DeepSeek-Coder 论文解读
论文
- DeepSeek-Coder: When the Large Language Model Meets Programming – The Rise of Code Intelligence
- DeepSeek LLM: Scaling Open-Source Language Models with Longtermism
- LLaMA: Open and Efficient Foundation Language Models
- Llama 2: Open Foundation and Fine-Tuned Chat Models
模型的性能
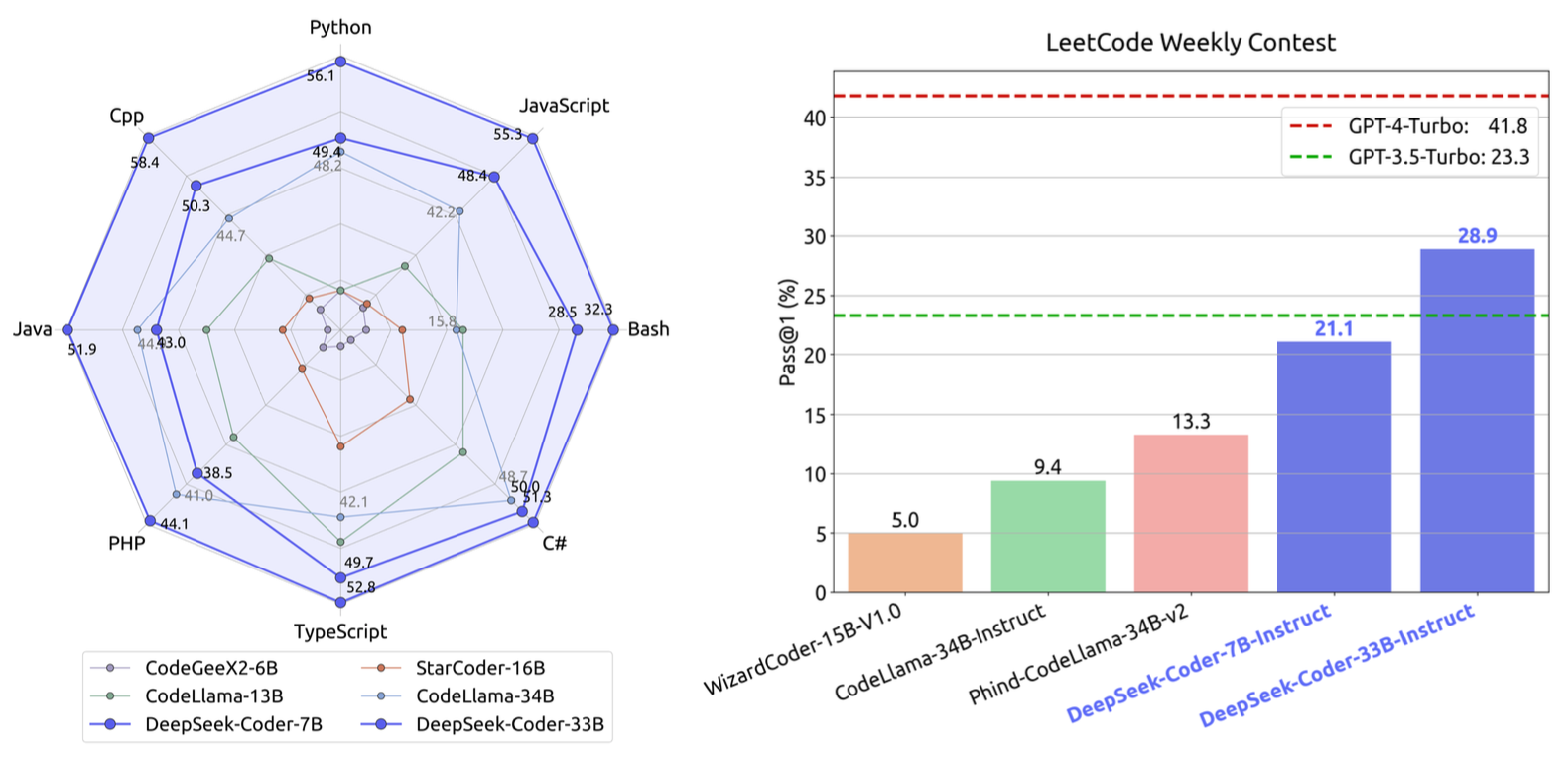
多语言基准性能
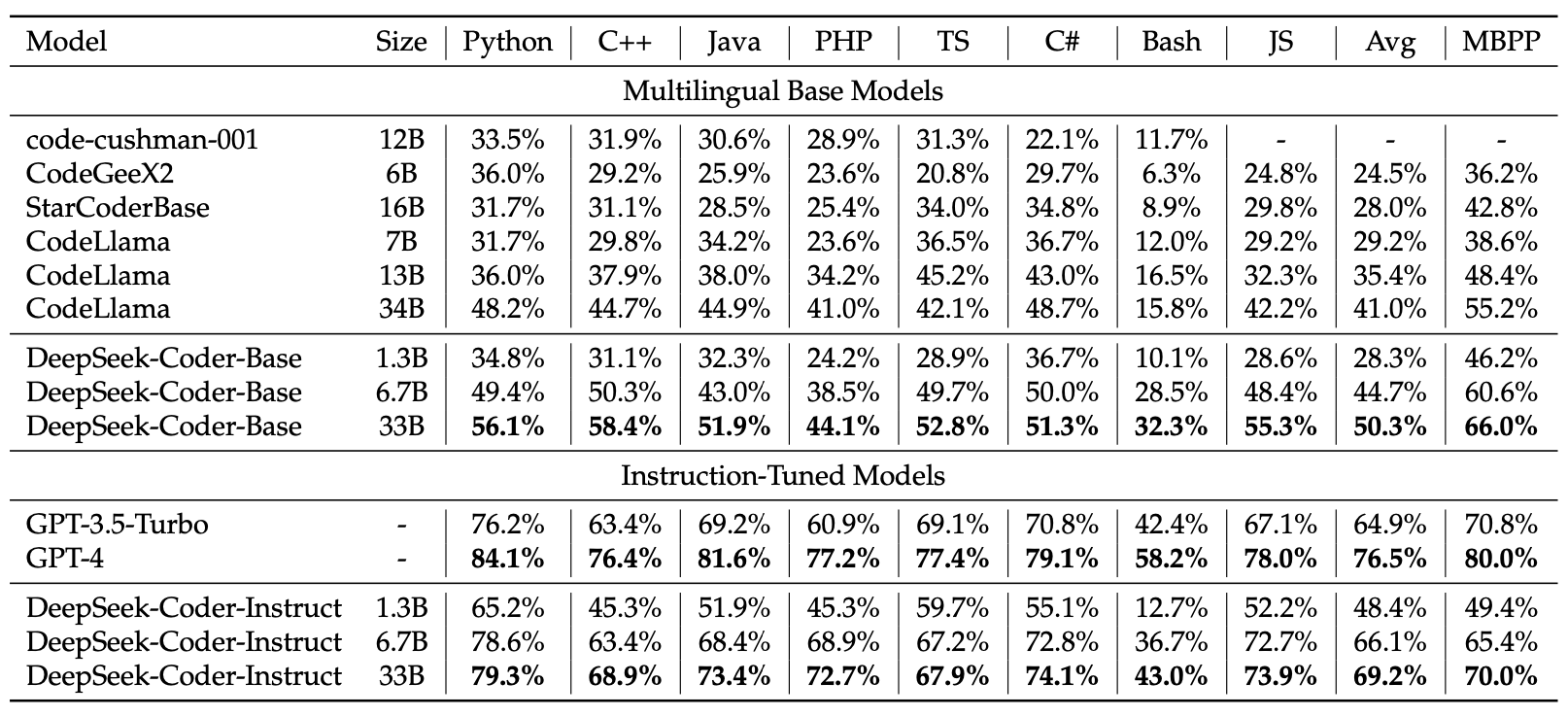
训练数据集
数据来源:2023年2月之前在GitHub上创建的公共仓库。
数据集创建过程
- GitHub数据抓取
- 规则过滤
- 依存分析
- 仓库级重复数据删除
- 质量筛选
规则过滤
- 过滤掉平均行长度超过100个字符或最大行长度超过1000个字符的文件。
