How Diffusion Models Work
Intuition(直觉)
Making images useful to a neural network(使图像对神经网络有用)
噪声处理:添加不同的噪声级别到训练数据中。
灵感来源于物理学,你可以想像一滴墨水滴入一杯水中,最初你确切地知道它落在哪里,但随着时间的推移,你看到到扩散到水中,直到消失。
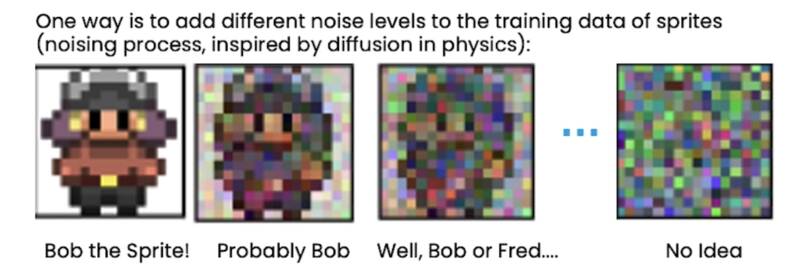
神经网络真正应该思考的是在每个噪声级别,当你逐渐向图像添加噪声时:
- Bob the Sprite!: 如果是 Bob Sprite,你想让神经网络说那是 Bob Sprite,让 Bob 保持原样。
- Probable Bob: 如果可能是 Bob Sprite,你可能想让神经网络说你知道这里有些噪声,建议可能填写的详细信息,让它看起来就像 Bob Sprite。
- Well, Bob or Fred…: 如果它只是精灵的轮廓,你想建议可能的精灵的一般细节。
- No Idea: 如果看起来什么也不知道,建议提出什么是轮廓,让它看起来更像精灵。
Training a neural network to make sprites(训练神经网络制作精灵)
神经网络学习不同的噪声图像并将它们变回精灵。
它学会消除您添加的噪声。

“No Idea” 的噪声级别很重要,因为它是正态分布的,每一个像素的采样都来自于正态分布。正态分布也可以称为 Gaussian distribution 或 bell shaped curve
当你向神经网络请求一个新的精灵时:
- 你可以从正态分布中采样噪声
- 使用网络消除噪声获得全新的精灵
Sampling(采样)
NN 试图完全预测每一步的噪声。实际上,这只是一个预测。您需要多个 step 才能获得高质量的精灵。
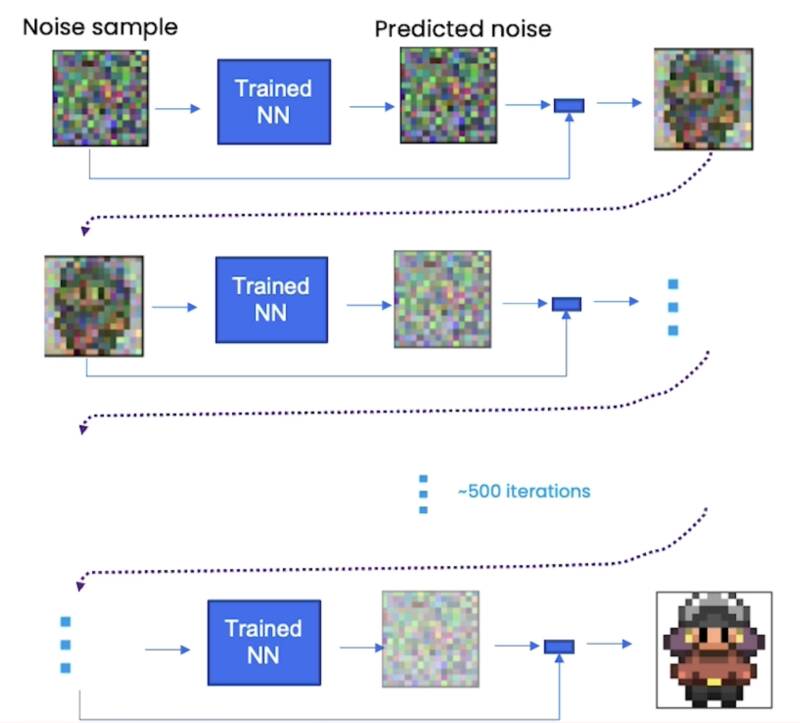
DDPM (Denoising Diffusion Probabilistic Models) 去噪扩散概率模型
Sampling Iteration Details

去噪后就不是正态分布了,所以在每个步骤后和下一个步骤前,您需要添加额外的噪声,其缩放基于所处的时间步骤,作为下一次迭代的输入。
根据经验,这有助于稳定神经网络,使其不会坍缩到接近数据集平均值的状态。意味着,当我们不添加额外的噪声,神经网络只会生成这些平均外观的精灵。
Sample

