LiteLLM: [Python SDK] [Proxy Server (LLM Gateway)]
LiteLLM Proxy Server (LLM Gateway)
安装
pip install 'litellm[proxy]'
编辑配置文件:config.yaml
model_list:
- model_name: qwen-coder
litellm_params:
model: ollama/qwen2.5-coder:7b
- model_name: bge-m3
litellm_params:
model: ollama/bge-m3
- model_name: llava
litellm_params:
model: ollama/llava:7b
api_base: "http://localhost:11434"
# api_base: http://127.0.0.1:11434/v1 # ❌ 500 Internal Server Error
- model_name: gpt-4
litellm_params:
model: openai/gpt-4-32k
api_base: http://172.16.33.66:9997/v1
api_key: none
- model_name: bge
litellm_params:
model: openai/bge-m3
api_base: http://172.16.33.66:9997/v1
api_key: none
general_settings:
master_key: sk-1234 # [OPTIONAL] Only use this if you to require all calls to contain this key (Authorization: Bearer sk-1234)
命令部署
# 集成 Langfuse
LANGFUSE_PUBLIC_KEY=pk-lf-fd5d8fba-5134-4037-884d-d6780894a65a
LANGFUSE_SECRET_KEY=sk-lf-10122a92-da11-4423-b3f7-ad10e5f268fc
LANGFUSE_HOST=http://127.0.0.1:3000
litellm --config config.yaml
Docker 部署
NO DB
docker run --name litellm \
-v $(pwd)/litellm_config.yaml:/app/config.yaml \
-p 4000:4000 \
ghcr.io/berriai/litellm:main-stable \
--config /app/config.yaml \
--detailed_debug
DB
# Get the code
git clone https://github.com/BerriAI/litellm
# Go to folder
cd litellm
# Add the master key - you can change this after setup
echo 'LITELLM_MASTER_KEY="sk-1234"' > .env
# Add the litellm salt key - you cannot change this after adding a model
# It is used to encrypt / decrypt your LLM API Key credentials
# We recommned - https://1password.com/password-generator/
# password generator to get a random hash for litellm salt key
echo 'LITELLM_SALT_KEY="sk-1234"' > .env
source .env
# Start
docker-compose up
模型测试
Chat Completions
curl -X POST 'http://127.0.0.1:4000/v1/chat/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data-raw '{
"model": "gpt-4",
"messages": [
{ "role": "system", "content": "你是一名数学家。" },
{ "role": "user", "content": "1 + 1 = ?"}
]
}'
Completions
curl -X POST 'http://127.0.0.1:4000/v1/completions' \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer sk-1234' \
--data-raw '{
"model": "gpt-4",
"prompt": "天空为什么是蓝色的?",
"max_tokens": 256,
"temperature": 0
}'
Embeddings
curl -X POST http://127.0.0.1:4000/v1/embeddings \
-H "Content-Type: application/json" \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "bge",
"input": "Hello!"
