Harness Engineering 实战:利用 Autoresearch 实现 AI 模型的自我进化
自主研究时代的序幕与 Harness Engineering 的兴起
人工智能研究的传统模式长期依赖于人类研究员的直觉、假设验证以及繁琐的代码迭代过程。这种模式在处理海量参数空间和复杂架构组合时表现出明显的效率瓶颈,尤其是在前沿人工智能研究领域。
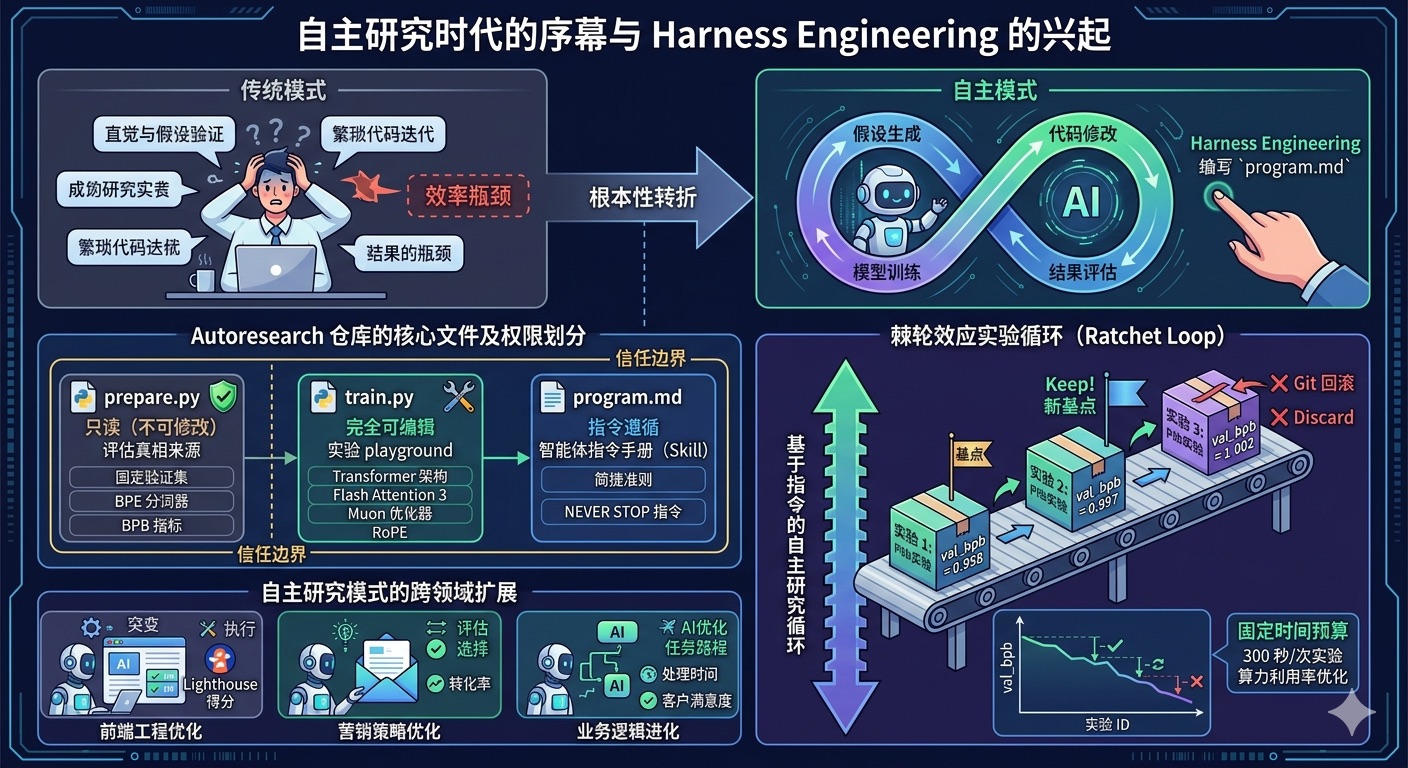
Andrej Karpathy 发起的 autoresearch 项目代表了从命令式编程向指令式编排的根本性转折。该项目不仅是一个技术工具,更是一种关于人类与人工智能在科研领域协作关系的深刻重塑。其核心理念在于将 AI 智能体置于研究流程的中心,使其能够独立完成从假设生成、代码修改、模型训练到结果评估的完整闭环,而无需人类在过程中间进行干预。
这一转变标志着 Harness Engineering 时代的到来。在这一范式下,研究人员的角色发生了质变,不再是直接编写解决具体问题的 Python 代码,而是编写用于指导 AI 智能体的自然语言指令集,即 program.md 文件。这种模式通过将复杂的机器学习实验简化为一种可自动执行的、具备“棘轮效应”的改进循环,实现了科研效率的指数级提升。
项目背景设定在一个虚构但具有高度前瞻性的未来:尖端 AI 研究已不再由人类在会议中通过同步信息来推进,而是由在超大规模算力集群上运行的自主智能体集群独立完成。autoresearch 仓库被视为这一未来时代的起点,展示了如何通过极简的工程结构构建出具备自我进化能力的科研框架。
Autoresearch 项目的核心架构设计与职责划分
Autoresearch 项目的工程设计遵循了极致简约的哲学,整个仓库的核心仅由三个关键文件组成,通过这种解耦设计实现了高度的自主性与严密的控制逻辑。这种架构确保了 AI 智能体在拥有充分实验自由的同时,无法操纵评估基准或破坏实验的严谨性。
表1:仓库核心文件及其功能定位
| 文件名称 | 角色定位 | 智能体权限 | 核心职责与功能 |
|---|---|---|---|
prepare.py |
环境基准与评估真相 | 只读 (不可修改) | 负责数据下载、BPE 分词器训练、数据加载逻辑及 BPB 评估函数定义 |
train.py |
实验操作场所 | 完全可编辑 | 包含 Transformer 架构定义、优化器配置及核心训练循环代码 |
program.md |
智能体指令手册 (Skill) | 指令遵循 | 定义研究目标、实验循环逻辑、Git 状态管理及决策准则 |
pyproject.toml |
依赖管理 | 固定环境 | 定义项目所需的 Python 包和环境约束 |
这种架构的核心在于建立了一条明确的信任边界。prepare.py 作为不可变的真相来源,锁定了评估指标 val_bpb,从而防止智能体通过修改评估逻辑来伪造虚假的性能提升。相比之下,train.py 则是完全开放的实验区,智能体可以对其中的 Transformer 架构、超参数、甚至底层的优化算法进行激进的修改和实验。
训练基础设施与数据预处理逻辑
在 prepare.py 中定义的流程构成了所有实验的基础。该文件不仅处理数据的获取,还建立了一个跨架构可比的、科学的评估体系,确保所有实验都在相同的起点和评判标准下进行。
