直接和它对话——智能体工程的实用指南
Peter Steinberger (OpenClaw 的创造者) 分享了核心主张 “拒绝套路,直接对话”。他认为当前的 AI 智能体(尤其是 GPT-5-Codex)已足够强大,无需过度依赖 RAG、复杂的子智能体或繁琐的规格文档等“炒作”手段。
最近我在这里变得安静了许多,因为我正埋头于最新的项目。Agent 智能体工程(Agentic engineering)已经变得如此强大,以至于现在它几乎包揽了我 100% 的代码编写。然而,我看到仍有许多人在解决问题时,还在搞那些华而不实的复杂套路,而不是专注于把活干完(Getting sh*t done)。
这篇文章的灵感部分来自昨晚在伦敦参加的 Claude Code Anonymous 交流会,部分原因是从我上次更新工作流以来已经过了“AI 领域的一年”(实际才几个月,但变化巨大)。是时候同步一下进度了。
所有的基本理念仍然适用,所以我不会再提上下文管理等简单的事情。你可以阅读我的 《AI 开发最佳工作流》 作为入门。
背景与技术栈
我独立工作,当前项目是一个约 30 万行代码(LOC)的 TypeScript React 应用,包含 Chrome 扩展、CLI、基于 Tauri 的客户端以及基于 Expo 的移动端。我使用 Vercel 托管,一个 PR(拉取请求)大约在 2 分钟内就能交付新版本网页进行测试。其他部分(App 等)尚未自动化。
装备与通用方法
我已经完全转向使用 codex 命令行界面(CLI)作为日常主力。我会同时开启 3 到 8 个并行的终端窗口(采用 3x3 布局),其中大多数运行在 同一个文件夹 下,一些实验性的改动则放在单独的文件夹里。我尝试过 worktrees 和 PR,但最终还是回到了这套方案,因为它干活最快。
我的 Agent 会自己进行 Git 原子提交。为了保持 commit 历史整洁,我多次迭代了我的 Agent 配置文件。这让 Git 操作更精准,每个 Agent 只会提交它修改过的文件。
没错,用 Claude 你可以设置 hooks,而 Codex 目前还不支持,但模型非常聪明,如果它们铁了心要干某事,任何 hook 都拦不住。
过去我曾被人嘲笑是 垃圾代码生成器(slop-generator),很高兴看到现在并行运行多个 Agent 正逐渐成为主流。
模型选择
我几乎所有的东西都用 gpt-5-codex 中等配置来构建。它是智能与速度的完美平衡,且能自动调节思考深度(Thinking)。我发现过度纠结这些设置并不会带来显著提升,而且不用去考虑所谓的“极度思考(ultrathink)”也很省心。
爆炸半径 (Blast Radius) 💥
每当我开始干活,我都会考虑“爆炸半径”。这不是我发明的词,但我非常喜欢。每当我构思一个改动,我能直觉地预判它需要多久、会触动多少文件。我可以向代码库扔一堆小炸弹,或者扔一个“大伊万”加几个小炸弹。如果你一次扔多个大型炸弹,就不可能做到隔离提交,一旦出错,回滚也会难得多。
这也是我观察 Agent 时的重要指标。如果某个任务花费的时间超过了我的预期,我就按 Esc 键并问一句“现在进度如何”,获取状态更新,然后要么引导模型找对方向,要么中止,要么继续。不要害怕中途停止模型,文件更改是原子性的,它们非常擅长从断点处重新开始。
当我拿不准影响范围时,我会说“在修改前给我几个方案”,以此来评估风险。
为什么不用 worktrees?
我只运行一个开发服务器。在推进项目时,我会点击测试并同时测试多个更改。如果每个更改都对应一个 worktree/分支,速度会明显变慢,启动多个开发服务器很快就会让人烦躁。此外,我的 Twitter OAuth 回调域名限制也让我无法注册太多的测试域名。
Claude Code 怎么样?
