LangChain Blog: In the Loop
What is an agent?
“什么是代理?”
几乎每天都会有人问我这个问题。在 LangChain,我们构建工具来帮助开发者构建 LLM 应用程序,特别是那些充当推理引擎并与外部数据和计算源交互的应用程序。这包括通常被称为“代理”的系统。
每个人似乎对代理都有稍微不同的定义。我的定义可能比大多数人更技术性:
💡 代理是一个使用 LLM 来决定应用程序控制流的系统。
即使在这里,我也承认我的定义并不完美。人们通常认为代理是高级的、自主的、类人的——但如果是一个简单的系统,LLM 在两个不同路径之间进行路由呢?这符合我的技术定义,但不符合人们对代理应具备能力的普遍看法。很难准确定义什么是代理!
这就是为什么我非常喜欢 Andrew Ng 上周的推文。在推文中,他建议“与其争论哪些工作应被包括或排除为真正的代理,我们可以承认系统可以有不同程度的代理性。”就像自动驾驶汽车有不同的自动化级别一样,我们也可以将代理能力视为一个光谱。我非常同意这个观点,我认为 Andrew 表达得很好。将来,当有人问我什么是代理时,我会转而讨论什么是“代理性”。
什么是代理性(agentic)?
去年我在 TED 演讲中谈到了 LLM 系统,并使用下面的幻灯片讨论了 LLM 应用程序中存在的不同自主级别。
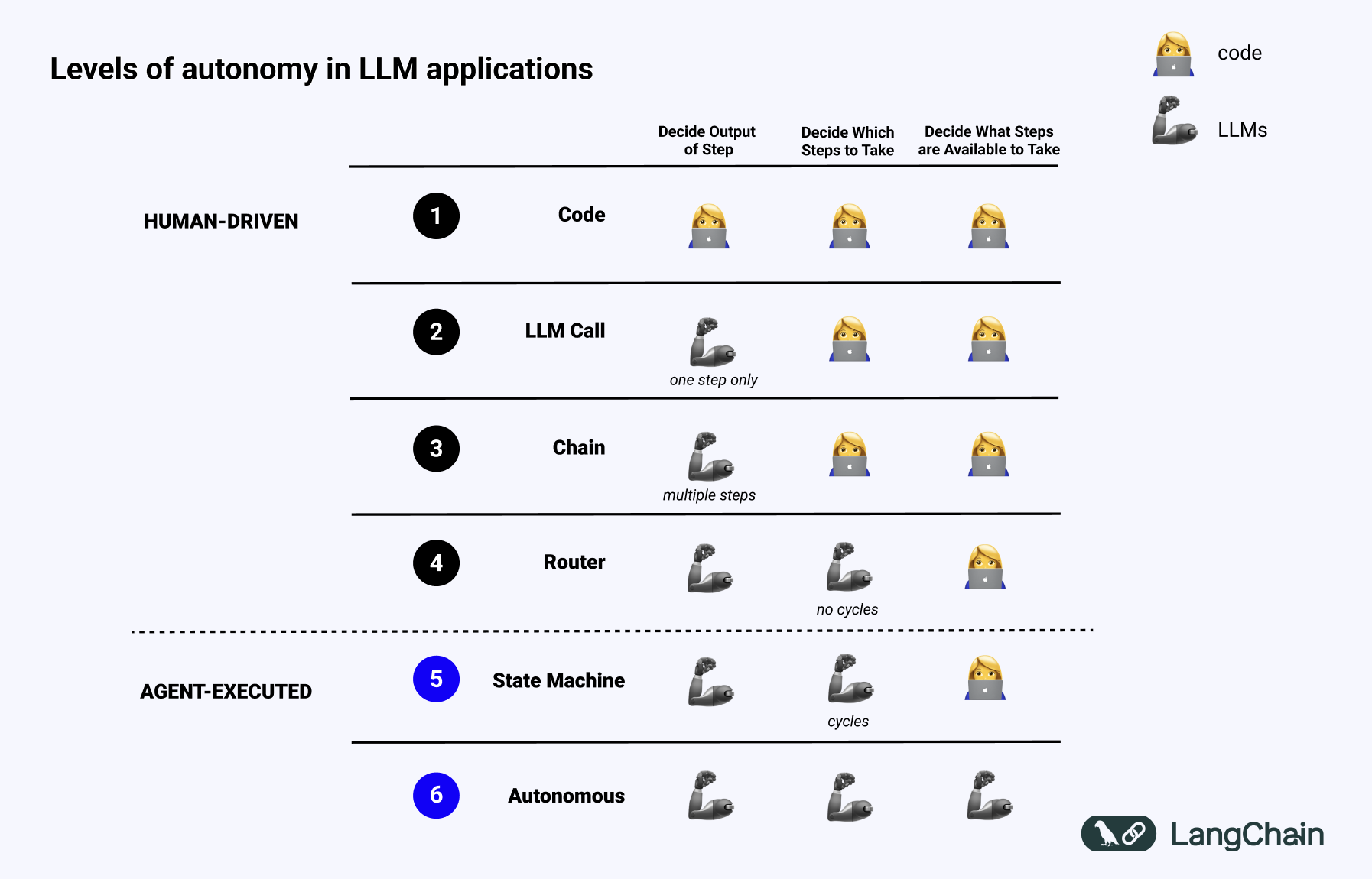
一个系统越“代理性”,LLM 决定系统行为的程度就越高。
使用 LLM 将输入路由到特定的下游工作流中具有一些小的“代理性”行为。这将属于上图中的路由器类别。
如果你使用多个 LLM 进行多个路由步骤呢?这将介于路由器和状态机之间。
如果其中一个步骤决定是否继续或结束——有效地允许系统在完成之前循环运行?这将属于状态机。
如果系统正在构建工具,记住这些工具,然后在未来的步骤中使用它们?这类似于 Voyager 论文中实现的内容,具有极高的代理性,属于更高级的自主代理类别。
这些“代理性”的定义仍然相当技术性。我更喜欢“代理性”的技术定义,因为我认为它在设计和描述 LLM 系统时很有用。
为什么“代理性”是一个有用的概念?
与所有概念一样,值得问一下为什么我们甚至需要“代理性”这个概念。它有什么帮助?
了解系统的代理性可以指导你在开发过程中的决策——包括构建、运行、交互、评估甚至监控它。
系统越代理性,编排框架的帮助就越大。如果你正在设计一个复杂的代理性系统,拥有一个具有正确抽象概念的框架可以加快开发速度。这个框架应该对分支逻辑和循环提供一流的支持。
系统越代理性,运行起来就越困难。它将变得越来越复杂,有些任务需要很长时间才能完成。这意味着你会希望将作业作为后台运行。这也意味着你需要持久的执行来处理中途发生的任何错误。
系统越代理性,你就越希望在运行时与之交互。你会希望能够观察内部发生的事情,因为确切的步骤可能事先未知。你会希望能够在特定时间点修改代理的状态或指令,如果它偏离预定路径,可以将其拉回正轨。
系统越代理性,你就越希望有一个为这些类型的应用程序构建的评估框架。你会希望多次运行评估,因为有大量的随机性。你会希望能够测试不仅是最终输出,还包括中间步骤,以测试代理的效率。
系统越代理性,你就越希望有一个新的监控框架。你会希望能够深入了解代理采取的所有步骤。你还会希望能够根据代理采取的步骤查询运行情况。
理解和利用系统中代理能力的光谱可以提高开发过程的效率和稳健性。
代理性是新的
我经常思考的一件事是,在这场狂热中,什么是真正新的。我们是否需要新的工具和基础设施来支持人们构建的 LLM 应用程序?还是以前的通用工具和基础设施就足够了?
对我来说,你的应用程序越代理性,拥有新的工具和基础设施就越关键。这正是我们构建 LangGraph(一个帮助构建、运行和交互代理的代理编排器)和 LangSmith(一个用于 LLM 应用程序的测试和可观察性平台)的动机。随着我们在代理性光谱上进一步发展,整个支持工具的生态系统需要重新构想。
What is a “cognitive architecture”?
更新:一些读者指出,“认知架构”一词在神经科学和计算认知科学中有着丰富的历史。根据维基百科,“认知架构既指关于人类心智结构的理论,也指这种理论的计算实现”。这个定义(以及相关的研究和文章)比我在这里尝试提供的定义要全面得多,因此这篇博客应该被视为我在过去一年中构建和帮助构建基于LLM的应用程序的经验与这一研究领域的映射。
在过去六个月中,我经常使用的一个短语是“认知架构”,并且可能会使用更多。这是我第一次从Flo Crivello那里听到的术语——所有的功劳都归于他,我认为这是一个很棒的术语。那么我到底是什么意思呢?
