LongCat-Flash-Thinking-2601 技术报告
LongCat-Flash-Thinking-2601 创新性地开启了全栈式的智能体推理(Agentic Reasoning)训练体系与架构优化。首先,提出了自动化的环境扩展流水线,构建了覆盖 20 多个领域的高质量、可执行且可验证的智能体环境,有效解决了真实世界中复杂智能体交互数据匮乏的难题。其次,针对现实任务的不确定性,创新性地引入了鲁棒性智能体训练流程,通过系统性分析现实噪声模式并采用课程强化学习(Curriculum RL)将噪声整合进训练,显著增强了模型在非理想环境下的泛化与生存能力。在底层支撑上,扩展了异步强化学习框架 DORA 以支持高达 32,000 个环境的大规模并发训练,并引入了 Heavy Thinking(深思考)模式,通过在推理阶段同时扩展思考的深度与广度(Test-time Scaling),进一步突破了复杂任务的性能边界。此外,还设计了 Zigzag Attention 稀疏注意力机制,使模型能以极低开销实现高达 100 万 token 的长上下文扩展,为长程智能体任务提供了坚实的架构基础。
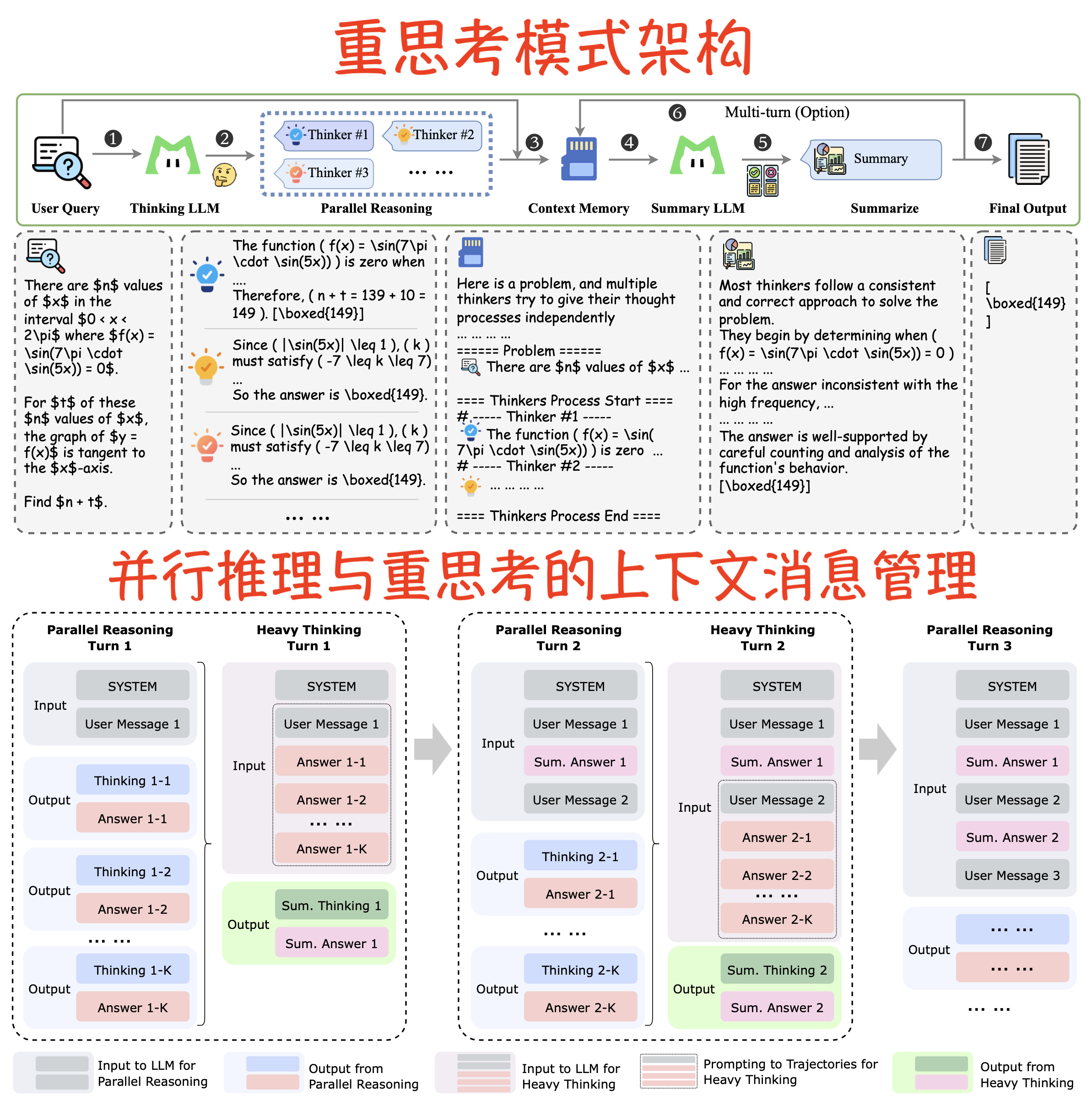
重思考模式架构
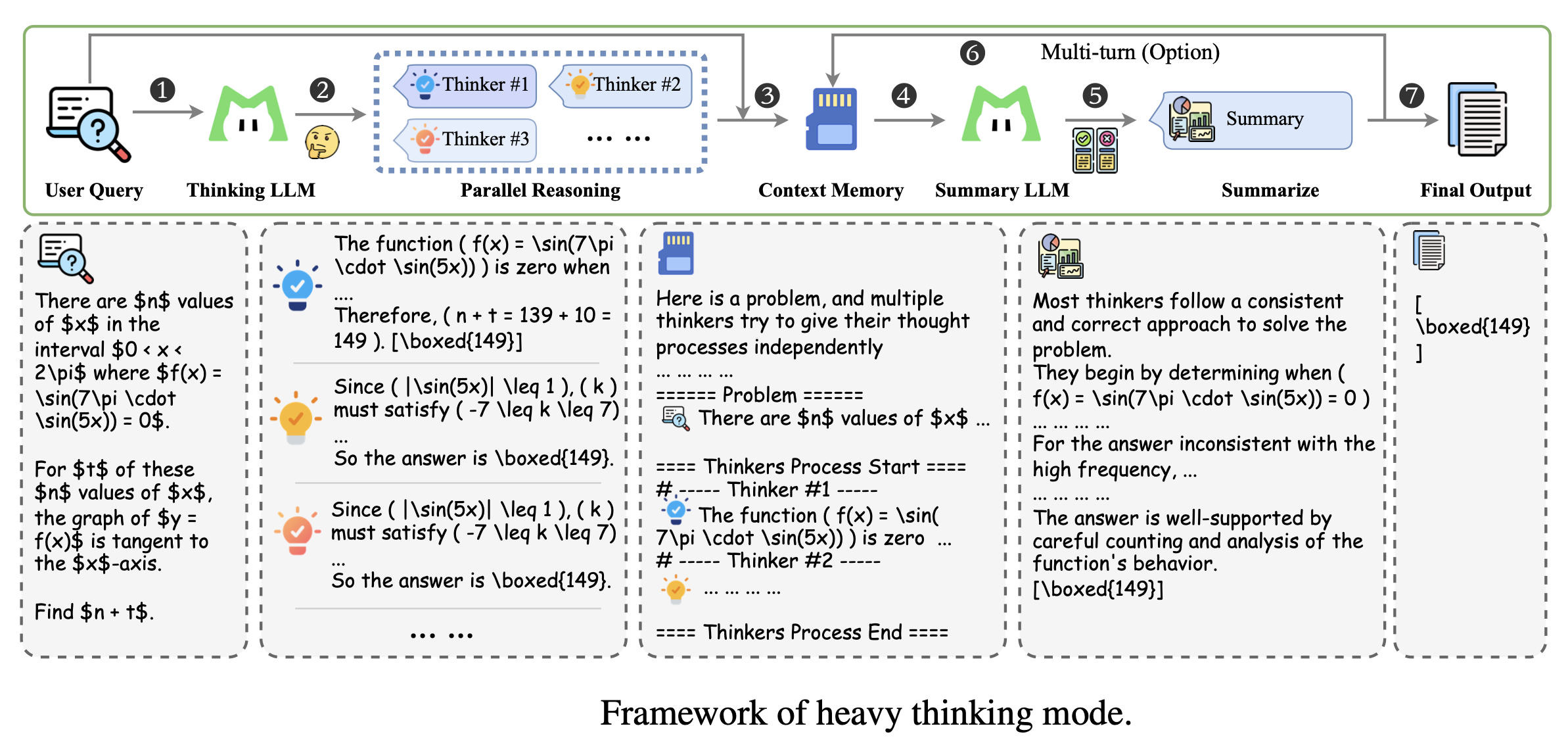
“重思考模式”(Heavy Thinking Mode)是 LongCat-Flash-Thinking-2601 模型为了突破现有推理能力极限而引入的一种推理时扩展(Test-Time Scaling)架构。该模式的核心在于通过增加推理过程中的计算量,同时在深度和宽度两个维度上扩展模型的推理能力。
以下是该架构的详细组成和工作流程:
1. 核心设计理念
重思考模式旨在通过联合扩展计算资源来提升性能:
- 扩展宽度:通过并行探索多种不同的推理路径(类似于自一致性或蒙特卡洛树搜索)。
- 扩展深度:通过长链条思维(CoT)和自我反思,让模型能够迭代完善推理过程。
2. 架构的两大阶段
该架构将推理过程分解为两个互补的阶段:
- 第一阶段:并行推理 (Parallel Reasoning)
