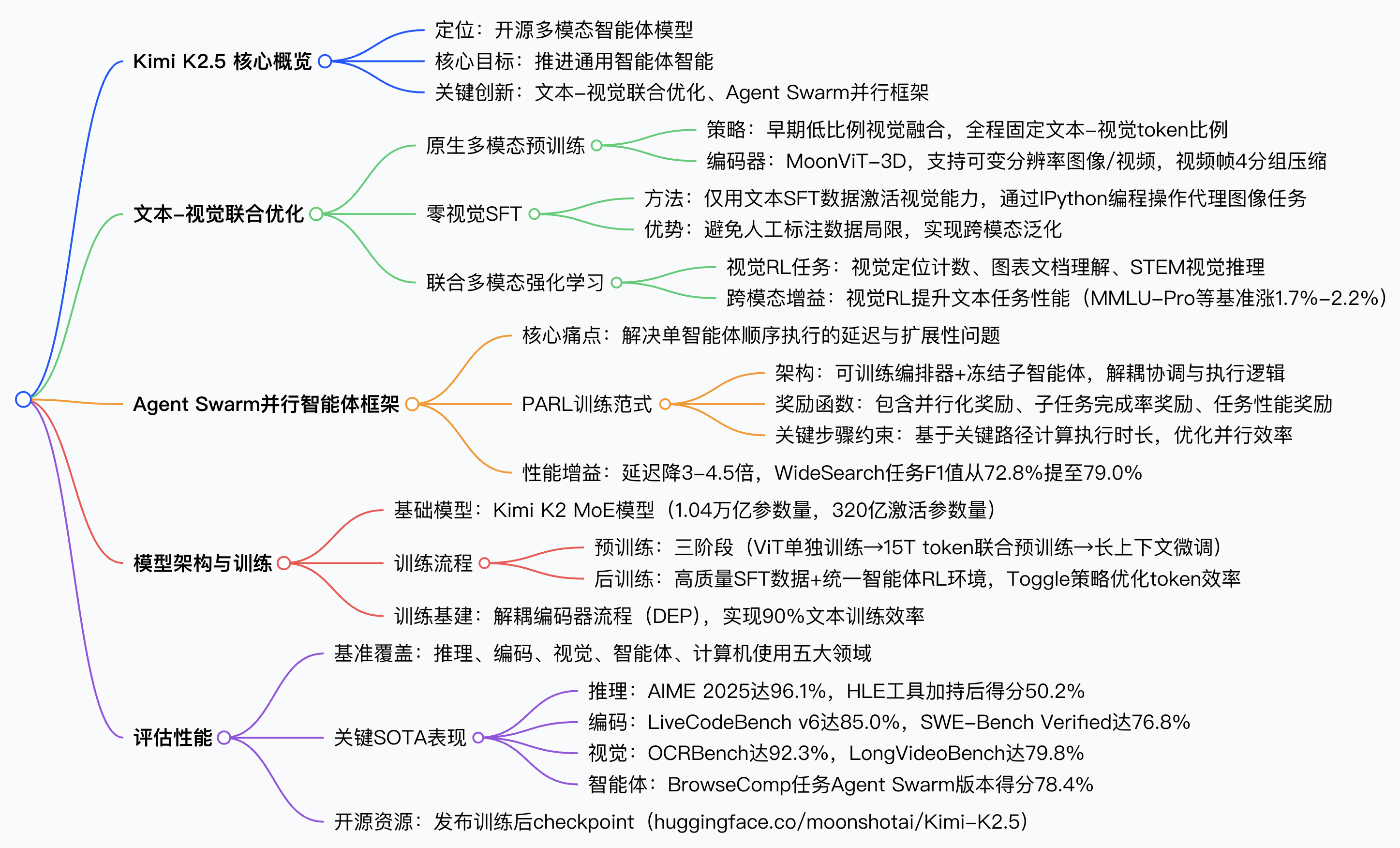
Kimi K2.5:首个开源多模态智能体集群
感觉 Kimi K2.5 在国内被低估了,让子弹飞一会儿 🚀🚀🚀
基准测试(Benchmarks)
Agent Swarm 基准测试
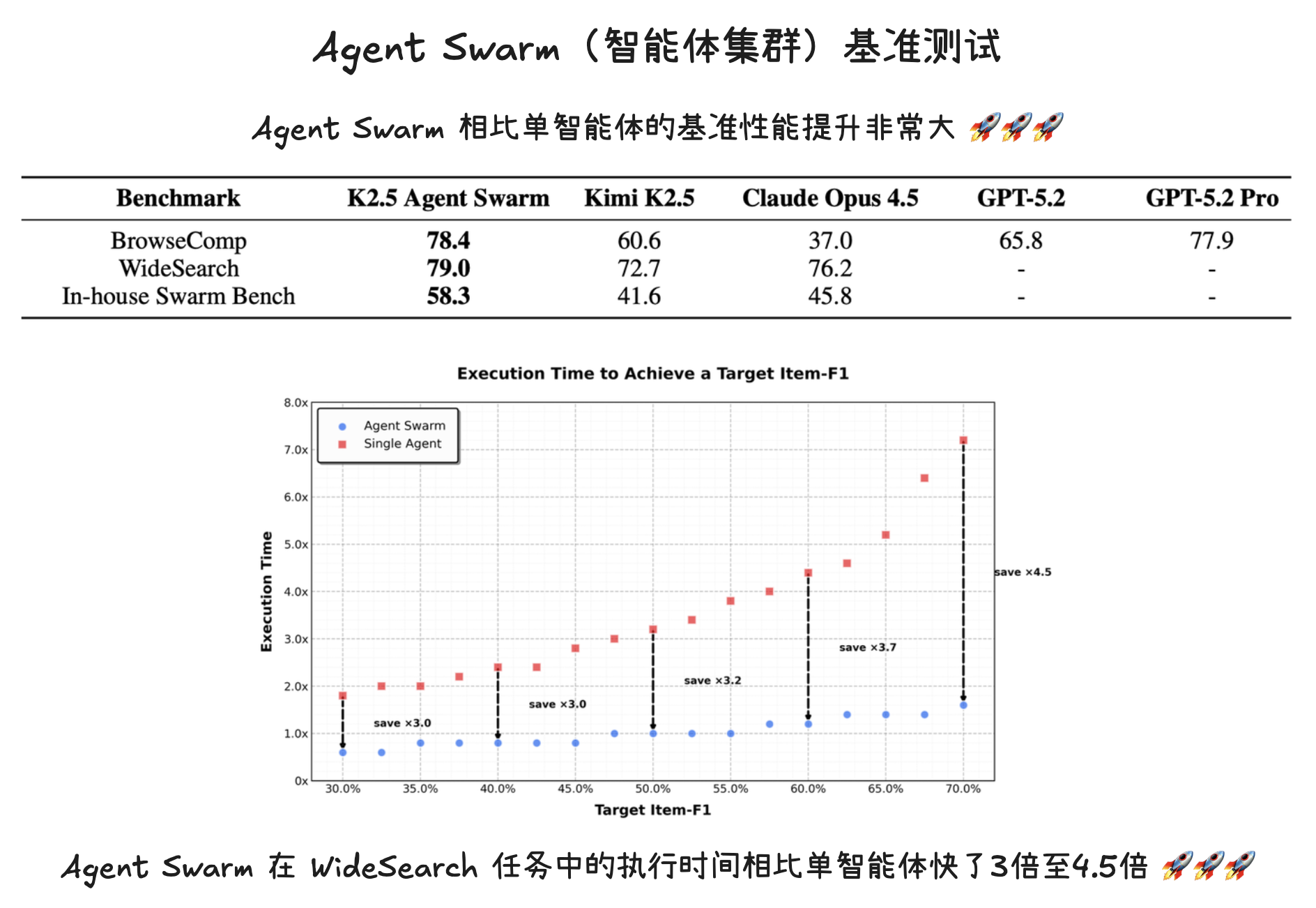
为了严格评估智能体集群(Agent Swarm)框架的有效性,选择了三个具有代表性的基准测试,它们共同涵盖了深度推理、大规模检索以及真实世界的复杂性:
- BrowseComp:一项具有挑战性的深度研究基准,需要多步推理和复杂的信息综合。
- WideSearch:旨在评估在不同来源中进行广泛、多步信息寻求和推理能力的基准。
- In-house Swarm Bench:一项内部开发的集群基准,旨在评估智能体集群在真实世界、高复杂度条件下的性能。 它涵盖了四个领域:
- WildSearch(开放网络上不受约束的真实世界信息检索);
- Batch Download(大规模获取多样化资源);
