State of GPT - Andrej Karpathy
介绍
Learn about the training pipeline of GPT assistants like ChatGPT, from tokenization to pretraining, supervised finetuning, and Reinforcement Learning from Human Feedback (RLHF). Dive deeper into practical techniques and mental models for the effective use of these models, including prompting strategies, finetuning, the rapidly growing ecosystem of tools, and their future extensions.
了解 ChatGPT 等 GPT 助手的训练管道,从标记化到预训练、监督微调和人类反馈强化学习 (RLHF)。 深入研究有效使用这些模型的实用技术和心智模型,包括提示策略、微调、快速增长的工具生态系统及其未来的扩展。
- State of GPT - Video
- 微软2023年Build大会演讲:如何训练和应用GPT
- State of GPT - PDF
- State of GPT:大神Andrej揭秘OpenAI大模型原理和训练过程
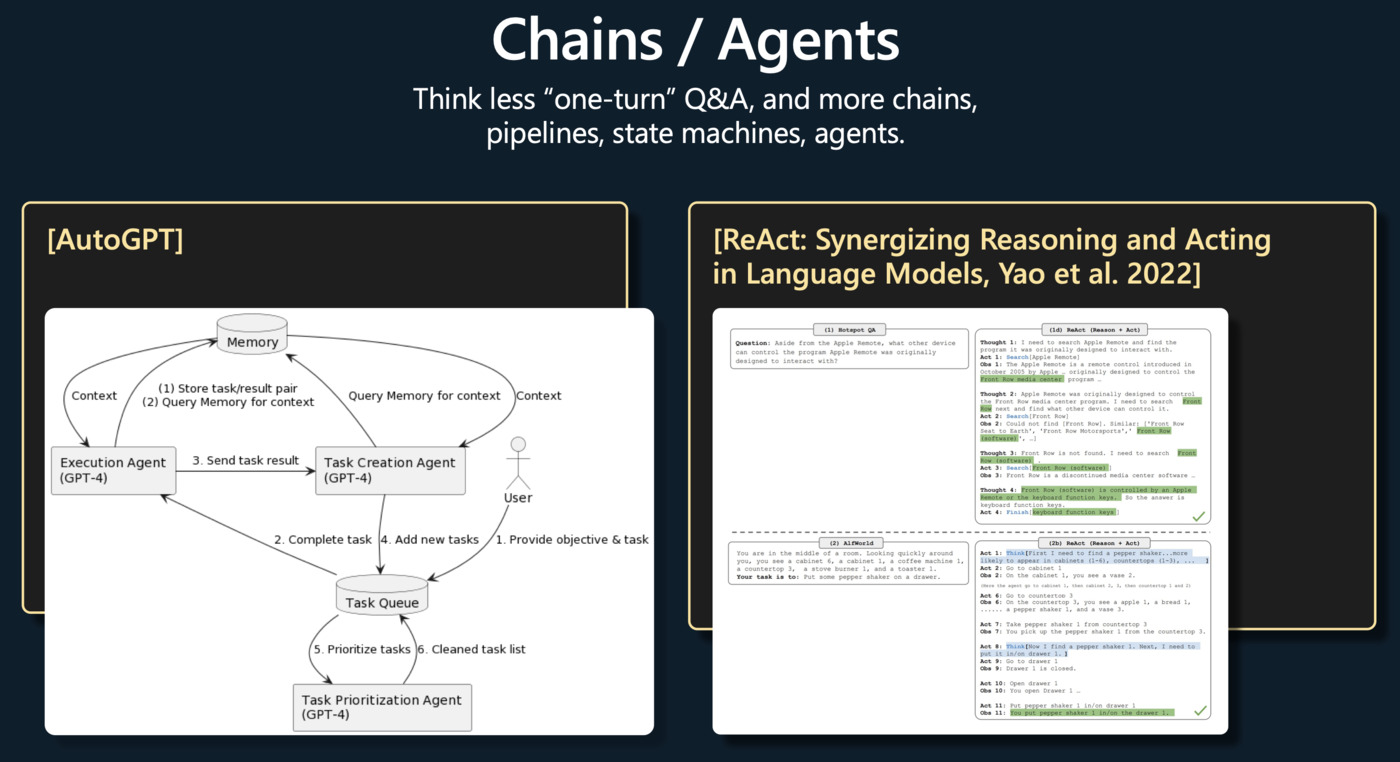
GPT Assistant training pipeline

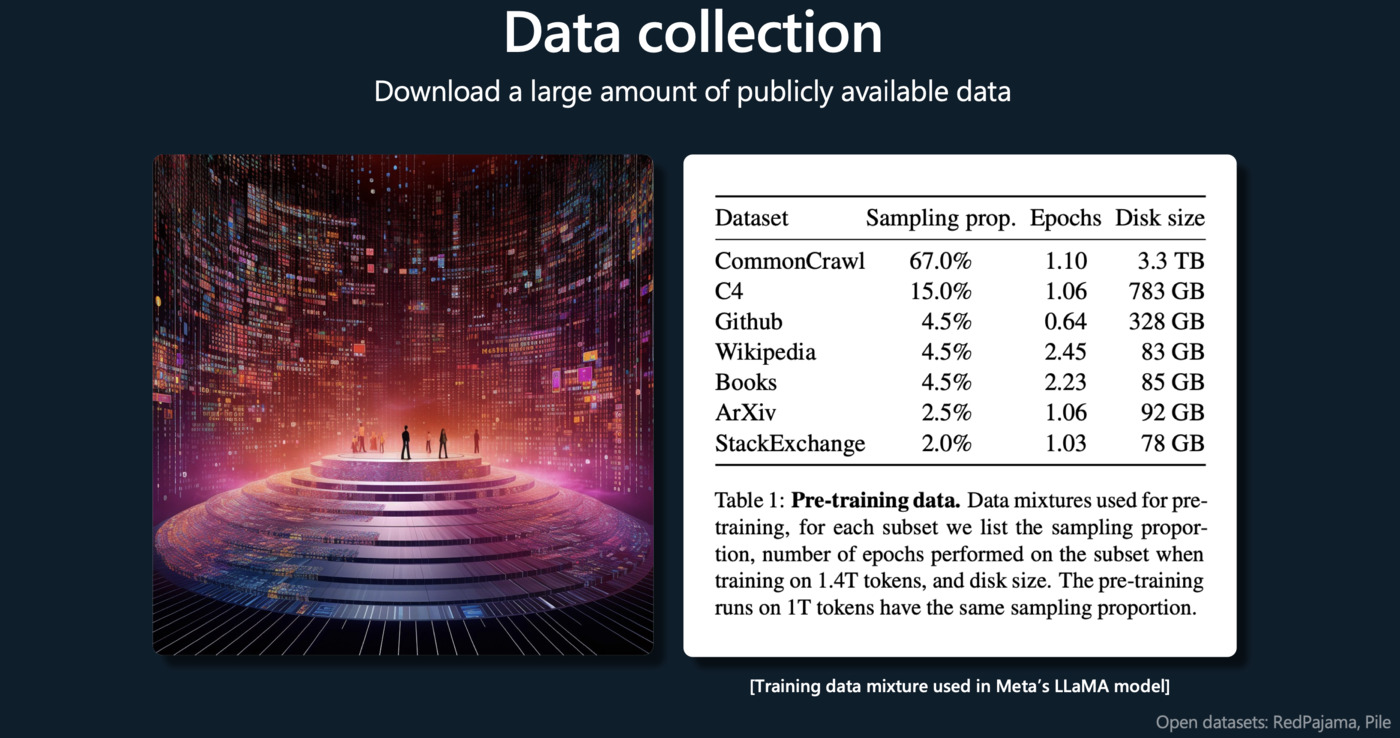
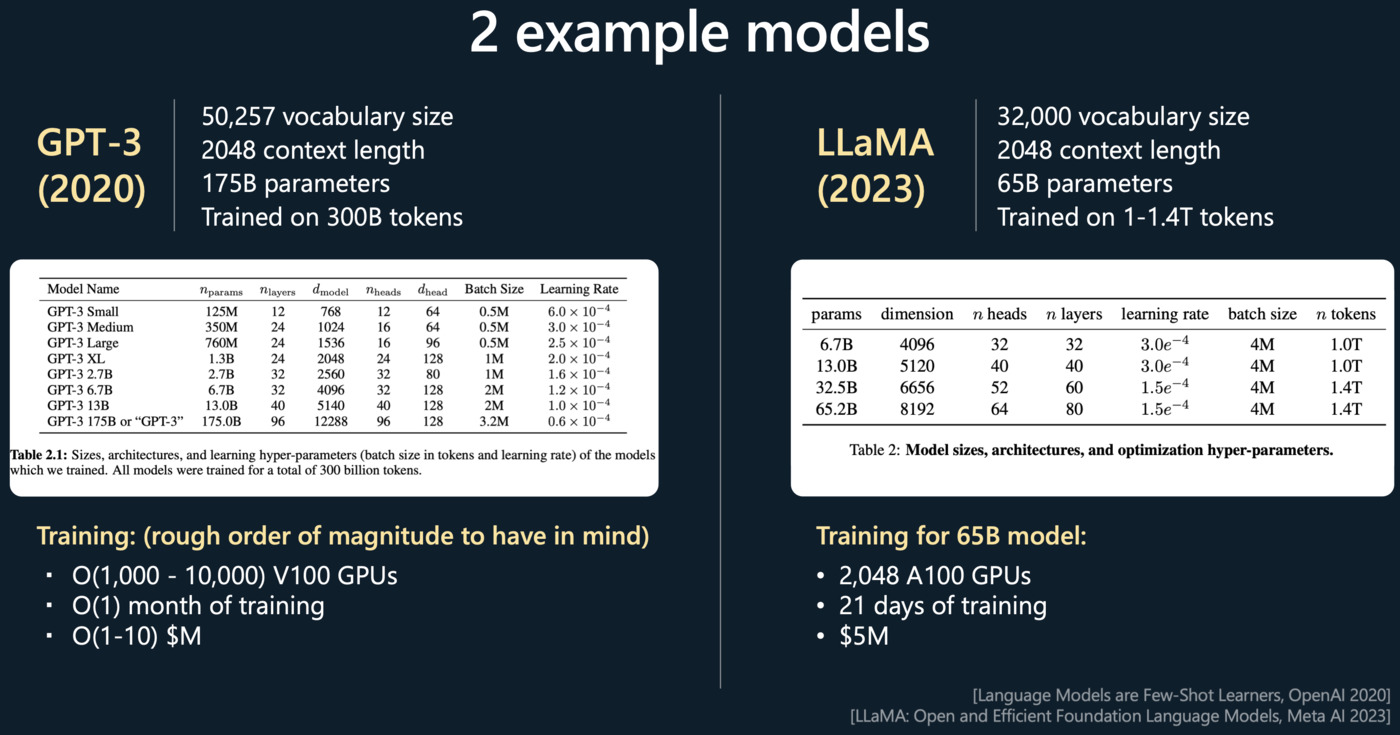
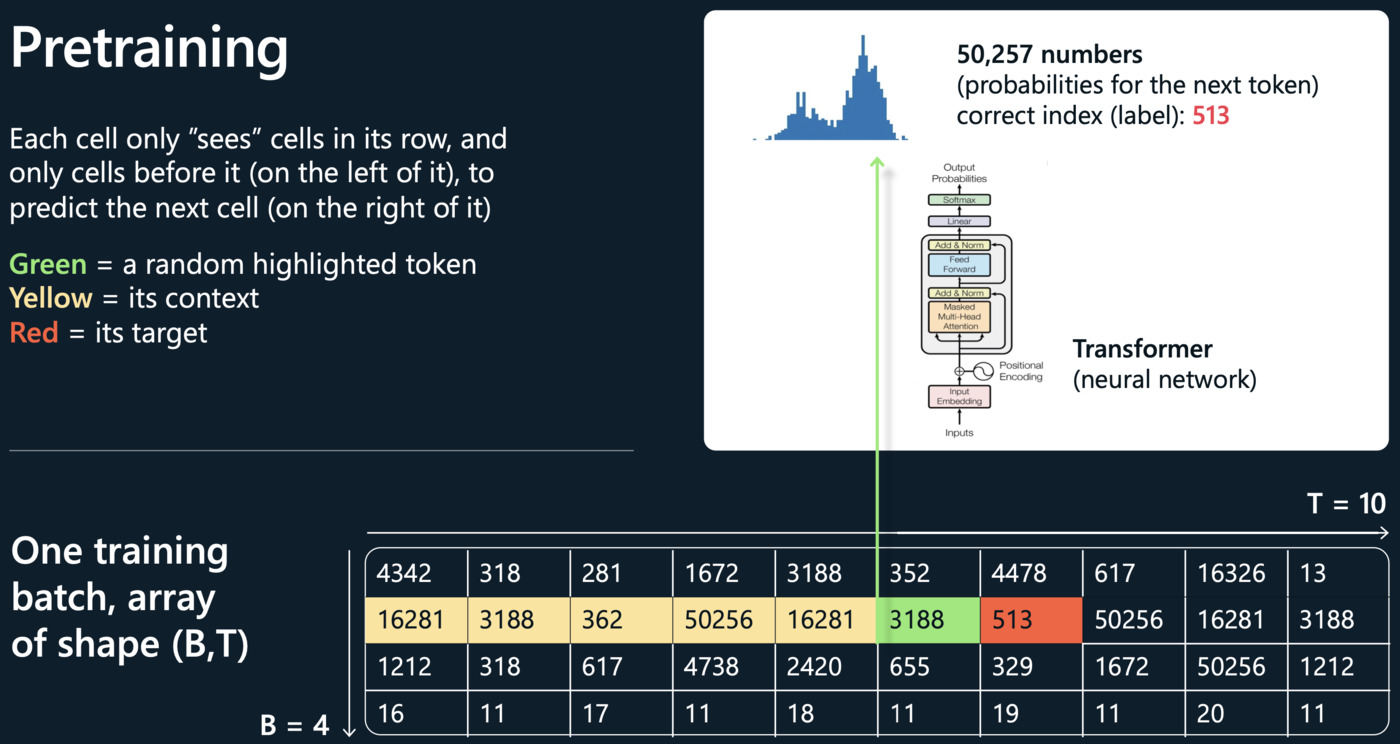