- 思考模型(Thinking Model) 并行执行多次生成,产生多个候选推理轨迹。
- 这一步实现了“宽度”的扩展,让模型能够探索多样的解题路径。
- 第二阶段:重思考/总结 (Heavy Thinking / Summary)
- 总结模型(Summary Model) 对第一阶段产生的所有轨迹进行反思性推理。
- 该阶段负责综合中间推理过程和结果,剔除不一致或错误的路径,最终做出决策。
- 总结模型和思考模型可以是同一个模型,也可以是独立实例。
3. 关键辅助模块
为了支持复杂的工具调用和多轮对话,架构还包含以下组件:
- 上下文记忆模块 (Context Memory Module):用于存储消息历史,确保在多轮交互中保留上下文。
- 特定提示模板 (Specific Prompt Template):用于组织并行轨迹的排列组合,引导总结模型进行高效的答案聚合或精炼。
- 一致性约束:总结模型的输出被约束为与并行推理阶段的风格和格式保持一致,以便直接拼接到消息历史中。
并行推理与重思考的上下文消息管理
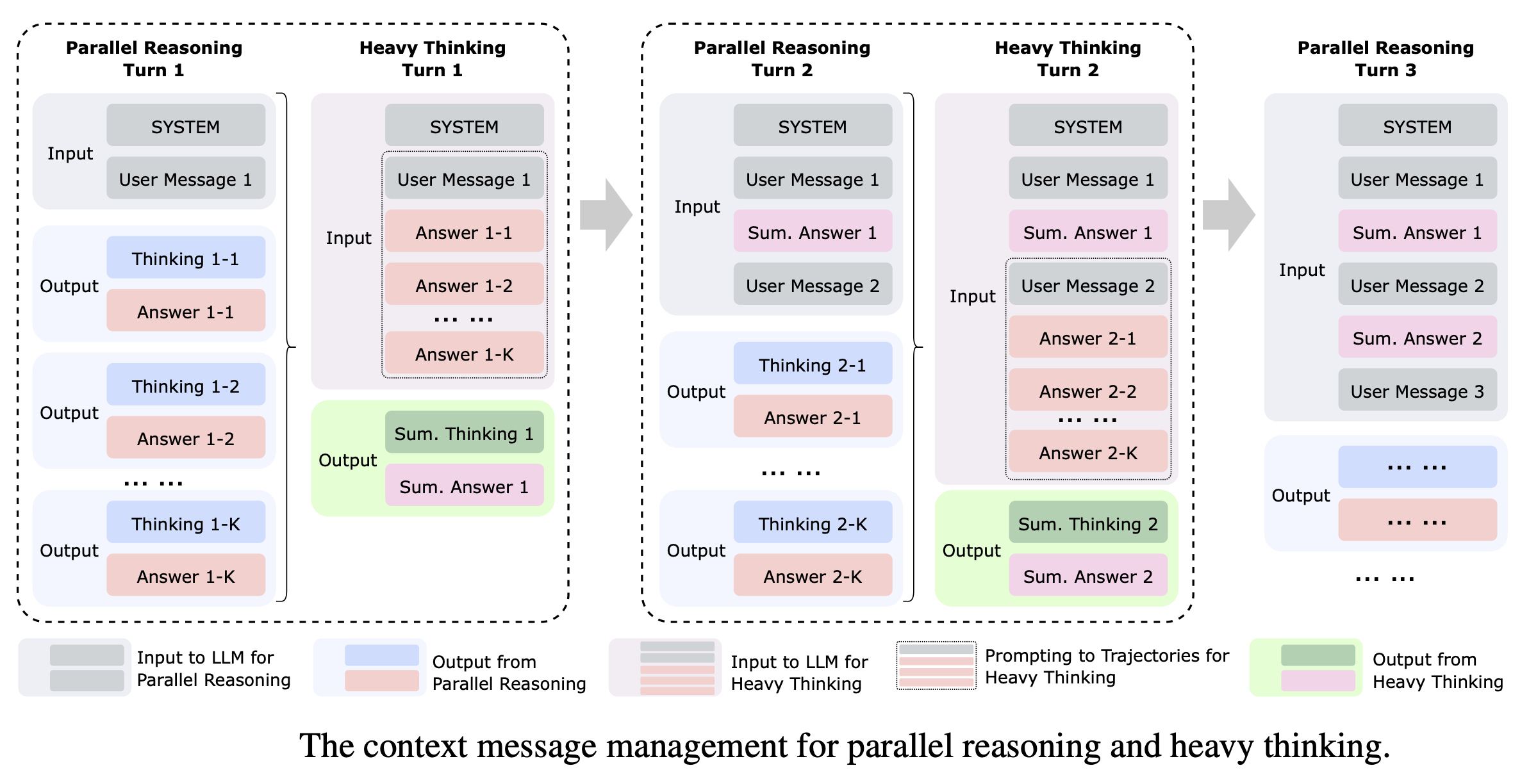