- 移除了字母字符少于25%的文件。
- 除了XSLT编程语言外,过滤掉在前100个字符中出现字符串 “<?xml_version=” 的文件。
- 对于HTML文件,考虑可见文本与HTML代码的比例,保留可见文本占代码至少20%且不少于100个字符的文件。
- 对于包含更多数据的JSON和YAML文件,只保留字符计数在50到5000个字符范围内的文件。有效地移除了大多数数据量大的文件。
依存分析
考虑如何利用同一仓库中文件之间的依赖关系。首先解析文件之间的依赖关系,然后将这些文件按照确保每个文件所依赖的上下文在输入序列中排在该文件之前的顺序进行排列。通过根据它们的依赖关系对文件进行对齐,数据集更准确地代表了真实的编码实践和结构。这种增强的对齐不仅使数据集更具相关性,而且可能增加了模型在处理项目级代码场景中的实用性和适用性。
仓库级重复数据删除
在代码的仓库级别进行去重,而不是在文件级别,因为后者可能会过滤掉仓库中的某些文件,可能会破坏仓库的结构。具体来说,将仓库级别的连接代码视为一个单一样本,并应用相同的近似去重算法,以确保仓库结构的完整性。
质量筛选
使用编译器和质量模型,结合启发式规则,进一步筛选出低质量的数据。这包括包含语法错误、可读性差和模块化程度低的代码。 为了确保代码的训练数据不被GitHub上可能存在的测试集信息污染,实施了n-gram过滤过程。过滤掉包含来自HumanEval、MBPP、GSM8K和MATH等来源的docstrings、问题和解决方案的文件。对于过滤标准,应用以下规则:如果一段代码包含与测试数据中任何10-gram字符串完全相同的字符串,它将被排除在我们的训练数据之外。在测试数据包含短于10-gram但不少于3-gram的字符串的情况下,使用精确匹配方法进行过滤。
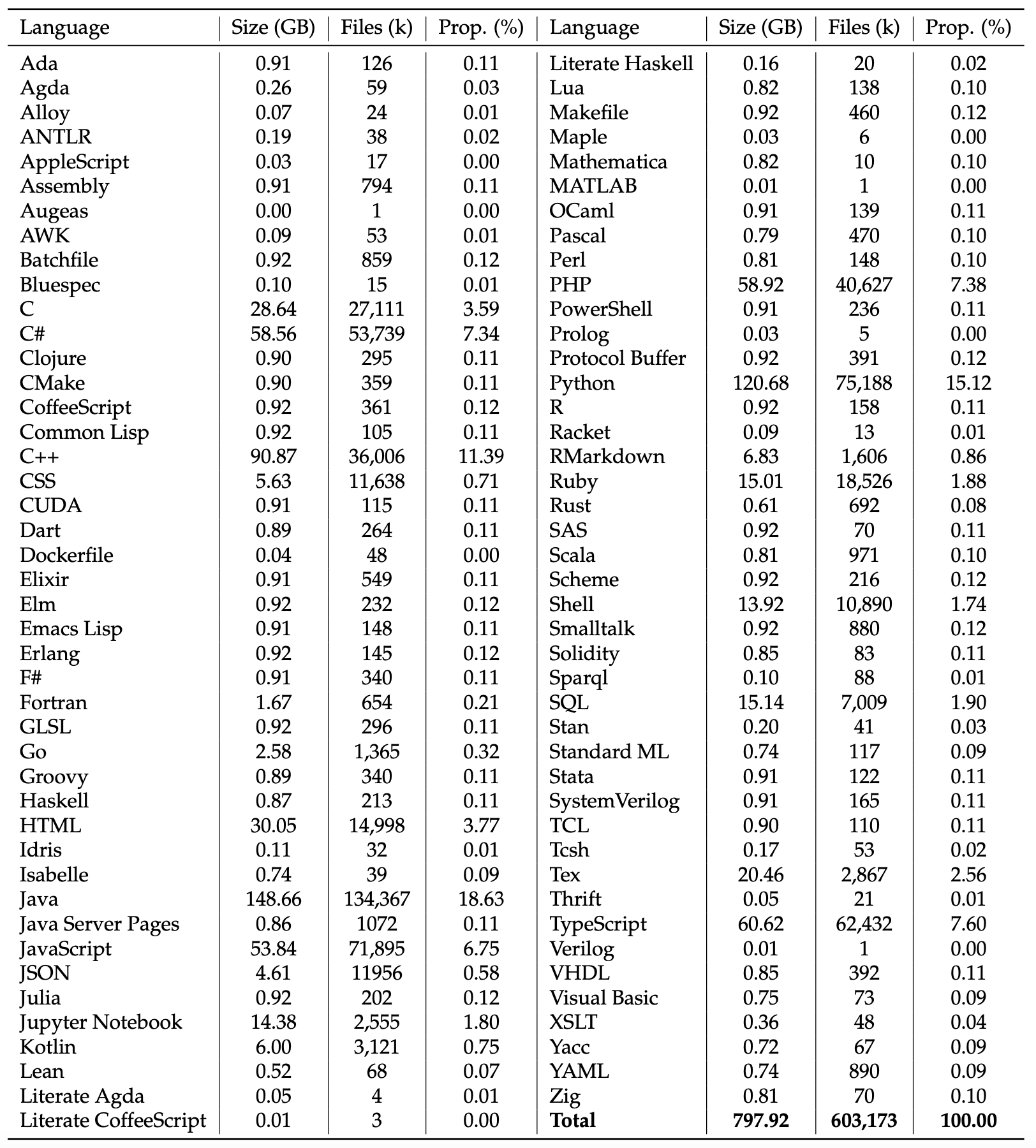
下表中列出保留的87种编程语言统计摘要(磁盘大小、文件数量和百分比),总数据量为798 GB,包含603百万个文件。
数据集组成
- 源代码(87%)
- 代码相关的英文自然语言语料库(10%)
- GitHub 上的 Markdown
- StackExchange
- 代码无关的中文自然语言语料库(3%)
- 高质量文章
训练策略
- 预测下一个token
- 填写中间 (FIM)
模型架构
![]()