---
layout: single
title: "DeepSeek Engram:类脑记忆存储与检索新范式"
date: 2026-01-14 08:00:00 +0800
categories: [AI 与大模型, 硬件加速]
tags: [DeepSeek, Engram, 大语言模型, 记忆存储, 稀疏模型]
---
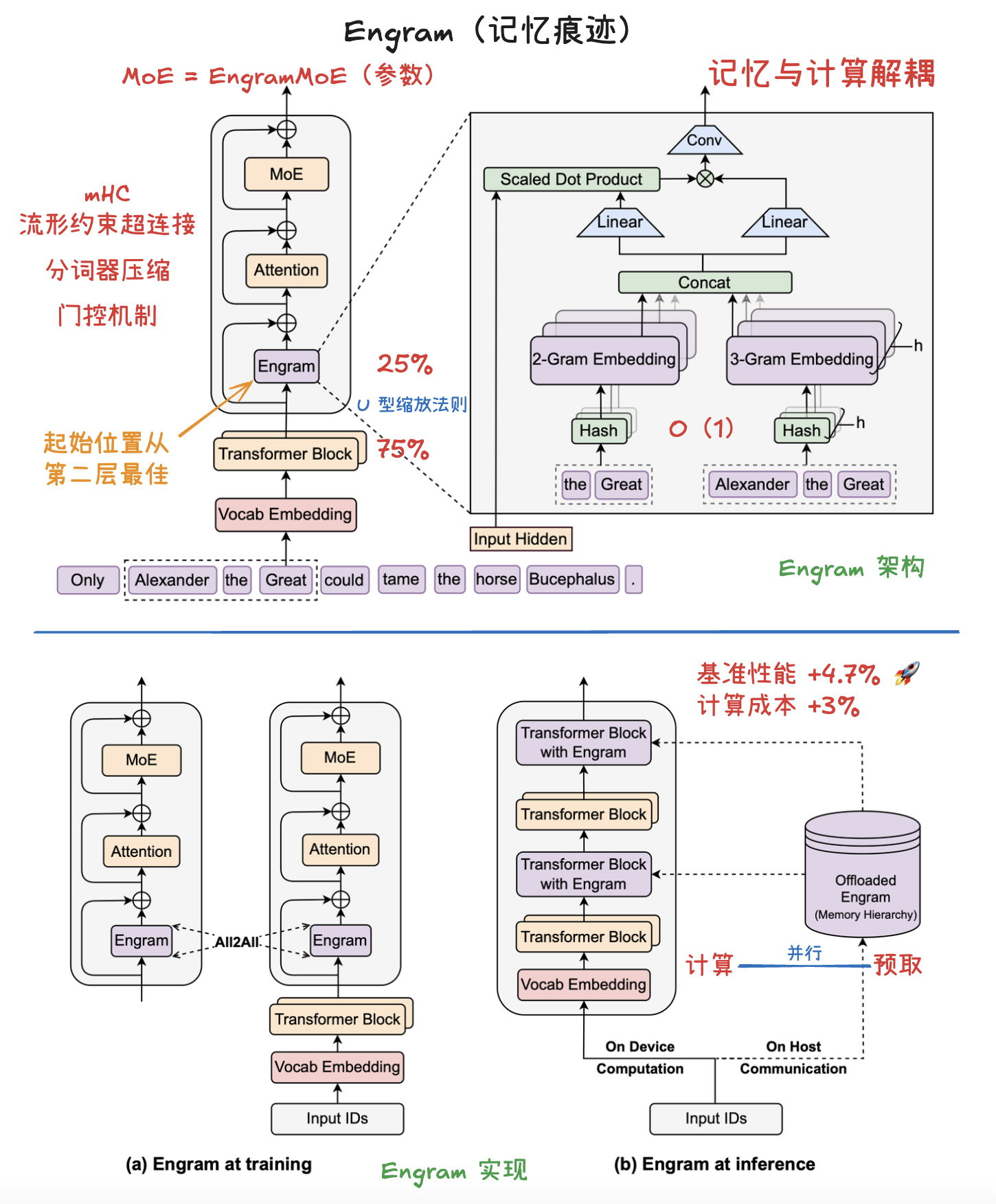
**Engram** 是一种旨在增强大语言模型性能的**条件记忆(Conditional Memory)**模块。传统的 Transformer 架构在处理**静态知识检索**时效率较低,往往需要通过复杂的计算来模拟记忆,而 Engram 通过现代化的 **N-gram 哈希查找**实现了常数级时间复杂度 `O(1)` 的知识获取。研究者揭示了一种 **U 型缩放法则**,证明在固定参数预算下,平衡**条件计算(MoE)**与**静态内存(Engram)** 能显著提升模型在推理、代码及数学任务中的表现。**实验分析**表明,Engram 能减轻模型底层对基础模式的重复构建,从而释放更多算力用于处理**全球上下文**和深度推理。此外,Engram 的**确定性寻址**特性支持从主机内存预取数据,使其能在不增加硬件负担的情况下实现大规模参数扩张。最终,该技术为构建更高效、具备**长文本处理能力**的新一代稀疏模型提供了核心原语。
## Engram 架构
**记忆内存的参数**就像是图书馆书架上的一本本**百科全书**,记录着世界上的事实;而 **Engram 模块的参数**就像是一位**经验丰富的图书管理员**。