我所说的认知架构是指你的系统如何思考——换句话说,就是代码/提示/LLM调用的流程,这些流程接收用户输入并执行操作或生成响应。
我喜欢“认知”这个词,因为代理系统依赖于使用LLM来推理该做什么。
我喜欢“架构”这个词,因为这些代理系统仍然涉及大量类似于传统系统架构的工程。
将自主级别映射到认知架构
如果我们回到这张幻灯片(最初来自我的TED演讲)关于LLM应用程序中不同自主级别的幻灯片,我们可以看到不同认知架构的例子。
首先是纯代码——一切都是硬编码的。甚至不是真正的认知架构。
接下来是单个LLM调用。一些数据预处理前和/或后,但单个LLM调用构成了应用程序的主要部分。简单的聊天机器人可能属于这一类。
接下来是一系列LLM调用。这个序列可以是将问题分解成不同的步骤,或者只是服务于不同的目的。更复杂的RAG管道属于这一类:使用第一个LLM调用生成搜索查询,然后使用第二个LLM调用生成答案。
之后是路由器。在此之前,你提前知道应用程序将采取的所有步骤。现在,你不再知道。LLM决定采取哪些行动。这增加了一些随机性和不可预测性。
下一个级别是我称之为状态机的东西。这是将LLM进行一些路由与循环结合起来。这更加不可预测,因为通过将路由器与循环结合起来,系统理论上可以调用无限数量的LLM调用。
自主级别的最终级别是我称之为代理,或者真正的“自主代理”。在状态机中,仍然对可以采取的行动和在采取该行动后执行的流程有约束。在自主代理中,这些护栏被移除。系统本身开始决定可以采取哪些步骤以及指令是什么:这可以通过更新提示、工具或用于驱动系统的代码来完成。
选择认知架构
当我谈论“选择认知架构”时,我指的是选择你想采用的这些架构中的哪一个。这些架构没有一个是严格“优于”其他的——它们都有各自的目的,适用于不同的任务。
在构建LLM应用程序时,你可能会像实验提示一样频繁地实验不同的认知架构。我们正在构建LangChain和LangGraph来实现这一点。我们过去一年的大部分开发工作都集中在构建低级、高度可控的编排框架(LCEL和LangGraph)上。
这与早期的LangChain有些不同,早期的LangChain专注于易于使用的现成链条。这些对于入门非常有用,但难以定制和实验。早期这没问题,因为每个人都只是想开始,但随着领域的成熟,设计很快达到了它的极限。
我对我们在过去一年中所做的改变感到非常自豪,这些改变使LangChain和LangGraph更加灵活和可定制。如果你只通过高级包装器使用过LangChain,请查看低级部分。它们更加可定制,真的可以让你控制应用程序的认知架构。
如果你在构建简单的链条和检索流程,请查看Python和JavaScript中的LangChain。对于更复杂的代理工作流,请尝试Python和JavaScript中的LangGraph。
Why you should outsource your agentic infrastructure, but own your cognitive architecture
为什么你应该外包你的代理基础设施,但拥有你的认知架构
When OpenAI Assistants API came out, it was a bold step towards the future of agents. It moved OpenAI from a company producing LLM APIs to a company producing Agent APIs. 当 OpenAI 助手 API 推出时,这是迈向代理未来的大胆一步。它将 OpenAI 从一家生产 LLM API 的公司转变为一家生产代理 API 的公司。
There are several things that I think the OpenAI Assistants API got right - it introduced a lot of new and helpful infrastructure specifically aimed at running agentic applications. At the same time, it limits what “cognitive architectures” can be built on top of it for really complex (and valuable!) agents. 我认为 OpenAI 助手 API 做对了几件事——它引入了许多专门针对运行代理应用程序的新且有用的基础设施。同时,它限制了可以在其上构建的“认知架构”,以用于真正复杂(且有价值!)的代理。
This shows off the difference between “agentic infrastructure” and “cognitive architectures”. Jeff Bezos has the brilliant quote: “Focus on what makes your beer taste better”. If we take this metaphor and apply it to companies building agents: 这展示了“代理基础设施”和“认知架构”之间的区别。杰夫·贝索斯有一句精彩的名言:“专注于让你的啤酒味道更好的东西”。如果我们采用这个比喻并将其应用于构建代理的公司:
💡 Agentic infrastructure does not make your beer taste better 代理基础设施不会让你的啤酒味道更好
💡 Cognitive architectures absolutely make your beer taste better 认知架构绝对会让你的啤酒味道更好
The need for agentic infrastructure
代理基础设施的需求
OpenAI was pretty spot on in that developers want better infrastructure for running agentic applications. In particular: OpenAI 非常准确地指出,开发人员需要更好的基础设施来运行代理应用程序。特别是:
-
The ability to “configure” assistants with a prompt and tools made it easy to get started and create different agents 通过提示和工具“配置”助手的能力使得入门和创建不同的代理变得容易
-
The ability to run assistants as background runs made it easier to manage longer running workflows 将助手作为后台运行的能力使得管理长时间运行的工作流程变得更容易
-
The built-in persistence of messages made it easy to manage state 内置的消息持久性使得管理状态变得容易
All of these things are things that developers shouldn’t really have to think about. None of these things make your application differentiated - in Jeff Bezos’s words, they don’t make your beer taste better. 所有这些事情都是开发人员不应该真正考虑的事情。这些都不会使你的应用程序与众不同——用杰夫·贝索斯的话来说,它们不会让你的啤酒味道更好。
There is still even more infrastructure that can be built to assist developers! In OpenAI Assistants AI, you currently can’t run multiple runs on the same thread. You can’t easily modify the state of a thread. Still - the Assistants API was a fantastic step in the right direction. 仍然有更多的基础设施可以构建来帮助开发人员!在 OpenAI 助手 AI 中,你目前不能在同一个线程上运行多个运行。你不能轻易修改线程的状态。不过——助手 API 是朝着正确方向迈出的绝佳一步。
The importance of an application-specific cognitive architecture
应用程序特定认知架构的重要性
The issue with the Assistants API is that it is too limiting in what you can easily build on top of it. 助手 API 的问题在于它对你可以轻松构建的内容限制太多。
If you are looking to build a chatbot - fantastic! The “state” of a thread is a list of messages, perfect for that. 如果你想构建一个聊天机器人——太棒了!线程的“状态”是消息列表,非常适合。
If you are looking to build a simple ReAct style agent - great! It also probably works well for that - basically just running an LLM in a while loop. 如果你想构建一个简单的 ReAct 风格代理——很好!它也可能对此非常有效——基本上只是在 while 循环中运行一个 LLM。
But agentic applications are more than just a single chat model invoking the same tools with the same prompt over and over again. They have more complex state that they track than just a list of messages. This control over the state and flow of an application is crucial for bringing any semblance of reliability to agents. 但代理应用程序不仅仅是一个单一的聊天模型,一遍又一遍地调用相同的工具和提示。它们跟踪的状态比消息列表更复杂。对应用程序状态和流程的控制对于为代理带来任何可靠性至关重要。
From working with thousands of builders, we see that the agents making their way to production all have slightly different cognitive architectures. The cognitive architecture of an application is how you get it to really work well - this is where teams are innovating. This is what they are building to make their application differentiated - to make their beer taste better. 通过与成千上万的构建者合作,我们看到进入生产的代理都有略微不同的认知架构。应用程序的认知架构是让它真正运行良好的方式——这是团队创新的地方。这是他们构建的使其应用程序与众不同的东西——让他们的啤酒味道更好。
This isn’t to say you can’t do more complex things with the Assistants API. You probably can. But the API doesn’t make it easy. It doesn’t want you to. OpenAI made a bet on a generic cognitive architecture, which in turn makes it hard to build the application-specific cognitive architectures that are needed to make agents reliable. 这并不是说你不能用助手 API 做更复杂的事情。你可能可以。但 API 并不容易。它不希望你这样做。OpenAI 押注于通用的认知架构,这反过来使得构建使代理可靠的应用程序特定认知架构变得困难。
Why do we care?
我们为什么关心?
Why do I care so much? Why am I writing so many words on this? It’s because I actually think OpenAI got a lot of things right, and they took a stance early in the market that there is a need for agentic infrastructure. They made it easy for developers not to worry about where to store the state of their agents, how to manage a task queue, etc — which is fantastic. 我为什么这么在意?为什么我要写这么多字?因为我实际上认为 OpenAI 做对了很多事情,他们在市场早期就采取了立场,认为需要代理基础设施。他们使开发人员不必担心在哪里存储代理的状态、如何管理任务队列等——这非常棒。
Our goal at LangChain is to make it as easy as possible to build agentic applications. This type of infrastructure is absolutely part of what is needed. LangChain 的目标是使构建代理应用程序尽可能容易。这种类型的基础设施绝对是所需的一部分。
We want to bring the benefits of that agentic infrastructure and marry it with the control that LangGraph gives you over your cognitive architecture. That’s why we built LangGraph Cloud. Write your custom cognitive architecture with LangGraph, then deploy it with LangGraph Cloud and get all the benefits of this agentic infrastructure. 我们希望将这种代理基础设施的好处与 LangGraph 提供的对认知架构的控制结合起来。这就是我们构建 LangGraph Cloud 的原因。使用 LangGraph 编写你的自定义认知架构,然后使用 LangGraph Cloud 部署它,并获得这种代理基础设施的所有好处。
LangGraph Cloud provides fault-tolerant scalability, optimized for real-world interactions. We designed it to have horizontally-scaling task queues and servers, a built-in persistence layer optimized for heavy loads, and configurable caching of nodes across runs. This lets you own the differentiating parts of your application and outsource the rest. LangGraph Cloud 提供容错扩展性,针对现实世界的交互进行了优化。我们设计了水平扩展的任务队列和服务器,内置的持久层针对重负载进行了优化,并且可以跨运行配置节点缓存。这让你拥有应用程序的差异化部分,并将其余部分外包。
In conclusion, focus on what makes your beer taste better: cognitive architectures, not infrastructure. 总之,专注于让你的啤酒味道更好的东西:认知架构,而不是基础设施。
Planning for Agents
规划代理
At Sequoia’s AI Ascent conference in March, I talked about three limitations for agents: planning, UX, and memory. Check out that talk here. In this post, I will dive more into planning for agents. 在三月的红杉AI Ascent会议上,我谈到了代理的三个局限性:规划、用户体验和记忆。在这里查看该演讲。在这篇文章中,我将深入探讨代理的规划。
If you ask any developer building agents with LLMs, he or she will probably cite the inability for agents to plan and reason well as a big pain point for agent reliability. What does planning mean for an agent, and how do we see people currently overcoming this shortcoming? What is (our best guess at what) the future of planning and reasoning for agents will look like? We’ll cover all of this below. 如果你问任何使用LLM构建代理的开发人员,他或她可能会提到代理无法很好地规划和推理是代理可靠性的一大痛点。规划对代理意味着什么,我们如何看到人们目前克服这一缺点?我们对代理规划和推理的未来(我们最好的猜测)会是什么样子?我们将在下面讨论所有这些。
What exactly is meant by planning and reasoning?
规划和推理到底是什么意思?
Planning and reasoning by an agent involves the LLM’s ability to think about what actions to take. This involves both short-term and long term steps. The LLM evaluates all available information and then decides: what are the series of steps that I need to take, and which is the first one I should take right now? 代理的规划和推理涉及LLM思考采取哪些行动的能力。这涉及短期和长期步骤。LLM评估所有可用信息,然后决定:我需要采取哪些步骤,哪一个是我现在应该采取的第一个步骤?
Most of the time, developers use function calling (also known as tool calling) to let LLMs choose what actions to take. Function calling is a capability first added to LLM APIs by OpenAI in June of 2023 and then by others in late 2023/early 2024. With function calling, you can provide JSON schemas for different functions and have the LLM output object match one (or more) of those schemas. For more information on how to do this, see our guide here. 大多数时候,开发人员使用函数调用(也称为工具调用)让LLM选择采取哪些行动。函数调用是OpenAI在2023年6月首次添加到LLM API中的功能,然后在2023年底/2024年初由其他人添加。通过函数调用,您可以为不同的函数提供JSON模式,并让LLM输出对象匹配其中一个(或多个)模式。有关如何执行此操作的更多信息,请参阅我们的指南。
Function calling is used to let the agent choose what to do as an immediate action. Often times though, to successfully accomplish a complex task you need to take a number of actions in sequence. This long-term planning and reasoning is a tougher task for LLMs for a few reasons. First, the LLM must think about a longer time-horizon goal, but then jump back into a short-term action to take. Second, as the agent takes more and more actions, the results of those actions are fed back to the LLM; this lead to the context window growing, which can cause the LLM to get “distracted” and perform poorly. 函数调用用于让代理选择作为即时行动的操作。然而,成功完成复杂任务通常需要按顺序采取多个行动。长期规划和推理对LLM来说是一个更艰难的任务,原因有几个。首先,LLM必须考虑一个更长时间范围的目标,然后再回到要采取的短期行动。其次,随着代理采取越来越多的行动,这些行动的结果会反馈给LLM;这导致上下文窗口增长,可能会导致LLM“分心”并表现不佳。
Like most things in the LLM world, it is tough to measure exactly how well current models do at planning and reasoning. There are reasonable benchmarks like the Berkeley Function Calling Leaderboard for evaluating function calling. We’ve done a little research on evaluating multi-step applications. But the best way to get a sense for this is build up an evaluation set for your specific problem and attempt to evaluate on that yourself. 像LLM世界中的大多数事情一样,很难准确衡量当前模型在规划和推理方面的表现。评估函数调用有合理的基准,如伯克利函数调用排行榜。我们已经对评估多步骤应用程序进行了一些研究。但最好的方法是为您的特定问题建立一个评估集,并尝试自行评估。
💡 Anecdotally, it’s a common conclusion that planning and reasoning is still not at the level it’s needed to be for real-world tasks. 据传,普遍的结论是,规划和推理仍未达到实际任务所需的水平。
What are current fixes to improve planning by agents?
