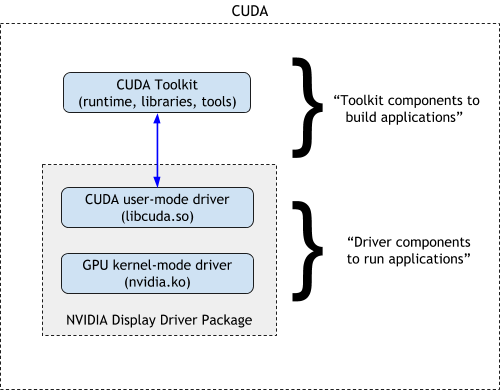
NVIDIA 软件栈搭建
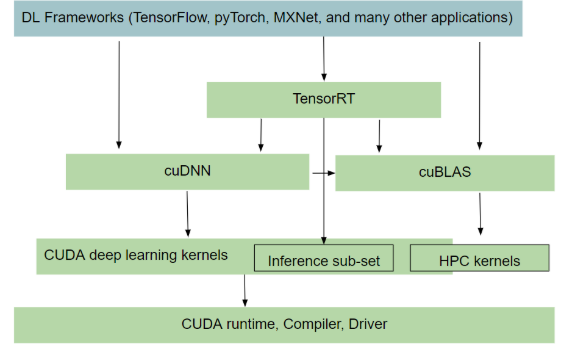
NVIDIA 软件栈
GPU Driver
Ubuntu
- 搜索有效的显卡驱动
sudo ubuntu-drivers devices #搜索匹配 sudo apt search nvidia- - 安装驱动
sudo apt install nvidia-driver-510 - 重启系统
sudo reboot - 查看
nvidia-smi - 卸载驱动
sudo apt purge nvidia*
CUDA Toolkit
CUDA Toolkit 自带驱动。
下载
这里下载 run 格式安装包。
安装
$ sudo sh cuda_xx.x.x_xxx.xx.xx_linux.run
deviceQuery
$ ./deviceQuery
./deviceQuery Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce GTX 1060 6GB"
CUDA Driver Version / Runtime Version 11.6 / 11.0
CUDA Capability Major/Minor version number: 6.1
Total amount of global memory: 6078 MBytes (6373638144 bytes)
(10) Multiprocessors, (128) CUDA Cores/MP: 1280 CUDA Cores
GPU Max Clock rate: 1785 MHz (1.78 GHz)
Memory Clock rate: 4004 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 1572864 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 2048
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: 2147483647 bytes
Texture alignment: 512 bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: No
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 11.6, CUDA Runtime Version = 11.0, NumDevs = 1
Result = PASS
cuDNN
CUDA 深度神经网络库(cuDNN)是用于深度神经网络的GPU加速原语库。cuDNN为正向和反向卷积、池化、归一化和激活层等标准例程提供了高度调谐的实现。
cuDNN Accelerated Frameworks
下载
这里下载 tar 包。
安装(Tar File Installation)
tar -xvf cudnn-linux-x86_64-8.4.0.27_cuda11.6-archive.tar.xz
sudo cp cudnn-*-archive/include/cudnn*.h /usr/local/cuda/include
sudo cp -P cudnn-*-archive/lib/libcudnn* /usr/local/cuda/lib64
sudo chmod a+r /usr/local/cuda/include/cudnn*.h /usr/local/cuda/lib64/libcudnn*
TensorRT
NVIDIA TensorRT 是一款用于高性能深度学习推理的 SDK,包括深度学习推理优化器和运行时,可为推理应用程序提供低延迟和高吞吐量。
TensorRT 功能

-
降低精度(Reduced Precision) 通过量化模型,同时保持准确性,最大限度地提高FP16或INT8的吞吐量。
-
层和张量融合(Layer and Tensor Fusion) 通过融合内核中的节点来优化GPU内存和带宽的使用。
-
内核自动调谐(Kernel Auto-Tuning) 根据目标GPU平台选择最佳数据层和算法。
-
动态张量内存(Dynamic Tensor Memory) 最大限度地减少内存占用,并有效地将内存重用到张量上。
-
多流执行(Multi-Stream Execution) 使用可扩展的设计并行处理多个输入流。
-
时间融合(Time Fusion) 使用动态生成的内核优化时间步骤中的循环神经网络。
下载
这里下载 tar 包。
安装(Tar File Installation)
tar -xzvf TensorRT-8.2.4.2.Linux.x86_64-gnu.cuda-11.4.cudnn8.2.tar.gz
sudo mv TensorRT-8.2.4.2 /usr/local/
sudo ln -s /usr/local/TensorRT-8.2.4.2 /usr/local/tensorrt
配置环境变量 LD_LIBRARY_PATH
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/tensorrt/lib
#Install the Python TensorRT wheel file.
pip install /usr/local/tensorrt/python/tensorrt-8.2.4.2-cp39-none-linux_x86_64.whl
#Install the Python graphsurgeon wheel file.
pip install /usr/local/tensorrt/graphsurgeon/graphsurgeon-0.4.5-py2.py3-none-any.whl
#Install the Python onnx-graphsurgeon wheel file.
pip install /usr/local/tensorrt/onnx_graphsurgeon/onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl
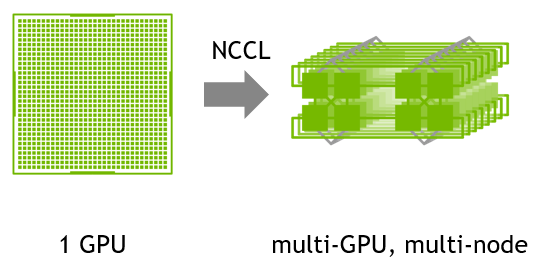
NCCL
针对 NVIDIA GPU 和 网络进行优化多 GPU 和 多节点的通信原语。提供 all-gather, all-reduce, broadcast, reduce, reduce-scatter 等功能作为点到点的发送和接收,这些功能经过优化,可通过 PCIe 和 NVLink 实现高带宽和低延迟节点内以及跨节点的 NVIDIA Mellanox 网络。
NVIDIA HPC - High Performance Computing
NVIDIA HPC SDK