管理员通过训练(学习),能够根据你当前提出的研究课题(隐藏状态),迅速判断哪些百科全书的条目是有用的,哪些是由于名字相似而找错的(哈希冲突),并帮你把这些知识翻译成你研究报告能用的语言(投影整合)。
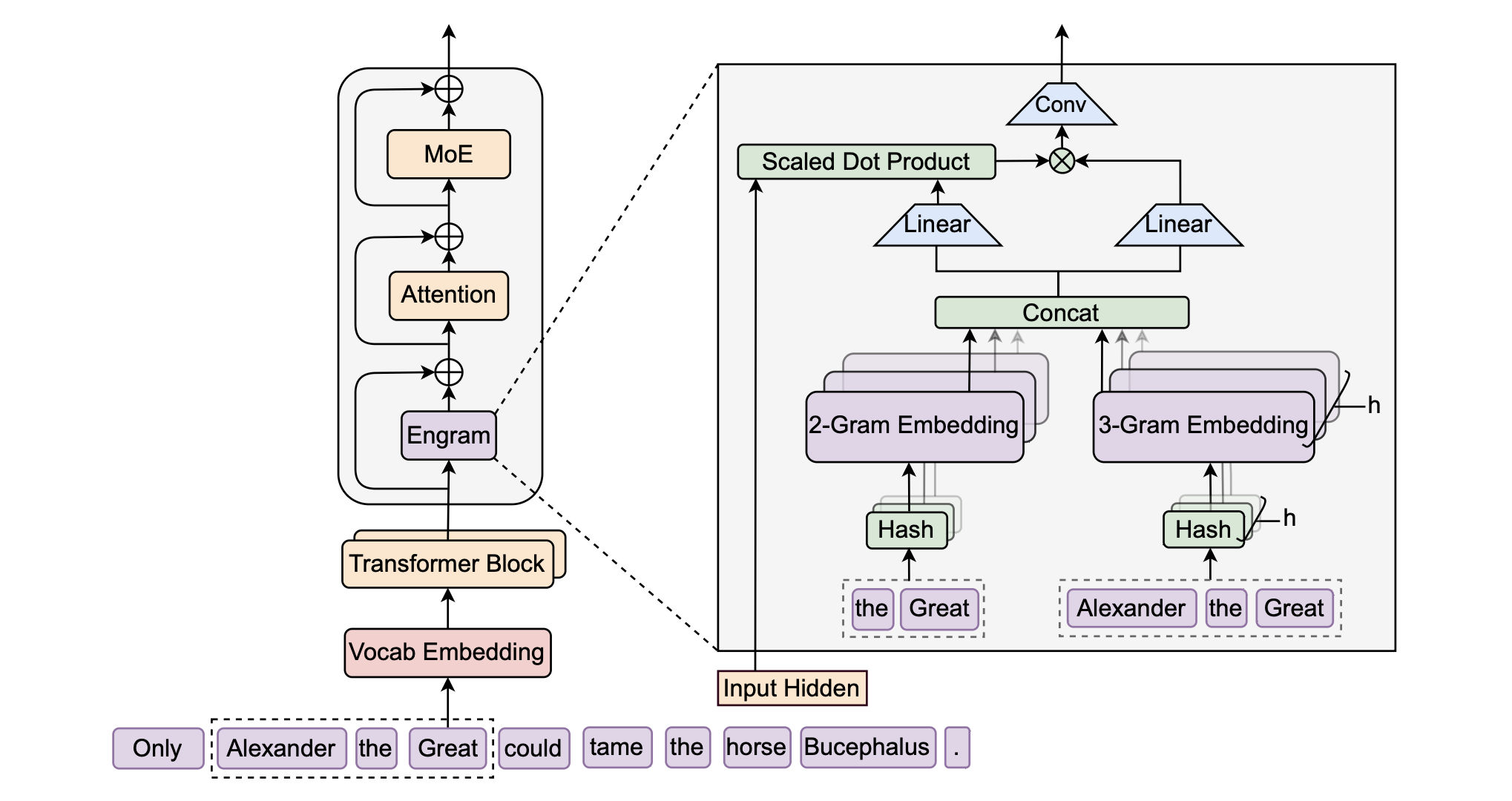
该模块通过检索静态 `N-gram` 记忆,并利用上下文感知门控(context-aware gating)将其与动态隐藏状态融合,从而对主干网络(backbone)进行增强。该模块仅应用于特定层,以实现 **记忆** 与 **计算** 的解耦,同时保持标准输入嵌入(第一层)和反嵌入(最后一层)模块不变。
### Engram 的系统实现
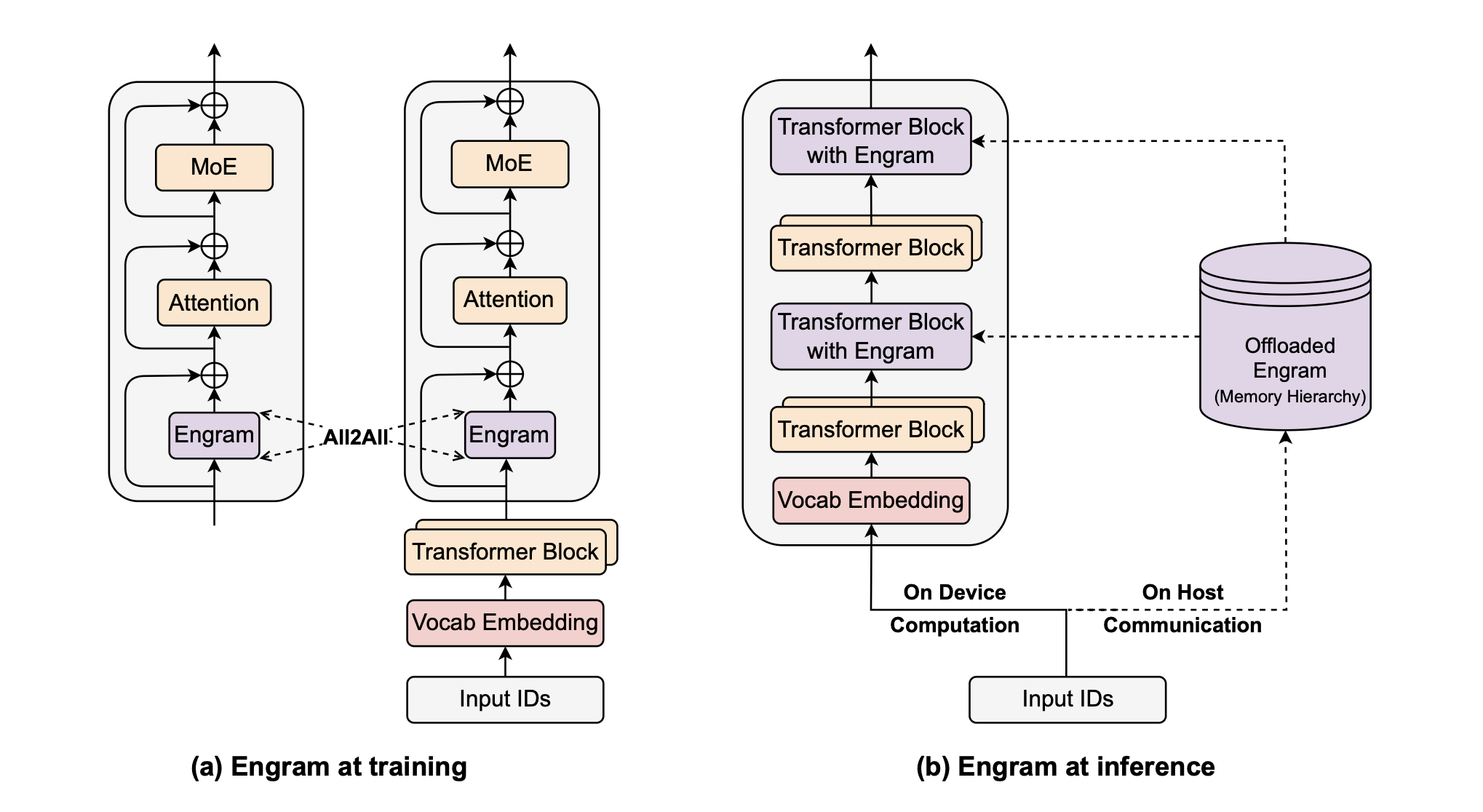
- (a) **训练阶段**:海量的嵌入表(embedding tables)被分片存储在所有可用的 GPU 上。通过使用全对全(All-to-All)通信算子,实现跨设备检索激活的嵌入行。
- (b) **推理阶段**:Engram 表被卸载(offload)到主机内存(CPU memory)中。利用确定性的检索逻辑,主机能够异步地预取并传输嵌入向量,从而使通信过程与设备上先前 Transformer 块的计算重叠(并行)。
#### 系统效率与层次化缓存 (System Efficiency)
- **Zipfian 分布利用**:由于 `N-gram` 的访问频率符合**齐夫定律**(极少数模式占据绝大多数访问),Engram 支持**多级缓存层次结构(Multi-Level Cache Hierarchy)**。高频模式缓存在 GPU HBM 或主机内存中,长尾稀疏模式则可存放于 SSD,从而以极低延迟支持海量参数扩张。
