探索多模态大模型 GLM-4.1V-Thinking
本文档介绍了多模态大模型GLM-4.1V-Thinking,这是一个基于 GLM-4-9B-0414 的开源视觉语言模型,通过强化学习显著提升了其性能。文档详细阐述了该模型在设计图转代码(Design2Code)任务上的卓越表现,能将设计图转换为高质量的HTML/CSS代码,并提供了与Qwen-2.5-VL-32B-Instruct的对比示例。此外,资源还展示了如何通过智谱API免费使用GLM-4.1V-Thinking进行图像识别,并给出了一个安全检测系统的代码示例,该系统能够识别图像中的火灾、烟雾以及人员安全帽佩戴情况,并进行坐标标注,强调了模型在实际应用中的潜力。
模型介绍
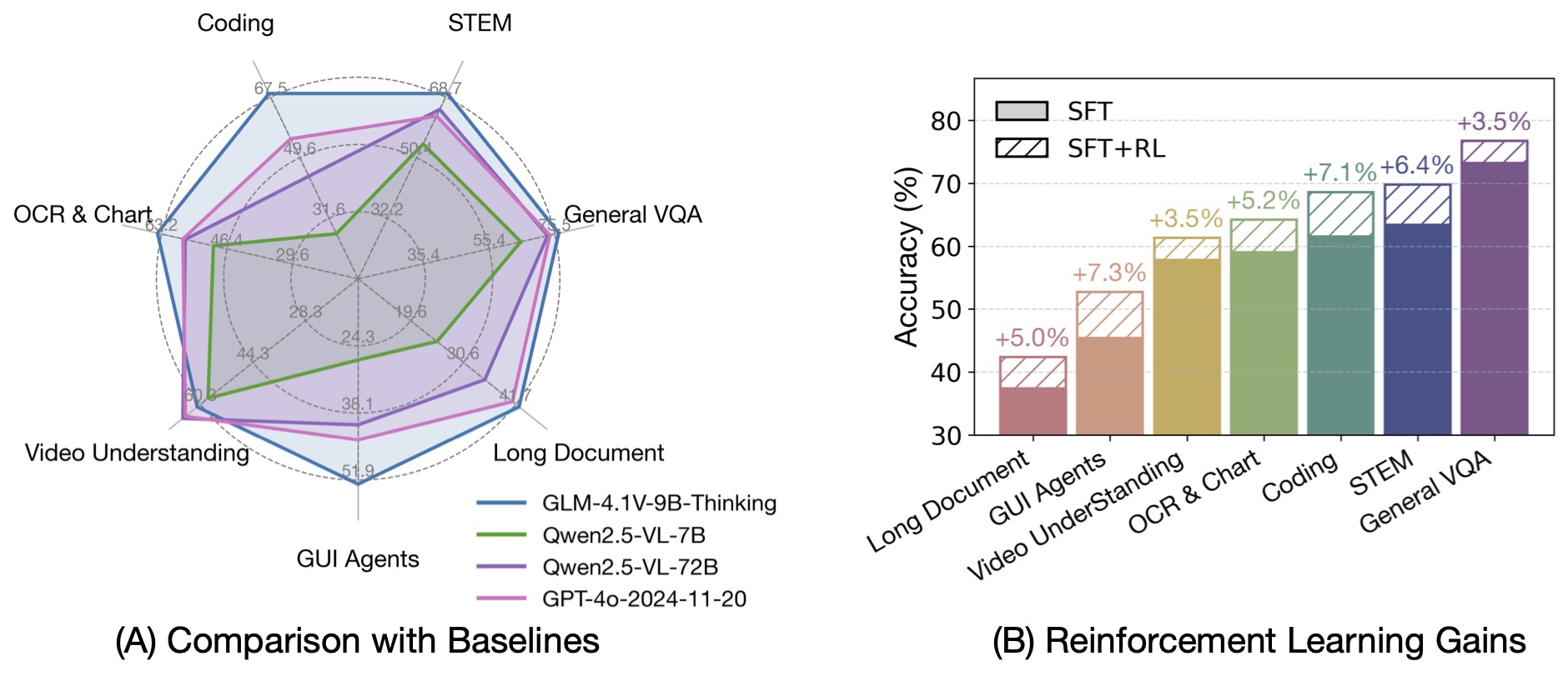
基于 GLM-4-9B-0414 基座模型,我们推出新版VLM开源模型 GLM-4.1V-9B-Thinking ,引入思考范式,通过课程采样强化学习 RLCS(Reinforcement Learning with Curriculum Sampling)全面提升模型能力, 达到 10B 参数级别的视觉语言模型的最强性能,在18个榜单任务中持平甚至超过8倍参数量的 Qwen-2.5-VL-72B。
论文 GLM-4.1V-Thinking:通过可扩展强化学习实现通用多模态推理
模型文件
在线体验
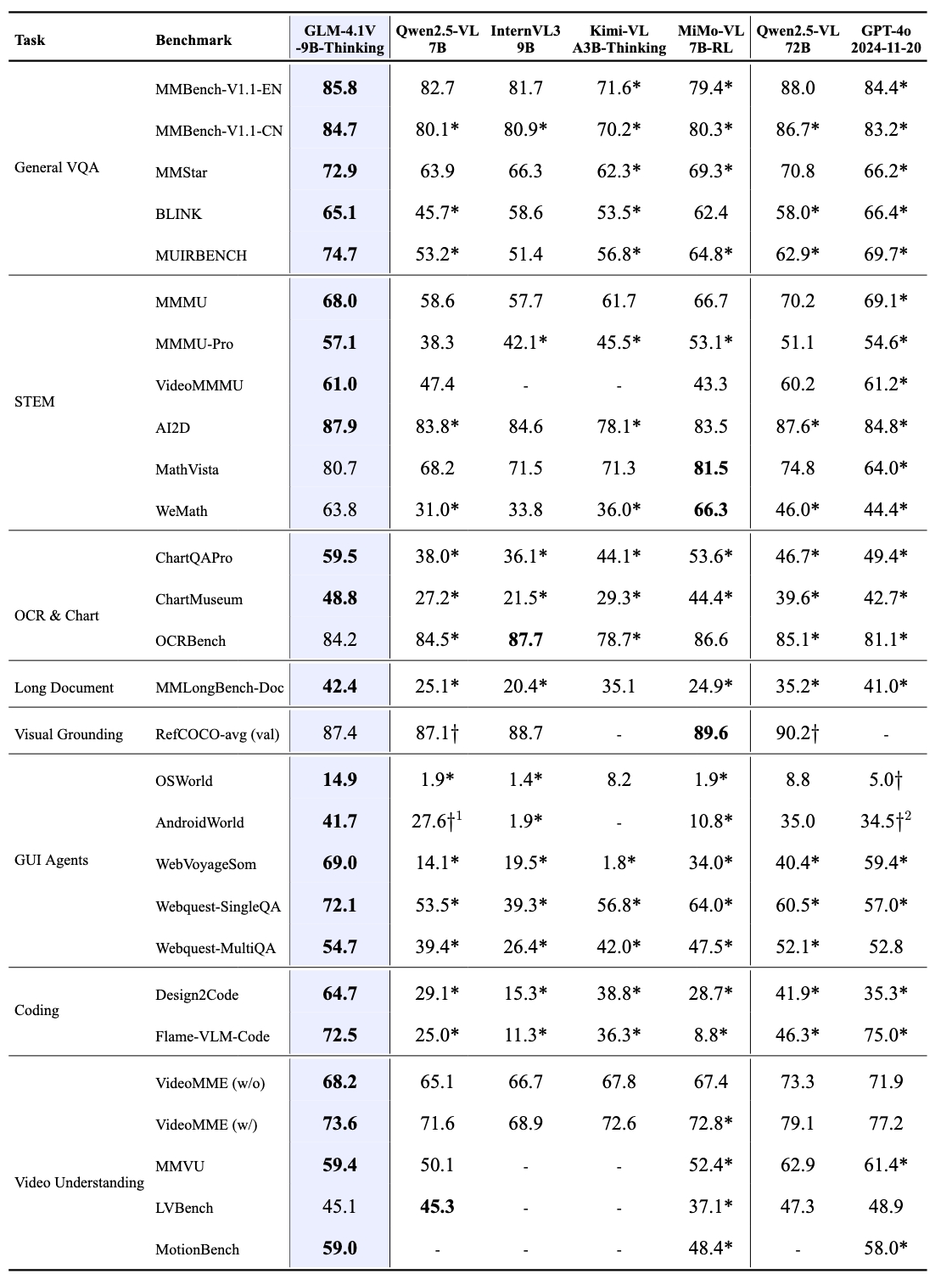
基准性能
Design2Code

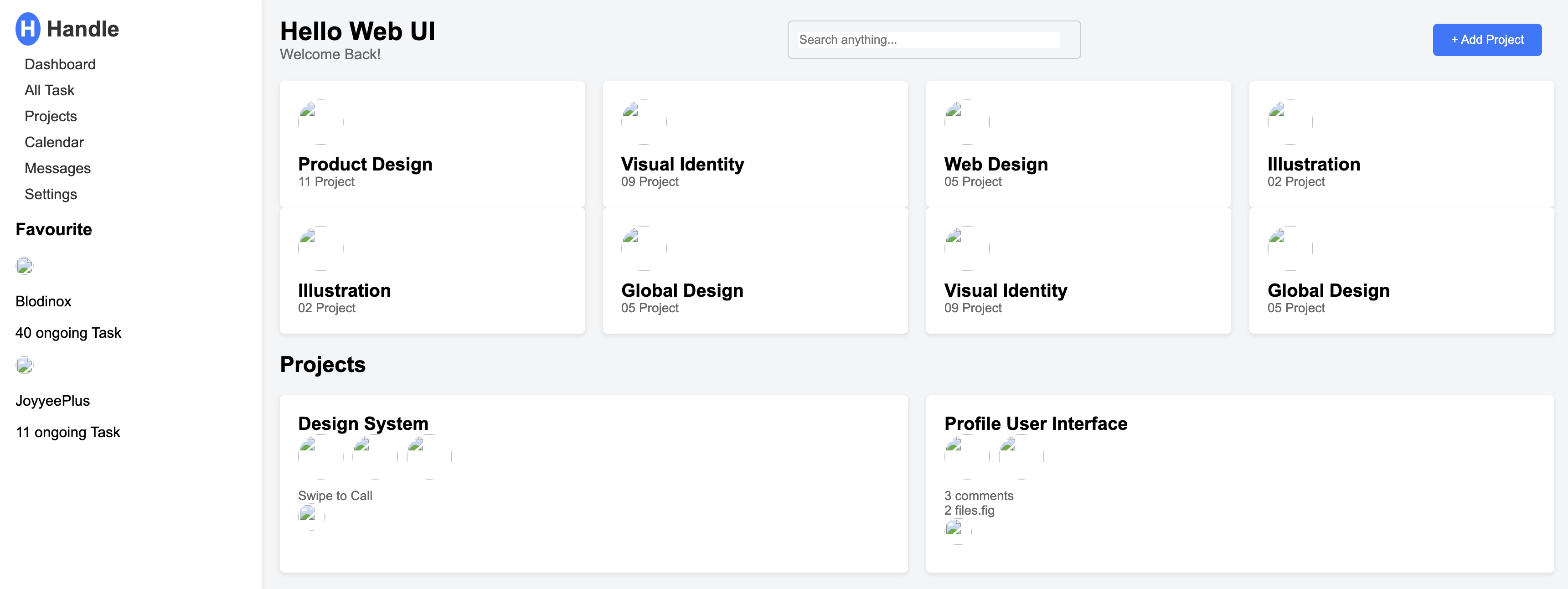
GLM-4.1V-Thinking 在设计到代码的转换任务上表现出色,能够将设计图转换为高质量的 HTML/CSS 代码。以下是一些示例:
Web 应用
-
设计图
-
生成代码(HTML/CSS)通过浏览器渲染
- GLM-4.1V-9B-Thinking
- Qwen2.5-VL-32B-Instruct
- GLM-4.1V-9B-Thinking
大屏
-
设计图

-
生成代码(HTML/CSS)通过浏览器渲染
- GLM-4.1V-9B-Thinking
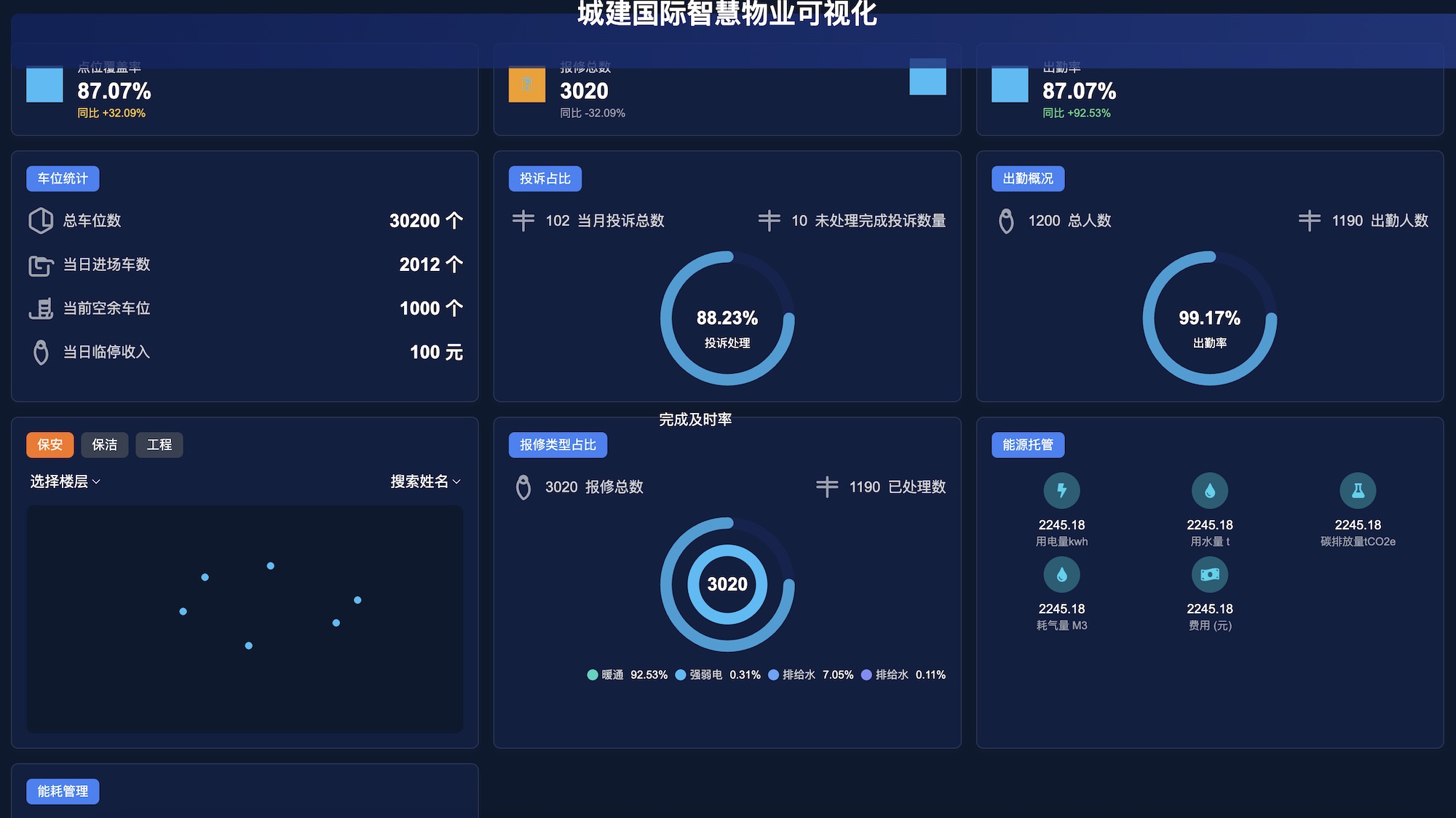
- Qwen2.5-VL-32B-Instruct
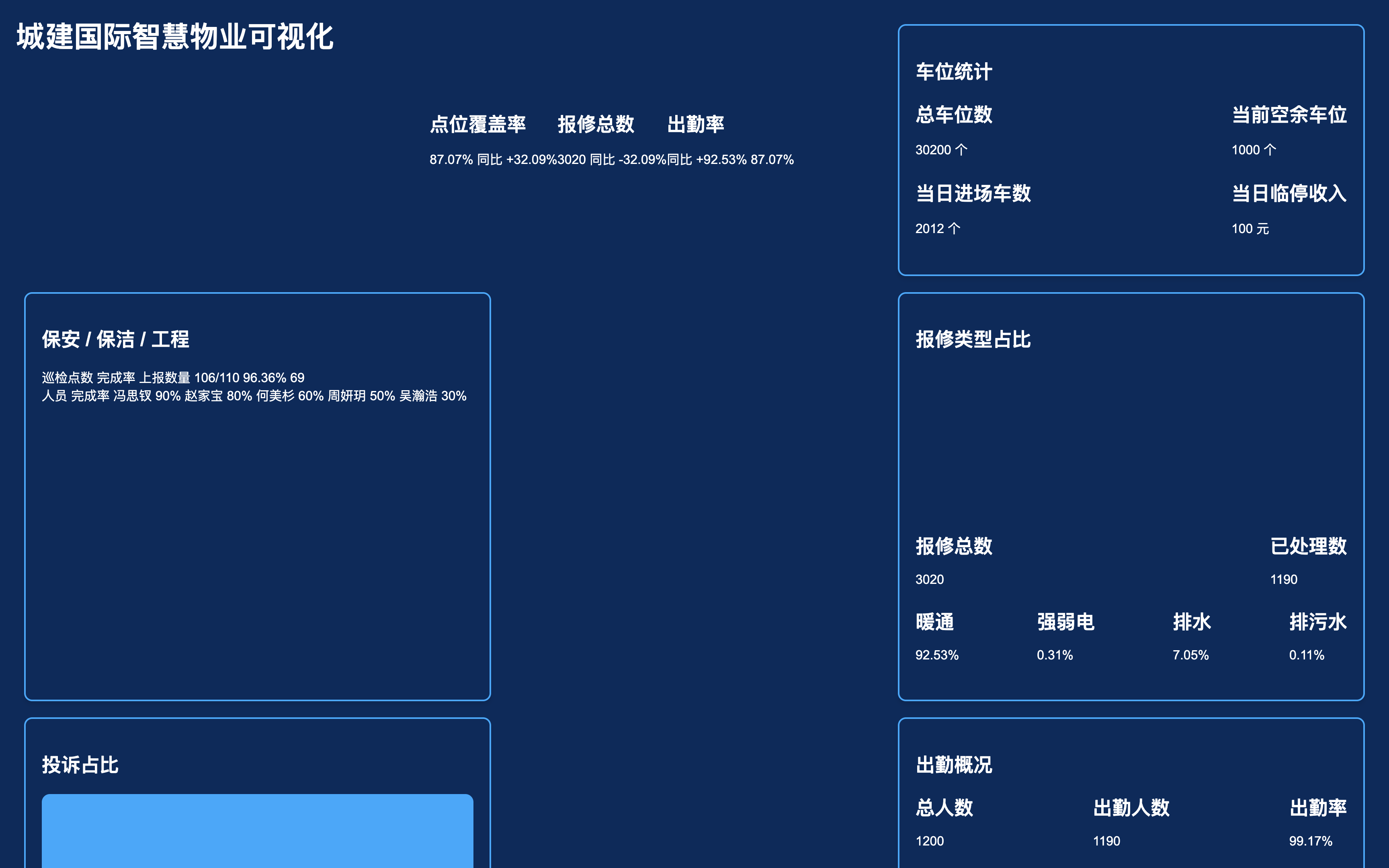
- GLM-4.1V-9B-Thinking
低代码平台
-
设计图
-
生成代码(HTML/CSS)通过浏览器渲染
- GLM-4.1V-9B-Thinking
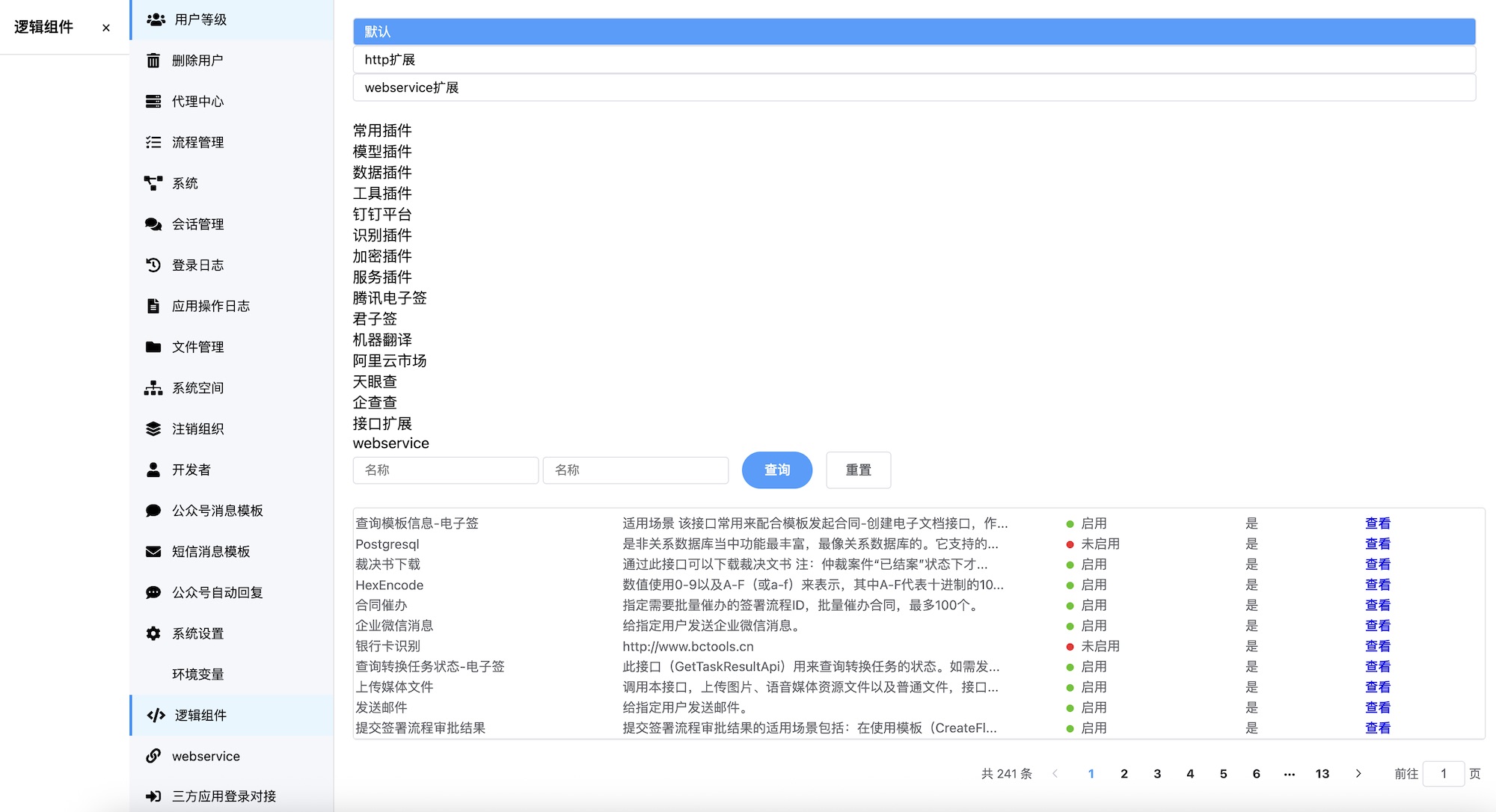
- Qwen2.5-VL-32B-Instruct
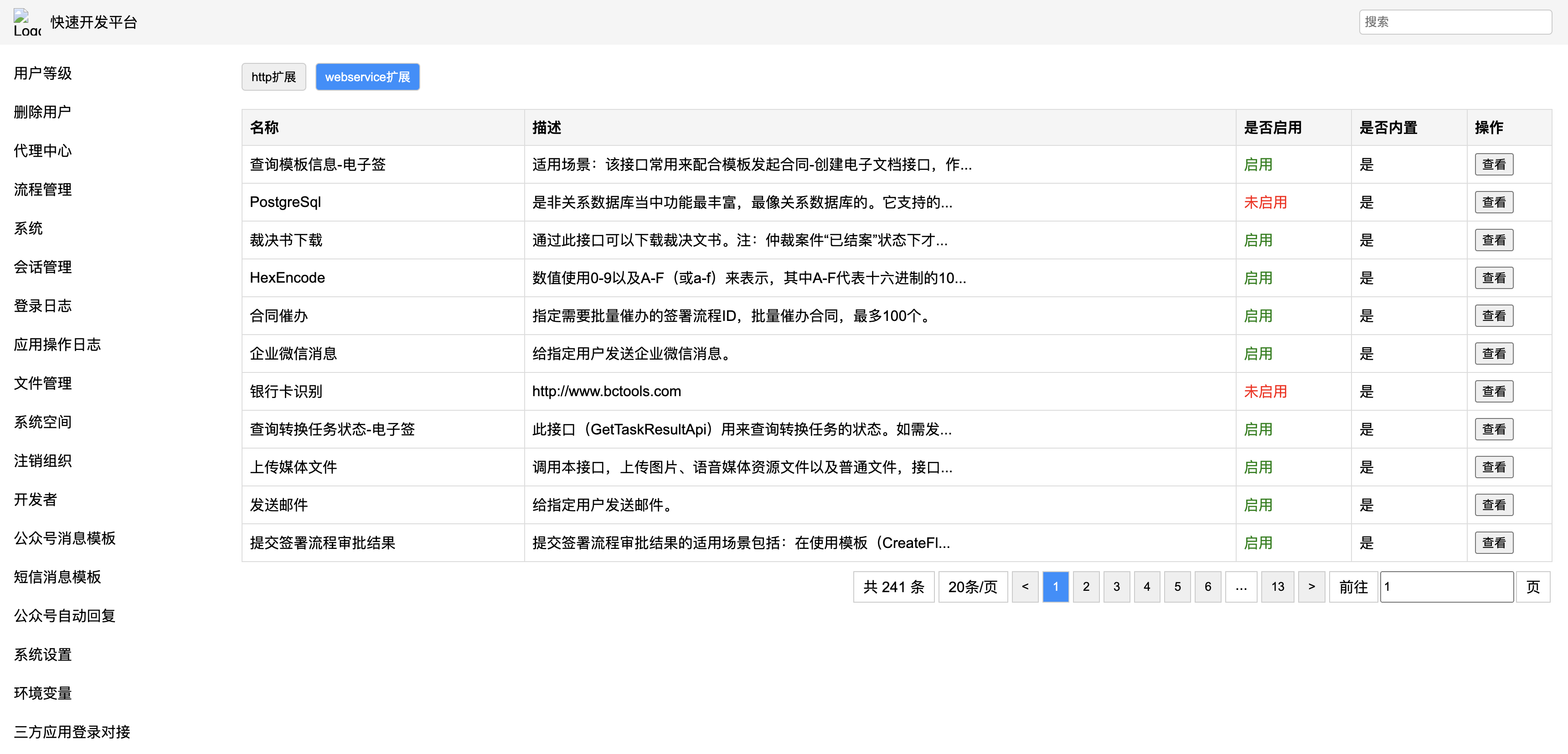
- GLM-4.1V-9B-Thinking
企业OA
-
设计图
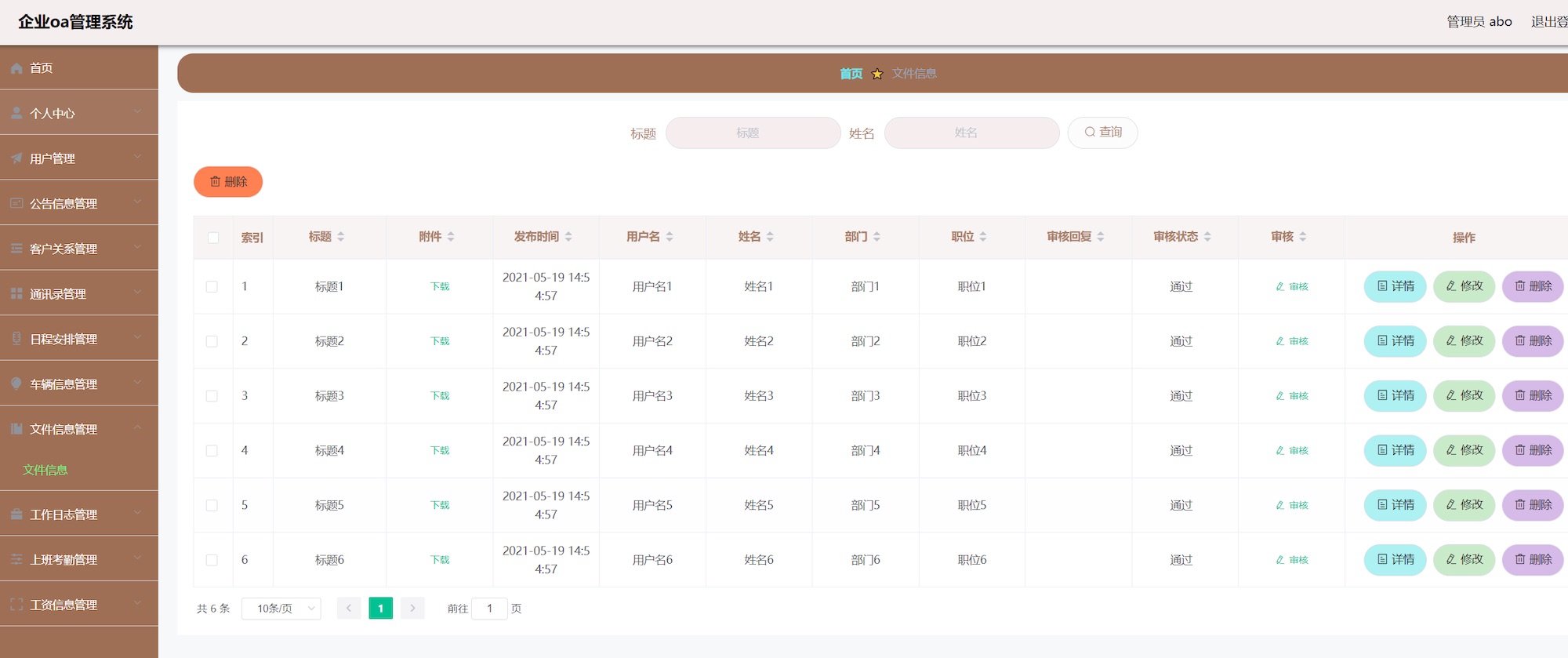
-
生成代码(HTML/CSS)通过浏览器渲染
- GLM-4.1V-9B-Thinking


- GLM-4.1V-9B-Thinking
PK 总结
| 评估维度 | GLM-4.1V-9B-Thinking | Qwen2.5-VL-32B-Instruct |
|---|---|---|
| 设计忠实度 | 中高 整体布局和颜色主题保留良好,但图标和复杂图表再现不足。 |
波动大,从高到极低 部分简单设计忠实度高;复杂设计(如仪表盘)则完全失败,丢失视觉风格和元素。 |
| 元素准确性 | 中等 大部分元素被识别,但图标常为通用占位符或不准确,复杂图表无法准确重现。 |
中低 图标和图像处理极差,常为占位符;但少数设计中特定组件样式还原更佳。 |
| 文本和内容保留 | 高 绝大部分文本内容和数值数据被准确提取和显示。 |
高 绝大部分文本内容和数值数据被准确提取和显示,但偶尔有小部分内容遗漏。 |
| 布局和间距 | 中高 整体布局结构与原图一致性高,但局部间距和对齐可能存在微小偏差。 |
中等 整体布局有时与原图存在较大偏差;元素间距和对齐也常有细微问题。 |
| 交互元素 | 中高 可识别并渲染按钮、输入框、选项卡、分页等,暗示其功能。 |
中高 可识别并渲染交互元素,但在视觉呈现上(如颜色状态)有时更优,有时则因缺乏视觉元素而表现不佳。 |
| 响应性/适应性 | 未明确测试,无直接视觉线索表明其优劣。 | 未明确测试,无直接视觉线索表明其优劣。 |
| 中高 输出通常是完整的UI,虽然有瑕疵但可作为开发基线。复杂图表缺失影响完整度。 |