我曾经很喜欢 Claude Code,但现在我已经受不了它了(即便 Codex 是它的粉丝)。它的语气、那些“绝对没问题”的废话、以及测试还没过就宣称“100% 生产就绪”的姿态——我真的够了。Codex 更像是一个性格内向的工程师,默默无闻地把事办好。它在动工前会读取更多的文件,所以即使是简单的提示词通常也能精准实现我的需求。
Codex 的其他优势
- 约 23 万可用上下文 vs Claude 的 15.6 万。 没错,如果你运气好或者付得起 API 费用,Sonnet 有 100 万上下文,但现实中,Claude 在用完这些上下文之前早就变得逻辑混乱了,所以并没多大实用价值。
- 更高效的 Token 利用。 我不知道 OpenAI 做了什么优化,但我的上下文填充速度比 Claude Code 慢得多。用 Claude 时经常看到“正在压缩(Compacting…)”,但在 Codex 中我很少能用爆上下文。
- 消息队列。 Codex 支持 消息排队。Claude 曾有这个功能,但几个月前改掉了,现在你的消息会“干扰”模型。如果我想引导 Codex,只需按 Esc 再输入新消息。拥有两种选择显然更好。我经常排队一系列相关的需求任务,它会非常可靠地逐一完成。
- 速度。 OpenAI 用 Rust 重写了 Codex,效果立竿见影。它快得惊人。用 Claude Code 时,我经常遇到数秒的卡顿,进程占用到几个 GB 的内存。还有终端闪烁问题,特别是在用 Ghostty 时。Codex 没这些毛病,感觉非常轻巧、快速。
- 语气语言。 这对我的心理健康真的很重要。 我对 Claude 吼过无数次,但我很少对 Codex 发火。即使 Codex 模型稍弱,单凭这一点我也会选它。你两个都用上几周就能理解我的意思。
- 不会到处乱丢 Markdown 文件。懂的都懂。
为什么不选 $harness(第三方 Agent 工具)
在我看来,最终用户和模型公司之间并没有太大的中间生存空间。通过订阅(Subscription)能得到目前最划算的方案。我目前有 4 个 OpenAI 订阅和 1 个 Anthropic 订阅,每月成本约 1000 美元,换来的是几乎无限的 Token。如果用 API 调用,成本可能是现在的 10 倍。别纠结具体数学,我用过一些 Token 统计工具,虽然不算精确,但即使只是 5 倍,订阅制也是超值的。
我很高兴看到像 amp 或 Factory 这样的工具出现,但我不认为它们能长期存活。Codex 和 Claude Code 的每一次发布都在变强,它们的功能集都在趋同。有些工具可能暂时在 Todo 列表或 DX(开发者体验)上领先,但我认为它们无法在核心竞争力上胜过 AI 巨头。
amp 已经不再把 GPT-5 作为主力,而是称其为 “神谕 (Oracle)”。而我直接用 Codex,相当于时刻在和那个更聪明的模型(神谕)共事。 没错,虽然有跑分测试,但鉴于数据偏差,我不信那一套。Codex 给我的结果远好于 amp。不过要给他们的会话共享点个赞,他们确实推进了一些有趣的理念。
至于 Factory,我不确定。他们的视频有点尬,虽然我时间线上有人夸它,但目前还不支持图片,且有 标志性的闪烁问题。
Cursor……如果你还要自己写代码,它的 Tab 补全模型是行业领先的。我主要用 VS Code,但我很喜欢他们推动的浏览器自动化和计划模式(Plan mode)。我试过 GPT-5-Pro,但 Cursor 仍然存在那些从 5 月份就开始困扰我的 bug。听说他们正在修,所以它还在我的 dock 栏里。
其他的像 Auggie 只是昙花一现,很快就没人提了。归根结底,它们都只是 GPT-5 或 Sonnet 的套壳,是可替代的。RAG 以前对 Sonnet 还有点用,但 GPT-5 的搜索能力太强了,你根本不需要为代码搞一个单独的向量索引。
目前最有潜力的候选者是 opencode 和 crush,尤其是结合开源模型时。你完全可以通过 一些巧妙的 hack 在这些工具里使用你的 OpenAI/Anthropic 订阅,但这是否合规存疑,而且为什么要用一个针对性优化较弱的工具去运行 Codex 或 Claude Code 呢?