- **异步预取 (Prefetching)**:与 MoE 的动态路由不同,Engram 的**索引**仅取决于 `Token ID`。这意味着系统可以在执行当前层计算时,**异步地从主机内存预取下一层所需的嵌入**,使通信开销完全被计算所掩盖,。
### 稀疏性分配
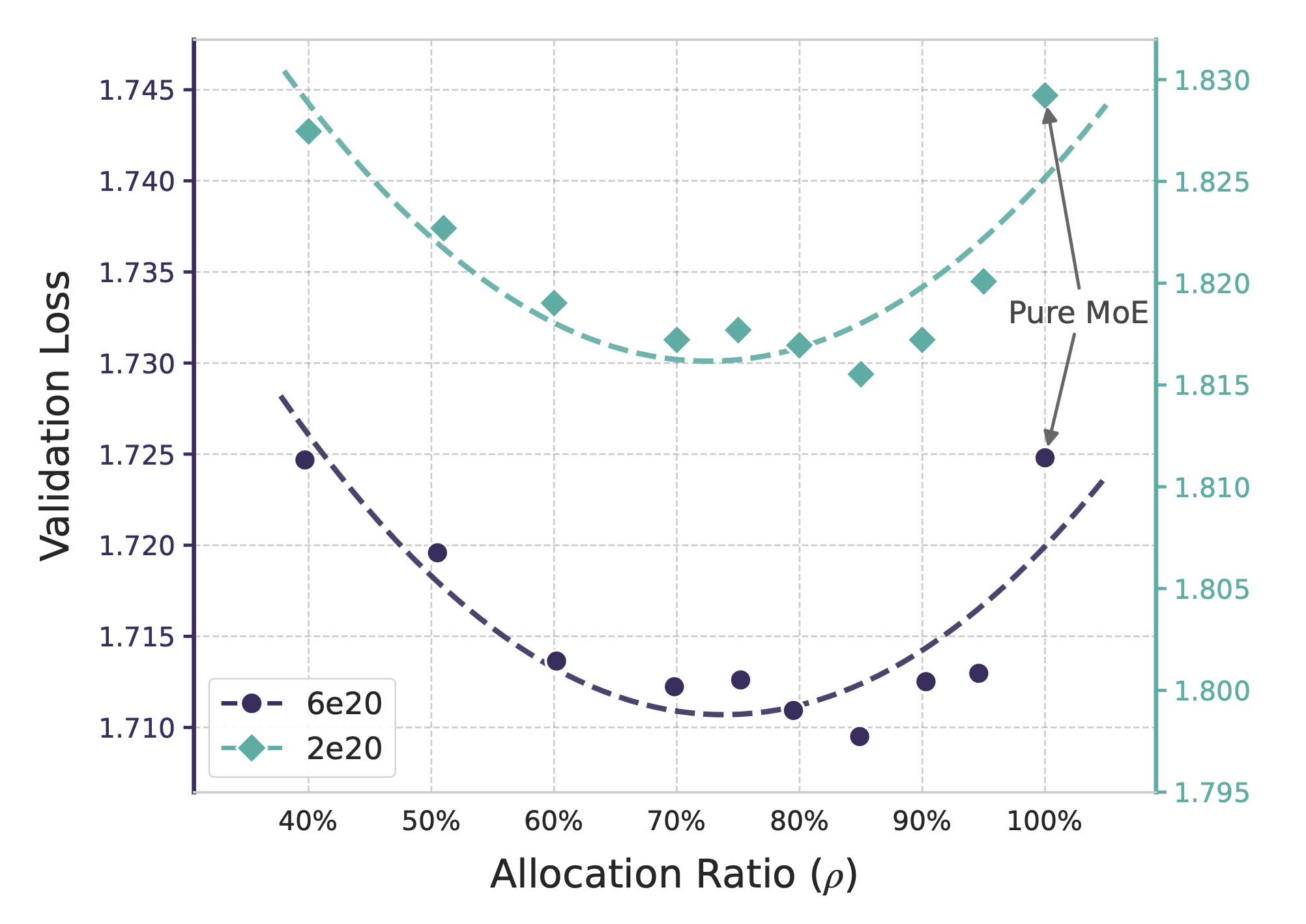
不同分配比例 `ρ` 下的验证集损失。图中展示了两种计算预算($2 \times 10^{20}$ 和 $6 \times 10^{20}$ FLOPs)。两种情况均呈现出 `U 型`曲线,其中混合分配的效果优于纯 MoE(混合专家模型)。
在固定总参数量和计算量的情况下,实验表明**最佳**的 `ρ` 值通常处于 **0.75 到 0.80(即 75% 到 80%)** 之间。
### Engram 扩展
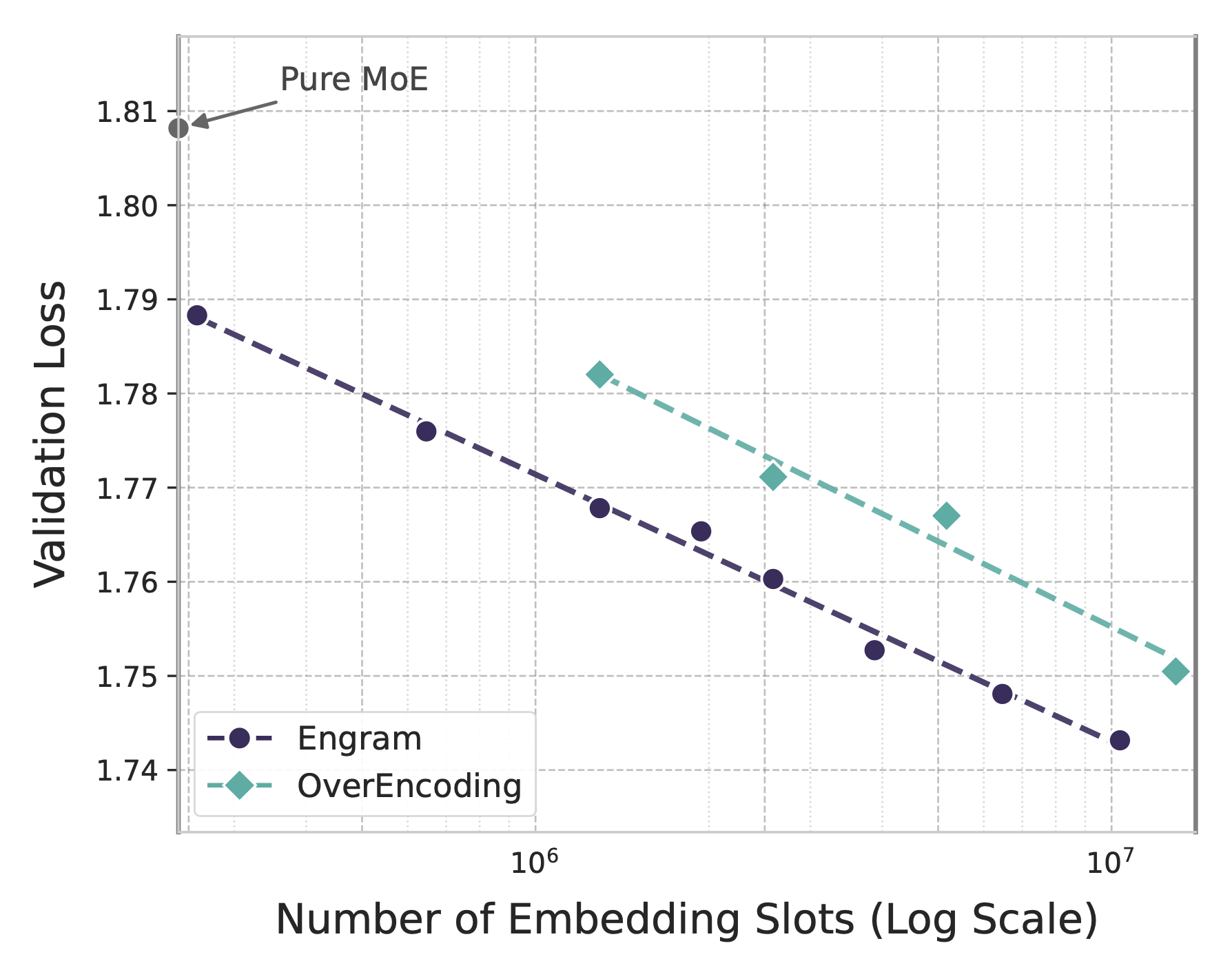
无限内存模式下的扩展行为。验证集损失相对于嵌入(embeddings)数量呈现出对数线性趋势。
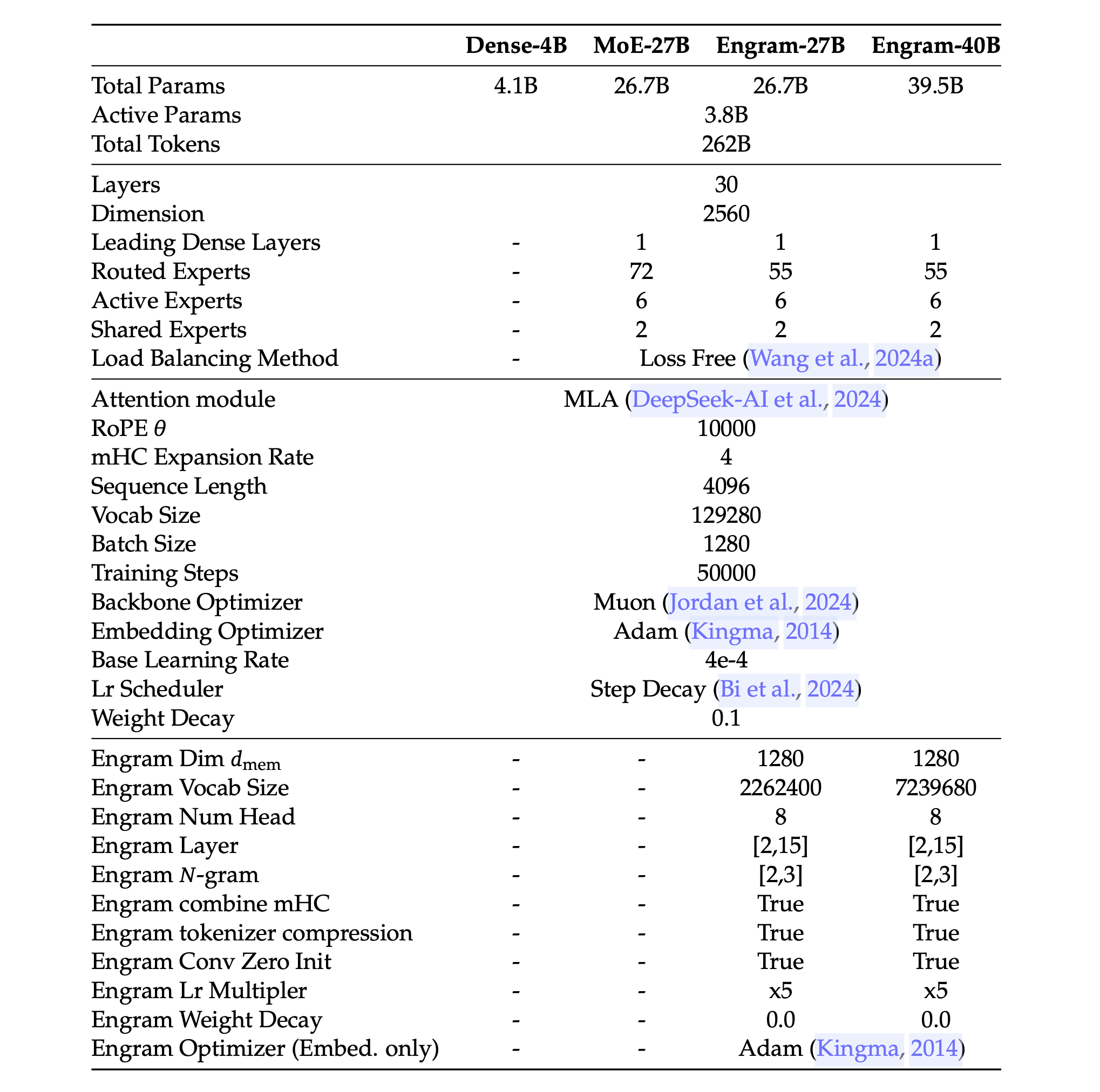
### 详细模型架构与训练超参数
## 基准性能
### 预训练性能比较(Dense vs MoE vs Engram)
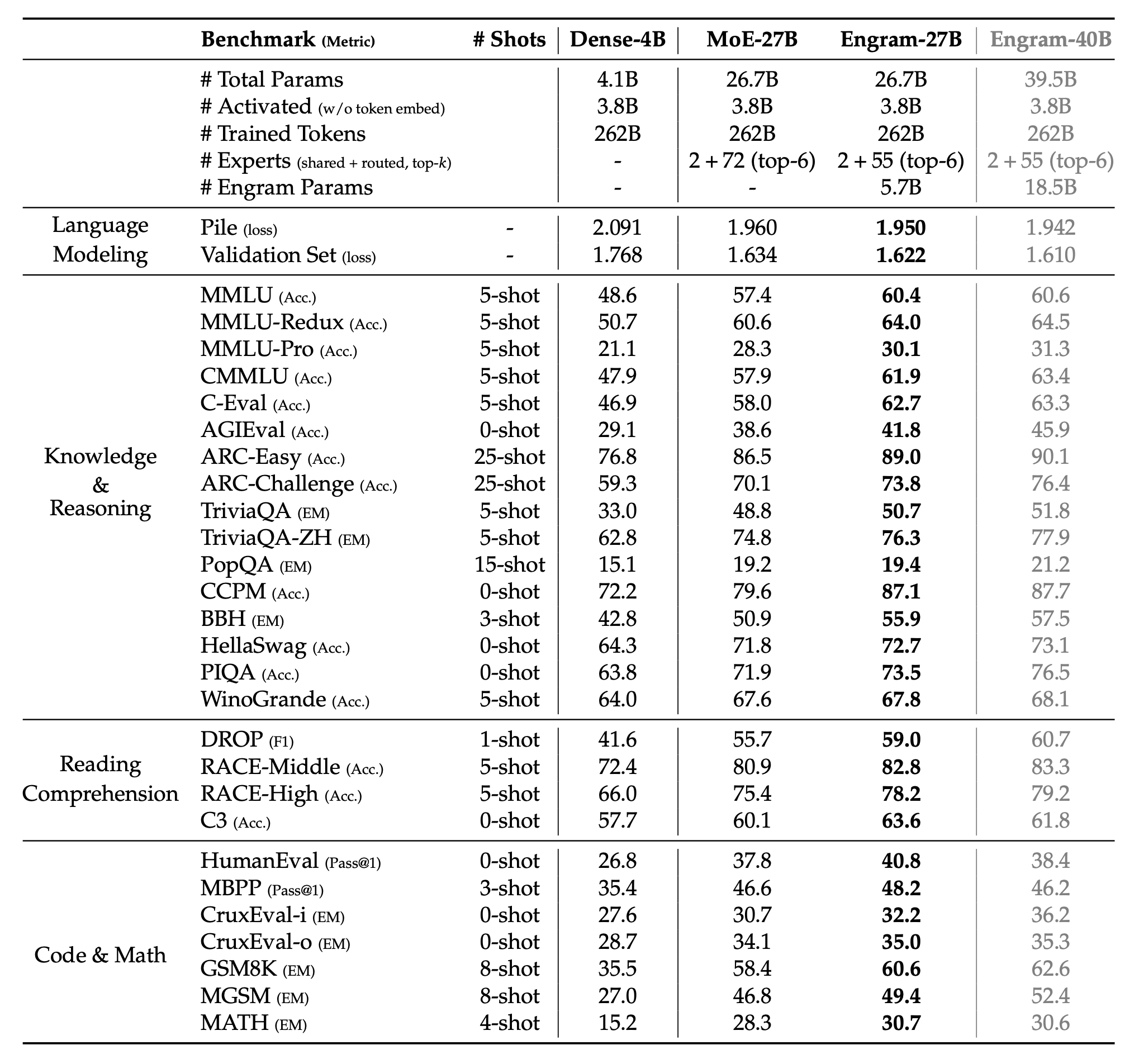