1. 上下文记忆模块 (Context Memory Module)
为了支持多轮对话和工具调用,架构引入了一个专门的上下文记忆模块。该模块的主要职责是存储和维护消息的历史记录,确保模型能够感知之前的交互背景。
2. 两阶段消息处理流程
上下文管理遵循一个清晰的迭代循环:
- 第一阶段:并行推理输入 (Input to Parallel Reasoning):
- 系统将当前的消息历史(Message History)和最新的用户查询发送给多个并行运行的“思考模型”实例。
- 每个实例独立生成候选的推理轨迹(Thinking 1-1, 1-2, …, 1-K)。
- 第二阶段:重思考/总结输入 (Input to Heavy Thinking):
- 上下文管理系统利用一个 特定的提示模板(Specific Prompt Template) 来组织这一轮产生的所有并行轨迹。
- 为了保持高效,该模板通常仅保留轨迹中的“答案内容”,并将它们连同原始消息历史一起喂给“总结模型”。
- 总结模型随后进行反思性推理,聚合或提炼出最终的总结答案(Sum. Answer)。
3. 消息集成与格式约束
该架构在消息管理上有一个精妙的设计,即输出的一致性约束:
- 直接拼接:系统约束总结模型的输出风格和格式,使其与并行推理阶段保持一致。
- 无缝衔接:这种一致性允许系统将总结模型的响应(例如 Sum. Answer 1)直接拼接到消息历史中,作为下一轮对话的上下文基础。
4. 多轮对话中的演进 (Multi-turn Evolution)
在进入下一轮(如 Turn 2)时,上下文管理的优势得以体现:
- 之前的“总结答案 1”和新的“用户消息 2”共同构成新的输入,传递给下一轮的并行推理。
- 这种机制确保了模型在不断增加推理深度(通过多轮总结和反思)的同时,也能通过并行的宽度扩展来探索多样化的解题路径。
这种上下文消息管理机制通过 “并行探索 -> 结构化聚合 -> 格式化回填” 的闭环,解决了大规模并行推理轨迹与长程历史对话之间的协调问题,使模型在处理 AIME-2025 等极高难度任务时能够保持逻辑的一致性和鲁棒性。
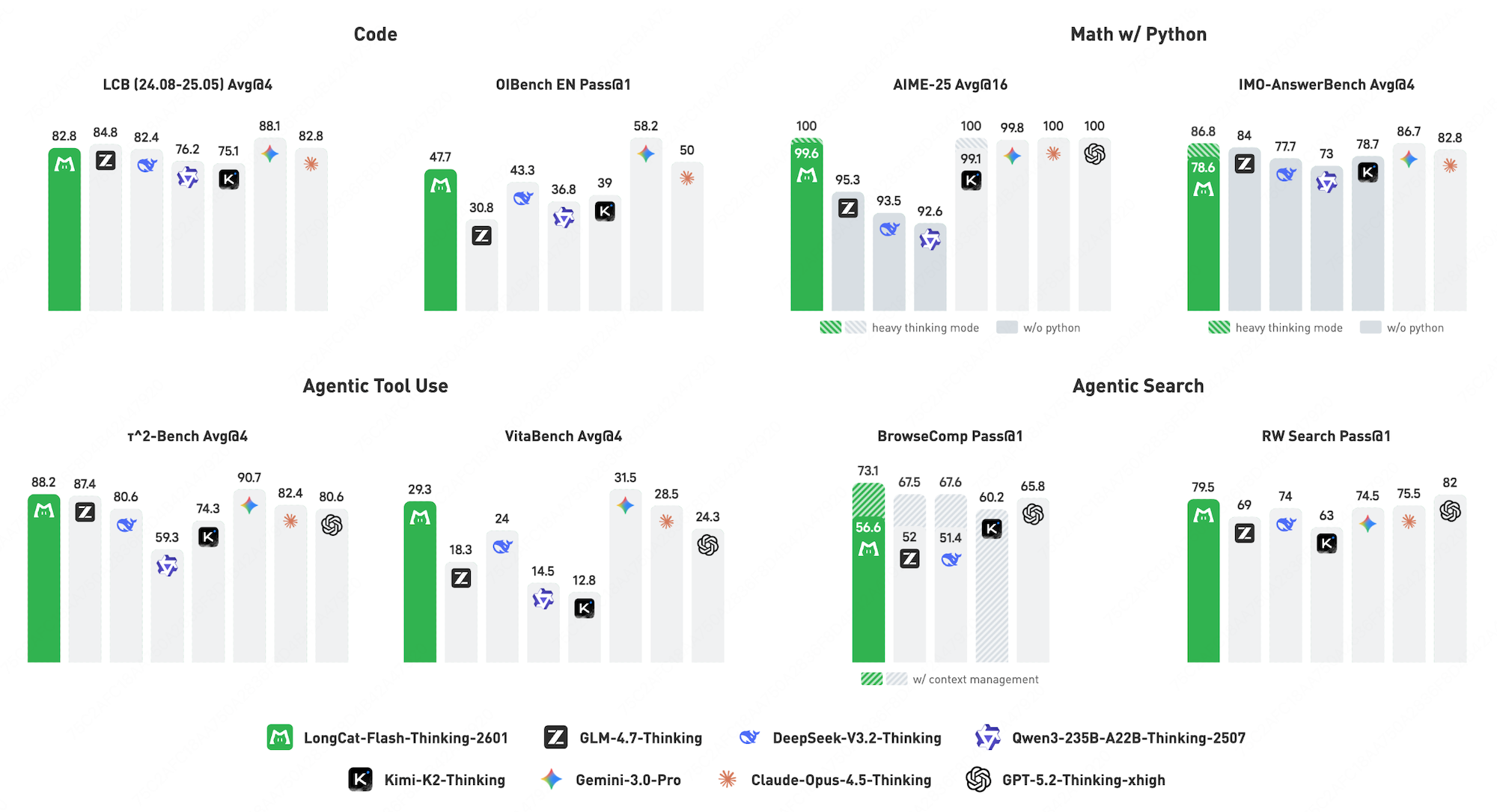