开源模型 ($openmodel) 怎么样?
我一直关注着中国的开源模型,它们追赶的速度令人印象深刻。GLM 4.6 和 Kimi K2.1 都是强有力的竞争者,正逐渐达到 Sonnet 3.7 的水平,但我目前还不建议将其作为 生产力主力。
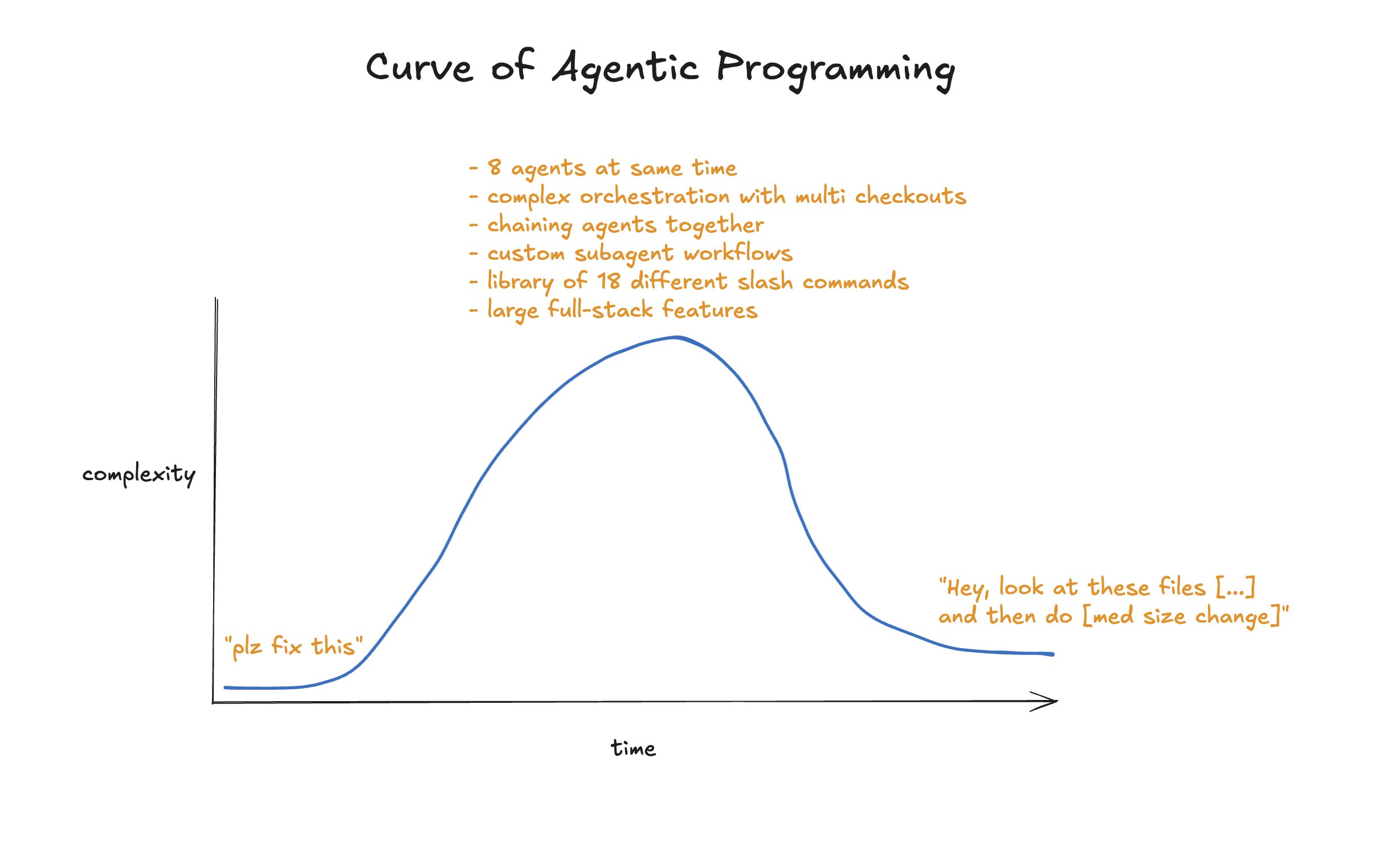
跑分只体现了一半的情况。在我看来,Agent 智能体工程在 5 月份 Sonnet 4.0 发布时实现了从“没法用”到“能用”的转变,而 gpt-5-codex 则完成了从“能用”到“惊艳”的飞跃。
计划模式与方法论
跑分测试忽略了一点:模型+工具在接到提示词后的“执行策略”。Codex 明显更谨慎,它在决定怎么做之前会读取库里更多的文件。当你提出愚蠢的请求时,它的回绝也更强硬。相比之下,Claude 或其他 Agent 表现得过于积极,总是急于尝试 某些 方案。虽然可以通过“计划模式”和严格的结构文档来缓解,但对我来说,这感觉像是在为一个有缺陷的系统打补丁。
我现在很少在 Codex 里用大型计划文件。Codex 甚至没有专门的计划模式——但它对提示词的遵循能力极强,我只需写“先讨论一下”或“给我方案”,它就会乖乖等着我确认。不需要那些复杂的工具花招。直接跟它说就行。
但是 Claude Code 现在有 插件 (Plugins) 了!
听到远处的叹息声了吗?那是我发出的。真是槽点满满。这让我对 Anthropic 的专注点感到失望。他们在试图掩盖模型效率低下的事实。没错,维护特定任务的文档是个好主意,我自己也会在 docs 文件夹里存一堆 Markdown。
但是……子智能体(Subagents)!!!1!
关于“子智能体”这一套,我得说两句。5 月份的时候这叫“子任务(Subtasks)”,主要是为了在模型不需要全文信息时,把任务分拆到独立上下文中——本质上是并行化或减少上下文浪费(例如应对嘈杂的构建脚本)。后来他们改进并重新包装成了“子智能体”。
使用场景其实没变。别人用子智能体做的事,我通常通过多窗口解决。如果我想调研某事,我会在单独的终端窗口里做,然后把结果粘回来。这让我对上下文工程拥有完全的控制力和透明度,而不像子智能体那样难以查看、引导或控制回传内容。
还有 Anthropic 官推的子智能体。看看这个 “AI 工程师”智能体。它简直是一堆废话的集合,里面居然还在提 GPT-4o 和 o1 的集成,整体看起来就像一锅自动生成的词语浓汤。里面没有任何实质内容能让你的 Agent 变成更好的“AI 工程师”。