目前有哪些改进代理规划的方法?
The lowest hanging fix for improving planning is to ensuring the LLM has all the information required to reason/plan appropriately. As basic as this sounds, oftentimes the prompt being passed into the LLM simply does not contain enough information for the LLM to make a reasonable decision. Adding a retrieval step, or clarifying the prompt instructions, can be an easy improvement. That’s why its crucial to actually look at the data and see what the LLM is actually seeing. 改进规划的最低悬挂修复是确保LLM拥有进行适当推理/规划所需的所有信息。尽管这听起来很基本,但通常传递给LLM的提示根本不包含足够的信息,LLM无法做出合理的决定。添加检索步骤或澄清提示说明可以是一个简单的改进。这就是为什么实际查看数据并查看LLM实际看到的内容至关重要。
After that, I’d recommend you try changing the cognitive architecture of your application. By “cognitive architecture”, I mean the data engineering logic your application uses to reason. There are two categories of cognitive architectures you can look towards to improve reasoning: general purpose cognitive architectures and domain specific cognitive architectures. 在那之后,我建议您尝试更改应用程序的认知架构。通过“认知架构”,我的意思是您的应用程序用于推理的数据工程逻辑。您可以考虑改进推理的两类认知架构:通用认知架构和特定领域认知架构。
General purpose cognitive architectures vs domain specific cognitive architectures
通用认知架构与特定领域认知架构
General purpose cognitive architectures attempt to achieve better reasoning generically. They can be applied to any task. One good example of this is the “plan and solve” architecture. This paper explores an architecture where first you come up with a plan, and then execute on each step in that plan. Another general purpose architecture is the Reflexion architecture. This paper explores putting an explicit “reflection” step after the agent does a task to reflect on whether it did it correctly or not. 通用认知架构试图在一般情况下实现更好的推理。它们可以应用于任何任务。一个很好的例子是“计划和解决”架构。这篇论文探讨了一种架构,首先你提出一个计划,然后执行该计划中的每一步。另一个通用架构是Reflexion架构。这篇论文探讨了在代理执行任务后放置一个明确的“反思”步骤,以反思它是否正确完成了任务。
Though these ideas show improvement, they are often too general for practical use by agents in production. Rather, we see agents being built with domain-specific cognitive architectures. This often manifests in domain-specific classification/routing steps, domain specific verification steps. Some of the general ideas of planning and reflection can be applied here, but they are often applied in a domain specific way. 尽管这些想法显示出改进,但它们通常对于生产中的代理实际使用来说过于笼统。相反,我们看到代理是用特定领域的认知架构构建的。这通常表现为特定领域的分类/路由步骤,特定领域的验证步骤。规划和反思的一些一般想法可以在这里应用,但它们通常以特定领域的方式应用。
As a concrete example, let’s look at the AlphaCodium paper. This achieved state-of-the-art performance by using what they called “flow engineering” (another way to talk about cognitive architectures). See a diagram of the flow they use below. 作为一个具体的例子,让我们看看AlphaCodium论文。通过使用他们所谓的“流工程”(另一种谈论认知架构的方式),它实现了最先进的性能。请参见下面他们使用的流程图。
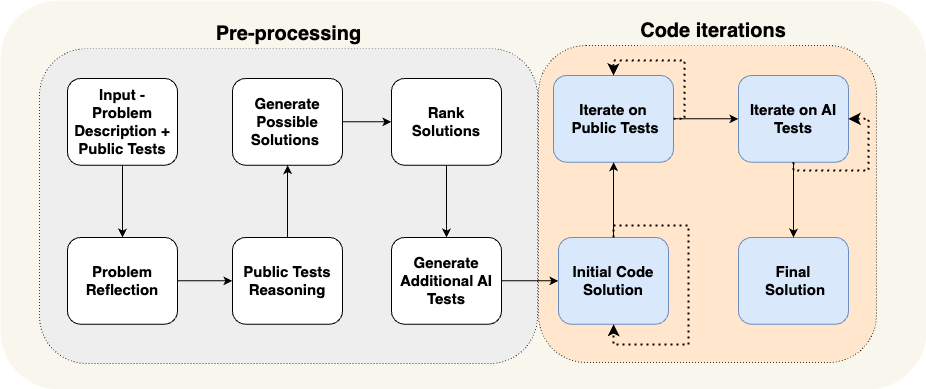
The flow is VERY specific to the problem they are trying to solve. They are telling the agent what to do in steps - come up with tests, then come up with a solution, then iterate on more tests, etc. This cognitive architecture is highly domain specific - it wouldn’t help you write essays, for example. 该流程非常具体地针对他们试图解决的问题。他们告诉代理分步骤做什么——提出测试,然后提出解决方案,然后在更多测试上迭代,等等。这种认知架构是高度特定领域的——例如,它不会帮助你写文章。
Why are domain specific cognitive architectures so helpful?
为什么特定领域的认知架构如此有用?
There are two ways I like to think about this. 我喜欢从两个方面考虑这个问题。
First: you can view this as just another method of communicating to the agent what it should do. You can communicate instructions in prompt instructions, or you can hardcode specific transitions in code. Either one is valid! Code is fantastic way of communicating what you want to have happen. 首先:你可以将其视为向代理传达其应做什么的另一种方法。您可以在提示说明中传达指令,或者可以在代码中硬编码特定的转换。两者都是有效的!代码是传达您想要发生的事情的绝佳方式。
Second: this is essentially removing the planning responsibilities from the LLM to us as engineers. We are are basically saying: “don’t worry about planning, LLM, I’ll do it for you!” Of course, we’re not removing ALL planning from the LLM, as we still ask it do some planning in some instances. 其次:这本质上是将规划责任从LLM转移到我们工程师身上。我们基本上是在说:“不要担心规划,LLM,我会为你做!”当然,我们并没有从LLM中删除所有规划,因为我们仍然在某些情况下要求它进行一些规划。
For example, let’s look back at the AlphaCodium example above. The steps in the flow are basically us doing planning for the LLM! We’re telling it to first write tests, then code, then run the tests, etc. This is presumably what the authors thought a good plan for writing software was. If they were planning how to do a problem, this is how they would do it. And rather than tell the LLM to do in the prompt - where it may ignore it, not understand it, not have all the details - they told the system to do it by constructing a domain specific cognitive architecture. 例如,让我们回顾上面的AlphaCodium示例。流程中的步骤基本上是我们为LLM进行规划!我们告诉它先编写测试,然后编写代码,然后运行测试,等等。这大概是作者认为编写软件的好计划。如果他们在规划如何解决问题,这就是他们会这样做的方式。与其在提示中告诉LLM去做——它可能会忽略它,不理解它,没有所有细节——他们通过构建特定领域的认知架构告诉系统去做。
💡 Nearly all the advanced “agents” we see in production actually have a very domain specific and custom cognitive architecture. 我们在生产中看到的几乎所有高级“代理”实际上都有一个非常特定领域和定制的认知架构。
We’re making building these custom cognitive architectures easier with LangGraph. One of the big focus points of LangGraph is on controllability. We’ve designed LangGraph to very low level and highly controllable - this is because we’ve seen that level of controllability is 100% needed to create a reliable custom cognitive architecture. 我们正在通过LangGraph使构建这些定制认知架构变得更容易。LangGraph的一个重要关注点是可控性。我们设计LangGraph的目的是非常低级和高度可控的——这是因为我们已经看到这种可控性水平是创建可靠的定制认知架构所必需的。
What does the future of planning and reasoning look like?
规划和推理的未来是什么样的?
