用通俗易懂的方式理解 Harness Engineering
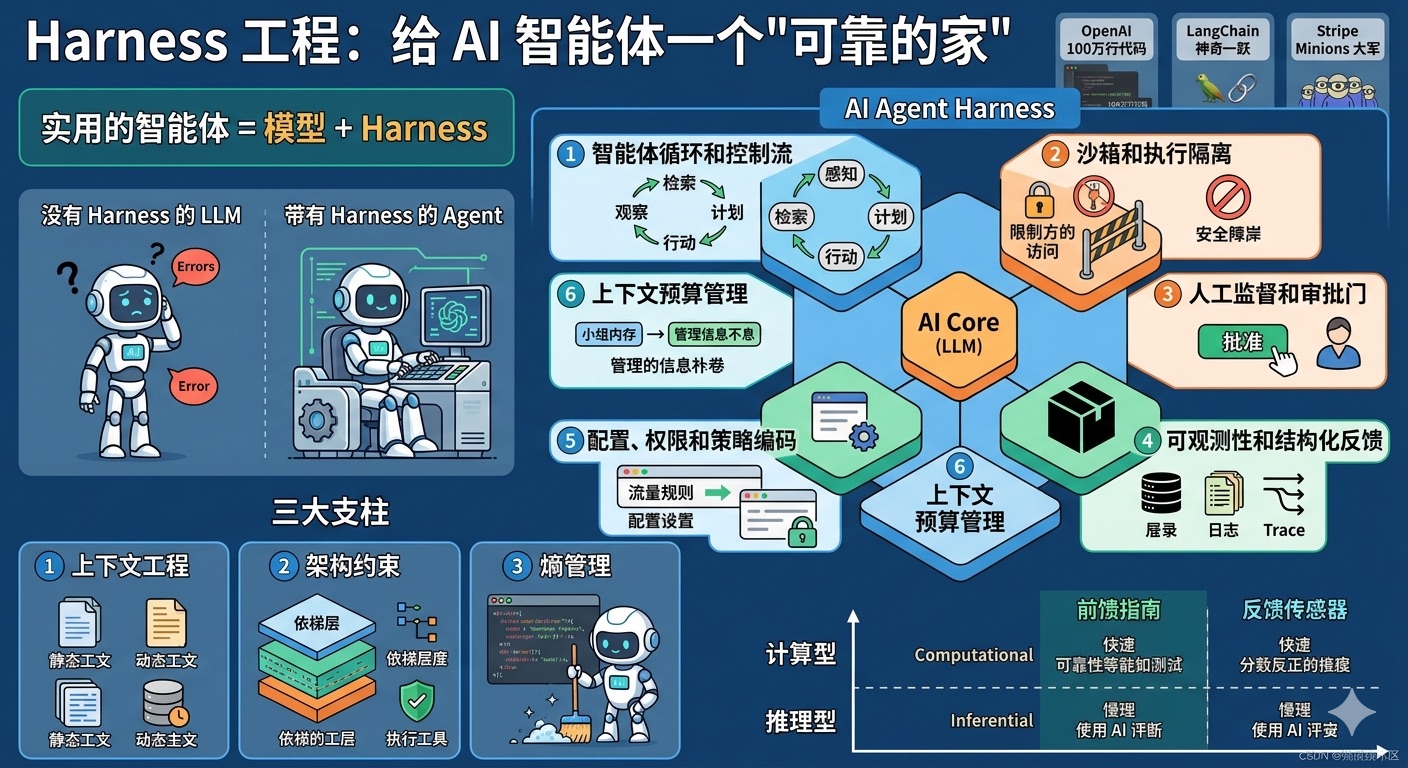
Harness 工程:给 AI 智能体一个”可靠的家”
想象一下,你有一个非常聪明但有点冲动的助手——它知识渊博、能说会道,但有时候会:
- 忘记五分钟前你们讨论的事情
- 直接执行危险操作而不问你
- 在复杂任务中迷路,绕来绕去
- 做错了事,但你不知道为什么
这就是没有 Harness 的 LLM 智能体。
什么是 Harness?
Harness 这个词在英文里有”马具”、”安全带”的意思。在 AI 智能体的世界里,它就是那个让智能体既能够发挥能力,又不会失控的”安全脚手架”。
这个隐喻是有意的:
- 马是 AI 模型——强大、快速,但它自己不知道去哪里
- Harness是基础设施——约束、护栏、反馈循环,以富有成效地引导模型的力量
- 骑手是人类工程师——提供方向,而不是亲自奔跑
用一个更贴近生活的比喻:Harness 就像是智能体的”驾驶舱 + 安全带 + 导航系统 + 黑匣子”的组合体。
根据 Harness Engineering 将原始模型能力转化为可靠 Agent 行为的脚手架。实用的 Agent 最好被理解为在 Harness 内部运行的模型,而不是带有外围能力的模型。
真实故事:Harness 工程的威力
在我们深入技术细节之前,让我们看看几个真实的例子,了解为什么 Harness 工程如此重要:
OpenAI 的 100 万行代码实验
OpenAI 团队做了一件令人震惊的事情:他们用 AI 智能体构建了一个超过 100 万行代码的生产应用,而且零行代码是人工手写的!
