开源 OCR 引擎基准测试
OCR 引擎
EasyOCR
EasyOCR 支持 80+ 语言。
Abaza = 'abq'
Adyghe = 'ady'
Afrikaans = 'af'
Angika = 'ang'
Arabic = 'ar'
Assamese = 'as'
Avar = 'ava'
Azerbaijani = 'az'
Belarusian = 'be'
Bulgarian = 'bg'
Bihari = 'bh'
Bhojpuri = 'bho'
Bengali = 'bn'
Bosnian = 'bs'
Simplified_Chinese = 'ch_sim'
Traditional_Chinese = 'ch_tra'
Chechen = 'che'
Czech = 'cs'
Welsh = 'cy'
Danish = 'da'
Dargwa = 'dar'
German = 'de'
English = 'en'
Spanish = 'es'
Estonian = 'et'
Persian_Farsi = 'fa'
French = 'fr'
Irish = 'ga'
Goan_Konkani = 'gom'
Hindi = 'hi'
Croatian = 'hr'
Hungarian = 'hu'
Indonesian = 'id'
Ingush = 'inh'
Icelandic = 'is'
Italian = 'it'
Japanese = 'ja'
Kabardian = 'kbd'
Kannada = 'kn'
Korean = 'ko'
Kurdish = 'ku'
Latin = 'la'
Lak = 'lbe'
Lezghian = 'lez'
Lithuanian = 'lt'
Latvian = 'lv'
Magahi = 'mah'
Maithili = 'mai'
Maori = 'mi'
Mongolian = 'mn'
Marathi = 'mr'
Malay = 'ms'
Maltese = 'mt'
Nepali = 'ne'
Newari = 'new'
Dutch = 'nl'
Norwegian = 'no'
Occitan = 'oc'
Pali = 'pi'
Polish = 'pl'
Portuguese = 'pt'
Romanian = 'ro'
Russian = 'ru'
Serbian_cyrillic = 'rs_cyrillic'
Serbian_latin = 'rs_latin'
Nagpuri = 'sck'
Slovak = 'sk'
Slovenian = 'sl'
Albanian = 'sq'
