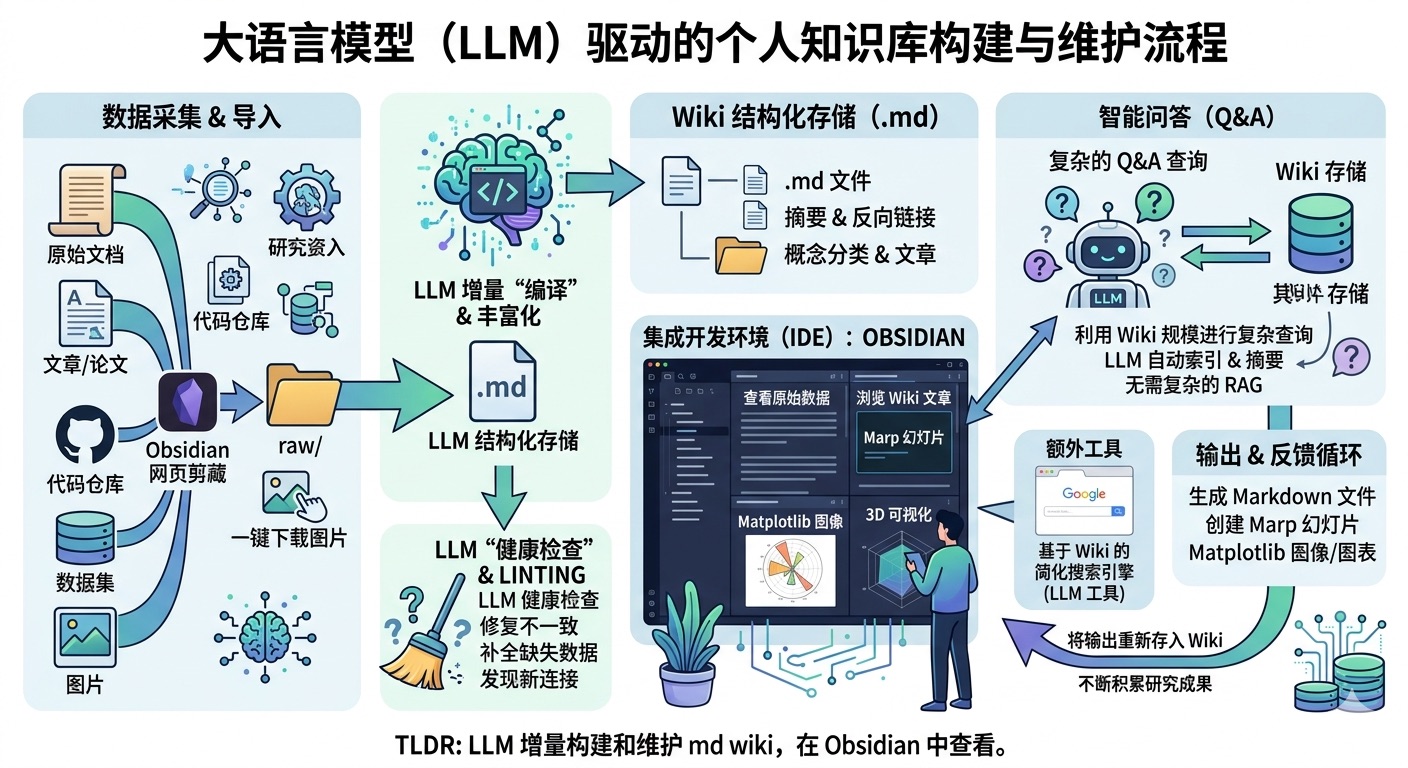
最近我发现一个非常实用的方法:利用大语言模型(LLM)为各类感兴趣的研究方向搭建个人知识库。这样一来,我近期消耗的模型令牌中,用于处理代码的占比大幅减少,更多被用于处理知识(以 Markdown 文件和图片形式存储)。最新的大语言模型在这方面表现十分出色。具体做法如下:
数据导入
我先将各类源文件(文章、论文、代码仓库、数据集、图片等)归档到 raw/ 目录下,再通过大语言模型逐步“编译”生成一份知识库,这份知识库本质就是按目录结构组织的一系列 .md 文件。
知识库会包含 raw/ 目录下所有数据的摘要、反向链接,还会将数据按概念分类、撰写对应词条并完成相互关联。
为把网页文章转为 .md 文件,我习惯使用 Obsidian 网页剪藏插件,同时通过快捷键将相关图片批量下载到本地,方便大语言模型直接调用。
集成开发环境
我把 Obsidian 当作前端 IDE,既能查看原始数据、编译后的知识库,也能查看衍生的可视化内容。 需要重点说明的是:整个知识库的内容撰写与维护均由大语言模型完成,我几乎不直接手动修改。我还试用过多款 Obsidian 插件,以其他形式渲染和查看数据(比如用 Marp 制作幻灯片)。
问答交互
真正有意思的是,当知识库规模足够大时(比如我近期的研究知识库已有约 100 篇词条、40 万字),就可以向大语言模型智能体提出各类复杂问题,它会自主检索、梳理并给出答案。 我原本以为需要用上复杂的检索增强生成(RAG)技术,但在当前这种小规模场景下,大语言模型能自动维护索引文件和所有文档的精简摘要,轻松读取全部关键相关数据,效果已经很好。
结果输出
我不满足于仅在文本或终端获取答案,更倾向于让模型直接生成 Markdown 文件、幻灯片(Marp 格式)或 Matplotlib 图表,所有内容都能在 Obsidian 中查看。 根据不同查询需求,还可以生成更多种可视化格式。通常我会把这些输出结果“归档”回知识库,进一步丰富内容,让后续的查询和探索持续为知识库积累价值。
内容校验
我会让大语言模型对知识库进行“健康检查”,比如排查数据矛盾、通过联网搜索补全缺失信息、挖掘潜在关联以生成新词条候选等,逐步优化知识库、提升整体数据完整性。大语言模型还很擅长提出值得进一步探究的问题。
辅助工具
我还自行开发了一些数据处理工具,比如快速编写了一个简易的知识库搜索引擎,既可以通过网页界面直接使用,也更常通过命令行接口(CLI)将其作为工具交给大语言模型,用于处理更复杂的查询。
后续探索
随着知识库仓库不断扩容,自然而然会考虑结合合成数据生成与模型微调,让大语言模型通过模型权重“真正记住”这些数据,而不只是依赖上下文窗口。
总结
从多个来源收集原始数据,由大语言模型编译为 Markdown 格式知识库;再通过各类命令行工具驱动大语言模型完成问答,并逐步完善知识库,所有内容均可在 Obsidian 中查看。几乎无需手动编写或编辑知识库,全程由大语言模型主导维护。我认为这一方向完全有潜力诞生一款出色的新产品,而非目前这种零散脚本的组合方案。
构建自己的知识系统(Gemini 3.1 Pro)
根据 Andrej Karpathy(前特斯拉 AI 总监、OpenAI 创始成员)在 2026 年 4 月分享的 “LLM Knowledge Bases”(大模型知识库) 概念,构建个人知识系统的方法论正在发生根本性的转变:放弃耗时的手动整理笔记,也暂时绕开复杂的 RAG(检索增强生成)系统;转而将 LLM 作为“全职图书管理员”,让它自动把海量原始资料“编译”成一个结构化的 Markdown Wiki。