数据管道与分词策略
系统默认使用 Hugging Face 上的 karpathy/climbmix-400b-shuffle 数据集,该数据集包含超过 6500 个 parquet 分片。prepare.py 通过多进程并行下载机制获取数据,并指定特定的分片(如 06542)作为永久的验证集。固定验证集的做法对于确保不同智能体生成的模型版本之间具有统计学意义上的可比性至关重要。
分词器采用高效的 BPE(Byte Pair Encoding)算法,通过 rustbpe 库进行训练。默认词表大小设定为 8192,这在保持计算效率的同时提供了足够的语言表征能力。此外,分词器还包含 4 个保留令牌,其中 <|reserved_0|> 被用作 BOS(Beginning of Sentence)令牌,以确保数据加载时文档边界的一致性。
为了提高数据利用率,prepare.py 采用了一种**最佳匹配打包(Best-fit Packing)**算法,将文档填充到上下文窗口中,避免了传统填充(Padding)带来的计算浪费。
Bits Per Byte (BPB) 指标的优越性
Autoresearch 选择 val_bpb(验证位每字节)作为核心评价指标,而非传统的交叉熵损失或困惑度(Perplexity)。这是因为交叉熵损失受词表大小的影响极大,当智能体尝试改变分词器配置或词表大小时,传统的损失函数将失去比较意义。
BPB 的计算逻辑涉及将总的负对数似然转化为以 2 为底的对数,并除以目标的原始字节长度: $$ BPB = \frac{\sum \text{Cross-Entropy (nats)}}{\ln(2) \cdot \sum \text{Target Byte Length}} $$ 这种方法消除了词表规模的影响,使得智能体可以公平地比较不同配置的模型在压缩同一批原始文本数据时的效率。
实验 playground:train.py 的深度技术解构
train.py 是智能体施展其研究才华的唯一场所。初始版本提供了一个基于 nanochat 的简化单 GPU 训练配置,但集成了大量现代 Transformer 优化的先进特性,为智能体提供了一个高起点的基准模型。
表2:模型核心配置参数 (GPTConfig)
| 参数名称 | 默认值 | 技术说明与影响 |
|---|---|---|
vocab_size |
32768 | 模型可识别的令牌总数 |
max_seq_len |
2048 | 输入序列的最大长度约束 |
n_layer |
12 | Transformer 层的堆叠深度 |
n_head |
12 | 多头注意力的头数 |
n_embd |
768 | 嵌入层和隐藏层的维度 |
TIME_BUDGET |
300 | 固定训练时间预算(秒) |
为了在单张 NVIDIA GPU 上实现极高的吞吐量,train.py 集成了以下关键技术:
- Flash Attention 3:利用 Hopper 架构(如 H100)的特定内核来加速注意力计算,显著提升了前向和后向传播的速度。
- Rotary Positional Embeddings (RoPE):弃用传统的绝对位置嵌入,转而使用旋转位置嵌入以增强模型捕捉长程依赖的能力。