基准性能
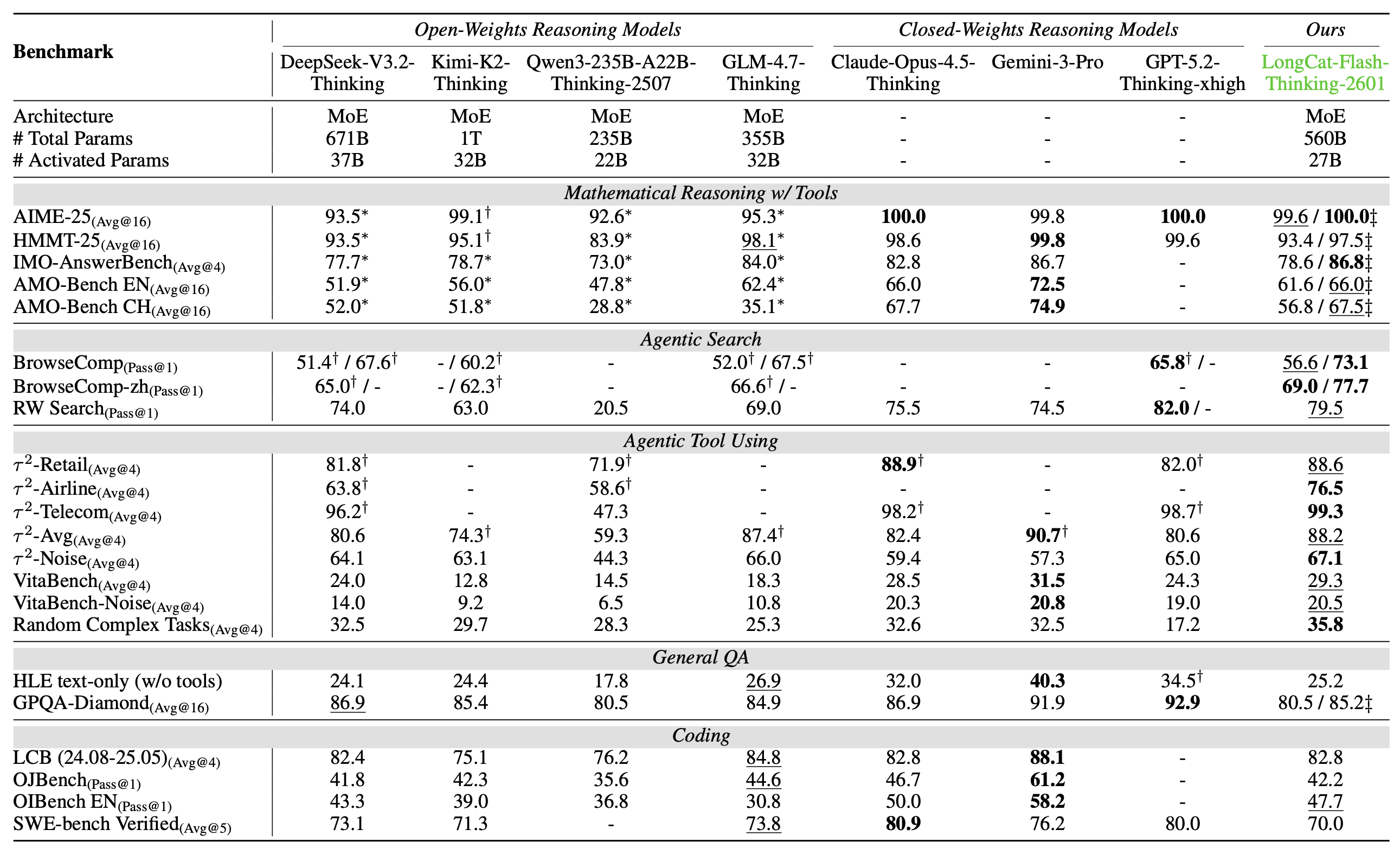
表格中对比了 LongCat-Flash-Thinking-2601 与主流开源推理模型(如 DeepSeek-V3.2、GLM-4.7 等)及闭源模型(如 GPT-5.2、Claude-4.5 等)在数学推理、智能体搜索、工具使用、通用问答和代码编程五个核心领域的性能表现。结果显示,该模型在智能体搜索和工具使用(Agentic Search & Tool Use)基准上表现卓越,在 BrowseComp、VitaBench 和随机复杂任务等多项测试中均位居开源模型首位,甚至在 RW Search 上表现仅次于 GPT-5.2。此外,在开启重思考模式(Heavy Thinking Mode)后,其数学推理(如 AIME-25 满分)和通用问答能力显著提升,达到了可比肩顶级闭源推理模型的第一梯队水平。
Zigzag Attention
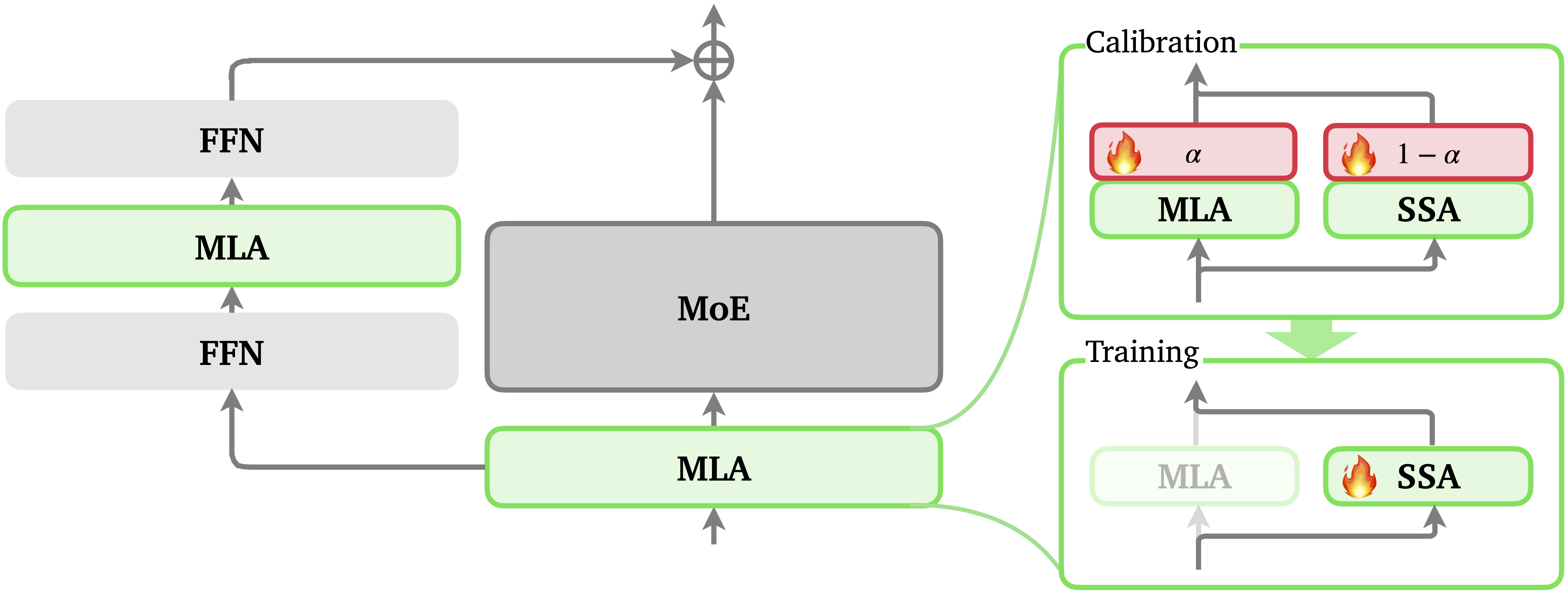
1. 为什么要引入?