所有模型均经过 262B(2620 亿)token 的训练,且激活参数量(3.8B)保持一致。Engram-27B 通过将路由专家(routed experts)的参数进行重新分配(数量从 72 个减少到 55 个)并转入一个 5.7B 参数的 Engram 内存模块,从而实现了与 MoE-27B 的等参数量对标。Engram-40B 则在保持激活参数预算不变的情况下,进一步增加了 Engram 内存(达到 18.5B 参数)。
#### 1. 知识与推理 (16个指标)
| 基准测试 | MoE-27B | Engram-27B | 提升幅度 (%) |
| --- | --- | --- | --- |
| MMLU | 57.4 | 60.4 | +5.23% |
| MMLU-Redux | 60.6 | 64.0 | +5.61% |
| MMLU-Pro | 28.3 | 30.1 | +6.36% |
| CMMLU | 57.9 | 61.9 | +6.91% |
| C-Eval | 58.0 | 62.7 | +8.10% |
| AGIEval | 38.6 | 41.8 | +8.29% |
| ARC-Easy | 86.5 | 89.0 | +2.89% |
| ARC-Challenge | 70.1 | 73.8 | +5.28% |
| TriviaQA | 48.8 | 50.7 | +3.89% |
| TriviaQA-ZH | 74.8 | 76.3 | +2.01% |
| PopQA | 19.2 | 19.4 | +1.04% |
| CCPM | 79.6 | 87.1 | +9.42% |