波动大,从高到极低 在简单设计中表现完整;在复杂设计中因大量视觉元素缺失而显得不完整或无凝聚力。 |
|
| 生产代码适用性 | 更佳 提供稳定且通常可用的代码基线,易于后续优化。 |
一般 在复杂设计中生成结果不可用,需大量重构;在简单设计中表现良好。 |
移动端应用
-
设计图
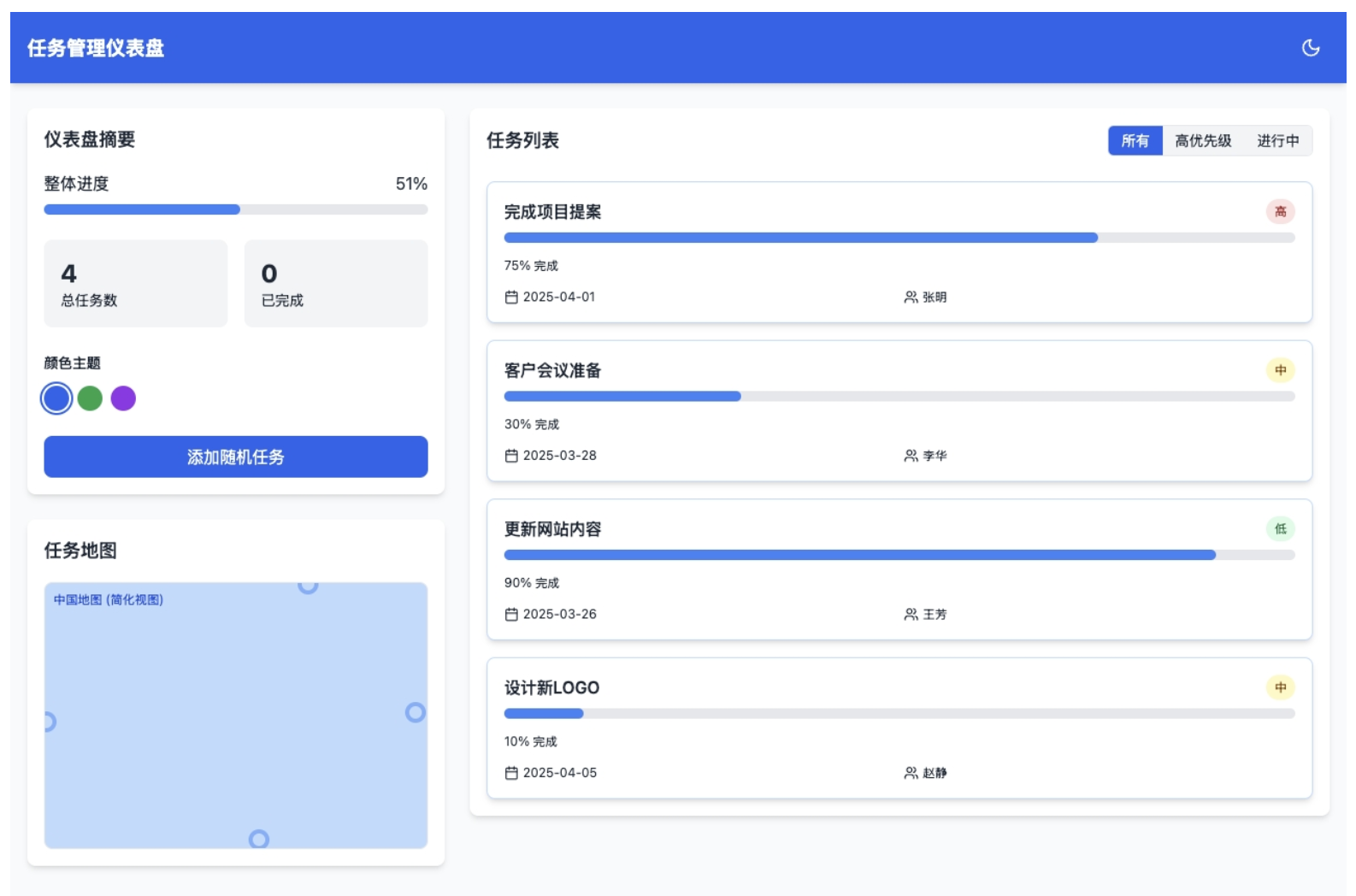
-
生成代码(HTML/CSS)通过浏览器渲染
- GLM-4.1V-9B-Thinking
- Qwen2.5-VL-32B-Instruct
- GLM-4.1V-9B-Thinking
智谱 API 开发
在 智谱大模型开放平台 免费使用 GLM-4.1V-9B-Thinking 的API服务。
安装依赖
pip install zhipuai
示例
上传图片 Base64 或 URL,调用模型进行推理。
import base64
from zhipuai import ZhipuAI
# img_path = "/YourCompluter/xxxx.jpeg" # 替换为您的图片路径
# with open(img_path, 'rb') as img_file:
# img_base = base64.b64encode(img_file.read()).decode('utf-8')
img_url = "https://www.cdstm.cn/gallery/hycx/child/201703/W020170307572370556544.jpg" # 替换为您的图片URL
client = ZhipuAI(api_key="") # 填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4.1v-thinking-flash", # 填写需要调用的模型名称
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": img_url # img_base
}
},
{
"type": "text",
"text": "请描述这个图片"
}
]
}
]
)
# print(response.choices[0].message)
print(response.to_json())
结果
{
"model": "glm-4.1v-thinking-flash",
"created": 1751677006,
"choices": [
{
"index": 0,
"finish_reason": "stop",
"message": {
"content": "这张图片展现了**一场激烈的火焰燃烧场景**。 \n\n画面中心及四周是被熊熊烈焰吞噬的木柴与树枝,火焰以明亮的橙红色为主,火势猛烈,火焰翻卷、跳跃,呈现出极强的动态感与炽热的热量感。木柴多为细枝和木棍,杂乱堆叠,部分木柴在火光映照下轮廓略显朦胧,却仍能看到它们正被火焰快速灼烧。 \n\n背景是一片漆黑的夜色,与明亮的火焰形成强烈对比,进一步突出了火焰的绚烂与炽热。整体画面给人紧张、热烈且充满力量的感受,仿佛能直观感受到火焰的温度与燃烧时的轰鸣气息。",
"role": "assistant",
"reasoning_content": "用户现在需要描述这张图片。首先看画面主体是一堆正在燃烧的木柴,火焰非常旺盛,颜色主要是橙色、黄色,火焰呈现出强烈的动态感,木柴的轮廓在火光中显得有些模糊但能看出是树枝和木棍堆成的。背景是黑暗的,可能是夜晚,这样火焰更明亮对比强烈。整体氛围很热烈,火焰翻滚,木柴被烧得剧烈,可能是在篝火或者焚烧木材的场景,视觉上充满力量感和热量感。\n\n先分解元素:火焰(颜色、形态)、木柴(形状、排列)、背景(黑色,突出火焰)。然后组织语言:这张图片展示了**一场激烈的火焰燃烧场景**。画面中央及周围是被熊熊烈焰吞噬的木柴与树枝,火焰呈现出明亮的橙红色调,火势猛烈,火焰翻卷、跳跃,展现出极强的动态感与热量感。木柴多为细枝和木棍,杂乱地堆叠在一起,部分木柴的轮廓在火光的映照下略显朦胧,却仍能看出它们正被火焰迅速灼烧。背景为一片漆黑的夜色,与明亮的火焰形成强烈对比,使得火焰的绚烂与炽热更加突出。整个画面给人一种紧张、热烈且充满力量的感觉,仿佛能感受到火焰的温度与燃烧时的轰鸣声。\n\n检查是否覆盖主要元素:火焰的状态(激烈、动态)、燃料(木柴/树枝)、色彩(橙红等暖色调)、背景(黑夜对比),以及整体氛围。确保描述准确生动,让读者能想象画面。"
}
}
],
"request_id": "20250705085641185ac9049ceb47c0",