- WideRead(涉及 100 多个输入文档的大规模文档理解);
- Long-Form Writing(连贯生成超过 10 万字的海量内容)。 该基准整合了极端规模的场景,旨在压力测试基于智能体系统的编排(Orchestration)、可扩展性(Scalability)和协作能力。
主要基准测试

Kimi K2.5 评估涵盖了多个领域的基准测试,下面是按能力维度分类的各基准测试说明:
推理与通用能力 (Reasoning & General)
- Humanity’s Last Exam (HLE):一项严苛的深度推理基准,包含文本和图像子集,用于测试模型的极限推理能力。
- AIME 2025:美国数学邀请赛,用于评估模型在数学和 STEM 领域的深度推理。
- HMMT 2025 (Feb):哈佛-麻省理工数学锦标赛,测试高难度数学竞赛问题的解决能力。
- IMO-AnswerBench:基于国际数学奥林匹克竞赛水平的问题基准。
- GPQA-Diamond:研究生水平的“防谷歌”问答基准,侧重于评估高难度的科学知识与推理。
- MMLU-Pro:比标准 MMLU 更具挑战性的多任务语言理解基准。
- SimpleQA Verified:用于衡量模型参数化知识可靠性的事实性评估基准。
- AdvancedIF:基于规则的指令遵循能力评估。
- LongBench v2:针对真实长文本场景的深度理解与推理测试。
编程能力 (Coding)
- SWE-bench (Verified/Pro/Multilingual):软件工程基准,测试模型解决真实 GitHub 仓库问题和多语言编程的能力。
- Terminal Bench 2.0:评估智能体在命令行界面(CLI)中处理复杂、真实任务的能力。
- PaperBench (CodeDev):测试模型复现 AI 研究论文代码的能力。
- CyberGym:网络安全能力评估,要求模型根据高层描述在真实开源项目中发现漏洞。
- SciCode:由科学家编写的科学研究编程基准。
- OJBench (cpp):竞赛级代码评估基准。
- LiveCodeBench (v6):使用实时更新的编程挑战进行防污染的综合评估。
智能体能力 (Agentic Capabilities)