The LLM space has been changing and evolving rapidly, and we should keep that in mind when building applications, and especially when building tools. LLM领域一直在快速变化和发展,我们在构建应用程序时,尤其是在构建工具时,应该牢记这一点。
My current take is that general purpose reasoning will get more and more absorbed into the model layer. The models will get more and more intelligent, whether through scale or research breakthroughs - it seems foolish to bet against that. Models will get faster and cheaper as well, so it will become more and more feasible to pass a large amount of context to them. 我目前的看法是,通用推理将越来越多地被吸收到模型层中。无论是通过规模还是研究突破,模型将变得越来越智能——反对这一点似乎是愚蠢的。模型也会变得更快和更便宜,因此将大量上下文传递给它们将变得越来越可行。
However, I believe that no matter how powerful the model becomes, you will always need to communicate to the agent, in some form, what it should do. As a result, I believe prompting and custom architectures are here to stay. For simple tasks, prompting may suffice. For more complex tasks, you may want to put the logic of how it should behave in code. Code-first approaches may be faster, more reliable, more debuggable, and oftentimes easier/more logical to express. 然而,我相信无论模型变得多么强大,您总是需要以某种形式向代理传达它应该做什么。因此,我相信提示和定制架构将继续存在。对于简单的任务,提示可能就足够了。对于更复杂的任务,您可能希望将其行为逻辑放在代码中。代码优先的方法可能更快、更可靠、更易调试,并且通常更容易/更合乎逻辑地表达。
I went on a podcast recently with Sonya and Pat from Sequoia and talked about this topic. They drew a fantastic diagram showing how the role / importance of prompting, cognitive architectures, and the model may evolve over time. 最近,我与红杉的Sonya和Pat一起参加了一期播客,讨论了这个话题。他们绘制了一张精彩的图表,展示了提示、认知架构和模型的角色/重要性如何随时间演变。
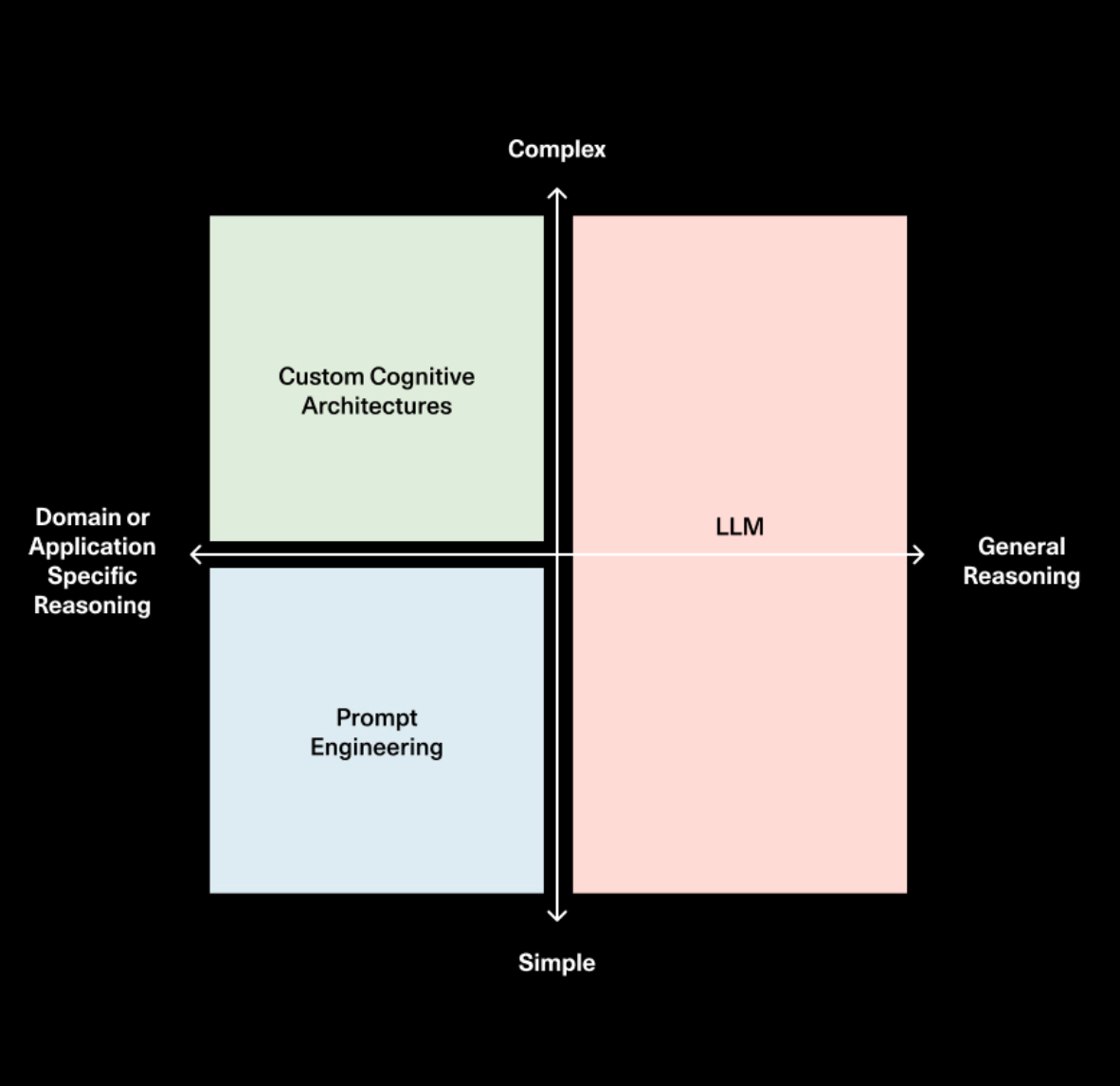
So while the planning and reasoning of LLMs will certainly get better, we also strongly believe that if you are building a task-specific agent then you will need to build a custom cognitive architecture. That’s why we’re so bullish on the future of LangGraph. 因此,虽然LLM的规划和推理肯定会变得更好,但我们也坚信,如果您正在构建特定任务的代理,那么您将需要构建一个定制的认知架构。这就是为什么我们对LangGraph的未来如此看好。
UX for Agents, Part 1: Chat
代理的用户体验,第1部分:聊天
At Sequoia’s AI Ascent conference in March, I talked about three limitations for agents: planning, UX, and memory. Check out that talk here. In this post I will dive deeper into UX for agents. Thanks to Nuno Campos, LangChain founding engineer for many of the original thoughts and analogies here. 在三月的红杉AI Ascent会议上,我谈到了代理的三个限制:规划、用户体验和记忆。请在这里查看该演讲。在这篇文章中,我将深入探讨代理的用户体验。感谢LangChain创始工程师Nuno Campos提供的许多原始想法和类比。
Because there are so many different aspects of UX for agents, this topic will be split into three separate blogs. This is first in the series. 由于代理的用户体验有很多不同的方面,这个话题将分成三篇独立的博客。这是系列中的第一篇。
Human-Computer Interaction has been a well-studied area for years. I believe that in the coming years, Human-Agent Interaction will also become a key area of research. 人机交互多年来一直是一个研究得很透彻的领域。我相信在未来几年,人机代理交互也将成为一个关键的研究领域。
Agentic systems differ from traditional computer systems of the past due to new challenges stemming from latency, unreliability, and natural language interfaces. As such, I strongly believe that new UI/UX paradigms for interacting with these agentic applications will emerge. 代理系统与过去的传统计算机系统不同,因为它们面临来自延迟、不可靠性和自然语言接口的新挑战。因此,我坚信与这些代理应用程序交互的新UI/UX范式将会出现。
While it’s still early days for agentic systems, I think there are multiple emerging UX paradigms. In this blog we will discuss perhaps the most dominant UX so far: chat. 虽然代理系统还处于早期阶段,但我认为有多种新兴的用户体验范式。在这篇博客中,我们将讨论迄今为止可能最主要的用户体验:聊天。
Streaming Chat
流式聊天
The “streaming chat” UX is the most dominant UX so far. This quite simply is an agentic system that streams back its thoughts and actions in a chat format — ChatGPT is the most popular example. This interaction pattern seems basic, but is actually quite good for a few reasons. “流式聊天”用户体验是迄今为止最主要的用户体验。这实际上是一个代理系统,它以聊天格式流回其想法和行动——ChatGPT是最流行的例子。这种交互模式看起来很基本,但实际上有几个原因使其非常好。
The main way to “program” an LLM is with natural language. In chat, you interact directly with the LLM through natural language. This means there is little to no barrier between you and the LLM. “编程”大型语言模型的主要方式是使用自然语言。在聊天中,你通过自然语言直接与大型语言模型互动。这意味着你和大型语言模型之间几乎没有障碍。
💡 In some ways, streaming chat is the “terminal” of early computers. 在某些方面,流式聊天是早期计算机的“终端”。
A terminal (especially in early computers) provides lower-level and more direct access to the underlying OS. But over time, computers have shifted to more UI-based interactions. Streaming chat may be similar - it’s the first way we built to interact with LLMs, and it provides pretty direct access to the underlying LLM. Over time, other UXs may emerge (just as computers became more UI-based) – but low-level access has significant benefits, especially at the start! 终端(尤其是在早期计算机中)提供了对底层操作系统的更低级和更直接的访问。但随着时间的推移,计算机已经转向更多基于UI的交互。流式聊天可能类似——这是我们与大型语言模型互动的第一种方式,它提供了对底层大型语言模型的相当直接的访问。随着时间的推移,其他用户体验可能会出现(就像计算机变得更多基于UI一样)——但低级访问在开始时具有显著的优势!
One of the reasons that streaming chat is great is that LLMs can take a while to work. Streaming enables the user to understand exactly what is happening under the hood. You can stream back both intermediate actions the LLM takes (both what actions they take, and what the results are) as well as the tokens as the LLM “thinks”. 流式聊天很棒的原因之一是大型语言模型可能需要一段时间才能工作。流式聊天使用户能够确切了解底层发生了什么。你可以流回大型语言模型采取的中间动作(包括它们采取的动作和结果)以及大型语言模型“思考”时的 tokens。
Another benefit of streaming chat is that LLMs can mess up often. Chat provides a great interface to naturally correct and guide it! We’re very used to having follow-up conversations and discussing things iteratively over chat already. 流式聊天的另一个好处是大型语言模型经常会出错。聊天提供了一个很好的界面来自然地纠正和引导它!我们已经非常习惯于在聊天中进行后续对话和迭代讨论。
Still, streaming chat has its drawbacks. First - streaming chat is a relatively new UX, so our existing chat platforms (iMessage, Facebook messenger, Slack, etc) don’t have this mode built in. Second, it’s a bit awkward for longer-running tasks — am I just going to sit there and watch the agent work? Third, streaming chat generally needs to be triggered by a human, which means the human is still very much in the loop. 尽管如此,流式聊天也有其缺点。首先——流式聊天是一种相对较新的用户体验,因此我们现有的聊天平台(iMessage、Facebook Messenger、Slack等)没有内置这种模式。其次,对于长时间运行的任务来说,这有点尴尬——我只是坐在那里看着代理工作吗?第三,流式聊天通常需要由人来触发,这意味着人仍然在循环中。
Non-streaming Chat
非流式聊天
It feels odd to call it “non-streaming” chat, since we would have just called this “chat” up until two years ago — but here we are. Non-streaming chat has many of the same properties of streaming chat - it exposes the LLM pretty directly to the user, and it allows for very natural corrections. 称其为“非流式”聊天感觉很奇怪,因为直到两年前我们还只是称其为“聊天”——但现在我们在这里。非流式聊天具有流式聊天的许多相同属性——它非常直接地向用户展示大型语言模型,并允许非常自然的纠正。
The big difference for non-streaming chat is that responses come back in completed batches, which has its pros and cons. The main con is that you can’t see what’s going on under the hood, leaving you in the dark. 非流式聊天的最大区别在于响应以完成的批次返回,这有其优缺点。主要的缺点是你看不到底层发生了什么,让你一无所知。
But… is that actually okay? 但是……这真的可以吗?
Linus Lee had some great thoughts on “delegation” recently that I really liked. A snippet just to illustrate: Linus Lee最近对“委派”有一些很好的想法,我非常喜欢。以下是一个片段来说明:
I intentionally built the interface to be as opaque as possible. 我故意将界面设计得尽可能不透明。
He argues that an opaque interface requires a certain amount of trust, but once established, allows you to just delegate tasks to the agent without micro-managing. This async nature also lends itself to longer-running tasks - which means agents doing more work for you. 他认为,不透明的界面需要一定程度的信任,但一旦建立起来,就允许你将任务委派给代理而无需微观管理。这种异步性质也适用于长时间运行的任务——这意味着代理为你做更多的工作。
Assuming trust is established, this seems good. But it also opens up other issues. For example, how do you handle “double-texting” — where the user messages once, the agent starts doing something, and then the user messages again with a different (and sometimes unrelated) thought before the agent finishes its task. With streaming chat, you generally don’t have this issue because the streaming of the agent blocks the user from typing new input. 假设信任已经建立,这看起来不错。但它也带来了其他问题。例如,你如何处理“双重文本”——用户发送一次消息,代理开始做某事,然后在代理完成任务之前,用户再次发送不同(有时不相关)的想法。在流式聊天中,你通常不会有这个问题,因为代理的流式传输会阻止用户输入新内容。
One of the benefits of the non-streaming chat UX is also much more native to us, which means that it may be easier to integrate into existing workflows. People are used to texting humans - why shouldn’t they easily adapt to texting with an AI? 非流式聊天用户体验的一个好处是它对我们来说更加本土化,这意味着它可能更容易集成到现有的工作流程中。人们习惯于与人类发短信——为什么他们不能轻松适应与AI发短信呢?