Lab 1, Sampling
from typing import Dict, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.utils import save_image, make_grid
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import numpy as np
from IPython.display import HTML
from diffusion_utilities import *
Setting Things Up
class ContextUnet(nn.Module):
def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context features
super(ContextUnet, self).__init__()
# number of input channels, number of intermediate feature maps and number of classes
self.in_channels = in_channels
self.n_feat = n_feat
self.n_cfeat = n_cfeat
self.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...
# Initialize the initial convolutional layer
self.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
# Initialize the down-sampling path of the U-Net with two levels
self.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]
self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]
# original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())
self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())
# Embed the timestep and context labels with a one-layer fully connected neural network
self.timeembed1 = EmbedFC(1, 2*n_feat)
self.timeembed2 = EmbedFC(1, 1*n_feat)
self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)
self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)
# Initialize the up-sampling path of the U-Net with three levels
self.up0 = nn.Sequential(
nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4), # up-sample
nn.GroupNorm(8, 2 * n_feat), # normalize
nn.ReLU(),
)
self.up1 = UnetUp(4 * n_feat, n_feat)
self.up2 = UnetUp(2 * n_feat, n_feat)
# Initialize the final convolutional layers to map to the same number of channels as the input image
self.out = nn.Sequential(
nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0
nn.GroupNorm(8, n_feat), # normalize
nn.ReLU(),
nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input
)
def forward(self, x, t, c=None):
"""
x : (batch, n_feat, h, w) : input image
t : (batch, n_cfeat) : time step
c : (batch, n_classes) : context label
"""
# x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on
# pass the input image through the initial convolutional layer
x = self.init_conv(x)
# pass the result through the down-sampling path
down1 = self.down1(x) #[10, 256, 8, 8]
down2 = self.down2(down1) #[10, 256, 4, 4]
# convert the feature maps to a vector and apply an activation
hiddenvec = self.to_vec(down2)
# mask out context if context_mask == 1
if c is None:
c = torch.zeros(x.shape[0], self.n_cfeat).to(x)
# embed context and timestep
cemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)
temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)
cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)
temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)
#print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")
up1 = self.up0(hiddenvec)
up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddings
up3 = self.up2(cemb2*up2 + temb2, down1)
out = self.out(torch.cat((up3, x), 1))
return out
# hyperparameters
# diffusion hyperparameters
timesteps = 500
beta1 = 1e-4
beta2 = 0.02
# network hyperparameters
device = torch.device("cuda:0" if torch.cuda.is_available() else torch.device('cpu'))
n_feat = 64 # 64 hidden dimension feature
n_cfeat = 5 # context vector is of size 5
height = 16 # 16x16 image
save_dir = './weights/'
# construct DDPM noise schedule
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
a_t = 1 - b_t
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
ab_t[0] = 1
# construct model
nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)
Sampling
# helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
def denoise_add_noise(x, t, pred_noise, z=None):
if z is None:
z = torch.randn_like(x)
noise = b_t.sqrt()[t] * z
mean = (x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) / a_t[t].sqrt()
return mean + noise
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_trained.pth", map_location=device))
nn_model.eval()
print("Loaded in Model")
# sample using standard algorithm
@torch.no_grad()
def sample_ddpm(n_sample, save_rate=20):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
for i in range(timesteps, 0, -1):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
# sample some random noise to inject back in. For i = 1, don't add back in noise
z = torch.randn_like(samples) if i > 1 else 0
eps = nn_model(samples, t) # predict noise e_(x_t,t)
samples = denoise_add_noise(samples, i, eps, z)
if i % save_rate ==0 or i==timesteps or i<8:
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
# visualize samples
plt.clf()
samples, intermediate_ddpm = sample_ddpm(32)
animation_ddpm = plot_sample(intermediate_ddpm,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm.to_jshtml())

Demonstrate incorrectly sample without adding the ‘extra noise’(在不添加“额外噪音”的情况下展示不正确的样本)
# incorrectly sample without adding in noise
@torch.no_grad()
def sample_ddpm_incorrect(n_sample):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
for i in range(timesteps, 0, -1):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
# don't add back in noise
z = 0
eps = nn_model(samples, t) # predict noise e_(x_t,t)
samples = denoise_add_noise(samples, i, eps, z)
if i%20==0 or i==timesteps or i<8:
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
# visualize samples
plt.clf()
samples, intermediate = sample_ddpm_incorrect(32)
animation = plot_sample(intermediate,32,4,save_dir, "ani_run", None, save=False)
HTML(animation.to_jshtml())