}'
视觉问答(llava)
curl "http://127.0.0.1:4000/v1/chat/completions" \
-X POST \
-H "Content-Type: application/json" \
-H 'Authorization: Bearer sk-1234' \
-d '{
"model": "llava",
"messages": [
{
"role": "user",
"content": [
{ "type": "text", "text": "图像上面有几只动物(用中文回答)" },
{ "type": "image_url", "image_url": { "url": "'$(base64 -i /Users/junjian/截屏/catdog.jpg)'" } }
]
}
]
}'
- Ollama vision models call arguments (like : llava) #2201
- Ollama llava proxy_server_config.yaml and curl request #1864
http://127.0.0.1:4000/v1/chat/completions 换成 http://127.0.0.1:4000/chat/completions 也可以。
LiteLLM Proxy Server UI
登录 http://localhost:4000/ui 进入 LiteLLM Proxy Server UI。
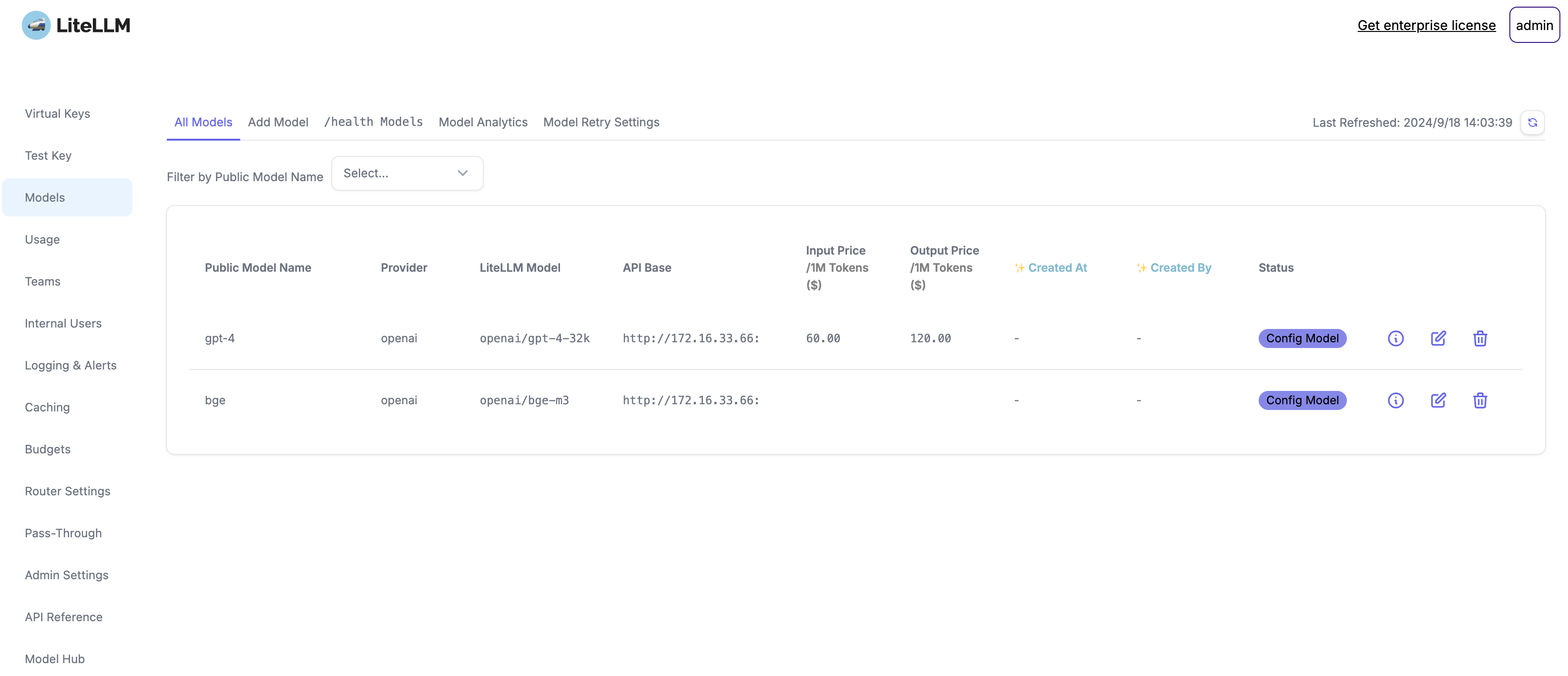
模型列表
添加模型
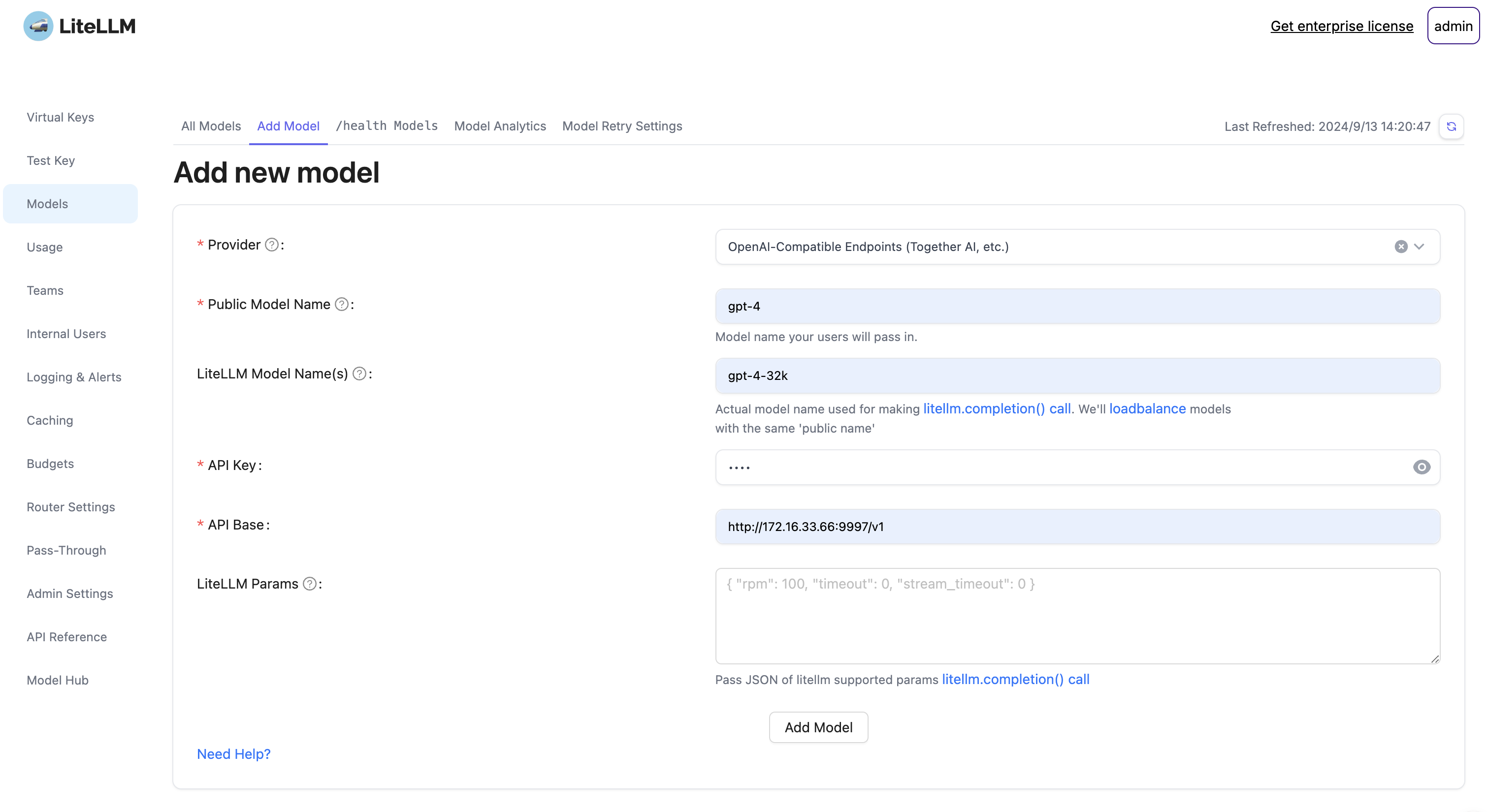
Provider: OpenAI-Compatible Endpoints (Together AI, etc.)Public Model Name: gpt-4LiteLLM Model Name(s): gpt-4-32kAPI Key: NONEAPI Base: http://172.16.33.66:9997/v1LiteLLM Params: Pass JSON of litellm supported params litellm.completion() call
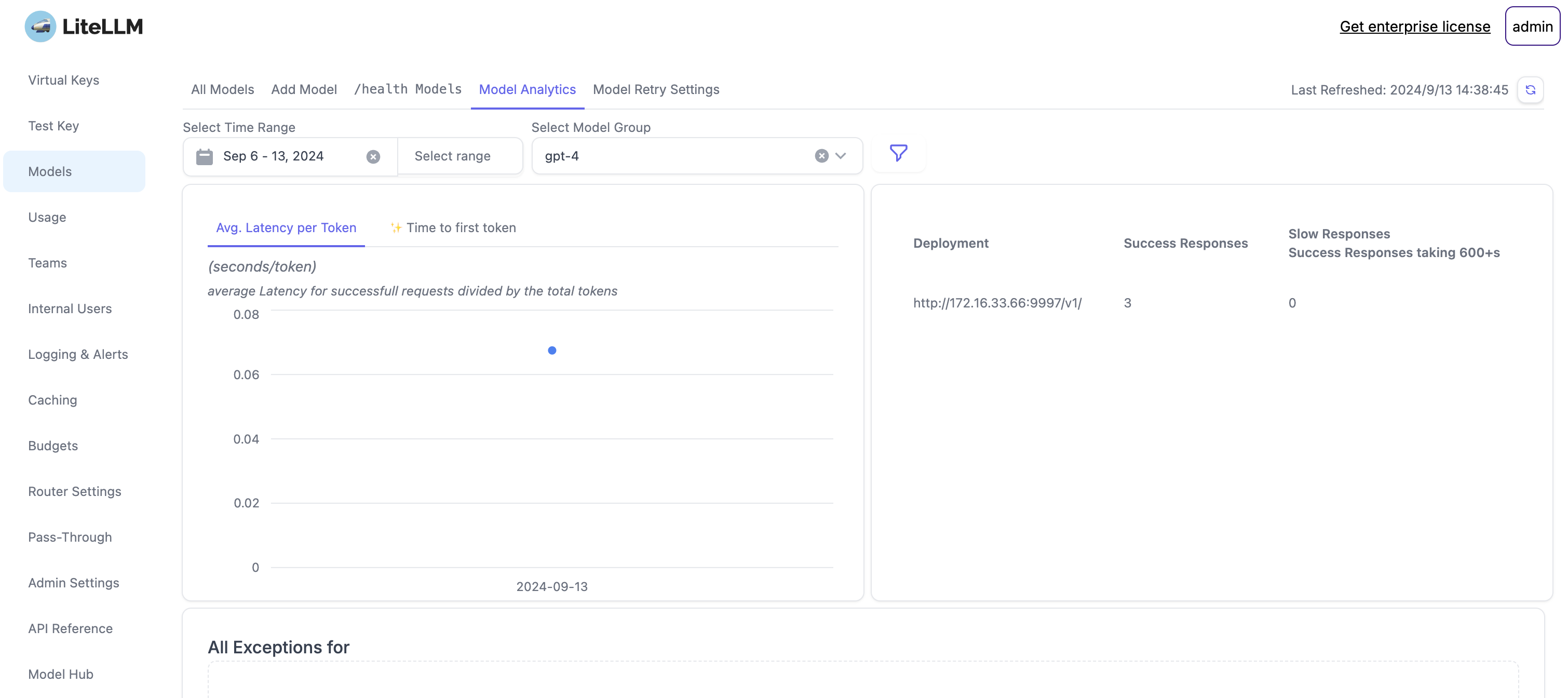
模型分析
LiteLLM Python SDK
安装
pip install litellm
OpenAI-Compatible Endpoints
import os
import litellm
os.environ['LITELLM_LOG'] = 'DEBUG'
os.environ["OPENAI_API_BASE"] = "http://172.16.33.66:9997/v1"
os.environ["OPENAI_API_KEY"] = "NONE"
openai_response = litellm.completion(
model="gpt-4-32k",
messages=[
{"role": "system", "content": "您是人工智能助手。"},
{"role": "user", "content": "介绍一下自己。"}
]
)
print(openai_response)
视觉问答(llava)
import litellm
# model = "ollama/minicpm-v:8b" # ❌ 没有成功,可能是 LiteLLM 组织的提示词有问题吧。
model = "ollama/llava:7b"