那到底意味着什么?如果你想获得更好的输出,告诉模型“你是一个擅长生产级 LLM 应用的 AI 工程师”并不会起作用。给它文档、示例、规范(Do/Don’t)才有用。我敢打赌,如果你让 Agent “去 Google 搜索构建 AI Agent 的最佳实践”并加载几个网页,效果绝对比这堆废话好。你甚至可以说这种废话是 上下文毒药。
我如何写提示词
以前用 Claude 时,我会写(其实是口述)非常详尽的提示词,因为那个模型提供的上下文越多,它才越能“懂我”。虽然这对任何模型都适用,但我发现换成 Codex 后,我的提示词变短了很多。通常只需 1-2 句话 + 一张图片。这个模型阅读代码库的能力极强,一说就通。我甚至有时会恢复打字,因为 Codex 理解我所需的字数变少了。
添加图片是提供上下文的神技。模型非常擅长精准定位你展示的内容,它能识别字符串并匹配,直接跳转到你提到的位置。我至少 50% 的提示词里都带截图。我很少在图上做标注,标注效果固然更好但太慢。把截图拖进终端只需 2 秒。
带有语义纠错功能的 Wispr Flow 依然是语音输入的王者。👍
Web 端智能体
最近我又尝试了 Web 端 Agent:Devin、Cursor 和 Codex。Google 的 Jules 看起来不错但配置起来烦死人,Gemini 2.5 已经不再是个好模型了。等 Gemini 3 Pro 出来可能会有转机。唯一留下来的是 Codex Web。虽然它配置也挺麻烦且有 bug(终端目前 加载不正常),但我用旧版环境搞定了。
我把 Codex Web 当作我的短期问题追踪器(Issue tracker)。当我在外面有了灵感,我就用 iOS App 发一条指令,回头在 Mac 上审阅。虽然我完全可以用手机审阅/合并代码,但我选择不这么做。我的工作已经够让人上瘾了,我不想在陪朋友或外出时还陷进去。嘿,我可是 花了两个月做了一个方便在手机上写代码工具 的人,但我现在依然克制。
Codex Web 甚至曾经不计入使用限额,但 那段好日子看来要结束了。
Agent 之旅
聊聊工具。Conductor、Terragon、Sculptor 以及其他成千上万个工具。有些是业余爱好项目,有些快被 VC 的钱淹死了。我试过很多,没一个能留下。我认为它们都在试图绕过当前模型的不完善,并推行一种并不理想的工作流。而且,大多数工具都隐藏了终端,不让你看模型展示的所有信息。