Swedish = 'sv'
Swahili = 'sw'
Tamil = 'ta'
Tabassaran = 'tab'
Telugu = 'te'
Thai = 'th'
Tajik = 'tjk'
Tagalog = 'tl'
Turkish = 'tr'
Uyghur = 'ug'
Ukranian = 'uk'
Urdu = 'ur'
Uzbek = 'uz'
Vietnamese = 'vi'
安装
pip install torch==2.0.1 torchvision==0.15.2 -i https://download.pytorch.org/whl/cpu
pip install easyocr
代码示例
import easyocr
languages = ['ch_sim', 'en']
model = easyocr.Reader(languages)
result = model.readtext(img_path)
print(result)
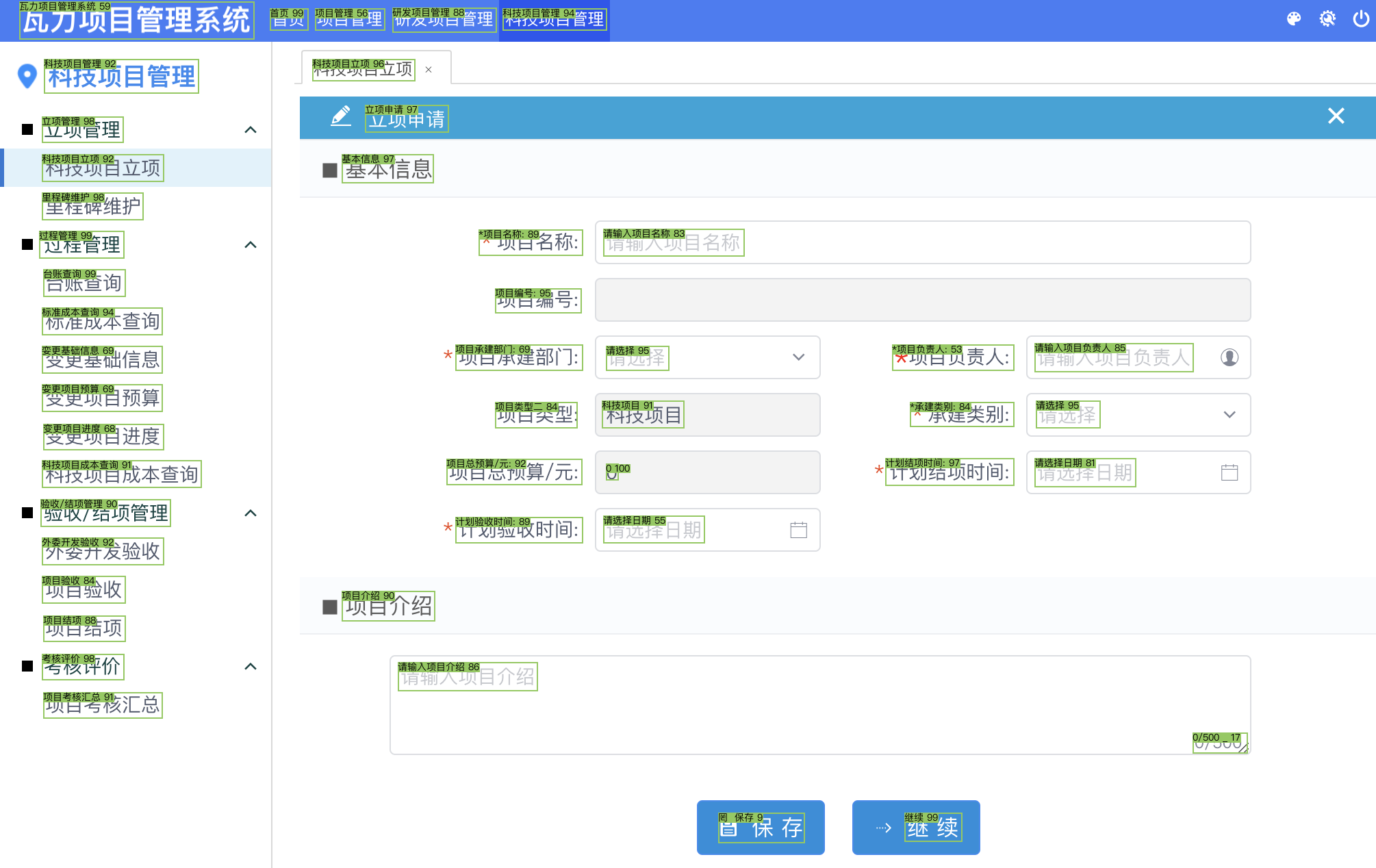
[([[28, 2], [372, 2], [372, 58], [28, 58]], '瓦力项目管理系统', 0.7662331484609081), ([[393, 11], [451, 11], [451, 47], [393, 47]], '首页', 0.9506149347953033), ([[460, 12], [562, 12], [562, 44], [460, 44]], '项目管理', 0.5817481294832926)]
PaddleOCR
PaddleOCR 支持中英文、英文、法语、德语、韩语、日语。
Simplified_Chinese = 'ch'
English = 'en'
French = 'french'
German = 'german'
Korean = 'korean'
Japanese = 'japan'
安装
pip install numpy==1.23.5 PyMuPDF==1.21.1 # paddleocr 依赖
pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install paddleocr
代码示例
from paddleocr import PaddleOCR
PADDLEOCR_MODULE_PATH = 'models/paddleocr'
language = ['ch']
model = PaddleOCR(use_angle_cls=True,
lang=language,
det_limit_side_len=2000,
