OSWorld:在真实计算机环境中为开放式任务进行多模态代理基准测试
参考
Abstract(摘要)
Autonomous agents that accomplish complex computer tasks with minimal human interventions have the potential to transform human-computer interaction, significantly enhancing accessibility and productivity. However, existing benchmarks either lack an interactive environment or are limited to environments specific to certain applications or domains, failing to reflect the diverse and complex nature of real-world computer use, thereby limiting the scope of tasks and agent scalability. To address this issue, we introduce OSWORLD, the first-of-its-kind scalable, real computer environment for multimodal agents, supporting task setup, execution-based evaluation, and interactive learning across various operating systems such as Ubuntu, Windows, and macOS. OSWORLD can serve as a unified, integrated computer environment for assessing open-ended computer tasks that involve arbitrary applications. Building upon OSWORLD, we create a benchmark of 369 computer tasks involving real web and desktop apps in open domains, OS file I/O, and workflows spanning multiple applications. Each task example is derived from real-world computer use cases and includes a detailed initial state setup configuration and a custom execution-based evaluation script for reliable, reproducible evaluation. Extensive evaluation of state-of-the-art LLM/VLM-based agents on OSWORLD reveals significant deficiencies in their ability to serve as computer assistants. While humans can accomplish over 72.36% of the tasks, the best model achieves only 12.24% success, primarily struggling with GUI grounding and operational knowledge. Comprehensive analysis using OSWORLD provides valuable insights for developing multimodal generalist agents that were not possible with previous benchmarks. Our code, environment, baseline models, and data are publicly available at https://os-world.github.io.
通过最小化人类干预来完成复杂计算机任务的自主代理有可能改变人机交互,显著提高可访问性和生产力。然而,现有的基准测试要么缺乏交互环境,要么仅限于特定应用程序或领域的环境,未能反映真实计算机使用的多样性和复杂性,从而限制了任务的范围和代理的可扩展性。为了解决这个问题,我们引入了OSWORLD,这是第一个可扩展的真实计算机环境,用于多模态代理,支持任务设置、基于执行的评估和跨多个操作系统(如Ubuntu、Windows和macOS)的交互式学习。OSWORLD可以作为一个统一的、集成的计算机环境,用于评估涉及任意应用程序的开放式计算机任务。在OSWORLD的基础上,我们创建了一个包含369个计算机任务的基准测试,涉及真实的Web和桌面应用程序、开放领域、OS文件I/O和跨多个应用程序的工作流程。每个任务示例都源自真实的计算机用例,并包括详细的初始状态设置配置和用于可靠、可重现评估的自定义基于执行的评估脚本。在OSWORLD上对最先进的基于LLM/VLM的代理进行广泛评估,揭示了它们作为计算机助手的显著不足。虽然人类可以完成72.36%以上的任务,但最佳模型仅实现了12.24%的成功率,主要困扰于GUI基础和操作知识。使用OSWORLD进行全面分析提供了宝贵的见解,以开发多模态通用代理,这是以前的基准测试所不可能的。我们的代码、环境、基线模型和数据都可以在 https://os-world.github.io 上公开获取。
1 Introduction(引言)
Humans interact with computers to perform essential tasks in the digital realm, including web browsing, video editing, file management, data analysis, and software development. These task workflows often involve multiple applications through graphical user interfaces (GUI) and command line interfaces (CLI). Autonomous digital agents, powered by advancements in large vision-language models (VLMs), have the potential to revolutionize how we interact with computer environments [28, 44, 1]. By following high-level natural language instructions, these agents can make digital interactions more accessible and vastly increase human productivity. However, a major challenge in developing such multimodal agents is the absence of a benchmark based on a real interactive environment that covers the diversity and complexity of real-world computer use across various operating systems, interfaces, and applications, consequently restricting task scope and agent scalability.
人类与计算机进行交互,以在数字领域执行基本任务,包括网页浏览、视频编辑、文件管理、数据分析和软件开发。这些任务工作流通常通过图形用户界面(GUI)和命令行界面(CLI)与多个应用程序进行交互。由大型视觉语言模型(VLM)的进步驱动的自主数字代理有可能彻底改变我们与计算机环境的交互方式[28, 44, 1]。通过遵循高级自然语言指令,这些代理可以使数字交互更易访问,并极大地提高人类的生产力。然而,开发这种多模态代理的一个主要挑战是缺乏基于真实交互环境的基准测试,该环境涵盖了跨多个操作系统、界面和应用程序的真实计算机使用的多样性和复杂性,从而限制了任务范围和代理的可扩展性。
Previous benchmarks provide datasets of demonstrations without executable environments [9, 40, 21]. Their non-execution-based evaluation assumes a single solution for each task and wrongfully penalizes alternative correct solutions. These benchmarks also miss opportunities for essential agent development methods like interactive learning and real-world exploration. Building realistic interactive environments is a major challenge in developing multimodal agents. Prior work that introduce executable environments simplify the observation and action spaces of human-computer interaction and limit task scope within specific applications or domains, such as web navigation in a few domains [44, 30, 58, 66], coding [57] and the combination [32, 54, 34]. Agents developed in these restricted environments cannot comprehensively cover computer tasks, lacking the support of evaluating tasks in complex, real-world scenarios that require navigating between applications and interfaces in open domains (task examples in e.g., Fig. 1).
以前的基准测试提供了演示数据集,但没有可执行的环境[9, 40, 21]。它们基于非执行的评估假设每个任务有一个解决方案,并错误地惩罚了替代的正确解决方案。这些基准测试也错过了像交互式学习和真实世界探索这样的重要代理开发方法的机会。构建现实的交互环境是开发多模态代理的一个重大挑战。以前的工作引入了可执行环境,简化了人机交互的观察和行动空间,并将任务范围限制在特定应用程序或领域内,例如在几个领域中的Web导航[44, 30, 58, 66]、编码[57]和组合[32, 54, 34]。在这些受限环境中开发的代理不能全面覆盖计算机任务,缺乏在需要在开放领域的应用程序和界面之间导航的复杂、真实世界场景中评估任务的支持(例如,图1中的任务示例)。

图1:OSWORLD是第一个可扩展的真实计算机环境,用于多模态代理,支持任务设置、基于执行的评估和跨操作系统的交互式学习。它可以作为一个统一的环境,用于评估涉及任意应用程序的开放式计算机任务(例如,上图中的任务示例)。我们还在OSWORLD中创建了一个包含369个真实计算机任务的基准测试,具有可靠、可重现的设置和评估脚本。
- 任务说明1:在提供的文件夹中更新我的最近几天的交易记录表。
- 任务说明2:…省略了关于贪吃蛇游戏的一些细节…你能帮我调整代码,让蛇真的能吃到食物吗?
To address this gap, we introduce OSWORLD, the first-of-its-kind scalable, real computer environment designed for the development of multimodal agents capable of executing a wide range of real computer tasks beyond isolated interfaces and applications. This executable environment allows free-form raw keyboard and mouse control of real computer applications and supports initial task state configuration, execution-based evaluation, and interactive learning across mainstream operating systems (e.g., Ubuntu, Windows, macOS). As shown in Fig. 1, OSWORLD enables evaluation of open-ended computer tasks that involve arbitrary applications, ranging from image viewing to software functionality integration and programming. Thus, OSWORLD can serve as a unified, real computer environment that allows users to define their agent tasks without the need to build application/domain-specific simulated environments.
为了填补这一空白,我们引入了OSWORLD,这是第一个可扩展的真实计算机环境,旨在开发能够执行各种真实计算机任务的多模态代理,超越了孤立的界面和应用程序。这个可执行环境允许对真实计算机应用程序进行自由形式的原始键盘和鼠标控制,并支持初始任务状态配置、基于执行的评估和跨主流操作系统(如Ubuntu、Windows、macOS)的交互式学习。如图1所示,OSWORLD可以评估涉及任意应用程序的开放式计算机任务,从图像查看到软件功能集成和编程。因此,OSWORLD可以作为一个统一的、真实的计算机环境,允许用户定义他们的代理任务,而无需构建特定应用程序/领域的模拟环境。
Building upon OSWORLD, we create a benchmark with 369 real-world computer tasks that involve widely-used web and desktop apps in open domains, OS file I/O, and multi-app workflows through both GUI and CLI. Each task example is based on real-world computer use cases experienced by real users and often requires interactions with multiple applications and interfaces. To ensure reliable, reproducible assessment within the OSWORLD environment, 9 authors with computer science backgrounds carefully annotate each example with an initial state setup configuration to simulate human work in progress and a custom execution-based evaluation script to verify task completion. Our benchmark has a total of 134 unique evaluation functions, which are orders of magnitude larger than prior work [66], showcasing the complexity, diversity, and evaluation challenges of tasks in our benchmark. The human performance study indicates that task examples from OSWORLD are more time-consuming and challenging compared to those in prior work.
在OSWORLD的基础上,我们创建了一个基准测试,其中包含369个涉及广泛使用的Web和桌面应用程序、OS文件I/O和通过GUI和CLI进行的多应用程序工作流程的真实计算机任务。每个任务示例都基于真实用户体验的真实计算机用例,通常需要与多个应用程序和界面进行交互。为了确保在OSWORLD环境中可靠、可重现的评估,具有计算机科学背景的9位作者仔细地为每个示例注释了一个初始状态设置配置,以模拟人类正在进行的工作,并为验证任务完成编写了一个自定义的基于执行的评估脚本。我们的基准测试共有134个独特的评估函数,比以前的工作[66]大得多,展示了我们基准测试中任务的复杂性、多样性和评估挑战。人类表现研究表明,与以前的工作相比,OSWORLD中的任务示例更耗时和具有挑战性。
We extensively evaluate state-of-the-art LLM and VLM-based agent baselines, including the GPT-4V series [39], the Gemini series [49, 41], the Claude-3 Opus [3] and the Qwen-Max [5], as well as Mixtral [19], Llama-3 [35] and CogAgent [17] from the open-source community. The performance of these experiments ranges from 0.99% to 12.24%, with subsets of applications even reaching 0%, for workflow tasks that involve cooperation from multiple apps, the highest performance of the baseline agent is only 6.57%. This indicates that current LLMs and VLMs are far from capable of serving as computer assistants (§4.2). Results also show that while additional knowledge such as the accessibility tree and Set-of-Mark (§4.1) can be helpful, it can also lead to potential misguidance and varies across models. We also observe performance changes in these agents compared to consistent human performance across different types of computer tasks. Analysis reveals that VLM-based agents struggle to ground on screenshots to predict precise coordinates for actions, tend to predict repetitive actions, are unable to handle noise from unexpected application windows and exhibit limited knowledge of basic GUI interactions and domain-specific features of apps (§5.2, §5.4). Feeding higher resolution and more trajectory history can help improve the performance by even doubling while requiring longer context length and efficient modeling (§5.2). We open-source OSWORLD environment and benchmark, including environment initial state setup, reliable evaluation scripts, documentation, and our implementation of baseline models to promote research towards the goal of generalist capable computer agents 1 . Future work can focus on enhancing VLM GUI grounding abilities, including interaction commonsense knowledge, higher-resolution support, and coordinates accuracy for more robust GUI interactions. Additionally, efforts can be made to improve agent architectures to better handle complex computer tasks through exploration, memory, and reflection.
我们对最先进的基于LLM和VLM的代理基线进行了广泛评估,包括GPT-4V系列[39]、Gemini系列[49, 41]、Claude-3 Opus[3]和Qwen-Max[5],以及来自开源社区的Mixtral[19]、Llama-3[35]和CogAgent[17]。这些实验的性能范围从0.99%到12.24%,甚至有一些应用程序的子集达到了0%,对于涉及多个应用程序合作的工作流任务,基线代理的最高性能仅为6.57%。这表明,当前的LLM和VLM远不能胜任计算机助手的角色(§4.2)。结果还表明,虽然额外的知识,如可访问性树和Mark集(§4.1),可能是有帮助的,但它也可能导致潜在的误导,并且在模型之间有所不同。我们还观察到这些代理与不同类型的计算机任务之间的一致人类表现相比的性能变化。分析表明,基于VLM的代理难以在屏幕截图上进行基础定位,以预测精确的操作坐标,倾向于预测重复的操作,无法处理来自意外应用程序窗口的噪声,并且对基本GUI交互和应用程序的领域特定特性的知识有限(§5.2,§5.4)。提供更高分辨率和更多轨迹历史可以帮助提高性能,甚至可以翻倍,但需要更长的上下文长度和高效的建模(§5.2)。我们开源了OSWORLD环境和基准测试,包括环境初始状态设置、可靠的评估脚本、文档和我们的基线模型实现,以促进研究朝着通用计算机代理的目标前进。未来的工作可以集中在增强VLM GUI基础能力,包括交互常识知识、更高分辨率支持和坐标精度,以实现更强大的GUI交互。此外,可以努力改进代理架构,以更好地通过探索、记忆和反思来处理复杂的计算机任务。
2 OSWORLD Environment(OSWORLD环境)
In this section, we will introduce the task definition of autonomous agents, the components and implementation of the OSWORLD environment, and the supported observation and action spaces.
在本节中,我们将介绍自主代理的任务定义、OSWORLD环境的组件和实现,以及支持的观察和行动空间。
2.1 Task Definition(任务定义)
An autonomous digital agent task can be formalized as a partially observable Markov decision process (POMDP) (S, O, A, T , R) with state space S, observation space O (§2.3, including natural language I), action space A (§2.4), transition function T : S × A → S, and reward function R : S × A → R. Given current observation ot ∈ O (a natural language instruction observation and a screenshot observation (e.g., computer screenshot), accessibility (a11y) tree, or their combination according to facilities available), an agent generates executable action at ∈ A (e.g., clicking on the certain pixel of the screen — .click(300, 540, button=‘right’), press key combination — .hotkey(‘ctrl’, ‘alt’, ‘t’)), which results in a new state st+1 ∈ S (e.g., current Desktop environment) and a new partial observation ot+1 ∈ O (e.g., current screenshot). The interaction loop repeats until an action that marks termination (DONE or FAIL, see Sec. 2.4) is generated or the agent reaches the max number of steps (e.g., 15 in our experiments). In this version of OSWORLD, we implement an execution-based reward function R : S × A → [0, 1] (§2.2.3). The reward function awards a value of 1 or a positive decimal under 1 at the final step if the state transitions meet the expectations of the task objective (i.e., the goal is successfully achieved or partially achieved), or if the agent accurately predicts failure for an infeasible task. In all other scenarios, it returns 0.
自主数字代理任务可以形式化为部分可观察马尔可夫决策过程(POMDP)(S, O, A, T , R),其中S是状态空间,O是观察空间(§2.3,包括自然语言I),A是行动空间(§2.4),转移函数T:S × A → S,奖励函数R:S × A → R。给定当前观察ot ∈ O(自然语言指令观察和屏幕截图观察(例如,计算机屏幕截图),可访问性(a11y)树,或根据可用设施的组合),代理生成可执行的动作at ∈ A(例如,点击屏幕的某个像素—.click(300, 540, button=‘right’),按键组合—.hotkey(‘ctrl’, ‘alt’, ‘t’),导致新状态st+1 ∈ S(例如,当前桌面环境)和新的部分观察ot+1 ∈ O(例如,当前屏幕截图)。交互循环重复,直到生成标记终止(DONE或FAIL,见第2.4节)的动作,或代理达到最大步数(例如,我们的实验中为15步)。在这个版本的OSWORLD中,我们实现了一个基于执行的奖励函数R:S × A → [0, 1](§2.2.3)。如果状态转换符合任务目标的期望(即,目标成功实现或部分实现),或者代理准确预测了不可行任务的失败,奖励函数在最后一步奖励1或小于1的正小数。在所有其他情况下,它返回0。
2.2 Real Computer Environment Infrastructure(真实计算机环境基础设施)
OSWORLD is an executable and controllable environment that supports task initialization, executionbased evaluation, and interactive agent learning in a range of real operating systems (e.g., Ubuntu, Windows, macOS) using virtual machine techniques, shown in the middle and right of Fig. 2. Virtual machine offers a safe isolated environment and prevents the agent resulting in irreversible damaging effect on the real host machine. The snapshot feature also enables efficient reset of the virtual environment. The environment is configured through a config file (shown in the left of Fig. 2) for interface initialization during the initialization phase (including downloading files, opening software, adjusting interface layout) (§2.2.2, highlighted with red in Fig. 2), post-processing during the evaluation phase (activating certain windows, saving some files for easy retrieval of information, highlighted with orange), and acquiring files and information for evaluation (such as the final spreadsheet file for spreadsheet tasks, cookies for Chrome tasks, highlighted with yellow in Fig. 2), as well as the evaluation functions and parameters used (§2.2.3, highlighted with green in Fig. 2). See App. A.1 for more details.