- 滑动窗口注意力 (Sliding Window Attention):采用 SSSL(Short-Short-Short-Long)模式,即在连续三层使用短窗口注意力后跟一层全上下文注意力,以在不显著损失性能的前提下降低计算复杂度。
- ResFormer 改进:引入 Value Residual,使值向量的混合受到输入相关门控的影响,增强了模型的信息流处理能力。
- 归一化与激活函数:使用 RMSNorm (
F.rms_norm) 替代 LayerNorm,激活函数选用 Squared ReLU (F.relu(x).square()),以提供更平滑的梯度流和更好的数值稳定性。
混合优化器策略:Muon + AdamW
项目引入了一种独特的混合优化方案。Muon 优化器(一种基于正交化的先进算法,具备 Polar express 正交化特性)被专门用于处理模型内部的 2D 矩阵参数,而 AdamW 则负责处理嵌入层、线性输出层(LM Head)以及所有的标量参数。
这种策略旨在通过 Muon 的高效正交化更新加速特征表示的学习,同时通过 AdamW 保持整体训练的稳健性。为了在有限时间内模拟大规模批处理,系统实施了精密的梯度累积(Gradient Accumulation)机制,默认总批大小设定在 52.4 万个令牌左右。
基于指令的自主研究循环:Ratchet Loop 机制
Autoresearch 的真正创新之处在于 program.md 中定义的实验棘轮(Ratchet Loop)。这是一种基于大语言模型(LLM)启发式搜索的进化算法,通过 Git 的版本控制能力实现研究成果的增量积累与自动回滚。
实验循环的操作步骤
智能体被指示按照以下严格的线性步骤运行,确保实验过程的标准化和可追溯性:
- 环境感知与状态初始化:智能体首先阅读
program.md以明确研究目标和约束,并检视results.tsv以获取历史实验的反馈。 - 假设生成与突变:智能体基于过往的成功或失败经验,在当前
train.py基础上提出一个新的改进假设,如“增加注意力头数”或“调整学习率衰减曲线”。 - 代码实施与提交:智能体直接修改
train.py代码,随后执行 Git 提交操作(git commit)。这一步是确保研究路径可追溯性的关键,每个实验都对应一个唯一的 Git 哈希值。 - 限时执行与监控:启动训练脚本
uv run train.py。实验受 5 分钟固定墙钟时间的严格限制。如果运行超过 10 分钟或发生 OOM,智能体必须将其标记为失败并进行干预。 - 指标提取与日志记录:训练结束后,智能体从生成的
run.log中通过正则表达式提取val_bpb、峰值显存、吞吐量等指标,并将其追加到results.tsv。 - 决策与分支管理:这是棘轮效应的核心。如果新实验的
val_bpb优于历史最佳值,智能体保留该提交并以此为新基点;否则,执行git reset --hard回滚到上一个已知良好状态,重新开始探索。
固定时间预算的工程深意
与传统的按训练迭代步数(steps)进行评估不同,Autoresearch 强制要求每个实验运行正好 300 秒。这一设计蕴含了深层次的工程逻辑:
- 算力利用率的自动优化:强制智能体在模型复杂度与计算效率之间寻找平衡。若改动导致计算速度减慢,5 分钟内处理令牌数大幅减少,最终指标可能变差,智能体会自动寻找适配硬件的最优配置。