# 参考:https://github.com/BerriAI/litellm/blob/main/litellm/llms/ollama.py#L169
# ollama wants plain base64 jpeg/png files as images. strip any leading dataURI
# and convert to jpeg if necessary.
def _convert_image(image):
import base64
import io
try:
from PIL import Image
except:
raise Exception(
"ollama image conversion failed please run `pip install Pillow`"
)
image_data = Image.open(image)
jpeg_image = io.BytesIO()
image_data.convert("RGB").save(jpeg_image, "JPEG")
jpeg_image.seek(0)
return base64.b64encode(jpeg_image.getvalue()).decode("utf-8")
is_file = True
if is_file:
image_path = "/Users/junjian/截屏/catdog.jpg"
base64_image = _convert_image(image_path)
url = f"data:image/jpeg;base64,{base64_image}"
else:
url = "http://book.d2l.ai/_images/catdog.jpg"
response = litellm.completion(
model=model,
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "图像上面有几只动物(用中文回答)"
},
{
"type": "image_url",
"image_url": {
"url": url
}
},
]
}
],
)
print(response.choices[0].message.content)
这张图片显示了一只狗和一只猫。狗是一种可爱的家庭宠物,而猫则是另一种广受喜爱的家庭宠物。两者在一起看着相机,表现出一种互动感的关系。
- litellm/litellm/llms/ollama.py
- LiteLLM - Ollama
- gpt-4o error when analysis image #3629
- Bytes64-encoded api calls failing with Azure and Vertex in 1.45.16 #5515
- MiniCPM-V
LiteLLM & Langfuse Integration(集成)
LiteLLM Proxy Server (LLM Gateway)
部署 Langfuse
编辑 docker-compose.yml
networks:
shared-network:
name: shared-network
services:
langfuse-server:
image: langfuse/langfuse:2
depends_on:
db:
condition: service_healthy
ports:
- "3000:3000"
environment:
- DATABASE_URL=postgresql://postgres:postgres@db:5432/postgres
- NEXTAUTH_SECRET=mysecret
- SALT=mysalt
- ENCRYPTION_KEY=0000000000000000000000000000000000000000000000000000000000000000 # generate via `openssl rand -hex 32`
- NEXTAUTH_URL=http://localhost:3000
- TELEMETRY_ENABLED=${TELEMETRY_ENABLED:-true}
- LANGFUSE_ENABLE_EXPERIMENTAL_FEATURES=${LANGFUSE_ENABLE_EXPERIMENTAL_FEATURES:-false}
networks:
- shared-network
db:
image: postgres
restart: always
healthcheck:
test: ["CMD-SHELL", "pg_isready -U postgres"]
interval: 3s
timeout: 3s
retries: 10
environment:
- POSTGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
- POSTGRES_DB=postgres
ports:
- 5432:5432
volumes:
- database_data:/var/lib/postgresql/data
networks:
- shared-network
volumes:
database_data:
driver: local
- 创建共享网络
shared-network - 设置每个服务的网络为
shared-network
启动服务
docker-compose up -d
部署 LiteLLM
编辑配置文件 config.yaml
model_list:
- model_name: gpt-4
litellm_params:
model: openai/gpt-4-32k
api_base: http://172.16.33.66:9997/v1
api_key: NONE
- model_name: bge
litellm_params:
model: openai/bge-m3
api_base: http://172.16.33.66:9997/v1
api_key: NONE
general_settings:
master_key: sk-1234 # [OPTIONAL] Only use this if you to require all calls to contain this key (Authorization: Bearer sk-1234)
litellm_settings:
success_callback: ["langfuse"]
failure_callback: ["langfuse"]
编辑 docker-compose.yml
version: "3.11"
networks:
shared-network:
name: shared-network
services:
litellm:
build:
context: .