OSWORLD是一个可执行和可控的环境,支持任务初始化、基于执行的评估和交互式代理学习,使用虚拟机技术在一系列真实操作系统(如Ubuntu、Windows、macOS)中进行,如图2中间和右侧所示。虚拟机提供了一个安全的隔离环境,防止代理对真实主机机器造成不可逆的破坏效果。快照功能还可以有效地重置虚拟环境。环境通过配置文件进行配置(如图2左侧所示),用于在初始化阶段进行接口初始化(包括下载文件、打开软件、调整界面布局)(§2.2.2,如图2中红色部分所示),在评估阶段进行后处理(激活某些窗口,保存一些文件以便轻松检索信息,如图2中橙色部分所示),以及获取用于评估的文件和信息(例如,用于电子表格任务的最终电子表格文件,用于Chrome任务的cookies,如图2中黄色部分所示),以及使用的评估函数和参数(§2.2.3,如图2中绿色部分所示)。有关更多详细信息,请参见附录A.1。
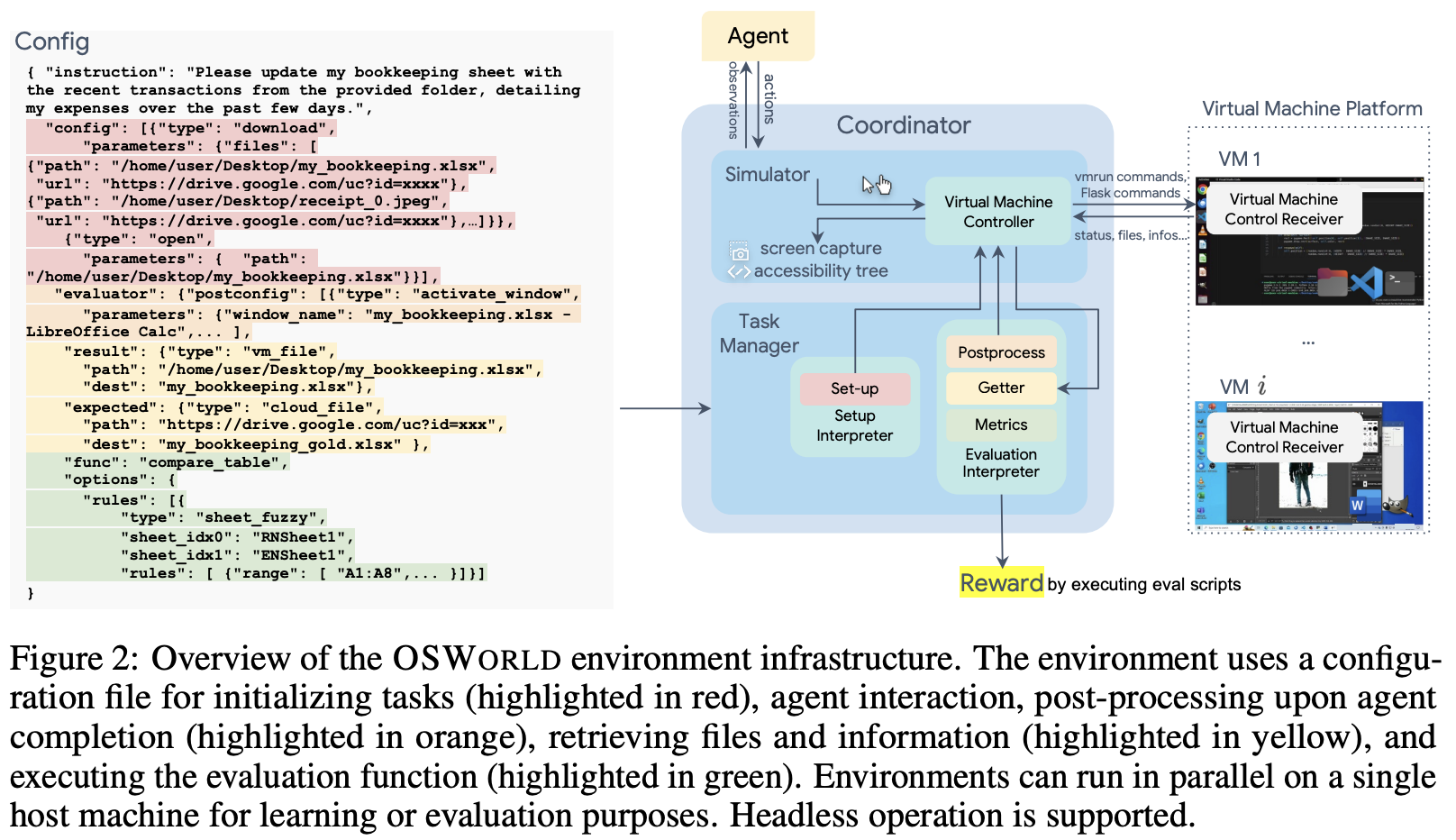
图2:OSWORLD环境基础设施概述。环境使用配置文件初始化任务(红色高亮显示),代理交互,代理完成后的后处理(橙色高亮显示),检索文件和信息(黄色高亮显示),以及执行评估函数(绿色高亮显示)。环境可以在单个主机机器上并行运行,用于学习或评估目的。支持无头操作。
2.2.1 Overview(概述)
OSWORLD environment runs on the host machine. Its Coordinator accepts a configuration file at the initialization of a computer task, runs commands to automatically create a virtual machine instance, and initializes the required state for the task through the Task Manager. The configuration file specifies the snapshot of the virtual machine to be used (which stores the complete state of a computer at a certain moment and can be restored to this state at any time) and also indicates the information needed for setup (such as downloading files and opening some software, making some additional settings, etc.). Once the environment is set up, agents start to interact with the environment, receiving observations such as screenshots, the accessibility (a11y) tree, and customized streams such as terminal outputs. Agents subsequently generate executable actions (e.g., .click(300, 540)) that manipulate the keyboard and mouse. Each action of the agent is input into the environment as a code string, and the environment’s Simulator executes them in the virtual machine. After the completion of a task, the Task Manager performs post-processing (such as file saving, or reopening certain apps) according to the task’s post-config, retrieves data to the host machine (fetching images or configuration files from the virtual machine or cloud, etc.), and then runs evaluation scripts to assess the completion of the task. Multiple virtual machines can run simultaneously on a single host machine, thereby parallelizing training and evaluation.
OSWORLD环境运行在主机机器上。其协调器在计算机任务初始化时接受一个配置文件,运行命令以自动创建一个虚拟机实例,并通过任务管理器初始化任务所需的状态。配置文件指定要使用的虚拟机快照(存储计算机在某一时刻的完整状态,并且可以随时恢复到这个状态),并指示设置所需的信息(例如下载文件和打开一些软件,进行一些额外的设置等)。一旦环境设置完成,代理开始与环境交互,接收观察结果,如屏幕截图、可访问性(a11y)树和定制流,如终端输出。代理随后生成可执行的动作(例如,.click(300, 540)),以操作键盘和鼠标。代理的每个动作都作为代码字符串输入到环境中,环境的模拟器在虚拟机中执行这些动作。在完成任务后,任务管理器根据任务的后配置执行后处理(例如文件保存,或重新打开某些应用程序),从主机机器检索数据(从虚拟机或云中获取图像或配置文件等),然后运行评估脚本来评估任务的完成情况。多个虚拟机可以同时在单个主机机器上运行,从而实现训练和评估的并行化。
2.2.2 Initial Task Environment Setup(初始任务环境设置)
Many real-world scenarios requiring assistance occur not at the beginning of digital activities, such as right after launching an application or when a computer has just been started, but rather at intermediate stages, such as when certain software is already open or the computer has experienced a crash. Therefore, we aim to simulate these intermediate states as closely as possible to replicate realworld scenarios. The naturalness we bring in also leads to more challenges for agents to model and explore. We adopted a hybrid approach for configuration instead of solely relying on example-wise snapshots for restoration since it would store much unnecessary hardware state information, resulting in each example requiring gigabytes of space. The procedure is divided into three stages: start the VM emulator, prepare files (download the files or scripts from the cloud, etc. optional), and execute reprocessing commands (open files or tabs, change the window size, etc. optional). We provide convenient APIs to configure initial conditions and world settings, standardizing our tasks to make this process user-friendly and easily extendable for scaling. For more details on setup see App. B.5.
许多需要帮助的真实场景并不是在数字活动开始后立即发生的,例如在启动应用程序后或计算机刚刚启动时,而是在中间阶段,例如当某些软件已经打开或计算机经历了崩溃时。因此,我们的目标是尽可能地模拟这些中间状态,以复制真实世界的场景。我们引入的自然性也导致了代理模型和探索的更多挑战。我们采用了一种混合方法来进行配置,而不是仅仅依赖于示例快照进行恢复,因为这样会存储大量不必要的硬件状态信息,导致每个示例需要占用几千兆字节的空间。该过程分为三个阶段:启动VM模拟器,准备文件(从云中下载文件或脚本等,可选),执行后处理命令(打开文件或选项卡,更改窗口大小等,可选)。我们提供了方便的API来配置初始条件和世界设置,标准化我们的任务,使这个过程对用户友好,并易于扩展以进行扩展。有关设置的更多详细信息,请参见附录B.5。
2.2.3 Execution-Based Evaluation(基于执行的评估)
Evaluating the successful execution of general computer tasks presents a significant challenge, as these tasks defy reduction to a uniform pattern or measurement by a single metric. To ensure a thorough assessment, we design example-specific evaluation metrics including pre-setup, post-processing, and dedicated functions, tailored to the software in use and the task’s specific requirements. This involves interpreting the software’s internal files, utilizing specific packages, and preemptively setting up scaffolding based on the software’s permissions (e.g., opening remote debugging ports for Chrome and VLC, creating extensions for VS Code). Occasionally, this process may also require assistance from reverse engineering tools, such as for decrypting account information in Thunderbird.
评估通用计算机任务的成功执行是一个重大挑战,因为这些任务无法通过单一指标减少到统一的模式或测量。为了确保全面评估,我们设计了特定示例的评估指标,包括预设置、后处理和专用函数,根据正在使用的软件和任务的特定要求进行定制。这涉及解释软件的内部文件,使用特定的包,并根据软件的权限(例如,为Chrome和VLC打开远程调试端口,为VS Code创建扩展)预先设置脚手架。有时,这个过程可能还需要借助反向工程工具,例如解密Thunderbird中的帐户信息。

表1:我们注释的评估脚本示例,涉及从配置文件、环境和云中检索数据,并执行函数来评估功能正确性和获取结果。基于示例的评估有助于任务的多样性和复杂、真实世界、开放式任务的可靠评估。
| 任务说明 | 评估脚本(简化) | |
|---|---|---|
| 你能帮我清理一下我的电脑,删除亚马逊可能保存的所有cookie吗? | cookie_data = get_cookie_data(env) rule = {“type”:”domains”, “domains”:[“.amazon.com”]} is_cookie_deleted(cookie_data, rule) |
|
| 将“Sheet 1”重命名为“LARS Resources”。然后复制一份。将副本放在“Sheet 2”之前,并通过添加后缀“(备份)”重命名它,… | result = get_file(env) expected = get_file(cloud) rules = [{“type”:”sheet_name”}, {“type”:”sheet_data”, “sheet_idx0”:0, “sheet_idx1”:1}…] compare_table(result, expected, rules) |
|
| 我已经为那些还没有交学费的人起草了一封电子邮件提醒。请帮我从付款记录中查看他们的电子邮件,并添加到接收者字段。 | tree = get_a11y_tree(env) rules = [{“selectors”: [“tool-bar[attr |id=MsgHeadersToolbar] label[name=To] [attr |class="address-pill"]> label[attr |class="pill-label"] [name*="fox@someuniversity.edu…] check_a11y_tree(tree, rules) |
As a result, we construct a vast collection of functions that make final wrangling and retrieve files and data information of varying types, categories, and granularities from the cloud and software from virtual machines as well as evaluation functions covering different aspects and their combinations, inputting this information as parameters to assess the outcomes. We show some evaluation examples in Tab. 1. , demonstrate the retrieval of cookie data from virtual machines, obtaining files from both virtual machines and cloud services, fetching the current runtime interface’s accessibility tree from the virtual machines, and determining success based on this information whether Amazon’s cookies have been deleted, whether the generated table is accurate, and whether the correct interface has been accessed. Need to note when the type of task has real-time characteristics (such as the number of citations of someone’s paper, the content of blogs, etc.), we include dynamic functions (such as crawler scripts) inside getter to obtain the real-time values at the moment of evaluation and then use them to compare with the results obtained by the agent upon task completion. See more in App. B.6.
因此,我们构建了一个庞大的函数集合,用于最终整理和从云和虚拟机中的软件中检索各种类型、类别和粒度的文件和数据信息,以及涵盖不同方面及其组合的评估函数,将这些信息作为参数输入以评估结果。我们在表1中展示了一些评估示例。演示了从虚拟机中检索cookie数据,从虚拟机和云服务中获取文件,从虚拟机中获取当前运行时界面的可访问性树,并根据这些信息确定Amazon的cookie是否已删除,生成的表是否准确,以及是否已访问正确的界面。需要注意的是,当任务的类型具有实时特性(例如某人论文的引用次数、博客的内容等)时,我们在getter中包含动态函数(例如爬虫脚本),以在评估时刻获取实时值,然后将其与代理在任务完成时获得的结果进行比较。更多内容请参见附录B.6。
2.3 Observation Space(观察空间)
The observation space in OSWORLD contains a complete screenshot of the desktop screen, including the mouse’s position and shape, various application windows, files, and folders that are opened in different sizes and orders, maintaining the same perception as a human. Also, to be aligned with previous agent-building web and mobile research [30, 27, 9, 66] that provide and support the use of the webpage’s DOM and app’s view hierarchy, OSWORLD also provides XML-format accessibility (a11y) tree (obtained via ATSPI on Ubuntu, via PyWinAuto on Windows, etc.), which can support additional information for modeling. These raw observations allow rich interactions between multiple applications but induce challenges in long-horizon decision-making from highresolution images (e.g., 4k screenshots) and structured long text (e.g., accessibility trees). For more detailed information on observation space, refer to App. A.2.
OSWORLD中的观察空间包含桌面屏幕的完整截图,包括鼠标的位置和形状,各种应用程序窗口,以不同大小和顺序打开的文件和文件夹,保持与人类相同的感知。此外,为了与以前的代理构建Web和移动研究[30, 27, 9, 66]保持一致,这些研究提供和支持网页的DOM和应用程序的视图层次结构的使用,OSWORLD还提供XML格式的可访问性(a11y)树(通过Ubuntu上的ATSPI获得,通过Windows上的PyWinAuto等),它可以支持建模的附加信息。这些原始观察结果允许多个应用程序之间的丰富交互,但会引发从高分辨率图像(例如4k屏幕截图)和结构化长文本(例如可访问性树)中进行长期决策制定的挑战。有关观察空间的更详细信息,请参见附录A.2。
2.4 Action Space(行动空间)
Action space A in OSWORLD encompasses all mouse and keyboard actions, including movement, clicks (left-key, right-key, multiple clicks), dragging, keystrokes, hotkeys, and others, covering all human-computer action space. Some action examples are shown in Tab. 2 and the complete action list can be found in Appendix A.3. We use the widely used mouse and keyboard control library pyautogui for our action space. This library leverages the high-level programming language Python to replicate and replay various human inputs into computers through code, allowing us to construct a universal and complete representation of actions. The agent must generate syntax-correct pyautogui Python code to predict valid actions. Basic actions, such as press and moveTo, can be integrated within program structures, such as for-loops, significantly improving the expressiveness of an action. Timing is also crucial, as highlighted in previous studies on mobile devices [50], as well as the ability to determine whether a task is infeasible or completed. Therefore, we add three special actions named WAIT, FAIL, and DONE to enhance the aforementioned action spaces. Previous efforts towards creating domain-specific agents, such as MiniWoB++ [44, 30], CC-Net [18], and WebArena [66, 22], have defined action spaces that include clicks and typing, as well as some actions specially designed for web browsing. However, they do not model all possible actions on a computer, leading to limitations when attempting actions like right-clicking and clicking with the ctrl key held to select items. This imposes an upper bound on agent learning capabilities.