"id": "20250705085641185ac9049ceb47c0",
"usage": {
"prompt_tokens": 563,
"completion_tokens": 477,
"total_tokens": 1040
}
}
- 火灾:https://www.cdstm.cn/gallery/hycx/child/201703/W020170307572370556544.jpg
- 烟雾:https://www.2008php.com/2019_Website_appreciate/2019-12-24/20191224155746ewIAu.jpg
- 正确配带安全帽:https://img95.699pic.com/photo/60051/3724.jpg_wh860.jpg
- 安全帽:https://cbu01.alicdn.com/img/ibank/2020/925/277/13785772529_800623862.jpg
安全检测系统

代码
测试发现,模型在处理图片输入时会以 1000 × 1000 分辨率进行推理,但输出的实体定位坐标未转换为原图坐标系,导致标注位置错误。所以,代码中增加了坐标转换。需要注意的是,Qwen2.5-VL 模型无需此转换。
import os
import base64
import json
import re
import logging
from typing import List, Dict, Any, Union, Optional
from pathlib import Path
from zhipuai import ZhipuAI
from reportlab.lib.pagesizes import A4
from reportlab.pdfgen import canvas
from reportlab.lib.utils import ImageReader
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
from PIL import Image, ImageDraw, ImageFont
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.StreamHandler(),
logging.FileHandler("fire_safety_detection.log")
]
)
logger = logging.getLogger("FireSafetyDetector")
# 配置API参数
CONFIG = {
"ZHIPU_API_KEY": "0d772d50289f4916aae7deb104409e2f.e5CN6Rf2k3tNNOTC",
"MODEL_NAME": "glm-4.1v-thinking-flash",
"IMAGE_DIR": "images0",
"MARKED_DIR": "marked_images0",
"FONT_DIR": "fonts",
"OUTPUT_PDF": "detection_results.pdf",
"SUPPORTED_IMAGE_EXTS": ('.png', '.jpg', '.jpeg'),
# 模型输入图像尺寸配置,如果为None则自动推断
# GLM-4V 可能的输入尺寸,可以根据实际情况调整
"MODEL_INPUT_SIZE": (1000, 1000),
# 是否启用坐标缩放调试日志
"ENABLE_COORD_DEBUG": True
}
PROMPT = """
请检测图像中的所有火灾、烟雾和人员安全帽佩戴情况,并以坐标形式返回每个目标的位置。输出格式如下:
- 火灾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "火灾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 烟雾对象:{"bbox_2d": [x1, y1, x2, y2], "label": "烟雾", "sub_label": "轻微" / "中等" / "严重" / "不确定"}
- 人员对象:{"bbox_2d": [x1, y1, x2, y2], "label": "人员", "sub_label": "佩戴安全帽" / "未佩戴安全帽" / "不确定"}
请严格按照上述格式输出所有检测到的对象及其坐标和属性,三类对象分别输出。如无法确定,请将 "sub_label" 设置为 "不确定"。
检测规则:
- 火灾:图像中存在明显火焰或燃烧迹象。