基于他分享的工作流,以下是构建你自己 AI 驱动知识系统的核心逻辑与具体步骤:
1. 核心理念:从“手动记录”到“AI 编译”
- 抛弃复杂架构,回归文件系统:在个人知识库规模(约 100 篇文章,40 万字左右)下,传统的向量数据库和 RAG 系统往往会引入“检索噪音”和不必要的复杂性。现代 LLM 已经足够聪明,完全可以直接阅读并维护索引文件和文档摘要。
- Wiki 是 LLM 的领地:在这个系统中,人类主要负责收集高质量的“原始素材”,并把握大方向。知识库的目录结构、摘要提取、概念分类、双向链接等“脏活累活”,全部由 LLM 自动生成和维护。
2. 构建知识系统的三层架构
第一步:Data Ingest(收集原始素材)
建立一个 /raw 文件夹,专门存放未经加工的原始资料。这些是知识库的“基石”,属于不可变的精选文档。
- 输入内容:研究论文、网页文章、GitHub 仓库代码、数据集以及相关的图表。
- 推荐工具:利用 Obsidian Web Clipper 等插件,将网页内容一键转换为干净的 Markdown(
.md)文件。相关的图片也应下载到本地,以便 LLM 可以在后续利用其视觉能力(Vision)进行分析和引用。
第二步:LLM Compilation(LLM 自动编译)
这是该架构的核心创新。LLM 不仅仅是为文件建立索引,而是像编译器一样,将零散的原始数据“编译”成相互关联的知识网络。
- 生成全局索引与摘要:LLM 会自动阅读
/raw中的文件,并编写index.md(总目录)及每份文档的要点摘要。 - 构建实体页面与链接:LLM 会提取出核心概念,生成百科式的“概念页面”,并在不同页面之间自动创建双向链接(Backlinks),形成网状结构。
第三步:Query & Filing Back(查询与知识沉淀)
当知识库初具规模后,传统的“单次问答”将被“Agent 主导的探索”取代。
- 复杂推理:你可以向 LLM 提出需要深度综合的复杂问题,LLM 会在它自己搭建的 Wiki 中搜索、查阅关联链接并生成回答。
- 知识回填(Filing Back):最重要的一点是,LLM 的回答不仅是一次性的聊天气泡,它可以输出为新的 Markdown 文件、幻灯片(通过 Marp 插件)或数据可视化图表(通过 matplotlib),并将这些解答直接存回 Wiki 中。这意味着你提问得越多,知识库就越庞大、越聪明。
3. 知识库的日常维护:Linting(健康体检)
像程序员维护代码一样,Karpathy 引入了对知识进行 Linting(代码检查)的机制:
- 定期让 LLM 扫描整个 Wiki,进行“体检”。
- LLM 会自动发现知识库中相互矛盾的数据、过时的结论、孤立无链接的页面,以及缺失的逻辑环节。
- 对于缺失的信息,LLM 可以主动调用网络搜索工具(Web Search)进行自动补全,并建议修改方案。
4. 推荐的基础工具栈
- 知识库前端(IDE):Obsidian。Karpathy 将 Obsidian 视作知识库的“集成开发环境”。它对 Markdown 的原生支持、丰富的插件生态以及双向链接视图,非常适合用来展示 LLM 生成的知识网络。
- 数据格式:纯 Markdown。体积小巧、排版干净、没有平台锁定风险,且是 LLM 最容易理解和生成的格式。