💡 Another large benefit of non-streaming chat is that it’s often acceptable for the AI to take longer to respond. 非流式聊天的另一个大好处是AI通常可以接受更长时间的响应。
This is often due to non-streaming chat being integrated more natively into our existing workflows. We don’t expect our friends to text us back instantaneously - why should we expect an AI to? This makes it easier to interact with more complex agentic systems - these systems often take a while, and if there is the expectation of an instantaneous response that could be frustrating. Non-streaming chat often removes that expectation, making it easier to do more complex things. 这通常是因为非流式聊天更本地化地集成到我们现有的工作流程中。我们不期望朋友立即回复我们的短信——为什么我们期望AI这样做呢?这使得与更复杂的代理系统交互变得更容易——这些系统通常需要一段时间,如果期望即时响应可能会令人沮丧。非流式聊天通常消除了这种期望,使得做更复杂的事情变得更容易。
It may initially seem that streaming is newer, flashier, and more futuristic than standard chat… but as we trust our agentic systems more, will this reverse? 最初可能看起来流式聊天比标准聊天更新、更炫、更具未来感……但随着我们对代理系统的信任增加,这会逆转吗?
Is there more than just chat?
除了聊天还有更多吗?
As this is just part one of a three-part series, we believe there are more UXs to consider beyond chat. Still - it is worth reminding that chat is a very good UX, and that here’s a reason it’s so widely used. 由于这只是三部分系列中的第一部分,我们相信除了聊天还有更多的用户体验需要考虑。尽管如此——值得提醒的是,聊天是一种非常好的用户体验,这就是它被广泛使用的原因。
Benefits of chat: 聊天的好处:
- Allows user to interact directly with the model 允许用户直接与模型互动
- Allows for easy follow up questions and/or corrections 允许轻松进行后续问题和/或纠正
Pros/Cons of streaming vs. non-streaming chat 流式聊天与非流式聊天的优缺点
| Pros (优点) | Cons (缺点) | |
|---|---|---|
| Streaming Chat | - Shows the user that some work is being done - 向用户展示正在进行一些工作 - If you stream intermediate steps, allows the user to build trust by seeing what is going on under the hood - 如果您流式传输中间步骤,允许用户通过看到底层发生的事情来建立信任 |
- Most apps today aren’t designed for streaming - 大多数应用程序今天并不是为流式设计的 |
| - Usually has less of an expectation of an instantaneous response, allowing the agent to take on more work - 通常不会期望即时响应,从而使代理可以承担更多工作 - More apps natively support non-streaming already - 更多应用程序已经本地支持非流式 |
- Hard to know what’s happening under the hood - 很难知道底层发生了什么 - UX needs to handle double-texting, where the user interacts again with the system before the first response is completed - 用户在第一个响应完成之前再次与系统互动,UX需要处理双重文本 |
UX for Agents, Part 2: Ambient
代理的用户体验,第2部分:环境
In our previous blog post on chat-based UX for agents, we discussed how chat requires users to proactively think about messaging an AI. But what if the AI could just work in the background for you? 在我们之前关于基于聊天的代理用户体验的博客文章中,我们讨论了聊天如何要求用户主动考虑向AI发送消息。但如果AI可以在后台为你工作呢?
I’d argue that in order for agentic systems to really reach their potential, this shift towards allowing AI to work in the background needs to happen. 我认为,为了使代理系统真正发挥其潜力,这种允许AI在后台工作的转变是必要的。
When tasks are handled in the background, users are generally more tolerant of longer completion times (as they relax expectations for low latency). 当任务在后台处理时,用户通常对较长的完成时间更为宽容(因为他们放松了对低延迟的期望)。
This frees up the agent to do more work, often more carefully / diligently than in a chat UX. 这使得代理可以做更多的工作,通常比在聊天用户体验中更仔细/勤奋。
Additionally, running agents in the background enables us humans to scale our capabilities more effectively. 此外,在后台运行代理使我们人类能够更有效地扩展我们的能力。
Chat interfaces typically limit us to one task at a time. But if agents are running ambiently in the background, there can be many agents handling multiple tasks simultaneously. 聊天界面通常限制我们一次只能处理一个任务。但如果代理在后台环境中运行,可以有许多代理同时处理多个任务。
So, what would this background agent UX look like? 那么,这种后台代理用户体验会是什么样子呢?
Building trust with background agents: Moving from “Human-in-the-loop” to “Human-on-the-loop”
与后台代理建立信任:从“人类在循环内”到“人类在循环上”
It requires a certain level of trust to let an agent run in the background. How do you build this trust? 让代理在后台运行需要一定程度的信任。你如何建立这种信任?
One straightforward idea is to just show users exactly what the agent is doing. 一个简单的想法是向用户展示代理正在做什么。
Display all the steps it is taking, and let users observe what is happening. 显示它正在采取的所有步骤,并让用户观察正在发生的事情。
While this information may not be immediately visible (as it would be when streaming a response back), it should be available for users to click into and observe. 虽然这些信息可能不会立即可见(就像流式传输响应时那样),但用户应该可以点击并观察。
The next step is to not only let users see what is happening, but also let them correct the agent. 下一步不仅是让用户看到正在发生的事情,还要让他们纠正代理。
If they see that the agent made an incorrect choice on step 4 of 10, they should be able to go back to step 4 and correct the agent in some way. 如果他们看到代理在第10步中的第4步做出了错误的选择,他们应该能够回到第4步并以某种方式纠正代理。
What does this correction look like? There are a few forms this can take. 这种纠正是什么样子的?这可以采取几种形式。
Let’s take a concrete example of correcting an agent that called a tool incorrectly: 让我们举一个具体的例子来纠正一个错误调用工具的代理:
-
You could manually type out the correct tool invocation and make it as if the agent had outputted that, then resume from there. 你可以手动输入正确的工具调用,并使其看起来像是代理输出的那样,然后从那里继续。
-
You give the agent explicit instructions on how to call the tool better - e.g., “call it with argument X, not argument Y” - and ask the agent to update its prediction. 你给代理明确的指示,告诉它如何更好地调用工具——例如,“用参数X调用它,而不是参数Y”——并要求代理更新其预测。
-
You could update the instructions or state of the agent at the point in time, and then rerun from that step onwards. 你可以在那个时间点更新代理的指令或状态,然后从那一步重新运行。
The difference between options 2 and 3 lies in whether the agent is aware of its previous mistakes. 选项2和3之间的区别在于代理是否意识到其先前的错误。
In option 2, the agent is presented with its previous poor generation and asked to correct it, while in option 3, it does not know of its bad prediction (and simply follows updated instructions). 在选项2中,代理被告知其先前的错误生成并被要求纠正,而在选项3中,它不知道其错误预测(并且只是遵循更新的指令)。
This approach moves the human from being “in-the-loop” to “on-the-loop”. 这种方法将人类从“在循环内”转移到“在循环上”。
“On-the-loop” requires the ability to show the user all intermediate steps the agent took, allowing the user to pause a workflow halfway through, provide feedback, and then let the agent continue. “在循环上”需要能够向用户展示代理采取的所有中间步骤,允许用户在中途暂停工作流程,提供反馈,然后让代理继续。
One application that has implemented a UX similar to this is Devin, the AI software engineer. 一个实现了类似用户体验的应用程序是Devin,AI软件工程师。
Devin runs for an extended period of time, but you can see all the steps taken, rewind to the state of development at a specific point in time, and issue corrections from there. Devin运行了很长时间,但你可以看到所有采取的步骤,倒回到特定时间点的开发状态,并从那里发出纠正。
Integrating human input: How agents can ask for help when needed
整合人类输入:代理如何在需要时寻求帮助
Although the agent may be running in the background, that does not mean that it needs to perform a task completely autonomously. 虽然代理可能在后台运行,但这并不意味着它需要完全自主地执行任务。
There will be moments when the agent does not know what to do or how to answer. 会有一些时候代理不知道该做什么或如何回答。
At this point, it needs to get the attention of a human and ask for help. 在这一点上,它需要引起人类的注意并寻求帮助。
A concrete example of this is with an email assistant agent I am building. 一个具体的例子是我正在构建的电子邮件助手代理。
Although the email assistant can answer basic emails, it often needs my input on certain tasks I do not want to automate away. 虽然电子邮件助手可以回答基本的电子邮件,但它经常需要我对某些我不想自动化的任务进行输入。
These tasks include reviewing complicated LangChain bug reports, decisions on whether I want to go to conferences, etc. 这些任务包括审查复杂的LangChain错误报告,决定我是否想参加会议等。
In this case, the email assistant needs a way of communicating to me that it needs information to respond. 在这种情况下,电子邮件助手需要一种与我沟通的方式,告诉我它需要信息来回应。
Note that it’s not asking me to respond directly; instead, it’s seeks my opinion on certain tasks, which it can then use to craft and send a nice email or schedule a calendar invite. 请注意,它不是要求我直接回应;相反,它是寻求我对某些任务的意见,然后它可以用这些意见来制作并发送一封漂亮的电子邮件或安排一个日历邀请。
Currently, I have this assistant set up in Slack. 目前,我在Slack中设置了这个助手。
It pings me a question and I respond to it in a thread, natively integrating with my workflow. 它向我发送一个问题,我在一个线程中回应它,与我的工作流程本地集成。
If I were to think about this type of UX at a larger scale than just an email assistant for myself, I would envision a UX similar to a customer support dashboard. 如果我考虑这种类型的用户体验在比仅仅是为我自己提供的电子邮件助手更大的规模上,我会设想一个类似于客户支持仪表板的用户体验。
This interface would show all the areas where the assistant needs human help, the priority of requests, and any additional metadata. 这个界面将显示助手需要人类帮助的所有区域,请求的优先级和任何附加的元数据。
I initially used the term “Agent Inbox” when describing this email assistant - but more accurately, it’s an inbox for humans to assist agents on certain tasks… a bit of a chilling thought. 我最初在描述这个电子邮件助手时使用了“代理收件箱”这个术语——但更准确地说,它是一个人类帮助代理处理某些任务的收件箱……有点令人毛骨悚然的想法。
Conclusion 结论
I am incredibly bullish on ambient agents, as I think they are key to allowing us to scale our own capabilities as humans. 我对环境代理非常看好,因为我认为它们是允许我们扩展自己作为人类的能力的关键。
As our team continues building LangGraph, we are building with these types of UXs in mind. 随着我们的团队继续构建LangGraph,我们正在考虑这些类型的用户体验。
We checkpoint all states, easily allowing for human-on-the-loop observability, rewinding, and editing. 我们检查所有状态,轻松实现人类在环上的可观察性、倒回和编辑。
This also enables agents to reach out to a human and wait for their response before continuing. 这也使得代理能够联系到人类并等待他们的回应,然后再继续。
If you’re building an application with ambient agents, please reach out. We’d love to hear about your experience! 如果你正在构建一个带有环境代理的应用程序,请联系我们。我们很想听听你的经验!