| BBH | 50.9 | 55.9 | +9.82% |
| HellaSwag | 71.8 | 72.7 | +1.25% |
| PIQA | 71.9 | 73.5 | +2.23% |
| WinoGrande | 67.6 | 67.8 | +0.30% |
#### 2. 阅读理解 (4个指标)
| 基准测试 | MoE-27B | Engram-27B | 提升幅度 (%) |
| --- | --- | --- | --- |
| DROP | 55.7 | 59.0 | +5.92% |
| RACE-Middle | 80.9 | 82.8 | +2.35% |
| RACE-High | 75.4 | 78.2 | +3.71% |
| C3 | 60.1 | 63.6 | +5.82% |
#### 3. 代码与数学 (7个指标)
| 基准测试 | MoE-27B | Engram-27B | 提升幅度 (%) |
| --- | --- | --- | --- |
| HumanEval | 37.8 | 40.8 | +7.94% |
| MBPP | 46.6 | 48.2 | +3.43% |
| CruxEval-i | 30.7 | 32.2 | +4.89% |
| CruxEval-o | 34.1 | 35.0 | +2.64% |
| GSM8K | 58.4 | 60.6 | +3.77% |
| MGSM | 46.8 | 49.4 | +5.56% |
| MATH | 28.3 | 30.7 | +8.48% |