- 烟雾:图像中存在明显的烟雾扩散现象。
- 人员:图像中有完整或部分可见的人体。
- 安全帽佩戴:安全帽必须正确佩戴在头部,且帽檐朝前;若无法判断,则标记为 "不确定"。
注意事项:
- 输出结果应尽量准确。
- 不要输出任何其他信息或解释。
- 不要输出空对象。
- 输出检测到的对象不要超过 20 个。
结果示例:
[
{"bbox_2d": [100, 200, 180, 300], "label": "火灾", "sub_label": "严重"},
{"bbox_2d": [220, 150, 350, 280], "label": "烟雾", "sub_label": "轻微"},
{"bbox_2d": [400, 320, 480, 420], "label": "人员", "sub_label": "佩戴安全帽"},
{"bbox_2d": [520, 330, 600, 430], "label": "人员", "sub_label": "未佩戴安全帽"}
]
"""
class FireSafetyDetector:
def __init__(self, config: Dict[str, Any] = CONFIG):
self.config = config
self.client = ZhipuAI(api_key=config["ZHIPU_API_KEY"])
self._setup_directories()
def _setup_directories(self):
"""创建必要的目录"""
Path(self.config["IMAGE_DIR"]).mkdir(exist_ok=True)
Path(self.config["MARKED_DIR"]).mkdir(exist_ok=True)
Path(self.config["FONT_DIR"]).mkdir(exist_ok=True)
@staticmethod
def is_url(path: str) -> bool:
"""检查路径是否为URL"""
return path.startswith("http://") or path.startswith("https://")
@staticmethod
def encode_image_to_base64(image_path: str) -> str:
"""将图像编码为Base64格式"""
with open(image_path, "rb") as f:
encoded_image = base64.b64encode(f.read()).decode("utf-8")
return encoded_image
def detect_image(self, image: str, prompt: str = PROMPT) -> str:
"""调用模型进行图像检测"""
try:
# 对于本地图片,编码为base64;对于URL,直接使用URL
if self.is_url(image):
image_data = image
else:
image_data = self.encode_image_to_base64(image)
response = self.client.chat.completions.create(
model=self.config["MODEL_NAME"],
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": image_data
}
},
{
"type": "text",
"text": prompt
}
]
}
]
)
return response.choices[0].message.content if response.choices else ""
except Exception as e:
logger.error(f"检测失败: {str(e)}", exc_info=True)
return f"检测失败: {str(e)}"
def get_local_images(self) -> List[str]:
"""获取本地图像列表"""
images = []
for ext in self.config["SUPPORTED_IMAGE_EXTS"]:
images.extend(Path(self.config["IMAGE_DIR"]).glob(f"*{ext}"))
return [str(img) for img in images]
def register_chinese_font(self) -> str:
"""注册中文字体"""
font_path = Path(self.config["FONT_DIR"]) / "Arial Unicode.ttf"
if font_path.exists():
try:
pdfmetrics.registerFont(TTFont('ArialUnicode', str(font_path)))
return 'ArialUnicode'
except Exception as e:
logger.warning(f"字体注册失败: {str(e)}")
logger.warning("未找到可用的中文字体(建议放置 Arial Unicode.ttf 到 fonts 目录)")
return 'Helvetica'
def save_results_to_pdf(self, results: List[Dict[str, Any]], pdf_path: str = None):
"""将结果保存为PDF"""
pdf_path = pdf_path or self.config["OUTPUT_PDF"]
c = canvas.Canvas(pdf_path, pagesize=A4)
width, height = A4
margin = 40
font_name = self.register_chinese_font()
max_img_width = width - 2 * margin
max_img_height = height / 2 - margin
for item in results:
y = height - margin
img_path = item["image"]
result = item["result"]
# 标题
c.setFont(font_name, 13)
c.drawString(margin, y, f"图片: {Path(img_path).name}")
y -= 20
# 尝试加载并显示图像
display_img_path = self._get_display_image_path(img_path)
if display_img_path and display_img_path.exists():
try:
img = ImageReader(str(display_img_path))
iw, ih = img.getSize()
scale = min(max_img_width / iw, max_img_height / ih, 1)
img_w, img_h = iw * scale, ih * scale
img_x = margin + (max_img_width - img_w) / 2
c.drawImage(img, img_x, y - img_h, width=img_w, height=img_h)
y -= img_h + 10
except Exception as e:
logger.error(f"PDF图片渲染失败: {str(e)}")
c.setFont(font_name, 10)
c.drawString(margin, y, "[图片无法显示]")
y -= 20
# 检测结果
c.setFont(font_name, 12)
for line in result.split("\n"):
if y < margin: # 确保不会超出页面底部
c.showPage()
y = height - margin
c.setFont(font_name, 12)
c.drawString(margin, y, line)
y -= 16
c.showPage() # 每张图片和结果单独一页
c.save()
logger.info(f"检测结果已保存为PDF: {pdf_path}")
def _get_display_image_path(self, img_path: str) -> Optional[Path]:
"""获取用于显示的图像路径(优先使用标注后的图像)"""
if not self.is_url(img_path):
marked_path = Path(self.config["MARKED_DIR"]) / Path(img_path).name
if marked_path.exists():
return marked_path
if Path(img_path).exists():
return Path(img_path)
return None
@staticmethod
def extract_json_array(text: str) -> Optional[str]:
"""从文本中提取第一个完整的JSON数组字符串"""
text = text.replace('```json', '').replace('```', '').strip()
start = text.find('[')
if start == -1:
return None
bracket_count = 0
for i in range(start, len(text)):
if text[i] == '[':
bracket_count += 1
elif text[i] == ']':
bracket_count -= 1
if bracket_count == 0:
return text[start:i+1]
return None
@staticmethod
def try_fix_json(text: str) -> str:
"""尝试修复常见的JSON格式错误"""
text = text.replace('"', '"').replace('"', '"').replace("'", "'").replace("'", "'")
text = re.sub(r',\s*([\]}])', r'\1', text)
text = re.sub(r'("[\]}])\s*("[a-zA-Z_]+"\s*:)', r'\1, \2', text)
return text
def scale_coordinates(self, bbox: List[int], original_size: tuple, model_input_size: tuple = None) -> List[int]:
"""
将模型输出的坐标缩放到原图坐标系
Args:
bbox: 模型输出的边界框坐标 [x1, y1, x2, y2]
original_size: 原图尺寸 (width, height)
model_input_size: 模型输入图像尺寸,如果为None则自动推断
Returns:
缩放后的坐标 [x1, y1, x2, y2]
"""
if len(bbox) != 4:
return bbox
orig_w, orig_h = original_size
# 如果没有指定模型输入尺寸,根据坐标值和图像尺寸推断
if model_input_size is None:
# 基于坐标的最大值来推断模型输入尺寸
max_x = max(bbox[0], bbox[2])
max_y = max(bbox[1], bbox[3])
# 常见的视觉模型输入尺寸,GLM-4V可能使用的尺寸
possible_sizes = [
(224, 224), (256, 256), (384, 384), (448, 448),
(512, 512), (640, 640), (800, 600), (1024, 768),
(336, 336), # 一些多模态模型常用尺寸
(448, 336), # 长宽比不同的尺寸
]
# 选择最合理的模型输入尺寸
model_input_size = (512, 512) # 默认
# 根据坐标值选择最合适的尺寸
for w, h in possible_sizes:
if max_x <= w and max_y <= h:
# 选择能容纳坐标且最接近原图比例的尺寸
model_input_size = (w, h)
break
# 如果坐标值很小,可能是归一化后的值或小尺寸输入
if max_x <= 1 and max_y <= 1:
# 可能是归一化坐标 [0,1]
logger.info("检测到可能的归一化坐标,直接按比例缩放")
return [
int(bbox[0] * orig_w),
int(bbox[1] * orig_h),
int(bbox[2] * orig_w),
int(bbox[3] * orig_h)
]
model_w, model_h = model_input_size
# 计算缩放比例
scale_x = orig_w / model_w
scale_y = orig_h / model_h
# 缩放坐标
x1, y1, x2, y2 = bbox
scaled_bbox = [
int(x1 * scale_x),
int(y1 * scale_y),
int(x2 * scale_x),
int(y2 * scale_y)
]
# 确保坐标在图像范围内
scaled_bbox[0] = max(0, min(scaled_bbox[0], orig_w))