Acknowledgments
Sprites by ElvGames, FrootsnVeggies and kyrise
This code is modified from, https://github.com/cloneofsimo/minDiffusion
Diffusion model is based on Denoising Diffusion Probabilistic Models and Denoising Diffusion Implicit Models
Neural Network(神经网络)
介绍了神经网络的架构,以及如何将额外的信息融入其中。
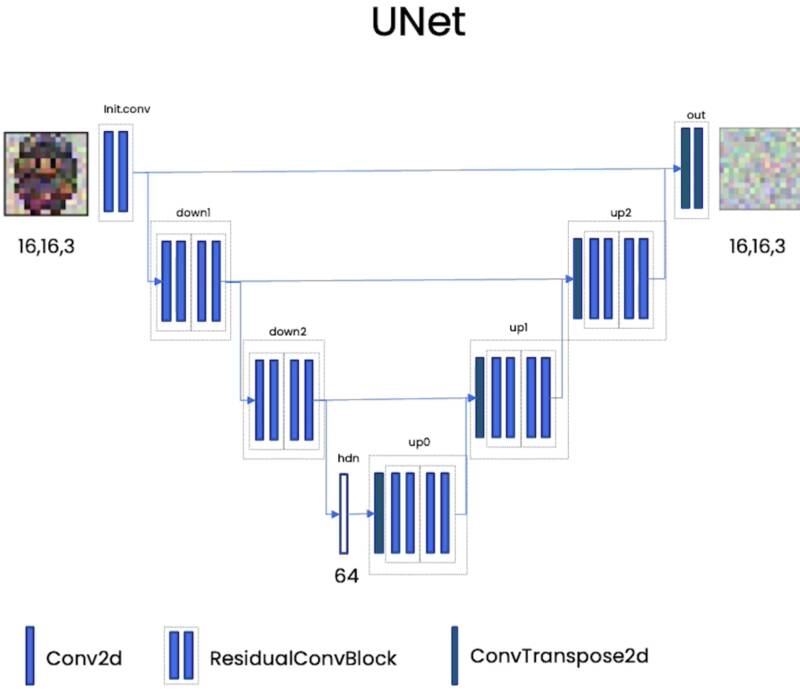
UNet
输入输出尺寸相同。以图像作为输入,并且以与该图像相同尺寸的输出产生噪声。
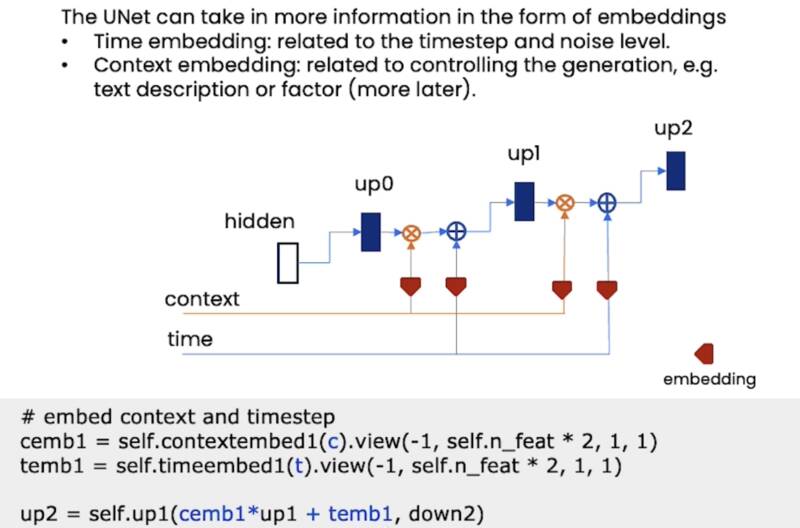
Embedding More Information(嵌入更多信息)
UNet 的另一个优点是可以接受额外的信息。
- 时间嵌入:告诉模型时间步长以及我们需要的噪声级别
- 上下文嵌入:帮助您控制模型生成的内容
Lab 1, Sampling
from typing import Dict, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.utils import save_image, make_grid
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import numpy as np
from IPython.display import HTML
from diffusion_utilities import *
Setting Things Up
class ContextUnet(nn.Module):
def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context features
super(ContextUnet, self).__init__()
# number of input channels, number of intermediate feature maps and number of classes
self.in_channels = in_channels
self.n_feat = n_feat
self.n_cfeat = n_cfeat
self.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...
# Initialize the initial convolutional layer
self.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
# Initialize the down-sampling path of the U-Net with two levels
self.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]
self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]
# original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())
self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())
# Embed the timestep and context labels with a one-layer fully connected neural network
self.timeembed1 = EmbedFC(1, 2*n_feat)
self.timeembed2 = EmbedFC(1, 1*n_feat)
self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)
self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)
# Initialize the up-sampling path of the U-Net with three levels
self.up0 = nn.Sequential(
nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4), # up-sample
nn.GroupNorm(8, 2 * n_feat), # normalize
nn.ReLU(),
)
self.up1 = UnetUp(4 * n_feat, n_feat)
self.up2 = UnetUp(2 * n_feat, n_feat)
# Initialize the final convolutional layers to map to the same number of channels as the input image
self.out = nn.Sequential(
nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0
nn.GroupNorm(8, n_feat), # normalize
nn.ReLU(),
nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input
)
def forward(self, x, t, c=None):
"""
x : (batch, n_feat, h, w) : input image
t : (batch, n_cfeat) : time step
c : (batch, n_classes) : context label
"""
# x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on
# pass the input image through the initial convolutional layer
x = self.init_conv(x)
# pass the result through the down-sampling path
down1 = self.down1(x) #[10, 256, 8, 8]
down2 = self.down2(down1) #[10, 256, 4, 4]
# convert the feature maps to a vector and apply an activation
hiddenvec = self.to_vec(down2)
# mask out context if context_mask == 1
if c is None:
c = torch.zeros(x.shape[0], self.n_cfeat).to(x)
# embed context and timestep
cemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)
temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)
cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)
temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)
#print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")
up1 = self.up0(hiddenvec)
up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddings
up3 = self.up2(cemb2*up2 + temb2, down1)
out = self.out(torch.cat((up3, x), 1))
return out
# hyperparameters
# diffusion hyperparameters
timesteps = 500
beta1 = 1e-4
beta2 = 0.02
# network hyperparameters
device = torch.device("cuda:0" if torch.cuda.is_available() else torch.device('cpu'))
n_feat = 64 # 64 hidden dimension feature
n_cfeat = 5 # context vector is of size 5
height = 16 # 16x16 image
save_dir = './weights/'
# construct DDPM noise schedule
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
a_t = 1 - b_t
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
ab_t[0] = 1
# construct model
nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)
Sampling
# helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
def denoise_add_noise(x, t, pred_noise, z=None):
if z is None:
z = torch.randn_like(x)
noise = b_t.sqrt()[t] * z
mean = (x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) / a_t[t].sqrt()
return mean + noise
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_trained.pth", map_location=device))
nn_model.eval()
print("Loaded in Model")
# sample using standard algorithm
@torch.no_grad()
def sample_ddpm(n_sample, save_rate=20):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
for i in range(timesteps, 0, -1):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
# sample some random noise to inject back in. For i = 1, don't add back in noise
z = torch.randn_like(samples) if i > 1 else 0
eps = nn_model(samples, t) # predict noise e_(x_t,t)
samples = denoise_add_noise(samples, i, eps, z)
if i % save_rate ==0 or i==timesteps or i<8:
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
# visualize samples
plt.clf()
samples, intermediate_ddpm = sample_ddpm(32)
animation_ddpm = plot_sample(intermediate_ddpm,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm.to_jshtml())
Demonstrate incorrectly sample without adding the ‘extra noise’
# incorrectly sample without adding in noise
@torch.no_grad()
def sample_ddpm_incorrect(n_sample):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
for i in range(timesteps, 0, -1):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
# don't add back in noise
z = 0
eps = nn_model(samples, t) # predict noise e_(x_t,t)
samples = denoise_add_noise(samples, i, eps, z)
if i%20==0 or i==timesteps or i<8:
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
# visualize samples
plt.clf()
samples, intermediate = sample_ddpm_incorrect(32)
animation = plot_sample(intermediate,32,4,save_dir, "ani_run", None, save=False)
HTML(animation.to_jshtml())
Training(训练)
训练 UNet 神经网络,并使其预测噪声。
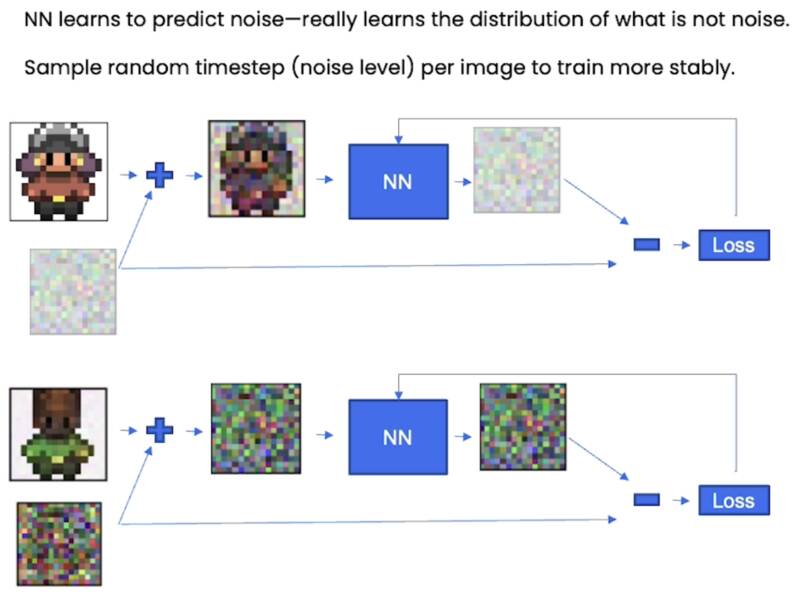
在实际训练中,我们不希望神经网络一直看着同一个精灵。如果它在一个时期内看到不同的精灵,它会更加稳定和均匀。因此,实际上我们随机采样这个时间步长可能是多少。然后,我们得到适合该时间步长的噪声水平。我们将其添加到这个精灵图像中,然后让神经网络进行预测。
我们在训练数据中取下一个精灵图像,我们再次采样一个时间步长,可能完全不同,就像您在这里看到的,然后我们将其添加到这个精灵图像中,再次让神经网络预测添加的噪声。这样可能得到一个更加稳定的训练方案。
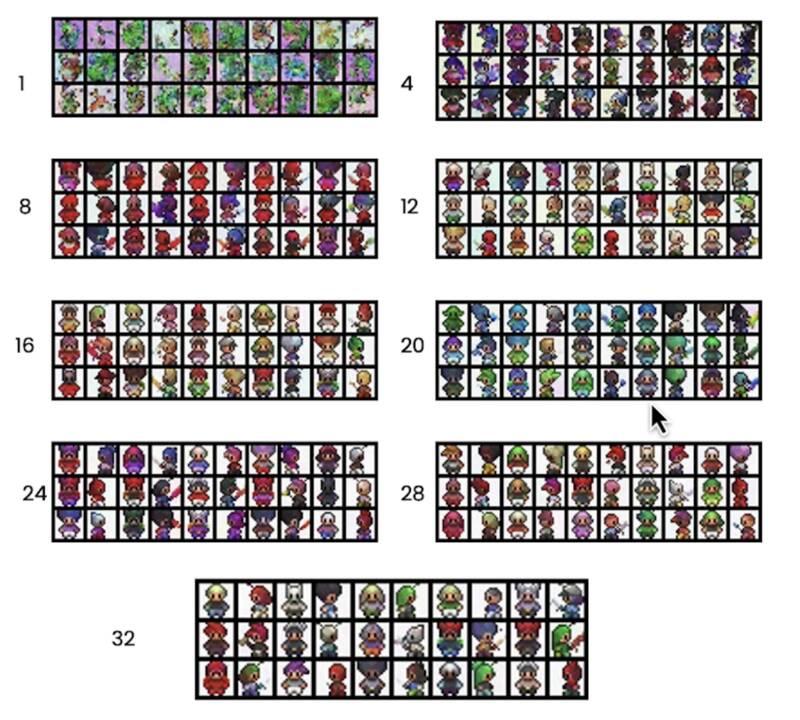
Epochs
预测出噪声,然后从输入图像减去该噪声,Epoch 越往后输出越像巫师帽子。

