算下一 token 的 logits
2.18 Transformer(第 770-828 行)
完整模型:
__init__
- 设置全局状态(world_size, rank, dtype, scale_fmt, scale_dtype)
- ParallelEmbedding
- N 个 Block
- RMSNorm
- ParallelHead
- N 个 MTPBlock(共享 embed 和 head)
- HC head 参数(
hc_head_fn,hc_head_base,hc_head_scale)
forward
h = embed(input_ids) # [b,s,d]
h = h.unsqueeze(2).repeat(1,1,hc_mult,1) # [b,s,hc,d] 扩展为 HC 多副本
for layer in layers:
h = layer(h, start_pos, input_ids) # 逐层前向
logits = head(h, hc_head_fn, hc_head_scale, hc_head_base, norm)
return logits
三、kernel.py 深度分析
使用 TileLang(>=0.1.8)编写自定义 CUDA Kernel,实现量化、矩阵乘法和稀疏注意力。
3.1 TileLang 全局配置(第 9-12 行)
pass_configs = {
tilelang.PassConfigKey.TL_DISABLE_WARP_SPECIALIZED: True,
tilelang.PassConfigKey.TL_DISABLE_TMA_LOWER: True,
}
禁用 warp specialization 和 TMA(Tensor Memory Accelerator)降低,确保兼容性。
3.2 数据类型别名(第 14-19 行)
| 别名 | TileLang 类型 | 说明 |
|---|---|---|
| FP8 | float8_e4m3 | E4M3 8-bit 浮点 |
| FP4 | float4_e2m1fn | E2M1 4-bit 浮点 |
| FE8M0 | float8_e8m0fnu | E8M0 8-bit 指数(仅 scale) |
| BF16 | bfloat16 | 16-bit 脑浮点 |
| FP32 | float32 | 32-bit 浮点 |
| INT32 | int32 | 32-bit 整数 |
3.3 快速位操作函数(第 22-37 行)
利用 IEEE 754 浮点位操作避免慢速对数/指数 intrinsic:
fast_log2_ceil(x)
bits_x = reinterpret(uint32, x)
exp_x = (bits_x >> 23) & 0xFF
man_bits = bits_x & ((1 << 23) - 1)
return exp_x - 127 + (man_bits != 0 ? 1 : 0)
通过提取指数位快速计算 ceil(log2(x))。
fast_pow2(x)
bits_x = (x + 127) << 23
return reinterpret(float32, bits_x)
通过构造指数位快速计算 2^x。
fast_round_scale(amax, fp8_max_inv)
将 scale 舍入为 2 的幂次(MXFP 格式要求):
return fast_pow2(fast_log2_ceil(amax * fp8_max_inv))
3.4 act_quant_kernel(第 40-126 行)
FP8 激活量化 Kernel:
参数
N: 输入最后一维大小block_size=128: 量化块大小in_dtype=BF16: 输入类型out_dtype=FP8: 输出类型scale_dtype=FP32: scale 存储类型round_scale=False: 是否将 scale 舍入为 2 的幂inplace=False: 是否原地量化和反量化回 BF16
Kernel 流程
- 每个线程块处理
[blk_m=32, group_size=128]的子矩阵 T.copy从全局内存加载到 shared memoryT.reduce_absmax计算每行的绝对最大值amax = max(amax, 1e-4)防止除零- 计算 scale:
amax * fp8_max_inv或fast_round_scale(...) - inplace 模式:量化 → clamp → 反量化回 BF16
- 非 inplace 模式:量化到 FP8(clamp 到 [-448, 448])
- 写回 global memory
act_quant Python 包装
- 断言
N % block_size == 0 - 分配输出张量和 scale 张量
- 调用 JIT kernel
- inplace 模式时
x.copy_(y)
3.5 fp4_quant_kernel(第 128-201 行)
FP4 激活量化 Kernel:
与 FP8 类似,但:
block_size=32(FP4 使用更小的块)fp4_max=6.0(FP4 E2M1 的最大值)- 强制
round_scale=True(FP4 必须 2 的幂次 scale) amax = max(amax, 6 * 2^-126)防止下溢
输出 FP4 时,y 分配为 float4_e2m1fn_x2 类型,每字节存 2 个 FP4 值。
3.6 fp8_gemm_kernel(第 203-274 行)
FP8 矩阵乘法:C[M,N] = A[M,K] @ B[N,K]^T
分块策略
block_M=32, block_N=128, block_K=128- 每个线程块处理
[32, 128]的输出块 group_size=128(scale 块大小)
关键实现
T.use_swizzle(panel_size=10)优化 L2 cache 局部性- 双累加器设计:
C_local(原始 GEMM 结果)+C_local_accum(scale 修正后结果) - K 维循环,每步加载 A_shared 和 B_shared