- 5 个月的开发时间
- 约为人类所需时间的 1/10
- 产品有内部日常用户和外部 alpha 测试者
- 它交付、部署、崩溃并得到修复——所有这些都由 Harness 内的智能体完成
工程师的工作不是编写代码,而是设计 Harness:指定意图、提供反馈、构建让 AI 可靠编写代码的系统。
LangChain 的神奇一跃
LangChain 团队证明了一个令人不安的事实:底层模型的重要性不如其周围的系统。
他们的编码智能体在 Terminal Bench 2.0 上从 52.8% 提升到 66.5%——从前 30 名跃升至前 5 名——只改变了 Harness,模型本身没有任何变化!
他们做了什么?
- 添加了自我验证循环
- 优化了上下文工程
- 实现了循环检测
- 使用了”推理三明治”策略(规划/验证使用高推理,实现使用中推理)
相同的模型。不同的 Harness。显著更好的结果。
Stripe 的 Minions 大军
Stripe 的内部编码智能体,称为 Minions,现在每周产生超过 1,000 个合并的拉取请求:
- 开发者在 Slack 中发布任务
- Minion 编写代码
- Minion 通过 CI
- Minion 打开 PR
- 人类审查并合并
第 1 步和第 5 步之间没有开发者交互。Harness 处理一切。
Harness 工程的六大核心维度
让我们用”自动驾驶汽车”来类比,看看 Harness 工程到底做了什么:
1️⃣ 智能体循环和控制流 —— “自动驾驶的行车电脑”
就像汽车有油门、刹车、限速器一样,Harness 控制智能体:
- 最多可以走多少步
- 每一步花多少钱
- 什么时候必须停下来
智能体循环是 Harness 的时间骨干,实现感知-检索-计划-行动-观察周期。
2️⃣ 沙箱和执行隔离 —— “安全试驾场地”
你不会让新手直接开上高速公路,对吧?Harness 给智能体提供:
- 封闭的测试环境
- 分级的权限控制
- 出了问题可以”回滚”
沙箱的双重作用:
- 安全围栏 - 限制危险操作
- 认知边界 - 通过移除不相关状态简化 Agent 的操作环境
3️⃣ 人工监督和审批门 —— “副驾驶的刹车”
完全自动驾驶目前还不靠谱,Harness 会在关键时刻让人类介入:
- 执行前:”这个操作危险,确认吗?”
- 执行后:”我做完了,你检查一下?”
- 异常时:”情况不对,你来看看?”
4️⃣ 可观测性和结构化反馈 —— “飞机的黑匣子”
如果智能体做错了事,你需要知道为什么。Harness 记录:
- 每一次思考
- 每一个操作
- 每一个结果
可观测性有双重目的:
- 外部 - 支持调试、合规审计和事件后分析
- 内部 - 关闭将执行结果连接回产生它们的模块的反馈循环
5️⃣ 配置、权限和策略编码 —— “交通规则”
不同的场景有不同的规矩,Harness 会设置:
- 这个智能体能用哪些工具?
- 它能访问哪些文件?
- 什么情况下需要批准?
配置通常分为三层:用户级设置、项目级设置、组织级设置。
6️⃣ 上下文预算管理 —— “智能体的记忆力管理”
LLM 的”记忆力”是有限的,Harness 要精打细算:
- 旧的对话压缩成摘要
- 不重要的信息往后放
- 需要时才加载详细指导
上下文窗口仍然是任何 Agent 系统中最稀缺的共享资源。
Harness 工程的三大支柱
根据 Harness 工程完整指南,OpenAI 的框架将 Harness 工程组织为三个核心类别:
支柱 1:上下文工程 —— “智能体需要知道什么?”