args:
target: runtime
image: ghcr.io/berriai/litellm:main-stable
volumes:
- ./config.yaml:/etc/litellm/config.yaml
ports:
- "4000:4000" # Map the container port to the host, change the host port if necessary
command:
- '--config=/etc/litellm/config.yaml'
- '--debug'
environment:
DATABASE_URL: "postgresql://llmproxy:dbpassword9090@db:5434/litellm"
STORE_MODEL_IN_DB: "True" # allows adding models to proxy via UI
LANGFUSE_PUBLIC_KEY: "pk-lf-fd5d8fba-5134-4037-884d-d6780894a65a"
LANGFUSE_SECRET_KEY: "sk-lf-10122a92-da11-4423-b3f7-ad10e5f268fc"
LANGFUSE_HOST: "http://langfuse-server:3000"
env_file:
- .env # Load local .env file
networks:
- shared-network
db:
image: postgres
restart: always
environment:
PGPORT: 5434
POSTGRES_DB: litellm
POSTGRES_USER: llmproxy
POSTGRES_PASSWORD: dbpassword9090
healthcheck:
test: ["CMD-SHELL", "pg_isready -d litellm -U llmproxy"]
interval: 1s
timeout: 5s
retries: 10
networks:
- shared-network
prometheus:
image: prom/prometheus
volumes:
- prometheus_data:/prometheus
- ./prometheus.yml:/etc/prometheus/prometheus.yml
ports:
- "9090:9090"
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=15d'
restart: always
networks:
- shared-network
volumes:
prometheus_data:
driver: local
- 创建共享网络
shared-network - 设置每个服务的网络为
shared-network - services.litellm.environment
- 设置
LANGFUSE_HOST为http://langfuse-server:3000 - 设置
LANGFUSE_PUBLIC_KEY和LANGFUSE_SECRET_KEY为 Langfuse 的公钥和私钥 - volumes
- 挂载
config.yaml到/etc/litellm/config.yaml
- 挂载
- command
- 开启调试模式
--debug - 指定配置文件路径
--config=/etc/litellm/config.yaml
- 开启调试模式
- 设置
- db.environment
- 修改 postgre 数据库的默认端口
PGPORT: 5434,避免与 Langfuse 的数据库端口冲突🛑。
- 修改 postgre 数据库的默认端口
启动服务
docker-compose up -d
可以运行上面的模型测试(curl 命令)
LiteLLM Python SDK
编辑 main.py
import os
import litellm
os.environ["LANGFUSE_HOST"]="http://localhost:3000"
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-fd5d8fba-5134-4037-884d-d6780894a65a"
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-10122a92-da11-4423-b3f7-ad10e5f268fc"
os.environ["OPENAI_API_BASE"] = "http://172.16.33.66:9997/v1"
os.environ["OPENAI_API_KEY"] = "NONE"
os.environ['LITELLM_LOG'] = 'DEBUG'
litellm.success_callback = ["langfuse"]
litellm.failure_callback = ["langfuse"]
openai_response = litellm.completion(
model="gpt-4-32k",
messages=[
{"role": "system", "content": "您是人工智能助手。"},
{"role": "user", "content": "介绍一下自己。"}
]
)
print(openai_response)
运行 main.py
查看 Langfuse Dashboard
登录 http://localhost:3000 进入 Langfuse Dashboard。
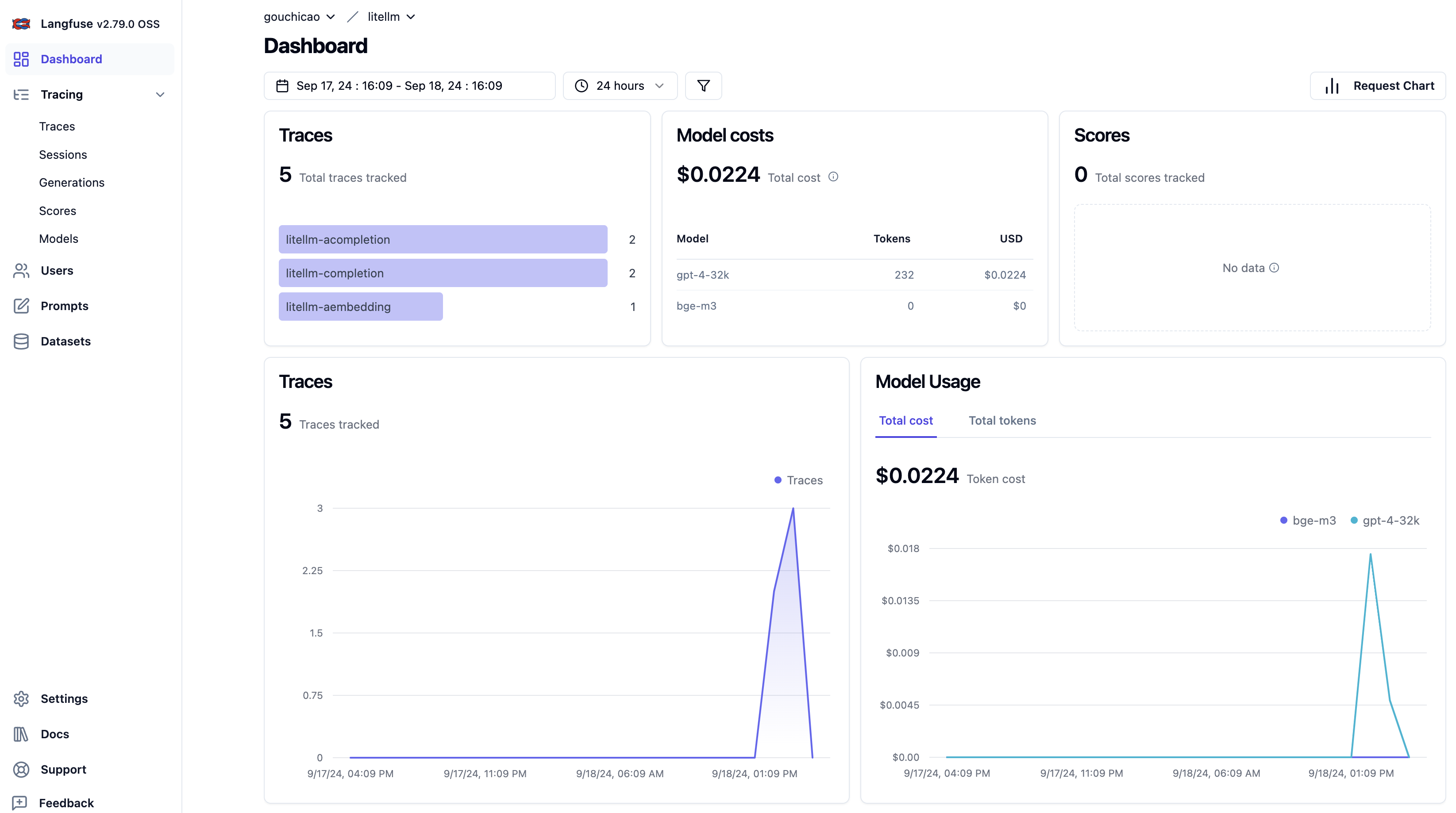
❌ 没有撤梯子出现了莫名其妙的问题
调试了半天 😅
INFO: 127.0.0.1:65383 - "POST /v1/chat/completions HTTP/1.1" 200 OK