大多数工具都只是 Anthropic SDK + 工作树管理的薄封装,没有护城河。而且我怀疑你是否真的需要更方便地在手机上用编程 Agent。它们能做的极少数场景,Codex Web 都能覆盖。
不过我确实观察到一个模式:几乎每个工程师都会经历一个“亲手造工具”的阶段,主要是因为这很好玩,而且现在造起来太容易了。除了造那些(我们认为)能让造其他工具更简单的工具,还能造啥呢?
但 Claude Code 能处理后台任务!
确实。Codex 目前缺乏一些 Claude 拥有的花里胡哨的功能。最痛苦的缺失是后台任务管理。虽然理论上它有超时机制,但我确实见过它在一些不会自动结束的任务上卡死(比如启动开发服务器或陷入死锁的测试)。
这是我曾经退回到 Claude 的原因之一,但既然那个模型在其他方面太笨了,我现在改用 tmux 了。这是一个在持久会话中运行 CLI 的老工具,模型对它了如指掌,所以你只需要说“通过 tmux 运行”。不需要任何自定义 Agent 的 Markdown 戏法。
MCP(模型上下文协议)怎么样?
关于 MCP 别人已经写得够多了。在我看来,大多数 MCP 只是给市场部刷存在感、打勾显摆用的。几乎所有的 MCP 本质上都应该是 CLI。我作为一个 亲手写过 5 个 MCP 的人这么说是有分量的。
我可以直接按名称调用 CLI。我不需要在 Agent 文件里做任何解释。Agent 会在第一次调用时尝试运行,CLI 会弹出帮助菜单,上下文随后就包含了完整的使用说明,从此我们就步入正轨。我不需要为这些工具付出“Token 税”,而 MCP 是持续的上下文消耗。看看 GitHub 的 MCP,23k Token 瞬间消失。刚发布时甚至要消耗 50k Token。而使用 gh CLI 具有几乎相同的功能集,模型已经知道怎么用它,且 Token 消耗为零。
我开源了一些我的 CLI 工具,比如 bslog 和 inngest。
我最近确实在用 chrome-devtools-mcp 来 闭环调试。它取代了 Playwright 成为我 Web 调试的首选 MCP。我用它的次数不多,但确实好用。我的网站设计得可以通过 API key 让模型通过 curl 调用任何端点,这在大多数情况下更快、更节省 Token,所以连这个 MCP 我也不是每天都用。
但是生成的代码是垃圾(Slop)!