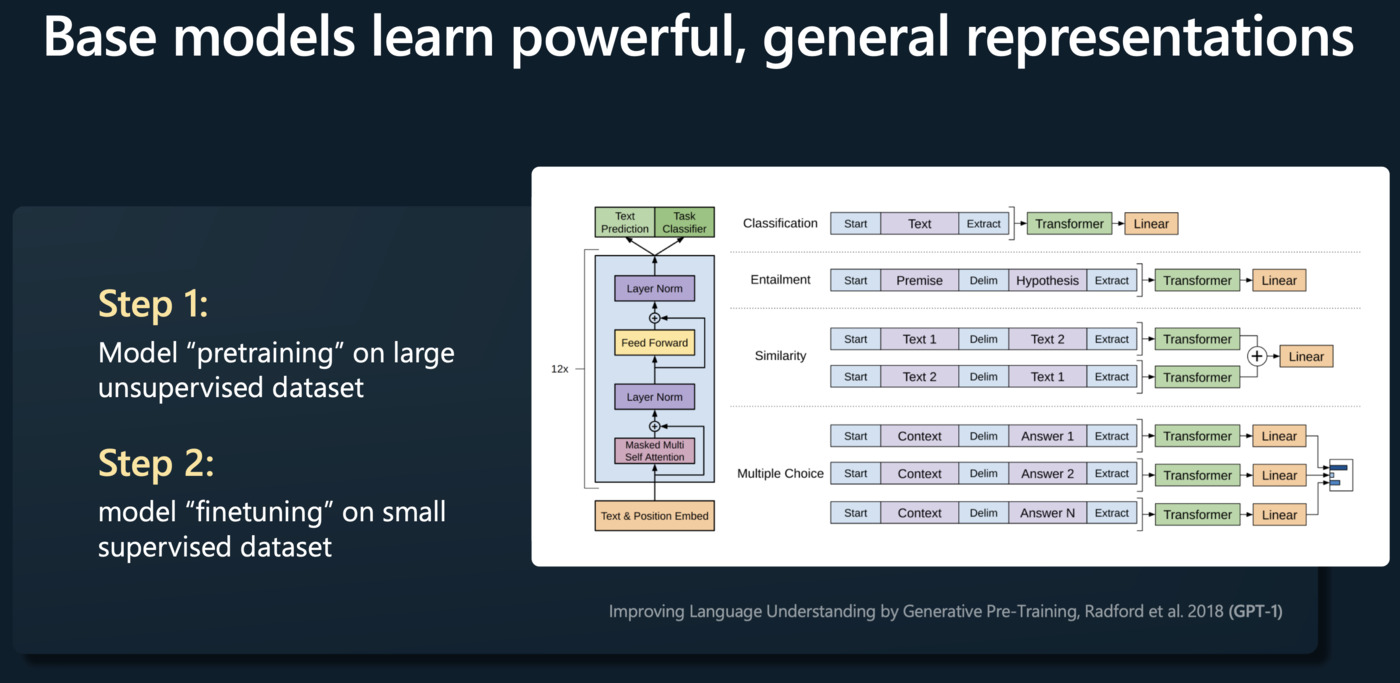
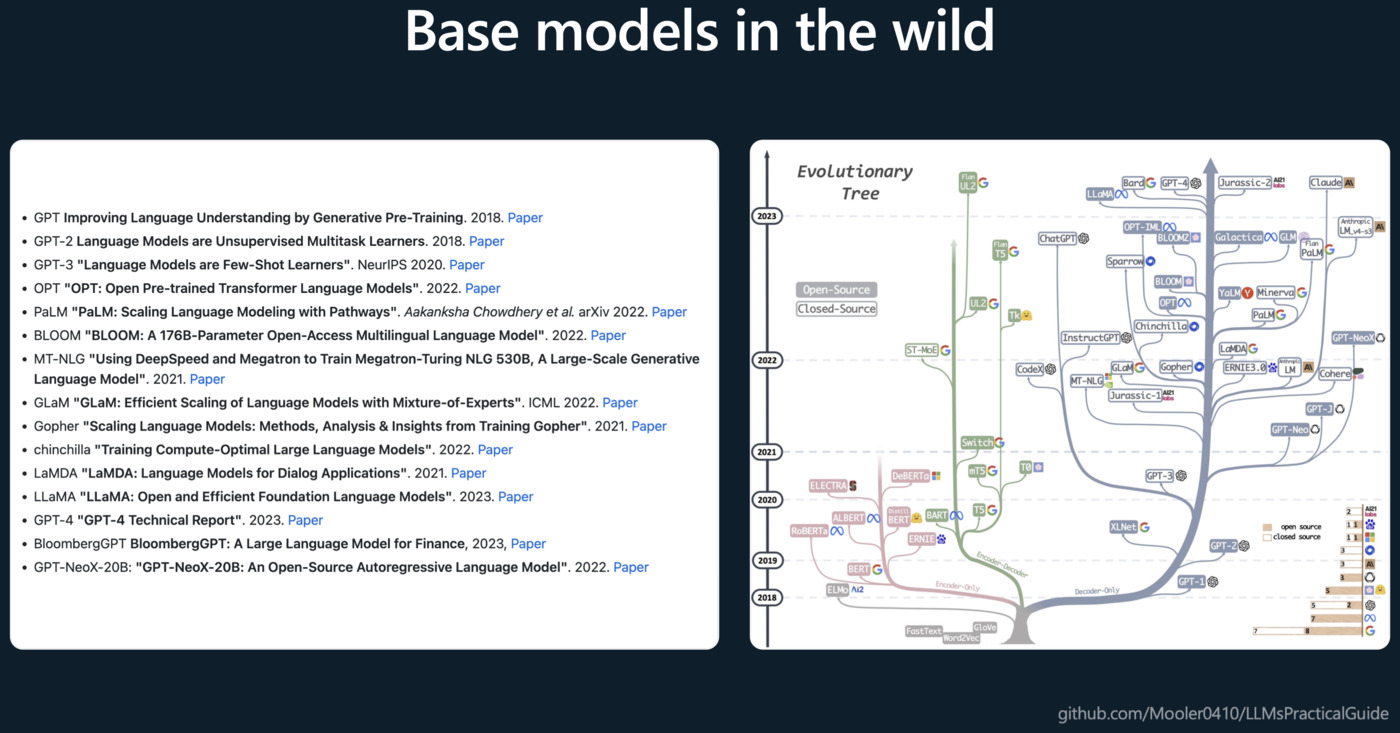
Pretraining(预训练)
这个阶段的目标是让模型学习一种语言模型,用于预测文本序列中的下一个单词。训练数据通常是互联网上的大量文本。模型从这些文本中学习词汇、语法、事实以及某种程度的推理能力。这个阶段结束后,模型可以生成一些有意义且语法正确的文本,但可能无法理解具体任务的需求。