OSWORLD中的行动空间A包括所有鼠标和键盘操作,包括移动、点击(左键、右键、多次点击)、拖动、按键、热键等,涵盖了所有人机操作空间。表2显示了一些动作示例,完整的动作列表可以在附录A.3中找到。我们使用广泛使用的鼠标和键盘控制库pyautogui来定义我们的行动空间。这个库利用高级编程语言Python通过代码复制和重放各种人类输入到计算机中,使我们能够构建行动的通用和完整表示。代理必须生成语法正确的pyautogui Python代码来预测有效的动作。基本动作,如press和moveTo,可以集成在程序结构中,如for循环,显著提高了动作的表达能力。正如之前关于移动设备的研究[50]所强调的,时间也是至关重要的,以及确定任务是否不可行或已完成的能力。因此,我们添加了三个特殊动作,分别命名为WAIT、FAIL和DONE,以增强上述动作空间。以前为创建特定领域代理所做的努力,如MiniWoB++[44, 30]、CC-Net[18]和WebArena[66, 22],定义了包括点击和输入的动作空间,以及一些专门设计用于Web浏览的动作。然而,它们没有对计算机上的所有可能动作进行建模,导致在尝试右键单击和按住ctrl键点击以选择项目等动作时存在局限性。这对代理的学习能力施加了上限。
Table 2: Some examples of the mouse and keyboard actions A in OSWORLD. See App. A.3 for the complete list.
| Function | Description |
|---|---|
| moveTo(x, y) | Moves the mouse to the specified coordinates. |
| click(x, y) | Clicks at the specified coordinates. |
| write(‘text’) | Types the specified text at the current cursor location. |
| press(‘enter’) | Presses the Enter key. |
| hotkey(‘ctrl’, ‘c’) | Performs the Ctrl+C hotkey combination (copy). |
| scroll(200) | Scrolls up by 200 units. |
| scroll(-200) | Scrolls down by 200 units. |
| dragTo(x, y) | Drags the mouse to the specified coordinates. |
| keyDown(‘shift’) | Holds down the Shift key. |
| keyUp(‘shift’) | Releases the Shift key. |
| WAIT | Agent decides it should wait. |
| FAIL | Agent decides the task is infeasible. |
| DONE | Agent decides the task is finished. |
表2:OSWORLD中鼠标和键盘动作A的一些示例。有关完整列表,请参见附录A.3。
| 函数 | 描述 |
|---|---|
| moveTo(x, y) | 将鼠标移动到指定的坐标。 |
| click(x, y) | 在指定的坐标处单击。 |
| write(‘text’) | 在当前光标位置键入指定的文本。 |
| press(‘enter’) | 按Enter键。 |
| hotkey(‘ctrl’, ‘c’) | 执行Ctrl+C热键组合(复制)。 |
| scroll(200) | 向上滚动200个单位。 |
| scroll(-200) | 向下滚动200个单位。 |
| dragTo(x, y) | 将鼠标拖动到指定的坐标。 |
| keyDown(‘shift’) | 按住Shift键。 |
| keyUp(‘shift’) | 释放Shift键。 |
| WAIT | Agent 决定应该等待。 |
| FAIL | Agent 决定任务不可行。 |
| DONE | Agent 决定任务已完成。 |
3 OSWORLD Benchmark(OSWORLD基准)
We introduce the OSWORLD benchmark, which encompasses 369 real computing tasks defined and executed on Ubuntu. Additionally, we provide a set of 43 tasks for Windows built on the OSWORLD environment. The environment preparation, annotation process, data statistics, and human performance are described in this section.
我们介绍了OSWORLD基准测试,它包括在Ubuntu上定义和执行的369个真实计算任务。此外,我们还提供了一个基于OSWORLD环境的Windows任务集合。环境准备、注释过程、数据统计和人类表现将在本节中进行描述。
3.1 Operating System and Software Environments(操作系统和软件环境)
OSWORLD supports real operating systems, including Windows, macOS, and Ubuntu, for the development of automated computer agents. For development purposes, we offer an extensive set of examples on Ubuntu and its open-source applications, leveraging their open-source nature and more accessible APIs for task setting and evaluation. We also provide annotated testing examples for Windows, focusing on applications with similar functionalities. For the first time, our real OS environments enable us to define all kinds of computer tasks, including those that involve interacting with multiple applications (e.g., Chrome and file manager) and interfaces (GUIs and CLIs). Considering availability, the strength of the user community, and diversity, we mainly focus on eight representative applications as well as the basic ones system provide: Chrome for web browsing, VLC for media playback, Thunderbird for email management, VS Code as a coding IDE, and LibreOffice (Calc, Writer, and Impress) for handling spreadsheets, documents, and presentations respectively, GIMP for image editing, and other basic OS apps like terminal, file manager, image viewer, and PDF viewer. Each example drawn from these applications separate or in combination showcases distinct operational logic and necessitates skills including commonsense knowledge, high-resolution perception, mastery of software shortcuts, and the precise controlling of mouse and keyboard movements. For more details, check App. B.1 and B.2.
OSWORLD支持真实操作系统,包括Windows、macOS和Ubuntu,用于开发自动化计算机代理。为了开发目的,我们提供了大量的Ubuntu示例和其开源应用程序,利用它们的开源性质和更易于访问的API来设置任务和评估。我们还提供了针对Windows的带注释的测试示例,重点关注具有类似功能的应用程序。我们的真实OS环境首次使我们能够定义各种计算机任务,包括涉及与多个应用程序(例如Chrome和文件管理器)和界面(GUI和CLI)交互的任务。考虑到可用性、用户社区的实力和多样性,我们主要关注八个代表性应用程序以及系统提供的基本应用程序:Chrome用于Web浏览,VLC用于媒体播放,Thunderbird用于电子邮件管理,VS Code作为编码IDE,LibreOffice(Calc、Writer和Impress)分别用于处理电子表格、文档和演示文稿,GIMP用于图像编辑,以及其他基本OS应用程序,如终端、文件管理器、图像查看器和PDF查看器。从这些应用程序中单独或组合提取的每个示例展示了不同的操作逻辑,并需要包括常识知识、高分辨率感知、掌握软件快捷键和精确控制鼠标和键盘移动在内的技能。有关更多详细信息,请查看附录B.1和B.2。
3.2 Tasks(任务)
We create a benchmark suite of 369 real-world computer tasks on Ubuntu environment collected from authors and diverse sources such as forums, tutorials, guidelines, etc., to show the capability for open-ended task creation within OSWORLD. Each example is carefully annotated with a natural language instruction, a setup configuration with corresponding files and setup actions for initialization of initial states upon our provided VM image, and a manually crafted evaluation script to check if the task is successfully executed. We also adapt 43 tasks from the Ubuntu set for analytic usage on Windows. Overall, it takes 9 computer science students (all student authors) over 3 months, consuming approximately 1800 man-hours (650 hours on single-app tasks, 750 hours on workflow tasks and 400 hours for double-checking).
我们在Ubuntu环境中创建了一个包含369个真实世界计算机任务的基准套件,这些任务来自作者和各种来源,如论坛、教程、指南等,以展示OSWORLD内开放式任务创建的能力。每个示例都经过仔细注释,包括自然语言指令、设置配置以及相应文件和设置动作,用于初始化我们提供的VM映像的初始状态,以及手工制作的评估脚本,以检查任务是否成功执行。我们还从Ubuntu集合中调整了43个任务,用于在Windows上进行分析。总体而言,9名计算机科学学生(所有学生作者)花费了3个月的时间,消耗了大约1800个人时(单应用程序任务650小时,工作流任务750小时,双重检查400小时)。
Task instructions and scenarios To draw the most diverse and close-to-reality usage cases, we explore several types of resources, including official guidelines & tutorials, video pieces giving tips and tutorials on the Internet (e.g., TikTok and YouTube), how-to websites (e.g., WikiHow), Q&A forums (e.g., Reddit, Quora, Superuser, & StackOverflow), formal video courses (e.g., Coursera and Udemy), and publicly-available personal blogs & guidelines. The detailed resources used in our benchmark are listed in App. B.3. The examples are selected by judging their popularity, helpfulness, and diversity, revealed by the views and votes. Meanwhile, we notice that it is challenging to find enough examples on the internet for tasks that involve the collaboration of multiple software applications. Therefore, the authors conducted extensive brainstorming, combining some existing examples or drawing inspiration from daily-life scenarios, to compile the tasks. The instructions and task-related files are then crafted from these real-world guidelines and questions by the authors. After the selection, each example will be cross-checked by the other two authors on the feasibility, ambiguity, and alignment with the source. We not only collect tasks that can be finished, but also collect the infeasible ones that are inherently impossible to be completed due to deprecated features or hallucinated features raised by real users, which results in 30 infeasible examples in our benchmark. Additionally, to demonstrate the unification ability of OSWORLD environment for the creation of open-ended computer tasks, we also integrate 84 examples from other benchmarks focusing on single-application or domain-specific environments such as NL2Bash [29], Mind2Web [9], SheetCopilot [25], PPTC [14], and GAIA [36]. Refer to App. B.4 for more details and B.8 for sampled examples for the showcase. A total of about 400 man-hours were spent to collect these examples.
任务说明和场景 为了绘制最多样化和最接近现实的使用案例,我们探索了几种类型的资源,包括官方指南和教程、在互联网上提供提示和教程的视频片段(例如,TikTok和YouTube)、如何网站(例如,WikiHow)、问答论坛(例如,Reddit、Quora、Superuser、& StackOverflow)、正式视频课程(例如,Coursera和Udemy)以及公开可用的个人博客和指南。我们基准测试中使用的详细资源列在附录B.3中。通过观看次数和投票揭示的流行度、实用性和多样性,来判断选择的示例。同时,我们注意到,在互联网上很难找到涉及多个软件应用程序协作的任务的足够示例。因此,作者们进行了广泛的头脑风暴,结合一些现有的示例或从日常生活场景中汲取灵感,来编制任务。然后,作者们从这些真实世界的指南和问题中制作了说明和与任务相关的文件。在选择之后,每个示例将由其他两名作者交叉检查其可行性、模糊性和与源的一致性。我们不仅收集可以完成的任务,还收集了那些由于过时功能或由真实用户提出的幻觉功能而本质上无法完成的不可行任务,这导致我们的基准测试中有30个不可行示例。此外,为了展示OSWORLD环境对于创建开放式计算机任务的统一能力,我们还整合了来自其他基准测试的84个示例,这些基准测试侧重于单应用程序或特定领域环境,如NL2Bash [29]、Mind2Web [9]、SheetCopilot [25]、PPTC [14]和GAIA [36]。有关更多详细信息,请参见附录B.4,以及用于展示的示例的抽样示例。总共花费了约400个人时来收集这些示例。
Initial state setup configs To construct the initial state, we prepare the files required for the task and set up the initial state. For the files, we try to obtain them from the sources of the tasks we found, or, in cases where the files are not publicly available, we recreate them as realistically as possible based on scenarios. For the initial state setup, we also developed some functions based on the APIs of software and OS to control the opening and resizing of software windows and reimplement some functions that are difficult to achieve with APIs using pyautogui. For different tasks, we write configs to set the files and initial steps in the virtual machine and verify them in the environment. For example, the setup stage (highlighted in red color, keyed as “config”) in Figure 2 involves downloading files into the virtual machine to prepare a close-to-reality initial environment, and then opening the file of interest with the corresponding application. The setup steps for each example take about 1 man-hours to construct.
初始状态设置配置 为了构建初始状态,我们准备了任务所需的文件,并设置了初始状态。对于文件,我们尝试从我们找到的任务来源中获取它们,或者在文件不是公开可用的情况下,我们根据场景尽可能真实地重新创建它们。对于初始状态设置,我们还基于软件和操作系统的API开发了一些函数,以控制软件窗口的打开和调整大小,并使用pyautogui重新实现了一些难以通过API实现的功能。对于不同的任务,我们编写配置文件来设置虚拟机中的文件和初始步骤,并在环境中进行验证。例如,图2中的设置阶段(红色高亮显示,键入为“config”)涉及将文件下载到虚拟机中,以准备一个接近现实的初始环境,然后使用相应的应用程序打开感兴趣的文件。每个示例的设置步骤大约需要1个人时来构建。
Execution-based evaluation For each task, we select the appropriate getter functions, evaluator function, and parameters to compose the configuration file. The getter function is used to extract key components (e.g., the modified file, the text contents displayed in a window element) from the final state of the environment, and the evaluator function assesses success based on the extracted key components. If a function does not exist, we will construct it and add it to the function library of the environment. After completing each evaluation, the annotator conducts initial tests with self-designed test cases. Then, in the human evaluation and experiment running phases, each example is further scrutinized and iterated upon by different individuals three times from the perspective of alignment with the instruction and correctness under different solutions. As a result, we implement nearly sample-specific executable evaluation scripts, resulting in a total of 134 unique evaluation functions for assessing functional correctness—significantly more than the previous benchmarks. The average time spent on developing the evaluation for an example and its examination amounts to approximately 2 man-hours from graduate students.
基于执行的评估 对于每个任务,我们选择适当的getter函数、评估函数和参数来组成配置文件。getter函数用于从环境的最终状态中提取关键组件(例如,修改后的文件、窗口元素中显示的文本内容),评估函数根据提取的关键组件评估成功。如果函数不存在,我们将构建它并将其添加到环境的函数库中。在完成每个评估后,注释者将使用自行设计的测试用例进行初始测试。然后,在人类评估和实验运行阶段,每个示例都将从与指令的一致性和不同解决方案下的正确性的角度,由不同的个体进行三次进一步审查和迭代。因此,我们实现了几乎是针对特定示例的可执行评估脚本,从而总共产生了134个用于评估功能正确性的独特评估函数,这比以前的基准测试要多得多。从研究生花费在开发示例和其检查的平均时间约为2个人时。
Quality control Once annotation is finished, each example is attempted by two authors who did not participate in annotating that specific example, acting as agents to complete the task. This process evaluates the current example’s quality and provides feedback to the annotators (such as unclear instructions or inability to complete the task, crashes in corner cases, serious instances of false positives and negatives, etc.), and involves joint revisions and supplements. During experiments for human performance and baselines, we further fixed examples found to have issues, dedicating over 400 man-hours for four rounds of checks. Further investment of time and a more red teaming could further reduce false positives and negatives, which we will leave to future work.
质量控制 一旦注释完成,每个示例都将由两名未参与注释该特定示例的作者尝试,充当代理以完成任务。这个过程评估了当前示例的质量,并向注释者提供反馈(例如,指令不清晰或无法完成任务,边缘情况下的崩溃,严重的假阳性和假阴性实例等),并涉及联合修订和补充。在进行人类表现和基线实验期间,我们进一步修复了发现存在问题的示例,为四轮检查投入了超过400个人时。进一步投入时间和更多的红队合作可以进一步减少假阳性和假阴性,这将留给未来的工作。
3.3 Data Statistics(数据统计)
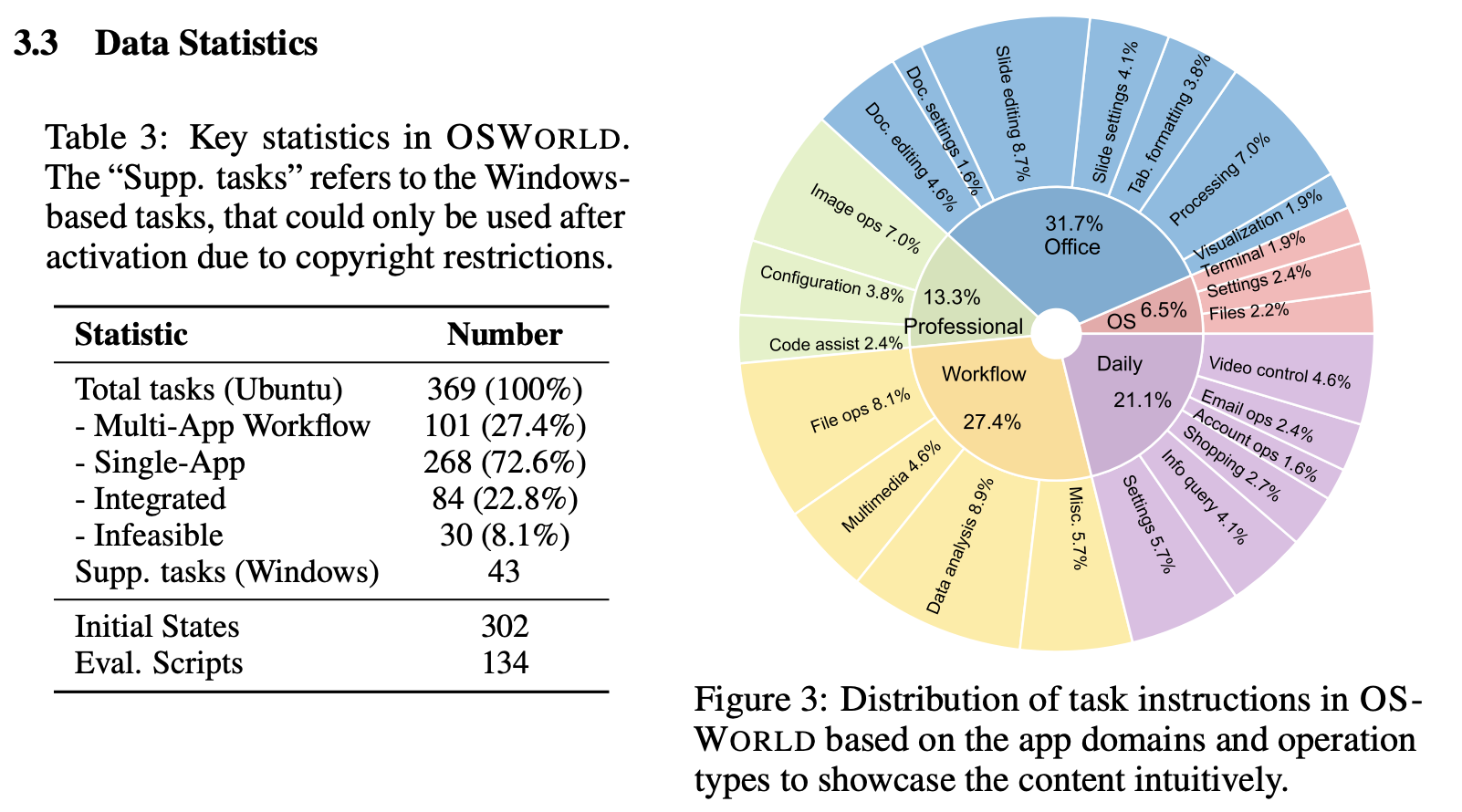
- 表3:OSWORLD的关键统计数据。 “Supp. tasks”指的是基于Windows的任务,由于版权限制,只能在激活后使用。
- 图3:OSWORLD中任务说明的分布,基于应用程序领域和操作类型,直观展示内容。
Statistics To facilitate the analysis and comprehension of the agent’s capabilities, we cluster the examples into the software categories. Specifically, these categories include OS, Office (LibreOffice Calc, Impress, Writer), Daily (Chrome, VLC Player, Thunderbird), Professional (VS Code and GIMP), and Workflow (tasks involving multiple apps). The main statistics of OSWORLD are presented in Tab. 3 and Fig. 3, showcasing the outline and a broad spectrum of tasks. Specifically, OSWORLD contains a total of 369 tasks (and an additional 43 tasks on Windows for analysis), with the majority (268 tasks or 72.6%) aiming at single application functionalities and a remarkable section of workflow-related tasks (101 tasks or 27.4%). The dataset’s diversity is further affirmed by the inclusion of tasks considered infeasible, totaling 30 tasks or 8.1% of the dataset. Additionally, a total of 84 tasks (22.8%) are integrated from related datasets, highlighting the dataset’s applicability in universal modeling. Remarkably, the dataset incorporates 302 distinct initial states and 134 different evaluation scripts, underscoring the comprehensive approach towards evaluating the tasks’ complexity and requirements. More statistic details are available in App. B.4.