- BrowseComp:具有挑战性的深度研究基准,要求多步推理和复杂的信息综合能力。
- WideSearch:评估智能体在多元来源中进行广度信息搜索和推理的能力。
- DeepSearchQA:评估深度研究智能体在信息获取完整性方面的表现。
- FinSearchComp (T2&T3):针对金融领域搜索与推理的专家级真实评估。
- Seal-0:SealQA 的主要子集,旨在提升搜索增强型模型的推理门槛。
- GDPVal:评估 AI 模型处理具有实际经济价值任务的表现。
图像理解 (Image Understanding)
- MMMU / MMMU-Pro:大规模跨学科多模态理解与推理基准。
- CharXiv (RQ):评估模型对真实图表理解能力的基准。
- Math-Vision / MathVista (mini):评估视觉语境下的数学推理能力。
- SimpleVQA / WorldVQA:评估多模态事实性、视觉识别及地理知识。
- ZeroBench:一项极具挑战性的视觉基准,用于测试多步视觉推理。
- BLINK / MMVP:测试多模态模型是否真正“看清”并感知到了图像内容。
- OCR-Bench / OmniDocBench 1.5 / InfoVQA:评估文本识别、文档解析及信息图表理解能力。
视频理解 (Video Understanding)
- VideoMMMU / MMVU:专家级多学科视频理解评估。
- MotionBench:细粒度的视频动作与运动理解基准。
- Video-MME:首个多模态大模型视频分析综合评估基准。
- LongVideoBench / LVBench:针对极长视频(包含数千帧)理解能力的评估基准。
计算机操作 (Computer Use)
- OSWorld-Verified:在真实计算机环境中评估多模态智能体执行开放式任务的能力。
- WebArena:一个用于构建自主智能体的真实网页环境操作基准。
模型训练
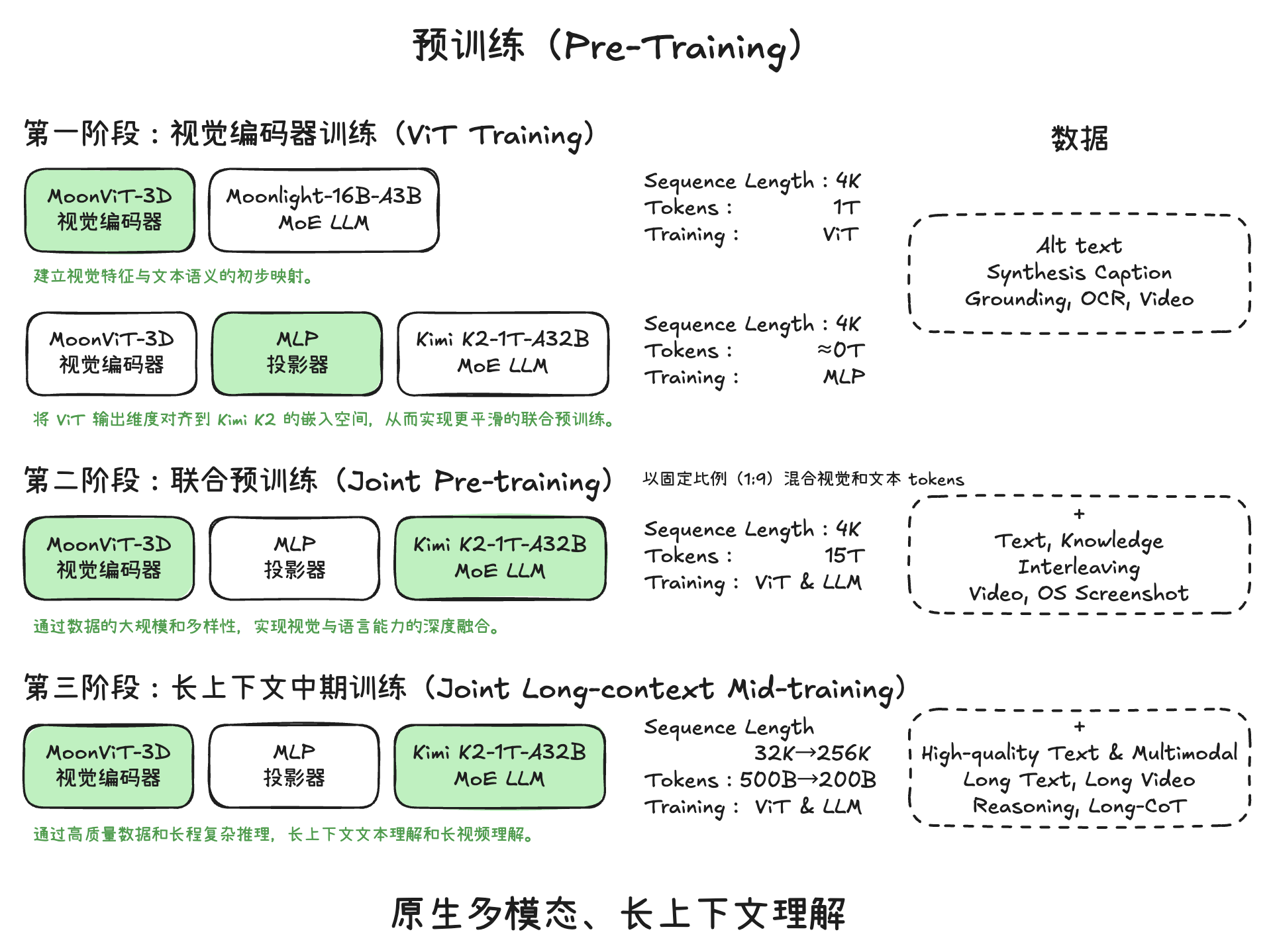

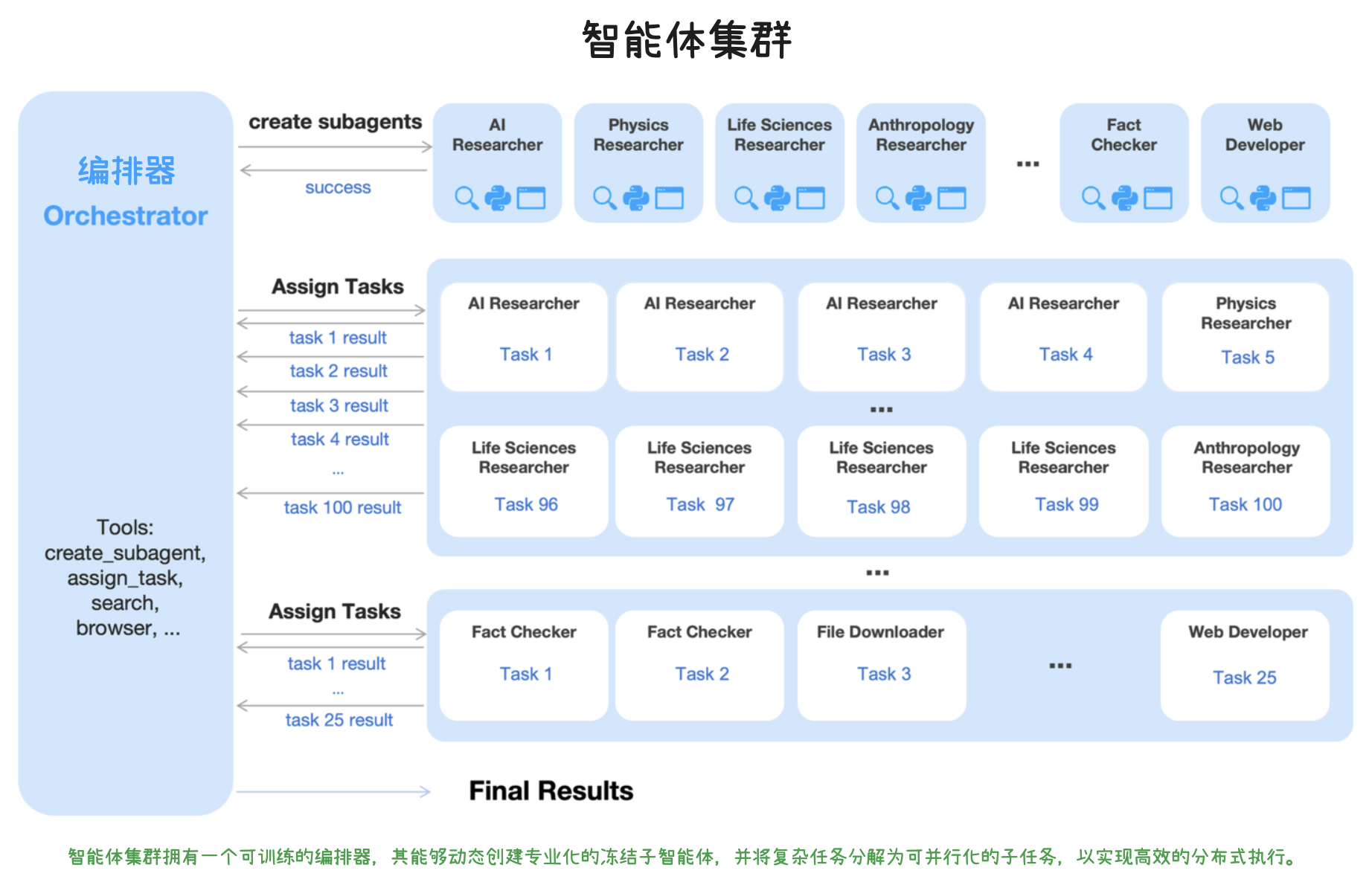
统一智能体强化学习环境