det_model_dir=os.path.join(PADDLEOCR_MODULE_PATH, 'det'),
rec_model_dir=os.path.join(PADDLEOCR_MODULE_PATH, 'rec'),
cls_model_dir=os.path.join(PADDLEOCR_MODULE_PATH, 'cls'))
result = model.ocr(img_path)
print(result)
[[[[36.0, 13.0], [361.0, 13.0], [361.0, 45.0], [36.0, 45.0]], ('瓦力项自管理系统', 0.9391518235206604)], [[[397.0, 15.0], [466.0, 15.0], [466.0, 41.0], [397.0, 41.0]], ('首页:', 0.8162643909454346)], [[[455.0, 16.0], [563.0, 16.0], [563.0, 38.0], [455.0, 38.0]], ('项目管理', 0.9921224117279053)]]
Tesseract OCR
效果图
EasyOCR
PaddleOCR
det_limit_side_len=960 (default)

det_limit_side_len=2000
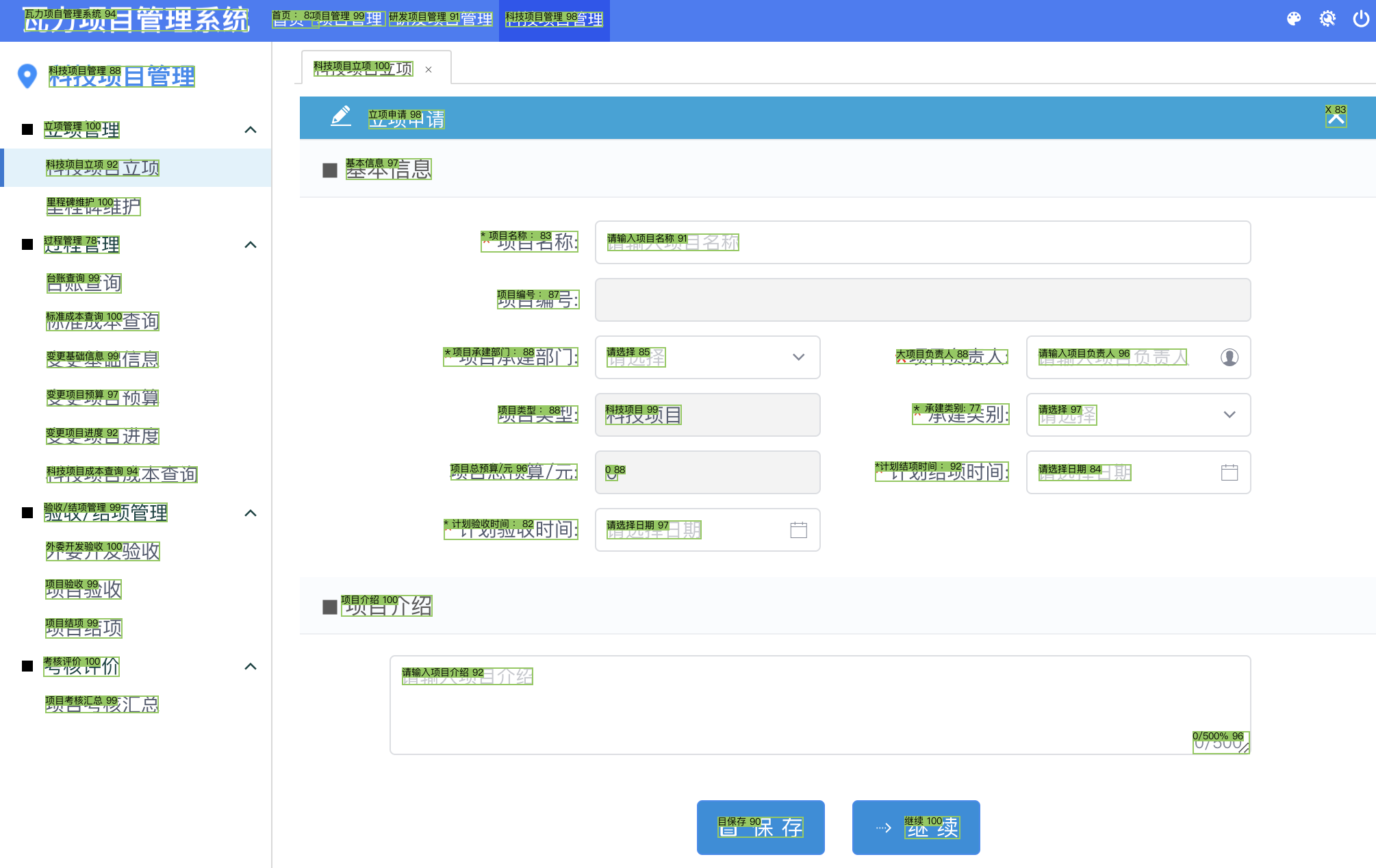
EasyOCR的效果更好
镜像构建
EasyOCR
CPU
| Package | Version ✅ | Version ❌ |
|---|---|---|
| easyocr | 1.7.1 | 1.7.1 |
| torch | 2.0.1 | 2.1.0 |
| torchvision | 0.15.2 | 0.16.0 |
❌ torch 升级到最新版本后,easyocr 会报错:Segmentation fault。
包依赖关系
EasyOCR
| Package | Version |
|---|---|
| easyocr | 1.7.1 |
| torch | 2.0.1 |
| torchvision | 0.15.2 |
PaddleOCR
| Package | Version |
|---|---|
| paddleocr | 2.6.0 |
| numpy | 1.23.5 |
| paddlepaddle | 2.5.1 |
| PyMuPDF | 1.21.1 |
python app/aimodels/ocr_aimodel.pyc
🚗 Loading EasyOCR model...
Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
Segmentation fault
❌ 在 Apple M2 Max 上用 CPU 计算是通过容器的方式运行的 amd64 平台,出现错误:Illegal instruction。
docker run --rm -it -e MAX_WORKERS=1 wangjunjian/wall-e-ai:amd64 bash
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
root@daa9a1886e87:/WALL-E-AI# export PYTHONPATH=`pwd`
root@daa9a1886e87:/WALL-E-AI# python app/aimodels/ocr_aimodel.pyc
🚗 Loading EasyOCR model...
Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
[W NNPACK.cpp:64] Could not initialize NNPACK! Reason: Unsupported hardware.
Illegal instruction
虽然在 macOS 上运行出现错误,但是在 Linux amd64 平台上运行是正常的。
PaddleOCR
CPU
❌ 在 Apple M2 Max 上用 CPU 计算是通过容器的方式运行的 amd64 平台,出现错误:Illegal instruction。
docker run --rm -it -p 9999:80 -e MAX_WORKERS=1 wangjunjian/wall-e-ai:amd64-paddleocr bash
WARNING: The requested image's platform (linux/amd64) does not match the detected host platform (linux/arm64/v8) and no specific platform was requested
root@d0e437177daf:/WALL-E-AI# export PYTHONPATH=`pwd`
root@d0e437177daf:/WALL-E-AI# python app/aimodels/ocr_aimodel.pyc
🚗 Loading PaddleOCR model...
Illegal instruction
虽然在 macOS 上运行出现错误,但是在 Linux amd64 平台上运行是正常的。
❌ 构建 arm64 平台的镜像,出现找不到 paddlepaddle 软件包的错误。
速度测试
| EasyOCR 1 (MS) | EasyOCR 2~ (MS) | PaddleOCR 1 (MS) | PaddleOCR 2~ (MS) | |
|---|---|---|---|---|
| CPU (Intel Xeon Silver 4216) | 11015 | 6184(🚀 35%) | 11508 | 8135 |
| CPU (Apple M2 Max) | 36398 | 31618 | 5334 | 3939 |
| MPS (Apple M2 Max) | 10271 | 6792 | X | X |
| CUDA (NVIDIA Tesla T4) | 18727 | 1194 | 17780 | 784(🚀 52%) |
- 1 指的是第一次识别,需要加载模型,所以速度会慢。
- 2~ 指的是第二次识别的平均速度。
- X 表示不支持。
- PaddleOCR 参数
det_limit_side_len设置为 2000,主要是为了提高大图的识别精度。 - EasyOCR 在 Apple M2 Max 上用 CPU 计算是通过容器的方式运行的 arm64 平台。
- EasyOCR 在 T4 上需要
3G的显存。 - PaddleOCR 在 T4 上需要
2G的显存。
调试:faulthandler — Dump the Python traceback
当出现下面的错误(主要是 C、C++ 库的问题):
- Segmentation fault
- Illegal instruction
可以通过 faulthandler 定位到错误位置,在代码中加入下面的代码:
import faulthandler
faulthandler.enable()
代码实现如下:
import faulthandler
faulthandler.enable()
import os
from app.config import *
from app.aimodels.aimodel import AIModel
from app.models.base_model import Object, Box
class EasyOCR(AIModel):
DEFAULT_LANGUAGE_CHINESE_ENGLISH = ['ch_sim', 'en']
def __init__(self, languages = DEFAULT_LANGUAGE_CHINESE_ENGLISH):
super().__init__()
self.languages = languages
self._load_model()
def _load_model(self):
print(f'🚗 Loading {self.__class__.__name__} model...')
import easyocr
self.model = easyocr.Reader(self.languages)
def load(self, languages = DEFAULT_LANGUAGE_CHINESE_ENGLISH):
self.languages = languages
self._load_model()
def __call__(self, img_path):
result = self.model.readtext(img_path)
return result
if __name__ == "__main__":
img_path = 'static/docs/images/vision/image_match/crop_menuitem1.png'
easyocr = EasyOCR()
easyocr(img_path)
运行代码后,出现下面的错误信息:
Neither CUDA nor MPS are available - defaulting to CPU. Note: This module is much faster with a GPU.