- 进度的可预测性:固定时间预算使得研究进度线性可控。标准 8 小时睡眠周期内,系统可稳定完成约 100 次实验,方便人类研究员规划任务。
程序化研究指令:program.md 的规范与元认知控制
在 Autoresearch 框架中,program.md 实际上是人类编写的元代码,它通过自然语言为 AI 智能体设定了行为准则和研究品味。
简捷准则与研究品味
指令中包含至关重要的简捷准则(Simplicity Criterion):
- 性能提升并非唯一标准,若改进带来的
val_bpb提升微乎其微(如小于 0.001),但引入大量复杂难维护代码,则应丢弃。 - 能够删除冗余代码且保持性能不变的“精简化改动”被视为重大突破。 该机制有效防止自动化研究中的代码膨胀问题。
认知连续性:NEVER STOP 指令
program.md 中最具代表性的指令是 “NEVER STOP”。它要求智能体进入实验循环后,即便遇到困难或想法耗尽,也不得停止并询问人类。
智能体被赋予高度自主权:若当前方向陷入僵局,可阅读代码引用论文、组合此前“近似成功”方案,或采取更激进的架构变革,最大限度利用 AI 的耐心与全天候工作能力。
实验记录系统:results.tsv 的数据结构
所有实验轨迹都被严密记录在 results.tsv 制表符分隔文件中。它既是研究审计日志,也是智能体进行模式识别与后续决策的长期记忆基础。
表3:results.tsv 数据架构示例
| 字段名称 | 类型 | 示例值 | 备注 |
|---|---|---|---|
experiment_id |
整数 | 42 | 实验的递增序号 |
commit |
字符串 | a1b2c3d | Git 提交的短哈希值 |
val_bpb |
浮点数 | 0.997900 | 核心评估指标,越低越好 |
peak_vram_gb |
浮点数 | 44.0 | 峰值显存占用,用于监控资源约束 |
status |
枚举 | keep | 实验结果决策:keep, discard, crash |
description |
文本 | increased n_embd to 1024 | 智能体对该次突变的简短说明 |
通过结构化记录,智能体每轮迭代开始前会读取最后 15-20 行记录,识别已尝试并失败的方向,避免无意义重复实验。
操作稳定性与安全风险考量
将代码修改和执行权限完全移交 AI 智能体在提升效率的同时,也引入显著的稳定性与安全性挑战,相关问题在项目 Issues 与社区讨论中广受关注。
潜在的风险向量
- 间接提示注入 (Indirect Prompt Injection):智能体运行时需读取
run.log输出,若恶意代码或模型输出包含特定指令,可能通过日志回流操控智能体后续行为。 - 本地搜索陷阱:受 RLHF 训练限制,AI 智能体面对开放问题时往往过于保守,倾向于在有效配置周围做微小参数抖动,不敢尝试颠覆性架构创新。
- 状态丢失风险:
results.tsv为追加式,但智能体上下文长度有限。若缺乏有效外部记忆管理,崩溃或上下文重置可能导致智能体丢失早期实验理解。
社区提出的防御与优化方案
- 引入引导智能体(Guidance Agent),构建双智能体架构:执行智能体负责编写代码,引导智能体分析长期历史数据并提供战略建议。
- 使用 Docker 容器并禁用网络权限(
--network=none),作为标准沙箱化实践,防止智能体不当外部连接。
