Langchain‐Chatchat 和 FastChat 结合
FastChat
安装
# 克隆仓库
git clone https://github.com/lm-sys/FastChat
cd FastChat
# 创建虚拟环境
python -m venv env
source env/bin/activate
# 安装
pip install --upgrade pip
pip install -e ".[model_worker,webui]"
创建大模型链接
LLM
mkdir THUDM
ln -s /Users/junjian/HuggingFace/THUDM/chatglm3-6b THUDM/chatglm3-6b
Embedding Model
mkdir BAAI
ln -s /Users/junjian/HuggingFace/BAAI/bge-base-zh-v1.5 BAAI/bge-base-zh-v1.5
启动服务 Controller
python -m fastchat.serve.controller
启动服务 Model Worker LLM
python -m fastchat.serve.model_worker \
--model-path THUDM/chatglm3-6b --port 21002 \
--worker-address http://localhost:21002 \
--model-names chatglm3-6b,gpt-3.5-turbo \
--device mps
启动服务 Model Worker Embedding Model
python -m fastchat.serve.model_worker \
--model-path BAAI/bge-base-zh-v1.5 --port 21100 \
--worker-address http://localhost:21100 \
--model-names bge-base-zh,text-embedding-ada-002 \
--device mps
启动服务 OpenAI API Server
python -m fastchat.serve.openai_api_server --port 8000
启动服务 Web Server
python -m fastchat.serve.gradio_web_server --port 8001
启动服务 Chatbot Arena
python -m fastchat.serve.gradio_web_server_multi --port 8002
Langchain-Chatchat
克隆仓库
git clone https://github.com/chatchat-space/Langchain-Chatchat
fatal: fetch-pack: invalid index-pack output
Cloning into 'Langchain-Chatchat'...
remote: Enumerating objects: 8958, done.
remote: Counting objects: 100% (270/270), done.
remote: Compressing objects: 100% (168/168), done.
error: 6146 bytes of body are still expectediB | 367.00 KiB/s
fetch-pack: unexpected disconnect while reading sideband packet
fatal: early EOF
fatal: fetch-pack: invalid index-pack output
这个错误可能是由于网络问题或者 Git 服务器问题导致的。当 Git 在克隆仓库时,它需要从服务器下载一些数据。如果在这个过程中连接被中断,或者服务器发送的数据有问题,就可能会出现这个错误。
你可以尝试以下几种解决方法:
-
检查你的网络连接。如果可能,尝试切换到不同的网络环境,例如从 Wi-Fi 切换到有线连接,或者切换到不同的 Wi-Fi 网络。
-
尝试使用不同的 Git 服务器。如果你在克隆 GitHub 上的仓库时遇到问题,你可以尝试使用其他的 Git 服务器,例如 GitLab 或 Bitbucket。
- 尝试增加 Git 的 HTTP 缓冲区大小。你可以使用以下命令来增加缓冲区大小:
git config --global http.postBuffer 524288000- 这个命令会将 HTTP 缓冲区大小设置为 500 MB。这可能会帮助解决由于大文件导致的问题。
- 如果以上方法都不能解决问题,你可能需要联系你的网络管理员或者 Git 服务器的管理员,看看是否有其他的解决方法。
安装依赖(lite 版本)
pip install -r requirements_lite.txt
拷贝配置文件
python copy_config_example.py
修改配置文件 configs/model_config.py
EMBEDDING_MODEL = "text-embedding-ada-002"
LLM_MODELS = ["gpt-3.5-turbo"]
ONLINE_LLM_MODEL = {
"gpt-3.5-turbo": {
"model_name": "gpt-3.5-turbo",
"api_base_url": "http://127.0.0.1:8000/v1",
"api_key": "NULL",
"openai_proxy": "",
},
MODEL_PATH = {
"embed_model": {
"text-embedding-ada-002": "NULL",
},
修改文件 server/knowledge_base/kb_cache/base.py
class EmbeddingsPool(CachePool):
def load_embeddings(self, model: str = None, device: str = None) -> Embeddings:
# ...
if model == "text-embedding-ada-002":
from langchain.embeddings.openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model=model,
base_url="http://127.0.0.1:8000/v1", # change
openai_api_key=get_model_path(model),
chunk_size=CHUNK_SIZE)
启动
python startup.py -a --lite
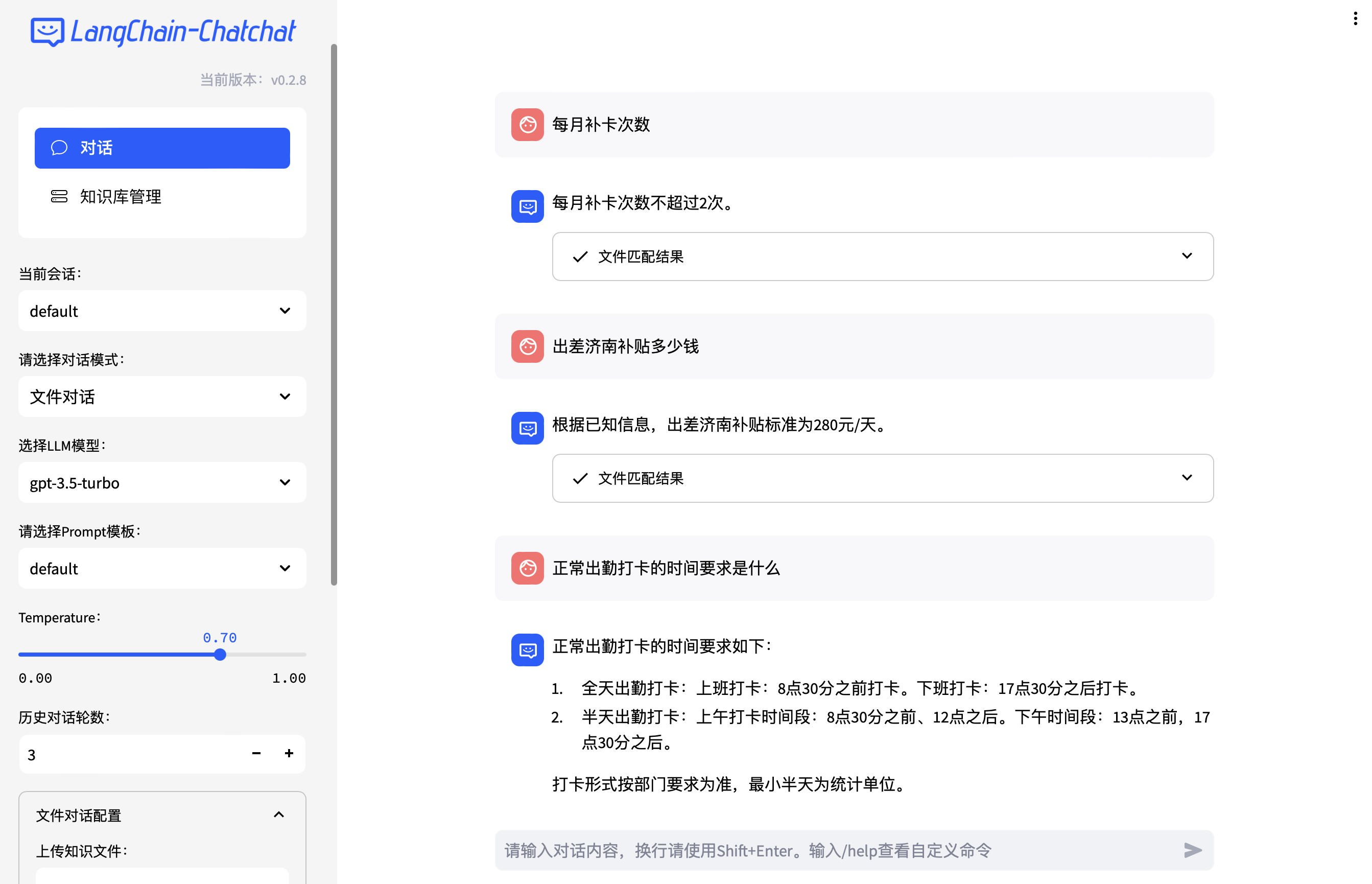
使用 Langchain-Chatchat
LLM 对话

文件对话