- 核心驱动:前沿大语言模型。使用具有长文本处理能力和代码能力的模型,通过 API 或脚本让它们在后台处理你的文件夹。
总结行动指南:
要实践这一套理念,你可以从最简单的本地文件夹开始。专注于阅读和收集高质量的素材(存入 /raw),然后通过编写简单的 Python 脚本调用大模型 API,让 AI 帮你生成摘要、建立目录和双向链接。把你过去花在排版、打标签和整理文件夹上的时间,全部用来思考和提出更深刻的问题。
构建自己的知识系统(Grok 4.20)
Karpathy 的这篇 X 帖子(2026 年 4 月 2 日)核心讲的是:用 LLM(大型语言模型)来构建和管理「个人知识库」(LLM Knowledge Bases),把零散的原始资料变成一个结构化、可查询、能自我进化的 Markdown Wiki。
他把知识工作从“手动记笔记”升级成“让 LLM 自动维护知识系统”,自己很少直接编辑文件,而是让 LLM 做编译、总结、链接、纠错和生成输出。最终目标是:知识会随着你的每次查询而自动积累、优化,形成一个“第二大脑”。
1. Karpathy 知识系统的核心流程(原帖 TLDR)
Data Ingest(数据摄入)
- 把文章、论文、代码仓库、数据集、图片等原始资料丢进
raw/目录。 - 用 Obsidian Web Clipper 快速把网页转成 Markdown,并用快捷键把相关图片下载到本地(方便 LLM 引用)。
- 把文章、论文、代码仓库、数据集、图片等原始资料丢进
Compile(编译)
- 用 LLM 增量地把
raw/里的内容“编译”成一个 Markdown Wiki(一堆.md文件 + 目录结构)。 - LLM 会自动做:
- 每篇文档的总结
- 提取概念、写概念文章
- 建立 backlinks(双向链接)
- 维护索引文件
- 用 LLM 增量地把
IDE / 前端
- 用 Obsidian 查看(支持 graph view、可视化、插件如 Marp 做幻灯片)。
- LLM 才是真正的主人——你几乎不手动改 wiki 文件。
Q&A(查询与对话)
- 当 Wiki 足够大(他举例 ~100 篇文章、40 万字),直接问 LLM 复杂问题。
- LLM 会自己去 wiki 里检索、阅读相关文件、做推理。
- 小规模下不需要复杂 RAG,LLM 自己维护索引就够用。
Output(输出)
- LLM 不只回答文字,还能生成 Markdown 文件、Marp 幻灯片、Matplotlib 图表等。
- 把这些输出“归档”回 wiki,形成闭环(每次查询都在丰富知识库)。
Linting & Maintenance(健康检查与维护)
- LLM 定期做“健康检查”:找矛盾、补缺失数据、发现新连接、建议新文章。
Extra Tools & 未来
- 他自己 vibe code 了一个小搜索引擎,让 LLM 通过 CLI 调用。
- 未来方向:生成合成数据 + 微调,让 LLM 把知识“刻”进权重里(而非只靠上下文)。
一句话总结:原始资料 → LLM 自动编译成 Markdown Wiki → LLM 在 Wiki 上做研究、生成、优化 → 全程在 Obsidian 里可视化。你几乎不用手动写笔记,知识系统自己“长大”。
2. 如何自己动手构建相同的知识系统(实用指南)
以下是零基础也能快速上手的步骤(2026 年当前最成熟方案):
步骤 1:搭建基础环境(10 分钟)