scaled_bbox[1] = max(0, min(scaled_bbox[1], orig_h))
scaled_bbox[2] = max(0, min(scaled_bbox[2], orig_w))
scaled_bbox[3] = max(0, min(scaled_bbox[3], orig_h))
logger.debug(f"坐标缩放: {bbox} -> {scaled_bbox}, 原图尺寸: {original_size}, 推断模型尺寸: {model_input_size}")
return scaled_bbox
def get_image_size(self, image_path: str) -> tuple:
"""获取图像尺寸"""
try:
with Image.open(image_path) as img:
return img.size # (width, height)
except Exception as e:
logger.error(f"无法获取图像尺寸: {image_path}, 错误: {str(e)}")
return (512, 512) # 默认尺寸
def parse_detection_result(self, result: str) -> Union[List[Dict], str]:
"""解析检测结果,返回对象列表或错误信息"""
try:
return json.loads(result)
except json.JSONDecodeError:
json_part = self.extract_json_array(result)
if json_part:
try:
return json.loads(json_part)
except json.JSONDecodeError:
try:
fixed = self.try_fix_json(json_part)
return json.loads(fixed)
except json.JSONDecodeError as e:
logger.error(f"JSON解析失败: {str(e)}\n原始内容: {json_part}")
return f"JSON解析失败: {str(e)}"
return f"未找到有效JSON数据: {result[:100]}..."
def draw_boxes_on_image(self, image_path: str, detection_result: Union[str, list], output_path: str):
"""在图像上绘制检测框和标签"""
# 解析结果
if isinstance(detection_result, str):
parsed_result = self.parse_detection_result(detection_result)
if isinstance(parsed_result, str):
logger.error(f"无法解析检测结果: {parsed_result}")
return False
results = parsed_result
else:
results = detection_result
if not isinstance(results, list):
logger.error(f"检测结果格式错误,应为列表: {type(results)}")
return False
try:
# 打开图像并获取尺寸
image = Image.open(image_path).convert("RGB")
original_size = image.size # (width, height)
draw = ImageDraw.Draw(image)
# 尝试加载字体
font_path = Path(self.config["FONT_DIR"]) / "Arial Unicode.ttf"
try:
font = ImageFont.truetype(str(font_path), 18) if font_path.exists() else ImageFont.load_default()
except Exception:
font = ImageFont.load_default()
# 绘制检测框
for obj in results:
bbox = obj.get("bbox_2d")
label = obj.get("label", "")
sub_label = obj.get("sub_label", "")
if not bbox or len(bbox) != 4 or sub_label == "不确定":