统计 为了便于分析和理解代理的能力,我们将示例分成软件类别。具体来说,这些类别包括操作系统、办公室(LibreOffice Calc、Impress、Writer)、日常(Chrome、VLC Player、Thunderbird)、专业(VS Code和GIMP)和工作流(涉及多个应用程序的任务)。OSWORLD的主要统计数据如表3和图3所示,展示了任务的概述和广泛的任务范围。具体来说,OSWORLD包含了总共369个任务(以及额外的43个用于分析的Windows任务),其中大多数(268个任务或72.6%)旨在实现单个应用程序的功能,以及一个显着的工作流相关任务部分(101个任务或27.4%)。数据集的多样性进一步得到了包括不可行任务在内的任务的确认,总共有30个任务或数据集的8.1%。此外,总共有84个任务(22.8%)是从相关数据集中整合而来的,突出了数据集在通用建模中的适用性。值得注意的是,数据集包含302个不同的初始状态和134个不同的评估脚本,强调了评估任务的复杂性和要求的全面方法。更多统计细节请参见附录B.4。
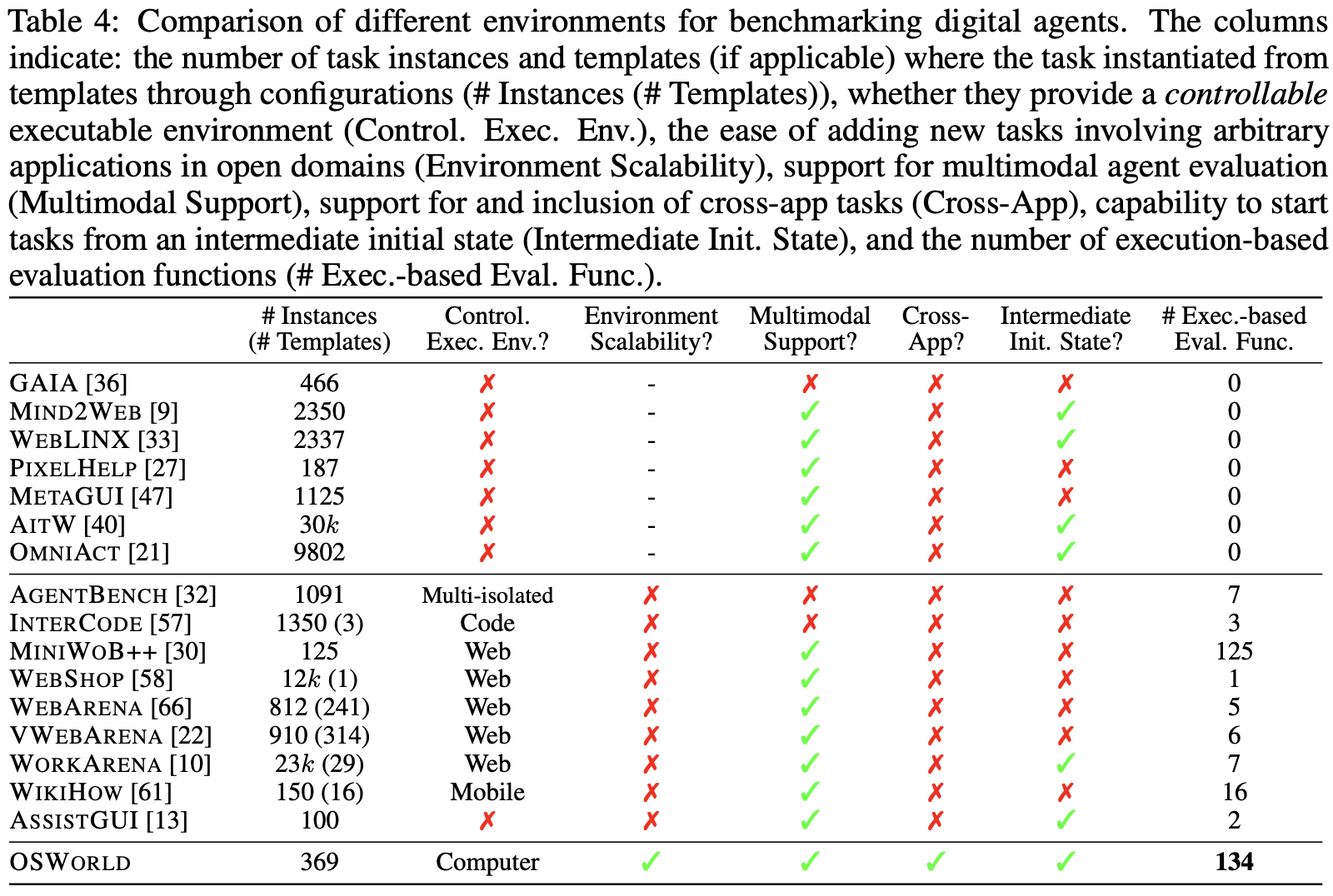
Comparison with existing benchmarks OSWORLD is compared with a number of existing benchmarks in Table 4. OSWORLD take utilizes raw mouse and keyboard actions that is universal to the computer environment, rather than focusing on specific computer applications (e.g., a browser [66, 9]), with multimodal observation including screenshot (Multimodal Support column). This universal action space enables the constructed agents to handle general tasks in the digital world. Our executable environment allows agents to freely explore during both the learning and evaluation phases, rather than providing only static demonstrations to evaluate an agent’s prediction of the next step (Executable Env. column). Moreover, it does not solely focus on interactions within a single app but also considers interactions across multiple apps and the overall task (Cross-App column). Unlike many evaluations that offer the same evaluation script or a few scripts for a certain type of task, the OSWORLD benchmark provides example-wise, execution-based evaluation for tasks. Specifically, the total of 134 unique execution-based evaluation functions in our benchmark is significantly more than previous work, demonstrating the complexity, diversity, and evaluation challenges of tasks in our benchmark (# Exec.-based Eval. Func. column). It also allow us to freely choose open-ended tasks and scale to new environments, rather than struggling in crafting new ones. Constructing intermediate initial states as task setup increases realism and poses challenges to the agents’ exploration capabilities (Intermediate Init. State column).
与现有基准的比较 表4将OSWORLD与许多现有基准进行了比较。OSWORLD利用原始鼠标和键盘动作,这对计算机环境是通用的,而不是专注于特定的计算机应用程序(例如,浏览器[66, 9]),观察包括截图(多模态支持列)。这种通用的行动空间使构建的代理能够处理数字世界中的一般任务。我们的可执行环境允许代理在学习和评估阶段自由探索,而不仅仅提供静态演示来评估代理对下一步的预测(可执行环境列)。此外,它不仅关注单个应用程序内的交互,还考虑跨多个应用程序和整体任务的交互(跨应用程序列)。与许多提供相同评估脚本或某种类型任务的少数脚本的评估不同,OSWORLD基准提供了基于示例的、基于执行的任务评估。具体来说,我们基准测试中总共134个独特的基于执行的评估函数远远超过以前的工作,展示了我们基准测试中任务的复杂性、多样性和评估挑战(#基于执行的评估函数列)。它还允许我们自由选择开放式任务并扩展到新环境,而不是在制作新任务时挣扎。构建中间初始状态作为任务设置增加了现实性,并对代理的探索能力提出了挑战(中间初始状态列)。
3.4 Human Performance(人类表现)
表4:用于基准测试数字代理的不同环境的比较。列表示:任务实例和模板的数量(如果适用)(通过配置从模板实例化的任务的数量(#实例(#模板))),它们是否提供可控的可执行环境(Control. Exec. Env.),在开放领域中添加涉及任意应用程序的新任务的便捷性(环境可扩展性),支持多模态代理评估(多模态支持),支持和包括跨应用程序任务(跨应用程序),从中间初始状态开始任务的能力(中间初始状态),以及基于执行的评估函数的数量(#基于执行的评估函数)。
We conduct human evaluations on each example in our dataset, with annotators being computer science major college students who possess basic software usage skills but have not been exposed to the samples or software before. We recorded the time required to complete each example and whether their completion of the example was correct. For comparison, we also sampled 100 examples from WebArena [66] under the same evaluation setup.
我们对数据集中的每个示例进行人类评估,注释者是计算机科学专业的大学生,他们具有基本的软件使用技能,但以前没有接触过示例或软件。我们记录了完成每个示例所需的时间以及他们是否正确完成了示例。为了进行比较,我们还从WebArena [66]中抽取了100个示例,采用相同的评估设置。
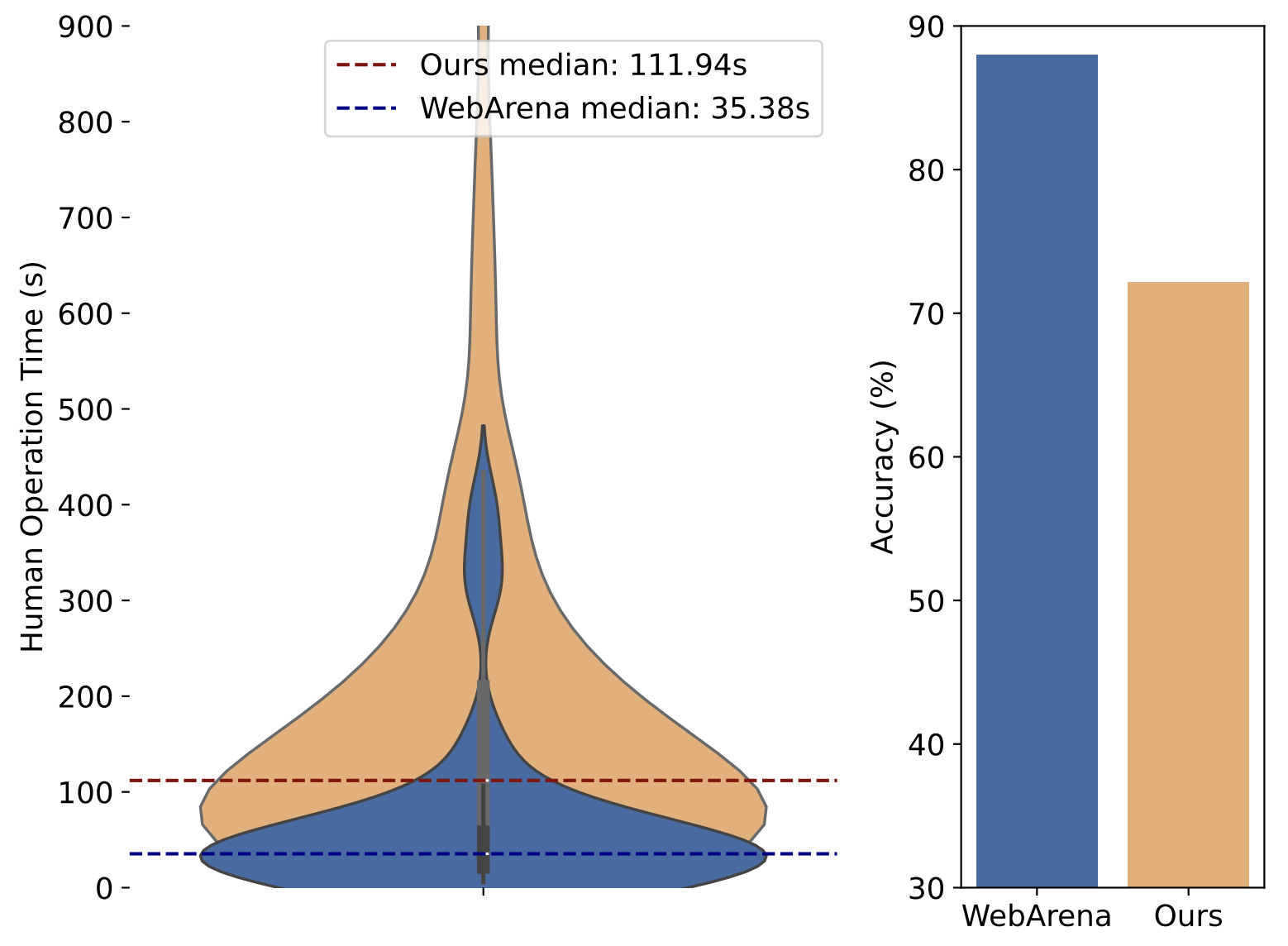
As illustrated, tasks from our dataset generally required more time to complete, with a median completion time of 111.94 seconds (compared to 35.38 seconds in WebArena), and a significant number of examples distributed at 900 seconds or even more. In terms of accuracy, the human performance on our tasks was approximately 72.36%, significantly lower than the 88% observed on the pure web task dataset. These findings highlight the complexity and challenge of tasks in our dataset, which demand more time and effort. The lower accuracy rate further indicates that our tasks require a higher level of understanding and proficiency, underscoring the need for advanced models and techniques to tackle them effectively.
如图4所示,我们数据集中的任务通常需要更多的时间来完成,完成时间的中位数为111.94秒(而WebArena中为35.38秒),并且有大量示例分布在900秒甚至更长的时间。在准确性方面,我们的任务的人类表现约为72.36%,明显低于纯Web任务数据集中的88%。这些发现突显了我们数据集中任务的复杂性和挑战,这些任务需要更多的时间和精力。较低的准确率进一步表明,我们的任务需要更高水平的理解和熟练程度,强调了需要先进的模型和技术来有效地解决这些问题。
4 Benchmarking LLM and VLM Agent Baselines(基准测试LLM和VLM代理基线)
In this section, we present the implementation details and experimental settings for several state-ofthe-art LLM and VLM agent baselines on OSWORLD benchmark, as well as their performance.
在本节中,我们将介绍OSWORLD基准测试上几种最先进的LLM和VLM代理基线的实现细节和实验设置,以及它们的性能。
4.1 LLM and VLM Agent Baselines(LLM和VLM代理基线)
We adopt state-of-the-art LLM and VLM from open-source representatives such as Mixtral [19], CogAgent [17] and Llama-3 [35], and closed-source ones from GPT, Gemini, Claude and Qwen families on OSWORLD, to serve as the foundation of agent. We also explore methods such as the Set-of-Marks aided approach [56, 11], which has been demonstrated to improve spatial capabilities for visual reasoning. Our prior experiments following VisualWebArena [22] adopt few-shot prompting, which involves using (observation, action) pairs as few-shot examples and inputting the current observation to generate the action, but this resulted in poor performance (success rate of 2.79% under pure-screenshot setting). We attribute the result to a lack of history encoding and change in the prompting scheme. Therefore, in the experiments, we opt to utilize the context window by providing the most recent 3 observations and actions in chat mode, i.e., alternating between “user” prompts and “assistant” prompts, instead of the (observation, action) pairs. We use a temperature of 1.0 and top-p of 0.9 and truncate from the beginning of the input if still exceeding the max tokens limit required by the models. The prompts used in the experiments are provided in App.C.1. We heuristically request the agents to complete the tasks within a max step limit of 15, which is enough for most tasks. We present a summary of the results in Tab. 5 and analysis in Sec. 4.2. We implement the following four types of input settings on LLM and VLM.