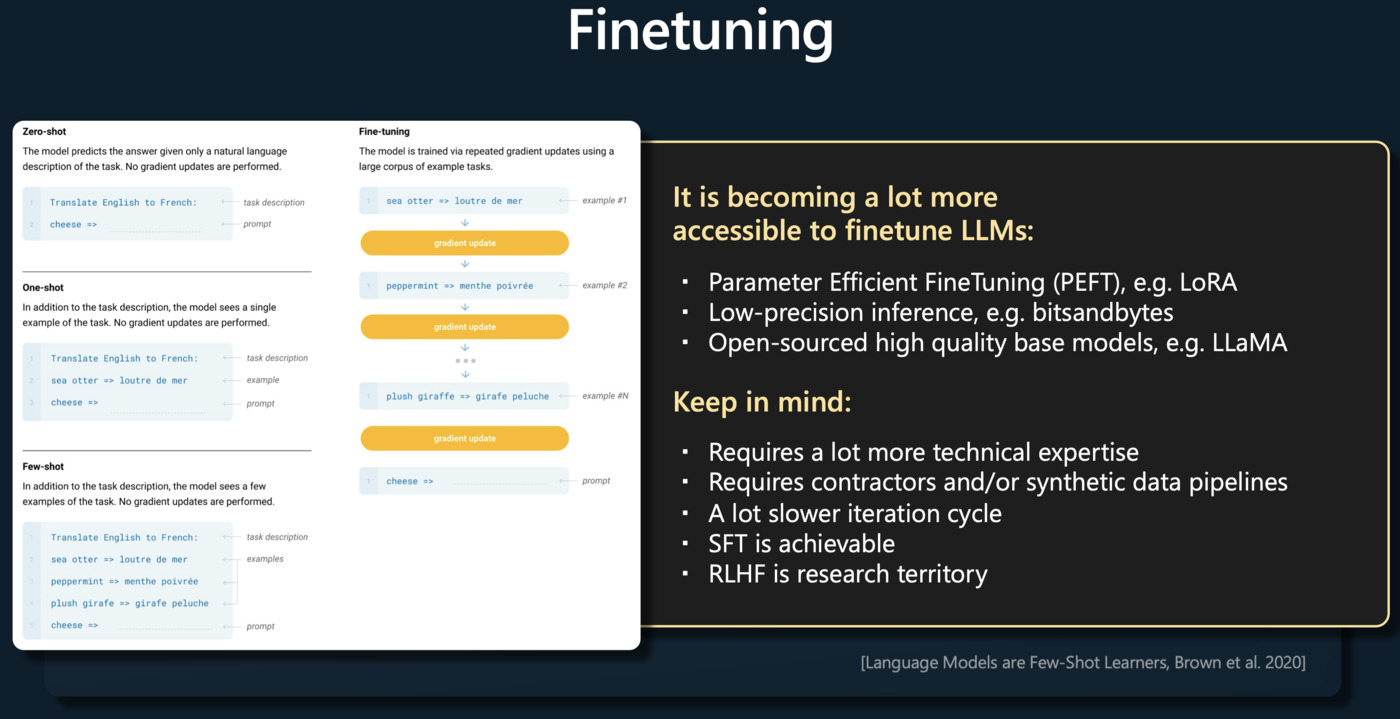
Supervised Finetuning(监督微调)
在预训练后,模型会进入微调阶段。在这个阶段,人类评估员将参与并给出指导,他们会给模型提供对话样本,样本中包含了输入和期望的输出。这使得模型能更好地适应特定任务或应用,例如回答问题或编写文章。

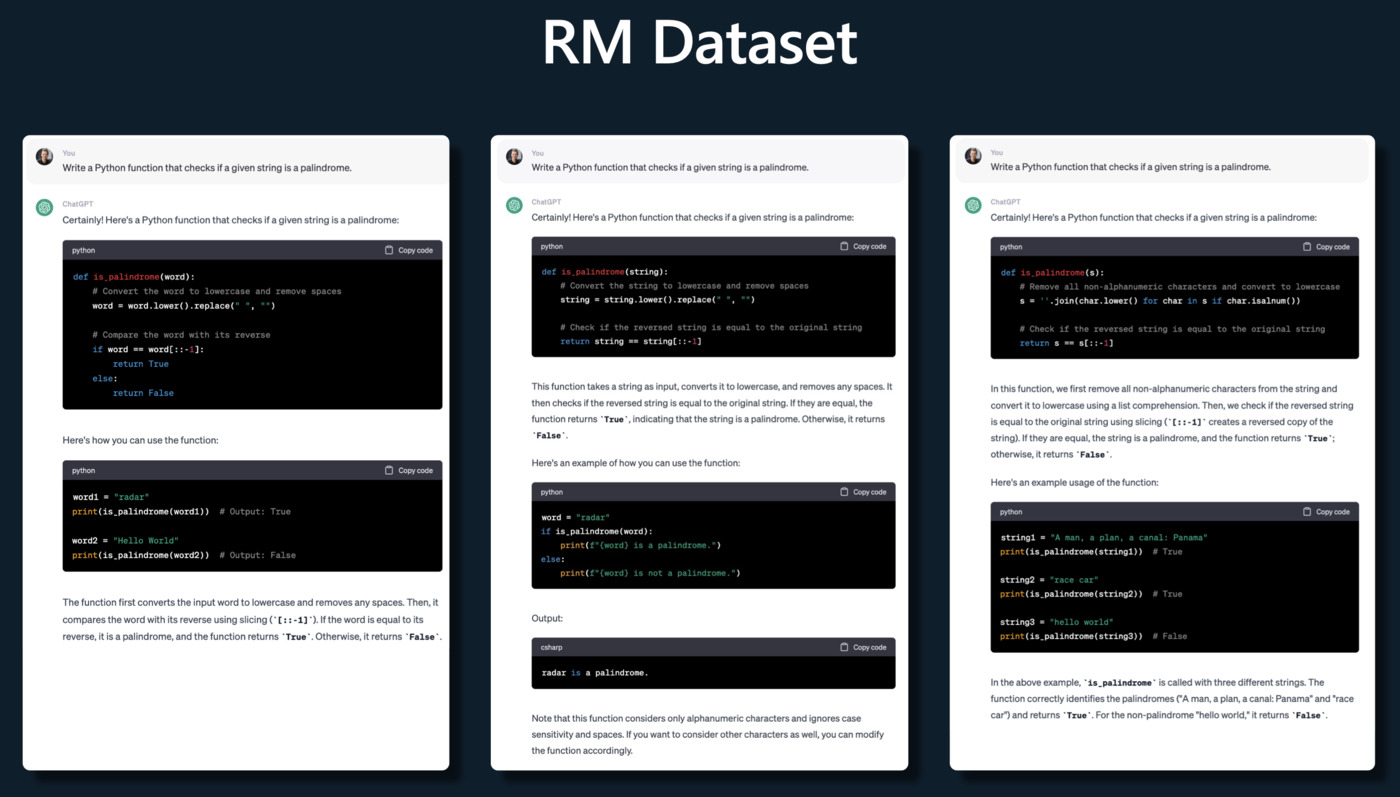