16:30:59 - LiteLLM Proxy:ERROR: proxy_server.py:2586 - litellm.proxy.proxy_server.async_data_generator(): Exception occured - b''
Traceback (most recent call last):
File "/opt/miniconda/lib/python3.10/site-packages/litellm/proxy/proxy_server.py", line 2565, in async_data_generator
async for chunk in response:
File "/opt/miniconda/lib/python3.10/site-packages/litellm/llms/ollama.py", line 426, in ollama_async_streaming
raise e # don't use verbose_logger.exception, if exception is raised
File "/opt/miniconda/lib/python3.10/site-packages/litellm/llms/ollama.py", line 381, in ollama_async_streaming
raise OllamaError(
litellm.llms.ollama.OllamaError: b''
ERROR: Exception in ASGI application
Traceback (most recent call last):
File "/opt/miniconda/lib/python3.10/site-packages/starlette/responses.py", line 265, in __call__
await wrap(partial(self.listen_for_disconnect, receive))
File "/opt/miniconda/lib/python3.10/site-packages/starlette/responses.py", line 261, in wrap
await func()
File "/opt/miniconda/lib/python3.10/site-packages/starlette/responses.py", line 238, in listen_for_disconnect
message = await receive()
File "/opt/miniconda/lib/python3.10/site-packages/uvicorn/protocols/http/httptools_impl.py", line 596, in receive
await self.message_event.wait()
File "/opt/miniconda/lib/python3.10/asyncio/locks.py", line 214, in wait
await fut
asyncio.exceptions.CancelledError: Cancelled by cancel scope 16e0d7ac0
During handling of the above exception, another exception occurred:
+ Exception Group Traceback (most recent call last):
| File "/opt/miniconda/lib/python3.10/site-packages/uvicorn/protocols/http/httptools_impl.py", line 435, in run_asgi
| result = await app( # type: ignore[func-returns-value]
| File "/opt/miniconda/lib/python3.10/site-packages/uvicorn/middleware/proxy_headers.py", line 78, in __call__
| return await self.app(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/fastapi/applications.py", line 1054, in __call__
| await super().__call__(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/applications.py", line 123, in __call__
| await self.middleware_stack(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/middleware/errors.py", line 186, in __call__
| raise exc
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/middleware/errors.py", line 164, in __call__
| await self.app(scope, receive, _send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/middleware/cors.py", line 85, in __call__
| await self.app(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/middleware/exceptions.py", line 65, in __call__
| await wrap_app_handling_exceptions(self.app, conn)(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/_exception_handler.py", line 64, in wrapped_app