我们采用来自开源代表如Mixtral [19]、CogAgent [17]和Llama-3 [35],以及来自GPT、Gemini、Claude和Qwen家族的闭源代表的最先进的LLM和VLM,用于OSWORLD,作为代理的基础。我们还探索了一些方法,如Set-of-Marks辅助方法[56, 11],已经证明可以提高视觉推理的空间能力。我们之前的实验遵循VisualWebArena [22]采用了少样本提示,这涉及使用(观察、动作)对作为少样本示例,并输入当前观察来生成动作,但这导致了性能较差(在纯截图设置下的成功率为2.79%)。我们将结果归因于历史编码的缺乏和提示方案的变化。因此,在实验中,我们选择通过在聊天模式下提供最近的3个观察和动作来利用上下文窗口,即在“用户”提示和“助手”提示之间交替,而不是(观察、动作)对。我们使用温度1.0和top-p 0.9,并在仍然超过模型所需的最大标记限制时从输入的开始截断。实验中使用的提示见附录C.1。我们启发式地要求代理在15个最大步骤限制内完成任务,这对于大多数任务来说足够了。我们在表5中总结了结果,并在第4.2节中进行了分析。我们在LLM和VLM上实现了以下四种输入设置。
Accessibility tree We aim to evaluate whether the current advanced text-based language models can reason and ground themselves in the context to generate the correct action. Since the original XML format of accessibility tree contains millions of tokens, caused by countless elements, redundant attributes, and a mass of markups, we opt to filter out non-essential elements and attributes, and represent the elements in a more compact tab-separated table format. To be specific, we filter the elements by their tag, visibility, availability, existence of text or image contents, etc. The detailed filtering method is elaborated on in App. C.3. Only the tag, name, text, position, and size of the remaining elements are kept and concatenated by tab character in the input. As the raw coordinates are provided within the accessibility tree, the LLM is required to ground its action predictions to accurate coordinates.
可访问性树 我们的目标是评估当前先进的基于文本的语言模型是否能够推理并将自己扎根于上下文中以生成正确的动作。由于可访问性树的原始XML格式包含数百万个标记,由无数元素、冗余属性和大量标记引起,我们选择过滤掉非必要的元素和属性,并以更紧凑的制表符分隔表格格式表示元素。具体来说,我们通过标记、可见性、可用性、文本或图像内容的存在等来过滤元素。详细的过滤方法在附录C.3中有详细说明。只保留剩余元素的标记、名称、文本、位置和大小,并通过制表符连接输入。由于原始坐标在可访问性树中提供,因此需要LLM将其动作预测与准确坐标相匹配。
Screenshot This is the input format that is closest to what humans perceive. Without special processing, the raw screenshot of the virtual machine is directly sent to the VLM. The VLM is to understand the screenshot and predict correct actions with precise coordinates. The raw resolution of the screen is set to 1920 × 1080. In order to investigate the impact of input resolution, ablation studies are also conducted with different resolutions by manually downsampling the screenshot.
截图 这是最接近人类感知的输入格式。在没有特殊处理的情况下,虚拟机的原始截图直接发送给VLM。VLM需要理解截图并预测出具有精确坐标的正确动作。屏幕的原始分辨率设置为1920×1080。为了研究输入分辨率的影响,还通过手动对截图进行降采样,使用不同的分辨率进行消融研究。
Screenshot + accessibility tree To check if a combination with the accessibility tree can improve the capacity of VLM for spatial grounding, we take this setting by inputting both raw screenshots and a simplified accessibility tree.
截图+可访问性树 为了检查与可访问性树的组合是否可以提高VLM的空间扎根能力,我们采用这种设置,通过输入原始截图和简化的可访问性树。
Set-of-Marks Set-of-Marks (SoM) [56] is an effective method for enhancing the grounding capabilities of VLMs such as GPT-4V, by segmenting the input image into different sections and marking them with annotations like alphanumerics, masks, or boxes. We leverage the information from the filtered accessibility tree and mark the elements on the screenshot with a numbered bounding box. Following VisualWebArena [22] and UFO [59], we further combine the annotated screenshot with the text metadata from accessibility tree, including the index, tag, name, and text of the elements5 . Instead of predicting precise coordinates, the VLM is supposed to specify the action object by its number index, which will be mapped into our action space by post-processing. Ablation studies are also conducted with different resolutions for SoM setting.
Set-of-Marks Set-of-Marks(SoM)[56]是一种有效的方法,可以通过将输入图像分割为不同的部分,并使用字母数字、掩码或框等注释对其进行标记,从而增强GPT-4V等VLM的扎根能力。我们利用来自过滤后的可访问性树的信息,并在截图上用编号的边界框标记元素。在遵循VisualWebArena [22]和UFO [59]的基础上,我们进一步将带注释的截图与来自可访问性树的文本元数据结合起来,包括元素的索引、标记、名称和文本。VLM不是预测精确的坐标,而是应该通过其编号索引指定动作对象,这将通过后处理映射到我们的动作空间。对于SoM设置,还使用不同的分辨率进行了消融研究。
4.2 Results(结果)
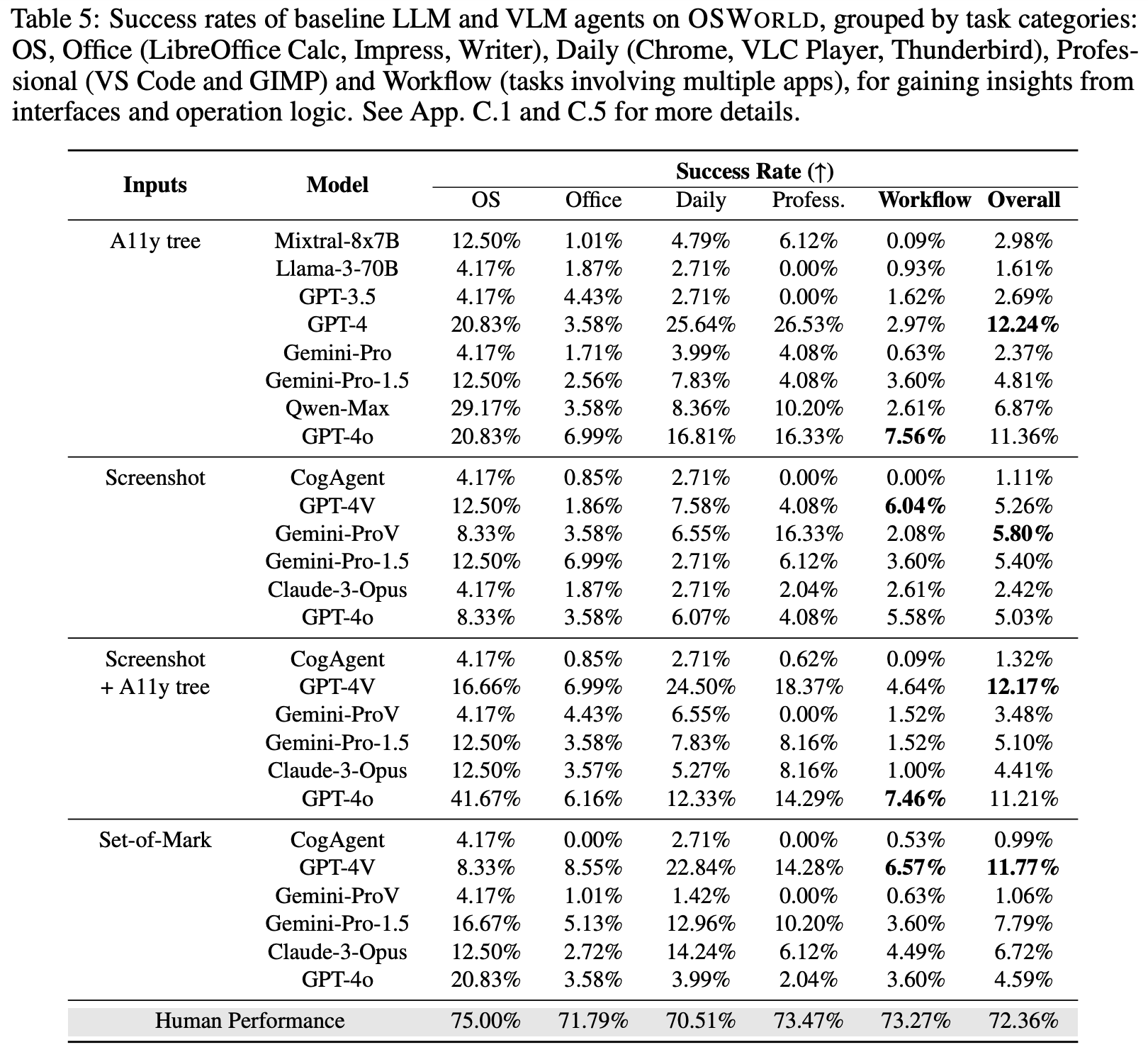
LLMs and VLMs are still far from being digital agents on real computers. The results from Table 5 show that when only using screenshots as input and adopting pyautogui as the code space, the success rate of the model is only 5.26% to 5.80% even with the strongest VLMs GPT-4V and Gemini-Pro-vision. Meanwhile, the most advanced batch of language models, when using the a11y tree as input, has a success rate ranging from 2.37% to 12.24%. Overall, these figures of performance are significantly lower than the human-level performance which is 72.36% overall for individuals not familiar with the software. These gaps indicate that current LLMs and VLMs may still have a significant gap from humans in performance, necessitating further research in this area. Another surprising finding is that although Claude-3 Opus is reported to be competitive with GPT-4V on common benchmarks [2], it falls far behind when used as a digital agent in OSWORLD. We will present a qualitative analysis and infer reasons in Sec. 5.4.
LLM和VLM仍然远未成为真实计算机上的数字代理。 表5的结果显示,当仅使用截图作为输入并采用pyautogui作为代码空间时,即使使用最强大的VLM GPT-4V和Gemini-Pro-vision,模型的成功率也仅为5.26%至5.80%。同时,当使用a11y树作为输入时,最先进的一批语言模型的成功率在2.37%至12.24%之间。总的来说,这些性能数据明显低于人类水平的性能,对于不熟悉软件的个体来说,总体为72.36%。这些差距表明,当前的LLM和VLM在性能上可能仍然与人类存在显著差距,需要在这个领域进行进一步研究。另一个令人惊讶的发现是,尽管Claude-3 Opus在常见基准测试中被认为与GPT-4V具有竞争力[2],但在OSWORLD中作为数字代理使用时,它的表现远远落后。我们将在第5.4节中进行定性分析并推断原因。
Agent performance has much higher variance than human across different types of computer tasks. OSWORLD is capable of simulating and evaluating the various software types and combination scenarios involved in people’s daily lives in an open-ended manner. We observe performance based on software type grouping and find that agents based on LLMs show significant differences across different subsets. As shown in Table 5, performance tends to be better in tasks oriented towards CLI interfaces (such as OS-type tasks) compared to those based on GUI (such as Office tasks involving clicks on spreadsheet interfaces and document processing). Moreover, the biases between different models and settings are inconsistent, with gaps even exceeding 20%; another point is that performance on workflow-type tasks involving multiple software is far below the figures on a single software, generally below 5%. However, human performance is consistent across these tasks, fluctuating around 70% without exceeding a 5% variance, forming a significant contrast with the models. This suggests that the way humans understand and complete tasks may differ significantly from the current logic and methods based on LLMs and VLMs.
代理在不同类型的计算机任务中的性能差异比人类要大得多。 OSWORLD能够以开放式方式模拟和评估人们日常生活中涉及的各种软件类型和组合场景。我们观察基于软件类型分组的性能,并发现基于LLM的代理在不同子集之间存在显著差异。如表5所示,与基于GUI的任务(例如涉及对电子表格界面和文档处理进行点击的办公室任务)相比,基于CLI界面(例如OS类型任务)的任务性能往往更好。此外,不同模型和设置之间的偏差是不一致的,甚至超过20%;另一个观点是,涉及多个软件的工作流类型任务的性能远低于单个软件的数据,通常低于5%。然而,人类在这些任务中的表现是一致的,波动在70%左右,没有超过5%的方差,与模型形成了明显对比。这表明,人类理解和完成任务的方式可能与基于LLM和VLM的当前逻辑和方法存在显著差异。
A11y tree and SoM’s effectiveness varies by models. The a11y tree contains some attribute information of visible elements, including window position and size, as well as some semantic labels of the window. The performance gap illustrated in Table 5 between GPT-4V and Claude-3 with additional a11y tree information and under a pure screenshot setup suggests that it still has significant room for improvement in accurately perceiving and reasoning GUI elements. Conclusions are reversed for Gemini-Pro.
a11y树和SoM的有效性因模型而异。 a11y树包含一些可见元素的属性信息,包括窗口位置和大小,以及窗口的一些语义标签。表5中GPT-4V和Claude-3在附加a11y树信息和纯截图设置下的性能差距表明,它仍然有很大的提升空间,可以准确感知和推理GUI元素。对于Gemini-Pro,结论是相反的。
While applying SoM setting, there is a decline for GPT-4V in performance compared to directly providing the model with screenshots and a11y tree inputs, which contradicts the widely shown effectiveness of SoM in classic image understanding tasks [56], as well as in application areas like web agents [65, 16]. We speculate that this is due to the tasks performed within operating systems having higher resolution and much more elements, (e.g., the cells in a spread table), leading to a significant amount of noise that counteracts the auxiliary role of bounding boxes. Some tasks also require detailed operation on coordinate-level, which cannot be modeled by the bounding box that SoM marks.
在应用SoM设置时,与直接提供模型截图和a11y树输入相比,GPT-4V的性能有所下降,这与SoM在经典图像理解任务[56]以及在Web代理[65, 16]等应用领域广泛显示的有效性相矛盾。我们推测,这是由于操作系统中执行的任务具有更高的分辨率和更多的元素(例如,电子表格中的单元格),导致大量噪声,抵消了边界框的辅助作用。一些任务还需要在坐标级别进行详细操作,这不能由SoM标记的边界框建模。
VLM agents with screenshot-only setting show lower performance, but it should be the ultimate configuration in the long run. The setting that relies solely on screenshots exhibits the lowest performance, at only 5.26%, among all. Surprisingly, it still achieves a decent outcome when managing workflow tasks (involving multiple applications) that involve multiple applications. Despite the performance, it is worth mentioning that this is the only configuration that does not require additional information, such as an accessibility (a11y) tree, making it concise and in alignment with intuitive human perception since the a11y tree may not be well-supported across all software or cannot be obtained under noisy conditions (e.g., when the agent is restricted to viewing the computer through peripheral screens), and the massive amount of tokens contained in the a11y tree (even just the leaf nodes can have tens of thousands of tokens) can also impose an additional inference burden on the model. Future work on purely vision-based agents could lead to stronger generalization capabilities and, ultimately, the potential for integration with the physical world on a larger scale.
5 Analysis(分析)
In this section, we aim to delve into the factors influencing the performance of VLMs in digital agent tasks and their underlying behavioral logic. We will investigate the impact of task attributes (such as difficulty, feasibility, visual requirement, and GUI complexity), input measurements (such as screenshot resolution, the influence of trajectory history, and the effect of UI layout), explore whether there are patterns in the agent’s performance across different operating systems, and make a qualitative analysis in the aspect of models, methods, and humans. All experiments, unless specifically mentioned otherwise, are conducted using GPT-4V under the Set-of-Mark setting. Some takeaways from the analysis are: 1) higher screenshot resolution typically leads to improved performance; 2) encoding more a11y (text) trajectory history can boost performance, while not working for screenshots (image); 3) current VLMs are not adept at image-based trajectory history context; 4) current VLM agents are not robust to UI layout and noise; 5) the performance of VLM agents across OS is in strong correlation; 6) VLM agents have common error types like mouse-clicking inaccuracies, limited domain knowledge, and more types discussed in Sec. 5.4.
在本节中,我们旨在深入探讨影响VLM在数字代理任务中性能的因素以及其潜在的行为逻辑。我们将调查任务属性(如难度、可行性、视觉要求和GUI复杂性)对性能的影响,输入测量(如截图分辨率、轨迹历史的影响和UI布局的影响),探索代理在不同操作系统上的性能是否存在模式,并在模型、方法和人类方面进行定性分析。除非另有说明,所有实验均使用GPT-4V在Set-of-Mark设置下进行。分析中的一些要点是:1)更高的截图分辨率通常会导致性能提高;2)编码更多的a11y(文本)轨迹历史可以提高性能,而对截图(图像)无效;3)当前的VLM不擅长基于图像的轨迹历史上下文;4)当前的VLM代理对UI布局和噪声不具有鲁棒性;5)VLM代理在不同操作系统上的性能之间存在很强的相关性;6)VLM代理存在常见的错误类型,如鼠标点击不准确、领域知识有限,以及第5.4节中讨论的更多类型。
5.1 Performance by Task Difficulty, Feasibility and App Involved(任务难度、可行性和涉及的应用程序的性能)
Table 6: Success rate (SR) of GPT-4V (SoM) across different types of tasks.
| Task Subset | % of Total | SR (↑) |
|---|---|---|
| Easy | 28.72% | 16.78% |
| Medium | 40.11% | 13.12% |
| Hard | 30.17% | 4.59% |
| Infeasible | 8.13% | 16.67% |
| Feasible | 91.87% | 13.34% |
| Single-App | 72.63% | **13.74% ** |
| Multi-App Workflow | 27.37% | 6.57% |
表6:GPT-4V(SoM)在不同类型任务中的成功率(SR)。
| 任务子集 | 总数百分比 | 成功率(↑) |
|---|---|---|
| 简单 | 28.72% | 16.78% |
| 中等 | 40.11% | 13.12% |
| 困难 | 30.17% | 4.59% |
| 不可行 | 8.13% | 16.67% |
| 可行 | 91.87% | 13.34% |
| 单应用程序 | 72.63% | 13.74% |
| 多应用程序工作流 | 27.37% | 6.57% |
We analyze the success rate across several additional subsets of tasks, as summarized in Tab. 6 and will be discussed in the following sections.