UX for Agents, Part 3: Spreadsheet, Generative, and Collaborative UI/UX
代理的用户体验,第3部分:电子表格、生成和协作UI/UX
The UI/UX space for agents is one of the spaces I am most excited about and will be watching closely for innovation in the coming months. 代理的UI/UX领域是我最感兴趣的领域之一,我将在未来几个月密切关注这一领域的创新。
In an attempt to wrap up the discussion on agent UI/UX, I’ll highlight three lesser-known UXs that have recently become more popular. 为了总结代理UI/UX的讨论,我将重点介绍最近变得更受欢迎的三种不太为人所知的用户体验。
Each of these could easily deserve its own blog post (which may happen down the line!). 每一种都可以轻松地成为一篇独立的博客文章(这可能会在以后发生!)。
Spreadsheet UX
电子表格用户体验
One UX paradigm I’ve seen a lot in the past ~2 months is a spreadsheet UX. I first saw this when Matrices, an AI-native spreadsheet, was launched earlier this year. 在过去的两个月里,我看到的一个用户体验范式是电子表格用户体验。我第一次看到这个是今年早些时候推出的AI原生电子表格Matrices。
I loved seeing this. First and foremost, the spreadsheet UX a super intuitive and user friendly way to support batch workloads. 我很喜欢看到这个。首先,电子表格用户体验是一种超级直观和用户友好的方式来支持批量工作负载。
Each cell becomes it own agent, going to off to research a particular thing. This batching allows users to scale up and interact with multiple agents simultaneously. 每个单元格都成为自己的代理,去研究特定的事情。这种批处理允许用户扩展并同时与多个代理互动。
There are other benefits of this UX as well. The spreadsheet format is a very common UX familiar to most users, so it fits in well with existing workflows. 这种用户体验还有其他好处。电子表格格式是一种非常常见的用户体验,大多数用户都很熟悉,因此它很好地适应了现有的工作流程。
This type of UX is perfect for data enrichment, a common LLM use case where each column can represent a different attribute to enrich. 这种类型的用户体验非常适合数据丰富,这是一个常见的大型语言模型用例,其中每列可以代表不同的属性进行丰富。
Since then, I’ve seen this UX pop up in a few places (Clay and Otto are two great examples of this). 从那时起,我在一些地方看到了这种用户体验(Clay和Otto是两个很好的例子)。
Generative UI
生成式用户界面
The concept of “generative UI” can mean a few different things. “生成式用户界面”的概念可以意味着几种不同的事情。
One interpretation is a truly generative UI where the model generates the raw components to display. 一种解释是一个真正的生成式用户界面,其中模型生成要显示的原始组件。
This is similar to applications like WebSim. Under the hood, the agent is largely writing raw HTML, allowing it to have FULL control over what is displayed. 这类似于WebSim这样的应用程序。在底层,代理主要编写原始HTML,使其能够完全控制显示的内容。
However, this approach allows for a lot of variability in the quality of the generated HTML, so the end result may look a bit wild or unpolished. 然而,这种方法允许生成的HTML质量有很大的变化,因此最终结果可能看起来有点粗糙或不完善。
Another more constrained approach to generative UI involves programmatically mapping the LLM response to different pre-defined UI components. 另一种更受限制的生成式用户界面方法涉及以编程方式将大型语言模型的响应映射到不同的预定义用户界面组件。
This is often done with tool calls. For instance, if an LLM calls a weather API, it then triggers the rendering of a weather map UI component. 这通常通过工具调用来完成。例如,如果大型语言模型调用天气API,它会触发天气图用户界面组件的渲染。
Since the components rendered are not truly generated (but more chosen), the resulting UI will be more polished, though less flexible in what it can generate. 由于渲染的组件不是完全生成的(而是更多选择的),因此生成的用户界面将更加完善,尽管在生成内容方面不那么灵活。
You can learn more about generative UI in our video series here. 您可以在我们的视频系列中了解更多关于生成式用户界面的信息。
Collaborative UX
协作用户体验
A lesser explored UX: what happens when agents and humans are working together? 一个较少探索的用户体验:当代理和人类一起工作时会发生什么?
Think Google Docs, where you can collaborate with teammates on writing or editing documents - but instead, one of your collaborators is an agent. 想想Google Docs,您可以与团队成员合作编写或编辑文档——但其中一个合作者是代理。
The leading thinkers in the space in my mind are Geoffrey Litt and Ink & Switch, with their Patchwork project being a great example of human-agent collaboration. 在我看来,这个领域的领先思想家是Geoffrey Litt和Ink & Switch,他们的Patchwork项目是人类与代理合作的一个很好的例子。
How does collaborative UX compare to the previously discussed ambient UX? 协作用户体验与之前讨论的环境用户体验有何不同?
Our founding engineer Nuno highlights the key differences between the two: 我们的创始工程师Nuno强调了两者之间的主要区别:
The main difference between ambient and collaborative is concurrency: 环境用户体验和协作用户体验之间的主要区别是并发性:
-
In a collaborative UX, you and the LLM often do work simultaneously, “feeding” off of each others work 在协作用户体验中,您和大型语言模型通常同时工作,相互“借鉴”彼此的工作
-
In an ambient UX, the LLM is continuously doing work in the background while you, the user, focus on something else entirely 在环境用户体验中,大型语言模型在后台持续工作,而您,用户,完全专注于其他事情
These differences also translate into distinct requirements when building these applications: 这些差异在构建这些应用程序时也转化为不同的需求:
-
For collaborative UX, you may need to display granular pieces of work being done by the LLM.(This falls somewhere on the spectrum between individual tokens and larger, application-specific pieces of work like paragraphs in a text editor).A common requirement might be having an automated way to merge concurrent changes, similar to how Google Doc manages real-time collaboration. 对于协作用户体验,您可能需要显示大型语言模型正在完成的细粒度工作。(这介于单个标记和更大的、特定于应用程序的工作之间,例如文本编辑器中的段落)。一个常见的需求可能是有一种自动合并并发更改的方法,类似于Google Doc管理实时协作的方式。
-
For ambient UX, you may need to summarize the work done by the LLM or highlight any changes.A common requirement might be to trigger a run from an event that happened in some other system, e.g. via a webhook. 对于环境用户体验,您可能需要总结大型语言模型完成的工作或突出任何更改。一个常见的需求可能是从其他系统中发生的事件触发运行,例如通过webhook。
Why are we thinking about this?
为什么我们要考虑这个?
LangChain is not known for being a UI/UX focused company. But we spend a lot of time thinking about this. Why? LangChain并不是一家以用户界面/用户体验为重点的公司。但我们花了很多时间思考这个。为什么?
Our goal is to make it as easy as possible to build agentic applications. 我们的目标是尽可能简化构建代理应用程序的过程。
How humans interact with these applications greatly affects the type of infrastructure that we need to build. 人类如何与这些应用程序互动极大地影响了我们需要构建的基础设施类型。
For example - we recently launched LangGraph Cloud, our infrastructure for deploying agentic applications at scale. 例如——我们最近推出了LangGraph Cloud,这是我们用于大规模部署代理应用程序的基础设施。
It features multiple streaming modes, support for “double-texting” use cases, and async background runs. 它具有多种流模式,支持“双文本”用例和异步后台运行。
All of these were directly influenced by UI/UX trends that we saw emerging. 所有这些都直接受到我们看到的新兴用户界面/用户体验趋势的影响。
If you are building an application with a novel or interesting UI/UX (e.g. non-streaming chat) we would love to hear from you at hello@langchain.dev! 如果您正在构建一个具有新颖或有趣的用户界面/用户体验的应用程序(例如非流式聊天),我们很想听到您的消息,请发送邮件至hello@langchain.dev!
Memory for agents
代理的记忆
If agents are the biggest buzzword of LLM application development in 2024, memory might be the second biggest. But what even is memory? 如果代理是2024年LLM应用开发中最大的流行词,那么记忆可能是第二大的。但记忆究竟是什么?
At a high level, memory is just a system that remembers something about previous interactions. This can be crucial for building a good agent experience. 从高层次来看,记忆只是一个记住先前交互内容的系统。这对于构建良好的代理体验至关重要。
Imagine if you had a coworker who never remembered what you told them, forcing you to keep repeating that information - that would be insanely frustrating! 想象一下,如果你有一个同事从不记得你告诉他们的事情,迫使你不断重复这些信息——那将是非常令人沮丧的!
People often expect LLM systems to innately have memory, maybe because LLMs feel so human-like already. However, LLMs themselves do NOT inherently remember things — so you need to intentionally add memory in. 人们常常期望LLM系统天生就有记忆,可能是因为LLM已经感觉非常像人类。然而,LLM本身并不会天生记住事情——所以你需要有意地添加记忆。
But how exactly should you think about doing that? 但你究竟应该如何考虑这样做呢?
Memory is application-specific
记忆是特定于应用的
We’ve been thinking about memory for a while, and we believe that memory is application-specific. 我们已经思考记忆有一段时间了,我们相信记忆是特定于应用的。
What Replit’s coding agent may choose to remember about a given user is very different than what Unify’s research agent might remember. Replit的编码代理可能选择记住给定用户的内容与Unify的研究代理可能记住的内容非常不同。
Replit may choose to remember Python libraries that the user likes; Unify may remember the industries of the companies a user is researching. Replit可能会选择记住用户喜欢的Python库;Unify可能会记住用户正在研究的公司的行业。
Not only does what an agent remember vary by application, but how the agent remembers may differ too. 不仅代理记住的内容因应用而异,代理记住的方式也可能不同。
As discussed in a previous post, a key aspect of agents is the UX around them. Different UXs offer distinct ways to gather and update feedback accordingly. 如之前的文章所讨论的,代理的一个关键方面是围绕它们的用户体验。不同的用户体验提供了不同的方式来相应地收集和更新反馈。
So, how are we approaching memory at LangChain? 那么,我们在LangChain是如何处理记忆的呢?