Algorithm

Lab 2, Training
from typing import Dict, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.utils import save_image, make_grid
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import numpy as np
from IPython.display import HTML
from diffusion_utilities import *
Setting Things Up
class ContextUnet(nn.Module):
def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context features
super(ContextUnet, self).__init__()
# number of input channels, number of intermediate feature maps and number of classes
self.in_channels = in_channels
self.n_feat = n_feat
self.n_cfeat = n_cfeat
self.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...
# Initialize the initial convolutional layer
self.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
# Initialize the down-sampling path of the U-Net with two levels
self.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]
self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]
# original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())
self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())
# Embed the timestep and context labels with a one-layer fully connected neural network
self.timeembed1 = EmbedFC(1, 2*n_feat)
self.timeembed2 = EmbedFC(1, 1*n_feat)
self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)
self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)
# Initialize the up-sampling path of the U-Net with three levels
self.up0 = nn.Sequential(
nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4), # up-sample
nn.GroupNorm(8, 2 * n_feat), # normalize
nn.ReLU(),
)
self.up1 = UnetUp(4 * n_feat, n_feat)
self.up2 = UnetUp(2 * n_feat, n_feat)
# Initialize the final convolutional layers to map to the same number of channels as the input image
self.out = nn.Sequential(
nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0
nn.GroupNorm(8, n_feat), # normalize
nn.ReLU(),
nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input
)
def forward(self, x, t, c=None):
"""
x : (batch, n_feat, h, w) : input image
t : (batch, n_cfeat) : time step
c : (batch, n_classes) : context label
"""
# x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on
# pass the input image through the initial convolutional layer
x = self.init_conv(x)
# pass the result through the down-sampling path
down1 = self.down1(x) #[10, 256, 8, 8]
down2 = self.down2(down1) #[10, 256, 4, 4]
# convert the feature maps to a vector and apply an activation
hiddenvec = self.to_vec(down2)
# mask out context if context_mask == 1
if c is None:
c = torch.zeros(x.shape[0], self.n_cfeat).to(x)
# embed context and timestep
cemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)
temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)
cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)
temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)
#print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")
up1 = self.up0(hiddenvec)
up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddings
up3 = self.up2(cemb2*up2 + temb2, down1)
out = self.out(torch.cat((up3, x), 1))
return out
# hyperparameters
# diffusion hyperparameters
timesteps = 500
beta1 = 1e-4
beta2 = 0.02
# network hyperparameters
device = torch.device("cuda:0" if torch.cuda.is_available() else torch.device('cpu'))
n_feat = 64 # 64 hidden dimension feature
n_cfeat = 5 # context vector is of size 5
height = 16 # 16x16 image
save_dir = './weights/'
# training hyperparameters
batch_size = 100
n_epoch = 32
lrate=1e-3
# construct DDPM noise schedule
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
a_t = 1 - b_t
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
ab_t[0] = 1
# construct model
nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)
Training
# load dataset and construct optimizer
dataset = CustomDataset("./sprites_1788_16x16.npy", "./sprite_labels_nc_1788_16x16.npy", transform, null_context=False)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=1)
optim = torch.optim.Adam(nn_model.parameters(), lr=lrate)
# helper function: perturbs an image to a specified noise level
def perturb_input(x, t, noise):
return ab_t.sqrt()[t, None, None, None] * x + (1 - ab_t[t, None, None, None]) * noise
此代码将需要数小时才能在 CPU 上运行。 我们建议您在此处跳过此步骤并查看下面的中间结果。
# training without context code
# set into train mode
nn_model.train()
for ep in range(n_epoch):
print(f'epoch {ep}')
# linearly decay learning rate
optim.param_groups[0]['lr'] = lrate*(1-ep/n_epoch)
pbar = tqdm(dataloader, mininterval=2 )
for x, _ in pbar: # x: images
optim.zero_grad()
x = x.to(device)
# perturb data
noise = torch.randn_like(x)
t = torch.randint(1, timesteps + 1, (x.shape[0],)).to(device)
x_pert = perturb_input(x, t, noise)
# use network to recover noise
pred_noise = nn_model(x_pert, t / timesteps)
# loss is mean squared error between the predicted and true noise
loss = F.mse_loss(pred_noise, noise)
loss.backward()
optim.step()
# save model periodically
if ep%4==0 or ep == int(n_epoch-1):
if not os.path.exists(save_dir):
os.mkdir(save_dir)
torch.save(nn_model.state_dict(), save_dir + f"model_{ep}.pth")
print('saved model at ' + save_dir + f"model_{ep}.pth")
Sampling
# helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
def denoise_add_noise(x, t, pred_noise, z=None):
if z is None:
z = torch.randn_like(x)
noise = b_t.sqrt()[t] * z
mean = (x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) / a_t[t].sqrt()
return mean + noise
# sample using standard algorithm
@torch.no_grad()
def sample_ddpm(n_sample, save_rate=20):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
for i in range(timesteps, 0, -1):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
# sample some random noise to inject back in. For i = 1, don't add back in noise
z = torch.randn_like(samples) if i > 1 else 0
eps = nn_model(samples, t) # predict noise e_(x_t,t)
samples = denoise_add_noise(samples, i, eps, z)
if i % save_rate ==0 or i==timesteps or i<8:
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
View Epoch 0
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_0.pth", map_location=device))
nn_model.eval()
print("Loaded in Model")
# visualize samples
plt.clf()
samples, intermediate_ddpm = sample_ddpm(32)
animation_ddpm = plot_sample(intermediate_ddpm,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm.to_jshtml())

View Epoch 4
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_4.pth", map_location=device))
nn_model.eval()
print("Loaded in Model")
# visualize samples
plt.clf()
samples, intermediate_ddpm = sample_ddpm(32)
animation_ddpm = plot_sample(intermediate_ddpm,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm.to_jshtml())

View Epoch 8
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_8.pth", map_location=device))
nn_model.eval()
print("Loaded in Model")
# visualize samples
plt.clf()
samples, intermediate_ddpm = sample_ddpm(32)
animation_ddpm = plot_sample(intermediate_ddpm,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm.to_jshtml())

View Epoch 31
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_31.pth", map_location=device))
nn_model.eval()
print("Loaded in Model")
# visualize samples
plt.clf()
samples, intermediate_ddpm = sample_ddpm(32)
animation_ddpm = plot_sample(intermediate_ddpm,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm.to_jshtml())