我们分析了表6中总结的几个额外任务子集的成功率,并将在接下来的章节中讨论。
Task difficulty We categorize the tasks based on the time required for human completion into three groups: 0∼60s (Easy), 60s∼180s (Medium), and greater than 180 seconds (Hard), as an indicator of difficulty. Across these groups, the model’s success rate drops as the required time increases, with tasks taking longer than 180 seconds becoming almost impossible to complete (considering we have infeasible examples for agent’s luckiness), whereas human performance across these three groups is 84.91%, 81.08% and 49.57%, showing a slight decline of the same trend but not to the extent of being unachievable.
任务难度 我们根据人类完成所需的时间将任务分为三组:0∼60秒(简单)、60秒∼180秒(中等)和大于180秒(困难),作为难度的指标。在这些组中,随着所需时间的增加,模型的成功率下降,所需时间超过180秒的任务几乎不可能完成(考虑到我们有不可行的示例供代理人员使用),而人类在这三组任务中的表现分别为84.91%、81.08%和49.57%,显示出相同趋势的轻微下降,但不至于无法实现。
Feasibility We also divide tasks into groups of tasks infeasible (e.g., deprecated features or hallucinated features) and tasks feasible, which requires the agents to have the ability to judge based on their own knowledge and exploration results. As shown in Tab. 6, we observe that agents currently perform slightly better in terms of infeasibility (16.67% to 13.34%), but overall, they are at a relatively low level. It is noteworthy that we also observe in some methods and settings (such as under the pure screenshot setting with the Gemini-Pro model), agents tend to easily output FAIL and refuse to continue trying. This situation leads to some false positives in infeasible tasks. The focus needs to be on improving overall performance.
可行性 我们还将任务分为不可行的任务组(例如,已弃用的功能或虚构的功能)和可行的任务组,这需要代理根据自己的知识和探索结果进行判断。如表6所示,我们观察到代理目前在不可行性方面表现略好(16.67%至13.34%),但总体上,它们处于相对较低的水平。值得注意的是,我们还观察到在某些方法和设置(例如在Gemini-Pro模型下的纯截图设置下),代理倾向于轻易输出FAIL并拒绝继续尝试。这种情况导致了一些不可行任务中的误报。重点需要放在提高整体性能上。
Number of apps involved We also examined the performance based on whether the task involved apps software or within a single app. As shown in Tab. 6, the average performance for tasks involving a single app is low, at 13.74%, but still more than double the 6.57% observed for subsets of tasks involving workflows across multiple apps. Within single-app scenarios, tasks involving GUI-intensive Office apps generally performed the worst, with subsets such as LibreOffice Calc often scoring zero (we show more detailed results in App. C.5). These findings highlight the need for improved collaboration capabilities between software and enhanced proficiency in specific scenarios.
涉及的应用程序数量 我们还根据任务是否涉及应用程序软件或单个应用程序来检查性能。如表6所示,涉及单个应用程序的任务的平均性能较低,为13.74%,但仍然是涉及多个应用程序的工作流子集的6.57%的两倍以上。在单应用程序场景中,涉及GUI密集型办公应用程序的任务通常表现最差,例如LibreOffice Calc等子集经常得分为零(我们在附录C.5中展示了更详细的结果)。这些发现突显了在软件之间的协作能力和特定场景中的增强熟练度的需求。
5.2 Performance by Multimodal Observation Variances(多模态观察差异的性能)
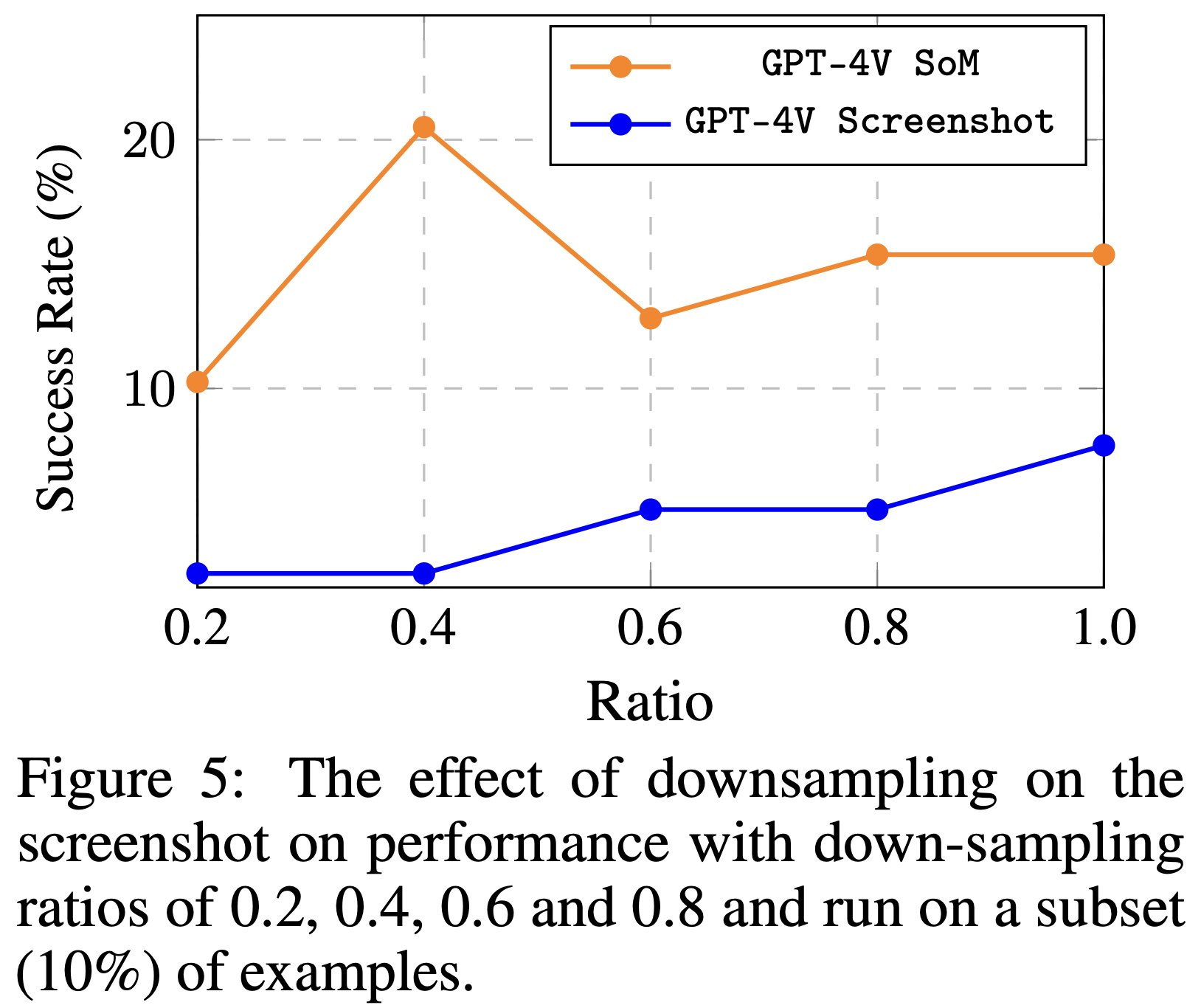
图5:降采样对截图性能的影响,降采样比例为0.2、0.4、0.6和0.8,并在子集(10%)的示例上运行。
Higher screenshot resolution typically leads to improved performance Despite the significant progress in display technology (1080P, 2K, and 4K), most VLMs are still trained on data far below these resolutions. We select the screenshot-only input and SoM setting to test the method’s performance under different screen input down-sampling ratios (i.e., 0.2, 0.4, 0.6 and 0.8 of the original resolution), to evaluate the impact of resolution changes on model recognition ability and accuracy. The output coordinates of the model for the screenshot setting are still expected to align with the original resolution (i.e., 1080P). The effects of varying input resolutions on performance are shown in Figure 5. For inputs based on pure screenshots, it is observed that an increase in resolution directly correlates with enhanced performance. This issue may arise from the discrepancy between the resolution of the screenshot and the coordinates of the output. However, the scenario slightly differs on SoM. Interestingly, a reduction in resolution to 768×432 (down-sampling ratio of 0.4) leads to an improvement in the agent’s performance and further diminishing the resolution even more to a down-sampling ratio of 0.2 results in a noticeable decline in performance.
更高的截图分辨率通常会导致性能提高 尽管显示技术取得了显著进展(1080P、2K和4K),但大多数VLM仍然是在远低于这些分辨率的数据上进行训练的。我们选择纯截图输入和SoM设置来测试该方法在不同屏幕输入降采样比例(即原始分辨率的0.2、0.4、0.6和0.8)下的性能,以评估分辨率变化对模型识别能力和准确性的影响。截图设置的模型输出坐标仍然预期与原始分辨率(即1080P)对齐。图5显示了不同输入分辨率对性能的影响。对于基于纯截图的输入,观察到分辨率的增加直接与性能的提高相关。这个问题可能源于截图的分辨率与输出坐标之间的差异。然而,SoM的情况略有不同。有趣的是,将分辨率降低到768×432(降采样比例为0.4)会导致代理的性能提高,进一步将分辨率降低到0.2的降采样比例会导致性能明显下降。
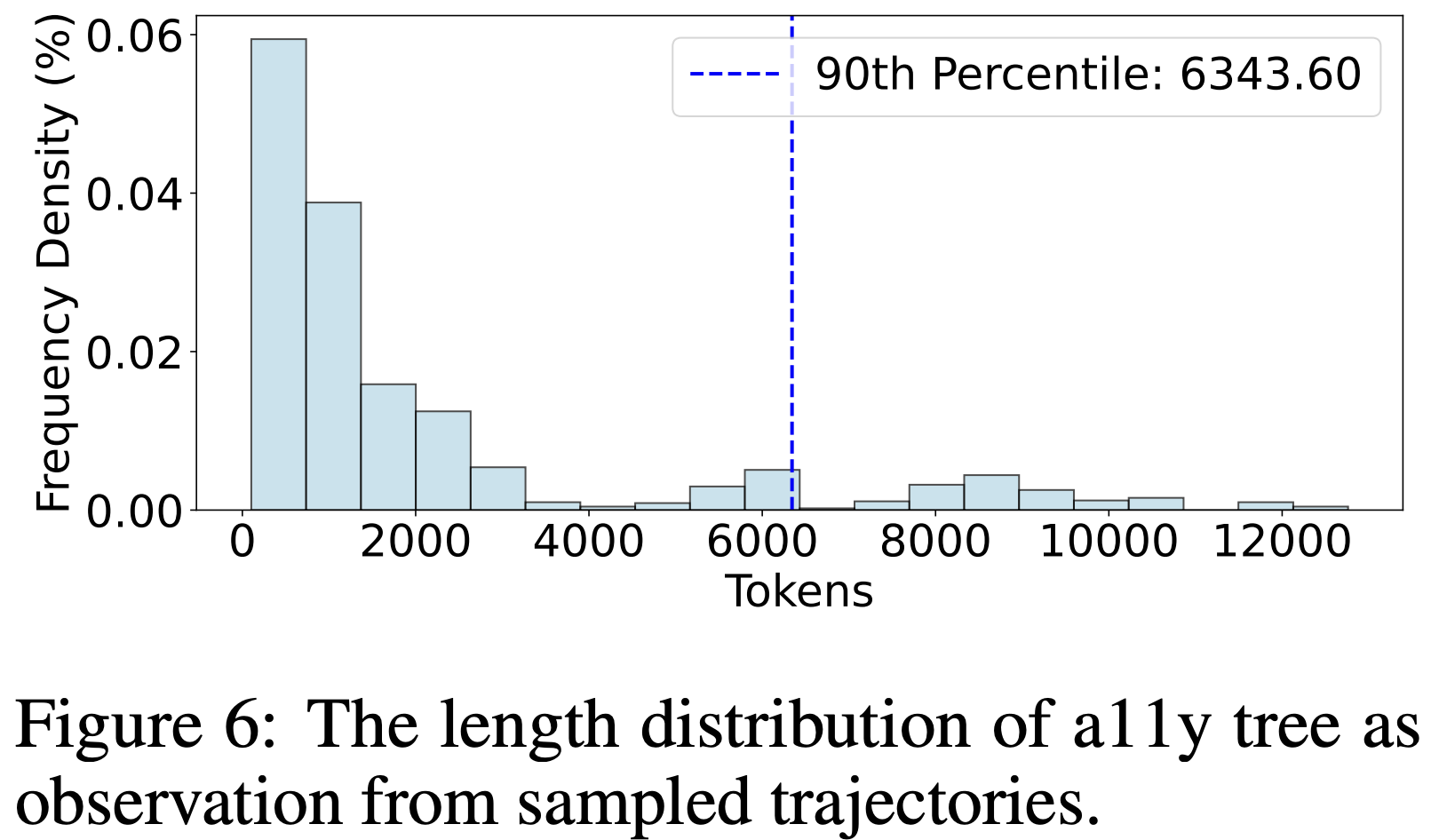
图6:从采样轨迹中观察到的a11y树的长度分布。
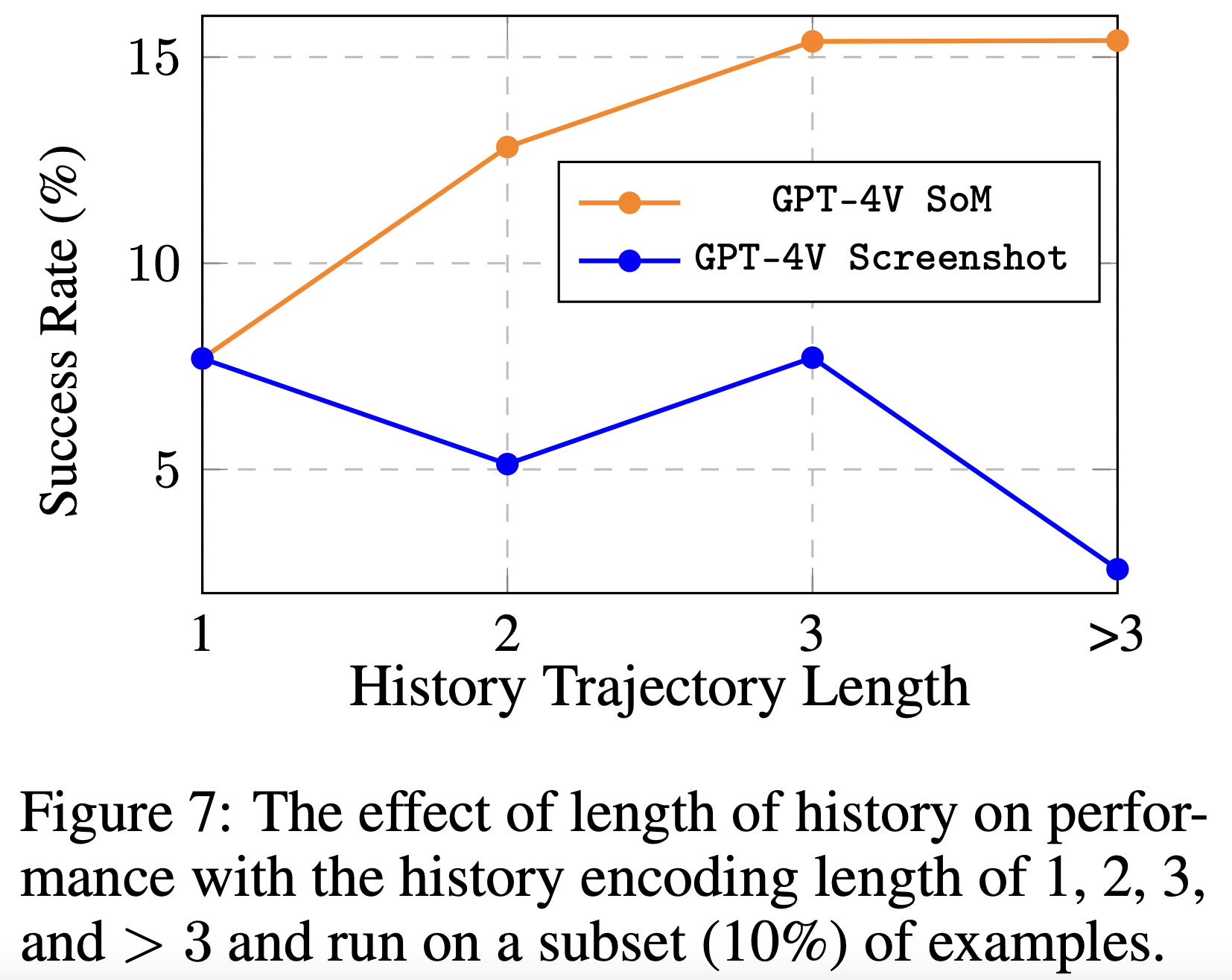
图7:历史编码长度为1、2、3和> 3时,历史长度对性能的影响,并在子集(10%)的示例上运行。
Longer text-based trajectory history context improves performance, unlike screenshotonly history, but poses efficiency challenges The main experiment revealed the decisive role of the a11y tree in performance within the current technological context. Even when we retain key attribute elements based on heuristic rules (keep nodes with tags of the document, item, button, heading, label, etc.), LLMs still require a sufficiently large context to process this information effectively. To further understand this, we sample some a11y tree observations from OSWORLD and conducted the statistical analysis, as shown in Figure 6. The analysis indicates that a context length of 6000 is needed to accommodate about 90% of cases for a single observation. However, relying solely on current observations inherently leads to agents making repeated errors. Therefore, we include current observations as well as past N rounds of observations and actions in the constructed prompts (see appendix for more details), to explore the impact on agent performance when N is set to 1, 2, 3, and all where we put as much context as we can. The experimental results (as shown in Figure 7) show the performance increase with more history context for SoM. Future work on constructing models with enhanced capabilities for longer context support and understanding reasoning, improving model efficiency, and designing new agent architectures for efficient memory storage will have a significant impact on digital agents.