continue
# 缩放坐标到原图坐标系
scaled_bbox = self.scale_coordinates(
bbox,
original_size,
self.config.get("MODEL_INPUT_SIZE")
)
# 如果启用调试,打印原坐标和缩放后坐标
if self.config.get("ENABLE_COORD_DEBUG", False):
logger.info(f"原坐标: {bbox}, 缩放后: {scaled_bbox}, 图像尺寸: {original_size}")
# 设置颜色
color_map = {
"火灾": (255, 0, 0), # 红色
"烟雾": (0, 0, 255), # 蓝色
"人员": (0, 255, 0) # 绿色
}
color = color_map.get(label, (128, 128, 128)) # 默认为灰色
# 绘制边界框
draw.rectangle(scaled_bbox, outline=color, width=3)
# 绘制标签
text = f"{label}:{sub_label}"
bbox_text = draw.textbbox((0, 0), text, font=font)
text_width = bbox_text[2] - bbox_text[0]
text_height = bbox_text[3] - bbox_text[1]
# 文本背景
text_bg = [
scaled_bbox[0],
scaled_bbox[1] - text_height - 4,
scaled_bbox[0] + text_width + 4,
scaled_bbox[1]
]
draw.rectangle(text_bg, fill=color)
# 文本
draw.text(
(scaled_bbox[0] + 2, scaled_bbox[1] - text_height - 2),
text,
fill=(255, 255, 255),
font=font
)
# 保存结果
image.save(output_path)
logger.info(f"标注图片已保存: {output_path}")
return True
except Exception as e:
logger.error(f"图片标注失败: {str(e)}", exc_info=True)
return False
def run(self, url_images: List[str] = None):
"""执行整个检测流程"""
url_images = url_images or []
local_images = self.get_local_images()
all_images = local_images + url_images
logger.info(f"共检测 {len(all_images)} 张图片(本地{len(local_images)},URL{len(url_images)})")
results = []
for img in all_images:
logger.info(f"处理图片: {img}")
try:
result = self.detect_image(img)
results.append({"image": img, "result": result})
# 仅处理本地图片的标注
if not self.is_url(img):
marked_path = Path(self.config["MARKED_DIR"]) / Path(img).name
self.draw_boxes_on_image(img, result, str(marked_path))
except Exception as e:
logger.error(f"处理图片失败: {img}, 错误: {str(e)}", exc_info=True)
results.append({"image": img, "result": f"处理失败: {str(e)}"})
# 保存结果到PDF
self.save_results_to_pdf(results)
logger.info("处理完成")
if __name__ == "__main__":
# 可在此处添加需要检测的互联网图片URL
url_images = [
]
detector = FireSafetyDetector()
detector.run(url_images=url_images)