Controlling(控制)
控制模型生成的内容。您可以告诉模型您想要什么,它会为您想像出来。
Embeddings

Adding Context

Context

Lab 3, Context
from typing import Dict, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.utils import save_image, make_grid
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import numpy as np
from IPython.display import HTML
from diffusion_utilities import *
Setting Things Up
class ContextUnet(nn.Module):
def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context features
super(ContextUnet, self).__init__()
# number of input channels, number of intermediate feature maps and number of classes
self.in_channels = in_channels
self.n_feat = n_feat
self.n_cfeat = n_cfeat
self.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...
# Initialize the initial convolutional layer
self.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
# Initialize the down-sampling path of the U-Net with two levels
self.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]
self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]
# original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())
self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())
# Embed the timestep and context labels with a one-layer fully connected neural network
self.timeembed1 = EmbedFC(1, 2*n_feat)
self.timeembed2 = EmbedFC(1, 1*n_feat)
self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)
self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)
# Initialize the up-sampling path of the U-Net with three levels
self.up0 = nn.Sequential(
nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4), # up-sample
nn.GroupNorm(8, 2 * n_feat), # normalize
nn.ReLU(),
)
self.up1 = UnetUp(4 * n_feat, n_feat)
self.up2 = UnetUp(2 * n_feat, n_feat)
# Initialize the final convolutional layers to map to the same number of channels as the input image
self.out = nn.Sequential(
nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0
nn.GroupNorm(8, n_feat), # normalize
nn.ReLU(),
nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input
)
def forward(self, x, t, c=None):
"""
x : (batch, n_feat, h, w) : input image
t : (batch, n_cfeat) : time step
c : (batch, n_classes) : context label
"""
# x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on
# pass the input image through the initial convolutional layer
x = self.init_conv(x)
# pass the result through the down-sampling path
down1 = self.down1(x) #[10, 256, 8, 8]
down2 = self.down2(down1) #[10, 256, 4, 4]
# convert the feature maps to a vector and apply an activation
hiddenvec = self.to_vec(down2)
# mask out context if context_mask == 1
if c is None:
c = torch.zeros(x.shape[0], self.n_cfeat).to(x)
# embed context and timestep
cemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)
temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)
cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)
temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)
#print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")
up1 = self.up0(hiddenvec)
up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddings
up3 = self.up2(cemb2*up2 + temb2, down1)
out = self.out(torch.cat((up3, x), 1))
return out
# hyperparameters
# diffusion hyperparameters
timesteps = 500
beta1 = 1e-4
beta2 = 0.02
# network hyperparameters
device = torch.device("cuda:0" if torch.cuda.is_available() else torch.device('cpu'))
n_feat = 64 # 64 hidden dimension feature
n_cfeat = 5 # context vector is of size 5
height = 16 # 16x16 image
save_dir = './weights/'
# training hyperparameters
batch_size = 100
n_epoch = 32
lrate=1e-3
# construct DDPM noise schedule
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
a_t = 1 - b_t
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
ab_t[0] = 1
# construct model
nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)
Context
# reset neural network
nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)
# re setup optimizer
optim = torch.optim.Adam(nn_model.parameters(), lr=lrate)
# training with context code
# set into train mode
nn_model.train()
for ep in range(n_epoch):
print(f'epoch {ep}')
# linearly decay learning rate
optim.param_groups[0]['lr'] = lrate*(1-ep/n_epoch)
pbar = tqdm(dataloader, mininterval=2 )
for x, c in pbar: # x: images c: context
optim.zero_grad()
x = x.to(device)
c = c.to(x)
# randomly mask out c
context_mask = torch.bernoulli(torch.zeros(c.shape[0]) + 0.9).to(device)
c = c * context_mask.unsqueeze(-1)
# perturb data
noise = torch.randn_like(x)
t = torch.randint(1, timesteps + 1, (x.shape[0],)).to(device)
x_pert = perturb_input(x, t, noise)
# use network to recover noise
pred_noise = nn_model(x_pert, t / timesteps, c=c)
# loss is mean squared error between the predicted and true noise
loss = F.mse_loss(pred_noise, noise)
loss.backward()
optim.step()
# save model periodically
if ep%4==0 or ep == int(n_epoch-1):
if not os.path.exists(save_dir):
os.mkdir(save_dir)
torch.save(nn_model.state_dict(), save_dir + f"context_model_{ep}.pth")
print('saved model at ' + save_dir + f"context_model_{ep}.pth")
# load in pretrain model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/context_model_trained.pth", map_location=device))
nn_model.eval()
print("Loaded in Context Model")
Sampling with context
# helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
def denoise_add_noise(x, t, pred_noise, z=None):
if z is None:
z = torch.randn_like(x)
noise = b_t.sqrt()[t] * z
mean = (x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) / a_t[t].sqrt()
return mean + noise
# sample with context using standard algorithm
@torch.no_grad()
def sample_ddpm_context(n_sample, context, save_rate=20):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
for i in range(timesteps, 0, -1):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
# sample some random noise to inject back in. For i = 1, don't add back in noise
z = torch.randn_like(samples) if i > 1 else 0
eps = nn_model(samples, t, c=context) # predict noise e_(x_t,t, ctx)
samples = denoise_add_noise(samples, i, eps, z)
if i % save_rate==0 or i==timesteps or i<8:
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
# visualize samples with randomly selected context
plt.clf()
ctx = F.one_hot(torch.randint(0, 5, (32,)), 5).to(device=device).float()
samples, intermediate = sample_ddpm_context(32, ctx)
animation_ddpm_context = plot_sample(intermediate,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm_context.to_jshtml())

def show_images(imgs, nrow=2):
_, axs = plt.subplots(nrow, imgs.shape[0] // nrow, figsize=(4,2 ))
axs = axs.flatten()
for img, ax in zip(imgs, axs):
img = (img.permute(1, 2, 0).clip(-1, 1).detach().cpu().numpy() + 1) / 2
ax.set_xticks([])
ax.set_yticks([])
ax.imshow(img)
plt.show()
# user defined context
ctx = torch.tensor([
# hero, non-hero, food, spell, side-facing
[1,0,0,0,0],
[1,0,0,0,0],
[0,0,0,0,1],
[0,0,0,0,1],
[0,1,0,0,0],
[0,1,0,0,0],
[0,0,1,0,0],
[0,0,1,0,0],
]).float().to(device)
samples, _ = sample_ddpm_context(ctx.shape[0], ctx)
show_images(samples)

# mix of defined context
ctx = torch.tensor([
# hero, non-hero, food, spell, side-facing
[1,0,0,0,0], #human
[1,0,0.6,0,0],
[0,0,0.6,0.4,0],
[1,0,0,0,1],
[1,1,0,0,0],
[1,0,0,1,0]
]).float().to(device)
samples, _ = sample_ddpm_context(ctx.shape[0], ctx)
show_images(samples)