💡 Much like our approach to agents: we aim to give users low-level control over memory and the ability to customize it as they see fit. 就像我们对代理的处理方式一样:我们旨在让用户对记忆有低层次的控制权,并能够根据需要进行定制。
This philosophy guided much of our development of the Memory Store, which we added into LangGraph last week. 这种理念指导了我们对Memory Store的大部分开发,我们上周将其添加到LangGraph中。
Types of memory
记忆的类型
While the exact shape of memory that your agent has may differ by application, we do see different high level types of memory. These types of memory are nothing new - they mimic human memory types. 虽然你的代理拥有的记忆的确切形态可能因应用而异,但我们确实看到了不同的高级记忆类型。这些记忆类型并不新鲜——它们模仿人类的记忆类型。
There’s been some great work to map these human memory types to agent memory. My favorite is the CoALA paper.Below is my rough, ELI5 explanation of each type and practical ways for how todays agents may use and update this memory type. 已经有一些很好的工作将这些人类记忆类型映射到代理记忆中。我最喜欢的是CoALA论文。以下是我对每种类型的粗略、ELI5解释,以及当今代理可能如何使用和更新这种记忆类型的实际方法。
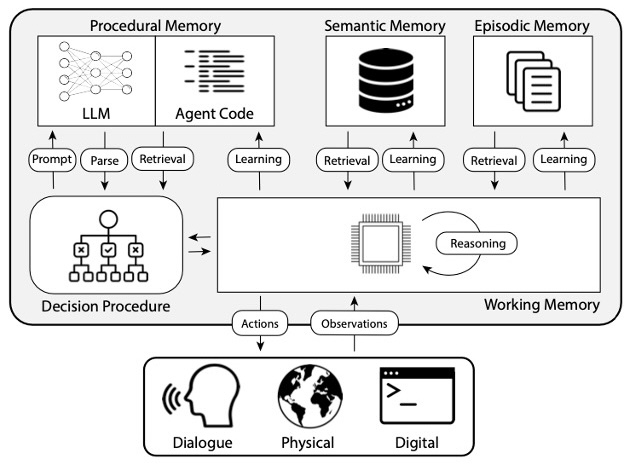
Decision procedure diagram from CoALA paper (Sumers, Yao, Narasimhan, Griffiths 2024) CoALA论文中的决策程序图(Sumers, Yao, Narasimhan, Griffiths 2024)
- Procedural Memory: 程序性记忆
- Semantic Memory: 语义记忆
- Episodic Memory: 情景记忆
- Working Memory: 工作记忆
Procedural Memory
程序性记忆
This term refers to long-term memory for how to perform tasks, similar to a brain’s core instruction set. 这个术语指的是如何执行任务的长期记忆,类似于大脑的核心指令集。
Procedural memory in humans: remembering how to ride a bike. 人类的程序性记忆:记住如何骑自行车。
Procedural memory in Agents: the CoALA paper describes procedural memory as the combination of LLM weights and agent code, which fundamentally determine how the agent works. 代理的程序性记忆:CoALA论文将程序性记忆描述为LLM权重和代理代码的组合,这些基本上决定了代理的工作方式。
In practice, we don’t see many (any?) agentic systems that update the weights of their LLM automatically or rewrite their code. 在实践中,我们没有看到很多(任何?)代理系统自动更新其LLM的权重或重写其代码。
We do, however, see some examples of an agent updating its own system prompt. While this is the closest practical example, it remains relatively uncommon. 然而,我们确实看到了一些代理更新其自身系统提示的例子。虽然这是最接近的实际例子,但它仍然相对罕见。
Semantic Memory
语义记忆
This is someone’s long-term store of knowledge. 这是某人的长期知识储存。
Semantic memory in humans: it’s composed of pieces of information such as facts learned in school, what concepts mean and how they are related. 人类的语义记忆:它由在学校学到的事实、概念的含义及其关系等信息组成。
Semantic memory in agents: the CoALA paper describes semantic memory as a repository of facts about the world. 代理的语义记忆:CoALA论文将语义记忆描述为关于世界事实的存储库。
Today, this is most often used by agents to personalize an application. 今天,这通常被代理用来个性化应用程序。
Practically, we see this being done by using an LLM to extract information from the conversation or interactions the agent had. 实际上,我们看到这是通过使用LLM从代理的对话或交互中提取信息来完成的。
The exact shape of this information is usually application-specific. This information is then retrieved in future conversations and inserted into the system prompt to influence the agent’s responses. 这些信息的确切形态通常是特定于应用的。这些信息随后在未来的对话中被检索并插入系统提示中,以影响代理的响应。
Episodic Memory
情景记忆
This refers to recalling specific past events. 这指的是回忆特定的过去事件。
Episodic memory in humans: when a person recalls a particular event (or “episode”) experienced in the past. 人类的情景记忆:当一个人回忆过去经历的特定事件(或“情节”)时。
Episodic memory in agents: the CoALA paper defines episodic memory as storing sequences of the agent’s past actions. 代理的情景记忆:CoALA论文将情景记忆定义为存储代理过去行动的序列。
This is used primarily to get an agent to perform as intended. 这主要用于让代理按预期执行。
In practice, episodic memory is implemented as few-shot example prompting. 在实践中,情景记忆被实现为少量示例提示。
If you collect enough of these sequences, then this can be done via dynamic few-shot prompting. 如果你收集了足够多的这些序列,那么可以通过动态少量示例提示来完成。
This is usually great for guiding the agent if there is a correct way to perform specific actions that have been done before. 如果有一种正确的方法来执行之前完成的特定操作,这通常非常适合指导代理。
In contrast, semantic memory is more relevant if there isn’t necessarily a correct way to do things, or if the agent is constantly doing new things so the previous examples don’t help much. 相比之下,如果没有必要的正确方法来做事情,或者代理不断在做新事情,那么语义记忆更为相关,因为之前的示例帮助不大。
How to update memory
如何更新记忆
Besides just thinking about the type of memory to update in their agents, we also see developers thinking about how to update agent memory. 除了考虑在代理中更新的记忆类型外,我们还看到开发人员在考虑如何更新代理记忆。
One way to update agent memory is “in the hot path”. This is where the agent system explicitly decides to remember facts (usually via tool calling) before responding. This is the approach taken by ChatGPT. 更新代理记忆的一种方法是“在热路径中”。这是代理系统在响应之前明确决定记住事实(通常通过工具调用)的地方。这是ChatGPT采用的方法。
Another way to update memory is “in the background”. In this case, a background process runs either during or after the conversation to update memory. 另一种更新记忆的方法是在“后台”。在这种情况下,后台进程在对话期间或之后运行以更新记忆。
Comparing these two approaches, the “in the hot path” approach has the downside of introducing some extra latency before any response is delivered. It also requires combining the memory logic with the agent logic. 比较这两种方法,“在热路径中”的方法的缺点是,在任何响应交付之前引入了一些额外的延迟。它还需要将记忆逻辑与代理逻辑结合起来。
However, running in the background avoids those issues - there’s no added latency, and memory logic remains separate. 然而,在后台运行避免了这些问题——没有增加延迟,记忆逻辑保持独立。
But running “in the background” also has its own drawbacks: the memory is not updated immediately, and extra logic is needed determine when to kick off the background process. 但在“后台”运行也有其自身的缺点:记忆不会立即更新,并且需要额外的逻辑来确定何时启动后台进程。
Another way to updating memory involves user feedback, which is particularly relevant to episodic memory. 另一种更新记忆的方法涉及用户反馈,这与情景记忆特别相关。
For example, If the user marks an interaction as a positive one, you can save that feedback to recall in the future. 例如,如果用户将某次交互标记为正面交互,你可以保存该反馈以供将来回忆。
Why do we care about memory for agents?
为什么我们关心代理的记忆?
How does this impact what we’re building at LangChain? Well, memory greatly affects the usefulness of an agentic system, so we’re extremely interested in making it as easy as possible to leverage memory for applications. 这对我们在LangChain构建的内容有何影响?嗯,记忆极大地影响了代理系统的有用性,所以我们非常感兴趣的是尽可能简化利用记忆来应用。
To this end, we’ve built a lot of functionality for this into our products. This includes: 为此,我们在产品中构建了许多功能。这包括:
-
Low-level abstractions for a memory store in LangGraph to give you full control over your agent’s memory 在LangGraph中为记忆存储提供的低层次抽象,以便你完全控制代理的记忆
-
Template for running memory both “in the hot path” and “in the background” in LangGraph 在LangGraph中运行记忆的“热路径”和“后台”模板
-
Dynamic few shot example selection in LangSmith for rapid iteration 在LangSmith中进行快速迭代的动态少量示例选择
We’ve even built a few applications of our own that leverage memory! It’s still early though, so we’ll keep on learning about agent memory and the areas it can be used effectively 🙂 我们甚至构建了一些利用记忆的应用程序!不过还处于早期阶段,所以我们将继续学习代理记忆及其可以有效使用的领域🙂
Communication is all you need
沟通就是你需要的一切
“What we’ve got here is failure to communicate” - Cool Hand Luke (1967) “我们这里的问题是沟通失败” - 《冷手卢克》(1967)
Communication is the hardest part of life. It’s also the hardest part of building LLM applications. 沟通是生活中最难的部分。它也是构建LLM应用程序中最难的部分。
New hires always requires a lot of communication when first joining a company, no matter how smart they may be. This might include getting a guidebook of key procedures and best practices, having a manager step in to help the new hire get up to speed, and gaining access to specific software to do the job properly. While ramping up, giving and receiving continuous feedback ensures that the new hire is successful in their role. 新员工在刚加入公司时总是需要大量的沟通,无论他们多么聪明。这可能包括获取关键程序和最佳实践的指南手册,经理介入帮助新员工跟上进度,以及获得正确完成工作的特定软件。在适应过程中,持续的反馈确保新员工在其角色中取得成功。
Just as onboarding a new hire requires thoughtful communication, building an agent also requires high standards for good communication. As smart as the underlying LLMs may become, they will still need the proper context to function reliably, and that context needs to be communicated properly. 正如入职新员工需要周到的沟通,构建代理也需要高标准的良好沟通。尽管底层LLM可能变得非常智能,它们仍然需要适当的上下文才能可靠地运行,而这些上下文需要正确地传达。
💡 Most of the time when an agent is not performing reliably the underlying cause is not that the model is not intelligent enough, but rather that context and instructions have not been communicated properly to the model. 大多数情况下,当代理表现不可靠时,根本原因不是模型不够智能,而是上下文和指令没有正确传达给模型。
Don’t get me wrong - the models do mess up and have room to improve. But more often than not, it comes down to basic communication issues. 不要误会——模型确实会出错并且有改进的空间。但更多时候,这归结为基本的沟通问题。
If we believe that communication is a key part of building LLM applications, then from that axiom, we can derive some other “hot takes” about agents that should hold. I’ve listed a few below in brief detail. All of these could (and maybe will) be individual blogs. 如果我们认为沟通是构建LLM应用程序的关键部分,那么从这个公理出发,我们可以得出一些关于代理的其他“热门观点”。我在下面简要列出了一些。所有这些都可以(也许会)成为单独的博客。
Why prompt engineering isn’t going away
为什么提示工程不会消失
As models improve, prompt engineering tricks like bribing an LLM with a tip or worrying about JSON vs XML formatting will become near obsolete. However, it will still be critical for you to effectively and clearly communicate to the model and give it clear instructions on how to handle various scenarios. 随着模型的改进,像用小费贿赂LLM或担心JSON与XML格式化之类的提示工程技巧将变得几乎过时。然而,能够有效且清晰地与模型沟通并给出明确的处理各种场景的指令仍然至关重要。
💡 The model is not a mind reader - if you want it to behave a certain way or process specific information, you must provide that context. 模型不是读心术者——如果你希望它以某种方式行为或处理特定信息,你必须提供那个上下文。
The best tip for diagnosing why your agent isn’t working is to simply look at the actual calls to the LLM and the exact inputs to the prompts— then make sure that if you gave these inputs to the smartest human you know, they would be able to respond as you expect. If they couldn’t do that, then you need to clarify your request, typically by adjusting the prompt. This process, known as prompt engineering, is unlikely to disappear anytime soon. 诊断代理为何不起作用的最佳建议是简单地查看对LLM的实际调用和提示的确切输入——然后确保如果你将这些输入给你认识的最聪明的人,他们能够按你预期的方式回应。如果他们不能做到这一点,那么你需要澄清你的请求,通常通过调整提示。这一过程被称为提示工程,短期内不太可能消失。
Why code will make up a large part of the “cognitive architecture” of an agent
为什么代码将构成代理“认知架构”的大部分
Prompts are one way to communicate to an LLM how they should behave as part of an agentic system, but code is just as important. Code is a fantastic way to communicate how a system should behave. Compared to natural language, code lets you communicate much more precisely the steps you expect a system to take. 提示是与LLM沟通它们在代理系统中应如何行为的一种方式,但代码同样重要。代码是一种传达系统应如何行为的绝佳方式。与自然语言相比,代码让你更精确地传达你期望系统采取的步骤。
💡 The “cognitive architecture” of your agent will consist of both code and prompts. 你的代理的“认知架构”将由代码和提示组成。
Some instructions an agent can only be communicated in natural language. Others could be either code or language. Code can be more precise and more efficient, and so there are many spots we see code being more useful than prompts when building the “cognitive architecture” of your agent. 有些指令只能用自然语言传达给代理。其他的可以是代码或语言。代码可以更精确和更高效,因此在构建代理的“认知架构”时,我们看到许多地方代码比提示更有用。
Why you need an agent framework
为什么你需要一个代理框架
Some parts of coding are necessary for you, as an agent developer, to write, in order to best communicate to the agent what it should be doing. This makes up the cognitive architecture of your application and is part of your competitive advantage and moat. 作为代理开发者,有些代码部分是你必须编写的,以便最好地传达给代理它应该做什么。这构成了你的应用程序的认知架构,是你竞争优势和护城河的一部分。
💡 There are other pieces of code that you will have to write that are generic infrastructure and tooling that you need to build, but don’t provide any differentiation. This is where an agent framework can assist. 还有一些代码部分是你必须编写的,它们是你需要构建的通用基础设施和工具,但不提供任何差异化。这就是代理框架可以帮助的地方。
An agent framework facilitates this by letting you focus on the parts of code that matter - what the agent should be doing — while taking care of common concerns unrelated to your application’s cognitive architecture, such as: 代理框架通过让你专注于重要的代码部分——代理应该做什么——同时处理与你的应用程序认知架构无关的常见问题来促进这一点,例如:
- Clear streaming of what the agent is doing 代理正在做什么的清晰流式传输
- Persistence to enable multi-tenant memory 持久性以实现多租户内存
- Infrastructure to power human-in-the-loop interaction patterns 支持人类在循环内交互模式的基础设施
- Running agents in a fault tolerant, horizontally scalable way 以容错、水平可扩展的方式运行代理
Why it matters that LangGraph is the most controllable agent framework out there
为什么LangGraph是最可控的代理框架很重要
You want an agent framework that takes care of some of the issues that are listed above, but that still lets you communicate as clearly as possible (through prompts and code) what the agent should be doing. Any agent framework that obstructs that is just going to get in the way - even if it makes it easier to get started. Transparently, that’s what we saw with langchain - it made it easy to get started but suffered from built-in prompts, a hard-coded while loop, and wasn’t easy to extend. 你需要一个代理框架来处理上述一些问题,但仍然让你尽可能清晰地(通过提示和代码)传达代理应该做什么。任何阻碍这一点的代理框架都会妨碍——即使它让入门变得更容易。显然,这就是我们在langchain中看到的——它让入门变得容易,但受限于内置提示、硬编码的while循环,并且不易扩展。
We made sure to fix that with LangGraph. 我们确保用LangGraph解决了这个问题。
💡 LangGraph stands apart from all other agent frameworks for its focus on being low-level, highly controllable, and highly customizable. LangGraph与所有其他代理框架不同,因为它专注于低级、高度可控和高度可定制。
There is nothing built in that restricts the cognitive architectures you can build. The nodes and edges are nothing more than Python functions - you can put whatever you want inside them! 没有任何内置的东西限制你可以构建的认知架构。节点和边不过是Python函数——你可以在其中放置任何你想要的东西!