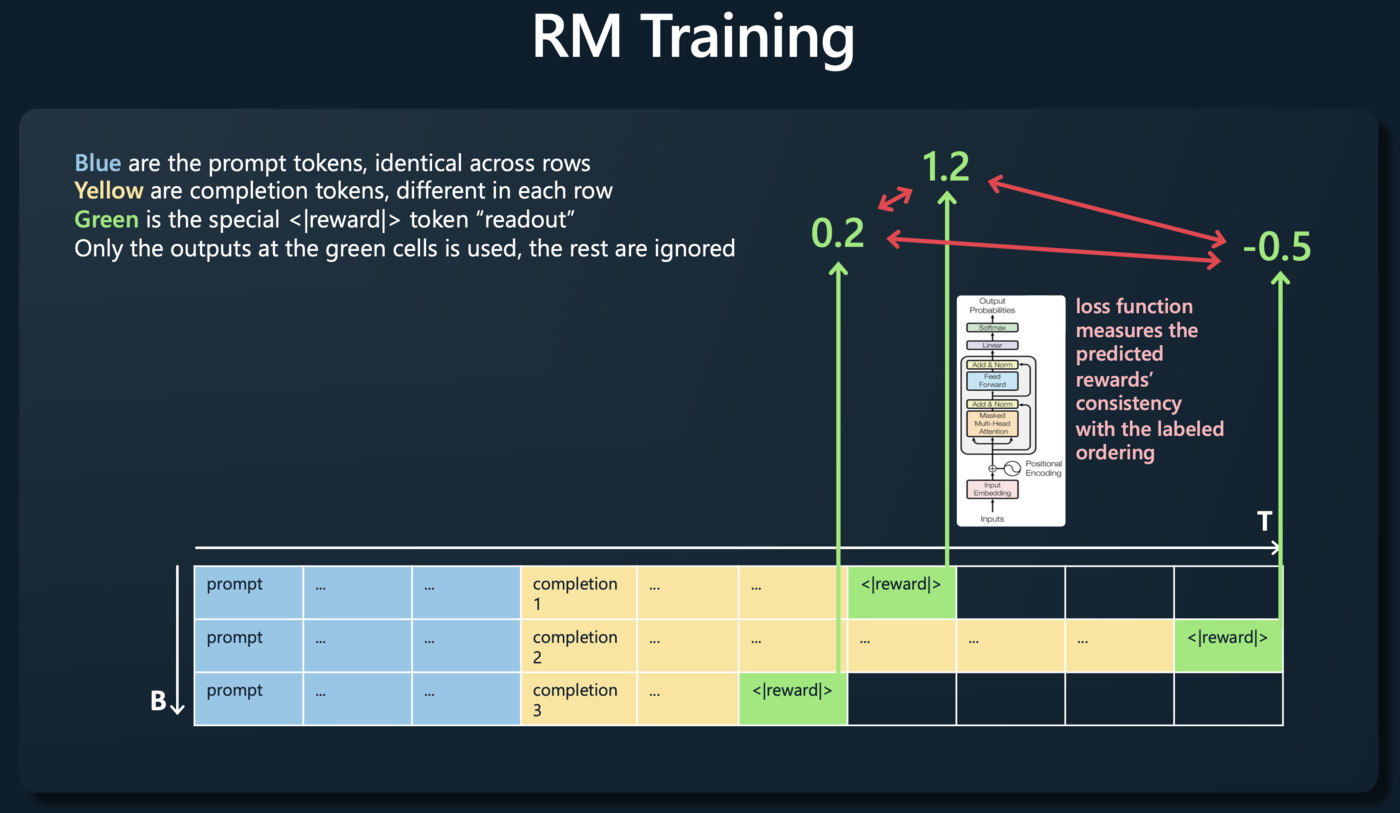
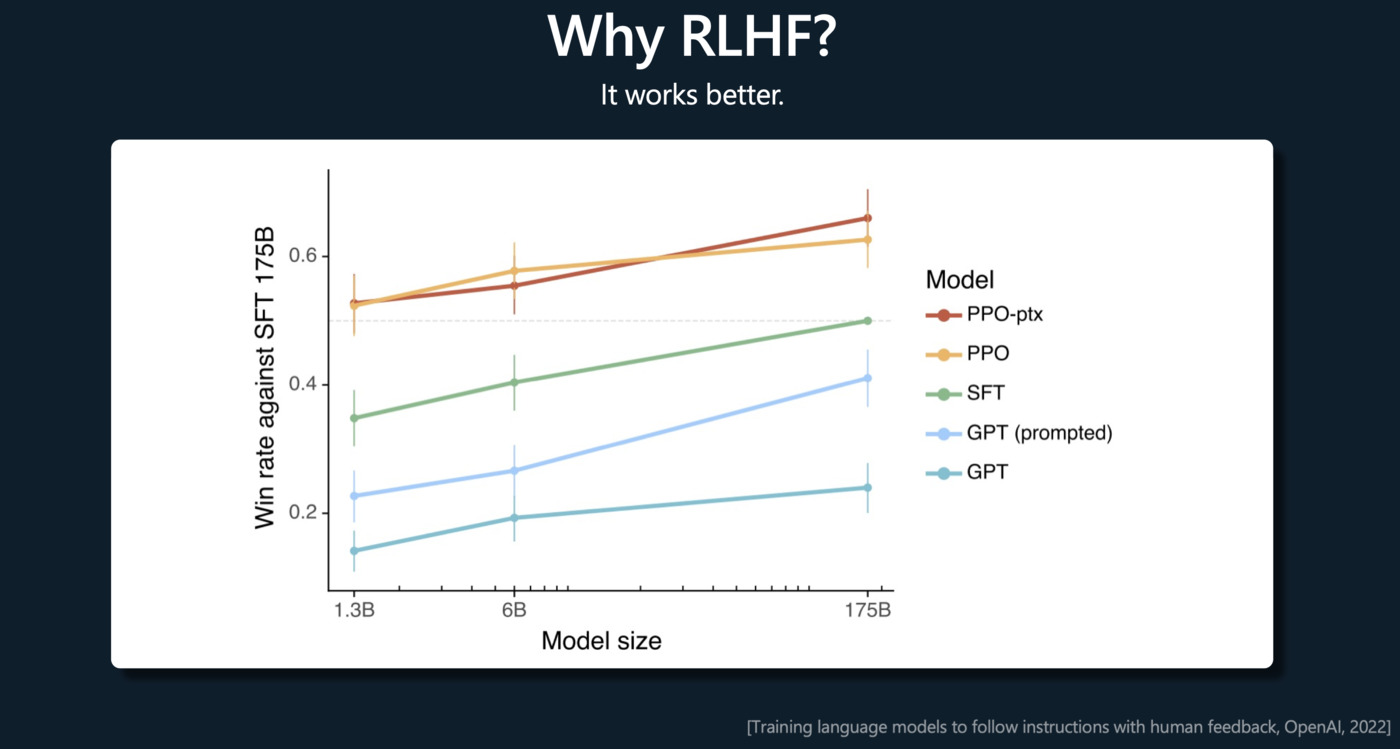
Reward Modeling(奖励建模)
评估员将对模型生成的不同输出进行排名,以表示它们的质量。这个排名将被用作奖励函数,指导模型优化其生成的输出。

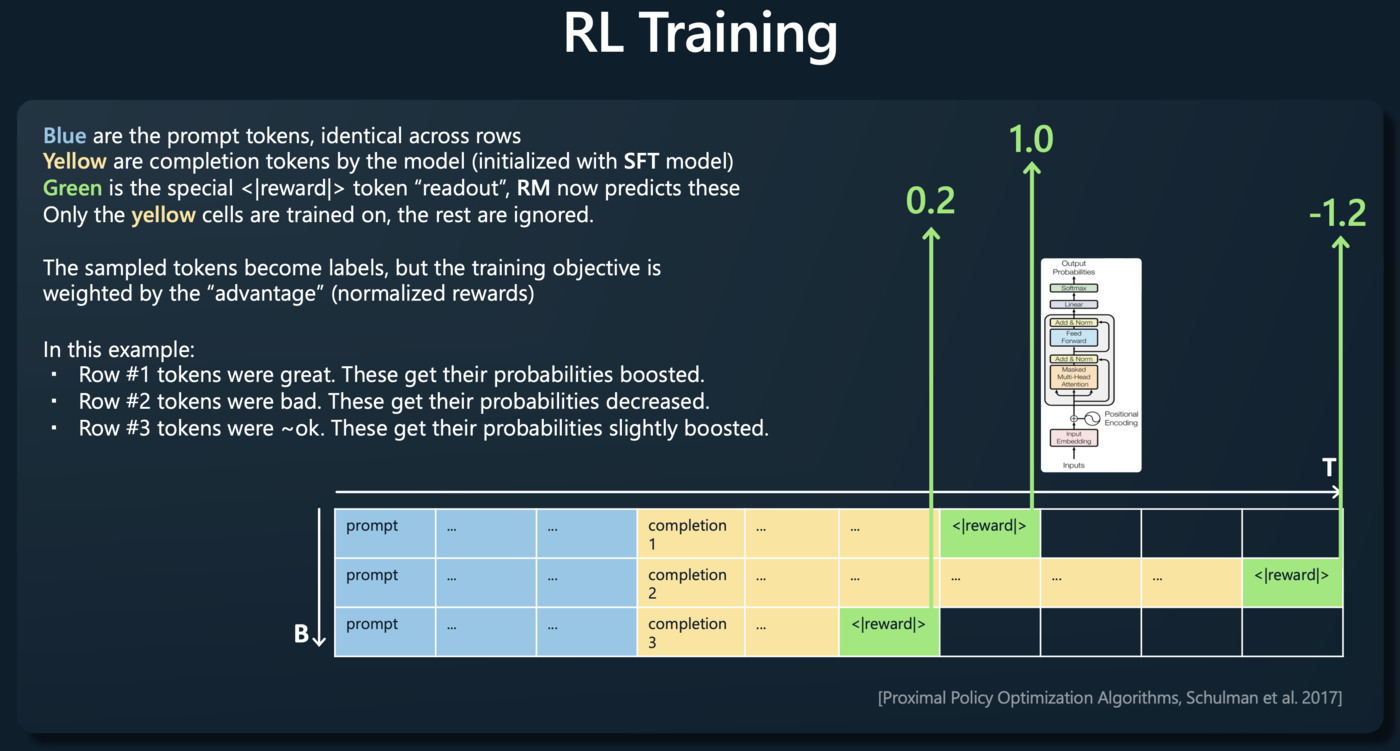
Reinforcement Learning(强化学习)