Speeding Up(加速)
Sampling is slow
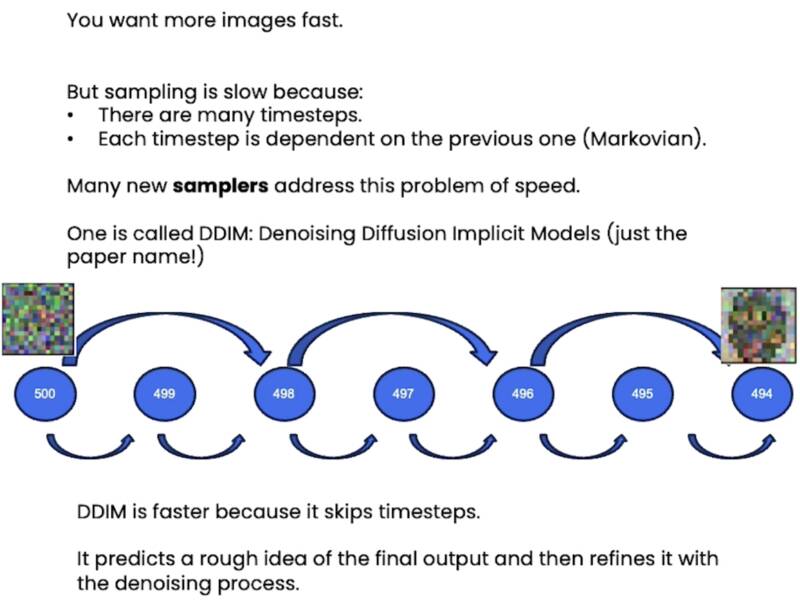
DDIM (Denoising Diffusion Implicit Models) 去噪扩散隐式模型
DDIM 不需要从时间步长 500 到 499 再到 498,它可以直接路过相应的步长,打破了马尔卡夫链的假设。马尔卡夫链只用于概率过程,但是 DDIM 实际上从这个采样过程中删除了随机性,因此是确定性的。
它的基本原理是,先预测最终输出的大致草图,然后通过去噪过程对其进行改进。
DDIM 比 DDPM 的采样速度快 10-50 倍。
Lab 4, Fast Sampling
from typing import Dict, Tuple
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.utils import save_image, make_grid
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation, PillowWriter
import numpy as np
from IPython.display import HTML
from diffusion_utilities import *
Setting Things Up
class ContextUnet(nn.Module):
def __init__(self, in_channels, n_feat=256, n_cfeat=10, height=28): # cfeat - context features
super(ContextUnet, self).__init__()
# number of input channels, number of intermediate feature maps and number of classes
self.in_channels = in_channels
self.n_feat = n_feat
self.n_cfeat = n_cfeat
self.h = height #assume h == w. must be divisible by 4, so 28,24,20,16...
# Initialize the initial convolutional layer
self.init_conv = ResidualConvBlock(in_channels, n_feat, is_res=True)
# Initialize the down-sampling path of the U-Net with two levels
self.down1 = UnetDown(n_feat, n_feat) # down1 #[10, 256, 8, 8]
self.down2 = UnetDown(n_feat, 2 * n_feat) # down2 #[10, 256, 4, 4]
# original: self.to_vec = nn.Sequential(nn.AvgPool2d(7), nn.GELU())
self.to_vec = nn.Sequential(nn.AvgPool2d((4)), nn.GELU())
# Embed the timestep and context labels with a one-layer fully connected neural network
self.timeembed1 = EmbedFC(1, 2*n_feat)
self.timeembed2 = EmbedFC(1, 1*n_feat)
self.contextembed1 = EmbedFC(n_cfeat, 2*n_feat)
self.contextembed2 = EmbedFC(n_cfeat, 1*n_feat)
# Initialize the up-sampling path of the U-Net with three levels
self.up0 = nn.Sequential(
nn.ConvTranspose2d(2 * n_feat, 2 * n_feat, self.h//4, self.h//4),
nn.GroupNorm(8, 2 * n_feat), # normalize
nn.ReLU(),
)
self.up1 = UnetUp(4 * n_feat, n_feat)
self.up2 = UnetUp(2 * n_feat, n_feat)
# Initialize the final convolutional layers to map to the same number of channels as the input image
self.out = nn.Sequential(
nn.Conv2d(2 * n_feat, n_feat, 3, 1, 1), # reduce number of feature maps #in_channels, out_channels, kernel_size, stride=1, padding=0
nn.GroupNorm(8, n_feat), # normalize
nn.ReLU(),
nn.Conv2d(n_feat, self.in_channels, 3, 1, 1), # map to same number of channels as input
)
def forward(self, x, t, c=None):
"""
x : (batch, n_feat, h, w) : input image
t : (batch, n_cfeat) : time step
c : (batch, n_classes) : context label
"""
# x is the input image, c is the context label, t is the timestep, context_mask says which samples to block the context on
# pass the input image through the initial convolutional layer
x = self.init_conv(x)
# pass the result through the down-sampling path
down1 = self.down1(x) #[10, 256, 8, 8]
down2 = self.down2(down1) #[10, 256, 4, 4]
# convert the feature maps to a vector and apply an activation
hiddenvec = self.to_vec(down2)
# mask out context if context_mask == 1
if c is None:
c = torch.zeros(x.shape[0], self.n_cfeat).to(x)
# embed context and timestep
cemb1 = self.contextembed1(c).view(-1, self.n_feat * 2, 1, 1) # (batch, 2*n_feat, 1,1)
temb1 = self.timeembed1(t).view(-1, self.n_feat * 2, 1, 1)
cemb2 = self.contextembed2(c).view(-1, self.n_feat, 1, 1)
temb2 = self.timeembed2(t).view(-1, self.n_feat, 1, 1)
#print(f"uunet forward: cemb1 {cemb1.shape}. temb1 {temb1.shape}, cemb2 {cemb2.shape}. temb2 {temb2.shape}")
up1 = self.up0(hiddenvec)
up2 = self.up1(cemb1*up1 + temb1, down2) # add and multiply embeddings
up3 = self.up2(cemb2*up2 + temb2, down1)
out = self.out(torch.cat((up3, x), 1))
return out
# hyperparameters
# diffusion hyperparameters
timesteps = 500
beta1 = 1e-4
beta2 = 0.02
# network hyperparameters
device = torch.device("cuda:0" if torch.cuda.is_available() else torch.device('cpu'))
n_feat = 64 # 64 hidden dimension feature
n_cfeat = 5 # context vector is of size 5
height = 16 # 16x16 image
save_dir = './weights/'
# training hyperparameters
batch_size = 100
n_epoch = 32
lrate=1e-3
# construct DDPM noise schedule
b_t = (beta2 - beta1) * torch.linspace(0, 1, timesteps + 1, device=device) + beta1
a_t = 1 - b_t
ab_t = torch.cumsum(a_t.log(), dim=0).exp()
ab_t[0] = 1
# construct model
nn_model = ContextUnet(in_channels=3, n_feat=n_feat, n_cfeat=n_cfeat, height=height).to(device)
Fast Sampling
# define sampling function for DDIM
# removes the noise using ddim
def denoise_ddim(x, t, t_prev, pred_noise):
ab = ab_t[t]
ab_prev = ab_t[t_prev]
x0_pred = ab_prev.sqrt() / ab.sqrt() * (x - (1 - ab).sqrt() * pred_noise)
dir_xt = (1 - ab_prev).sqrt() * pred_noise
return x0_pred + dir_xt
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/model_31.pth", map_location=device))
nn_model.eval()
print("Loaded in Model without context")
# sample quickly using DDIM
@torch.no_grad()
def sample_ddim(n_sample, n=20):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
step_size = timesteps // n
for i in range(timesteps, 0, -step_size):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
eps = nn_model(samples, t) # predict noise e_(x_t,t)
samples = denoise_ddim(samples, i, i - step_size, eps)
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
# visualize samples
plt.clf()
samples, intermediate = sample_ddim(32, n=25)
animation_ddim = plot_sample(intermediate,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddim.to_jshtml())