Agents are going to heavily feature code as part of their cognitive architecture. Agent frameworks can help remove some of the common infrastructure needs. But they CANNOT restrict the cognitive architecture of your agent. That will impede your ability to communicate what exactly you want to happen and the agent won’t be reliable. 代理将在其认知架构中大量使用代码。代理框架可以帮助消除一些常见的基础设施需求。但它们不能限制你的代理的认知架构。这将妨碍你传达你确切想要发生的事情的能力,并且代理将不可靠。
Why agent frameworks like LangGraph are here to stay
为什么像LangGraph这样的代理框架会一直存在 A somewhat common question I get asked is: “as the models get better, will that remove the need for frameworks like LangGraph?”. The underlying assumption is that the models will get so good that they will remove the need for any code around the LLM. 我经常被问到的一个问题是:“随着模型变得更好,这会消除对像LangGraph这样的框架的需求吗?”。潜在的假设是模型会变得如此好,以至于不再需要围绕LLM的任何代码。
No. 不会。
If you’re using LangGraph to elicit better general purpose reasoning from models, then sure, maybe. 如果你使用LangGraph从模型中引出更好的通用推理,那么当然,可能。
But that’s not how most people are using it. 但这不是大多数人使用它的方式。
💡 Most people are using LangGraph to build vertical-specific, highly customized agentic applications. 大多数人使用LangGraph来构建特定垂直领域的高度定制的代理应用程序。
Communication is a key part of that, and code is a key part of communication. Communication isn’t going away, and so neither is code — and so neither is LangGraph. 沟通是其中的关键部分,代码是沟通的关键部分。沟通不会消失,因此代码也不会消失——LangGraph也不会消失。
Why building agents is a multidisciplinary endeavor
为什么构建代理是一个多学科的努力
One thing that we noticed quickly is that teams building agents aren’t just made up of engineers. 我们很快注意到,构建代理的团队不仅仅由工程师组成。
💡 Non-technical subject matter experts also often play a crucial role in the building process. 非技术主题专家在构建过程中也经常扮演关键角色。
One key area is prompt engineering, where domain experts often write the best natural language instructions for prompts, since they know how the LLM should behave (more so than the engineers). 一个关键领域是提示工程,领域专家通常为提示编写最佳的自然语言指令,因为他们比工程师更了解LLM应该如何行为。
Yet, the value of domain experts goes beyond prompting. They can review the entire “cognitive architecture” of the agent, to make sure all logic (whether expressed in language or in code) is correct. Tools like LangGraph Studio, which visualize the flow of your agent, make this process easier. 然而,领域专家的价值不仅限于提示。他们可以审查代理的整个“认知架构”,以确保所有逻辑(无论是用语言还是代码表达)都是正确的。像LangGraph Studio这样的工具,可以可视化你的代理的流程,使这个过程更容易。
Domain experts can also help debug why an agent is messing up, as agents often mess up because of a failure to communicate - a gap that domain experts are well-equipped to spot. 领域专家还可以帮助调试代理为何出错,因为代理经常因为沟通失败而出错——这是领域专家能够很好地发现的差距。
Why we made LangSmith the most user friendly “LLM Ops” tool
为什么我们将LangSmith打造成最用户友好的“LLM Ops”工具
Since AI engineering requires multiple teams to collaborate to figure out how to best build with LLMs, an “LLM Ops” tool like LangSmith also focuses on facilitating that type of collaboration. What most of the triaging flow amounts to is – “Look at your data!”, and we want to make looking at large, mostly text responses very easy in LangSmith. 由于AI工程需要多个团队合作以找出如何最好地使用LLM构建,像LangSmith这样的“LLM Ops”工具也专注于促进这种类型的合作。大多数分类流程的实质是——“查看你的数据!”,我们希望在LangSmith中轻松查看大量主要是文本的响应。
One thing we’ve invested in really heavily from the beginning is a beautiful UI for visualizing agent traces. This beauty serves a purpose - it makes it easier for domain experts of all levels of technical ability to understand what is going on. It communicates so much more clearly what is happening that JSON logs ever would. 从一开始我们就投入大量资金在一个美丽的UI上,用于可视化代理的踪迹。这种美丽是有目的的——它使各个技术能力水平的领域专家更容易理解正在发生的事情。它比JSON日志更清晰地传达了正在发生的事情。
💡 The visualization of traces within LangSmith allows everyone - regardless of technical ability - to understand what is happening inside the agent, and contribute to diagnosing any issues. LangSmith中的踪迹可视化允许每个人——无论技术能力如何——都能理解代理内部发生的事情,并有助于诊断任何问题。
LangSmith also facilitates this cross team collaboration in other areas - most notably, the prompt playground- but I like to use tracing as an example because it is so subtle yet so important. LangSmith还在其他领域促进了这种跨团队合作——最显著的是提示操场——但我喜欢用踪迹作为例子,因为它如此微妙却如此重要。
Why people have asked us to expose LangSmith traces to their end users
为什么人们要求我们向他们的最终用户公开LangSmith踪迹
For the same reasons listed above, we have had multiple companies ask to expose LangSmith traces to their end users. Understanding what the agent is doing isn’t just important for developers - it’s also important for end users! 出于上述相同的原因,我们有多家公司要求向他们的最终用户公开LangSmith踪迹。了解代理在做什么不仅对开发人员重要——对最终用户也很重要!
There are other (more user-friendly ways) to do this than our traces, of course. But it is still flattering to hear this request. 当然,还有其他(更用户友好的方式)来做到这一点,而不是我们的踪迹。但听到这个请求仍然令人感到受宠若惊。
Why UI/UX is the most important place to be innovating with AI
为什么UI/UX是AI创新最重要的地方
Most of this post has focused on the importance of communication with AI agents when building them, but this also extends to end users. Allowing users to interact with an agent in a transparent, efficient, and reliable way can be crucial for adoption. 这篇文章的大部分内容都集中在构建AI代理时与其沟通的重要性,但这也延伸到最终用户。允许用户以透明、高效和可靠的方式与代理互动对于采用至关重要。
💡 The power an AI application comes down to how well it facilitates human-AI collaboration, and for that reason we think UI/UX is one of the most important places to be innovating. AI应用程序的力量归结于它如何促进人类与AI的合作,因此我们认为UI/UX是创新最重要的地方之一。
We’ve talked about different agentic UXs we see emerging (here, here, and here), but it’s still super early on in this space. 我们已经讨论了我们看到的不同的代理UX,但在这个领域仍然非常早期。
Communication is all you need, and so UI/UXs that best facilitate this human-agent interaction patterns will lead to better products. 沟通是你所需要的一切,因此最能促进这种人类与代理互动模式的UI/UX将带来更好的产品。
Communication is all you need
沟通是你所需要的一切
Communication can mean a lot of things. It’s an integral part of the human experience. As agents attempt to accomplish more and more humanlike tasks, I strongly believe that good communication skills will make you a better agent developer — whether it’s through prompts, code, or UX design. 沟通可以意味着很多事情。它是人类体验的一个组成部分。随着代理尝试完成越来越多的人类任务,我坚信良好的沟通技巧会让你成为更好的代理开发者——无论是通过提示、代码还是UX设计。
Communication is not just expression in natural language, but it can also involve code to communicate more precisely. The best people to communicate something are the ones who understand it best, and so building these agents will become cross-functional. 沟通不仅仅是自然语言的表达,它还可以涉及代码以更精确地传达。最能传达某事的人是最了解它的人,因此构建这些代理将变得跨职能。
And I’ll close with a tip from George Bernard Shaw “The single biggest problem in communication is the illusion that it has taken place.” If we want a future in which LLM applications are solving real problems, we need to figure out how to communicate with them better. 最后,我引用乔治·伯纳德·肖的一句话结束:“沟通中最大的一个问题是它已经发生的错觉。”如果我们想要一个LLM应用程序解决实际问题的未来,我们需要弄清楚如何更好地与它们沟通。