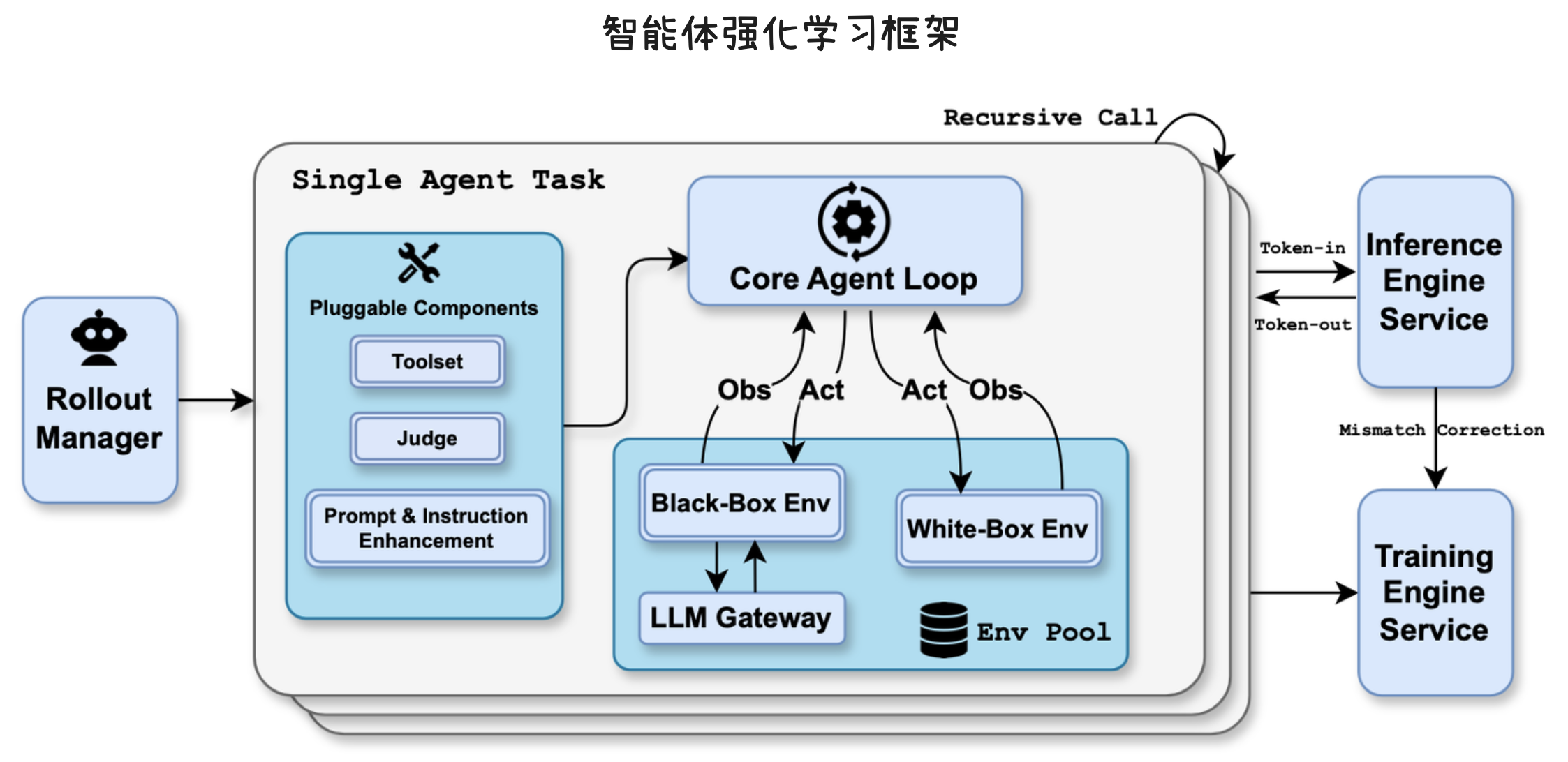
Unified Agentic Reinforcement Learning Environment(统一智能体强化学习环境)是 Kimi K2.5 为了推进通用智能体能力而开发的标准化、模块化的强化学习(RL)框架。
核心设计理念
该环境旨在简化不同任务场景下的智能体训练流程,其核心特点包括:
- 标准化接口:提供了一个类似 Gym 的标准化接口,使得实现和自定义各种复杂的交互环境变得非常简便。
- 组合模块化:优先考虑模块化设计,集成了一系列可插拔组件,例如:
- 工具集(Toolset):支持各种带有沙箱环境的工具。
- 评判模块(Judge):提供多维度的奖励信号。
- 增强模块:专门用于提示词多样化和指令遵循能力的提升。
执行与架构机制
该环境在执行层面上表现出极高的并发能力和灵活性:
- 异步协程处理:每一个智能体任务都被视为一个独立的异步协程。
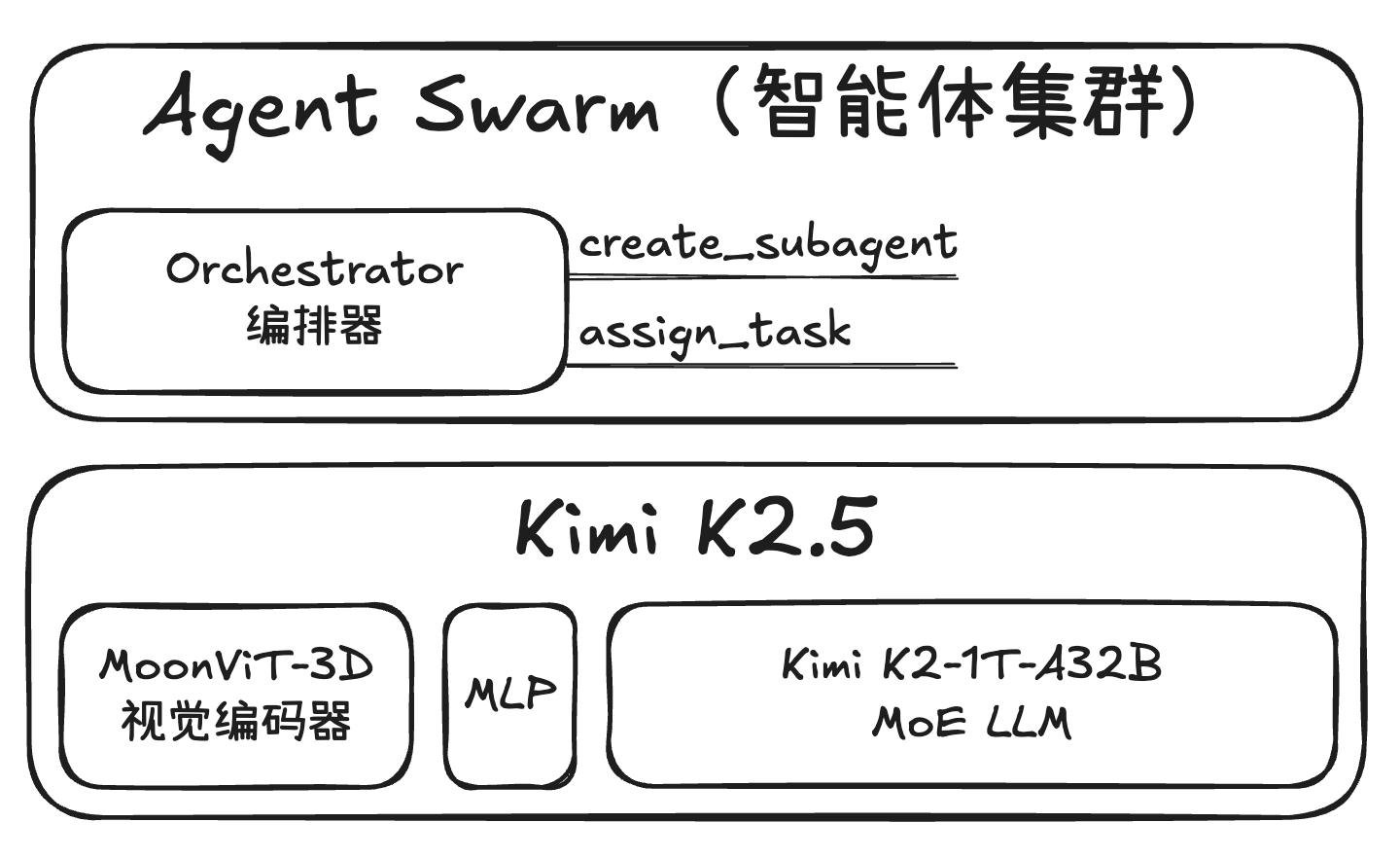