| raise exc
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
| await app(scope, receive, sender)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/routing.py", line 756, in __call__
| await self.middleware_stack(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/routing.py", line 776, in app
| await route.handle(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/routing.py", line 297, in handle
| await self.app(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/routing.py", line 77, in app
| await wrap_app_handling_exceptions(app, request)(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/_exception_handler.py", line 64, in wrapped_app
| raise exc
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/_exception_handler.py", line 53, in wrapped_app
| await app(scope, receive, sender)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/routing.py", line 75, in app
| await response(scope, receive, send)
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/responses.py", line 258, in __call__
| async with anyio.create_task_group() as task_group:
| File "/opt/miniconda/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 680, in __aexit__
| raise BaseExceptionGroup(
| exceptiongroup.ExceptionGroup: unhandled errors in a TaskGroup (1 sub-exception)
+-+---------------- 1 ----------------
| Traceback (most recent call last):
| File "/opt/miniconda/lib/python3.10/site-packages/litellm/proxy/proxy_server.py", line 2565, in async_data_generator
| async for chunk in response:
| File "/opt/miniconda/lib/python3.10/site-packages/litellm/llms/ollama.py", line 426, in ollama_async_streaming
| raise e # don't use verbose_logger.exception, if exception is raised
| File "/opt/miniconda/lib/python3.10/site-packages/litellm/llms/ollama.py", line 381, in ollama_async_streaming
| raise OllamaError(
| litellm.llms.ollama.OllamaError: b''
|
| During handling of the above exception, another exception occurred:
|
| Traceback (most recent call last):
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/responses.py", line 261, in wrap
| await func()
| File "/opt/miniconda/lib/python3.10/site-packages/starlette/responses.py", line 250, in stream_response
| async for chunk in self.body_iterator:
| File "/opt/miniconda/lib/python3.10/site-packages/litellm/proxy/proxy_server.py", line 2607, in async_data_generator
| proxy_exception = ProxyException(
| File "/opt/miniconda/lib/python3.10/site-packages/litellm/proxy/_types.py", line 1839, in __init__
| "No healthy deployment available" in self.message
| TypeError: a bytes-like object is required, not 'str'
+------------------------------------