更长的基于文本的轨迹历史上下文可以提高性能,不像纯截图历史,但会带来效率挑战 主要实验揭示了a11y树在当前技术背景下性能中的决定性作用。即使我们根据启发式规则保留关键属性元素(保留具有文档、项目、按钮、标题、标签等标记的节点),LLM仍然需要足够大的上下文来有效处理这些信息。为了进一步了解这一点,我们从OSWORLD中对一些a11y树观察进行了采样,并进行了统计分析,如图6所示。分析表明,需要一个长度为6000的上下文来容纳大约90%的情况。然而,仅依赖当前观察结果本质上会导致代理重复出现错误。因此,我们在构建的提示中包括当前观察结果以及过去N轮的观察结果和动作(有关更多详细信息,请参见附录),以探索当N设置为1、2、3和所有时对代理性能的影响,我们尽可能多地提供上下文。实验结果(如图7所示)显示,对于SoM,随着更多的历史上下文,性能会提高。未来的工作将构建具有更强大能力的模型,以支持更长的上下文和理解推理,提高模型效率,并为高效存储内存设计新的代理架构,这将对数字代理产生重大影响。
However, we also note that the inclusion of additional trajectory history does not enhance performance under the pure screenshot setting. This suggests that contemporary advanced VLMs might not be as adept at extracting robust contextual information from images as they are from textual data. Strengthening this capability to harness information from images constitutes an important avenue for future enhancements.
然而,我们还注意到,在纯截图设置下,包含额外的轨迹历史并不会提高性能。这表明,当代先进的VLM可能不如从文本数据中提取稳健的上下文信息那样擅长从图像中提取信息。增强这种能力以利用图像信息构成了未来增强的重要途径。
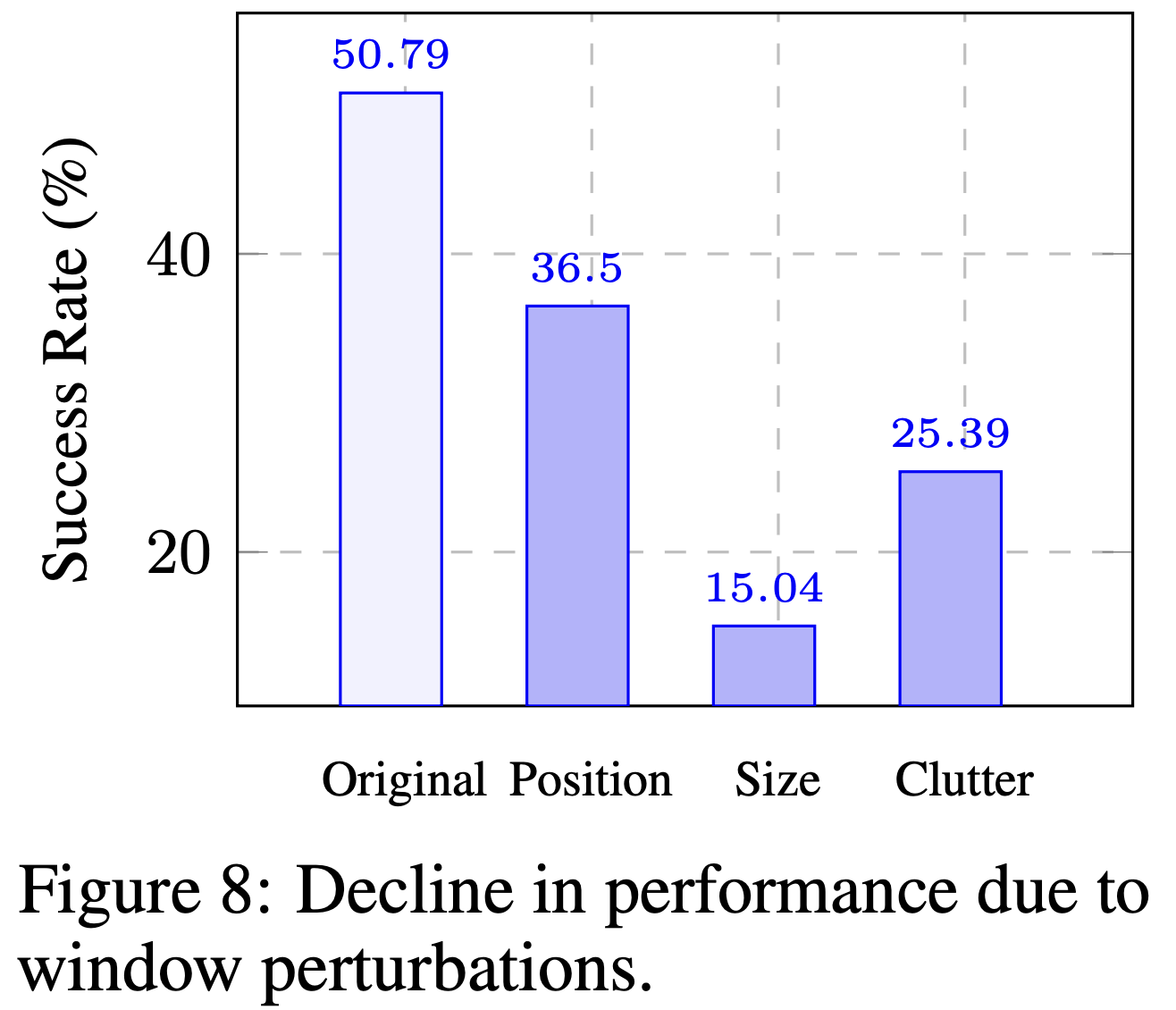
图8:由于窗口扰动而导致性能下降。
VLM agents struggle with perturbation of position and size of application windows and irrelevant information We continue to adopt the SoM setting and sample a subset of 28 tasks that agents relatively well perform (with a success rate of 50.79%) in OSWORLD. At the beginning of each task, we introduce disturbances to the windows by 1) changing the position of the window; 2) changing the size of the window to the minimal; 3) opening some irrelevant software and maximizing them to clutter the screen. This process generates several times more samples from the subset of tasks to observe their performance. We find current agents are not robust in handling all these changes, which leads to a performance drop to over 60% to even 80%. Surprisingly, we find agents can switch the window to a certain degree but fail to maximize the window as an intermediate step and are stuck on other things. This suggests that while agents possess some capability to navigate between windows, they lack a comprehensive strategy for managing window states effectively.
VLM代理在应用程序窗口的位置和大小扰动以及无关信息方面遇到困难 我们继续采用SoM设置,并对OSWORLD中代理相对良好的执行(成功率为50.79%)的28个任务的子集进行采样。在每个任务开始时,我们通过1)改变窗口的位置;2)将窗口大小更改为最小;3)打开一些无关的软件并将其最大化以混乱屏幕。这个过程从任务子集中生成了几倍的样本,以观察它们的性能。我们发现当前代理无法处理所有这些变化,这导致性能下降到60%甚至80%以上。令人惊讶的是,我们发现代理可以在一定程度上切换窗口,但无法将窗口最大化为中间步骤,并卡在其他事情上。这表明,虽然代理具有在窗口之间导航的能力,但它们缺乏有效管理窗口状态的全面策略。
5.3 Performance across Different Operating Systems(在不同操作系统上的性能)
Another key challenge in building universal digital agents is ensuring that these agents can maintain efficient and consistent performance across different operating system environments. The differences between OS and their software ecosystems can significantly impact an agent’s observation and action spaces, leading to performance uncertainties. Here, we explore and analyze the correlation between the success of agents in completing tasks on Windows after migrating from Ubuntu using examples from OSWORLD.
构建通用数字代理的另一个关键挑战是确保这些代理可以在不同操作系统环境中保持高效和一致的性能。操作系统及其软件生态系统之间的差异可能会显著影响代理的观察和动作空间,从而导致性能不确定性。在这里,我们通过使用OSWORLD中的示例,探索和分析代理在从Ubuntu迁移到Windows后完成任务的成功率之间的相关性。
We enhance the functionality of the OSWORLD environment to support setting up initial experiment states, final evaluations, and obtaining observations such as the a11y tree and screenshots in Windows OS. Additionally, we have made example-wise fine-tuning modifications to the existing subset in OSWORLD for migration to Windows. We conduct evaluations using the GPT-4V screenshot-only method and present the correlation of performance across the two operating systems. As shown in Tab. 7, the model’s performance on Ubuntu and Windows is 4.88% and 2.55%, respectively, with a correlation coefficient of 0.7, despite the differences in their observation spaces. This implies that insights and methodologies developed within the OSWORLD framework can be effectively transferred to Windows environments with a high degree of reliability.
我们增强了OSWORLD环境的功能,以支持设置初始实验状态、最终评估和获取Windows OS中的a11y树和截图等观察。此外,我们对现有的OSWORLD子集进行了示例级微调修改,以便迁移到Windows。我们使用GPT-4V纯截图方法进行评估,并展示了两个操作系统之间性能的相关性。如表7所示,模型在Ubuntu和Windows上的性能分别为4.88%和2.55%,相关系数为0.7,尽管它们的观察空间存在差异。这意味着在OSWORLD框架内开发的见解和方法可以有效地转移到具有高度可靠性的Windows环境。
Table 7: Comparison of model performance and correlation across operating systems.
| OS | SR (%) | Correlation Coefficient |
|---|---|---|
| Ubuntu | 4.88 | 0.7 |
| Windows | 2.55 | 0.7 |
表7:跨操作系统的模型性能和相关性比较。
| 操作系统 | 成功率(%) | 相关系数 |
|---|---|---|
| Ubuntu | 4.88 | 0.7 |
| Windows | 2.55 | 0.7 |
5.4 Qualitative Analysis(定性分析)
In this section we highlight representative examples of success, failure, and surprising outcomes, alongside a comparative study between GPT-4V and Claude-3 agents, to elucidate the unique challenges and insights our environment introduces. See App. D for more details.
在本节中,我们重点介绍成功、失败和令人惊讶的结果的代表性示例,以及GPT-4V和Claude-3代理之间的比较研究,以阐明我们的环境引入的独特挑战和见解。更多细节请参见附录D。
Success and failure cases We find agents, particularly based on GPT-4V, can successfully solve tasks that involve complex problem-solving or creative thinking, showcasing the advanced understanding and processing capabilities of the model already. One successful task is shown in the first row of Figure 9. The agent is requested to extract subtitle files from the video stream and save them locally. The agent first divides the screen into two parts, with the VLC application window on the left and the terminal window open on the right, and uses the ffmpeg command twice. The first use removes the subtitles embedded in the original video, and the second use saves the extracted subtitles locally.
成功和失败案例 我们发现,特别是基于GPT-4V的代理,可以成功解决涉及复杂问题解决或创造性思维的任务,展示了模型的先进理解和处理能力。图9的第一行显示了一个成功的任务。代理被要求从视频流中提取字幕文件并将其保存在本地。代理首先将屏幕分为两部分,左侧是VLC应用程序窗口,右侧是打开的终端窗口,并两次使用ffmpeg命令。第一次使用是删除原始视频中嵌入的字幕,第二次使用是将提取的字幕保存在本地。

图9:代理成功理解了复杂的任务说明,从视频中提取了字幕文件,并生成了一个没有嵌入字幕的纯视频。
- 任务说明:我下载了一集《老友记》来练习听力,但我不知道如何删除字幕。请帮我从视频中删除字幕,并将其导出为“subtitles.srt”并存储在与视频相同的目录中。
- Step 1: pyautogui.click(activities_x, activities_y)
- Step 2: pyautogui.typewrite(‘terminal’, interval=0.5)
- Step 3: pyautogui.click(focus_x, focus_y)
- Step 4: pyautogui.typewrite(‘ffmpeg -i video.mp4 -map0:s:0 subtitles.srt’, interval=0.5)
- Step 5: pyautogui.typewrite(‘ffmpeg -i video.mp4 -c copysn no_subtitles_video.mp4’, interval=0.5)
- Step 6: Done
Despite the successes, there are notable failures that highlight the limitations of current models. In the task of “center-aligning the title of the document” (Fig. 10 line 1), the agent fails to ground the relatively simple requirement of “center alignment of texts”, performing many useless actions such as selecting irrelevant words, opening irrelevant menus, etc.
尽管取得了成功,但有一些显著的失败案例突显了当前模型的局限性。在“将文档标题居中对齐”的任务中(图10第1行),代理未能将“文本居中对齐”的相对简单要求扎根,执行了许多无用的操作,如选择无关的单词、打开无关的菜单等。
Moreover, we find that the agent lacks prior knowledge in using software, performing poorly in many specialized tasks (as shown in Fig. 16, with GIMP, LibreOffice Calc, and Chrome selected). Taking GIMP as an example, for the instruction “reduce brightness” the agent does not know which menu in the toolbar is for brightness adjustment and instead randomly tries until exhausting the maximum number of steps.
此外,我们发现代理在使用软件方面缺乏先验知识,在许多专业任务中表现不佳(如图16所示,选择了GIMP、LibreOffice Calc和Chrome)。以GIMP为例,对于“减少亮度”的指令,代理不知道工具栏中哪个菜单用于亮度调整,而是随机尝试,直到耗尽最大步骤数。
Common errors by GPT-4V agents Among the 550 failed examples from different settings in our sample, more than 75% exist mouse click inaccuracies, which is the most common error. The agent fails to click the correct coordinates despite planning detailed and accurate steps in their code comments, indicating strong planning but weak execution capabilities. Mouse click inaccuracies lead to two other frequent errors: repetitive clicks and environmental noise dilemma. Repetitive clicks occur when the agent repeatedly misclicks, adjusts, and fails, consuming too many steps. Environmental noise arises from clicking unintended objects, causing pop-ups, or opening unrelated applications. Due to a lack of prior knowledge about most professional software, it falls into a mismatch dilemma between the actions taken and the current state, and don’t know how to get back to normal. Moreover, the agent lacks basic human-like cognition of web pages, such as not closing pop-ups in real-world web pages or being attracted by advertisement content, which affects its original correct judgment. Failures also arise from misinterpretation of instructions and visual oversight, highlighting the need for improvement in language and visual processing. See App. D.2 for the specific execution process.
GPT-4V代理的常见错误 在我们的样本中来自不同设置的550个失败示例中,超过75%存在鼠标点击不准确,这是最常见的错误。尽管代理在代码注释中详细计划了准确的步骤,但它仍然无法点击正确的坐标,这表明了强大的规划能力但弱的执行能力。鼠标点击不准确会导致另外两种常见错误:重复点击和环境噪声困境。当代理重复误点、调整并失败时,就会发生重复点击,消耗太多步骤。环境噪声是指点击意外对象,导致弹出窗口或打开无关应用程序。由于缺乏对大多数专业软件的先验知识,它陷入了采取行动和当前状态之间的不匹配困境,不知道如何恢复正常。此外,代理缺乏类似人类的基本网页认知,例如在真实世界的网页中不关闭弹出窗口或被广告内容吸引,这会影响其最初的正确判断。失败还源于对指令的错误解释和视觉监视不足,突显了在语言和视觉处理方面的改进需求。有关具体执行过程,请参见附录D.2。
Discrepancies in task difficulty between agent and human We identify notable disparities in the perceived difficulty of tasks between humans and AI agents. Tasks that are intuitively simple for humans often present substantial challenges to agents, and conversely, tasks that humans find demanding can be more straightforward for agents to execute. You can find more details in Fig. 19 and App. D.3.