**Engram-27B** 相比 **MoE-27B** 在所有 27 个测试基准上的**平均性能提升为 4.73%**。
### 长文本性能比较(LongPPL & RULER)
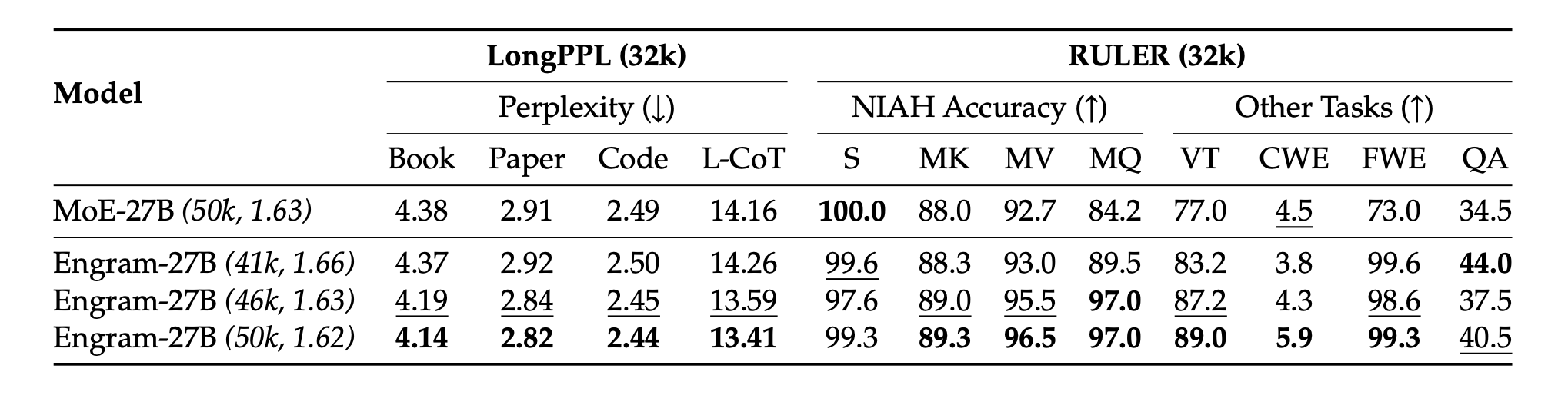
括号中的数值(如 (50k, 1.62))表示预训练步数及长文本扩展前对应的损失值。两个关键发现:(1) 仅需 82% 的预训练计算量(FLOPs,即 41k 对比 50k 步),Engram-27B 即可达到基准模型的 LongPPL 性能,同时在 RULER 基准测试中获得显著更高的准确率;(2) 在等预训练损失(46k 步)和等预训练计算量(50k 步)的设定下,Engram-27B 在所有指标上均大幅超越基准模型。加粗表示最优,下划线表示次优。
## 实验结果
### 表征对齐与收敛速度分析
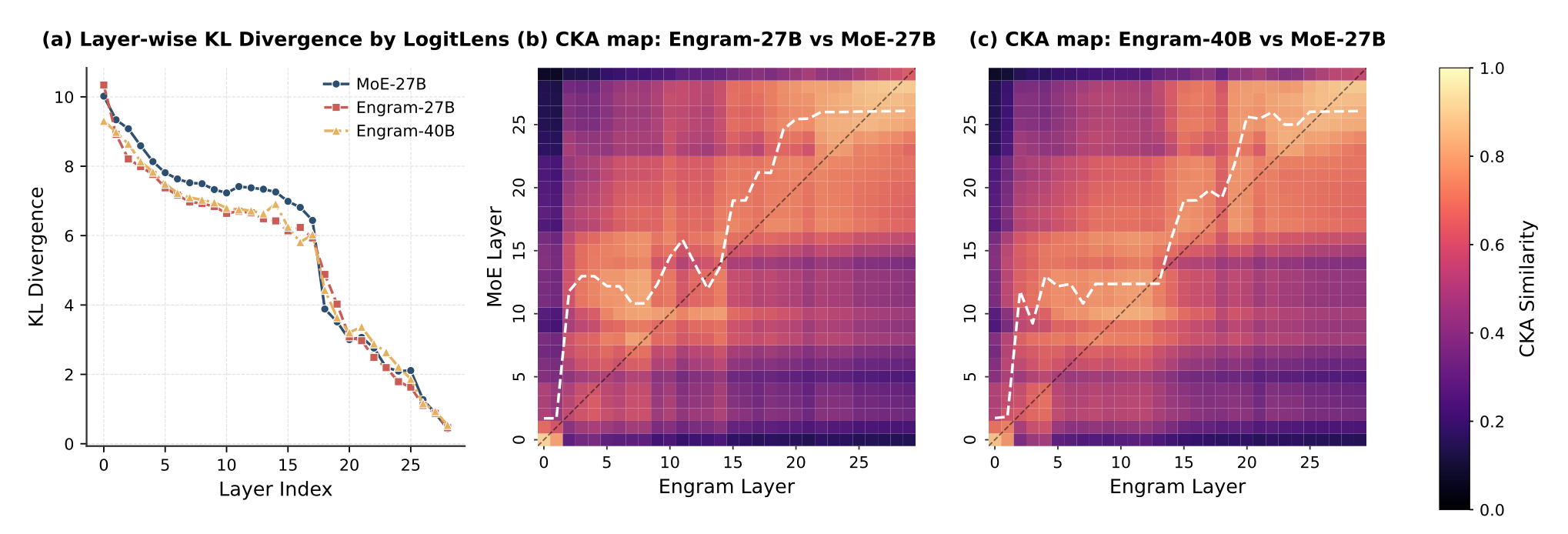
- (a) 通过 LogitLens 计算的分层 KL 散度。早期层中持续较低的散度表明 **Engram 加速了预测的收敛过程**。
- (b-c) 通过 CKA(中心化核对齐)计算的相似度热图。高相似度对角线明显的向上偏移表明,**Engram 的浅层在功能上等同于 MoE 模型的更深层,从而有效地增加了模型的深度**。
### 架构消融实验结果
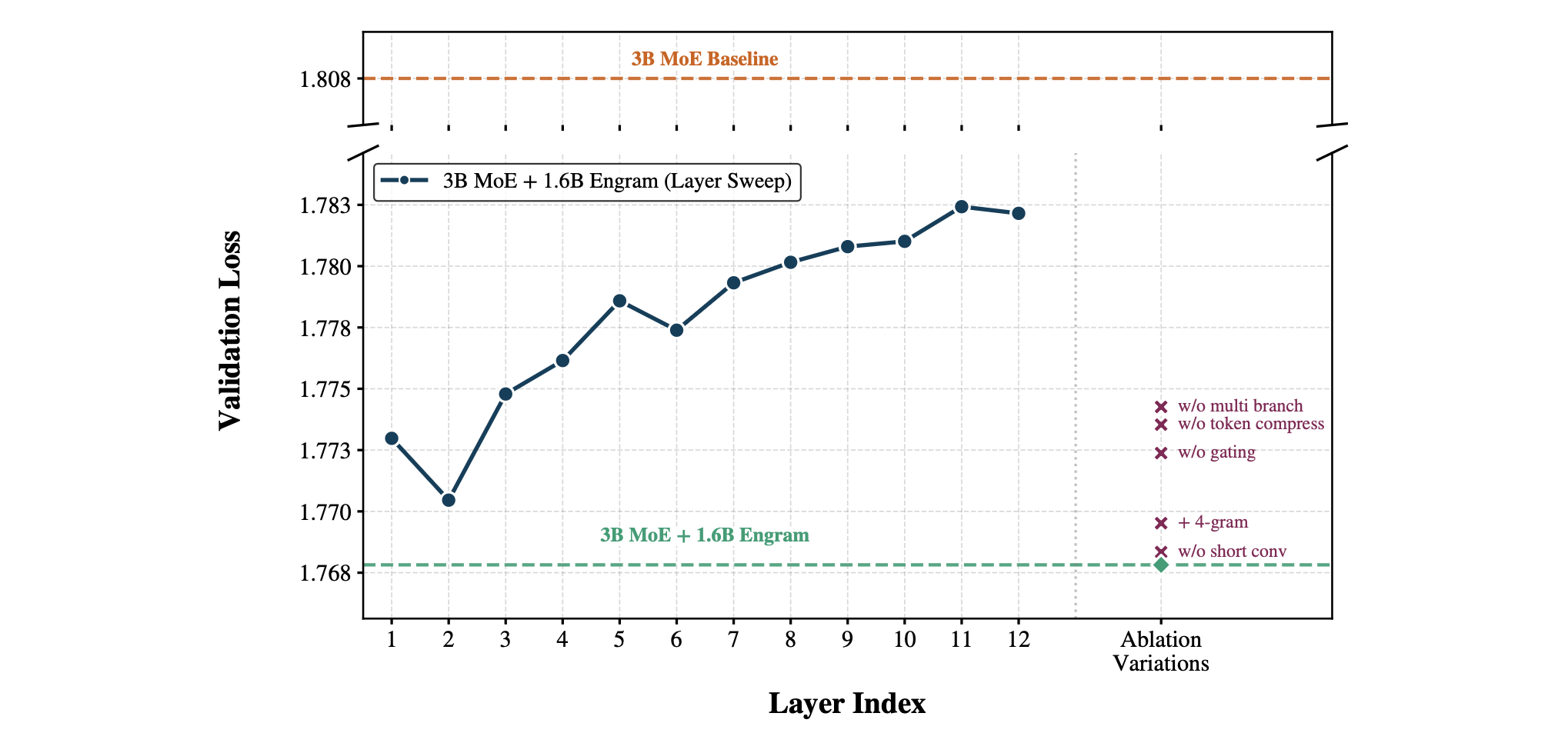
在两种设置下将 3B MoE 基准模型与 Engram 变体进行了对比:
- (1) **层敏感度**(深蓝色曲线):通过对单个 Engram 模块插入深度的扫描,确认了**早期注入(第 2 层)效果最优,而随着层数加深,其效能逐渐下降**。