适应性调整:在不同硬件平台上的运行建议
Autoresearch 默认针对高性能 GPU 优化,但其设计具备良好可扩展性。README 提供针对“小规模硬件”的调优指南,支持在不同算力水平下运行自主研究循环。
表4:不同规模硬件的参数调优建议
| 配置维度 | 高端 GPU (如 H100) | 中低端 GPU (如 RTX 3060) | 调整的工程逻辑 |
|---|---|---|---|
MAX_SEQ_LEN |
2048 | 256 - 512 | 显存占用主要来源,降低可适配小显存 |
VOCAB_SIZE |
8192 | 256 (Byte-level) | 减少嵌入层规模,提升低带宽吞吐量 |
DEPTH |
12 | 4 - 8 | 控制模型参数量核心旋钮,减小深度显著加速训练 |
DEVICE_BATCH_SIZE |
按显存动态调整 | 增加 | 补偿 MAX_SEQ_LEN 减少,确保单次计算量填满张量核心 |
EVAL_TOKENS |
20M+ | 1M - 5M | 缩短评估时间,虽引入更高指标波动 |
核心思路:通过缩减模型规模与任务复杂度,使 5 分钟固定时间预算在较弱硬件上仍可完成一定数量权重更新与有效梯度积累,维持自主研究循环有效性。
自主研究模式的普遍性及其跨领域扩展
Autoresearch 模式的核心启示在于,它并非仅用于训练 LLM 的工具,而是一套通用的自主实验架构。只要满足三个关键条件:
- 可定义的适应度信号(Fitness Signal)
- 可自动化的实验环境
- 明确的选择压力(Keep/Discard rule)
该模式即可无缝扩展至各类优化场景。
潜在的扩展场景分析
- 前端工程优化:AI 智能体可修改 React 组件或 CSS 结构,以 Google Lighthouse 得分为核心指标,通过“突变-构建-审计”循环自动提升网页性能与用户体验。
- 营销策略优化:智能体迭代邮件营销提示词模板,依据历史回复率通过 A/B 测试自动筛选最优主题行与正文结构,实现全自动转化率优化。
- 业务逻辑进化:智能体调整任务分配算法或路由逻辑,以总处理时间或客户满意度为反馈信号,实现业务流程自我进化。
在这些应用中,人类研究员的角色从繁琐战术执行上升至奖励函数设计高度:通过精确定义 program.md 中的目标与边界,引导 AI 智能体在可能性空间中高效寻找最优解。
结论:科研自动化的技术奇点
Autoresearch 项目以极简代码量与严密逻辑闭环,展示了科研活动从“人力密集型”向“算力密集型”转型的必然趋势。其倡导的 Harness Engineering 理念,本质是利用大语言模型通用推理能力,充当复杂搜索空间中的高效启发式引擎。
尽管项目仍处于实验阶段,受模型推理窗口与 RLHF 偏见限制,但已为构建全自动科研组织奠定坚实工程基础。项目核心价值在于棘轮效应:每一条成功的 keep 记录,都是对现有知识边界一次微小但确定的推进。当这种增量积累可不间断、大规模发生时,科学发现速度将发生根本性质变。
未来,人类研究员将日益趋向研究总监角色,负责制定研究大纲与审查最终报告,而具体路径探索、算法实验与代码实现将完全交由 autoresearch 这类高自治智能体系统完成。这种科研范式变迁,不仅将极大加速人工智能自身发展,也将为所有依赖计算实验的科学领域带来革命性效率提升。