- scale 计算:
Scale_C = scale_a[by*block_M+i, k] * scale_b[bx*block_N//group_size, k] T.gemm(A_shared, B_shared, C_local, transpose_B=True)C_local_accum += C_local * Scale_C_shared[i]- 循环结束后写回 C
fp8_gemm Python 包装
- 断言输入和 scale 都是 contiguous
- 自动推导 M, N, K
- 输出 dtype 为当前默认 dtype(bfloat16)
3.7 sparse_attn_kernel(第 276-368 行)
稀疏多头注意力,通过索引收集实现:
参数
h: 头数d: 每头维度scale: softmax 缩放(默认(1.0/d)^0.5)
分块策略
block=64, threads=256- 每个线程块处理一个
(batch, seq_pos) num_blocks = ceil(topk, block)
Kernel 流程(FlashAttention 风格在线 softmax)
初始化:
acc_o = 0(输出累加器)sum_exp = 0(指数和)scores_max = -inf(当前最大值)
循环每个 block:
- 加载
topk_idxs,越界用-1 - 根据索引从
kv收集到kv_shared(越界位置填 0) acc_s中越界位置设为-infT.gemm(q_shared, kv_shared, acc_s, transpose_B=True)- 缩放:
acc_s *= scale - 在线 softmax 更新:
scores_max_prev = scores_maxreduce_max(acc_s, scores_max)scores_scale = exp(scores_max_prev - scores_max)acc_o *= scores_scale(修正之前累加的结果)sum_exp *= scores_scaleacc_s = exp(acc_s - scores_max)reduce_sum(acc_s, scores_sum)sum_exp += scores_sum
acc_o += gemm(acc_s_cast, kv_shared)(注意力加权值累加)
循环结束后:
sum_exp += exp(attn_sink - scores_max)(加入可学习 sink 偏置)acc_o /= sum_exp(归一化)- 写回输出
sparse_attn Python 包装
- 若头数 < 16,padding 到 16 以适配 kernel(返回时截取)
- 调用 JIT kernel
3.8 hc_split_sinkhorn_kernel(第 371-438 行)
Hyper-Connections 的 Sinkhorn 归一化拆分:
输入
mixes:[n, (2+hc)*hc]混合系数hc_scale:[3]三个部分的缩放因子hc_base:[(2+hc)*hc]偏置
输出
pre:[n, hc]预权重(sigmoid)post:[n, hc]后权重(2*sigmoid)comb:[n, hc, hc]组合矩阵
算法
- 按 hc 拆分为 pre、post、comb 三部分
- pre:
sigmoid(mixes * scale[0] + base[:hc]) + eps - post:
2 * sigmoid(mixes * scale[1] + base[hc:2*hc]) - comb: softmax 按行归一化 + eps
- Sinkhorn 迭代(默认 20 次):
- 按行归一化:
comb /= comb.sum(-1) + eps - 按列归一化:
comb /= comb.sum(-2) + eps
- 按行归一化:
Sinkhorn 确保组合矩阵接近双随机矩阵(行和列和均约等于 1)。
3.9 fp4_gemm_kernel(第 442-537 行)
FP8 激活 × FP4 权重 GEMM:C[M,N] = A_fp8[M,K] @ B_fp4[N,K]^T
量化策略
- A(激活): per-128 块 FP8 量化
- B(权重): per-32 块 FP4 量化,E8M0 scale
分块策略
block_M=32, block_N=128, block_K=32n_sub = 128/32 = 4(每个 act scale 组包含 4 个 weight block)
关键步骤
- 加载 A_shared(FP8)和 B_fp4_shared(FP4)
- FP4 → FP8 转换:
Cast(FP8, Cast(FP32, B_fp4_shared[i,j])) - 加载 weight scale:
scale_b[i] = scales_b[bx*block_N+i, k] - 加载 act scale:
scale_a[i] = scales_a[by*block_M+i, k//4] T.gemm(A_shared, B_shared, C_local)C_local_accum += C_local * scale_a[i] * scale_b[j]
四、generate.py 分析
4.1 sample 函数(第 19-25 行)
Gumbel-max 采样:
logits = logits / max(temperature, 1e-5)
probs = torch.softmax(logits, dim=-1, dtype=torch.float32)
return probs.div_(torch.empty_like(probs).exponential_(1)).argmax(dim=-1)
利用指数分布的 Gumbel-max 技巧,等价于多项式采样但避免了 torch.multinomial 的 GPU→CPU 同步,速度更快。
4.2 generate 函数(第 27-69 行)
批处理生成:
- 计算 prompt 长度,确定