- 解决计算复杂度问题:标准的全注意力机制具有平方阶(quadratic)复杂度,在处理长推理轨迹或长上下文任务时,计算成本和推理延迟会变得极其昂贵。
- 应对重思考模式(Heavy Thinking):在重思考模式下,模型需要同时解码多个并行推理轨迹,这对注意力机制的效率提出了更高要求。
2. 工作原理
- 稀疏策略:它结合了多头潜变量注意力(MLA)与流式稀疏注意力(SSA),将每个查询标记(query token)的注意力限制在 局部窗口(近期标记)和全局锚点(序列开头的初始标记) 上。
- 层间交错稀疏化:大约 50% 的全注意力层被替换为 SSA 层。这种“层级稀疏”避免了硬件利用率不均的问题,通过在不同层间交错全注意力和稀疏层,信息仍能在序列中远距离传递,形成 Zigzag 的连接路径。
- 无损转换:这种设计允许现有的全注意力模型在模型中期训练(mid-training)阶段以极低的开销转换为稀疏变体,同时能够外推支持高达 100 万(1M)标记的超长上下文。
3. 性能提升
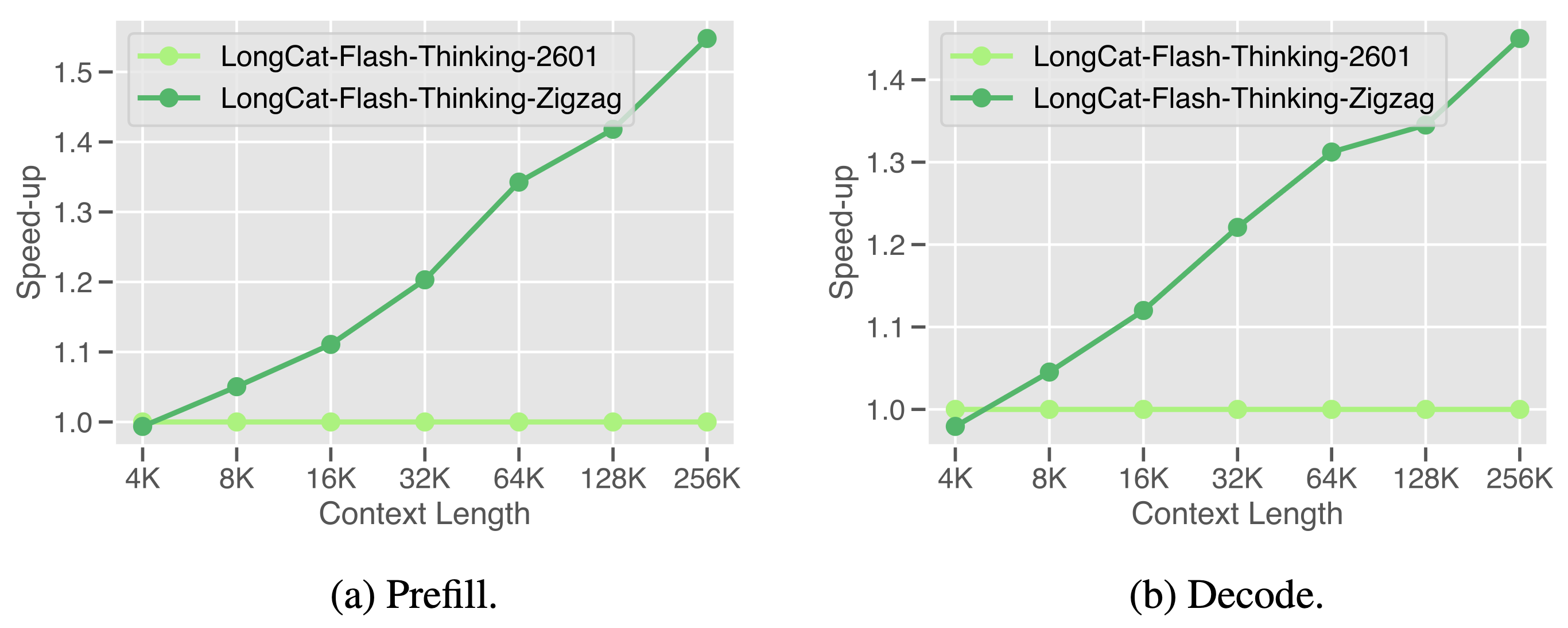
展示了 LongCat-Flash-Thinking-2601(标准全注意力模型)与 LongCat-Flash-Thinking-ZigZag(引入 Zigzag Attention 的稀疏注意力变体)在推理效率上的对比。
最优超参数预测(Optimal Hyperparameter Prediction)
解决大规模模型在 中期训练(mid-training) 阶段面临的挑战:由于搜索空间巨大且计算成本极高,如何高效地确定最优超参数配置。