上下文工程是关于确保智能体在正确的时间拥有正确的信息。
静态上下文:
- 存储库本地文档(架构规范、API 契约、风格指南)
- 编码项目特定规则的
AGENTS.md或CLAUDE.md文件 - 由 linter 验证的交叉链接设计文档
动态上下文:
- 智能体可访问的可观测性数据(日志、指标、追踪)
- 智能体启动时的目录结构映射
- CI/CD 管道状态和测试结果
关键规则:从智能体的角度来看,它无法在上下文中访问的任何内容都不存在。Google Docs、Slack 线程或人们头脑中的知识对系统是不可见的。存储库必须是唯一的真实来源。
支柱 2:架构约束 —— “机械地强制执行好代码的样子”
这是 Harness 工程与传统 AI 提示最显著不同的地方。与其告诉智能体”编写好的代码”,不如机械地强制执行好代码的样子。
依赖分层:
Types → Config → Repo → Service → Runtime → UI
每一层只能从其左侧的层导入。这不是建议——它由结构测试和 CI 验证强制执行。
约束强制执行工具:
- 确定性 linter——自动标记违规的自定义规则
- 基于 LLM 的审计器——审查其他智能体代码的架构合规性的智能体
- 结构测试——像 ArchUnit,但用于 AI 生成的代码
- 预提交钩子——任何代码提交前的自动检查
为什么约束可以改善输出:矛盾的是,约束解决方案空间使智能体更有生产力,而不是更少。当智能体可以生成任何东西时,它会浪费 token 探索死胡同。当 Harness 定义清晰的边界时,智能体会更快地收敛到正确的解决方案。
支柱 3:熵管理 —— “定期清理智能体”
这是最被低估的组件。随着时间的推移,AI 生成的代码库会积累熵——文档与现实脱节、命名约定发散、死代码积累。
Harness 工程通过定期清理智能体来解决这个问题:
- 文档一致性智能体——验证文档与当前代码匹配
- 约束违规扫描器——找到通过早期检查的代码
- 模式强制执行智能体——识别并修复与既定模式的偏差
- 依赖审计器——跟踪并解决循环或不必要的依赖
这些智能体按计划运行——每天、每周或由特定事件触发——保持代码库对人类审查者和未来 AI 智能体都健康。
前馈指南和反馈传感器:Harness 的双重目标
根据 面向编码智能体用户的 Harness 工程,一个构建良好的 Harness 服务于两个目标:
- 提高智能体第一次就做对的概率(前馈指南)
- 提供一个反馈循环,在问题到达人眼之前自我纠正尽可能多的问题(反馈传感器)
计算型 vs 推理型
指南和传感器有两种执行类型:
| 类型 | 描述 | 示例 | 速度 | 可靠性 |
|---|---|---|---|---|
| 计算型(Computational) | 确定性且快速,由 CPU 运行 | 测试、lint、类型检查器、结构分析 | 毫秒到秒 | 可靠 |
| 推理型(Inferential) | 语义分析、AI 代码审查、”LLM 作为法官” | 语义分析、AI 代码审查 | 更慢更昂贵 | 更不确定 |
前馈指南在智能体行动之前提供:原则、规则、参考文档、操作指南等,增加智能体第一次就做对的概率。
反馈传感器在智能体行动之后提供验证:静态分析、日志、浏览器测试、代码审查智能体等,用于自我纠正问题。
构建你的第一个 Harness:从简单开始
你不需要一开始就构建完整的生产级 Harness。根据 Harness 工程完整指南,你可以分三个级别逐步构建:
级别 1:基础 Harness(单个开发者)
如果你正在使用 Claude Code、Cursor 或 Codex 进行个人项目:
需要设置什么:
- 带有项目约定的
CLAUDE.md或.cursorrules文件 - 用于 linting 和格式化的预提交钩子
- 智能体可以运行以自我验证的测试套件
- 具有一致命名的清晰目录结构
设置时间:1-2 小时 影响:防止最常见的智能体错误
级别 2:团队 Harness(小团队)
对于 3-10 个共享代码库的开发者团队:
添加到级别 1:
- 带有团队范围约定的
AGENTS.md - 由 CI 强制执行的架构约束
- 常见任务的共享提示模板
- 由 linter 验证的文档即代码
- 专门针对智能体生成 PR 的代码审查检查清单
设置时间:1-2 天 影响:跨团队一致的智能体行为
级别 3:生产 Harness(工程组织)
对于运行数十个并发智能体的组织:
添加到级别 2:
- 自定义中间件层(循环检测、推理优化)
- 可观测性集成(智能体读取日志和指标)
- 计划运行的熵管理智能体
- Harness 版本控制和 A/B 测试
- 智能体性能监控仪表板
- 智能体卡住时的升级策略
设置时间:1-2 周 影响:智能体作为自主贡献者运作
为什么 Harness 工程很重要?
让我们回到 LLM Agent 中的外部化理论——从语言、文字、印刷术到计算机,每一次进步都是将认知负担从大脑外部化。
Harness 工程就是在为 AI 做同样的事情:
- 不是让模型变得更”大”,而是让它变得更”稳”
- 不是用更多参数去硬扛,而是用外部结构去辅助
- 不是让智能体”假装”可靠,而是让它在一个设计好的环境中”真的”可靠
核心洞见
实用的智能体 = 模型 + Harness
这就像说:
- 实用的汽车 = 发动机 + 整车(刹车、方向盘、仪表盘…)
- 实用的飞机 = 引擎 + 机身(控制系统、起落架、黑匣子…)
发动机很重要,但没有整车,它只是一个会转的铁块。
同样,LLM 很重要,但没有 Harness,它只是一个会说话的模型。
如果说 2025 年是 AI 智能体证明它们可以编写代码的一年,那么 2026 年就是我们认识到智能体不是难点——Harness 才是的一年。