- 递归任务触发:任务可以递归地触发子任务的 Rollout(Rollout 指模型生成序列的过程),这为“智能体集群”(Agent Swarm)这种并行智能体强化学习(PARL)以及“智能体作为评判者”(Agent-as-Judge)等复杂范式提供了基础。
- 大规模并发管理:拥有专门的 Rollout 管理器,在 RL 过程中能够同时调度多达 100,000 个并发智能体任务,并支持 partial rollout 功能。
技术集成与优化
为了确保训练的稳定性和效率,该环境集成了多项关键技术:
- 推理引擎协同设计:严格遵循“Token-in-Token-out”(Token 进 Token 出)范式,并记录所有推理输出的对数概率(log probabilities),以便进行“训练-推理失配修正”,确保 RL 训练的稳定性。
- LLM Gateway(大模型网关):这是一个代理服务,用于处理那些仅支持标准 API 协议的“黑盒环境”,使其能够通过该网关利用 Kimi 自定义协议的高级功能。
- 监控与调试工具:开发了一系列用于性能监控、剖析(Profiling)、数据可视化和验证的工具,以确保这个高度并行的异步系统运行正确且高效。
应用价值
这一环境是 Kimi K2.5 实现文本与视觉联合优化 以及 Agent Swarm(并行智能体编排) 的关键基础。它允许模型通过与真实和合成环境的互动,在开源域之外的开放性任务中不断学习、调整行为并获取新技能。
提示词



示例


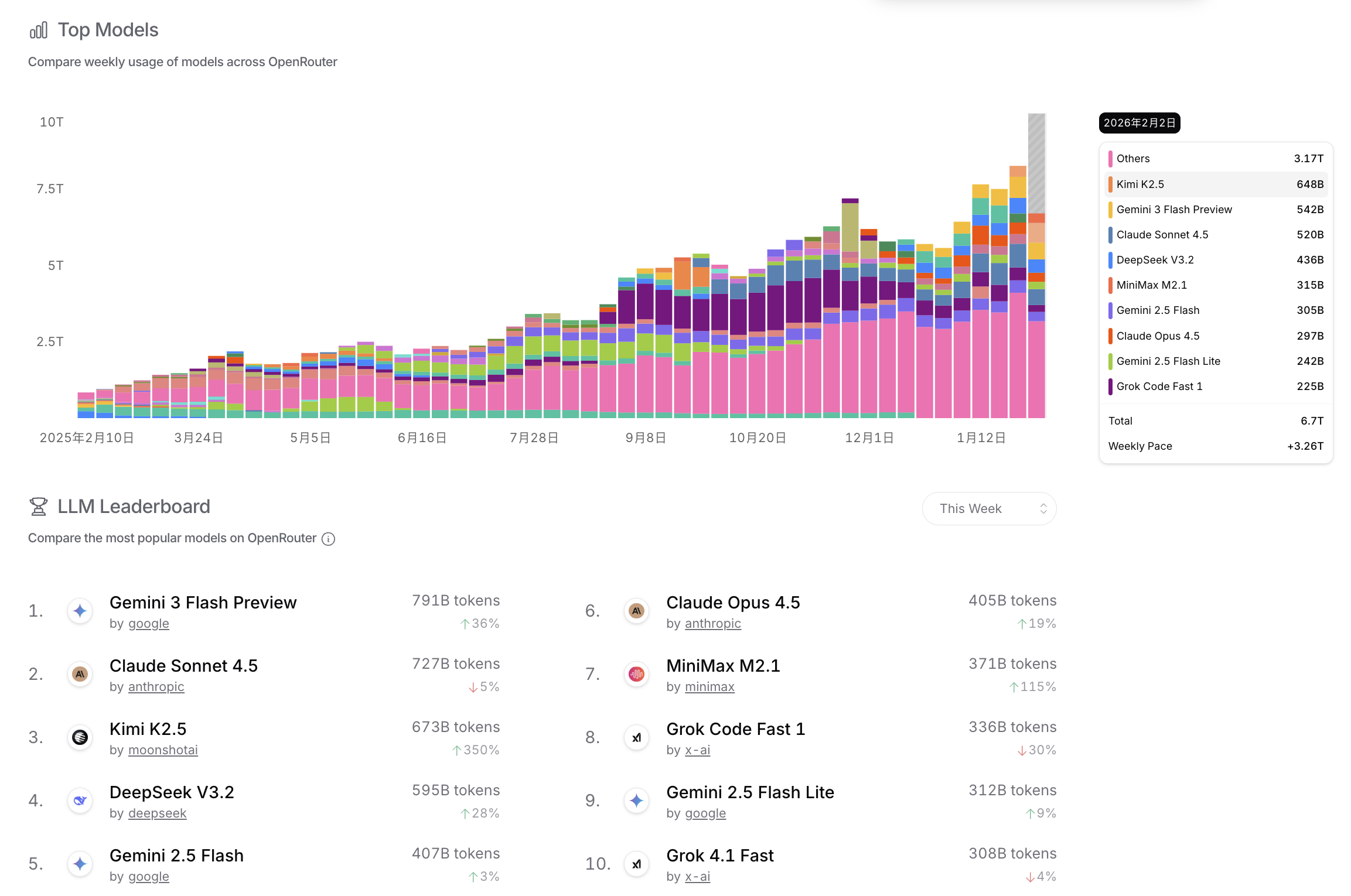
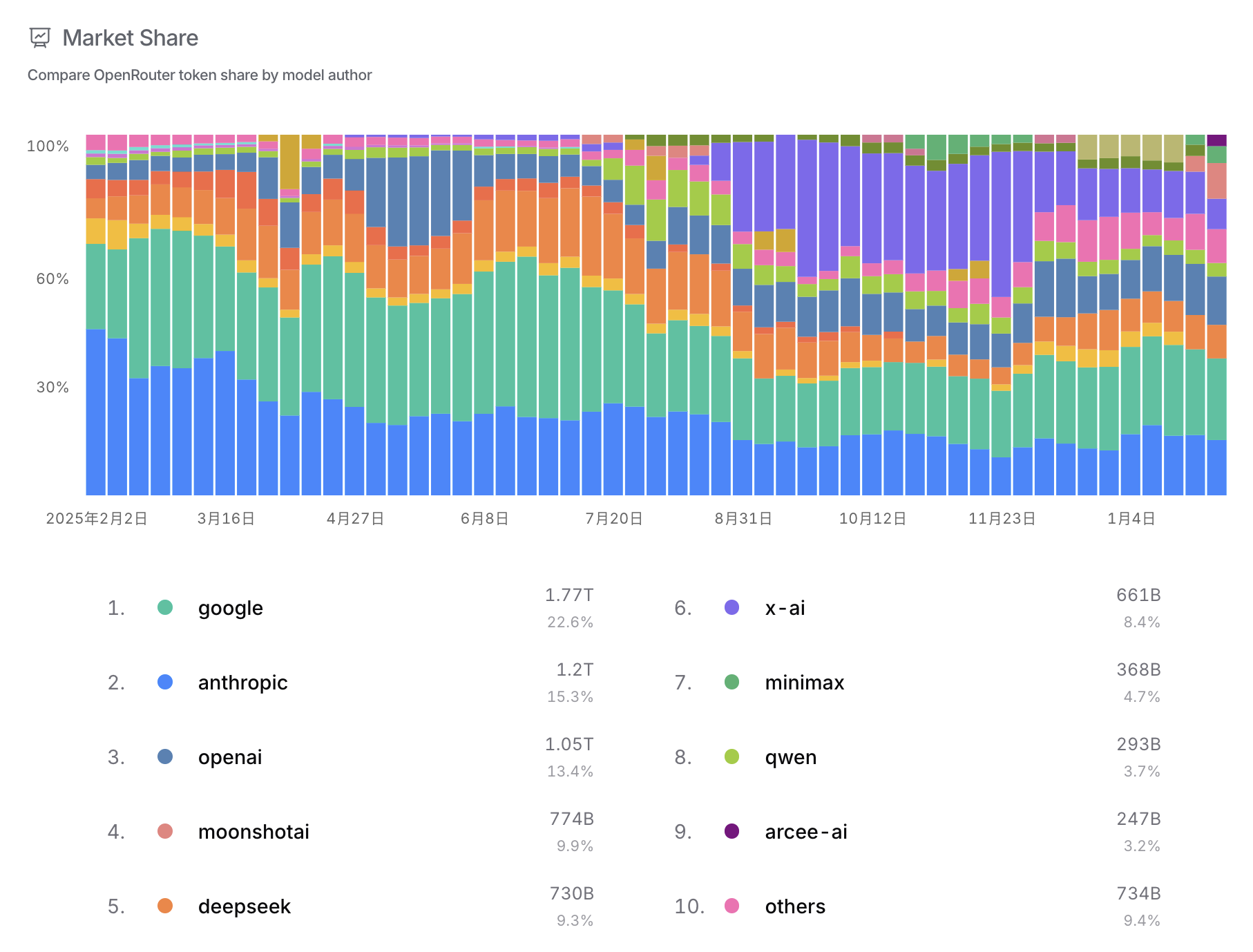
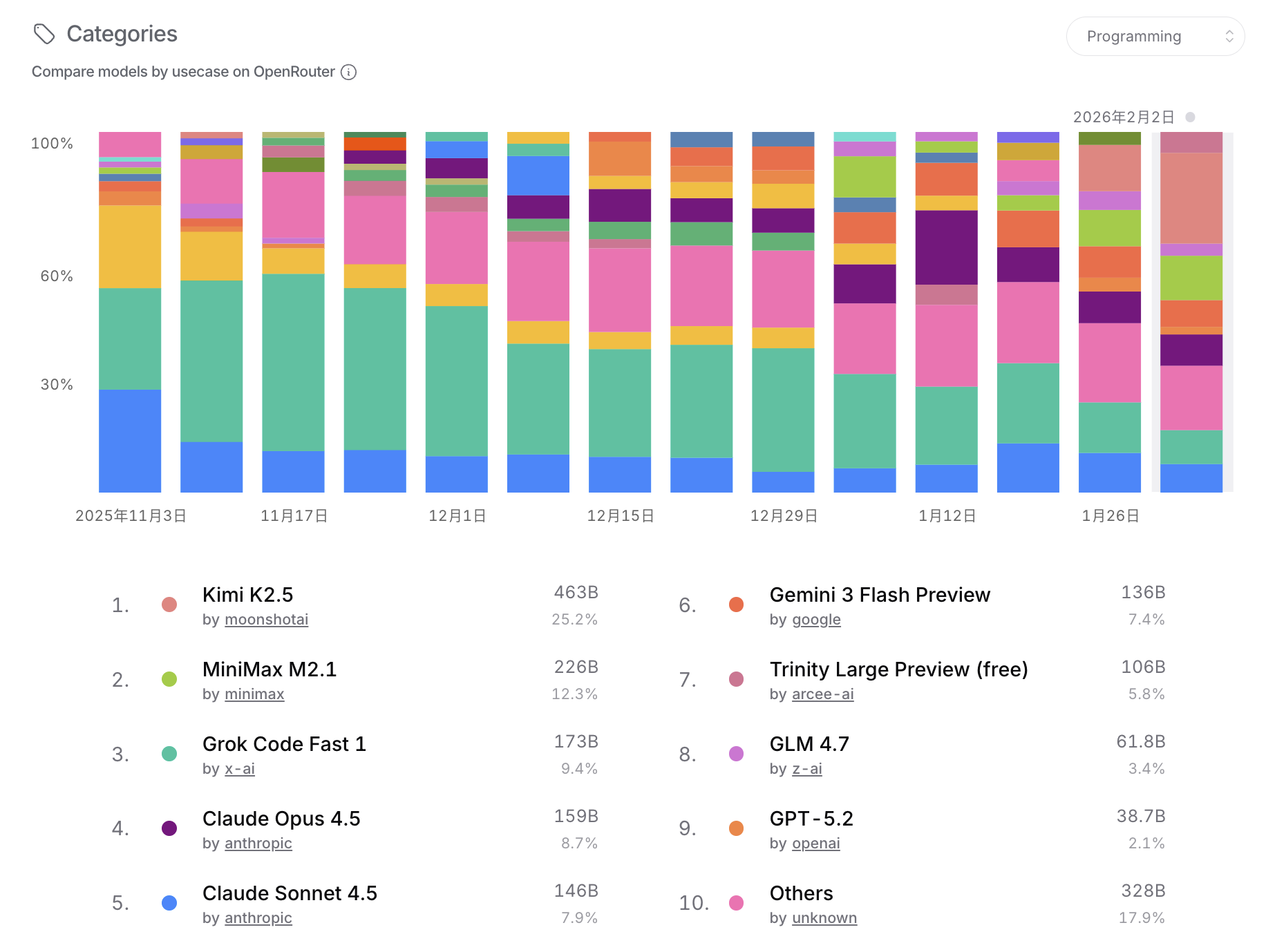
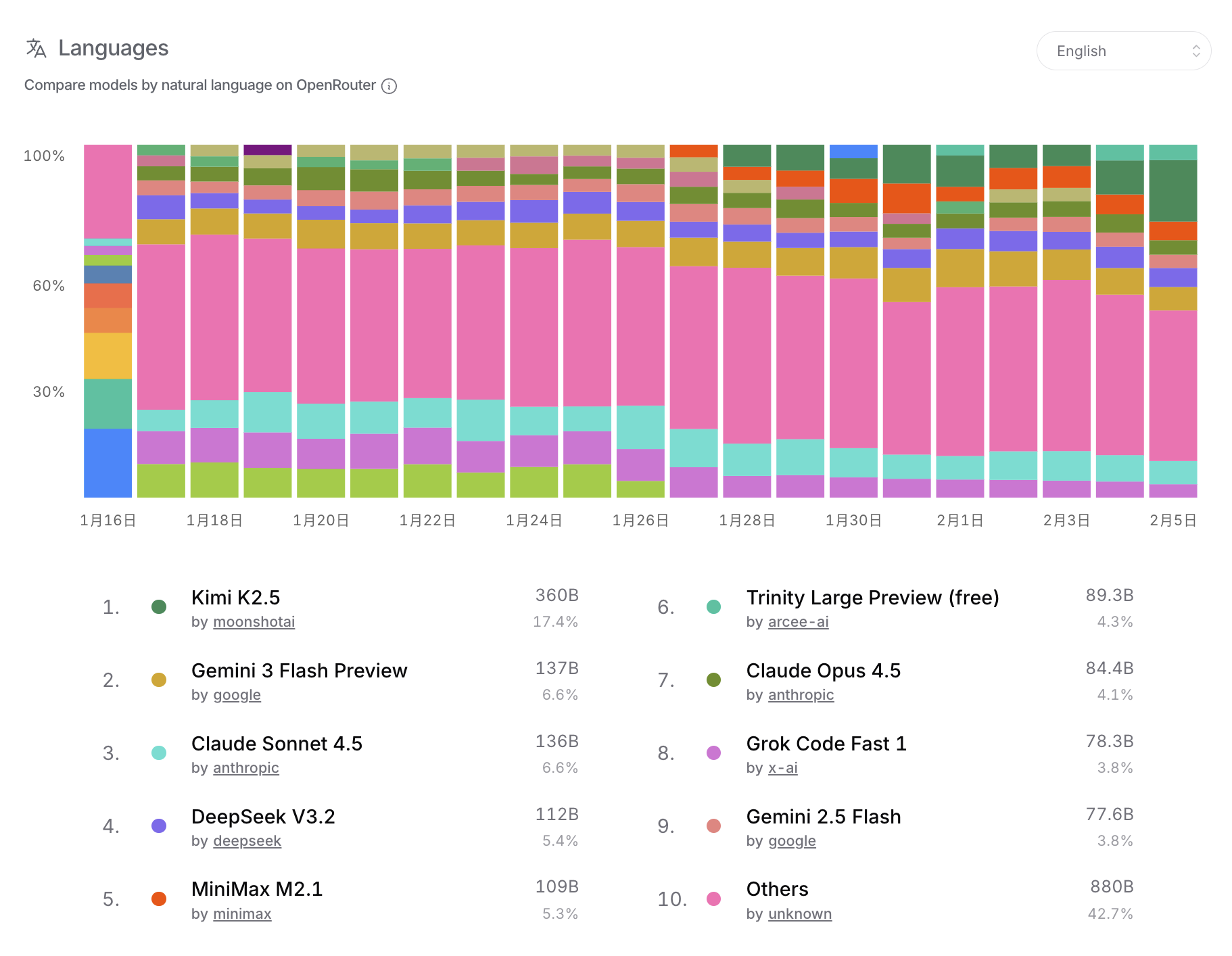
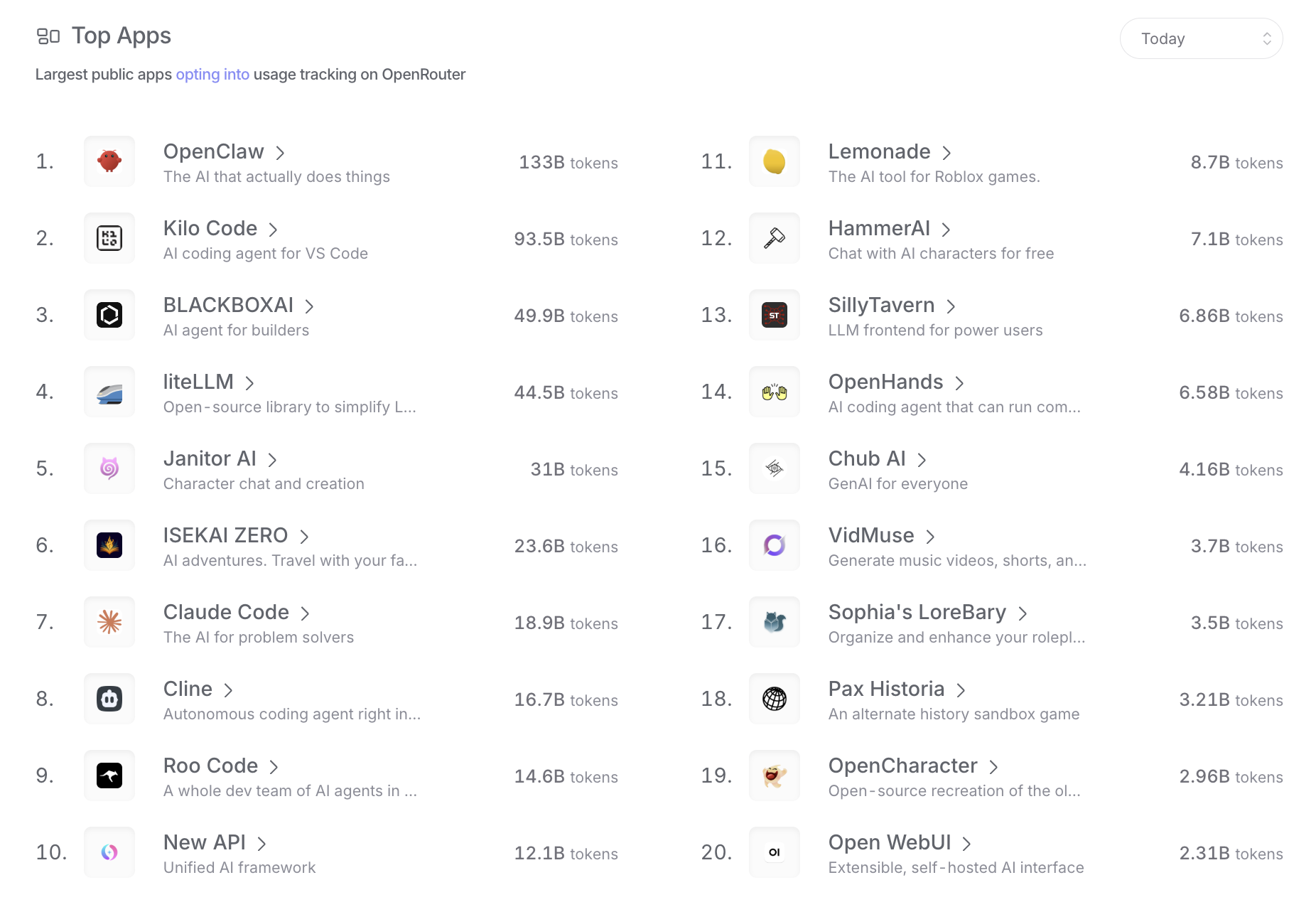
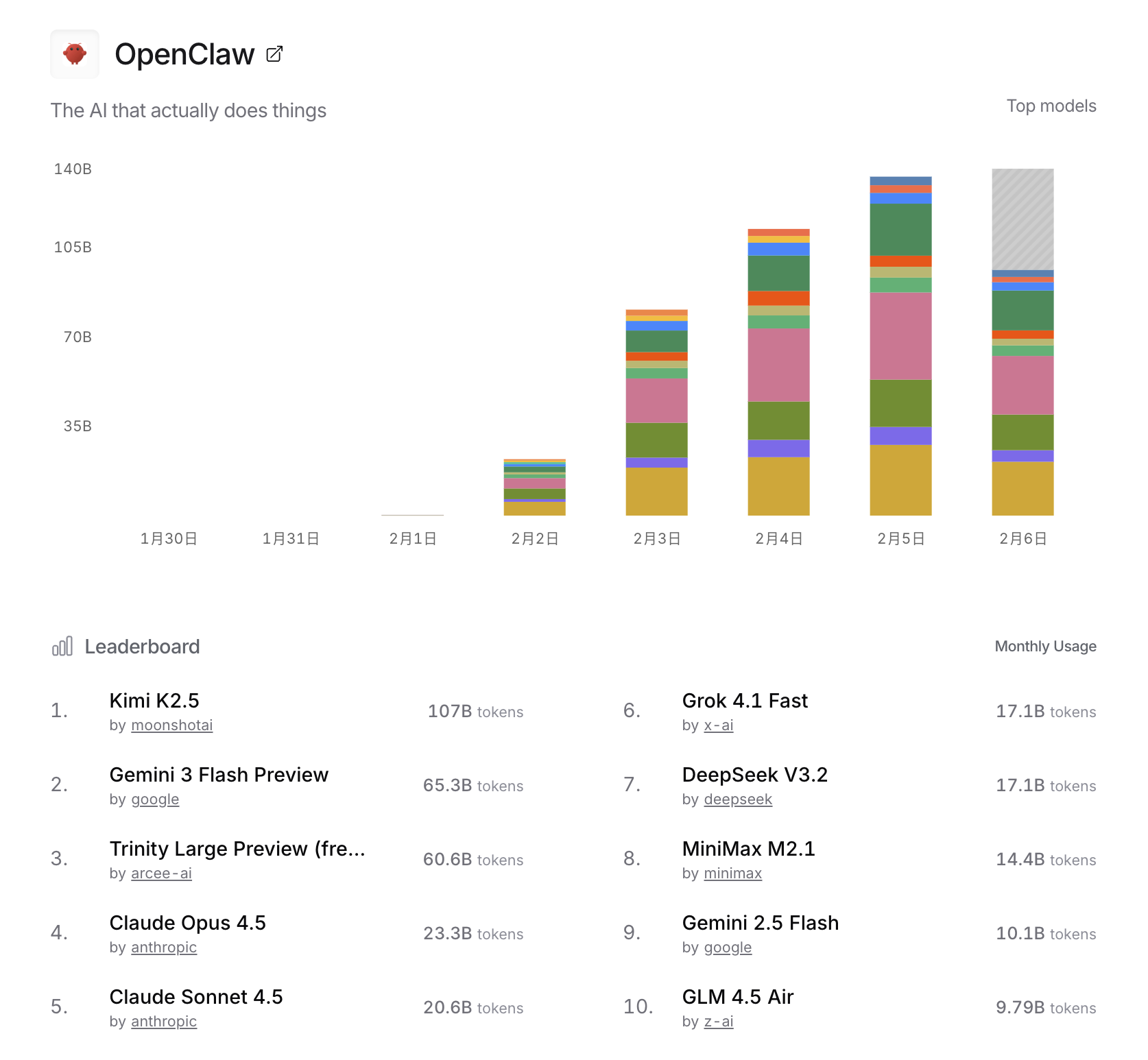
OpenRouter
在 OpenRouter 上 Kimi K2.5 已经是绝对的第一了。
Kimi K2.5: 视觉智能体智能思维导图