我大约花 20% 的时间 进行重构。当然,这些活全是 Agent 干的,我不会亲自浪费时间。重构日通常是我精力不集中或疲惫的时候,因为我不需要深度思考也能取得巨大进展。
典型的重构工作包括:使用 jscpd 查重、使用 knip 清理死代码、运行 ESLint 的 React Compiler 和弃用插件、检查是否有可以合并的 API 路由、维护文档、拆分过大的文件、为棘手部分添加测试和注释、更新依赖、升级工具、重组文件结构、重写运行缓慢的测试、引入现代 React 模式(比如 [你可能不需要 useEffect](https://www.google.com/search?q=%5Bhttps://react.dev/learn/you-might-not-need-an-effect%5D(https://react.dev/learn/you-might-not-need-an-effect)))。总有活干。
你可以争辩说这些事应该在每次提交时做。但我发现,“快速迭代”和“维护改进代码库(偿还技术债)”交替进行的模式生产力更高,也更有趣。
你做“规格驱动开发(Spec-driven Development)”吗?
我 6 月份的时候做过。设计一个庞大的规格书(Spec),然后让模型构建好几个小时。我认为那是思考软件构建的“老办法”了。
我目前的方法通常是:先和 Codex 讨论,粘贴一些网站链接、一些想法,让它读代码,然后一起勾勒新功能。如果是棘手的事,我会让它把所有内容写进 Spec,交给 GPT-5-Pro 审阅(通过 chatgpt.com),看看有没有更好的主意(出人意料的是,这经常能大幅提升我的计划),然后把有用的部分粘回主上下文更新文件。
现在我对哪些任务消耗多少上下文有了直觉。Codex 的上下文空间很大,所以我通常直接动手。有些人比较死板,总是用全新的上下文结合计划书——我认为那对 Sonnet 有用,但 GPT-5 处理大上下文的能力强得多。每次都开新上下文,模型又得重新慢吞吞地读取所有文件,平白增加 10 分钟成本。
更有趣的方法是 UI 相关的工作。我通常从简单的开始,给出的要求极其简略(under-spec),然后看着模型构建,在浏览器里实时看更新。接着我排队添加更多改动,不断迭代。通常我并不完全清楚某样东西该长啥样,这种方式让我可以不断玩弄想法,看着它慢慢成形。我经常看到 Codex 构建出一些我压根没想到的有趣东西。我不回滚,我只是不断迭代,把混乱揉捏成对的形状。
在构建主功能时,我经常会有其他交互灵感,并由另一个 Agent 去迭代相关部分。通常我一个 Agent 攻克主功能,另一个做些切相关的零碎活。
写这篇文章的同时,我正在 Chrome 插件里开发一个新的 Twitter 数据导入器,为此我正在重塑 GraphQL 导入逻辑。因为不太确定这个方法对不对,我把它放在一个单独的文件夹里,这样我可以看 PR 来判断逻辑。主仓库正在重构,这样我就可以专心写这篇文章了。
晒晒你的斜杠命令(Slash commands)!
我只有几个,而且很少用:
/commit(自定义指令,解释说有多个 Agent 在同文件夹工作,只提交你自己的改动,这样我就能得到整洁的注释,模型也不会因为 Linter 报错就试图撤销别人的改动)/automerge(逐个处理 PR,响应机器人评论,回复,跑通 CI,成功后 squash 合并)/massageprs(和 automerge 类似但不 squash,方便我有大量 PR 时并行处理)/review(内置命令,偶尔用,因为我在 GitHub 上有 review 机器人)
即使有了这些命令,我通常也只是输入“commit”,除非我知道脏文件太多,Agent 可能会翻车。在我有信心的时候,没必要搞那些花招浪费上下文。你也会培养出这种直觉。我还没发现其他真正有用的命令。
你还有什么其他技巧?
与其费尽心思写完美的提示词来激励 Agent 完成长任务,不如用一些偷懒的替代方案。如果你在做大重构,Codex 经常会在半路停下。提前排队发送“继续(continue)”消息,这样你就可以走开,回来直接收工。如果 Codex 干完了任务,它会愉快地忽略掉剩下的“继续”消息。
要求模型在每个功能/修复完成后编写测试。使用相同的上下文。这会产生更好的测试,并极有可能发现实现中的 bug。如果是纯 UI 调整,测试意义不大,但除此之外,必做。AI 写测试通常一般,但很有帮助。而且说实话,你自己手动修复 bug 时会每次都写测试吗?