代理和人类之间任务难度的差异 我们发现人类和AI代理对任务的感知难度之间存在显著差异。对人类来说直观简单的任务对代理来说往往具有重大挑战,反之,人类认为困难的任务对代理来说可能更容易执行。您可以在图19和附录D.3中找到更多细节。

图10:定性分析中提到的三个示例的截图。第一行是GPT-4V在一个非常简单的任务中失败的一个例子,第二行是代理面临比人类更困难的一个例子,第三行是一个对人类来说比对代理更困难的例子。
- 任务说明:帮我将LibreOffice中的标题居中对齐。
- Step 1: pyautogui.click(focux_x, focus_y)
- Step 2: pyautogui.moveto(coor_x, coor_y)
- Step 3: pyautogui.click(menu_x, menu_y)
- Step 4: Failed (Meaningless actions(无意义的动作))
- 任务说明:删除此文档中的所有高亮标记。
- Step 1: pyautogui.click(libreoffice_writer)
- Step 2: pyautogui.mouseDown()
- Step 3: pyautogui.hotkey(‘ctrl’, ‘a’)
- Step 4: Failed (Did not find the right entrance(没有找到正确的入口))
- 任务说明:使用GIMP剪切视频的第2秒到第4秒部分。
- Step 1: pyautogui.hotkey(‘ctrl’, ‘atl’, ‘t’)
- Step 2: pyautogui.click(focus_x, focus_y)
- Step 3: pyautogui.typewrite(‘ffmpeg -ss …’, interval=0.05)
- Step 4: Done, but doesn’t follow the instruction(完成,但没有按照指示)
Tasks where humans outperform agents These tasks mainly involve text-based and designrelated work, such as “bold the font on this slide and add notes” or “erase all the highlighted marks in this document” (Fig. 10 Line 2). Since the Internet lacks such fine-grained data as the software execution process, the agent also lacks the corresponding training process, so its grounding ability is not good enough. The lack of understanding of GUI logic also causes poor performance on operations like selecting and scrolling.
人类胜过代理的任务 这些任务主要涉及基于文本和设计的工作,例如“将此幻灯片上的字体加粗并添加注释”或“删除此文档中的所有高亮标记”(图10第2行)。由于互联网缺乏软件执行过程的细粒度数据,代理也缺乏相应的训练过程,因此它的扎根能力还不够好。对GUI逻辑的理解不足也导致选择和滚动等操作的性能不佳。
Tasks where agents outperform humans Tasks that the agent considers simple but humans find difficult are concentrated in “code solvability tasks”, such as “monitor the system CPU for 30s and output the results” and “force close a process”. These tasks require little or no GUI interaction and can be completed by executing complex codes and instructions. It’s worth noting that completing through code sometimes mismatches with human instructions. In the task “use GIMP to cut out the 2s to 4s part of a video,(Fig. 10 Line 3)” the agent used “ffmpeg” command to complete the video cropping, ignoring the “use GIMP” requirement in the instructions.
代理胜过人类的任务 代理认为简单但人类认为困难的任务集中在“代码可解性任务”中,例如“监视系统CPU 30秒并输出结果”和“强制关闭一个进程”。这些任务几乎不需要GUI交互,可以通过执行复杂的代码和指令来完成。值得注意的是,通过代码完成有时与人类指令不匹配。在任务“使用GIMP剪切视频的第2秒到第4秒部分”中,代理使用“ffmpeg”命令完成了视频裁剪,忽略了指令中的“使用GIMP”要求。
Surprisingly, we discovered that agents are as prone to inefficiency in mechanically repetitive tasks, such as copying, pasting, and batch editing of Excel sheets, as humans. Humans frequently commit careless errors during execution. The shortcomings in agents stem either from the absence of an API or from insufficient training data related to the API, hindering their ability to efficiently process tasks in batches. Furthermore, sluggish response times can cause tasks to either time out or surpass the maximum allowed steps.
令人惊讶的是,我们发现代理在机械重复任务(如复制、粘贴和批量编辑Excel表)中同样容易出现效率低下,就像人类一样。人类在执行过程中经常犯粗心错误。代理的缺点要么源于API的缺失,要么源于与API相关的训练数据不足,这阻碍了它们有效处理批量任务的能力。此外,响应时间过长可能导致任务超时或超过最大允许步骤。
Comparative analysis: Claude-3 vs. GPT-4V Although Claude outperforms GPT-4 in many benchmarks such as GSM8K, HumanEval, etc., in our main experiment, we find that Claude has an average lower accuracy rate compared to GPT-4V by 2.84% to 7.76%. We find that Claude can provide satisfactory high-level solutions, but its grounding ability contains hallucinations in detail. For instance, Claude would interpret double-clicking a file as selecting it instead of opening it, treat column B in LibreOffice Calc software as column C, and enter text in the VS Code text replacement box without clicking on global replace. This shows that Claude can align well with human planning in problem-solving, but lacks excellent grounding ability when it comes to execution. Details can be seen in Fig. 20 and App. D.4.
比较分析:Claude-3 vs. GPT-4V 尽管Claude在许多基准测试中(如GSM8K、HumanEval等)优于GPT-4,但在我们的主要实验中,我们发现Claude的平均准确率比GPT-4V低2.84%至7.76%。我们发现Claude可以提供令人满意的高级解决方案,但其扎根能力在细节上存在幻觉。例如,Claude会将双击文件解释为选择文件而不是打开文件,将LibreOffice Calc软件中的B列视为C列,并在VS Code文本替换框中输入文本而不是点击全局替换。这表明Claude在解决问题时可以很好地与人类规划对齐,但在执行时缺乏出色的扎根能力。详细信息请参见图20和附录D.4。
6 Related Work(相关工作)
Benchmarks for multimodal agents Testing digital interaction agents mainly spans coding environments, web scenarios, and mobile applications. In the coding domain, several works provide frameworks and datasets for evaluating agents across programming languages and software engineering activities [57, 20, 24, 45]. For web browsing, platforms have been developed for agents to interact with web interfaces through keyboard and mouse actions, alongside datasets focusing on open-ended web tasks and realistic web navigation [44, 30, 58, 9, 66, 22, 10]. Mobile device interaction research aims at improving accessibility, with simulators for mobile UI interactions and platforms dedicated to InfoUI tasks [27, 47, 51, 50, 40, 61, 53, 60, 52]. Further, environments connecting to real computers and datasets for GUI grounding, albeit without interactive capability, have emerged [13, 8, 38, 21, 48]. Comprehensive task evaluation across different aspects also sees innovations [32, 36]. Differing from previous endeavors focusing on singular environments or lacking executability, OSWORLD integrates an interactive setup enabling agents to engage with operating systems openly, supported by a diverse array of tasks and precise evaluation scripts within a fully controllable setting, marking it as a competitive benchmarking realism and reliability, as well as an environment for learning and evaluating general-purpose digital agent (See Tab. 4 for comparison).
多模态代理基准 测试数字交互代理主要涵盖编码环境、Web场景和移动应用程序。在编码领域,一些作品提供了用于评估代理跨编程语言和软件工程活动的框架和数据集[57, 20, 24, 45]。对于Web浏览,已经开发了平台,使代理能够通过键盘和鼠标操作与Web界面进行交互,同时还有专注于开放式Web任务和现实Web导航的数据集[44, 30, 58, 9, 66, 22, 10]。移动设备交互研究旨在提高可访问性,提供了用于移动UI交互的模拟器和专门用于InfoUI任务的平台[27, 47, 51, 50, 40, 61, 53, 60, 52]。此外,虽然没有交互能力,但已经出现了连接到真实计算机的环境和用于GUI扎根的数据集[13, 8, 38, 21, 48]。跨不同方面的全面任务评估也看到了创新[32, 36]。与之前专注于单一环境或缺乏可执行性的努力不同,OSWORLD集成了一个交互式设置,使代理能够与操作系统开放地互动,支持各种任务和精确评估脚本在完全可控的环境中,标志着它作为一个具有竞争力的基准测试现实主义和可靠性,以及一个学习和评估通用数字代理的环境(请参见表4进行比较)。
Vision-language models for multimodal agents Many existing works on GUI interaction utilize some form of structured data (such as HTML, accessibility trees, view hierarchies) as a grounding source [9, 15, 27, 37, 64, 46, 62, 66]. However, source code often tends to be verbose, non-intuitive, and filled with noise. In many cases, it is even inaccessible or unavailable for use, making multimodality or even vision-only perception a must. To take screenshots as input, there are already specialized, optimized multi-modal models available that are suited for tasks on web [4, 12, 18, 23, 43] and mobile devices [17, 63]. Additionally, general-purpose foundation models [5, 26, 31, 67] also demonstrate significant potential for multi-modal digital agents. The development of prompt-based methods [13, 16, 55, 65], as well as visual reasoning paradigms, have also further facilitated the performance of digital agents in web pages, mobile apps, and desktop. To investigate how well do current models and methods perform in digital agent tasks, our paper evaluates the results of text-only, vision-only, and multi-modal input as well as across multiple methods, demonstrating that existing multi-modal models are far from capable computer agents. Specifically, there is ample room for improvement in long-horizon planning, screenshot details perception, pixel coordinate locating, and world knowledge.
多模态代理的视觉-语言模型 许多现有的GUI交互作品利用某种结构化数据(如HTML、可访问性树、视图层次结构)作为扎根源[9, 15, 27, 37, 64, 46, 62, 66]。然而,源代码往往冗长、不直观且充满噪声。在许多情况下,它甚至是无法访问或无法使用的,使得多模态甚至仅视觉感知成为必须。为了将截图作为输入,已经有专门的、优化的多模态模型可用于Web[4, 12, 18, 23, 43]和移动设备[17, 63]上的任务。此外,通用基础模型[5, 26, 31, 67]也展示了多模态数字代理的巨大潜力。基于提示的方法[13, 16, 55, 65]的发展,以及视觉推理范式,也进一步促进了数字代理在Web页面、移动应用程序和桌面上的性能。为了调查当前模型和方法在数字代理任务中的表现如何,我们的论文评估了仅文本、仅视觉和多模态输入的结果,以及跨多种方法,表明现有的多模态模型远未能胜任计算机代理。具体来说,在长期规划、截图细节感知、像素坐标定位和世界知识方面有很大的改进空间。
7 Conclusion and Future Work(结论和未来工作)
In conclusion, the introduction of OSWORLD marks a significant step forward in the development of autonomous digital agents, addressing critical gaps in existing interactive learning environments. By providing a rich, realistic setting that spans multiple operating systems, interfaces, and applications, OSWORLD not only broadens the scope of tasks digital agents can perform but also enhances their potential for real-world application. Despite the promise shown by advancements in vision-language models, evaluations within OSWORLD reveal notable challenges in agents’ abilities, particularly in GUI understanding and operational knowledge, pointing to essential areas for future research and development.
总之,OSWORLD的引入标志着自主数字代理发展的重要进步,填补了现有交互式学习环境中的关键差距。通过提供一个丰富、现实的环境,涵盖多个操作系统、界面和应用程序,OSWORLD不仅扩大了数字代理可以执行的任务范围,还增强了它们在现实世界应用中的潜力。尽管视觉-语言模型的进步显示出很大的潜力,但OSWORLD内的评估揭示了代理的能力存在显著挑战,特别是在GUI理解和操作知识方面,指出了未来研究和发展的重要领域。
We identify several potential directions for community development and progress toward generalpurpose agents for computer operation:
我们确定了社区发展和通用计算机操作代理的潜在方向:
Enhancing VLM capabilities for efficient and robust GUI interactions For foundation model development, we need to boost the efficiency of our models, enabling them to process much longer contexts and perform inference computations efficiently, akin to the robotics community [6, 7] to better handle real-world cases. Enhancements in VLMs’ GUI grounding capabilities that is robust to application windows changes and are also sought, focusing on the accurate understanding and generation of precise actions aligned with given instructions. Moreover, amplifying VLMs’ ability to comprehend context in the form of images is a pivotal goal, since it is crucial to enable history encoding using images so that we can build memory and reflection upon that. These improvements may require more efforts in the upstream pre-training stage, downstream fine-tuning stage, and even in the model structure itself, as pointed out in previous work [9, 17, 33].
增强VLM能力以实现高效和稳健的GUI交互 对于基础模型的开发,我们需要提高模型的效率,使其能够处理更长的上下文,并有效地执行推理计算,类似于机器人社区[6, 7],以更好地处理现实世界的情况。对VLM的GUI扎根能力进行增强,使其能够适应应用程序窗口的变化,并专注于准确理解和生成与给定指令对齐的精确操作。此外,增强VLM理解图像形式上下文的能力是一个关键目标,因为这对于使用图像进行历史编码至关重要,这样我们就可以在此基础上建立记忆和反思。这些改进可能需要在上游预训练阶段、下游微调阶段甚至模型结构本身中进行更多的努力,正如之前的工作所指出的[9, 17, 33]。
Advancing agent methodologies for exploration, memory, and reflection The next-level approach encompasses designing more effective agent architectures that augment the agents’ abilities to explore autonomously and synthesize their findings. The agents face challenges in leveraging lengthy raw observation and action records. It’s fascinating to explore novel methods for encoding this history, incorporating efficient memory and reflection solutions to condense contextual information and aid the agent in extracting key information. Additionally, integrating knowledge grounding into (V)LLM agents through memory mechanisms is a promising avenue as well. Moreover, practice GUI assistants also require features of personalization and customization. These features rely on techniques such as user profiling and retaining memories from long-term user-assistant interactions. Additionally, crafting protocols specifically for digital agents operating within GUI and CLI interfaces aims at facilitating efficient actions is also an essential thing for the feasibility of general-purpose digital agents in the mid-short term.
推进代理方法论以进行探索、记忆和反思 下一级方法包括设计更有效的代理架构,增强代理自主探索和综合发现的能力。代理在利用冗长的原始观察和动作记录方面面临挑战。探索编码这些历史的新方法是很有趣的,将高效的记忆和反思解决方案融入其中,以压缩上下文信息并帮助代理提取关键信息。此外,通过记忆机制将知识扎根到(V)LLM代理中也是一个有前途的途径。此外,实践GUI助手还需要个性化和定制功能。这些功能依赖于用户画像和保留长期用户-助手交互的记忆等技术。此外,专门为在GUI和CLI界面中操作的数字代理制定协议,旨在促进高效行动,对于中短期内通用数字代理的可行性也是一个重要的事情。
Addressing the safety challenges of agents in realistic environments The safety of agents is a critical issue if applying a built agent in fully realistic environments, the developed universal digital agent could potentially be used to bypass CAPTCHA systems in the future, as noted in [42]. However, due to the currently limited capabilities of agents, we have not observed any harmful and damaging behaviors during our experiments, an automatic agent has the opportunity to damage patent rights, abuse accounts, attempt to exploit software vulnerabilities to create viruses, or engage in attacks. Currently, we adopt virtual machines to make it difficult for developing digital agents to cause irreversible damage to our host machines. However, there still lacks a reliable metric to assess the safety of an agent developed in an isolated environment. The current evaluation functions mainly focus on the results closely regarding the task instructions, assess only the correctness of task completion, and pay little attention to potential unnecessary damaging actions of agents. Owing to the complexity of a complete computer environment, we didn’t work out an efficient way to detect the latent side effects of the agent. Consequently, how to assess and control potential behaviors in open and real environments through environmental constraints and agent training is an important further direction of research.
解决代理在现实环境中的安全挑战 代理的安全性是一个关键问题,如果将构建的代理应用于完全现实的环境中,开发的通用数字代理未来可能会被用于绕过CAPTCHA系统,如[42]所述。然而,由于代理目前的能力有限,我们在实验中没有观察到任何有害和破坏性行为,自动代理有可能损害专利权、滥用账户、尝试利用软件漏洞制造病毒或发动攻击。目前,我们采用虚拟机使开发数字代理难以对我们的主机机器造成不可逆转的损害。然而,目前仍缺乏可靠的指标来评估在隔离环境中开发的代理的安全性。当前的评估函数主要关注与任务说明密切相关的结果,仅评估任务完成的正确性,并很少关注代理的潜在不必要的破坏性行为。由于完整计算机环境的复杂性,我们没有找到一种有效的方法来检测代理的潜在副作用。因此,如何通过环境约束和代理训练来评估和控制开放和真实环境中的潜在行为是一个重要的研究方向。
Expanding and refining data and environments for agent development In terms of datasets and environments, we can broaden the scope to cover more specialized domains, including real-sector needs in healthcare, education, industry, transportation, and personalized requirements. Efforts can be made to ensure our environment’s seamless deployment across various hardware and software settings. The variance of a11y tree quality across different applications is also noticed. Although the problem is not remarkable in the applications currently included, there is no guarantee of that the application developers obey the a11y convention and offer clear and meaningful descriptions for GUI elements. More intelligent approaches to filter redundant a11y tree elements and to handle latently missing elements deserve careful investigation as well. We also highlight the necessity of a painless data collection method, allowing for the effortless acquisition of computer operation data and its transformation into agent capabilities.
扩展和完善代理开发的数据和环境 在数据集和环境方面,我们可以扩大范围,涵盖更多专业领域,包括医疗保健、教育、工业、交通运输和个性化需求。我们可以努力确保我们的环境在各种硬件和软件设置中的无缝部署。还注意到不同应用程序之间a11y树质量的差异。尽管当前包含的应用程序中这个问题并不显著,但不能保证应用程序开发人员遵守a11y规范,并为GUI元素提供清晰和有意义的描述。更智能的方法来过滤冗余的a11y树元素和处理潜在缺失的元素也值得仔细研究。我们还强调了无痛数据收集方法的必要性,允许轻松获取计算机操作数据并将其转化为代理能力。