total_len = min(max_seq_len, max_new_tokens + max_prompt_len) - 构造 left-padded tokens 矩阵(
-1填充) - Prefill 阶段:从
min(prompt_lens)开始,处理所有 prompt token - Decode 阶段:逐个位置生成
- 对仍在 prompt 内的位置,用 ground-truth token 覆盖模型预测
- 遇到 eos_id 标记该样本完成
- 全部完成后提前退出
- 截取生成的 token(去掉 prompt 部分,截断到 eos)
4.3 main 函数(第 72-143 行)
推理入口:
- 初始化分布式环境(
nccl) - 设置 CUDA 设备
- 启用 expandable segments 内存分配器
- 默认 dtype 设为 bfloat16
- 加载 ModelArgs 配置
- 构建 Transformer 模型
- 加载 tokenizer
load_model从 safetensors 加载权重
交互模式:
- 循环读取用户输入
- 支持
/exit退出、/clear清空历史 - rank 0 广播 prompt 给其他 rank
- 编码 messages → generate → 解码输出 → 解析后追加到 messages
批量模式:
- 从文件读取 prompts(双换行分隔)
- 批量编码和生成
- 输出 prompt + completion 对
五、convert.py 分析
5.1 FP4 → FP8 无损转换(第 11-52 行)
FP4_TABLE
FP4 E2M1 的 16 个值映射表(包含正负):
0.0, 0.5, 1.0, 1.5, 2.0, 3.0, 4.0, 6.0,
0.0, -0.5, -1.0, -1.5, -2.0, -3.0, -4.0, -6.0
cast_e2m1fn_to_e4m3fn
将 int8 存储的 FP4 权重无损转换为 FP8:
- 解包高低 4 位:
low = x & 0x0F, high = (x >> 4) & 0x0F - 查表得到 FP32 值
- 重排为
[bOut, fp8_block_size, bIn, fp8_block_size] - 计算 scale 的最大偏移:
scale_max_offset = scale.amax() / 2^6- 因为
max_fp4(6.0) * 2^6 = 384 < 448(max_fp8)
- 因为
- 计算 offset:
scale / scale_max_offset - 扩展 offset 到每个 FP4 元素位置
- 权重乘以 offset,转为 FP8
- 返回 FP8 权重和新的 E8M0 scale
5.2 名称映射表(第 55-79 行)
将 HuggingFace 参数名映射到本项目格式:
| HF 名称 | 本项目名称 | 切分维度 |
|---|---|---|
| embed_tokens | embed | 0 |
| input_layernorm | attn_norm | None |
| post_attention_layernorm | ffn_norm | None |
| q_proj | wq | 0 |
| q_a_proj | wq_a | None |
| q_a_layernorm | q_norm | None |
| q_b_proj | wq_b | 0 |
| kv_a_proj_with_mqa | wkv_a | None |
| kv_a_layernorm | kv_norm | None |
| kv_b_proj | wkv_b | 0 |
| o_proj | wo | 1 |
| gate_proj | w1 | 0 |
| down_proj | w2 | 1 |
| up_proj | w3 | 0 |
| lm_head | head | 0 |
5.3 main 转换流程(第 82-168 行)
- 为每个 rank 初始化空 state_dict
- 遍历 HF checkpoint 的所有 safetensors 文件
- 对每个参数:
- 去掉
model.前缀 - 替换
self_attn→attn,mlp→ffn - 替换
weight_scale_inv→scale - 根据映射表转换名称和切分维度
- 专家权重按 rank 范围筛选
- 其他权重按维度切分
- 去掉
- 处理特殊权重:
wo_a.weight:与 scale 融合后展平- 专家 int8 权重:根据
expert_dtype转为 FP8 或 FP4
- 保存为
model{i}-mp{mp}.safetensors - 复制 tokenizer 文件
六、关键设计总结
6.1 量化策略
| 组件 | 存储格式 | Scale 格式 | 块大小 |
|---|---|---|---|
| 普通权重 | FP8 E4M3 | E8M0 | 128×128 |
| 专家权重 | FP4 E2M1 | E8M0 | 1×32 |
| 激活 | 动态 FP8 | E8M0/FP32 | 1×128 |
| KV Cache(压缩) | FP8/FP4 | - | 64 |
6.2 并行策略
| 层/操作 | 并行方式 | 通信 |
|---|---|---|
| Embedding | 词表切分 | all_reduce |
| Q/KV 投影 | ColumnParallel | 无 |
| O 投影 | RowParallel | all_reduce |
| FFN | ColumnParallel | 无 |
| MoE Gate | 复制 | all_reduce(score) |
| MoE Expert | 专家切分 | all_reduce(输出) |
| Head | 词表切分 | all_gather |
6.3 内存优化
- KV Cache 滑动窗口(128)+ 压缩(最高 128:1)
- FP4/FP8 混合量化减少显存占用
expandable_segmentsCUDA 内存分配器- 推理时
torch.inference_mode()禁用梯度