要求模型保留你的意图并“在棘手部分添加代码注释”,这对你和未来的模型运行都有帮助。
当遇到硬骨头时,通过提示词加入一些触发词,如“慢慢来(take your time)”、“全面(comprehensive)”、“读取所有相关的代码”、“建立可能的假设”,能让 Codex 解决最棘手的问题。
你的 Agents/Claude 配置文件长啥样?
我有一个 Agents.md 文件,并用软链接连到 claude.md,因为 Anthropic 没能把这个标准统一。我承认这很麻烦且不完美,因为 GPT-5 喜欢的提示词风格 和 Claude 完全不同。如果你还没读过他们的提示指南,现在就去读。
Claude 对 🚨 全大写咆哮式 🚨 指令 反应良好(比如威胁它如果失败就会死掉 100 只小猫之类),但这会让 GPT-5 感到困惑(这也合情合理)。所以,扔掉那一套,像对待人类一样交流。这意味着这些文件无法完美共享,但这对我不是问题,因为我主要用 Codex,我接受在偶尔用 Claude 时指令不够强。
我的 Agent 文件目前大约 800 行,感觉像是一个“组织架构疤痕”的集合。它不是我写的,是 Codex 写的。每当发生什么状况,我就会让它在那里加一条简洁的备忘。我迟早得清理它,但尽管它很大,效果却极好,GPT 基本上能遵循里面的条目。至少比 Claude 遵循得好得多(公平地说,Sonnet 4.5 也有进步)。
除了 Git 指令,它还包含对我产品的解释、我偏好的命名和 API 模式、React Compiler 的注意事项——通常是那些比模型训练数据更新的技术栈。我预计随着模型更新,可以再次精简这些内容。比如 Sonnet 4.0 需要引导才能理解 Tailwind 4,但 Sonnet 4.5 和 GPT-5 已经知道了,所以我删掉了那部分。
大块的重点在于:我偏好的 React 模式、数据库迁移管理、测试、使用和编写 ast-grep 规则。(如果你还不知道或没用 ast-grep 做代码库 Linter,现在就停下来,让你的模型把它设为 Git Hook 以拦截不合规的提交)。
我还尝试并开始使用一种 基于文本的“设计系统” 来规定样式,目前效果还有待观察。
所以 GPT-5-Codex 是完美的吗?
绝对不是。有时它重构了半小时,然后突然 惊慌失措 地撤销所有改动,你需要像安抚小孩一样重新运行并告诉它“时间够用”。有时它会忘了它能执行 Bash 命令,需要你鼓励一下。有时它会用 俄语或韩语 回复。 偶尔它还会翻车,把原始思考过程直接发给 Bash 执行。 但总的来说,这些情况很罕见,它在其他方面太出色了,这些小瑕疵完全可以原谅。人类也不完美。
我对 Codex 最大的不满是它会“丢行”,快速向上滚动会让部分文本消失。我真心希望这在 OpenAI 的 bug 修复名单榜首,因为这是我不得不慢下来的主要原因——怕消息丢了。
结论
别把时间浪费在 RAG、子智能体、Agents 2.0 或其他花架子上。直接跟它对话。跟它玩。培养直觉。你和 Agent 协作越多,结果就越好。
Simon Willison 的文章说得很对 ——管理 Agent 所需的许多技能,与 管理工程师 所需的技能非常相似——这些几乎都是资深软件工程师的特质。
没错,写出优秀的软件依然很难。我不再亲手写代码,不代表我不再深入思考架构、系统设计、依赖、功能或如何惊艳用户。使用 AI 只是意味着我们对交付成果的预期上限提高了。
PS: 这篇文章 100% 由人类手工编写。我热爱 AI,但我也深知有些事还是 老牌方式 更好。保留我的错别字,保留我的声音。🚄✌️
PPS: 题图致谢 Thorsten Ball。