Fatal Python error: Segmentation fault
Current thread 0x0000ffff976b7d40 (most recent call first):
File "/usr/local/lib/python3.10/site-packages/torch/_ops.py", line 692 in __call__
File "/usr/local/lib/python3.10/site-packages/torch/ao/nn/quantized/dynamic/modules/rnn.py", line 119 in __init__
File "/usr/local/lib/python3.10/site-packages/torch/ao/nn/quantized/dynamic/modules/rnn.py", line 400 in __init__
File "/usr/local/lib/python3.10/site-packages/torch/ao/nn/quantized/dynamic/modules/rnn.py", line 291 in from_float
File "/usr/local/lib/python3.10/site-packages/torch/ao/nn/quantized/dynamic/modules/rnn.py", line 495 in from_float
File "/usr/local/lib/python3.10/site-packages/torch/ao/quantization/quantize.py", line 623 in swap_module
File "/usr/local/lib/python3.10/site-packages/torch/ao/quantization/quantize.py", line 590 in _convert
File "/usr/local/lib/python3.10/site-packages/torch/ao/quantization/quantize.py", line 588 in _convert
File "/usr/local/lib/python3.10/site-packages/torch/ao/quantization/quantize.py", line 588 in _convert
File "/usr/local/lib/python3.10/site-packages/torch/ao/quantization/quantize.py", line 550 in convert
File "/usr/local/lib/python3.10/site-packages/torch/ao/quantization/quantize.py", line 465 in quantize_dynamic
File "/usr/local/lib/python3.10/site-packages/easyocr/recognition.py", line 177 in get_recognizer
File "/usr/local/lib/python3.10/site-packages/easyocr/easyocr.py", line 231 in __init__
File "/WALL-E-AI/app/aimodels/ocr_aimodel.py", line 25 in _load_model
File "/WALL-E-AI/app/aimodels/ocr_aimodel.py", line 19 in __init__
File "/WALL-E-AI/app/aimodels/aimodel.py", line 11 in __call__
File "/WALL-E-AI/app/aimodels/ocr_aimodel.py", line 92 in <module>
Extension modules: PIL._imaging, numpy.core._multiarray_umath, numpy.core._multiarray_tests, numpy.linalg._umath_linalg, numpy.fft._pocketfft_internal, numpy.random._common, numpy.random.bit_generator, numpy.random._bounded_integers, numpy.random._mt19937, numpy.random.mtrand, numpy.random._philox, numpy.random._pcg64, numpy.random._sfc64, numpy.random._generator, torch._C, torch._C._fft, torch._C._linalg, torch._C._nested, torch._C._nn, torch._C._sparse, torch._C._special, PIL._imagingft, charset_normalizer.md, scipy._lib._ccallback_c, scipy.ndimage._nd_image, scipy.special._ufuncs_cxx, scipy.special._ufuncs, scipy.special._specfun, scipy.special._comb, scipy.linalg._fblas, scipy.linalg._flapack, scipy.linalg.cython_lapack, scipy.linalg._cythonized_array_utils, scipy.linalg._solve_toeplitz, scipy.linalg._decomp_lu_cython, scipy.linalg._matfuncs_sqrtm_triu, scipy.linalg.cython_blas, scipy.linalg._matfuncs_expm, scipy.linalg._decomp_update, scipy.sparse._sparsetools, _csparsetools, scipy.sparse._csparsetools, scipy.sparse.linalg._isolve._iterative, scipy.sparse.linalg._dsolve._superlu, scipy.sparse.linalg._eigen.arpack._arpack, scipy.sparse.csgraph._tools, scipy.sparse.csgraph._shortest_path, scipy.sparse.csgraph._traversal, scipy.sparse.csgraph._min_spanning_tree, scipy.sparse.csgraph._flow, scipy.sparse.csgraph._matching, scipy.sparse.csgraph._reordering, scipy.linalg._flinalg, scipy.special._ellip_harm_2, _ni_label, scipy.ndimage._ni_label, skimage._shared.geometry, yaml._yaml (total: 58)
Segmentation fault
参考资料
- PyTorch Install
- pypi PaddleOCR
- PaddlePaddle Install
- Dockerfile reference
- Docker python
- Docker PyTorch
- Docker 中 arg 和 env 的区别
- 中文开源字体集
- PaddleOCR学习 - det_limit_side_len
- JaidedAI/EasyOCR
- EasyOCR vs Tesseract vs Amazon Textract: an OCR engine comparison
- Training and Deploying a fully Dockerized License Plate Recognition app with IceVision, Amazon Textract and FastAPI
- Query on image resolution used for detection and recognition #1078 default=2560