- 下载 Obsidian(免费,本地 Markdown 编辑器)。
- 新建一个 Vault(知识库文件夹),推荐结构:
MyKnowledgeBase/
├── raw/ ← 原始资料(不要动)
├── wiki/ ← LLM 编译后的结构化知识(核心)
├── images/ ← 图片
├── index.md ← 总索引(LLM 维护)
└── concepts/ ← 概念文章目录
步骤 2:选择 LLM 工具(推荐组合)
| 工具 | 用途 | 推荐理由 |
|---|---|---|
| Claude / Cursor | 主要编译 & 编辑 | 最擅长长上下文 + Markdown |
| Grok(Projects) | 日常查询 & 文件管理 | 项目文件夹支持持久文件 |
| Obsidian 插件 | 终端 / AI 集成 | 如 Terminal + Claude Code |
步骤 3:开始编译(核心 Prompt 模板)
每次加新资料时,把下面 Prompt 发给 LLM(Claude/Cursor 最佳):
“你现在是我的个人知识库管理员。我的 wiki 位于 ./wiki/ 目录,raw/ 里有新文档
xxx.md。
请按以下规则增量编译:
- 读取 raw/xxx.md 并总结关键内容
- 提取 3-8 个核心概念,检查是否已有对应文章
- 更新或新建 concepts/ 下的文章,加入 backlinks
- 更新 index.md 和所有相关索引
- 输出所有需要修改/新建的文件完整内容
保持风格一致、链接准确。”
LLM 会直接输出多个 .md 文件,你复制进对应目录即可(或让 Cursor 直接写文件)。
步骤 4:日常使用闭环
- 提问:直接把问题 + “参考 wiki/ 目录下所有内容” 扔给 LLM。
- 输出归档:让 LLM 把答案生成 Markdown 或 Marp 幻灯片,再让它“归档到 wiki/”。
- 定期维护:每周让 LLM 跑一次 linting:
“对整个 wiki 做健康检查:找矛盾、缺失、潜在新连接,并建议 3 个新文章主题。”
步骤 5:进阶技巧(很多人已经在用)
- 自动捕获:用 Obsidian Web Clipper + 手机快捷键把日常阅读、聊天记录、PDF 自动扔进 raw/。
- 搜索增强:vibe code 一个简单本地搜索(或用 Obsidian 自带 + 插件)。
- 多主题隔离:不同研究方向建不同子文件夹,避免污染。
- 语音/跑步模式(Lex Fridman 做法):让 LLM 基于当前 wiki 生成一个临时 mini-knowledge-base,用语音模式边跑步边对话。
3. 常见坑 & 建议
- 从小主题开始:先做一个 10 篇文章的小 wiki,熟悉流程,再扩大。
- 防止污染:很多人建议“个人 vault(高信号)” 和 “agent vault(实验区)” 分开,只把高质量输出手动搬进来。
- 工具链:Obsidian + Claude/Cursor 是目前最强组合,几乎零成本。
- 产品化趋势:Karpathy 说“这里有空间做一个了不起的新产品”,目前大家都在用“脚本 + Obsidian”的 hacky 方式,但很快会有更丝滑的一键工具出现。
照着上面做,你就能在几天内拥有一个会自己生长、自己纠错、自己回答复杂问题的个人知识系统——这正是 Karpathy 最近把大量 token 从“写代码”转向“管理知识”的原因。