- (2) **组件消融**(右侧标记):从参考配置中移除各子模块的结果表明,多分支集成、分词器压缩(tokenizer compression)以及上下文感知门控(context-aware gating)均具有重要意义。
### Engram 消融下的性能保留情况
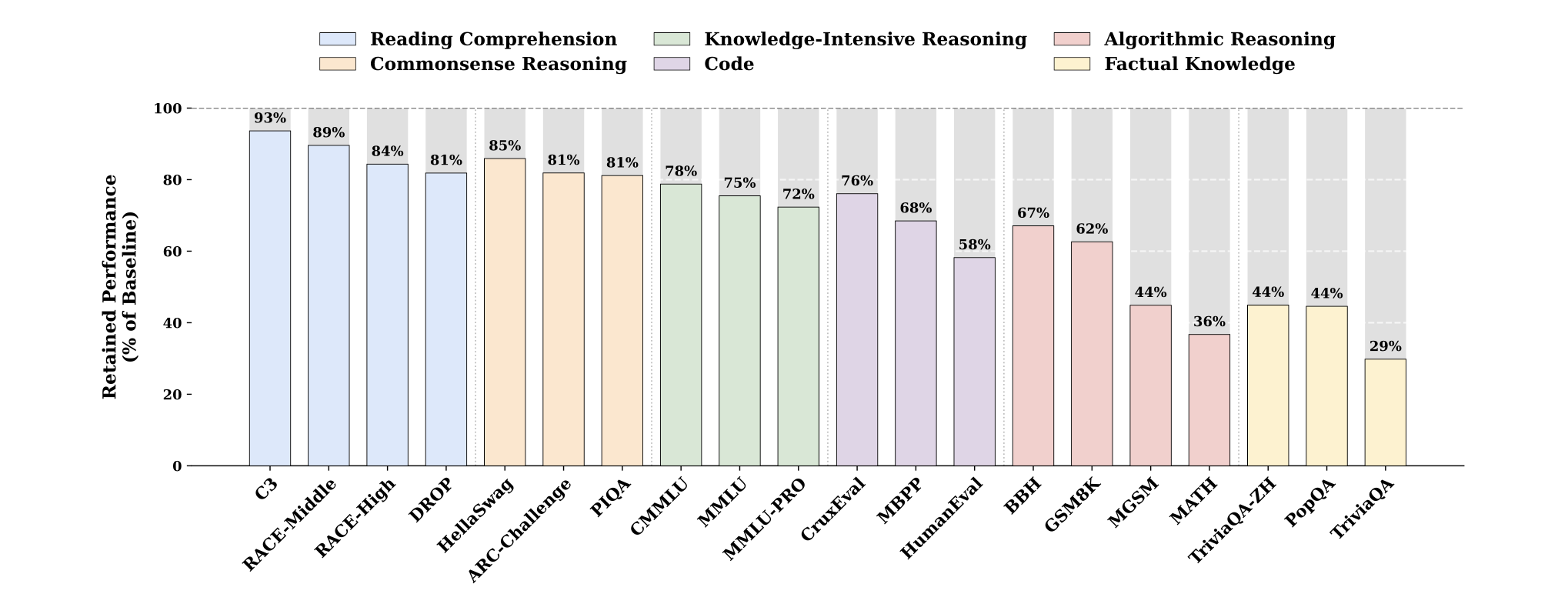
**事实性知识**高度依赖于 Engram 模块,而**阅读理解能力**则在很大程度上由骨干网络(backbone)保留。
- Reading Comprehension(阅读理解)
- Knowledge-Intensive Reasoning(知识密集型推理)
- Algorithmic Reasoning(算法推理)
- Commonsense Reasoning(常识推理)
- Code(编程能力/代码理解与生成)
- Factual Knowledge(事实知识)
### 端到端推理吞吐量
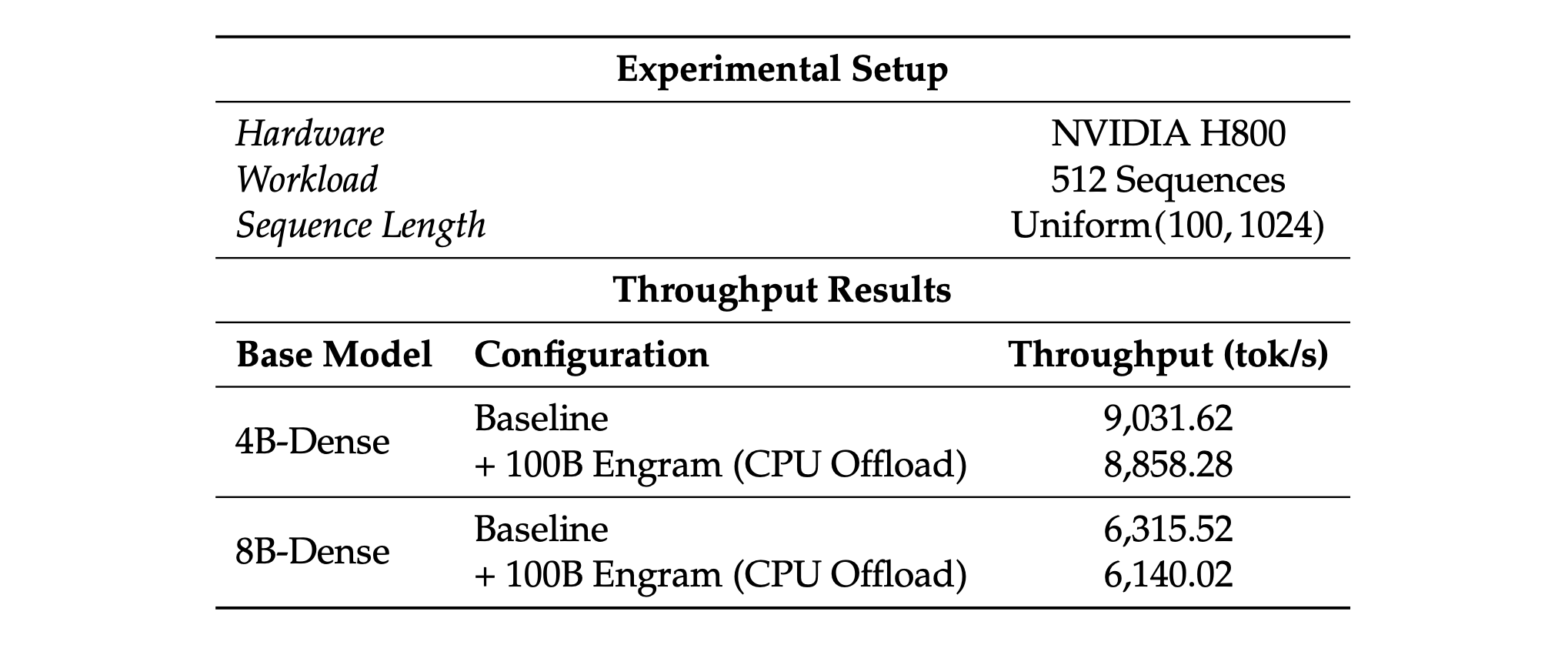
测量了在将一个 100B 参数的 Engram 层完全卸载(offload)到主机内存(host memory)情况下的推理吞吐量。
### 完整的基准测试曲线
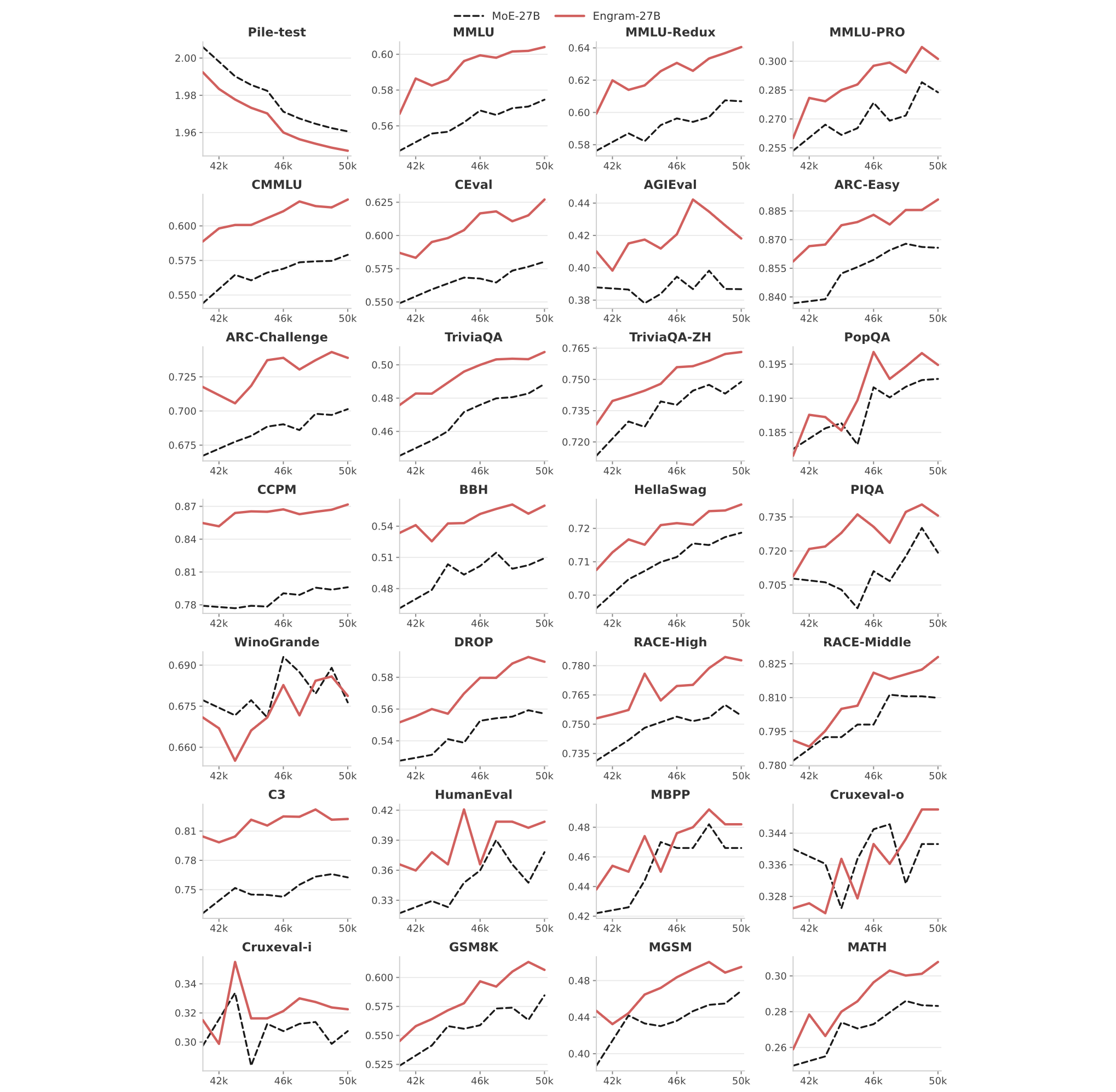
预训练最后 10k 步的基准测试曲线。