根据经验,人们发现,对于这500个步长训练的模型,如果您进行500个步长的采样,DDPM的表现更好。但是少于500个步长的任何数字,DDIM会做的更好。
# load in model weights and set to eval mode
nn_model.load_state_dict(torch.load(f"{save_dir}/context_model_31.pth", map_location=device))
nn_model.eval()
print("Loaded in Context Model")
# fast sampling algorithm with context
@torch.no_grad()
def sample_ddim_context(n_sample, context, n=20):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
step_size = timesteps // n
for i in range(timesteps, 0, -step_size):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
eps = nn_model(samples, t, c=context) # predict noise e_(x_t,t)
samples = denoise_ddim(samples, i, i - step_size, eps)
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
# visualize samples
plt.clf()
ctx = F.one_hot(torch.randint(0, 5, (32,)), 5).to(device=device).float()
samples, intermediate = sample_ddim_context(32, ctx)
animation_ddpm_context = plot_sample(intermediate,32,4,save_dir, "ani_run", None, save=False)
HTML(animation_ddpm_context.to_jshtml())

# helper function; removes the predicted noise (but adds some noise back in to avoid collapse)
def denoise_add_noise(x, t, pred_noise, z=None):
if z is None:
z = torch.randn_like(x)
noise = b_t.sqrt()[t] * z
mean = (x - pred_noise * ((1 - a_t[t]) / (1 - ab_t[t]).sqrt())) / a_t[t].sqrt()
return mean + noise
# sample using standard algorithm
@torch.no_grad()
def sample_ddpm(n_sample, save_rate=20):
# x_T ~ N(0, 1), sample initial noise
samples = torch.randn(n_sample, 3, height, height).to(device)
# array to keep track of generated steps for plotting
intermediate = []
for i in range(timesteps, 0, -1):
print(f'sampling timestep {i:3d}', end='\r')
# reshape time tensor
t = torch.tensor([i / timesteps])[:, None, None, None].to(device)
# sample some random noise to inject back in. For i = 1, don't add back in noise
z = torch.randn_like(samples) if i > 1 else 0
eps = nn_model(samples, t) # predict noise e_(x_t,t)
samples = denoise_add_noise(samples, i, eps, z)
if i % save_rate ==0 or i==timesteps or i<8:
intermediate.append(samples.detach().cpu().numpy())
intermediate = np.stack(intermediate)
return samples, intermediate
%timeit -r 1 sample_ddim(32, n=25)
%timeit -r 1 sample_ddpm(32, )
7.27 s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
1min 51s ± 0 ns per loop (mean ± std. dev. of 1 run, 1 loop each)
Summary(总结)
将所有知识综合起来,您可以训练一个扩散模型来预测噪声,并迭代地从纯噪声中减去预测的噪声,得到一张好的图像。您还可以使用一个更高效的采样器 DDIM,快速地从训练好的神经网络中采样图像。您已经学习了模型的架构 UNet,您将上下文引入到模型中,以便决定您想要食物、法术还是一个英雄角色精灵,或者一些有趣的东西。
现在您可以创建自己的数据集,并尝试生成新的东西。扩散模型不仅仅适用于图像,那只是它最受欢迎的领域。有用于音乐的扩散模型,您可以给它任何提示,就能生成音乐,还可以用于加速药物发现的新分子。
稳定扩散使用一种称为潜在扩散的方法,它在图像嵌入而不是图像本身上操作,使整个过程更加高效。研究界仍在致力于更快的采样方法,因为扩散模型在推断时仍然比其他生成模型慢。