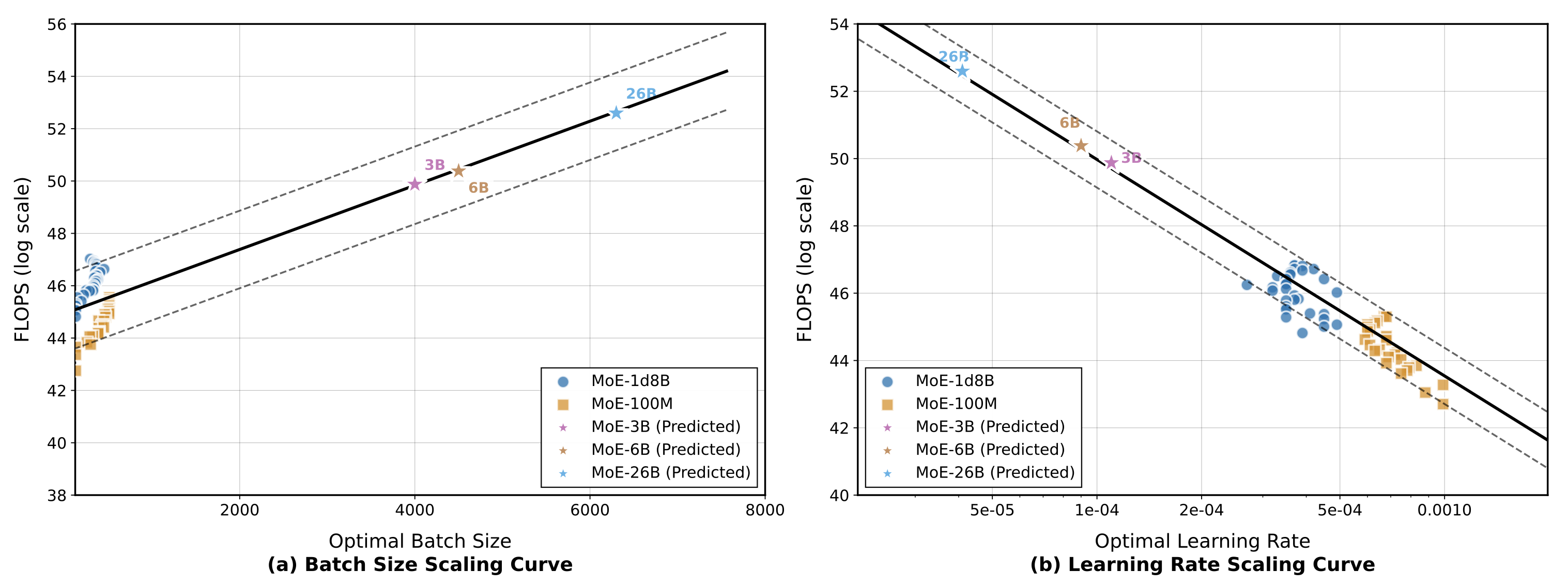
1. 核心目标
该方法专门设计用于最小化寻找最佳配置所需的计算成本。通过这种预测机制,模型可以在持续训练(continual training)过程中以极低的计算开销提升性能。
2. 实现步骤
该预测过程主要分为两个关键步骤:
- 超参数映射 (Hyperparameter Mapping):
- 首先训练多个不同超参数设置的小型模型(例如 MoE-1.8B 和 MoE-100M)。
- 利用验证损失(validation loss)和浮点运算量(FLOPS),将最优超参数与它们的计算成本建立映射关系。
- 这有助于理解不同配置如何影响训练效率和最终性能。
- 超参数预测 (Hyperparameter Prediction):
- 对于给定的预训练检查点(checkpoint),通过其验证损失来估算“等效计算成本”(即从零开始达到相同损失所需的计算量)。
- 结合这一估算值与实际的计算负载,预测出在该阶段进行持续训练的最优超参数。
3. 应用与验证
- 涉及参数:该方法主要预测最优批次大小(Optimal Batch Size)和最优学习率(Optimal Learning Rate)。
- 缩放定律(Scaling Laws):利用幂律拟合(power-law fitting)建立了缩放曲线。先在 MoE-3B 和 MoE-6B 模型上得到验证,随后被外推(extrapolated)以预测 MoE-26B(即 LongCat-Flash-Thinking-2601 激活参数规模)的最优配置。
演示