## 机理分析
### 实体解析示例

该表展示了大型语言模型(LLMs)如何通过层层注意力和前馈网络(FFNs)逐渐整合上下文 token,从而构建出实体“威尔士王妃戴安娜(Diana, Princess of Wales)”的内部表征。“潜状态转换(Latent State Translation)”列显示了由 PatchScope 针对最后一个 token“Wales”自动生成的文本,而“解释(Explanation)”列则给出了原作者提供的人工解读。
**中文**:
| 层数 | 潜状态转换 | 解释 |
|------|---------|------|
| 1-2 | 位于联合王国的国家:威尔士 | 威尔士 |
| 3 | 欧洲国家 | 威尔士 |
| 4 | 女性君主或王后所持有的头衔 | 威尔士王妃(泛指) |
| 5 | 授予威尔士亲王(及后来的国王)妻子的头衔 | 威尔士王妃(泛指) |
| 6 | 威尔士王妃戴安娜(1961-1997),威尔士亲王查尔斯的第一任妻子,以其美貌和人道主义工作闻名 | 威尔士王妃戴安娜 |
### Engram 门控机制的可视化

热图的深浅程度对应于门控标量 $\alpha_t \in [0, 1]$ 的大小,其中深红色表示更强的激活度。由于 Engram 作用于后缀 `N-gram`(此处 **N=3**),特定 token $x_t$ 上的高激活度意味着:以该 token 结尾的前序 token 序列(例如,在 $t$ 处结束的短语)被识别为一种能够从内存中有效检索的静态模式(static pattern)。
### 分词器压缩(Tokenizer Compression)案例研究

该表展示了通过分词器压缩合并出的前 5 个 token;对于我们的 128k 分词器,其整体压缩率为 23.43%。