强化学习阶段是一个迭代的过程,模型会试图优化其行为以获得最大的奖励。在这个阶段,模型会产生新的输出,评估员会对这些输出进行排名,然后模型根据这个反馈调整其行为。

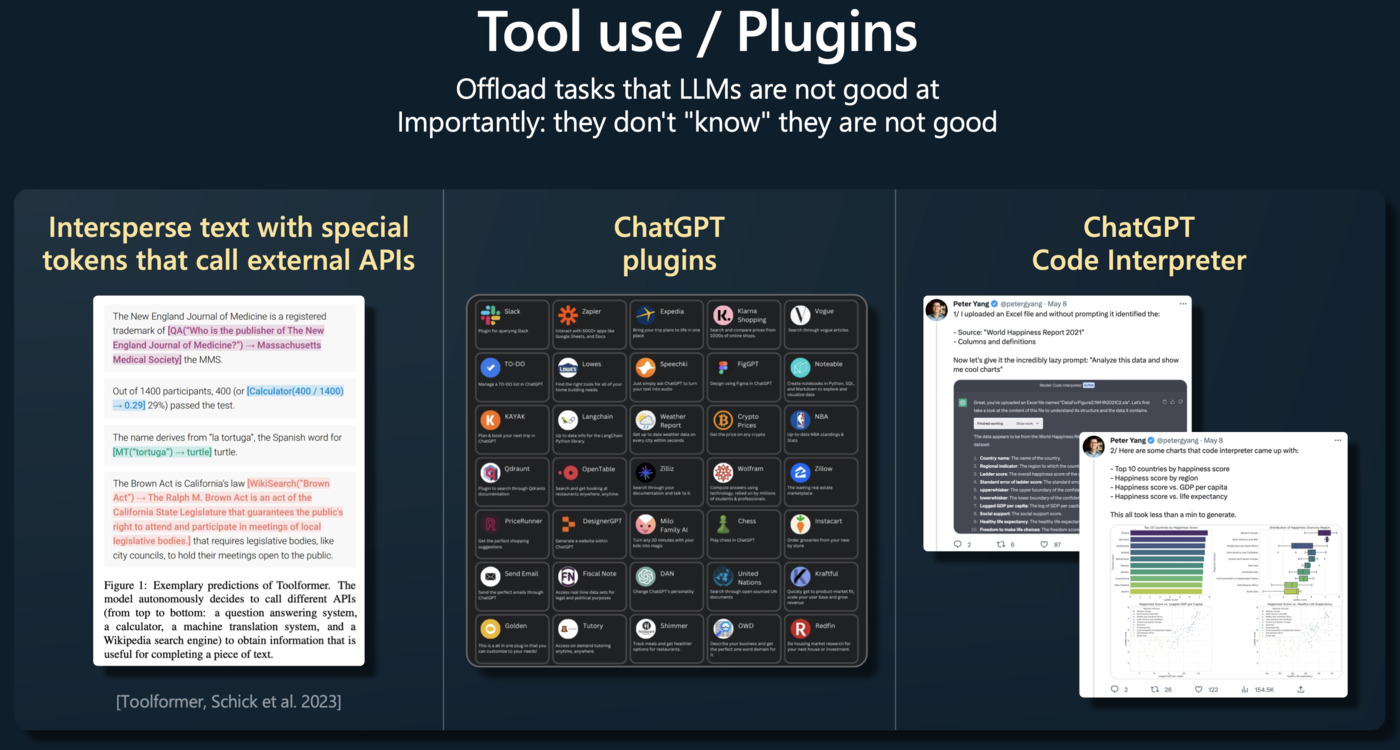
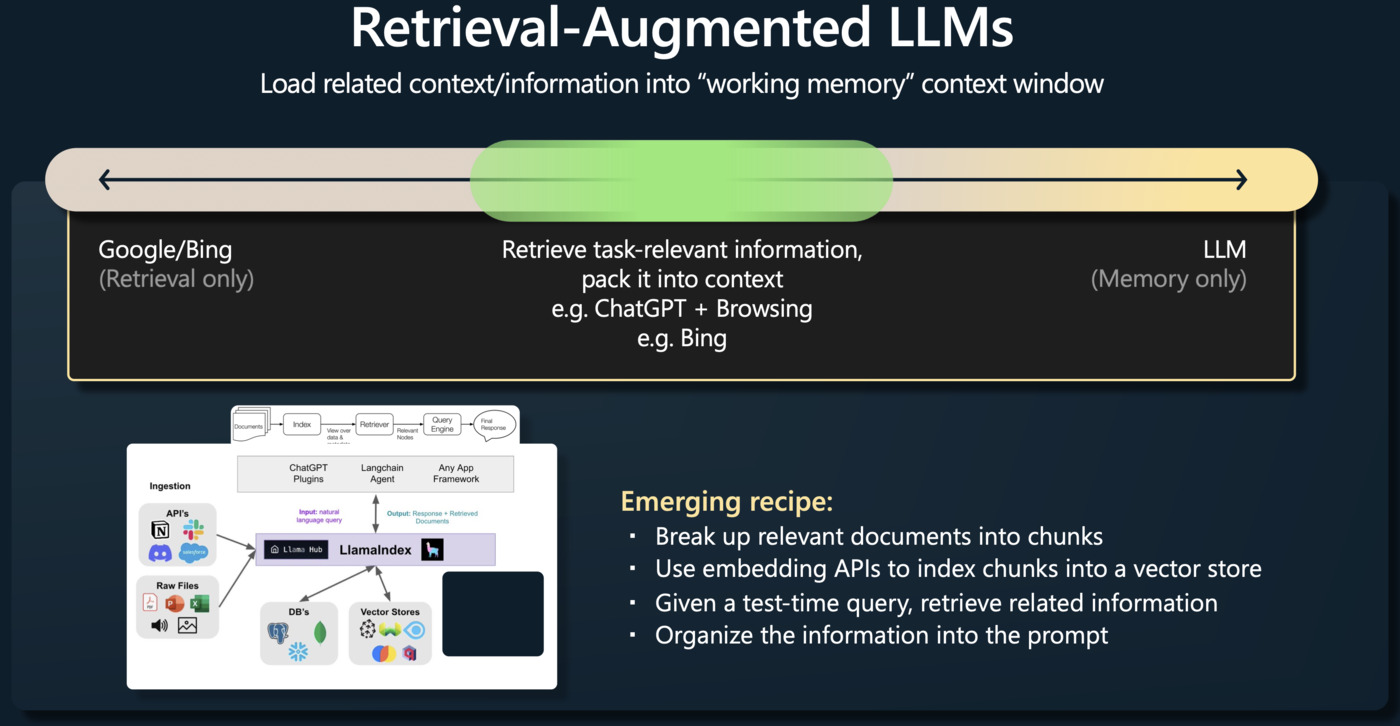
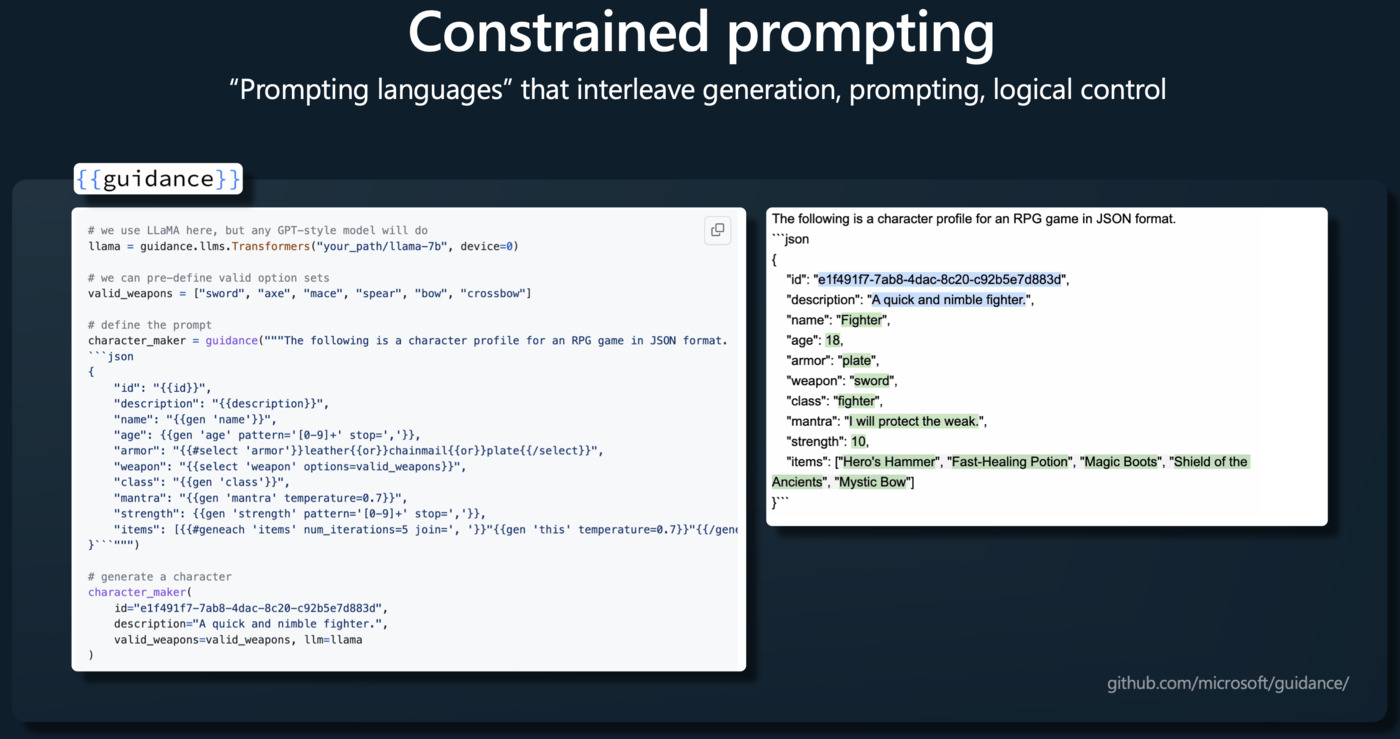
Applications